
A Pattern Mining Method for Teaching Practices


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
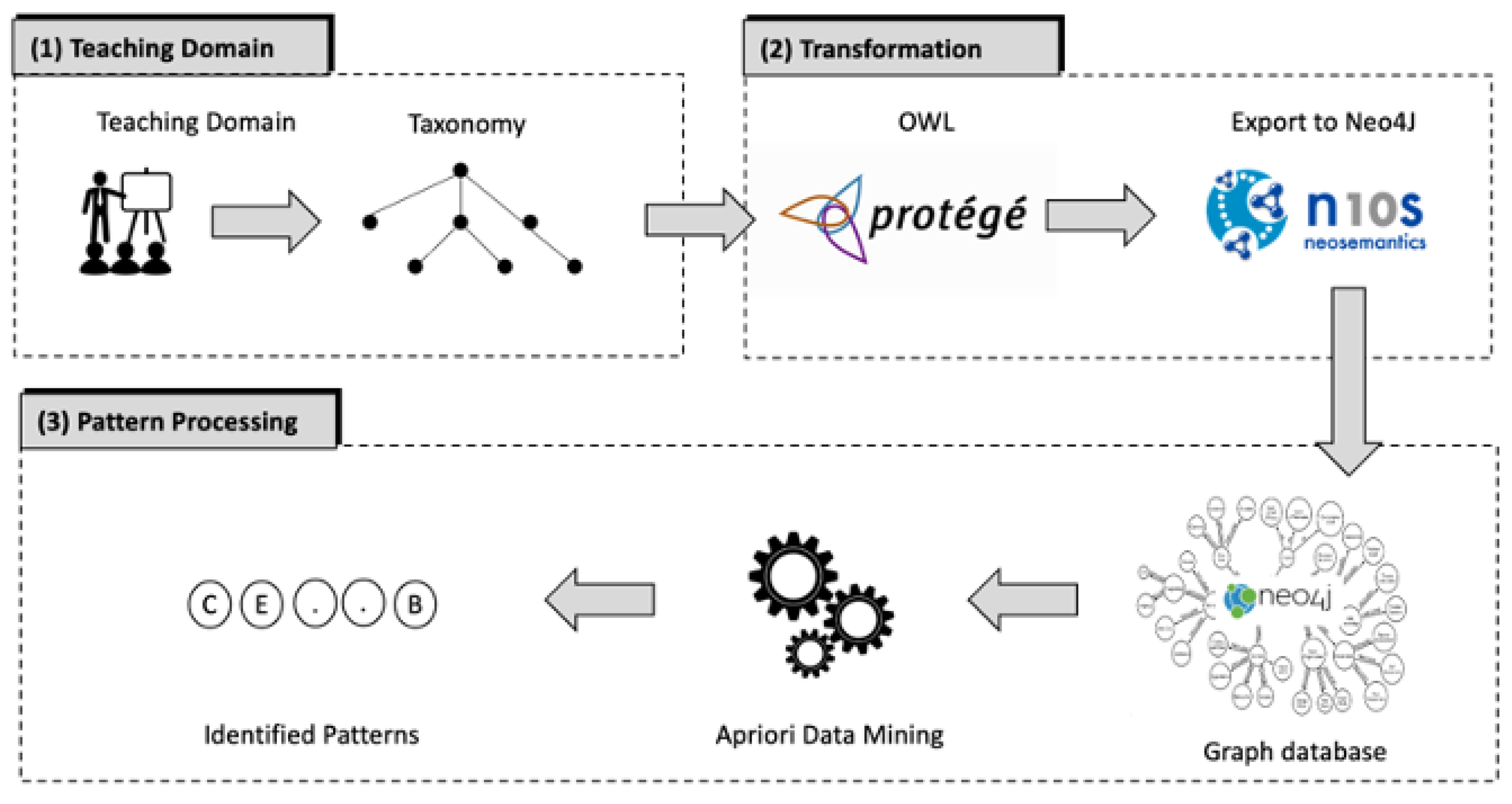
