3D-CNN-Based Fused Feature Maps with LSTM Applied to Action Recognition



Abstract
:1. Introduction
- We propose an iterative training method for our neural network to generate a motion map from input video, which can integrate information into a motion map from each video frame.
- We intelligently incorporate C3D and LSTM networks and capture long-range spatial and temporal dynamics. C3D features on video shots contain richer motion information; LSTM can explore the temporal relationship between video shots.
- We introduce an effective fusion technique i.e., a linear weighted fusion method which can fuse correspondence between spatial and temporal features and boost recognition accuracy.
- The effectiveness of our approach is evaluated on benchmark datasets, in which it obtained state-of-the-art recognition results.
2. Related Work
3. The Proposed Approach
3.1. Extraction of Spatio-Temporal Fused Features
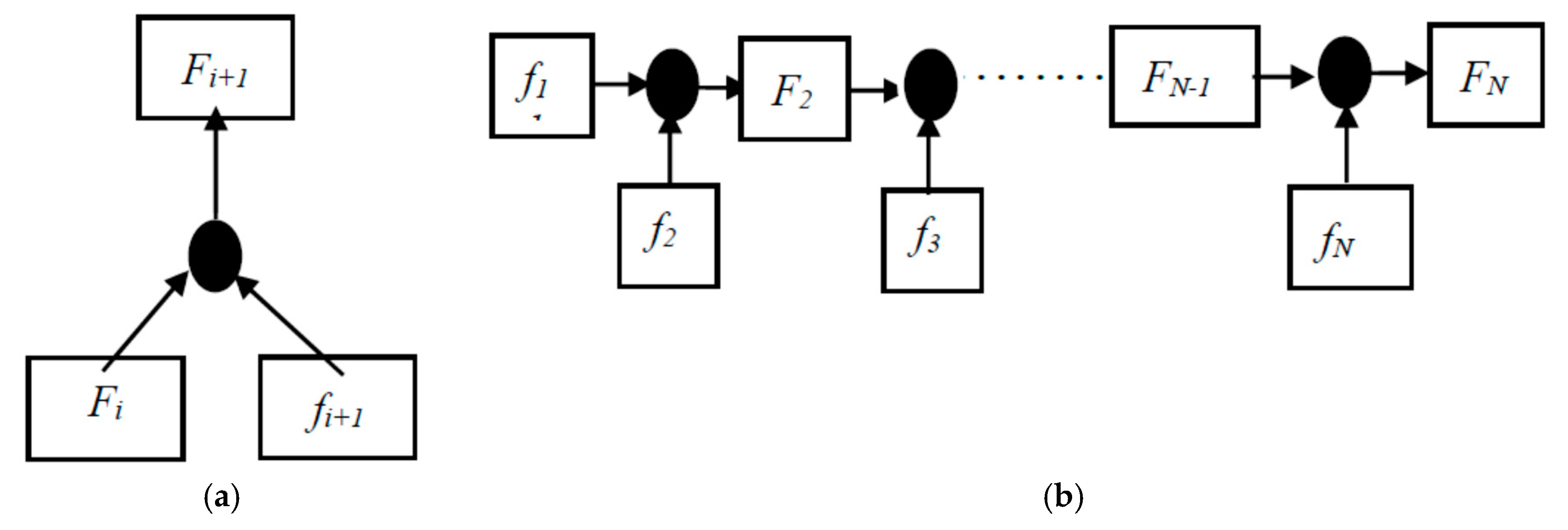
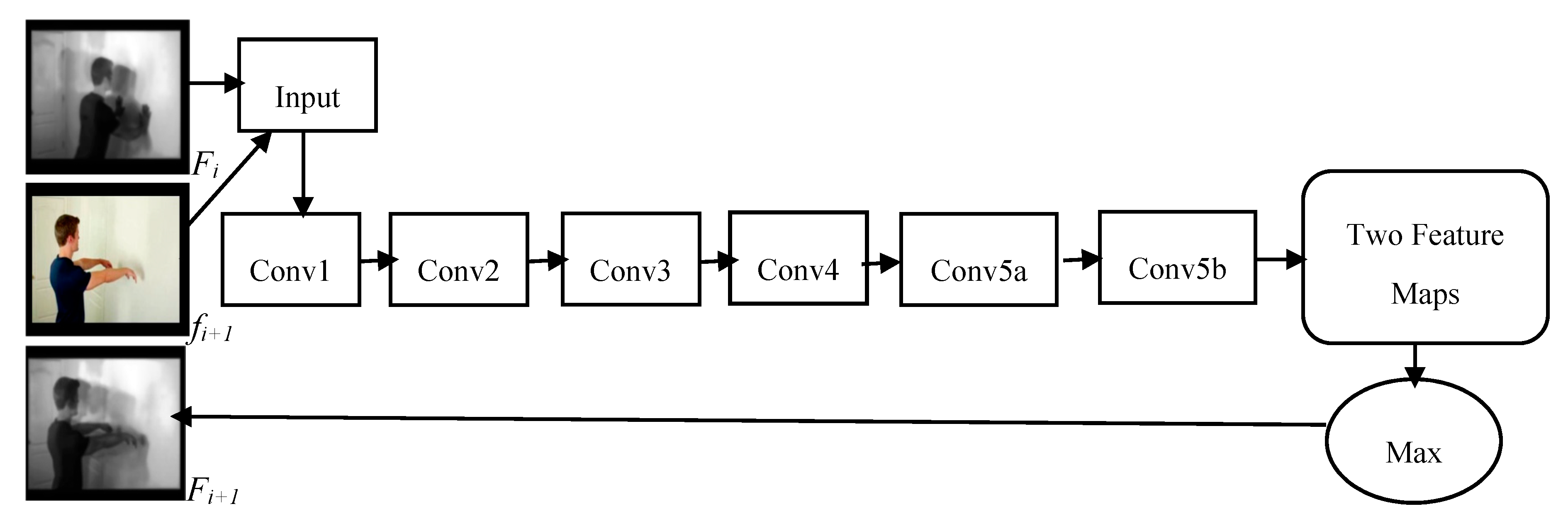
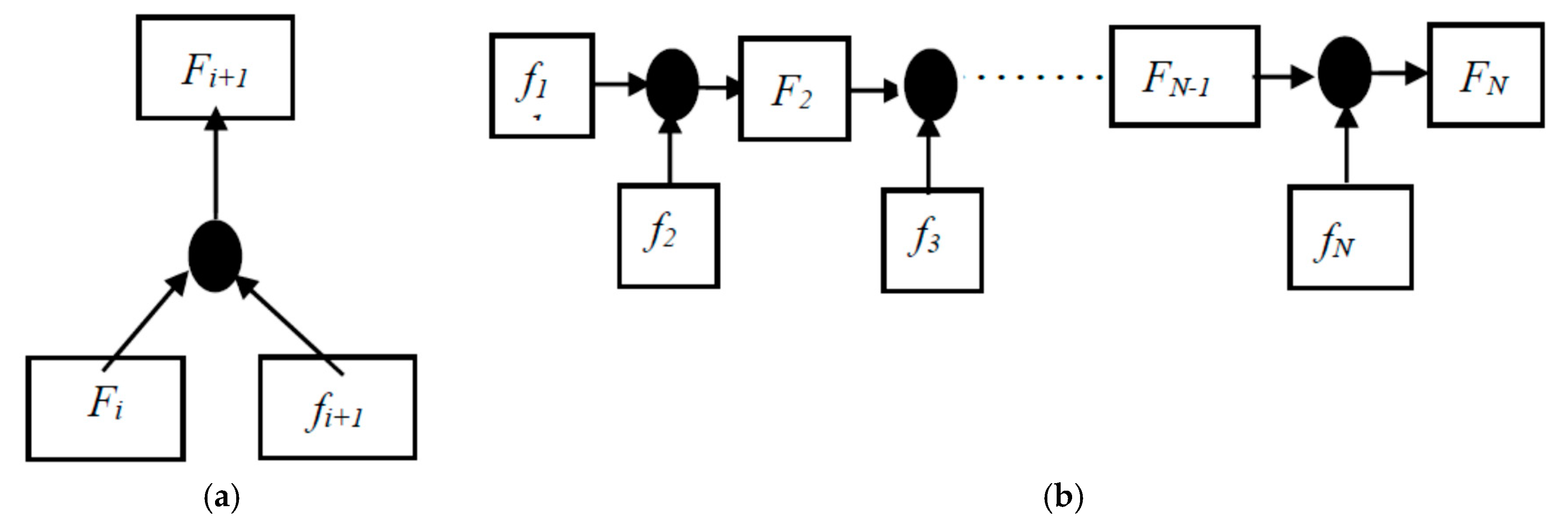
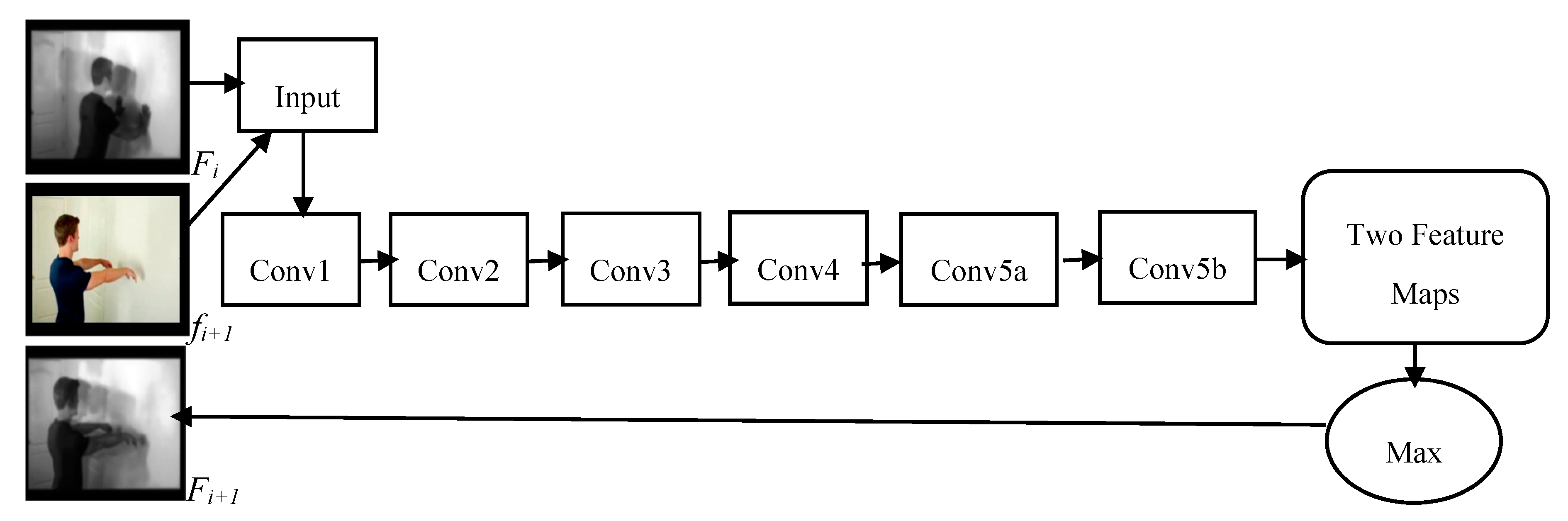
3.1.1. Generation of Motion Map
3.1.2. C3D Network Architecture
3.1.3. Training of Motion Map Network (MMN)
| Algorithm 1. Training of Our Motion Map Network |
| Input:V is Video dataset; Frame number of video dataset, N; Video labels, L; Maximum training iteration length, S; Parameters of our model, ; Output: Final parameters of Network, ; 1: Initialize the parameter for our model; 2: for each s∈2,3,…,S do 3: cut Vi into s-length clips ) with overlap 0.7; 4: Extract the video frames from as ; 5: for each j ∈1, 2… N/s do 6: for k ∈1, 2… s − 1 do 7: Generate the motion map using ) end for 8: Train the MMN using and Li end for 9: Get the MMN parameters θs; end for |
