
Architecting an Agent-Based Fault Diagnosis Engine for IEC 61499 Industrial Cyber-Physical Systems


Abstract
:1. Introduction
2. Background
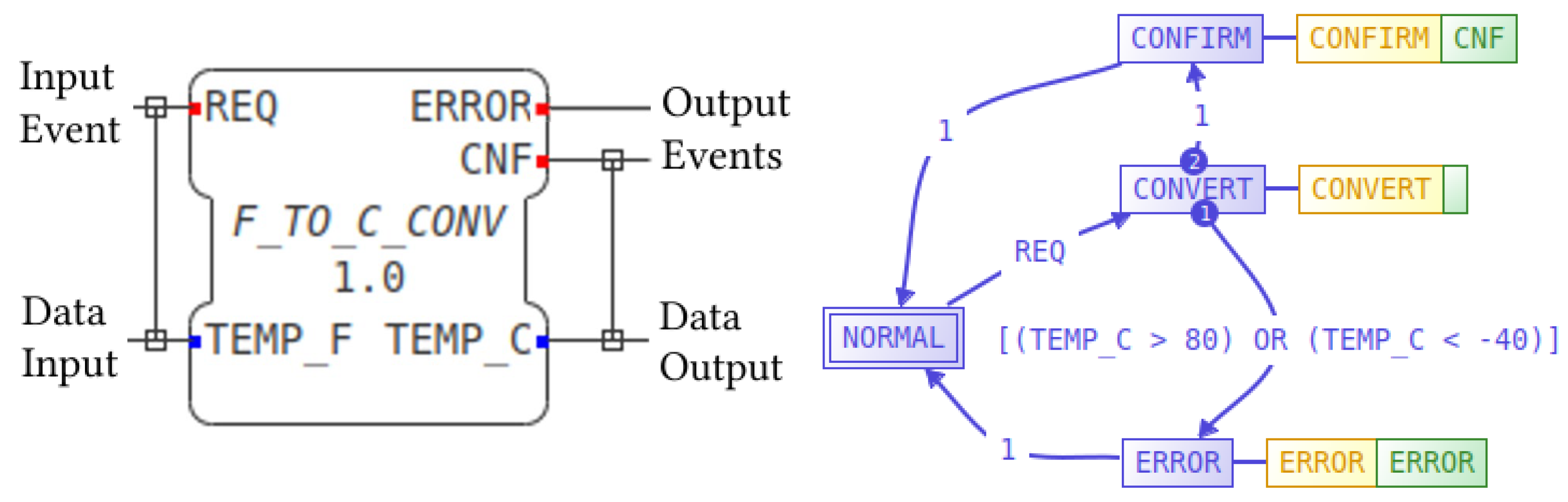
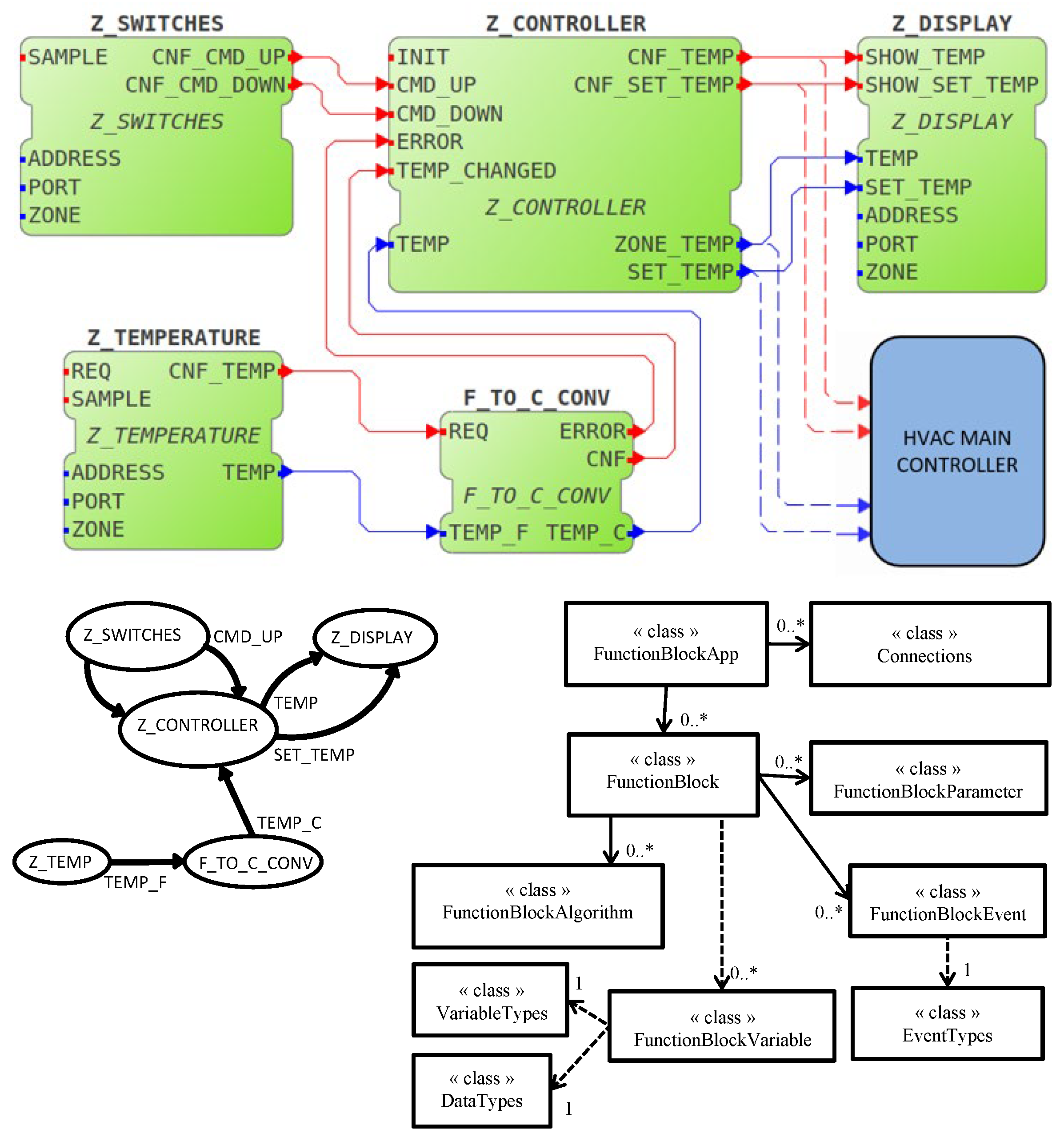
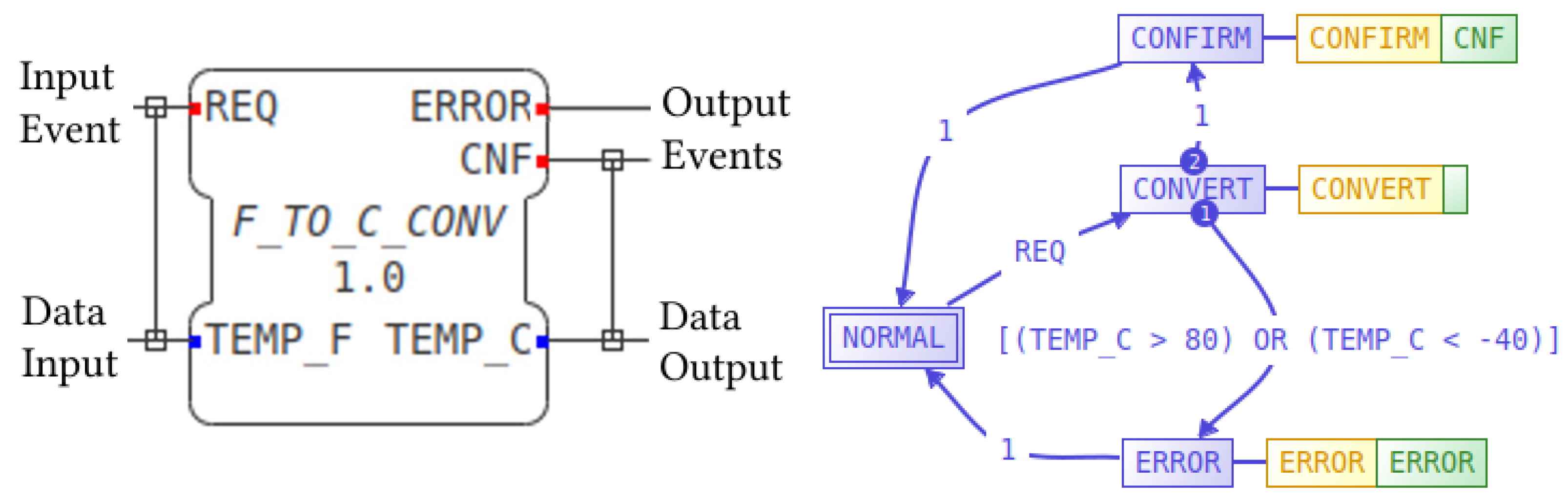
2.1. The IEC 61499 Function Block Reference Architecture
2.2. Fault Identification and Diagnosis in ICPS
2.3. Intentional Agents for Fault Finding
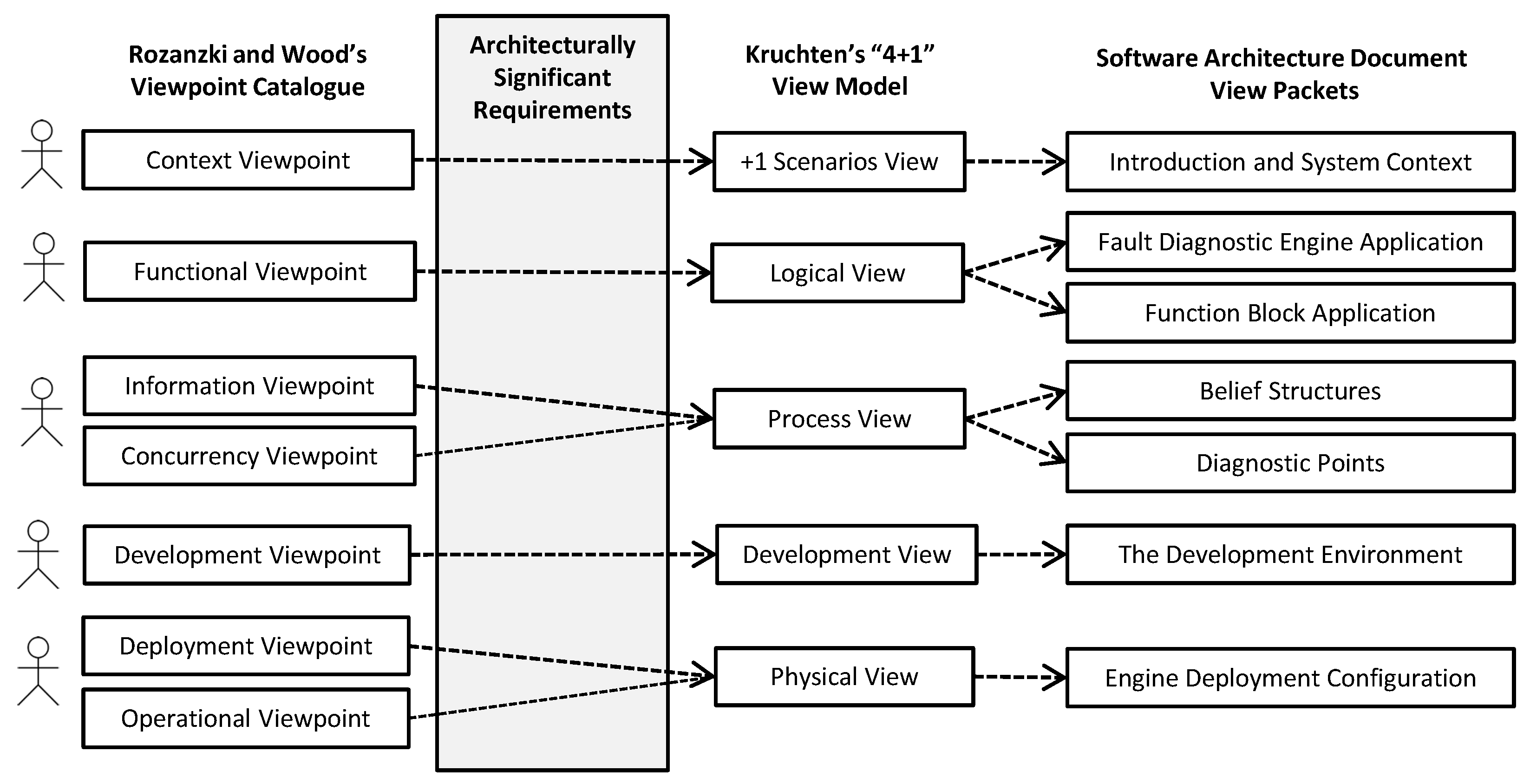
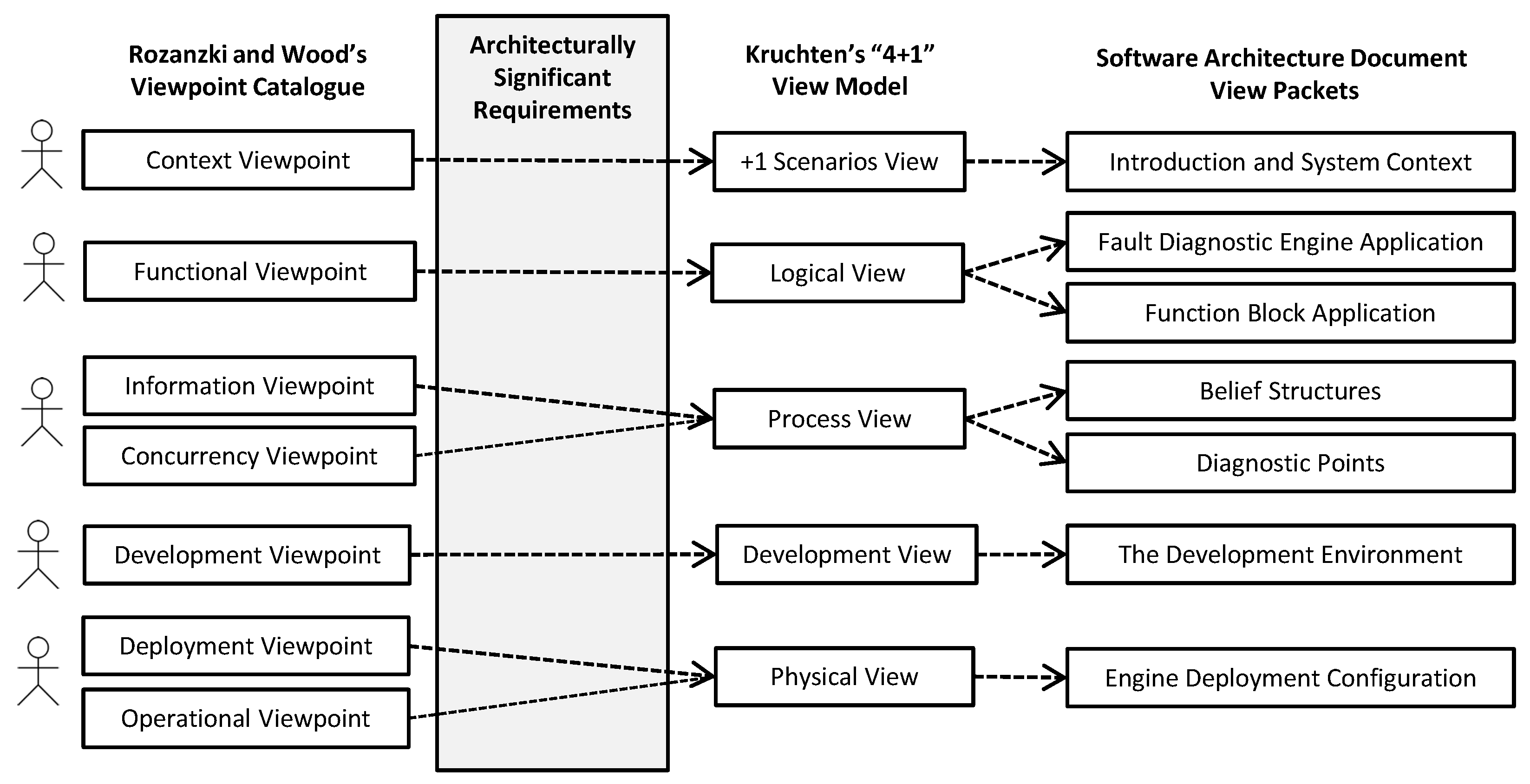
3. Architecting the Engine
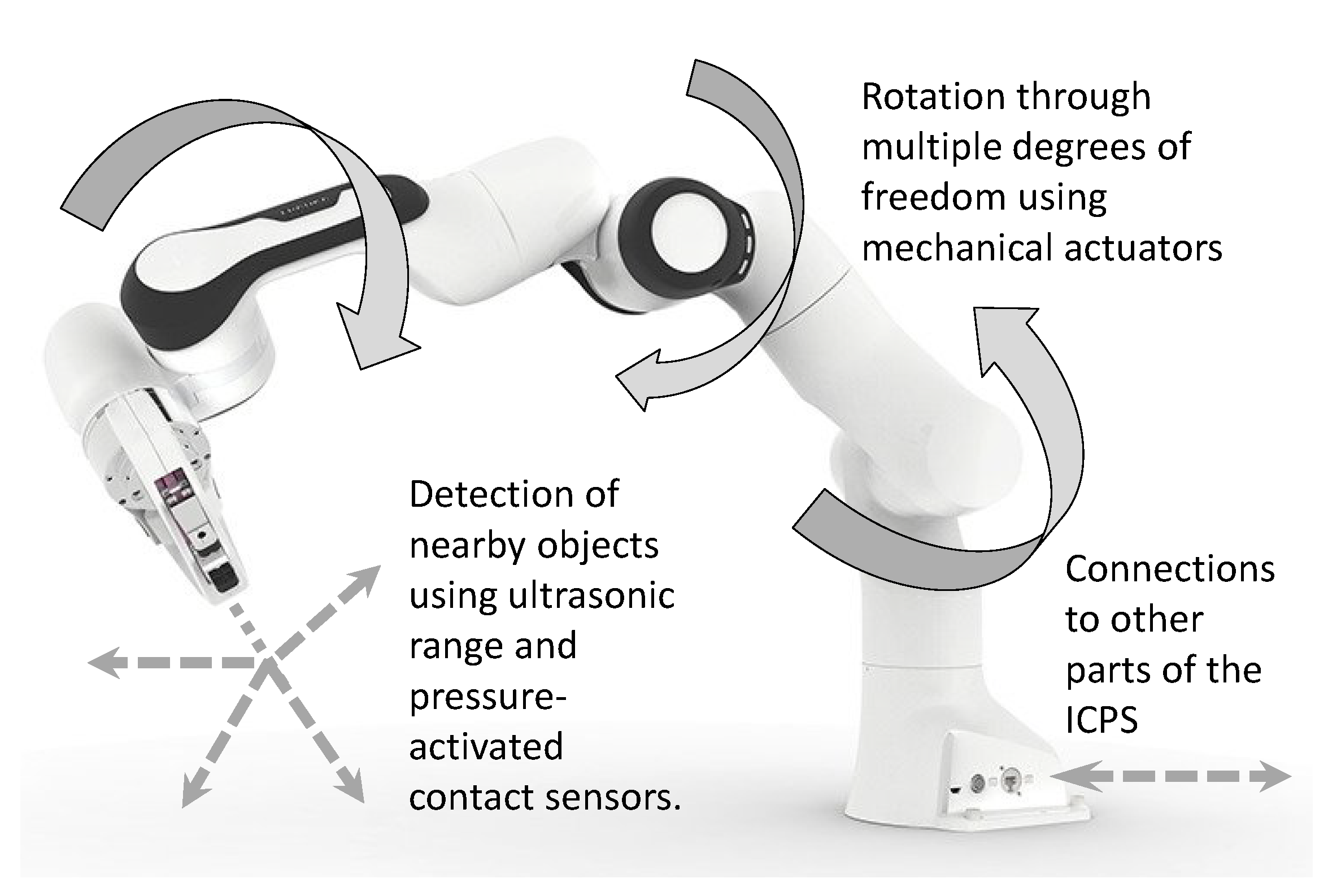
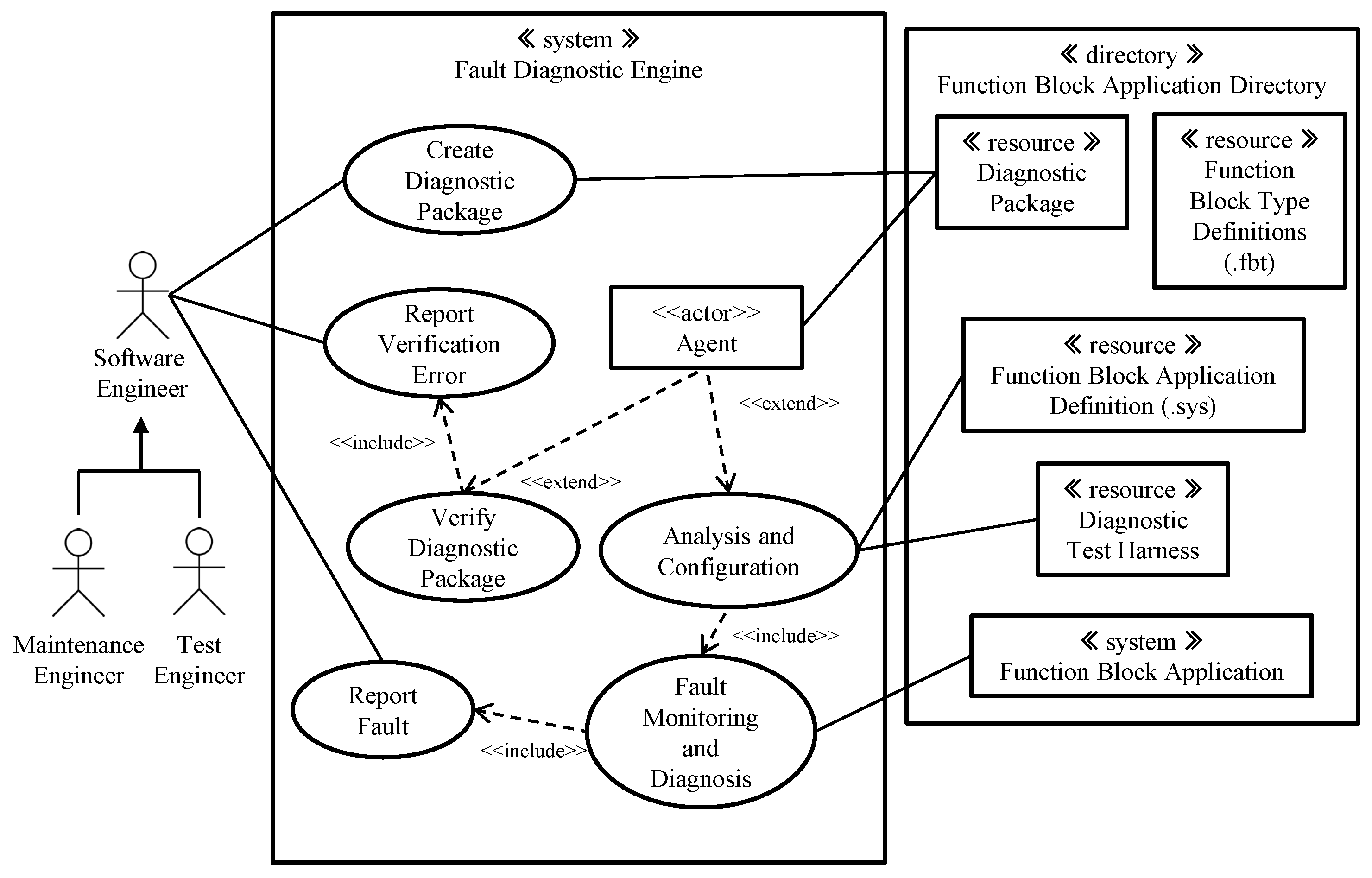
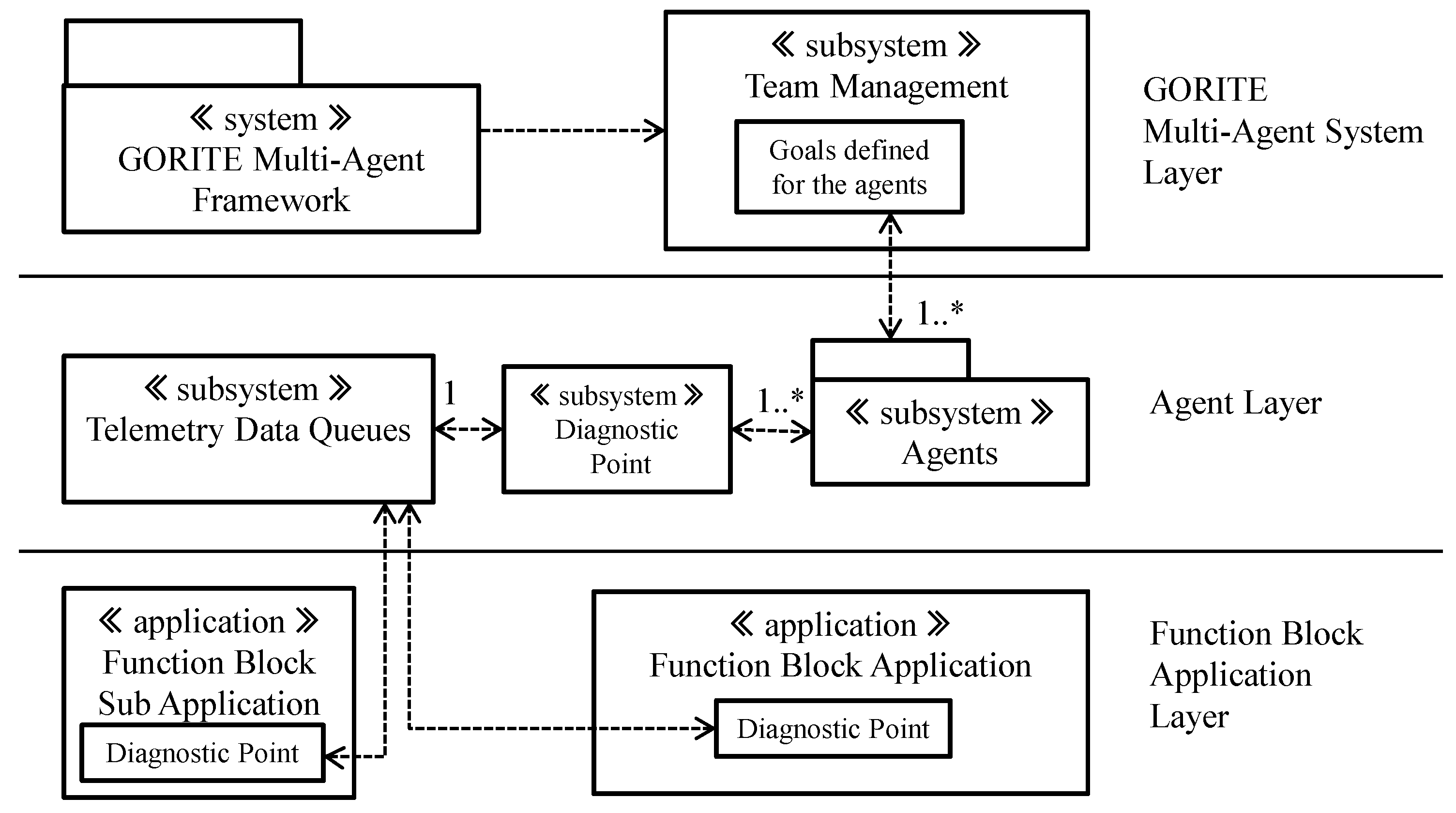
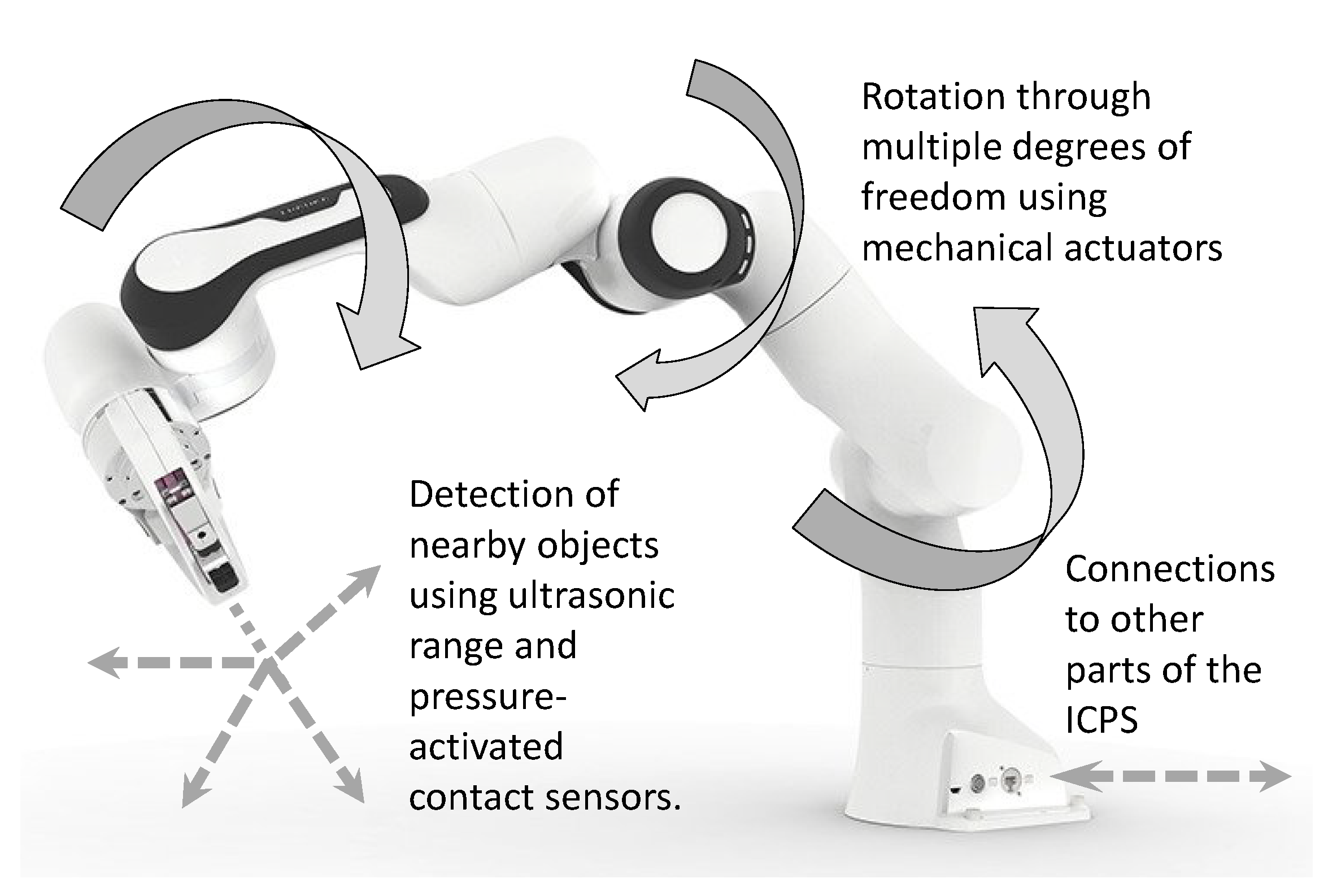
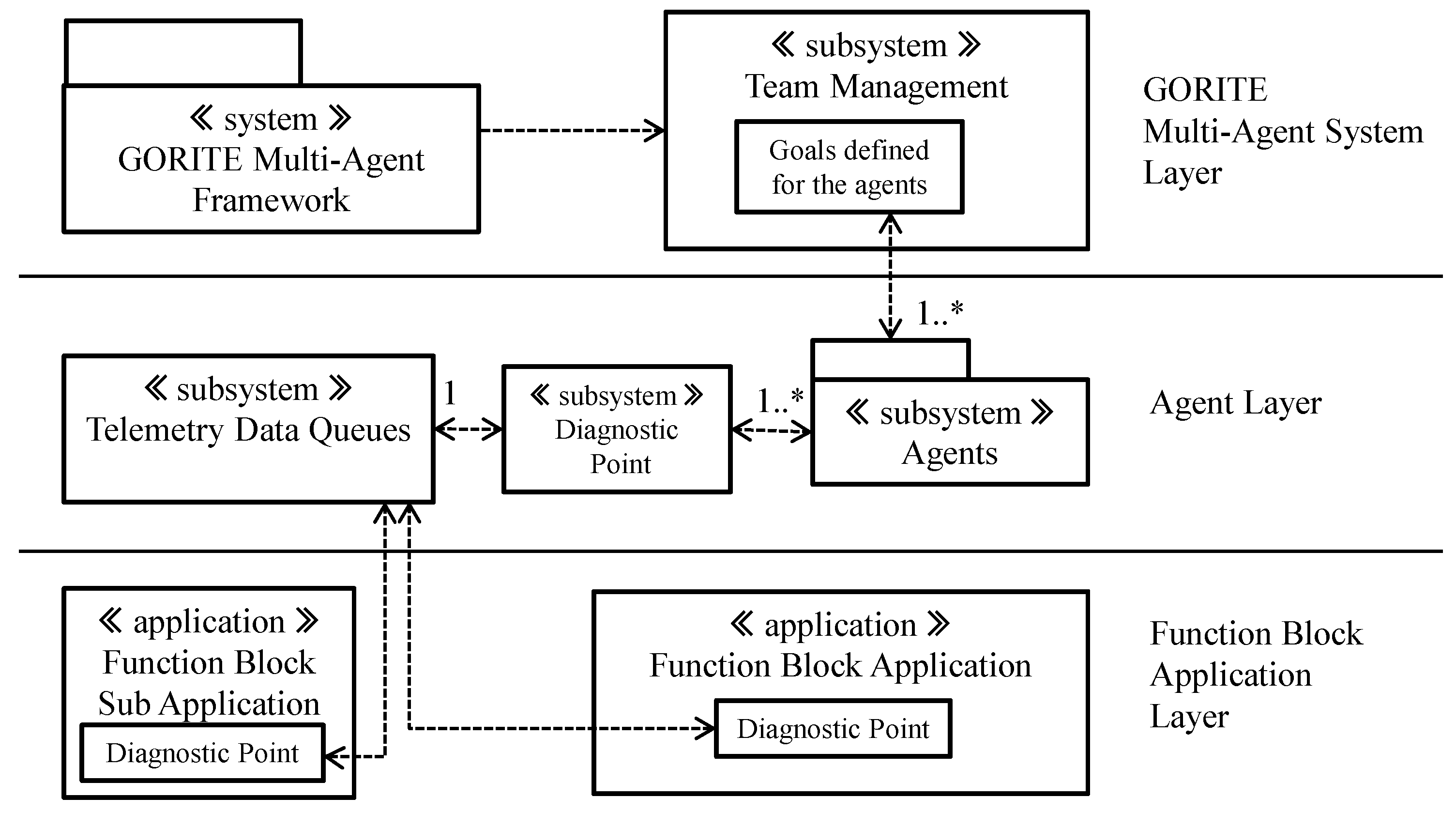
