Real-Time Stream Processing in Social Networks with RAM3S



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
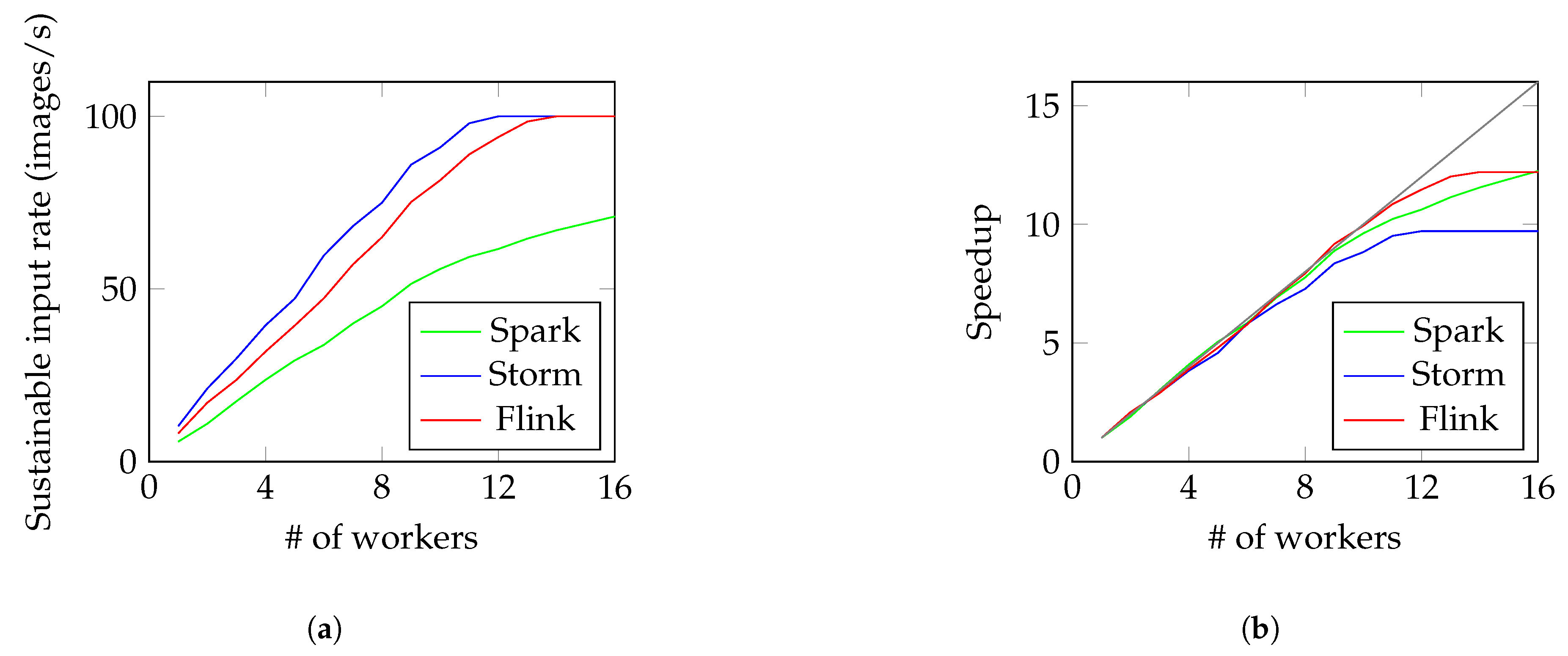{kind=link}
{kind=link}
Abstract
1. Introduction
Outline
- Section 2 provides the motivation for our work, presenting examples of modern social network services requiring real-time processing of massive multimedia data streams.
