1. Introduction
The proliferation of service types accessible through the Internet has radically changed the behavior of Internet users. Contents are continuously generated by both the organizations that leverage the capillary diffusion of the Internet, and the individual users. The resulting situation is characterized by a plethora of contents, consisting of images, videos, game updates, containerized applications and many other types. These contents represent the context that holds together the networked behavioral nature of the users. This huge volume service data is stored in repositories, typically located in large data centers and often accessible through a cloud-computing interface. The user requests determine the so-called
of contents. A typical approach for taking advantage of this feature for both improving the customer services and relieving the network load, is caching contents. It essentially consists of temporarily storing popular contents in suitable network locations, different from repositories where they are originally stored and forward user requests towards such locations instead of repositories. Temporary storage could be done in different network elements, such as in browsers’ caches, in Content Distribution Network (CDN) servers [
1,
2], in base stations of cellular networks [
3], in servers delivering metafiles for networked bioinformatics services [
4], in caches of Information Centric Networking architectures [
5,
6] and in Service and Network Function Virtualization platforms [
4]. The approach of caching content is not recent. For example, the Domain Name Service (DNS) has been using it for decades. Nevertheless, the current data consumption rate has induced companies, such as YouTube [
7], Facebook [
8] and Netflix [
9], to make an extensive use of caches distributed over networks. This interest has also stimulated theoretical studies [
10]. The
network caching, which is the subject of this paper, is indeed one of the most popular research areas on caching. In fact, although a lot of research has been done on content replication strategies and content eviction policies in individual caches, the aggregate performance of a hierarchy of caches still needs to be analyzed in depth.
In this paper, we consider a two-layer hierarchy of caches. This cache organization is widely used in operation (for example by Facebook [
8]), since the interaction between caches positioned at different depths in the network can help improve the effects of caching. In this work we assume that it is indifferent for a user to take an item from the cache closest to him, or from the furthest one, in the second caching level. In fact, we assume that the latter can be allocated at the most in the edge of the network, where the storage resources cannot be very large but the access latency for the contents is not significant. Therefore we do not consider any penalty if a content is available in second level caches. Furthermore, we stress that in this paper we do not specify in detail all the details to implement the content access service, but rather focus on the algorithms that are used to populate the caches. In this regard, it is worth considering that a complete caching protocol, which is beyond the scope of the paper, should include details relevant to keeping the caching system active when exceptions happen, such as network malfunctions, or getting rid of corrupted chunks, or even managing memory failures. Another aspect to be managed is the introduction of a robust cache authentication for avoiding making the system vulnerable to spoofing and similar attacks. Thus our contribution, which is algorithmic, needs to be included in a detailed protocol for it to be used in operation.
Furthermore, since many types of caching system exist, which cannot be addressed all in a single paper, we organized our proposal for contributing to CDN systems.
The original contribution of the paper is as follows:
We identify a caching problem, to be further specialized in separate case studies. For this problem we propose a solution consisting of a cache management algorithm based on a hierarchical 2-layer caching structure.
We show that the proposed algorithm outperforms the Least-Frequently Used (LFU) policy [
11,
12]. The performance metric used for this comparison is the probability of finding contents in caches, also referred to as
hit ratio. It is indeed the main performance metric of any caching system.
We specialize the basic caching problem and the relevant solution in other specific network caching scenarios. Each scenario is a variation of the basic caching problem, characterized by particular requirements in terms of content management and specific network limitations. For each scenario we formulate an optimization problem, which results to be NP-complete and propose some feasible solutions for pre-loading caches in order to maximize the hit ratio. Each solution consists of a greedy algorithm. We show that each proposed algorithm is characterized by guaranteed approximation performance. This property is based on recent results related to the maximization of submodular functions subject to matroid constraints.
We analyze each model under the hypothesis of both known and unknown content popularity. The former hypothesis is used to analyze the asymptotically achievable hit ratio, and the latter is used for analyzing the proposals under more realistic conditions. All greedy algorithms have been implemented numerically, and integrated in a simulator. For the numerical analysis we selected some values of the configuration parameters that refer to the scenario of the distribution of movies through a content distribution network. Numerical results confirm the expectations.
The paper is organized as follows—the
Section 2 includes some background information. The
Section 3 shows the mathematical model of each considered scenarios, the associated optimization problems, the relevant greedy heuristics and the theoretical analysis. The numerical results are illustrated in
Section 4. Some final considerations can be found in
Section 5.
Appendix A includes some basic introduction to the matroid theory and a theorem useful in the theoretical analysis.
2. Background
In this section, we describe the general network caching problem that is the background of this paper.
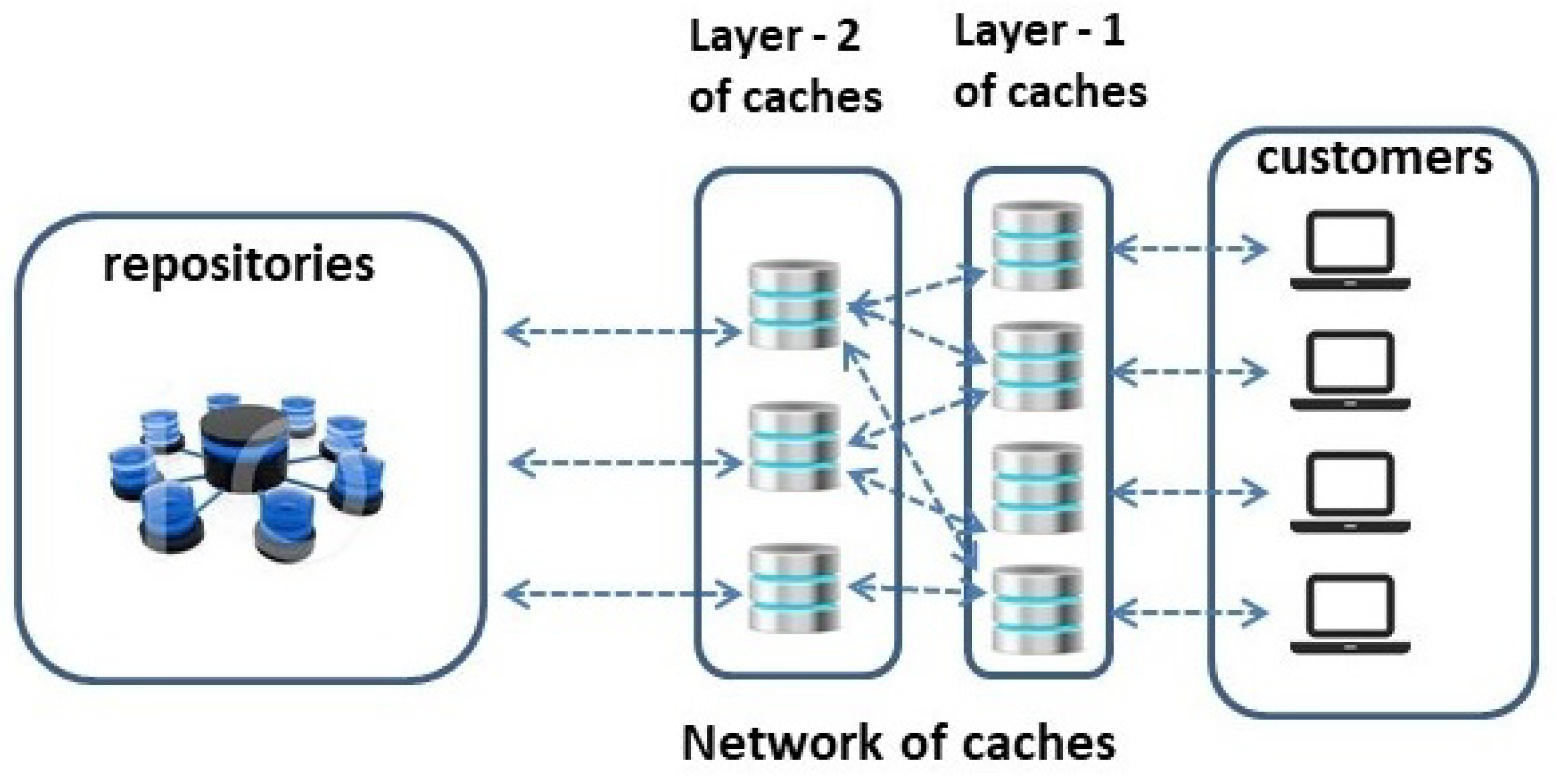
We assume the presence of a logical network of caches, having a known topology, connecting repositories with customers. With reference to
Figure 1, we consider a generic content distribution system having the purpose of providing customers with the desired contents. In this paper the terms “customers”, “clients”, and "users" are used interchangeably. Customers’ requests (1) are routed through the network towards the repositories that store the desired contents. A contacted repository can either send the requested contents (2), if its location is the most convenient, or the only one, for providing the requesting customer with the content, or inform the client that the content is available in a cache
closer to it. If deemed convenient, the content can be pre-fetched (3) in any caches in the network or even during their propagation through the network if it is frequently requested by customers.This way, the client can issue a content request to the indicated cache (4) and download it (5).