3.1.4. Fusion Method
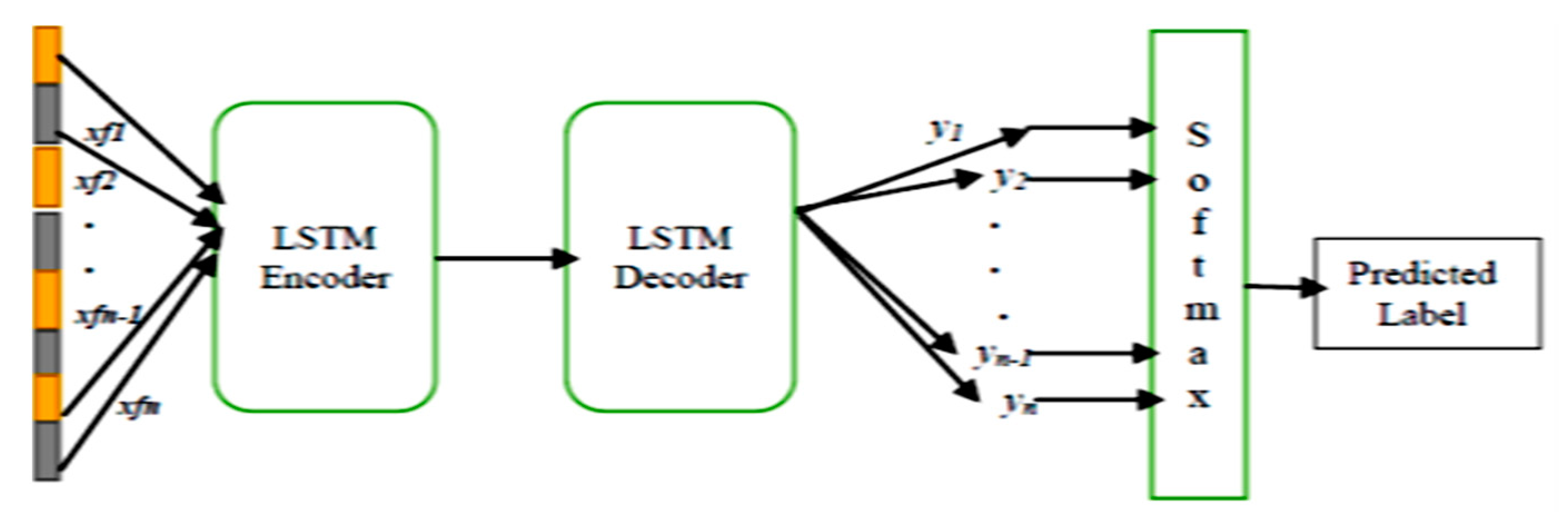
3.2. Encoding and Activity Classification
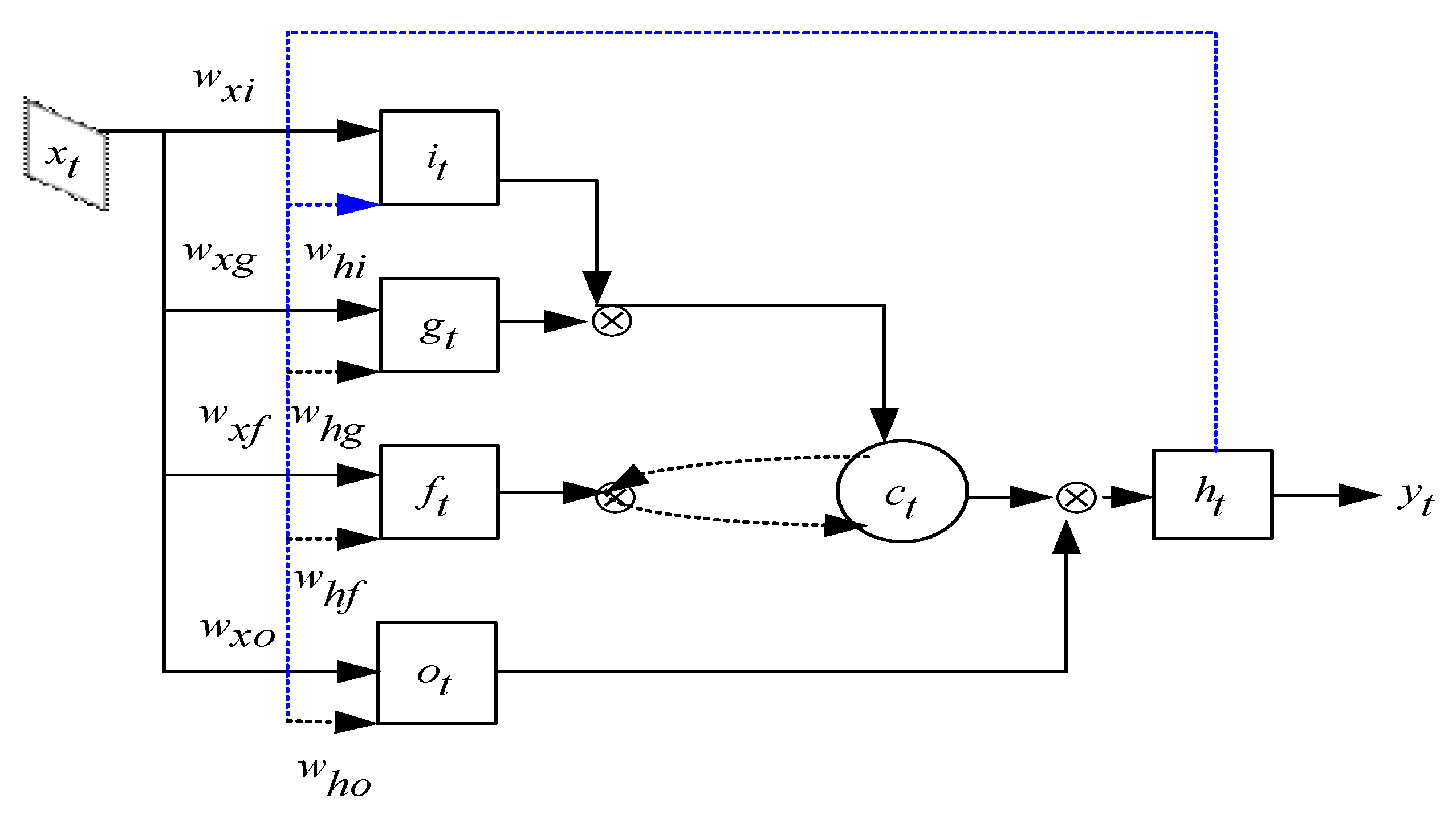
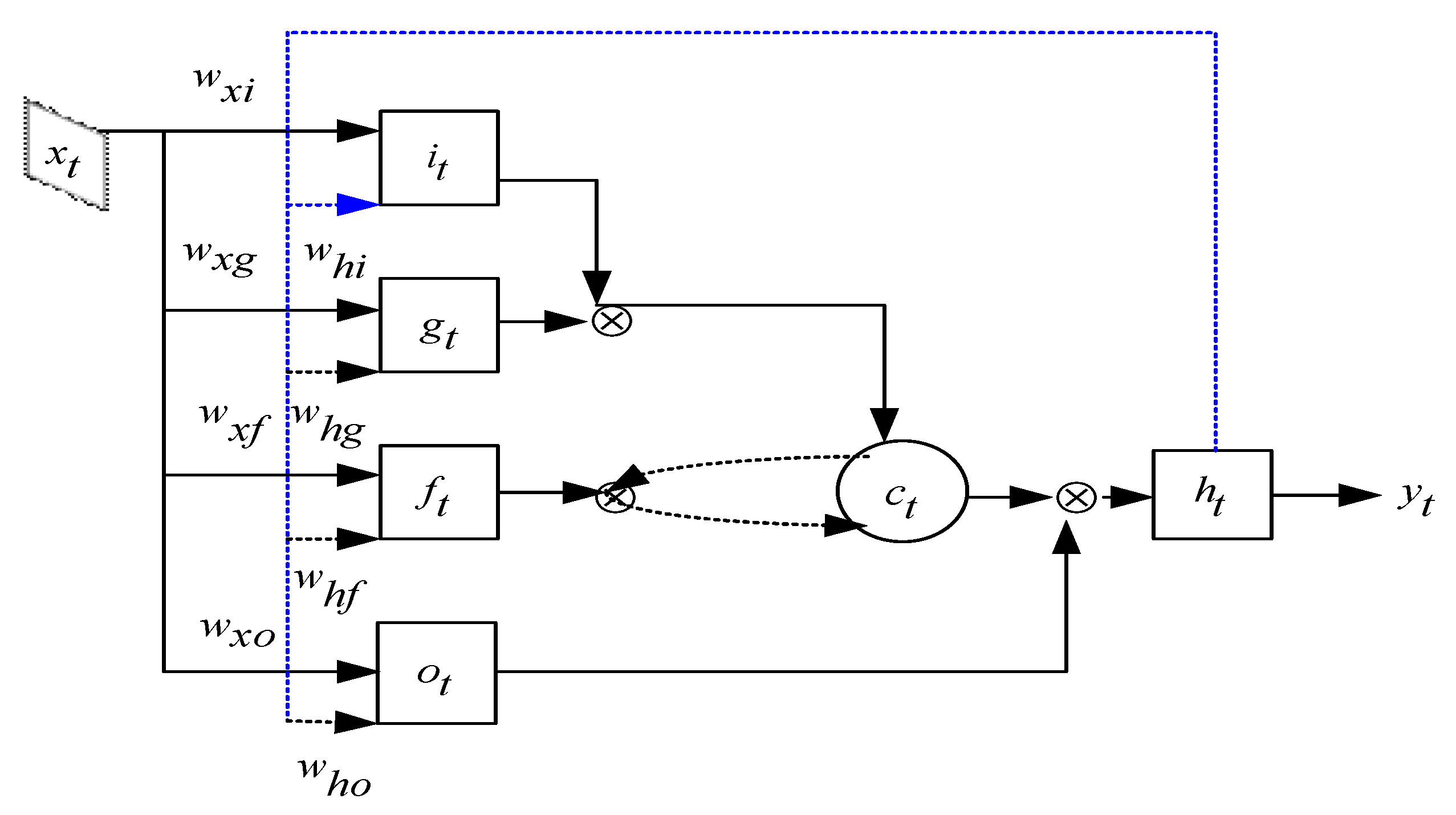
3.2.1. Long Short-Term Memory (LSTM)
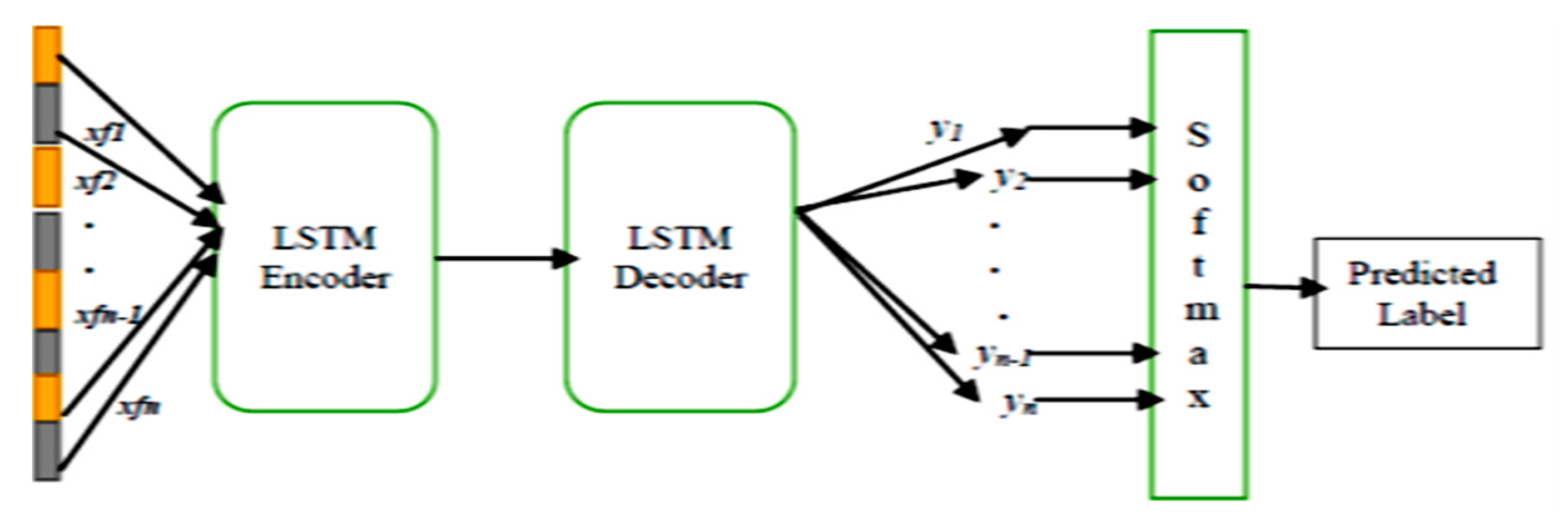
3.2.2. Encoding and Classification Process by LSTM
4. Experiments
4.1. Datasets
4.2. Experimental Setup and Implementation Details
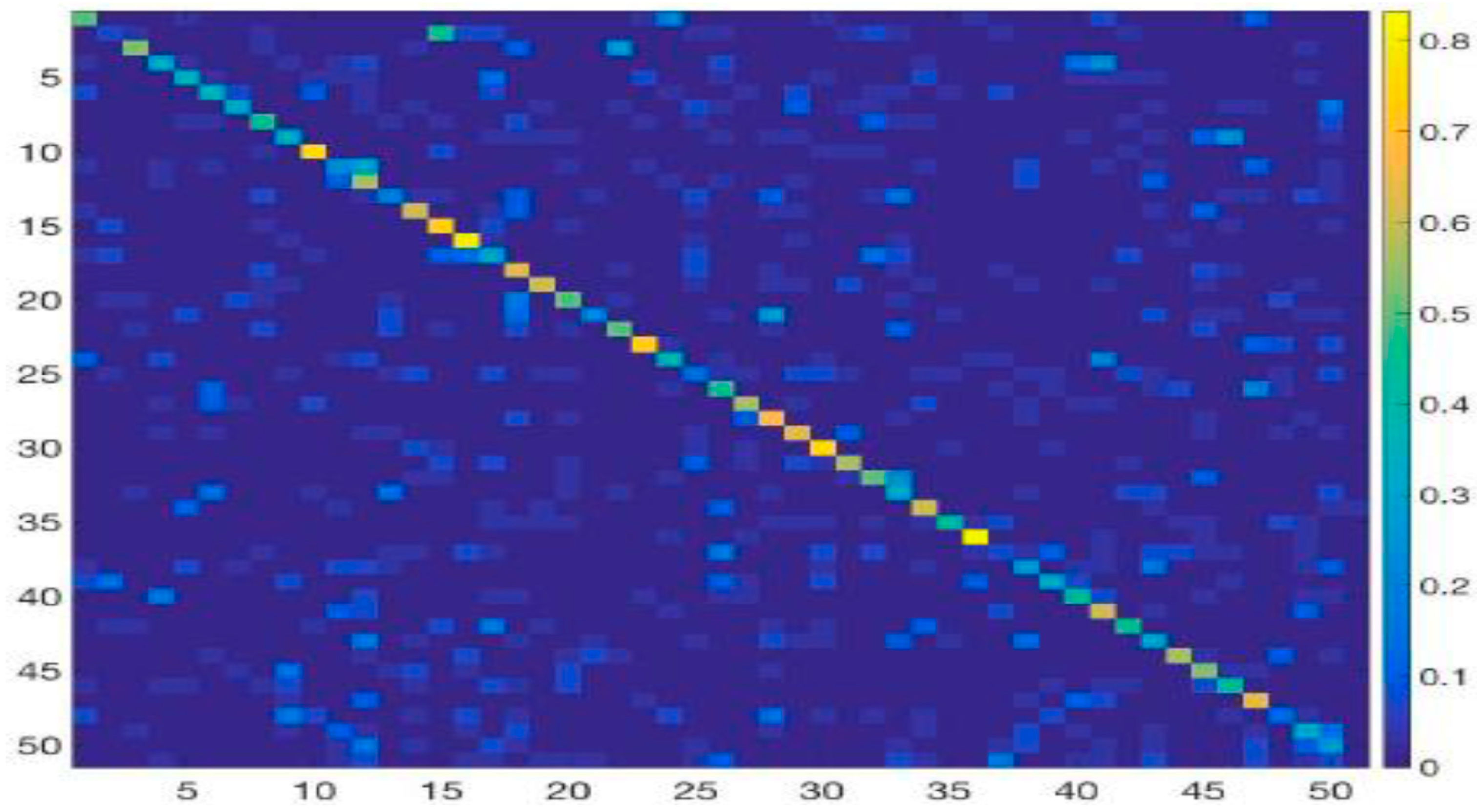
4.3. Results and Comparison Analysis
4.3.1. Effect of Different Feature Fusion Techniques
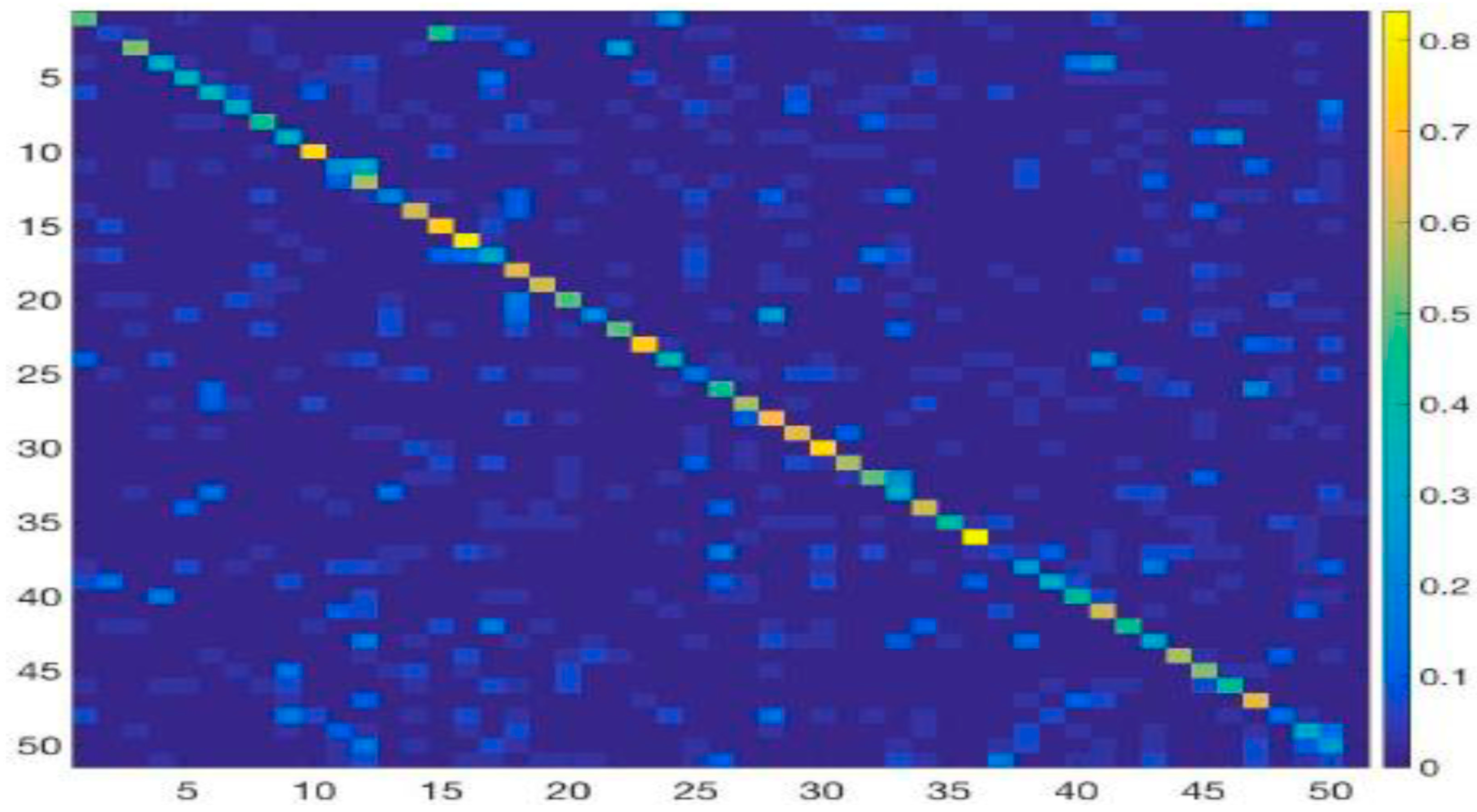
4.3.2. Class-Wise Accuracy for Activity Recognition
4.3.3. Comparison to the State-Of-The-Art Methods
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Laptev, I. On space-time interest points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Willems, G.; Tuytelaars, T.; Gool, L. An efficient dense and scale-invariant spatio-temporal interest point detector. In Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 650–663. [Google Scholar]
- Yeffet, Y.; Wolf, L. Local trinary patterns for human action recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 492–497. [Google Scholar]
- Dollr, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior recognition via sparse spatio-temporal features. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; pp. 65–72. [Google Scholar]
- Scovanner, P.; Ali, S.; Shah, M. A 3-dimensional SIFT descriptor and its application to action recognition. In Proceedings of the 15th ACM international conference on Multimedia, Augsburg, Germany, 25–29 September 2007; pp. 357–360. [Google Scholar]
