Performance Analysis of On-Demand Scheduling with and without Network Coding in Wireless Broadcast



Abstract
1. Introduction
- We transform the scheduling problem to the problem of finding maximum clique in the derived CR-graph, which is a well-known NP-complete problem in graph theory [30,31]. Accordingly, we propose a heuristic coding-based approach, which ensures that each scheduling algorithm will transform into its corresponding coding version while preserving its original scheduling criterion.
- For the three groups of scheduling algorithms, namely real-time, non-real-time and stretch optimal, we select representative solutions in each group and present the detailed implementation of their coding versions with the proposed approach.
- To evaluate the impact of network coding to different groups of algorithms, we build the simulation model for each group and define the used performance metrics.
- We give a comprehensive performance evaluation, which demonstrates the efficiency of network coding on enhancing system performance with respect to different scheduling objectives under various circumstances.
2. Related Works
2.1. Real-Time Model
2.2. Non-Real-Time Model
2.3. Stretch Optimal Model
2.4. Network Coding
3. System Model
3.1. System Architecture
3.2. Graph Model
- with means that if clients and request the same data item, there will be an edge between the two vertices and .
- with , , and means that if client ’s cache contains the data item being requested by client and vice versa, there will be an edge between vertices and .
3.3. Coding-Based On-Demand Broadcast
- Relationship 1: Real-time scheduling algorithms which aim to serve the request with the minimum slack time such as EDF, should select the largest clique which includes the vertex with the largest value. The other real-time algorithm SIN, also considers popularity in addition of slack time.
- Relationship 2: Non-real-time scheduling algorithms which aim to serve the request with the longest waiting time such as FCFS, should select the largest clique which includes the vertex with the largest value.
- Relationship 3: Non-real-time scheduling algorithms which aim to broadcast the data item with the highest popularity such as MRF, should select the largest clique which includes the maximum number of vertices.The working properties of other non-real-time algorithms are the combination of the properties of FCFS (waiting time) and MRF (data item popularity), such as LWF and R×W, both consider waiting time and data item popularity for scheduling.
- Relationship 4: Stretch optimal scheduling algorithms which aim to reduce the stretch such as LTSF, should select the clique which has the maximum current stretch, namely with the maximum summation of value. The other stretch optimal scheduling algorithm STOBS considers data item popularity in addition of request waiting time and data item size.
4. Proposed Heuristic Coding-Based On-Demand Broadcast
- Find the vertex, which holds the maximum priority value of the scheduling algorithm. If a data item of a client is selected to broadcast, the corresponding vertex is , we call as selected vertex.
- To maximizing the exploitation of network coding and reducing encoding complexity, need to find the maximal clique (approximate maximum clique) which covers the selected vertex . Please note that is the maximum among all the possible maximal cliques covering in G. will be used to form the encoded packet for broadcasting.
4.1. The Heuristic Algorithm
| Algorithm 1: Heuristic coding-based on-demand broadcast. |
 |
4.2. Scheduling Algorithms with Heuristic Coding Implementation
4.2.1. Real-Time Algorithms
- EDF [25]: EDF serves the request with the minimum slack time. In other words, it prioritizes the request urgency in scheduling. The network coding version of EDF, needs to find the largest clique which contains the vertex with the minimum slack time among all the vertices in graph G. In the heuristic coding implementation (denoted by EDF_N), the system first finds the selected vertex with . In Algorithm 1, this is done in Step 2. is the vertex with the highest EDF scheduling priority, i.e., . Then Step 3 searches for the maximal clique to ensure that the encoded packet consists the requested data item of the most urgent client.
- SIN [9]: SIN broadcasts the item with the minimum value. The network coding version of SIN, needs to find the clique in G with the maximum value, where is the minimum value among all in . In the heuristic coding implementation (denoted by SIN_N), the system first finds the selected vertex with the minimum value, In Step 2 of Algorithm 1, the selection is done by finding the vertex with the maximum value, i.e., . Then Step 3 searches for the maximal clique to ensure that the encoded packet consists the requested data item of the client with the minimum value.
