An Analysis of the Supply of Open Government Data


Abstract
1. Introduction
2. Literature Review
2.1. Determinants of the Supply of Open Government Data
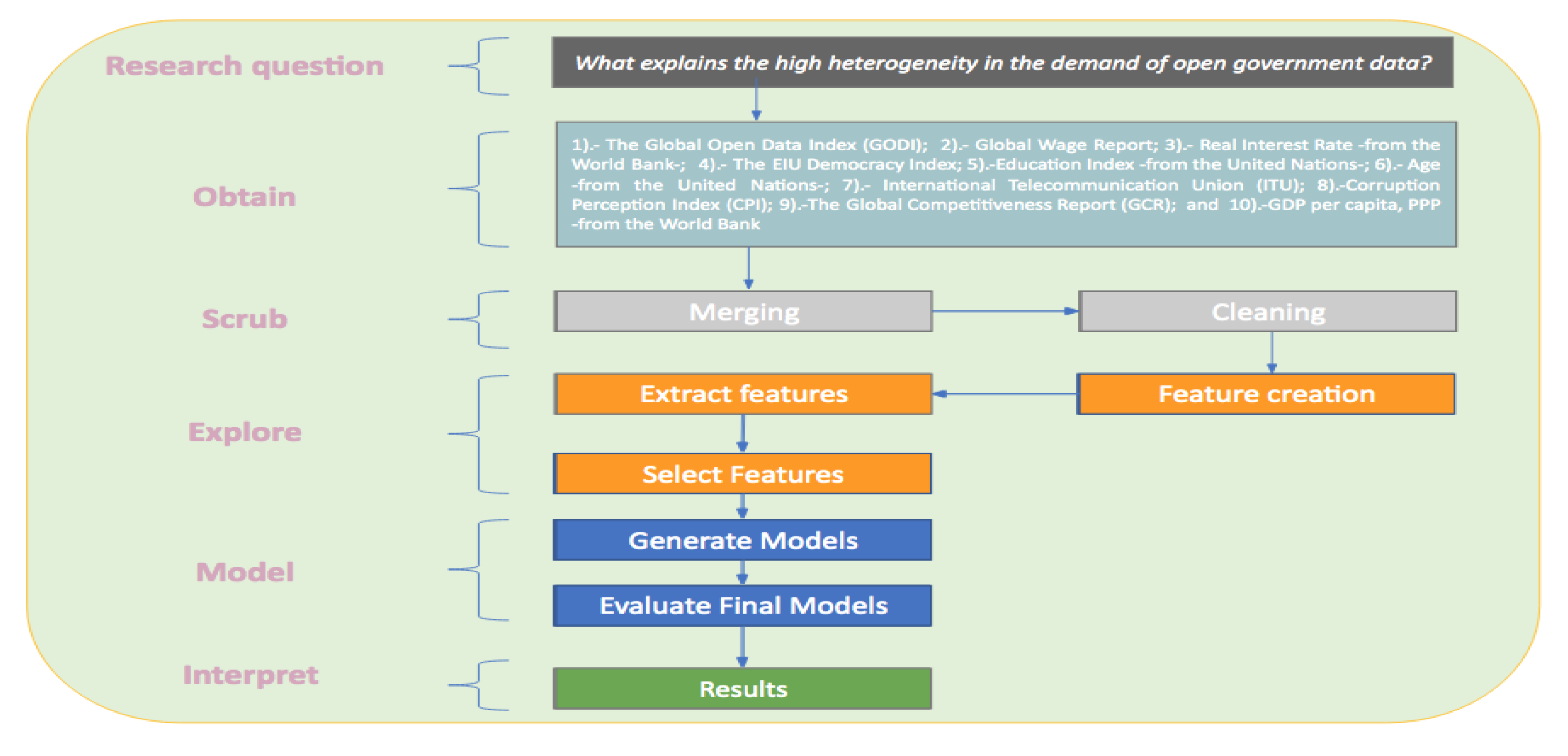
3. Material and Methods
3.1. Data Collection and Preprocessing
3.2. Empirical Analysis
4. Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wainwright, T.; Huber, F.; Rentocchini, F. Open Wide? Business Opportunities and Risks in using Open Data eprints.soton.ac.uk. 2014. Available online: https://eprints.soton.ac.uk/366901/ (accessed on 27 October 2020).
