Feature Fusion Text Classification Model Combining CNN and BiGRU with Multi-Attention Mechanism

Abstract
:1. Introduction
2. Related Work
Aspect-Based Sentiment Analysis
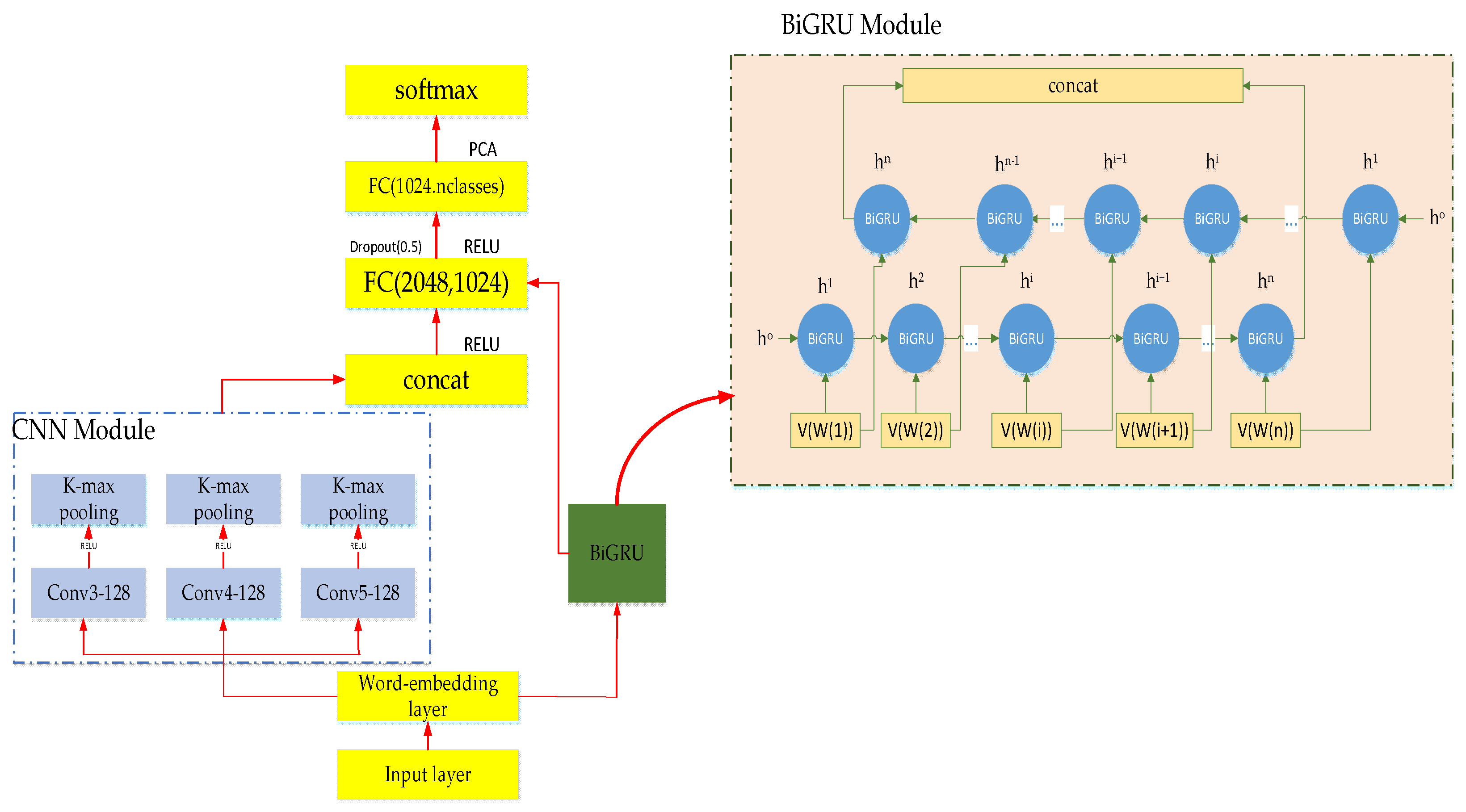
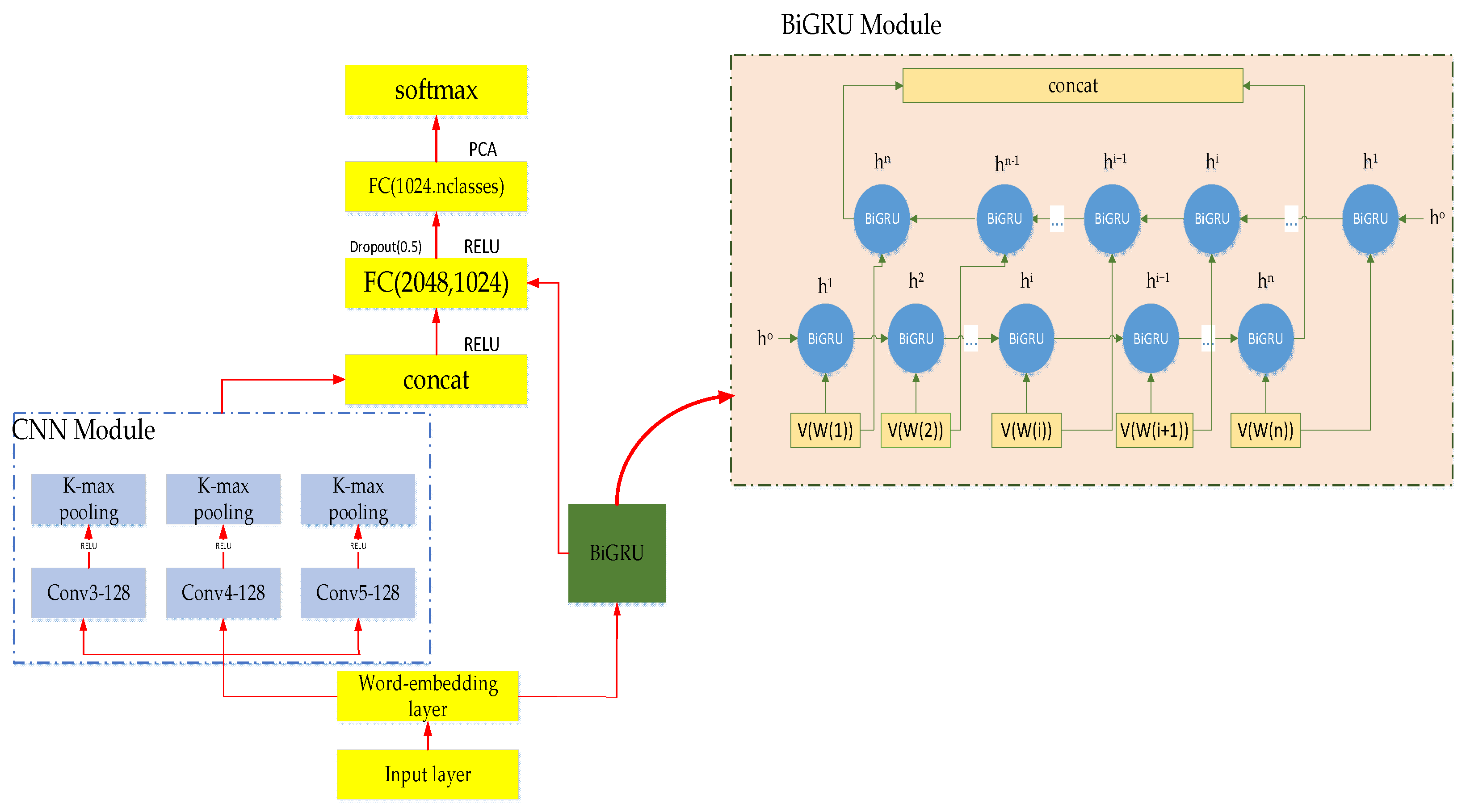
3. MATT-CNN+BiGRU Feature Fusion Model
3.1. The Brief Introduction of MATT-CNN+BiGRU
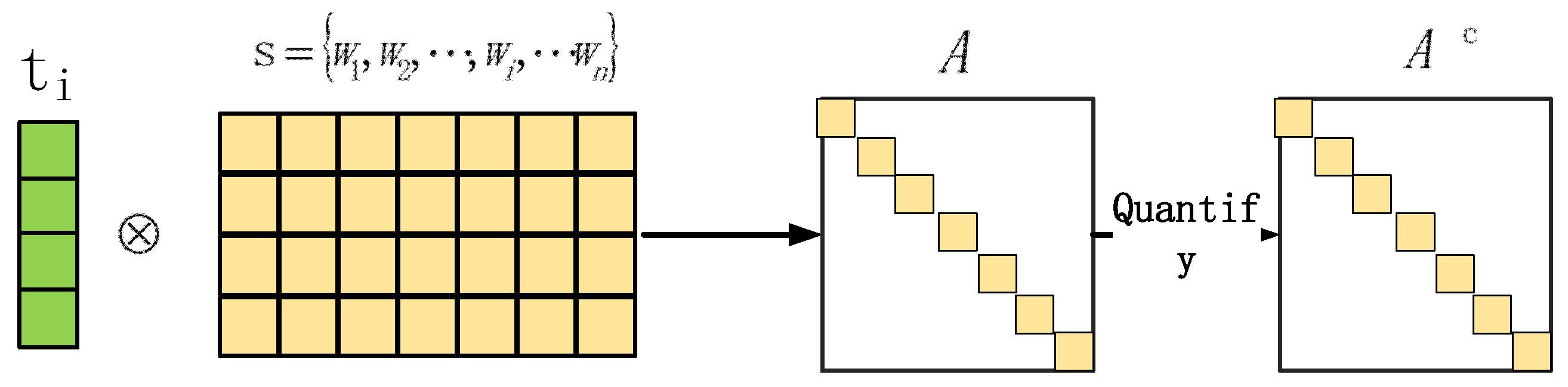
3.1.1. Principal Component Analysis
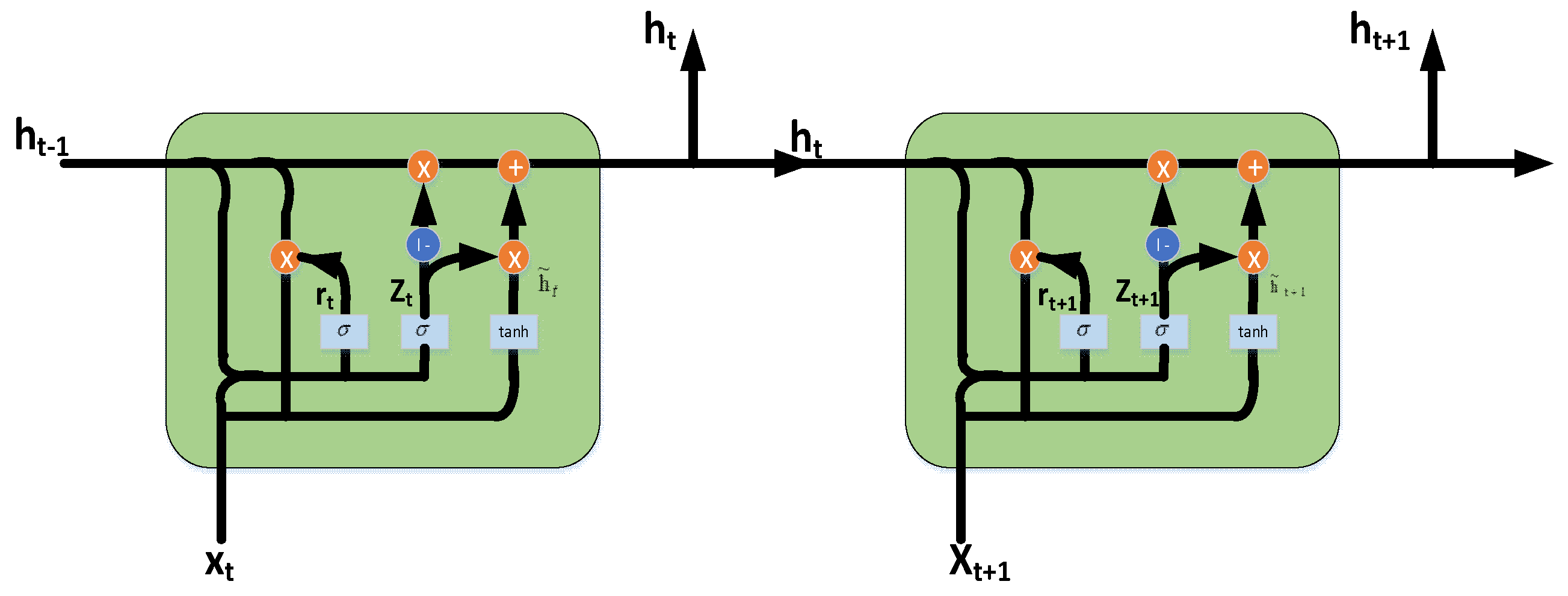
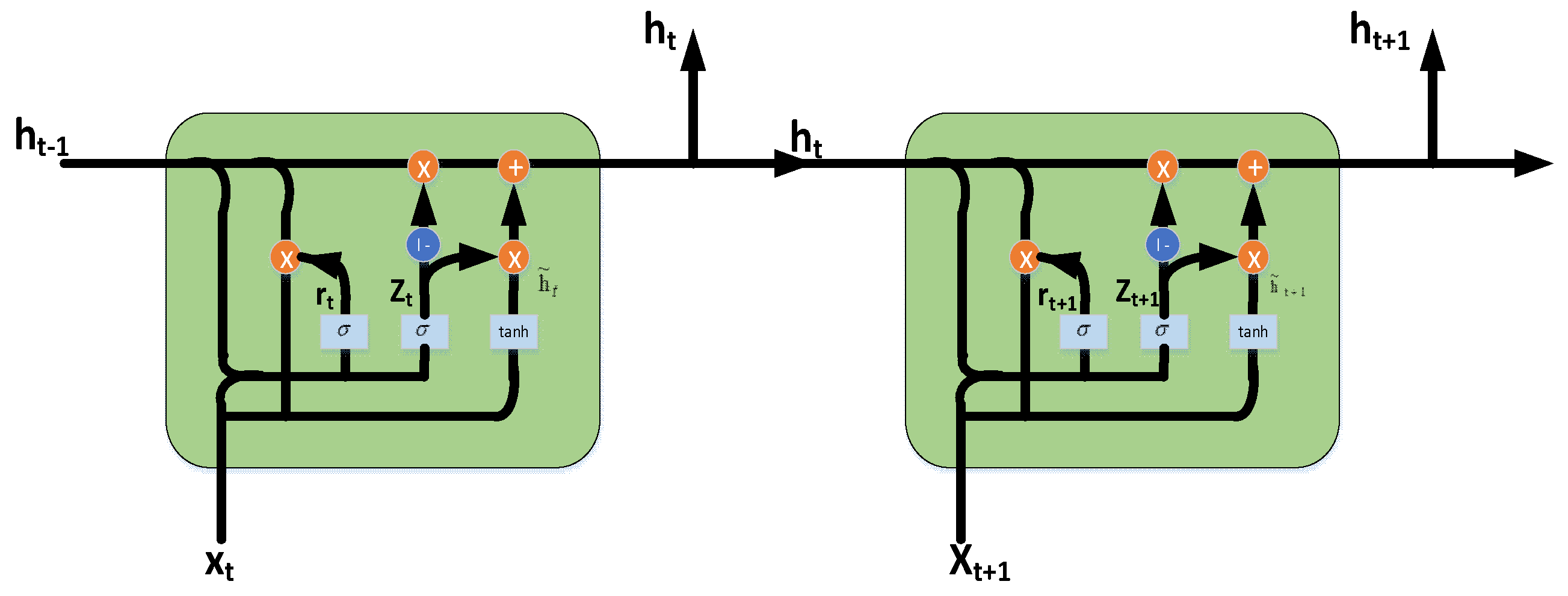
3.1.2. Basic Structure of GRU and BiGRU
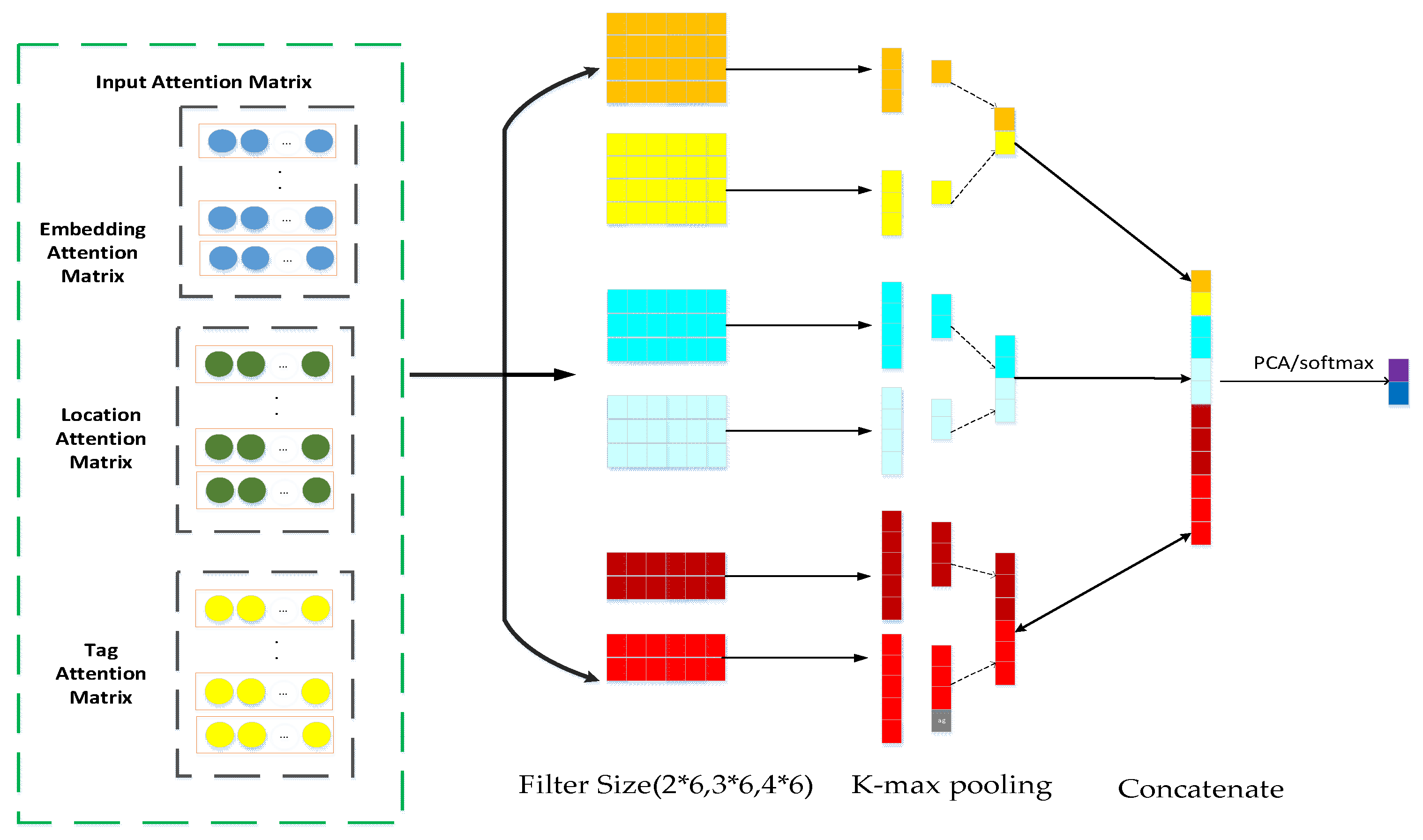
3.2. MATT-CNN Model
3.3. Text Preprocessing
3.3.1. Task Definition
3.3.2. Keyword Extraction Algorithm
| Algorithm 1. Keyword extraction algorithm |
| Input: Document collection P Output: Keyword and its eigenvector matrix Begin: For to //The segment function is a word segmentation using NLTK //Vectorize the results of the word segmentation //Use the tf-idf method for each category of text to get high frequency words, arranged in descending order. //Use cross entropy to identify whether these high frequency words are used frequently in other categories //Get high frequency words representing each category, select the words with the highest frequency //The high frequency words of each category are composed into a feature vector matrix of this category using a splicing method. End For End |
3.4. Word Vector Attention Mechanism
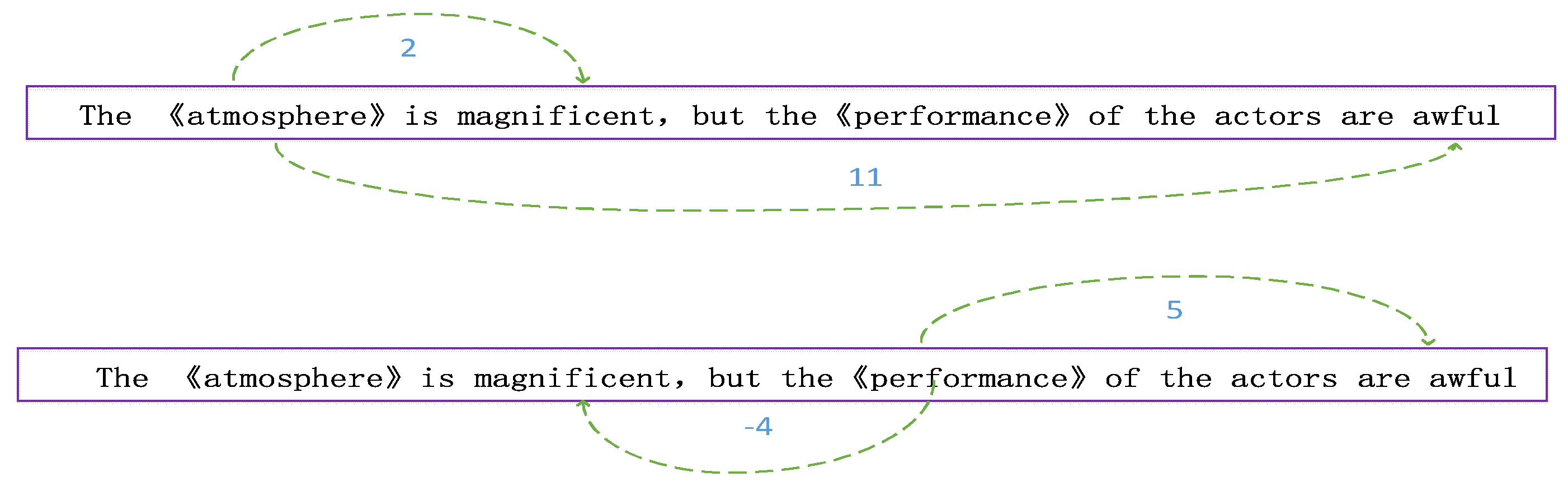
3.5. Position Attention Mechanism
| Algorithm 2. Two-way scanning algorithm |
