
FakeNewsLab: Experimental Study on Biases and Pitfalls Preventing Us from Distinguishing True from False News



Abstract
1. Introduction
2. Related Works
3. Data and Methodology
- Room 1 showed, for every news, the bare headline and a short excerpt as they would appear on social media platforms, but was devoid of any contextual clues.
- Room 2 showed the full text of the articles, as they were presented on the original website, again without any clear references to the source.
- Room 3 showed the headline with a short excerpt and the source of the article, as it would appear on social media but devoid of social features. The article source was clickable, and the article could be read at its original source.
- Room 4 showed the headline with a short excerpt, as well as the percentages of users that classified the news as true or false. We will refer to this information as “social ratings” from now on.
- Room 5 was similar to Room 4, but with randomly generated percentages. We will refer to these ratings as “random ratings” from now on.
3.1. News Selection
4. Results
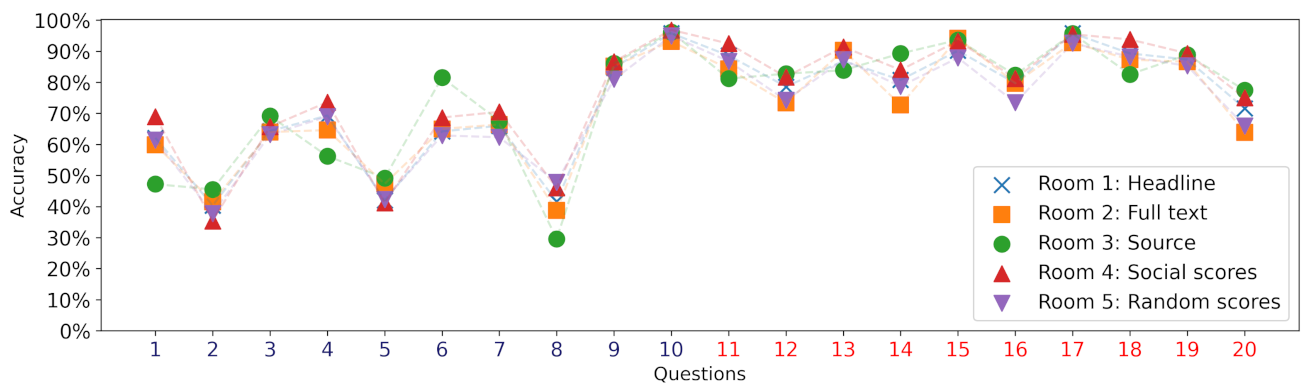
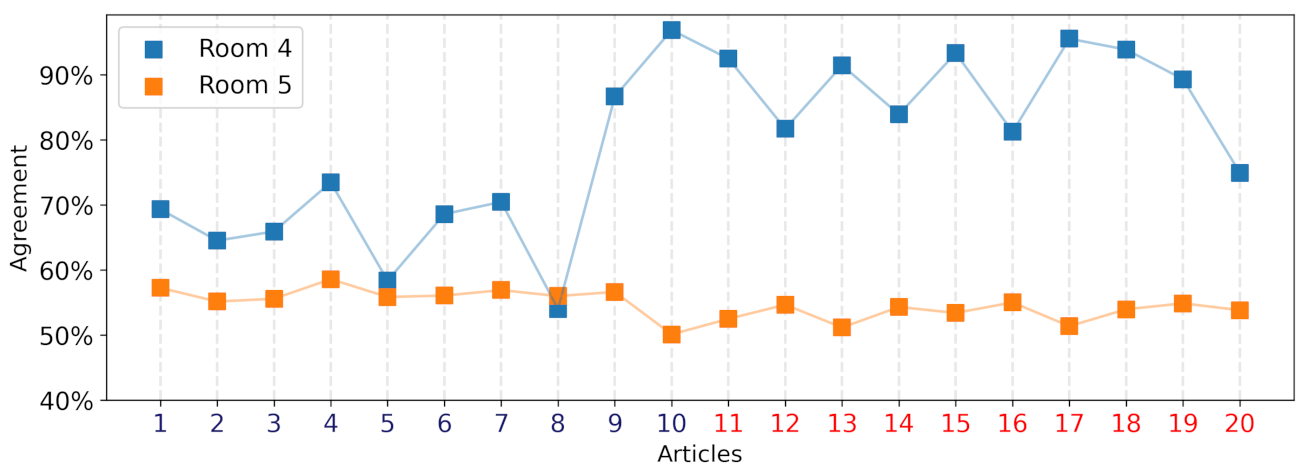
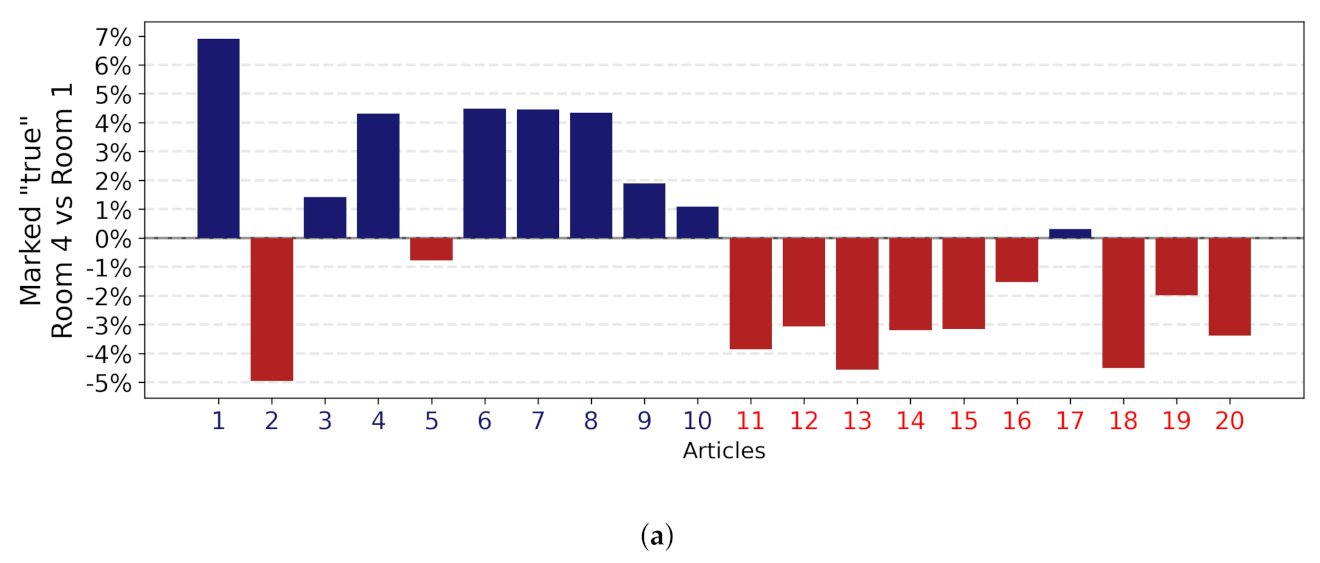
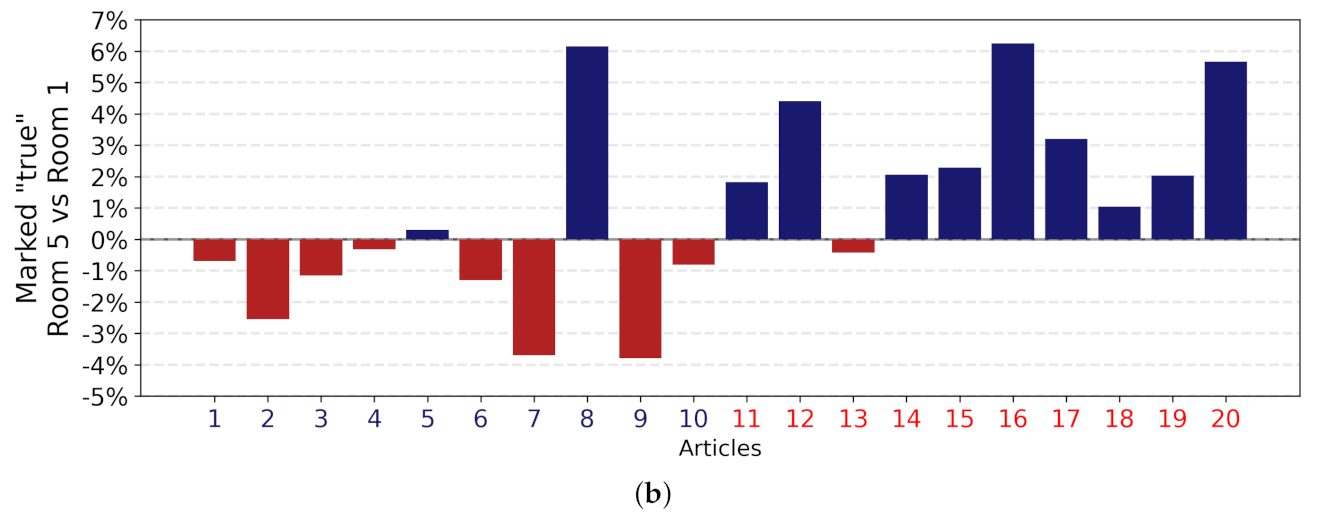
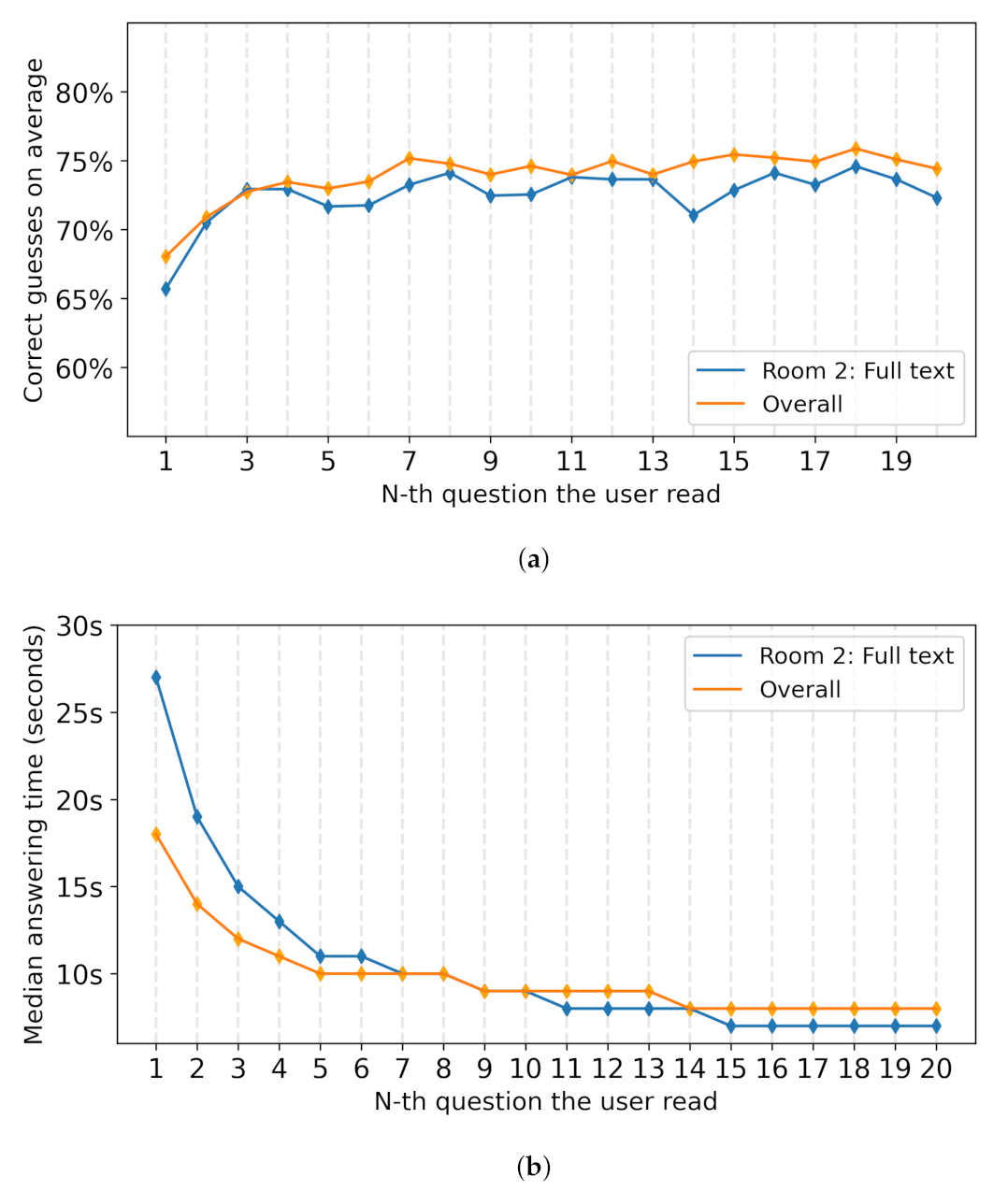
4.1. Individual Decisions and Social Influence
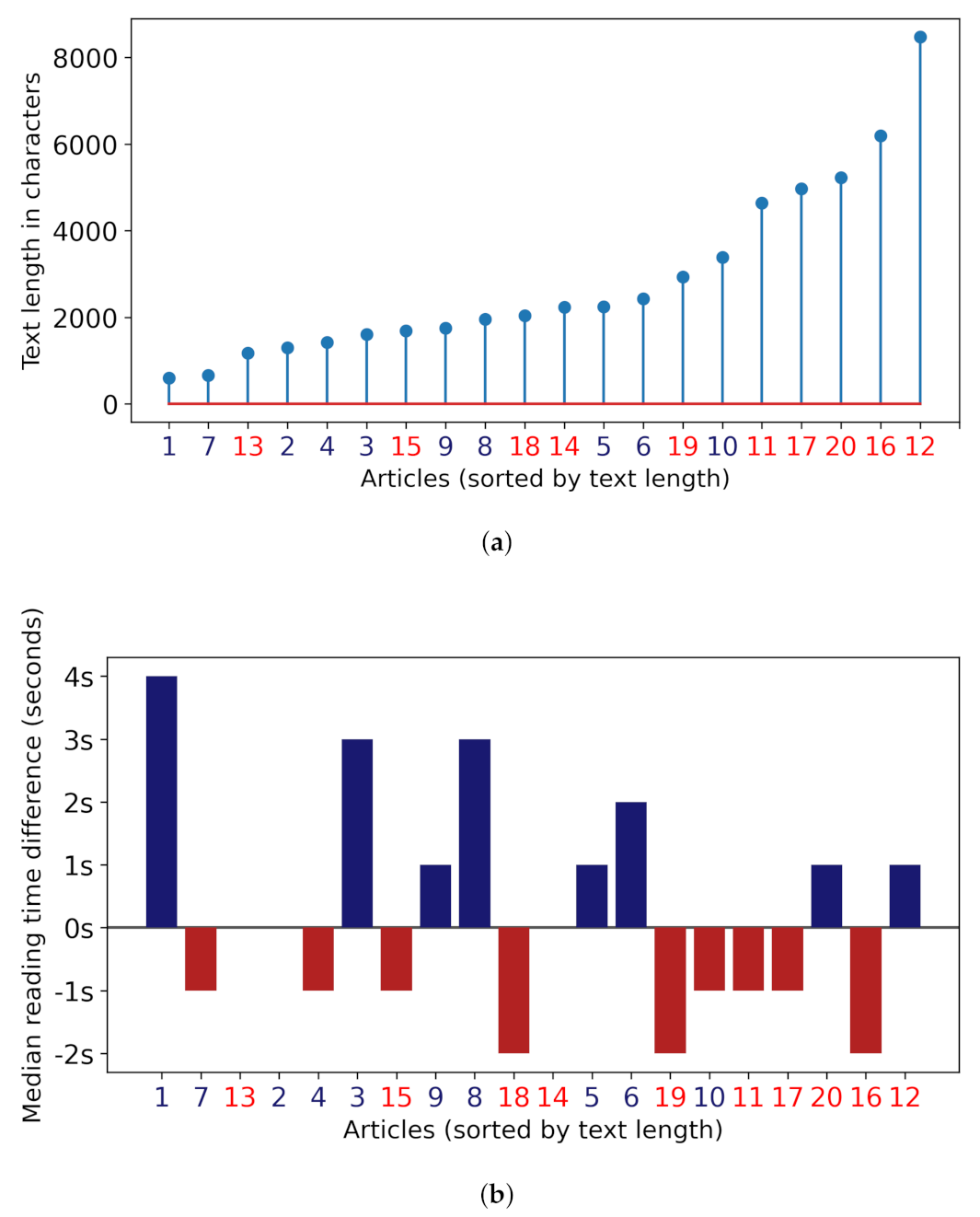
4.2. More Information Is Not Better Information
4.3. Web Familiarity, Fact Checking and Young Users