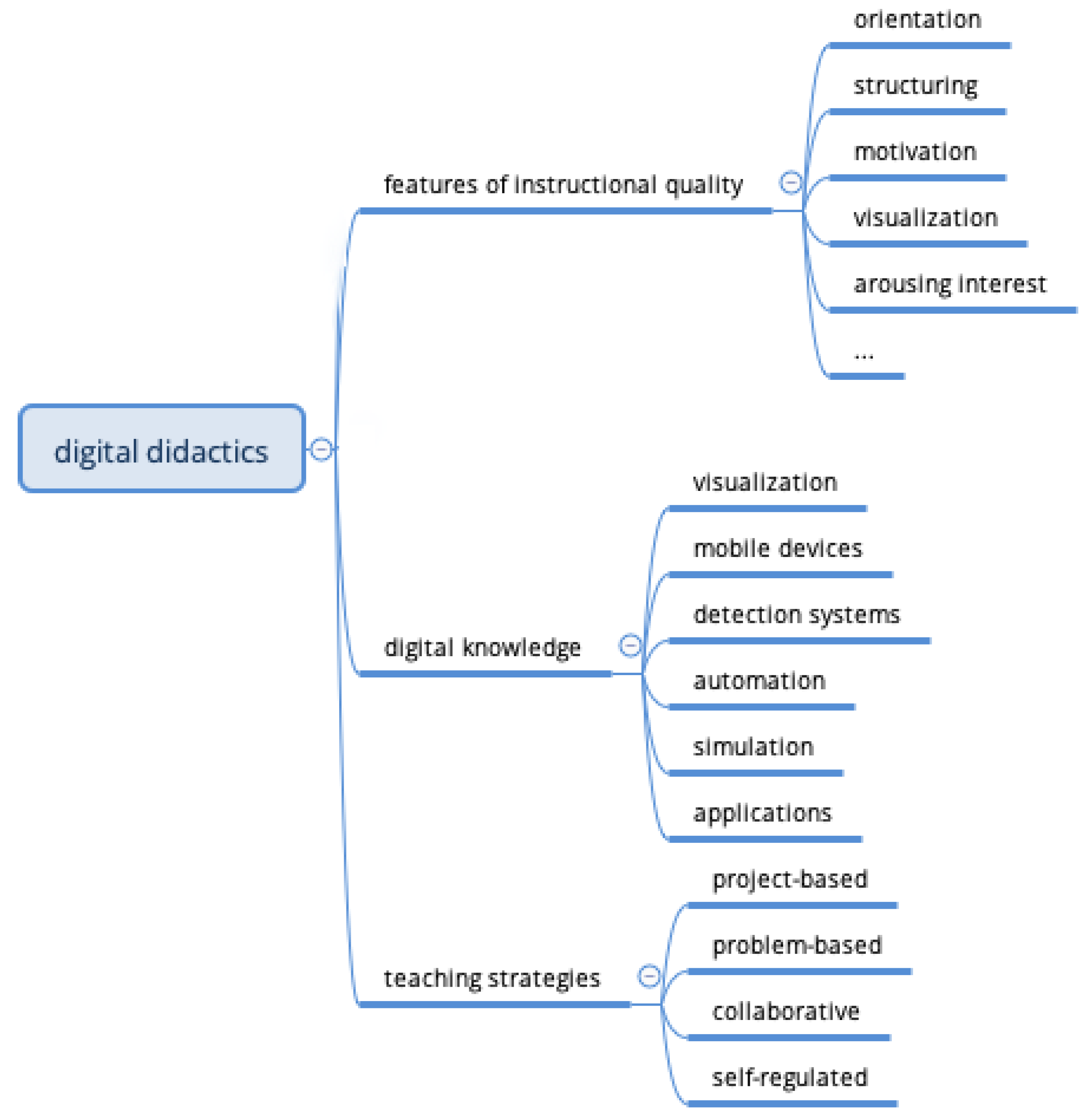
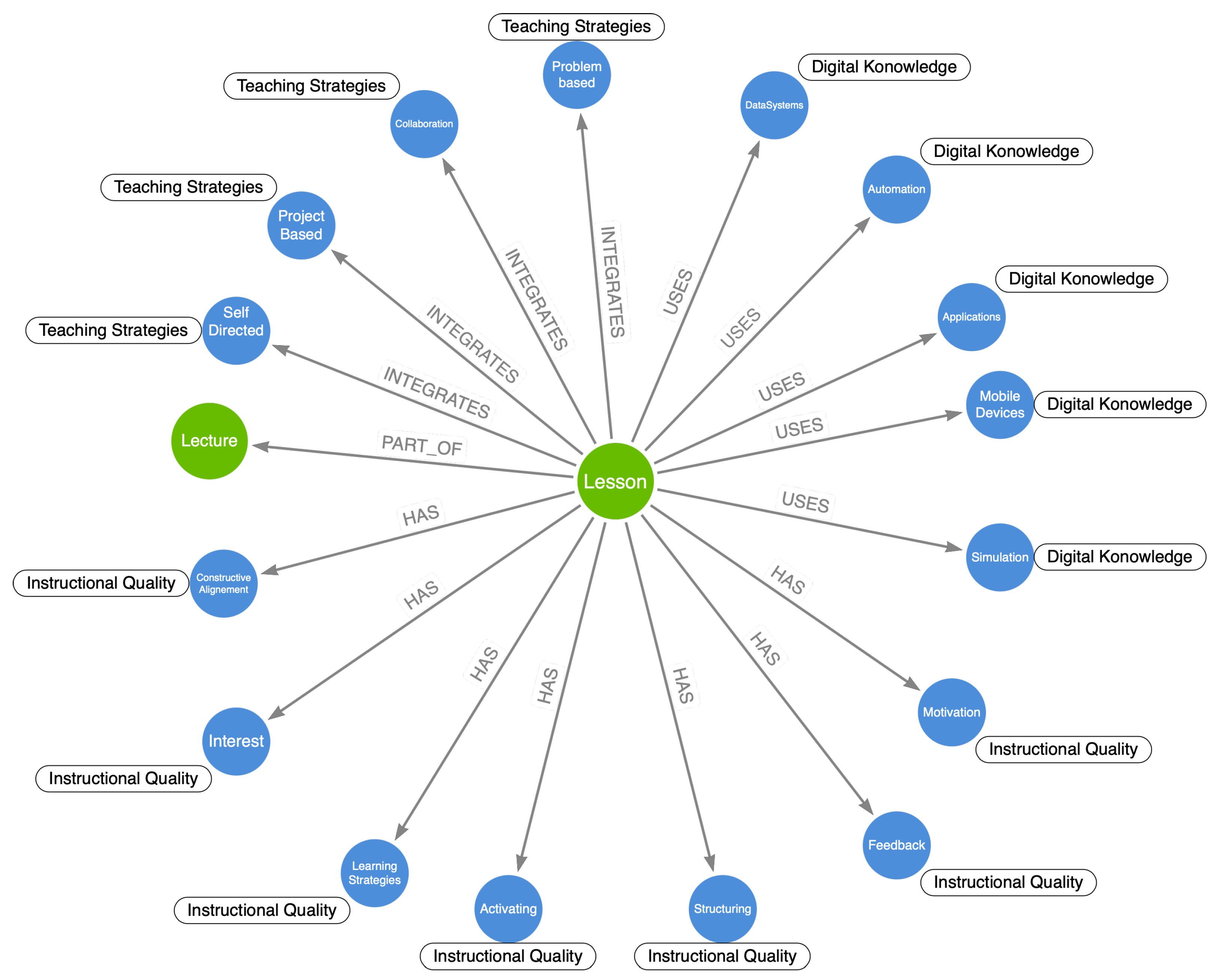
2.1. Conceptualizing a Domain-Specific Teaching Model