- Matikanen, P.; Hebert, M.; Sukthankar, R. Trajectons: Action recognition through the motion analysis of tracked features. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 514–521. [Google Scholar]
- Sun, J.; Wu, X.; Yan, S.; Cheong, L.; Chua, T.S.; Li, J. Hierarchical spatio-temporal context modeling for action recognition. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2004–2011. [Google Scholar]
- Wang, H.; Klser, A.; Schmid, C.; Liu, C.L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Visi. 2013, 103, 60–79. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Bilen, H.; Fernando, B.; Gavves, E.; Vedaldi, A.; Gould, S. Dynamic image networks for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3034–3042. [Google Scholar]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time human action recognition based on depth motion maps. J. Real-Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. arXiv, 2015; arXiv:1412.0767. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.F. Large-scale video classification with convolutional neural networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv, 2014; arXiv:1406.2199. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. arXiv, 2016; arXiv:1608.00859. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lu, X.; Yao, H.; Zhao, S. Action recognition with multi-scale trajectory-pooled 3D convolutional descriptors. Trans. Multimedia Tools Appl. 2017, 1–17. [Google Scholar] [CrossRef]
- Taylor, G.; Fergus, R.; LeCun, Y.; Bregler, C. Convolutional learning of spatiotemporal features. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 140–153. [Google Scholar]
- Fernando, B.; Gavves, E.; Oramas, J.M.; Ghodrati, A.; Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5378–5387. [Google Scholar]