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Ethical and Reproducibility Statement
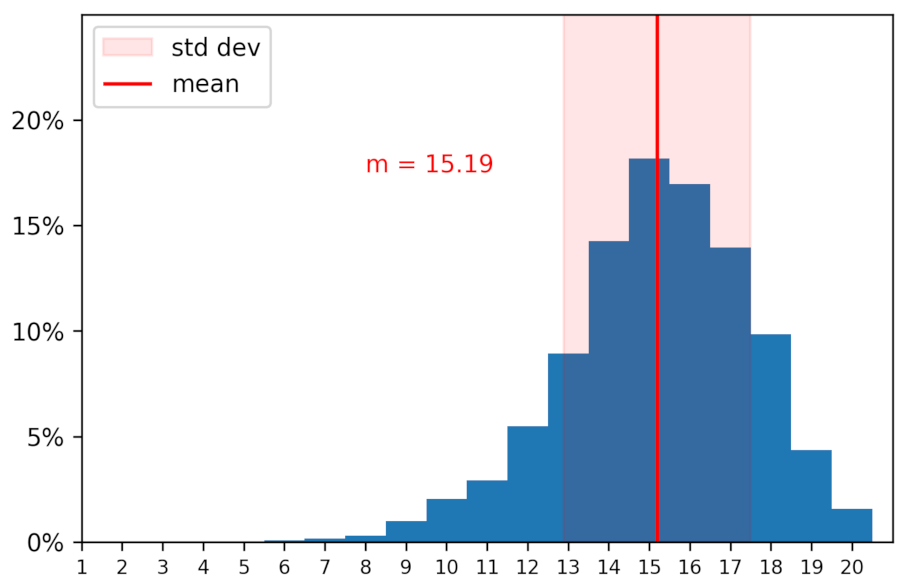
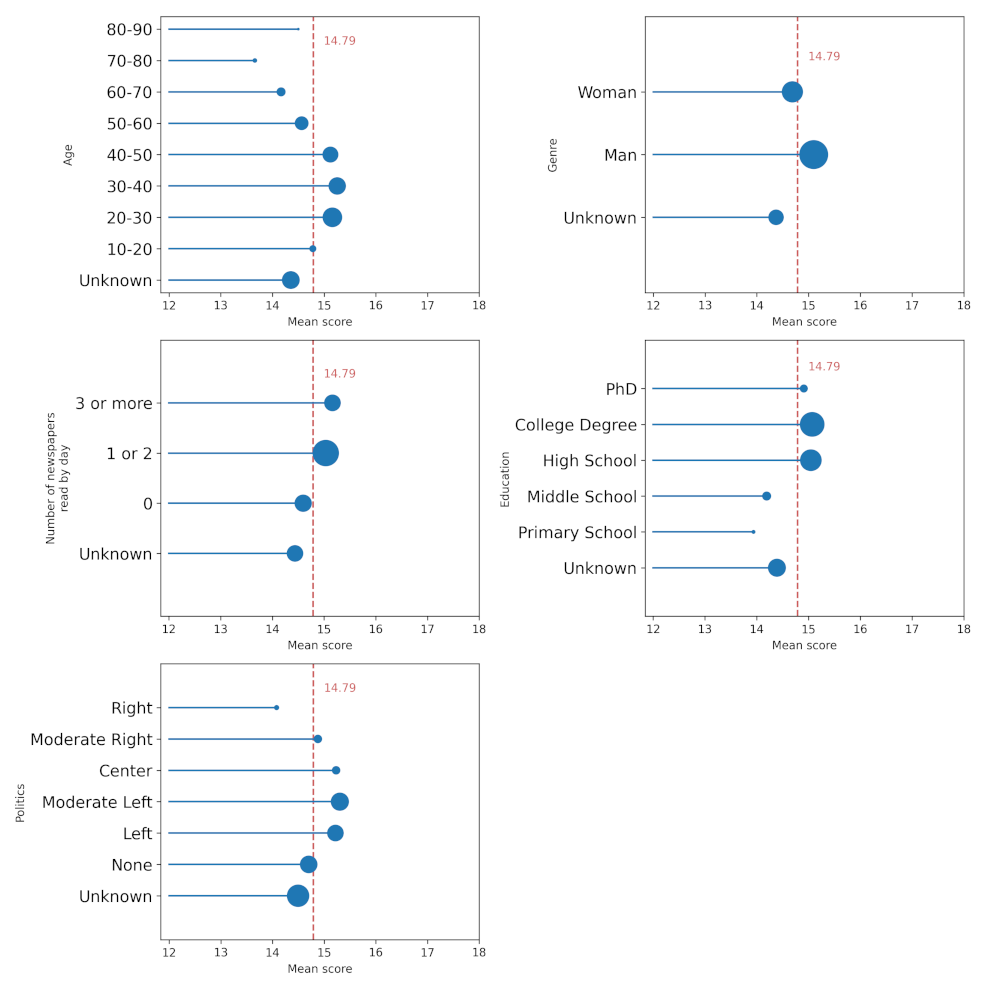
Appendix A.2. Demography of Users

Appendix A.3. News

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Headline | |
|---|---|---|
| True news | 1 | A “too violent arrest”: policeman sentenced on appeal trial to compensate the criminal |
| 2 | The Islamic headscarf will be part of the Scottish police uniform | |
| 3 | Savona, drunk and drug addict policeman runs over and kills an elderly man | |
| 4 | Erdogan: The West is more concerned about gay rights than Syria | |
| 5 | # Cop20: the ancient Nazca lines damaged by Greenpeace activists | |
| 6 | Rome, policemen attacked and stoned in the Roma camp | |
| 7 | Thief tries to break into a house but the dog bites him: he asks for damages | |
| 8 | These flowers killed my kitty - don’t keep them indoors if you have them | |
| 9 | Climate strike, Friday for future Italy launches fundraising | |
| 10 | Paris, big fire devastates Notre-Dame: roof and spire collapsed | The firefighters: “The structure is safe” | |
| False news | 11 | Carola Rackete: “The German government ordered me to bring migrants to Italy” |
| 12 | With the agreement of Caen Gentiloni sells Italian waters (and oil) to France | |
| 13 | Vinegar eliminated from school canteens because prohibited by the Koran | |
| 14 | He kills an elderly Jewish woman at the cry of Allah Akbar: acquitted because he was drugged | |