2.2. Transformation
2.3. Pattern Mining
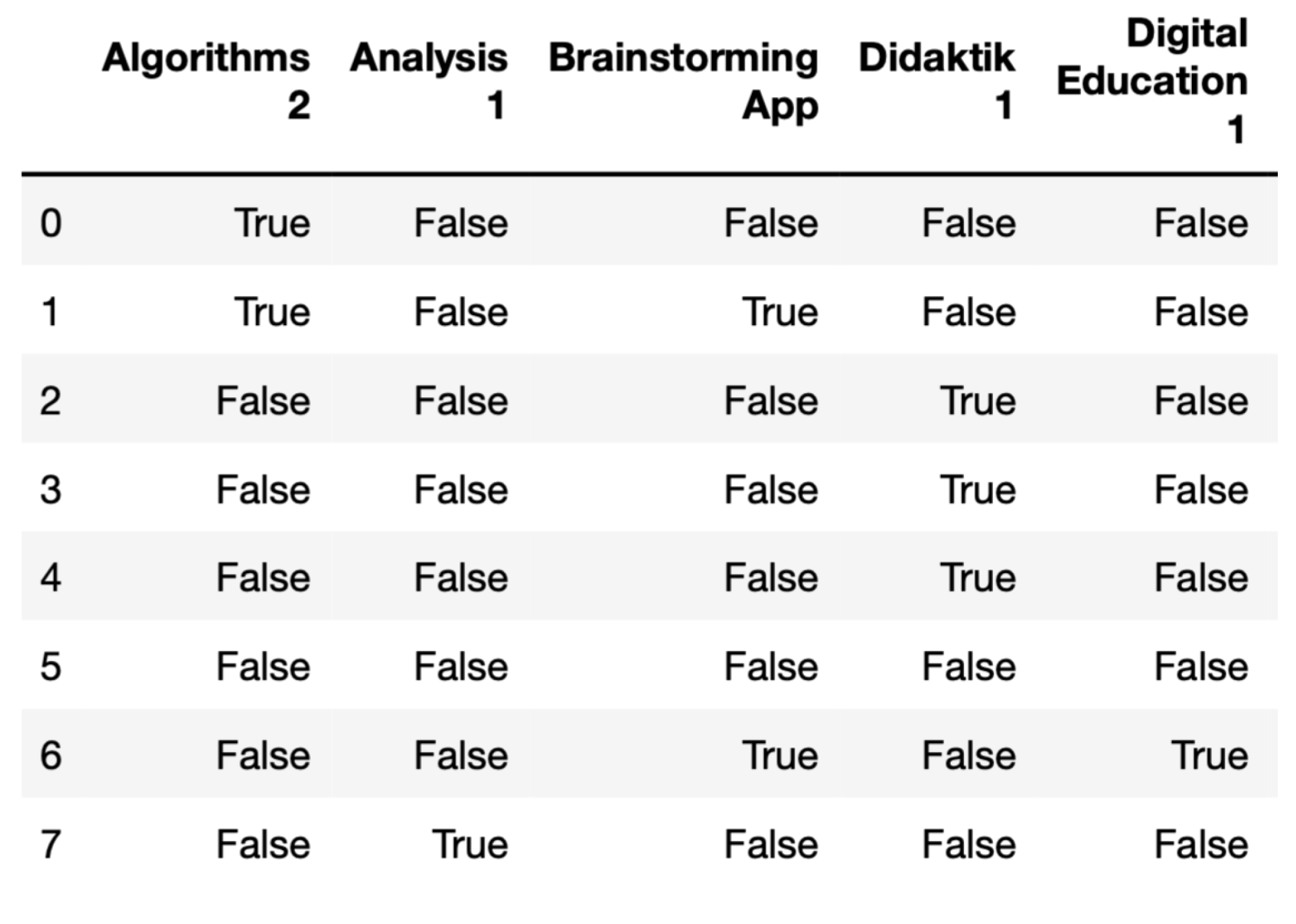
- Identification of frequent associations (Apriori algorithm);
- Description of a hypothesis;
- Manual review and comparison of the lesson data;
- Description of a possible pattern.