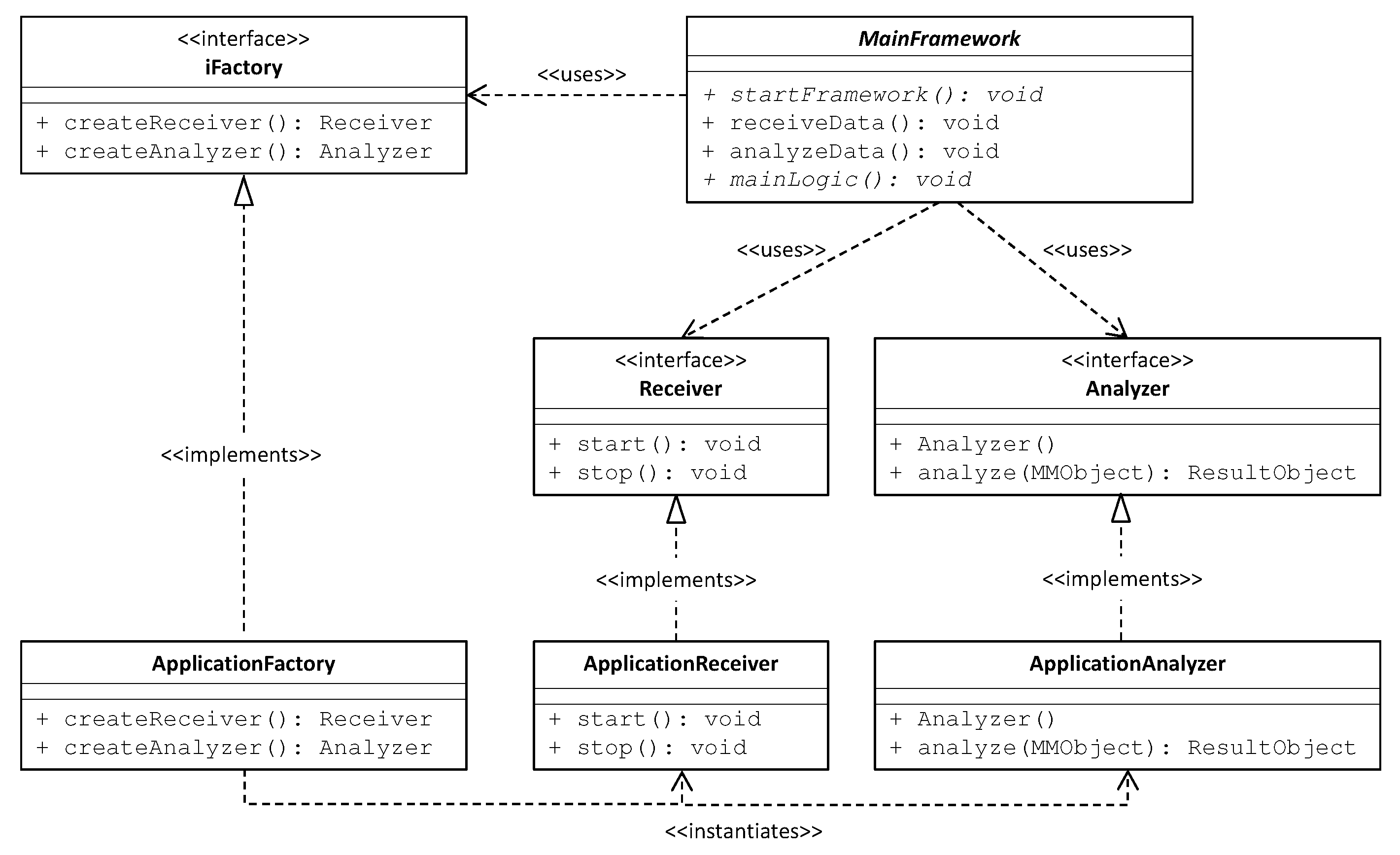
- In Section 3 we introduce the RAMS framework, detailing its programming interface that allows generalizing it to the specific application at hand.
- Section 4 shows the three different use cases that we implemented on top of RAMS, proving its wide range of applicability.
- Finally, Section 5 concludes, pointing out interesting directions for further research.
2. Motivation
“Our service includes automated systems to detect and remove abusive and dangerous activity that could hurt the community at large.”
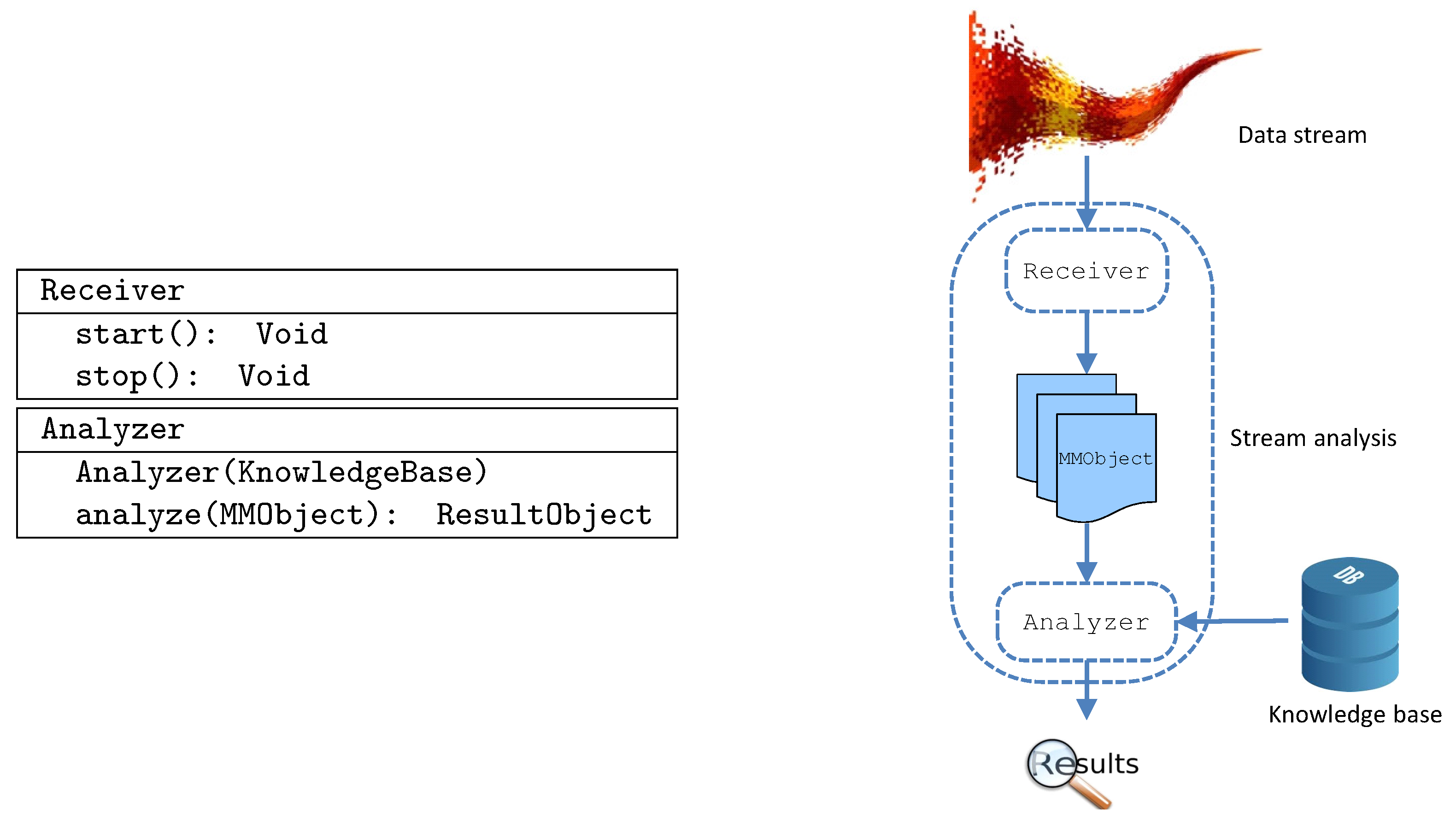
3. Background
3.1. Interface to Big Data Platforms
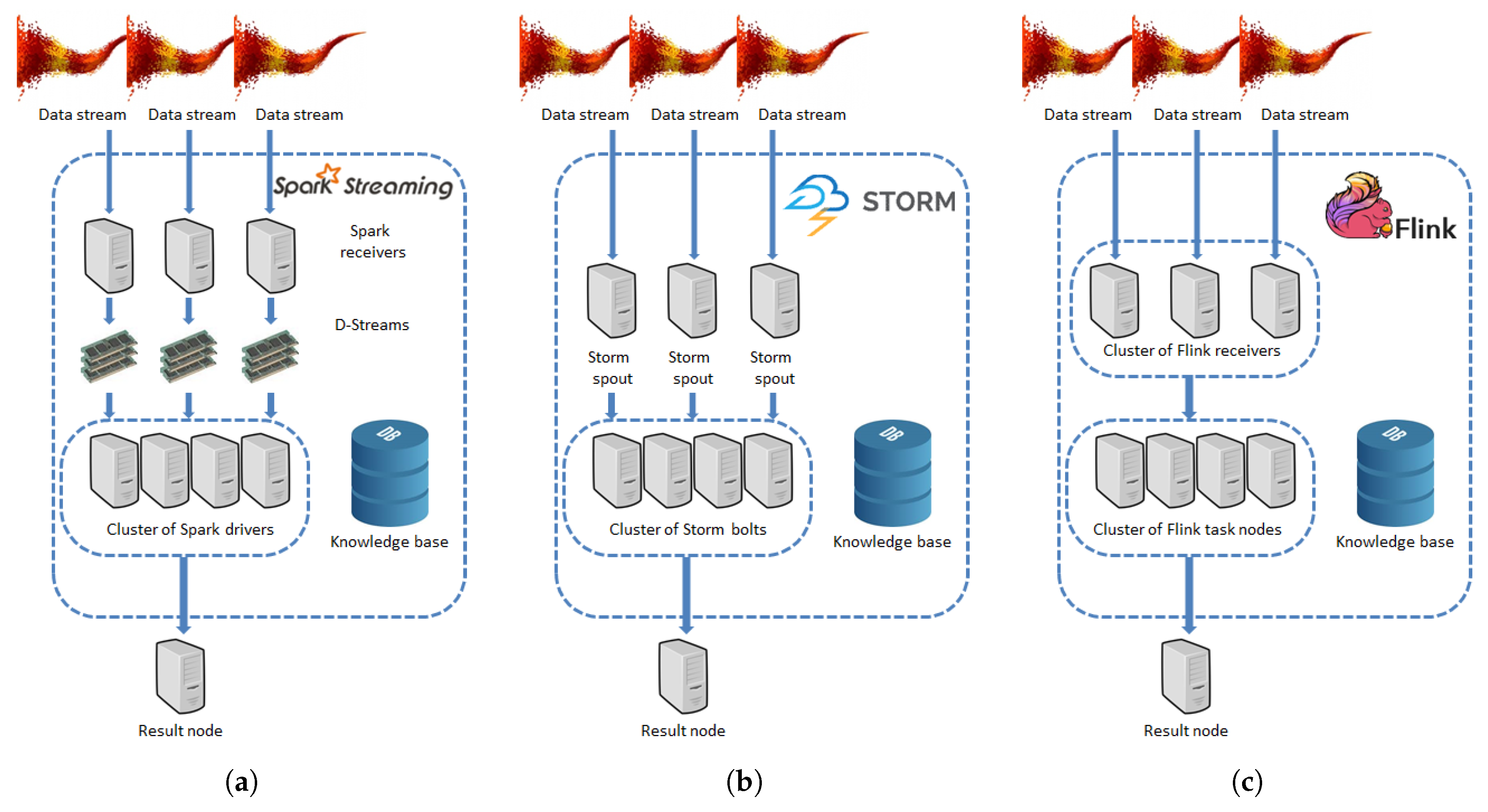
3.1.1. Apache Spark
3.1.2. Apache Storm
3.1.3. Apache Flink
4. Use Cases
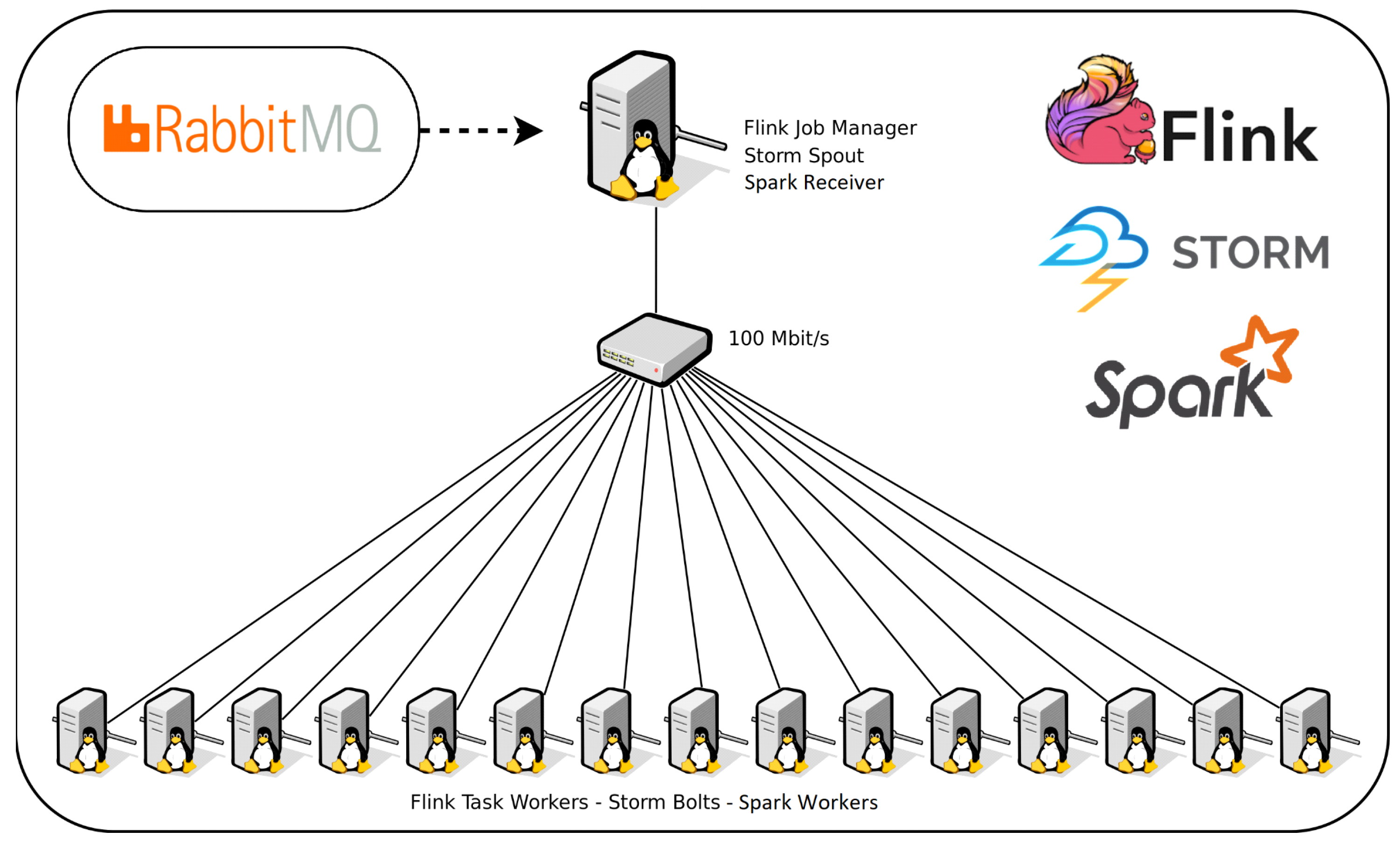
4.1. Experimental Setup
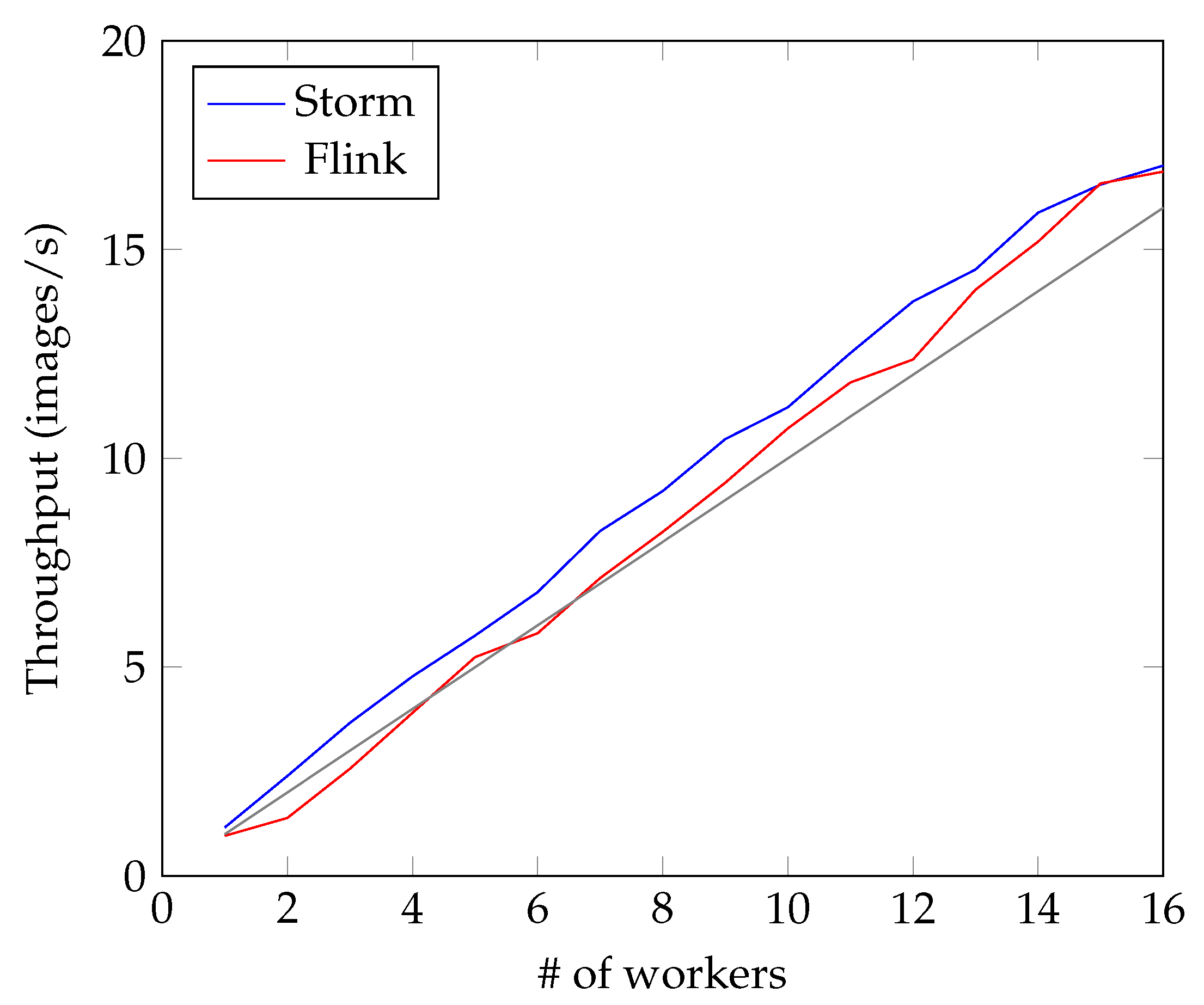
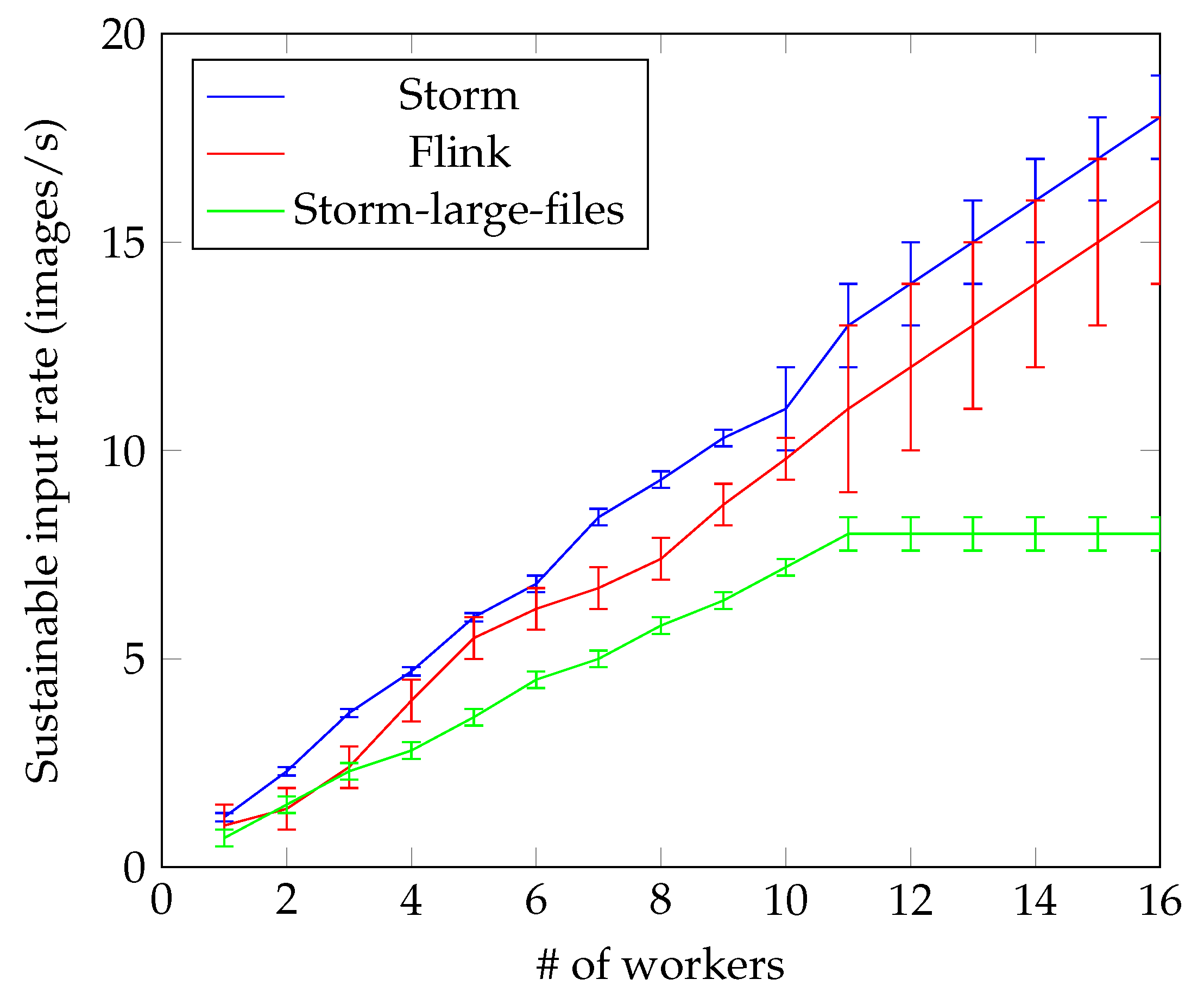
4.2. Face Recognition
- Frame splitting consists of separating into frames the video coming from the camera(s), producing one (or more) sequence of images.