| 15 | The measles virus defeats cancer. But we persist in defeating the measles virus! | |
| 16 | 193 million from the EU to free children from the stereotypes of father and mother | |
| 17 | Astonishing: parliament passes the law to check our Facebook profiles | |
| 18 | Italy. The first illegal immigrant mayor elected: “This is how I will change Italian politics” | |
| 19 | INPS: 60,000 IMMIGRANTS IN RETIREMENT WITHOUT HAVING EVER WORKED | |
| 20 | EU: 700 million on 5G, but no risk controls |
| Id | Source | Type | Tagged as | |
|---|---|---|---|---|
| True news | 1 | Sostenitori delle Forze dell’Ordine | blacklisted | |
| 2 | Il Giornale | mainstream | ||
| 3 | Today | mainstream | ||
| 4 | L’antidiplomatico | online newspaper | ||
| 5 | Greenme | online newspaper | ||
| 6 | Il Messaggero | online newspaper | ||
| 7 | CorriereAdriatico | mainstream | ||
| 8 | PostVirale | blog | ||
| 9 | Adnkronos | mainstreeam | ||
| 10 | TgCom | mainstreeam | ||
| False news | 11 | IlGiornale | mainstreeam | Wrong Translation–Pseudo-Journalism |
| 12 | Diario Del Web | online newspaper | Hoax–Alarmism | |
| 13 | ImolaOggi | blacklisted | Hoax | |
| 14 | La Voce del Patriota | blog | Clarifications Needed | |
| 15 | Il Sapere è Potere | blackisted | Disinformation | |
| 16 | Jeda News | blacklisted | Well Poisoning | |
| 17 | Italiano Sveglia | blacklisted | Hoax–Disinformation | |
| 18 | Il Fatto Quotidaino | blacklisted | Hoax | |