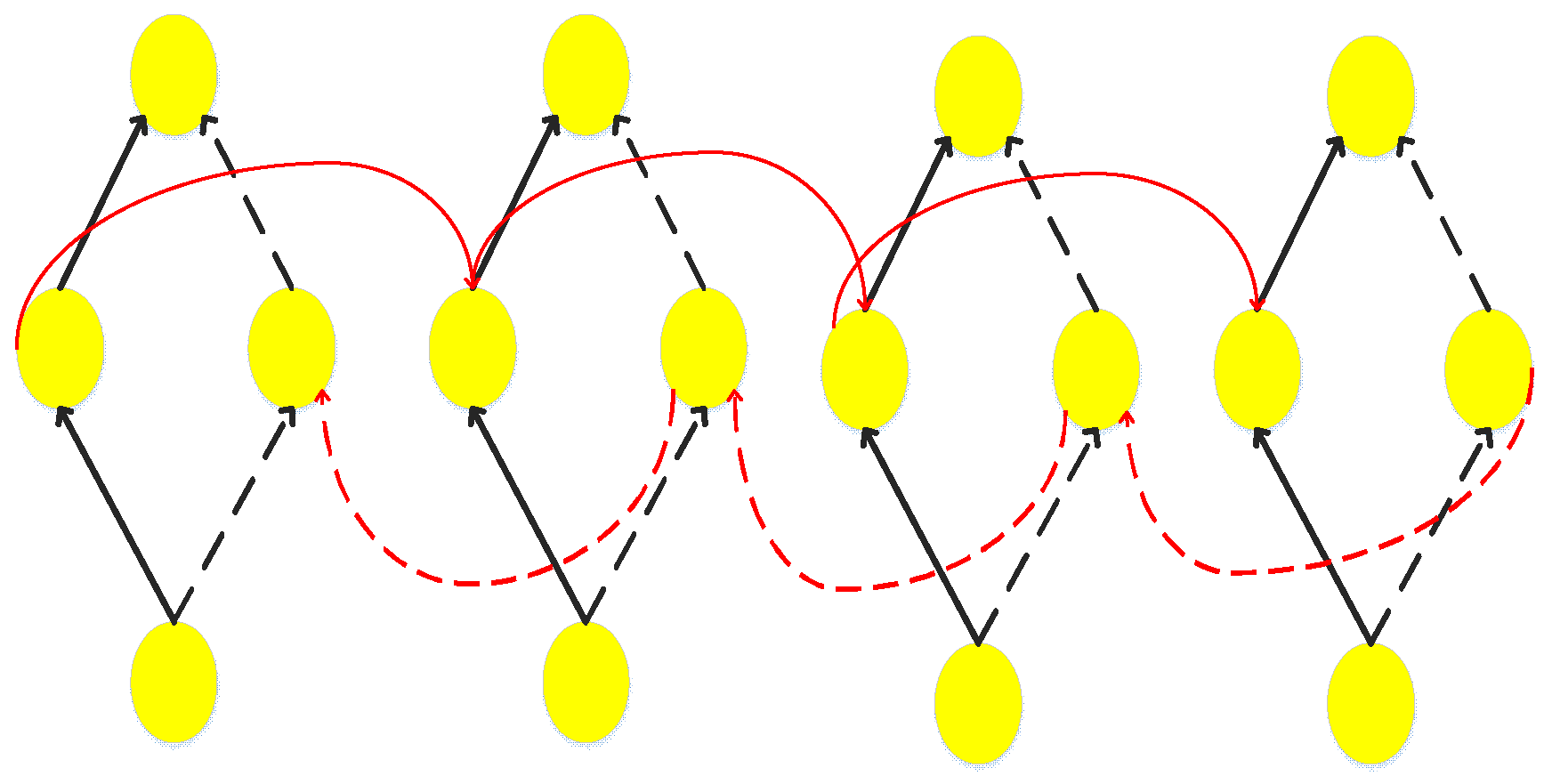
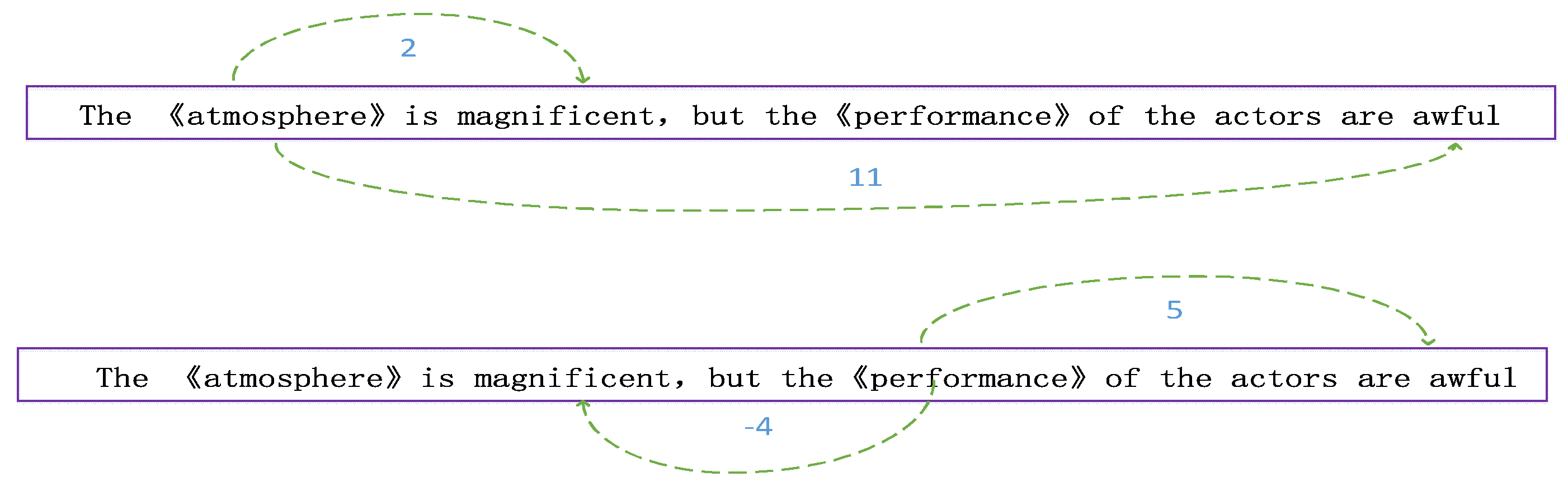
| Input: Sentence after word segmentation; output: Positional value set between each word and target word. Begin: Step (1) Set the target word and position value to 0 and set the value of the other words to n, which is the length of the sentence. Step (2) Centering on the target keyword, set two working pointers to scan left and right, respectively (the following steps take one of the pointers as an example, and vice versa) Step (3) Record the value of the work pointer and the target relative position , if the word at the position is punctuation, perform step (4); else, if the word at the position is the word in the target word set, then perform step (5); else, execute step (6); Step (4) Use this formula to update the value of , add the location to the collection, and continue scanning; Step (6) Add the position value to the set and continue scanning; Step (7) When the two pointers respectively reach the start and end positions of the sentence, the position value is added to the set to stop scanning. |
3.6. Part of the Attention Mechanism
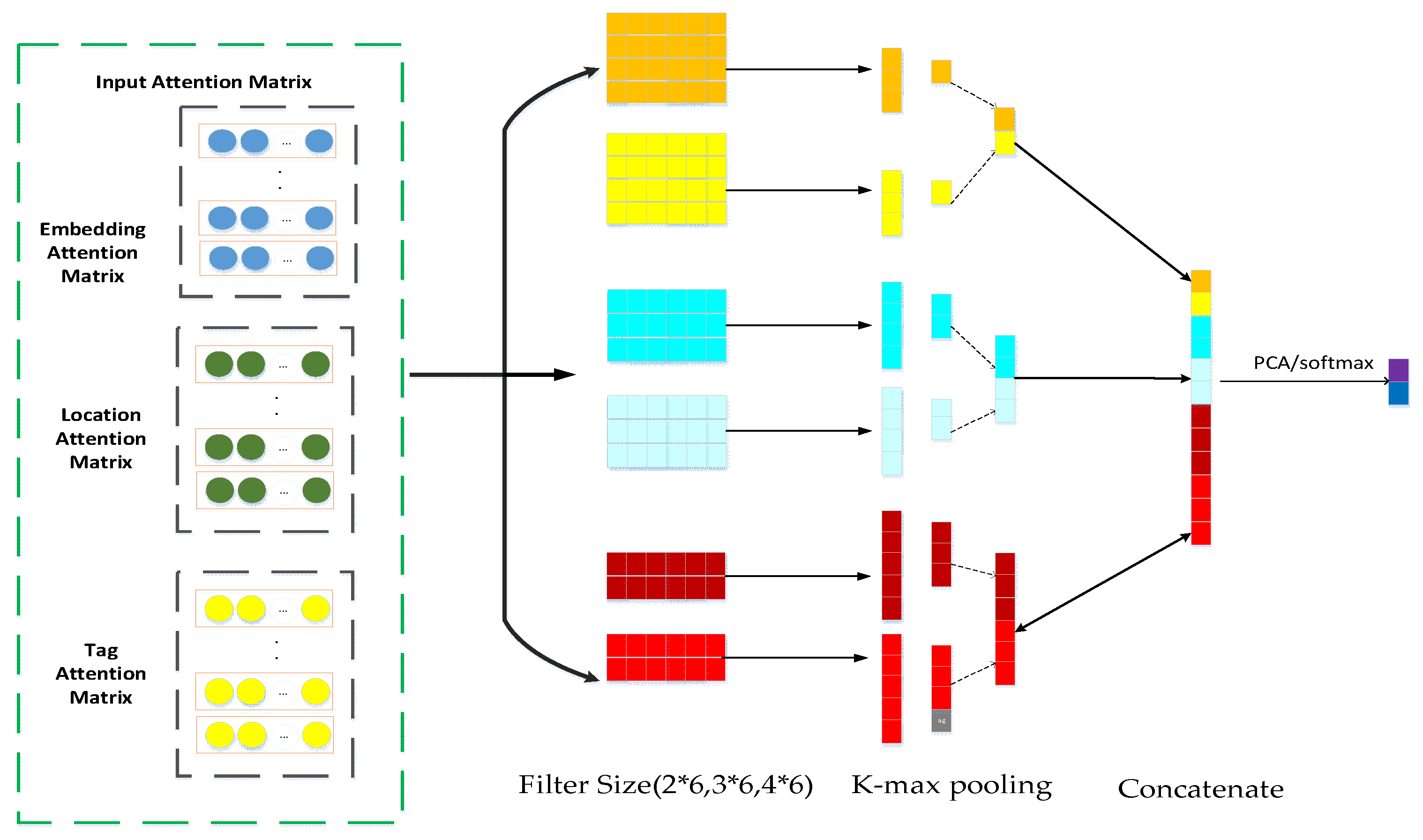
3.7. Input Matrix Construction Method
3.8. Text Feature Fusion Model
4. Experimental Results and Analysis
4.1. Datasets
4.2. Model Parameter Setting
4.3. Experimental Environment
4.4. Model Comparison
4.5. Experimental Results and Analysis
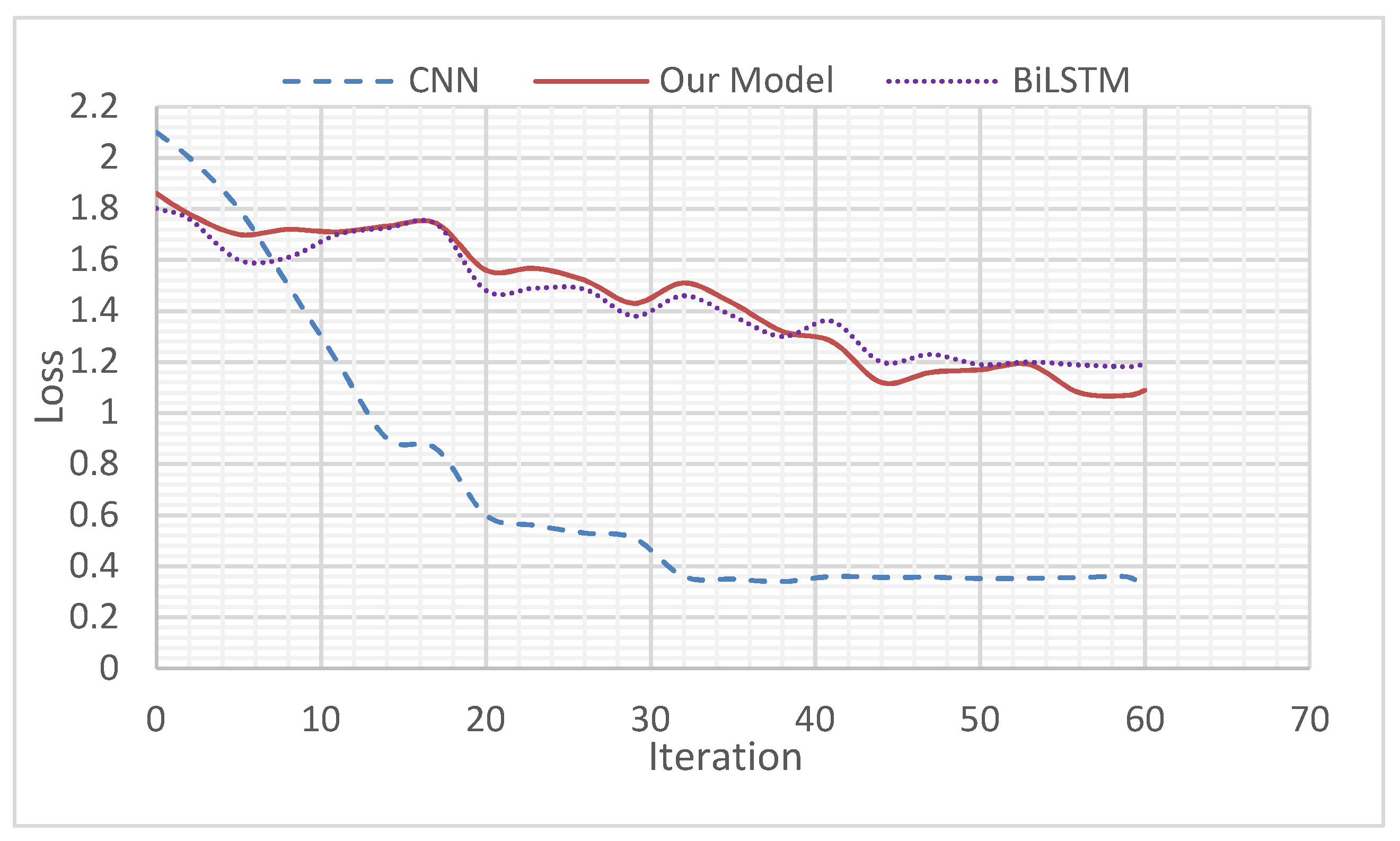
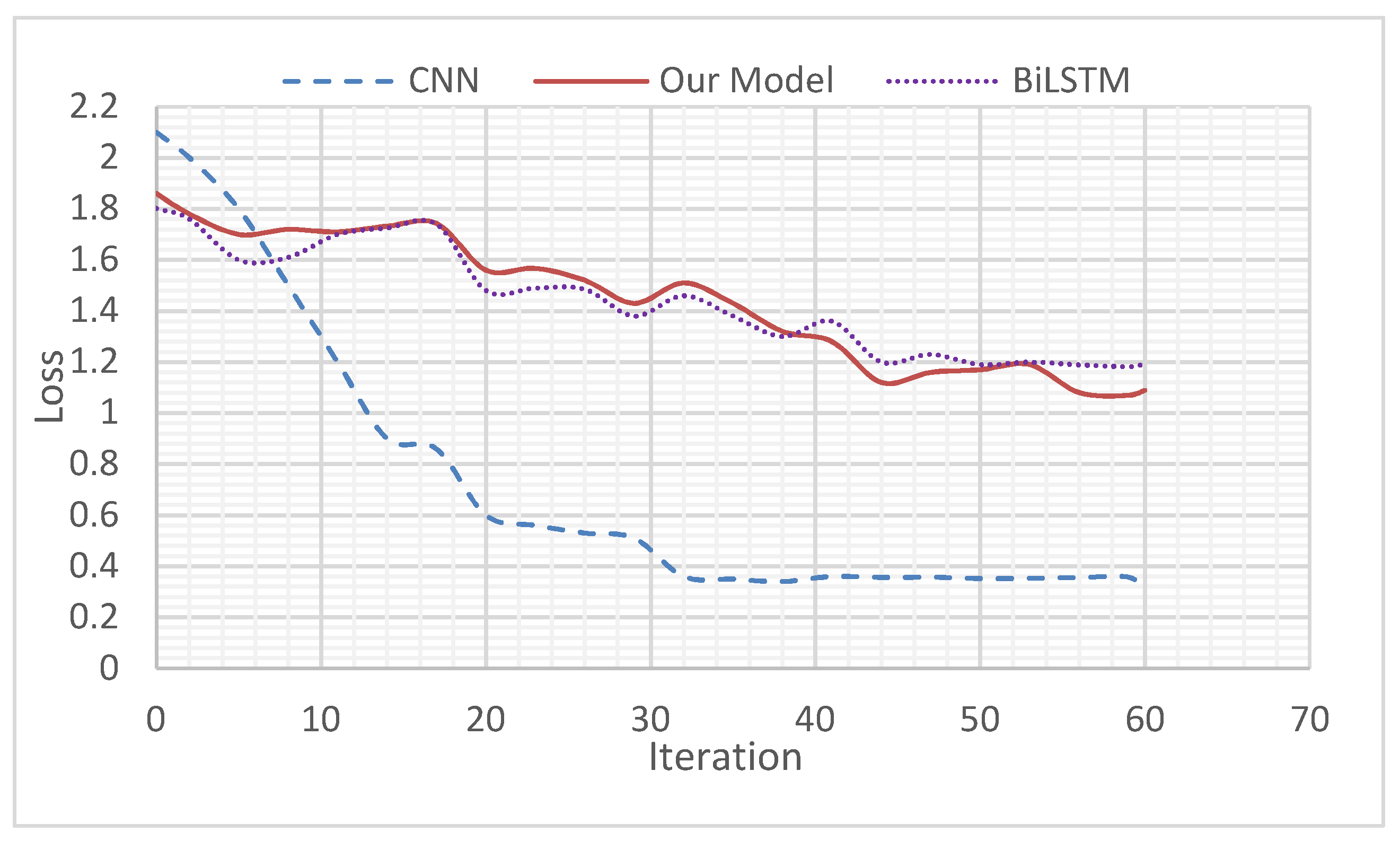
4.5.1. Comparison of Loss Functions
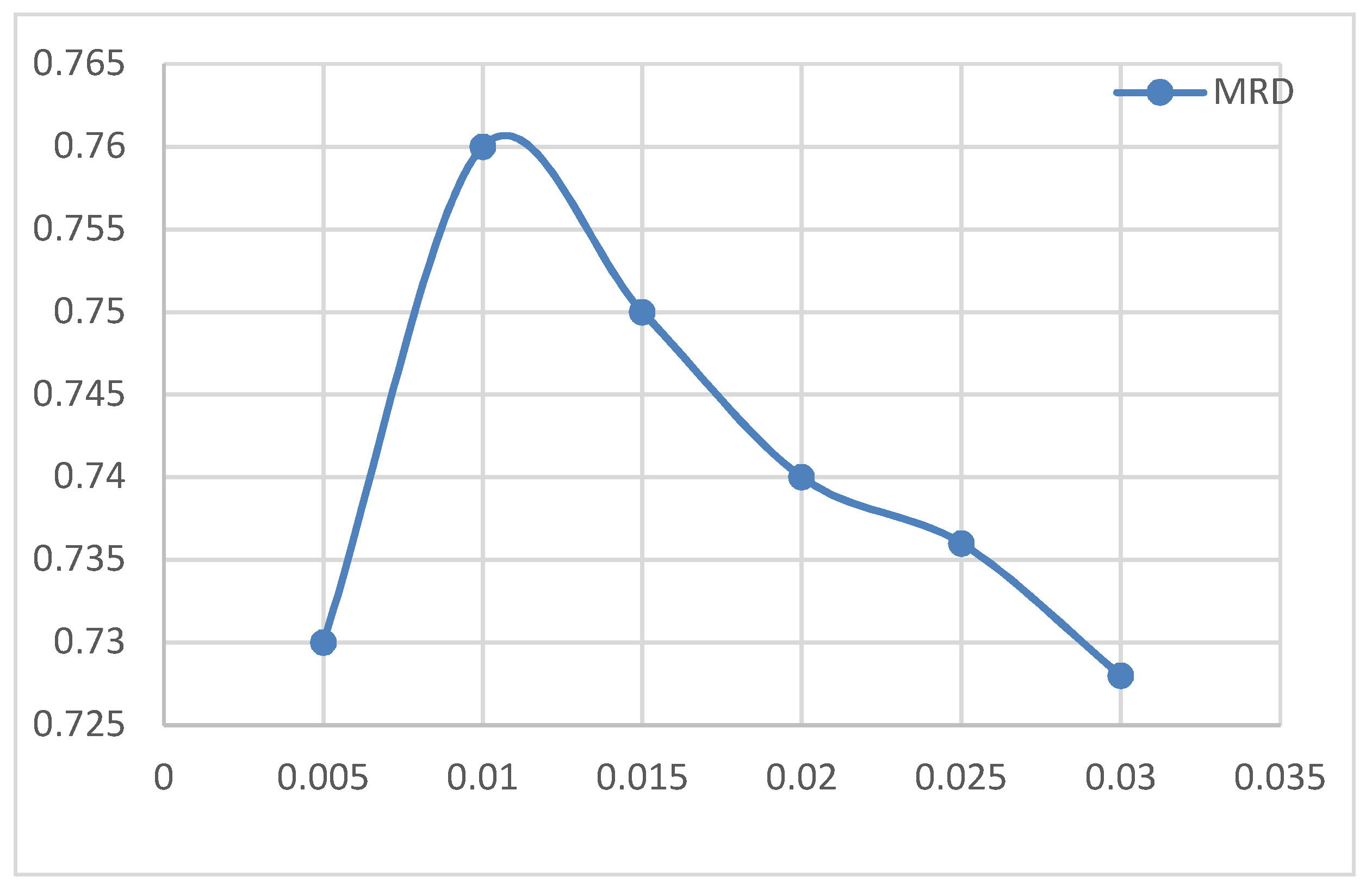
