
Query Processing in Blockchain Systems: Current State and Future Challenges




Abstract
:1. Introduction
- Based on use cases from different application domains, we derive common types of usage of blockchain technologies in terms of types of data and queries.
- For these types of data and queries, we investigate how they can be implemented in blockchain systems and how they can be supported by the available data history.
- We explore the state of the art regarding query processing in blockchains and identify future research challenges.
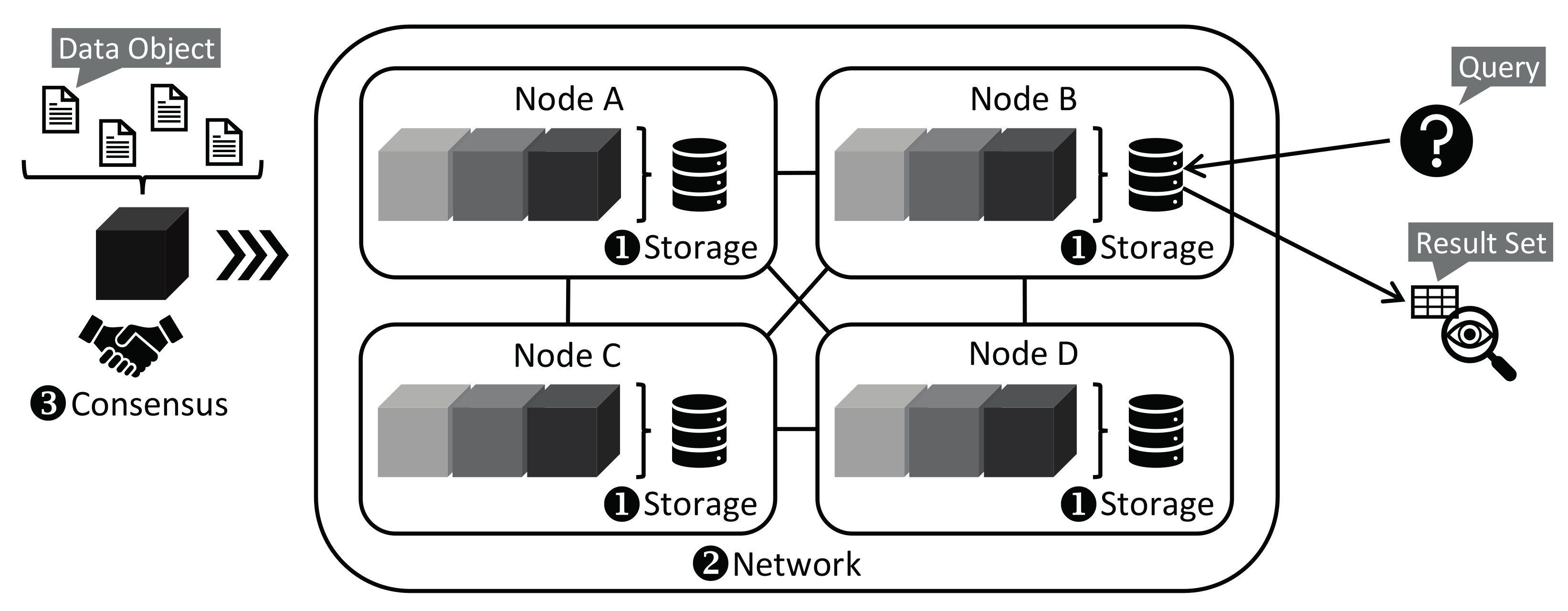
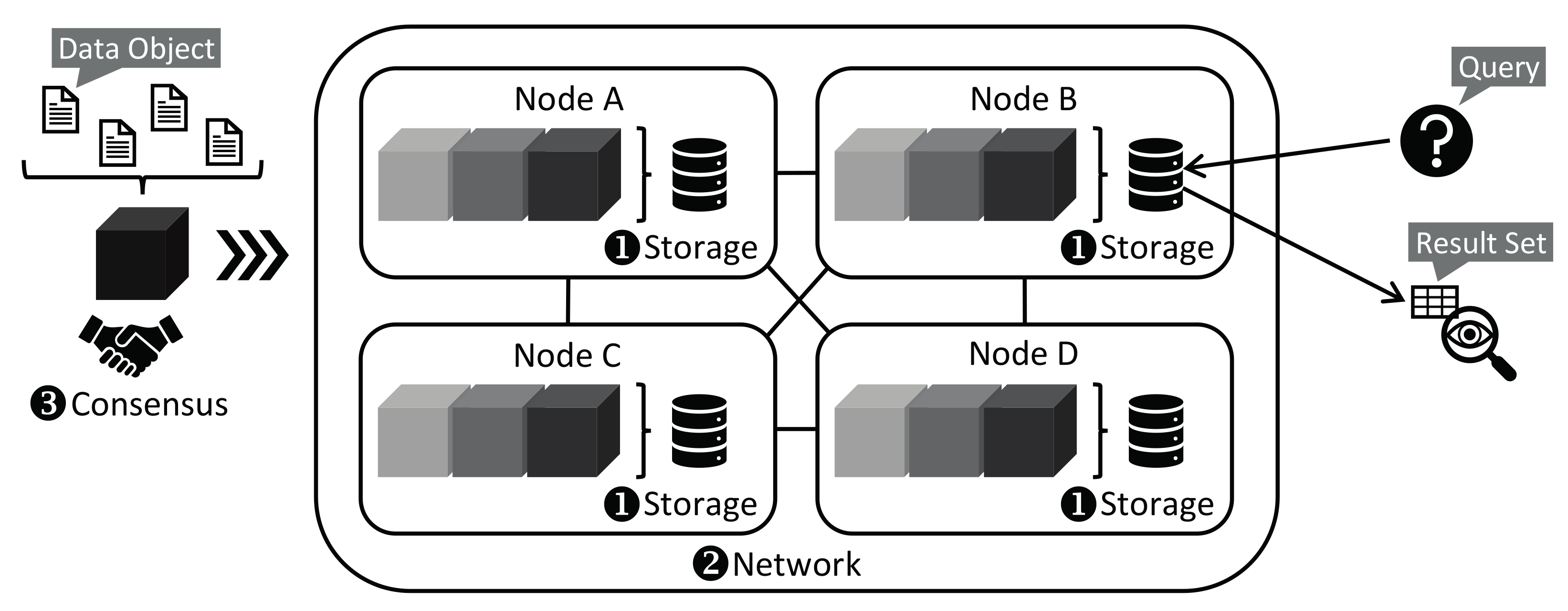
2. Fundamentals of Blockchain Technology
- I.
- It is immutable: Once a block is created, it is final. It cannot be modified subsequently, not even the link to its predecessor. The blockchain is an append-only data store. A new block can only be appended to an existing blockchain.
- II.
- It is tamper-resistant: The data of a block are stored in authenticated data structures. These data structures are capable of verifying the integrity of their content. Tampering with their content gets therefore detected.
- III.
- It is decentralized: Each node in a blockchain network manages its own instance of the blockchain. Thus, there is no single point of failure or attack. A consensus mechanism ensures that all nodes append the same, new block to the blockchain.
3. Application Domains Identified through Literature Review
- There is a need for establishing a trustworthy foundation between several parties without having to involve external authorities (e.g., notaries).
- There is a need for a single view of the truth (e.g., when different companies have to share data).
- There is a need for greater auditability by stakeholders through transparency (i.e., all published data are visible to every participant in the blockchain network) and provenance (i.e., the full history of data is available).
- There is a need for data being immutable (i.e., already stored data cannot be subsequently modified or deleted) and tamper-resistant (i.e., preventing an attacker from manipulating stored data).
3.1. Health Data Management
- The data entered by physicians are usually documents, e.g., diagnosis and treatment plans, that are modified over time.
- The data entered by patients are usually measurements carried out by medical IoT devices that are only valid at a specific point in time.
- Retrieve all diagnoses of a specific patient from a given date.