| 19 | VoxNews | blacklisted | Unsubstantiated–Disinformation | |
| 20 | Oasi Sana | blog | Well Poisoning–Pseudo-Journalism |
Appendix A.4. Qualitative Assessment of Biases about Perception of Credibility
- Q1: What are, based on your experience and competencies, the main indicators of the credibility of a news article on social networks?Participants spontaneously converged on the source of the article (9 out of 10), followed at a distance by the sources cited by the article, the coverage of the news across diverse sources, and who the social network users are that broke the news.
- Q2: In your experience, what makes you think a news piece could be false?Participants pointed out mainly the poor quality of the news (8 out of 10), but also an unreliable publisher (5 out of 10) and a lack of support in other news outlets (3 out of 10).
- Q3: Based on your experience, how do you rate the quality and quantity of information reported in the news previews on social networks?Participants found the quality of news previews to be poor (7 out of 10), with a slight tendency to clickbait, regardless of the news publisher. Additionally, the quantity of information was pointed out as insufficient (4 out of 10).
- Q4: Does there exist, according to you, a relationship between news credibility and the response of users on social networks? If you think it exists, could you explain what you think it is?A total of 6 out of 10 participants believed that bold claims, especially from false news publishers, result in higher arousal among readers, which can also foster news diffusion. However, 4 out of 10 participants did not acknowledge any direct relationship between credibility and public response.
- Q5: How do you make sure a piece of news is credible when you are in doubt, in your experience as a user?Participants unanimously indicated a parallel search on other news sources. Additionally, 4 out of 10 participants mentioned the need for checking on reliable sources, such as debunking websites.
- Q1 Based on your knowledge of the domain, do you think that the source a news article is taken from is an important feature for assessing news credibility?Most users agreed that news outlets play a role in the perception of credibility.
- Q2 From Round 1, it emerged that information contained in news previews on social networks is often poor in terms of quality. Do you think that reading the entirety of an article can bring more useful information to decide whether the article is credible or not?A total of 6 out of 10 users strongly agreed, while the remaining mildly agreed.
- Q3 From the previous round, a relationship emerged between the credibility of news and users’ response. Based on your knowledge of the domain, do you think that an interface that shows the opinion of the majority of users about the credibility of the news piece can be effective in influencing the opinion of an individual?Experts are divided, as 3 out of 10 answered "Not much", while 3 out of 10 answered "Very much".
