
Enriching Artificial Intelligence Explanations with Knowledge Fragments

 ,
,  , , ,
, , ,  , and
, and
Abstract
:
1. Introduction
2. Related Work
2.1. Industry 4.0 and Industry 5.0
2.2. Demand Forecasting
2.3. Explainable Artificial Intelligence
3. Use Case
4. Evaluation and Results
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GDPR | General Data Protection Regulation |
| Google KG | Google Knowledge Graph |
| LACE | Local Agnostic attribute Contribution Explanation |
| LIME | Local Interpretable Model-agnostic Explanations |
| LoRE | Local Rule-based Explanation |
| Media Events’ K&WC | Media Events’ Keywords and Concepts |
| RDE | Ratio of Diverse Entries |
| SHAP | Shapley Additive Explanations |
References
- Lasi, H.; Fettke, P.; Kemper, H.G.; Feld, T.; Hoffmann, M. Industry 4.0. Bus. Inf. Syst. Eng. 2014, 6, 239–242. [Google Scholar] [CrossRef]
- Erro-Garcés, A. Industry 4.0: Defining the research agenda. Benchmarking Int. J. 2019, 28, 1858–1882. [Google Scholar] [CrossRef]
- Maddikunta, P.K.R.; Pham, Q.V.; Prabadevi, B.; Deepa, N.; Dev, K.; Gadekallu, T.R.; Ruby, R.; Liyanage, M. Industry 5.0: A survey on enabling technologies and potential applications. J. Ind. Inf. Integr. 2021, 26, 100257. [Google Scholar] [CrossRef]
- Lu, Y. Cyber physical system (CPS)-based industry 4.0: A survey. J. Ind. Integr. Manag. 2017, 2, 1750014. [Google Scholar] [CrossRef]
- Shafto, M.; Conroy, M.; Doyle, R.; Glaessgen, E.; Kemp, C.; LeMoigne, J.; Wang, L. Draft modeling, simulation, information technology & processing roadmap. Technol. Area 2012, 32, 1–38. [Google Scholar]
- Arinez, J.F.; Chang, Q.; Gao, R.X.; Xu, C.; Zhang, J. Artificial intelligence in advanced manufacturing: Current status and future outlook. J. Manuf. Sci. Eng. 2020, 142, 110804. [Google Scholar] [CrossRef]
- Ghobakhloo, M. Industry 4.0, digitization, and opportunities for sustainability. J. Clean. Prod. 2020, 252, 119869. [Google Scholar] [CrossRef]
- Martynov, V.V.; Shavaleeva, D.N.; Zaytseva, A.A. Information technology as the basis for transformation into a digital society and industry 5.0. In Proceedings of the 2019 International Conference “Quality Management, Transport and Information Security, Information Technologies” (IT&QM&IS), Sochi, Russia, 23–27 September 2019; pp. 539–543. [Google Scholar]
- Rožanec, J.M.; Novalija, I.; Zajec, P.; Kenda, K.; Tavakoli, H.; Suh, S.; Veliou, E.; Papamartzivanos, D.; Giannetsos, T.; Menesidou, S.A.; et al. Human-Centric Artificial Intelligence Architecture for Industry 5.0 Applications. arXiv 2022, arXiv:2203.10794. [Google Scholar]
- Rožanec, J.M.; Kažič, B.; Škrjanc, M.; Fortuna, B.; Mladenić, D. Automotive OEM demand forecasting: A comparative study of forecasting algorithms and strategies. Appl. Sci. 2021, 11, 6787. [Google Scholar] [CrossRef]
- Trajkova, E.; Rožanec, J.M.; Dam, P.; Fortuna, B.; Mladenić, D. Active Learning for Automated Visual Inspection of Manufactured Products. arXiv 2021, arXiv:2109.02469. [Google Scholar]
- Bhatt, P.M.; Malhan, R.K.; Shembekar, A.V.; Yoon, Y.J.; Gupta, S.K. Expanding capabilities of additive manufacturing through use of robotics technologies: A survey. Addit. Manuf. 2020, 31, 100933. [Google Scholar] [CrossRef]
- Dhanorkar, S.; Wolf, C.T.; Qian, K.; Xu, A.; Popa, L.; Li, Y. Who needs to know what, when?: Broadening the Explainable AI (XAI) Design Space by Looking at Explanations Across the AI Lifecycle. In Proceedings of the Designing Interactive Systems Conference 2021, Virtual Event, 28 June–2 July 2021; pp. 1591–1602. [Google Scholar]