- Retrieve the latest diagnosis of a specific patient where changes to the document are highlighted.
- Aggregate the measurements of a specific patient over a given period.
3.2. Financial Accounting
- The data entered by companies and tax advisors are financial records that are only valid at a specific point in time.
- List all financial records for a given period (e.g., usually for a day, week, month, quarter, or year).
- Generate an accounting report by aggregating the financial records grouped by accounts for a given period.
3.3. Registries
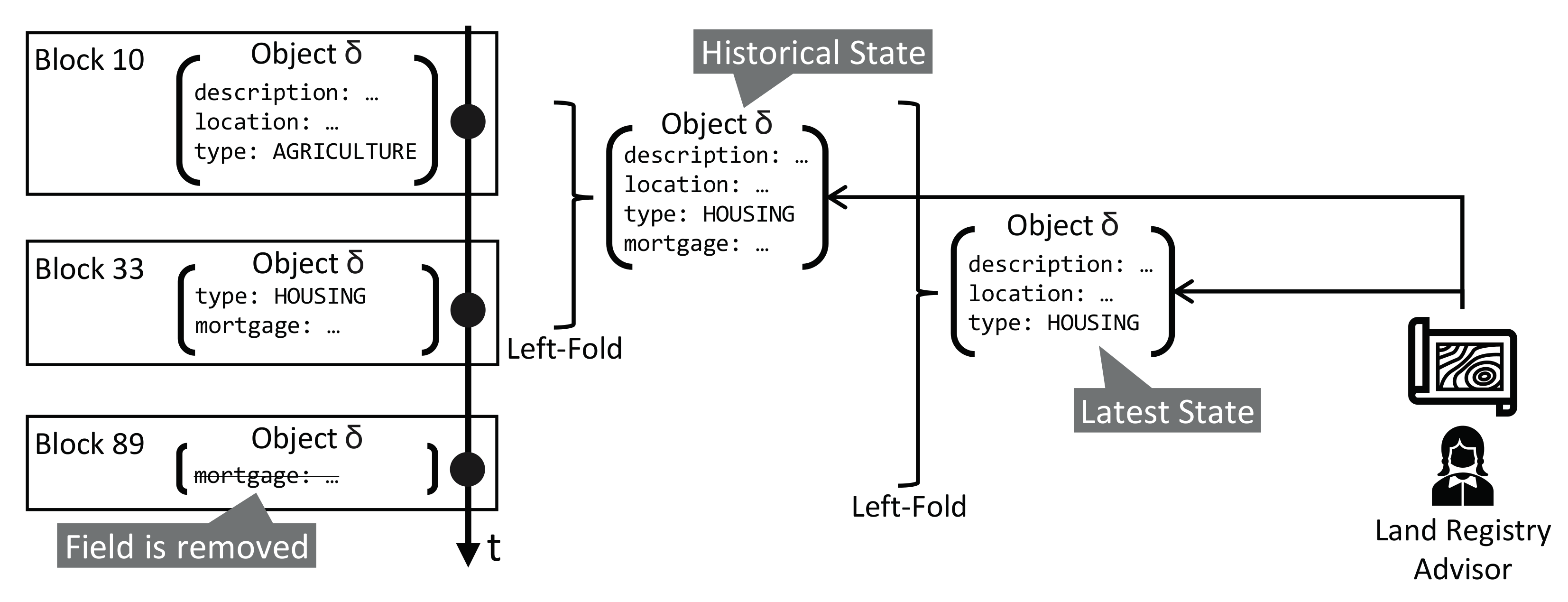
- The data entered into registries are usually documents (i.e., semi-structured data) that are modified over time. Typically, the latest state of a document is of importance, but in cases of conflicts, its history is also required (e.g., in court).
- Retrieve the latest state of a specific document.
- Retrieve the latest state and a prior state of a specific document to highlight changes in the latest state.
- Join two or more registries on a certain attribute to get a holistic view of all stored documents.
3.4. Food Supply Chains
- The data generated by IoT devices are events and thus, only valid at a specific point in time (e.g., temperature or location).
- There may exist accompanying documents (i.e., semi-structured data) to the goods that are modified over time (e.g., during customs inspections).
- Aggregate the events by specific attributes for a given period.
- Retrieve the latest state of an accompanying document for a given transport.
- Retrieve the latest state and a prior state of a specific document to highlight changes in the latest state.
3.5. E-Voting
- The votes are stored in the blockchain as independent records. Once a vote has been cast, it must not be subsequently altered or deleted. Without any loss of generality, we assume that some kind of verification of whether a ballot is valid takes place before the votes are entered into the blockchain. Therefore, no extensions to the stored data are required.
- Determine the final result of an election.
- Determine the voting behavior of different groups of voters.
- Determine which shifts of voters happened compared to the last election.
3.6. Lessons Learned
| Listing 1. An object with three attributes and their values represented as a JSON document, RDF triples, and an XML instance. |
 |
4. Object Types in Blockchains
5. Query Capabilities for Blockchain Technology
- BlockRange. SELECT <attributes> BETWEEN BLOCK AND(where and of type Integer and )A block range is necessary when a blockchain stores constant objects with block-dependent timestamps.
- TimestampRange. SELECT <attributes> BETWEEN TIMESTAMP AND(where and of type DateTime (e.g., ISO 8601 [100]) and )A timestamp range is necessary when a blockchain stores constant objects with object-dependent timestamps.
- BlockNumber. SELECT <attributes> ASOF BLOCK N(where N of type Integer)A block number is necessary when a blockchain stores expandable objects.
- (A)
- JOIN operators as provided by traditional database systems, do not need to be considered here, as there is no demand for this functionality in practice. Unlike traditional database systems, blockchain typically store data on a single topic only. An internal structuring into separate tables, each with its own schema, is therefore not necessary in blockchain systems. Consequently, joins cannot be performed within the data set of a single blockchain. However, there are use cases that require a join between data sets held in different blockchains. For instance, Blockchain X contains health data that are captured self-reliant by patients as part of the Quantified Self Movement, while Blockchain Y contains clinical data of these patients captured by hospital staff as part of health checks. In order to get a comprehensive view of a patient’s health situation or history, physicians need to be able to join the data from these two blockchains. Since each blockchain system has its unique technical architecture regarding its storage, network, and consensus (see Section 2), such a join represents a substantial technical challenge.
- (B)
- Unlike a relational table, where all data are applied to a table schema, blockchain objects have no common well-defined schema. Here, the structuring of the objects is done solely at the application level. That is, each application stores its objects in its own predefined schema. However, when several applications share a blockchain to store their data, multiple schemas are simultaneously present in that blockchain. Therefore, the question is how this inhomogeneity affects query processing?
- (C)
- Data read from a blockchain should always be verified to detect any tampering. However, data could also be stored externally to a blockchain in a database system with better query capabilities, but without verification capabilities. Therefore, the question here is how, and when does the verification of the data take place? During query processing, if possible, or as an additional step by verifying an externally computed result against the blockchain?
- (D)
- Database systems utilize index structures to facilitate query processing. Can such structures also be used for query processing in blockchains? If so, how could these look like for constant objects and/or expandable objects? Is it possible to verify the data in these index structures?
- (E)
- Blockchains lack an internal structuring that has a semantic meaning. While the segmentation into blocks is beneficial for some queries—think of queries for expandable objects, for instance, where the state up to a specific point in time is required, which can be easily realized via a query on the block number—this complicates queries on the timestamp of a constant object, for instance, since all blocks created at this timestamp or later have to be traversed for this purpose.
- (F)
- The query processing of constant objects and expandable objects is very different. Can these objects be technically processed simultaneously in a blockchain? If so, does it make sense from a query language perspective?
- (G)
- The query processing of constant objects with object-dependent timestamps is more complex than that of constant objects with block-dependent timestamps. Can these objects be technically processed simultaneously in a blockchain? If so, does it make sense from a query language perspective?
