
The Time Machine in Columnar NoSQL Databases: The Case of Apache HBase


Abstract
:1. Introduction
- Failure recovery: As mentioned, existing Col-NoSQL DBs can be recovered to a prior state. However, the restored state is the most recent state immediately before the failure. The objective of failure recovery in present Col-NoSQL is to leverage the availability of DBs to offer services.
- Analysis for historical data: Col-NoSQL DBs are often operated in a manner that enable DBs to operate online to accommodate any newly inserted/updated data items even with the existence of other DBs that act as backups which clone parts of past data items stored in the tables maintained by the serving DBs. Analysis is then performed on the backups.
- Debugging: Col-NoSQL DBs are improved over time. Rich features are incrementally released along with the later versions. Enterprises may prefer to test newly introduced features. Therefore, with their prior data sets in standalone environments, serving Col-NoSQL DBs are isolated from the tests. Restoring the past data items in Col-NoSQL database tables on the fly into standalone ones means that testing environments becomes an issue.
- Auditing: State-of-the-art Col-NoSQL DBs such as HBase and Phoenix [9] have enhanced security features such as access control lists (ACL). Users who intend to manipulate a database table are authorized first, and then authenticated before they gain access. However, even with authorized and authenticated users, information in accessed database tables may be critical. Preferably, a database management system can report when a user reads and/or writes a database table in certain values, thus tracing the user’s access pattern.
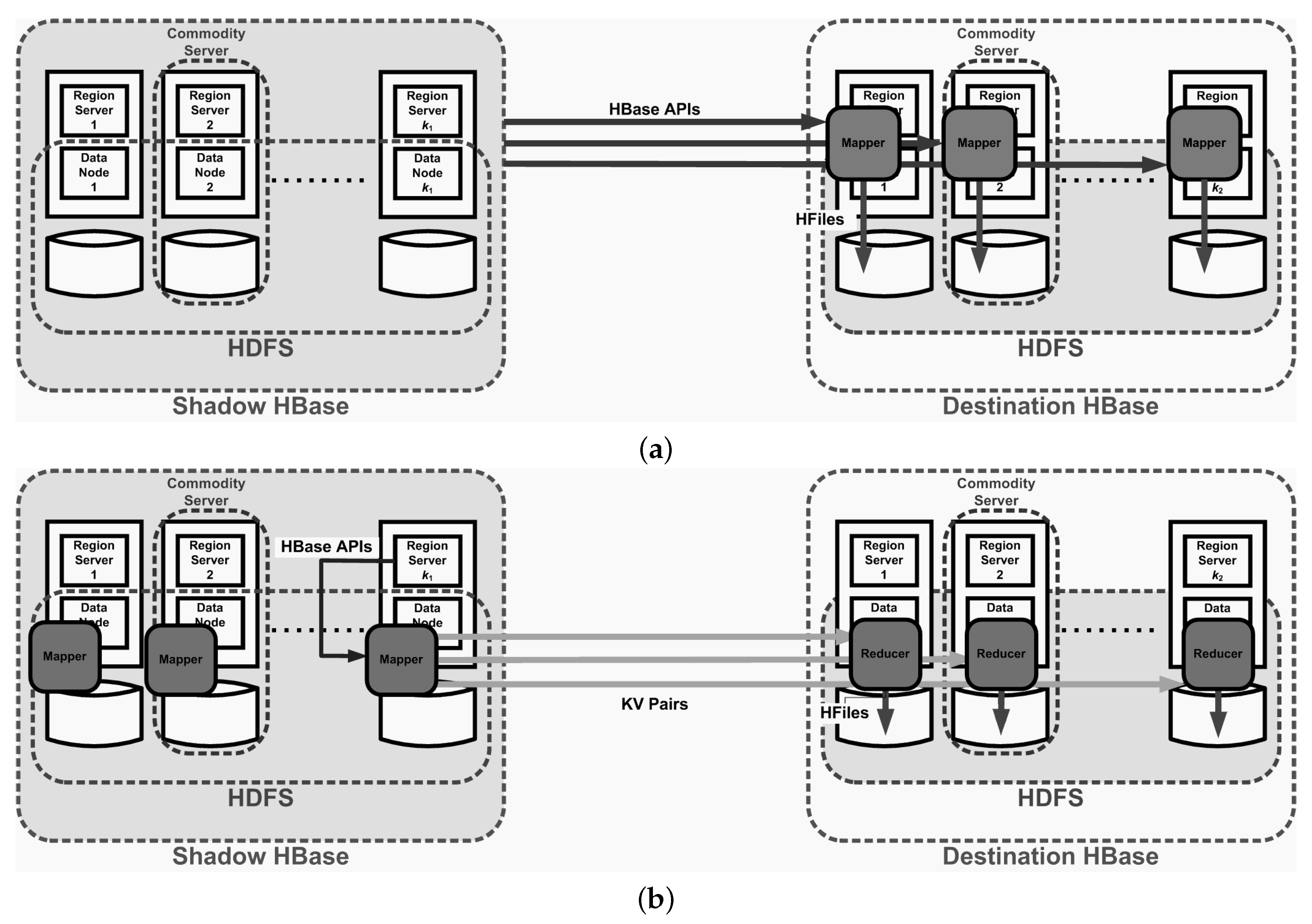
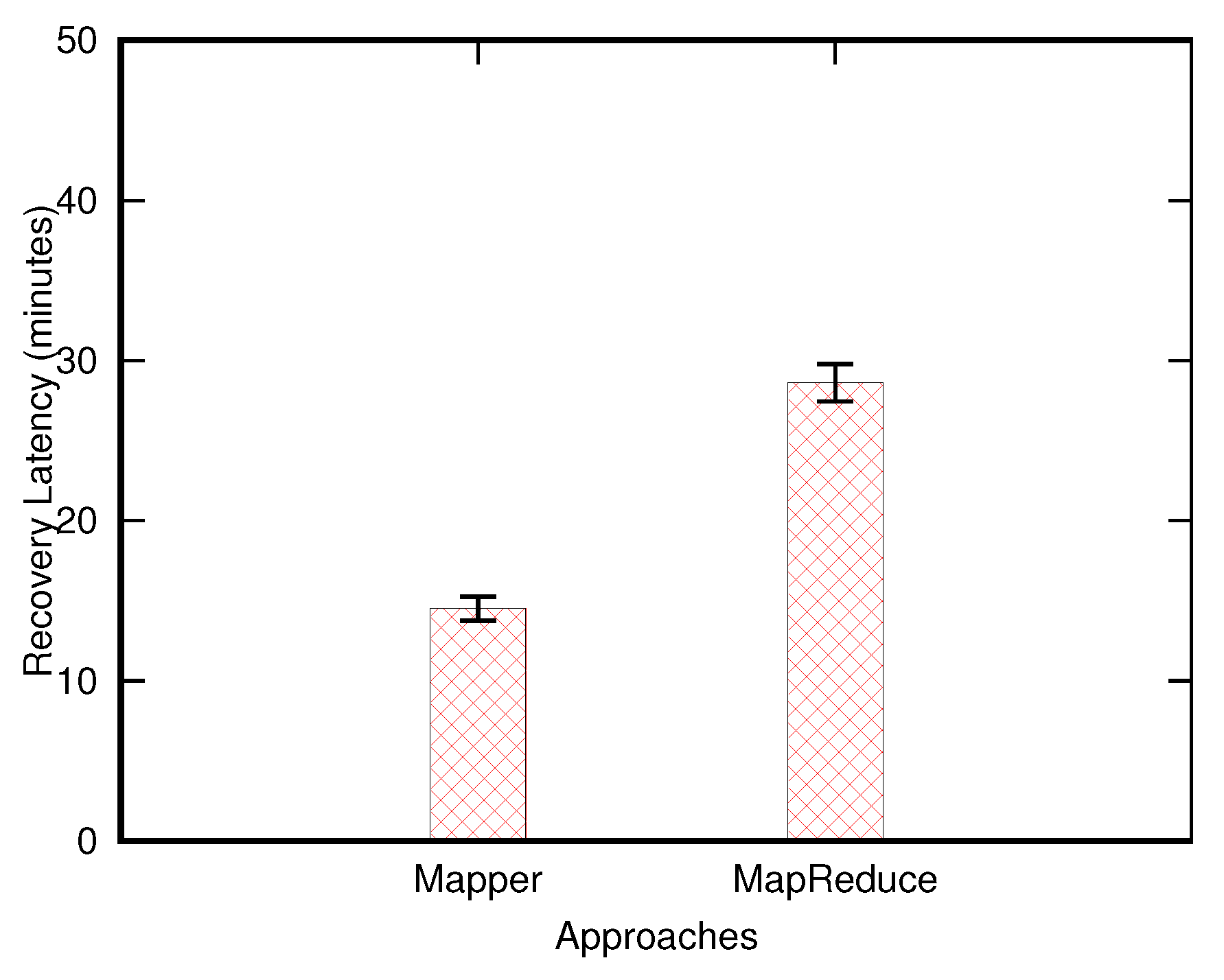
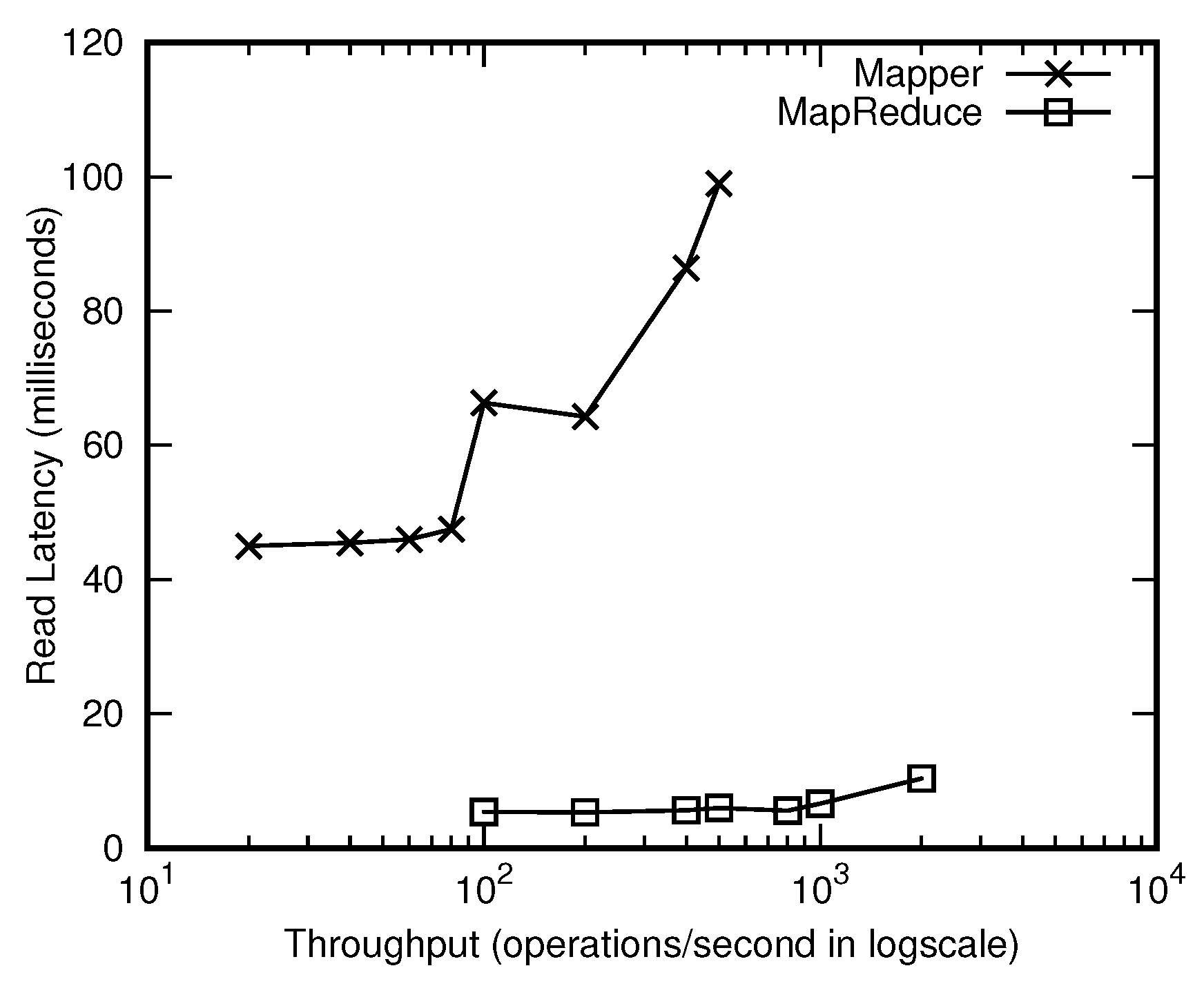
- Mapper-based: The mapper-based approach operates when the MapReduce framework [11,12] is available. Specifically, the framework shall be present in the target HBase cluster. The mapper-based approach takes advantage of parallelism for transforming and loading the data set for the destination cluster to minimize the delay of recovery. However, the mapper-based solution would place an additional burden on memory utilization in the target cluster side.
- Mapreduce-based: The mapreduce-based approach is yet another solution that depends on the MapReduce framework to extract, transform, and load designated data items into the destination HBase cluster. This approach is guaranteed to operate reliably, thereby ensuring that the recovery process is complete. Our proposed solutions not only bear scalability in mind, but also take the quality of recovered tables into our design considerations.
