
A Register Access Control Scheme for SNR System to Counter CPA Attack Based on Malicious User Blacklist


Abstract
:1. Introduction
- We introduce a novel scheme to counter content pollution attack from the perspective of SNR system security. We analyze the significant impact of content pollution attacks on the SNR system. As far as we know, the existing content pollution attacks carry out security detection and defense measures on the cache.
- We give the complete rules of invalid content discovery, reporting and voting revocation process, and the progressive relationship between invalid content revocation and public key revocation, which gives the reasonable process of being identified as blacklist users.
- We designed a series of rules for network users to automate responses about the potential malicious behavior report and prove the rationality and high reliability of these rules. We prove the robustness of the voting scheme compared with others in different collusion attacker probabilities. Experiments show that with the voting weight continuously increased, the probability of successful collusion attack can be reduced to less than 0.1 when the attacker ratio is 0.5.
2. Related Work
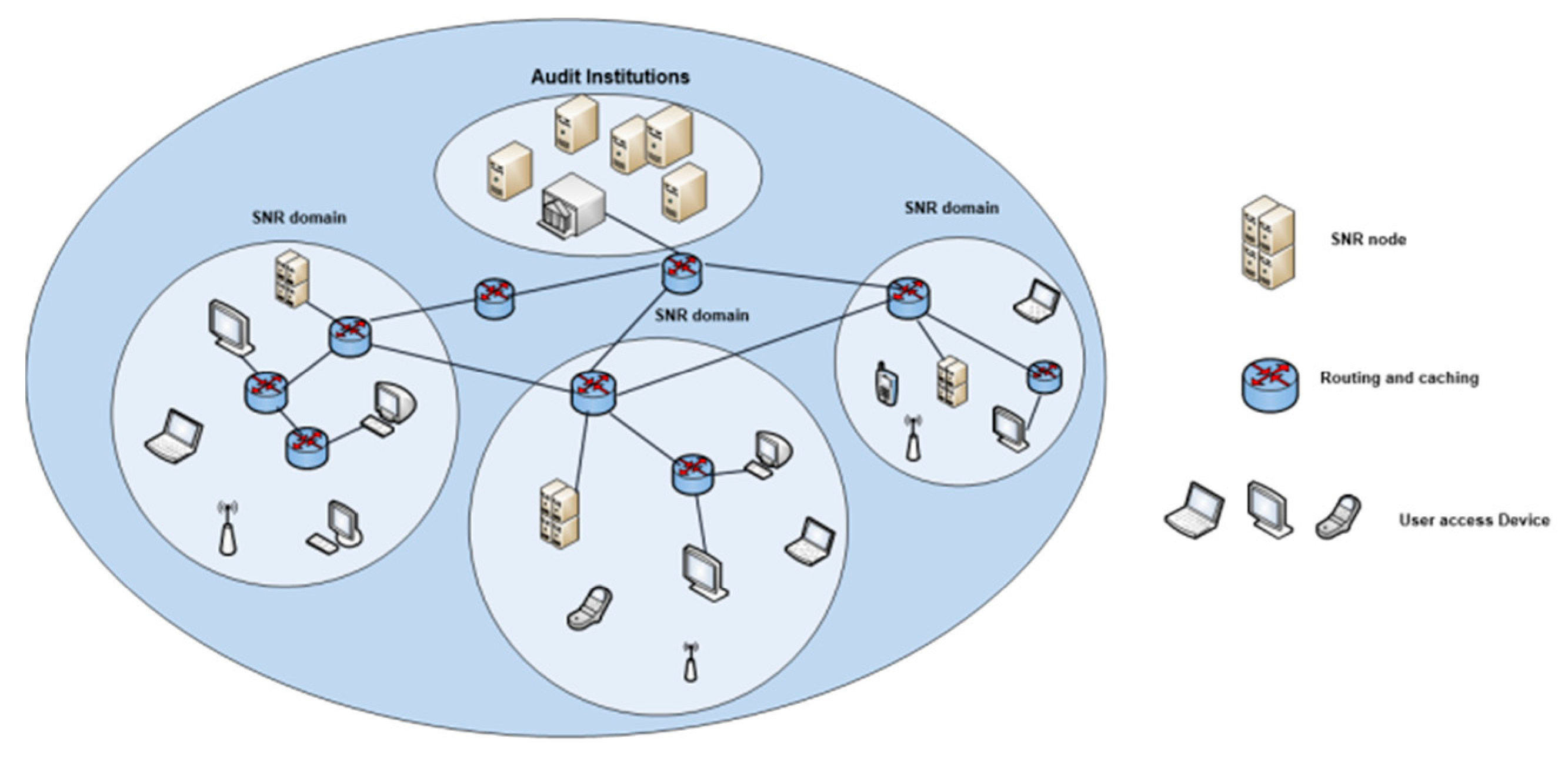
3. Basic Definitions and System Framework
3.1. System Framework
- Independently generate public and private key, user ID.
- Initiate content query request, initiate name registration request, content registration request.
- Initiate public key or content revocation events, reply the corresponding voting request.
- Verify public key and user ID, complete the registration and query request.
- Store PKBL (Public Key Revocation Blacklist), update PKBL, and synchronize malicious PKBL to other SNR nodes.
- Handle error content or key pairs revocation reports in the resolution domain, store and update the SWL (Security Weight List) period.

