Systematic Evaluation of LibreSocial—A Peer-to-Peer Framework for Online Social Networks



Abstract
1. Introduction
2. Benchmarking P2P Systems
2.1. P2P Benchmarking Model
2.2. P2P Quality Properties and Relevant Metrics
2.2.1. Workload-Independent Quality Properties
- Performance: For a feel of the system’s performance, aspects to consider are responsiveness (how fast the system reacts), throughput (how much load that system can handle in a given time frame) and the extent to which the results match the expectation. The metrics chosen for performance measurements are hop-count, storage time (), retrieval time (), message sending rate () and message receiving rate ().
- Cost: This property describes the amount of resources that are used to ensure a given task is fulfilled or a service is provided. Relevant cost metrics are used storage space, used memory and network bandwidth.
2.2.2. Workload-Dependent Quality Properties
- Stability: This describes the system’s ability to continue performing despite inherent system behavior dynamics, such as high churn rate, and eventually converge to a stable state if the workload remains the same. Stability correlates to resilience under adverse conditions, i.e., sudden changes that may occur in the system architecture due to the workload. These changes may be expected since the defined protocols account for them, or unexpected because the protocols do not consider them. To ascertain the level of stability, the system needs to be evaluated against a baseline to show the relative differences of a particular parameter from the stable, baselined system. The relevant metrics are number of nodes in the network at any given time, the leafset size, routing table size, memory size, number of messages sent and the messaging rate, the amount of data transferred and the data transfer rate, the data items stored and the number of replicas, and the DDS data stored.
- Scalability: Revolves around the system’s ability to handle changing workloads. Two scaling dimensions are considered: horizontal which affects number of peers in the system, i.e., increase and decrease in the number of peers in the network, and vertical which concerns the ability of the P2P system to handle increasing workload from the participating peers. For this study, the focus was on horizontal scaling. The relevant metrics that will be looked at are the same as in the case of stability.
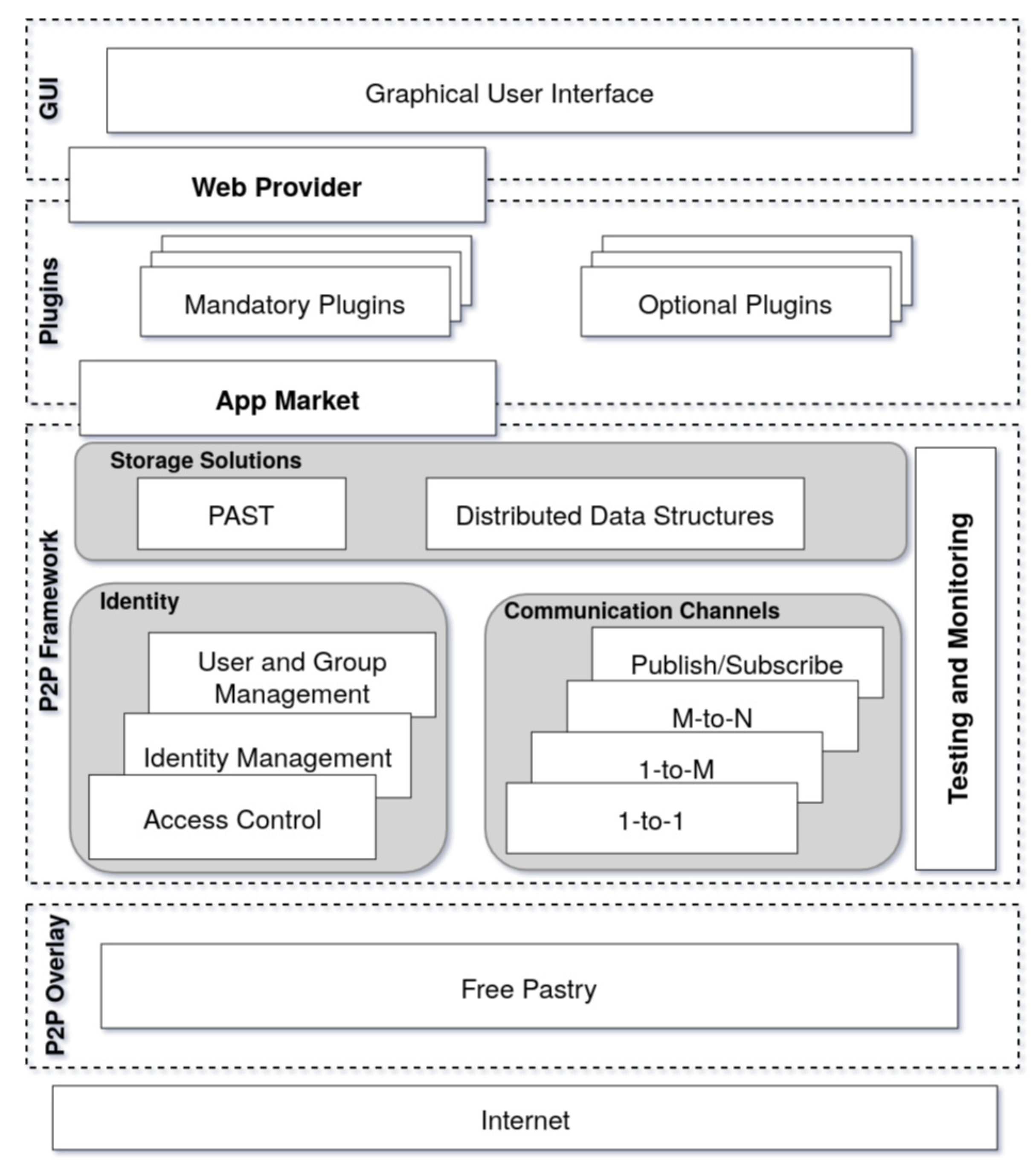
3. A P2P Framework for Online Social Networks
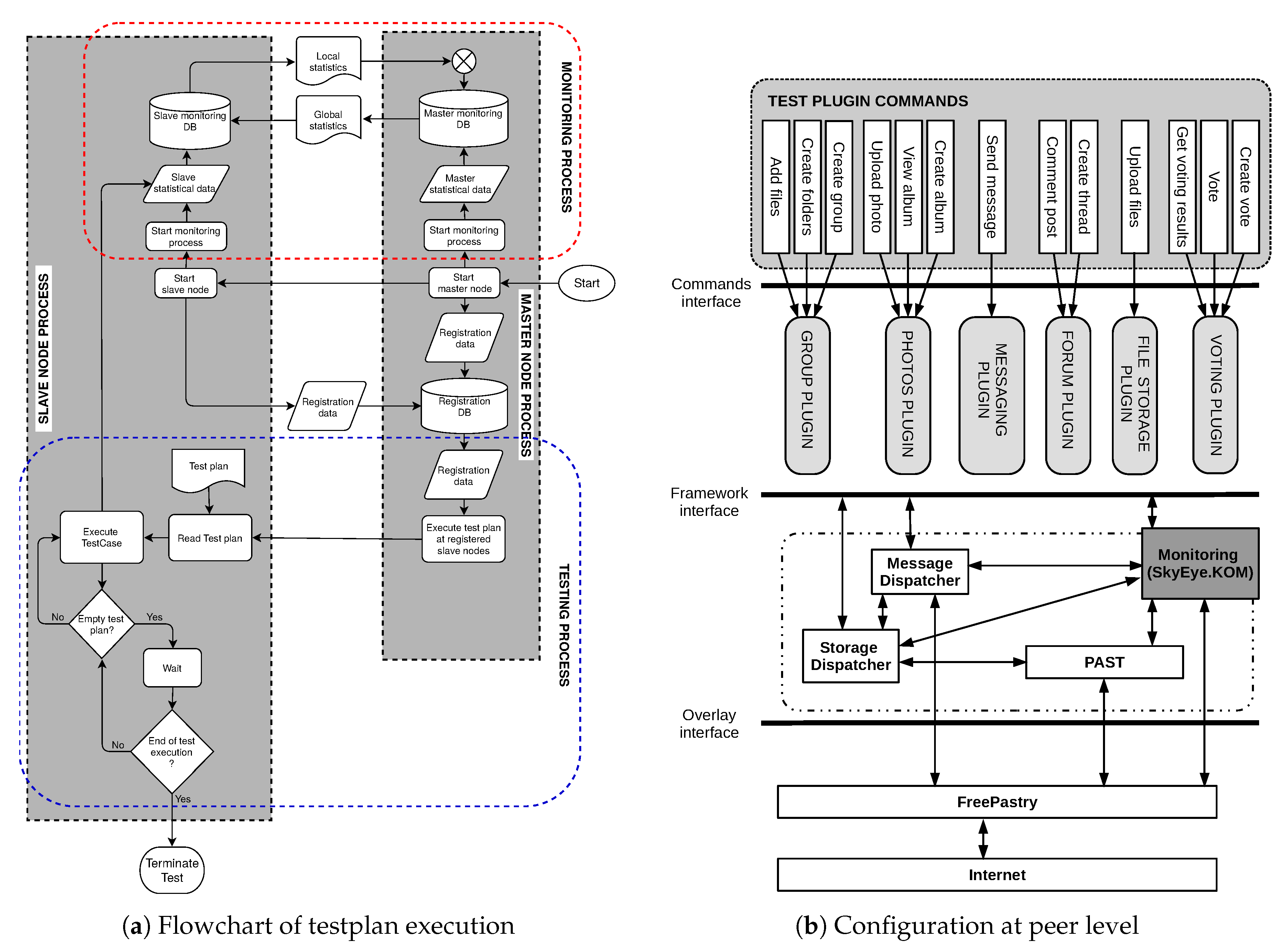
3.1. P2P Overlay
3.2. P2P Framework
3.2.1. Storage
3.2.2. Communication
3.2.3. Identity
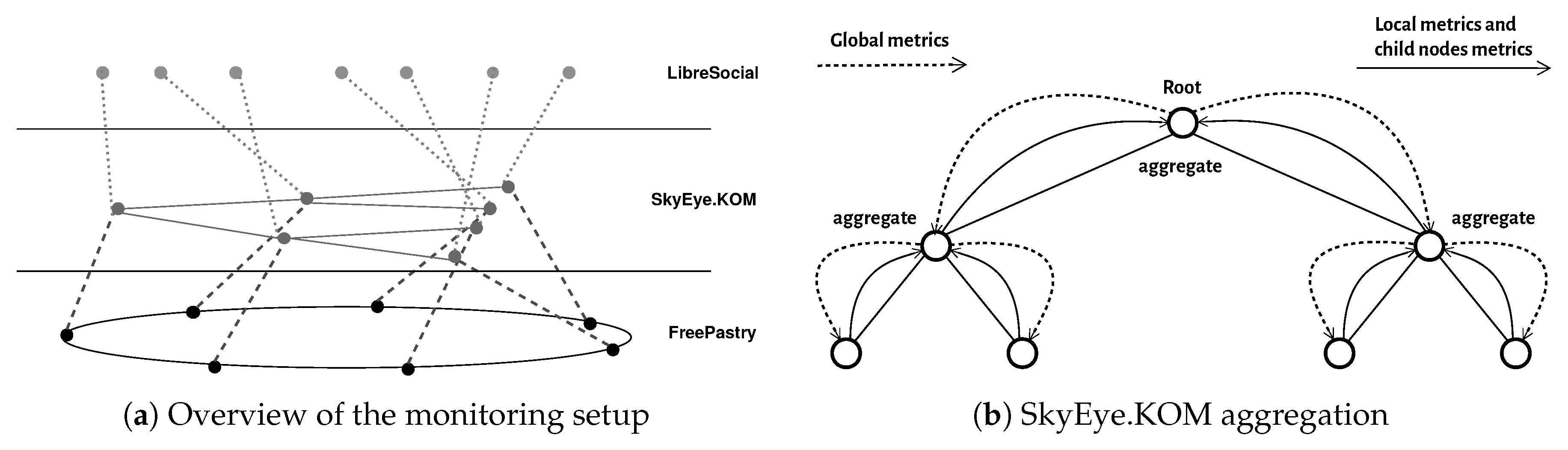
3.2.4. Testing and Monitoring
3.3. Plugins and Application
3.4. Graphical User Interface (GUI)
4. The Test Environment
4.1. Workload
4.1.1. Baseline Tests: Plugin Analysis
4.1.2. Pseudo-Random Behavior
4.1.3. Scalability/Stability
- (i)
- Phase 1-Network growth: The test begins with 250 nodes, which is incremented in steps of 250 nodes representing 100%, 50% and 33.3% increments, respectively. At each step, the workload shown in Table 4 is executed.
