
An Innovative Approach for the Evaluation of the Web Page Impact Combining User Experience and Neural Network Score



Abstract
1. Introduction
2. Material and Methods
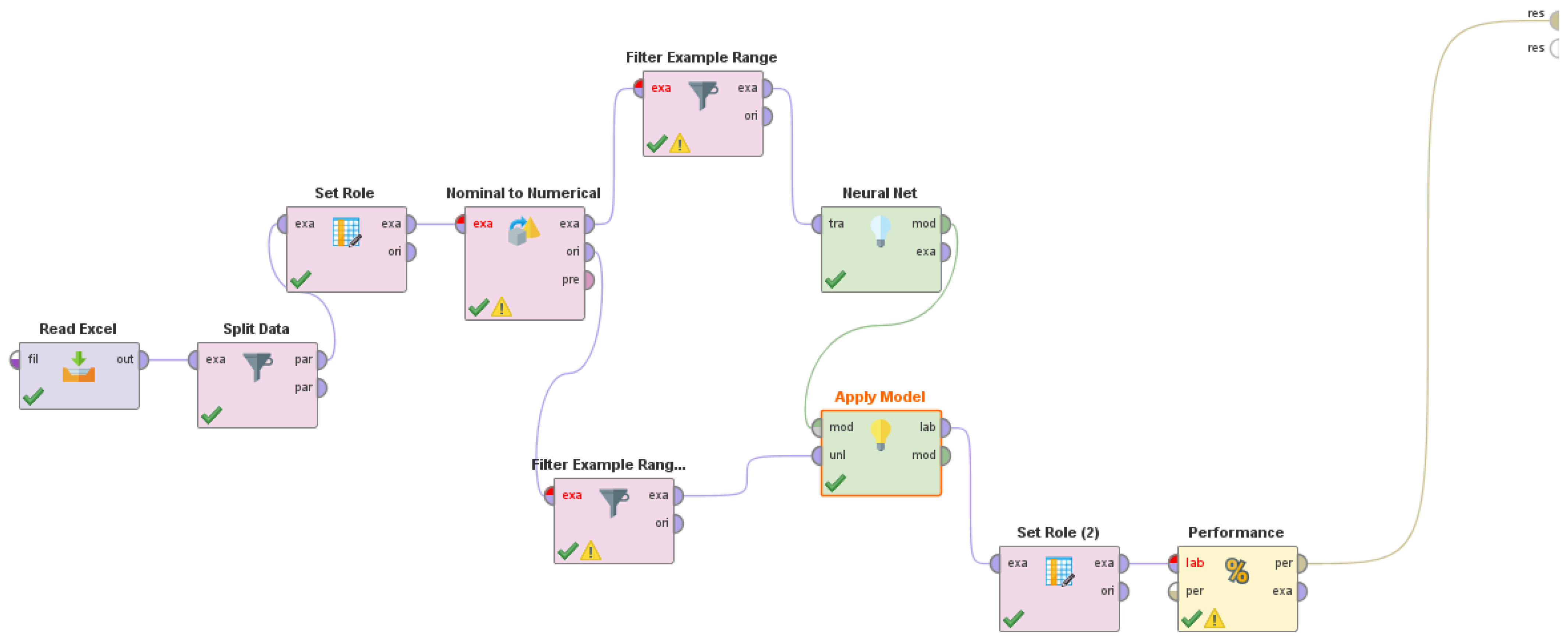
2.1. Main “ANDUIA” Project Framework: Specifications and Platform Architecture Design
- Approval module form, which, by analyzing the data collected on all types of users (user experience), allows to identify those behaviors that slow down the use of web platform features (user behavior);
- Optimal site design module, which, taking into account the results processed by the approval module, allows the design optimization of the web page.
- Designer/developer (user);
- Backend (‘ANDUIA’ platform);
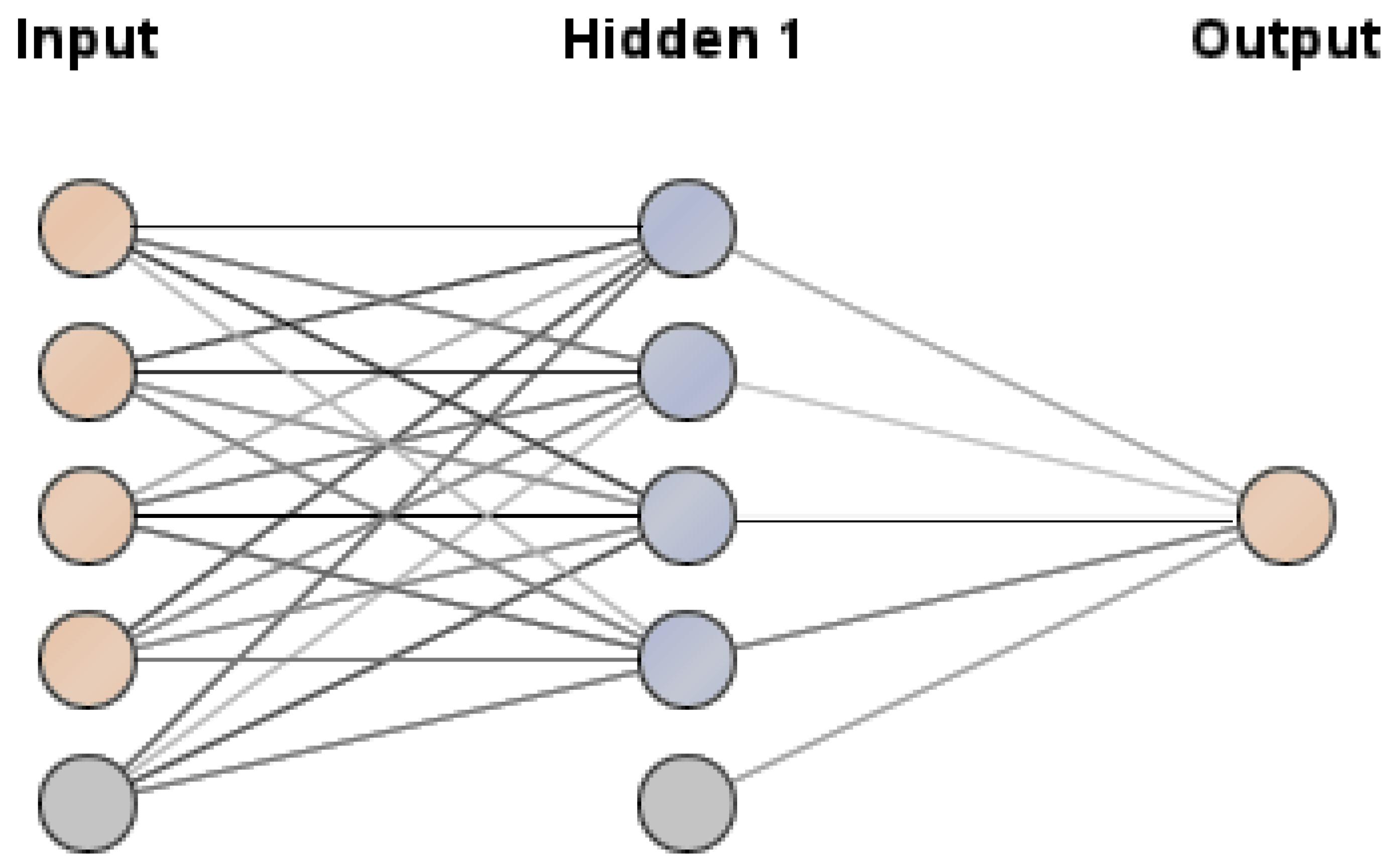
- AI algorithm (LSTM model listed in Appendix A).