3.1. The System Context View of the Engine
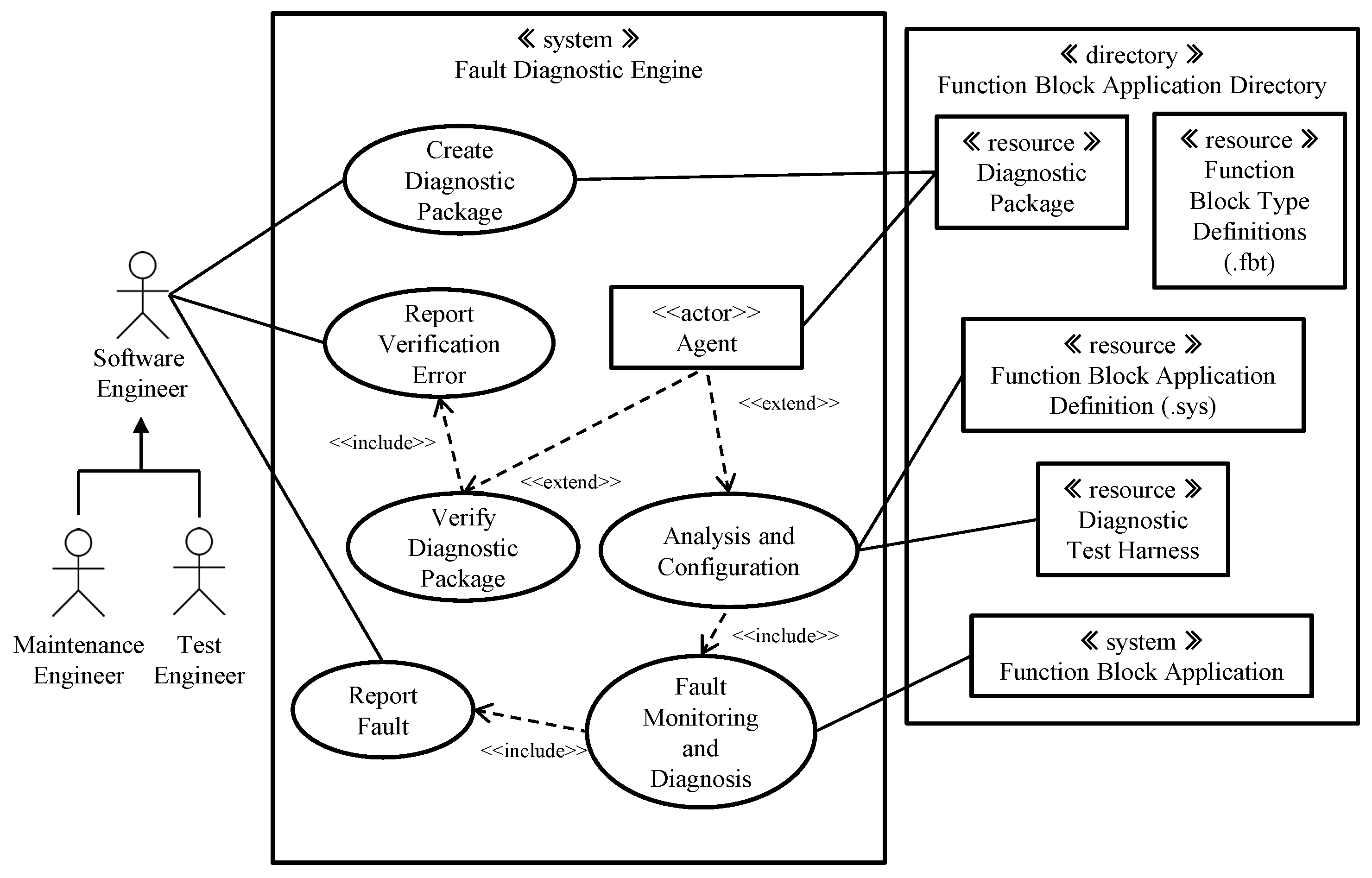
3.2. The Logical View
- 1.
- is the set of situations that an agent can be in. The characteristics of the agents’ situation is defined by the nature of the goal it is pursuing or an individual task within that goal it is performing.
- 2.
- is the set of actions that an agent can perform in that environment.
- 3.
- is the set of internal data the agent maintains about its state and the environment it is situated in.
- 4.
- is a function defined for the current situation over the data values that allows the agent to determine its next actions such that .
- 1.
- , are the actions the agent is capable of performing, and
- 2.
- is the action that causes the agent to terminate its operations when that task is completed. Since agents have the ability to self-determine what the appropriate course of action might be in a given environment, it is possible that a number of different behaviors could be exhibited that still achieve the same outcome.
- 1.
- N is a unique identifier that names the goal, and
- 2.
- is the set of actions the agent can perform while pursuing the goal where , and
- 3.
- is the current state of the goal where , the set of defined GORITE goal states.
- PASSED: The current goal has been completed successfully by the DiagnosticAgent. This usually results in the TeamManagerAgent assigning a new goal if there is a subsequent task that follows on from the goal that has just been completed.
- STOPPED: The agent cannot complete the current goal at the present time. This usually signifies that there has been some sort of obstruction in the environment that is stopping the agent working on the goal. The agent is recommending to the TeamManagerAgent that the goal should be re-scheduled to be attempted again at a later time.
- FAILED: The agent cannot complete the current goal and has determined that further attempts to re-start and complete the goal would be futile. The TeamManagerAgent will not attempt to re-schedule this goal again during the current fault diagnostic session.