This simple network caching model includes some crucial aspects that need to be considered. The most important ones are the content replication strategy and the content eviction (or cache replacement) policy. The first one consists of the strategy used to distribute content replicas through the network of caches. The second one consists of the policy used to replace the cached replicas with other ones, if this is considered convenient. The principal known replication strategies and eviction policies are presented in the remainder of this Section.
The effectiveness of caching largely depends on the distribution of the content popularity [
9,
13]. In this paper, the popularity of a content indicates its mass probability of being requested. If the content size and popularity are the same for all of them, it is clear that the hit ratio in a given cache equals the ratio between the cache size and the catalogue size. If the popularity of contents is different, it is possible to take advantage of the difference between popularity values for increasing the hit ratio by preferably caching the most popular contents. In what follows, we assume that the content popularity follows the Mandelbrot-Zipf
distribution. According to this distribution, the probability that a content is at popularity rank
i, out of a catalog size
M, is:
where
, and
and
q are parameters of the distribution. This is a very general model, customizable by suitable parameter values, largely used to represent the distribution of popularity characterizing real processes [
12]. It is also commonly agreed that the popularity of a significant portion of IP traffic follows this distribution. For example, a very good matching was observed for the Web traffic [
14], YouTube [
15] and Bit Torrent [
16].
Another important aspect of cache management is the computational cost of the caching strategy. It typically corresponds to a feasible solution, sufficiently close to the optimum, of an optimization problem. If the strategy requires heavy content-wise management, it could result in being impractical.
Recently, given the proliferation of overlay networks, the proposals relating to caching systems are concerning the external part of the networks, which is close to the users. Some proposals have emerged for the management of caching on Fog nodes, characterized by scarcity of resources, but useful to contain the latency of access to services and to preserve data privacy. A caching management protocol for edge nodes is presented in [
17].
In the same line of research that involves the use of network resources at the edges to create caches, regarded as elements of a more complex network, the survey [
18] presents the state-of-the-art relating to caching at Edge nodes based on machine learning algorithms. The authors formulate a taxonomy based on network hierarchy and describe a number of related algorithms of supervised, unsupervised, and reinforcement learning.
In this paper, we consider different caching problems, typical of different applications and network environments, over a hierarchical cache network topology. All these problems are NP -complete. For all of them, we propose a feasible solution based on the theory of submodular function maximization bound to matroid constraints. These problems are formulated and analyzed in
Section 3.
2.1. Individual Cache Management
A large number of cache replacement policies have been proposed over time. They refer to different usage of caches, such as disk buffering, WEB proxies, ICN and other [
5,
6,
17]. A comprehensive description cannot be included in this paper. In what follows we introduce some of them, selected by their relevance with our proposals although, to the best of our knowledge, no solutions exist for the problems analyzed in this paper. The simplest conceivable approach is the First In First Out (FIFO). It consists of managing a cache as a FIFO queue. The Least Recently Used (LRU) policy [
11,
12] refines the FIFO approach in that when an uncached content is requested, the cached element that has been requested less recently is replaced with the requested one. In this case, the cache management becomes more complex since it is necessary to keep an “age” metric updated for each cached item, whatever the implementation of this metric is. The LRU policy has inspired a family of other proposals. A variation of LRU is q-LRU [
13], where any new requested content is stored in the cache with probability q. The eviction policy is LRU. k-LRU [
13] is another variant of the LRU policy. It consists of a chain of virtual LRU caches attached to the real one. Newly arrived contents are “stored” in the last virtual cache, and any hit before its removal cause an advancement in the chain, until the physical cache is entered. In some particular cases, when the use of contents has a circular nature, it might be convenient to evict the most recently used (MRU) contents [
6]. This situation can occur when users request a movie and the chunks of the related file are always sent from the first to the last ones.
A significant change of strategy has been brought by the Least-Frequently Used (LFU) policy [
11,
12]. It aims at populating a cache with the most popular contents. Assuming the content popularity to be known and constant over time, this policy maximizes the hit ratio. A practical implementation of it consists of counting references to the contents of the whole catalog. If a content that arrives at a cache has a higher reference count than the minimum of the cached contents, the latter is replaced by the arrived content. A family of proposals followed the basic LFU policy. All of them assume variable popularity over time and aim to quickly replace cached content that has suffered a sudden drop in popularity. The variant LFU with Dynamic Aging (LFUDA) [
12] requires that the reference count of a content is incremented by a cache age when it enters the cache and when a cached object is hit. The proposal in [
19], called TinyLFU, consists of maintaining an approximate representation of the access frequency of the recently accessed items. This proposal in based on the Bloom filter theory. Its aim is to implement a lightweight estimation, although sufficiently reliable, that leverages frequency-based cache admission policy that adapts to skewed access distributions. The Frequency Based Replacement (FBR) [
20] combines LRU and LFU policies. It makes use of LRU content ordering in the cache, but the eviction policy is based on the reference count. The Least Frequent Recently Use (LFRU) [
21] policy consists of organizing caches in two partitions, called privileged and unprivileged. The privileged one is managed by using the LRU policy, whilst the unprivileged partition makes use of an approximated LFU, for which content eviction metrics are computed on limited time windows.
2.2. Networks of Caches
In this subsection, we consider the aspects related to both content replication strategies and coordinated cache management. A hierarchical cache organization, rooted at a single content repository, is presented in [
22]. Cooperative cache management algorithms for minimizing bandwidth occupancy and maximizing hit ratio are proposed. The Leave Copy Everywhere (LCE) content replication strategy [
5,
6], consists in replicating the contents on all the caches present in the path followed by the content for its delivery to the requesting customers. An LCE variant is the so-called Conditional LCE (CLCE), for which a cache node stores an arriving content if it satisfies a qualifying condition [
21]. Another strategy is the Leave a Copy Down (LCD) [
23], which consists of replicating contents only downward the location of a cached copy on the path to the requesting client. Move Copy Down (MCD) [
6] is a strategy consisting of moving a cached content from the cache where is found to the connected downward cache. Leave Copy Probability (LCP) [
6] is a strategy according to which a content copy is cached with a given probability
p in the caches staying in the path to the requesting customers. In the strategy Centrality-based caching [
6], a content is stored in the cache node having the highest betweenness centrality. A significant strand of research on cache networks is related to coded caching, which is worth of mention although it is not in the scope of our proposal. In [
24] the authors investigated coded caching in a multiserver network of different types. Servers are connected to multiple caches implemented in clients. The Multi Queue caching algorithm [
25] consists of a hierarchical organization of LRU queues in a cache. Each hierarchical level is associated with an expected lifetime. The position of a content at a given hierarchy level is determined by its request counts within the expected lifetime and the contents at the lowest hierarchy level are candidates for eviction. The a-NET was proposed in [
26]. It approximates the behavior of multi-cache networks by making use of other approximation algorithms designed for isolated LRU caches. An analytical model of an uncooperative two-level LRU caching system is presented in [
27]. A Time-to-Live based policy is proposed in [
28] and performance is determined for both a linear network and a tree network with a root cache and multiple leaf caches with infinite buffer size. In the context of
content centric networking, content placement schemes and request routing are tightly coupled. The relevant optimization problems typically consists maximization of a submodular functions subject to matroid constraints [
29,
30]. Such mathematical framework is also used in this paper.
4. Numerical Results
In this section we present some results of the numerical analysis of the caching problems illustrated above, performed by using a simulator specifically implemented [
35]. The simulation general parameters were chosen according to the description of some existing popular content distribution systems [
7,
8,
9]:
,
,
; the size of layer-1 caches was set equal to the size of layer-2 caches; layer-1 caches and layer-2 caches are fully connected, that is
. From the algorithmic viewpoint, this is the most challenging cache interconnection. As for the traffic model, we used
and
. In the experiments with equal content size, all volumes are normalized to the individual content size. So the size of each item equals 1. In experiments with variable content size, all volumes are normalized to the minimum value. For what concerns the content size, the value range that can be observed in operation is extremely variable. For these experiments we inspired to the typical file size of a movie, which depends on various factors, such as the length, resolution and encoding. In this paper we report the numerical results relevant to a range between 0.5 to 2.5 gigabytes, resulting in a normalized uniform distribution between 1 and 5. Some variations in this range do not significantly change results. In the experiments with a constraint on the link bandwidth, we assumed that
units. In the experiments with stochastic links, we used a probability threshold
and assumed that each link has a probability of being active
. In order to analyze the proposal in more realistic experiments, we introduced the estimation of the content popularity. In this paper we report the performance of two extreme situations, relevant to a length of the estimation window
N, equal to 2000 and 10,000 inter-arrival times, respectively. In fact, a low value should be used when the popularity of content, especially those requested most frequently, is expected to change rapidly. A value of 2000, for a cache serving content in a restricted area, could be used for a stationary period of content popularity of the order of a few minutes. A value equal to 10,000 is used to manage slower variations, however evident. Even slower variations, such as those that occur on time scales in the order of hours, allow for very reliable estimates, therefore with performance that approach the ideal one, corresponding to the hypothesis of known popularity values. All hit ratio values shown in the following figures are plotted with the 99% confidence interval. The initial set of experiments, relevant to equal size items, with and without popularity estimation, are finalized to evaluate the capability of the proposed algorithm to approach the optimal known values of hit ratio, evaluated by means of (
2), considering the actual size of the layer-1 caches and the sum of the size of layer-2 caches accessible by each user. Since the main elements of
Algorithm2
bis are included in
Algorithm3, the set of algorithms implemented are
Algorithm1,
Algorithm3 and
Algorithm4 for equal-size contents, and
Algorithm2,
Algorithm3, and
Algorithm4 for variable size items. Please note that
Algorithm4 corresponds to
Algorithm3 used in conjunction with
Procedure3 . In addition, a comparison with LFU is presented in order to compare the proposal with one of the most appreciated solutions.
