
Education 4.0: Teaching the Basics of KNN, LDA and Simple Perceptron Algorithms for Binary Classification Problems




Abstract
:1. Introduction
2. Classification Algorithms Theory
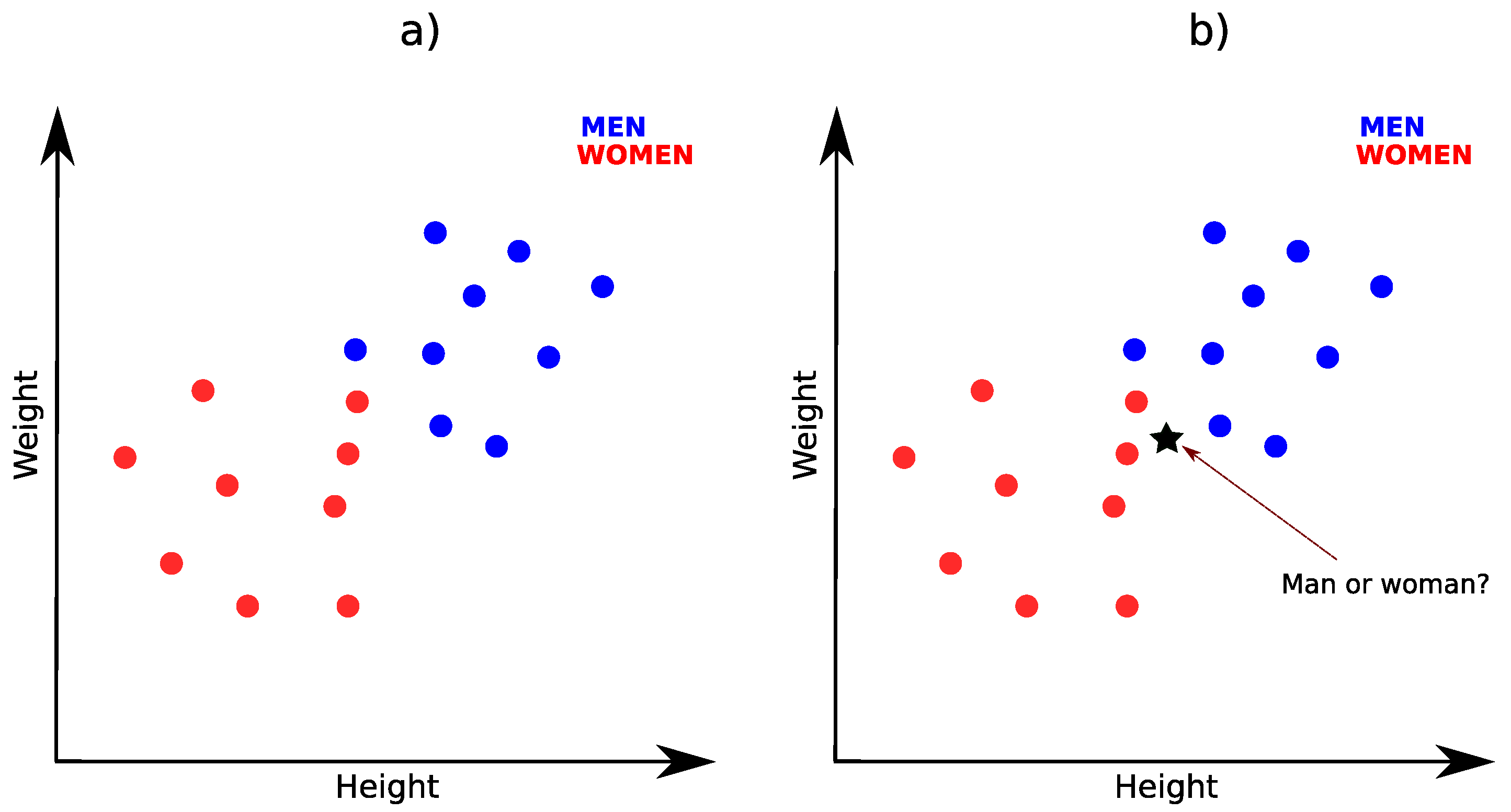
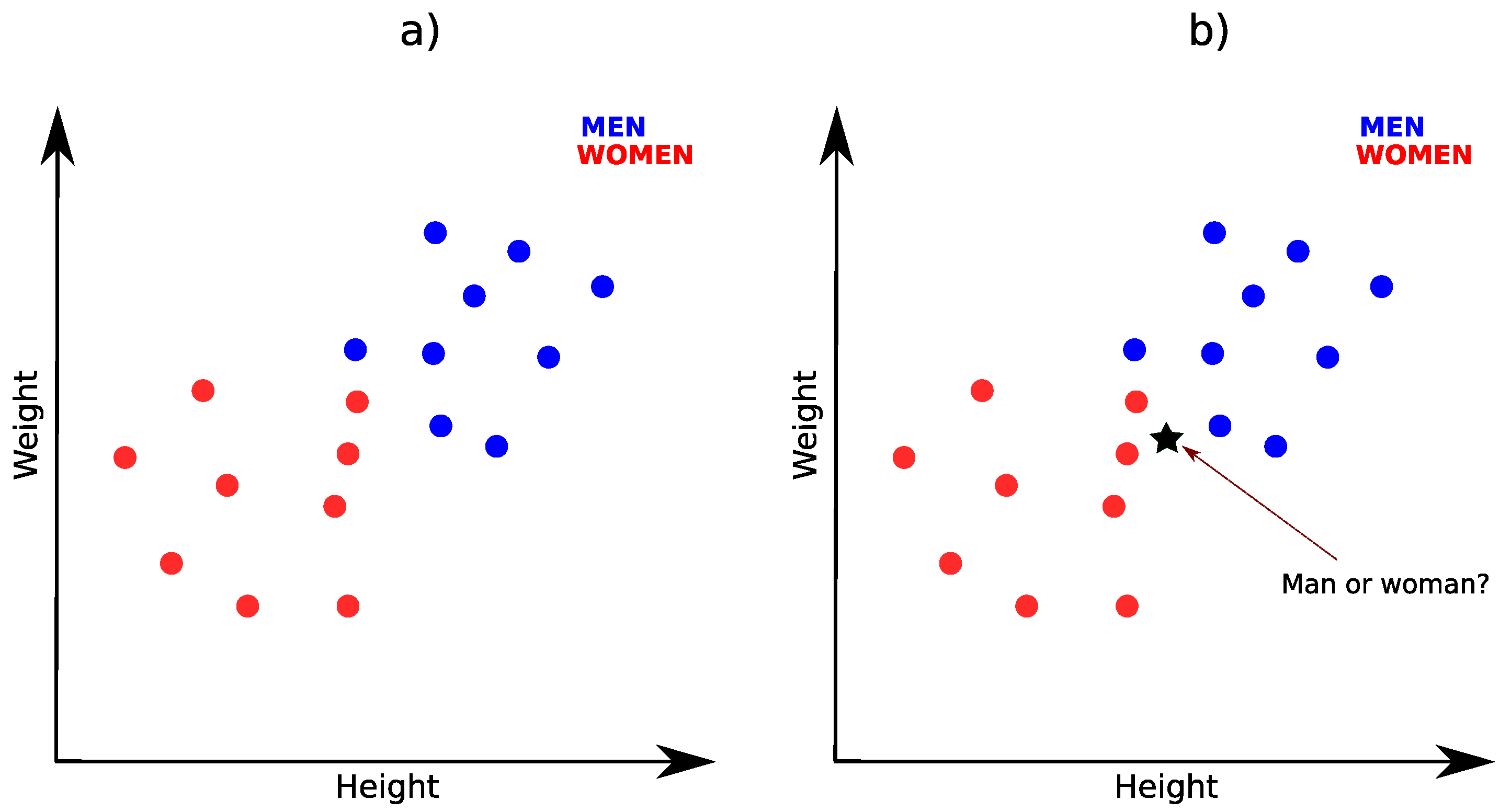
2.1. K-Nearest-Neighbors