- (ii)
- Phase 2-Network churn: Once we reach 1000 nodes, i.e., at the end of the network growth phase, joined the network, the churn phase begins. 250 nodes are removed a step-wise manner similar to network growth, representing, a 25%, 33.3% and 50% churn, until the network has only 250 nodes. Similar to the growth phase, after each churn, the workload is again executed.
4.1.4. Replication Factor
4.2. Test Execution and Data Collection
5. Evaluation of Results
5.1. Baseline Tests: Plugin Analysis
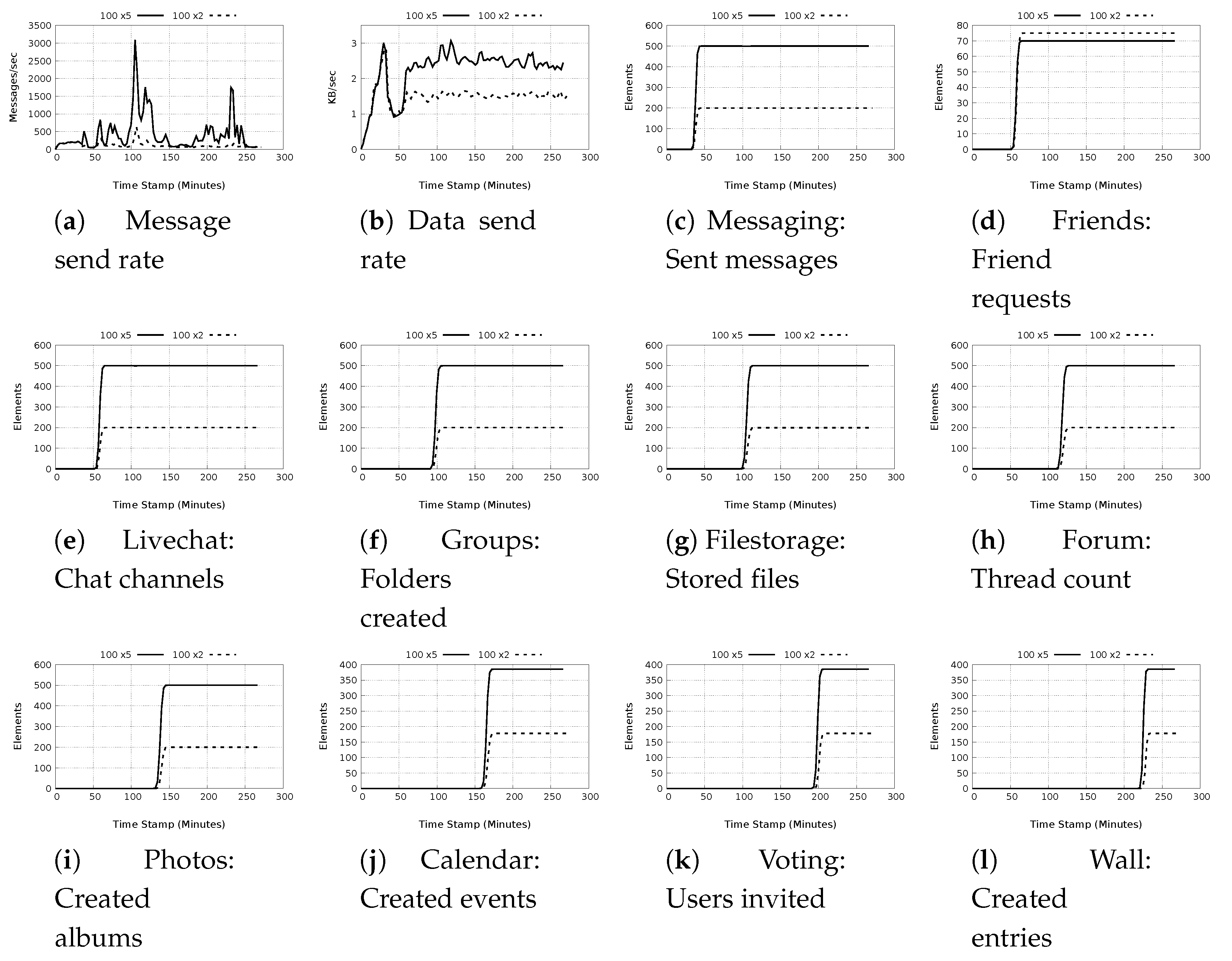
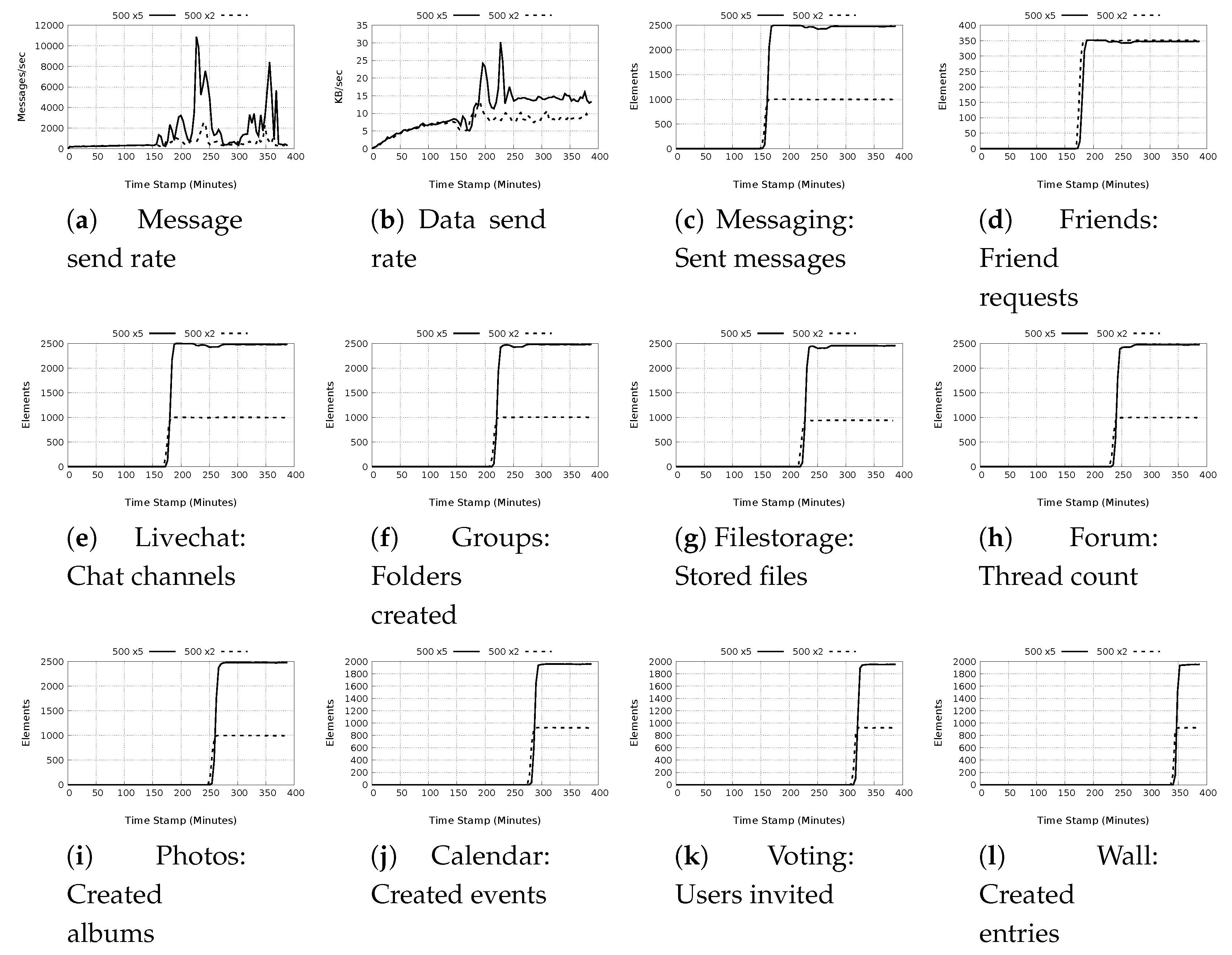
5.1.1. Plugin Actions
5.1.2. Test Completion Times
5.1.3. Message and Data Rates Characteristics
- a)
- Low message and low data rates: These test cases result in lower than 1000 messages/sec with data rates not exceeding 10 Kb/s. The majority of the test in this groups focus on data retrieval as opposed to acting on the data. With the use of the available caching mechanisms, it is expected that there will be only minimal messaging as well as network calls. The exception to this observation is the Create Calendar action, which is a local action rather than a global action with data replication for redundancy, and the livechat message which sends a short message that does not include large data. The actions in this class are associated with four plugins, Calendar, Livechat, Messaging and Photos.