- Perronnin, F.; S´anchez, J.; Mensink, T. Improving the fisher kernel for large-scale image classification. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 143–156. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv, 2014; arXiv:1409.2329. [Google Scholar]
- Donahue, J.; Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 677–691. [Google Scholar] [CrossRef] [PubMed]
- Veeriah, V.; Zhuang, N.; Qi, G.J. Differential recurrent neural networks for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Santiago, Chile, 7–13 December 2015; pp. 4041–4049. [Google Scholar]
- Yue-Hei, J.; Hausknecht, M.; Vijayanarasimhan, S. Beyond short snippets: Deep networks for video classification. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Wu, Z.; Wang, X.; Jiang, Y. Modelling spatial-temporal clues in a hybrid deep learning framework for video classification. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 461–470. [Google Scholar]
- Ji-Hae, K.; Gwang-soo, H.; Byung-Gyu, K.; Debi, D. deepGesture: Deep learning-based gesture recognition scheme using motion sensors. Displays 2018, 55, 38–45. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhutdinov, R. Unsupervised Learning of Video Representations using LSTMs. arXiv, 2015; arXiv:1502.04681. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Soomro, K.; Zamir, A.R.; Shah, M. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv, 2012; arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. Hmdb: A large video database for human motion recognition. In Proceedings of the IEEE 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Rodriguez, M.D.; Ahmed, J.; Shah, M. Action MACH a spatiotemporal maximum average correlation height filter