- During face detection, each image of the sequences is analyzed to check whether it contains a face.
- In case a face is discovered, the recognition phase compares it against a number of known faces, to retrieve the known face most similar to the discovered face.
- In case the similarity between the discovered face and its most similar known face is sufficiently high, the face is considered as correctly recognized, otherwise it is regarded as an unknown face. For the purpose of suspect identification, whenever a discovered face is sufficiently similar to one of the faces in the knowledge base, an alarm is raised.
- Simplicity: The user does not have to directly interface with the code of the three frameworks.
- Generality: The user is able to choose at runtime which of the three big data platforms she wants to use.
- Efficiency: The overall number of lines of code is reduced (124 vs. about 500).
4.3. Plate Recognition
- Plate localization: To discover the plate in the image.
- Plate orientation: To correct the possible skewing of the plate.
- Character segmentation: To detect actual characters within the plate.
- OCR: To recognize the extracted characters.
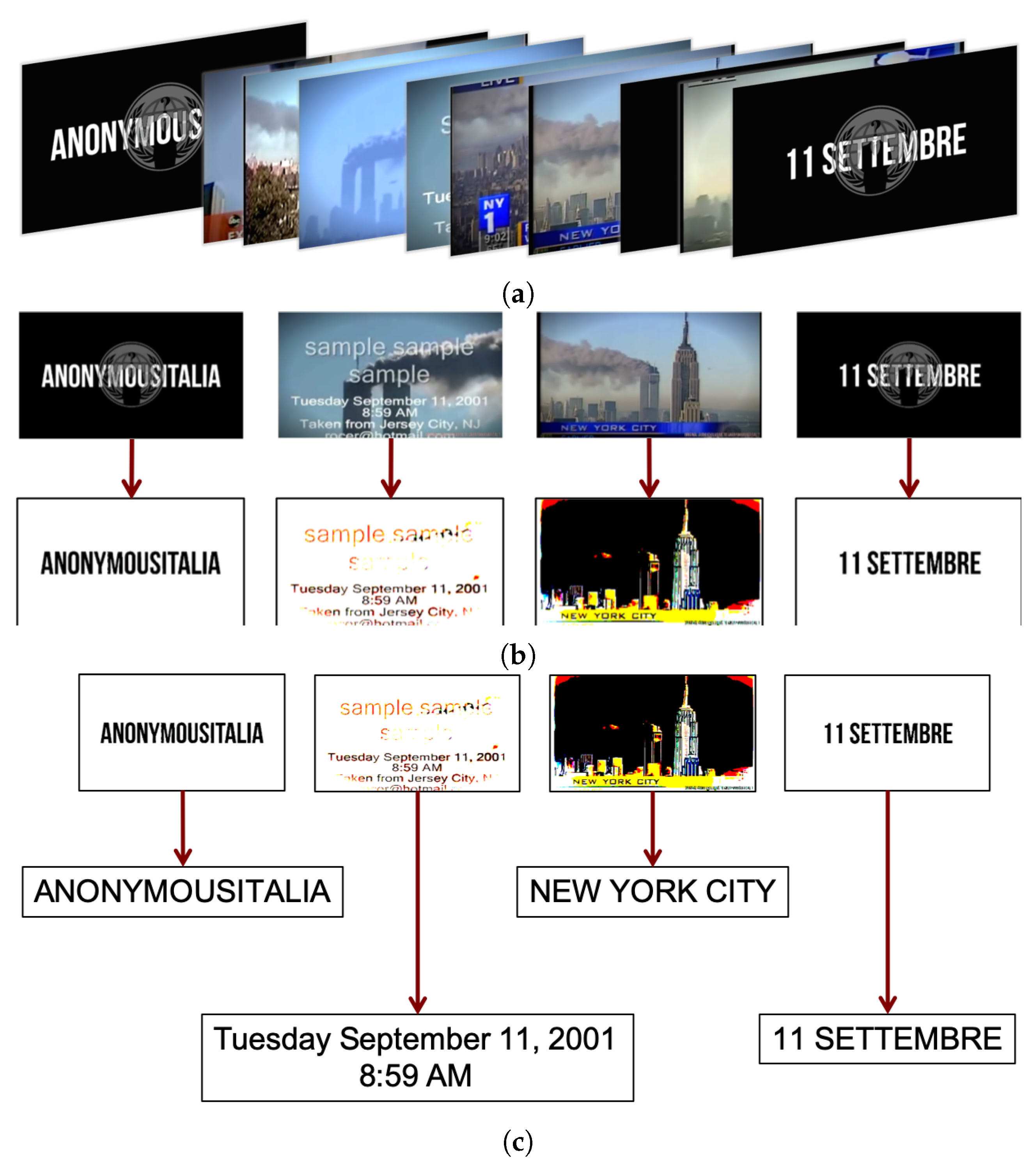
4.4. Printed Text Recognition in Videos
- Identifying “critical” videos by analyzing and automatically interpreting the streams of a significant data sample.
- Defining new useful services in the context of monitoring proselytizing phenomena by terrorist groups.
- The first summarization step aims to eliminate all superfluous frames, maintaining only those relevant to the purpose of the final application, thus only key frames in which true information is present are retained. This was obtained with a frame-to-frame analysis, eliminating frames that are too similar to each other. The summarization process exploits the functionalities of the SHIATSU video retrieval tools [19], based on HSV color histograms [20] and the edge change ratio (ECR) [21].