- b)
- High message and low data rates: The test cases classified in this group are characterized as having message rates above 100 and less than 15,000 messages/sec with data rate not exceeding 15 Kb/s. The plugin actions in this class are associated with Filestorage, Forum, Photo, Voting and Wall plugins. Of particular interest is the Forum, Photo voting and wall plugins because they use DDSs to store data. Most of the plugin actions in this category make repeated calls for the DDSs relating to the data requested with each call resulting in significant messaging as the entire DDS is retrieved.
- c)
- High message and high data rates: These tests have the largest overall impact on the message and data rates. The message rates range from 500 to slightly less than 23,000 messages/sec. The highest data rates recorded is 51.98 Kb/s observed for the plugin Filestorage store files action in the 500 node test with light workload. The actions in this classification are associated with Filestorage, Forum, Group, Messaging and Livechat. The actions, such as store files by the Filestorage plugin, or send message by the Messaging plugin generate high messages as well as data because they use DDSs.
5.2. Pseudo-Random Behavior
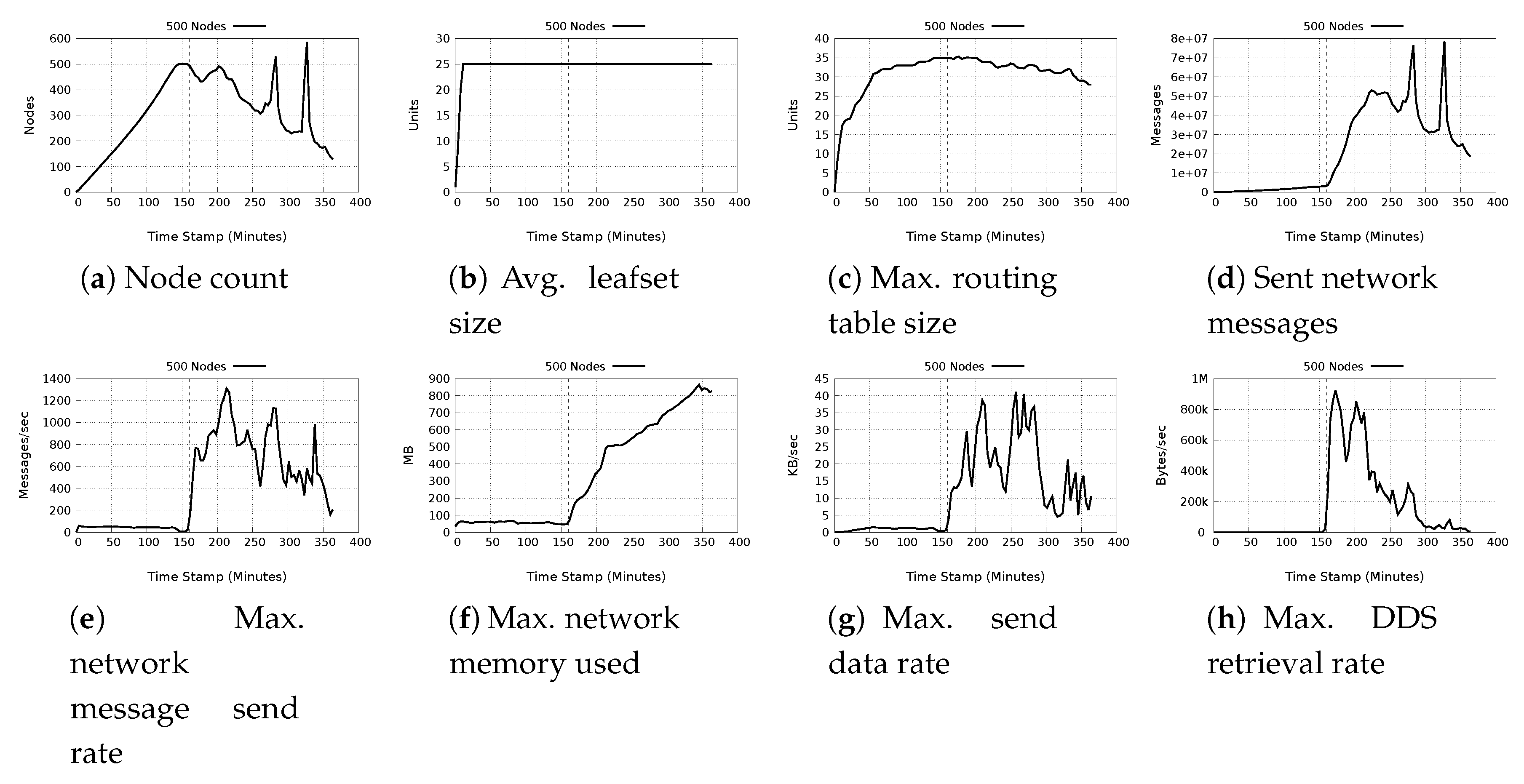
5.3. Stability and Scalability
- a)
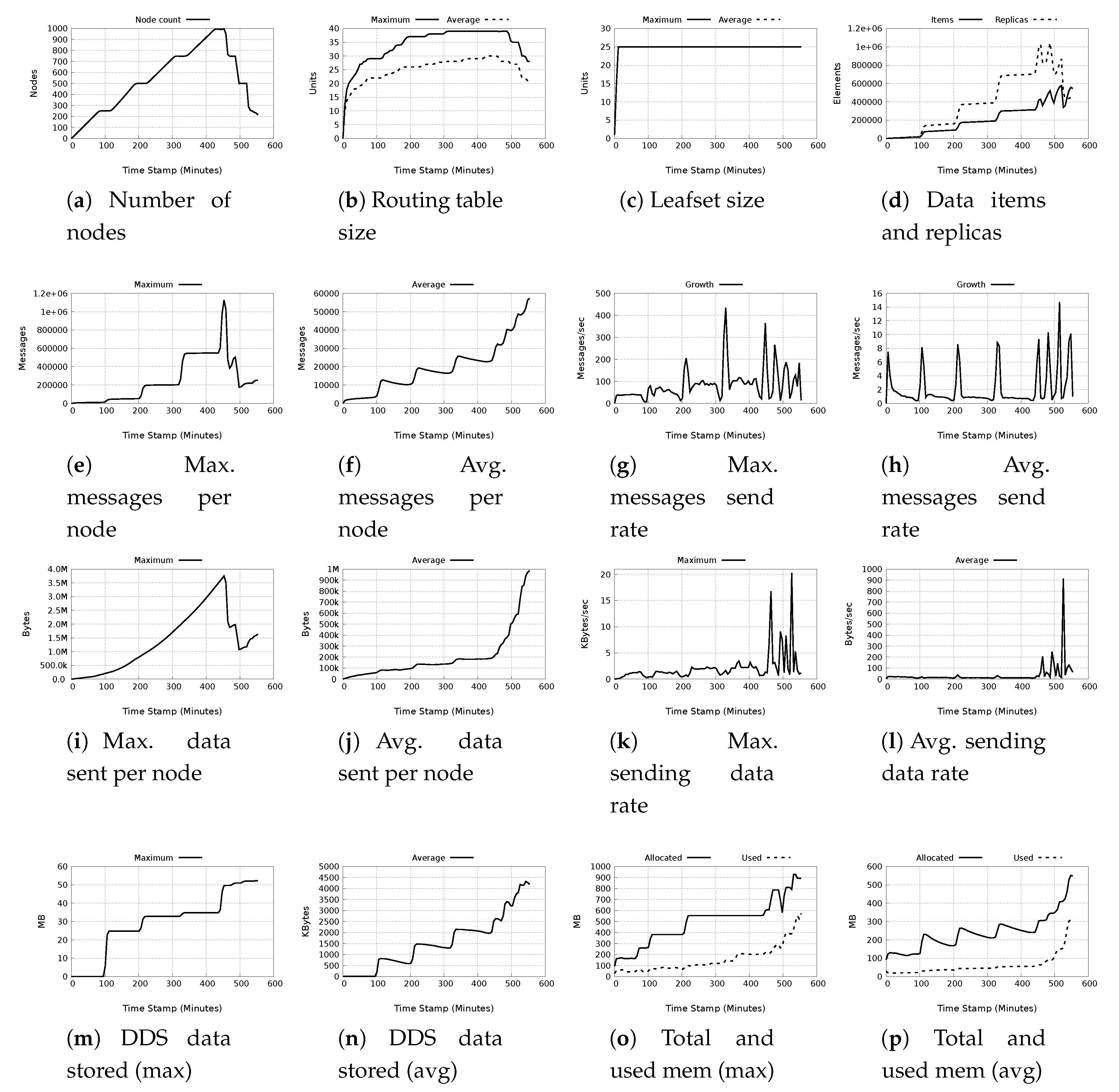
- Node count: Throughout the experiment, the node count is stable both in the growth and churn phases as depicted in Figure 9a. There is also seamless transition from the growth phase into the churn phase. As the network is able to support up to 1000 nodes, we can deduce that the system can be easily scale up. During the churn phases, we notice that despite massive churn, (of up to 50%), the network remains operational.