- Dragoni, M.; Donadello, I. A Knowledge-Based Strategy for XAI: The Explanation Graph; IOS Press: Amsterdam, The Nertherlands, 2022. [Google Scholar]
- Rožanec, J.M.; Fortuna, B.; Mladenić, D. Knowledge graph-based rich and confidentiality preserving Explainable Artificial Intelligence (XAI). Inf. Fusion 2022, 81, 91–102. [Google Scholar] [CrossRef]
- Rožanec, J.M.; Zajec, P.; Kenda, K.; Novalija, I.; Fortuna, B.; Mladenić, D. XAI-KG: Knowledge graph to support XAI and decision-making in manufacturing. In Proceedings of the International Conference on Advanced Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2021; pp. 167–172. [Google Scholar]
- Sovrano, F.; Vitali, F. An Objective Metric for Explainable AI: How and Why to Estimate the Degree of Explainability. arXiv 2021, arXiv:2109.05327. [Google Scholar]
- Majstorovic, V.D.; Mitrovic, R. Industry 4.0 programs worldwide. In Proceedings of the International Conference on the Industry 4.0 Model for Advanced Manufacturing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 78–99. [Google Scholar]
- Bogoviz, A.V.; Osipov, V.S.; Chistyakova, M.K.; Borisov, M.Y. Comparative analysis of formation of industry 4.0 in developed and developing countries. In Industry 4.0: Industrial Revolution of the 21st Century; Springer: Berlin/Heidelberg, Germany, 2019; pp. 155–164. [Google Scholar]
- Raj, A.; Dwivedi, G.; Sharma, A.; de Sousa Jabbour, A.B.L.; Rajak, S. Barriers to the adoption of industry 4.0 technologies in the manufacturing sector: An inter-country comparative perspective. Int. J. Prod. Econ. 2020, 224, 107546. [Google Scholar] [CrossRef]
- Frank, A.G.; Dalenogare, L.S.; Ayala, N.F. Industry 4.0 technologies: Implementation patterns in manufacturing companies. Int. J. Prod. Econ. 2019, 210, 15–26. [Google Scholar] [CrossRef]
- Ghobakhloo, M. The future of manufacturing industry: A strategic roadmap toward Industry 4.0. J. Manuf. Technol. Manag. 2018, 29, 910–936. [Google Scholar] [CrossRef] [Green Version]
- Zheng, T.; Ardolino, M.; Bacchetti, A.; Perona, M. The applications of Industry 4.0 technologies in manufacturing context: A systematic literature review. Int. J. Prod. Res. 2021, 59, 1922–1954. [Google Scholar] [CrossRef]
- Qi, Q.; Tao, F.; Zuo, Y.; Zhao, D. Digital twin service towards smart manufacturing. Procedia Cirp 2018, 72, 237–242. [Google Scholar] [CrossRef]
- Rožanec, J.M.; Lu, J.; Rupnik, J.; Škrjanc, M.; Mladenić, D.; Fortuna, B.; Zheng, X.; Kiritsis, D. Actionable cognitive twins for decision making in manufacturing. Int. J. Prod. Res. 2022, 60, 452–478. [Google Scholar] [CrossRef]
- Xu, X.; Lu, Y.; Vogel-Heuser, B.; Wang, L. Industry 4.0 and Industry 5.0—Inception, conception and perception. J. Manuf. Syst. 2021, 61, 530–535. [Google Scholar] [CrossRef]
- Nahavandi, S. Industry 5.0—A human-centric solution. Sustainability 2019, 11, 4371. [Google Scholar] [CrossRef] [Green Version]
- Demir, K.A.; Döven, G.; Sezen, B. Industry 5.0 and human-robot co-working. Procedia Comput. Sci. 2019, 158, 688–695. [Google Scholar] [CrossRef]
- Industry 5.0: Towards More Sustainable, Resilient and Human-Centric Industry. Available online: https://op.europa.eu/en/publication-detail/-/publication/468a892a-5097-11eb-b59f-01aa75ed71a1/ (accessed on 15 March 2022).