4.5.2. Effect of Learning Rate on MATT-CNN+BiGRU
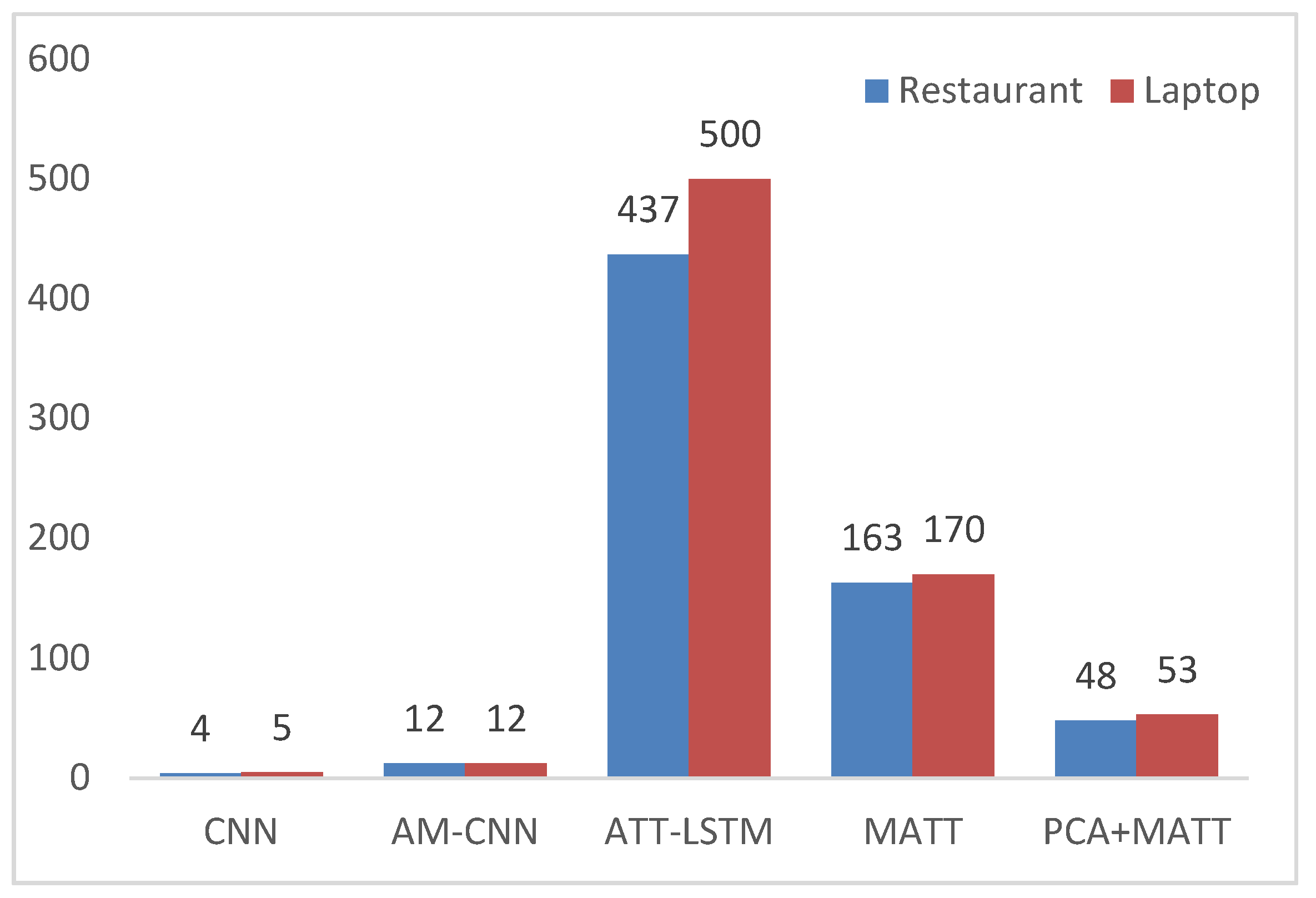
4.5.3. Analysis of the Impact of PCA on Training Time
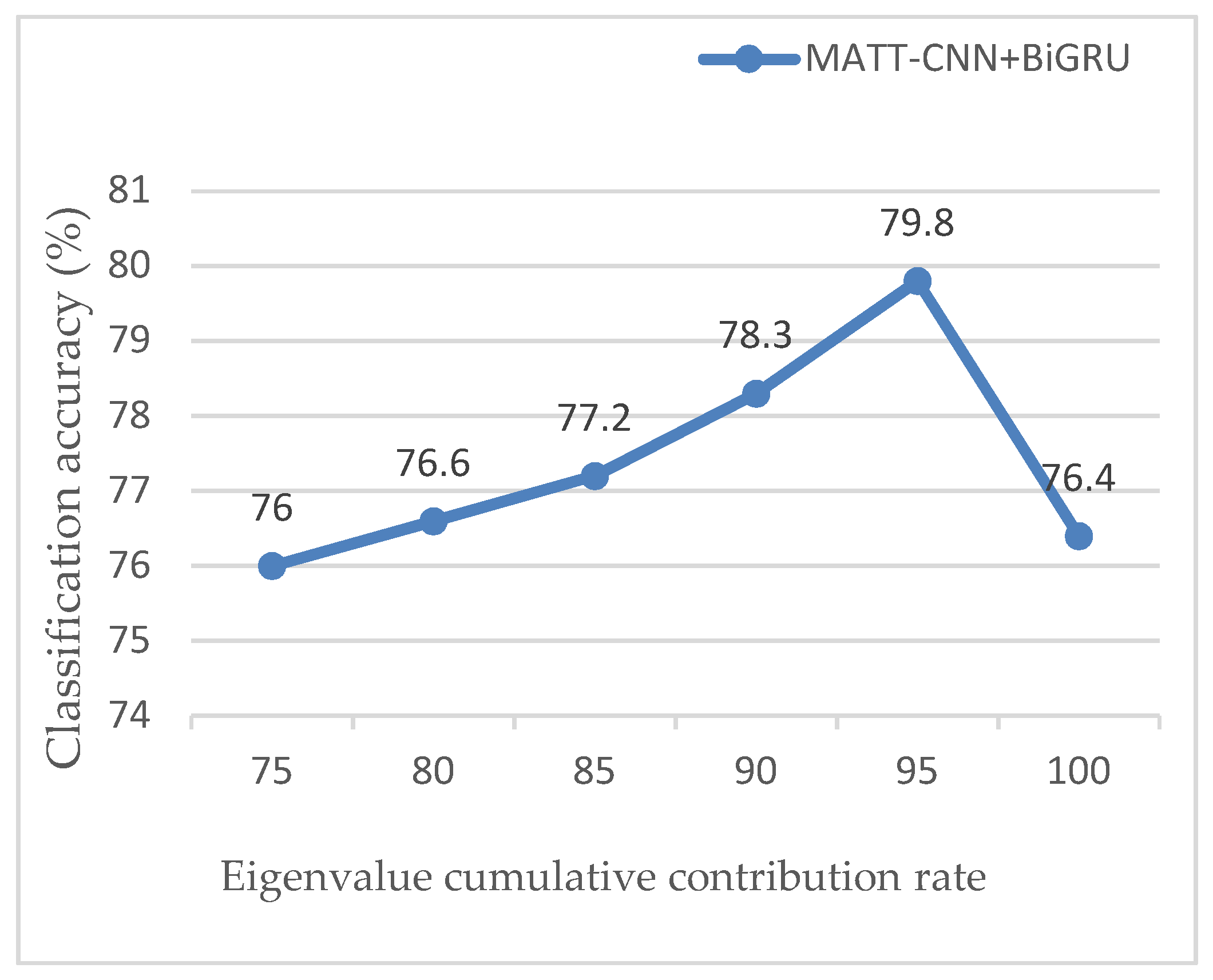
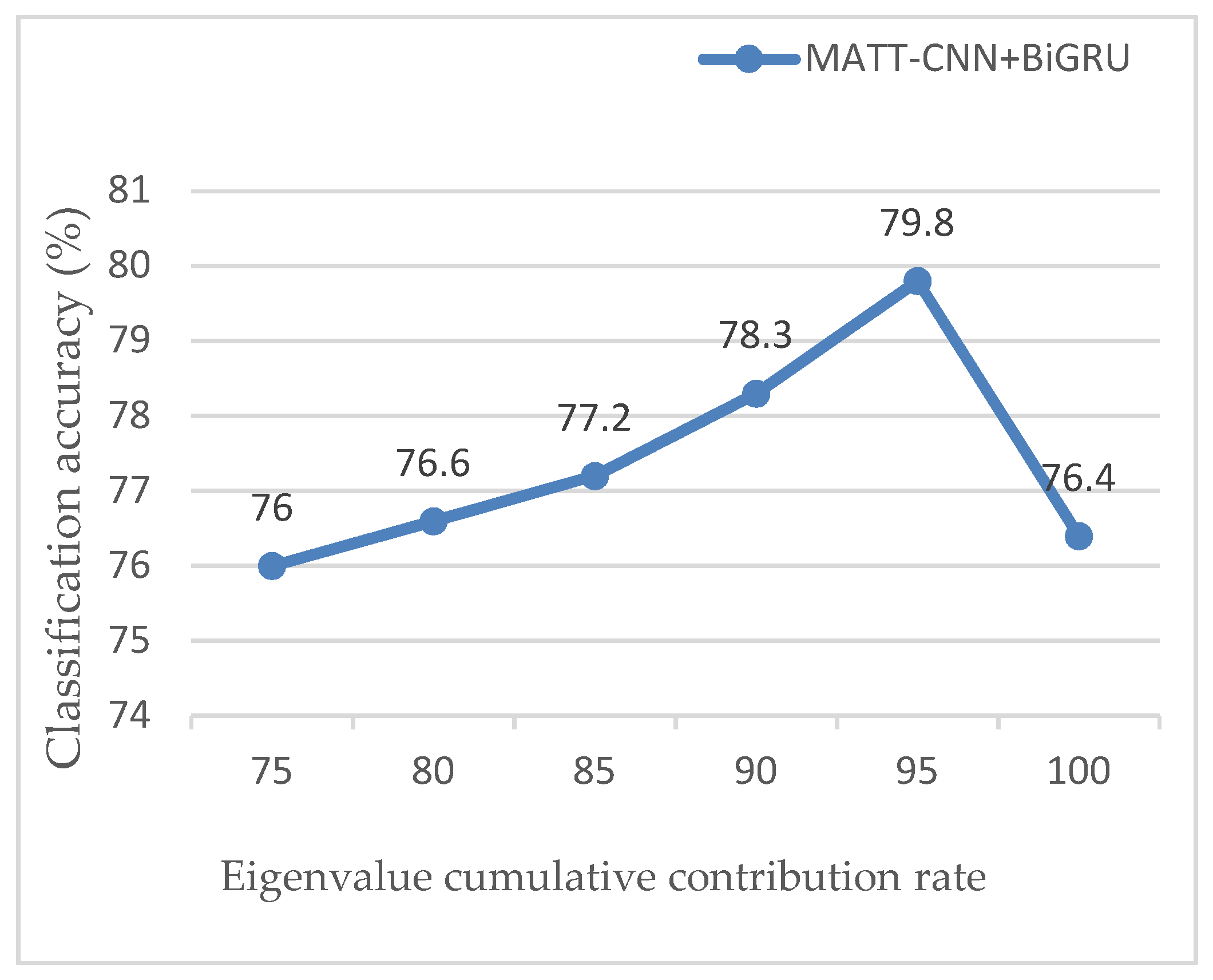
4.5.4. Effect of Cumulative Contribution Rate of Eigenvalues on Classification Accuracy
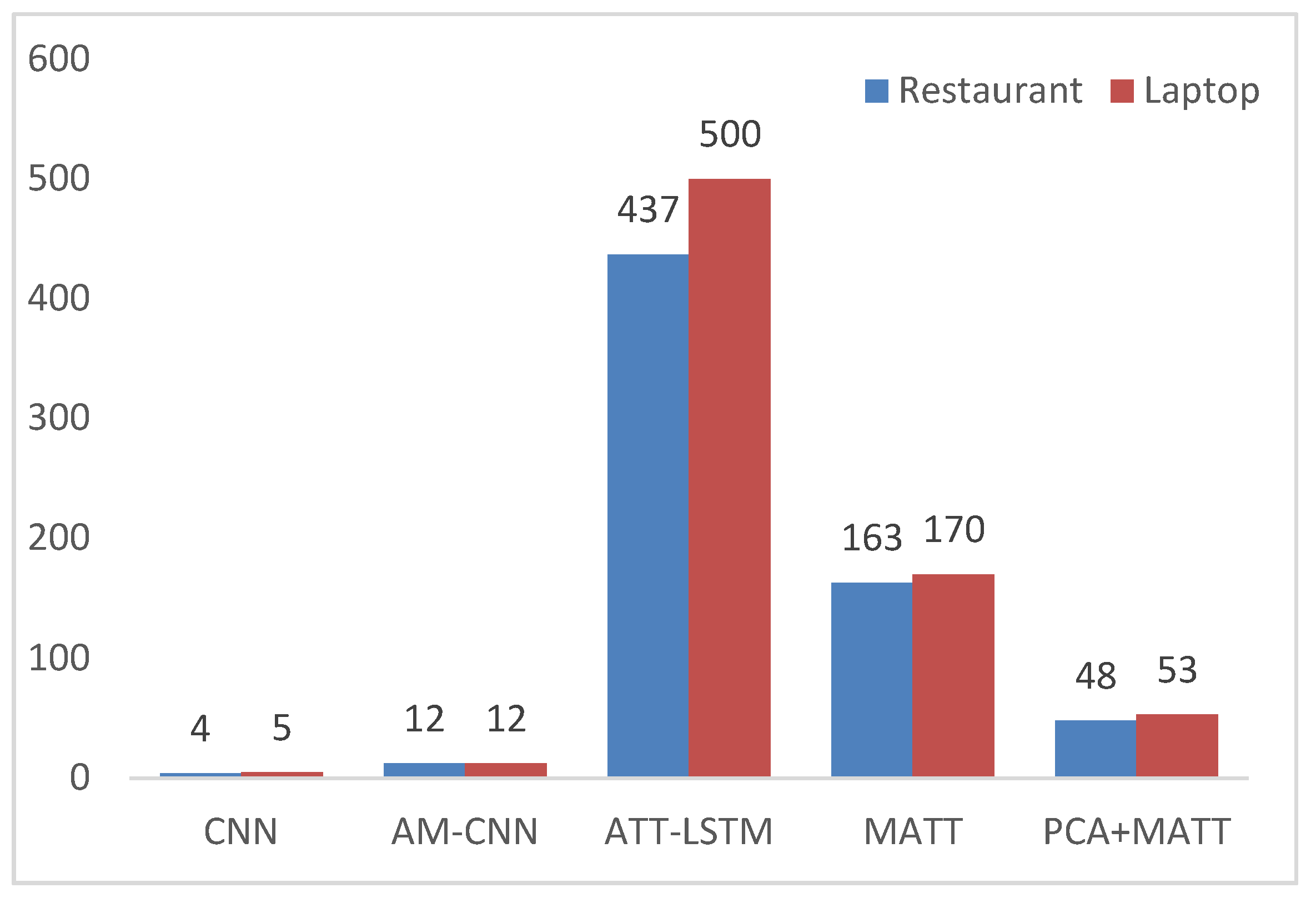
4.5.5. Multi-Attention Mechanism Effectiveness Analysis
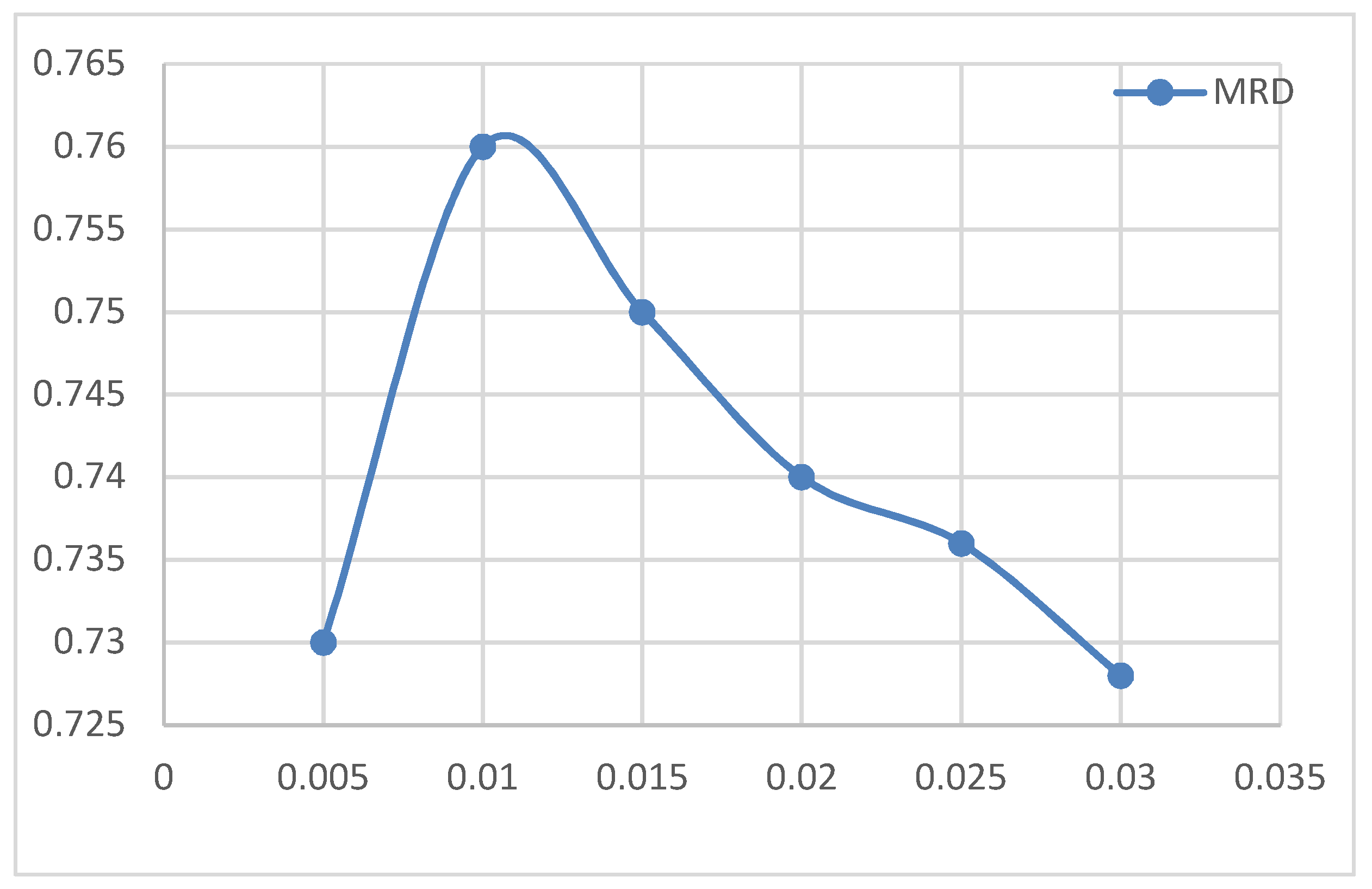
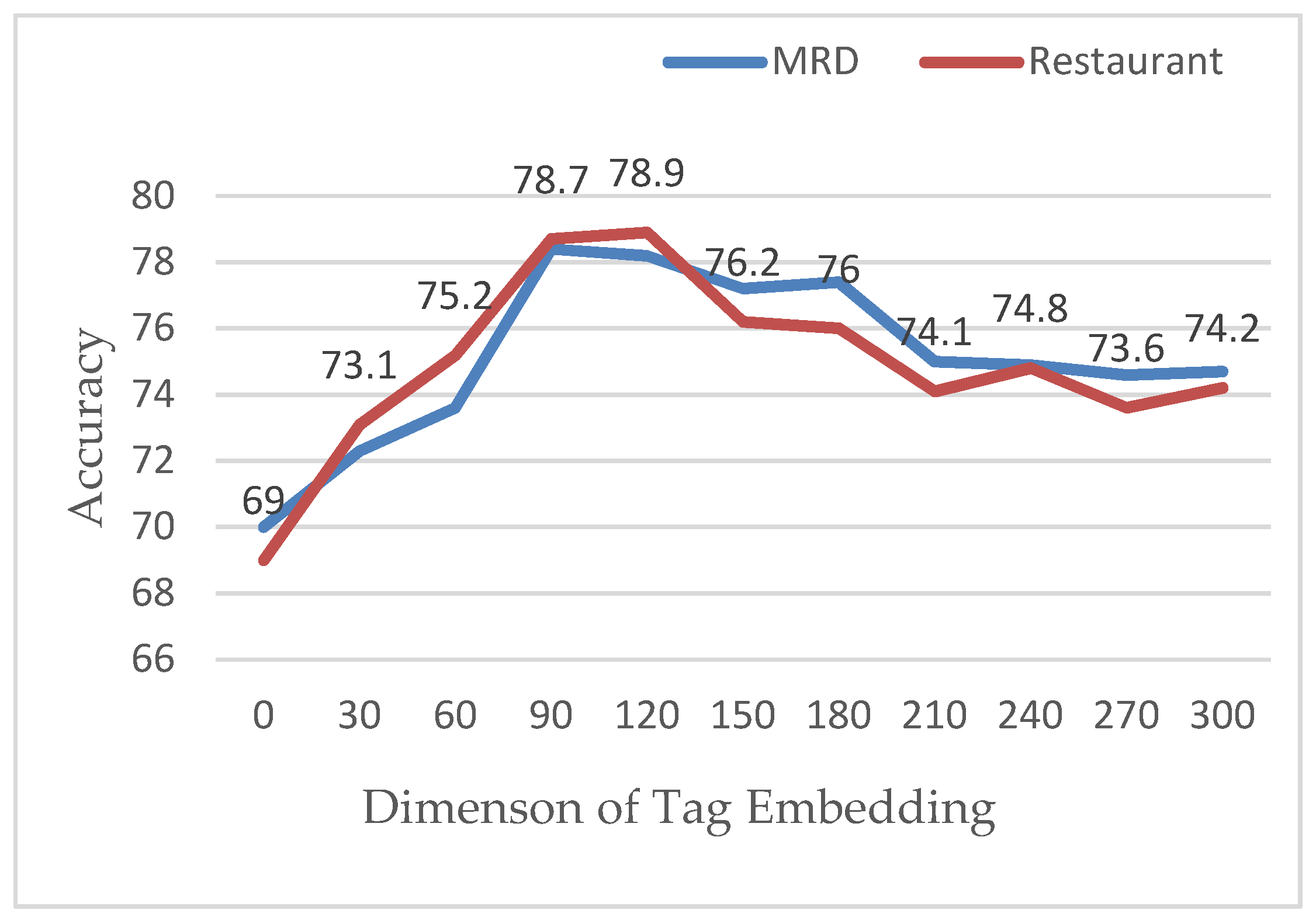
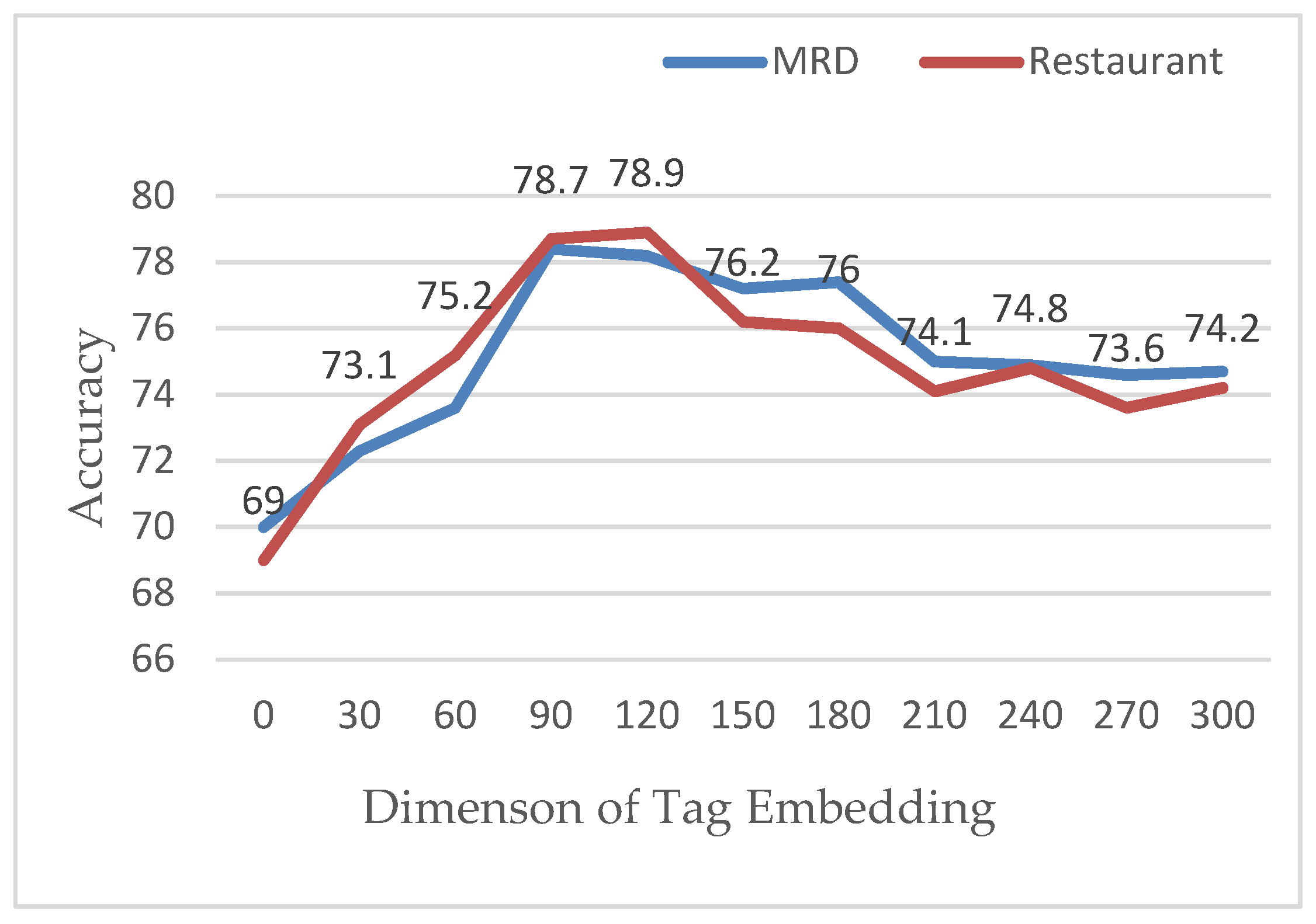
4.5.6. The Influence of Word Vector Dimension
4.6. Case Study
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nasukawa, T.; Yi, J. Sentiment analysis: Capturing favorability using natural language processing. In Proceedings of the International Conference on Knowledge Capture, New York, NY, USA, 23–25 October 2003. [Google Scholar]
- Chen, K.; Liang, B.; Ke, W.; Xu, B.; Zeng, G.C. Chinese Micro—Blog Sentiment Analysis Based on Multi-Channels Convolutional Neural Networks. J. Comput. Res. Dev. 2018, 55, 945–957. [Google Scholar]
- Liu, J.Z.; Chang, W.C.; Wu, Y.X.; Yang, Y.M. Deep Learning for Extreme Multi-label Text Classification. In Proceedings of the International ACM SIGIR Conference on Research & Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Xing, S.; Wang, Q.; Zhao, X.; Li, T. A hierarchical attention model for rating prediction by leveraging user and product reviews. Neurocomputing 2019, 332, 417–427. [Google Scholar] [CrossRef]
