Novel Approach to Task Scheduling and Load Balancing Using the Dominant Sequence Clustering and Mean Shift Clustering Algorithms



Abstract
:1. Introduction
2. Motivation
- Most of the existing task schedulers doesn’t consider the task’s requirements, e.g., number of tasks and the task’s priority, and some of them consider only the waiting time and response time reduction. [3] In this paper, we introduce a hybrid task scheduling algorithm that utilizes the shortest job first (SJF) and round-robin (RR) algorithms. The hybrid task scheduling algorithm comprises two major stages. First, the waiting time between short and long tasks is balanced. Waiting time and starvation are decreased via two sub-queues, Q1 and Q2. The combination in both versions of SJF and RR is evaluated with dynamic and static quanta, and optimality in the task scheduling and load balancing methods is achieved via evaluation. Second, the ready queue is divided into two sub-queues, in which Q1 denotes short tasks, whereas Q2 denotes long tasks [4].
- A good task scheduler considers environmental changes in its scheduling strategy [5]. This research proposes to use the ant colony optimization (ACO) algorithm for effectively allocating tasks to virtual machines (VMs). Slave ants adapt to diversification and reinforcement. The ACO algorithm avoids long paths with pheromones incorrectly accumulated by leading ants, thereby rectifying the ubiquitous optimization problem with slave ants [6].
- An NP-hard problem is a critical issue in cloud task scheduling. A metaheuristic algorithm can be used to solve this problem. A cloud task scheduling algorithm based on the ACO algorithm is proposed in this research to achieve efficient load balancing.
- The primary contribution of this research is minimizing the makespan time of a given set of tasks. ACO or a modified ACO algorithm is used to optimize makespan time [7]. The key aspects of cloud computing are task scheduling and resource allocation. A heuristic approach that combines the modified analytic hierarchy process (MAHP), bandwidth-aware divisible scheduling (BATS) + BAR optimization, longest expected process time (LEPT) preemption, and divide-and-conquer methods is adopted to schedule tasks and allocate resources. MAHP is used to rank incoming tasks. The BATS + BAR methodology is utilized to allocate resources to each ranked task. The loads of VMs are continuously checked with the LEPT method. If a VM has a large load, then other VMs are assigned tasks via the divide-and-conquer methodology [8]. The additional load is distributed across multiple servers using the load balancing strategy to optimize the performance of cloud computing. Load balancing issues are addressed via a hybrid bacterial swarm optimization algorithm. The particle swarm optimization (PSO) and bacteria foraging optimization (BFO) algorithms are combined—the former is for global search and the latter is for local search [9,10]. A critical factor in conflicting bottlenecks is to improve the response time for user requests on cloud computing. Accordingly, the throttled modified algorithm (TMA) is proposed in this research to improve the response time of VMs and enhance the performance of end to end users. Load balancing is performed via the TMA load balancer by updating and maintaining two index variables: Busy and available indices [10]. This research introduces a new and extensible VM migration scheduler to minimize completion time in scheduling. Live migration, which consumes network bandwidth and energy, is a high-cost scheduler. A migration scheduler computes the best moment for each migration and the amount of bandwidth to allocate by relying on realistic migration and network models. The migrations that will be executed in parallel for fast migrations and short completion times are also decided by the scheduler [11].
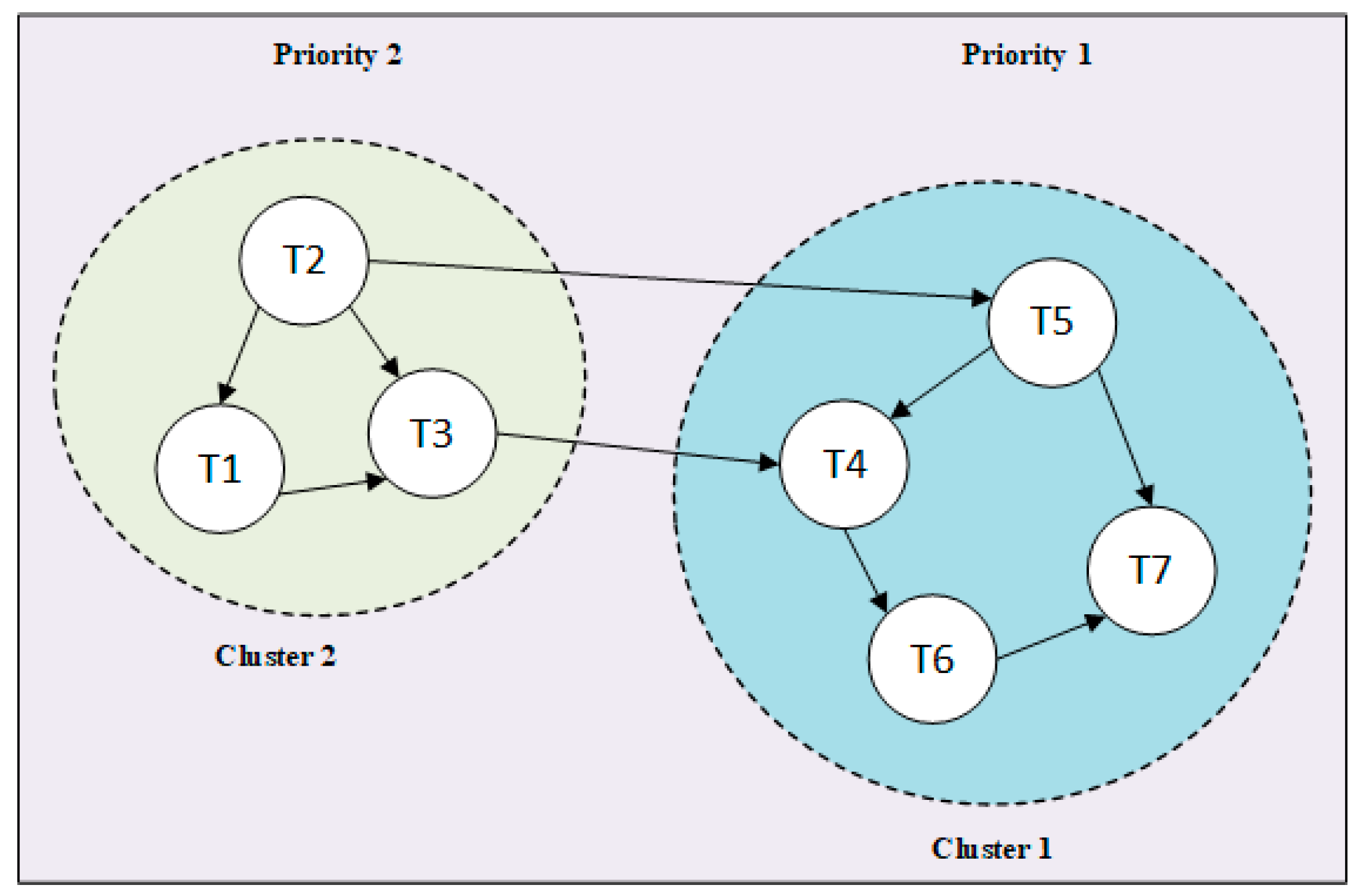
- The dominant sequence clustering (DSC) algorithm, which represents upcoming tasks as graphs, is adopted to schedule user tasks. More than one cluster exists in each graph. Metrics, such as deadline and makespan, are used to prioritize tasks and schedule them accordingly.
