
A Vote-Based Architecture to Generate Classified Datasets and Improve Performance of Intrusion Detection Systems Based on Supervised Learning




Abstract
:1. Introduction
2. Related Work
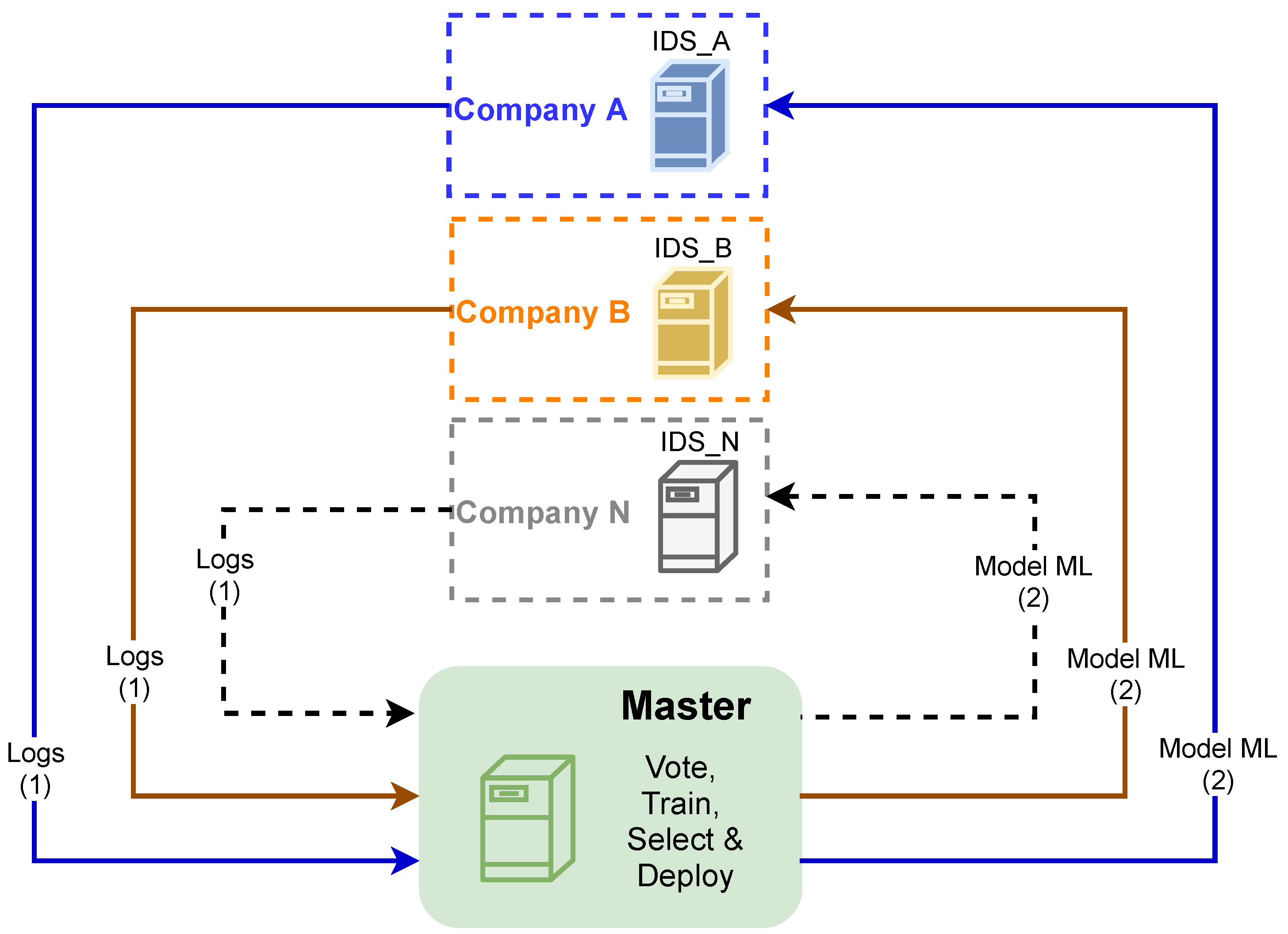
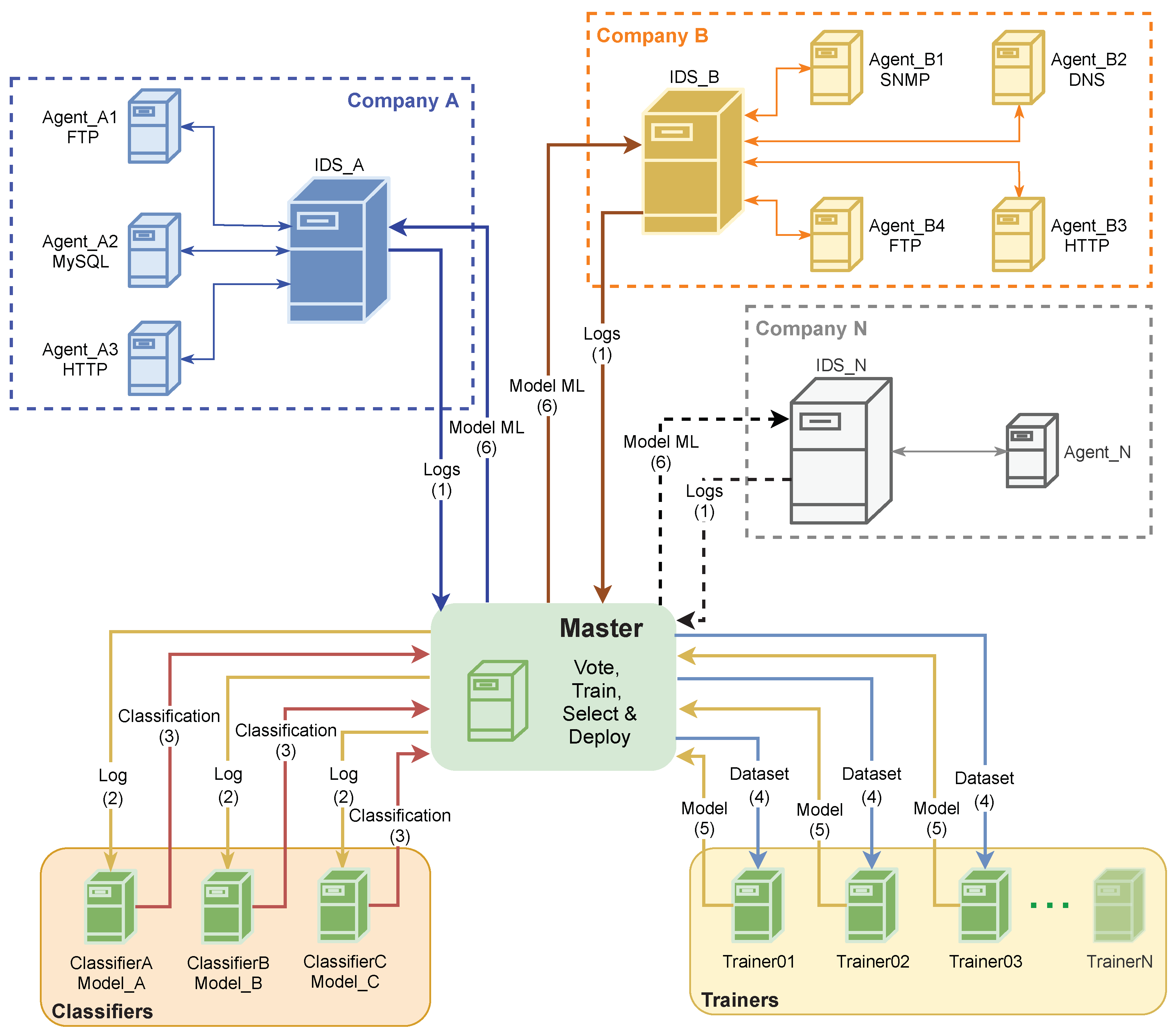
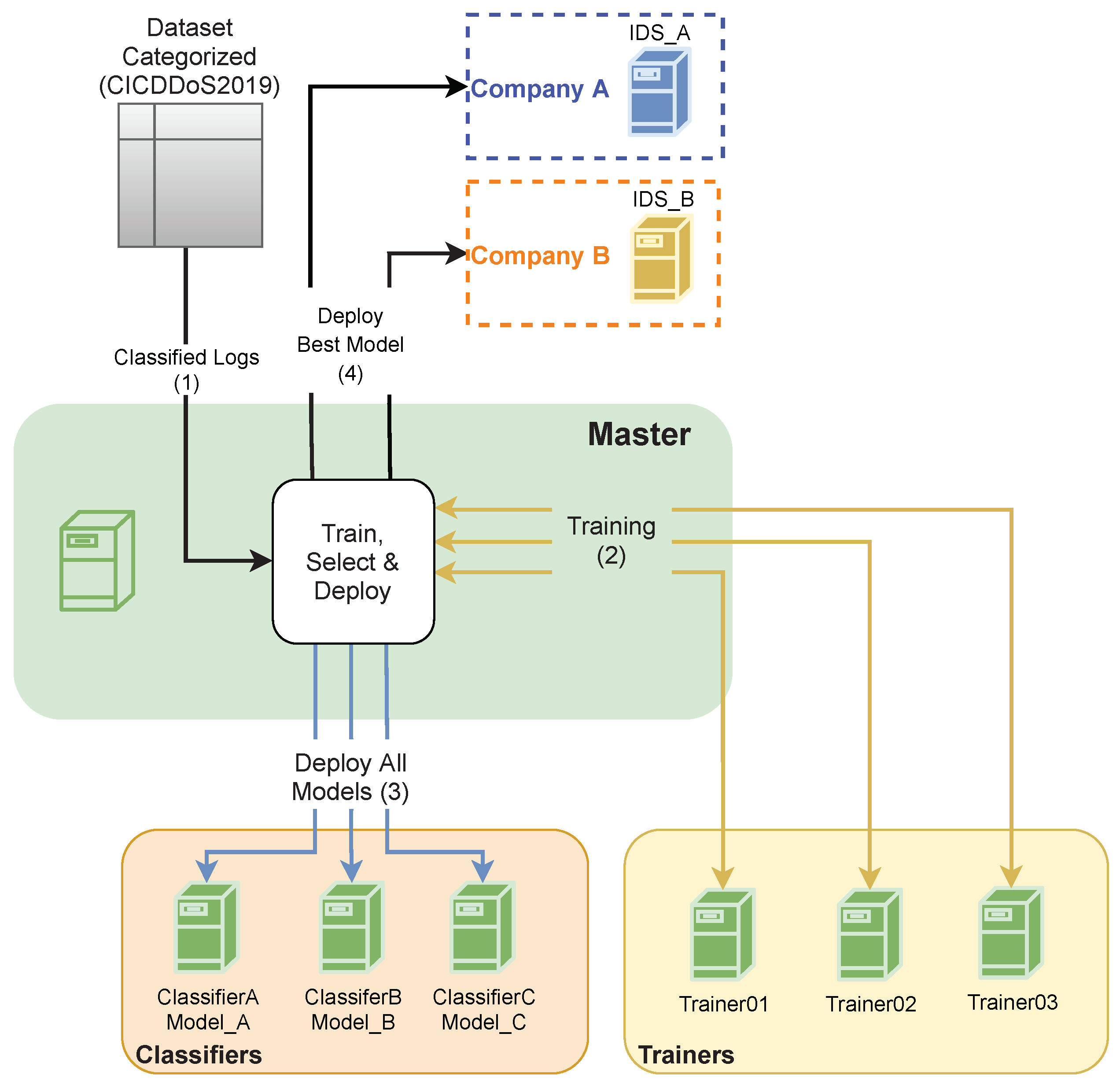
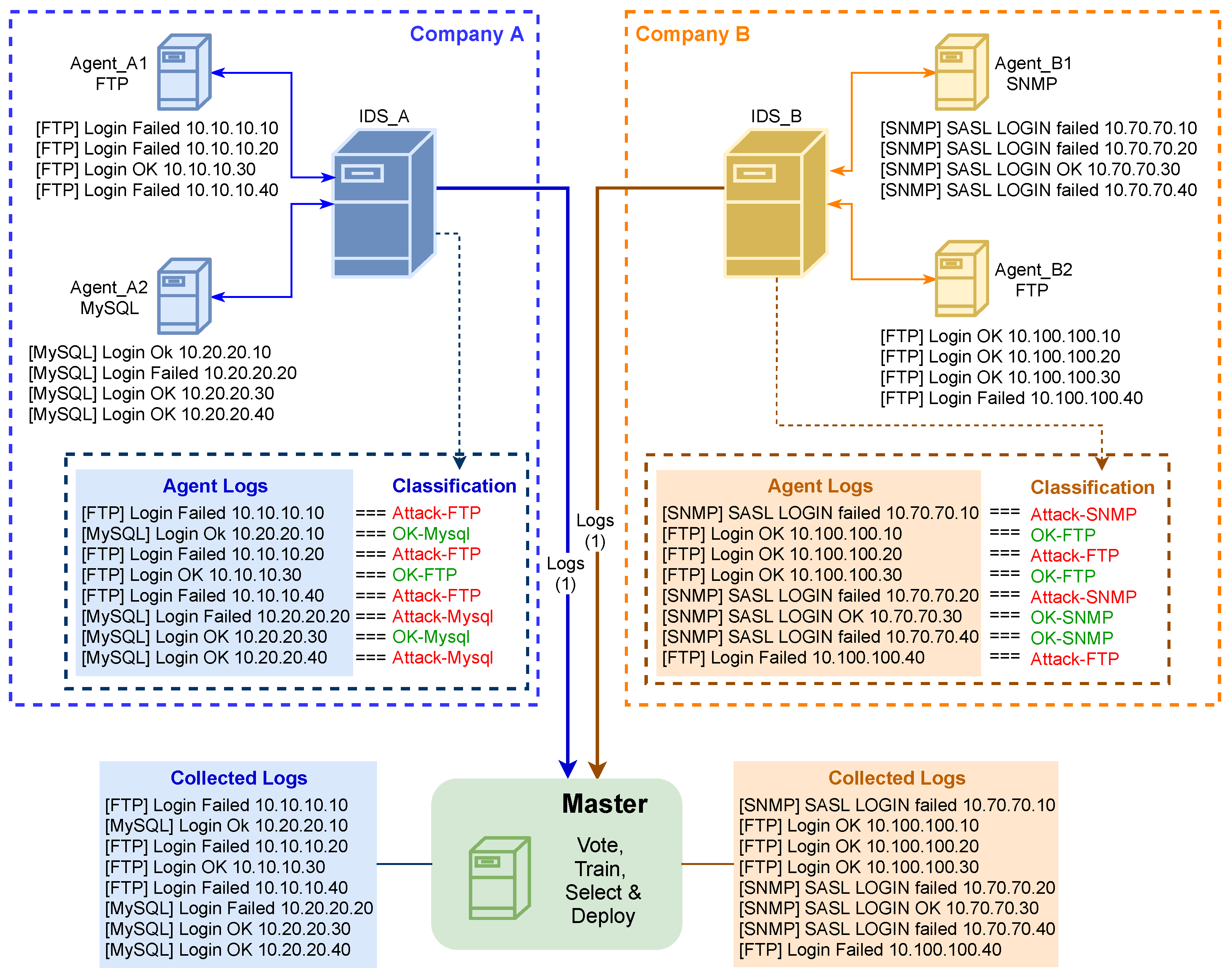
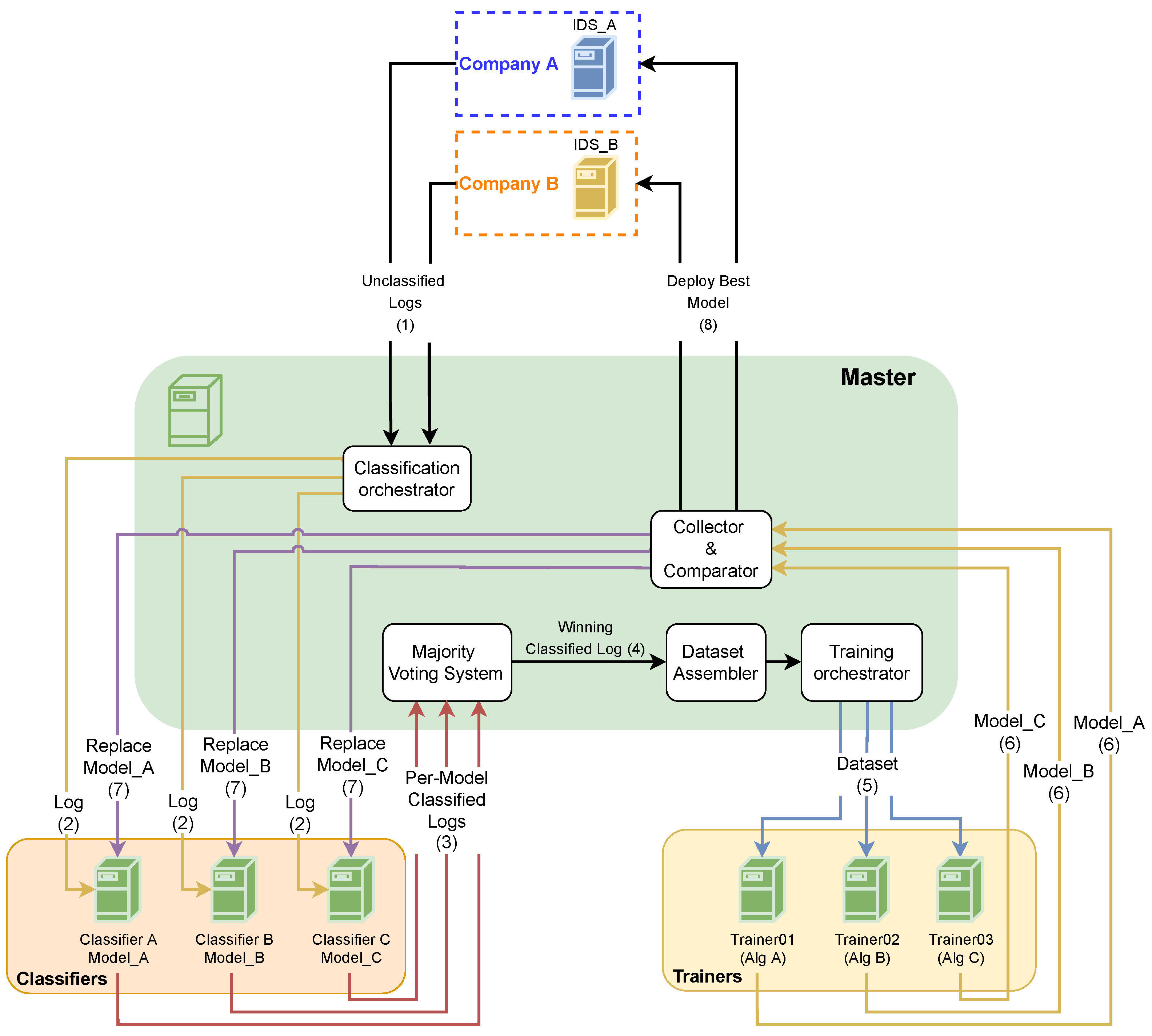
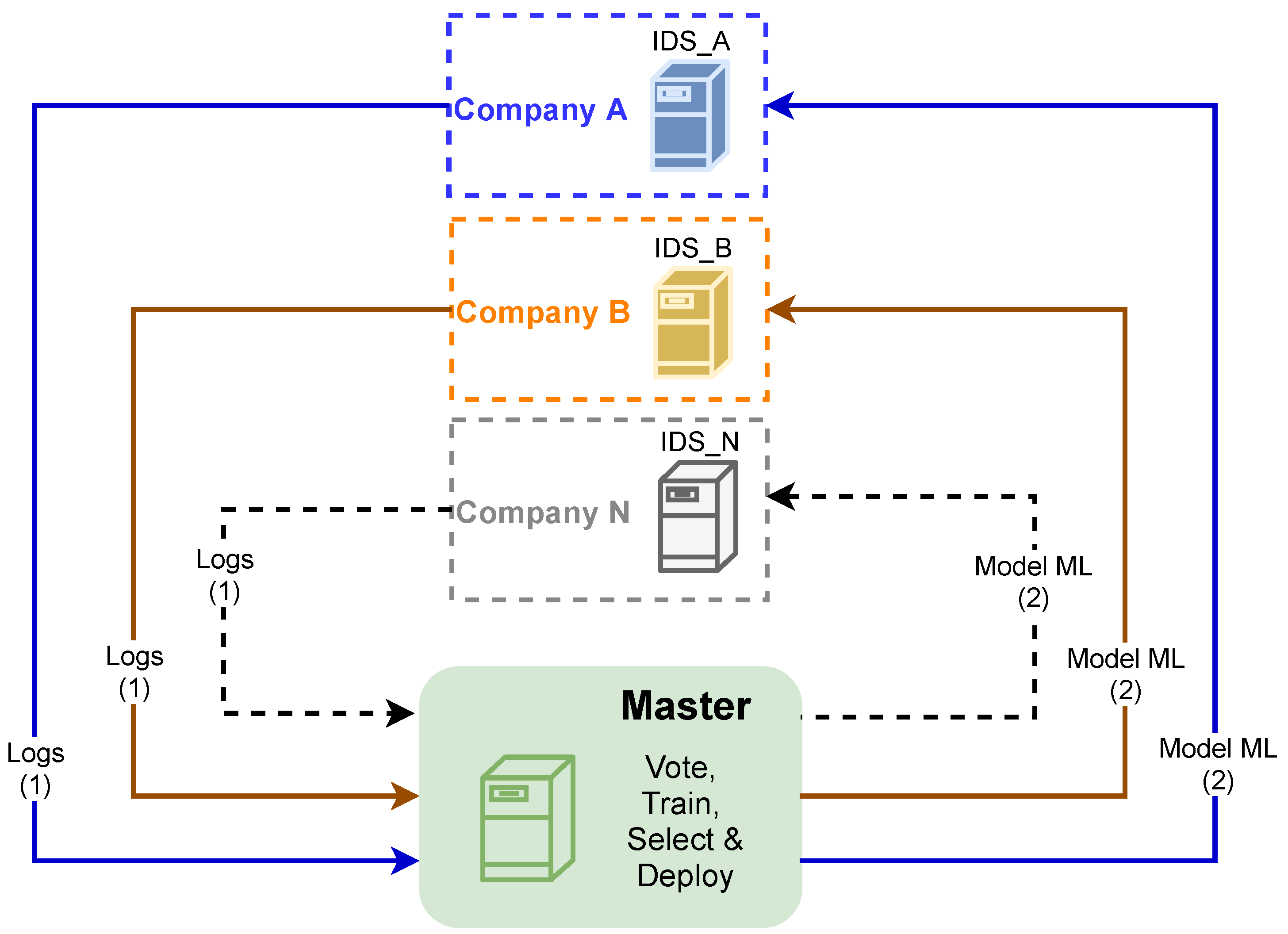
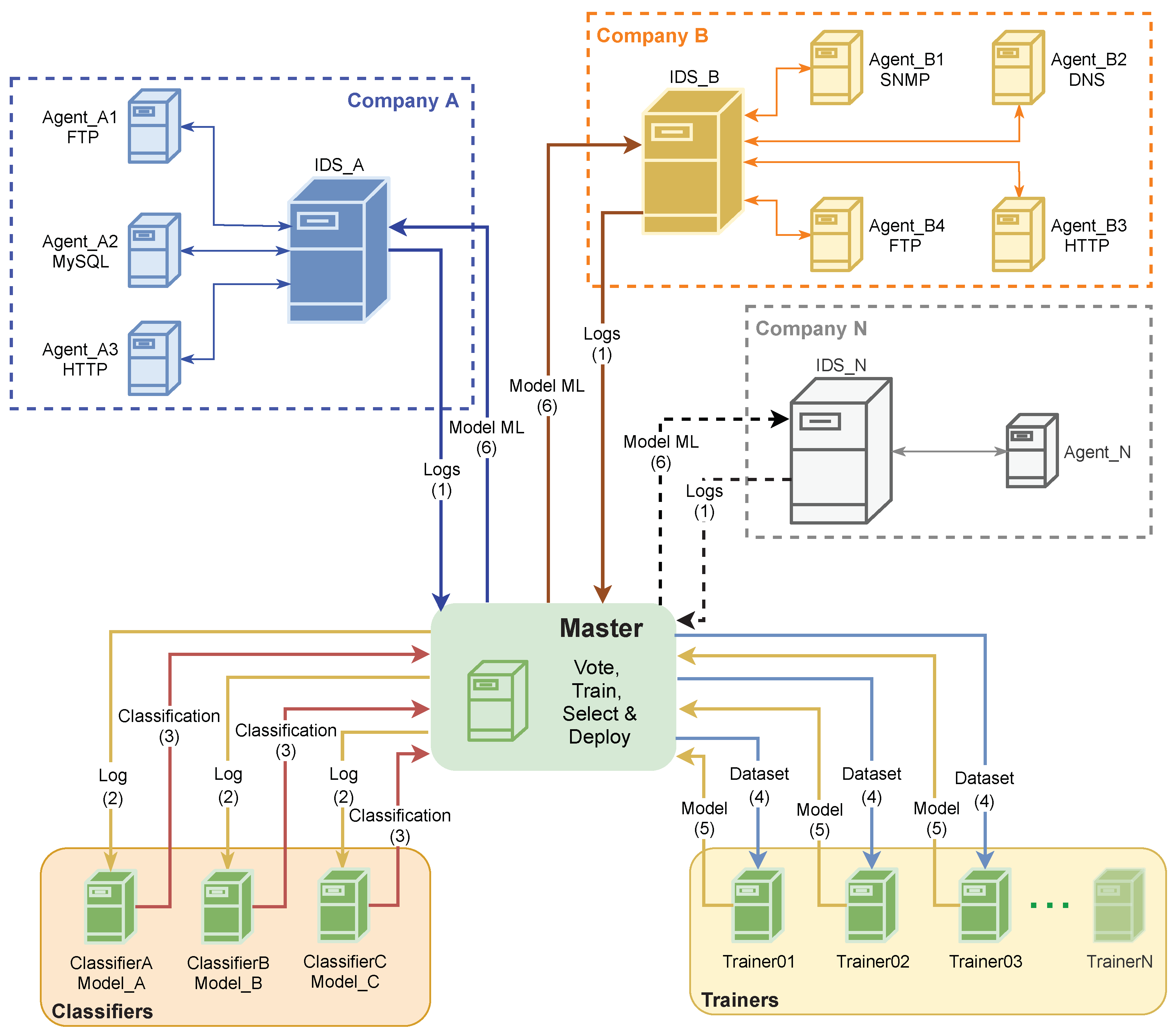
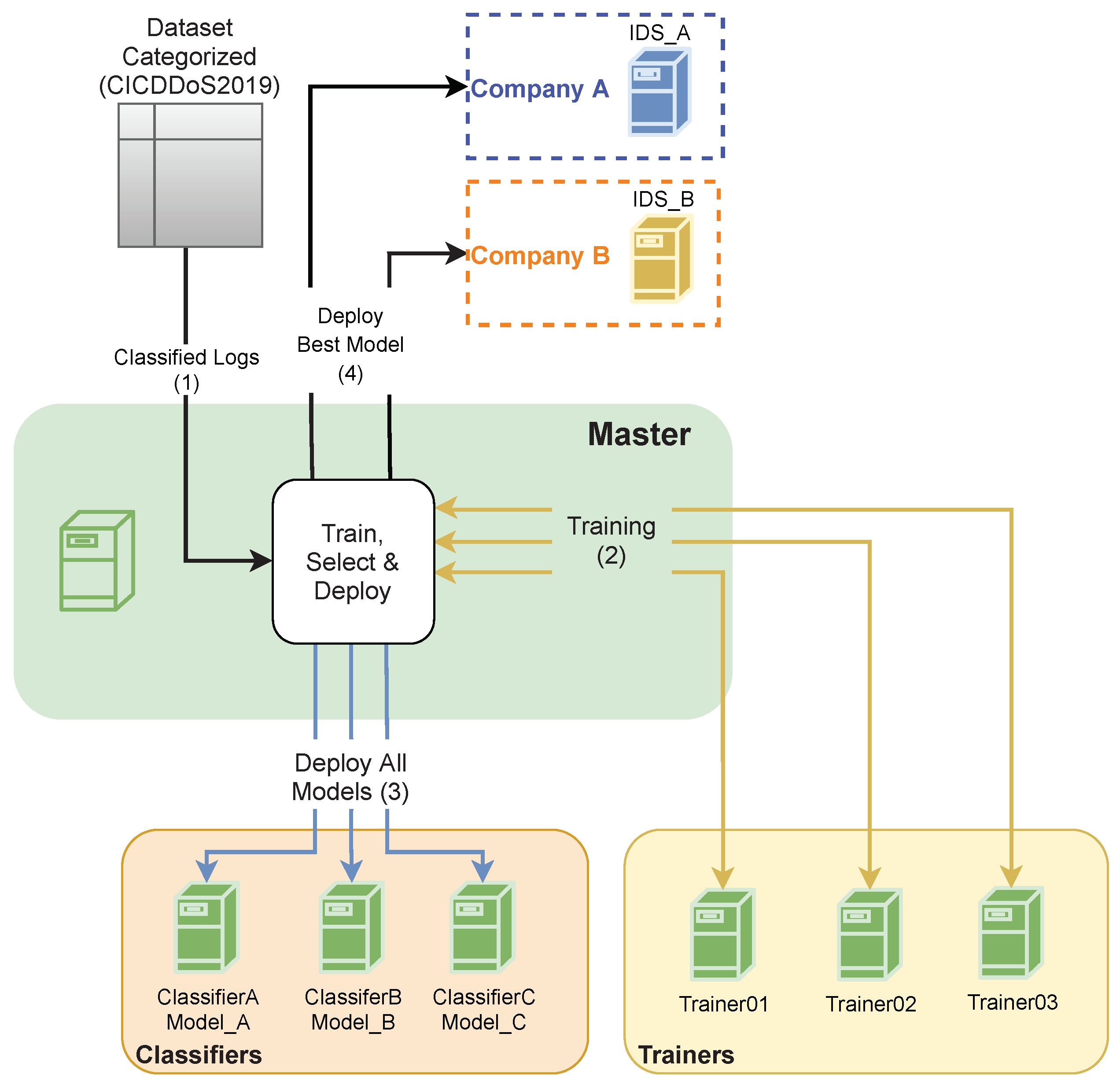
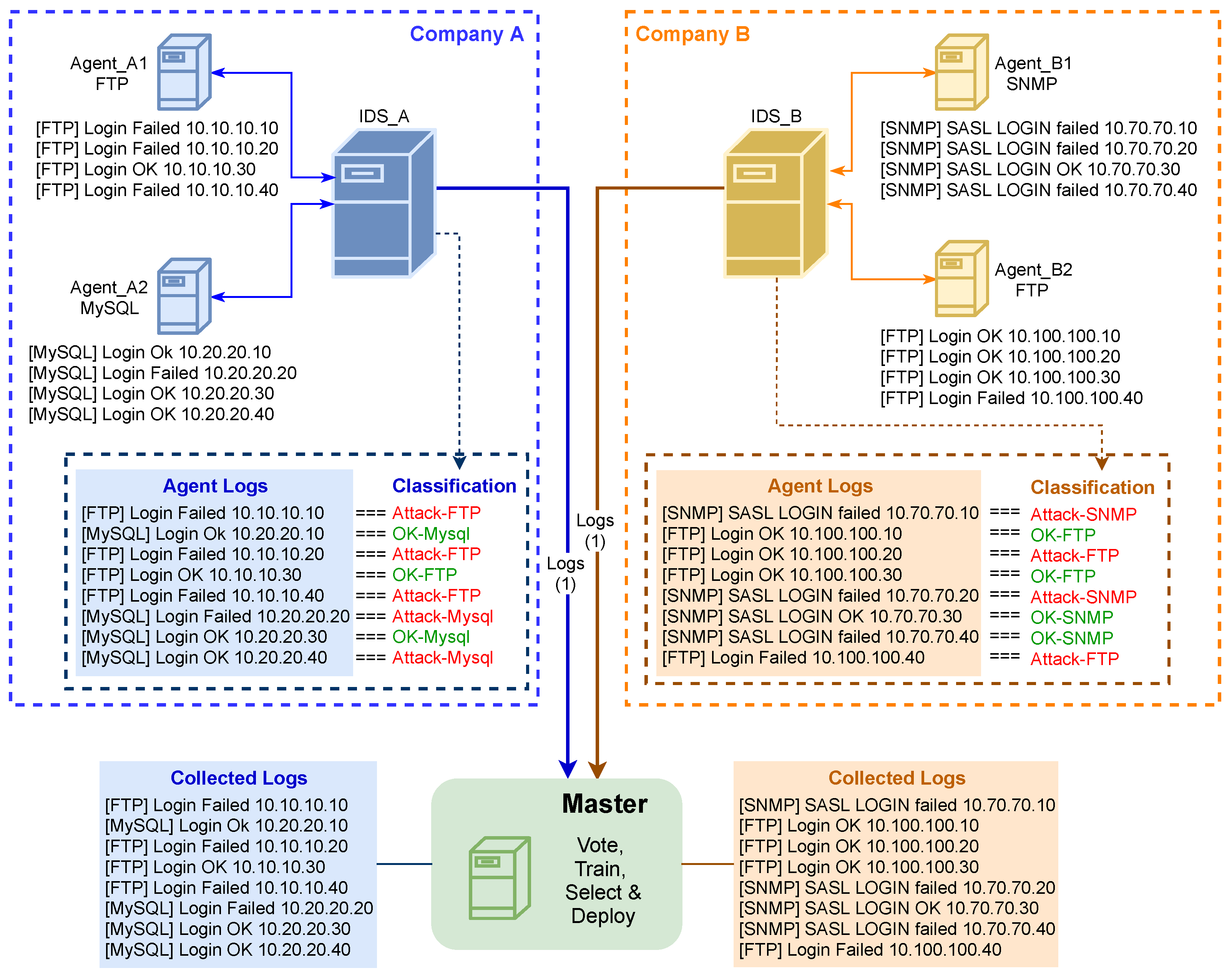
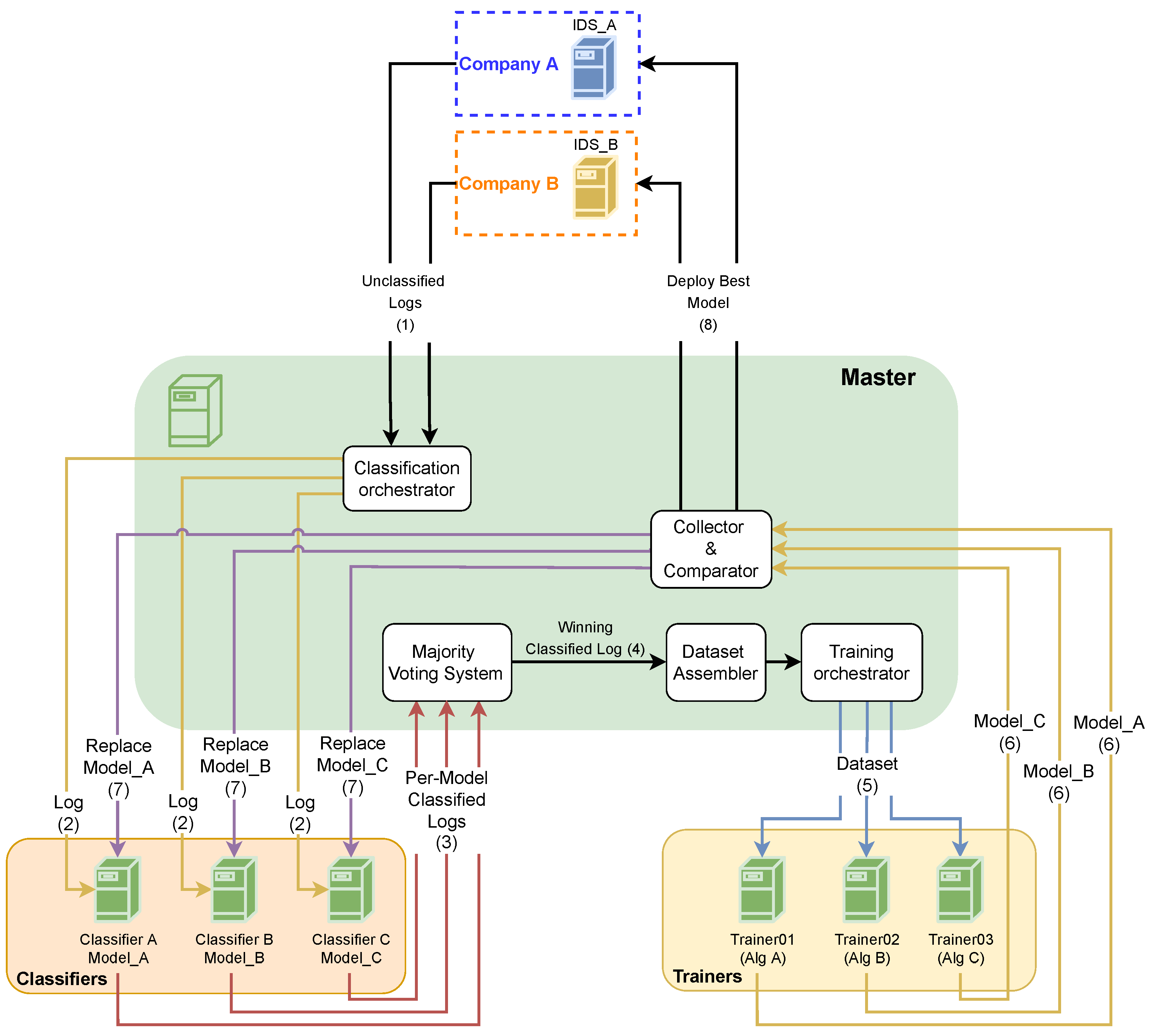
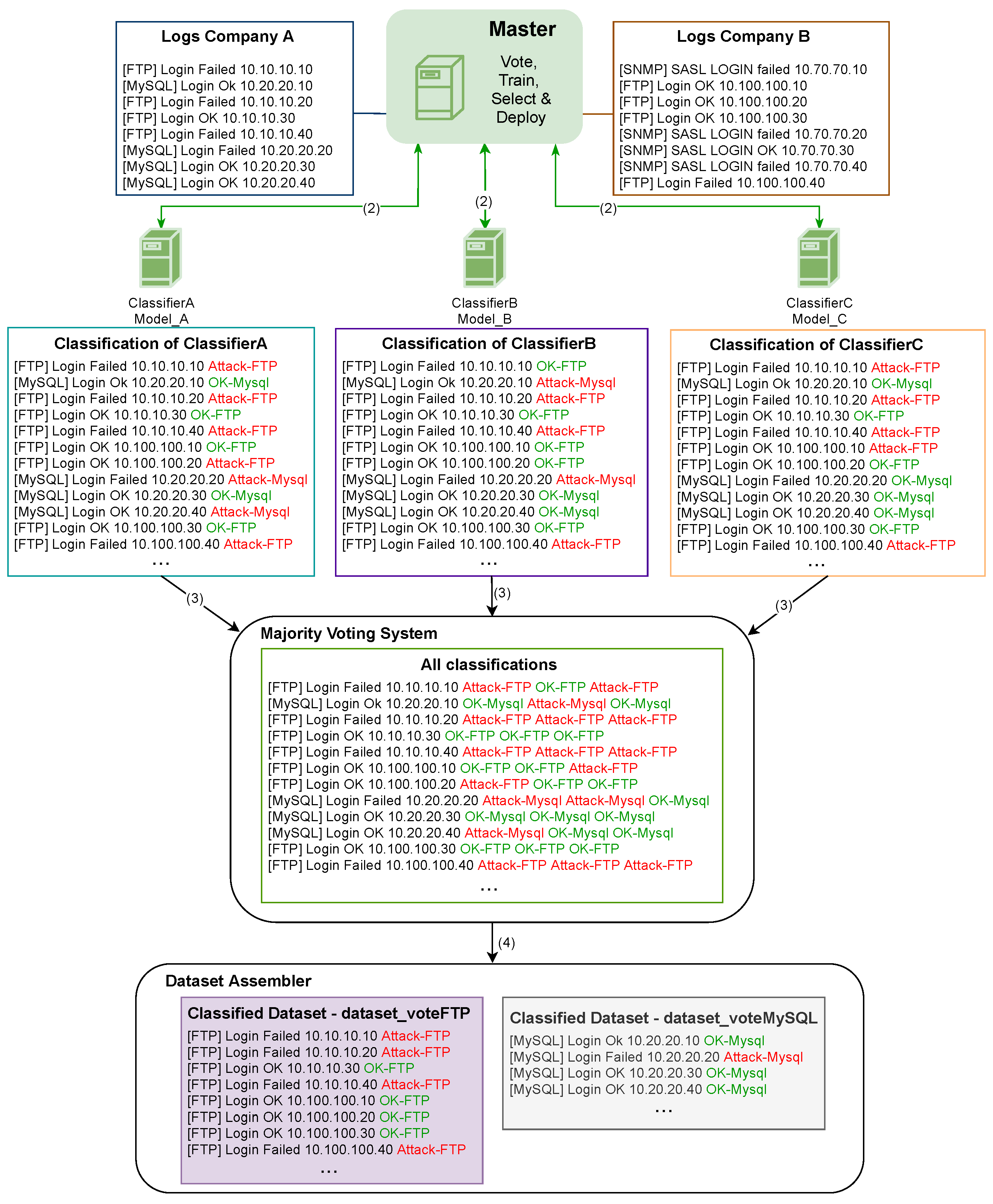
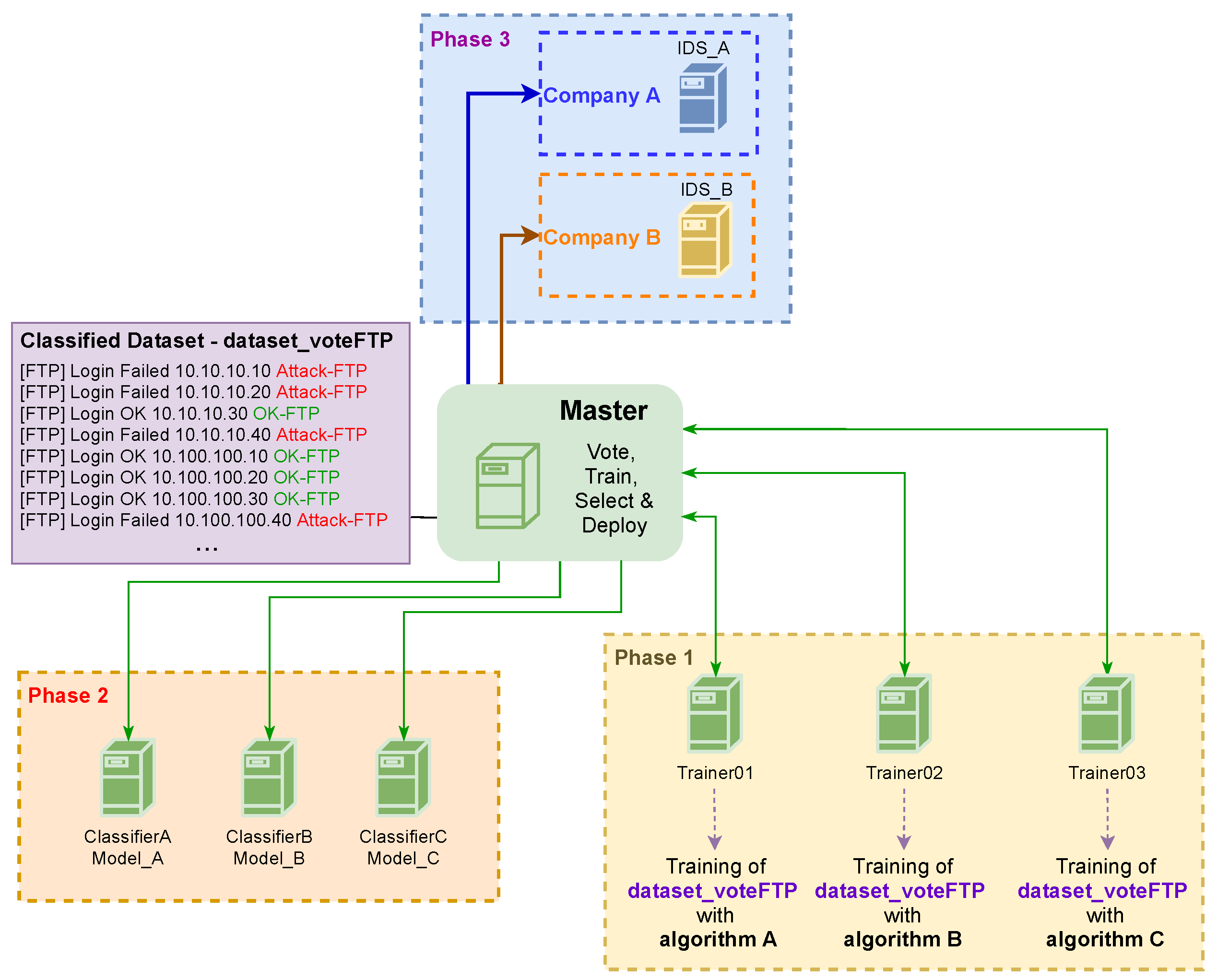
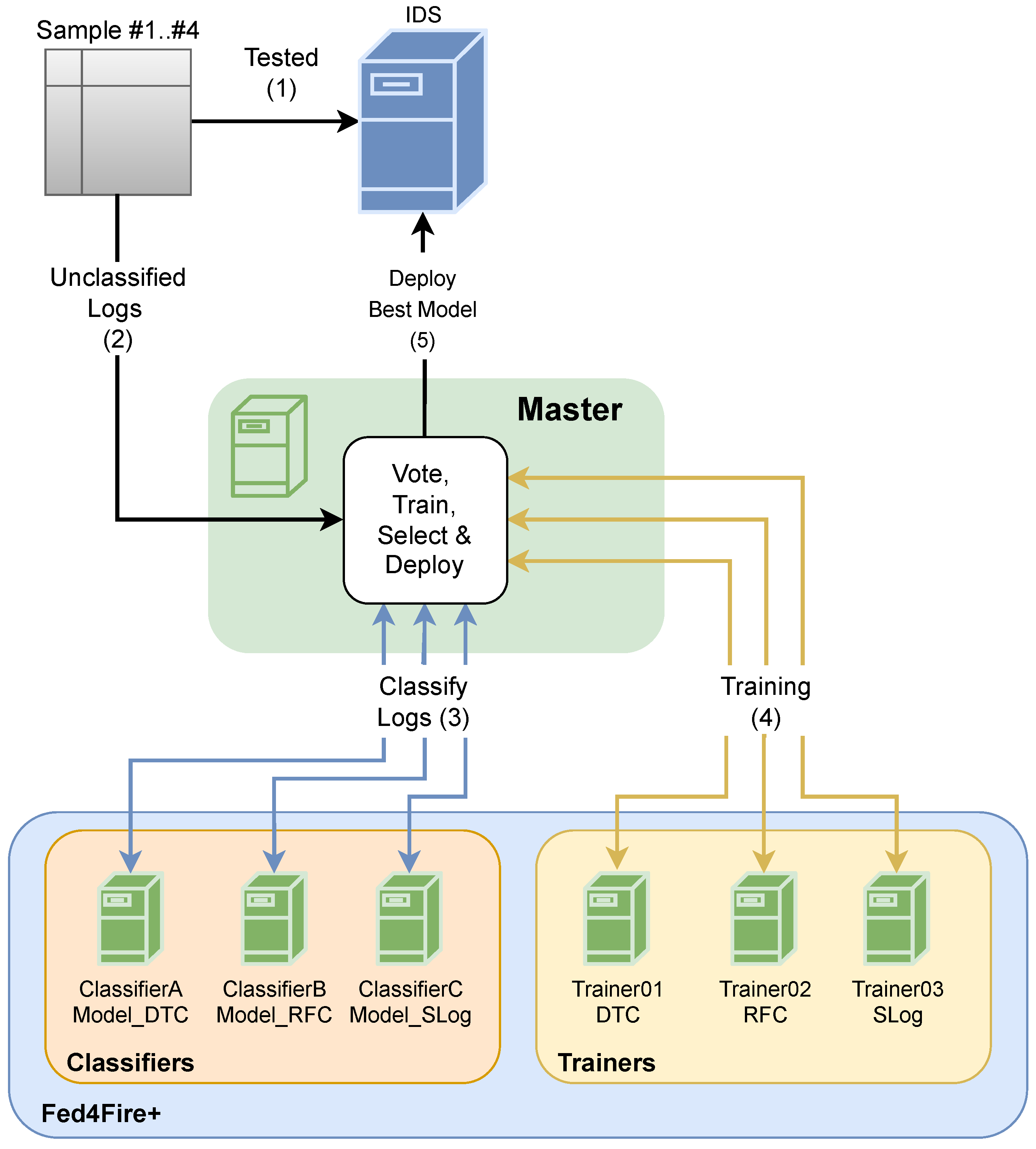
3. The Proposed Architecture
4. Results and Analysis
- Subset A—collected using 186,960 records categorized as DDoS_Portmap and 4734 as Benign. Oversampling over minority class was applied and resulted in a balanced dataset with 373,920 records (186,960 DDoS_Portmap and 186,960 Benign);
- Subset B—collected using 782,590 records categorized as DDoS_UDP and 1071 as Benign. Oversampling over minority class was applied and resulted in a balanced dataset with 1,565,180 records (782,590 DDoS_UDP and 782,590 Benign);
- Subset C—collected using 1,289,043 records categorized as DDoS_SNMP and 925 as Benign. Oversampling over minority class was applied and resulted in a balanced dataset with 2,578,086 records (1,289,043 DDoS_SNMP and 1,289,043 Benign);
- Subset M—collected using 1,059,153 records (125,032 DDoS_DNS, 54,490 DDoS_LDAP, 112,410 DDoS_MSSQL, 101,756 DDoS_NetBIOS, 17,740 DDoS_NTP, 128,951 DDoS_SNMP, 65,155 DDoS_SSDP, 39,551 DDoS_SYN, 300,367 DDoS_TFTP, 77,466 DDoS_UDP, 14,280 Portmap and 21,955 Benign). Although this subset contains records from several datasets and therefore has multi classification, it was adjusted to also have binary classification (Attack, Benign).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grispos, G. Criminals: Cybercriminals. Encycl. Secur. Emerg. Manag. 2019, 1–7. [Google Scholar] [CrossRef]