3. Experimental Results
4. Interpretation of Results for Pattern Candidates
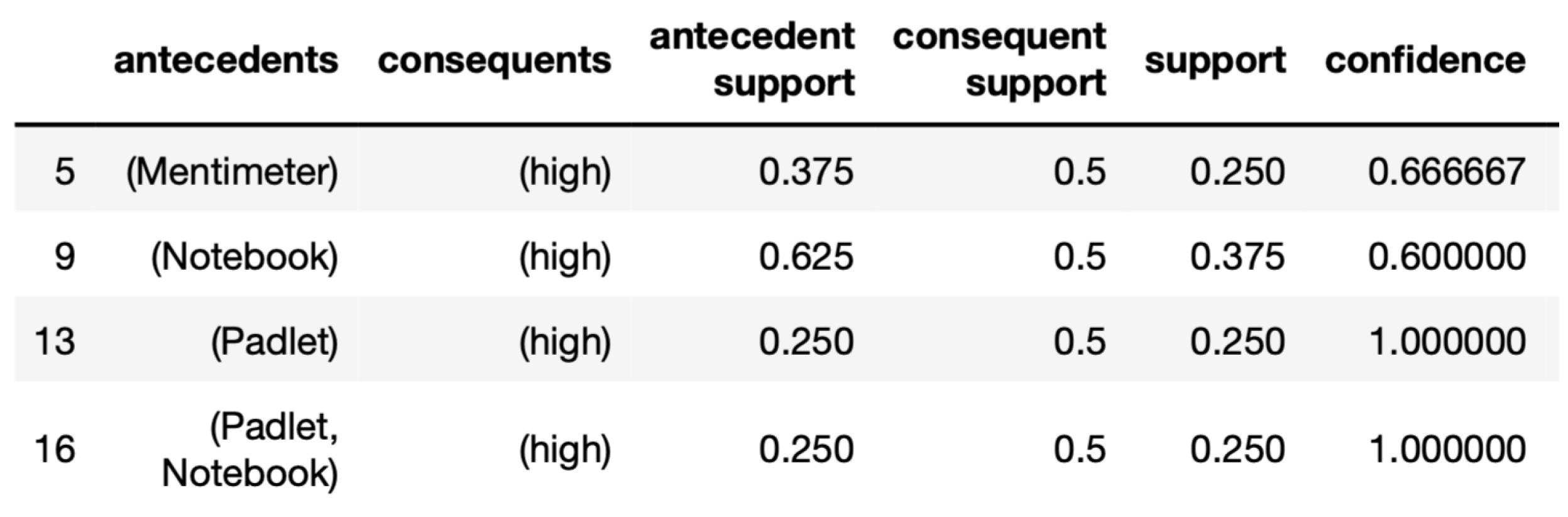
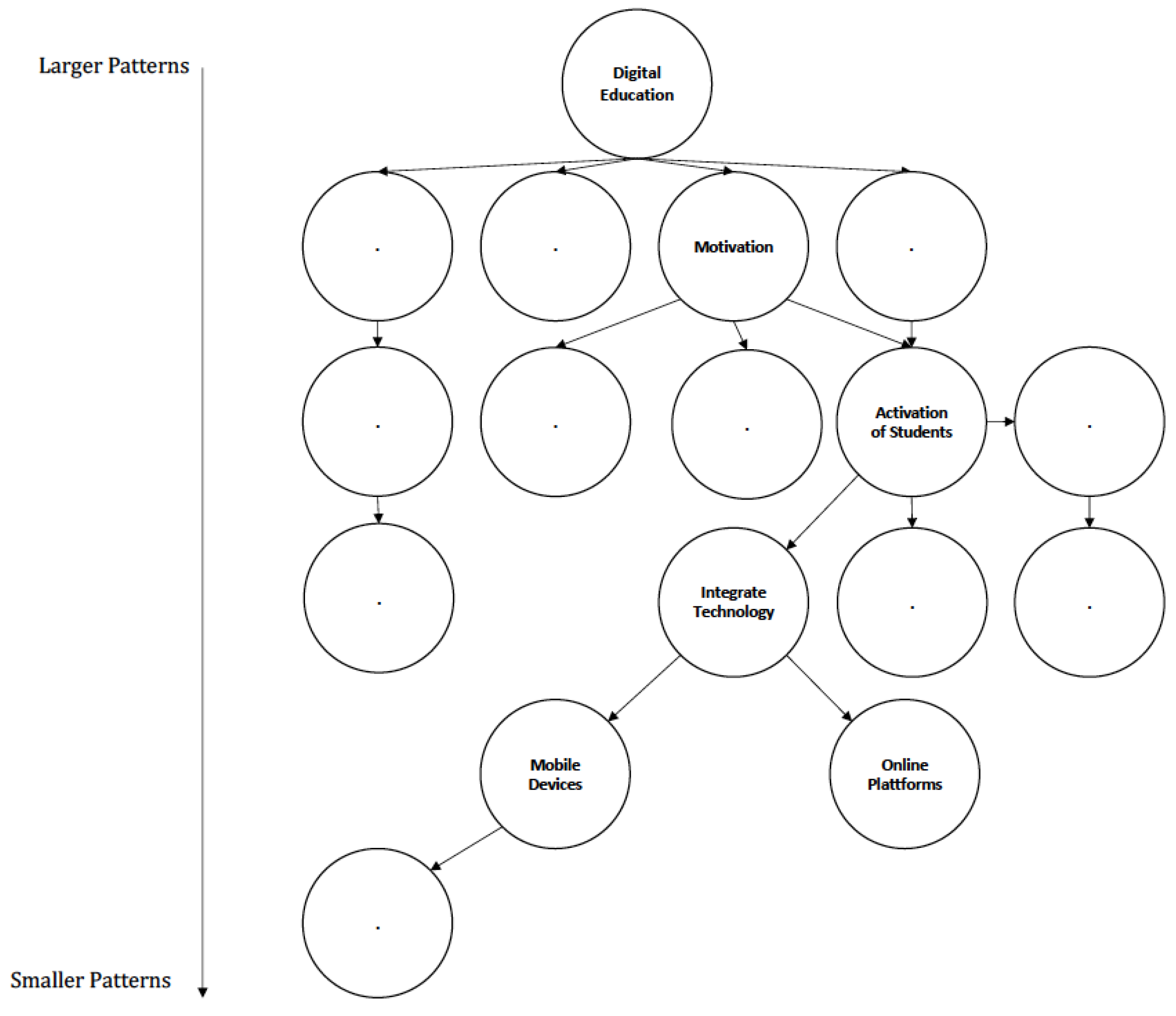
4.1. Example Pattern
4.2. Towards a Pattern Language
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vercoustre, A.M.; McLean, A. Reusing educational material for teaching and learning: Current approaches and directions. Int. J. E-Learn. 2005, 4, 57–68. [Google Scholar]
- Fincher, S.; Utting, I. Pedagogical patterns: Their place in the genre. In ITiCSE 2002—Proceedings of the 7th Annual SIGCSE Conference on Innovation and Technology in Computer Science Education; Association for Computing Machinery: New York, NY, USA, 2002; pp. 199–202. [Google Scholar]
- Magnusson, E. Pedagogical Patterns—A Method to Capture Best Practices in Teaching and Learning. 2013. Available online: https://www.lth.se/fileadmin/lth/genombrottet/konferens2006/PedPatterns.pdf (accessed on 19 April 2021).
- Alexander, C.; Ishikawa, S.; Silverstein, M. A Pattern Language: Towns, Buildings, Construction; University Press: Oxford, UK, 1977; p. 1171. [Google Scholar]
- Alexander, C. The Timeless Way of Building; University Press: Oxford, UK, 1979; p. 552. [Google Scholar]
- Gamma, E.; Helm, R.; Johnson, R.E.; Vlissides, J. Design Patterns. Elements of Reusable Object-Oriented Software, 1st ed.; Addison-Wesley Longman: Amsterdam, The Netherlands, 1995; p. 416. [Google Scholar]
- Bergin, J.; Eckstein, J.; Volter, M.; Sipos, M.; Wallingford, E.; Marquardt, K.; Chandler, J.; Sharp, H.; Manns, M.L. Pedagogical Patterns: Advice for Educators; CreateSpace: Scotts Valley, CA, USA, 2012. [Google Scholar]