- (H)
- The query processing of expandable objects is significantly more complex than that of constant objects with block-dependent timestamps, since for each object it is first necessary to determine which attributes it has, and in which blocks they are located.
6. Overview of the State of the Art
6.1. State of Technology
- BlockchainDB [103] provides a key-value database layer on top of a blockchain, which provides a simple get/put interface as well as an additional verify method for data verification.
- FalconDB [104] provides a “traditional” database layer with temporal attributes on top of a blockchain. It relies on smart contracts for querying as there is an incentive model that each node remains honest.
- Veritas [105] provides a verifiable database layer on top of a blockchain.
- BigchainDB [106] provides a blockchain layer on top of a MongoDB (see https://www.mongodb.com; accessed on 15 December 2021) database. As all blocks, transactions, and metadata are stored in it, the full query power of MongoDB can be used to query data.
- Blockchain Relational Database [107] integrates a blockchain layer into a relational database management system, namely PostgreSQL (see https://www.postgresql.org; accessed on 15 December 2021). PostgreSQL was chosen because it keeps all versions of a row. Usually, relational database systems update data in-place and maintain a rollback log.
6.2. State of Research
- What happens, if the data in the relational database SQLite is tampered with?
- Smart contracts in Ethereum only have access to the latest state of their data. Is this also the case here?
7. Future Research Challenges
7.1. Data Models
7.2. Data Structures
7.3. Block Structures
7.4. Query Processing
7.5. New Blockchain Architectures
7.6. Legal Restrictions
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Faroukhi, A.Z.; El Alaoui, I.; Gahi, Y.; Amine, A. Big data monetization throughout Big Data Value Chain: A comprehensive review. J. Big Data 2020, 7, 3:1–3:22. [Google Scholar] [CrossRef]
- Wiens, J.; Price, W.N.; Sjoding, M.W. Diagnosing bias in data-driven algorithms for healthcare. Nat. Med. 2020, 26, 25–26. [Google Scholar] [CrossRef]
- Saetta, S.; Caldarelli, V. How to increase the sustainability of the agri-food supply chain through innovations in 4.0 perspective: A first case study analysis. Procedia Manuf. 2020, 42, 333–336. [Google Scholar] [CrossRef]
- Ren, L.; Meng, Z.; Wang, X.; Zhang, L.; Yang, L.T. A Data-Driven Approach of Product Quality Prediction for Complex Production Systems. IEEE Trans. Ind. Inform. 2021, 17, 6457–6465. [Google Scholar] [CrossRef]
- Stach, C.; Bräcker, J.; Eichler, R.; Giebler, C.; Mitschang, B. Demand-Driven Data Provisioning in Data Lakes: BARENTS—A Tailorable Data Preparation Zone. In Proceedings of the 23rd International Conference on Information Integration and Web Intelligence, iiWAS ’21, Linz, Austria, 29 November–1 December 2021; pp. 191–202. [Google Scholar]
- Diènea, B.; Rodrigues, J.J.; Diallo, O.; Ndoye, E.H.M.; Korotaev, V.V. Data management techniques for Internet of Things. Mech. Syst. Signal Process. 2020, 138, 106564:1–106564:19. [Google Scholar] [CrossRef]
- Pavlou, K.E.; Snodgrass, R.T. Forensic Analysis of Database Tampering. ACM Trans. Database Syst. 2008, 33, 1–47. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, M.; Matulevičius, R. Blockchain as a Countermeasure Solution for Security Threats of Healthcare Applications. In Proceedings of the 19th Business Process Management Conference, BPM ’21, Rome, Italy, 6–10 September 2021; pp. 67–84. [Google Scholar]
- Chopade, R.; Pachghare, V. Data Tamper Detection from NoSQL Database in Forensic Environment. J. Cyber Secur. Mobil. 2021, 10, 421–450. [Google Scholar]
- Nwosu, A.U.; Goyal, S.B.; Bedi, P. Blockchain Transforming Cyber-Attacks: Healthcare Industry. In Proceedings of the 11th International Conference on Innovations in Bio-Inspired Computing and Applications, IBICA ’20, Online, 16–18 December 2020; pp. 258–266. [Google Scholar]
- Maity, M.; Tolooie, A.; Sinha, A.K.; Tiwari, M.K. Stochastic batch dispersion model to optimize traceability and enhance transparency using Blockchain. Comput. Ind. Eng. 2021, 154, 107134:1–107134:12. [Google Scholar] [CrossRef]
- Ge, C.; Liu, Z.; Fang, L. A blockchain based decentralized data security mechanism for the Internet of Things. J. Parallel Distrib. Comput. 2020, 141, 1–9. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. White Paper, Bitcoin. 2008. Available online: https://klausnordby.com/bitcoin/Bitcoin_Whitepaper_Document_HD.pdf (accessed on 12 December 2021).
- Zhu, Y.; Zhang, Z.; Jin, C.; Zhou, A.; Qin, G.; Yang, Y. Towards Rich Query Blockchain Database. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM’20, Ireland (Virtual Event), 19–23 October 2020; pp. 3497–3500. [Google Scholar]
- Ruan, P.; Anh Dinh, T.T.; Lin, Q.; Zhang, M.; Chen, G.; Chin Ooi, B. Revealing Every Story of Data in Blockchain Systems. ACM SIGMOD Rec. 2020, 49, 70–77. [Google Scholar] [CrossRef]
- Hellwig, D.; Karlic, G.; Huchzermeier, A. Build Your Own Blockchain: A Practical Guide to Distributed Ledger Technology; Management for Professionals; Springer Nature: Cham, Switzerland, 2020. [Google Scholar]
- Krishnan, S.; Balas, V.E.; Golden Julie, E.; Robinson, Y.H.; Balaji, S.; Kumar, R. (Eds.) Handbook of Research on Blockchain Technology; Academic Press: London, UK; San Diego, CA, USA; Cambridge, UK; Oxford, UK, 2020. [Google Scholar]
- Merkle, R.C. A Digital Signature Based on a Conventional Encryption Function. In Proceedings of the 7th Conference on Advances in Cryptology, CRYPTO ’87, Santa Barbara, CA, USA, 16–20 August 1987; pp. 369–378. [Google Scholar]
- Vujičić, D.; Jagodić, D.; Rand̄ić, S. Blockchain technology, bitcoin, and Ethereum: A brief overview. In Proceedings of the 2018 17th International Symposium INFOTEH-JAHORINA, INFOTEH ’18, East Sarajevo, Bosnia and Herzegovina, 21–23 March 2018; pp. 1–6. [Google Scholar]
- Yue, C.; Xie, Z.; Zhang, M.; Chen, G.; Ooi, B.C.; Wang, S.; Xiao, X. Analysis of Indexing Structures for Immutable Data. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, SIGMOD ’20, Portland, OR, USA, 14–19 June 2020; pp. 925–935. [Google Scholar]
- Ruoti, S.; Kaiser, B.; Yerukhimovich, A.; Clark, J.; Cunningham, R. Blockchain Technology: What is It Good For? Commun. ACM 2019, 63, 46–53. [Google Scholar] [CrossRef]
- Nofer, M.; Gomber, P.; Hinz, O.; Schiereck, D. Blockchain. Bus. Inf. Syst. Eng. 2017, 59, 183–187. [Google Scholar] [CrossRef]
- Muzammal, M.; Qu, Q.; Nasrulin, B. Renovating blockchain with distributed databases: An open source system. Future Gener. Comput. Syst. 2019, 90, 105–117. [Google Scholar] [CrossRef]