4.2.2. Non-Real-Time Algorithms
- FCFS [26]: FCFS serves requests according to their arrival order. The network coding version of FCFS, needs to find the largest clique which contains the vertex with longest waiting time among all in G. In the heuristic coding implementation (denoted by FCFS_N), the system first finds the selected vertex with . In Step 2 of Algorithm 1, is the vertex with the highest FCFS scheduling priority, i.e., . Then Step 3 searches for the maximal clique to ensure that the encoded packet consists the requested data item of the client with the longest waiting time.
- MRF [27]: MRF broadcasts the data item with the largest number of pending requests. The network coding version of MRF, needs to find the maximum clique in G, where is the maximum clique among all the possible cliques in G. In the heuristic coding implementation (denoted by MRF_N), the system first finds the selected vertex with the maximum value. In Step 2 of Algorithm 1, is the vertex with the highest MRF scheduling priority, i.e., . Then Step 3 searches for the maximal clique to ensure that the encoded packet consists the requested data item with the largest number of pending requests.
- LWF [27]: LWF broadcasts the data item with the largest total waiting time. The network coding version of LWF, needs to find the largest clique in G with the maximum summed waiting time of the corresponding vertices. In the heuristic coding implementation (denoted by LWF_N), the system first finds the selected vertex with the maximum sum waiting time (, ) value of data item , denoted as . In Step 2 of Algorithm 1, is the vertex with the highest LWF scheduling priority, i.e., . Then Step 3 searches for the maximal clique to ensure that the encoded packet consists the requested data item with the largest total waiting time of the pending requests.
- R × W [4]: R × W schedules the data item with the maximum R × W value, where R is the number of pending requests for that data item and W is the waiting time of the earliest request for that data item. The network coding version of R × W, needs to find the largest clique with the maximum value, where is the maximum waiting time value among all in . In the heuristic coding implementation (denoted by R × W_N), the system first finds the selected vertex with the maximum value. In Step 2 of Algorithm 1, the selection is done by finding the vertex with the maximum value, i.e., . Then Step 3 searches for the maximal clique to ensure that the encoded packet consists the requested data item with the maximum R × W value.
4.2.3. Stretch Optimal Algorithms
- LTSF [29]: LTSF broadcasts the data item with the largest total current stretch. The network coding version of LTSF, needs to select the largest clique with the maximum value, where is the total waiting time of the vertices in and is the service time of the vertices in . Please note that the service time of the coded packet will be the service time of the largest data item in the clique. In the heuristic coding implementation (denoted by LTSF_N), the system first finds the selected vertex with the largest total current stretch for the data item . In Step 2 of Algorithm 1, the selection is done by finding the vertex with the maximum value, i.e., . Then Step 3 searches for the maximal clique to ensure that the encoded packet consists the requested data item with the largest total current stretch.
- STOBS [28]: STOBS broadcasts the data item with the largest value, where R, W and S denote, respectively, the number of pending requests, waiting time of the earliest pending request and the item size. The network coding version of STOBS, needs to find the largest clique with the maximum value, where and are respectively the maximum waiting time and the maximum item size among all the vertices in . Please note that also denotes the size of the encoded packet. In the heuristic coding implementation (denoted by STOBS_N), the system first finds the selected vertex with the maximum value. In Step 2 of Algorithm 1, the selection is done by finding the vertex with the maximum value, i.e., .Then Step 3 searches for the maximal clique to ensure that the encoded packet consists the requested data item with the largest value.