for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Jiang, Y.G.; Liu, J.; Zamir, R.; Laptev, I.; Piccardi, M.; Shah, M.; Sukthankar, R. THUMOS challenge: Action Recognition with a Large Number of Classes. The First International Workshop on Action Recognition with a Large Number of Classes, in Conjunction with ICCV’13, Sydney, Australia. 2013. Available online: http://crcv.ucf.edu/ICCV13-Action-Workshop/ (accessed on 28 January 2019).
- Murthy, V.R.; Goecke, R. Ordered trajectories for large scale human action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 412–419. [Google Scholar]
- Ni, B.; Moulin, P.; Yang, X. Motion part regularization: Improving action recognition via trajectory selection. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3698–3706. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Mofap: A multi-level representation for action recognition. Int. J. Comput. Vis. 2016, 119, 119–254. [Google Scholar] [CrossRef]
- Seo, J.; Kim, H.; Ro, Y.M. Effective and efficient human action recognition using dynamic frame skipping and trajectory rejection. J. Image Vis. Comput. 2017, 58, 76–85. [Google Scholar] [CrossRef]
- Sun, L.; Jia, K.; Shi, B.E. Human action recognition using factorized spatio-temporal convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4597–4605. [Google Scholar]
- Zhang, B.; Wang, L.; Wang, Z.Y. Real-time action recognition with enhanced motion vector CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2718–2726. [Google Scholar]