- Weitz, K.; Schiller, D.; Schlagowski, R.; Huber, T.; André, E. “Do you trust me?” Increasing user-trust by integrating virtual agents in explainable AI interaction design. In Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents, Paris, France, 2–5 July 2019; pp. 7–9. [Google Scholar]
- Honeycutt, D.; Nourani, M.; Ragan, E. Soliciting human-in-the-loop user feedback for interactive machine learning reduces user trust and impressions of model accuracy. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Virtul, 26–28 October 2020; Volume 8, pp. 63–72. [Google Scholar]
- Moroff, N.U.; Kurt, E.; Kamphues, J. Machine Learning and statistics: A Study for assessing innovative demand forecasting models. Procedia Comput. Sci. 2021, 180, 40–49. [Google Scholar] [CrossRef]
- Purohit, D.; Srivastava, J. Effect of manufacturer reputation, retailer reputation, and product warranty on consumer judgments of product quality: A cue diagnosticity framework. J. Consum. Psychol. 2001, 10, 123–134. [Google Scholar] [CrossRef]
- Callon, M.; Méadel, C.; Rabeharisoa, V. The economy of qualities. Econ. Soc. 2002, 31, 194–217. [Google Scholar] [CrossRef]
- Teunter, R.H.; Babai, M.Z.; Syntetos, A.A. ABC classification: Service levels and inventory costs. Prod. Oper. Manag. 2010, 19, 343–352. [Google Scholar] [CrossRef]
- Scholz-Reiter, B.; Heger, J.; Meinecke, C.; Bergmann, J. Integration of demand forecasts in ABC-XYZ analysis: Practical investigation at an industrial company. Int. J. Product. Perform. Manag. 2012, 61, 445–451. [Google Scholar] [CrossRef] [Green Version]
- Syntetos, A.A.; Boylan, J.E.; Croston, J. On the categorization of demand patterns. J. Oper. Res. Soc. 2005, 56, 495–503. [Google Scholar] [CrossRef]
- Rožanec, J.M.; Mladenić, D. Reframing demand forecasting: A two-fold approach for lumpy and intermittent demand. arXiv 2021, arXiv:2103.13812. [Google Scholar]
- Brühl, B.; Hülsmann, M.; Borscheid, D.; Friedrich, C.M.; Reith, D. A sales forecast model for the german automobile market based on time series analysis and data mining methods. In Proceedings of the Industrial Conference on Data Mining; Springer: Berlin/Heidelberg, Germany, 2009; pp. 146–160. [Google Scholar]
- Vahabi, A.; Hosseininia, S.S.; Alborzi, M. A Sales Forecasting Model in Automotive Industry using Adaptive Neuro-Fuzzy Inference System (Anfis) and Genetic Algorithm (GA). Management 2016, 1, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Ubaidillah, N.Z. A study of car demand and its interdependency in sarawak. Int. J. Bus. Soc. 2020, 21, 997–1011. [Google Scholar] [CrossRef]
- Dwivedi, A.; Niranjan, M.; Sahu, K. A business intelligence technique for forecasting the automobile sales using Adaptive Intelligent Systems (ANFIS and ANN). Int. J. Comput. Appl. 2013, 74, 1–7. [Google Scholar] [CrossRef]
- Wang, X.; Zeng, D.; Dai, H.; Zhu, Y. Making the right business decision: Forecasting the binary NPD strategy in Chinese automotive industry with machine learning methods. Technol. Forecast. Soc. Chang. 2020, 155, 120032. [Google Scholar] [CrossRef]
- Chandriah, K.K.; Naraganahalli, R.V. RNN/LSTM with modified Adam optimizer in deep learning approach for automobile spare parts demand forecasting. Multimed. Tools Appl. 2021, 80, 26145–26159. [Google Scholar] [CrossRef]
- Halford, G.S.; Baker, R.; McCredden, J.E.; Bain, J.D. How many variables can humans process? Psychol. Sci. 2005, 16, 70–76. [Google Scholar] [CrossRef] [PubMed]
- Barnes, J.H., Jr. Cognitive biases and their impact on strategic planning. Strateg. Manag. J. 1984, 5, 129–137. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Confalonieri, R.; Coba, L.; Wagner, B.; Besold, T.R. A historical perspective of explainable Artificial Intelligence. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11, e1391. [Google Scholar] [CrossRef]
- Davydenko, A.; Fildes, R.A.; Trapero Arenas, J. Judgmental Adjustments to Demand Forecasts: Accuracy Evaluation and Bias Correction; The Department of Management Science, Lancaster University: Lancaster, UK, 2010. [Google Scholar]
- Davydenko, A.; Fildes, R. Measuring forecasting accuracy: The case of judgmental adjustments to SKU-level demand forecasts. Int. J. Forecast. 2013, 29, 510–522. [Google Scholar] [CrossRef]
- Alvarado-Valencia, J.; Barrero, L.H.; Önkal, D.; Dennerlein, J.T. Expertise, credibility of system forecasts and integration methods in judgmental demand forecasting. Int. J. Forecast. 2017, 33, 298–313. [Google Scholar] [CrossRef]
- Goodman, B.; Flaxman, S. European Union regulations on algorithmic decision-making and a “right to explanation”. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of such Data, and Repealing Directive 95/46/EC (General Data Protection Regulation). Available online: https://eur-lex.europa.eu/eli/reg/2016/679/oj (accessed on 15 March 2022).