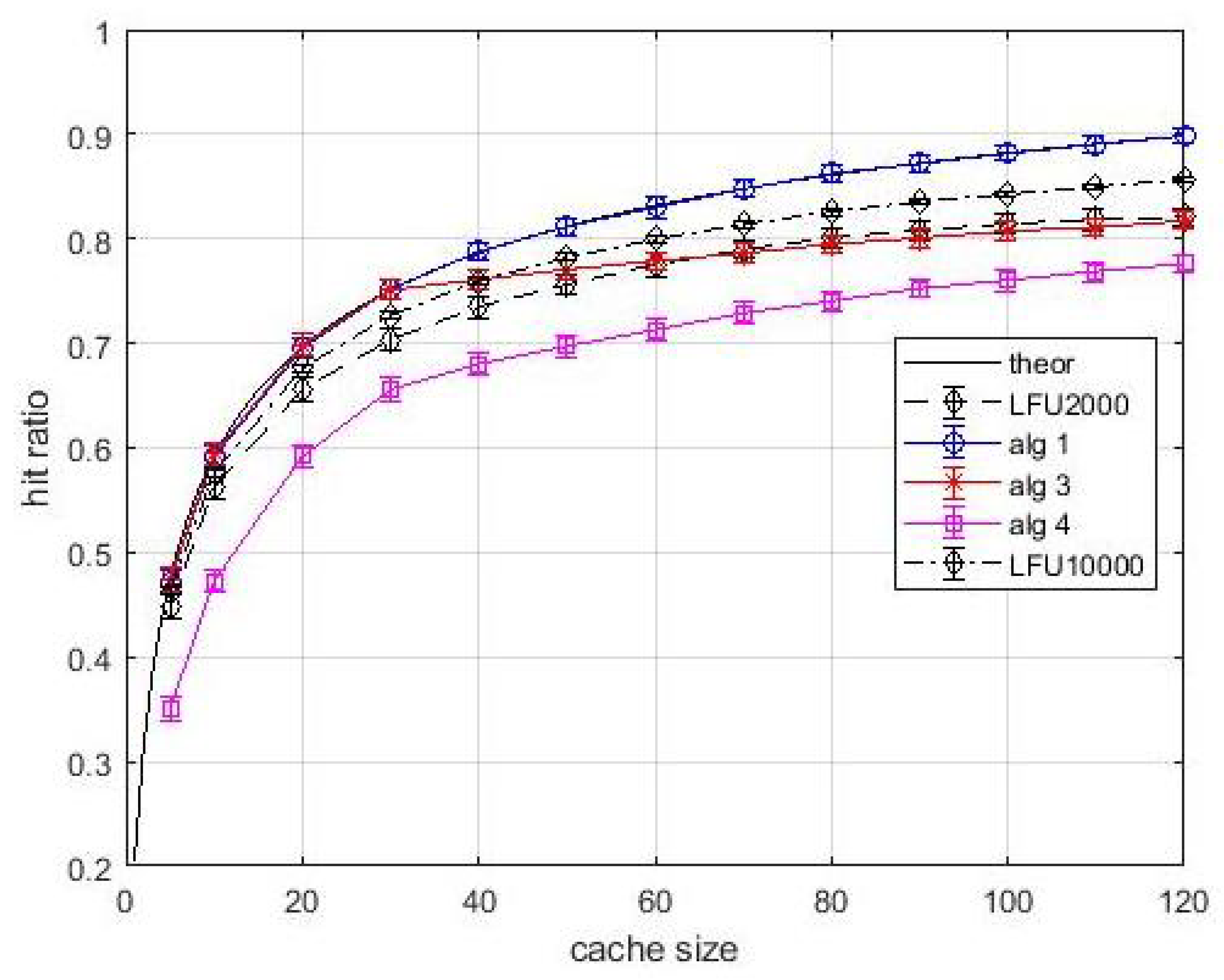
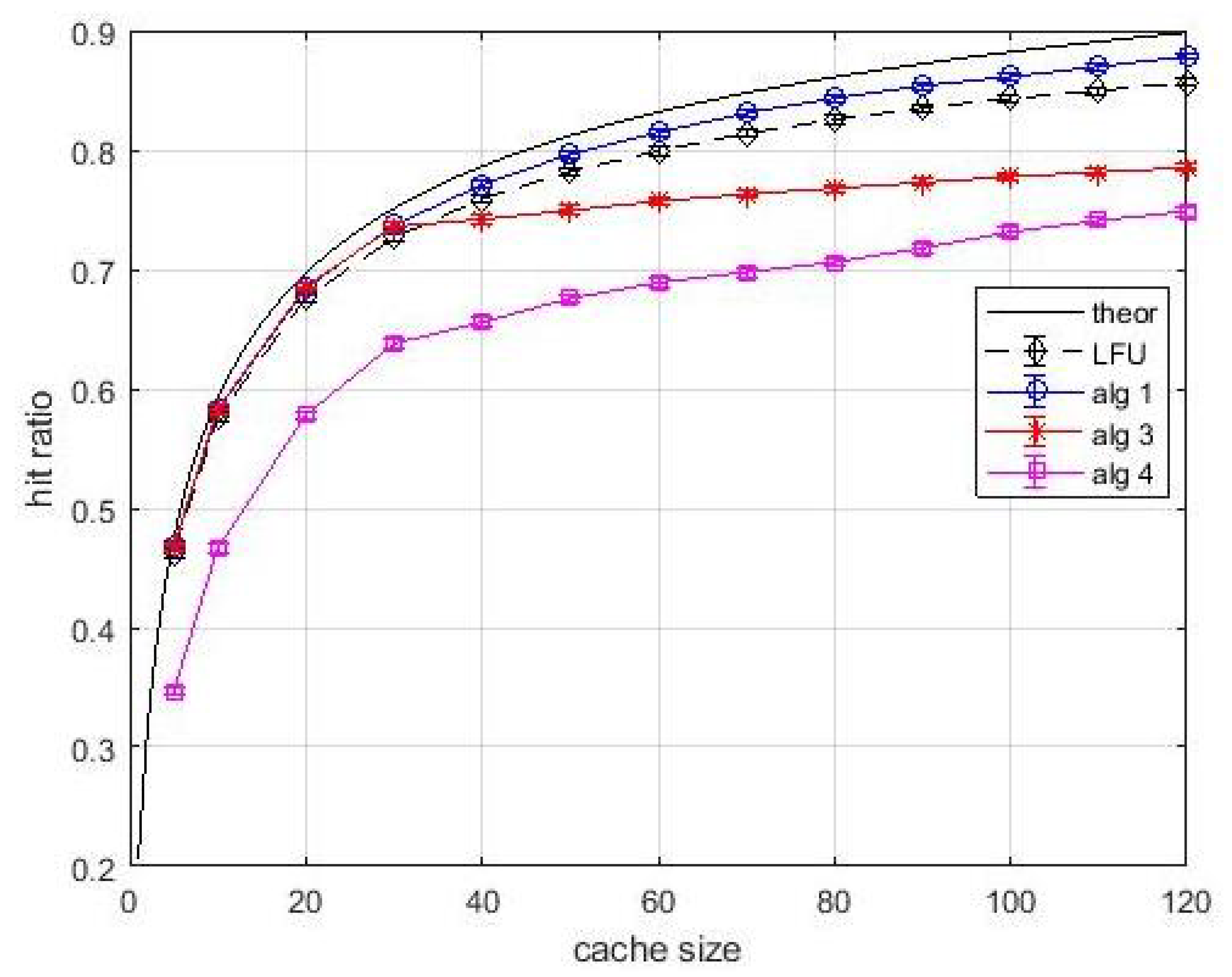
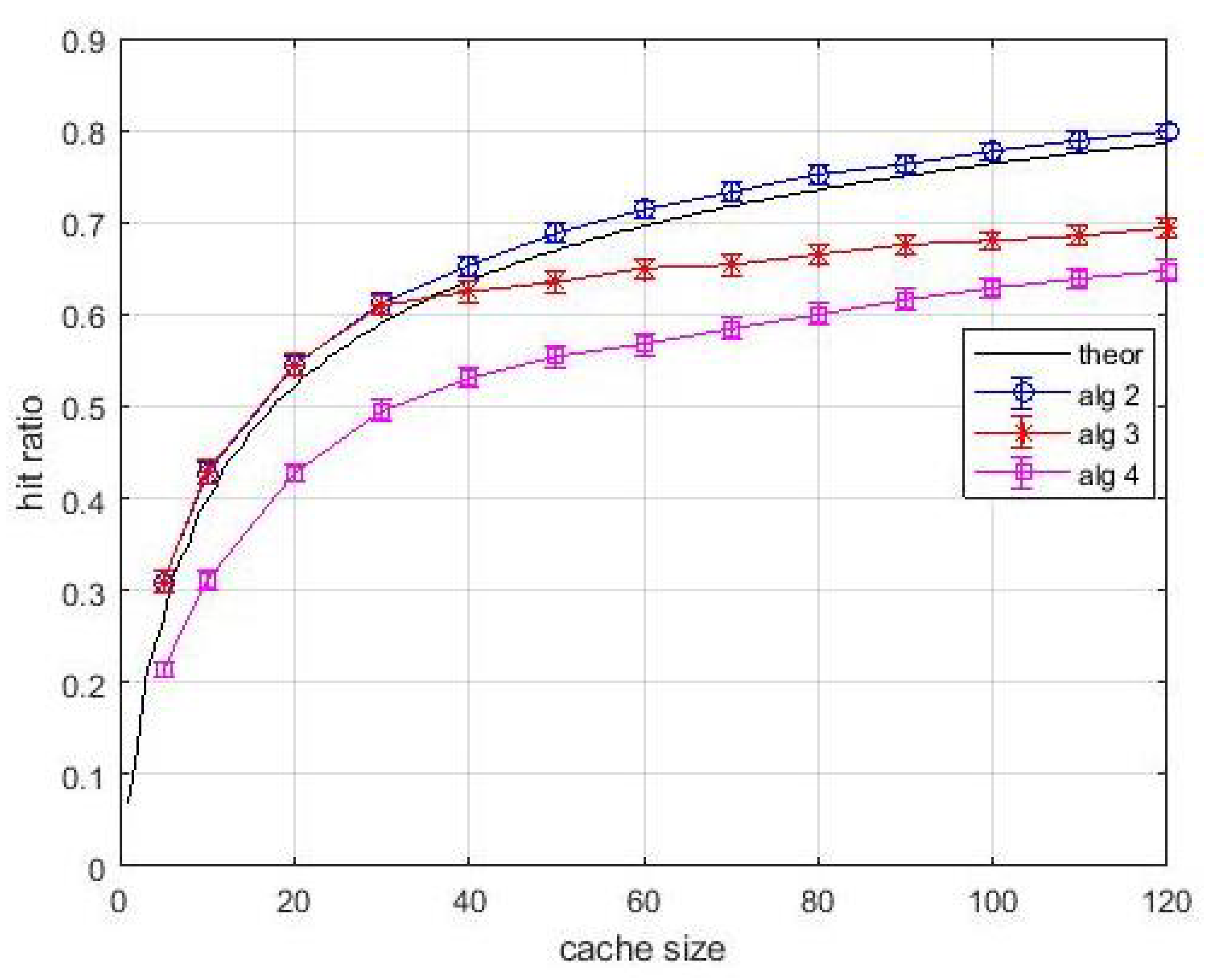
Figure 5 shows the hit ratio vs. cache size. The popularity of each item is the same for all users. The solid black line is relevant to the optimal value which is easily determined by using (
2) when caches are loaded with the items by decreasing popularity, or popularity density, starting with layer-2 caches. Thus, the black solid curve is the performance upper bound. Note that this upper is just a baseline, and our proposal in based on estimated popularity values. In our analysis the LFU content
estimation windows are equal to 2000 and 10,000 inter-arrival times, respectively. Note that the only meaningful comparison in this figure and in the following ones is between
Algortithm1 and LFU, since all other performance curves are relevant to different caching problems. The first general observation is that the 99% confidence intervals are very tight, so the estimate is accurate. We can observe that
Algortithm1 produces hit ratio values coincident with the upper bound. Hence, in this easy situation, the greedy approach not only guarantees
approximation ratio, but can converge towards the optimum. The LFU performance is lower than that of