- Zhao, W.; Ye, J.B.; Yang, M.; Lei, Z.Y.; Zhang, S.F.; Zhao, Z. Investigating Capsule Networks with Dynamic Routing for Text Classification. arXiv 2018, arXiv:1804.00538. [Google Scholar]
- Ntalianis, K.; Doulamis, A.D.; Tsapatsoulis, N.; Mastorakis, N.E. Social relevance feedback based on multimedia content power. IEEE Trans. Comput. Soc. Syst. 2017, 5, 109–117. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 3, 2204–2212. [Google Scholar]
- Yin, W.; Schütze, H.; Xiang, B.; Zhou, B. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs. Comput. Sci. 2016, 4, 259–272. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An Unsupervised Neural Attention Model for Aspect Extraction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 388–397. [Google Scholar]
- Sun, A.; Lim, E.P.; Liu, Y. On strategies for imbalanced text classification using SVM: A comparative study. Decis. Support Syst. 2010, 481, 191–201. [Google Scholar] [CrossRef]
- Jing, L.; Wang, T.; Zhao, M.; Wang, P. An adaptive multi-sensor data fusion method based on deep convolutional neural networks for fault diagnosis of planetary gearbox. Sensors 2017, 17, 414. [Google Scholar] [CrossRef] [PubMed]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 22 September 2016; Springer: Cham, Switzerland, 2016; pp. 180–196. [Google Scholar]
- Bakalos, N.; Voulodimos, A.; Doulamis, N.; Doulamis, A.; Ostfeld, A.; Salomons, E.; Caubet, J.; Jimenez, V.; Li, P. Protecting Water Infrastructure from Cyber and Physical Threats: Using Multimodal Data Fusion and Adaptive Deep Learning to Monitor Critical Systems. IEEE Signal Process. Mag. 2019, 36, 36–48. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Wang, G.; Li, C.; Wang, W.; Zhang, Y.; Shen, D.; Zhang, X.; Henao, R.; Carin, L. Joint Embedding of Words and Labels for Text Classification. arXiv 2018, arXiv:1805.04174. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Available online: http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf (accessed on 8 November 2019).
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent Attention Network on Memory for Aspect Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Rozental, A.; Fleischer, D. Amobee at SemEval-2018 Task 1: GRU Neural Network with a CNN Attention Mechanism for Sentiment Classification. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Kumar, A.; Kawahara, D.; Kurohashi, S. Knowledge-enriched Two-layered Attention Network for Sentiment Analysis. arXiv 2018, arXiv:1805.07819. [Google Scholar]
- Nguyen, T.H.; Shirai, K.; Velcin, J. Sentiment analysis on social media for stock movement prediction. Expert Syst. Appl. 2015, 42, 9603–9611. [Google Scholar] [CrossRef]
- Ruder, S.; Ghaffari, P.; Breslin, J.G. A Hierarchical Model of Reviews for Aspect-based Sentiment Analysis. arXiv 2016, arXiv:1609.02745. [Google Scholar]
- Zhou, X.; Wan, X.; Xiao, J. Attention-based LSTM Network for Cross-Lingual Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Song, Y.; Wang, J.; Jiang, T.; Liu, Z.; Rao, Y. Attentional Encoder Network for Targeted Sentiment Classification. arXiv 2019, arXiv:1902.09314. [Google Scholar]