- Standl, B. Conceptual Modeling and Innovative Implementation of Person-Centered Computer Science Education at Secondary School Level. Ph.D. Thesis, University of Vienna, Vienna, Austria, 2014. [Google Scholar]
- Baker, R. Data mining for education. Int. Encycl. Educ. 2010, 7, 112–118. [Google Scholar]
- Derntl, M. Patterns for Person Centered E-Learning. Ph.D. Thesis, University of Vienna, Vienna, Austria, 2006. [Google Scholar]
- Schön, M.; Ebner, M.; Das Gesammelte Interpretieren. Educational Data Mining und Learning Analytics. Available online: https://www.pedocs.de/volltexte/2013/8367/pdf/L3T_2013_Schoen_Ebner_Das_Gesammelte_interpretieren.pdf (accessed on 19 April 2021).
- Falkenthal, M.; Barzen, J.; Breitenbücher, U.; Brügmann, S.; Joos, D.; Leymann, F.; Wurster, M. Pattern research in the digital humanities: How data mining techniques support the identification of costume patterns. Comput. Sci. Res. Dev. 2017, 32, 311–321. [Google Scholar] [CrossRef]
- Weichselbraun, A.; Kuntschik, P.; Francolino, V.; Saner, M.; Dahinden, U.; Wyss, V. Adapting Data-Driven Research to the Fields of Social Sciences and the Humanities. Future Internet 2021, 13, 59. [Google Scholar] [CrossRef]
- Agostinho, S.; Bennett, S.J.; Lockyer, L.; Kosta, L.; Jones, J.; Harper, B. An Examination of Learning Design Descriptions in a Repository. 2009. Available online: https://ro.uow.edu.au/edupapers/115/ (accessed on 19 April 2021).