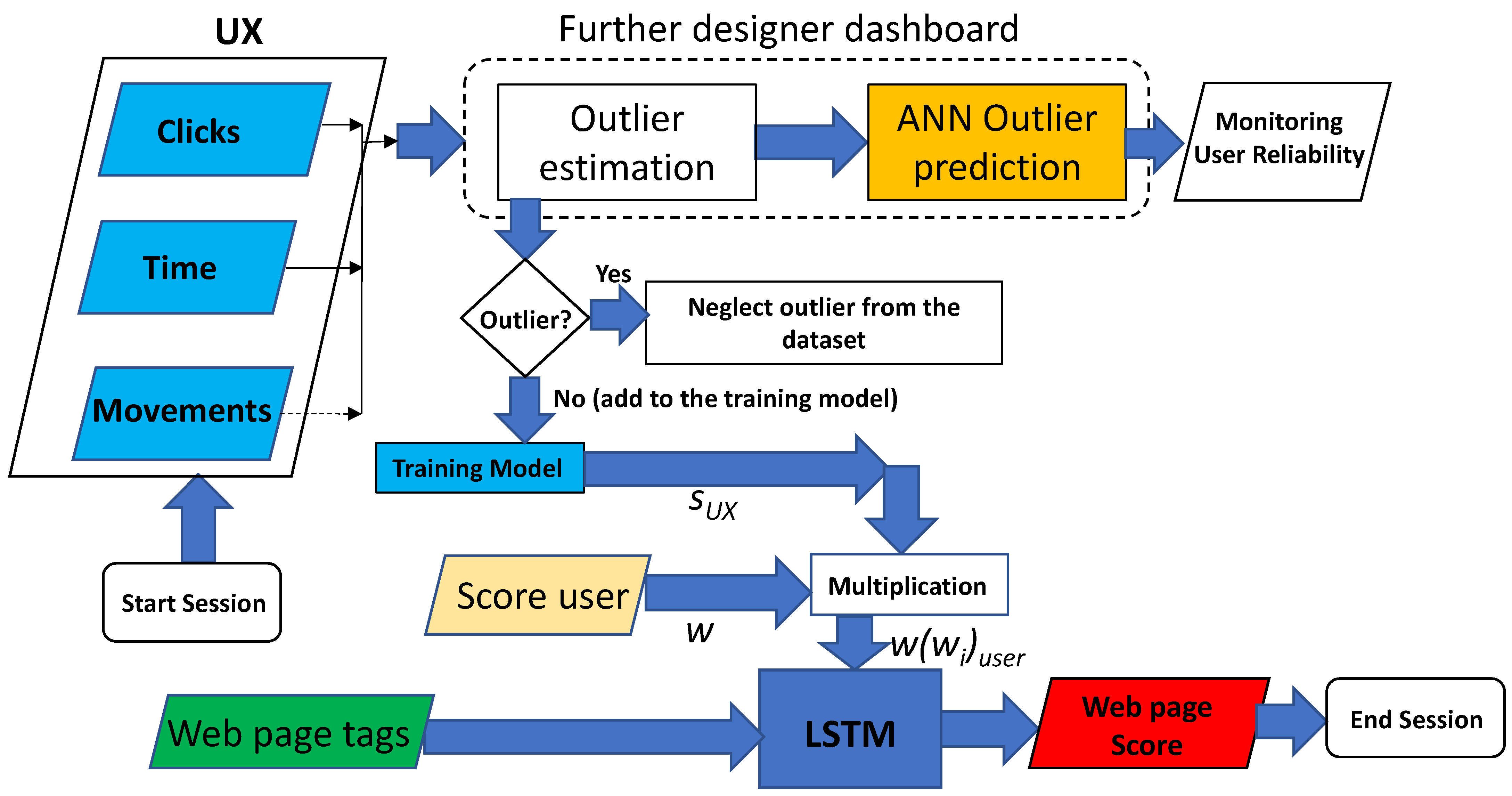
2.2. Methods: Web Page Scoring Based on Ccombined UX and LSTM Approaches
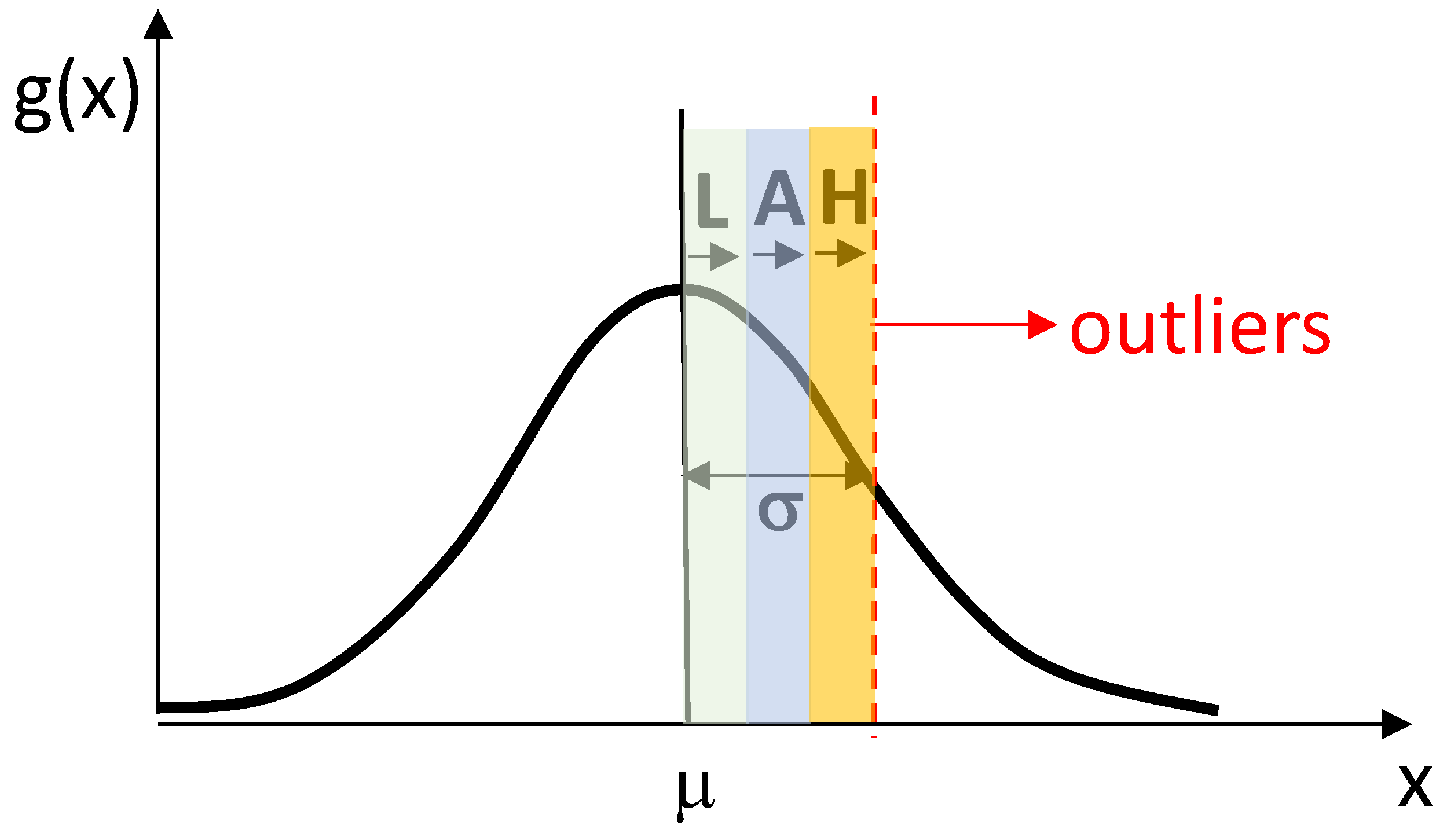
- Outlier dashboard providing information about anomalous user navigation behaviors to not consider for the final web page scoring;
- LSTM score dashboard indicating the final results by processing UX data, score user (user feedback provided during the navigation), and web page tags.
- max_words = 5000
- max_len = 10,000
- tok = Tokenizer(num_words = max_words)