5. Simulation Model
5.1. Setup
5.2. Metrics
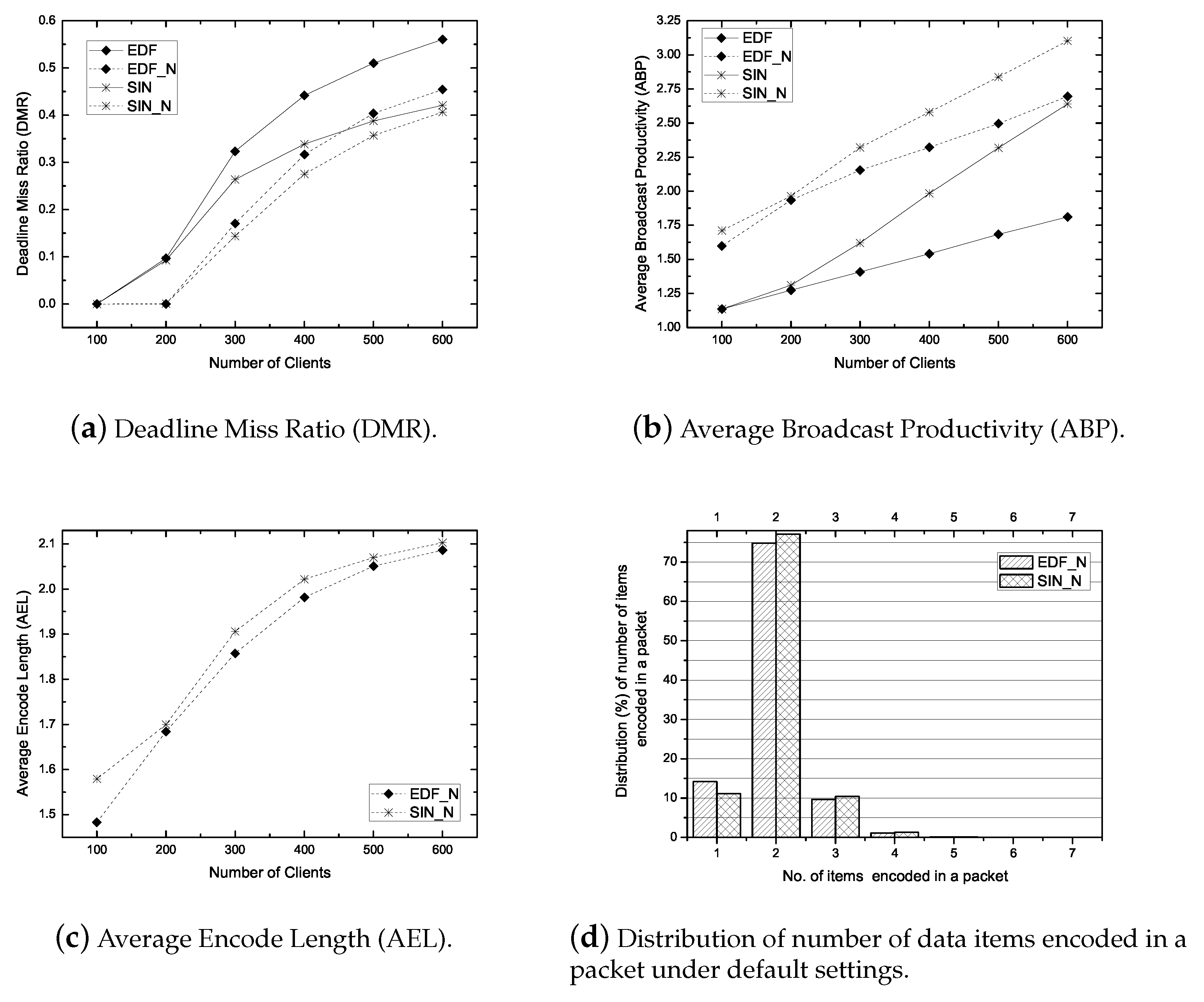
- Deadline Miss Ratio (DMR): It is the ratio of the number of deadline missed requests to the number of submitted requests. The primary objective of a real-time scheduling algorithm is to minimize the DMR.