- Mohammadi, F.; Zheng, C.; Su, R. Fault Diagnosis in Smart Grid Based on Data-Driven Computational Methods. In Proceedings of the 5th International Conference on Applied Research in Electrical, Mechanical, and Mechatronics Engineering, Tehran, Iran, 24 January 2019. [Google Scholar]
- Mohammadi, F.; Zheng, C. A Precise SVM Classification Model for Predictions with Missing Data. In Proceedings of the 4th National Conference on Applied Research in Electrical, Mechanical Computer and IT Engineering, Tehran, Iran, 4 Octorber 2018. [Google Scholar]
- Mohammadi, F.; Nazri, G.-A.; Saif, M. A Fast Fault Detection and Identification Approach in Power Distribution Systems. In Proceedings of the 5th International Conference on Power Generation Systems and Renewable Energy Technologies (PGSRET 2019), Istanbul, Turkey, 26–27 August 2019. [Google Scholar]
- Liang, B.; Liu, Q.; Xu, J.; Zhou, Q.; Zhang, P. Aspect-Based Sentiment Analysis Based on Multi-Attention CNN. J. Comput. Res. Dev. 2017, 54, 1724–1735. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Lei, T.; Barzilay, R.; Jaakkola, T. Molding CNNs for text: Non-linear, non-consecutive convolutions. Indiana Univ. Math. J. 2015, 58, 1151–1186. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. Available online: https://arxiv.org/pdf/1212.5701.pdf (accessed on 8 November 2019).
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. NRC–Canada–2014: Detecting Aspects and Sentiment in Customer Reviews. In Proceedings of the International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Wang, J.Z.; Peng, D.L.; Chen, Z.; Liu, C. AM–CNN: A Concentration-Based Convolutional Neural Network Text Classification Model. Mini-Micro Syst. 2019, 40, 710–714. [Google Scholar]