| Algorithm 1 KNN Pseudo-code |
| Input: // ; ; for i to training data size do: Compute the distance end for Select the desired number k of nearest neighbors Sort the distances by increasing order Count the number of occurrences of each label among the top k neighbors Output: Assign to s the most frequent label l |
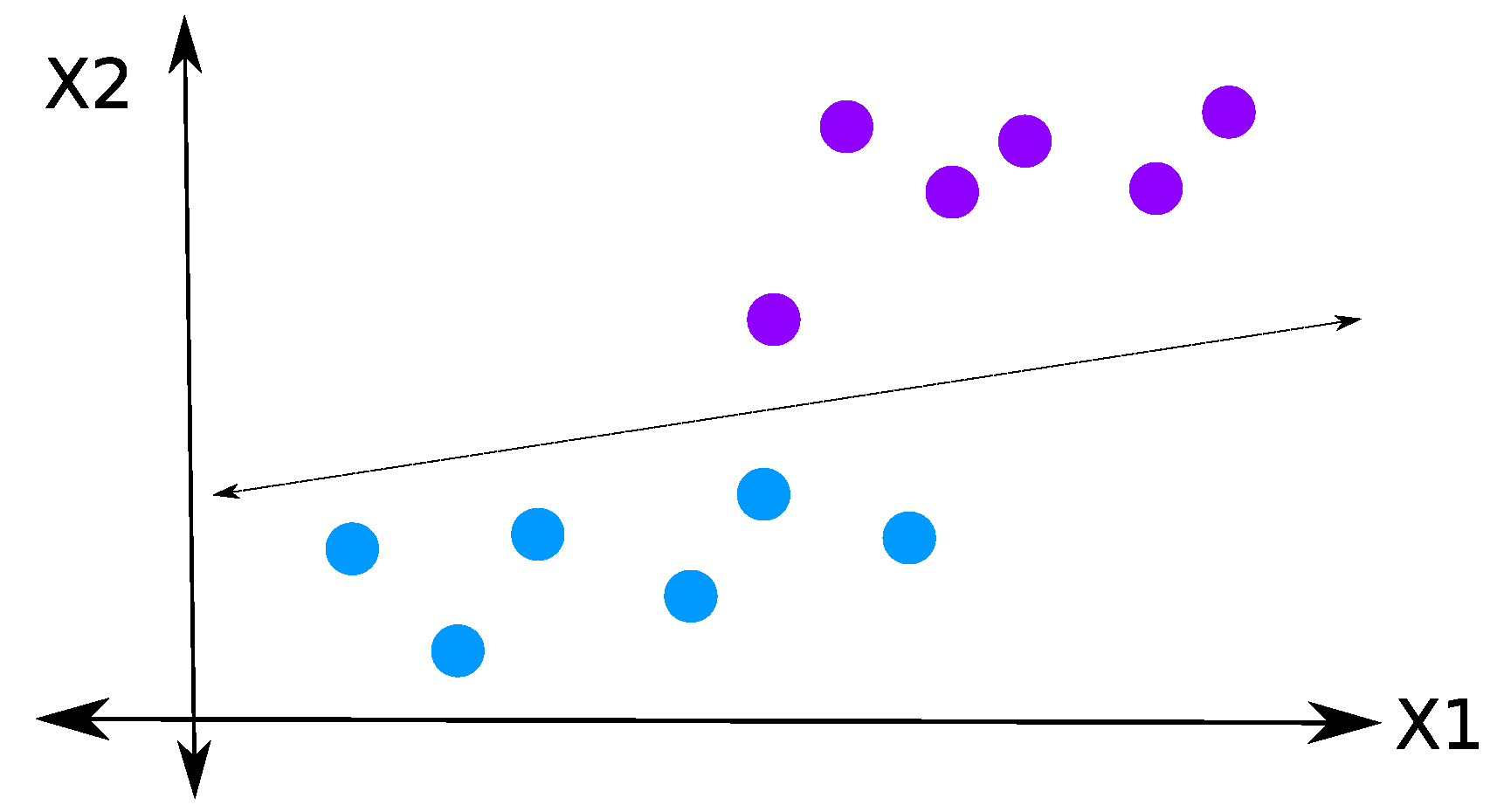
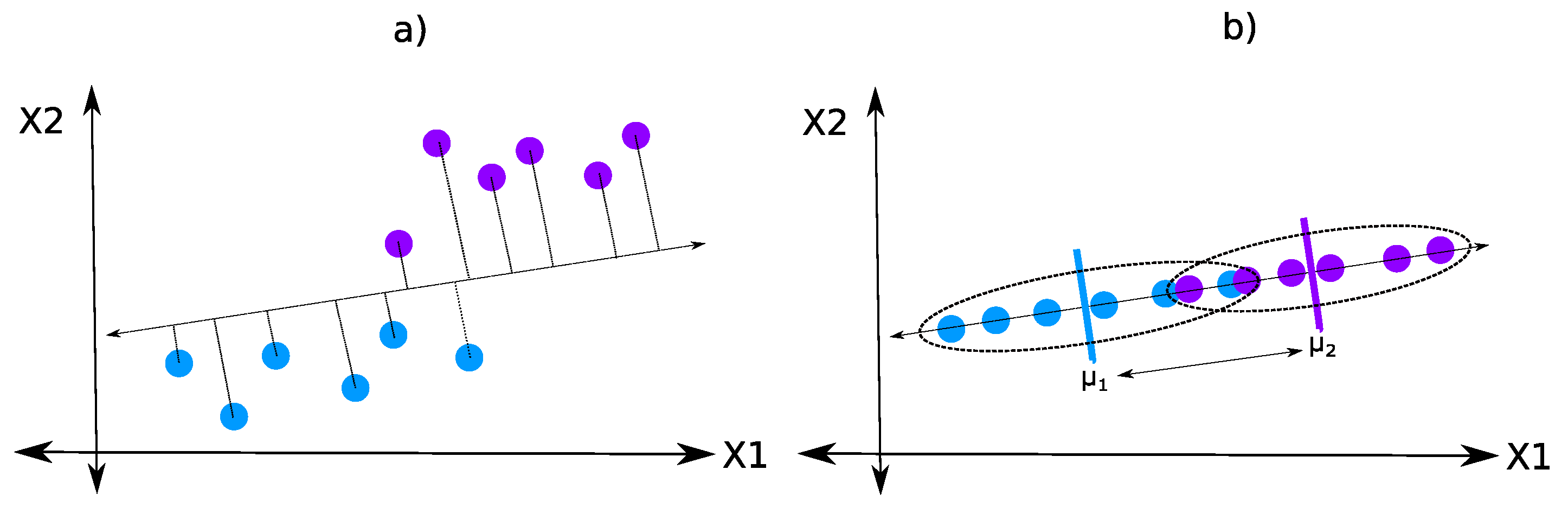
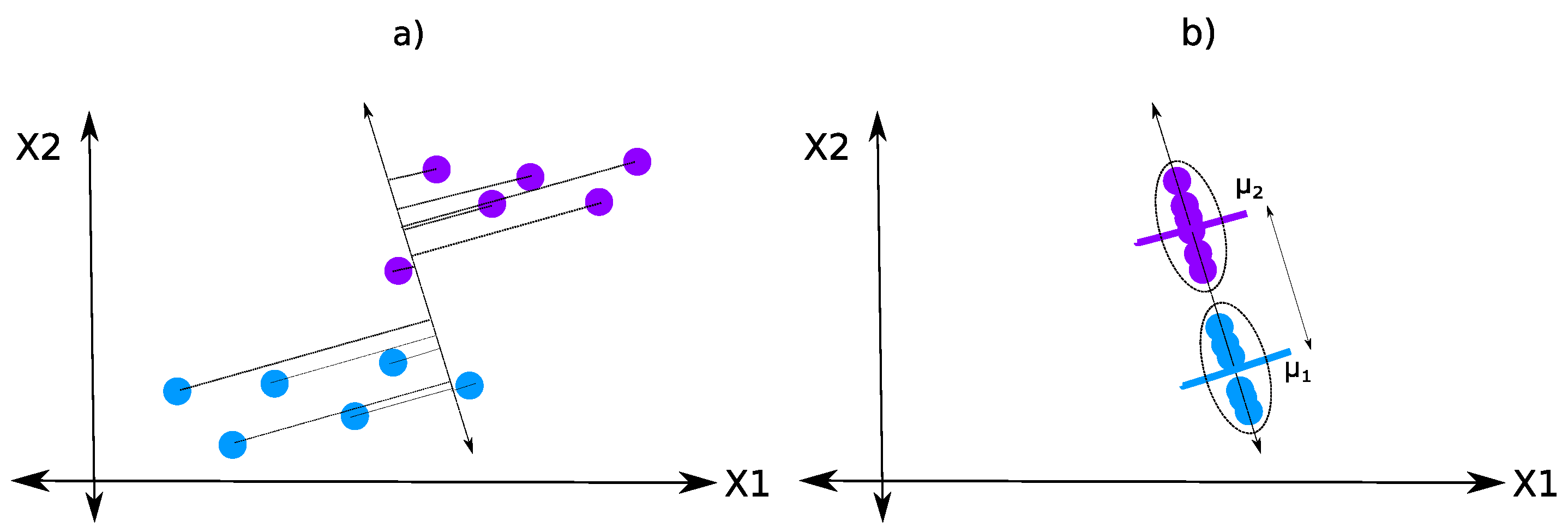
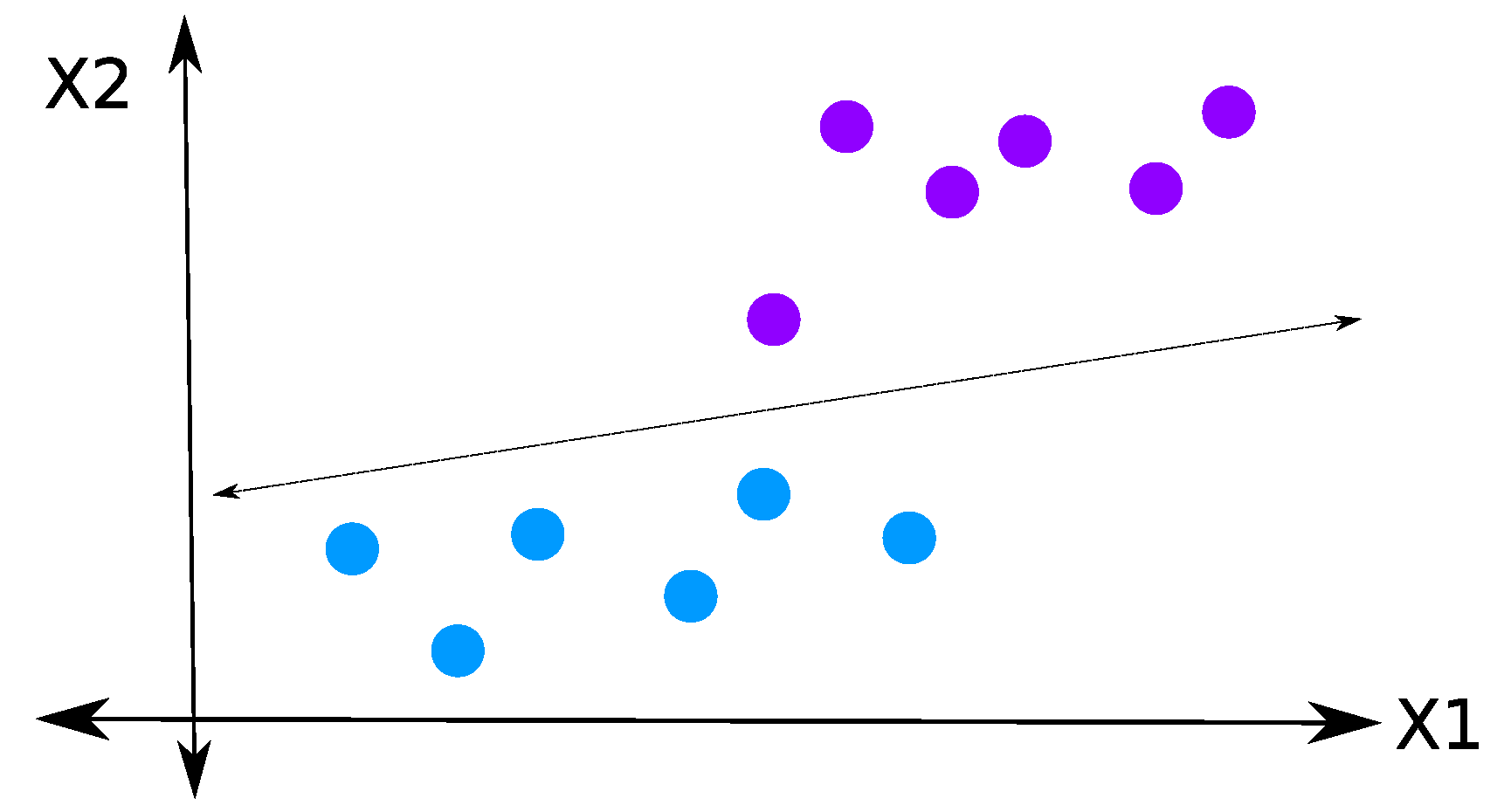
2.2. Linear Discriminant Analysis
| Algorithm 2 LDA Pseudo-code |