2. System Model and Research Problem
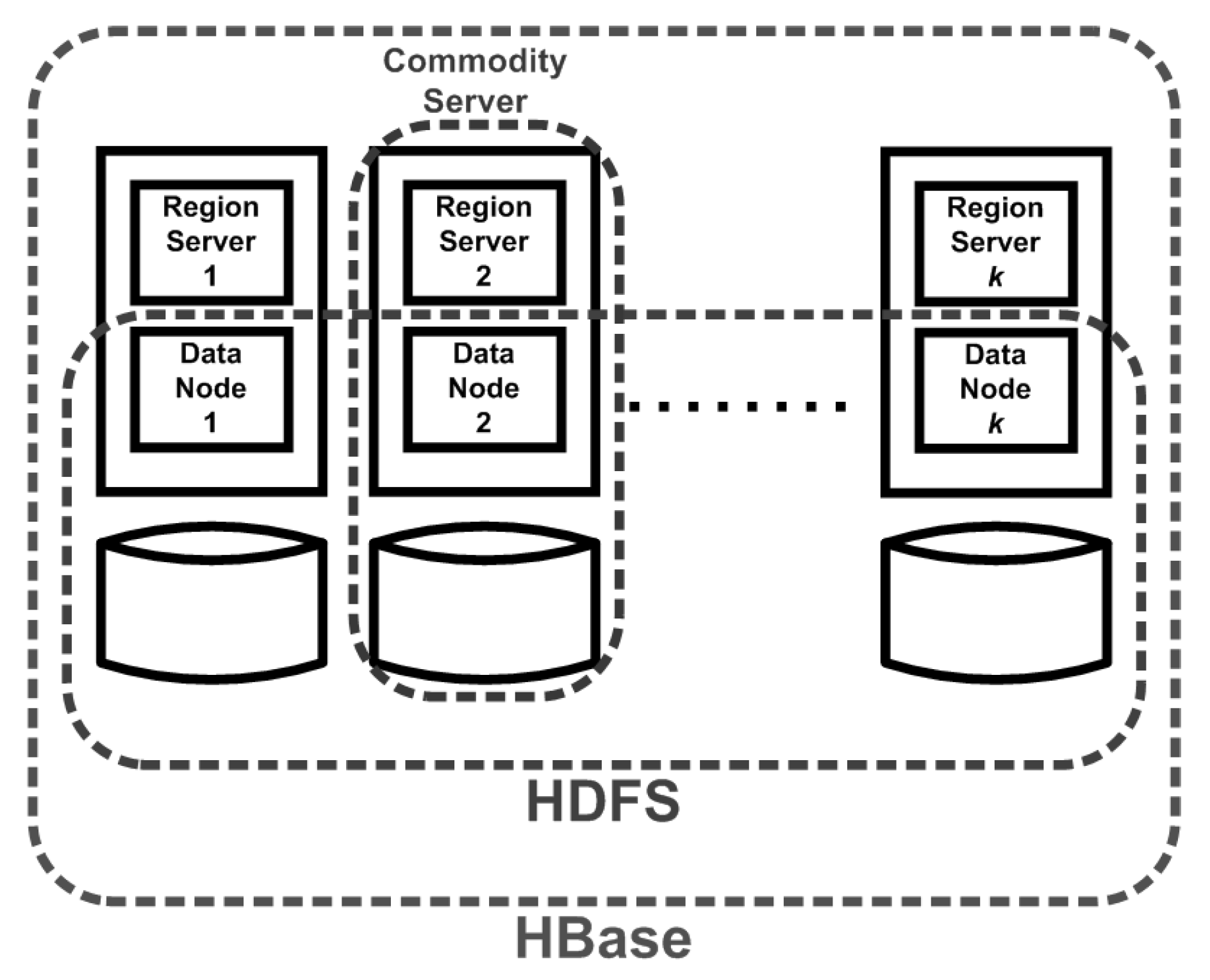
2.1. System Model
2.2. Research Problem
- is a region of T for any ;
- for any , and ;
- .
- a table restoration process that finds in for the time period between and ;
- a table deployment process that partitions into such that is a valid HBase cluster.
3. Architectures and Approaches
3.1. Design Considerations
- Time for recovery: Recovering requested data objects may take time. Specifically, the time required for recovery includes time periods for performing the table restoration and deployment processes as defined in Definitions 7 and 8, respectively. As the data to be recovered potentially are large (in terms of the number of bytes or rows), the table restoration and deployment processes shall be performed simultaneously to reduce the recovery time. On the other hand, we may have several computational entities to perform the recovery in parallel.
- Fault tolerance: As the recovery may take quite some time, entities involved in the recovery may fail, considering that failure is the norm. Solutions for recovery shall tolerate potential faults and can proceed subsequently once servers used to perform the recovery process fail. (We will specify clearly in Section 3.2 for our proposed architectures regarding computational entities in the recovery.)
- Scalability: As the size of data to be recovered can be very large, solutions designed for the DR problem shall be scalable in the sense that when the number of computational entities involved in addressing the problem increases, time for the table restoration and deployment processes shall be reduced accordingly. However, this situation depends on the availability of the entities that can join the recovery.
