Stacking-Based Ensemble Learning of Self-Media Data for Marketing Intention Detection

 ,
,
Abstract
1. Introduction
1.1. Background
1.2. Challenges
1.3. Contributions
- Optimization of Latent Semantic Analysis (LSI): The feature extraction model of LSI-Word2vec is proposed: combining the advantages of Word2vec [2] in document expression. The combined model not only can express the context features efficiently, but can express the semantic features of the words efficiently, and the text feature expression capability of the model is heightened.
- Simplification of stacking fusion: A set pruning method based on the decision tree classifier is proposed: using the model of the decision tree after pruning can reduce the computing resources of integrated learning and enhance the learning effect.
1.4. Organization
2. Related Work
2.1. Feature Extraction
2.2. Text Classification
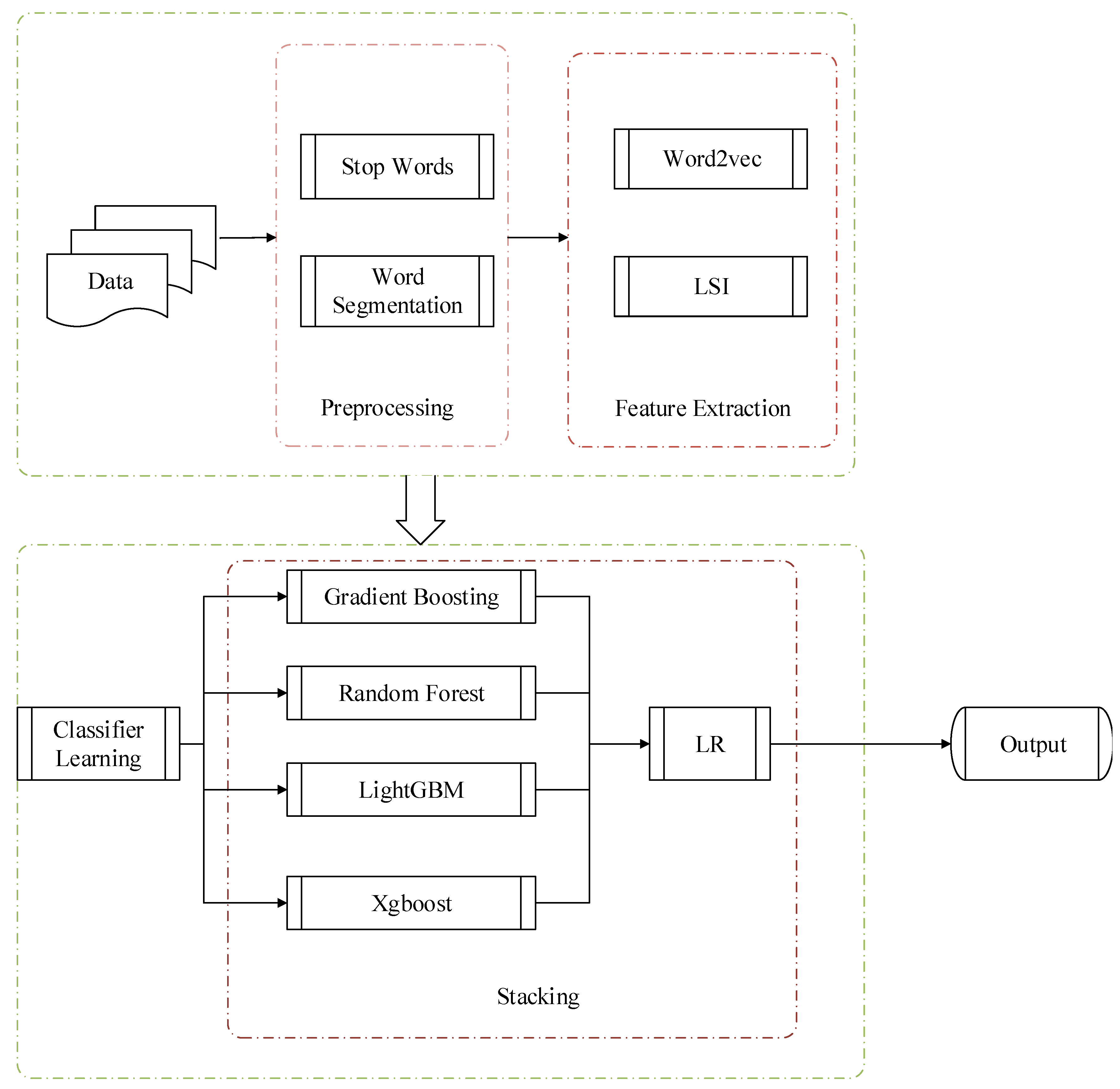
3. Approach
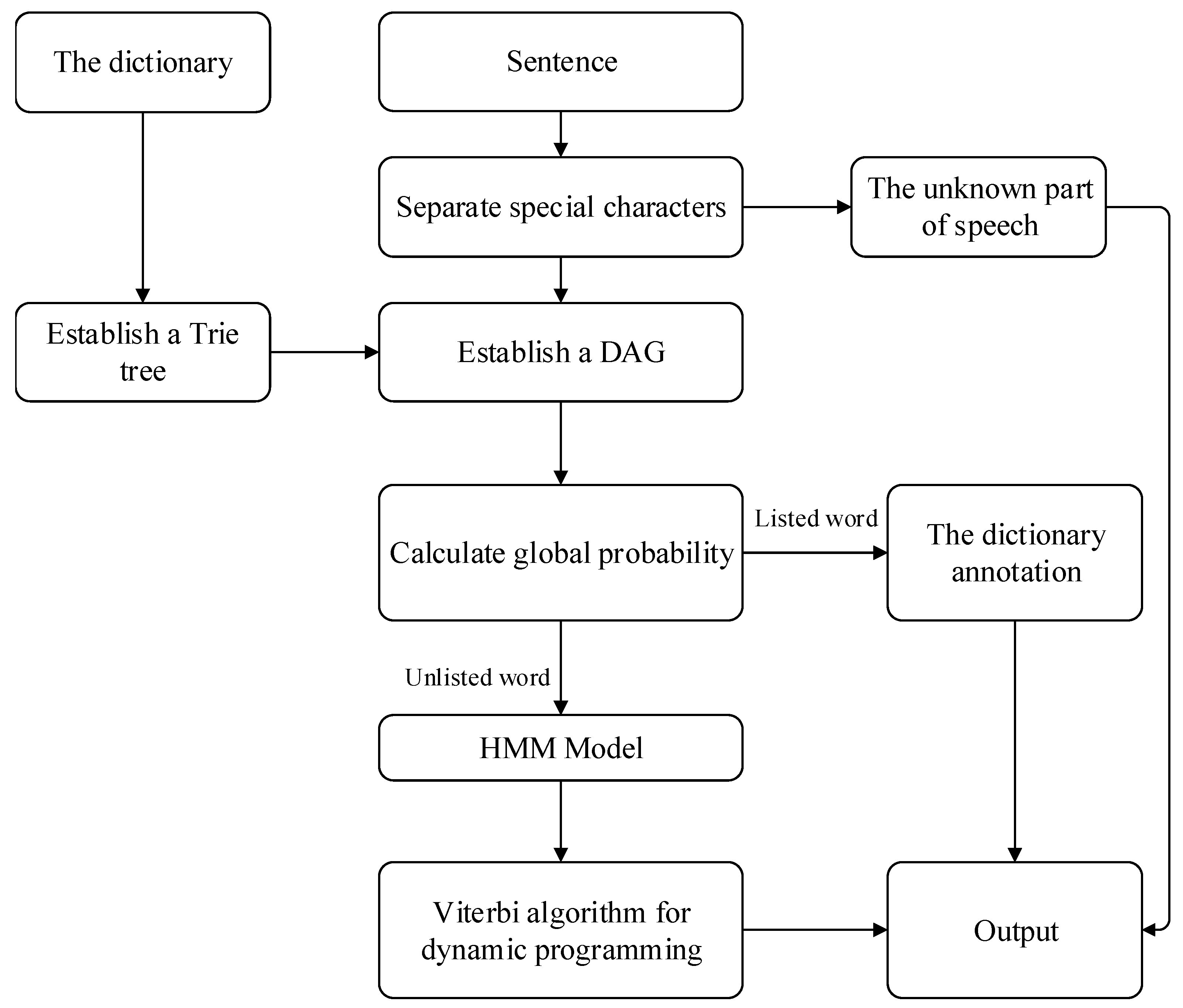
3.1. Preprocessing
3.2. Feature Extraction