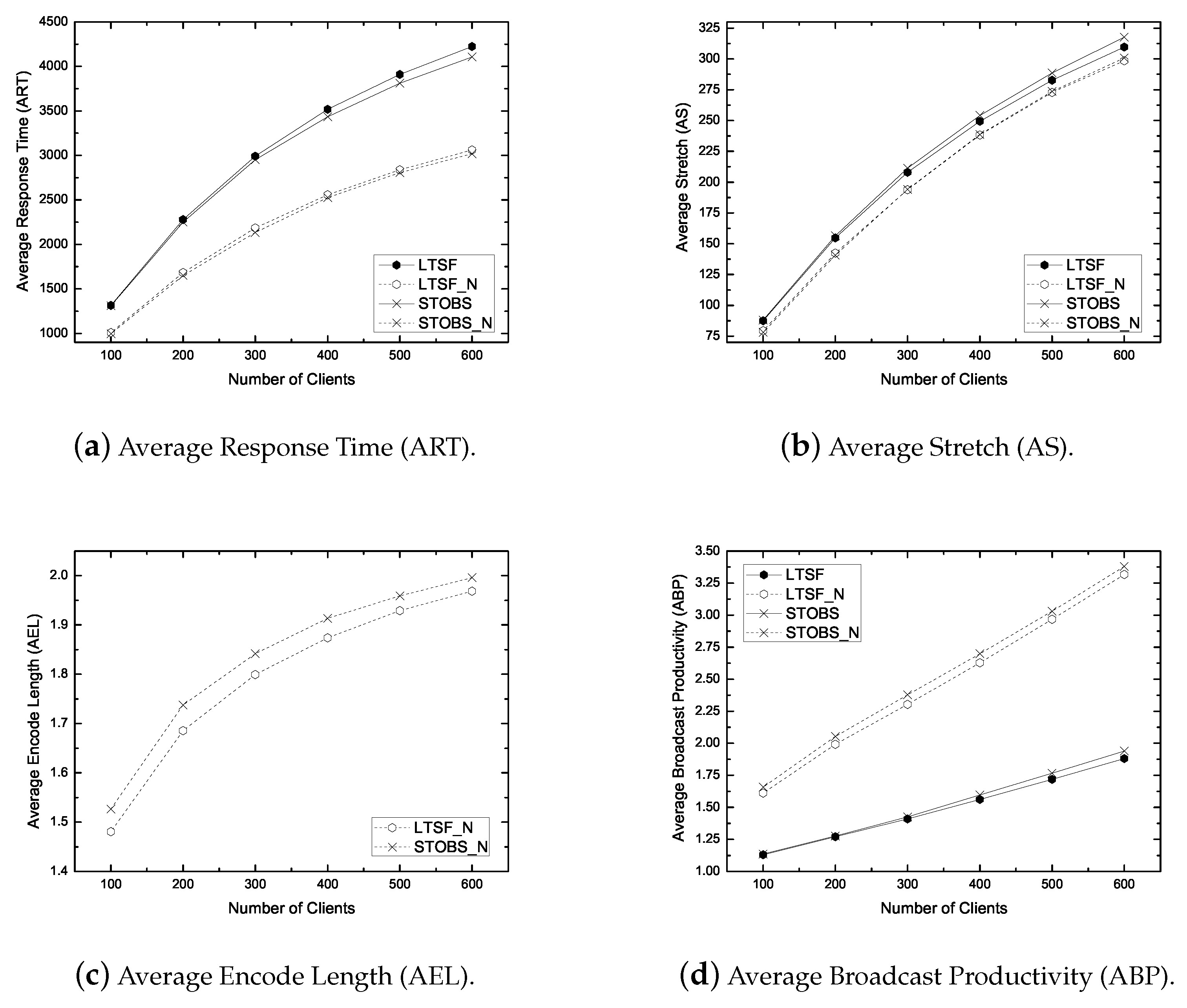
- Average Response Time (ART): It is the average duration for getting the response from the server after submitting a request. ART measures the responsiveness of the system. The primary objective of a non-real-time scheduling algorithm is to minimize the ART.
- Average Stretch (AS): It is the ratio of the response time to the service time of the corresponding data item. It is a widely used metric in heterogeneous database environments. The primary objective of a stretch optimal scheduling algorithm is to minimize the AS.
- Average Encode Length (AEL): It is the average size of an encoded packet. It measures how a scheduling algorithm exploits the coding opportunity. The larger AEL mean more coding benefit.
- Average Broadcast Productivity (ABP): It is the average number of requests satisfied per broadcast. It measures the productivity of a broadcasted packet/item. A large ABP implies the efficient bandwidth use.