- Rich, P. The organizational taxonomy: Definition and design. Acad. Manag. Rev. 1992, 17, 758–781. [Google Scholar] [CrossRef]
- Moreira, E.J.V.F.; Ramalho, J.C. SPARQLing Neo4J (Short Paper). In Proceedings of the 9th Symposium on Languages, Applications and Technologies (SLATE 2020), Schloss Dagstuhl-Leibniz-Zentrum für Informatik, Rende, Italy, 13–14 July 2020. [Google Scholar]
- Codd, E. Relational Data Model. Commun. ACM 1970, 13, 1. [Google Scholar] [CrossRef]
- Niu, J.; Issa, R.R.A. Developing taxonomy for the domain ontology of construction contractual semantics: A case study on the AIA A201 document. Adv. Eng. Informatics 2015, 29, 472–482. [Google Scholar] [CrossRef]
- Giunchiglia, F.; Zaihrayeu, I. Lightweight Ontologies. 2007. Available online: http://eprints.biblio.unitn.it/1289/ (accessed on 19 April 2021).
- Lal, M. Neo4j Graph Data Modeling; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Greller, W.; Ebner, M.; Schön, M. Learning analytics: From theory to practice–data support for learning and teaching. In International Computer Assisted Assessment Conference; Springer: Berlin/Heidelberg, Germany, 2014; pp. 79–87. [Google Scholar]
- Hao, X.; Han, S. An Algorithm for Generating a Recommended Rule Set Based on Learner’s Browse Interest. Int. J. Emerg. Technol. Learn. 2018, 13, 102–116. [Google Scholar] [CrossRef]
- Salihoun, M. State of Art of Data Mining and Learning Analytics Tools in Higher Education. Int. J. Emerg. Technol. Learn. 2020, 15, 58–76. [Google Scholar] [CrossRef]
- Prieto, L.P.; Sharma, K.; Dillenbourg, P.; Jesús, M. Teaching analytics: Towards automatic extraction of orchestration graphs using wearable sensors. In Proceedings of the Sixth International Conference on Learning Analytics & Knowledge, Edinburgh, UK, 25–29 April 2016; pp. 148–157. [Google Scholar]
- Vatrapu, R.K. Towards semiology of teaching analytics. In Workshop Towards Theory and Practice of Teaching Analytics, at the European Conference on Technology Enhanced Learning, TAPTA; Citeseer: University Park, PA, USA, 2012; Volume 12. [Google Scholar]
- Seidel, T.; Rimmele, R.; Prenzel, M. Clarity and coherence of lesson goals as a scaffold for student learning. Learn. Instr. 2005, 15, 539–556. [Google Scholar] [CrossRef]
- Eine, B.; Jurisch, M.; Quint, W. Ontology-based big data management. Systems 2017, 5, 45. [Google Scholar] [CrossRef]
- Diogo, M.; Cabral, B.; Bernardino, J. Consistency models of NoSQL databases. Future Internet 2019, 11, 43. [Google Scholar] [CrossRef]
- Gilchrist, A. Thesauri, taxonomies and ontologies—An etymological note. J. Doc. 2003. [Google Scholar] [CrossRef]
- De Nicola, A.; Missikoff, M. A lightweight methodology for rapid ontology engineering. Commun. ACM 2016, 59, 79–86. [Google Scholar] [CrossRef]
- Clayton, M.J. Delphi: A technique to harness expert opinion for critical decision-making tasks in education. Educ. Psychol. 1997, 17, 373–386. [Google Scholar] [CrossRef]
- OWL 2 Web Ontology Language. Structural Specification and Functional-Style Syntax (Second Edition). 2012. Available online: https://www.w3.org/TR/owl2-overview/ (accessed on 19 April 2021).