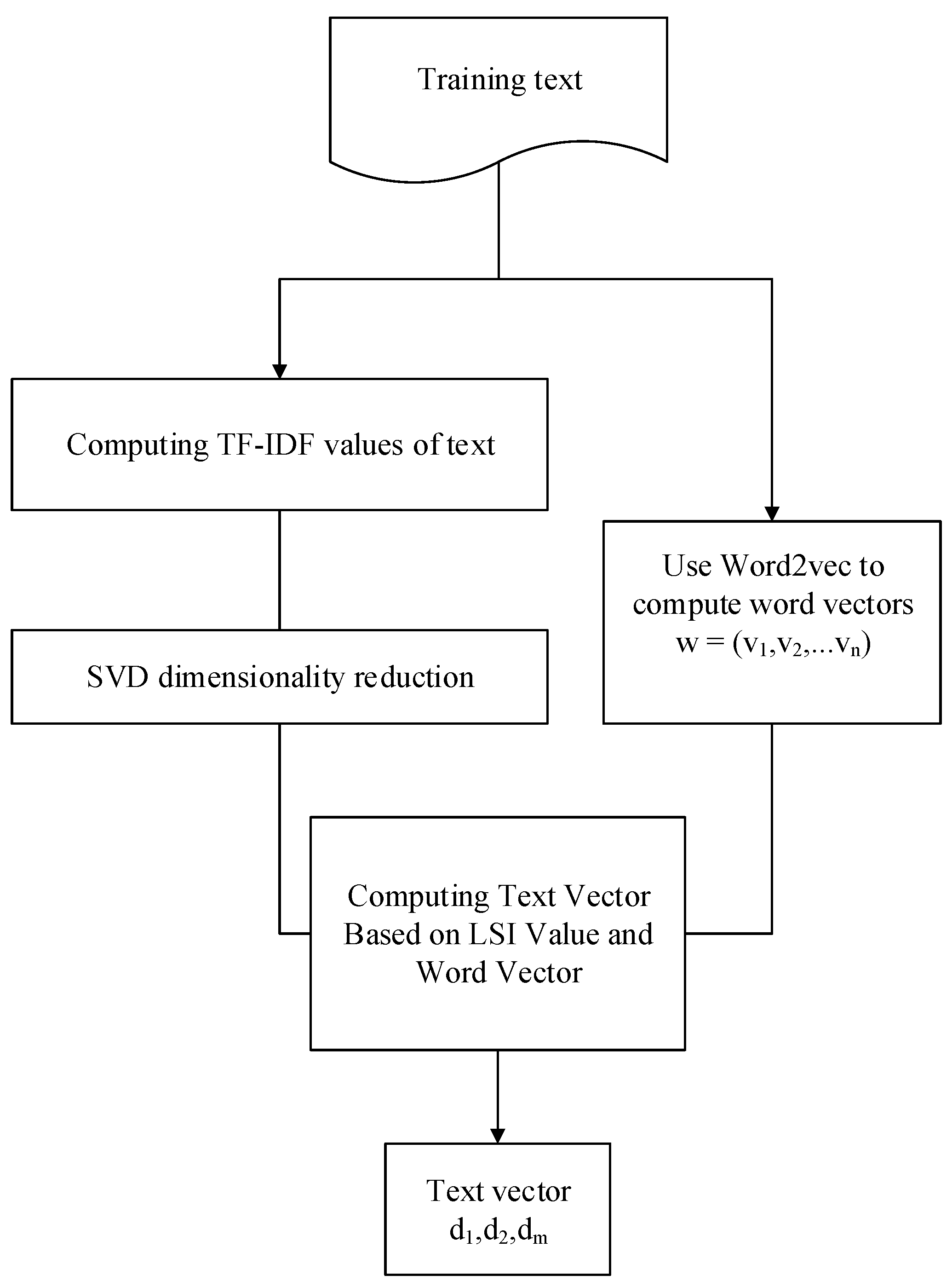
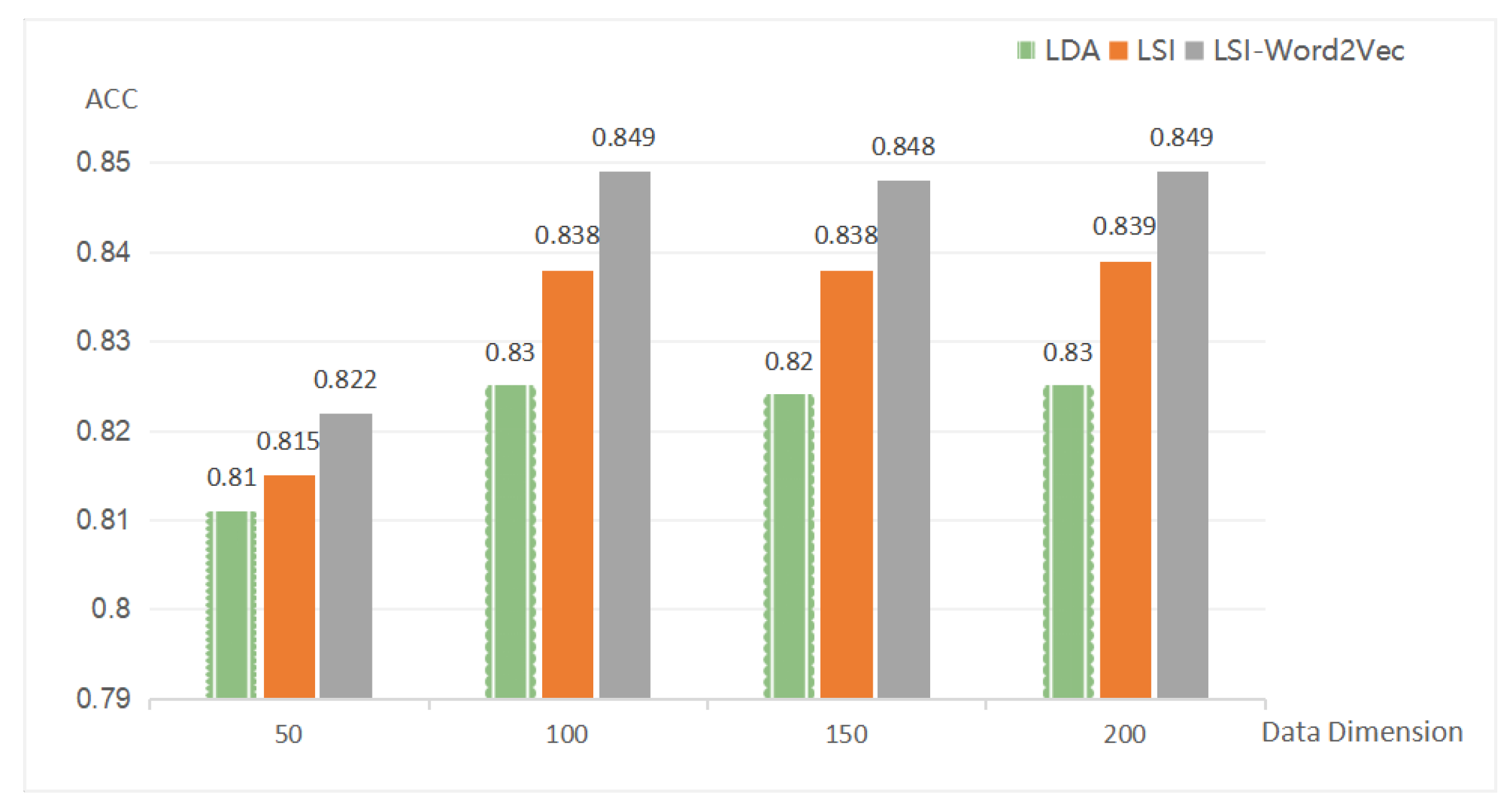
3.2.1. LSI-Word2vec
3.2.2. Extraction Processing
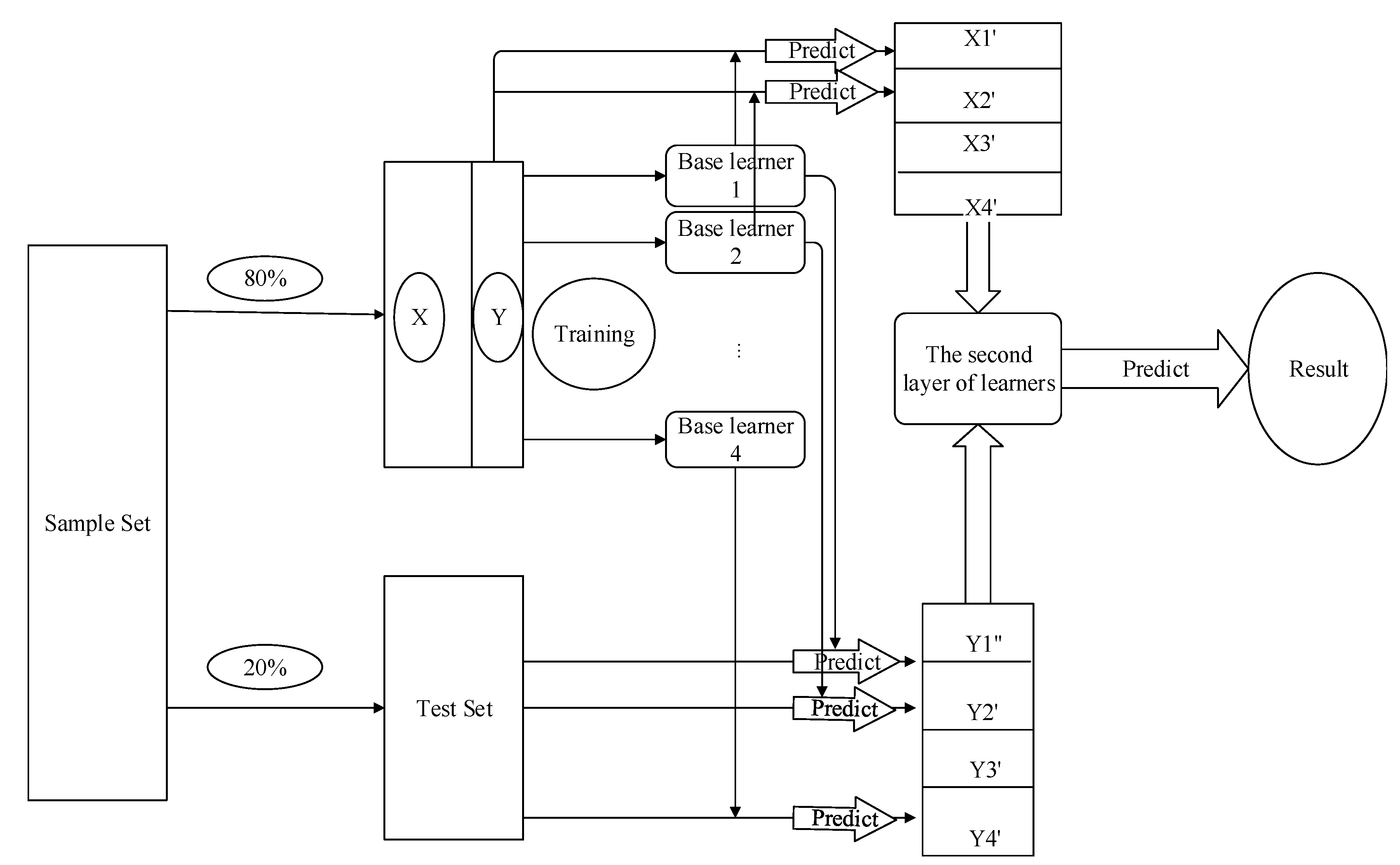
3.3. Model Fusion
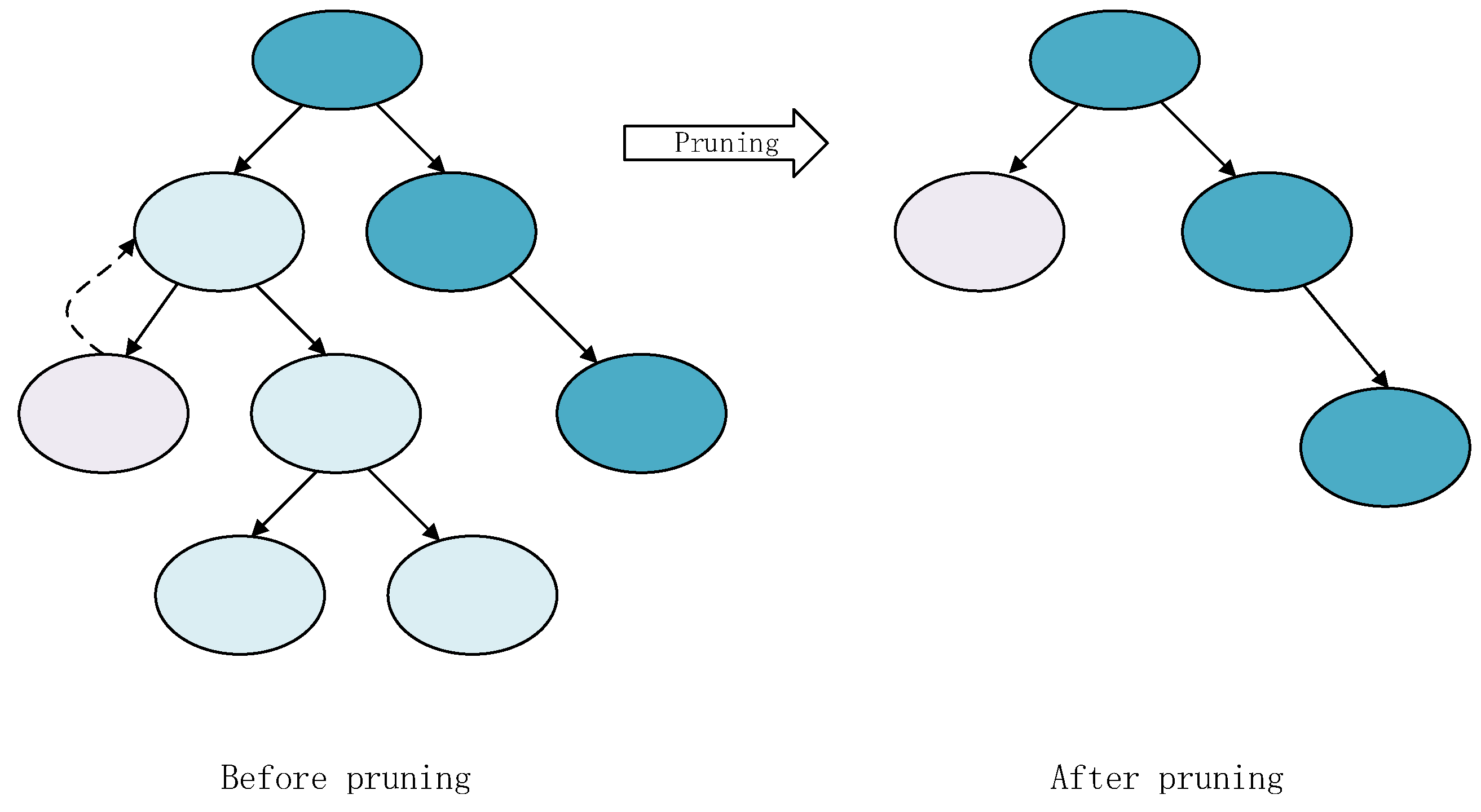
3.3.1. Pruning the Decision Tree
| Algorithm 1 The algorithm of decision tree pruning. |
Require:: matrix of continuous attributes;
|
3.3.2. Stacking
4. Experiment Settings
4.1. Experimental Setup
4.2. Experimental Parameters
4.3. Metrics
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ma, K.; Yu, Z.; Ji, K.; Yang, B. Stream-based live public opinion monitoring approach with adaptive probabilistic topic model. Soft Comput. 2018, 23, 7451–7470. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, X.; Yu, S.; Wang, Y. Research on Keyword Extraction of Word2vec Model in Chinese Corpus. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 339–343. [Google Scholar]
- Kalra, S.; Li, L.; Tizhoosh, H.R. Automatic Classification of Pathology Reports using TF-IDF Features. arXiv 2019, arXiv:1903.07406. [Google Scholar]