6. Performance Evaluation
6.1. Simulation Results in Real-Time Models
6.1.1. Impact of Workload
6.1.2. Impact of Deadline Range
6.2. Simulation Results in Non-Real-Time Models
6.2.1. Impact of Skewness Parameter ()
6.2.2. Impact of Workload
6.3. Simulation Results in Stretch Optimal Models
6.3.1. Impact of Workload
6.3.2. Impact of Data Item Size
7. Conclusions and Future Directions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| EDF | Earliest Deadline First |
| SIN | Slack time Inverse Number of pending requests |
| FCFS | Fist Come First Served |
| MRF | Most Requested First |
| LWF | Longest Wait First |
| RxW | Number of Pending Request Multiply Waiting Time |
| LTSF | Longest Total Stretch First |
| STOBS | Summary Table On-demand Broadcast Scheduler |
| CR-Graph | Cache-Request-Graph |
References
- Ji, H.; Lee, V.C.; Chow, C.Y.; Liu, K.; Wu, G. Coding-based Cooperative Caching in On-demand Data Broadcast Environments. Inf. Sci. 2017, 385, 138–156. [Google Scholar] [CrossRef]
- Ali, G.G.M.N.; Lee, V.C.S.; Chan, E.; Li, M.; Liu, K.; Lv, J.; Chen, J. Admission Control-Based Multichannel Data Broadcasting for Real-Time Multi-Item Queries. IEEE Trans. Broadcast. 2014, 60, 589–605. [Google Scholar] [CrossRef]
- Ali, G.G.M.N.; Noor-A-Rahim, M.; Rahman, M.A.; Ayalew, B.; Chong, P.H.J.; Guan, Y.L. Cooperative Cache Transfer-based On-demand Network Coded Broadcast in Vehicular Networks. ACM Trans. Embed. Comput. Syst. 2019, 18, 38:1–38:20. [Google Scholar] [CrossRef]
- Aksoy, D.; Franklin, M. R × W: A scheduling approach for large-scale on-demand data broadcast. IEEE/ACM Trans. Netw. 1999, 7, 846–860. [Google Scholar] [CrossRef]
- Liu, K.; Lee, V.C. Performance Analysis of data scheduling algorithms for multi-item requests in multi-channel broadcast environments. J. Commun. Syst. 2010, 23, 529–542. [Google Scholar] [CrossRef]
- Ye, F.; Roy, S.; Wang, H. Efficient Data Dissemination in Vehicular Ad Hoc Networks. IEEE J. Sel. Areas Commun. 2012, 30, 769–779. [Google Scholar] [CrossRef]
- Rehman, O.; Ould-Khaoua, M.; Bourdoucen, H. An adaptive relay nodes selection scheme for multi-hop broadcast in {VANETs}. Comput. Commun. 2016, 87, 76–90. [Google Scholar] [CrossRef]
- Liu, K.; Lee, V.C.S.; Ng, J.K.Y.; Chen, J.; Son, S.H. Temporal data dissemination in vehicular cyber–physical systems. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2419–2431. [Google Scholar] [CrossRef]
- Xu, J.; Tang, X.; Lee, W.C. Time-critical on-demand data broadcast: Algorithms, analysis, and performance evaluation. IEEE Trans. Parallel Distrib. Syst. 2006, 17, 3–14. [Google Scholar]
- Liu, K.; Lee, V. On-demand broadcast for multiple-item requests in a multiple-channel environment. Inf. Sci. 2010, 180, 4336–4352. [Google Scholar] [CrossRef]
- Chen, J.; Lee, V.C.; Liu, K.; Ali, G.; Chan, E. Efficient processing of requests with network coding in on-demand data broadcast environments. Inf. Sci. 2013, 232, 27–43. [Google Scholar] [CrossRef]
- Ahlswede, R.; Cai, N.; Li, S.Y.; Yeung, R.W. Network information flow. IEEE Trans. Inf. Theory 2000, 46, 1204–1216. [Google Scholar] [CrossRef]
- Ho, T.; Medard, M.; Koetter, R.; Karger, D.R.; Effros, M.; Shi, J.; Leong, B. A Random Linear Network Coding Approach to Multicast. IEEE Trans. Inf. Theory 2006, 52, 4413–4430. [Google Scholar] [CrossRef]
- Hassanabadi, B.; Valaee, S. Reliable Periodic Safety Message Broadcasting in VANETs Using Network Coding. IEEE Trans. Wirel. Commun. 2014, 13, 1284–1297. [Google Scholar] [CrossRef]