- Dwork, C.; Naor, M. Pricing via Processing or Combatting Junk Mail. In Proceedings of the 12th Annual International Cryptology Conference, CRYPTO ’92, Santa Barbara, CA, USA, 16–20 August 1992; pp. 139–147. [Google Scholar]
- Chowdhury, M.J.M.; Colman, A.; Kabir, M.A.; Han, J.; Sarda, P. Blockchain Versus Database: A Critical Analysis. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering, TrustCom/BigDataSE ’18, New York, NY, USA, 1–3 August 2018; pp. 1348–1353. [Google Scholar]
- Rehmani, M.H. Blockchain Technology and Database Management System. In Blockchain Systems and Communication Networks: From Concepts to Implementation; Springer International Publishing: Cham, Switzerland, 2021; Chapter 2; pp. 15–22. [Google Scholar]
- Chen, S.; Zhang, J.; Shi, R.; Yan, J.; Ke, Q. A Comparative Testing on Performance of Blockchain and Relational Database: Foundation for Applying Smart Technology into Current Business Systems. In Proceedings of the 6th International Conference on Distributed, Ambient, and Pervasive Interactions, DAPI ’18, Las Vegas, NV, USA, 15–20 July 2018; pp. 21–34. [Google Scholar]
- Ozdayi, M.S.; Kantarcioglu, M.; Malin, B. Leveraging blockchain for immutable logging and querying across multiple sites. BMC Med. Genom. 2020, 13, 82–88. [Google Scholar] [CrossRef] [PubMed]
- Eberhardt, J.; Tai, S. On or Off the Blockchain? Insights on Off-Chaining Computation and Data. In Proceedings of the 6th IFIP WG 2.14 European Conference on Service-Oriented and Cloud Computing, ESOCC ’17, Oslo, Norway, 27–29 September 2017; pp. 3–15. [Google Scholar]
- Lo, S.K.; Xu, X.; Chiam, Y.K.; Lu, Q. Evaluating Suitability of Applying Blockchain. In Proceedings of the 2017 22nd International Conference on Engineering of Complex Computer Systems, ICECCS ’17, Fukuoka, Japan, 5–8 November 2017; pp. 158–161. [Google Scholar]
- Alladi, T.; Chamola, V.; Rodrigues, J.J.P.C.; Kozlov, S.A. Blockchain in Smart Grids: A Review on Different Use Cases. Sensors 2019, 19, 4862. [Google Scholar] [CrossRef] [Green Version]
- Mollah, M.B.; Zhao, J.; Niyato, D.; Lam, K.Y.; Zhang, X.; Ghias, A.M.Y.M.; Koh, L.H.; Yang, L. Blockchain for Future Smart Grid: A Comprehensive Survey. IEEE Internet Things J. 2021, 8, 18–43. [Google Scholar] [CrossRef]
- Gaber, T.; Ahmed, A.; Mostafa, A. PrivDRM: A Privacy-Preserving Secure Digital Right Management System. In Proceedings of the Evaluation and Assessment in Software Engineering, EASE ’20, Trondheim, Norway, 15–17 April 2020; pp. 481–486. [Google Scholar]
- Hei, Y.; Liu, J.; Feng, H.; Li, D.; Liu, Y.; Wu, Q. Making MA-ABE fully accountable: A blockchain-based approach for secure digital right management. Comput. Netw. 2021, 191, 108029:1–108029:12. [Google Scholar] [CrossRef]
- Ren, Q.; Man, K.L.; Li, M.; Gao, B. Using Blockchain to Enhance and Optimize IoT-based Intelligent Traffic System. In Proceedings of the 2019 International Conference on Platform Technology and Service, PlatCon ’19, Jeju, Korea, 28–30 January 2019; pp. 1–4. [Google Scholar]
- Wang, Q.; Ji, T.; Guo, Y.; Yu, L.; Chen, X.; Li, P. TrafficChain: A Blockchain-Based Secure and Privacy-Preserving Traffic Map. IEEE Access 2020, 8, 60598–60612. [Google Scholar] [CrossRef]
- Holderried, M.; Hoeper, A.; Holderried, F.; Heyne, N.; Nadalin, S.; Unger, O.; Ernst, C.; Guthoff, M. Attitude and potential benefits of modern information and communication technology use and telemedicine in cross-sectoral solid organ transplant care. Sci. Rep. 2021, 11, 9037:1–9037:9. [Google Scholar] [CrossRef]
- Hörbst, A.; Ammenwerth, E. Electronic health records: A systematic review on quality requirements. Methods Inf. Med. 2010, 49, 320–336. [Google Scholar]
- Lupton, D. The Quantified Self; Polity Press: Malden, MA, USA, 2016. [Google Scholar]
- Heinemann, L. Continuous Glucose Monitoring (CGM) or Blood Glucose Monitoring (BGM): Interactions and Implications. J. Diabetes Sci. Technol. 2018, 12, 873–879. [Google Scholar] [CrossRef] [Green Version]
- Isakadze, N.; Martin, S.S. How useful is the smartwatch ECG? Trends Cardiovasc. Med. 2020, 30, 442–448. [Google Scholar] [CrossRef]
- Stach, C.; Steimle, F.; Franco da Silva, A.C. TIROL: The Extensible Interconnectivity Layer for mHealth Applications. In Proceedings of the 23rd International Conference on Information and Software Technologies, ICIST ’17, Druskininkai, Lithuania, 12–14 October 2017; pp. 190–202. [Google Scholar]
- Pham, H.L.; Tran, T.H.; Nakashima, Y. A Secure Remote Healthcare System for Hospital Using Blockchain Smart Contract. In Proceedings of the 2018 IEEE Globecom Workshops, GC Wkshps ’18, Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Spanakis, E.G.; Bonomi, S.; Sfakianakis, S.; Santucci, G.; Lenti, S.; Sorella, M.; Tanasache, F.D.; Palleschi, A.; Ciccotelli, C.; Sakkalis, V.; et al. Cyber-attacks and threats for healthcare—A multi-layer thread analysis. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine Biology Society, EMBC ’20, Montreal, QC, Canada, 20–24 July 2020; pp. 5705–5708. [Google Scholar]
- Ball, M.J.; Smith, C.; Bakalar, R.S. Personal health records: Empowering consumers. J. Healthc. Inf. Manag. 2007, 21, 76–86. [Google Scholar]
- Peng, Z.; Xu, C.; Wang, H.; Huang, J.; Xu, J.; Chu, X. P2B-Trace: Privacy-Preserving Blockchain-Based Contact Tracing to Combat Pandemics. In Proceedings of the 2021 International Conference on Management of Data, SIGMOD/PODS ’21, China (Virtual Event), 20–25 June 2021; pp. 2389–2393. [Google Scholar]
- De Aguiar, E.J.; Faiçal, B.S.; Krishnamachari, B.; Ueyama, J. A Survey of Blockchain-Based Strategies for Healthcare. ACM Comput. Surv. 2020, 53, 27:1–27:27. [Google Scholar] [CrossRef] [Green Version]
- Hasselgren, A.; Kralevska, K.; Gligoroski, D.; Pedersen, S.A.; Faxvaag, A. Blockchain in healthcare and health sciences—A scoping review. Int. J. Med. Inform. 2020, 134, 104040:1–104040:10. [Google Scholar] [CrossRef]
- Khatoon, A. A Blockchain-Based Smart Contract System for Healthcare Management. Electronics 2020, 9, 94. [Google Scholar] [CrossRef] [Green Version]
- Przytarski, D.; Stach, C.; Gritti, C.; Mitschang, B. A Blueprint for a Trustworthy Health Data Platform Encompassing IoT and Blockchain Technologies. In Proceedings of the ISCA 29th International Conference on Software Engineering and Data Engineering, SEDE ’20, Las Vegas, NV, USA (Virtual Event), 19–21 October 2020; pp. 56–65. [Google Scholar]
- Tanwar, S.; Parekh, K.; Evans, R. Blockchain-based electronic healthcare record system for healthcare 4.0 applications. J. Inf. Secur. Appl. 2020, 50, 102407:1–102407:13. [Google Scholar] [CrossRef]