Algortithm1 for both estimation windows. This is indeed an expected behavior since the LFU policy requires the estimate of the frequency of arrival of contents. However, for avoiding a biased comparison, the hit statistics were collected after a start-up time of an estimation window. Although the performance gap between
Algortithm1 and LFU in this case study was expected, the fact that the proposed greedy approach converges towards the optimum is an encouraging result before proceeding to analyze more complex situations. For what concerns
Algortithm3, the effects of bandwidth constraints are evident. In fact, until the number of parallel contents that can be transmitted is higher than the cacheable contents, the performance of
Algortithm3 is the same as
Algortithm1. When the link bandwidth happens to be the actual bottleneck for allocating further contents, the rate of performance improvement with the cache size decreases. This improvement, although it occurs at a slower rate, is due only to layer-1 caches. This is another confirmation of the importance of layer-1 caches. As for the
Algortithm4, in addition to the bandwidth limitations, we consider the stochastic links between layer-1 and layer-2 caches. Note that all links have a probability of being active that is lower than the probability acceptance threshold. However, due to the introduction of virtual caches, which is central in
Algortithm4, the caching system is turned from unavailable to available with an appreciable performance, although not at the same level of the other situations analyzed above.
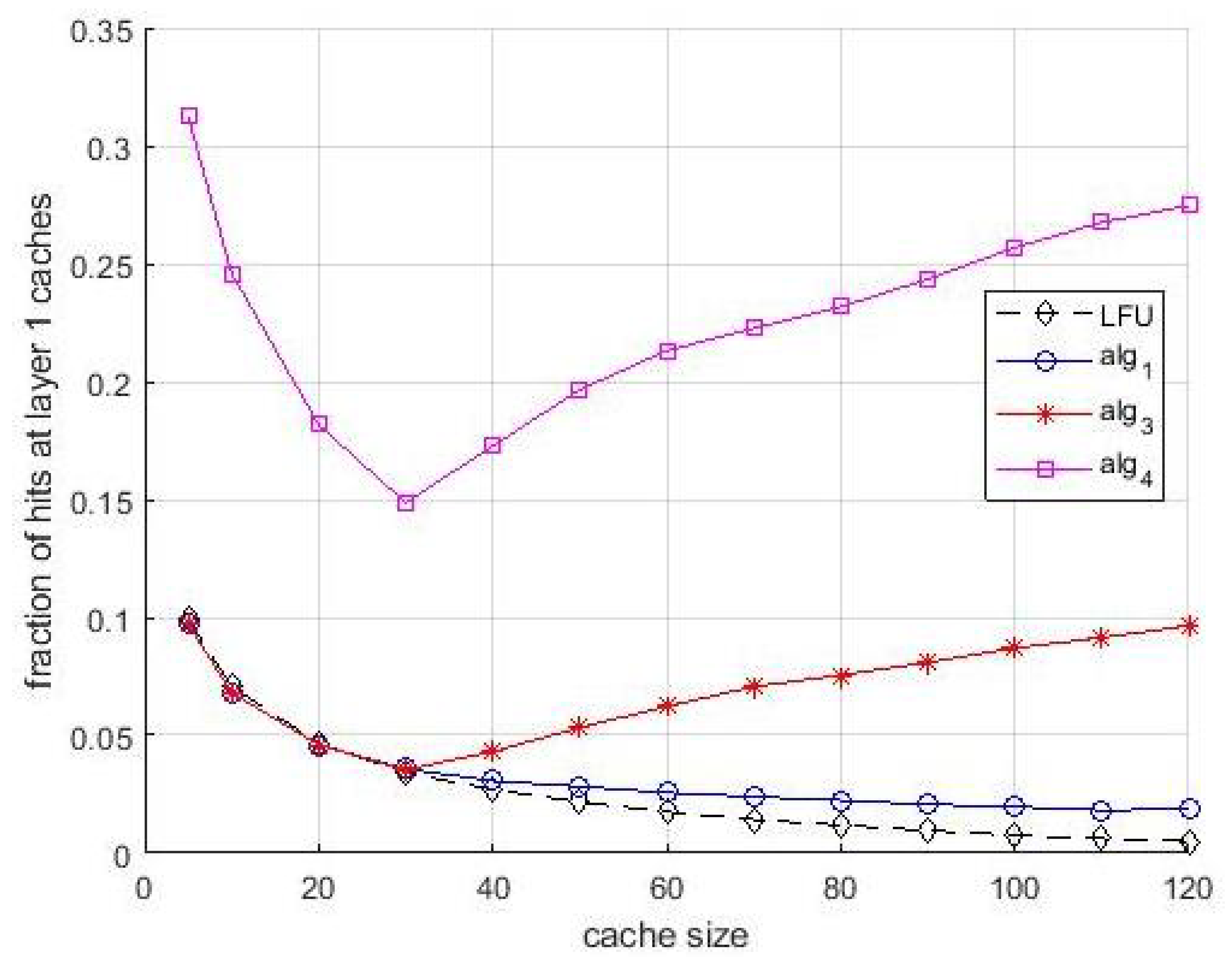
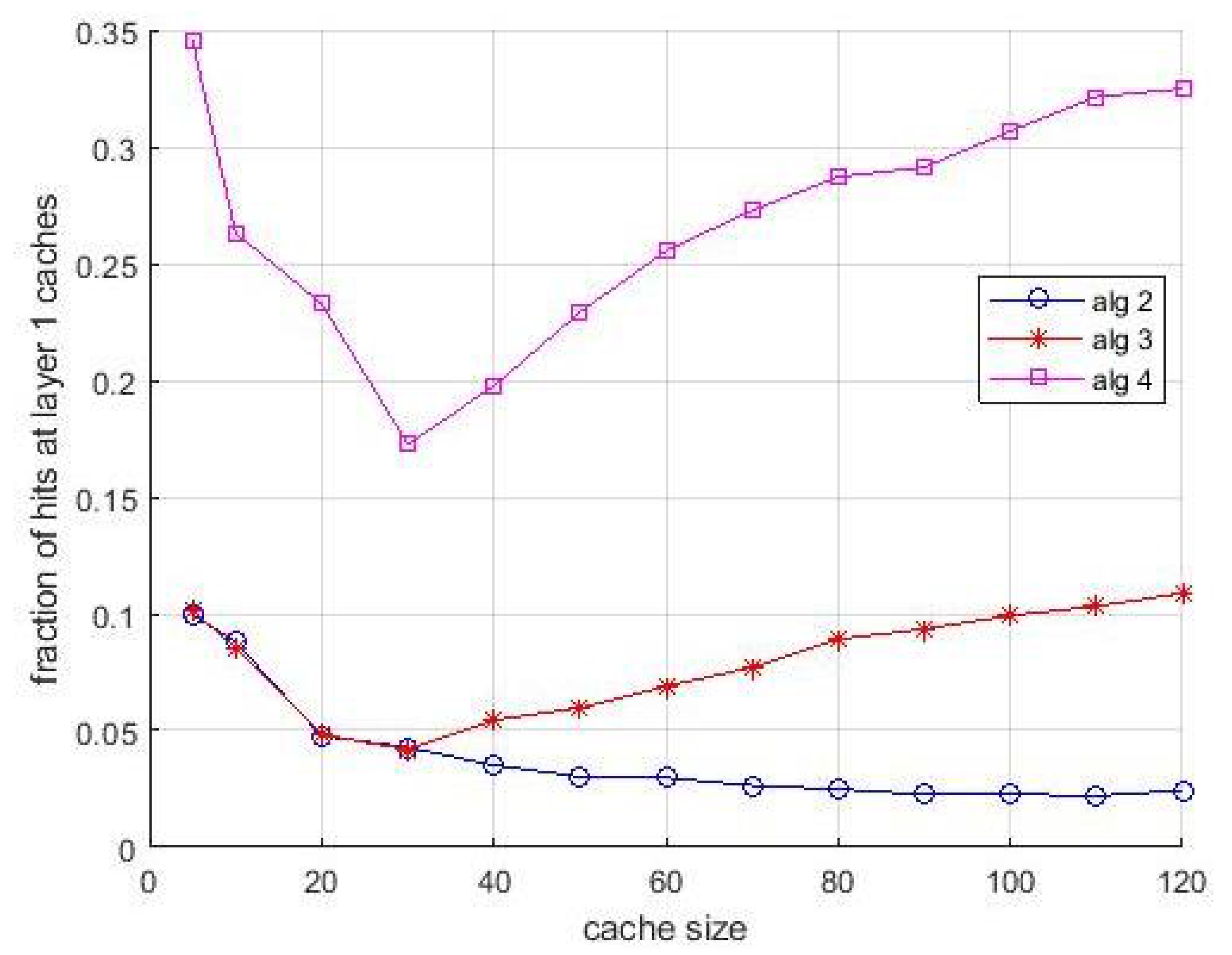
It is interesting to associate the observations of the performance shown in
Figure 5 with the behavior shown in
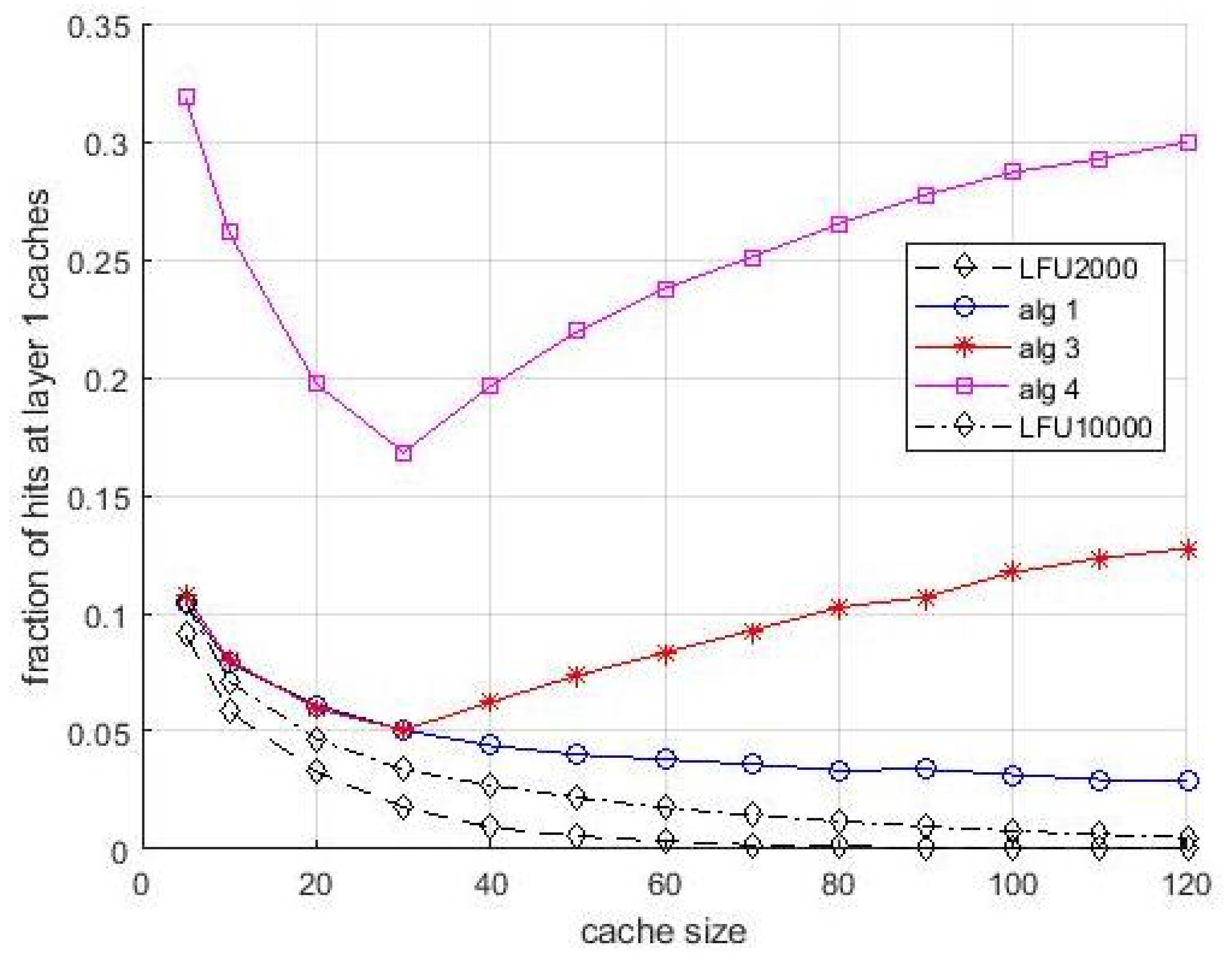
Figure 6. It shows the fraction of hits collected at the layer-1 caches vs. cache size. This figure confirms the compensating role of the layer-1 caches when the allocation in layer-2 caches is not optimal. For some situations, in particular for
Algortithm3 and
Algortithm4, this fraction is significant, and for both algorithms the effect of bandwidth limitations is even more evident. Notice that the evidence of this compensating effect is not only an interesting result per se, but makes the performance difference between the algorithms observed in
Figure 5 even more evident. The asymptotic difference in
Figure 6 between
Algortithm1 and LFU is due to the first miss that happens in caches the first time an item is requested. The presence of multiple caches compensate this effect almost totally, since if a content is cached in a layer-2 cache, the first miss for that content does not happen for the other users that can access the cache for receiving the same content.