| Input: // Calculate: The means Separations and Eigenvectors and eigenvalues: (), () Sort the eigenvectors from biggest to smallest depending on the eigenvalues Choose the top k eigenvectors Produce matrix Output: Return matrix W |
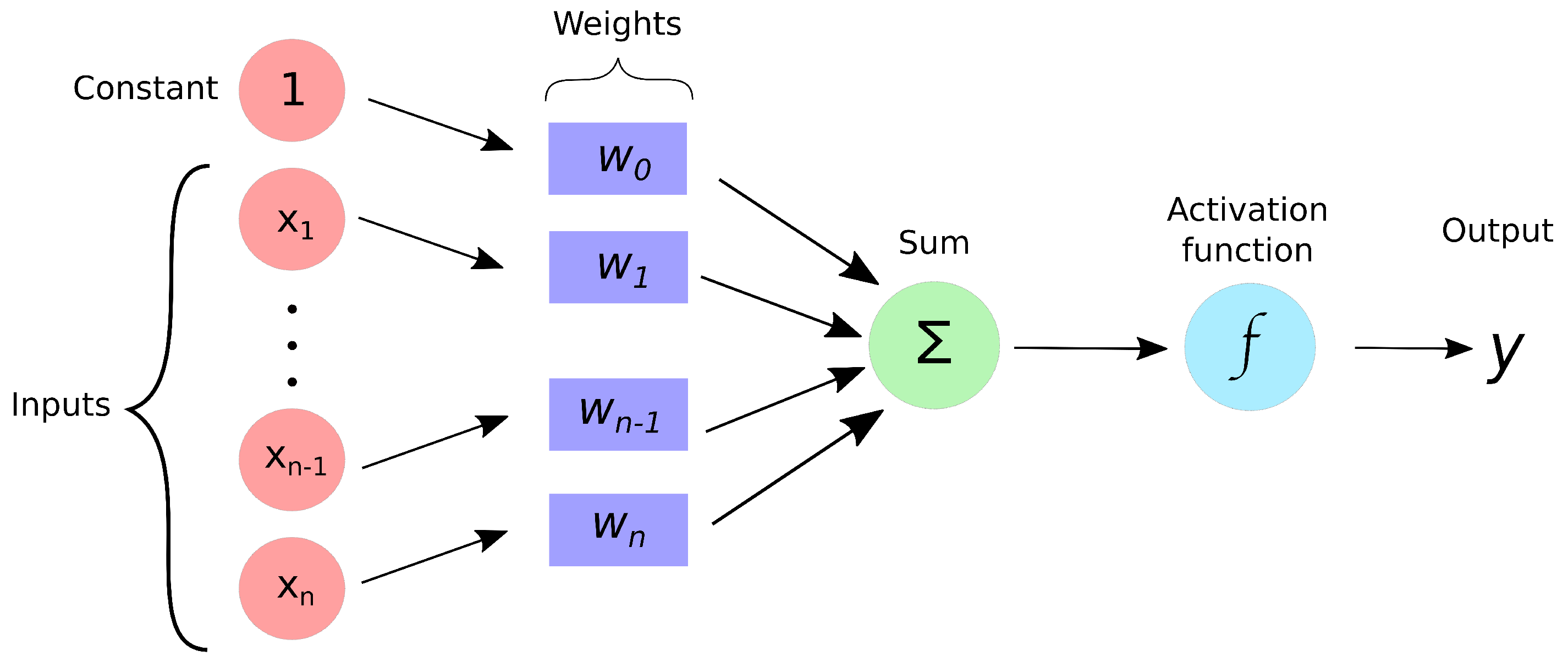