3.2. The Public Key Grades
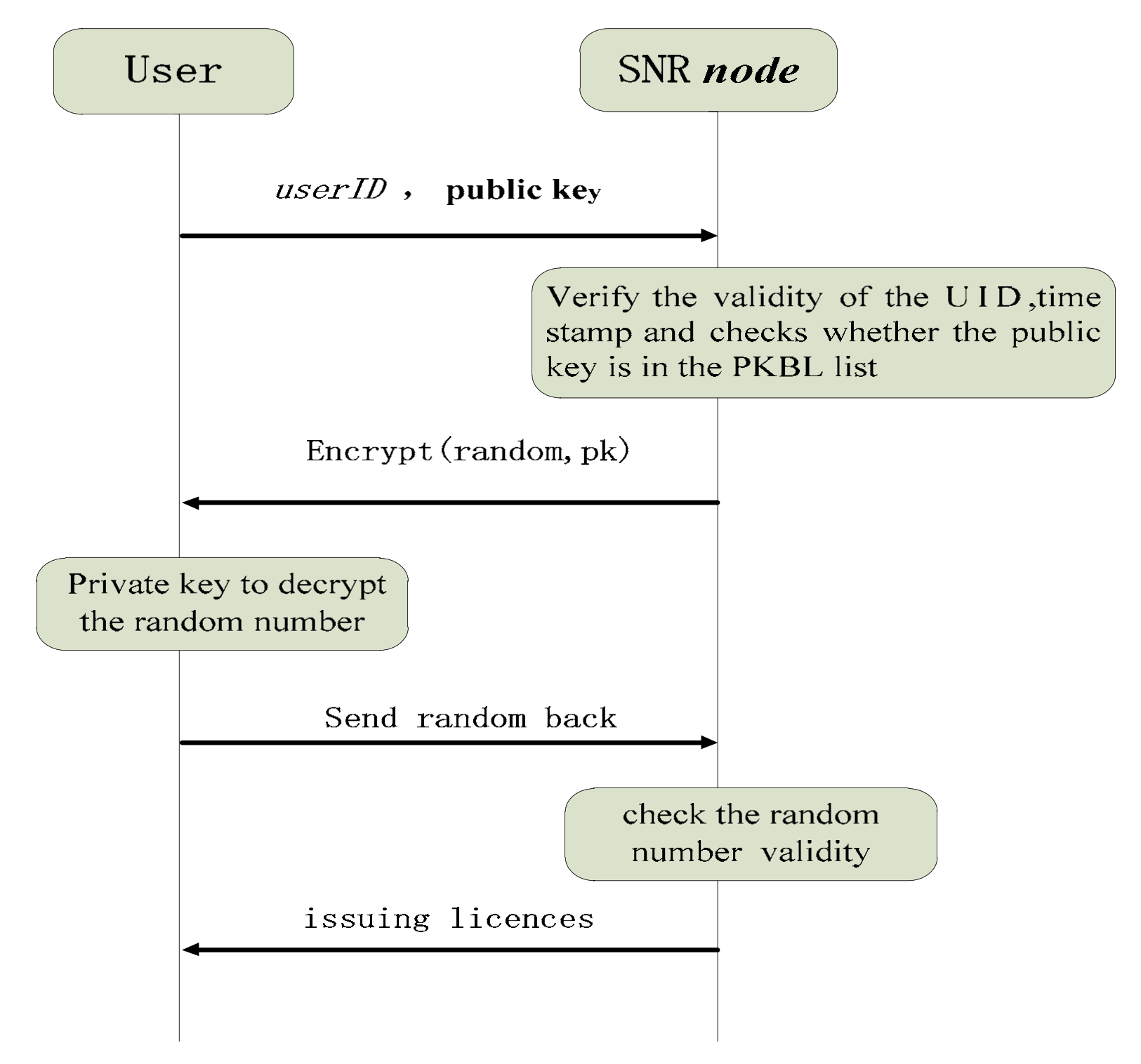
3.3. Name Registration Process and Content Publish or Query
4. Voting Algorithm
4.1. Revocation Scheme in Adversary Model
4.1.1. Adversary Model
- Attackers change contents or send unavailable contents during transmission for content pollution.
- Other malicious acts of attackers are found by legitimate users and the legitimate users can also initiate a vote for revocation. At this time, although the SNR system has not been attacked, malicious users pose a threat to other parts of the network and should also be blacklisted.
4.1.2. Revocation Scheme
4.2. Basic Definition and Rules of the Voting Algorithm
4.2.1. Advantages of User Active Response
- The number of allowable registered content items increases with the grades moving up. The relationship between UID and CID is a one-to-many mapping relationship. A user can publish more content when its security weight is at high grades.
- Users with high security weight will have more credibility with SNR nodes, which will result in a higher response speed. When they initiate voting or participate in voting, the users have the higher voting weight and own the higher reputation of other users in the network. If they receive attacks, they can quickly complete the revocation of the attack’s public key.
- Users with higher security weight enjoy higher tolerance of security misbehavior conducted by themselves. Both the ICN network and the traditional network have their own threshold definition for the occurrence of security attacks based on their own characteristics. However, there are misjudgments in the definition of the threshold. Even if a user enters the scope of the security attack threshold, it may be the normal behavior. In this case, the user with higher security weight can have a higher reputation and error tolerance, in order to avoid unnecessary loss caused by misjudgment.
4.2.2. Rules for Weight Increase and Decrease in Security Weight Value
- When the user participates in the voting process or reports misbehaving and malicious behavior to the network actively, the security weight is increased by one at one time.
- When publishing invalid or other prohibited content, the user’s security weight decreases with the number of times. The first time security weight is reduced by one, the second by two, and so on (the number of times is recorded by SNR nodes).
- If there are verified attacks on other users or SNR nodes in the network, the first-time attacking user’s security weight is halved and warned, and the second time, the public key is directly revoked.