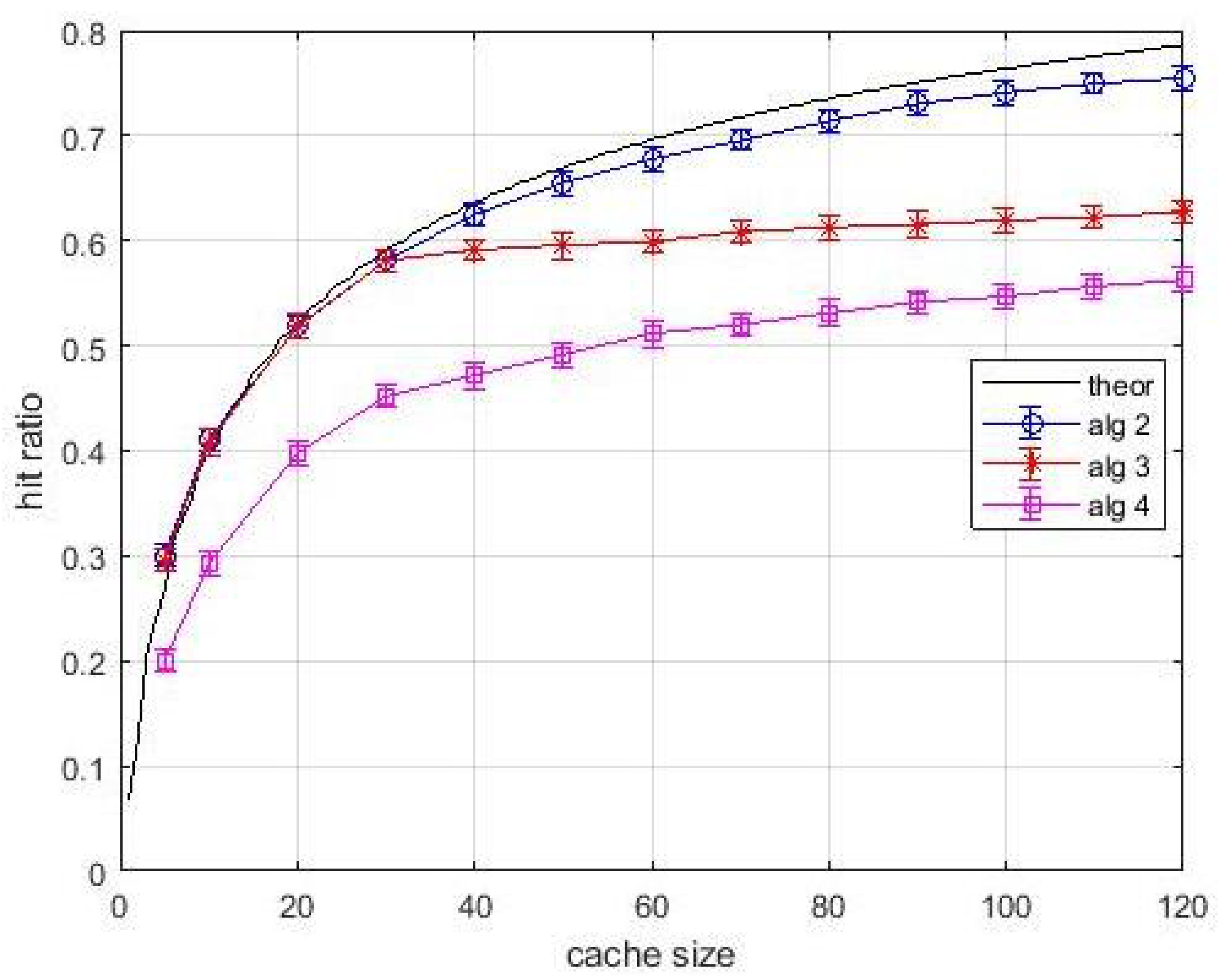
For what concerns the performance of the proposed algorithms when the content popularity is estimated,
Figure 7 and
Figure 8 show the hit ratio for fixed content size. Popularity is estimated by using the LFU estimation procedure, based on a sliding window, for all algorithms. Note that our approach could be used in conjunction with other estimation algorithms, such as that one used for implementing the TinyLFU [
19]. Hence, in the case of pre-allocation of contents, that is for
Algortithm1,
Algortithm3, and
Algortithm4, the popularity values estimated by LFU during an estimation window are used, so that the comparison is fair.
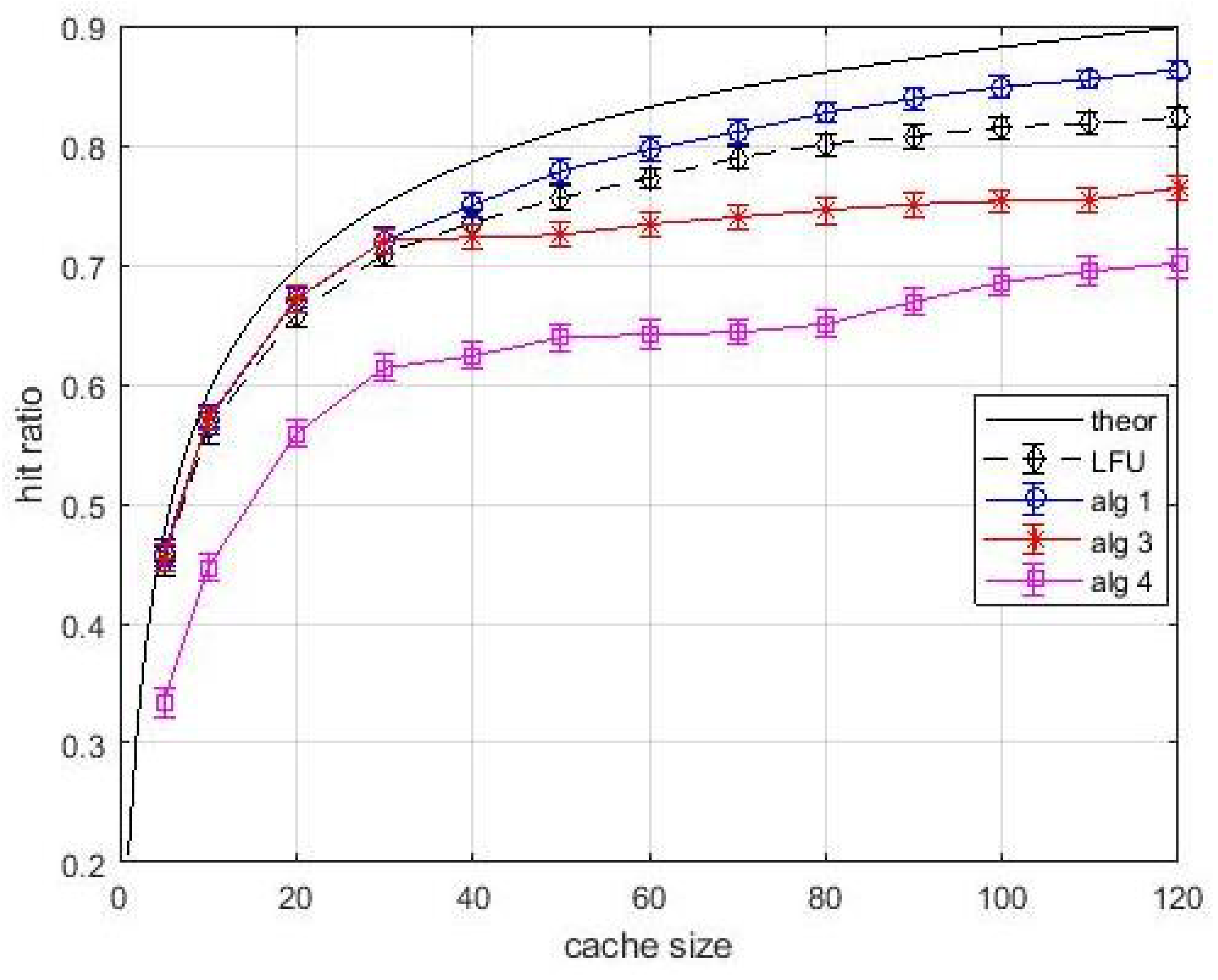
Figure 7, relevant to an estimation window of 2000 interarrival times, shows that the performance of
Algortithm1 is lower than the theoretical one. The performance degradation is due to the use of estimated popularity values. Nevertheless,
Algortithm1 still outperforms LFU. A slight performance degradation is observed also for
Algortithm3 and
Algortithm4. It is interesting to observe in
Figure 8 that the performance degradation is present also in layer-1 caches. This effect can be explained with the coarse estimation of the popularity of less frequently requested items over an (almost) fixes window. These items are typically found in layer-1 queues. However, their contribution to the average hit ratio is quite limited, and the observed degradation is acceptable. If the estimation window increases to 10,000 inter-arrival times, in
Figure 9 and
Figure 10 we can observe that the performance degradation is negligible.