- LI, Y.; Dong, H.B. Text sentiment analysis based on feature fusion of convolution neural network and bidirectional long short-term memory network. J. Comput. Appl. 2018, 38, 3075–3080. [Google Scholar]
- Wang, Y.; Huang, M.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2017; pp. 606–615. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for Target-Dependent Sentiment Classification. Available online: https://arxiv.org/pdf/1512.01100.pdf (accessed on 8 November 2019).
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive | Negative | Neutral |
|---|---|---|---|
| Laptop-train | 872 | 718 | 490 |
| Laptop-test | 361 | 152 | 122 |
| Restaurant-train | 2158 | 804 | 644 |
| Restaurant-test | 748 | 189 | 210 |
| MRD-train | 483 | 272 | 245 |
| MRD-test | 189 | 79 | 132 |
| Parameter | Parameter Description | Value |
|---|---|---|
| h | Windows Size | 3, 4, 5 |
| n | Features Map | 128 |
| p | Dropout Rate | 0.5 |
| s | Constrain L | 3 |
| b | Mini-Batch Size | 64 |
| m | Pooling Method | k-max |
| Model | Laptop | Restaurant | MRD |
|---|---|---|---|
| SVM | 65.17 | 74.18 | 70.13 |
| CNN | 65.23 | 69.90 | 68.43 |
| AM-CNN | 65.42 | 77.67 | 74.32 |
| CNN+BiLSTM | 63.20 | 79.54 | 73.28 |
| ATT-LSTM | 68.22 | 75.30 | 67.23 |
| BiLSTM-ATT-G | 73.34 | 79.12 | 69.89 |
| IAN | 73.24 | 77.40 | 78.19 |
| MATT-CNN+BiGRU | 74.21 | 78.47 | 79.22 |