- b)
- Routing table size: Figure 9b shows the maximum and average table size for a single node through the experimental duration. Observable is a corresponding adjustment of the routing table during the growth phase as well as during churn. The maximum value recorded is 39 nodes, but on average, the maximum is 30 nodes. Despite the relatively high growth (as well as churn) the routing table size does not significantly alter. If we take 250 nodes in the network as the base, hence a maximal value of 29 nodes and average of 22 nodes for the routing table size, the routing table maximally adds about 10 nodes and on average up to 9 nodes during the entire growth phase, and looses the same number of nodes during the entire churn phase. This means the the routing table adjusts accordingly to meet the demands of the network.
- c)
- Leafset size: From Figure 9c, we observe that the leafset is maintained at 25 nodes. The experimental setting for the leafset size is 24 nodes. The additional value is because the first and last value in the leafset is the node’s own ID. As the network has more nodes than 25, it is expected that the average and maximum values for the leafset size will be the same.
- d)
- Stored data items and replicas: The replication factor for the experiment is set to 4. It would be therefore expected that the number of replicas should be at least 3 times more than the local items. However, each node also stores some replica, which become local to it. That notwithstanding, we note that generally, there is about twice as many replicas as locally stored data items. This holds true throughout the experimental duration, except at the last churn, for which the network is reduced by 50%. This may have caused a drastic reduction in the number of replicas, but nonetheless, some are still present.
- e)
- Messages sent: The maximum and average messages sent in a single node are shown in Figure 9e,f respectively. There is a steady rise in messages sent per node in the growth phase, evident in both figures, with the maximum value recorded being about 1.1 million messages by a single node corresponding to the end of the growth phase. On average, during the growth phase, the maximum value is about 25,000 messages, which is acceptable. During the churn phase, we observe different characteristics from the two figures. While the maximum messages per node shows a sharp decline to a value of about 200,000 messages, the average messages show a sharp increase to a value of 58,000 messages. This rise in average messages may be due to route adjustment queries as nodes are removed from the network and new routes have to be established.
- f)
- Message send rate: The maximum and average rates are shown in Figure 9g,h respectively. The maximum recorded message rate is about 430 messages/sec corresponding to the last increment of growth phase. Essentially, the maximum message rate during growth oscillates around 100 messages/sec. The average value for the message rate on the other hand, reaches a maximum during the last step of churn, with a value of about 15 messages/sec. On average, the message rage oscillates between 1 and 10 messages/sec.
- g)
- Data sent: The values recorded for maximum and average data sent per node are shown in Figure 9i,j. Both figures show a direct correlation with the messages sent. The maximum recorded value for data sent by a single node is about 3.7 MB which is seen at the end of the growth phase which then drops to a minimum of slightly more than 1.0 MB during the churn phase. On the average values, during the growth phase, we see a steady rise in data sent to reach 190 kB at the end of the growth phase. During the churn phase however, rather than a decline, there is a sharp rise in data sent, reaching just below 1.0 MB at the end of the experiment. This sharp rise just as in the case of messages stored may be due to high messaging, as well as readjustments in replica placements for nodes still in the network.
- h)
- Data send rate: Figure 9k,l show the maximum and average data sending rates. During the growth phase, the maximum sending rate hardly exceeds 2.5 kB/s. However, during the churn phase, especially as nodes leave the network, there are significant surges in the data rate, with a maximum data rate of 20 KB/s during the last step of churn. On average, the values are quite different. During growth phase, the data rate hardly exceeds 20 bytes/sec, and just as in the case of maximum data send rates, the average shows surges during the churn phase, with a notable high of 900 bytes/sec at the last churn step. The reason for this phenomenon is explained in the same way as the messages stored and data sent.
- i)
- DDS data stored: The maximum and average DDS data stored are shown in Figure 9m,n, respectively. During the growth phase, there is an increase in the DDS data after the first growth step. No DDS data is recorded during the first growth phase as the workload is yet to be executed. At the end of the growth phase, the DDS data stored is maximum size of DDS data stored is about 34 MB, with the average maximum size being 2 MB. During the churn phase, rather than a decline, there is an increase in the amount of DDS data stored per node, reaching a maximum of about 52 MB and an average maximum of 4.3 MB just before the end of the experiment.
- j)
- Total and used memory: A comparison of the maximum and average values for total allocated and used memory is shown in Figure 9o,p, respectively. We note that both the maximum and average for allocated memory correlate with the graphs for messages sent and DDS data stored. This is indicative of the fact that messages sent and DDS data stored has a large impact on the memory allocated. The maximum memory allocated is 900 MB, and the average maximum is about 550 MB. However, the memory that is used is less than half of the allocated memory. The maximum used is about 580 MB and the average maximum used memory is about 300 MB.
5.4. Effect of the Replication Factor
5.4.1. System Performance
- a)
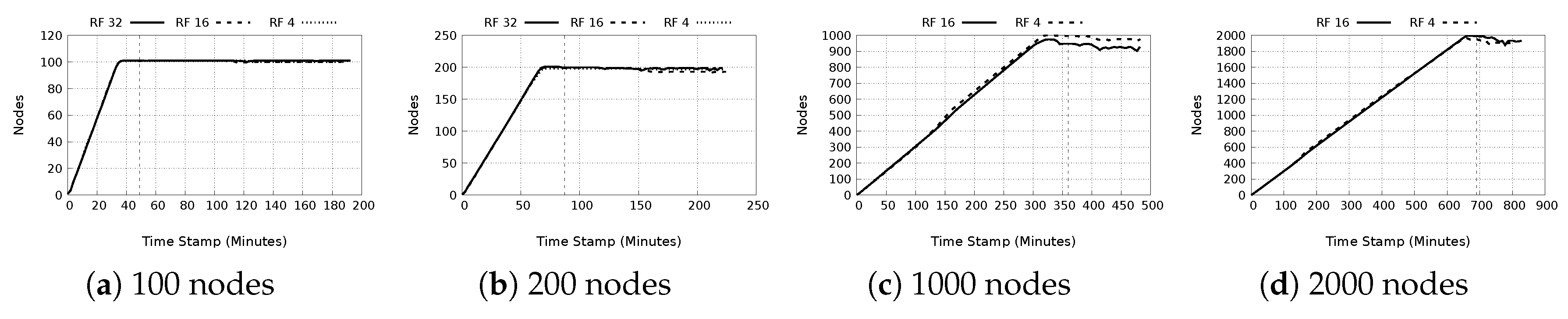
- Node count: Figure 10a–d portray the behavior nodes in the systems. The figures indicate successful monitoring of the network nodes, and in general the network, which is stable throughout the experimental period. Of note, is the slight reduction by about 100 nodes for both the 1000 and 2000 nodes experiments. A possible reason for this, evident from the logs, is that the nodes experienced insufficient memory errors resulting in overall node failure. However, this did not affect the aggregation of monitored statistics in the network.
- b)
- Hop count: The hop count for the experiments are given in Figure 11a–d. In general, the number of hops from sender to receiver is 1 because the number of nodes in the experiments do not exceed the maximum possible limit for the routing table of entries. Hence the average hop counts tends to be less than one in the network. It is however observed that as the network gets larger, there is less disparity in the network as the graphs show an overlap, as is the case with 1000 and 2000 node graphs.
- c)
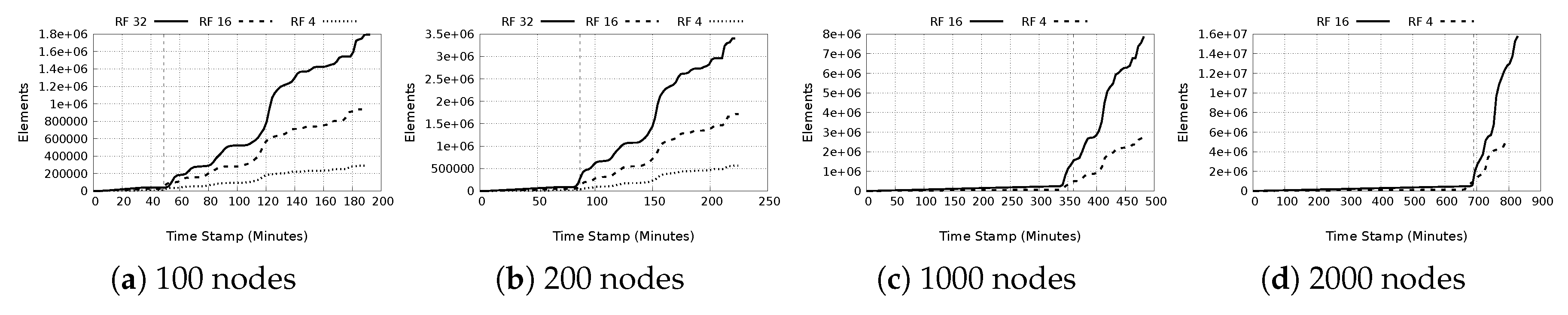
- Number of replicas: As the number of nodes increases, as can be seen in Figure 12a–d, the number of data replicas data also increases as well. In addition, with increasing replication factor, there is an equivalent increase in the replicas with the same magnitude, which is expected.