- Truong, T.C.; Diep, Q.B.; Zelinka, I. Artificial Intelligence in the Cyber Domain: Offense and Defense. Symmetry 2020, 12, 410. [Google Scholar] [CrossRef] [Green Version]
- Singh, M.D. Analysis of Host-Based and Network-Based Intrusion Detection System. Comput. Netw. Inf. Secur. 2014, 8, 41–47. [Google Scholar] [CrossRef] [Green Version]
- Jyothsna, V.; Prasad, R.; Prasad, K.M. A review of anomaly based intrusion detection systems. Int. J. Comput. Appl. 2011, 28, 26–35. [Google Scholar] [CrossRef]
- Fed4FIRE+. About Fed4FIRE+. 2022. Available online: https://www.fed4fire.eu/the-project/ (accessed on 10 January 2022).
- Kumar Singh Gautam, R.; Doegar, E.A. An Ensemble Approach for Intrusion Detection System Using Machine Learning Algorithms. In Proceedings of the 8th International Conference Confluence 2018 on Cloud Computing, Data Science and Engineering, Confluence 2018, Noida, India, 11–12 January 2018; pp. 61–64. [Google Scholar] [CrossRef]
- Tirumala, S.S.; Sathu, H.; Sarrafzadeh, A. Free and open source intrusion detection systems: A study. In Proceedings of the 2015 International Conference on Machine Learning and Cybernetics (ICMLC), Guangzhou, China, 12–15 July 2015; Voume 1, pp. 205–210. [Google Scholar] [CrossRef]
- Hussein, S.M. Performance Evaluation of Intrusion Detection System Using Anomaly and Signature Based Algorithms to Reduction False Alarm Rate and Detect Unknown Attacks. In Proceedings of the 2016 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016; pp. 1064–1069. [Google Scholar] [CrossRef]
- Ahmad, T.; Anwar, M.A.; Haque, M. Machine Learning Techniques for Intrusion Detection; IGI Global: Hershey, PA, USA, 2013; pp. 47–65. [Google Scholar] [CrossRef]