- tok.fit_on_texts(x)
- sequences = tok.texts_to_sequences(x)
- sequences_matrix = sequence.pad_sequences(sequences, maxlen = max_len)
- User information (device, browser);
- The time of the user remaining on a web page;
- The number of clicks nc;
- Mouse movements in terms of coordinates.
- sequences_matrix_train = sequences_matrix[5 :]
- sequences_matrix_test = sequences_matrix[:5]
- The user has left browsing, thus the session on that page remains open but is not actually browsing;
- The user has a real difficulty in finding what he wants and has a non-optimal user experience.
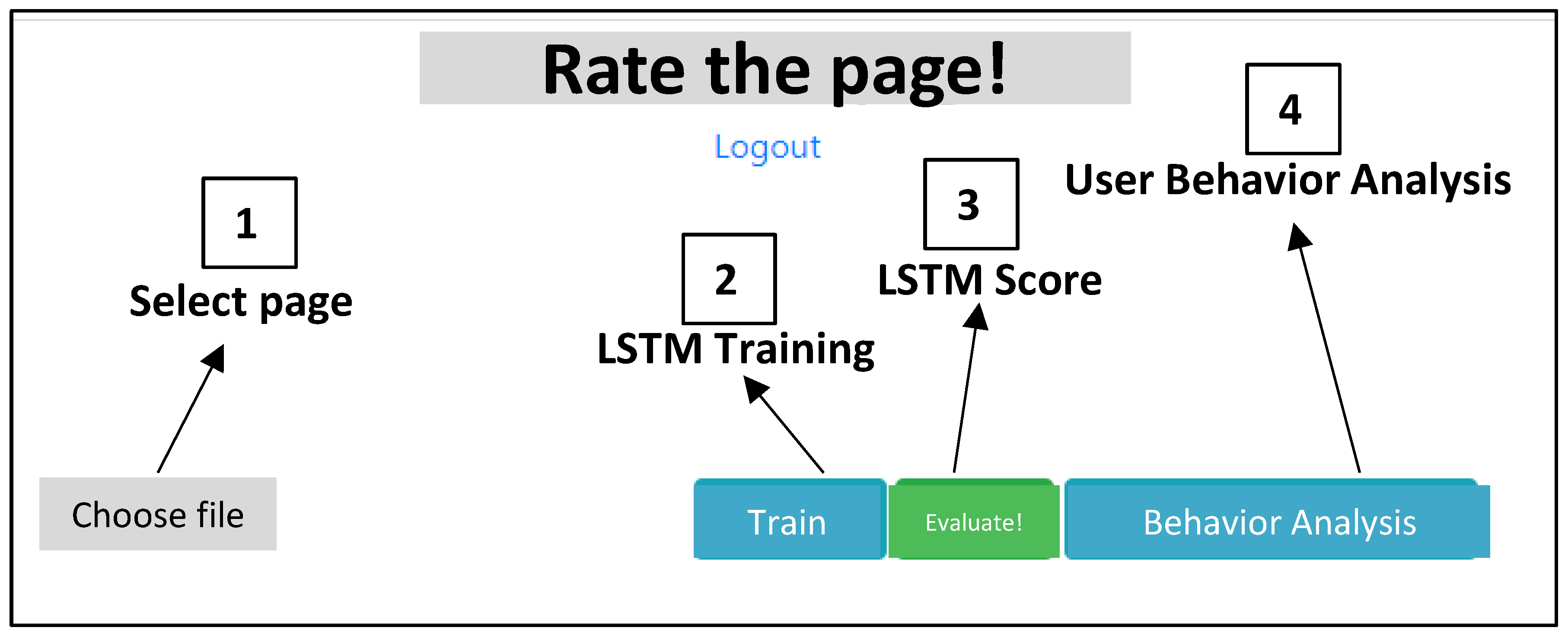
3. Results
- Command to select an HTML web page source for the training and for the testing data process;
- Training command related to training process;
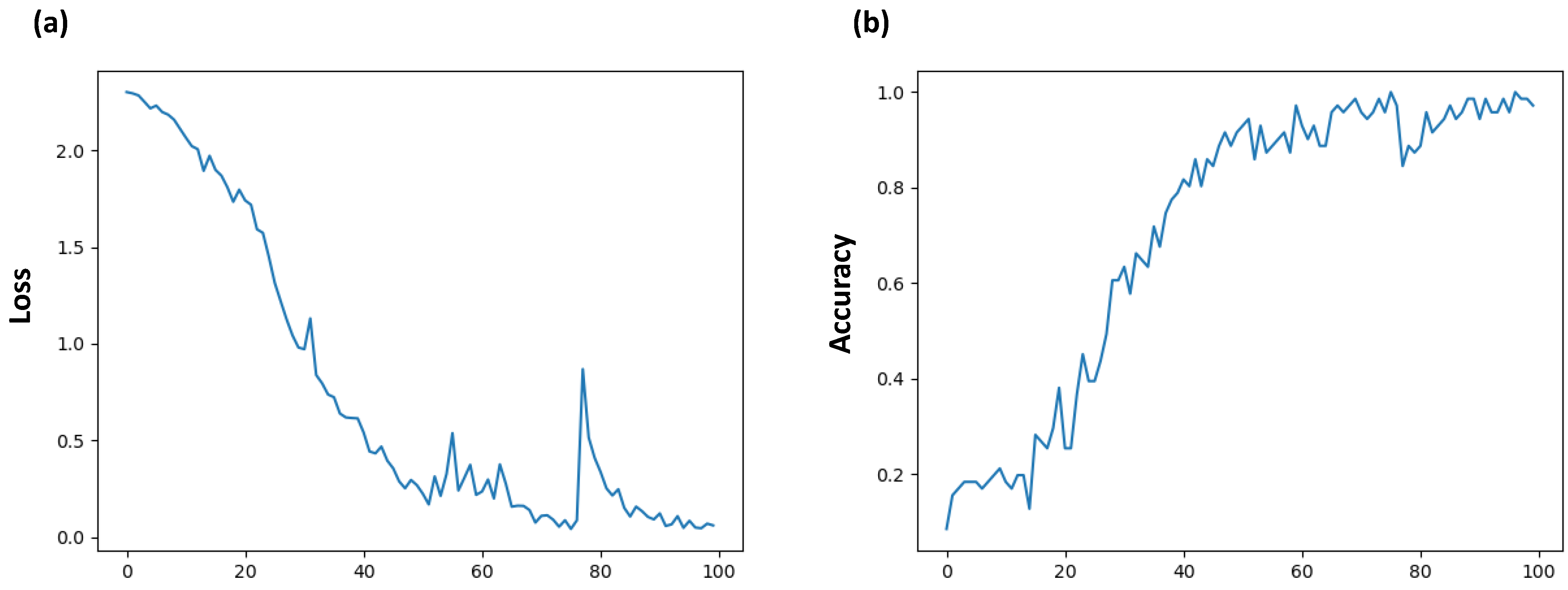
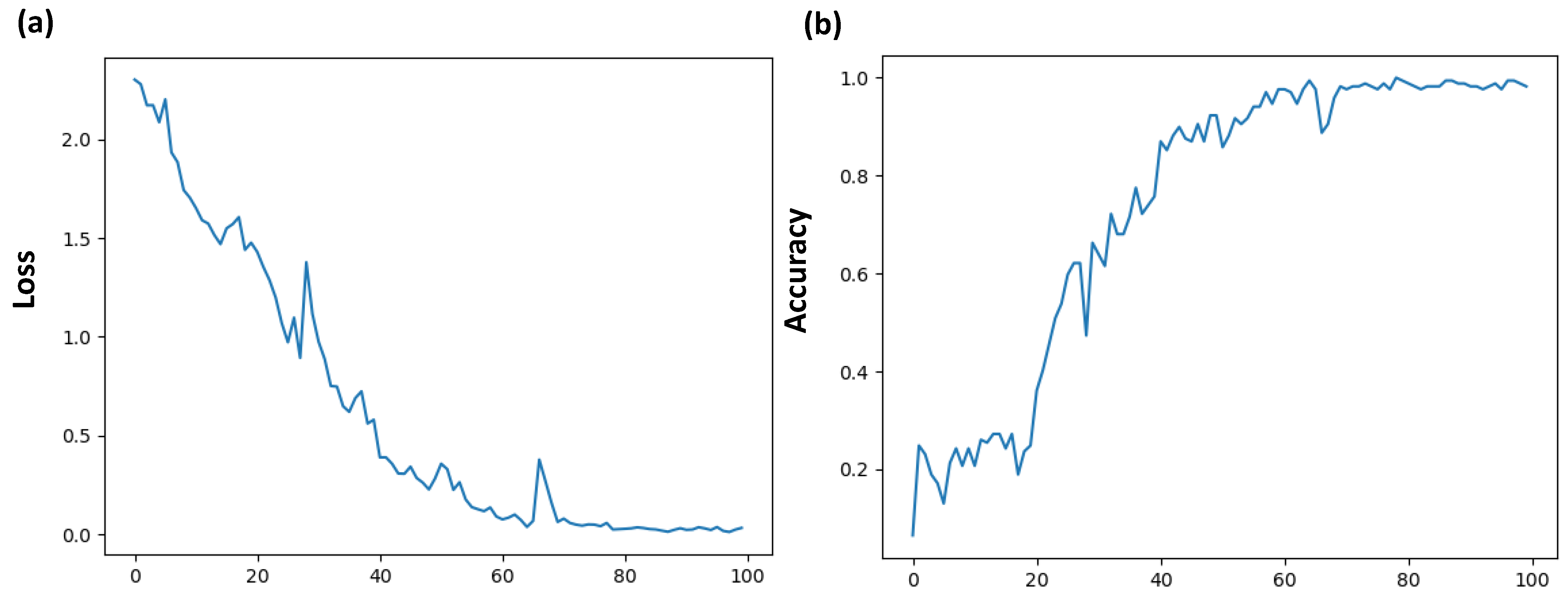
- LSTM score visualizing the output of Figure 3;
- User behavior analysis as separate evaluation of the UX (UX dashboard).