- The modified heterogeneous earliest finish time (MHEFT) algorithm, which schedules the highest priority task first for the subsequent process, is used to rank scheduled tasks.
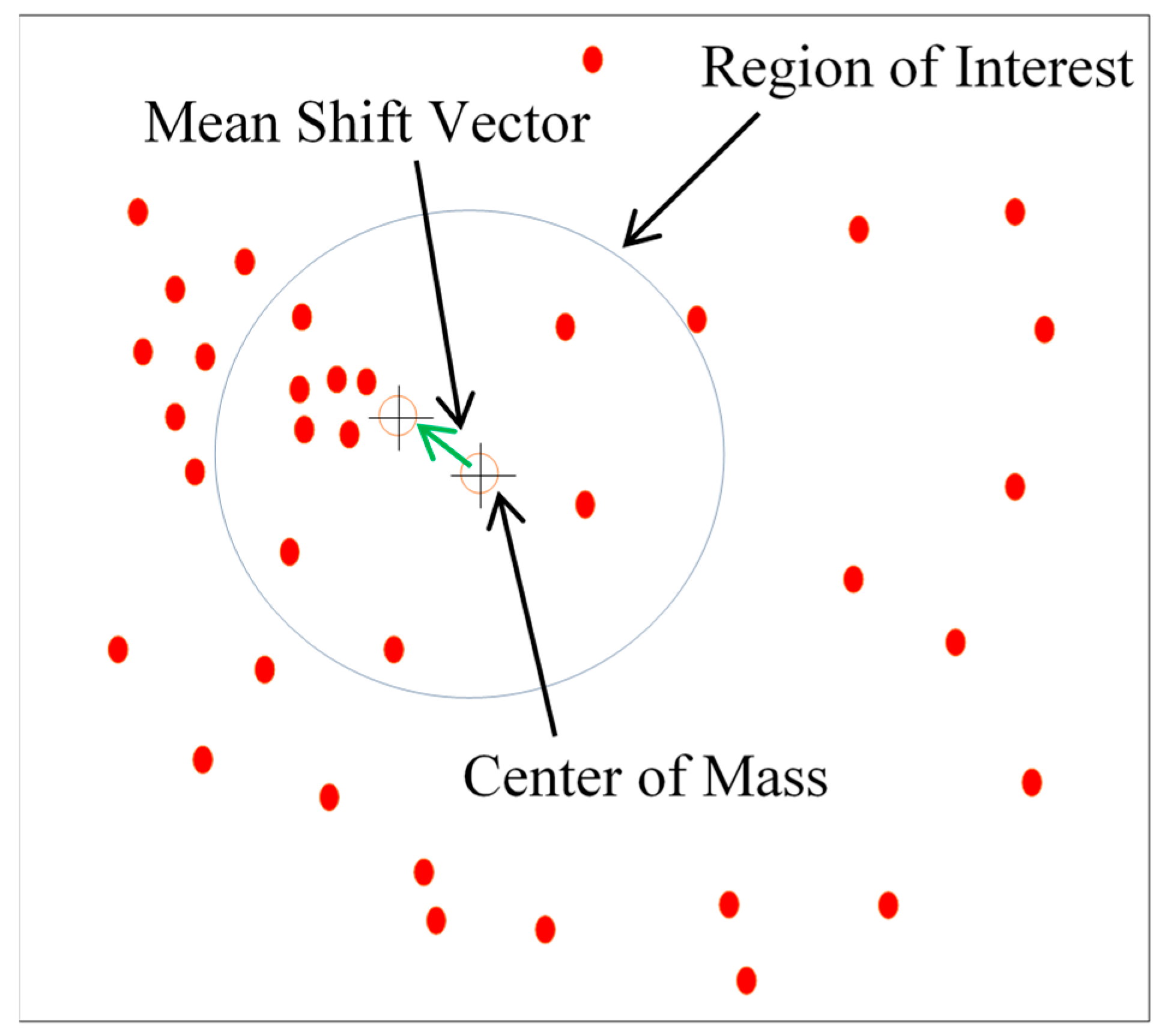
- The mean shift clustering (MSC) algorithm, which clusters VMs in accordance with a kernel function, is utilized to cluster VMs.
- The weighted least clustering (WLC) algorithm, which provides weight to each server on the basis of their capacity and client connectivity, is adopted to balance loads. Tasks are allocated by a highly weighted server, which increases response time.
3. Related Work
4. Problem Definition
- (a)
- Response time;
- (b)
- Makespan time;
- (c)
- Resource utilization;
- (d)
- Service reliability.
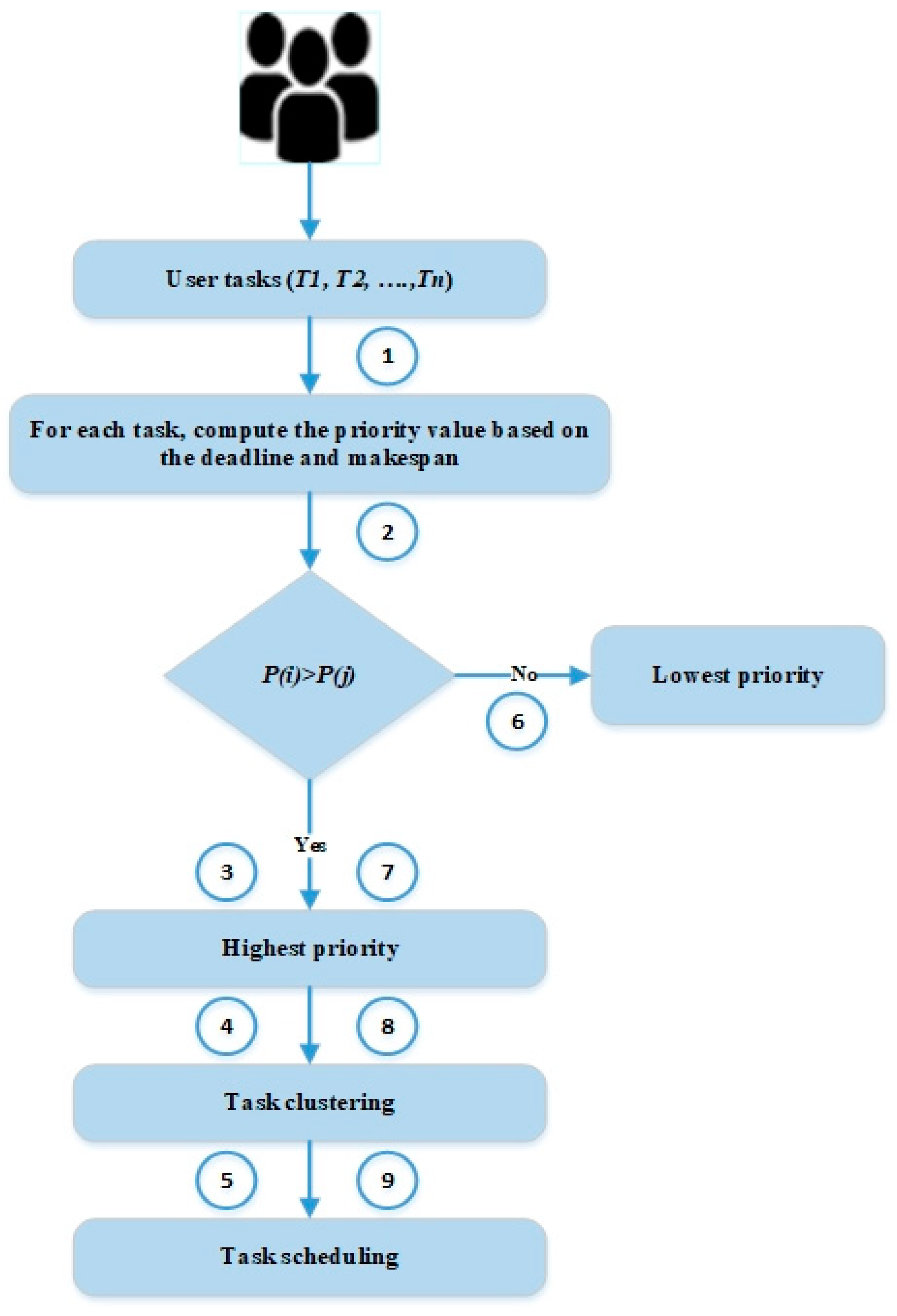
5. Proposed Work
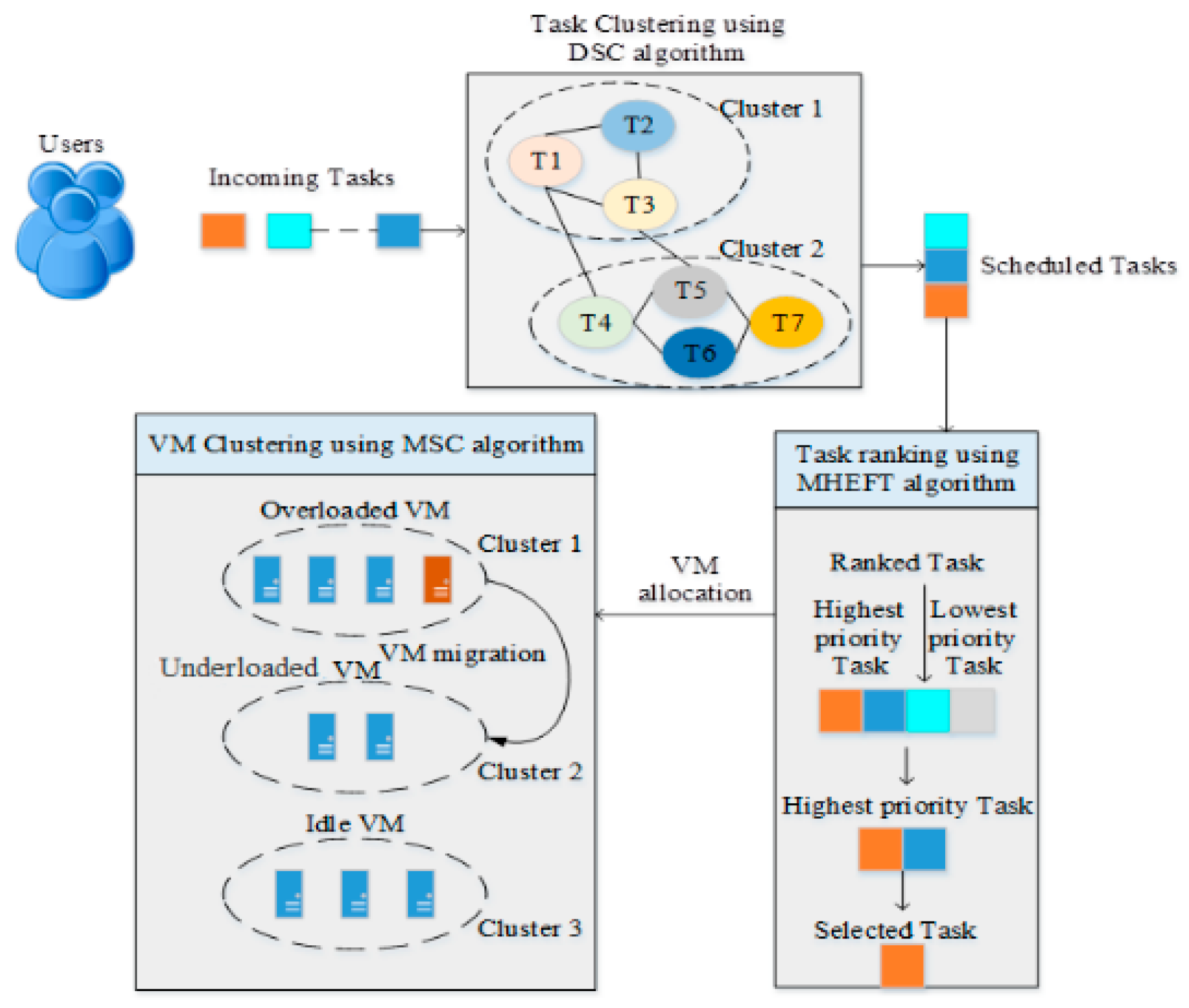
5.1. System Overview
5.2. Task Scheduling
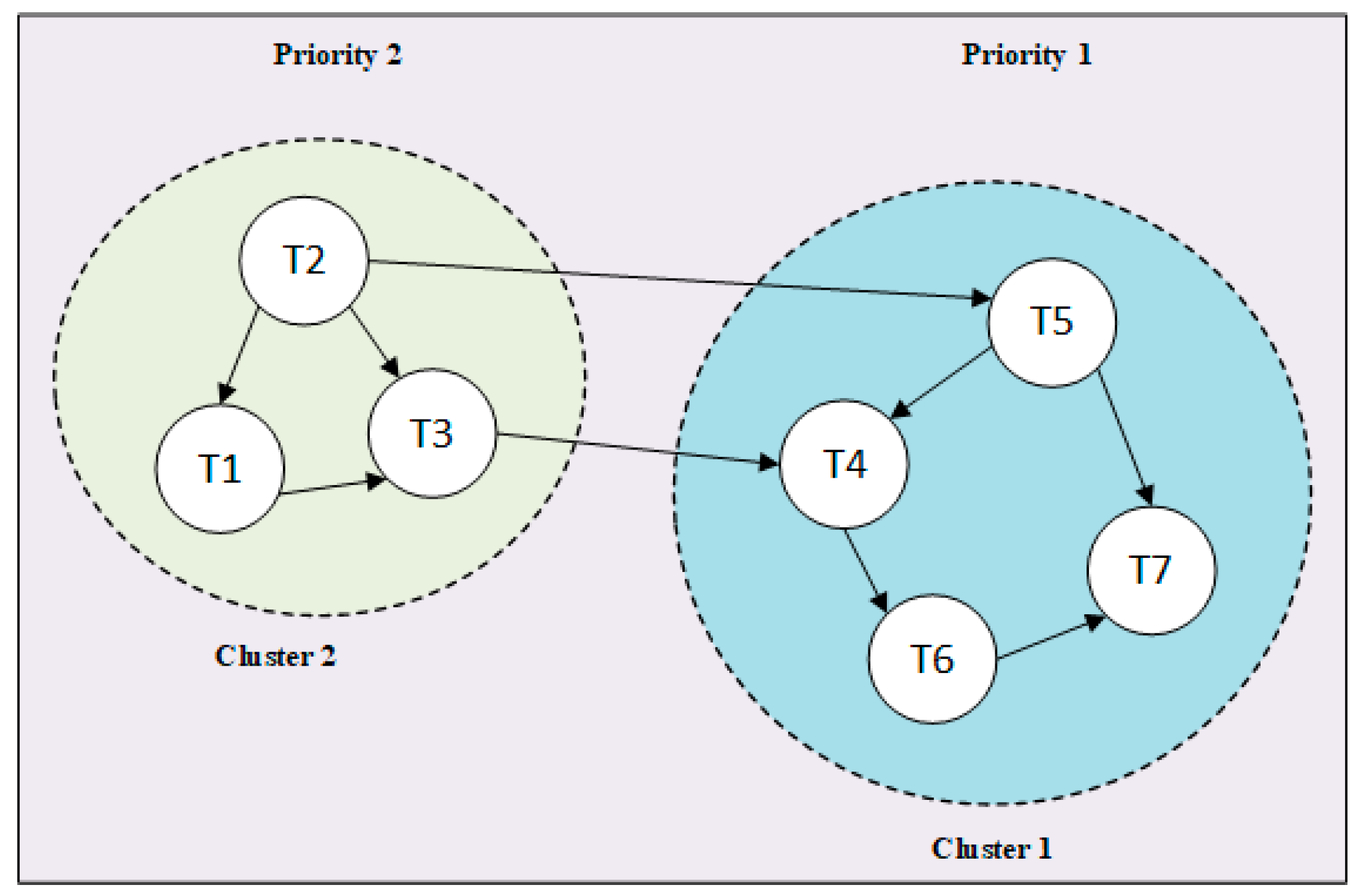
5.2.1. Task Clustering
5.2.2. Task Ranking
5.3. Load Balancing
5.3.1. VM Clustering
- Computation of mean shift vector Mr(xt);
- Translation of window xt+1 = xt + Mr(xt).
5.3.2. VM Allocation
6. Performance Evaluation
6.1. Simulation Setup
6.2. Performance Metrics
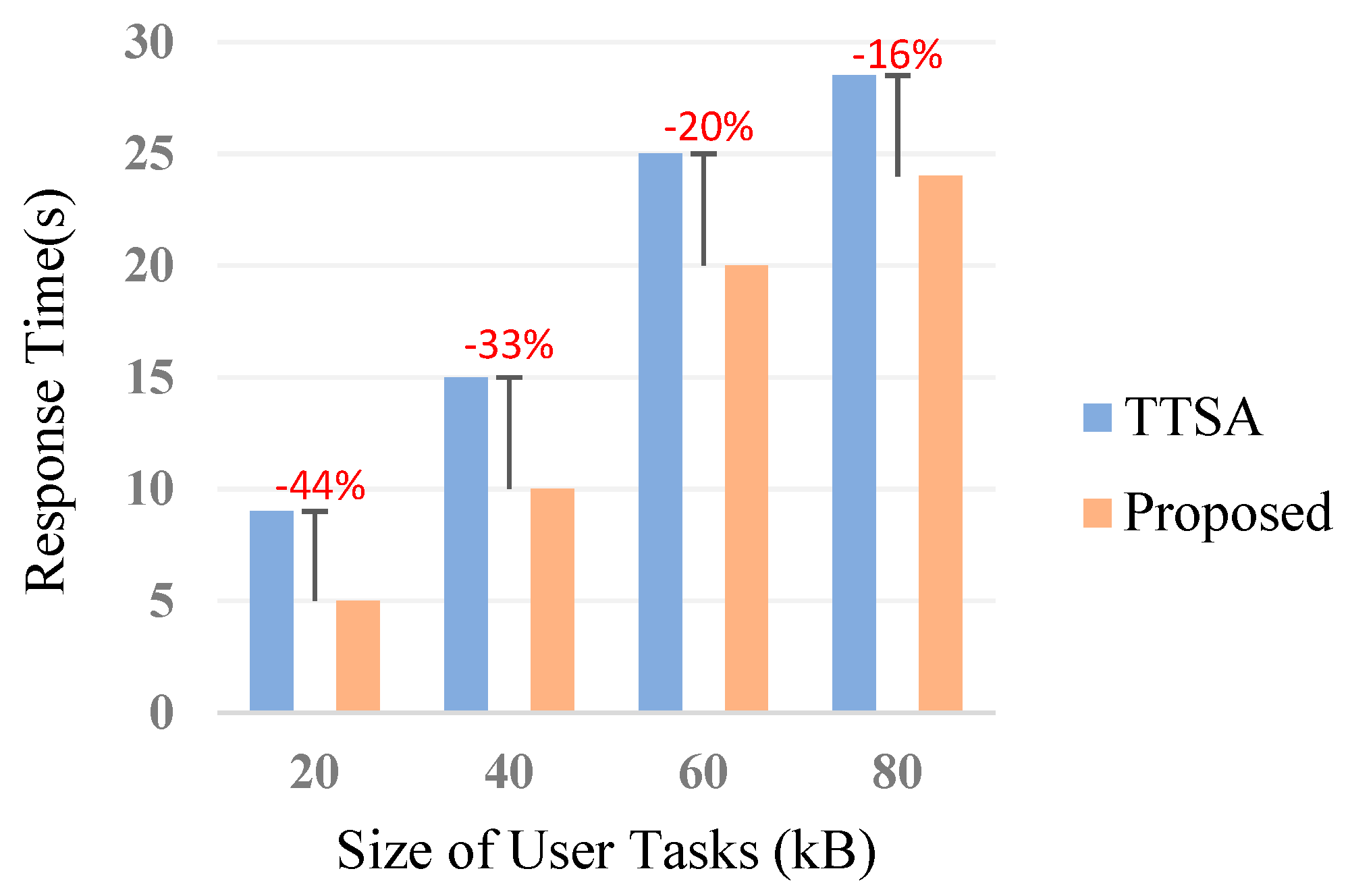
6.2.1. Response Time
6.2.2. Makespan
6.2.3. Resource Utilization
6.2.4. Service Reliability