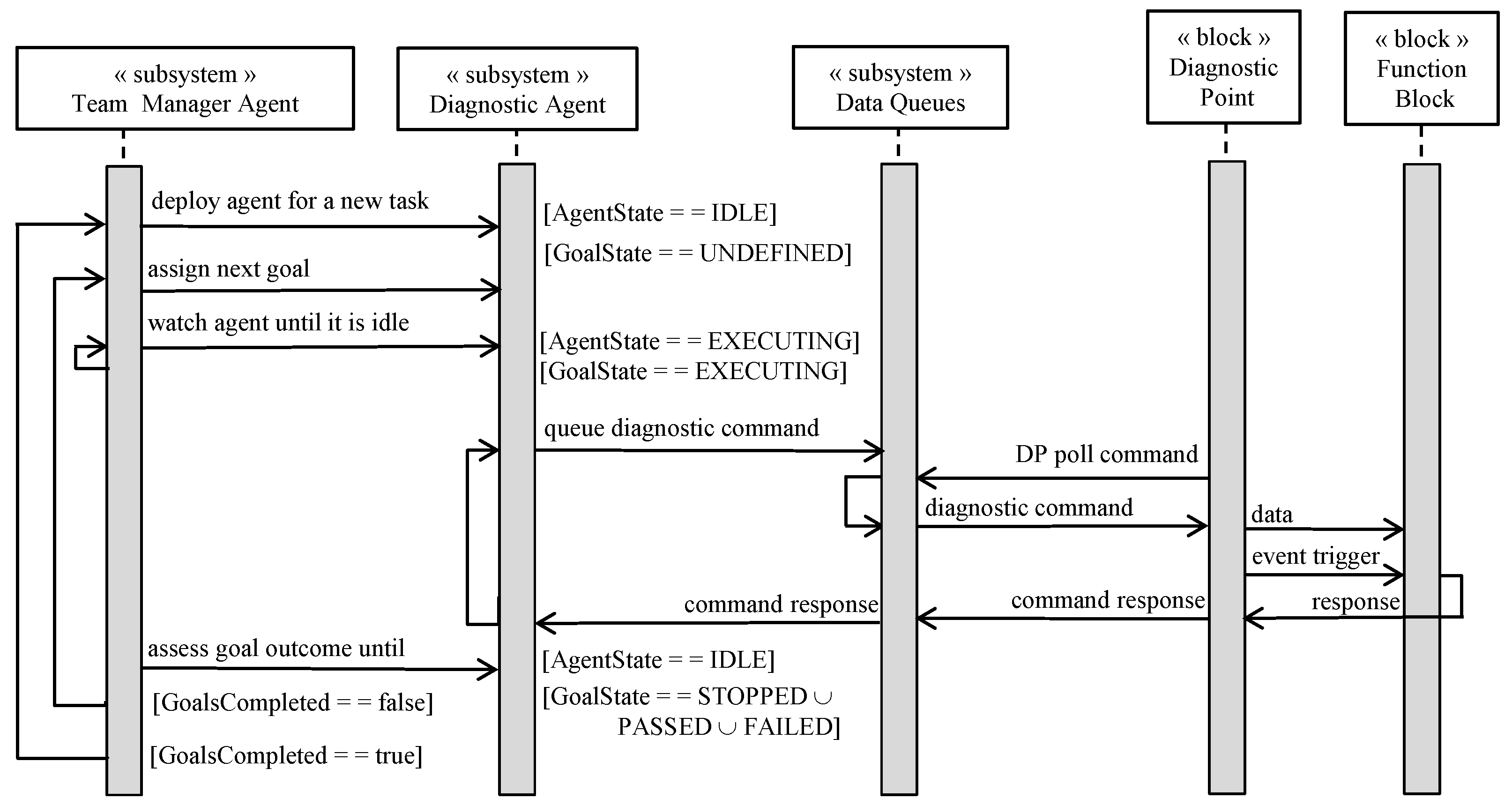
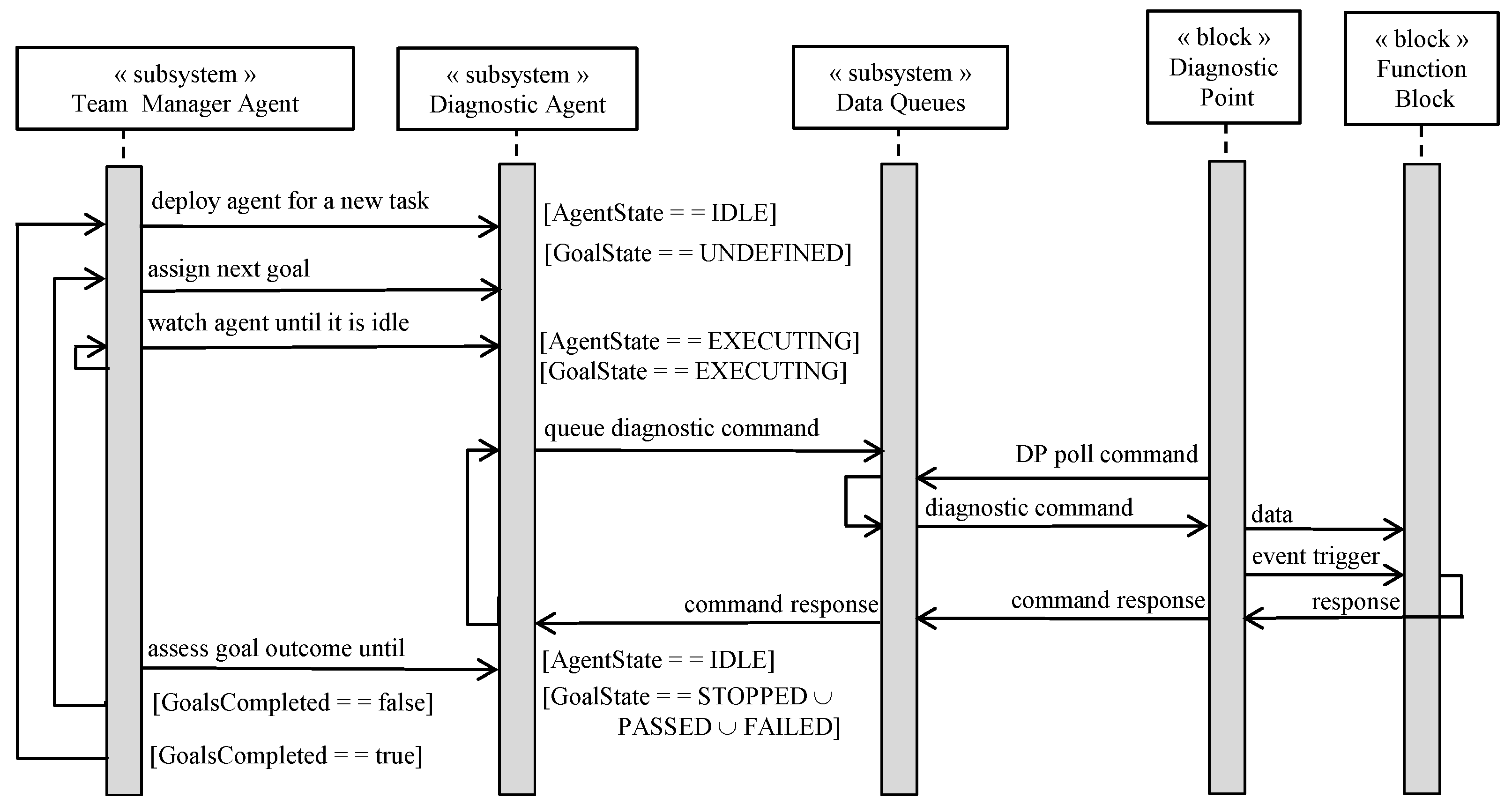
3.3. The Process View
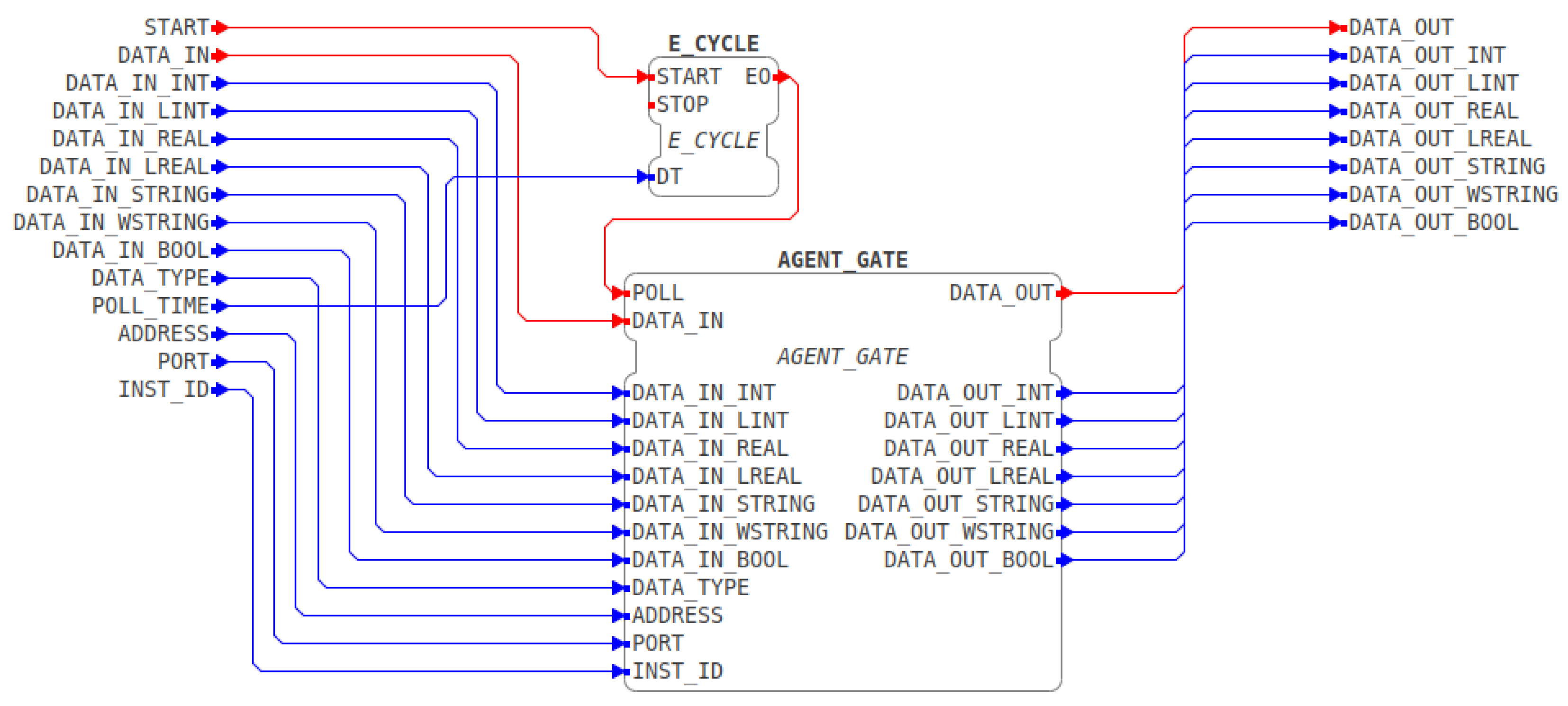
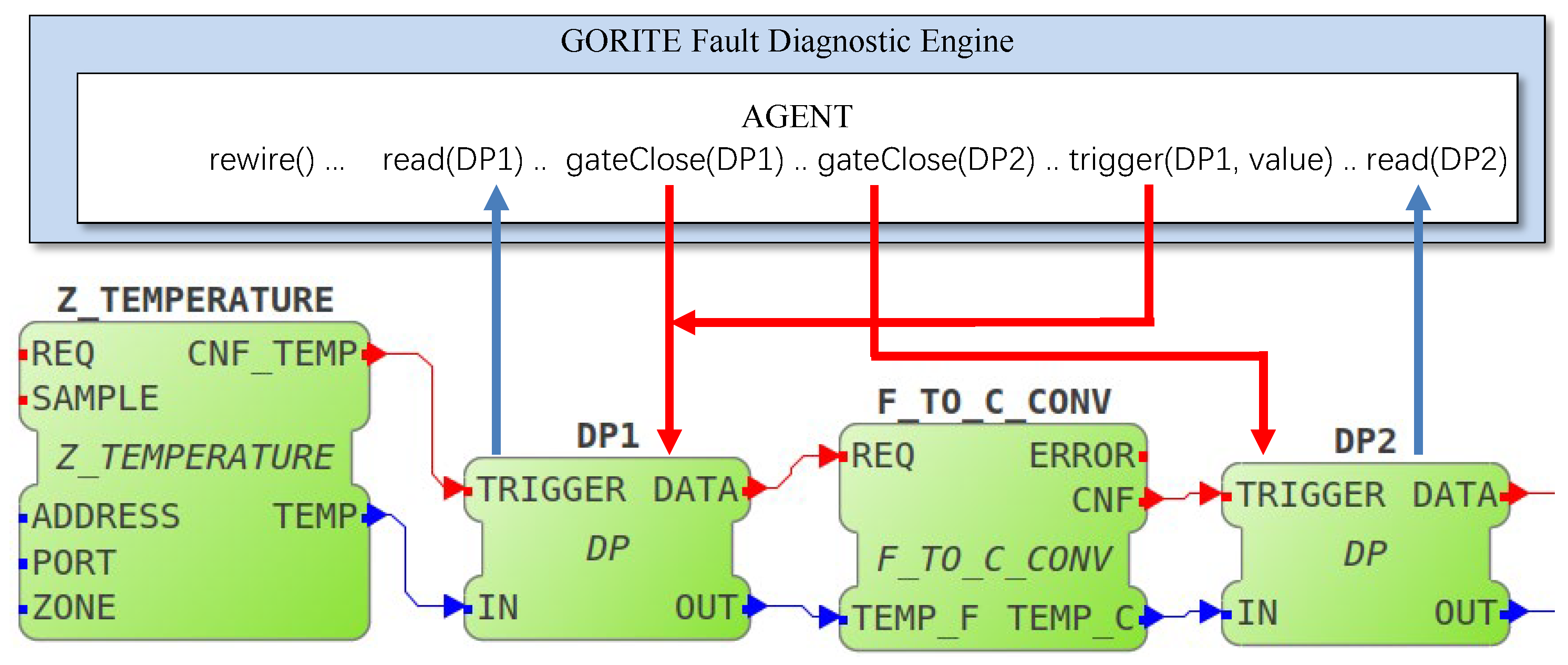
3.4. Diagnostic Points and Telemetry
3.5. Managing Agent Beliefs
- △ is a skill that the agent can use and
- v is the veracity of the belief held by the agent about the skill. This may be , , or .