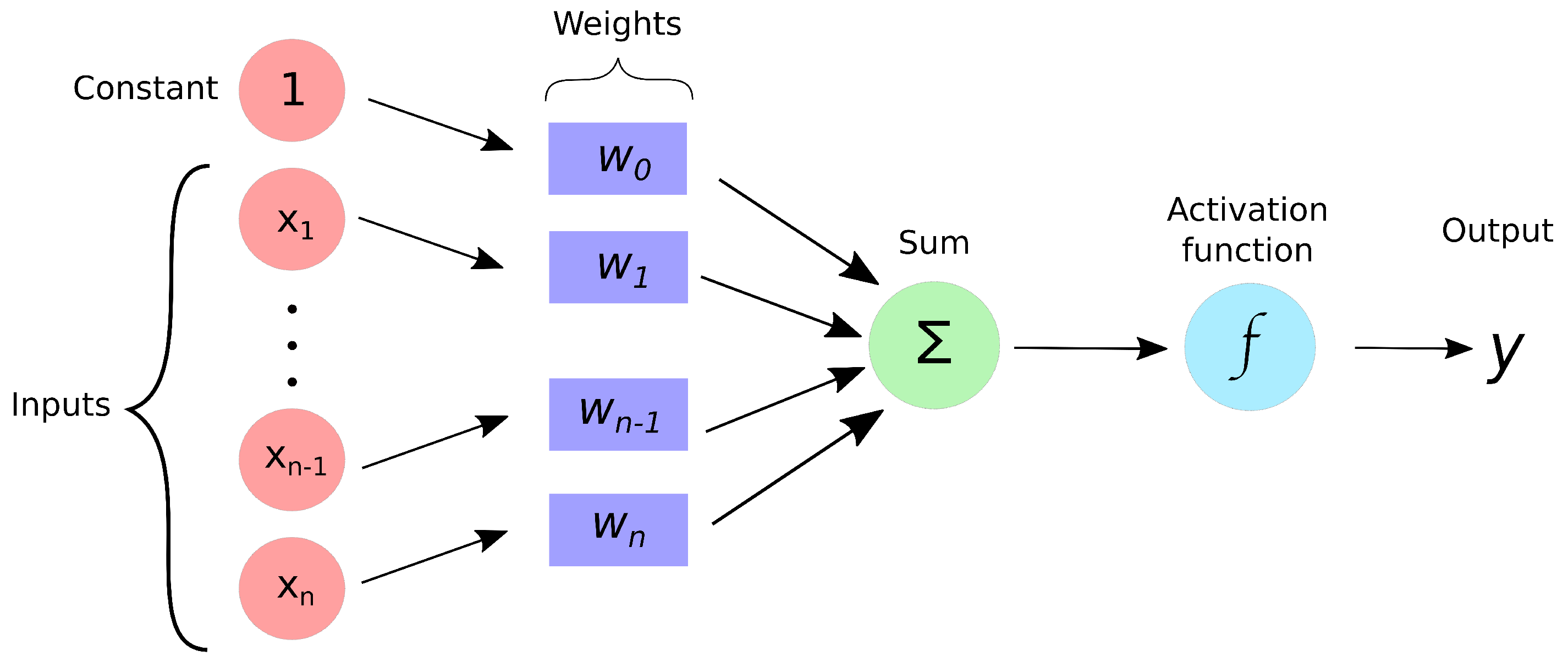
2.3. Simple Perceptron
- Input
- Weights and bias
- Net sum
- Activation function
- The input label is negative, and the dot product is greater or equal than 0. When this is the case, we must update w by subtracting the input vector to the weight vector.