6.3. Comparative Analysis
6.3.1. Response Time
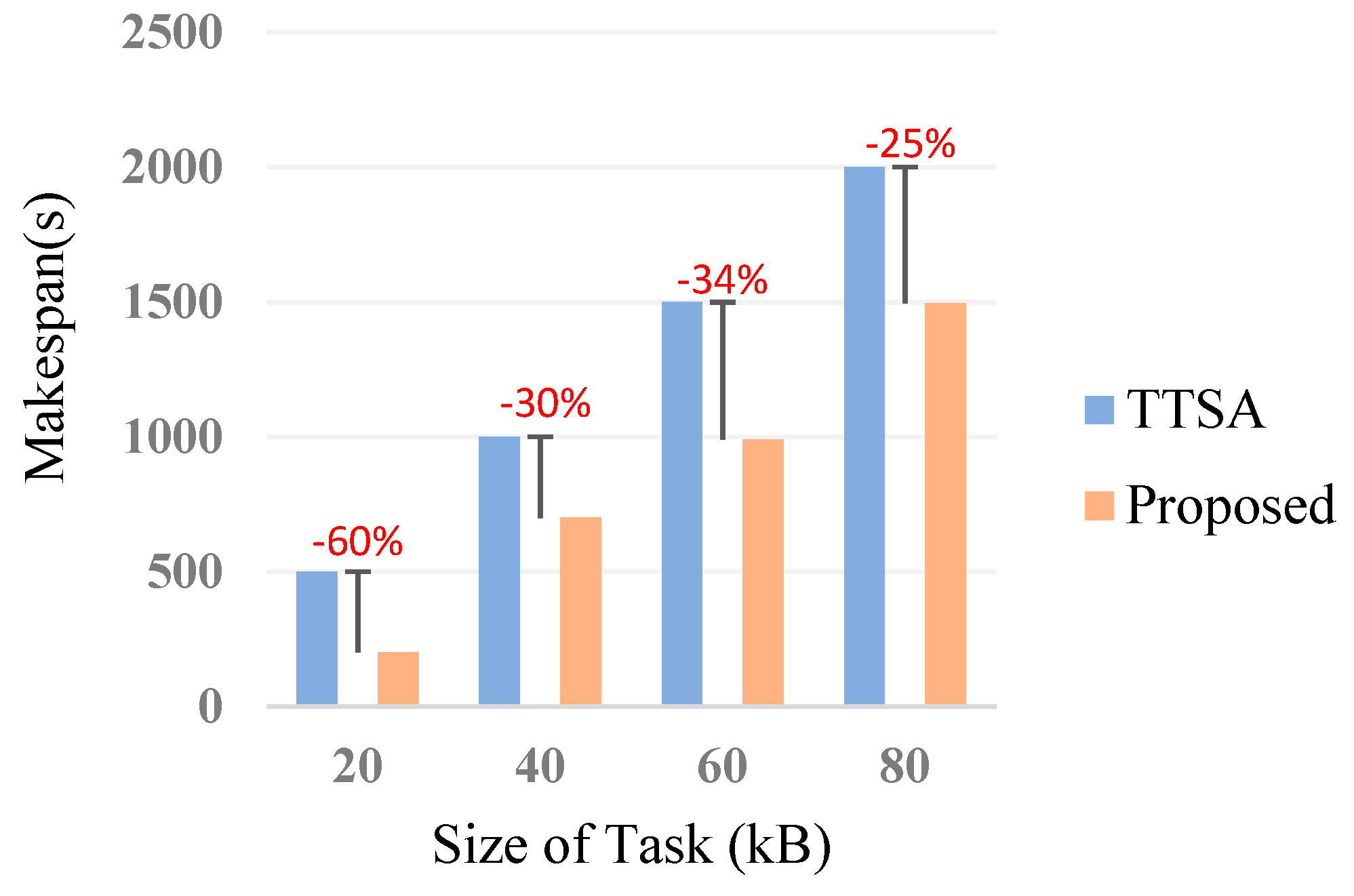
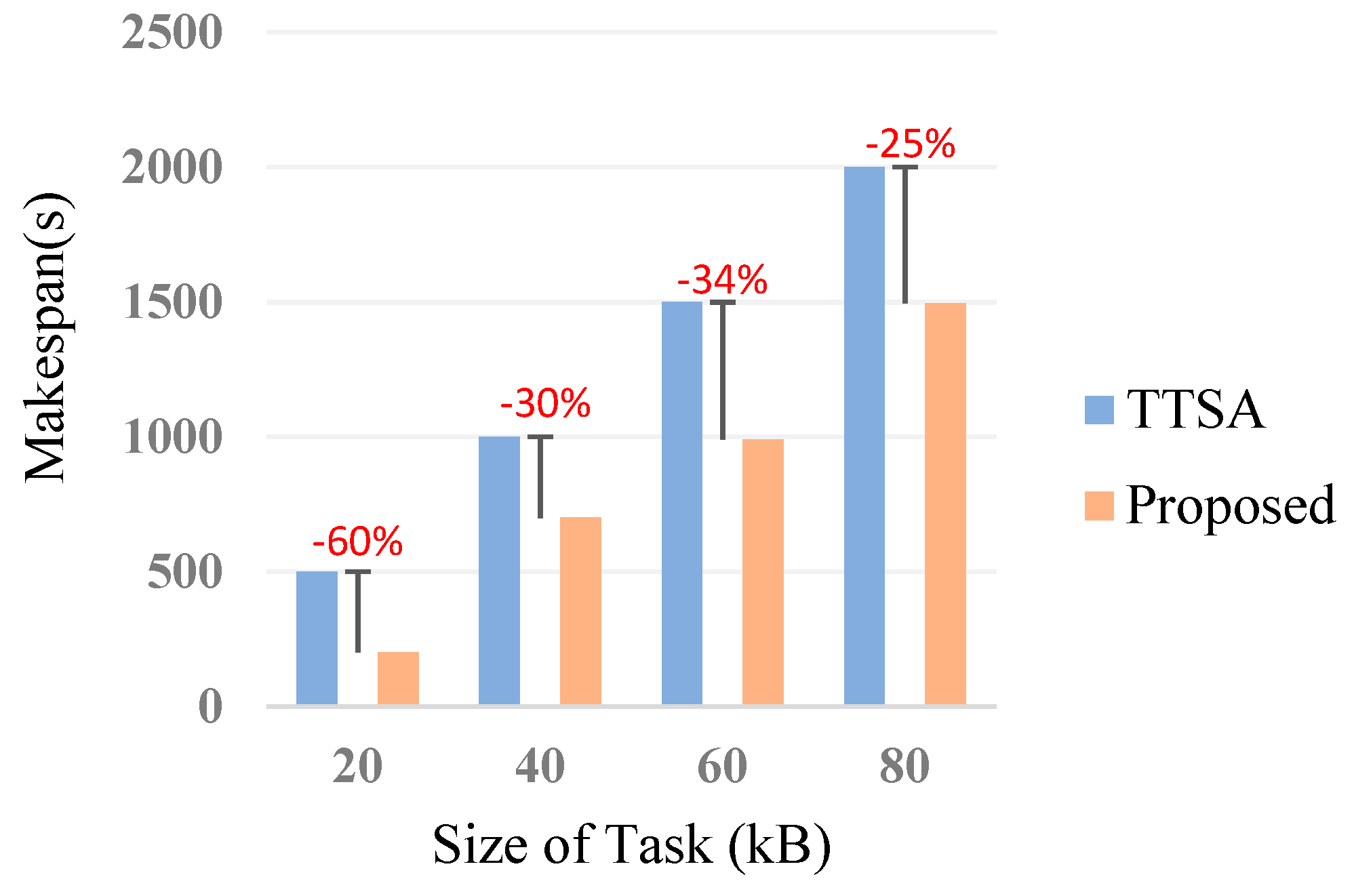
6.3.2. Makespan
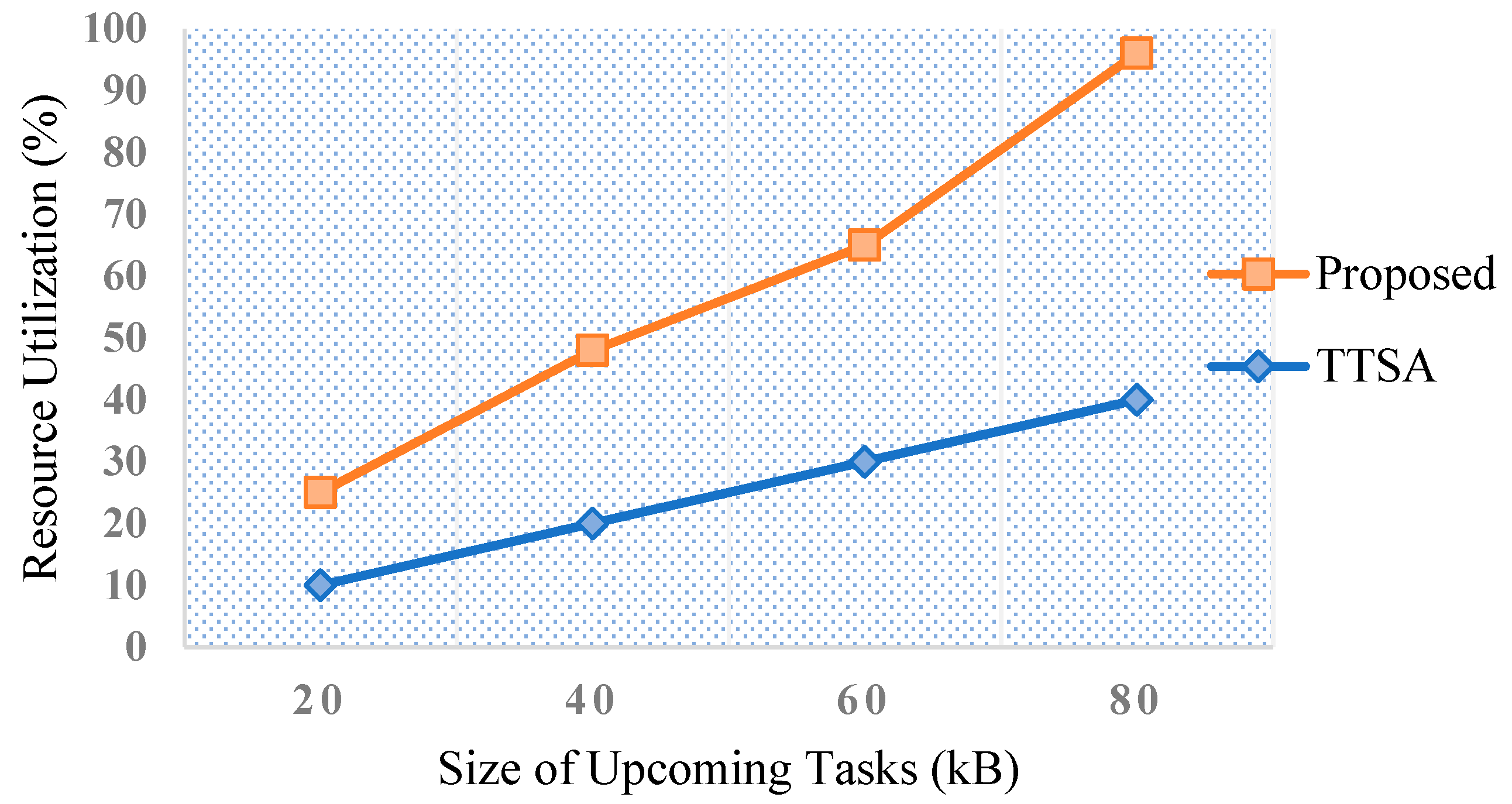
6.3.3. Resource Utilization
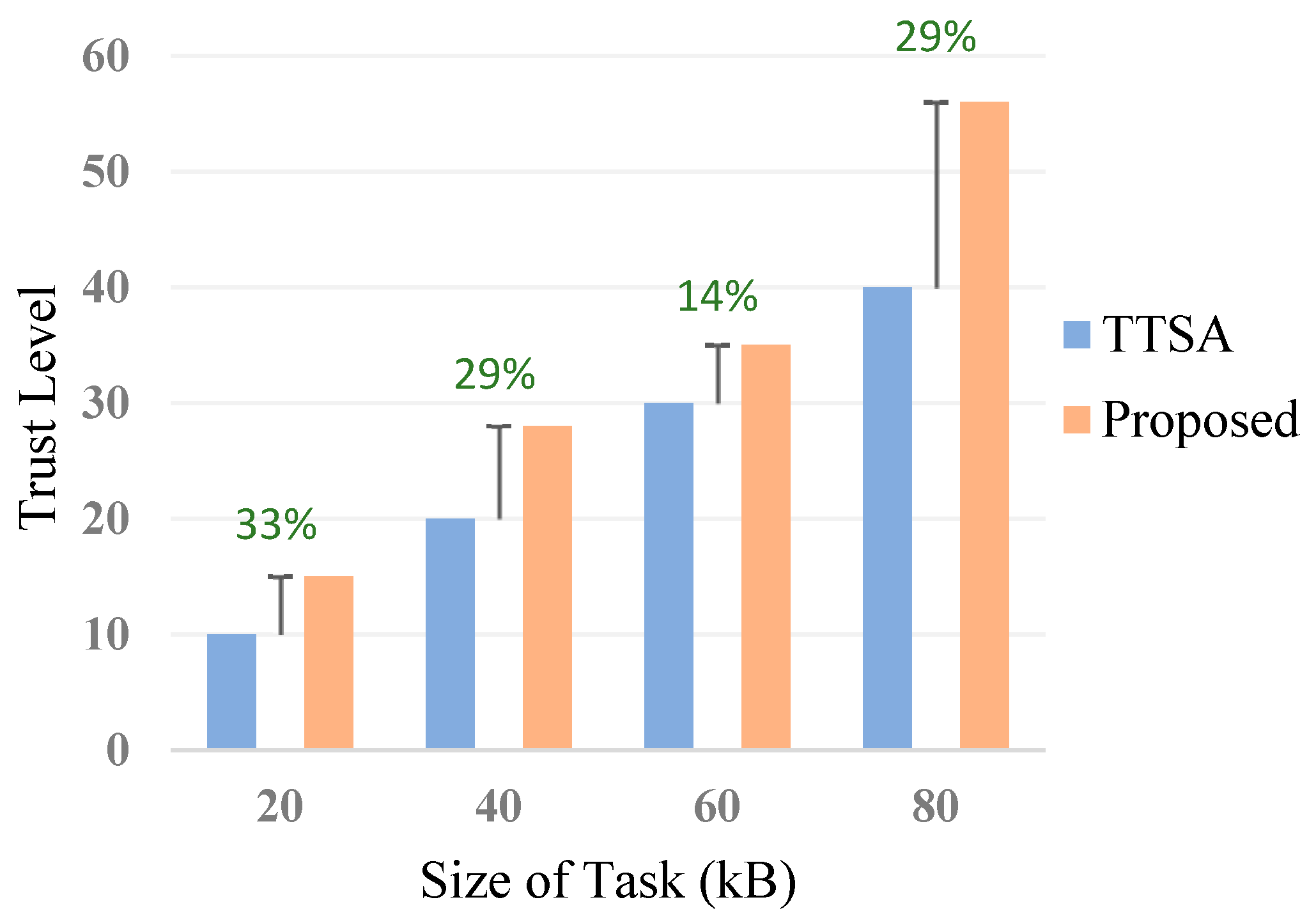
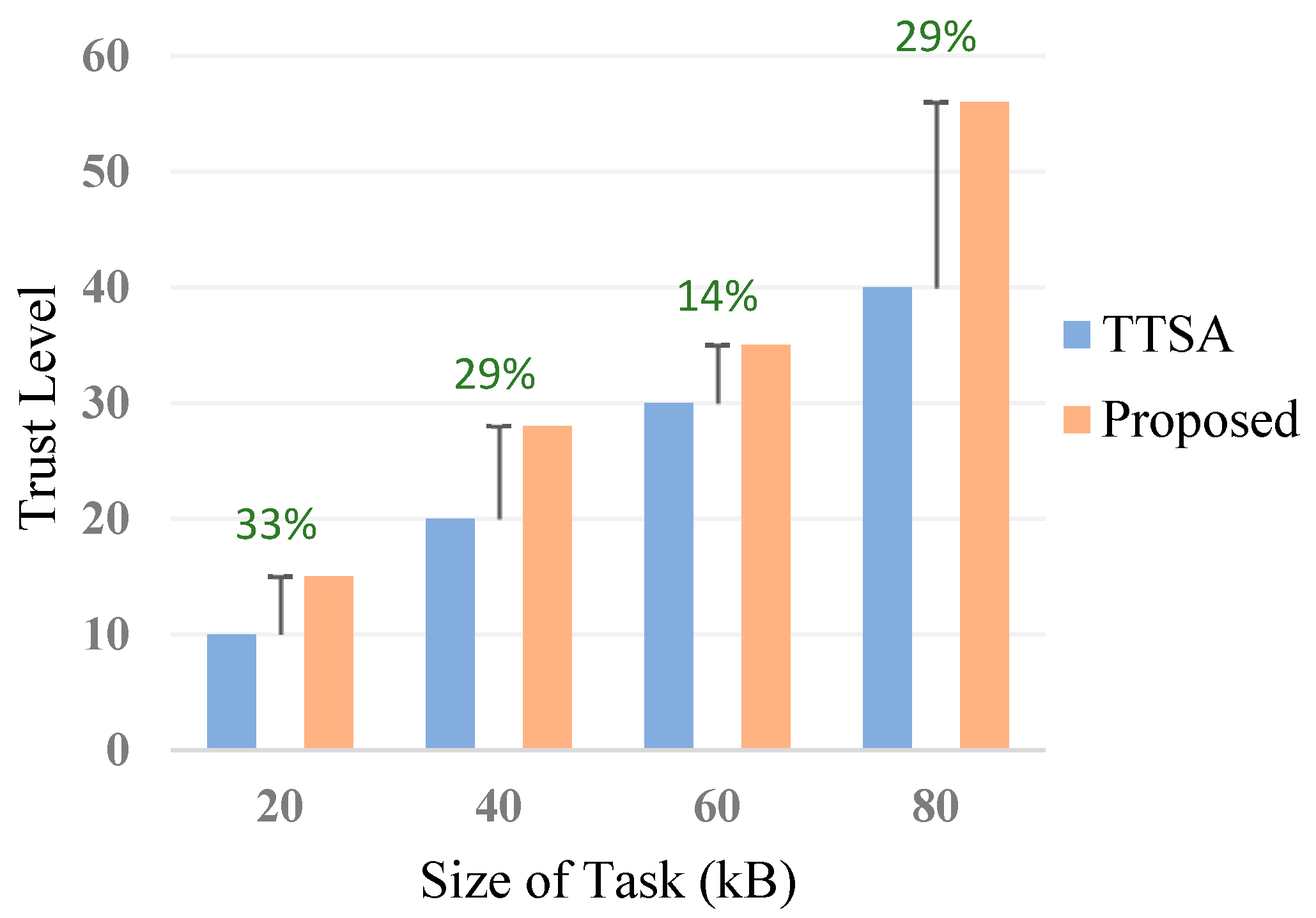
6.3.4. Service Reliability
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yuan, H.; Bi, J.; Tan, W.; Zhou, M.; Li, B.H.; Li, J. TTSA: An effective scheduling approach for delay bounded tasks in hybrid clouds. IEEE Trans. Cybernet. 2017, 47, 3658–3668. [Google Scholar] [CrossRef] [PubMed]
- Sharma, S.C.M.; Rath, A.K. Multi-Rumen Anti-Grazing approach of load balancing in cloud network. Int. J. Inf. Tech. 2017, 9, 129–138. [Google Scholar]
- Atiewi, S.; Yussof, S.; Ezanee, M.; Almiani, M. A review energy-efficient task scheduling algorithms in cloud computing. In Proceedings of the 2016 IEEE Long Island Systems, Applications and Technology Conference (LISAT), Farmingdale, NY, USA, 29 April 2016; pp. 1–6. [Google Scholar]
- Elmougy, S.; Sarhan, S.; Joundy, M. A novel hybrid of Shortest job first and round Robin with dynamic variable quantum time task scheduling technique. J. Cloud Comput. 2017, 6, 12. [Google Scholar] [CrossRef]