- Smith, F. The influence of Amatino Manucci and Luca Pacioli. BSHM Bull. J. Br. Soc. Hist. Math. 2008, 23, 143–156. [Google Scholar] [CrossRef]
- Ellerman, D.P. The Mathematics of Double Entry Bookkeeping. Math. Mag. 1985, 58, 226–233. [Google Scholar] [CrossRef]
- Brandon, D. The BLOCKCHAIN: The Future of Business Information Systems? Int. J. Acad. Bus. World 2016, 10, 33–40. [Google Scholar]
- Beck, R.; Avital, M.; Rossi, M.; Thatcher, J.B. Blockchain Technology in Business and Information Systems Research. Bus. Inf. Syst. Eng. 2017, 59, 381–384. [Google Scholar] [CrossRef] [Green Version]
- Carlin, T. Blockchain and the Journey Beyond Double Entry. Aust. Account. Rev. 2019, 29, 305–311. [Google Scholar] [CrossRef]
- Faccia, A.; Moşteanu, N.R.; Leonardo, L.P. Blockchain Hash, the Missing Axis of the Accounts to Settle the Triple Entry Bookkeeping System. In Proceedings of the 2020 12th International Conference on Information Management and Engineering, ICIME ’20, Amsterdam, The Netherlands, 16–18 September 2020; pp. 18–23. [Google Scholar]
- Gökten, S.; Özdoğan, B. The Doors Are Opening for the New Pedigree: A Futuristic View for the Effects of Blockchain Technology on Accounting Applications. In Digital Business Strategies in Blockchain Ecosystems: Transformational Design and Future of Global Business; Hacioglu, U., Ed.; Springer International Publishing: Cham, Switzerland, 2020; pp. 425–438. [Google Scholar]
- Schmitz, J.; Leoni, G. Accounting and Auditing at the Time of Blockchain Technology: A Research Agenda. Aust. Account. Rev. 2019, 29, 331–342. [Google Scholar] [CrossRef]
- Sveistrup Søgaard, J. A blockchain-enabled platform for VAT settlement. Int. J. Account. Inf. Syst. 2021, 40, 100502:1–100502:18. [Google Scholar]
- Zhang, Y.; Xiong, F.; Xie, Y.; Fan, X.; Gu, H. The Impact of Artificial Intelligence and Blockchain on the Accounting Profession. IEEE Access 2020, 8, 110461–110477. [Google Scholar] [CrossRef]
- Femenia-Ribera, C.; Mora-Navarro, G.; Martinez-Llario, J.C. Advances in the Coordination between the Cadastre and Land Registry. Land 2021, 10, 81. [Google Scholar] [CrossRef]
- Panda, S.K.; Mohammad, G.B.; Nandan Mohanty, S.; Sahoo, S. Smart contract-based land registry system to reduce frauds and time delay. Secur. Priv. 2021, 4, e172:1–e172:21. [Google Scholar] [CrossRef]
- Zhang, P.; Schmidt, D.C.; White, J.; Lenz, G. Blockchain Technology Use Cases in Healthcare. In Advances in Computers; Raj, P., Deka, G.C., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; Chapter 1; pp. 1–41. [Google Scholar]
- Peiró, N.N.; Martinez García, E.J. Blockchain and Land Registration Systems. Eur. Prop. Law J. 2017, 6, 296–320. [Google Scholar] [CrossRef]
- Vos, J. Blockchain-Based Land Registry: Panacea, Illusion or Something in Between; ELRA Annual Publication 7; European Land Registry Association: Brussels, Belgium, 2017. [Google Scholar]
- Dabbagh, M.; Choo, K.K.R.; Beheshti, A.; Tahir, M.; Safa, N.S. A survey of empirical performance evaluation of permissioned blockchain platforms: Challenges and opportunities. Comput. Secur. 2021, 100, 102078:1–102078:13. [Google Scholar] [CrossRef]
- Benarous, L.; Kadri, B.; Bouridane, A.; Benkhelifa, E. Blockchain-based forgery resilient vehicle registration system. In Transactions on Emerging Telecommunications Technologies; John Wiley & Sons: Hoboken, NI, USA, 2021; pp. 1–18. [Google Scholar]
- Rosado, T.; Vasconcelos, A.; Correia, M. A Blockchain Use Case for Car Registration. In Essentials of Blockchain Technology; Li, K.C., Chen, X., Jiang, H., Bertino, E., Eds.; Chapman & Hall/CRC: New York, NY, USA, 2019; Chapter 10; pp. 205–234. [Google Scholar]
- Sahai, A.; Pandey, R. Smart Contract Definition for Land Registry in Blockchain. In Proceedings of the 2020 IEEE 9th International Conference on Communication Systems and Network Technologies, CSNT ’20, Gwalior, India, 10–12 April 2020; pp. 230–235. [Google Scholar]
- Shinde, D.; Padekar, S.; Raut, S.; Wasay, A.; Sambhare, S.S. Land Registry Using Blockchain—A Survey of existing systems and proposing a feasible solution. In Proceedings of the 2019 5th International Conference On Computing, Communication, Control and Automation, ICCUBEA ’19, Pune, India, 19–21 September 2019; pp. 1–6. [Google Scholar]
- Singh Yadav, A.; Singh Kushwaha, D. Query Optimization in a Blockchain-Based Land Registry Management System. Ingénierie Systèmes D’Inf. 2021, 26, 13–21. [Google Scholar] [CrossRef]
- Shah, R.; Meyer Goldstein, S.; Ward, P.T. Aligning supply chain management characteristics and interorganizational information system types: An exploratory study. IEEE Trans. Eng. Manag. 2002, 49, 282–292. [Google Scholar] [CrossRef] [Green Version]
- Nastasijević, I.; Lakićević, B.; Petrović, Z. Cold chain management in meat storage, distribution and retail: A review. IOP Conf. Ser. Earth Environ. Sci. 2017, 85, 012022:1–012022:10. [Google Scholar] [CrossRef]
- Tian, F. A supply chain traceability system for food safety based on HACCP, blockchain & Internet of things. In Proceedings of the 2017 International Conference on Service Systems and Service Management, ICSSSM ’17, Dalian, China, 16–18 June 2017; pp. 1–6. [Google Scholar]
- Stach, C.; Gritti, C.; Przytarski, D.; Mitschang, B. Trustworthy, Secure, and Privacy-aware Food Monitoring Enabled by Blockchains and the IoT. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications Workshops, PerCom ’20, Austin, TX, USA, 23–27 March 2020; pp. 50:1–50:4. [Google Scholar]
- Fan, Y.; de Kleuver, C.; de Leeuw, S.; Behdani, B. Trading off cost, emission, and quality in cold chain design: A simulation approach. Comput. Ind. Eng. 2021, 158, 107442:1–107442:16. [Google Scholar] [CrossRef]
- Menon, K.N.; Thomas, K.; Thomas, J.; Titus, D.J.; James, D. ColdBlocks: Quality Assurance in Cold Chain Networks Using Blockchain and IoT. In Proceedings of the 2nd International Conference on Emerging Technologies in Data Mining and Information Security, IEMIS ’20, Kolkata, India, 2–4 July 2020; pp. 781–789. [Google Scholar]
- Duan, J.; Zhang, C.; Gong, Y.; Brown, S.; Li, Z. A Content-Analysis Based Literature Review in Blockchain Adoption within Food Supply Chain. Int. J. Environ. Res. Public Health 2020, 17, 1784. [Google Scholar] [CrossRef] [Green Version]
- Köhler, S.; Pizzol, M. Technology assessment of blockchain-based technologies in the food supply chain. J. Clean. Prod. 2020, 269, 122193:1–122193:10. [Google Scholar] [CrossRef]