- Q4 From the previous round, agreement about the need to check the coverage of a news piece on other sources before deciding about its credibility emerged. What do you think is the percentage of users that search for the credibility of some news before making up their minds on it?A total of 4 out of 10 participants indicated “5% to 10%”, while the remaining were equally divided into “10% to 20%” and “20% to 30%”.
- Q5 Considering a given percentage of users that check for the credibility of news on other sources, do you think that the majority of them belong to one (or more) of which of the following generations?Overall, 60% of answers indicated “Millennials 1981–1996” as the generation more likely to fact-check news online, while only a minority indicated older generations, such as “Gen X (1965–1980) ”, or younger, such as “Gen Z (1997–2012)” (both at 20%). For almost one-third of respondents, there was no relationship between age and the propensity to search for the same news on different outlets.
References
- Council of Europe. Information Disorder: Toward an Interdisciplinary Framework for Research and Policy Making. Available online: https://rm.coe.int/information-disorder-report-november-2017/1680764666 (accessed on 13 October 2020).
- Unesco. Journalism. ’Fake News’ and Disinformation: A Handbook for Journalism Education and Training. Available online: https://en.unesco.org/sites/default/files/f._jfnd_handbook_module_2.pdf (accessed on 13 October 2020).
- Speech of Vice President Vera Jourova on Countering Disinformation amid COVID-19 “From Pandemic to Infodemic”. Available online: https://ec.europa.eu/commission/presscorner/detail/it/speech_20_1000 (accessed on 6 August 2021).
- Shearer, E. More Than Eight-in-Ten Americans Get News from Digital Devices. Available online: https://www.pewresearch.org/fact-tank/2021/01/12/more-than-eight-in-ten-americans-get-news-from-digital-devices/ (accessed on 8 June 2021).
- Lazer, D.M.J.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, D.; et al. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef] [PubMed]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Grinberg, N.; Joseph, K.; Friedland, L.; Swire-Thompson, B.; Lazer, D. Fake news on Twitter during the 2016 U.S. presidential election. Science 2019, 363, 374–378. [Google Scholar] [CrossRef] [PubMed]
- Flaxman, S.; Goel, S.; Rao, J.M. Filter Bubbles, Echo Chambers, and Online News Consumption. Public Opin. Q. 2016, 80, 298–320. [Google Scholar] [CrossRef]
- Nadeau, R.; Cloutier, E.; Guay, J.H. New Evidence About the Existence of a Bandwagon Effect in the Opinion Formation Process. Int. Political Sci. Rev. 1993, 14, 203–213. [Google Scholar] [CrossRef]
- Nickerson, R.S. Confirmation Bias: A Ubiquitous Phenomenon in Many Guises. Rev. Gen. Psychol. 1998, 2, 175–220. [Google Scholar] [CrossRef]
- Butler, A.C.; Fazio, L.K.; Marsh, E. The hypercorrection effect persists over a week, but high-confidence errors return. Psychon. Bull. Rev. 2011, 18, 1238–1244. [Google Scholar] [CrossRef]
- Yuan, C.; Ma, Q.; Zhou, W.; Han, J.; Hu, S. Early Detection of Fake News by Utilizing the Credibility of News, Publishers, and Users based on Weakly Supervised Learning. In Proceedings of the 28th International Conference on Computational Linguistics; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 5444–5454. [Google Scholar] [CrossRef]
- Sitaula, N.; Mohan, C.K.; Grygiel, J.; Zhou, X.; Zafarani, R. Credibility-Based Fake News Detection. In Disinformation, Misinformation, and Fake News in Social Media: Emerging Research Challenges and Opportunities; Shu, K., Wang, S., Lee, D., Liu, H., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 163–182. [Google Scholar] [CrossRef]
- Mitra, T.; Gilbert, E. CREDBANK: A Large-Scale Social Media Corpus With Associated Credibility Annotations. Proc. Int. Aaai Conf. Web Soc. Media 2021, 9, 258–267. [Google Scholar]
- Shu, K.; Zheng, G.; Li, Y.; Mukherjee, S.; Awadallah, A.; Ruston, S.; Liu, H. Early Detection of Fake News with Multi-source Weak Social Supervision. In Proceedings of the Machine Learning and Knowledge Discovery in Databases-European Conference, ECML PKDD 2020, Ghent, Belgium, 14–18 September 2020, Proceedings; Hutter, F., Kersting, K., Lijffijt, J., Valera, I., Eds.; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2021; pp. 650–666. [Google Scholar] [CrossRef]
- Tschiatschek, S.; Singla, A.; Gomez Rodriguez, M.; Merchant, A.; Krause, A. Fake News Detection in Social Networks via Crowd Signals. In Proceedings of the Companion The Web Conference 2018, Lyon, France, 25–29 April 2018; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2018; pp. 517–524. [Google Scholar] [CrossRef]
- Qiu, X.; Oliveira, D.F.; Shirazi, A.S.; Flammini, A.; Menczer, F. Limited individual attention and online virality of low-quality information. Nat. Hum. Behav. 2017, 1, 0132. [Google Scholar] [CrossRef]
- Karnowski, V.; Kümpel, A.S.; Leonhard, L.; Leiner, D.J. From incidental news exposure to news engagement. How perceptions of the news post and news usage patterns influence engagement with news articles encountered on Facebook. Comput. Hum. Behav. 2017, 76, 42–50. [Google Scholar] [CrossRef]
- Sterrett, D.; Malato, D.; Benz, J.; Kantor, L.; Tompson, T.; Rosenstiel, T.; Sonderman, J.; Loker, K. Who Shared It?: Deciding What News to Trust on Social Media. Digit. J. 2019, 7, 783–801. [Google Scholar] [CrossRef]
- Pennycook, G.; Rand, D.G. Fighting misinformation on social media using crowdsourced judgments of news source quality. Proc. Natl. Acad. Sci. USA 2019, 116, 2521–2526. [Google Scholar] [CrossRef] [PubMed]
- Vargo, C.J.; Guo, L.; Amazeen, M.A. The agenda-setting power of fake news: A big data analysis of the online media landscape from 2014 to 2016. New Media Soc. 2018, 20, 2028–2049. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M.; Yu, C. Trends in the diffusion of misinformation on social media. Res. Politics 2019, 6, 205316801984855. [Google Scholar] [CrossRef]
- Guess, A.; Nyhan, B.; Reifler, J. Selective exposure to misinformation: Evidence from the consumption of fake news during the 2016 US presidential campaign. Eur. Res. Counc. 2018, 9, 4. [Google Scholar]
- Tacchini, E.; Ballarin, G.; Vedova, M.L.D.; Moret, S.; de Alfaro, L. Some Like it Hoax: Automated Fake News Detection in Social Networks. CoRR 2017. Available online: https://arxiv.org/abs/1704.07506 (accessed on 29 August 2022).