- Qureshi, J.; Foh, C.H.; Cai, J. Online {XOR} packet coding: Efficient single-hop wireless multicasting with low decoding delay. Comput. Commun. 2014, 39, 65–77. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, B.; Yao, Z. Spacetime efficient network coding for wireless multi-hop networks. Comput. Commun. 2016, 73 Pt A, 144–156. [Google Scholar] [CrossRef]
- Zhan, C.; Lee, V.C.; Wang, J.; Xu, Y. Coding-based data broadcast scheduling in on-demand broadcast. IEEE Trans. Wirel. Commun. 2011, 10, 3774–3783. [Google Scholar] [CrossRef]
- Wang, Z.; Hassan, M. Blind xor: Low-Overhead Loss Recovery for Vehicular Safety Communications. IEEE Trans. Veh. Technol. 2012, 61, 35–45. [Google Scholar] [CrossRef]
- Chaudhry, M.A.R.; Sprintson, A. Efficient algorithms for Index Coding. In Proceedings of the IEEE INFOCOM Workshops 2008, Phoenix, AZ, USA, 13–18 April 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Shujuan Wang, C.Y.; Yu, Z. Efficient Coding-Based Scheduling for Multi-Item Requests in Real-Time On-Demand Data Dissemination. Mob. Inf. Syst. 2016, 2016. [Google Scholar] [CrossRef]
- Chen, J.; Lee, V.C.S.; Liu, K.; Li, J. Efficient Cache Management for Network-Coding-Assisted Data Broadcast. IEEE Trans. Veh. Technol. 2017, 66, 3361–3375. [Google Scholar] [CrossRef]
- Asghari, S.M.; Ouyang, Y.; Nayyar, A.; Avestimehr, A.S. An Approximation Algorithm for Optimal Clique Cover Delivery in Coded Caching. IEEE Trans. Commun. 2019, 67, 4683–4695. [Google Scholar] [CrossRef]
- Ali, G.N.; Chan, E.; Li, W. Supporting real-time multiple data items query in multi-RSU vehicular ad hoc networks (VANETs). J. Syst. Softw. 2013, 86, 2127–2142. [Google Scholar] [CrossRef]
- Liu, K.; Ng, J.K.Y.; Lee, V.C.S.; Son, S.H.; Stojmenovic, I. Cooperative Data Scheduling in Hybrid Vehicular Ad Hoc Networks: VANET as a Software Defined Network. IEEE/ACM Trans. Netw. 2016, 24, 1759–1773. [Google Scholar] [CrossRef]
- Xuan, P.; Sen, S.; Gonzalez, O.; Fernandez, J.; Ramamritham, K. Broadcast on demand: Efficient and timely dissemination of data in mobile environments. In Proceedings of the 3rd IEEE Real-Time Technology and Applications Symposium (RTAS’97), Montreal, QC, Canada, 9–11 June 1997; pp. 38–48. [Google Scholar]
- Wong, J.; Ammar, M.H. Analysis of broadcast delivery in a videotex system. IEEE Trans. Comput. 1985, 100, 863–866. [Google Scholar] [CrossRef]
- Wong, J.W. Broadcast delivery. Proc. IEEE 1988, 76, 1566–1577. [Google Scholar] [CrossRef]
- Sharaf, M.A.; Chrysanthis, P.K. On-demand broadcast: New challenges and scheduling algorithms. In Proceedings of the 1st Hellenic Data Management Symposium (HDMS’02), Athens, Greece, 23–24 July 2002. [Google Scholar]
- Acharya, S.; Muthukrishnan, S. Scheduling on-demand broadcasts: New metrics and algorithms. In Proceedings of the 4th Annual ACM/IEEE International Conference on Mobile Computing and Networking (MobiCom’98), Dallas, TX, USA, 25–30 October 1998; pp. 43–54. [Google Scholar]
- Karp, R. Reducibility among Combinatorial Problems. In Complexity of Computer Computations; Miller, R., Thatcher, J., Bohlinger, J., Eds.; The IBM Research Symposia Series; Springer: New York, NY, USA, 1972; pp. 85–103. [Google Scholar] [CrossRef]
- Östergård, P.R. A fast algorithm for the maximum clique problem. Discret. Appl. Math. 2002, 120, 197–207. [Google Scholar] [CrossRef]