- Kayikci, Y.; Subramanian, N.; Dora, M.; Singh Bhatia, M. Food supply chain in the era of Industry 4.0: Blockchain technology implementation opportunities and impediments from the perspective of people, process, performance, and technology. In Production Planning & Control; Taylor & Francis: Zug, Switzerland; Saint Helier, Jersey, 2020; pp. 1–21. [Google Scholar]
- Shahid, A.; Almogren, A.; Javaid, N.; Al-Zahrani, F.A.; Zuair, M.; Alam, M. Blockchain-Based Agri-Food Supply Chain: A Complete Solution. IEEE Access 2020, 8, 69230–69243. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, P.; Xu, J.; Wang, X.; Yu, J.; Zhao, Z.; Dong, Y. Blockchain-Based Safety Management System for the Grain Supply Chain. IEEE Access 2020, 8, 36398–36410. [Google Scholar] [CrossRef]
- Gritzalis, D.A. Principles and requirements for a secure e-voting system. Comput. Secur. 2002, 21, 539–556. [Google Scholar] [CrossRef]
- Gibson, J.P.; Krimmer, R.; Teague, V.; Pomares, J. A review of E-voting: The past, present and future. Ann. Telecommun. 2016, 71, 279–286. [Google Scholar] [CrossRef]
- Boyd, C.; Gjøsteen, K.; Gritti, C.; Haines, T. A Blind Coupon Mechanism Enabling Veto Voting over Unreliable Networks. In Proceedings of the 20th International Conference on Cryptology in India, INDOCRYPT ’19, Hyderabad, India, 15–18 December 2019; pp. 250–270. [Google Scholar]
- Haines, T.; Gritti, C. Improvements in Everlasting Privacy: Efficient and Secure Zero Knowledge Proofs. In Proceedings of the 4th International Joint Conference on Electronic Voting, E-Vote-ID ’19, Bregenz, Austria, 1–4 October 2019; pp. 116–133. [Google Scholar]
- Moura, T.; Gomes, A. Blockchain Voting and Its Effects on Election Transparency and Voter Confidence. In Proceedings of the 18th Annual International Conference on Digital Government Research, dg.o ’17, Staten Island, NY, USA, 7–9 June 2017; pp. 574–575. [Google Scholar]
- Wani, S.; Imthiyas, M.; Almohamedh, H.; Alhamed, K.M.; Almotairi, S.; Gulzar, Y. Distributed Denial of Service (DDoS) Mitigation Using Blockchain–A Comprehensive Insight. Symmetry 2021, 13, 227. [Google Scholar] [CrossRef]
- Hanifatunnisa, R.; Rahardjo, B. Blockchain based e-voting recording system design. In Proceedings of the 2017 11th International Conference on Telecommunication Systems Services and Applications, TSSA ’17, Lombok, Indonesia, 26–27 October 2017; pp. 1–6. [Google Scholar]
- Hjálmarsson, F.Þ.; Hreiðarsson, G.K.; Hamdaqa, M.; Hjálmtýsson, G. Blockchain-Based E-Voting System. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing, CLOUD ’18, San Francisco, CA, USA, 2–7 July 2018; pp. 983–986. [Google Scholar]
- Kshetri, N.; Voas, J. Blockchain-Enabled E-Voting. IEEE Softw. 2018, 35, 95–99. [Google Scholar] [CrossRef] [Green Version]
- Ruparel, H.; Hosatti, S.; Shirole, M.; Bhirud, S. Secure Voting for Democratic Elections: A Blockchain-Based Approach. In Proceedings of the 2020 International Conference on Communication, Computing and Electronics Systems, ICCCES ’20, Coimbatore, India, 21–22 October 2020; pp. 615–628. [Google Scholar]
- Wang, B.; Sun, J.; He, Y.; Pang, D.; Lu, N. Large-scale Election Based On Blockchain. Procedia Comput. Sci. 2018, 129, 234–237. [Google Scholar] [CrossRef]
- Buchmann, A.; Koldehofe, B. Complex Event Processing. IT-Inf. Technol. 2009, 51, 241–242. [Google Scholar] [CrossRef]
- Pratama, F.A.; Mutijarsa, K. Query Support for Data Processing and Analysis on Ethereum Blockchain. In Proceedings of the 2018 International Symposium on Electronics and Smart Devices, ISESD ’18, Bandung, Indonesia, 23–24 October 2018; pp. 1–5. [Google Scholar]
- Zhu, Y.; Zhang, Z.; Jin, C.; Zhou, A.; Yan, Y. SEBDB: Semantics Empowered BlockChain DataBase. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering, ICDE ’19, Macao, China, 8–11 April 2019; pp. 1820–1831. [Google Scholar]
- Heuer, A.; Scholl, M.H. Principles of Object-Oriented Query Languages. In Datenbanksysteme in Büro, Technik und Wissenschaft; Appelrath, H.J., Ed.; Springer: Berlin/Heidelberg, Germany, 1991; pp. 178–197. [Google Scholar]
- Libkin, L. Expressive power of SQL. Theor. Comput. Sci. 2003, 296, 379–404. [Google Scholar] [CrossRef] [Green Version]
- Klyne, G.; Newman, C. Date and Time on the Internet: Timestamps; Standards Track RFC 3339, July; IETF—Network Working Group: Reston, VA, USA; Geneva, Switzerland, 2002. [Google Scholar]
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; De Caro, A.; Enyeart, D.; Ferris, C.; Laventman, G.; Manevich, Y.; et al. Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains. In Proceedings of the Thirteenth EuroSys Conference, EuroSys ’18, Porto, Portugal, 23–26 April 2018; pp. 30:1–30:15. [Google Scholar]
- Ruan, P.; Dinh, T.T.A.; Loghin, D.; Zhang, M.; Chen, G.; Lin, Q.; Ooi, B.C. Blockchains vs. Distributed Databases: Dichotomy and Fusion. In Proceedings of the 2021 International Conference on Management of Data, SIGMOD/PODS ’21, China (Virtual Event), 20–25 June 2021; pp. 1504–1517. [Google Scholar]
- El-Hindi, M.; Binnig, C.; Arasu, A.; Kossmann, D.; Ramamurthy, R. BlockchainDB: A Shared Database on Blockchains. Proc. VLDB Endow. 2019, 12, 1597–1609. [Google Scholar] [CrossRef]
- Peng, Y.; Du, M.; Li, F.; Cheng, R.; Song, D. FalconDB: Blockchain-Based Collaborative Database. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, SIGMOD ’20, Portland, OR, USA, 14–19 June 2020; pp. 637–652. [Google Scholar]
- Allen, L.; Antonopoulos, P.; Arasu, A.; Gehrke, J.; Hammer, J.; Hunter, J.; Kaushik, R.; Kossmann, D.; Lee, J.; Ramamurthy, R.; et al. Veritas: Shared Verifiable Databases and Tables in the Cloud. In Proceedings of the 9th Biennial Conference on Innovative Data Systems Research, CIDR ’19, Asilomar, CA, USA, 13–16 January 2019; pp. 111:1–111:9. [Google Scholar]
- BigchainDB GmbH. BigchainDB 2.0: The Blockchain Database; White Paper; BigchainDB GmbH: Berlin, Germany, 2018. [Google Scholar]
- Nathan, S.; Govindarajan, C.; Saraf, A.; Sethi, M.; Jayachandran, P. Blockchain Meets Database: Design and Implementation of a Blockchain Relational Database. Proc. VLDB Endow. 2019, 12, 1539–1552. [Google Scholar] [CrossRef]
- Schuhknecht, F.M.; Sharma, A.; Dittrich, J.; Agrawal, D. chainifyDB: How to get rid of your Blockchain and use your DBMS instead. In Proceedings of the 11th Annual Conference on Innovative Data Systems Research, CIDR ’21, Online, 11–15 January 2021; pp. 4:1–4:10. [Google Scholar]
- Eisenberg, A.; Melton, J. SQL: 1999, Formerly Known as SQL3. ACM SIGMOD Rec. 1999, 28, 131–138. [Google Scholar] [CrossRef]
- Wood, G. Ethereum: A Secure Decentralised Generalised Transaction Ledger. Ethereum Yellow Paper Berlin Version 888949c, Ethereum Project. 2021. Available online: https://files.gitter.im/ethereum/yellowpaper/VIyt/Paper.pdf (accessed on 12 December 2021).