4.2.3. The Initialization of Security Weight
4.2.4. Security Event Level and Blacklist Synchronization Time
- Users need to revoke their public key due to their own reasons, such as suspected key disclosure, and the revocation request is initiated by the user. The security event is primary and the synchronization time is the set PKBL synchronization cycle time.
- When a user publishes invalid content many times, the security weight is reduced to the set threshold, and the public key revocation request is initiated by the SNR nodes; then, the security event is intermediate, and the synchronization delay of the PKBL blacklist is half of the primary event.
- The malicious behavior of the user is reported by other nodes, and the revocation is initiated by the attacked node. The security event is advanced. After the revocation of the public key in the domain is completed, the SNR node directly synchronizes the list to the whole network.
4.3. Voting Procedure
4.3.1. Initiated Revocation Request
4.3.2. Vote Accumulation Stage
4.3.3. Synchronization Revocation Result
4.3.4. Synchronization Blacklist
| Algorithm 1 Voting procedure of neighbor subscribes Ex |
| Input:Mir |
| Output: A voting message VMxr |
|
| Algorithm 2 Voting information statistics of publisher Ei |
| Input:VMxr, thcs Output: A voting success or fail message, A voting list RVWL1
|
4.4. Threshold Setting Standard
5. Security Analysis
5.1. Security of the Voting Scheme
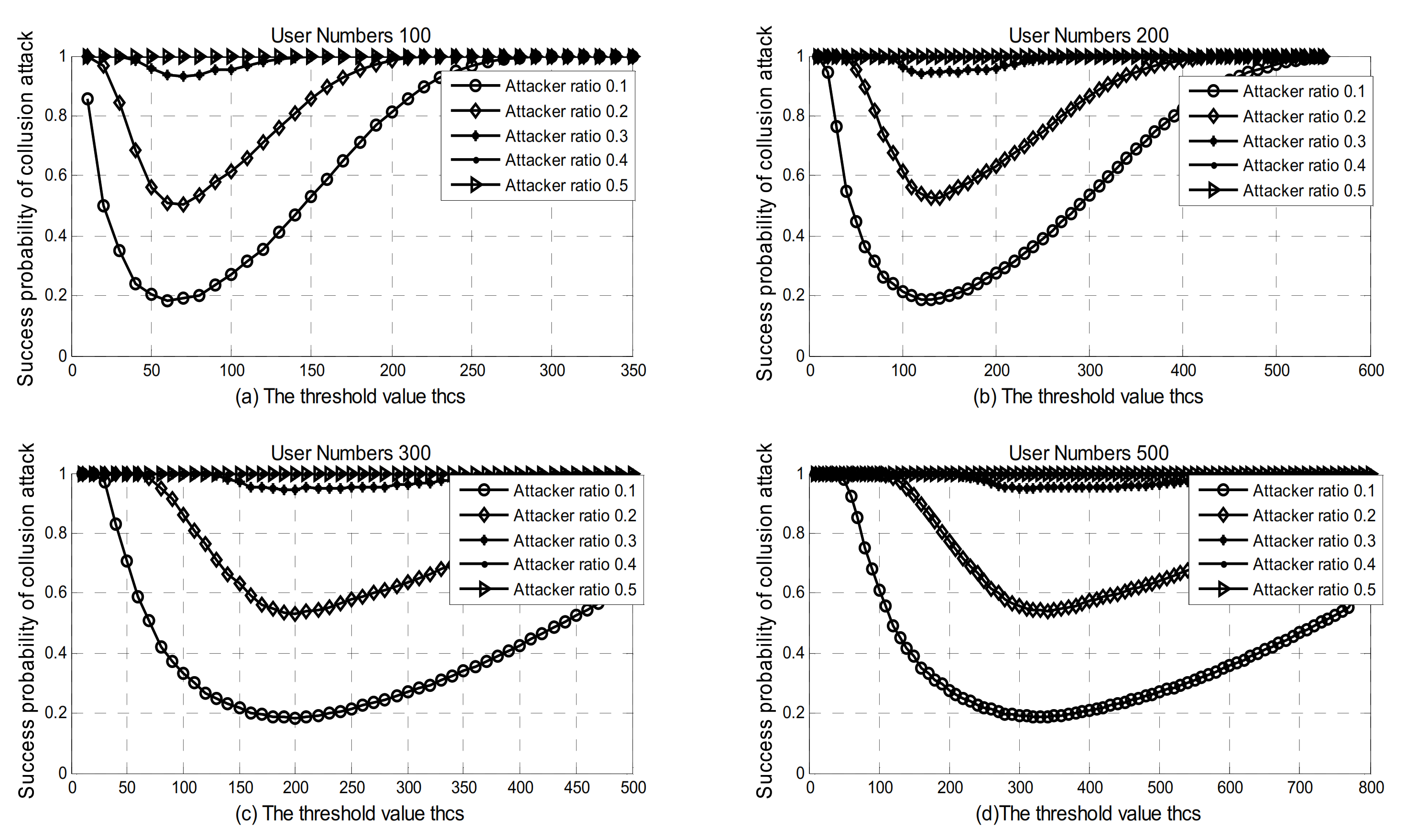
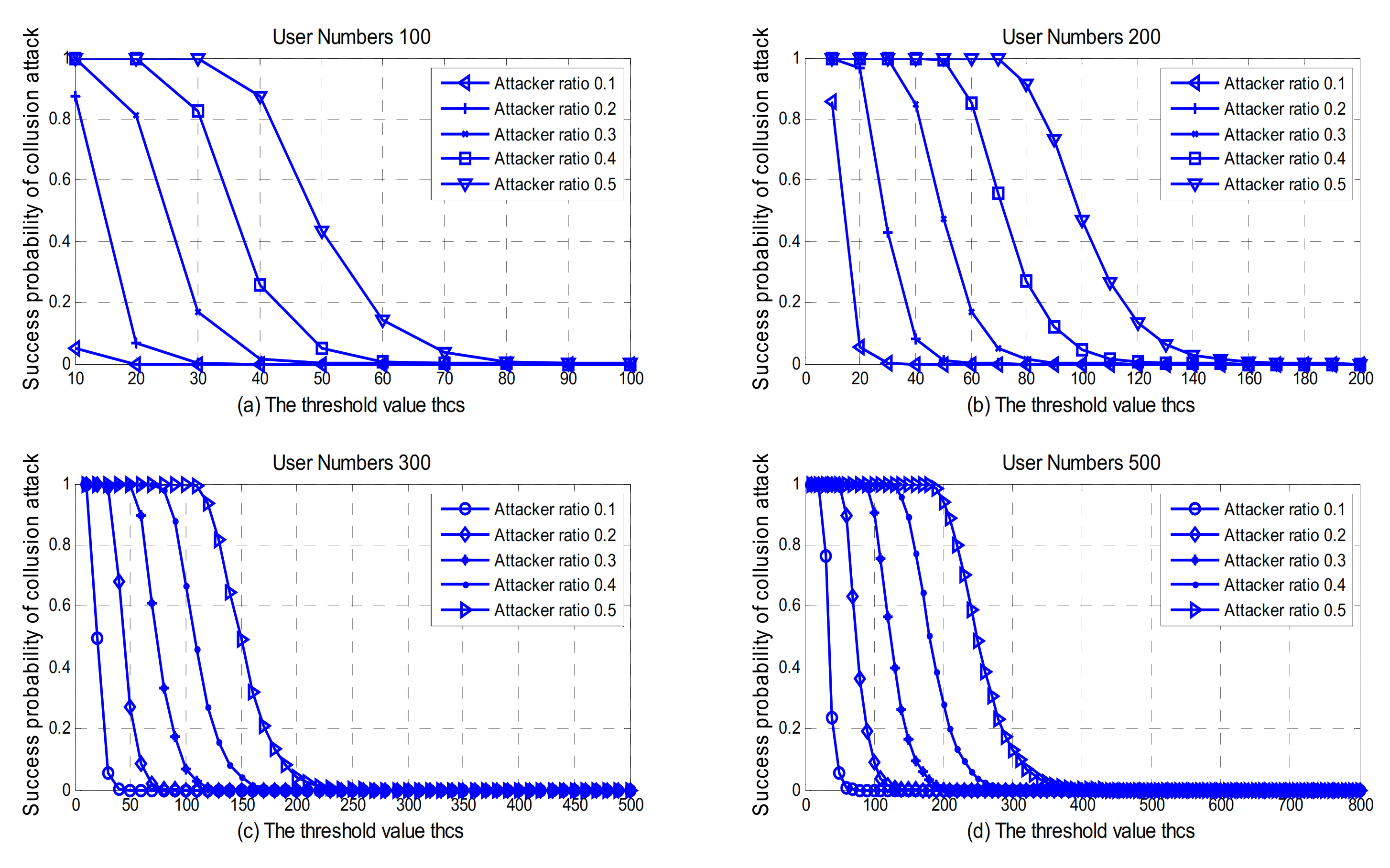
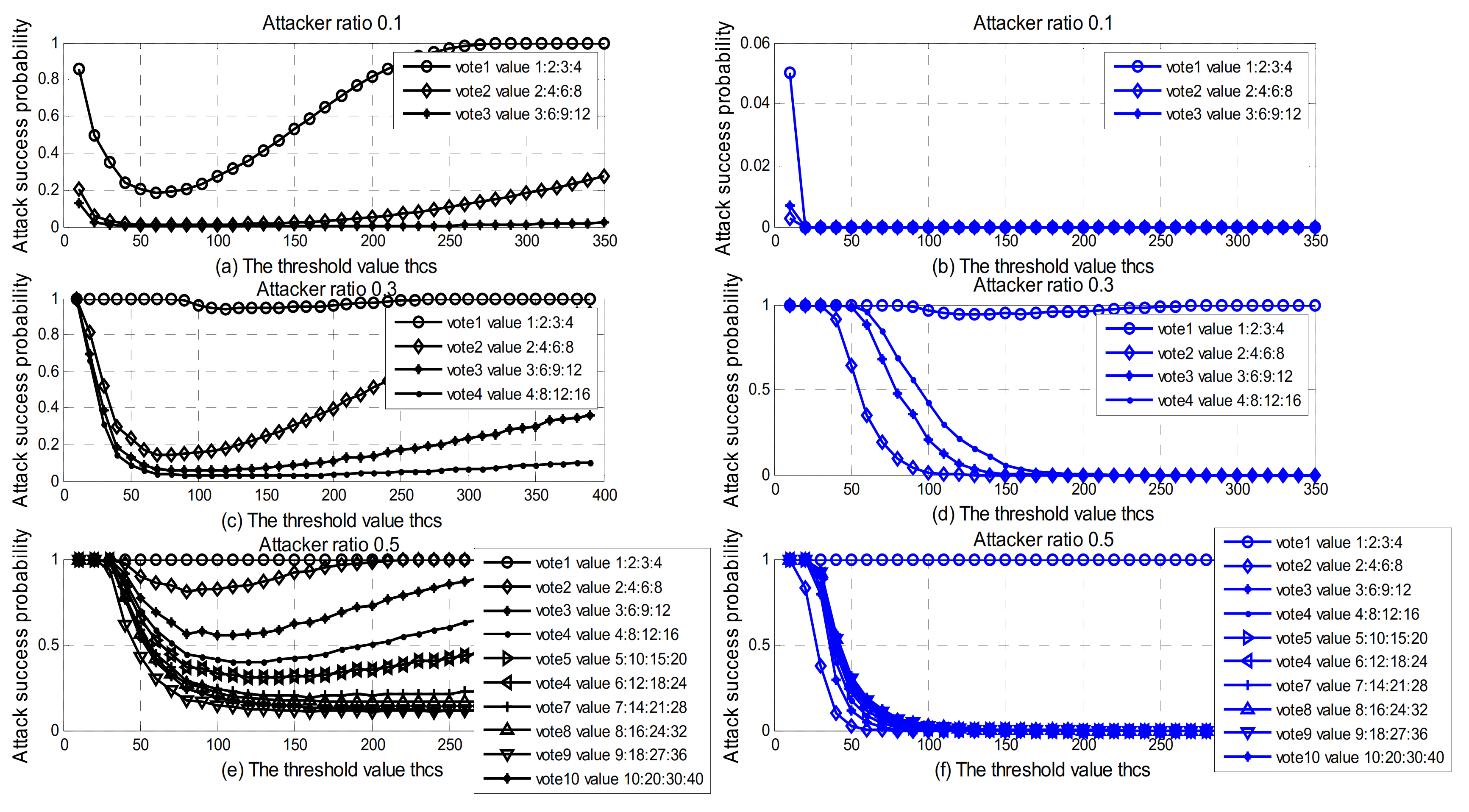
5.2. Collusion Attack and Independent Vote
5.3. Malicious User Mobility
5.4. Revocation Information Forged
5.5. Defense against Common Attacks of ICN
6. Performance Evaluation
6.1. Communication Overhead
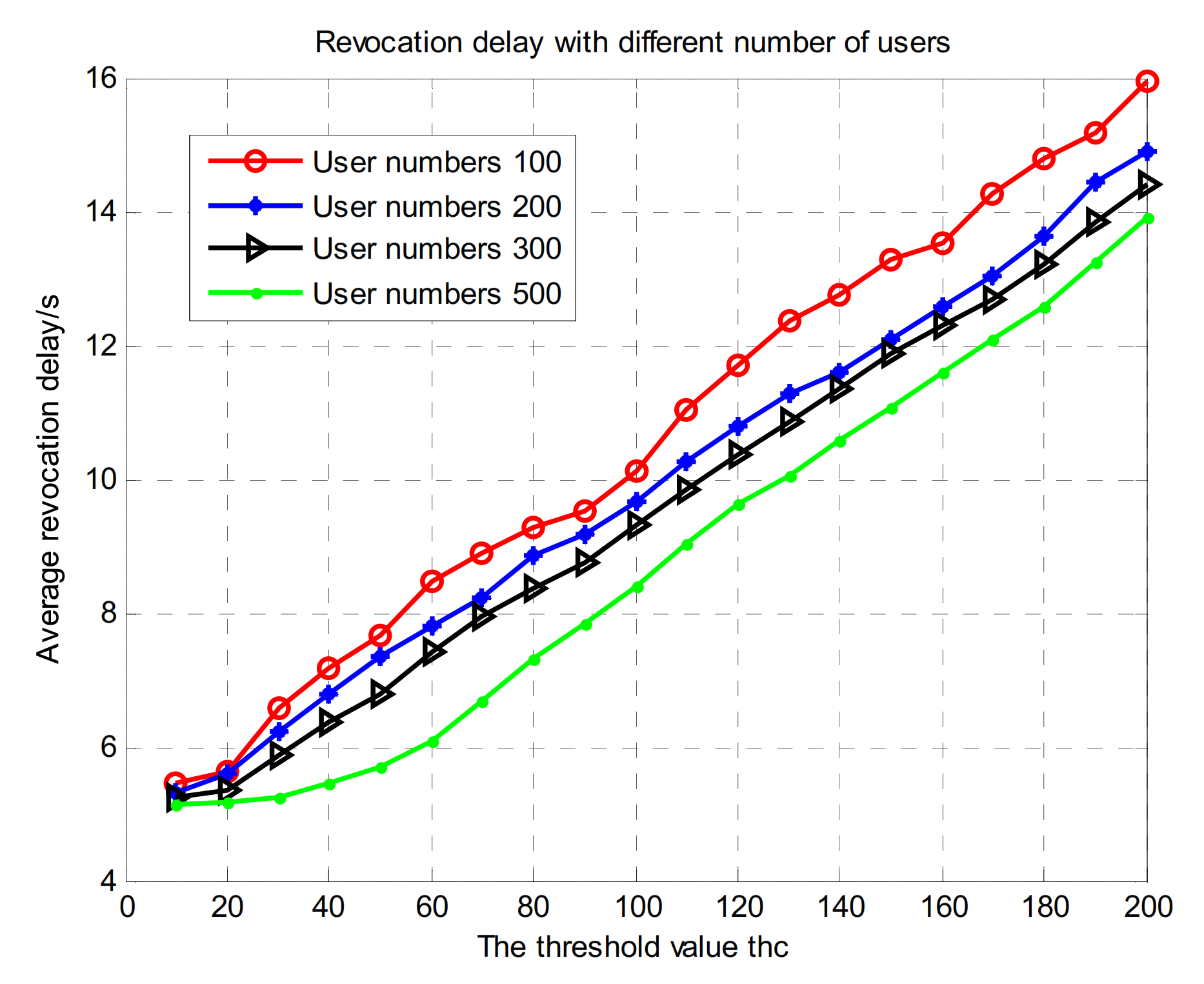
6.2. Average Revocation Delay