- Wang, J.; Wang, W.; Wang, R. Deep alternative neural network: Exploring contexts as early as possible for action recognition. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 4–9 December 2016; pp. 811–819. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1510–1517. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Gavves, E.; Jain, M. VideoLSTM convolves, attends and flows for action recognition. Comput. Vis. Image Underst. 2016, 166, 41–50. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Wang, P.; Liu, X. Two-stream 3D convNet Fusion for Action Recognition in Videos with Arbitrary Size and Length. IEEE Trans. Multimedia 2017, 20, 1–11. [Google Scholar]
- Yu, S.; Cheng, Y.; Xie, L. Fully convolutional networks for action recognition. Inst. Eng. Technol. Comput. Vis. 2017, 11, 744–749. [Google Scholar] [CrossRef]
- Zhu, Y.; Lan, Z.; Newsam, S. Hidden two-stream convolutional networks for action recognition. arXiv, 2017; arXiv:1704.00389. [Google Scholar]
- Yeung, S.; Russakovsky, O.; Jin, N. Every moment counts: Dense detailed labelling of actions in complex videos. Int. J. Comput. Vis. 2018, 126, 375–389. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Song, J.; Shen, H. Beyond frame-level CNN: Saliency-aware 3-D CNN with LSTM for video action recognition. IEEE Signal Process. Lett. 2017, 24, 510–514. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Conv1a | Conv2a | Conv3a | Conv3b | Conv4a | Conv4b | Conv5a | Conv5b |
| Size | 3 × 3 × 3 | 3 × 3 × 3 | 3 × 3 × 3 | 3 × 3 × 3 | 3 × 3 × 3 | 3 × 3 × 3 | 3 × 3 × 3 | 3 × 3 × 3 |
| Stride | 1 × 1 × 1 | 1 × 1 × 1 | 1 × 1 × 1 | 1 × 1 × 1 | 1 × 1 × 1 | 1 × 1 × 1 | 1 × 1 × 1 | 1 × 1 × 1 |
| Channel | 64 | 128 | 256 | 256 | 512 | 512 | 512 | 512 |
| Ratio | 1 | 1/2 | 1/4 | 1/4 | 1/8 | 1/8 | 1/16 | 1/1 |
| Layers | Pool1 | Pool2 | Pool3 | Pool4 | Pool5 | Fc6 | Fc7 | |
| Size | 1 × 2 × 2 | 2 × 2 × 2 | 2 × 2 × 2 | 2 × 2 × 2 | 2 × 2 × 2 | - | - | Softmax Layer |
