
A Multi-Model Approach for User Portrait



Abstract
1. Introduction
2. Related Work
3. The Multi-Stage User Portrait Model
3.1. User Portrait Based on SVM
- First, we calculate x = (z);
- The following decision function is calculated:
- The SVM classifier is initialized by classified document Dl (see Equations (1)–(3)), in which the parameters α, w, and b are obtained.
- The E_step: The category of d (di∈Dw) is calculated and judged by parameters α, w, and b using Formula (4).The M_stpe: The parameters of the SVM model, i.e., α, w, and b, are calculated again based on D = {Dl Dw}.
- If the category of the classified documents changes or k is less than the specified number of iterations, then k = k + 1 and go to step 2.
- The classifier tends to be stable and generates the final SVM classifier.
- The final SVM classifier is used to classify test documents and output the classification results.
3.2. User Portrait Based on Doc2vec Neural Network Model
3.3. User Portrait Based on CNN+LSTM
- Embedded layer sentence representation
- 2.
- Convolution layer feature extraction
- 3.
- K-max pooling feature dimensionality reduction
3.4. Integration of the Models
- (1)
- In the multi-classification task, the general model is based on OneVsRest or OneVsOne. Thus, the classifier can only see the classification information of two classes. After the probability value of each class is output by means of stacking, the second-layer model can see all the classification results to allow some threshold judgment, mutual checking, and so on. The fusion of the two classification tasks on gender is not as good as the other two and six classification tasks.
- (2)