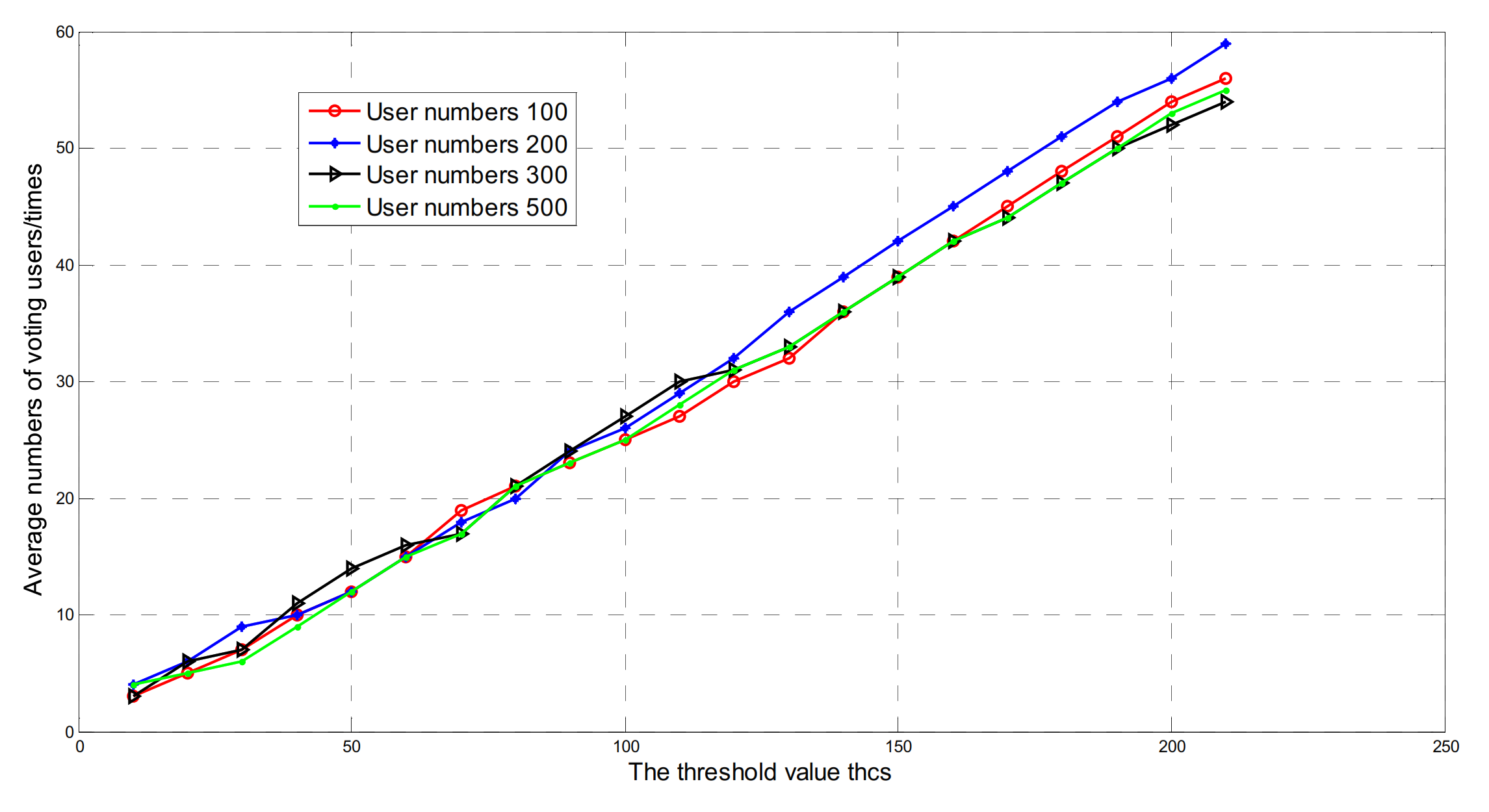
6.3. Average Number of Users Needed to Vote
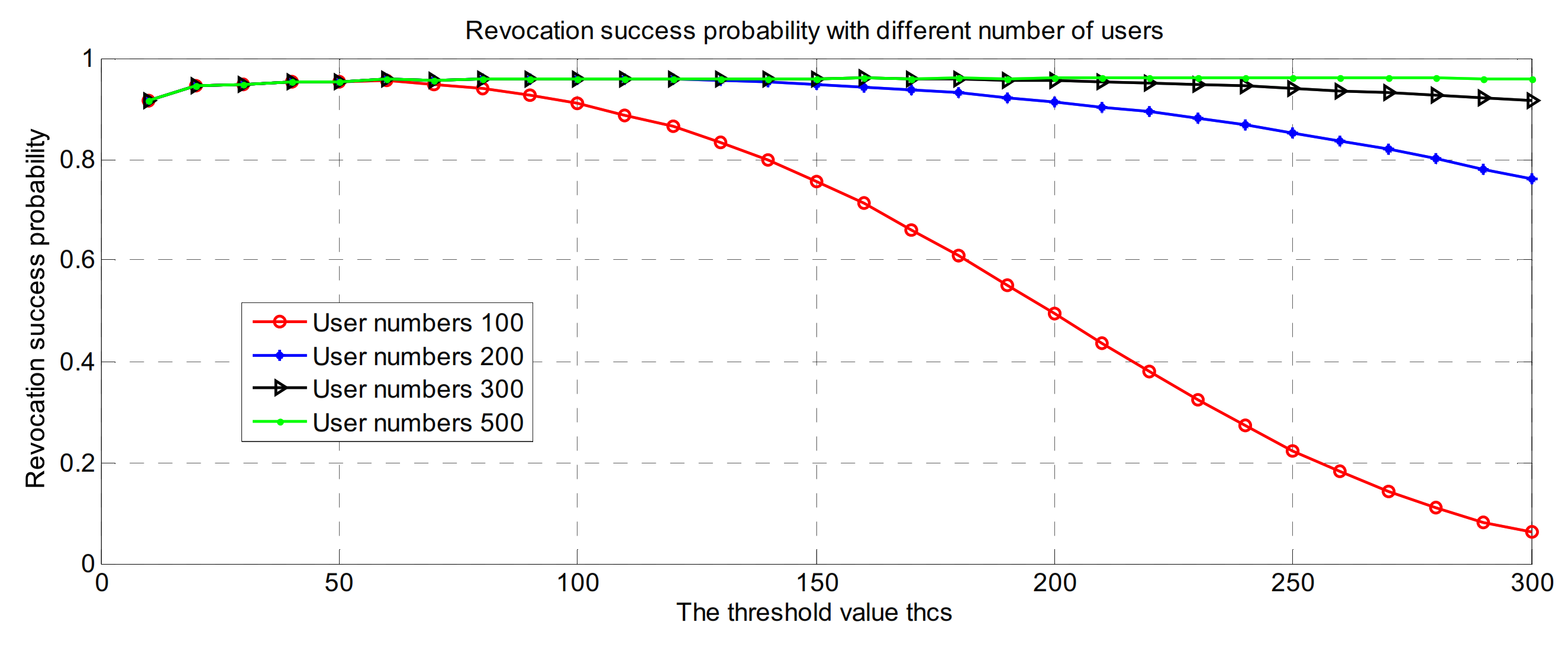
6.4. Selection of Threshold Value thcs
- As the number of users in the domain increases, the threshold thcs for the lowest successful attack probability also increases.
- When the number of users in the domain is constant, the greater the voting weight, and the lower the probability of successful attack.



7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xylomenos, G.; Ververidis, C.N.; Siris, V.A.; Fotiou, N.; Tsilopoulos, C.; Vasilakos, X.; Katsaros, K.V.; Polyzos, G.C. A survey of information-centric networking research. IEEE Commun. Surv. Tutor. 2013, 16, 1021049. [Google Scholar] [CrossRef]
- D’Ambrosio, M.; Dannewitz, C.; Karl, H.; Vercellone, V. MDHT: A hierarchical name resolution service for information-centric networks. In Proceedings of the ACM SIGCOMM Workshop on Information-Centric Networking, Toronto, ON, Canada, 19 August 2011; pp. 7–12. [Google Scholar]