- Atiewi, S.; Yussof, S.; Rusli, M.E.B.; Zalloum, M. A power saver scheduling algorithm using DVFS and DNS techniques in cloud computing data centres. Int. J. Grid Util. Comput. 2018, 9, 385–395. [Google Scholar] [CrossRef]
- Moon, Y.; Yu, H.; Gil, J.-M.; Lim, J. A slave ants based ant colony optimization algorithm for task scheduling in cloud computing environments. Hum.-Centric Comp. Inf. Sci. 2017, 7, 28. [Google Scholar] [CrossRef]
- Keshk, A.E.; El-Sisi, A.B.; Tawfeek, M.A. Cloud task scheduling for load balancing based on intelligent strategy. Int. J. Intell. Syst. Appl. 2014, 6, 25. [Google Scholar] [CrossRef]
- Gawali, M.B.; Shinde, S.K. Task scheduling and resource allocation in cloud computing using a heuristic approach. J. Cloud Comput. 2018, 7. [Google Scholar] [CrossRef]
- Jeyakrishnan, V.; Sengottuvelan, P. A hybrid strategy for resource allocation and load balancing in virtualized data centers using BSO algorithms. Wirel. Pers. Commun. 2017, 94, 2363–2375. [Google Scholar] [CrossRef]
- Jana, B.; Chakraborty, M.; Mandal, T. A Task Scheduling Technique Based on Particle Swarm Optimization Algorithm in Cloud Environment. In Soft Computing: Theories and Applications; Springer: Singapore, 2019; pp. 525–536. [Google Scholar]
- Phi, N.X.; Tin, C.T.; Thu, L.N.K.; Hung, T.C. Proposed Load Balancing Algorithm to Reduce Response Time and Processing Time on Cloud Computing. Int. J. Comput. Netw. Commun. 2018, 10, 87–98. [Google Scholar]