- Hu, C.L. Fair scheduling for on-demand time-critical data broadcast. In Proceedings of the IEEE International Conference on Communications (ICC’07), Glasgow, UK, 24–28 June 2007; pp. 5831–5836. [Google Scholar]
- Chen, C.C.; Lee, C.; Wang, S.C. On optimal scheduling for time-constrained services in multi-channel data dissemination systems. Inf. Syst. 2009, 34, 164–177. [Google Scholar] [CrossRef]
- Chen, J.; Lee, V.; Liu, K. On the performance of real-time multi-item request scheduling in data broadcast environments. J. Syst. Softw. 2010, 83, 1337–1345. [Google Scholar] [CrossRef]
- He, P.; Shen, H.; Tian, H. On-demand data broadcast with deadlines for avoiding conflicts in wireless networks. J. Syst. Softw. 2015, 103, 118–127. [Google Scholar] [CrossRef]
- Polatoglou, M.; Nicopolitidis, P.; Papadimitriou, G.I. On low-complexity adaptive wireless push-based data broadcasting. Int. J. Commun. Syst. 2014, 27, 194–200. [Google Scholar] [CrossRef]
- Lu, Z.; Wu, W.; Fu, B. Optimal Data Retrieval Scheduling in the Multichannel Wireless Broadcast Environments. IEEE Trans. Comput. 2013, 62, 2427–2439. [Google Scholar] [CrossRef]
- Wu, Y.; Cao, G. Stretch-optimal scheduling for on-demand data broadcasts. In Proceedings of the 10th International Conference on Computer, Communications and Networks (ICCCN’01), Scottsdale, AZ, USA, 15–17 October 2001; pp. 500–504. [Google Scholar]
- Lee, V.C.; Wu, X.; Ng, J.K.Y. Scheduling Real-time Requests in On-demand Data Broadcast Environments. Real-Time Syst. 2006, 34, 83–99. [Google Scholar] [CrossRef]
- Ploumidis, M.; Pappas, N.; Siris, V.A.; Traganitis, A. On the performance of network coding and forwarding schemes with different degrees of redundancy for wireless mesh networks. Comput. Commun. 2015, 72, 49–62. [Google Scholar] [CrossRef]
- Qu, Y.; Dong, C.; Chen, C.; Wang, H.; Tian, C.; Tang, S. DCNC: Throughput maximization via delay controlled network coding for wireless mesh networks. Wirel. Commun. Mob. Comput. 2014, 16, 137–149. [Google Scholar] [CrossRef]
- Chu, C.H.; Yang, D.N.; Chen, M.S. Multi-data delivery based on network coding in on-demand broadcast. In Proceedings of the Ninth International Conference on Mobile Data Management, Beijing, China, 27–30 April 2008; pp. 181–188. [Google Scholar]
- Gao, Z.; Xiang, W.; Tan, G.; Yao, N.; Li, P. An Enhanced XOR-based Scheme for Wireless Packet Retransmission Problem. Int. J. Commun. Syst. 2014, 27, 3657–3675. [Google Scholar] [CrossRef][Green Version]
- Chen, J.; Lee, V.C.S.; Zhan, C. Efficient Processing of Real-Time Multi-item Requests with Network Coding in On-demand Broadcast Environments. In Proceedings of the 2009 15th IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Beijing, China, 24–26 August 2009; pp. 119–128; pp. 119–128. [Google Scholar] [CrossRef]
- Ali, G.G.M.N.; Noor-A-Rahim, M.; Chong, P.H.J.; Guan, Y.L. Analysis and Improvement of Reliability Through Coding for Safety Message Broadcasting in Urban Vehicular Networks. IEEE Trans. Veh. Technol. 2018, 67, 6774–6787. [Google Scholar] [CrossRef]
- Sorour, S.; Valaee, S. On minimizing broadcast completion delay for instantly decodable network coding. In Proceedings of the IEEE International Conference on Communications (ICC’10), Cape Town, South Africa, 23–27 May 2010; pp. 1–5. [Google Scholar]
- Schwetman, H. CSIM19: A powerful tool for building system models. In Proceedings of the 33nd Conference on Winter Simulation (WSC’01), Arlington, VA, USA, 9–12 December 2001; pp. 250–255. [Google Scholar]