- Proposal for a Regulation of The European Parliament and of The Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act) and Amending Certain Union Legislative Acts. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52021PC0206 (accessed on 15 March 2022).
- Anitha, J. Determinants of employee engagement and their impact on employee performance. Int. J. Product. Perform. Manag. 2014, 63, 308–323. [Google Scholar]
- Emmert-Streib, F.; Yli-Harja, O.; Dehmer, M. Explainable artificial intelligence and machine learning: A reality rooted perspective. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1368. [Google Scholar] [CrossRef]
- Schwalbe, G.; Finzel, B. XAI Method Properties: A (Meta-) study. arXiv 2021, arXiv:2105.07190. [Google Scholar]
- Chan, L. Explainable AI as Epistemic Representation. Available online: https://aisb.org.uk/wp-content/uploads/2021/04/AISB21_Opacity_Proceedings.pdf#page=9 (accessed on 25 April 2022).
- Müller, V.C. Deep Opacity Undermines Data Protection and Explainable Artificial Intelligence. Available online: http://explanations.ai/symposium/AISB21_Opacity_Proceedings.pdf#page=20 (accessed on 25 April 2022).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Zafar, M.R.; Khan, N.M. DLIME: A deterministic local interpretable model-agnostic explanations approach for computer-aided diagnosis systems. arXiv 2019, arXiv:1906.10263. [Google Scholar]
- Hall, P.; Gill, N.; Kurka, M.; Phan, W. Machine Learning Interpretability with H2O Driverless AI. 2017. Available online: http://docs.h2o.ai/driverless-ai/latest-stable/docs/booklets/MLIBooklet.pdf (accessed on 25 April 2022).
- Sokol, K.; Flach, P. LIMEtree: Interactively Customisable Explanations Based on Local Surrogate Multi-output Regression Trees. arXiv 2020, arXiv:2005.01427. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. Available online: https://proceedings.neurips.cc/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf (accessed on 25 April 2022).
- Strumbelj, E.; Kononenko, I. An efficient explanation of individual classifications using game theory. J. Mach. Learn. Res. 2010, 11, 1–18. [Google Scholar]
- Pastor, E.; Baralis, E. Explaining black box models by means of local rules. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 510–517. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Pedreschi, D.; Turini, F.; Giannotti, F. Local rule-based explanations of black box decision systems. arXiv 2018, arXiv:1805.10820. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 18, pp. 1527–1535. [Google Scholar]
- Van der Waa, J.; Robeer, M.; van Diggelen, J.; Brinkhuis, M.; Neerincx, M. Contrastive explanations with local foil trees. arXiv 2018, arXiv:1806.07470. [Google Scholar]
- Rožanec, J.; Trajkova, E.; Kenda, K.; Fortuna, B.; Mladenić, D. Explaining Bad Forecasts in Global Time Series Models. Appl. Sci. 2021, 11, 9243. [Google Scholar] [CrossRef]
- Confalonieria, R.; Galliania, P.; Kutza, O.; Porellob, D.; Righettia, G.; Troquarda, N. Towards Knowledge-driven Distillation and Explanation of Black-box Models. In Proceedings of the International Workshop on Data meets Applied Ontologies in Explainable AI (DAO-XAI 2021), Bratislava, Slovakia, 18–19 September 2021. [Google Scholar]
- Panigutti, C.; Perotti, A.; Pedreschi, D. Doctor XAI: An ontology-based approach to black-box sequential data classification explanations. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 629–639. [Google Scholar]
- Lécué, F.; Abeloos, B.; Anctil, J.; Bergeron, M.; Dalla-Rosa, D.; Corbeil-Letourneau, S.; Martet, F.; Pommellet, T.; Salvan, L.; Veilleux, S.; et al. Thales XAI Platform: Adaptable Explanation of Machine Learning Systems-A Knowledge Graphs Perspective. In Proceedings of the ISWC Satellites, Auckland, New Zealand, 26–30 October 2019; pp. 315–316. [Google Scholar]