- Kherbache, V.; Madelaine, E.; Hermenier, F. Scheduling live migration of virtual machines. IEEE Trans. Cloud Comput. 2017. [Google Scholar] [CrossRef]
- Mousavi, S.; Mosavi, A.; Varkonyi-Koczy, A.R. A load balancing algorithm for resource allocation in cloud computing. In Proceedings of the International Conference on Global Research and Education, Iasi, Romania, 25–28 September 2017; Springer: Cham, Switzerland, 2017; pp. 289–296. [Google Scholar]
- Velde, V.; Rama, B. An advanced algorithm for load balancing in cloud computing using fuzzy technique. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017; pp. 1042–1047. [Google Scholar]
- Tang, F.; Yang, L.T.; Tang, C.; Li, J.; Guo, M. A dynamical and load-balanced flow scheduling approach for big data centers in clouds. IEEE Trans. Cloud Comput. 2016, 6, 915–928. [Google Scholar] [CrossRef]
- Yu, L.; Chen, L.; Cai, Z.; Shen, H.; Liang, Y.; Pan, Y. Stochastic load balancing for virtual resource management in datacenters. IEEE Trans. Cloud Comput. 2016. [Google Scholar] [CrossRef]
- Shen, H. RIAL: Resource intensity aware load balancing in clouds. IEEE Trans. Cloud Comput. 2017. [Google Scholar] [CrossRef]