- The input label is positive, and the dot product is lower than 0. When this happens, we must update w by adding the input vector to the weight vector.
| Algorithm 3 Simple Perceptron Pseudo-code |
| Input: Vector x Label 0 = Negative (N) input Label 1 = Positive (P) input Training: Randomly initialize w misclassification != 0 w = w − x w = w + x Output: Parameters w |
3. Advantages and Disadvantages of the Methods
4. Case Studies
4.1. Method
- Sensitivity (): represents the probability of detecting the condition when it is present.
- False negative rate (): represents the probability of not detecting the condition when it is present.
- False positive rate (): represents the probability of detecting the condition when it is not present.
- Specificity (): represents the probability of not detecting the condition when it is not present.
- Positive predictive value (): represents the probability of the patient really having the condition when the test is positive.
- Negative predictive value (): represents the probability of the patient not having the condition when the test is negative.
4.2. Results
5. Final Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, L.D.; Xu, E.L.; Li, L. Industry 4.0: State of the art and future trends. Int. J. Prod. Res. 2018, 56, 2941–2962. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Abitia, G.; Bribiesca-Correa, G. Assessing Digital Transformation in Universities. Future Internet 2021, 13, 52. [Google Scholar] [CrossRef]
- Ramirez-Mendoza, R.A.; Morales-Menendez, R.; Iqbal, H.; Parra-Saldivar, R. Engineering Education 4.0: Proposal for a new Curricula. In Proceedings of the 2018 IEEE Global Engineering Education Conference (EDUCON), Santa Cruz de Tenerife, Spain, 17–20 April 2018; pp. 1273–1282. [Google Scholar]
- Karacay, G. Talent development for Industry 4.0. In Industry 4.0: Managing the Digital Transformation; Springer: Berlin/Heidelberg, Germany, 2018; pp. 123–136. [Google Scholar]
- Quintana, C.D.D.; Mora, J.G.; Pérez, P.J.; Vila, L.E. Enhancing the development of competencies: The role of UBC. Eur. J. Educ. 2016, 51, 10–24. [Google Scholar] [CrossRef] [Green Version]
- Prieto, M.D.; Sobrino, Á.F.; Soto, L.R.; Romero, D.; Biosca, P.F.; Martínez, L.R. Active learning based laboratory towards engineering education 4.0. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 776–783. [Google Scholar]
- Zhang, X.D. A Matrix Algebra Approach to Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Ahmad, M.A.; Eckert, C.; Teredesai, A. Interpretable machine learning in healthcare. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 29 August–1 September 2018; pp. 559–560. [Google Scholar]
- Parthiban, G.; Srivatsa, S. Applying machine learning methods in diagnosing heart disease for diabetic patients. Int. J. Appl. Inf. Syst. (IJAIS) 2012, 3, 25–30. [Google Scholar] [CrossRef]
- Iyer, A.; Jeyalatha, S.; Sumbaly, R. Diagnosis of diabetes using classification mining techniques. arXiv 2015, arXiv:1502.03774. [Google Scholar] [CrossRef]
- Sen, S.K.; Dash, S. Application of meta learning algorithms for the prediction of diabetes disease. Int. J. Adv. Res. Comput. Sci. Manag. Stud. 2014, 2, 396–401. [Google Scholar]
- Senturk, Z.K.; Kara, R. Breast cancer diagnosis via data mining: Performance analysis of seven different algorithms. Comput. Sci. Eng. 2014, 4, 35. [Google Scholar] [CrossRef]
- Williams, K.; Idowu, P.A.; Balogun, J.A.; Oluwaranti, A.I. Breast cancer risk prediction using data mining classification techniques. Trans. Netw. Commun. 2015, 3, 1. [Google Scholar] [CrossRef]
- Papageorgiou, E.I.; Papandrianos, N.I.; Apostolopoulos, D.J.; Vassilakos, P.J. Fuzzy cognitive map based decision support system for thyroid diagnosis management. In Proceedings of the 2008 IEEE International Conference on Fuzzy Systems (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 1204–1211. [Google Scholar]
- Zhu, W.; Liu, C.; Fan, W.; Xie, X. Deeplung: Deep 3d dual path nets for automated pulmonary nodule detection and classification. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 673–681. [Google Scholar]
- Afshar, P.; Mohammadi, A.; Plataniotis, K.N. Brain tumor type classification via capsule networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3129–3133. [Google Scholar]
- Heaton, J.B.; Polson, N.G.; Witte, J.H. Deep learning for finance: Deep portfolios. Appl. Stoch. Model. Bus. Ind. 2017, 33, 3–12. [Google Scholar] [CrossRef]
- De Prado, M.L. Building diversified portfolios that outperform out of sample. J. Portf. Manag. 2016, 42, 59–69. [Google Scholar] [CrossRef]
- Raffinot, T. Hierarchical clustering-based asset allocation. J. Portf. Manag. 2017, 44, 89–99. [Google Scholar] [CrossRef]