- Memory constraint: Servers that are involved in the recovery are often resource constraints, particularly the memory space. If the size of data to be recovered is far greater than any memory space available to any server for recovery, then several servers may be employed in the recovery to aggregate the available memory space or pipeline the computation of the data to be recovered and retain the computed data on the fly during the recovery.
- Software compatibility: Recovery solutions shall be compatible with existing software packages. Specifically, our targeted software environment is the Hadoop HBase, which is an open-source project of the Hadoop ecosystem. The functionality and performance of HBase are enhanced and improved over time. Solutions to the problem shall be operational for HBase versions that will be developed later.
- Quality of recovery: Once a table with designated data objects is recovered, the table deployed in the targeted HBase cluster may serve upcoming read and write requests. The concern is not only the integrity for the set of recovered data objects in the recovered table, but also the service rate of the table that will be delivered.
3.2. Proposals
3.2.1. Architecture
3.2.2. Application Programming Interfaces (APIs)
| Algorithm 1: A code example of extracting and loading data items during the replay |
 |
3.2.3. Data Structure
- Prefix: As can be quite large (in terms of the number of its maintained key-value pairs), the prefix field is used to partition and distribute into the region servers in the destination HBase cluster. If the number of region servers in the destination cluster is k, then the prefix is generated uniformly at random over .
- Batch Time Sequence: In the HBase, clients may put their key-value pairs into T in batches to amortize the RPC overhead per inserted key-value pair. In T, each of the key-value pairs in a batch is labeled with a unique timestamp, namely, the batch time sequence, when it is mirrored to a shadow table (i.e., in ). The time sequence basically refers to the local clock of the region server that hosts , thereby enabling the proposed approaches to recover data within a designated time period, as will be discussed later.