4. Discussion
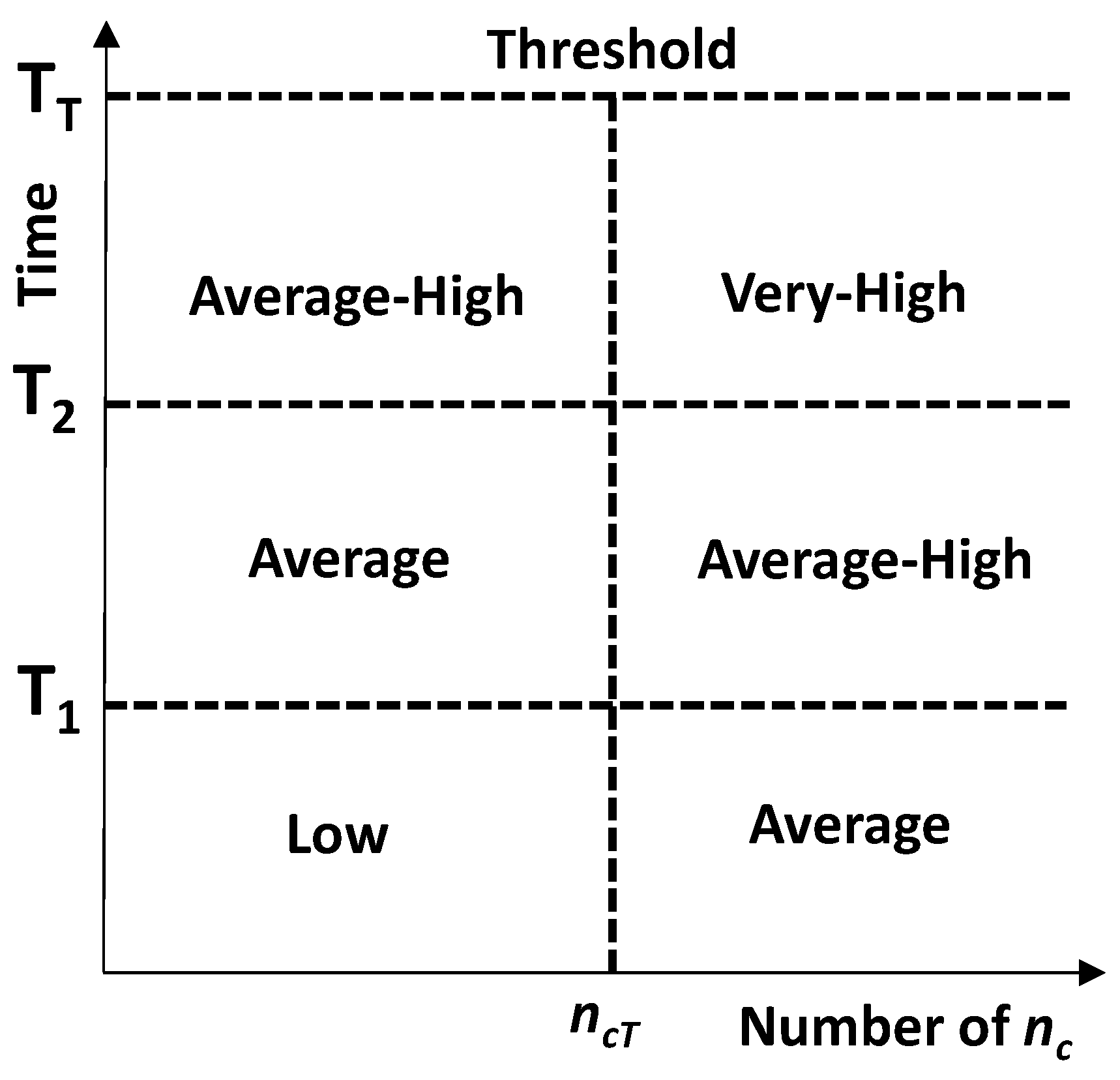
4.1. Attribute Distribution Function
4.2. Novelty Elements of the Proposed Approach and Possible Applications
- It is analyzed the final LSTM score based on UX adjustment and on the elimination of outlier conditions;
- If the score is too low are analyzed the tags of the same web page to not consider for the realization of a new web page;
- If the final score is high, are analyzed, and extracted the related tags concerning a major mouse interaction (movements and number of clicks); the “high impact” selected tags will also be adopted for the design of similar web page topics;
- If the final score is average are analyzed only the best tags, by substituting the other ones with the best tags of similar web pages characterized by high scores.