- are function block instances in the system under diagnosis, and
- represents the conditions (events and variable values) under which a transition can be triggered by the agent from to .
- is a function block instance of the system under diagnosis, and
- is a valid fault code for , obtained from a set of fault codes F.
4. Evaluating the Architecture of the Engine
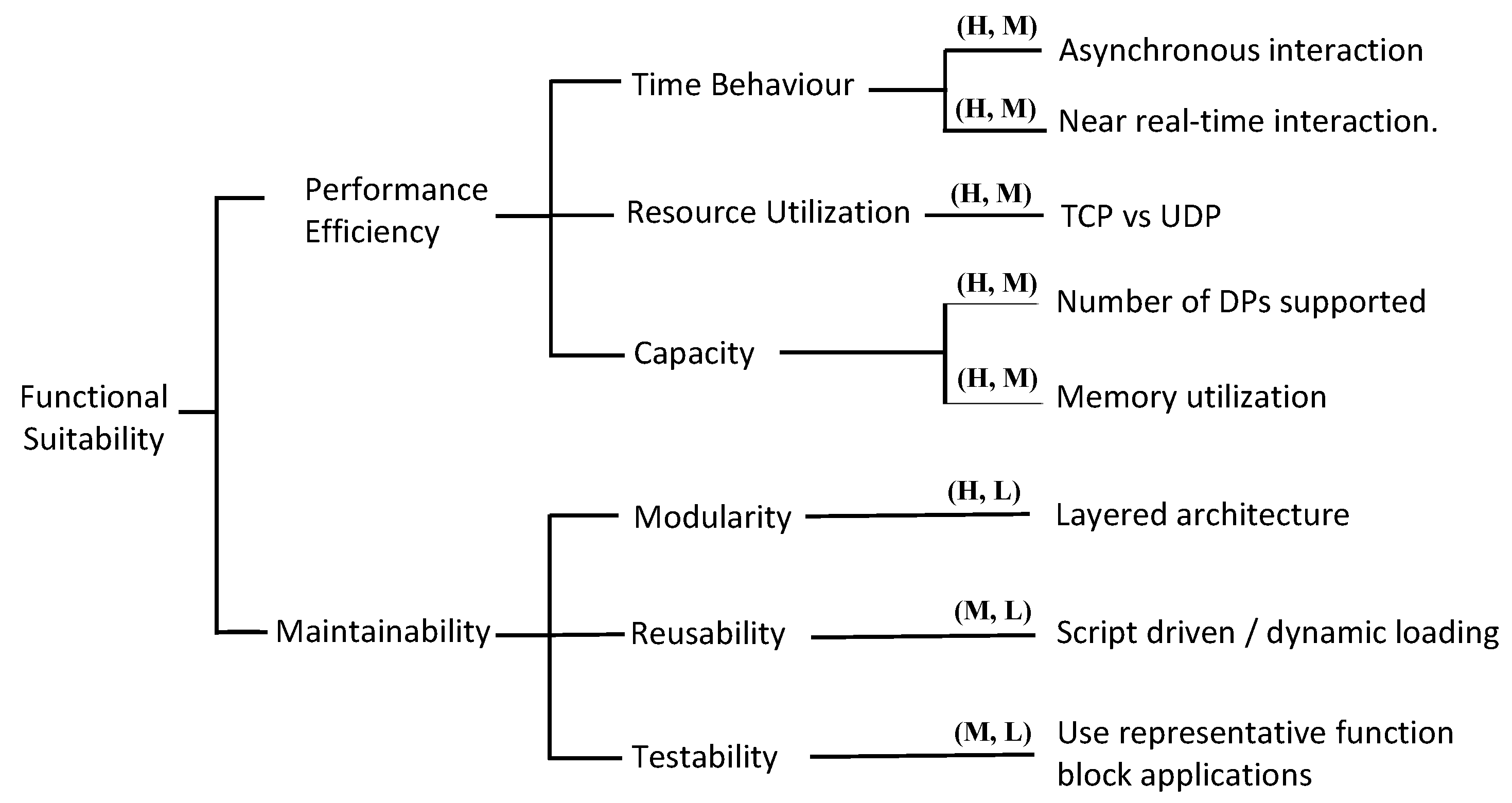
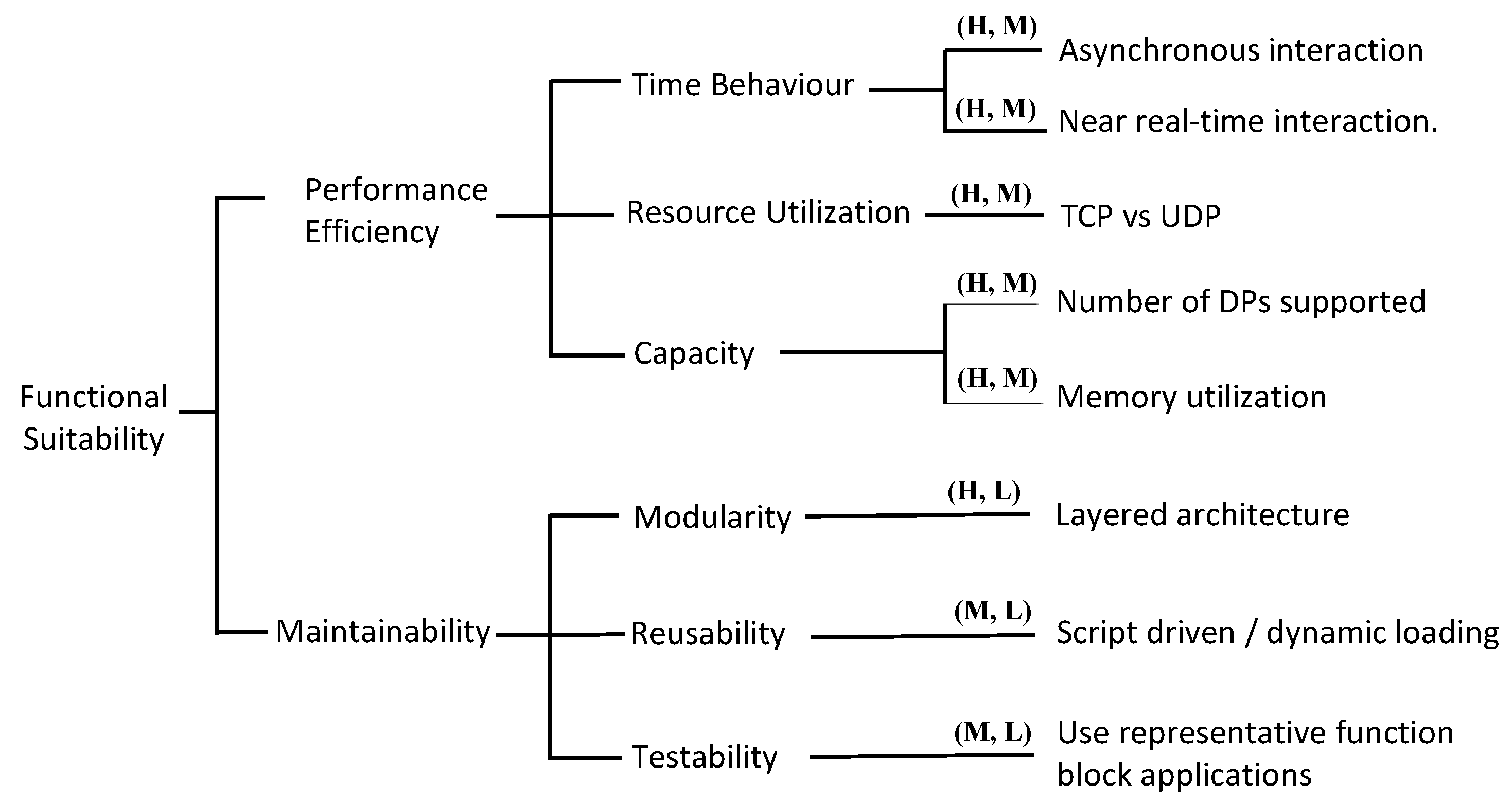
4.1. Constructing the ATAM Utility Tree
4.2. ISO 4.2.2 Performance Efficiency
4.3. ISO 4.2.8 Portability
4.4. ISO 4.2.5 Reliability
4.5. ISO 4.2.6 Security
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Glossary
| ADD | Attribute-Driven Design method [11]. |
| ATAM | Architectural Trade-off Analysis Method [69]. |
| CFB | Composite Function Block [2]. |
| DP | Diagnostic Point [8]. |
| FB | Function Block [2]. |
| ICPS | Industrial Cyber-Physical System. |
| PLC | Programmable Logic Controller. |
| QAW | Quality Attribute Workshop |
| ASR | Architecturally-Significant Requirement. |
| BFB | Basic Function Block [2]. |
| CPS | Cyber-Physical System [20]. |
| ECS | Embedded Control System. |
| FDE | Fault Diagnostic Engine. |
| IDE | Integrated Development Environment. |
| QA | Quality Attribute. |
| SAD | Software Architecture Document. |
References
- Lee, E.A.; Seshia, S.A. Introduction to Embedded Systems: A Cyber-Physical Systems Approach; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- IEC. Function Blocks–Part 1: Architecture; IEC: Geneva, Switzerland, 2013. [Google Scholar]
- Jarvis, D.; Jarvis, J.; Rönnquist, R.; Jain, L.C. Multi-Agent Systems. In Multiagent Systems and Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–12. [Google Scholar] [CrossRef]
- Ganzha, M.; Jain, L.C.; Jarvis, D.; Jarvis, J.; Rönnquist, R. Multiagent Systems and Applications; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Rönnquist, R. The Goal Oriented Teams (GORITE) framework. In International Workshop on Programming Multi-Agent Systems; Springer: Berlin/Heidelberg, Germany, 2007; pp. 27–41. [Google Scholar]
- Strasser, T.; Rooker, M.; Ebenhofer, G.; Zoitl, A.; Sünder, C.; Valentini, A.; Martel, A. Framework for distributed industrial automation and control (4DIAC). In Proceedings of the 2008 6th IEEE International Conference on Industrial Informatics, Daejeon, Korea, 13–16 July 2008; pp. 283–288. [Google Scholar]
- Zoitl, A.; Strasser, T.; Ebenhofer, G. Developing modular reusable IEC 61499 control applications with 4DIAC. In Proceedings of the 2013 11th IEEE International Conference on Industrial Informatics (INDIN), Bochum, Germany, 29–31 July 2013; pp. 358–363. [Google Scholar]
- Dowdeswell, B.; Sinha, R.; MacDonell, S.G. Diagnosable-by-Design Model-Driven Development for IEC 61499 Industrial Cyber-Physical Systems. In Proceedings of the IECON 2020 46th International Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020. [Google Scholar]
- Dowdeswell, B.; Sinha, R.; MacDonell, S.G. Finding faults: A scoping study of fault diagnostics for Industrial Cyber-Physical Systems. J. Syst. Softw. 2020, 168, 110638. [Google Scholar] [CrossRef]
- Clements, P.; Garlan, D.; Little, R.; Nord, R.; Stafford, J. Documenting software architectures: Views and Beyond. In Proceedings of the 25th International Conference on Software Engineering, Portland, OR, USA, 3–10 May 2003; pp. 740–741. [Google Scholar] [CrossRef]
- Wojcik, R.; Bachmann, F.; Bass, L.; Clements, P.; Merson, P.; Nord, R.; Wood, B. Attribute-Driven Design (ADD), Version 2.0.; Technical Report; Software Engineering Institute (SEI), Carnegie-Mellon University: Pittsburg, PA, USA, 2006. [Google Scholar]
- Dowdeswell, B.; Sinha, R.; MacDonell, S. Mendeley Dataset: A Software Architecture for a Fault Diagnostic Engine. Mendeley Data 2020. [Google Scholar] [CrossRef]
- Kalachev, A.; Zhabelova, G.; Vyatkin, V.; Jarvis, D.; Pang, C. Intelligent mechatronic system with decentralised control and multi-agent planning. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3126–3133. [Google Scholar] [CrossRef]
- Jarvis, D.; Jarvis, J.; Kalachev, A.; Zhabelova, G.; Vyatkin, V. PROSA/G: An architecture for agent-based manufacturing execution. In Proceedings of the 2018 IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Turin, Italy, 4–7 September 2018; Volume 1, pp. 155–160. [Google Scholar] [CrossRef]
- Christensen, J.H. Design Patterns, Frameworks, and Methodologies. In Distributed Control Applications: Guidelines, Design Patterns, and Application Examples with the IEC 61499; CRC Press: Boca Raton, FL, USA, 2017; p. 27. [Google Scholar] [CrossRef]
- Samad, T.; Parisini, T.; Annaswamy, A. Systems of systems. Impact Control. Technol. 2011, 12, 175–183. [Google Scholar]
- Laughton, M.A.; Say, M.G. Electrical Engineer’s Reference Book; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Parr, E.A. Industrial Control Handbook; Industrial Press Inc.: New York, NY, USA, 1998. [Google Scholar]
- Boem, F.; Ferrari, R.M.; Parisini, T. Distributed fault detection and isolation of continuous-time nonlinear systems. Eur. J. Control. 2011, 17, 603–620. [Google Scholar] [CrossRef]
- Baheti, R.; Gill, H. Cyber-physical systems. Impact Control. Technol. 2011, 12, 161–166. [Google Scholar]
- Leitao, P.; Karnouskos, S.; Ribeiro, L.; Lee, J.; Strasser, T.; Colombo, A.W. Smart agents in industrial cyber–physical systems. Proc. IEEE 2016, 104, 1086–1101. [Google Scholar] [CrossRef] [Green Version]
- Cremona, F.; Lohstroh, M.; Broman, D.; Lee, E.A.; Masin, M.; Tripakis, S. Hybrid co-simulation: Its about time. Softw. Syst. Model. 2019, 18, 1655–1679. [Google Scholar] [CrossRef] [Green Version]
- Workers, W. Franka Emika Panda Research Robot Manual. 2020. Available online: https://www.franka.de/ (accessed on 21 July 2021).
- Jazdi, N. Cyber physical systems in the context of Industry 4.0. In Proceedings of the 2014 IEEE International Conference on Automation, Quality and Testing, Robotics, Cluj-Napoca, Romania, 22–24 May 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Alur, R. Principles of Cyber-Physical Systems; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- IEC. Function Blocks–Part 1: Programmable Controllers. General Information; IEC: Geneva, Switzerland, 2003; p. 61131. [Google Scholar]
- Moore, E.F. Gedanken-experiments on sequential machines. Autom. Stud. 1956, 34, 129–153. [Google Scholar]
- Lindgren, P.; Lindner, M.; Lindner, A.; Vyatkin, V.; Pereira, D.; Pinho, L.M. A real-time semantics for the IEC 61499 standard. In Proceedings of the 2015 IEEE 20th Conference on Emerging Technologies & Factory Automation (ETFA), Luxembourg, 8–11 September 2015; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Hehenberger, P.; Vogel-Heuser, B.; Bradley, D.; Eynard, B.; Tomiyama, T.; Achiche, S. Design, modelling, simulation and integration of cyber physical systems: Methods and applications. Comput. Ind. 2016, 82, 273–289. [Google Scholar] [CrossRef] [Green Version]
- Atmojo, U.D.; Blech, J.O.; Vyatkin, V. A Plug and Produce-inspired Approach in Distributed Control Architecture: A Flexible Assembly Line and Product Centric Control Example. In Proceedings of the 2020 IEEE International Conference on Industrial Technology (ICIT), Buenos Aires, Argentina, 26–28 February 2020; pp. 271–277. [Google Scholar] [CrossRef]
- Yang, C.W.; Zhabelova, G.; Vyatkin, V.; Nair, N.K.C.; Apostolov, A. Smart Grid automation: Distributed protection application with IEC61850/IEC61499. In Proceedings of the IEEE 10th International Conference on Industrial Informatics, Beijing, China, 25–27 July 2012; pp. 1067–1072. [Google Scholar] [CrossRef]