- Carr, D.J.; Barnidge, M.; Lee, B.G.; Tsang, S.J. Cynics and Skeptics: Evaluating the Credibility of Mainstream and Citizen Journalism. J. Mass Commun. Q. 2014, 91, 452–470. [Google Scholar] [CrossRef]
- Go, E.; Jung, E.H.; Wu, M. The effects of source cues on online news perception. Comput. Hum. Behav. 2014, 38, 358–367. [Google Scholar] [CrossRef]
- Houston, J.B.; Hansen, G.J.; Nisbett, G.S. Influence of User Comments on Perceptions of Media Bias and Third-Person Effect in Online News. Electron. News 2011, 5, 79–92. [Google Scholar] [CrossRef]
- Rojas, H. “Corrective” Actions in the Public Sphere: How Perceptions of Media and Media Effects Shape Political Behaviors. Int. J. Public Opin. Res. 2010, 22, 343–363. [Google Scholar] [CrossRef]
- Lee, E.J.; Jang, Y.J. What Do Others’ Reactions to News on Internet Portal Sites Tell Us? Effects of Presentation Format and Readers’ Need for Cognition on Reality Perception. Commun. Res. 2010, 37, 825–846. [Google Scholar] [CrossRef]
- Colliander, J. “This is fake news”: Investigating the role of conformity to other users’ views when commenting on and spreading disinformation in social media. Comput. Hum. Behav. 2019, 97, 202–215. [Google Scholar] [CrossRef]
- Winter, S.; Brückner, C.; Krämer, N.C. They Came, They Liked, They Commented: Social Influence on Facebook News Channels. Cyberpsychology Behav. Soc. Netw. 2015, 18, 431–436. [Google Scholar] [CrossRef] [PubMed]
- Ruffo, G.; Semeraro, A.; Giachanou, A.; Rosso, P. Surveying the Research on Fake News in Social Media: A Tale of Networks and Language. arXiv 2021, arXiv:2109.07909. [Google Scholar]
- Pennycook, G. Who falls for fake news? The roles of bullshit receptivity, overclaiming, familiarity, and analytic thinking. J. Personal. 2019, 88, 185–200. [Google Scholar] [CrossRef] [PubMed]
- Micallef, N.; Avram, M.; Menczer, F.; Patil, S. Fakey: A Game Intervention to Improve News Literacy on Social Media. Proc. ACM-Hum.-Comput. Interact. 2021, 5, 1–27. [Google Scholar] [CrossRef]
- Pennycook, G.; Cannon, T.D.; Rand, D.G. Prior exposure increases perceived accuracy of fake news. J. Exp. Psychol. Gen. 2018, 147, 1865. [Google Scholar] [CrossRef]
- Salganik, M.J.; Dodds, P.S.; Watts, D.J. Experimental study of inequality and unpredictability in an artificial cultural market. Science 2006, 311, 854–856. [Google Scholar] [CrossRef]
- Hassan, N.; Arslan, F.; Li, C.; Tremayne, M. Toward Automated Fact-Checking: Detecting Check-Worthy Factual Claims by ClaimBuster. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery, New York, NY, USA, 13 August 2017; pp. 1803–1812. [Google Scholar] [CrossRef]
- Robertson, C.T.; Mourão, R.R.; Thorson, E. Who Uses Fact-Checking Sites? The Impact of Demographics, Political Antecedents, and Media Use on Fact-Checking Site Awareness, Attitudes, and Behavior. Int. J. Press. 2020, 25, 217–237. [Google Scholar] [CrossRef]
- Myers, D.G.; Wojcicki, S.B.; Aardema, B.S. Attitude Comparison: Is There Ever a Bandwagon Effect? J. Appl. Soc. Psychol. 1977, 7, 341–347. [Google Scholar] [CrossRef]
- Cialdini, R.B.; Goldstein, N.J. Social influence: Compliance and conformity. Annu. Rev. Psychol. 2004, 55, 591–621. [Google Scholar] [CrossRef] [PubMed]
- Aronson, E.; Wilson, T.D.; Akert, R.M. Social Psychology; Prentice Hall: Upper Saddle River, NJ, USA, 2005; Volume 5. [Google Scholar]
- Kremer, I.; Mansour, Y.; Perry, M. Implementing the “Wisdom of the Crowd”. J. Political Econ. 2014, 122, 988–1012. [Google Scholar] [CrossRef]
- Kumar, S.; West, R.; Leskovec, J. Disinformation on the Web: Impact, Characteristics, and Detection of Wikipedia Hoaxes. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2016; pp. 591–602. [Google Scholar] [CrossRef]
- Ghanem, B.; Rosso, P.; Rangel, F. An Emotional Analysis of False Information in Social Media and News Articles. ACM Trans. Internet Technol. 2020, 20, 1–18. [Google Scholar] [CrossRef]
- Chung, C.J.; Nam, Y.; Stefanone, M.A. Exploring Online News Credibility: The Relative Influence of Traditional and Technological Factors. J. Comp.-Med. Commun. 2012, 17, 171–186. [Google Scholar] [CrossRef]
- Wineburg, S.; McGrew, S. Lateral Reading: Reading Less and Learning More When Evaluating Digital Information. Soc. Sci. Res. Netw. 2017. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3048994 (accessed on 29 August 2022).