- Rabold, J.; Deininger, H.; Siebers, M.; Schmid, U. Enriching visual with verbal explanations for relational concepts–combining LIME with Aleph. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2019; pp. 180–192. [Google Scholar]
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Interpretable & explorable approximations of black box models. arXiv 2017, arXiv:1707.01154. [Google Scholar]
- Nguyen, A.p.; Martínez, M.R. On quantitative aspects of model interpretability. arXiv 2020, arXiv:2007.07584. [Google Scholar]
- Rosenfeld, A. Better metrics for evaluating explainable artificial intelligence. In Proceedings of the 20th international Conference on Autonomous Agents and Multiagent Systems, Virtual, 3–7 May 2021; pp. 45–50. [Google Scholar]
- Amparore, E.; Perotti, A.; Bajardi, P. To trust or not to trust an explanation: Using LEAF to evaluate local linear XAI methods. Peerj Comput. Sci. 2021, 7, e479. [Google Scholar] [CrossRef]
- Samek, W.; Müller, K.R. Towards explainable artificial intelligence. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 5–22. [Google Scholar]
- Pedreschi, D.; Giannotti, F.; Guidotti, R.; Monreale, A.; Pappalardo, L.; Ruggieri, S.; Turini, F. Open the black box data-driven explanation of black box decision systems. arXiv 2018, arXiv:1806.09936. [Google Scholar]
- El-Assady, M.; Jentner, W.; Kehlbeck, R.; Schlegel, U.; Sevastjanova, R.; Sperrle, F.; Spinner, T.; Keim, D. Towards XAI: Structuring the Processes of Explanations. In Proceedings of the ACM Workshop on Human-Centered Machine Learning, Glasgow, UK, 4 May 2019. [Google Scholar]
- Hsiao, J.H.w.; Ngai, H.H.T.; Qiu, L.; Yang, Y.; Cao, C.C. Roadmap of designing cognitive metrics for explainable artificial intelligence (XAI). arXiv 2021, arXiv:2108.01737. [Google Scholar]
- Hoffman, R.R.; Mueller, S.T.; Klein, G.; Litman, J. Metrics for explainable AI: Challenges and prospects. arXiv 2018, arXiv:1812.04608. [Google Scholar]
- Keane, M.T.; Smyth, B. Good counterfactuals and where to find them: A case-based technique for generating counterfactuals for explainable AI (XAI). In Proceedings of the International Conference on Case-Based Reasoning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 163–178. [Google Scholar]
- Keane, M.T.; Kenny, E.M.; Delaney, E.; Smyth, B. If only we had better counterfactual explanations: Five key deficits to rectify in the evaluation of counterfactual XAI techniques. arXiv 2021, arXiv:2103.01035. [Google Scholar]
- Verma, S.; Dickerson, J.; Hines, K. Counterfactual Explanations for Machine Learning: A Review. arXiv 2020, arXiv:2010.10596. [Google Scholar]
- Mohseni, S.; Zarei, N.; Ragan, E.D. A multidisciplinary survey and framework for design and evaluation of explainable AI systems. Acm Trans. Interact. Intell. Syst. (Tiis) 2021, 11, 1–45. [Google Scholar] [CrossRef]
- Lage, I.; Ross, A.S.; Kim, B.; Gershman, S.J.; Doshi-Velez, F. Human-in-the-loop interpretability prior. arXiv 2018, arXiv:1805.11571. [Google Scholar]
- Rozanec, J.M. Explainable demand forecasting: A data mining goldmine. In Proceedings of the Companion Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 723–724. [Google Scholar]
- Leban, G.; Fortuna, B.; Brank, J.; Grobelnik, M. Event registry: Learning about world events from news. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 107–110. [Google Scholar]
- Publications Office of the European Union. EU Open Data Portal: The Official Portal for European Data. Available online: https://data.europa.eu (accessed on 15 December 2020).