- Khosravifar, B.; Bentahar, J. An Experience Improving Intrusion Detection Systems False Alarm Ratio by Using Honeypot. In Proceedings of the 22nd International Conference on Advanced Information Networking and Applications (AINA 2008), Gino-wan, Japan, 25–28 March 2008; pp. 997–1004. [Google Scholar] [CrossRef]
- Venkatesan, R.; Devi, D.R.; Keerthana, R.; Kumar, A.A. A Novel Approach for Detecting Ddos Attack in H-IDS Using Association Rule. In Proceedings of the 2018 IEEE International Conference on System, Computation, Automation and Networking (ICSCA), Pondicherry, India, 6–7 July 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Teixeira, D.; Assunção, L.; Pereira, T.; Malta, S.; Pinto, P. OSSEC IDS Extension to Improve Log Analysis and Override False Positive or Negative Detections. J. Sens. Actuator Netw. 2019, 8, 46. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.; Shan, C.; Hu, C.; Niu, Z.; Liu, Z. An Adaptive Ensemble Machine Learning Model for Intrusion Detection. IEEE Access 2019, 7, 82512–82521. [Google Scholar] [CrossRef]
- Panda, M.; Patra, M. Ensemble voting system for anomaly based network intrusion detection. Full Pap. Int. J. Recent Trends Eng. 2009, 2, 8. [Google Scholar]
- Raykar, V.C.; Yu, S.; Zhao, L.H.; Jerebko, A.; Florin, C.; Valadez, G.H.; Bogoni, L.; Moy, L. Supervised Learning from Multiple Experts: Whom to Trust When Everyone Lies a Bit. In Proceedings of the 26th Annual International Conference on Machine Learning. Association for Computing Machinery, Montreal, QC, Canada, 14–18 June 2009; pp. 889–896. [Google Scholar] [CrossRef]
- Mauro, M.D.; Sarno, C.D. Improving SIEM capabilities through an enhanced probe for encrypted Skype traffic detection. J. Inf. Secur. Appl. 2018, 38, 85–95. [Google Scholar] [CrossRef] [Green Version]
- Mahfouz, A.; Abuhussein, A.; Venugopal, D.; Shiva, S. Ensemble Classifiers for Network Intrusion Detection Using a Novel Network Attack Dataset. Future Internet 2020, 12, 180. [Google Scholar] [CrossRef]
- Haghighat, M.H.; Li, J. Intrusion detection system using voting-based neural network. Tsinghua Sci. Technol. 2021, 26, 484–495. [Google Scholar] [CrossRef]