- Dong, L.; Wang, G. A hybrid approach for name resolution and producer selection in information centric network. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; p. 57580. [Google Scholar]
- Chen, Z.; Meng, H.W.; Guan, Z. Research on intrinsic security in future internet architecture. J. Cyber Secur. 2016, 1, 10–13. [Google Scholar]
- Koponen, T.; Chawla, M.; Chun, B.-G.; Ermolinskiy, A.; Kim, K.H.; Shenker, S.; Stoica, I. A data-oriented (and beyond) network architecture. In Proceedings of the ACM SIGCOMM, Kyoto, Japan, 27–31 August 2007. [Google Scholar]
- Raychaudhuri, D.; Nagaraja, K.; Venkataramani, A. MobilityFirst: A Robust and Trustworthy Mobility- Centric Architecture for the Future Internet. ACM SIGMobile Mob. Comput. Commun. Rev. 2012, 16, 2–13. [Google Scholar] [CrossRef]
- Fotiou, N.; Nikander, P.; Trossen, D.; Polyzos, G. Developing information networking further: From PSIRP to PURSUIT. In Proceedings of the International Conference on Broadband Communications, Networks and Systems, Athens, Greece, 25–27 October 2010; pp. 1–13. [Google Scholar]
- 4WARD: Web Site (2010). Available online: http://www.4ward-project.eu (accessed on 8 October 2021).
- Ohlman, B.; Karl, H.; Ahlgren, B.; Farrell, S.; Dannewitz, C.; Kutscher, D. Network of Information (NetInf)—An information-centric networking architecture. Comput. Commun. 2013, 36, 721–735. [Google Scholar]
- Wang, J.; Cheng, G.; You, J.; Sun, P. SEANet: Architecture and Technologies of an On-site, Elastic, Autonomous Network. J. Netw. New Media Technol. 2020, 9, 1–8. (In Chinese) [Google Scholar]
- Edwall, T. Scalable and Adaptive Internet Solutions (Sail). 2011. Available online: https://sail-project.eu/wp-content/uploads/2011/02/SAIL-project-summary.pdf (accessed on 8 October 2021).