- Attard, J.; Orlandi, F.; Scerri, S.; Auer, S. A systematic review of open government data initiatives. Gov. Inf. Q. 2015, 32, 399–418. [Google Scholar] [CrossRef]
- Hardy, K.; Maurushat, A. Opening up government data for Big Data analysis and public benefit. Comput. Law Secur. Rev. 2017, 33, 30–37. [Google Scholar] [CrossRef]
- Manolea, B.; Cretu, V. The influence of the Open Government Partnership (OGP) on the Open Data discussions. European Public Sector Information Platform. 2013. Available online: https://www.europeandataportal.eu/sites/default/files/2013_the_influence_of_the_ogp_on_the_open_data_discussions.pdf (accessed on 27 October 2020).
- Zuiderwijk, A.; Helbig, N.; Gil-García, J.R.; Janssen, M. Special issue on innovation through open data-A review of the state-of-the-art and an emerging research agenda: Guest editors’ introduction. J. Theor. Appl. Electron. Commer. Res. 2014, 9, I–XIII. [Google Scholar] [CrossRef]
- Hossain, M.A.; Dwivedi, Y.K.; Rana, N.P. State-of-the-art in open data research: Insights from existing literature and a research agenda. J. Organ. Comput. Electron. Commer. 2016, 26, 14–40. [Google Scholar] [CrossRef]
- Safarov, I.; Meijer, A.; Grimmelikhuijsen, S. Utilization of open government data: A systematic literature review of types, conditions, effects and users. Integr. Psychiatry 2017, 22, 1–24. [Google Scholar] [CrossRef]
- Sa, C.; Grieco, J. Open Data for Science, Policy, and the Public Good. Rev. Policy Res. 2016, 33, 526–543. [Google Scholar] [CrossRef]
- Zuiderwijk, A.; Janssen, M.; Choenni, S.; Meijer, R.; Sheikh, A.R. Socio-Technical Impediments of Open Data. Res. Gate 2012, 10, 156–172. [Google Scholar]
- Zuiderwijk, A.; Janssen, M. Open Data Policies, Their Implementation and Impact: A Framework for Comparison. Government Information Q. 2014. Available online: https://www.sciencedirect.com/science/article/pii/S0740624X13001202 (accessed on 27 October 2020).
- Janssen, M.; Charalabidis, Y.; Zuiderwijk, A. Benefits, Adoption Barriers and Myths of Open Data and Open Government. Inf. Syst. Manag. 2012, 29, 258–268. [Google Scholar] [CrossRef]
- Vetrò, A.; Canova, L.; Torchiano, M.; Minotas, C.O.; Iemma, R.; Morando, F. Open data quality measurement framework: Definition and application to Open Government Data. Gov. Inf. Q. 2016, 33, 325–337. [Google Scholar] [CrossRef]
- Kučera, J.; Chlapek, D.; Nečaský, M. Open Government Data Catalogs: Current Approaches and Quality Perspective. In Technology-Enabled Innovation for Democracy, Government and Governance; Kő, A., Leitner, C., Leitold, H., Prosser, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 152–166. [Google Scholar]
- O’Hara, K. Data Quality, Government Data and the Open Data Infosphere. Available online: http://eprints.soton.ac.uk/340045/ (accessed on 3 July 2012).
- Sadiq, S.; Indulska, M. Open data: Quality over quantity. Int. J. Inf. Manag. 2017, 37, 150–154. [Google Scholar] [CrossRef]
- Faichney, J.; Stantic, B. A Novel Framework to Describe Technical Accessibility of Open Data. ALLDATA 2015: The First International Conference on Big Data, Small Data, Linked Data and Open Data. (IARIA) XPS for Publishing. 2015. Available online: http://www.iaria.org/conferences2015/ComALLDATA15.html (accessed on 27 October 2020).