- Noy, N.; Gao, Y.; Jain, A.; Narayanan, A.; Patterson, A.; Taylor, J. Industry-scale knowledge graphs: Lessons and challenges. Queue 2019, 17, 48–75. [Google Scholar] [CrossRef]
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 957–966. [Google Scholar]
- Brank, J.; Leban, G.; Grobelnik, M. Annotating Documents with Relevant Wikipedia Concepts. Available online: https://ailab.ijs.si/Dunja/SiKDD2017/Papers/Brank_Wikifier.pdf (accessed on 25 April 2022).
- Lee, J.D.; See, K.A. Trust in automation: Designing for appropriate reliance. Hum. Factors 2004, 46, 50–80. [Google Scholar] [CrossRef]
- Kilani, Y.; Alhijawi, B.; Alsarhan, A. Using artificial intelligence techniques in collaborative filtering recommender systems: Survey. Int. J. Adv. Intell. Paradig. 2018, 11, 378–396. [Google Scholar] [CrossRef]
- Karimi, M.; Jannach, D.; Jugovac, M. News recommender systems–Survey and roads ahead. Inf. Process. Manag. 2018, 54, 1203–1227. [Google Scholar] [CrossRef]
- Sidana, S.; Trofimov, M.; Horodnytskyi, O.; Laclau, C.; Maximov, Y.; Amini, M.R. User preference and embedding learning with implicit feedback for recommender systems. Data Min. Knowl. Discov. 2021, 35, 568–592. [Google Scholar] [CrossRef]
- Michael, J.; Stanovsky, G.; He, L.; Dagan, I.; Zettlemoyer, L. Crowdsourcing question-answer meaning representations. arXiv 2017, arXiv:1711.05885. [Google Scholar]
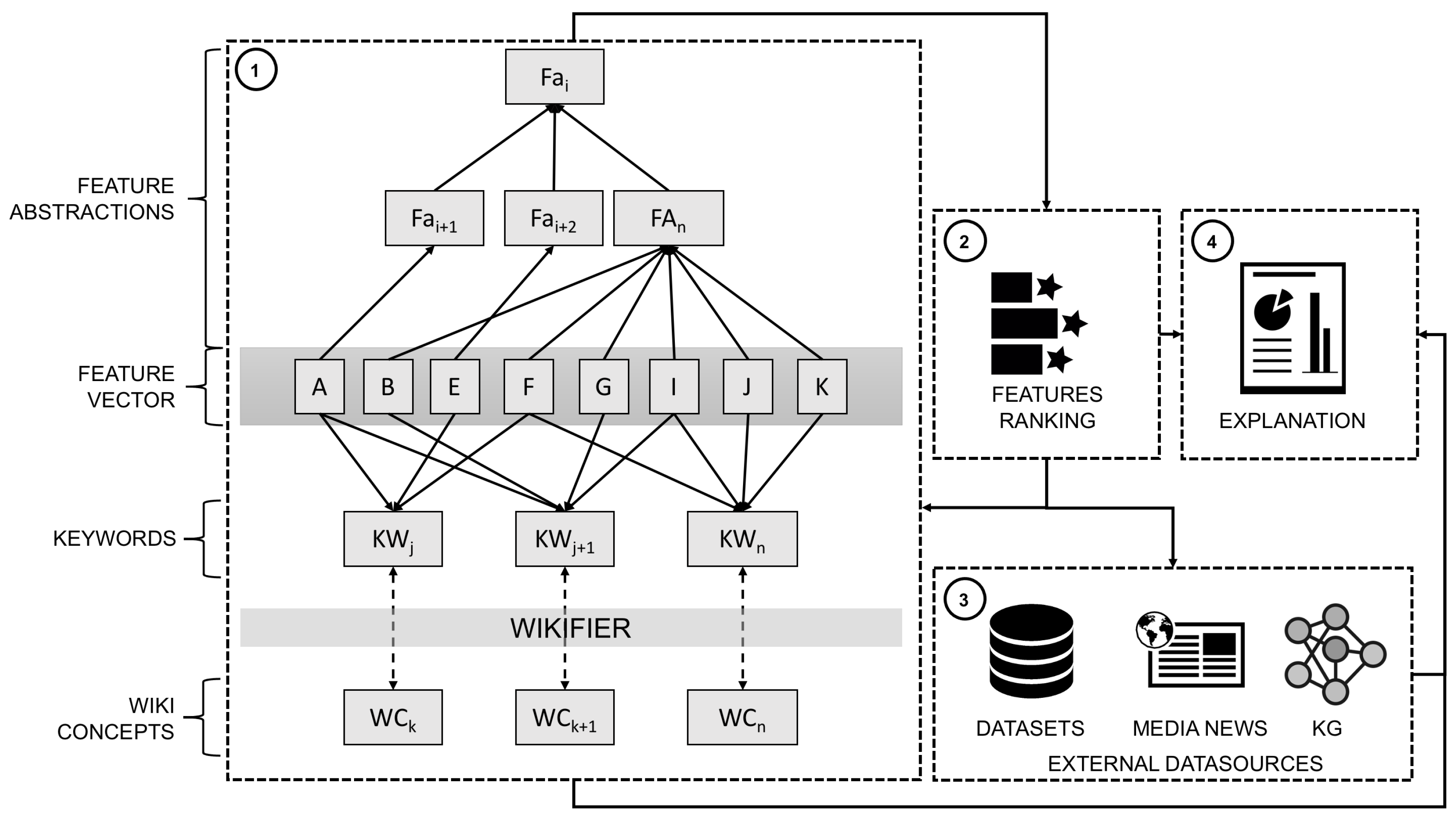

{kind=link}
{kind=link}
| Feature Keywords | Wiki Concepts |
|---|---|
| Car Sales Demand | Car |
| Demand | |
| New Car Sales | Car |
| Sales | |
| Vehicle Sales | Vehicle |
| Car Demand | Car |
| Demand | |
| Automotive Industry | Automotive Industry |
| Global Gross Domestic Product Projection | Gross Domestic Product |
| Gross World Product | |
| Global Economic Outlook | Economy |
| World economy | |
| Economic Forecast | Forecasting |