- Gulla, K.K.; Viswanath, P.; Veluru, S.B.; Kumar, R.R. Machine learning based intrusion detection techniques. In Handbook of Computer Networks and Cyber Security: Principles and Paradigms; Springer: Berlin/Heidelberg, Germany, 2019; pp. 873–888. [Google Scholar] [CrossRef]
- Haripriya, L.; Jabbar, M.A. Role of Machine Learning in Intrusion Detection System: Review. In Proceedings of the 2nd International Conference on Electronics, Communication and Aerospace Technology, ICECA 2018, Coimbatore, India, 29–31 March 2018; pp. 925–929. [Google Scholar] [CrossRef]
- Shin, I.; Choi, Y.; Kwon, T.; Lee, H.; Song, J. Platform design and implementation for flexible data processing and building ML models of IDS alerts. In Proceedings of the 2019 14th Asia Joint Conference on Information Security, AsiaJCIS 2019, Kobe, Japan, 1–2 August 2019; pp. 64–71. [Google Scholar] [CrossRef]
- Vikram, A.; Mohana. Anomaly detection in Network Traffic Using Unsupervised Machine learning Approach. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 476–479. [Google Scholar] [CrossRef]
- Anthi, E.; Williams, L.; Słowińska, M.; Theodorakopoulos, G.; Burnap, P. A Supervised Intrusion Detection System for Smart Home IoT Devices. IEEE Internet Things J. 2019, 6, 9042–9053. [Google Scholar] [CrossRef]
- Taher, K.A.; Mohammed Yasin Jisan, B.; Rahman, M.M. Network Intrusion Detection using Supervised Machine Learning Technique with Feature Selection. In Proceedings of the 2019 International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), Dhaka, Bangladesh, 10–12 January 2019; pp. 643–646. [Google Scholar] [CrossRef]
- Ahanger, A.S.; Khan, S.M.; Masoodi, F. An Effective Intrusion Detection System using Supervised Machine Learning Techniques. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 8–10 April 2021; pp. 1639–1644. [Google Scholar] [CrossRef]