| Stride | 1 × 2 × 2 | 2 × 2 × 2 | 2 × 2 × 2 | 2 × 2 × 2 | 2 × 2 × 2 | - | - | |
| Channel | 64 | 128 | 256 | 512 | 512 | 4096 | 4096 | |
| Ratio | 1/2 | 1/4 | 1/8 | 1/16 | 1/32 | - | - |
| Fusion Method | UCF Sports | Split 1 (UCF 101) | Split 2 (UCF 101) | Split 3 (UCF 101) | Average (UCF 101) |
|---|---|---|---|---|---|
| Element-wise max | 91.8 | 90.5 | 89.9 | 89.6 | 90.0 |
| Element-wise sum | 92.1 | 90.8 | 90.1 | 89.9 | 90.2 |
| Concatenation | 92.8 | 91.2 | 90.5 | 91.0 | 90.9 |
| Linear weighted | 93.9 | 91.6 | 90.9 | 91.7 | 91.4 |
| Categories | Diving | Golf -Swing | Kicking | Lifting | Horse Riding | Running | Skate Boarding | Swing Bench | Swing-Side | Walking |
|---|---|---|---|---|---|---|---|---|---|---|
| Diving | 1.00 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Golf-Swing | 0 | 0.91 | 0.07 | 0 | 0 | 0 | 0 | 0.02 | 0 | 0 |
| Kicking | 0 | 0.06 | 0.94 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Lifting | 0 | 0 | 0 | 0.95 | 0 | 0 | 0 | 0 | 0 | 0 |
| Riding Horse | 0 | 0 | 0 | 0 | 0.90 | 0 | 0 | 0 | 0 | 0 |
| Running | 0 | 0.06 | 0.01 | 0 | 0.01 | 0.91 | 0 | 0 | 0 | 0.01 |
| Skateboarding | 0 | 0 | 0 | 0 | 0 | 0 | 0.93 | 0 | 0 | 0 |
| Swing Bench | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.00 | 0 | 0 |
| Swing Side | 0 | 0.01 | 0 | 0 | 0 | 0 | 0 | 0 | 0.99 | 0 |
| Walking | 0 | 0.07 | 0 | 0 | 0 | 0 | 0 | 0.04 | 0 | 0.89 |
| Average Accuracy | 0.94 | |||||||||
| Modality | Method | Year | UCF101 | HDMB51 |
|---|---|---|---|---|
| Traditional | iDT+fisher vector [10] | 2013 | 84.7 | 57.2 |
| Ordered Trajectory [36] | 2015 | 72.8 | 47.3 | |
| MPR [37] | 2015 | - | 65.5 | |
| MoFAP [38] | 2016 | 88.3 | 61.7 | |
| Trajectory Rejection [39] | 2016 | 85.7 | 58.9 | |