| Economy | |
| Unemployment Rate | Unemployment |
| Unemployment Numbers | Unemployment |
| Unemployment Report | Unemployment |
| Employment Growth | Employment |
| Long-term Unemployment | Unemployment |
| Purchasing Managers’ Index | Manager (Gaelic games) |
| Metric | Embeddings-Based Approach | Semantics-Based Approach | |
|---|---|---|---|
| Media Events | Average Precision@1 | 0.97 | 0.95 |
| Average Precision@3 | 0.97 | 0.95 | |
| RDE@1 | 0.30 | 0.38 | |
| RDE@3 | 0.11 | 0.14 | |
| Media Events’ K&WC | Average Precision@1 | 0.77 | 0.71 |
| Average Precision@3 | 0.78 | 0.72 | |
| RDE@1 | 0.14 | 0.01 | |
| RDE@3 | 0.09 | 0.01 | |
| External Datasets | Average Precision@1 | 0.56 | 0.68 |
| RDE@1 | 0.41 | 0.43 | |
| Google KG | Average Precision@1 | NA | 0.76 |
| Average Precision@3 | NA | 0.46 | |
| RDE@1 | NA | 0.15 | |
| RDE@3 | NA | 0.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rožanec, J.; Trajkova, E.; Novalija, I.; Zajec, P.; Kenda, K.; Fortuna, B.; Mladenić, D. Enriching Artificial Intelligence Explanations with Knowledge Fragments. Future Internet 2022, 14, 134. https://doi.org/10.3390/fi14050134
Rožanec J, Trajkova E, Novalija I, Zajec P, Kenda K, Fortuna B, Mladenić D. Enriching Artificial Intelligence Explanations with Knowledge Fragments. Future Internet. 2022; 14(5):134. https://doi.org/10.3390/fi14050134
Chicago/Turabian StyleRožanec, Jože, Elena Trajkova, Inna Novalija, Patrik Zajec, Klemen Kenda, Blaž Fortuna, and Dunja Mladenić. 2022. "Enriching Artificial Intelligence Explanations with Knowledge Fragments" Future Internet 14, no. 5: 134. https://doi.org/10.3390/fi14050134
APA StyleRožanec, J., Trajkova, E., Novalija, I., Zajec, P., Kenda, K., Fortuna, B., & Mladenić, D. (2022). Enriching Artificial Intelligence Explanations with Knowledge Fragments. Future Internet, 14(5), 134. https://doi.org/10.3390/fi14050134