- Han, J.; Kim, H.; Eom, H.; Coignard, J.; Wu, K.; Son, Y. Enabling SQL-Query Processing for Ethereum-based Blockchain Systems. In Proceedings of the 9th International Conference on Web Intelligence, Mining and Semantics, WIMS ’19, Seoul, Korea, 26–28 June 2019; pp. 9:1–9:7. [Google Scholar]
- Tong, X.; Tang, H.; Jiang, N.; Fan, W.; Gao, Y.; Deng, S.; Zhang, Z.; Jin, C.; Yang, Y.; Qin, G. SQL-Middleware: Enabling the Blockchain with SQL. In Proceedings of the 26th International Conference on Database Systems for Advanced Applications, DASFAA ’21, Taipei, Taiwan, 11–14 April 2021; pp. 622–626. [Google Scholar]
- Li, Y.; Zheng, K.; Yan, Y.; Liu, Q.; Zhou, X. EtherQL: A Query Layer for Blockchain System. In Proceedings of the 22nd International Conference on Database Systems for Advanced Applications, DASFAA ’17, Suzhou, China, 27–30 March 2017; pp. 556–567. [Google Scholar]
- Bragagnolo, S.; Marra, M.; Polito, G.; Gonzalez Boix, E. Towards Scalable Blockchain Analysis. In Proceedings of the 2019 IEEE/ACM 2nd International Workshop on Emerging Trends in Software Engineering for Blockchain, WETSEB ’19, Montreal, QC, Canada, 27 May 2019; pp. 1–7. [Google Scholar]
- Xu, C.; Zhang, C.; Xu, J. vChain: Enabling Verifiable Boolean Range Queries over Blockchain Databases. In Proceedings of the 2019 International Conference on Management of Data, SIGMOD ’19, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 141–158. [Google Scholar]
- Xing, X.; Chen, Y.; Li, T.; Xin, Y.; Sun, H. A blockchain index structure based on subchain query. J. Cloud Comput. 2021, 10, 52:1–52:11. [Google Scholar] [CrossRef]
- Jia, D.Y.; Xin, J.C.; Wang, Z.Q.; Lei, H.; Wang, G.R. SE-Chain: A Scalable Storage and Efficient Retrieval Model for Blockchain. J. Comput. Sci. Technol. 2021, 36, 693–706. [Google Scholar] [CrossRef]
- Peng, Z.; Wu, H.; Xiao, B.; Guo, S. VQL: Providing Query Efficiency and Data Authenticity in Blockchain Systems. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering Workshops, ICDEW 19, Macao, China, 8–12 April 2019; pp. 1–6. [Google Scholar]
- Wu, H.; Peng, Z.; Guo, S.; Yang, Y.; Xiao, B. VQL: Efficient and Verifiable Cloud Query Services for Blockchain Systems. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 1393–1406. [Google Scholar] [CrossRef]
- Gritti, C.; Önen, M.; Molva, R. Privacy-Preserving Delegable Authentication in the Internet of Things. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, SAC ’19, Limassol, Cyprus, 8–12 April 2019; pp. 861–869. [Google Scholar]
- Stach, C.; Bräcker, J.; Eichler, R.; Giebler, C.; Gritti, C. How to Provide High-Utility Time Series Data in a Privacy-Aware Manner: A VAULT to Manage Time Series Data. Int. J. Adv. Secur. 2020, 13, 88–108. [Google Scholar]
- Wortner, P.; Schubotz, M.; Breitinger, C.; Leible, S.; Gipp, B. Securing the Integrity of Time Series Data in Open Science Projects using Blockchain-based Trusted Timestamping. In Proceedings of the Workshop on Web Archiving and Digital Libraries held in conjunction with the 18th ACM/IEEE Joint Conference on Digital Libraries, WADL ’19, Champaign, IL, USA, 2 June 2019; pp. 2:1–2:3. [Google Scholar]
- Dhanush, G.A.; Raj, K.S.; Kumar, P. Blockchain Aided Predictive Time Series Analysis in Supply Chain System. In Proceedings of the 2021 2nd International Conference on Electrical and Electronics Engineering, ICEEE ’21, NCR New Delhi, India, 2–3 January 2021; pp. 913–925. [Google Scholar]
- Yu, Z.; Cai, Y.; Hong, W. A Storage Architecture of Blockchain for Time-Series Data. In Proceedings of the 2019 2nd International Conference on Hot Information-Centric Networking, HotICN ’19, Chongqing, China, 13–15 December 2019; pp. 90–91. [Google Scholar]
- Qu, Q.; Nurgaliev, I.; Muzammal, M.; Jensen, C.S.; Fan, J. On spatio-temporal blockchain query processing. Future Gener. Comput. Syst. 2019, 98, 208–218. [Google Scholar] [CrossRef]
- Nurgaliev, I.; Muzammal, M.; Qu, Q. Enabling Blockchain for Efficient Spatio-Temporal Query Processing. In Proceedings of the 19th International Conference on Web Information Systems Engineering, WISE ’18, Dubai, United Arab Emirates, 12–15 November 2018; pp. 36–51. [Google Scholar]
- Zhang, Y.; Genkin, D.; Katz, J.; Papadopoulos, D.; Papamanthou, C. vSQL: Verifying Arbitrary SQL Queries over Dynamic Outsourced Databases. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, SP ’17, San Jose, CA, USA, 22–26 May 2017; pp. 863–880. [Google Scholar]
- Zhang, M.; Xie, Z.; Yue, C.; Zhong, Z. Spitz: A Verifiable Database System. Proc. VLDB Endow. 2020, 13, 3449–3460. [Google Scholar] [CrossRef]
- Wang, S.; Dinh, T.T.A.; Lin, Q.; Xie, Z.; Zhang, M.; Cai, Q.; Chen, G.; Ooi, B.C.; Ruan, P. Forkbase: An Efficient Storage Engine for Blockchain and Forkable Applications. Proc. VLDB Endow. 2018, 11, 1137–1150. [Google Scholar] [CrossRef]
- Zhou, W.; Cai, Y.; Peng, Y.; Wang, S.; Ma, K.; Li, F. VeriDB: An SGX-Based Verifiable Database. In Proceedings of the 2021 International Conference on Management of Data, SIGMOD/PODS ’21, China (Virtual Event), 20–25 June 2021; pp. 2182–2194. [Google Scholar]
- McKeen, F.; Alexandrovich, I.; Anati, I.; Caspi, D.; Johnson, S.; Leslie-Hurd, R.; Rozas, C. Intel® Software Guard Extensions (Intel® SGX) Support for Dynamic Memory Management Inside an Enclave. In Proceedings of the Hardware and Architectural Support for Security and Privacy 2016, HASP ’16, Seoul, Korea, 18 June 2016; pp. 1–9. [Google Scholar]
- Li, F.; Hadjieleftheriou, M.; Kollios, G.; Reyzin, L. Dynamic Authenticated Index Structures for Outsourced Databases. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, SIGMOD ’06, Chicago, IL, USA, 27–29 June 2006; pp. 121–132. [Google Scholar]
- Przytarski, D. Using Triples as the Data Model for Blockchain Systems. In Proceedings of the Blockchain enabled Semantic Web Workshop and Contextualized Knowledge Graphs Workshop co-located with the 18th International Semantic Web Conference, BlockSW/CKG@ISWC ’19, Auckland, New Zealand, 26–30 October 2019; pp. 1–2. [Google Scholar]
- Neumann, T.; Weikum, G. The RDF-3X engine for scalable management of RDF data. VLDB J. 2010, 19, 91–113. [Google Scholar] [CrossRef] [Green Version]
- Dang, H.; Dinh, T.T.A.; Loghin, D.; Chang, E.C.; Lin, Q.; Ooi, B.C. Towards Scaling Blockchain Systems via Sharding. In Proceedings of the 2019 International Conference on Management of Data, SIGMOD ’19, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 123–140. [Google Scholar]
- Levene, M.; Loizou, G. Why is the snowflake schema a good data warehouse design? Inf. Syst. 2003, 28, 225–240. [Google Scholar] [CrossRef] [Green Version]
- Herlihy, M. Atomic Cross-Chain Swaps. In Proceedings of the 2018 ACM Symposium on Principles of Distributed Computing, PODC ’18, Egham, UK, 23–27 July 2018; pp. 245–254. [Google Scholar]
- Xu, J.; Ackerer, D.; Dubovitskaya, A. A Game-Theoretic Analysis of Cross-Chain Atomic Swaps with HTLCs. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems, ICDCS ’21, Washington, DC, USA, 7–10 July 2021; pp. 584–594. [Google Scholar]
- European Parliament and Council of the European Union. Regulation on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (Data Protection Directive). Legislative Acts L119. Off. J. Eur. Union 2016. [Google Scholar]
- Hofman, D.; Lemieux, V.L.; Joo, A.; Alves Batista, D. “The margin between the edge of the world and infinite possibility”: Blockchain, GDPR and information governances. Rec. Manag. J. 2019, 29, 240–257. [Google Scholar] [CrossRef]
- Shi, S.; He, D.; Li, L.; Kumar, N.; Khan, M.K.; Choo, K.K.R. Applications of blockchain in ensuring the security and privacy of electronic health record systems: A survey. Comput. Secur. 2020, 97, 101966:1–101966:20. [Google Scholar] [CrossRef] [PubMed]
- Tatar, U.; Gokce, Y.; Nussbaum, B. Law versus technology: Blockchain, GDPR, and tough tradeoffs. Comput. Law Secur. Rev. 2020, 38, 105454:1–105454:11. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Property | Traditional Database | Blockchain |
|---|---|---|