- Kapoor, K.; Weerakkody, V.; Sivarajah, U. Open Data Platforms and Their Usability: Proposing a Framework for Evaluating Citizen Intentions. In Open and Big Data Management and Innovation; Janssen, M., Mantymaki, M., Hidders, J., Klievink, B., Lamersdorf, W., VanLoenen, B., Zuiderwijk, A., Eds.; Springer: Cham, Switzerland, 2015; Chapter 6330; pp. 261–271. [Google Scholar]
- Böhm, C.; Freitag, M.; Heise, A.; Lehmann, C.; Mascher, A.; Naumann, F.; Ercegovac, V.; Hernandez, M.; Haase, P.; Schmidt, M. GovWILD: Integrating Open Government Data for transparency. In Proceedings of the WWW’12—21st Annual Conference on World Wide Web Companion, Lyon, France, 16–20 April 2012; pp. 321–324. [Google Scholar]
- Peled, A. When Transparency and Collaboration Collide: The USA Open Data Program. J. Am. Soc. Inf. Sci. Technol. 2011, 62, 2085–2094. [Google Scholar] [CrossRef]
- Lourenço, R.P. An analysis of open government portals: A perspective of transparency for accountability. Gov. Inf. Q. 2015, 32, 323–332. [Google Scholar] [CrossRef]
- Gurin, J. Open Governments, Open Data: A New Lever for Transparency, Citizen Engagement, and Economic Growth. SAIS Rev. Int. Aff. 2014, 34, 71–82. [Google Scholar] [CrossRef]
- Ahmadi Zeleti, F.; Ojo, A.; Curry, E. Exploring the economic value of open government data. Gov. Inf. Q. 2016, 33, 535–551. [Google Scholar] [CrossRef]
- Alt, R.; Franczyk, B. Business Models in the Data Economy: A Case Study from the Business Partner Data Domain. In Proceedings of the 11th International Conference on Wirtschaftsinformatik (WI2013); Alt, R., Franczyk, B., Eds.; Universität Leipzig: Leipzig, Germany, 2013; p. 15. [Google Scholar]
- Hansen, H.S.; Hvingel, L.; Schrøder, L. Open Government Data—A Key Element in the Digital Society. In Technology-Enabled Innovation for Democracy, Government and Governance; Springer: Berlin/Heidelberg, Germany, 2013; pp. 167–180. [Google Scholar]
- Susha, I.; Grönlund, A.; Janssen, M. Driving factors of service innovation using open government data: An exploratory study of entrepreneurs in two countries. Inf. Polity 2015, 20, 19–34. [Google Scholar] [CrossRef]
- Jetzek, T.; Avital, M.; Bjorn-Andersen, N. Data-Driven Innovation through Open Government Data. 2014. Available online: https://www.researchgate.net/publication/260929913_Data-Driven_Innovation_through_Open_Government_Data (accessed on 27 October 2020).