- When the summary has been obtained, the image analysis phase takes place by considering the selected key frames only. Each image is first filtered to segment text and logos/symbols from the background, then OCR is performed by using the Tesseract library, while logos are extracted using the OpenIMAJ library.
- Once the text detection phase is over, extracted text and logos are compared with those included in the knowledge base, so as to recognize the ones that have been considered critical.
4.5. Shoes Classification
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Carrington, P.J.; Scott, J.; Wasserman, S. Models and Methods in Social Network Analysis; Structural Analysis in the Social Sciences; Cambridge University Press: Cambridge, UK, 2005; Volume 28, ISBN 978-051-181-139-5. [Google Scholar]
- Kim, J.; Hastak, M. Social Network Analysis: Characteristics of Online Social Networks After a Disaster. Int. J. Inf. Manag. 2018, 3, 86–96. [Google Scholar] [CrossRef]
- Tang, M.; Pongpaichet, S.; Jain, R. Research Challenges in Developing Multimedia Systems for Managing Emergency Situations. In Proceedings of the 24th ACM International Conference on Multimedia (ACM MM 2016), Amsterdam, The Netherlands, 15–19 October 2016; pp. 938–947. [Google Scholar]
- Liu, B.; Messina, E.; Fersini, E.; Pozzi, F.A. Sentiment Analysis in Social Networks; Morgan Kaufmann: Burlington, MA, USA, 2016; ISBN 978-012-804-412-4. [Google Scholar]
- Modoni, G.; Tosi, D. Correlation of Weather and Moods of the Italy Residents through an Analysis of Their Tweets. In Proceedings of the 2016 IEEE 4th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Vienna, Austria, 22–24 August 2016; pp. 216–219. [Google Scholar]
- Radzikowski, J.; Stefanidis, A.; Jacobsen, K.H.; Croitoru, A.; Crooks, A.; Delamater, P.L. The Measles Vaccination Narrative in Twitter: A Quantitative Analysis. JMIR Public Health Surveill. 2016, 2, e1:1–e1:15. [Google Scholar] [CrossRef] [PubMed]
- Hu, H.; Wen, Y.; Chua, T.-S.; Li, X. Toward Scalable Systems for big data Analytics: A Technology Tutorial. IEEE Access 2014, 2, 652–687. [Google Scholar]