- Louati, W.; Ben-Ameur, W.; Zeghlache, D. A bottleneck-free tree-based name resolution system for Information-Centric Networking. Comput. Netw. 2015, 91, 341–355. [Google Scholar] [CrossRef]
- Barakabitze, A.A.; Xiaoheng, T.; Tan, G. A Survey on Naming, Name Resolution and Data Routing in Information Centric Networking (ICN). Int. J. Adv. Res. Comput. Commun. Eng. 2014, 3, 8322–8330. [Google Scholar] [CrossRef]
- Sevilla, S.; Mahadevan, P.; Garcia-Luna-Aceves, J.J. FERN: A unifying framework for name resolution across heterogeneous architectures. Comput. Commun. 2015, 56, 124. [Google Scholar] [CrossRef] [Green Version]
- Hong, J.; Chun, W.; Jung, H. A flat-name based routing scheme for information-centric networking. In Proceedings of the 17th International Conference on Advanced Communication Technology (ICACT), Pyeonhchang, Korea, 1–3 July 2015. [Google Scholar]
- Liao, Y.; Sheng, Y.; Wang, J. A deterministic latency name resolution framework using network partitioning for 5G-ICN integration. Int. J. Innov. Comput. Inf. Control. 2019, 15, 1865–1880. [Google Scholar]
- Loo, J.; Aiash, M. Challenges and solutions for secure information centric networks: A case study of the netinf architecture. J. Netw. Comput. Appl. 2014, 50, 6472. [Google Scholar] [CrossRef]
- Pentikousis, K.; Ohlman, B. Information-Centric Networking: Evaluation Methodology; Technical Report; Internet Draft; Pentikousis, K., Ohlman, B., Davies, E., Spirou, S., Boggia, G., Mahadevan, P., Eds.; 2013; Available online: https://datatracker.ietf.org/doc/draft-irtf-icnrg-evaluation-methodology/00/ (accessed on 8 October 2021).
- Loo, J.; Aiash, M. An integrated authentication and authorization approach for the network of information architecture. J. Netw. Comput. Appl. 2014, 50, 7379. [Google Scholar]
- Aiash, M.; Loo, J. A formally verified access control mechanism for information centric networks. In Proceedings of the 12th International Conference on Security and Cryptography, Colmar, France, 20–22 July 2015; Volume 4, pp. 377–383. [Google Scholar]
- Gouge, J.; Seetharam, A.; Roy, S. On the scalability and effectiveness of a cache pollution-based DoS attack in information centric networks. In Proceedings of the International Conference on Computing, Networking and Communications, Kauai, HI, USA, 15–18 February 2016; pp. 1–5. [Google Scholar]
- Xie, M.; Widjaja, I.; Wang, H. Enhancing cache robustness for content-centric networking. In Proceedings of the IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2426–2434. [Google Scholar]
- Zhu, Y.; Shi, J.; Gong, P.; Cao, Q.; Su, D. Collaborative detection mechanism for low-rate cache pollution attack in named data networking. J. Beijing Univ. Posts Telecommun. 2015, 38, 44–48. [Google Scholar]
- Conti, M.; Gasti, P.; Teoli, M. A lightweight mechanism for detection of cache pollution attacks in Named Data Networking. Comput. Netw. 2013, 57, 3178–3191. [Google Scholar] [CrossRef]
- Li, M.; Sun, Y.; Lu, H.; Maharjan, S.; Tian, Z. Deep reinforcement learning for partially observable data poisoning attack in crowdsensing systems. IEEE Internet J. 2020, 7, 6266–6278. [Google Scholar] [CrossRef]
- Yao, L.; Fan, Z.; Deng, J.; Fan, X.; Wu, G. Detection and defense of cache pollution attacks using clustering in named data networks. IEEE Trans. Dependable Secur. Comput. 2020, 17, 1310–1321. [Google Scholar] [CrossRef]
- Raya, M.; Papadimitratos, P.; Aad, I.; Jungels, D.; Hubaux, J.-P. Eviction of misbehaving and faulty nodes in vehicular networks. IEEE J. Sel. Area. Commun. 2007, 25, 1557–1568. [Google Scholar] [CrossRef] [Green Version]
- Matsumoto, S.; Reischuk, R.M. IKP: Turning a PKI around with decentralized automated incentives. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 410–426. [Google Scholar]
- Lu, Z.; Wang, Q.; Qu, G.; Liu, Z. BARS: A Blockchain-Based Anonymous Reputation System for Trust Management in VANETs. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy In Computing And Communications, New York, NY, USA, 1–3 August 2018; pp. 98–103. [Google Scholar]
- Asghar, M.; Pan, L.; Doss, R. An efficient voting based decentralized revocation protocol for vehicular ad hoc networks. Digit. Commun. Netw. 2020, 6, 422–432. [Google Scholar] [CrossRef]
- Song, Y.; Ni, H.; Zhu, X. Analytical Modeling of Optimal Chunk Size forEfficient Transmission in Infor mation-Centric Networking. Int. J. Innov. Comput. Inf. Control. 2020, 16, 1511–1524. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNi | Mi | thc | UIDi | Pubi | Pubr/Contr | Ti | Sigi | αi | SWi |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 64 | 1 | 32 | 64 | 64 | 2 | 64 | 1 | 1 |
| CNi | SWx | UIDx | Pubx | αx | Sigx |
|---|---|---|---|---|---|
| 4 | 1 | 32 | 64 | 1 | 64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Zeng, X.; Li, Y. A Register Access Control Scheme for SNR System to Counter CPA Attack Based on Malicious User Blacklist. Future Internet 2021, 13, 262. https://doi.org/10.3390/fi13100262
Shi J, Zeng X, Li Y. A Register Access Control Scheme for SNR System to Counter CPA Attack Based on Malicious User Blacklist. Future Internet. 2021; 13(10):262. https://doi.org/10.3390/fi13100262
Chicago/Turabian StyleShi, Jia, Xuewen Zeng, and Yang Li. 2021. "A Register Access Control Scheme for SNR System to Counter CPA Attack Based on Malicious User Blacklist" Future Internet 13, no. 10: 262. https://doi.org/10.3390/fi13100262
APA StyleShi, J., Zeng, X., & Li, Y. (2021). A Register Access Control Scheme for SNR System to Counter CPA Attack Based on Malicious User Blacklist. Future Internet, 13(10), 262. https://doi.org/10.3390/fi13100262