- Zhang, P.; Zhou, M. Dynamic cloud task scheduling based on a two-stage strategy. IEEE Trans. Automation Science Eng. 2018, 15, 772–783. [Google Scholar] [CrossRef]
- Kumar, A.S.; Venkatesan, M. Task scheduling in a cloud computing environment using HGPSO algorithm. Cluster Comput. 2018, 1–7. [Google Scholar] [CrossRef]
- Pradeep, K.; Jacob, T.P. A hybrid approach for task scheduling using the cuckoo and harmony search in cloud computing environment. Wirel. Pers. Commun. 2018, 101, 2287–2311. [Google Scholar] [CrossRef]
- Krishnadoss, P.; Jacob, P. OCSA: task scheduling algorithm in cloud computing environment. Int. J. Intell. Engin. Syst. 2018, 11, 271–279. [Google Scholar] [CrossRef]
- Alla, H.B.; Alla, S.B.; Touhafi, A.; Ezzati, A. A novel task scheduling approach based on dynamic queues and hybrid meta-heuristic algorithms for cloud computing environment. Cluster Comput. 2018, 21, 1797–1820. [Google Scholar] [CrossRef]
- Wang, S.; Qian, Z.; Yuan, J.; You, I. A DVFS based energy-efficient tasks scheduling in a data center. IEEE Access 2017, 5, 13090–13102. [Google Scholar] [CrossRef]
- Seth, S.; Singh, N. Dynamic heterogeneous shortest job first (DHSJF): a task scheduling approach for heterogeneous cloud computing systems. Int. J. Inf. Tech. 2018, 2018, 1–5. [Google Scholar] [CrossRef]