Algortithm1 still outperforms LFU, and in case of
Algortithm3 and
Algortithm4 the performance is mostly determined by bandwidth limitations and stochastic links than by estimated popularity values. Given the well assessed performance comparison between
Algortithm1 and LFU, the following experiments, based on variable content size, will focus in
Algortithm2, which is the extension of
Algortithm1 for handling variable size,
Algortithm3 and
Algortithm4.
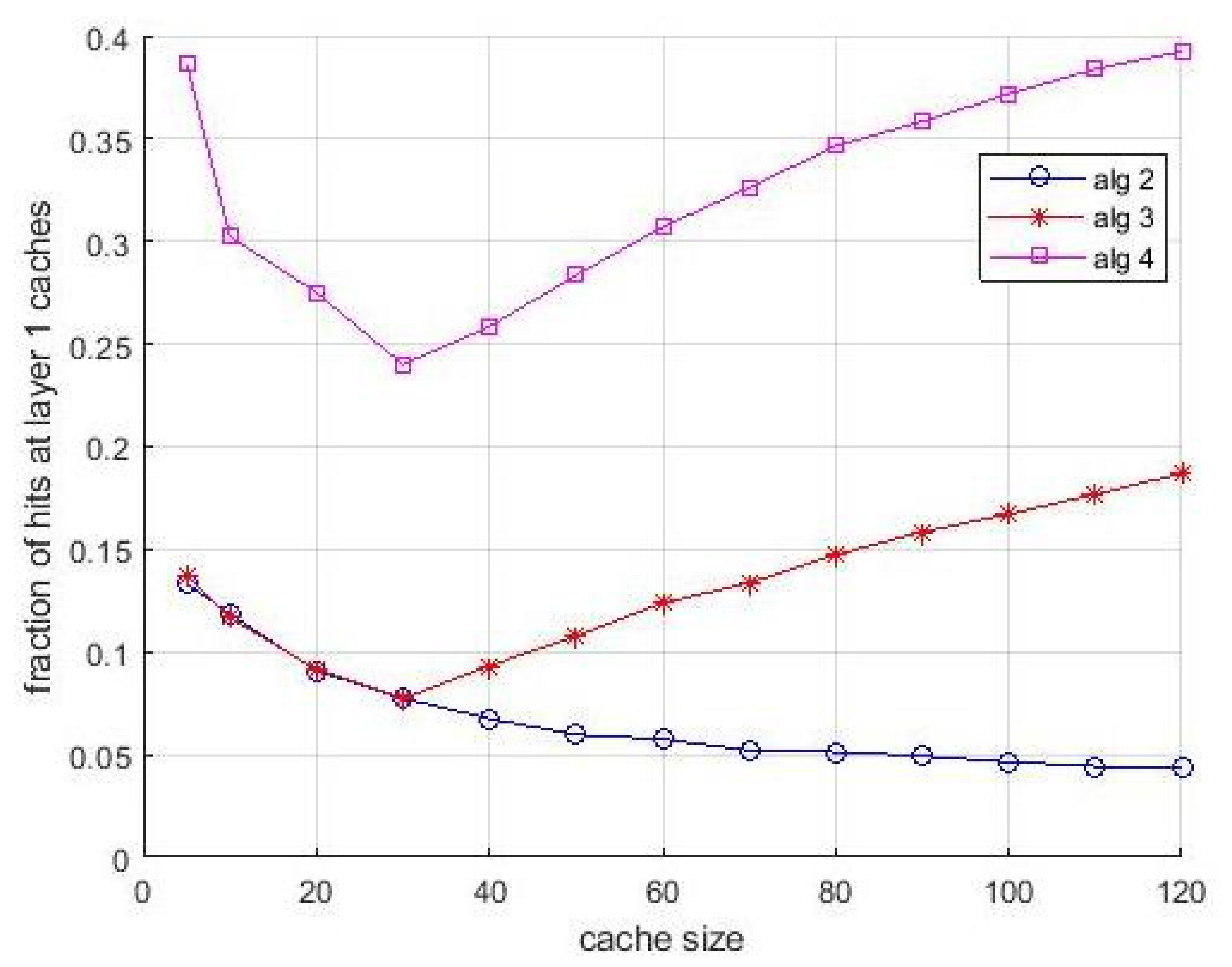
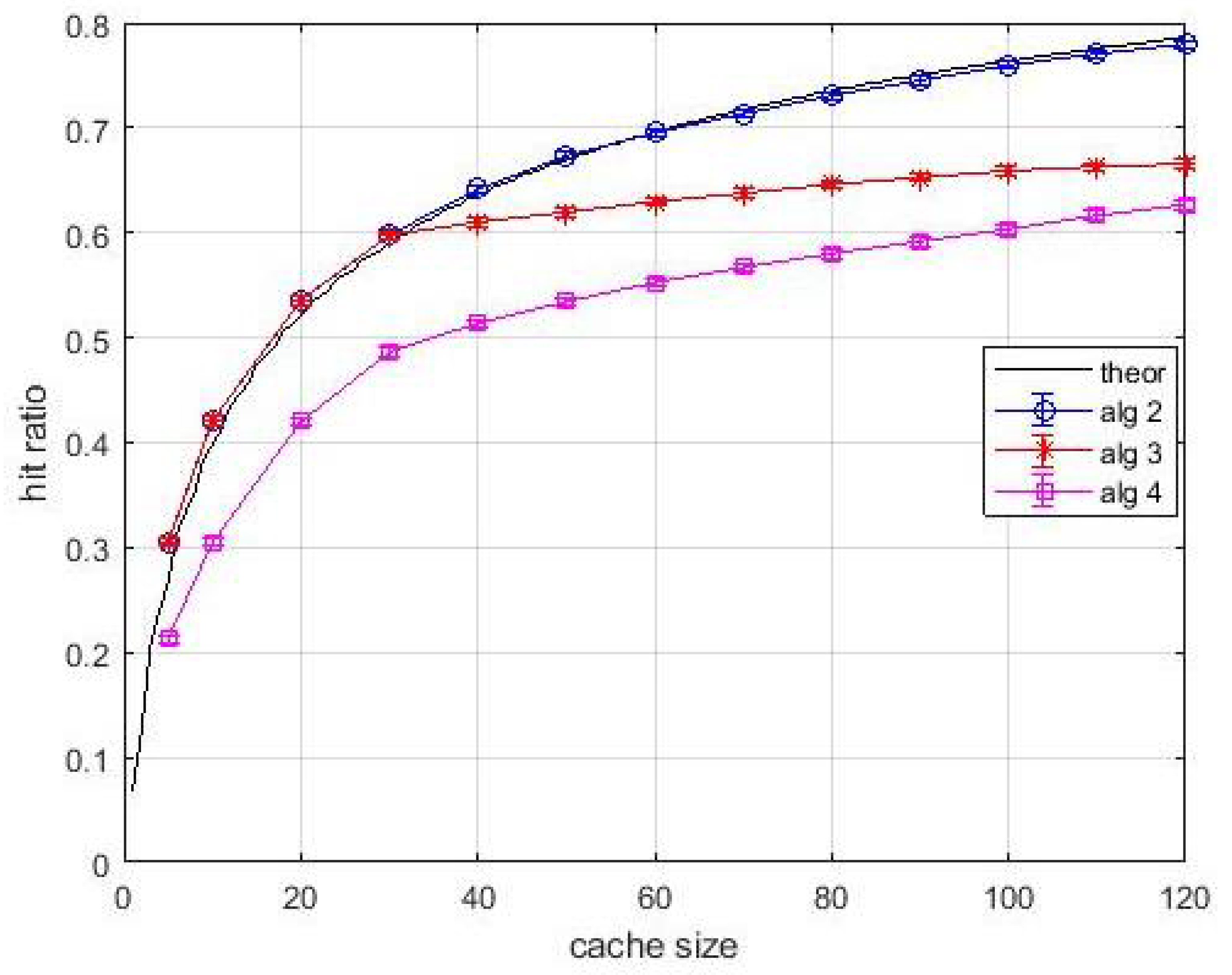
Figure 11 and
Figure 12 are relevant to an experiment with known content popularity and variable content size. The curve labelled as
theoretical shows the hit ratio computed by (
2) by considering popularity only. Differently, the proposed algorithms make use of the density of popularity. This choice is done for highlighting the benefits due to the use of this approach. In fact, we can observe in
Figure 11 that curve relevant to
Algortithm2 is above the theoretical one. The effect of resource constraints are still evident for
Algortithm3 and
Algortithm4, but the known popularity makes the effect of layer-1 queues appreciable. It can be observed both in
Figure 11, in the rate of performance improvement for increasing size of caches and in the neatness of
Figure 12, which shows a significant and steadily increasing contribution of layer-1 caches. Hence, the variable content size has not impaired the performance achievable by the proposed algorithms.