- There are some correlations between the three subtasks, especially between age and education. Therefore, the second-stage model can have good learning for this characteristic relationship. For example, when we tried to get rid of the age and the gender characteristics when predicting academic qualifications, the results became somewhat poor.
- (3)
- This dataset has a problem of data imbalance. However, since the evaluation index is acc, downsample and upsample become unnecessary. With the XGBoost model, we can learn the optimal threshold of each category very well.
- (1)
- Datasets are divided into training sets and retention sets.
- (2)
- The training set is processed by K-fold crossover, and thus the K-base classifiers are trained. The predicted results are spliced and processed as the training set of the second layer model.
- (3)
- The base classifier in step (2) is also used for prediction on the reserved set, with the prediction results being averaged out as the verification set of the second layer model.
- (4)
- The training set of step (2) and the verification set of step (3) are used to train the second layer of the XGBTree model.
- (5)
- Steps (4) is repeated to train multiple XGBTree models to perform linear fusing so as to further improve the generalization ability of the model.
4. Experiment and Analysis
4.1. Dataset and Experiment Setup
4.2. Experimental Results
4.2.1. Evaluation Metrics
4.2.2. Analysis of the Results
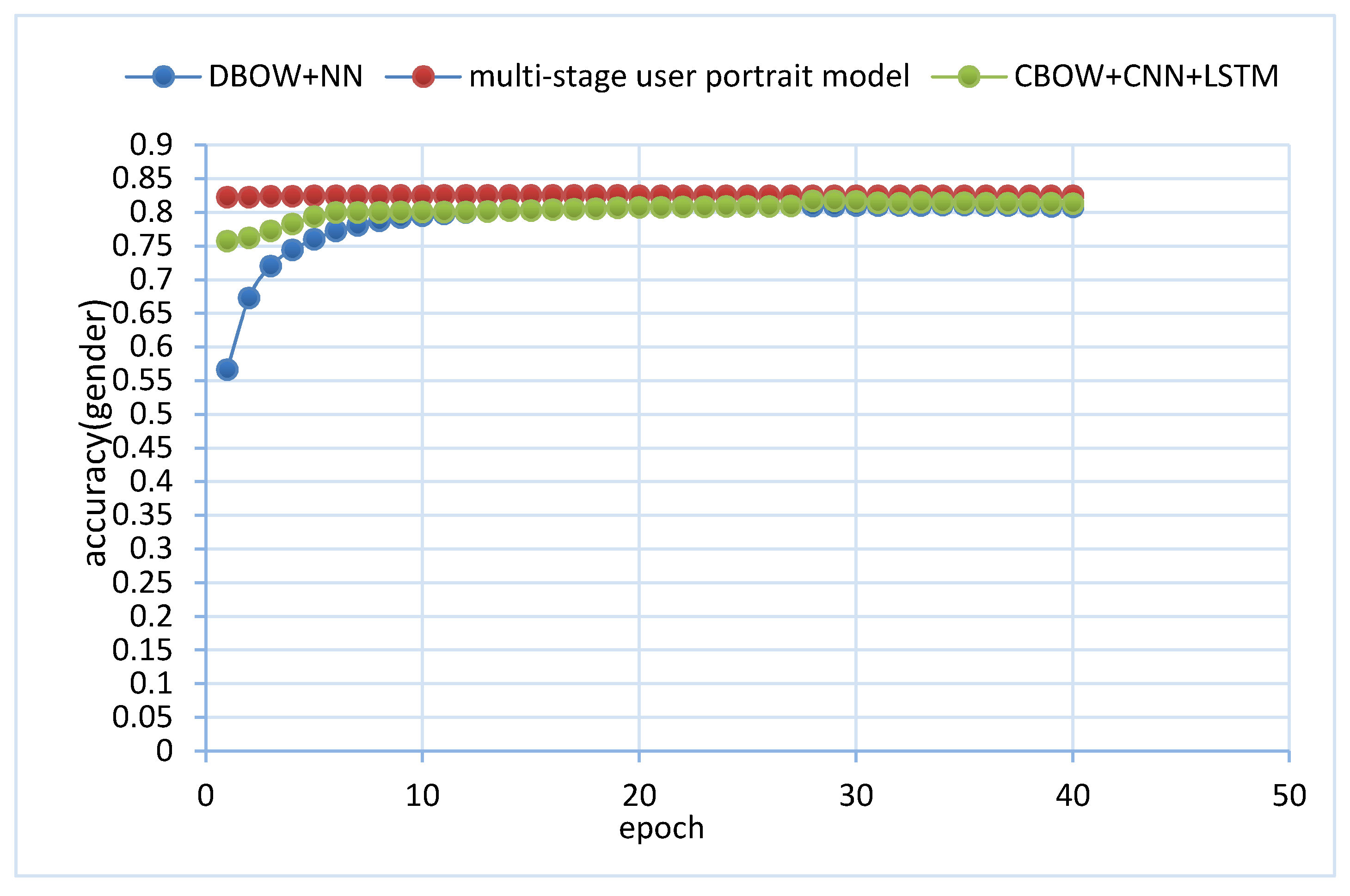
- According to the experimental results, the Word2vec + CNN + LSTM model performed better than the other two single models because CNN can mine the main features in sentences better, and LSTM can combine contextual semantics well to make up for the shortcomings of the Word2vec’s unclear semantics. Therefore, the Word2vec + CNN + LSTM model works well.
- At the 35th iteration, the DBOW-NN model achieved the highest accuracy on the verification dataset. So, we chose the result of the model at this time.