- Lin, Y. Open data and co-production of public value of BBC Backstage. Int. J. Digit. Telev. 2015, 6, 145–162. [Google Scholar] [CrossRef]
- Juell-Skielse, G.; Hjalmarsson, A.; Johannesson, P.; Rudmark, D. Is the Public Motivated to Engage in Open Data Innovation? Lect. Notes Comput. Sci. 2014, 277–288. [Google Scholar] [CrossRef]
- Chan, C.M.L. From Open Data to Open Innovation Strategies: Creating E-Services Using Open Government Data; IEEE: New York, NY, USA, 2013; pp. 1890–1899. [Google Scholar]
- Eckartz, S.; van Broek, T.D.; Ooms, M. Open Data Innovation Capabilities: Towards a Framework of How to Innovate with Open Data. In Electronic Government; Scholl, H.J., Glassey, O., Janssen, M., Klievink, B., Lindgren, I., Parycek, P., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 47–60. [Google Scholar]
- Worthy, B. The Impact of Open Data in the UK: Complex, Unpredictable, and Political. Public Adm. 2015, 93, 788–805. [Google Scholar] [CrossRef]
- Maier-Rabler, U.; Huber, S. “Open”: The changing relation between citizens, public administration, and political authority. JeDEM eJ. eDemocracy Open Gov. 2011, 3, 182–191. [Google Scholar] [CrossRef]
- Bates, J. The strategic importance of information policy for the contemporary neoliberal state: The case of Open Government Data in the United Kingdom. Gov. Inf. Q. 2014, 31, 388–395. [Google Scholar] [CrossRef]
- Ruijer, E.; Détienne, F.; Baker, M.; Groff, J.; Meijer, A.J. The Politics of Open Government Data: Understanding Organizational Responses to Pressure for More Transparency. Am. Rev. Public Adm. 2020, 50, 260–274. [Google Scholar] [CrossRef]
- Ubaldi, B. Open Government Data Towards Empirical Analysis of Open Government Data Initiatives; OECD: Paris, France, 2013. [Google Scholar] [CrossRef]
- Jetzek, T.; Avital, M.; Bjørn-Andersen, N. Generating Value from Open Government Data. ICIS 2013 Proceedings. 2013. Available online: https://aisel.aisnet.org/icis2013/proceedings/GeneralISTopics/5/ (accessed on 27 October 2020).
- Jetzek, T.; Avital, M.; Bjørn-Andersen, N. Generating value from open government data. In Proceedings of the 34th International Conference on Information Systems ICIS 2013, Milano, Italy, 15–18 December 2013; pp. 1737–1756. [Google Scholar]
- Attard, J.; Orlandi, F.; Auer, S. Value Creation on Open Government Data. In 2016 49th Hawaii International Conference on System Sciences (HICSS); IEEE: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Oakland, W.H. Chapter 9 Theory of Public Goods; Elsevier: New York, NY, USA, 1987; pp. 485–535. [Google Scholar]
- Cornes, R.; Sandler, T. The Theory of Externalities, Public Goods, and Club Goods; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar] [CrossRef]
- Hettich, W.; Winer, S.L. Democratic Choice and Taxation; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar] [CrossRef]
- Mueller, D.C. Public Choice III; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar] [CrossRef]
- Hankla, C.; Martinez-Vazquez, J.; Rodríguez, R.P. Local Accountability and National Coordination in Fiscal Federalism; Edward Elgar Publishing: Cheltenham, UK, 2019. [Google Scholar] [CrossRef]
- Roemer, J.E. Political Competition: Theory and Applications; Harvard University Press: Cambridge, UK, 2011. [Google Scholar]
- Bates, J. The Domestication of Open Government Data Advocacy in the United Kingdom: A Neo-Gramscian Analysis. Policy Internet 2013, 118–137. [Google Scholar] [CrossRef]