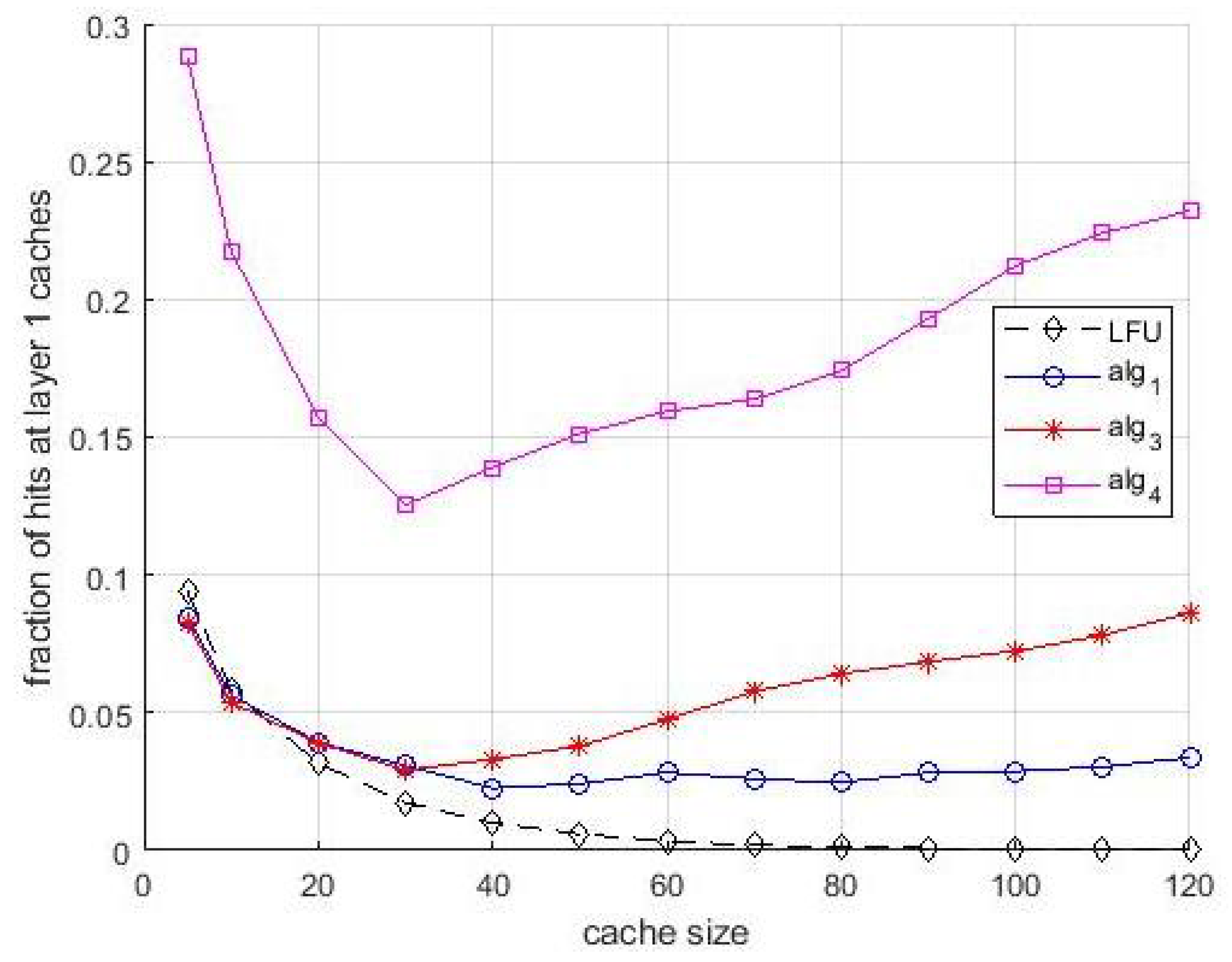
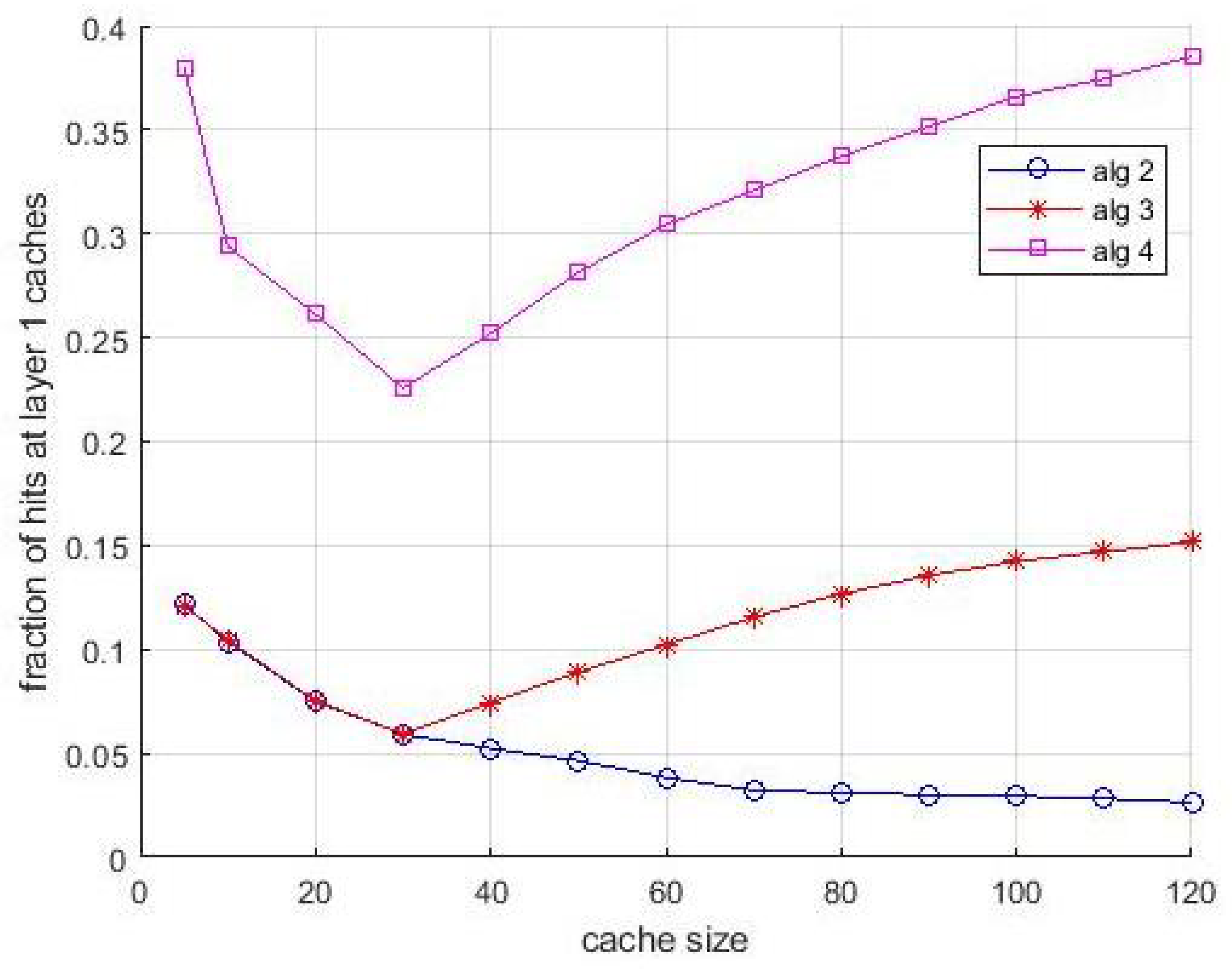
When popularity is unknown, it is estimated as in the previous experiments, through a preliminary estimation during a sliding window of 2000 and 10,000 interarrival times, respectively.
Figure 13 and
Figure 14 are relevant to first case. The theoretical curve is the same as in
Figure 11. We can observe a slight decrease of the hit ratio, negligible for small cache size, tolerable for large ones. Most of considerations done for
Figure 12 are valid also for
Figure 14. However, the not perfect popularity estimation has an impact on the hit rate in layer-1 caches. We stress that this decrease of the hit rate in layer-1 caches is not due to a decrease of their compensation capabilities, since their size allow caching some items that had to be cached in layer-1 caches. It is due to the coarse estimation of the popularity of items that are requested rarely by users. In fact, the overall penalty in the hit rate is quite tolerable.
This observation is confirmed by
Figure 15 and
Figure 16, which are relevant to the longer estimation window. In this case, although popularity values are estimated, the level of the observed performance is considerable.
The main outcomes of our performance evaluation campaign are summarized in in
Table 3. It focuses mainly on the best performing algorithm and its comparison with theoretical limit and with LFU (only for fixed item size). Clearly,
Algorithm3 and
Algorithm4, working with stronger constraints, will suffer of performance degradation. This has already been commented with figures and it is not captured in
Table 3.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}