4.3. Observations about the Training Dataset
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B


Appendix C
References
- Gonzalez-Rodriguez, M.; Diez-Diaz, F.; Vidau, A. Remote navigability testing using data gathering agents. In Proceedings of the 4th International Conference on Universal Access in Human Computer Interaction (UAHCI), Beijing, China, 22–27 July 2007. [Google Scholar]
- Obendorf, H.; Weinreich, H.; Hass, T. Automatic support for web user studies with SCONE and TEA. In Proceedings of the Conference on Human Factors in Computing Systems (CHI), Vienna, Austria, 24–29 April 2004. [Google Scholar]
- Ivory, M.; Hearst, M. Statistical profiles of highly-rated web sites. In Proceedings of the Conference on Human Factors in Computing Systems (CHI), Minneapolis, MN, USA, 20–25 April 2002. [Google Scholar]
- Katsanos, C.; Tselios, N.; Avouris, N. InfoScent evaluator: A semi-automated tool to evaluate semantic appropriateness of hyperlinks in a web site. In Proceedings of the OZCHI 2006, Sydney, Australia, 20–24 November 2006; pp. 373–376. [Google Scholar]
- Chiew, T.K.; Salim, S.S. Webuse: Website usability evaluation tool. Malays. J. Comp. Sci. 2003, 16, 47–57. [Google Scholar]
- Cybulski, P.; Horbiński, T. User Experience in Using Graphical User Interfaces of Web Maps. ISPRS Int. J. Geo-Inf. 2020, 9, 412. [Google Scholar] [CrossRef]
- Massaro, A.; Vitti, V.; Mustich, A.; Galiano, A. Intelligent Real-time 3D Configuration Platform for Customizing E-commerce Products. Int. J. Comp. Grsph. Animat. (IJCGA) 2019, 9, 13–28. [Google Scholar] [CrossRef]
- Atterer, R.; Wnuk, M.; Schmidt, A. Knowing the user’s every move—User activity tracking for website usability evaluation and implicit interaction. In Proceedings of the International World Wide Web Conference Committee (IW3C2), Edinburgh, Scotland, 22 May 2006. [Google Scholar]
- Liu, L.; Chen, J.; Song, H. The Research of web mining. In Proceedings of the 4th World Congress on Intelligent Control and Automation, Shanghai, China, 10–14 June 2002. [Google Scholar]
- Pal, S.; Talwar, V.; Mitra, P. Web Mining in soft computing framework: Relevance, state of the art and future directions. IEEE Trans. Neural Netw. 2002, 13, 1163–1177. [Google Scholar] [CrossRef]
- Filippi, S. PERSEL, a Ready-to-Use PERsonality-Based User SELection Tool to Maximize User Experience Redesign Effectiveness. Multimodal Technol. Interact. 2020, 4, 13. [Google Scholar] [CrossRef]
- Alonso-Virgós, L.; Rodríguez Baena, L.; Pascual Espada, J.; González Crespo, R. Web Page Design Recommendations for People with Down Syndrome Based on Users’ Experiences. Sensors 2018, 18, 4047. [Google Scholar] [CrossRef]
- Oyibo, K.; Vassileva, J. The Effect of Layout and Colour Temperature on the Perception of Tourism Websites for Mobile Devices. Multimodal Technol. Interact. 2020, 4, 8. [Google Scholar] [CrossRef]
- Buber, E.; Diri, B. Web Page Classification Using RNN. Proc. Comp. Sci. 2019, 154, 62–72. [Google Scholar] [CrossRef]
- Chen, R.C.; Hsieh, C.H. Web page Classification based on a Support Vector Machine using a Weighted Vote Schema. Exp. Syst. Appl. 2006, 31, 427–435. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, S.; Kalra, A.; Borcea, C.; Chen, Y. Webpage Depth Viewability Prediction Using Deep Sequential Neural Networks. IEEE Trans. Know. Data Eng. 2019, 31, 601–614. [Google Scholar] [CrossRef]
- Spiliotopoulos, K.; Rigou, M.; Sirmakessis, S. A Comparative Study of Skeuomorphic and Flat Design from a UX Perspective. Multimodal Technol. Interact. 2018, 2, 31. [Google Scholar] [CrossRef]
- Khrais, L.T. Role of Artificial Intelligence in Shaping Consumer Demand in E-Commerce. Future Internet 2020, 12, 226. [Google Scholar] [CrossRef]
- Li, R.; Sun, T. Assessing Factors for Designing a Successful B2C E-Commerce Website Using Fuzzy AHP and TOPSIS-Grey Methodology. Symmetry 2020, 12, 363. [Google Scholar] [CrossRef]
- Chaudhary, N.; Roy Chowdhury, D. Data Preprocessing for Evaluation of Recommendation Models in E-Commerce. Data 2019, 4, 23. [Google Scholar] [CrossRef]
- Saura, J.R.; Palos-Sánchez, P.; Cerdá Suárez, L.M. Understanding the Digital Marketing Environment with KPIs and Web Analytics. Future Internet 2017, 9, 76. [Google Scholar] [CrossRef]
- Kaushik, A. Web Analytics 2.0: The Art of Online Accountability and Science of Customer Centricity; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Veglis, A.; Giomelakis, D. Search Engine Optimization. Future Internet 2020, 12, 6. [Google Scholar] [CrossRef]
- López García, J.J.; Lizcano, D.; Ramos, C.M.; Matos, N. Digital Marketing Actions That Achieve a Better Attraction and Loyalty of Users: An Analytical Study. Future Internet 2019, 11, 130. [Google Scholar] [CrossRef]
- Huang, G.; Chen, Q.; Deng, C. A New Click-Through Rates Prediction Model Based on Deep&Cross Network. Algorithms 2020, 13, 342. [Google Scholar] [CrossRef]
- Seggie, S.H.; Cavusgil, E.; Phelan, S.E. Measurement of return on marketing investment: A conceptual framework and the future of marketing metrics. Ind. Mark. Manag. 2017, 36, 834–841. [Google Scholar] [CrossRef]
- Fagan, J.C. The suitability of web analytics key performance indicators in the academic library environment. J. Acad. Librariansh. 2014, 40, 25–34. [Google Scholar] [CrossRef]
- Wilson, R.D. Using web traffic analysis for customer acquisition and retention programs in marketing. Serv. Mark. Q. 2004, 26, 1–22. [Google Scholar] [CrossRef]
- Booth, D.; Jansen, B.J. A Review of Methodologies for Analyzing Websites. In Web Technologies: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2010; pp. 145–166. [Google Scholar] [CrossRef]
- Toleu, A.; Makazhanov, A.; Tolegen, G. Character-based Deep Learning Models for Token and Sentence Segmentation. In Proceedings of the 5th International Conference on Turkic Languages Processing (TurkLang), 18–21 October 2017. [Google Scholar]
- Keras. Available online: https://keras.io/ (accessed on 5 February 2021).
- User Behavior Library. Available online: https://github.com/shnere/user-behavior (accessed on 4 February 2021).