- Rani, D.; Kaushal, N.C. Supervised Machine Learning Based Network Intrusion Detection System for Internet of Things. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Shi, G.; He, G. Collaborative Multi-agent Reinforcement Learning for Intrusion Detection. In Proceedings of the 2021 7th IEEE International Conference on Network Intelligence and Digital Content (IC-NIDC), Beijing, China, 17–19 November 2021; pp. 245–249. [Google Scholar] [CrossRef]
- Latif, S.; Huma, Z.E.; Jamal, S.S.; Ahmed, F.; Ahmad, J.; Zahid, A.; Dashtipour, K.; Umar Aftab, M.; Ahmad, M.; Abbasi, Q.H. Intrusion Detection Framework for the Internet of Things using a Dense Random Neural Network. IEEE Trans. Ind. Informatics 2021, 1. [Google Scholar] [CrossRef]
- Kunal; Dua, M. Machine Learning Approach to IDS: A Comprehensive Review. In Proceedings of the 3rd International Conference on Electronics and Communication and Aerospace Technology, ICECA 2019, Coimbatore, India, 12–14 June 2019; pp. 117–121. [Google Scholar] [CrossRef]
- Mo, W.; Gutterman, C.L.; Li, Y.; Zhu, S.; Zussman, G.; Kilper, D.C. Deep-neural-network-based wavelength selection and switching in ROADM systems. J. Opt. Commun. Netw. 2018, 10, D1–D11. [Google Scholar] [CrossRef]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A Survey on Distributed Machine Learning. ACM Comput. Surv. 2020, 53, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Global Environment for Network Innovations (GENI). What Is GENI? 2022. Available online: https://www.geni.net/about-geni/what-is-geni/ (accessed on 10 January 2022).
- Smart Applications on Virtual Infrastructure (SAVI). 2022. Available online: https://www.savinetwork.ca/ (accessed on 10 January 2022).
- Kim, T.; Cha, Y.; Shin, B.; Cha, B. Survey and Performance Test of Python-Based Libraries for Parallel Processing. In Proceedings of the 9th International Conference on Smart Media and Applications. Association for Computing Machinery, New York, NY, USA, 23 August 2020; pp. 154–157. [Google Scholar] [CrossRef]