- Eswaran, S.; Rajakannu, M. Multiservice Load Balancing with Hybrid Particle Swarm Optimization in Cloud-Based Multimedia Storage System with QoS Provision. Mobile Netw. Appl. 2017, 22, 760–770. [Google Scholar] [CrossRef]
- Polepally, V.; Chatrapati, K.S. Dragonfly optimization and constraint measure-based load balancing in cloud computing. Cluster Comput. 2017, 2017, 1–13. [Google Scholar] [CrossRef]
- Rani, E.; Kaur, H. Efficient Load Balancing Task Scheduling in Cloud Computing using Raven Roosting Optimization Algorithm. Int. J. Adv. Res. Comput. Sci. 2017, 8, 2419–2424. [Google Scholar]
- Alworafi, M.A.; Mallappa, S. An enhanced task scheduling in cloud computing based on deadline-aware model. Int. Grid High Perform. Comput. 2018, 10, 31–53. [Google Scholar] [CrossRef]
- Fan, G.; Chen, L.; Yu, H.; Liu, D. Modeling and Analyzing Dynamic Fault-Tolerant Strategy for Deadline Constrained Task Scheduling in Cloud Computing. IEEE Trans. Syst. Man Cybernet. Syst. 2017, 2017, 1–15. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Specification |
|---|---|
| Operating system | Windows (X86 ultimate) 32-bit OS |
| Processor | Intel® Pentium® CPU G2030 @ 3.00 GHZ |
| RAM | 2.00 GB |
| System type | 32-bit OS |
| Hard disk | 500 GB |
| Entities | Specifications | Ranges |
|---|---|---|
| Cloudlets/tasks | Total number of tasks | 15–200 |