- Massaro, A.; Maritati, V.; Galiano, A. Data Mining Model Performance of Sales Predictive Algorithms Based on RapiMiner Workflow. Int. J. Comp. Sci. Inf. Technol. (IJCSIT) 2018, 10, 39–56. [Google Scholar] [CrossRef]
- Yi, D.; Ahn, J.; Ji, S. An Effective Optimization Method for Machine Learning Based on ADAM. Appl. Sci. 2020, 10, 1073. [Google Scholar] [CrossRef]
- Lee, S.; Chung, J.Y. The Machine Learning-Based Dropout Early Warning System for Improving the Performance of Dropout Prediction. Appl. Sci. 2019, 9, 3093. [Google Scholar] [CrossRef]
- Massaro, A.; Vitti, V.; Galiano, A. Model of Multiple Artificial Neural Networks oriented on Sales Prediction and Product Shelf Design. Int. J. Soft Comput. Artif. Intell. Appl. (IJSCAI) 2018, 7, 1–19. [Google Scholar] [CrossRef]
- Wang, B.; Ye, F.; Xu, J. A Personalized Recommendation Algorithm Based on the User’s Implicit Feedback in E-Commerce. Future Internet 2018, 10, 117. [Google Scholar] [CrossRef]
- Alsulami, M.M.; Al-Aama, A.Y. Employing Behavioral Analysis to Predict User Attitude towards Unwanted Content in Online Social Network Services: The Case of Makkah Region in Saudi Arabia. Computers 2020, 9, 34. [Google Scholar] [CrossRef]
- Yu, X.; Li, M.; Kim, K.A.; Chung, J.; Ryu, K.H. Emerging Pattern-Based Clustering of Web Users Utilizing a Simple Page-Linked Graph. Sustainability 2016, 8, 239. [Google Scholar] [CrossRef]
- Matošević, G.; Dobša, J.; Mladenić, D. Using Machine Learning for Web Page Classification in Search Engine Optimization. Future Internet 2021, 13, 9. [Google Scholar] [CrossRef]
- Martínez-García, M.; Zhang, Y.; Suzuki, K.; Zhang, Y.-D. Deep Recurrent Entropy Adaptive Model for System Reliability Monitoring. IEEE Trans. Ind. Inform. 2021, 17, 839–848. [Google Scholar] [CrossRef]
- Martínez-García, M.; Zhang, Y.; Gordon, T. Memory Pattern Identification for Feedback Tracking Control in Human–Machine Systems. Hum. Factors 2021, 63, 210–226. [Google Scholar] [CrossRef] [PubMed]
- Reinecke, K.; Yeh, T.; Miratrix, L.; Mardiko, R.; Zhao, Y.; Liu, J.; Gajos, K.Z. Predicting Users’ First Impressions of Website Aesthetics with a Quantification of Perceived Visual Complexity and Colorfulness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’13), Paris, France, 27 April–2 May 2013; pp. 2049–2058. [Google Scholar] [CrossRef]
- Cascardi, A.; Micelli, F.; Aiello, M.A. Analytical Model based on Artificial Neural Network for Masonry Shear Walls Strengthned with FRM Systems. Compos. Part B Eng. 2016, 95, 252–263. [Google Scholar] [CrossRef]
- Massaro, A.; Maritati, V.; Giannone, D.; Convertini, D.; Galiano, A. LSTM DSS Automatism and Dataset Optimization for Diabetes Prediction. Appl. Sci. 2019, 9, 3532. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric/Method | Reference | Category | Description |
|---|---|---|---|
| Visitor Type (method) | [29] | Site Usage | User accessing the web page |
| Visit Length (metric) | [29] | Site Usage | Total amount of time a visitor spends on the website |
| Visitor Location (method) | [29] | Site Usage | Location of visitors accessing the website |
| Number of Visitors (metric) | [29] | Site Usage | Number of visitors/users visiting a web page |
| Click-Through Rate (metric) | [25] | Site Usage | Ratio between the number of clicks generated by a web page and the number of times that web page itself has been viewed. |
| UX analysis (method) | [17,20] | Site Usage | UX adopted for web page usability |
| Visitor Path (method) | [29] | Site Content Analysis | Navigation path |