- Brashier, N.M.; Schacter, D.L. Aging in an Era of Fake News. Curr. Dir. Psychol. Sci. 2020, 29, 316–323. [Google Scholar] [CrossRef]
- Bhagat, S.; Kim, D.J. Examining users’ news sharing behaviour on social media: Role of perception of online civic engagement and dual social influences. Behav. Inf. Technol. 2022, 1–22. Available online: https://www.tandfonline.com/doi/abs/10.1080/0144929X.2022.2066019?journalCode=tbit20 (accessed on 29 August 2022).
- Turel, O.; Osatuyi, B. Biased credibility and sharing of fake news on social media: Considering peer context and self-objectivity state. J. Manag. Inf. Syst. 2021, 38, 931–958. [Google Scholar] [CrossRef]
- Robertson, C.T. Trust in Congruent Sources, Absolutely: The Moderating Effects of Ideological and Epistemological Beliefs on the Relationship between Perceived Source Congruency and News Credibility. J. Stud. 2021, 22, 896–915. [Google Scholar] [CrossRef]
- Wobbrock, J.O.; Hattatoglu, L.; Hsu, A.K.; Burger, M.A.; Magee, M.J. The Goldilocks zone: Young adults’ credibility perceptions of online news articles based on visual appearance. N. Rev. Hypermedia Multimed. 2021, 27, 51–96. [Google Scholar] [CrossRef]
- Waddell, T.F. What does the crowd think? How online comments and popularity metrics affect news credibility and issue importance. New Media Soc. 2018, 20, 3068–3083. [Google Scholar] [CrossRef]
- Petit, J.; Li, C.; Millet, B.; Ali, K.; Sun, R. Can we stop the spread of false information on vaccination? How online comments on vaccination news affect readers’ credibility assessments and sharing behaviors. Sci. Commun. 2021, 43, 407–434. [Google Scholar] [CrossRef]
- Breakstone, J.; Smith, M.; Connors, P.; Ortega, T.; Kerr, D.; Wineburg, S. Lateral reading: College students learn to critically evaluate internet sources in an online course. Harv. Kennedy Sch. Misinformation Rev. 2021. Available online: https://dash.harvard.edu/handle/1/37367209 (accessed on 29 August 2022).
- Brodsky, J.E.; Brooks, P.J.; Scimeca, D.; Galati, P.; Todorova, R.; Caulfield, M. Associations between online instruction in lateral reading strategies and fact-checking COVID-19 News Among College Students. AERA Open 2021, 7, 23328584211038937. [Google Scholar] [CrossRef]
- Guess, A.; Nagler, J.; Tucker, J. Less than you think: Prevalence and predictors of fake news dissemination on Facebook. Sci. Adv. 2019, 5, eaau4586. [Google Scholar] [CrossRef] [PubMed]
- Helmer-Hirschberg, O. Analysis of the Future: The Delphi Method; RAND Corporation: Santa Monica, CA, USA, 1967. [Google Scholar]












| Room | Finished Tests | Completion |
|---|---|---|
| 1: Headline | 21.72% | 81.76% |
| 2: Full text | 17.42% | 70.00% |
| 3: Source | 20.81% | 79.18% |
| 4: Social ratings | 20.50% | 79.97% |
| 5: Random ratings | 19.55% | 79.01% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruffo, G.; Semeraro, A. FakeNewsLab: Experimental Study on Biases and Pitfalls Preventing Us from Distinguishing True from False News. Future Internet 2022, 14, 283. https://doi.org/10.3390/fi14100283
Ruffo G, Semeraro A. FakeNewsLab: Experimental Study on Biases and Pitfalls Preventing Us from Distinguishing True from False News. Future Internet. 2022; 14(10):283. https://doi.org/10.3390/fi14100283
Chicago/Turabian StyleRuffo, Giancarlo, and Alfonso Semeraro. 2022. "FakeNewsLab: Experimental Study on Biases and Pitfalls Preventing Us from Distinguishing True from False News" Future Internet 14, no. 10: 283. https://doi.org/10.3390/fi14100283
APA StyleRuffo, G., & Semeraro, A. (2022). FakeNewsLab: Experimental Study on Biases and Pitfalls Preventing Us from Distinguishing True from False News. Future Internet, 14(10), 283. https://doi.org/10.3390/fi14100283