- Ray Team. What Is Ray? 2021. Available online: https://docs.ray.io/en/master/ (accessed on 12 January 2022).
- Using IPython for Parallel Computing. Available online: https://ipython.org/ipython-doc/3/parallel/ (accessed on 12 January 2022).
- Dispy: Distributed and Parallel Computing with/for Python—Dispy 4.12.0 Documentation. Available online: https://dispy.org/ (accessed on 12 January 2022).
- Pandaral lel. 2021. Available online: https://github.com/nalepae/pandarallel/tree/v1.5.4 (accessed on 12 January 2022).
- Dask. Dask—Documentation. 2022. Available online: https://docs.dask.org/en/stable/ (accessed on 12 January 2022).
- Joblib. Joblib: Running Python Functions as Pipeline Jobs. 2022. Available online: https://joblib.readthedocs.io/en/latest/ (accessed on 12 January 2022).
- Moritz, P.; Nishihara, R.; Wang, S.; Tumanov, A.; Liaw, R.; Liang, E.; Elibol, M.; Yang, Z.; Paul, W.; Jordan, M.I.; et al. Ray: A Distributed Framework for Emerging AI Applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). USENIX Association, Carlsbad, CA, USA, 8–10 October 2018; pp. 561–577. [Google Scholar]
- Fabbiani, E.; Vidal, P.; Massobrio, R.; Nesmachnow, S. Distributed Big Data Analysis for Mobility Estimation in Intelligent Transportation Systems. Transp. Rev. 2019, 6, 795–818. [Google Scholar] [CrossRef]
- Nsl-kdd Dataset. 2014. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 21 December 2021).
- KDD Cup 1999. 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 21 December 2021).
- The UNSW-NB15 Dataset Description. 2015. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 21 December 2021).
- Sharafaldin, I.; Lashkari, A.H.; Hakak, S.; Ghorbani, A.A. Developing realistic distributed denial of service (DDoS) attack dataset and taxonomy. In Proceedings of the International Carnahan Conference on Security Technology, Chennai, India, 1–3 October 2019. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute (Class Label) | Number of Instances |