| Architecture | The traditional database model assumes that there is a central trustable administrator for the entire database. On that account, the database is hosted on a server and subordinated clients have to send their queries to this server. | The blockchain model assumes a network of equal nodes. Each node hosts its own instance of the entire blockchain. Although each node can execute queries independently, the network must agree on which is the valid state of the blockchain. |
| Replication | Even though traditional databases can use replication techniques internally, e.g., to prevent failure of physical storage media, externally there is only one database instance. | In a blockchain, there is full replication of all data on all nodes, i.e., the failure of a single node does not affect the availability of the data. |
| Validation | Traditional databases only ensure that if the database was in a consistent state before a write operation, it is also consistent after that operation. In addition, it is ensured that no side effects can occur when several users operate on the database. | Two types of validation take place in blockchains: (a) The nodes in the network agree in a consensus feature on what the valid state of the blockchain is, i.e., what data are part of the blockchain. (b) Users can verify the integrity of the data due to the tamper-resistance. |
| Structuring | Traditional databases organize data into tables, each with its own schema. | Blockchains organize data into blocks that have no semantic meaning. |
| Operations | Traditional databases provide full CRUD support. | Blockchains support only read and write (add new data) operations. |
| History | Traditional databases contain the latest snapshot of the data only. | Blockchains provide the complete data history. |
| Insertion | Inserted data are immediately available in a traditional database. | Due to the consensus mechanism, data are inserted with a time delay. |
| Performance | Traditional databases are geared towards a high data throughput. | The data throughput is significantly low due to the consensus. |
| Type of Data | Main Property | Timestamp |
|---|---|---|
| Constant Object | This type of data is only valid at a specific point in time. Thus, it is final, i.e., its fields (key-value pairs) and corresponding values are constant and do not change over time. | block-dependent |
| object-dependent | ||
| Expandable Object | This type of data can grow and shrink over time, i.e., in the future, new fields may be added, values of existing fields may be modified, or existing fields may be removed. Any state of the object can be restored by exploiting the history feature of the blockchain. | block-dependent |
| Query Capability | Main Property |
|---|---|
| Projection | It is possible to specify which fields (i.e., key-value pairs) are included in the result set. |
| Selection | It is possible to specify which objects are included in the result set. |
| Sorting | It is possible to sort the result set by given fields. |
| Aggregation | It is possible to aggregate the values of certain fields using functions. |
| Grouping | It is possible to group given fields. |
| Join | It is possible to join different blockchains. |
| Temporal Queries | It is possible to query constant objects based on a timestamp. While for block-dependent objects there is an inherent timestamp given by the block they are stored in, object-dependent objects have their individual timestamp, which is specified in their attributes. |
| State-based Queries | It is possible to query expandable objects. Expandable objects can be scattered over multiple blocks, meaning that a state-based query must first find all pieces and compose them. |
| Query Capability | Relational Data Model | Blockchain Domain |
|---|---|---|
| Projection | SELECT <columns> An SQL statement starts with the projections, a list of columns to include in the final result set. | SELECT <attributes> Instead of columns, attributes of objects are specified. |
| Join | FROM <table> JOIN <other tables> This clause indicates the table from which to retrieve the data. JOIN subclauses enable the joining of additional tables. | FROM <blockchain> JOIN <other blockchains> Instead of a table, the blockchain is specified. If there is only one blockchain given, then the clause might be omitted. If there is more than one blockchain given, JOIN subclauses are required. |
| Selection | WHERE <comparison predicates on columns> This clause eliminates all rows from the result set where a comparison predicate does not evaluate to true. | WHERE <comparison predicates on attributes> Instead of rows, objects are eliminated. |
| Grouping & Aggregation | GROUP BY <columns> This clause groups values of one or more columns in conjunction with aggregation functions in the projection on those columns. | GROUP BY <attributes> Instead of columns, attributes of objects are specified. |
| HAVING <comparison predicates on groups> This clause eliminates all groups of returned rows to only those whose comparison predicate does not evaluate to true. | HAVING <comparison predicates on groups> Instead of rows, objects are returned. | |
| Sorting | ORDER BY <columns> This clause indicates the columns to use to sort the result set including the sort direction. | ORDER BY <attributes> Instead of columns, attributes of objects are specified. |
| Research Direction | Characteristics and Features |
|---|---|
| Blockchain Systems Enhanced with Database Features | A database layer is built on top of a blockchain system that is used as an integrity-protected data store. The database layer provides an interface for querying data efficiently. However, verifying the results of a query is an additional step, which increases the overhead significantly. |
| Database Systems Enhanced with Blockchain Features | A blockchain layer is built on top of a traditional database system. Data are queried directly from the database system. However, these database systems are not designed to detect tampered data during query processing. |
| Improvements to the Frontend Query Capabilities | Existing public blockchain systems such as Ethereum are internally modified or extended with a query layer to support familiar query languages such as SQL. However, queries regarding the data history are expensive. |
| Efficiency Improvements in Query Processing | Various techniques such as the parallelization of data processing or novel data structures enable more efficient querying of blockchain data. However, in order for query engines to benefit from this, they have first to be adapted accordingly. |
| Tailored Blockchain Optimizations for Specific Use Cases | Tailored index structures for blockchain systems increase the performance of specific types of queries such as time series queries. However, they are designed specifically for a certain use case, i.e., the blockchain system loses some of its universality. |
| Verifiable Queries and Database Systems | Verifiable queries are enabled over novel or existing database systems. However, these approaches do not necessarily require blockchain systems to be involved. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Przytarski, D.; Stach, C.; Gritti, C.; Mitschang, B. Query Processing in Blockchain Systems: Current State and Future Challenges. Future Internet 2022, 14, 1. https://doi.org/10.3390/fi14010001
Przytarski D, Stach C, Gritti C, Mitschang B. Query Processing in Blockchain Systems: Current State and Future Challenges. Future Internet. 2022; 14(1):1. https://doi.org/10.3390/fi14010001
Chicago/Turabian StylePrzytarski, Dennis, Christoph Stach, Clémentine Gritti, and Bernhard Mitschang. 2022. "Query Processing in Blockchain Systems: Current State and Future Challenges" Future Internet 14, no. 1: 1. https://doi.org/10.3390/fi14010001
APA StylePrzytarski, D., Stach, C., Gritti, C., & Mitschang, B. (2022). Query Processing in Blockchain Systems: Current State and Future Challenges. Future Internet, 14(1), 1. https://doi.org/10.3390/fi14010001