- Zhu, Z.; Liang, J.; Li, D.; Yu, H.; Liu, G. Hot Topic Detection Based on a Refined TF-IDF Algorithm. IEEE Access 2019, 7, 26996–27007. [Google Scholar] [CrossRef]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Altszyler, E.; Sigman, M.; Slezak, D.F. Corpus specificity in LSA and Word2vec: The role of out-of-domain documents. arXiv 2017, arXiv:1712.10054. [Google Scholar]
- Anandarajan, M.; Hill, C.; Nolan, T. Semantic Space Representation and Latent Semantic Analysis. In Practical Text Analytics; Springer: Cham, Switzerland, 2019; pp. 77–91. [Google Scholar]
- Rajalakshmi, R.; Aravindan, C. A Naive Bayes approach for URL classification with supervised feature selection and rejection framework. Comput. Intell. 2018, 34, 363–396. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, X.; Wang, T. A novel measurement data classification algorithm based on SVM for tracking closely spaced targets. IEEE Trans. Instrum. Meas. 2018, 68, 1089–1100. [Google Scholar] [CrossRef]
- Khaleel, M.I.; Hmeidi, I.I.; Najadat, H.M. An automatic text classification system based on genetic algorithm. In Proceedings of the the 3rd Multidisciplinary International Social Networks Conference on SocialInformatics 2016, Data Science 2016, Union, NJ, USA, 15–17 August 2016; ACM: New York, NY, USA, 2016; p. 31. [Google Scholar]
- Ding, X.; Shi, Q.; Cai, B.; Liu, T.; Zhao, Y.; Ye, Q. Learning Multi-Domain Adversarial Neural Networks for Text Classification. IEEE Access 2019, 7, 40323–40332. [Google Scholar] [CrossRef]
- Narayanan, A.; Shi, E.; Rubinstein, B.I. Link prediction by de-anonymization: How we won the kaggle social network challenge. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 1825–1834. [Google Scholar]
- Pavlyshenko, B. Using Stacking Approaches for Machine Learning Models. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 255–258. [Google Scholar]
- Zou, H.; Xu, K.; Li, J.; Zhu, J. The Youtube-8M kaggle competition: Challenges and methods. arXiv 2017, arXiv:1706.09274. [Google Scholar]