- d)
- Storage time: From Figure 13a–d, two important observations can be made. First is that increasing the number of nodes results in increased maximum storage time, although the increase is in the order of milliseconds, hence can be ignored. The second more significant deduction is that increasing the replication factor results in increased maximum storage time. In general, the average storage times, as shown in Table 8, are less than one second, but we note the extreme cases of maximum storage time in the order of 10 s of seconds, particularly the 2000 node experiment with replication factor of 4, which recorded a maximum storage time of 91 s. Bearing in mind that storage time includes time to store replicas, it is possible that this discrepancy may be related to storage of data related to distributed data structures such as wall posts and forum threads, which must be distributed and replicated at the same time.
- e)
- Retrieval time: This is shown in Figure 14a–d. The same observations as with storage time are also seen here. Again, we make the deduction that large retrieval times are related to distributed data structures. Interestingly, even with more replicas in the network, the maximum retrieval time does not significantly drop. The average system retrieval times are still less than one second. A significant observation is that for the 100 node tests, for replication factor of 16, a higher maximum retrieval time of 15.12 s is seen, in comparison to 0.189 and 0.6 s for replication factors 4 and 32 respectively. It is probable this is the result of a DDS data retrieval and is an outlier.
- f)
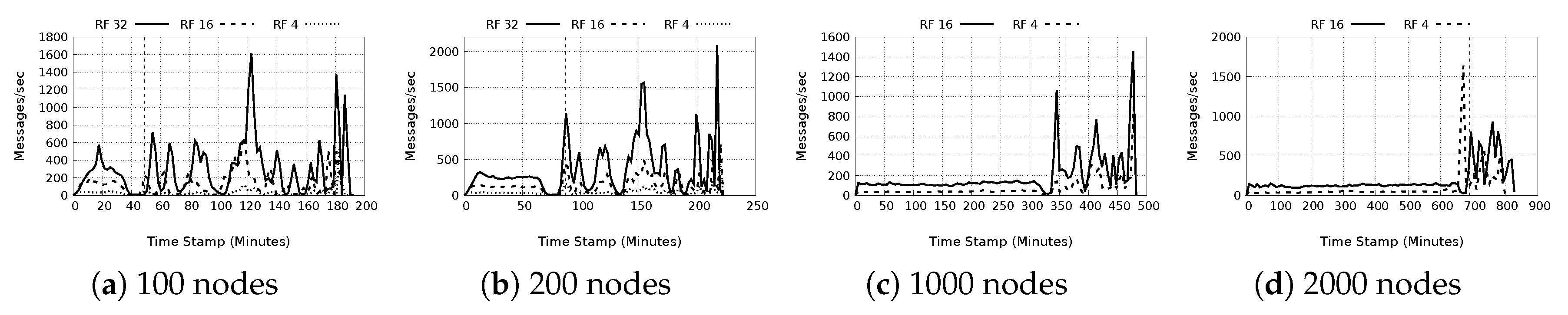
- Message send/receive rate: From Figure 15a–d, for message sending rates and Figure 16a–d for message receiving rates, it is noted that a higher replication factor there is a drop in the average messaging rates. Also surprising is that when comparing the 100 and 200 node experiments, it seems that a replication factor of 16 seems to generate higher maximum rates than the lower replication factor tests. This result may be an indicator that when considering replication factor, there are values that are accounted as optimum for the network performance. This result may need further investigation. The average rates also dropped as the network became larger, and as the replication factor increased.
5.4.2. Cost Analysis
- a)
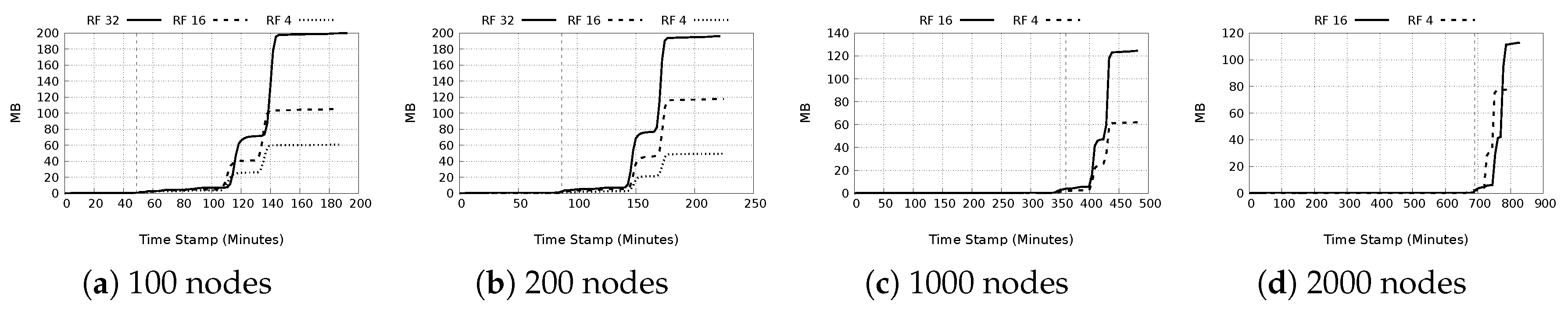
- Used storage space: From Figure 17a–d, it is seen that if the replication factor is held constant, the average used storage space per node is almost invariably similar with deviation of about ±10 MB. The maximum used storage space on the other hand varies and no general trend can be deduced. In general, as the replication factor increases, used space increases, both on average and also the maximum used space.
- b)
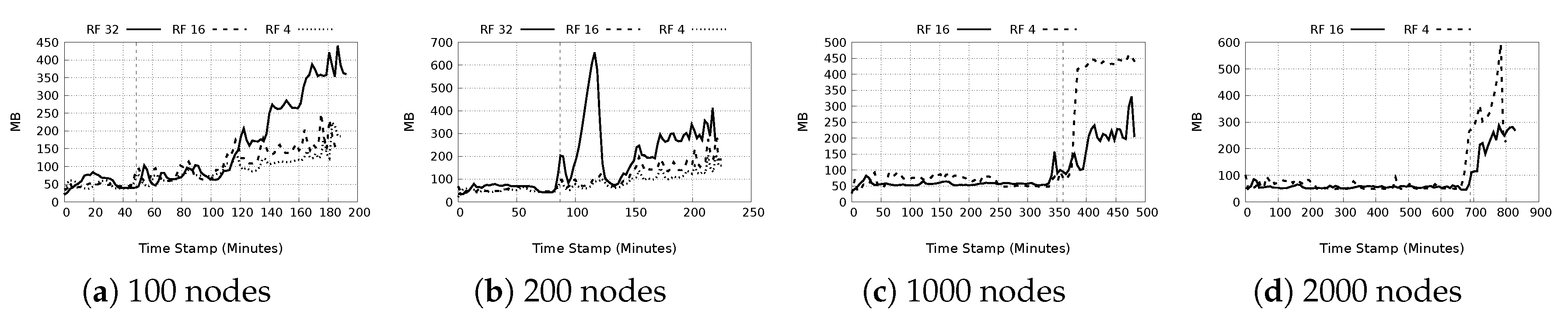
- Used memory: In Figure 18a–d, the maximum used memory for the four node groups is shown. With fewer nodes in the network, there is very little disparity in maximum memory use for replication factor 4 and 16, but a replication factor of 32 shows a notably large maximum memory usage. For the 1000 and 2000 node tests, with lower replication factor of 4, there is a drastically higher maximum memory consumption than for replication factor 16. This may be because there are fewer replicas in the network thus requiring more requests generated leading to more memory consumption as a suitable replica is located. It is also possible that with fewer replicas, the storing nodes may also experience a bottleneck in replying to all the requests. The average memory consumption tended to follow the expected norm, i.e., increase in replication factor causes an increase in memory consumption.