- NOJA. NOJA Power Smart Grid Automation Software. 2015. Available online: https://www.nojapower.com.au/tags/smart-grid-automation-software (accessed on 21 July 2021).
- Khairullah, S.S.; Elks, C.R. Self-repairing hardware architecture for safety-critical cyber-physical-systems. IET Cyber-Phys. Syst. Theory Appl. 2020, 5, 92–99. [Google Scholar] [CrossRef]
- Jackson, S. A multidisciplinary framework for resilence to disasters and disruptions. J. Integr. Des. Process. Sci. 2007, 11, 91–108. [Google Scholar]
- Holzmann, G.J. Mars Code. Commun. ACM 2014, 57, 64–73. [Google Scholar] [CrossRef]
- Benowitz, E. The Curiosity Mars Rover’s Fault Protection Engine. In Proceedings of the 2014 IEEE International Conference on Space Mission Challenges for Information Technology, Laurel, MD, USA, 24–26 September 2014; pp. 62–66. [Google Scholar] [CrossRef]
- Thombare, T.R.; Dole, L. Review on fault diagnosis model in automobile. In Proceedings of the 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 18–20 December 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Ragheb, M. Fault Tree Analysis and Alternative Configurations of Angle of Attack (AOA) Sensors as Part of Maneuvering Characteristics Augmentation System (MCAS). 2019. Available online: https://www.mragheb.com (accessed on 20 July 2021).
- Zolghadri, A.; Cieslak, J.; Efimov, D.; Henry, D.; Goupil, P.; Dayre, R.; Gheorghe, A.; Leberre, H. Signal and model-based fault detection for aircraft systems. IFAC-PapersOnLine 2015, 48, 1096–1101. [Google Scholar] [CrossRef]
- Dearden, R.; Willeke, T.; Simmons, R.; Verma, V.; Hutter, F.; Thrun, S. Real-time fault detection and situational awareness for rovers: Report on the mars technology program task. In Proceedings of the 2004 IEEE Aerospace Conference Proceedings (IEEE Cat. No. 04TH8720), Big Sky, MT, USA, 6–13 March 2004; Volume 2, pp. 826–840. [Google Scholar] [CrossRef]
- Provan, G. A Contracts-Based Framework for Systems Modeling and Embedded Diagnostics. In Proceedings of the International Conference on Software Engineering and Formal Methods, Grenoble, France, 1–5 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 131–143. [Google Scholar] [CrossRef]
- Harirchi, F.; Ozay, N. Guaranteed model-based fault detection in cyber–physical systems: A model invalidation approach. Automatica 2018, 93, 476–488. [Google Scholar] [CrossRef] [Green Version]
- Koitz, R.; Lüftenegger, J.; Wotawa, F. Model-based diagnosis in practice: Interaction design of an integrated diagnosis application for industrial wind turbines. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 440–445. [Google Scholar] [CrossRef]
- Sankavaram, C.; Kodali, A.; Pattipati, K. An integrated health management process for automotive cyber-physical systems. In Proceedings of the 2013 International Conference on Computing, Networking and Communications (ICNC), San Diego, CA, USA, 28–31 January 2013; pp. 82–86. [Google Scholar] [CrossRef]
- Milis, G.M.; Eliades, D.G.; Panayiotou, C.G.; Polycarpou, M.M. A cognitive fault-detection design architecture. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2819–2826. [Google Scholar] [CrossRef] [Green Version]
- Hametner, R.; Hegny, I.; Zoitl, A. A unit-test framework for event-driven control components modeled in IEC 61499. In Proceedings of the 2014 IEEE Emerging Technology and Factory Automation (ETFA), Barcelona, Spain, 16–19 September 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Calvaresi, D.; Marinoni, M.; Sturm, A.; Schumacher, M.; Buttazzo, G. The challenge of real-time multi-agent systems for enabling IoT and CPS. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017; ACM: New York, NY, USA, 2017; pp. 356–364. [Google Scholar] [CrossRef]
- Braberman, V.; D’Ippolito, N.; Kramer, J.; Sykes, D.; Uchitel, S. Morph: A reference architecture for configuration and behaviour self-adaptation. In Proceedings of the 1st International Workshop on Control Theory for Software Engineering, Bergamo, Italy, 31 August 2015. [Google Scholar] [CrossRef] [Green Version]
- Bratman, M.E.; Israel, D.J.; Pollack, M.E. Plans and resource-bounded practical reasoning. Comput. Intell. 1988, 4, 349–355. [Google Scholar] [CrossRef]
- Wooldridge, M. An Introduction to Multiagent Systems; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Wu, D.; Liu, S.; Zhang, L.; Terpenny, J.; Gao, R.X.; Kurfess, T.; Guzzo, J.A. A fog computing-based framework for process monitoring and prognosis in cyber-manufacturing. J. Manuf. Syst. 2017, 43, 25–34. [Google Scholar] [CrossRef]
- Janasak, K.M.; Beshears, R.R. Diagnostics to Prognostics—A product availability technology evolution. In Proceedings of the 2007 Annual Reliability and Maintainability Symposium, Orlando, FL, USA, 22–25 January 2007; pp. 113–118. [Google Scholar] [CrossRef]
- Klar, D.; Huhn, M. Interfaces and models for the diagnosis of cyber-physical ecosystems. In Proceedings of the 2012 6th IEEE International Conference on Digital Ecosystems and Technologies (DEST), Campione d’Italia, Italy, 18–20 June 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Modest, C.; Thielecke, F. SPYDER: A software package for system diagnosis engineering. CEAS Aeronaut. J. 2016, 7, 315–331. [Google Scholar] [CrossRef]
- Jones, R.M.; Wray, R.E. Comparative analysis of frameworks for knowledge-intensive intelligent agents. AI Mag. 2006, 27, 57. [Google Scholar] [CrossRef]
- Card, S.K.; Newell, A.; Moran, T.P. The Psychology of Human-Computer Interaction; CRC Press: Boca Raton, FL, USA, 1983. [Google Scholar]
- Laird, J.E.; Newell, A.; Rosenbloom, P.S. Soar: An architecture for general intelligence. Artif. Intell. 1987, 33, 1–64. [Google Scholar] [CrossRef]
- Fröhlich, P.; Móra, I.; Nejdl, W.; Schröder, M. Diagnostic agents for distributed systems. In ModelAge Workshop on Formal Models of Agents; Springer: Berlin/Heidelberg, Germany, 1997; pp. 173–186. [Google Scholar] [CrossRef]
- Santos, F.; Nunes, I.; Bazzan, A.L. Model-driven agent-based simulation development: A modeling language and empirical evaluation in the adaptive traffic signal control domain. Simul. Model. Pract. Theory 2018, 83, 162–187. [Google Scholar] [CrossRef]
- IEEE. IEEE Standard Glossary of Software Engineering Terminology. Office 1990, 121990, 1. [Google Scholar]
- Ribeiro, C.; Berry, D. The Prevalence and Severity of Persistent Ambiguity in Software Requirements Specifications: Is a Special Effort Needed to Find Them? Sci. Comput. Program. 2020, 195, 102472. [Google Scholar] [CrossRef]
- Sabriye, A.O.J.; Zainon, W.M.N.W. An Approach for Detecting Syntax and Syntactical Ambiguity in Software Requirement Specification. J. Theor. Appl. Inf. Technol. 2018, 96, 2275–2284. [Google Scholar]
- Segal, S. A framework for removing ambiguity from software requirements. IIOAB J. 2017, 8, 43–46. [Google Scholar]
- Van Heesch, U.; Avgeriou, P.; Hilliard, R. A documentation framework for architecture decisions. J. Syst. Softw. 2012, 85, 795–820. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Babar, M.A.; Nuseibeh, B. Characterizing architecturally significant requirements. IEEE Softw. 2012, 30, 38–45. [Google Scholar] [CrossRef] [Green Version]
- Bass, L.; Clements, P.; Kazman, R. Software Architecture in Practice, 3rd ed.; Addison-Wesley: Boston, MA, USA, 2013. [Google Scholar]