- ID of a Key-Value Pair in a Batch: To differentiate distinct key-value pairs in a batch for T, we assign each key-value pair in the batch an additional unique ID in . This step ensures that when a user performs two updates to the same (row) key at different times, if the two updates are allocated in the same batch, then they are labeled with different IDs in the batch. Consequently, our recovery solution can differentiate the two updates in case we want to recover any of them. On the other hand, in the HBase, if two updates go to the same key, the latter update will mask the former when they are issued by an identical client in the same batch. The ID of a key-value pair in a batch helps explicitly reveal the two updates.
- Region ID: The ID associated with in for the corresponding in T indicates the region server that hosts for T. Region IDs are critical when we aim to recover the distribution of regions in the HBase source cluster.
- Operation Type: The field denotes the operation for in T. Possible operations include PUT and DELETE provided by the HBase.
- Original Row Length: As a value of a key-value pair, , in T can be any byte string whose length varies. The original row length field indicates the number of bytes for the string length taken by the value of the key-value pair in T.
- Original Row Key Concatenated by Original Value: The original row key represents the row key of in T, and the original value is the value of . In addition to the value of , we also need to recover the row key of such that T with designated data objects is recovered.
3.2.4. Approaches
3.3. Discussion
4. Performance Evaluation
4.1. Experimental Setup
4.2. Performance Results
4.2.1. Overall Performance Comparisons
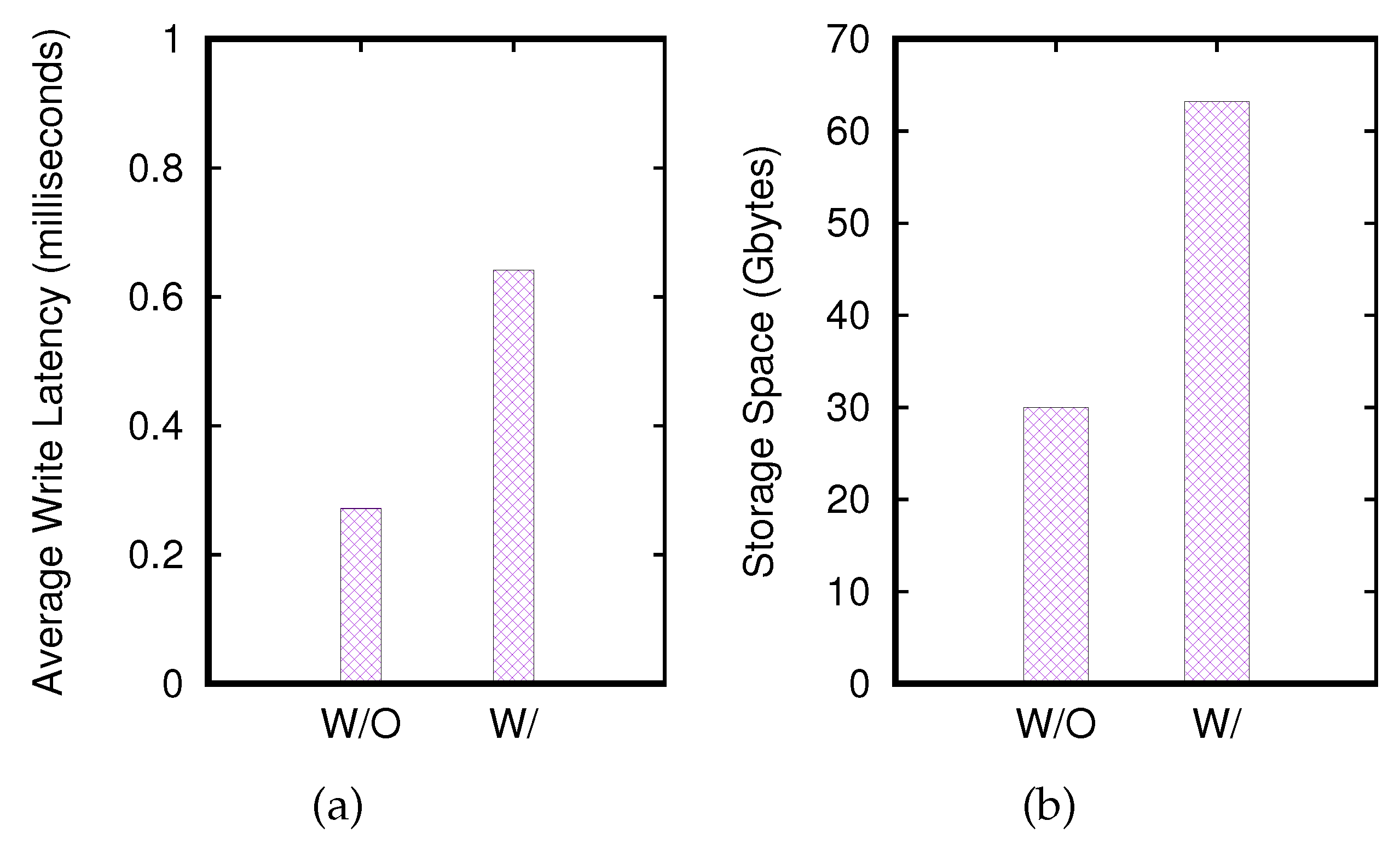
4.2.2. Effects of Varying the Data Set Size
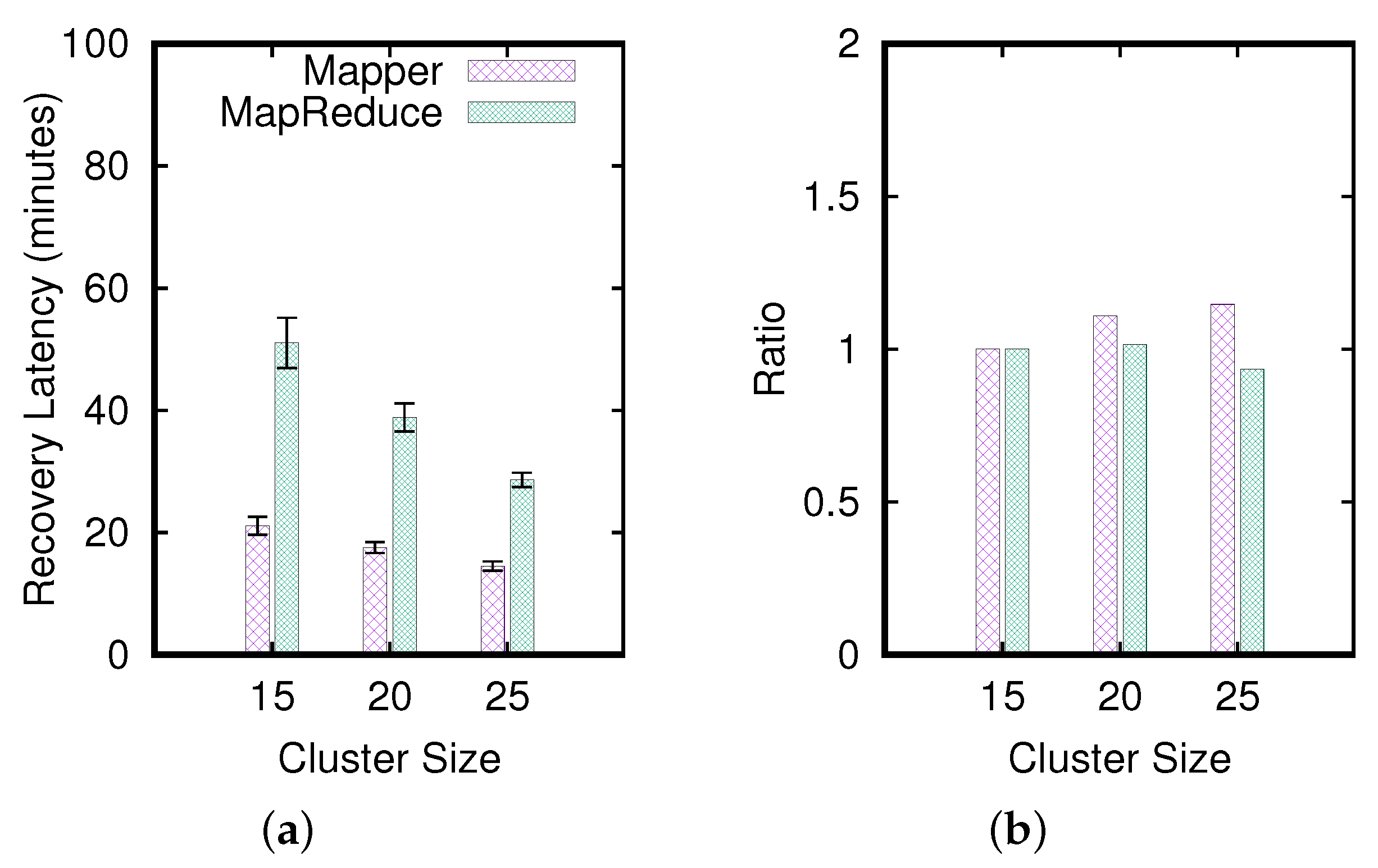
4.2.3. Effects of Varying the Cluster Size
5. Related Works
6. Summary and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Background of Apache HBase
References
- Deka, G.C. A Survey of Cloud Database Systems. IT Prof. 2014, 16, 50–57. [Google Scholar] [CrossRef]
- Leavitt, N. Will NoSQL Databases Live Up to Their Promise? IEEE Comput. 2010, 43, 12–14. [Google Scholar] [CrossRef]
- Apache Cassandra. Available online: http://cassandra.apache.org/ (accessed on 17 February 2022).
- Couchbase. Available online: http://www.couchbase.com/ (accessed on 17 February 2022).