|---|---|
| DDoS_WebDDoS | 439 |
| Benign (legitimate traffic) | 56,863 |
| DDoS_Portmap | 186,960 |
| DDoS_UDP-Lag | 366,461 |
| DDoS_NTP | 1,202,642 |
| DDoS_SYN | 1,582,289 |
| DDoS_LDAP | 2,179,930 |
| DDoS_SSDP | 2,610,611 |
| DDoS_UDP | 3,134,645 |
| DDoS_NetBIOS | 4,093,279 |
| DDoS_MSSQL | 4,522,492 |
| DDoS_DNS | 5,071,011 |
| DDoS_SNMP | 5,159,870 |
| DDoS_TFTP | 20,082,580 |
| Accuracy (%) | |||||
|---|---|---|---|---|---|
| Algorithm | Subset A | Subset B | Subset C | Subset M | Average |
| Random Forest Classifier | 93.25 | 91.54 | 92.93 | 81.26 | 89.75 |
| Simple Logistics | 92.38 | 91.16 | 91.27 | 80.93 | 88.94 |
| Decision Tree Classifier | 91.48 | 91.22 | 92.51 | 80.56 | 88.94 |
| K-Nearest Neighbors | 91.87 | 90.91 | 92.57 | 79.27 | 88.66 |
| Support Vector Machine | 88.83 | 86.12 | 91.34 | 80.19 | 86.62 |
| Precision (%) | |||||
|---|---|---|---|---|---|
| Algorithm | Subset A | Subset B | Subset C | Subset M | Average |
| Random Forest Classifier | 91.96 | 91.46 | 92.61 | 81.75 | 89.45 |
| Decision Tree Classifier | 90.31 | 91.88 | 92.83 | 80.54 | 88.89 |
| Simple Logistics | 91.36 | 91.45 | 90.78 | 80.35 | 88.49 |
| K-Nearest Neighbors | 90.93 | 89.52 | 91.82 | 79.79 | 88.02 |
| Support Vector Machine | 90.19 | 88.04 | 90.71 | 80.04 | 87.25 |
| Elapsed Runtime (s) | |||||
|---|---|---|---|---|---|
| Algorithm | Subset A | Subset B | Subset C | Subset M | Average |
| Decision Tree Classifier | 2 | 5 | 16 | 4 | 6.75 |
| Simple Logistics | 124 | 37 | 18 | 238 | 104.25 |
| Random Forest Classifier | 161 | 782 | 1489 | 472 | 726.00 |
| K-Nearest Neighbors | 426 | 6333 | 19,069 | 2988 | 7204.00 |
| Support Vector Machine | 1034 | 17,919 | 47,896 | 1834 | 17,170.75 |
| Sample #0 | ||
|---|---|---|
| Algorithm | Accuracy (%) | Precision (%) |
| Decision Tree Classifier | 93.04 | 91.85 |
| Random Forest Classifier | 92.43 | 91.07 |
| Simple Logistics | 91.78 | 90.32 |