- Zipf, G. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology; Addison-Wesley Press: Cambridge, MA, USA, 1949. [Google Scholar]
- Xu, J.; Hu, Q.; Lee, W.C.; Lee, D.L. Performance evaluation of an optimal cache replacement policy for wireless data dissemination. IEEE Trans. Knowl. Data Eng. 2004, 16, 125–139. [Google Scholar]
- Ali, G.N.; Chong, P.H.J.; Samantha, S.K.; Chan, E. Efficient data dissemination in cooperative multi-RSU Vehicular Ad Hoc Networks (VANETs). J. Syst. Softw. 2016, 117, 508–527. [Google Scholar] [CrossRef]
- Ali, G.G.M.N.; Noor-A-Rahim, M.; Rahman, M.A.; Samantha, S.K.; Chong, P.H.J.; Guan, Y.L. Efficient Real-Time Coding-Assisted Heterogeneous Data Access in Vehicular Networks. IEEE Internet Things J. 2018, 5, 3499–3512. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description | Notes |
|---|---|---|
| A client | ; | |
| A data item | ; | |
| Requested data items by | ||
| Cached data items by | ||
| A graph | ||
| A vertex representing client requests data item | , , | |
| popularity of | ||
| Client is pending for | ||
| Waiting time of | ||
| Summed waiting time of clients pending for | ||
| Slack time of | ||
| Size of the requested data item of | ||
| A clique | ||
| Number of vertices in | ||
| Set of clients covered in | ||
| Encoded packet for the clique | ||
| K | Number of different data items encoded in | |
| Maximum clique | ||
| Maximal clique covering vertex | ||
| B | Channel broadcast bandwidth |
| Type | Algorithm | Remarks |
|---|---|---|
| Real-time | EDF | Find the largest clique with |
| SIN | Find the largest clique with the maximum value | |
| Non-real-time | FCFS | Find the largest clique with |
| MRF | Find the largest clique | |
| LWF | Find the largest clique with the maximum summed waiting time | |
| Find the largest clique with the maximum value | ||
| Stretch optimal | LTSF | Find the largest clique with the maximum value |
| STOBS | Find the largest clique with the maximum value |
| Parameter | Default | Range | Description |
|---|---|---|---|
| 400 | 100∼600 | Number of clients | |
| 0.01 | — | Request generation interval | |
| m | 1000 | — | Size of the database |
| , | 1, 30 | —, 10∼60 | Min. and Max. data item size |
| 60 | 30∼180 | Client cache size | |
| 0.4 | 0.0∼1.0 | Zipf distribution parameter | |
| 120, 200 | 80∼160, 160∼240 | Min. and Max. laxity |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, G.G.M.N.; Lee, V.C.S.; Meng, Y.; Chong, P.H.J.; Chen, J. Performance Analysis of On-Demand Scheduling with and without Network Coding in Wireless Broadcast. Future Internet 2019, 11, 248. https://doi.org/10.3390/fi11120248
Ali GGMN, Lee VCS, Meng Y, Chong PHJ, Chen J. Performance Analysis of On-Demand Scheduling with and without Network Coding in Wireless Broadcast. Future Internet. 2019; 11(12):248. https://doi.org/10.3390/fi11120248
Chicago/Turabian StyleAli, G. G. Md. Nawaz, Victor C. S. Lee, Yuxuan Meng, Peter H. J. Chong, and Jun Chen. 2019. "Performance Analysis of On-Demand Scheduling with and without Network Coding in Wireless Broadcast" Future Internet 11, no. 12: 248. https://doi.org/10.3390/fi11120248
APA StyleAli, G. G. M. N., Lee, V. C. S., Meng, Y., Chong, P. H. J., & Chen, J. (2019). Performance Analysis of On-Demand Scheduling with and without Network Coding in Wireless Broadcast. Future Internet, 11(12), 248. https://doi.org/10.3390/fi11120248