- c)
- Network bandwidth: The last four columns of Table 8 show the average and maximum sending and receiving network data rates due to the workload. It is observed that increasing the nodes or replication factor leads to a corresponding increase in the needed network bandwidth as is shown by the increasing maximum data rates. The average data rates for both sending and receiving are nevertheless less than 1 KB/s except for the 2000 node test with replication factor of 16, which recorded values slightly greater than 1 KB/s.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DDS | Distributed data structure |
| ECC | Elliptic curve cryptography |
| GUI | Graphical user interface |
| HPC | High performance computing |
| KB | Kilobyte |
| MB | Megabyte |
| MVVM | Model-View-View-Model |
| OSGi | Open Services Gateway Initiative |
| OSN | Online social network |
| P2P | Peer-to-peer |
| RF | Replication factor |
| SN | Social network |
References
- Subrahmanyam, K.; Reich, S.M.; Waechter, N.; Espinoza, G. Online and offline social networks: Use of social networking sites by emerging adults. J. Appl. Dev. Psychol. 2008, 29, 420–433. [Google Scholar] [CrossRef]
- Guidi, B.; Conti, M.; Ricci, L. P2P architectures for distributed online social networks. In Proceedings of the IEEE International Conference on High Performance Computing & Simulation (HPCS) 2013, Helsinki, Finland, 1–5 July 2013; pp. 678–681. [Google Scholar]
- Lakshman, A.; Malik, P. Cassandra: A Decentralized Structured Storage System. SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Beaver, D.; Kumar, S.; Li, H.C.; Sobel, J.; Vajgel, P. Finding a Needle in Haystack: Facebook’s Photo Storage. In Proceedings of the 9th USENIX Conference on Operating Systems Design and Implementation; OSDI’10; USENIX Association: Berkeley, CA, USA, 2010; pp. 47–60. [Google Scholar]
- Spiekermann, S.; Acquisti, A.; Bohme, R.; Hui, K.L. The challenges of personal data markets and privacy. Electron. Mark. 2015, 25, 161–167. [Google Scholar] [CrossRef]
- Taddei, S.; Contena, B. Privacy, trust and control: Which relationships with online self-disclosure? Comput. Hum. Behav. 2013, 29, 821–826. [Google Scholar] [CrossRef]
- Tucker, C.E. Social networks, personalized advertising, and privacy controls. J. Mark. Res. 2014, 51, 546–562. [Google Scholar] [CrossRef]
- Barreda, A.A.; Bilgihan, A.; Nusair, K.; Okumus, F. Generating brand awareness in Online Social Networks. Comput. Hum. Behav. 2015, 50, 600–609. [Google Scholar] [CrossRef]
- Bakir, V.; McStay, A. Fake News and The Economy of Emotions. Digit. J. 2018, 6, 154–175. [Google Scholar] [CrossRef]
- Roy, R.; Gupta, N. Digital Capitalism and Surveillance on Social Networking Sites: A Study of Digital Labour, Security and Privacy for Social Media Users. In Digital India: Reflections and Practice; Kar, A.K., Sinha, S., Gupta, M.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 67–81. [Google Scholar]
- Brandimarte, L.; Acquisti, A.; Loewenstein, G. Misplaced Confidences: Privacy and the Control Paradox. Soc. Psychol. Personal. Sci. 2013, 4, 340–347. [Google Scholar] [CrossRef]
- Paul, T.; Buchegger, S.; Strufe, T. Decentralizing Social Networking Services. Int. Tyrrhenian Workshop Digit. Commun. 2010, 1230, 1–10. [Google Scholar]
- Buchegger, S.; Datta, A. A case for P2P Infrastructure for Social Networks-Opportunities & Challenges. In Proceedings of the 2009 Sixth International Conference on Wireless On-Demand Network Systems and Services, Snowbird, Utah, 2–4 February 2009. [Google Scholar]
- Buford, J.F.; Yu, H. Peer-to-Peer Networking and Applications: Synopsis and Research Directions. In Handbook of Peer-to-Peer Networking; Shen, X., Yu, H., Buford, J., Akon, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Chapter 1; pp. 3–45. [Google Scholar]
- Rodrigues, R.; Druschel, P. Peer-to-Peer Systems. Commun. ACM 2010, 53, 72–82. [Google Scholar] [CrossRef]
- Buchegger, S.; Schioberg, D.; Vu, L.H.; Datta, A. PeerSoN: P2P Social Networking: Early Experiences and Insights. In Proceedings of the Second ACM EuroSys Workshop on Social Network Systems; SNS ’09; ACM: New York, NY, USA, 2009; pp. 46–52. [Google Scholar]
- Cutillo, L.A.; Molva, R.; Strufe, T. Safebook: A privacy-preserving online social network leveraging on real-life trust. IEEE Commun. Mag. 2009, 47, 94–101. [Google Scholar] [CrossRef]
- Sharma, R.; Datta, A. SuperNova: Super-peers based architecture for decentralized online social networks. In Proceedings of the IEEE 2012 Fourth International Conference on Communication Systems and Networks (COMSNETS 2012), Bangalore, India, 3–7 January 2012; pp. 1–10. [Google Scholar]
- Jahid, S.; Nilizadeh, S.; Mittal, P.; Borisov, N.; Kapadia, A. DECENT: A decentralized architecture for enforcing privacy in online social networks. In Proceedings of the 2012 IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Lugano, Switzerland, 19–23 March 2012; pp. 326–332. [Google Scholar]
- Aiello, L.M.; Ruffo, G. LotusNet: Tunable Privacy for Distributed Online Social Network Services. Comput. Commun. 2012, 35, 75–88. [Google Scholar] [CrossRef]
- Guidi, B.; Amft, T.; De Salve, A.; Graffi, K.; Ricci, L. DiDuSoNet: A P2P architecture for distributed Dunbar-based social networks. Peer-to-Peer Netw. Appl. 2016, 9, 1177–1194. [Google Scholar] [CrossRef]
- Graffi, K.; Masinde, N. LibreSocial: A Peer-to-Peer Framework for Online Social Networks. CoRR 2020, arXiv:cs.SI/2001.02962. [Google Scholar]
- Graffi, K.; Podrajanski, S.; Mukherjee, P.; Kovacevic, A.; Steinmetz, R. A distributed platform for multimedia communities. In Proceedings of the 2008 Tenth IEEE International Symposium on Multimedia, Berkeley, CA, USA, 15–17 December 2008; pp. 208–213. [Google Scholar]
- Graffi, K.; Gross, C.; Mukherjee, P.; Kovacevic, A.; Steinmetz, R. LifeSocial. KOM: A P2P-based platform for secure online social networks. In Proceedings of the 2010 IEEE Tenth International Conference on Peer-to-Peer Computing (P2P), Delft, The Netherlands, 25–27 August 2010; pp. 1–2. [Google Scholar]
- Graffi, K.; Gross, C.; Stingl, D.; Hartung, D.; Kovacevic, A.; Steinmetz, R. LifeSocial. KOM: A Secure and P2P-based Solution for Online Social Networks. In Proceedings of the 2011 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2011; pp. 554–558. [Google Scholar]
- Buchert, T. Managing Large-Scale, Distributed Systems Research Experiments with Control-Flows. Ph.D. Thesis, Universite de Lorraine, Lorraine, France, 2016. [Google Scholar]
- Lehn, M.; Triebel, T.; Gross, C.; Stingl, D.; Saller, K.; Effelsberg, W.; Kovacevic, A.; Steinmetz, R. Designing Benchmarks for P2P Systems. In From Active Data Management to Event-Based Systems and More: Papers in Honor of Alejandro Buchmann on the Occasion of His 60th Birthday; Sachs, K., Petrov, I., Guerrero, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 209–229. [Google Scholar]
- Kounev, S. Performance Engineering of Distributed Component—Based Systems. Ph.D. Thesis, Technischen Universitat Darmstadt, Darmstadt, Germany, 2005. [Google Scholar]
- Sachs, K.; Kounev, S.; Carter, M.; Buchmann, A. Designing a Workload Scenario for Benchmarking Message-Oriented Middleware. In Proceedings of the 2007 SPEC Benchmark Workshop (SPEC), Dresden, Germany, 22 June 2007. [Google Scholar]
- Saller, K.; Panitzek, K.; Lehn, M. Benchmarking Methodology. In Benchmarking Peer-to-Peer Systems: Understanding Quality of Service in Large-Scale Distributed Systems; Effelsberg, W., Steinmetz, R., Strufe, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 19–45. [Google Scholar]
- Jain, R. The Art of Computer Systems Performance Analysis—Techniques for Experimental Design, Measurement, Simulation, and Modeling; Wiley Professional Computing, Wiley: Hoboken, NJ, USA, 1991. [Google Scholar]
- Masinde, N.; Graffi, K. Peer-to-Peer based Social Networks: A Comprehensive Survey. CoRR 2020, arXiv:2001.02611. [Google Scholar]