- Liu, J.; Shang, W.; Lin, W. Improved Stacking Model Fusion Based on Weak Classifier and Word2vec. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 820–824. [Google Scholar]
- Kim, K.H.; Park, Y.M.; Ryu, K.R. Deriving decision rules to locate export containers in container yards. Eur. J. Oper. Res. 2000, 124, 89–101. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Gao, X.; Luo, H.; Wang, Q.; Zhao, F.; Ye, L.; Zhang, Y. A Human Activity Recognition Algorithm Based on Stacking Denoising Autoencoder and LightGBM. Sensors 2019, 19, 947. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Lou, C.; Yu, R.; Gao, J.; Xu, T.; Yu, M.; Di, H. Research on Hot Micro-blog Forecast Based on XGBOOST and Random Forest. In International Conference on Knowledge Science, Engineering and Management; Springer: Cham, Switzerland, 2018; pp. 350–360. [Google Scholar]
- Xi, Y.; Zhuang, X.; Wang, X.; Nie, R.; Zhao, G. A Research and Application Based on Gradient Boosting Decision Tree. In International Conference on Web Information Systems and Applications; Springer: Cham, Switzerland, 2018; pp. 15–26. [Google Scholar]
- Li, Y.; Yan, C.; Liu, W.; Li, M. A principle component analysis-based random forest with the potential nearest neighbor method for automobile insurance fraud identification. Appl. Soft Comput. 2018, 70, 1000–1009. [Google Scholar] [CrossRef]
- Sun, J. ‘Jieba’ Chinese Word Segmentation Tool; Gitlab: San Francisco, CA, USA, 2012. [Google Scholar]
- Xu, Y.; Wang, J. The Adaptive Spelling Error Checking Algorithm based on Trie Tree. In Proceedings of the 2016 2nd International Conference on Advances in Energy, Environment and Chemical Engineering (AEECE 2016), Singapore, 29–31 July 2016; Atlantis Press: Paris, France, 2016. [Google Scholar] [CrossRef][Green Version]
- Liu, G.; Kang, Y.; Men, H. CHAR-HMM: An Improved Continuous Human Activity Recognition Algorithm Based on Hidden Markov Model. In Mobile Ad-hoc and Sensor Networks: 13th International Conference, MSN 2017, Beijing, China, 17–20 December 2017; Revised Selected Papers; Springer: Berlin, Germany, 2018; Volume 747, p. 271. [Google Scholar]