| Deep | Two-Stream [16] | 2013 | 88.9 | 59.4 |
| FSTCN [40] | 2015 | 88.1 | 59.1 | |
| EMV-CNN [41] | 2016 | 86.4 | - | |
| DANN [42] | 2016 | 89.2 | 63.3 | |
| Dynamic Images [11] | 2016 | 89.1 | 65.2 | |
| LTC-CNN [43] | 2018 | 92.7 | 67.2 | |
| Very deep | C3D [13] | 2015 | 85.2 | - |
| LSTM [27] | 2015 | 88.6 | - | |
| LRCN [25] | 2015 | 82.9 | - | |
| VideoLSTM [44] | 2016 | 89.2 | 56.4 | |
| 3D Convolution [14] | 2016 | 91.8 | 64.6 | |
| STPP-LSTM [45] | 2017 | 91.6 | 69.0 | |
| FCNs-16 [46] | 2017 | 90.5 | 63.4 | |
| Hidden-Two-stream [47] | 2017 | 90.3 | 58.9 | |
| Multi-LSTM [48] | 2018 | 90.8 | - | |
| Hybrid-Model | TDD-iDT [19] | 2015 | 91.5 | 65.9 |
| C3D-iDT [13] | 2015 | 90.4 | - | |
| TSN [17] | 2016 | 94.2 | 69.4 | |
| 3D conv + iDT [14] | 2016 | 93.5 | 69.2 | |
| SCLSTM [49] | 2017 | 84.0 | 55.1 | |
| LTC-iDT [43] | 2018 | 92.7 | 67.2 | |
| Ours | LSTM–3D ConvNet | - | 92.9 | 70.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arif, S.; Wang, J.; Ul Hassan, T.; Fei, Z. 3D-CNN-Based Fused Feature Maps with LSTM Applied to Action Recognition. Future Internet 2019, 11, 42. https://doi.org/10.3390/fi11020042
Arif S, Wang J, Ul Hassan T, Fei Z. 3D-CNN-Based Fused Feature Maps with LSTM Applied to Action Recognition. Future Internet. 2019; 11(2):42. https://doi.org/10.3390/fi11020042
Chicago/Turabian StyleArif, Sheeraz, Jing Wang, Tehseen Ul Hassan, and Zesong Fei. 2019. "3D-CNN-Based Fused Feature Maps with LSTM Applied to Action Recognition" Future Internet 11, no. 2: 42. https://doi.org/10.3390/fi11020042
APA StyleArif, S., Wang, J., Ul Hassan, T., & Fei, Z. (2019). 3D-CNN-Based Fused Feature Maps with LSTM Applied to Action Recognition. Future Internet, 11(2), 42. https://doi.org/10.3390/fi11020042