- Rowstron, A.; Druschel, P. Pastry: Scalable, Decentralized Object Location, and Routing for Large-Scale Peer-to-Peer Systems. Middleware 2001; Guerraoui, R., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 329–350. [Google Scholar]
- Rowstron, A.; Druschel, P. Storage Management and Caching in PAST, a Large-scale, Persistent Peer-to-peer Storage Utility. SIGOPS Opering Syst. Rev. 2001, 35, 188–201. [Google Scholar] [CrossRef]
- Druschel, P.; Rowstron, A. PAST: A large-scale, persistent peer-to-peer storage utility. In Proceedings of the IEEE Eighth Workshop on Hot Topics in Operating Systems, Elmau, Germany, 20–22 May 2001; pp. 75–80. [Google Scholar]
- Ramabhadran, S.; Ratnasamy, S.; Hellerstein, J.M.; Shenker, S. Brief Announcement: Prefix Hash Tree. In Proceedings of the Twenty-third Annual ACM Symposium on Principles of Distributed Computing; PODC ’04; ACM: New York, NY, USA, 2004; p. 368. [Google Scholar]
- Rowstron, A.; Kermarrec, A.M.; Castro, M.; Druschel, P. Scribe: The Design of a Large-Scale Event Notification Infrastructure. In Networked Group Communication; Crowcroft, J., Hofmann, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 30–43. [Google Scholar]
- Graffi, K.; Kovacevic, A.; Xiao, S.; Steinmetz, R. SkyEye.KOM: An Information Management Over-Overlay for Getting the Oracle View on Structured P2P Systems. In Proceedings of the 2008 14th IEEE International Conference on Parallel and Distributed Systems, Melbourne, Australia, 8–10 December 2008; pp. 279–286. [Google Scholar]
- Graffi, K.; Disterhoft, A. SkyEye: A tree-based peer-to-peer monitoring approach. Pervasive Mob. Comput. 2017, 40, 593–610. [Google Scholar] [CrossRef]
- Kovacevic, A.; Graffi, K.; Kaune, S.; Leng, C.; Steinmetz, R. Towards Benchmarking of Structured Peer-to-Peer Overlays for Network Virtual Environments. In Proceedings of the 2008 14th IEEE International Conference on Parallel and Distributed Systems, Melbourne, Australia, 8–10 December 2008; pp. 799–804. [Google Scholar]
- Benevenuto, F.; Rodrigues, T.; Cha, M.; Almeida, V. Characterizing User Behavior in Online Social Networks. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement; IMC ’09; ACM: New York, NY, USA, 2009; pp. 49–62. [Google Scholar]
- Olteanu, A.; Pierre, G. Towards Robust and Scalable Peer-to-Peer Social Networks. In Proceedings of the Fifth Workshop on Social Network Systems, SNS ’12, Bern, Switzerland, 10 April 2012. [Google Scholar]
- Nilizadeh, S.; Jahid, S.; Mittal, P.; Borisov, N.; Kapadia, A. Cachet: A Decentralized Architecture for Privacy Preserving Social Networking with Caching. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies; CoNEXT ’12; ACM: New York, NY, USA, 2012; pp. 337–348. [Google Scholar]
- Franchi, E.; Poggi, A.; Tomaiuolo, M. Blogracy: A peer-to-peer social network. Int. J. Distrib. Syst. Technol. (IJDST) 2016, 7, 37–56. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quality Aspect | Relevant Metrics |
|---|---|
| Performance | Hop-count |
| Data storage time | |
| Data retrieval time | |
| Message sending rate | |
| Message receiving rate | |
| Cost | Used space |
| Used memory | |
| Network bandwidth | |
| Stability/Scalability | Number of nodes |
| Leafset size | |
| Routing table size | |
| Memory size | |
| Messages sent | |
| Message sending rate | |
| Data transferred | |
| Data transfer rate | |
| Data items stored | |
| Number of replicas | |
| DDS data stored |
| Test | Network Size | Number of Nodes | Leafset Size | RF | Duration (mins) | |
|---|---|---|---|---|---|---|
| Setup | Test | |||||
| Plugin analysis | - | 100 | 127 | 4 | 40 | 240 |
| - | 500 | 127 | 4 | 184 | 240 | |
| Pseudo-random | - | 500 | 24 | 6 | 160 | 200 |
| Scalability/stability | - | 1000 | 24 | 4 | 480 | 200 |
| Replication | Medium | 100 | 127 | 4, 16, 32 | 40 | 141 |
| 200 | 127 | 4, 16, 32 | 80 | 141 | ||
| Large | 1000 | 127 | 4, 16 | 360 | 141 | |
| 2000 | 127 | 4, 16 | 800 | 141 | ||
| Plugin | Action | Repetitions (count) | Duration* (mins) | |
|---|---|---|---|---|
| Light | Medium | |||
| Messaging | Send message | 2 | 5 | 5 |
| View inbox message | 2 | 5 | 5 | |
| View outbox message | 2 | 5 | 5 | |
| Live chat | Send multichat invitation | 2 | 5 | 5 |
| Send multichat message | 2 | 5 | 5 | |
| Group | Create group | 2 | 5 | 5 |
| Invite friend to group | 2 | 5 | 5 | |
| View group | 2 | 5 | 5 | |
| View my group list | 2 | 5 | 5 | |
| File storage | Create folder | 2 | 5 | 5 |
| Upload file in folder | 2 | 5 | 5 | |
| View folder | 2 | 5 | 5 | |
| Forum | Create forum thread | 2 | 5 | 5 |
| Comment forum thread | 2 | 5 | 5 | |
| View forum | 2 | 5 | 5 | |
| Photos | Create photo album | 2 | 5 | 5 |
| Upload photo | 2 | 5 | 5 | |
| View own album | 2 | 5 | 5 | |
| View friend’s album | 2 | 5 | 5 | |
| Calendar | Create calendar event | 2 | 5 | 5 |
| Edit calendar event | 2 | 5 | 5 | |
| View calendar | 2 | 5 | 5 | |
| Voting | Create vote | 2 | 5 | 5 |
| Add public vote | 2 | 5 | 5 | |
| Voting invite user | 2 | 5 | 5 | |
| Vote | 2 | 5 | 5 | |
| Get my votings | 2 | 5 | 5 | |
| Get voting results | 2 | 5 | 5 | |
| Wall | Send wall post | 2 | 5 | 5 |
| Comment wall post | 2 | 5 | 5 | |
| View own wall | 2 | 5 | 5 | |
| View friend’s wall | 2 | 5 | 5 | |
| Plugin | Action | Repetitions | Duration * (mins) |
|---|---|---|---|
| Messaging | Send message | 5 | 2 |
| Photos | Upload photo | 5 | 2 |
| Forum | Comment forum thread | 5 | 2 |
| Wall | Send wall post | 5 | 2 |
| Plugin | Action | Repetitions (Count) | Duration * (mins) |
|---|---|---|---|
| Messaging | Send message | 10 | 1 |
| Delete inbox message | 10 | 1 | |
| Live chat | Send multichat invitation | 5 | 1 |
| Send multichat message | 10 | 1 | |
| Leave multichat message | 5 | 1 | |
| Group | Create group | 5 | 1 |
| Invite friend to group | 10 | 1 | |
| View group | 5 | 2 | |
| View my group list | 5 | 1 | |
| File storage | Create folder | 5 | 1 |
| Upload file in folder | 10 | 1 | |
| Forum | Create forum thread | 10 | 2 |
| Comment forum thread | 10 | 1 | |
| Photos | Create photo album | 5 | 1 |
| Upload photo | 10 | 1 | |
| View friend’s album | 8 | 1 | |
| Voting | Create vote | 4 | 1 |
| Add public vote | 4 | 1 | |
| Voting invite user | 4 | 1 | |
| Vote | 10 | 1 | |
| Get voting results | 10 | 1 | |
| Wall | Send wall post | 10 | 1 |
| Comment wall post | 10 | 1 |
| Plugins | Actions | Max. Completion Time (secs) | Network Messages Generated | Network Data Generated (MBs) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 Nodes | 500 Nodes | 100 Nodes | 500 Nodes | 100 Nodes | 500 Nodes | ||||||||
| Light | Medium | Light | Medium | Light | Medium | Light | Medium | Light | Medium | Light | Medium | ||
| Messaging | Send message | 15 | 35 | 5 | 15 | 101,820 | 169,408 | 694,239 | 1,147,379 | 0.152 | 0.191 | 4.206 | 4.907 |
| View inbox | 15 | 35 | 15 | 15 | 3463 | 4466 | 14840 | 40446 | 0.048 | 0.061 | 0.256 | 0.670 | |
| View outbox | 15 | 35 | 15 | 35 | 3310 | 4107 | 12,820 | 18,342 | 0.045 | 0.054 | 0.211 | 0.303 | |
| Livechat | Invitations | 15 | 35 | 15 | 35 | 187,904 | 268,320 | 857,484 | 1,248,916 | 0.169 | 0.229 | 3.464 | 3.644 |
| Send message | 15 | 55 | 15 | 35 | 13,996 | 21,793 | 79,543 | 83,693 | 0.081 | 0.196 | 0.474 | 0.987 | |
| Group | Add public group | 15 | 55 | 15 | 55 | 112,349 | 275,182 | 586,848 | 1,434,662 | 0.125 | 0.290 | 4.007 | 8.124 |
| Invite user | 25 | 55 | 15 | 75 | 95,112 | 225,731 | 264,031 | 1,218,640 | 0.116 | 0.224 | 0.514 | 4.886 | |
| View group | 15 | 30 | 15 | 30 | 29,279 | 85,149 | 172,107 | 518,014 | 0.080 | 0.137 | 0.805 | 1.432 | |
| Filestorage | Create folder | 25 | 45 | 25 | 55 | 64,227 | 160,869 | 324,113 | 885,438 | 0.102 | 0.182 | 1.023 | 1.819 |
| Store files | 15 | 90 | 5 | 100 | 352,122 | 1,074,538 | 1,742,799 | 5,427,956 | 0.172 | 0.484 | 7.614 | 11.665 | |
| View folder | 15 | 80 | 15 | 75 | 64,324 | 258,735 | 380,631 | 1,485,086 | 0.076 | 0.232 | 0.491 | 1.153 | |