| Task length | 1500–3000 | |
| VM | Host | 3 |
| VM/physical machine | Storage | 300 GB |
| Bandwidth | 200,000 | |
| Memory | 520 | |
| Butter capacity | 20 | |
| MIPS/PE | 400 | |
| Bandwidth cost | 0.2/MB |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Rahayfeh, A.; Atiewi, S.; Abuhussein, A.; Almiani, M. Novel Approach to Task Scheduling and Load Balancing Using the Dominant Sequence Clustering and Mean Shift Clustering Algorithms. Future Internet 2019, 11, 109. https://doi.org/10.3390/fi11050109
Al-Rahayfeh A, Atiewi S, Abuhussein A, Almiani M. Novel Approach to Task Scheduling and Load Balancing Using the Dominant Sequence Clustering and Mean Shift Clustering Algorithms. Future Internet. 2019; 11(5):109. https://doi.org/10.3390/fi11050109
Chicago/Turabian StyleAl-Rahayfeh, Amer, Saleh Atiewi, Abdullah Abuhussein, and Muder Almiani. 2019. "Novel Approach to Task Scheduling and Load Balancing Using the Dominant Sequence Clustering and Mean Shift Clustering Algorithms" Future Internet 11, no. 5: 109. https://doi.org/10.3390/fi11050109
APA StyleAl-Rahayfeh, A., Atiewi, S., Abuhussein, A., & Almiani, M. (2019). Novel Approach to Task Scheduling and Load Balancing Using the Dominant Sequence Clustering and Mean Shift Clustering Algorithms. Future Internet, 11(5), 109. https://doi.org/10.3390/fi11050109