- Musen, M.A. The protégé project: A look back and a look forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef]
- Reshma, P.K.; Lajish, V.L. Ontology Based Semantic Information Retrieval Model for University Domain. Int. J. Appl. Eng. Res. 2018, 13, 12142–12145. [Google Scholar]
- Rezgui, K.; Mhiri, H.; Ghédira, K. An Ontology-based Profile for Learner Representation in Learning Networks. Int. J. Emerg. Technol. Learn. 2014, 9. [Google Scholar] [CrossRef]
- Wiegand, S. And Now for Something Completely Different: Using OWL with Neo4j. 2013. Available online: https://neo4j.com/blog/using-owl-with-neo4j/ (accessed on 19 April 2021).
- Nsmntx—neo4j Redf and Semantics Toolkot. 2021. Available online: https://neo4j.com/nsmtx-rdf/ (accessed on 19 April 2021).
- Caiza, J.C.; Martín, Y.S.; Del Alamo, J.M.; Guamán, D.S. Organizing design patterns for privacy: A taxonomy of types of relationships. In Proceedings of the 22nd European Conference on Pattern Languages of Programs, Irsee, Germany, 12–16 July 2017; pp. 1–11. [Google Scholar]
- Köppe, C. Using pattern mining for competency-focused education. In Proceedings of Second Computer Science Education Research Conference—CSERC’12; ACM Press: Wroclaw, Poland, 2012; pp. 23–26. [Google Scholar] [CrossRef]
- Köppe, C.; Nørgård, R.T.; Pedersen, A.Y. Towards a pattern language for hybrid education. In Proceedings of the VikingPLoP 2017 Conference on Pattern Languages of Program, Grube, Schleswig-Holstein, Germany, 30 March–2 April 2017; pp. 1–17. [Google Scholar]
- Biggs, J.; Tang, C. Teaching for Quality Learning at University; Open University Press: Milton Keynes, UK, 2003. [Google Scholar]
- Seidel, T.; Shavelson, R.J. Teaching effectiveness research in the past decade: The role of theory and research design in disentangling meta-analysis results. Rev. Educ. Res. 2007, 77, 454–499. [Google Scholar] [CrossRef]
- Dorfner, T. Instructional Quality Features in Biology Instruction and Their Orchestration in the Form of a Lesson Planning Model. Ph.D. Thesis, LMU, Munich, Germany, 2019. [Google Scholar]
- Bandura, A. Self-efficacy: Toward a unifying theory of behavioral change. Psychol. Rev. 1977, 84, 191–215. [Google Scholar] [CrossRef]
- Deci, E.L.; Ryan, R.M. Intrinsic Motivation and Self-Determination in Human Behavior; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Friedrich, H.F.; Mandl, H. Lernstrategien: Zur Strukturierung des Forschungsfeldes. Handb. Lernstrategien 2006, 1, 23. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th VLDB Conference, Santiago de, Chile, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Beierle, C.; Kern-Isberner, G. Maschinelles Lernen. In Methoden Wissensbasierter Systeme: Grundlagen, Algorithmen, Anwendungen; Springer: Wiesbaden, Germany, 2019; pp. 99–160. [Google Scholar] [CrossRef]
- Kiel, E. Basiswissen Unterrichtsgestaltung. 1. Geschichte der Unterrichtsgestaltung; Schneider Verlag Hohengehren: Baltmannsweiler, Germany, 2011. [Google Scholar]
- Yen, S.J.; Lee, Y.S.; Wu, C.W.; Lin, C.L. An efficient algorithm for maintaining frequent closed itemsets over data stream. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 767–776. [Google Scholar]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Standl, B.; Schlomske-Bodenstein, N. A Pattern Mining Method for Teaching Practices. Future Internet 2021, 13, 106. https://doi.org/10.3390/fi13050106
Standl B, Schlomske-Bodenstein N. A Pattern Mining Method for Teaching Practices. Future Internet. 2021; 13(5):106. https://doi.org/10.3390/fi13050106
Chicago/Turabian StyleStandl, Bernhard, and Nadine Schlomske-Bodenstein. 2021. "A Pattern Mining Method for Teaching Practices" Future Internet 13, no. 5: 106. https://doi.org/10.3390/fi13050106
APA StyleStandl, B., & Schlomske-Bodenstein, N. (2021). A Pattern Mining Method for Teaching Practices. Future Internet, 13(5), 106. https://doi.org/10.3390/fi13050106