- For the multi-stage fusion, the three models in the first stage showed a lot of differences, but it can be seen that the generalization of the model after fusion was very strong. The second stage of the XGBoost model made full use of each sub-task of the first layer to predict the results, thus improving the accuracy of the prediction.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ouaftouh, S.; Zellou, A.; Idri, A. User profile model: A user dimension based classification. In Proceedings of the 2015 10th International Conference on Intelligent Systems: Theories and Applications, Rabat, Morocco, 20–21 October 2015; pp. 1–5. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Cooper, A. The Inmates are Running the Asylum; Publishing House of Electronics Industry: Beijing, China, 2006. [Google Scholar]
- Krismayer, T.; Schedl, M.; Knees, P.; Rabiser, R. Prediction of user demographics from music listening habits. In Proceedings of the 15th International Workshop on Content-Based Multimedia Indexing, Firenze, Italy, 19–21 June 2017. [Google Scholar]
- Culotta, A.; Ravi, N.K.; Cutler, J. Predicting Twitter User Demographics using Distant Supervision from Website Traffic Data. J. Artif. Intell. Res. 2016, 55, 389–408. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Ning, H. Mining user interest based on personality-aware hybrid filtering in social networks. Knowl. -Based Syst. 2020, 206, 106227. [Google Scholar] [CrossRef]
- Zeng, H.; Wu, S. User image and precision marketing on account of big data in Weibo. Mod. Econ. Inf. 2016, 16, 306–308. [Google Scholar]
- Xingx, L.; Song, Z.; Ma, Q. User interest model based on hybrid behaviors interest rate. Appl. Res. Comput. 2016, 33, 661–664. [Google Scholar]
- Liao, J.-F.; Chen, T.-G.; Chen, X. Research on the flow of social media users based on the theory of customer churn. Inf. Sci. 2018, V36, 45–48. [Google Scholar]
- Yang, Y.; Fu, J.; Zhu, T.; Sun, Z.; Xie, F. Characteristics mining and prediction of electricity customer’s behavior. Electr. Meas. Instrum. 2016, 53, 111–114. [Google Scholar]
- Rosenthai, S.; McKeown, K. Age prediction in blogs: A study of style, content, and online behavior in pre- and post-social media generations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Mueller, J.; Stumme, G. Vender Inference Using Statistical Name Characteristics in Twitter. Available online: https:/arxiv.org/pdf/1606.05467v2.pdf (accessed on 26 May 2021).
- Marquardt, J.; Farnadi, U.; Vasudevan, U.; Moens, M.; Davalos, S.; Teredesai, A.; De Cock, M. Age and gender identification in social media. Proc. CLEF 2014 Eval. Labs 2014, 1180, 1129–1136. [Google Scholar]
- Wu, L.; Ge, Y.; Liu, Q.; Chen, E.; Long, B.; Huang, Z. Modeling users’ preferences and social links in social networking services: A joint-evolving perspective. In Proceedings of the 13th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 279–286. [Google Scholar]
- Ma, H.; Cao, H.; Yang, Q.; Chen, E.; Tian, J. A habit mining approach for discovering similar mobile users. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–22 April 2012; pp. 231–240. [Google Scholar]
- Zhu, H.; Chen, E.; Xiong, H.; Yu, K.; Cao, H.; Tian, J. Mining mobile user preferences for personalized context-aware recommendation. Acm Trans. Intell. Syst. Technol. 2015, 5, 1–27. [Google Scholar] [CrossRef]
- Zhang, K. Mobile phone user profile in large data platform. Inf. Commun. 2014, 266–267. (In Chinese) [Google Scholar]
- Huang, W.; Xu, S.; Wu, J.; Wang, J. The profile construction of the mobile user. J. Mod. Inf. 2016, 36, 54–61. (In Chinese) [Google Scholar]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Wang, S.; Manning, C.D. Baselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; pp. 90–94. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sundermeyer, M.; Schluter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the InterSpeech 2012, Portland, OR, USA, 9–13 September 2012; pp. 601–608. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Technicolor, T.; Related, S.; Technicolor, T.; Related, S. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- Chen, D.; Mak, B. Multitask learning of deep neural networks for low-resource speech recognition. IEEE Trans. Audio Speech Lang. Process. 2015, 23, 1172–1183. [Google Scholar]
- Bercer, A.L.; Pietra, S.A.D.; Pietra, V.J.D. A maximum entropy approach to natural language processing. Comput. Linguist. 1996, 22, 39–71. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-stage performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 427–431. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. II-1188–II-1196. [Google Scholar]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; 1995. Available online: https://statisticalsupportandresearch.files.wordpress.com/2017/05/vladimir-vapnik-the-nature-of-statistical-learning-springer-2010.pdf (accessed on 26 May 2021).