- ISO. Systems and Software Engineering: Systems and Software Quality Requirements and Evaluation (SQuaRE): System and Software Quality Models; International Organization for Standardization: Geneva, Switzerland, 2011. [Google Scholar]
- Barbacci, M.R.; Ellison, R.J.; Lattanze, A.J.; Stafford, J.A.; Weinstock, C.B. Quality Attribute Workshops (QAWA); Technical Report; Carnegie-Mellon University: Pittsburgh, PA, USA, 2003. [Google Scholar]
- Kazman, R.; Klein, M.; Clements, P. ATAM: Method for Architecture Evaluation; Technical Report; Software Engineering Institute, Carnegie-Mellon University: Pittsburgh, PA, USA, 2000. [Google Scholar]
- Mellon, C. Views and Beyond: The SEI Approach for Architecture Documentation; Carnegie Mellon University: Pittsburgh, PA, USA, 2018. [Google Scholar]
- Kruchten, P.B. The 4 + 1 View Model of Architecture. IEEE Softw. 1995, 12, 42–50. [Google Scholar] [CrossRef] [Green Version]
- Rozanski, N.; Woods, E. Software Systems Architecture: Working with Stakeholders Usin Viewpoints and Perspectives; Addison-Wesley: Boston, MA, USA, 2011. [Google Scholar]
- May, N. A survey of software architecture viewpoint models. In Proceedings of the Sixth Australasian Workshop on Software and System Architectures, Brisbane, Australia, 29 March 2005; pp. 13–24. [Google Scholar]
- ISO. ISO Standard 19514:2017 Information Technology—The Object Management Group Systems Modeling Language (OMG SysML); ISO: Geneva, Switzerland, 2019. [Google Scholar]
- ISO. ISO Standard 19501:2005 Information Technology—The Unified Modeling Language (OMG UML); ISO: Geneva, Switzerland, 2019. [Google Scholar]
- Doberkat, E.E. Pipelines: Modelling a software architecture through relations. Acta Inform. 2003, 40, 37–79. [Google Scholar] [CrossRef]
- Shehory, O.M. Architectural Properties of Multi-Agent Systems; The Robotics Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 1998. [Google Scholar]
- Kidney, J.; Denzinger, J. Testing the limits of emergent behavior in MAS using learning of cooperative behavior. Front. Artif. Intell. Appl. 2006, 141, 260. [Google Scholar]
- Carden, F.; Jedlicka, R.P.; Henry, R. Telemetry Systems Engineering; Artech House: Norwood, MA, USA, 2002. [Google Scholar]
- Goupil, P.; Boada-Bauxell, J.; Marcos, A.; Cortet, E.; Kerr, M.; Costa, H. AIRBUS efforts towards advanced real-time fault diagnosis and fault tolerant control. IFAC Proc. Vol. 2014, 47, 3471–3476. [Google Scholar] [CrossRef] [Green Version]
- Kritzinger, W.; Karner, M.; Traar, G.; Henjes, J.; Sihn, W. Digital Twin in manufacturing: A categorical literature review and classification. IFAC-PapersOnLine 2018, 51, 1016–1022. [Google Scholar] [CrossRef]
- Dennett, D. Intentional Systems Theory. In The Oxford Handbook of Philosophy of Mind; Oxford University Press: Oxford, UK, 2009; pp. 339–350. [Google Scholar]
- Bratman, M. Intention, Plans, and Practical Reason; Harvard University Press: Cambridge, MA, USA, 1987; Volume 10. [Google Scholar] [CrossRef]
- Merriam-Webster. Veracity Dictonary Definition. 2021. Available online: https://www.merriam-webster.com/dictionary/veracity (accessed on 20 July 2021).
- nxtControl GmbH. The nxtCONTROL Development Environment. 2020. Available online: https://www.nxtcontrol.com/en/engineering/ (accessed on 20 July 2021).
- Hazzan, O. The reflective practitioner perspective in software engineering education. J. Syst. Softw. 2002, 63, 161–171. [Google Scholar] [CrossRef] [Green Version]
- Barcelos, R.F.; Travassos, G.H. Evaluation Approaches for Software Architectural Documents: A Systematic Review; CIbSE: London, UK, 2006; pp. 433–446. [Google Scholar]
- Reijonen, V.; Koskinen, J.; Haikala, I. Experiences from scenario-based architecture evaluations with ATAM. In Proceedings of the European Conference on Software Architecture, Copenhagen, Denmark, 23–26 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 214–229. [Google Scholar] [CrossRef]
- 4DIAC-RTE (FORTE): IEC 61499 Compliant Runtime Environment. 2019. Available online: https://www.eclipse.org/4diac/en_rte.php (accessed on 20 July 2021).
- Defense Advanced Research Projects Agency. RFC 793 Transmission Control Protocol; Defense Advanced Research Projects Agency: Arlington County, VA, USA, 1981; Available online: https://datatracker.ietf.org/doc/html/rfc793 (accessed on 20 July 2021).
- DARPA. RFC 768 User Datagram Protocol; DARPA: Arlington County, VA, USA, 1980; Available online: https://www.ietf.org/rfc/rfc768 (accessed on 20 July 2021).
- Tanveer, A.; Sinha, R.; MacDonell, S.G. On Design-time Security in IEC 61499 Systems: Conceptualisation, Implementation, and Feasibility. In Proceedings of the 2018 IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018; pp. 778–785. [Google Scholar] [CrossRef]
- The Selenium Testing Environment. 2020. Available online: https://developer.mozilla.org/en-US/docs/Learn/Tools_and_testing/Cross_browser_testing/Your_own_automation_environment (accessed on 20 July 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Requirement | Wide Impact? | Requires Trade-Offs? | Strict? | Breaks Assumptions? | Difficult to Achieve? | Architecturally Significant? |
|---|---|---|---|---|---|---|---|
| 1 | The agents must be able to interact with multiple, distributed parts of the system that is under diagnosis. | Yes | Yes | No | No | Yes | Yes |
| 2 | The operation of the Diagnostic Points shall not degrade the performance of the system under diagnosis by more than 5%. | No | Yes | Yes | No | Yes | Yes |
| Packet Type Enum | Description |
|---|---|
| SAMPLED_DATA_VALUE | A typed data value sent to the agent that has been either captured from an input or an output port on the function block. |
| PASSTHROUGH_ENABLED | Command received from the agent to switch the DP to its transparent pass-through mode. |
| POLL_AGENT | The DP is polling the agent, signaling that it is ready to receive a new data value to inject into the function block. The value is returned in a Post-Back from the NIOserver. |
| TRIGGER_ENABLED | Command received from the agent to switch from its transparent pass-through mode and begin requesting and injecting test data values. Used in conjunction with the GATE_OPEN and GATE_CLOSE commands. |
| GATE_OPEN | Instructs the DP to open the gate to traffic from other function blocks after switching back to its PASSTHROUGH_ENABLED mode. |
| GATE_CLOSE | Instructs the DP to close the gate, blocking traffic to and from other function blocks after switching to its TRIGGER_ENABLED mode. |
| TRIGGER_DATA_VALUE | A typed data value received from the agent to inject into the function block input and event ports. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dowdeswell, B.; Sinha, R.; MacDonell, S.G. Architecting an Agent-Based Fault Diagnosis Engine for IEC 61499 Industrial Cyber-Physical Systems. Future Internet 2021, 13, 190. https://doi.org/10.3390/fi13080190
Dowdeswell B, Sinha R, MacDonell SG. Architecting an Agent-Based Fault Diagnosis Engine for IEC 61499 Industrial Cyber-Physical Systems. Future Internet. 2021; 13(8):190. https://doi.org/10.3390/fi13080190
Chicago/Turabian StyleDowdeswell, Barry, Roopak Sinha, and Stephen G. MacDonell. 2021. "Architecting an Agent-Based Fault Diagnosis Engine for IEC 61499 Industrial Cyber-Physical Systems" Future Internet 13, no. 8: 190. https://doi.org/10.3390/fi13080190
APA StyleDowdeswell, B., Sinha, R., & MacDonell, S. G. (2021). Architecting an Agent-Based Fault Diagnosis Engine for IEC 61499 Industrial Cyber-Physical Systems. Future Internet, 13(8), 190. https://doi.org/10.3390/fi13080190