- Dos Santos Brito, K.; Da Silva Costa, M.A.; Garcia, V.C.; De Lemos Meira, S.R. Assessing the benefits of open government data: The Case of meu congresso nacional in Brazilian Elections 2014. In ACM International Conference Proceeding Series; Zhang, J.K.Y., Ed.; Association for Computing Machinery: New York, NY, USA, 2015; pp. 89–96. [Google Scholar]
- Purwanto, A.; Zuiderwijk, A.; Janssen, M. Citizen engagement with open government data. In Transforming Government: People, Process and Policy; Emerald Publishing Limited: Bingley, UK, 2020; pp. 1–30. [Google Scholar] [CrossRef]
- Hong, S. Electoral Competition, Transparency, and Open Government Data. In Proceedings of the 21st Annual International Conference on Digital Government Research, Seoul, Korea, 15–19 June 2020. [Google Scholar]
- Kochi, I.; Rodríguez, R.A.P. Voting in federal elections for local public goods in a fiscally centralized economy. Estud. Econ. 2011, 26, 123–149. [Google Scholar]
- Bergstrom, T.C.; Goodman, R.P. Private Demands for Public Goods. Am. Econ. Rev. 1973, 63, 280–296. [Google Scholar]
- Beron, K.J.; Murdoch, J.C.; Vijverberg, W.P.M. Why Cooperate? Public Goods, Economic Power, and the Montreal Protocol. Rev. Econ. Stat. 2003, 286–297. [Google Scholar] [CrossRef]
- Jackson, P.M.; Atkinson, A.B.; Stiglitz, J.E. Lectures on Public Economics. Econ. J. 1981, 573. [Google Scholar] [CrossRef]
- Tresch, R.W. Public Finance: A Normative Theory; Academic Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Mas-Colell, A.; Whinston, M.D.; Green, J.R. Microeconomic Theory; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Rubinfeld, D.L. The economics of the local public sector. In Handbook of Public Economics; Elsevier: New York, NY, USA, 1987; pp. 571–645. [Google Scholar]
- Mason, H.; Wiggins, C. A Taxonomy of Data Science. Available online: http://www.dataists.com/2010/09/a-taxonomy-of-data-science/ (accessed on 27 October 2020).
- Kotsiantis, S.B.; Kanellopoulos, D.; Pintelas, P.E. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Liu, H.; Motoda, H. Feature Extraction, Construction and Selection: A Data Mining Perspective; Kluwer Academic Publishers: Norwell, MA, USA, 1998. [Google Scholar]
- Garg, A.; Tai, K. Comparison of statistical and machine learning methods in modelling of data with multicollinearity. Int. J. Model. Identif. Control 2013, 18, 295–312. [Google Scholar] [CrossRef]
- George, G.; Osinga, E.C.; Lavie, D.; Scott, B.A. Big Data and Data Science Methods for Management Research. Acad. Manag. J. 2016, 59, 1493–1507. [Google Scholar] [CrossRef]
- John Lu, Z.Q. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. J. R. Stat. Soc. Ser. A Stat. Soc. 2010, 173, 693–694. [Google Scholar] [CrossRef]
- Cao, L. Data Science: Challenges and Directions. Commun. ACM 2017, 60, 59–68. [Google Scholar] [CrossRef]
- Salimans, T. Variable selection and functional form uncertainty in cross-country growth regressions. J. Econom. 2012, 171, 267–280. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis; Pearson Education India: Bengaluru, India, 2003. [Google Scholar]
- Long, J.S.; Ervin, L.H. Using Heteroscedasticity Consistent Standard Errors in the Linear Regression Model. Am. Stat. 2000, 54, 217–224. [Google Scholar]