- Singh, D.; Reddy, C.K. A Survey on Platforms for big data Analytics. J. Big Data 2015, 2, 8:1–8:20. [Google Scholar] [CrossRef] [PubMed]
- Bartolini, I.; Patella, M. A General Framework for Real-time Analysis of Massive Multimedia Streams. Multimed. Syst. 2018, 24, 391–406. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster Computing with Working Sets. In Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing (HotCloud ’10), Boston, MA, USA, 22 June 2010; p. 10. [Google Scholar]
- Alexandrov, A.; Bergmann, R.; Ewen, S.; Freytag, J.-C.; Hueske, F.; Heise, A.; Kao, O.; Leich, M.; Leser, U.; Markl, V.; et al. The Stratosphere Platform for big data Analytics. VLDB J. 2014, 23, 939–964. [Google Scholar] [CrossRef]
- Chandy, K.M.; Lamport, L. Distributed Snapshots: Determining Global States of Distributed Systems. ACM Trans. Comput. Syst. 1985, 3, 63–75. [Google Scholar] [CrossRef]
- Greene, L. Face Scans Match Few Suspects. Available online: https://web.archive.org/web/20141130123749/http://www.sptimes.com/News/021601/TampaBay/Face_scans_match_few_.shtml (accessed on 29 November 2019).