| Baseline | Proposed Architecture | |
|---|---|---|
| Sample #1 | Decision Tree Classifier | Decision Tree Classifier |
| Sample #2 | Random Forest Classifier | |
| Sample #3 | Decision Tree Classifier | |
| Sample #4 | Decision Tree Classifier |
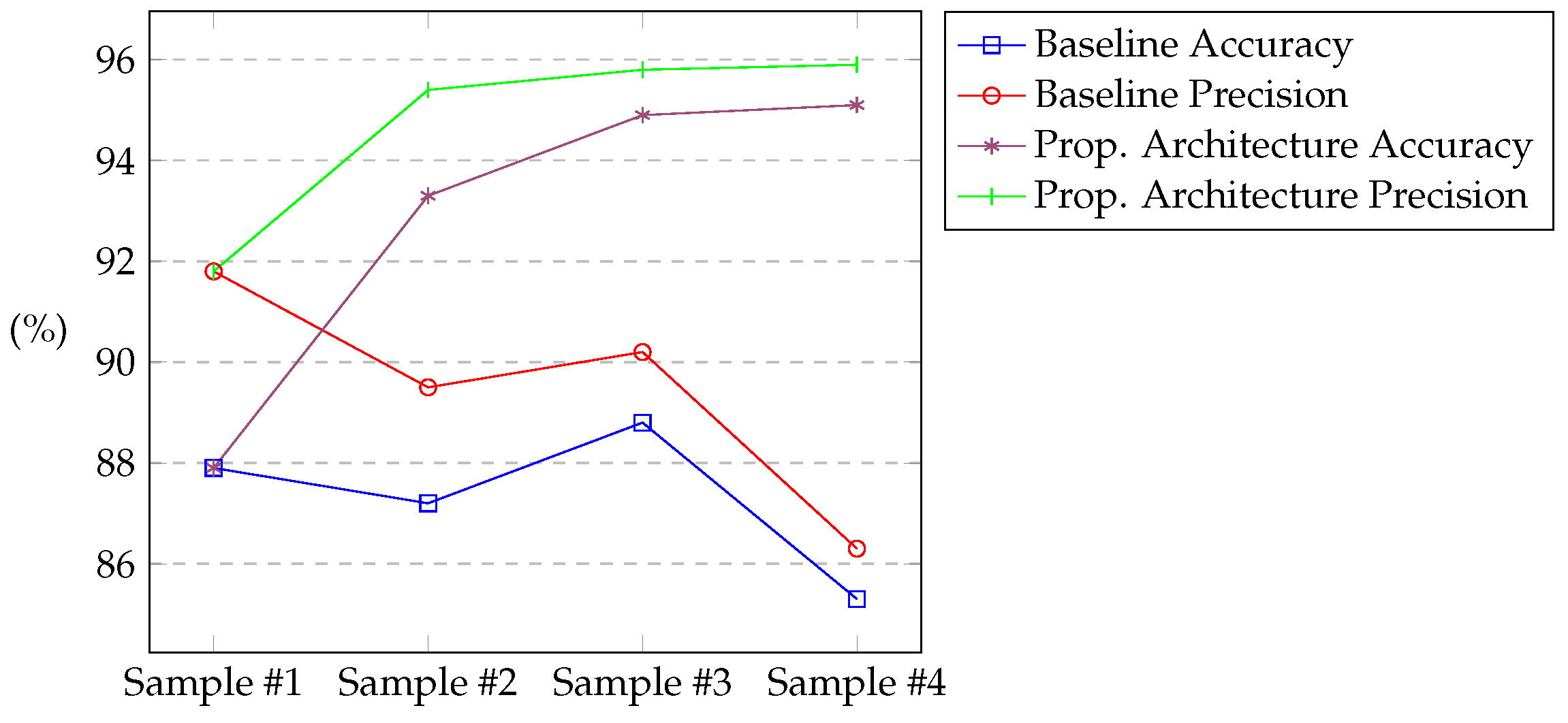
| Baseline (B) (%) | Proposed Architecture (PA) (%) | PA-B (p.p.) | PA-B (%) | |
|---|---|---|---|---|
| Sample #1 | 87.85 | 87.85 | 0 | 0 |
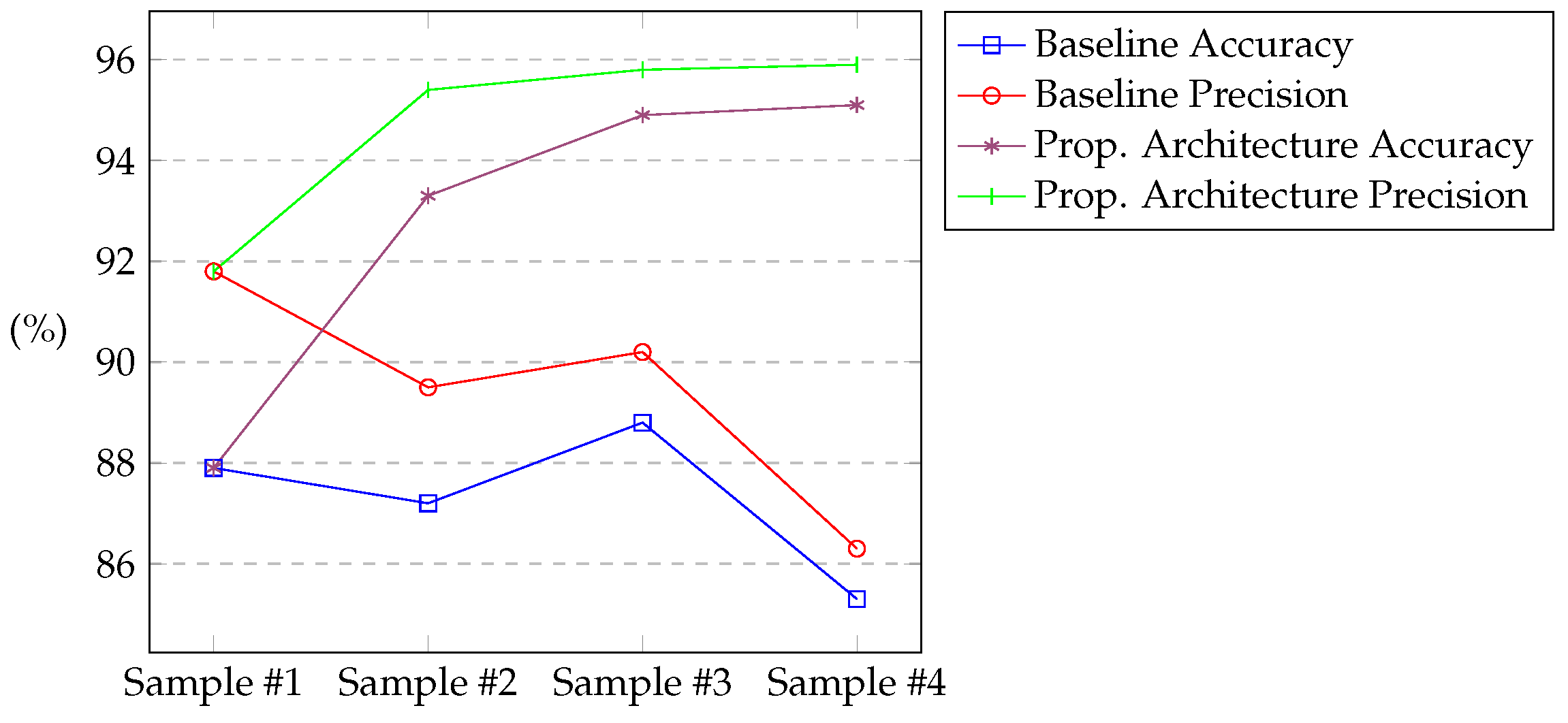
| Sample #2 | 87.17 | 93.27 | +6.10 | +6.99 |
| Sample #3 | 88.81 | 94.89 | +6.08 | +6.85 |
| Sample #4 | 85.29 | 95.11 | +9.82 | +11.51 |
| Baseline (B) (%) | Proposed Architecture (PA) (%) | PA-B (p.p.) | PA-B (%) | |
|---|---|---|---|---|
| Sample #1 | 91.76 | 91.76 | 0 | 0 |
| Sample #2 | 89.49 | 95.39 | +5.90 | +6.59 |
| Sample #3 | 90.22 | 95.77 | +5.55 | +6.15 |
| Sample #4 | 86.27 | 95.94 | +9.67 | +11.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teixeira, D.; Malta, S.; Pinto, P. A Vote-Based Architecture to Generate Classified Datasets and Improve Performance of Intrusion Detection Systems Based on Supervised Learning. Future Internet 2022, 14, 72. https://doi.org/10.3390/fi14030072
Teixeira D, Malta S, Pinto P. A Vote-Based Architecture to Generate Classified Datasets and Improve Performance of Intrusion Detection Systems Based on Supervised Learning. Future Internet. 2022; 14(3):72. https://doi.org/10.3390/fi14030072
Chicago/Turabian StyleTeixeira, Diogo, Silvestre Malta, and Pedro Pinto. 2022. "A Vote-Based Architecture to Generate Classified Datasets and Improve Performance of Intrusion Detection Systems Based on Supervised Learning" Future Internet 14, no. 3: 72. https://doi.org/10.3390/fi14030072
APA StyleTeixeira, D., Malta, S., & Pinto, P. (2022). A Vote-Based Architecture to Generate Classified Datasets and Improve Performance of Intrusion Detection Systems Based on Supervised Learning. Future Internet, 14(3), 72. https://doi.org/10.3390/fi14030072