- Apache HBase. Available online: http://hbase.apache.org/ (accessed on 17 February 2022).
- MongoDB. Available online: http://www.mongodb.org/ (accessed on 17 February 2022).
- Apache HDFS. Available online: http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html (accessed on 17 February 2022).
- MySQL. Available online: http://www.mysql.com/ (accessed on 17 February 2022).
- Apache Phoenix. Available online: http://phoenix.apache.org/ (accessed on 17 February 2022).
- DB-Engines. Available online: https://db-engines.com/en/ranking_trend/wide+column+store (accessed on 17 February 2022).
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. In Proceedings of the 6th Symposium Operating System Design and Implementation (OSDI’04), San Francisco, CA, USA, 6–8 December 2004; pp. 137–150. [Google Scholar]
- Apache Hadoop. Available online: http://hadoop.apache.org/ (accessed on 17 February 2022).
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking Cloud Serving Systems with YCSB. In Proceedings of the ACM Symposium Cloud Computing (SOCC’10), Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar]
- The Network Time Protocol. Available online: http://www.ntp.org/ (accessed on 17 February 2022).
- HBase Regions. Available online: https://hbase.apache.org/book/regions.arch.html (accessed on 17 February 2022).
- HBase APIs. Available online: http://hbase.apache.org/0.94/apidocs/ (accessed on 17 February 2022).
- IBM BladeCenter HS23. Available online: http://www-03.ibm.com/systems/bladecenter/hardware/servers/hs23/ (accessed on 17 February 2022).
- Webster, C. Hadoop Virtualization; O’Reilly: Sebastopol, CA, USA, 2015. [Google Scholar]
- VMware. Available online: http://www.vmware.com/ (accessed on 17 February 2022).
- HBase Snapshots. Available online: https://hbase.apache.org/book/ops.snapshots.html (accessed on 17 February 2022).
- Cloudera Snapshots. Available online: http://www.cloudera.com/content/cloudera-content/cloudera-docs/CM5/latest/Cloudera-Backup-Disaster-Recovery/cm5bdr_snapshot_intro.html (accessed on 17 February 2022).
- HBase Replication. Available online: http://blog.cloudera.com/blog/2012/07/hbase-replication-overview-2/ (accessed on 17 February 2022).
- HBase Export. Available online: https://hbase.apache.org/book/ops_mgt.html#export (accessed on 17 February 2022).