- Zecheng Zhan SOHU’s Second Content Recognition Algorithm Competition. Available online: https://github.com/zhanzecheng/SOHU_competition (accessed on 29 May 2019).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corpus | Num_Topics | id2Word | Chunksize | Decay | Size | Sentence | min_Count |
|---|---|---|---|---|---|---|---|
| corpus_tfidf | 2 | dictionary | 2000 | 1 | 50 | corpus | 5 |
| Model | max_Depth | n_Estimators | Num_Leaves | cv | min_Samples |
|---|---|---|---|---|---|
| Gradient Boosting | 13 | 100 | - | - | - |
| Random Forest | - | 32 | - | - | 2 |
| XGBoost | 3 | - | - | - | - |
| LightGBM | - | 2000 | 32 | - | - |
| Stacking | - | - | - | 5 | - |
| Model | Acc | F1 |
|---|---|---|
| LSI + XGBoost | 0.840 | 0.722 |
| LDA + XGBoost | 0.836 | 0.698 |
| Word2Vec + XGBoost | 0.832 | 0.694 |
| LSI-Word2vec + XGBoost | 0.848 | 0.739 |
| Model | F1 | Acc | Loss | Time |
|---|---|---|---|---|
| Gradient Boosting | 0.733 | 0.846 | 6.315 | - |
| Random Forest | 0.720 | 0.831 | 6.828 | - |
| XGBoost | 0.701 | 0.847 | 6.225 | - |