- Cao, L.J.; Tay, F.E.H. Support vector machine with adaptive parameters in financial time series forecasting. IEEE Trans. Neural Netw. 2003, 14, 1506–1518. [Google Scholar] [CrossRef] [Green Version]
- Fan, A.; Palaniswami, M. Stock selection using support vector machines. In Proceedings of the IJCNN’01. International Joint Conference on Neural Networks. Proceedings (Cat. No. 01CH37222), Washington, DC, USA, 15–19 July 2001; Volume 3, pp. 1793–1798. [Google Scholar]
- Nayak, R.K.; Mishra, D.; Rath, A.K. A Naïve SVM-KNN based stock market trend reversal analysis for Indian benchmark indices. Appl. Soft Comput. 2015, 35, 670–680. [Google Scholar] [CrossRef]
- Zhang, X.D.; Li, A.; Pan, R. Stock trend prediction based on a new status box method and AdaBoost probabilistic support vector machine. Appl. Soft Comput. 2016, 49, 385–398. [Google Scholar] [CrossRef]
- Anifowose, F.A.; Labadin, J.; Abdulraheem, A. Ensemble machine learning: An untapped modeling paradigm for petroleum reservoir characterization. J. Pet. Sci. Eng. 2017, 151, 480–487. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Heinermann, J.; Kramer, O. Machine learning ensembles for wind power prediction. Renew. Energy 2016, 89, 671–679. [Google Scholar] [CrossRef]
- Zeng, Y.R.; Zeng, Y.; Choi, B.; Wang, L. Multifactor-influenced energy consumption forecasting using enhanced back-propagation neural network. Energy 2017, 127, 381–396. [Google Scholar] [CrossRef]
- Zeng, Y.; Liu, J.; Sun, K.; Hu, L.W. Machine learning based system performance prediction model for reactor control. Ann. Nucl. Energy 2018, 113, 270–278. [Google Scholar] [CrossRef]
- Evans, J.; Jones, R.; Karvonen, A.; Millard, L.; Wendler, J. Living labs and co-production: University campuses as platforms for sustainability science. Curr. Opin. Environ. Sustain. 2015, 16, 1–6. [Google Scholar] [CrossRef]
- Detrano, R. The Cleveland Heart Disease Data Set; VA Medical Center, Long Beach and Cleveland Clinic Foundation: Long Beach, CA, USA, 1988. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California: Irvine, CA, USA, 2017. [Google Scholar]
- Evelyn, F.; Hodges, J. Discriminatory Analysis-Nonparametric Discrimination: Consistency Properties; Technical Report; International Statistical Institute (ISI): Voorburg, The Netherlands, 1989; pp. 238–247. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Sun, S.; Huang, R. An adaptive k-nearest neighbor algorithm. In Proceedings of the 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery, Yantai, China, 10–12 August 2010; Volume 1, pp. 91–94. [Google Scholar]
- Romeo, L.; Loncarski, J.; Paolanti, M.; Bocchini, G.; Mancini, A.; Frontoni, E. Machine learning-based design support system for the prediction of heterogeneous machine parameters in industry 4.0. Expert Syst. Appl. 2020, 140, 112869. [Google Scholar] [CrossRef]
- Taha, H.A.; Sakr, A.H.; Yacout, S. Aircraft Engine Remaining Useful Life Prediction Framework for Industry 4.0. In Proceedings of the 4th North America conference on Industrial Engineering and Operations Management, Toronto, ON, Canada, 23–25 October 2019. [Google Scholar]
- Zhou, C.; Tham, C.K. Graphel: A graph-based ensemble learning method for distributed diagnostics and prognostics in the industrial internet of things. In Proceedings of the 2018 IEEE 24th International Conference on Parallel and Distributed Systems (ICPADS), Singapore, 11–13 December 2018; pp. 903–909. [Google Scholar]
- Zhang, P.; Wang, R.; Shi, N. IgA Nephropathy Prediction in Children with Machine Learning Algorithms. Future Internet 2020, 12, 230. [Google Scholar] [CrossRef]
- Thapa, N.; Liu, Z.; Kc, D.B.; Gokaraju, B.; Roy, K. Comparison of machine learning and deep learning models for network intrusion detection systems. Future Internet 2020, 12, 167. [Google Scholar] [CrossRef]
- Hu, L.Y.; Huang, M.W.; Ke, S.W.; Tsai, C.F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Xanthopoulos, P.; Pardalos, P.M.; Trafalis, T.B. Linear discriminant analysis. In Robust Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 27–33. [Google Scholar]
- Kuo, C.J.; Ting, K.C.; Chen, Y.C. State of product detection method applicable to Industry 4.0 manufacturing models with small quantities and great variety: An example with springs. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 1650–1653. [Google Scholar]
- Natesha, B.; Guddeti, R.M.R. Fog-based Intelligent Machine Malfunction Monitoring System for Industry 4.0. IEEE Trans. Ind. Inform. 2021. [Google Scholar] [CrossRef]
- Bressan, G.; Cisotto, G.; Müller-Putz, G.R.; Wriessnegger, S.C. Deep learning-based classification of fine hand movements from low frequency EEG. Future Internet 2021, 13, 103. [Google Scholar] [CrossRef]