| Top Pages (metric) | [29] | Site Content Analysis | Web pages receiving the most traffic |
| Tags classification using neural network (method) | [14] | Site Content Analysis | Classification of a web page by tag and meta tag information |
| Keyword (method) | [29] | Referres | Keywords selected by visitors |
| Errors (metric) | [29] | Quality Assurance | Errors occurred attempting to retrieve the page |
| Score | Description |
|---|---|
| From 1 to 4 | Poor web pages of javascript libraries and css files |
| From 5 to 7 | Old-style web pages that do not use current frameworks |
| From 8 to 10 | Modern web pages, characterized by a strong use of div, javascript libraries and css files |
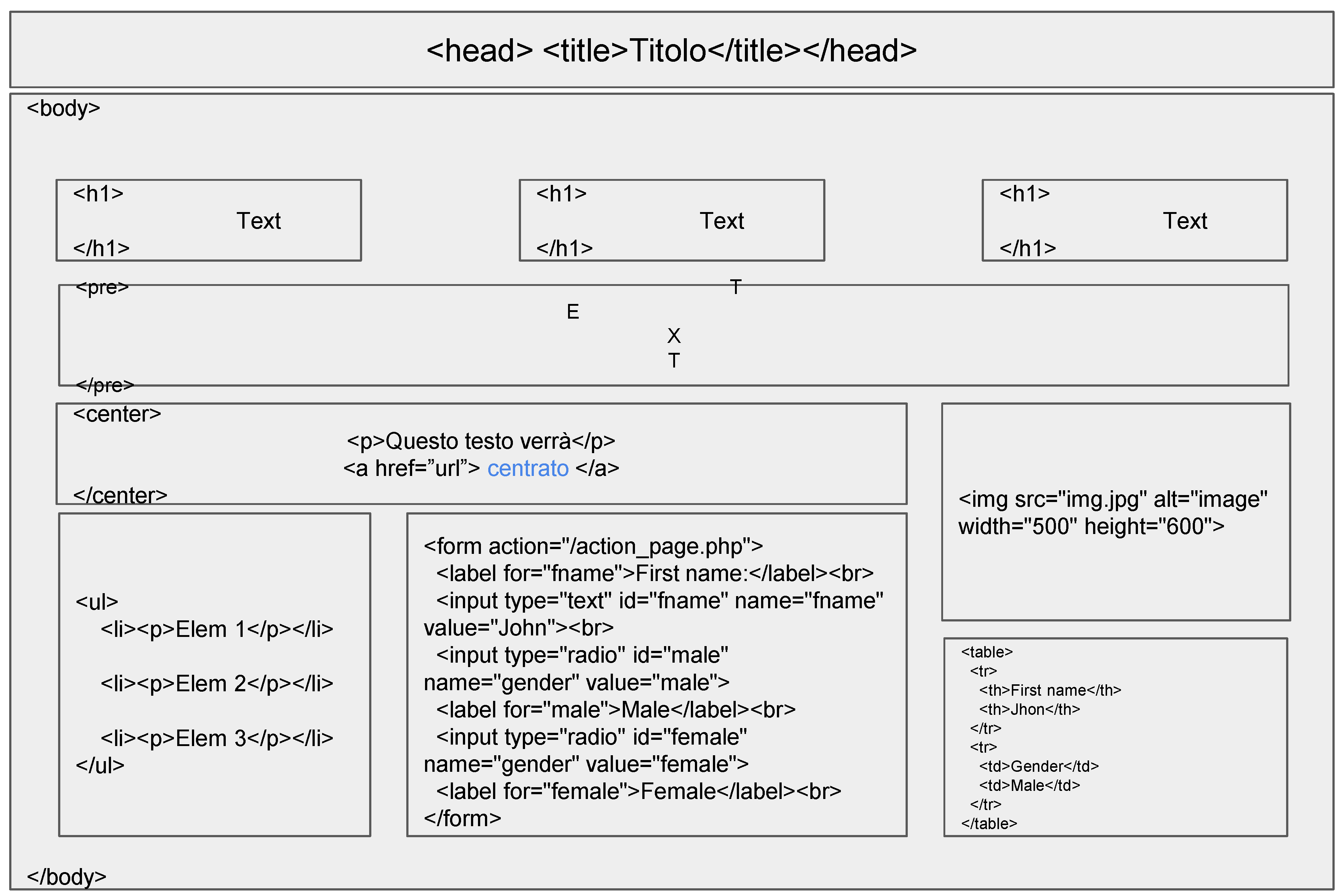
| Tag HTML | Use | Attributes |
|---|---|---|
| <HTML> | Beginning of document | // |
| <Title> | Page title | // |
| <Head> | Header | // |
| <body> | Body of the page | // |
| <h1>-<h6> | Other headers | // |
| <pre> | Preformatted, as written | // |
| <center> | Centered object | // |
| <a href = ”url”></a> | Hyperlink | Id, class |
| <img src = ”url”></a> | Insert image | Align, alt, id, class, width, height, border |
| <p> | Paragraph | Align |
| <br> | Next row | // |
| <ul><li> | Bulleted list and related items | Type, value, align |
| <form> | Data entry form | Align, action, enctype |
| <input> | Text input box | // |
| <select> | Multiple choice box | // |
| <table> | Table | Border, cellspacing, cellpadding, width, heitgh, align, bgcolor, |
| <th> | Cell header | // |
| <td> | Cell | // |
| <tr> | Row | // |
| Web Page (Template) | Score (User Feedback) | Clicks for Page [nc] | Time T [s] | Estimated Outlier * by UX (Mouse Movement, Clicks and Time) | Predicted Outlier (ANN Confirming the Estimation) | LSTM Score (Based on UX Adjustment) |
|---|---|---|---|---|---|---|
| 1 | 1 | 3 | 5 | 0 | 0 | 1 |
| 2 | 7 | 6 | 20 | 1 | 1 | 10 |
| 3 | 7 | 2 | 10 | 0 | 0 | 2 |
| 4 | 7 | 4 | 10 | 0 | 0 | 2 |
| 5 | 9 | 3 | 15 | 0 | 0 | 4 |
| 6 | 6 | 5 | 20 | 1 | 1 | 7 |
| 7 | 6 | 1 | 5 | 0 | 0 | 1 |
| 8 | 8 | 5 | 20 | 1 | 1 | 10 |
| 9 | 6 | 4 | 15 | 0 | 0 | 4 |
| 10 | 7 | 3 | 10 | 0 | 0 | 2 |
| 11 | 6 | 2 | 10 | 0 | 0 | 2 |
| 12 | 6 | 3 | 10 | 0 | 0 | 2 |
| 13 | 9 | 1 | 15 | 0 | 0 | 2 |
| 14 | 7 | 2 | 15 | 0 | 0 | 3 |
| 15 | 7 | 1 | 10 | 0 | 0 | 1 |
| 16 | 7 | 2 | 10 | 0 | 0 | 2 |
| 17 | 6 | 1 | 5 | 0 | 0 | 1 |
| 18 | 7 | 1 | 15 | 0 | 0 | 1 |
| 19 | 6 | 15 | 60 | 0 | 0 | 5 |
| 20 | 6 | 2 | 5 | 0 | 0 | 1 |
| 21 | 6 | 4 | 10 | 0 | 0 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Massaro, A.; Giannone, D.; Birardi, V.; Galiano, A.M. An Innovative Approach for the Evaluation of the Web Page Impact Combining User Experience and Neural Network Score. Future Internet 2021, 13, 145. https://doi.org/10.3390/fi13060145
Massaro A, Giannone D, Birardi V, Galiano AM. An Innovative Approach for the Evaluation of the Web Page Impact Combining User Experience and Neural Network Score. Future Internet. 2021; 13(6):145. https://doi.org/10.3390/fi13060145
Chicago/Turabian StyleMassaro, Alessandro, Daniele Giannone, Vitangelo Birardi, and Angelo Maurizio Galiano. 2021. "An Innovative Approach for the Evaluation of the Web Page Impact Combining User Experience and Neural Network Score" Future Internet 13, no. 6: 145. https://doi.org/10.3390/fi13060145
APA StyleMassaro, A., Giannone, D., Birardi, V., & Galiano, A. M. (2021). An Innovative Approach for the Evaluation of the Web Page Impact Combining User Experience and Neural Network Score. Future Internet, 13(6), 145. https://doi.org/10.3390/fi13060145