- Agunbiade, D.A.; Adeboye, N.O. Estimation of Heteroscedasticity Effects in a Classical Linear Regression Model of a Cross-Sectional Data. Prog. Appl. Math. 2012, 4, 18–28. [Google Scholar]
- Zhu, L.; Fujikoshi, Y.; Naito, K. Heteroscedasticity checks for regression models. Sci. China Ser. A Math. 2001, 44, 1236–1252. [Google Scholar] [CrossRef]
- Rao, C.R.; Toutenburg, H. Linear Models; Springer Series in Statistics: Cham, Switzerland, 1995; pp. 3–18. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Supply of Open Government Data GODI Score (I) | Supply of Open Government Data GODI Score (II) | Supply of Open Government Data GODI Score (III) | Supply of Open Government Data GODI Score (IV) | Supply of Open Government Data GODI Score (V) |
|---|---|---|---|---|---|
| C | 11.04 | 50.17 | 55.5180 | 53.3683 | 55.9864 |
| Gdppp | 0.0002 * | 0.0002 | 0.0002 | 0.0002 | 0.0002 |
| (1.6998) | (1.5876) | (1.6380) | (1.3166) | (1.4044) | |
| Liberty | 0.4111 ** | 0.4974 *** | 0.5252 ** | 0.4306 * | 0.4679 * |
| 2.1968 | 2.5259 | 2.4246 | 1.7019 | 1.6761 | |
| Dem | −0.4726 | −1.2298 * | −1.3926 * | −1.4452 * | −1.4923 * |
| −1.1856 | −1.8287 | −1.6874 | −1.8960 | −1.6831 | |
| Polpar | 0.1581 | 0.1925 | 0.1978 | 0.2730 | 0.2410 |
| 0.7461 | 0.8889 | 0.8105 | 1.1275 | 0.8072 | |
| Age | −0.3381 | −0.3287 | −0.2821 | 0.0522 | 0.0645 |
| -0.9542 | −0.9782 | −0.7732 | 0.1132 | 0.1178 | |
| Transparency | 15.8476 * | 17.48105 ** | 16.1369 * | 13.9994 | 14.4925 |
| 1.7610 | 1.9572 | 1.7938 | 1.5910 | 1.6067 | |
| Efficiency | −19.6248 ** | −22.12 ** | −20.8876 ** | −18.6995 * | −19.6564 * |
| −2.0313 | −2.2669 | −2.1968 | −1.8295 | −1.94 | |
| Population | 2.5681 *** | 3.1520 *** | 3.3581 *** | 3.3492 *** | 3.3951 *** |
| 3.4713 | 3.50 | 3.3188 | 3.0274 | 2.8543 | |
| Internet-Penetration | 0.5345 *** | −0.0142 | −0.1968 | −0.2213 | −0.2840 |
| 2.9659 | −0.0474 | −0.4547 | −0.4952 | −0.5341 | |
| Dem*Internet-Penetration | 0.0088 * | 0.0114 * | 0.0116 * | 0.0129 * | |
| 1.8122 | 1.8913 | 1.8565 | 1.8966 | ||
| High income | −0.015 | −2.8034 | |||
| −0.0009 | −0.1298 | ||||
| Upper Middle Income | 4.8105 | 1.6383 | |||
| 0.3667 | 0.1074 | ||||
| Lower Middle Income | 0.6255 | −0.0153 | |||
| 0.0842 | −0.0016 | ||||
| East Asia Pacific | 3.9374 | 2.9713 | |||
| 0.3864 | 0.2726 | ||||
| Europe Central Asia | −1.2709 | −2.5741 | |||
| −0.1179 | −0.2231 | ||||
| Latin America Caribbean | 8.0636 | 5.0072 | |||
| 0.6578 | 0.3605 | ||||
| Middle East North Africa | 0.8853 | 2.6890 | |||
| 0.0724 | 0.2168 | ||||
| North America | 2.0636 | 0.7462 | |||
| 0.1751 | 0.0595 | ||||
| Adjusted R-squared | 0.6387 | 0.6605 | 0.6689 | 0.6792 | 0.6824 |
| F-statistic | 7.66 *** | 7.39 *** | 5.43 *** | 4.65 *** | 3.58 *** |
| Sample | 49 | 49 | 49 | 49 | 49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ponce, A.; Ponce Rodriguez, R.A. An Analysis of the Supply of Open Government Data. Future Internet 2020, 12, 186. https://doi.org/10.3390/fi12110186
Ponce A, Ponce Rodriguez RA. An Analysis of the Supply of Open Government Data. Future Internet. 2020; 12(11):186. https://doi.org/10.3390/fi12110186
Chicago/Turabian StylePonce, Alan, and Raul Alberto Ponce Rodriguez. 2020. "An Analysis of the Supply of Open Government Data" Future Internet 12, no. 11: 186. https://doi.org/10.3390/fi12110186
APA StylePonce, A., & Ponce Rodriguez, R. A. (2020). An Analysis of the Supply of Open Government Data. Future Internet, 12(11), 186. https://doi.org/10.3390/fi12110186