- Rosenblatt, F. The Perceptron, a Perceiving and Recognizing Automaton Project Para; Cornell Aeronautical Laboratory: Buffalo, NY, USA, 1957. [Google Scholar]
- Matheri, A.N.; Ntuli, F.; Ngila, J.C.; Seodigeng, T.; Zvinowanda, C. Performance prediction of trace metals and cod in wastewater treatment using artificial neural network. Comput. Chem. Eng. 2021, 149, 107308. [Google Scholar] [CrossRef]
- Żabiński, T.; Mączka, T.; Kluska, J.; Madera, M.; Sęp, J. Condition monitoring in Industry 4.0 production systems-the idea of computational intelligence methods application. Procedia CIRP 2019, 79, 63–67. [Google Scholar] [CrossRef]
- Merayo, D.; Rodriguez-Prieto, A.; Camacho, A. Comparative analysis of artificial intelligence techniques for material selection applied to manufacturing in Industry 4.0. Procedia Manuf. 2019, 41, 42–49. [Google Scholar] [CrossRef]
- Hitimana, E.; Bajpai, G.; Musabe, R.; Sibomana, L.; Kayalvizhi, J. Implementation of IoT Framework with Data Analysis Using Deep Learning Methods for Occupancy Prediction in a Building. Future Internet 2021, 13, 67. [Google Scholar] [CrossRef]
- Sagheer, A.; Zidan, M.; Abdelsamea, M.M. A novel autonomous perceptron model for pattern classification applications. Entropy 2019, 21, 763. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jadhav, S.D.; Channe, H. Comparative study of K-NN, naive Bayes and decision tree classification techniques. Int. J. Sci. Res. (IJSR) 2016, 5, 1842–1845. [Google Scholar]
- De Leonardis, G.; Rosati, S.; Balestra, G.; Agostini, V.; Panero, E.; Gastaldi, L.; Knaflitz, M. Human Activity Recognition by Wearable Sensors: Comparison of different classifiers for real-time applications. In Proceedings of the 2018 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Rome, Italy, 11–13 June 2018; pp. 1–6. [Google Scholar]
- Lakshmi, M.R.; Prasad, T.; Prakash, D.V.C. Survey on EEG signal processing methods. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 84–91. [Google Scholar]
- Mahmood, S.H.; Khidir, H.H. Using Discriminant Analysis for Classification of Patient Status after Three Months from Brain Stroke. Zanco J. Humanit. Sci. 2020, 24, 206–223. [Google Scholar]
- Park, Y.S.; Lek, S. Artificial neural networks: Multilayer perceptron for ecological modeling. In Developments in Environmental Modelling; Elsevier: Amsterdam, The Netherlands, 2016; Volume 28, pp. 123–140. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Disadvantages | Ref |
|---|---|---|---|
| KNN |
|
| [52,53] |
| LDA |
|
| [54,55] |
| Perceptron |
|
| [56] |
| Algorithm | Metrics | |||||||
|---|---|---|---|---|---|---|---|---|
| AUC | ACC | TPR | FNR | FPR | TNR | PPV | NPV | |
| KNN | 0.9025 | 0.8342 | 0.8168 | 0.1831 | 0.1394 | 0.8606 | 0.8928 | 0.7684 |
| LDA | 0.9023 | 0.8349 | 0.8266 | 0.1734 | 0.1522 | 0.8477 | 0.8776 | 0.7864 |
| Perceptron | 0.8481 | 0.7840 | 0.8265 | 0.7812 | 0.2187 | 0.7407 | 0.7815 | 0.7407 |
| Algorithm | Metrics | |||||||
|---|---|---|---|---|---|---|---|---|
| AUC | ACC | TPR | FNR | FPR | TNR | PPV | NPV | |
| KNN | 0.9987 | 0.9985 | 1.0000 | 0.0000 | 0.0033 | 0.9967 | 0.9973 | 1.0000 |
| LDA | 0.9996 | 0.9762 | 0.9999 | 0.0001 | 0.0506 | 0.9494 | 0.9574 | 0.9999 |
| Perceptron | 0.9986 | 0.9805 | 1.0000 | 0.0000 | 0.0370 | 0.9629 | 0.9653 | 1.0000 |
| Algorithm | Metrics | |||||||
|---|---|---|---|---|---|---|---|---|
| AUC | ACC | TPR | FNR | FPR | TNR | PPV | NPV | |
| KNN | 0.9862 | 0.9657 | 0.9807 | 0.0193 | 0.0423 | 0.9577 | 0.9266 | 0.9890 |
| LDA | 0.9908 | 0.9564 | 0.9903 | 0.0096 | 0.0608 | 0.9392 | 0.8919 | 0.9949 |
| Perceptron | 0.9901 | 0.9663 | 1.0000 | 0.0000 | 0.0800 | 0.9200 | 0.8636 | 1.0000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopez-Bernal, D.; Balderas, D.; Ponce, P.; Molina, A. Education 4.0: Teaching the Basics of KNN, LDA and Simple Perceptron Algorithms for Binary Classification Problems. Future Internet 2021, 13, 193. https://doi.org/10.3390/fi13080193
Lopez-Bernal D, Balderas D, Ponce P, Molina A. Education 4.0: Teaching the Basics of KNN, LDA and Simple Perceptron Algorithms for Binary Classification Problems. Future Internet. 2021; 13(8):193. https://doi.org/10.3390/fi13080193
Chicago/Turabian StyleLopez-Bernal, Diego, David Balderas, Pedro Ponce, and Arturo Molina. 2021. "Education 4.0: Teaching the Basics of KNN, LDA and Simple Perceptron Algorithms for Binary Classification Problems" Future Internet 13, no. 8: 193. https://doi.org/10.3390/fi13080193
APA StyleLopez-Bernal, D., Balderas, D., Ponce, P., & Molina, A. (2021). Education 4.0: Teaching the Basics of KNN, LDA and Simple Perceptron Algorithms for Binary Classification Problems. Future Internet, 13(8), 193. https://doi.org/10.3390/fi13080193