- HBase CopyTable. Available online: https://hbase.apache.org/book/ops_mgt.htm#copytable (accessed on 17 February 2022).
- Oracle Database Backup and Recovery. Available online: http://docs.oracle.com/cd/E11882_01/backup.112/e10642/rcmintro.htm#BRADV8001 (accessed on 17 February 2022).
- Matos, D.R.; Correia, M. NoSQL Undo: Recovering NoSQL Databases by Undoing Operations. In Proceedings of the IEEE International Symposium Network Computing and Applications (NCA), Boston, MA, USA, 31 October–2 November 2016; pp. 191–198. [Google Scholar]
- Abadi, A.; Haib, A.; Melamed, R.; Nassar, A.; Shribman, A.; Yasin, H. Holistic Disaster Recovery Approach for Big Data NoSQL Workloads. In Proceedings of the IEEE International Conference Big Data (BigData), Atlanta, GA, USA, 10–13 December 2016; pp. 2075–2080. [Google Scholar]
- Zhou, J.; Bruno, N.; Lin, W. Advanced Partitioning Techniques for Massively Distributed Computation. In Proceedings of the ACM SIGMOD, Scottsdale, AZ, USA, 20–24 May 2012; pp. 13–24. [Google Scholar]
- Wang, X.; Zhou, Z.; Zhao, Y.; Zhang, X.; Xing, K.; Xiao, F.; Yang, Z.; Liu, Y. Improving Urban Crowd Flow Prediction on Flexible Region Partition. IEEE Trans. Mob. Comput. 2019, 19, 2804–2817. [Google Scholar] [CrossRef]
- Wu, W.; Lin, W.; He, L.; Wu, G.; Hsu, C.-H. A Power Consumption Model for Cloud Servers Based on Elman Neural Network. IEEE Trans. Cloud Comput. (TCC) 2020, 9, 1268–1277. [Google Scholar] [CrossRef] [Green Version]
- Ye, K.; Shen, H.; Wang, Y.; Xu, C.-Z. Multi-tier Workload Consolidations in the Cloud: Profiling, Modeling and Optimization. IEEE Trans. Cloud Comput. (TCC) 2020, preprint. [Google Scholar] [CrossRef]
- Christidis, A.; Moschoyiannis, S.; Hsu, C.-H.; Davies, R. Enabling Serverless Deployment of Large-Scale AI Workloads. IEEE Access 2020, 8, 70150–70161. [Google Scholar] [CrossRef]
- Deka, L.; Barua, G. Consistent Online Backup in Transactional File Systems. IEEE Trans. Knowl. Data Eng. (TKDE) 2014, 26, 2676–2688. [Google Scholar] [CrossRef] [Green Version]
- Delta Lake. Available online: https://databricks.com/blog/2019/02/04/introducing-delta-time-travel-for-large-scale-data-lakes.html (accessed on 17 February 2022).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Row Key | Value | |||||
|---|---|---|---|---|---|---|
| … | … | |||||
| Prefix | Batch Time Sequence | ID of Key-Value Pair in a Batch | Region ID | Operation Type | Original Row Length | Original Row Key ⊕ Original Value |
| … | … | |||||
| Recovery Time | Fault Tolerance | Scalability | Memory Constraint | Software Compatibility | Recovery Quality | |
|---|---|---|---|---|---|---|
| Mapper-based | fast | yes | yes | single memory buffer | yes | poor |
| Mapreduce-based | medium | yes | yes | disk | yes | yes |
| Source (Shadow) | Destination | |
|---|---|---|
| HDFS | ||
| Namenode | ||
| Datanode | ||
| HBase | ||
| Master | ||
| Region server | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, C.-P.; Chang, C.-W.; Hsiao, H.-C.; Shen, H. The Time Machine in Columnar NoSQL Databases: The Case of Apache HBase. Future Internet 2022, 14, 92. https://doi.org/10.3390/fi14030092
Tsai C-P, Chang C-W, Hsiao H-C, Shen H. The Time Machine in Columnar NoSQL Databases: The Case of Apache HBase. Future Internet. 2022; 14(3):92. https://doi.org/10.3390/fi14030092
Chicago/Turabian StyleTsai, Chia-Ping, Che-Wei Chang, Hung-Chang Hsiao, and Haiying Shen. 2022. "The Time Machine in Columnar NoSQL Databases: The Case of Apache HBase" Future Internet 14, no. 3: 92. https://doi.org/10.3390/fi14030092
APA StyleTsai, C.-P., Chang, C.-W., Hsiao, H.-C., & Shen, H. (2022). The Time Machine in Columnar NoSQL Databases: The Case of Apache HBase. Future Internet, 14(3), 92. https://doi.org/10.3390/fi14030092