- Lau, J.H.; Baldwin, T. An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv 2016, arXiv:1607.05368. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Instructions |
|---|---|
| ID | Encrypted ID |
| Age | 0:Unknown age; 1:0~18 years old; 2:19~23 years old; 3:24~30 years old; 4:31~40 years old; 5:41~50 years old; 6:51~99 years old |
| Gender | 0: unknown; 1: male; 2: female |
| Education | 0: unknown education; 1: doctor; 2: master; 3: college student 4: high school; 5: high school; 6: primary school |
| Query | Search word list, such as 100 piano music appreciation, baby’s right eye |
| List | Droppings, convulsions, cesarean section knife edge on the thread |
| Parameter Name | Parameter Value | Parameter Description |
|---|---|---|
| kernel | linear | Kernel function, where the linear kernel is selected |
| C | 3 | Penalty coefficient |
| probability | True | Probability estimation |
| Parameter Name | Parameter Value | Parameter Description |
|---|---|---|
| input_dim | 65,628 | The possible number of words in the text data and the number of words retained from the corpus |
| output_dim | 256 | The size of the vector space in which the word is embedded |
| input_length | 50 | The length of the input sequence, i.e., the number of words to be entered at a time |
| filters | [3,4,5] | Number of filters (convolution cores) |
| kernel_size | 128 | The size of the convolution kernel |
| input_dim | 256 | Dimensions of the input vector of the LSTM model |
| Parameter Name | Parameter Value | Parameter Description |
|---|---|---|
| batch_size | 128 | Number of batches per training session |
| epochs | 35 | Number of iterations |
| verbose | 2 | Number of records output per iteration |
| Parameter Name | Parameter Value (Education, Age, Gender) | Parameter Description |
|---|---|---|
| objective | multi:softprob | A loss function that needs to be minimized |
| booster | gbtree | Selects the model for each iteration. |
| num_class | [6,6,2] | Category number |
| max_depth | [8,7,7] | Maximum depth of the tree |
| min_child_weight | [2,3,0.8] | The sum of the minimum sample weights |
| subsample | [0.9,0.9,0.5] | Controls the proportion of random samples for each tree. |
| colsample_bytree | [0.8,1,1] | Used to control the percentage of randomly sampled features per tree |
| gamma | [2,2,1] | The value of the minimum loss function descent required for node splitting |
| eta | [0.01,0.01,0.01] | Learning rate |
| lambda | [0,0,0] | Control regularization |
| alpha | [0,0,0] | Weighted L1 regularization term |
| silent | [1,1,1] | Silent mode |
| Model | Education | Age | Gender |
|---|---|---|---|
| TF-IDF + SVM | 0.5102 | 0.5263 | 0.7801 |
| DBOW + NN | 0.5436 | 0.5570 | 0.8132 |
| DM + NN | 0.5163 | 0.5348 | 0.7820 |
| Word2vec + CNN + LSTM | 0.5768 | 0.6112 | 0.8174 |
| Multi-stage user portrait model | 0.5946 | 0.6153 | 0.8255 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; He, J.; Wei, W.; Zhu, N.; Yu, C. A Multi-Model Approach for User Portrait. Future Internet 2021, 13, 147. https://doi.org/10.3390/fi13060147
Chen Y, He J, Wei W, Zhu N, Yu C. A Multi-Model Approach for User Portrait. Future Internet. 2021; 13(6):147. https://doi.org/10.3390/fi13060147
Chicago/Turabian StyleChen, Yanbo, Jingsha He, Wei Wei, Nafei Zhu, and Cong Yu. 2021. "A Multi-Model Approach for User Portrait" Future Internet 13, no. 6: 147. https://doi.org/10.3390/fi13060147
APA StyleChen, Y., He, J., Wei, W., Zhu, N., & Yu, C. (2021). A Multi-Model Approach for User Portrait. Future Internet, 13(6), 147. https://doi.org/10.3390/fi13060147