| Forum | Create thread | 25 | 75 | 25 | 75 | 210,476 | 547,374 | 1,074,085 | 2,917,062 | 0.138 | 0.344 | 2.758 | 3.473 |
| Comment post | 25 | 95 | 25 | 95 | 164,276 | 538,011 | 898,757 | 2,173,601 | 0.117 | 0.276 | 1.466 | 2.339 | |
| View forum | 10 | 35 | 10 | 30 | 17,943 | 66,398 | 186,365 | 437,562 | 0.075 | 0.168 | 1.113 | 1.328 | |
| Photo | Create album | 15 | 45 | 15 | 45 | 31,916 | 76,467 | 162,415 | 240,881 | 0.095 | 0.186 | 0.789 | 0.651 |
| Upload photo | 15 | 55 | 15 | 55 | 57,109 | 141,724 | 309,335 | 728,483 | 0.090 | 0.243 | 1.097 | 2.026 | |
| View own album | 15 | 20 | 10 | 25 | 5373 | 9407 | 19,843 | 84,185 | 0.082 | 0.136 | 0.500 | 1.363 | |
| View friend’s album | 5 | 55 | 15 | 45 | 4972 | 10,899 | 9583 | 55,011 | 0.074 | 0.176 | 0.280 | 1.011 | |
| Calendar | Create event | 15 | 45 | 5 | 45 | 16,168 | 31,192 | 89,276 | 132,274 | 0.085 | 0.202 | 0.559 | 1.129 |
| Edit event | 15 | 45 | 5 | 55 | 14,734 | 29,985 | 81,296 | 155,881 | 0.079 | 0.190 | 0.514 | 1.437 | |
| View calendar | 10 | 20 | 10 | 25 | 3893 | 4668 | 17,044 | 59,337 | 0.074 | 0.132 | 0.355 | 1.105 | |
| Voting | Create vote | 15 | 35 | 15 | 45 | 62,783 | 120,471 | 365,981 | 632,771 | 0.092 | 0.197 | 1.085 | 1.503 |
| Invite user | 15 | 45 | 15 | 65 | 56,349 | 191,021 | 307,391 | 1,152,736 | 0.098 | 0.198 | 0.699 | 1.845 | |
| Vote | 15 | 55 | 15 | 75 | 60,632 | 201,765 | 353,137 | 1,200,553 | 0.087 | 0.224 | 0.508 | 1.607 | |
| View voting list | 10 | 30 | 10 | 35 | 15,092 | 71,721 | 100,671 | 446,388 | 0.081 | 0.154 | 0.616 | 1.113 | |
| Get voting results | 15 | 45 | 15 | 35 | 29,753 | 144,261 | 191,097 | 811,686 | 0.081 | 0.159 | 0.386 | 0.883 | |
| Wall | Create entry | 15 | 45 | 15 | 55 | 94,473 | 179,048 | 472,950 | 940,023 | 0.106 | 0.237 | 0.969 | 1.937 |
| Comment post | 15 | 75 | 25 | 80 | 121,486 | 524,681 | 855,278 | 2,876,806 | 0.090 | 0.245 | 1.263 | 1.764 | |
| View own wall | 10 | 35 | 15 | 30 | 30,130 | 162,590 | 190,977 | 962,130 | 0.089 | 0.152 | 0.532 | 1.457 | |
| View friend’s wall | 10 | 25 | 10 | 30 | 32,085 | 185,969 | 263,153 | 1,108,552 | 0.072 | 0.152 | 0.849 | 1.341 | |
| Impact | Plugin::Action | Message Rate (msg/sec) | Data Rate (Kb/sec) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 100 Nodes | 500 Nodes | 100 Nodes | 500 Nodes | ||||||
| Light | Medium | Light | Medium | Light | Medium | Light | Medium | ||
| Low messaging, low data | Calendar::Create Event | 101.05 | 164.17 | 595.17 | 696.18 | 0.54 | 1.09 | 3.82 | 6.08 |
| Calendar::Edit Event | 92.09 | 157.82 | 541.97 | 779.41 | 0.51 | 1.02 | 3.51 | 7.36 | |
| Calendar::View Calendar | 25.12 | 28.29 | 109.96 | 349.04 | 0.49 | 0.82 | 2.35 | 6.66 | |
| Livechat::Send Message | 87.48 | 108.97 | 497.14 | 464.96 | 0.52 | 1.00 | 3.03 | 5.61 | |
| Messaging::View Inbox | 21.64 | 24.81 | 92.75 | 252.79 | 0.31 | 0.35 | 1.64 | 4.29 | |
| Messaging::View Outbox | 20.69 | 22.82 | 80.13 | 101.90 | 0.29 | 0.31 | 1.35 | 1.72 | |
| Photo::View Friend’s Album | 33.15 | 54.50 | 59.89 | 289.53 | 0.51 | 0.90 | 1.79 | 5.45 | |
| Photo::View Own Album | 33.58 | 57.01 | 128.02 | 495.21 | 0.52 | 0.84 | 3.30 | 8.21 | |
| High messaging, low data | Filestorage::Create Folder | 377.81 | 846.68 | 1906.55 | 4427.19 | 0.61 | 0.98 | 6.16 | 9.31 |
| Filestorage::View Folder | 402.03 | 1149.93 | 2378.94 | 6750.39 | 0.49 | 1.06 | 3.14 | 5.37 | |
| Forum::Comment Post | 966.33 | 2241.71 | 5286.81 | 9056.67 | 0.70 | 1.18 | 8.83 | 9.98 | |
| Forum::View Forum | 115.76 | 368.88 | 1202.35 | 2500.35 | 0.50 | 0.96 | 7.35 | 7.77 | |
| Group::View Group | 182.99 | 486.57 | 1075.67 | 2960.08 | 0.51 | 0.80 | 5.15 | 8.38 | |
| Photo::Create Album | 199.48 | 402.46 | 1015.09 | 1267.79 | 0.61 | 1.00 | 5.05 | 3.51 | |
| Photo::Upload Photo | 356.93 | 708.62 | 1933.34 | 3642.42 | 0.58 | 1.24 | 7.02 | 10.37 | |
| Voting::Create Vote | 392.39 | 669.28 | 2287.38 | 3330.37 | 0.59 | 1.12 | 6.94 | 8.10 | |
| Voting::Get Voting Results | 185.96 | 759.27 | 1194.36 | 4509.37 | 0.52 | 0.86 | 2.47 | 5.02 | |
| Voting::Invite User | 352.18 | 1005.37 | 1921.19 | 5489.22 | 0.63 | 1.07 | 4.47 | 9.00 | |
| Voting::View Voting List | 97.37 | 409.83 | 649.49 | 2479.93 | 0.54 | 0.90 | 4.07 | 6.33 | |
| Voting::Vote | 378.95 | 1008.83 | 2207.11 | 5457.06 | 0.56 | 1.15 | 3.25 | 7.48 | |
| Wall::Comment Post | 759.29 | 2384.91 | 5031.05 | 12,785.80 | 0.58 | 1.14 | 7.61 | 8.03 | |
| Wall::Create Entry | 590.46 | 942.36 | 2955.94 | 4700.12 | 0.68 | 1.28 | 6.20 | 9.92 | |
| Wall::View Friend’s Wall | 207.00 | 1093.94 | 1697.76 | 6334.58 | 0.48 | 0.92 | 5.61 | 7.85 | |
| Wall::View Own Wall | 194.39 | 903.28 | 1193.61 | 5497.89 | 0.59 | 0.86 | 3.40 | 8.53 | |
| High messaging, high data | Filestorage::Store Files | 2200.76 | 4572.50 | 11,618.66 | 22,154.92 | 1.10 | 2.11 | 51.98 | 48.75 |
| Forum::Create Thread | 1238.09 | 2488.06 | 6318.15 | 13,259.37 | 0.83 | 1.60 | 16.61 | 16.17 | |
| Group::Add Public Group | 702.18 | 1375.91 | 3667.80 | 7173.31 | 0.80 | 1.48 | 25.64 | 41.59 | |
| Group::Invite User | 559.48 | 1128.66 | 1681.73 | 5539.27 | 0.70 | 1.15 | 3.35 | 22.74 | |
| Livechat::Invitations | 1174.40 | 1490.67 | 5359.28 | 6938.42 | 1.08 | 1.30 | 22.17 | 20.73 | |
| Messaging::Send message | 636.38 | 941.16 | 4628.26 | 7171.12 | 0.97 | 1.09 | 28.71 | 31.40 | |
| Nodes | RF | PERFORMANCE | COST | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Average Hops | (secs) | (secs) | (msgs/s) | (msgs/sec) | Used Storage (MB) | Used Memory (MB) | Data Rate (KB/s) | |||||||||||
| Avg | Max | Avg | Max | Avg | Max | Avg | Max | Avg | Max | Avg | Max | Send | Receive | |||||
| Avg | Max | Avg | Max | |||||||||||||||
| 100 | 4 | 1 | 0.081 | 0.189 | 0.012 | 0.138 | 15.19 | 90.54 | 15.19 | 95.59 | 25.24 | 57.77 | 101.38 | 350.51 | 0.13 | 0.97 | 0.07 | 1.21 |
| 16 | 1 | 0.314 | 15.120 | 0.037 | 0.553 | 13.68 | 105.08 | 13.68 | 105.08 | 82.23 | 100.22 | 148.35 | 334.96 | 0.18 | 1.30 | 0.12 | 1.58 | |
| 32 | 1 | 0.176 | 0.600 | 0.033 | 0.302 | 12.13 | 87.35 | 12.13 | 87.35 | 152.80 | 190.71 | 221.35 | 525.75 | 0.15 | 1.40 | 0.15 | 1.57 | |
| 200 | 4 | 1 | 0.068 | 0.368 | 0.018 | 0.232 | 14.72 | 84.52 | 14.72 | 84.52 | 24.76 | 47.03 | 111.67 | 301.14 | 0.06 | 15.53 | 0.05 | 3.98 |
| 16 | 1 | 0.767 | 15.212 | 0.023 | 15.147 | 11.69 | 120.10 | 11.69 | 201.64 | 83.27 | 112.29 | 158.27 | 383.30 | 0.35 | 2.81 | 0.17 | 2.74 | |
| 32 | 1 | 0.861 | 30.053 | 0.070 | 15.073 | 11.50 | 120.72 | 11.50 | 120.72 | 152.83 | 186.97 | 224.24 | 788.62 | 0.13 | 15.43 | 0.13 | 15.64 | |
| 1000 | 4 | 1 | 0.194 | 15.283 | 0.111 | 15.158 | 10 | 230.56 | 9.99 | 230.56 | 25.14 | 59.07 | 118.73 | 567.17 | 0.39 | 63.10 | 0.38 | 32.27 |
| 16 | 1 | 0.764 | 30.179 | 0.200 | 18.075 | 7.22 | 211.48 | 7.22 | 211.48 | 74.97 | 118.72 | 163.67 | 397.23 | 0.77 | 60.50 | 0.51 | 40.39 | |
| 2000 | 4 | 1 | 0.156 | 30.084 | 0.640 | 910 | 7.58 | 211.53 | 7.58 | 211.53 | 24.68 | 74.33 | 104.09 | 645.46 | 0.62 | 100.49 | 0.70 | 71.20 |
| 16 | 1 | 0.755 | 41.954 | 0.803 | 30.397 | 7.11 | 222.49 | 7.11 | 222.49 | 68.18 | 107.59 | 168.69 | 431.38 | 1.03 | 60.75 | 1.28 | 52.05 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Masinde, N.; Khitman, L.; Dlikman, I.; Graffi, K. Systematic Evaluation of LibreSocial—A Peer-to-Peer Framework for Online Social Networks. Future Internet 2020, 12, 140. https://doi.org/10.3390/fi12090140
Masinde N, Khitman L, Dlikman I, Graffi K. Systematic Evaluation of LibreSocial—A Peer-to-Peer Framework for Online Social Networks. Future Internet. 2020; 12(9):140. https://doi.org/10.3390/fi12090140
Chicago/Turabian StyleMasinde, Newton, Liat Khitman, Iakov Dlikman, and Kalman Graffi. 2020. "Systematic Evaluation of LibreSocial—A Peer-to-Peer Framework for Online Social Networks" Future Internet 12, no. 9: 140. https://doi.org/10.3390/fi12090140
APA StyleMasinde, N., Khitman, L., Dlikman, I., & Graffi, K. (2020). Systematic Evaluation of LibreSocial—A Peer-to-Peer Framework for Online Social Networks. Future Internet, 12(9), 140. https://doi.org/10.3390/fi12090140