| LightGBM | 0.737 | 0.846 | 6.312 | 280 |
| Stacking | 0.739 | 0.848 | 6.222 | 220 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Liu, S.; Li, S.; Duan, J.; Hou, Z.; Yu, J.; Ma, K. Stacking-Based Ensemble Learning of Self-Media Data for Marketing Intention Detection. Future Internet 2019, 11, 155. https://doi.org/10.3390/fi11070155
Wang Y, Liu S, Li S, Duan J, Hou Z, Yu J, Ma K. Stacking-Based Ensemble Learning of Self-Media Data for Marketing Intention Detection. Future Internet. 2019; 11(7):155. https://doi.org/10.3390/fi11070155
Chicago/Turabian StyleWang, Yufeng, Shuangrong Liu, Songqian Li, Jidong Duan, Zhihao Hou, Jia Yu, and Kun Ma. 2019. "Stacking-Based Ensemble Learning of Self-Media Data for Marketing Intention Detection" Future Internet 11, no. 7: 155. https://doi.org/10.3390/fi11070155
APA StyleWang, Y., Liu, S., Li, S., Duan, J., Hou, Z., Yu, J., & Ma, K. (2019). Stacking-Based Ensemble Learning of Self-Media Data for Marketing Intention Detection. Future Internet, 11(7), 155. https://doi.org/10.3390/fi11070155