| Model | Laptop | Restaurant |
|---|---|---|
| MATT+wvatt | 70.42 | 75.89 |
| MATT+patt | 71.37 | 74.46 |
| MATT+latt | 72.20 | 76.51 |
| MATT+latt+DDS | 73.98 | 77.15 |
| MATT+allatt | 75.21 | 79.22 |
| Aspect | Sentence | Polarity | Sen-Polarity |
|---|---|---|---|
| priced | Boot time is super fast, around anywhere from 35 seconds to 1 min, But quite unreasonable priced. | positive | positive |
| Boot time | Boot time is super fast, around anywhere from 35 seconds to 1 min, But quite unreasonable priced. | negative | neutral |
| Atmosphere | The atmosphere of this movie is magnificent, although it still have place to improve. | positive | positive |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Liu, F.; Xu, W.; Yu, H. Feature Fusion Text Classification Model Combining CNN and BiGRU with Multi-Attention Mechanism. Future Internet 2019, 11, 237. https://doi.org/10.3390/fi11110237
Zhang J, Liu F, Xu W, Yu H. Feature Fusion Text Classification Model Combining CNN and BiGRU with Multi-Attention Mechanism. Future Internet. 2019; 11(11):237. https://doi.org/10.3390/fi11110237
Chicago/Turabian StyleZhang, Jingren, Fang’ai Liu, Weizhi Xu, and Hui Yu. 2019. "Feature Fusion Text Classification Model Combining CNN and BiGRU with Multi-Attention Mechanism" Future Internet 11, no. 11: 237. https://doi.org/10.3390/fi11110237
APA StyleZhang, J., Liu, F., Xu, W., & Yu, H. (2019). Feature Fusion Text Classification Model Combining CNN and BiGRU with Multi-Attention Mechanism. Future Internet, 11(11), 237. https://doi.org/10.3390/fi11110237