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the 2001 Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Turk, M.; Pentland, A.P. Face Recognition Using Eigenfaces. In Proceedings of the 1991 Conference on Computer Vision and Pattern Recognition (CVPR 1991), Lahaina, HI, USA, 3–6 June 1991; pp. 586–591. [Google Scholar]
- Chintapalli, S.; Dagit, D.; Evans, B.; Farivar, R.; Graves, T.; Holderbaugh, M.; Liu, Z.; Nusbaum, K.; Patil, K.; Jerry Peng, B.; et al. Benchmarking Streaming Computation Engines at Yahoo! 2015. Available online: http://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-computation-engines-at (accessed on 29 November 2019).
- Wolf, L.; Hassner, T.; Maoz, I. Face Recognition in Unconstrained Videos with Matched Background Similarity. In Proceedings of the 2011 Conference on Computer Vision and Pattern Recognition (CVPR 2011), Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Du, S.; Ibrahim, M.; Shehata, M.; Badawy, W. Automatic License Plate Recognition (ALPR): A State-of-the-Art Review. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 311–325. [Google Scholar] [CrossRef]
- Bartolini, I.; Patella, M.; Romani, C. SHIATSU: Tagging and Retrieving Videos without Worries. Multimed. Tools Appl. 2013, 63, 357–385. [Google Scholar] [CrossRef][Green Version]
- Kasturi, R.; Strayer, S.H.; Gargi, U.; Antani, S. An Evaluation of Color Histogram Based Methods in Video Indexing. In Proceedings of the First International Workshop on Image Database and Multi-Media Search (IDB-MMS ’96), Amsterdam, The Netherlands, 22–23 August 1996; pp. 75–82. [Google Scholar]
- Jacobs, A.; Miene, A.; Ioannidis, G.T.; Herzog, O. Automatic Shot Boundary Detection Combining Color, Edge, and Motion Features of Adjacent Frames. In Proceedings of the TRECVID Workshop (TRECVID 2004), Gaithersburg, MD, USA, 15–16 November 2004; pp. 197–206. [Google Scholar]
- Yu, A.; Grauman, K. Fine-Grained Visual Comparisons with Local Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, OH, USA, 23–28 June 2014; pp. 192–199. [Google Scholar]
- Bartolini, I.; Patella, M.; Stromei, G. The Windsurf Library for the Efficient Retrieval of Multimedia Hierarchical Data. In Proceedings of the International Conference on Signal Processing and Multimedia Applications (SIGMAP 2011), Seville, Spain, 18–21 July 2011; pp. 139–148. [Google Scholar]
- Noghabi, S.A.; Paramasivam, K.; Pan, Y.; Ramesh, N.; Bringhurst, J.; Gupta, I.; Campbell, R.H. Samza: Stateful Scalable Stream Processing at LinkedIn. Proc. Vldb Endow. 2017, 10, 1634–1645. [Google Scholar] [CrossRef]











© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bartolini, I.; Patella, M. Real-Time Stream Processing in Social Networks with RAM3S. Future Internet 2019, 11, 249. https://doi.org/10.3390/fi11120249
Bartolini I, Patella M. Real-Time Stream Processing in Social Networks with RAM3S. Future Internet. 2019; 11(12):249. https://doi.org/10.3390/fi11120249
Chicago/Turabian StyleBartolini, Ilaria, and Marco Patella. 2019. "Real-Time Stream Processing in Social Networks with RAM3S" Future Internet 11, no. 12: 249. https://doi.org/10.3390/fi11120249
APA StyleBartolini, I., & Patella, M. (2019). Real-Time Stream Processing in Social Networks with RAM3S. Future Internet, 11(12), 249. https://doi.org/10.3390/fi11120249