Fog Computing in IoT Smart Environments via Named Data Networking: A Study on Service Orchestration Mechanisms

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
- We extend the NDN architecture to support service provisioning in the campus network and propose a new forwarding strategy that supports the decision of whether the IoT data processing has to be performed into fog nodes or remotely in the cloud in a fully distributed manner. Hence, the strategy is aligned with the fog computing concept.
- We conceive a service executor strategy, leveraging a bidding procedure that aims at minimizing the overall service provisioning time, accounting for the retrieval of input IoT data to be processed and for the execution of this processing.
- We implement the devised strategy in ndnSIM [11] and compare its performance through valuable metrics against a set of benchmark orchestration mechanisms available in the literature. The evaluation shows that our proposal outperforms the alternative benchmarking schemes by better scaling as the number of service requests increases. The achieved improvements come at the expense of a slightly higher amount of traffic exchanged among fog nodes.
2. Named Data Networking and Its Role in IoT Smart Environments
2.1. NDN in a Nutshell
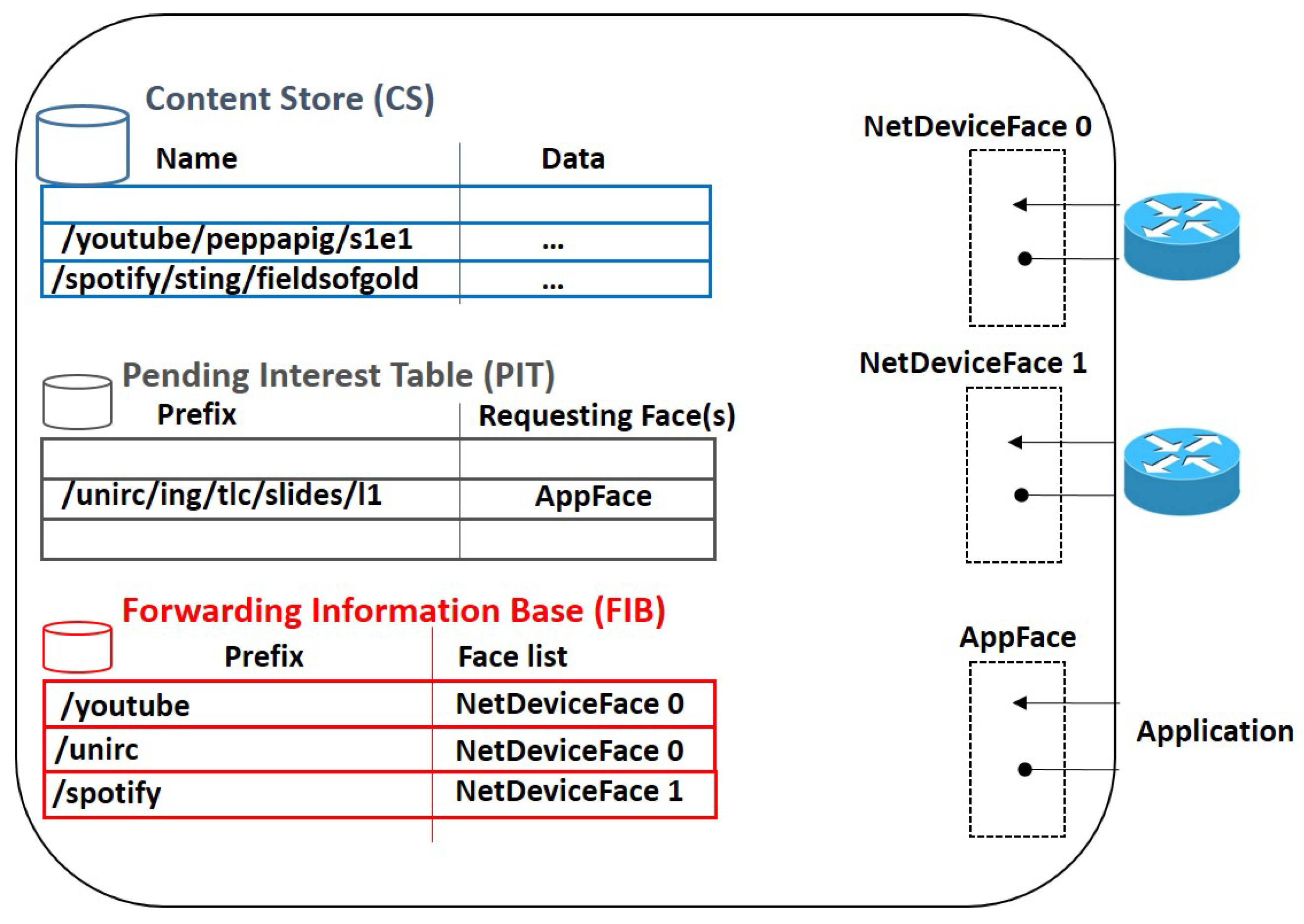
2.1.1. Data Plane
2.1.2. Forwarding Fabric
- First, the node looks in the CS. If a matching is found, the data packet is immediately sent over the same interface that the interest arrives from.
- Otherwise, the node looks in the PIT. If a match is found, it means that the same request has already been forwarded, the node is waiting for the data, and there is no need to transmit it again. As a result, the interest is discarded and the node only updates the PIT entry with the incoming interface of the received interest. Such a feature, typically referred to as request aggregation, reduces the number of accesses to the original content source.
- If also the PIT matching fails, the node looks in the FIB to forward the interest over an outgoing interface. In case of failure, a NACK can be sent back and the interest is discarded.
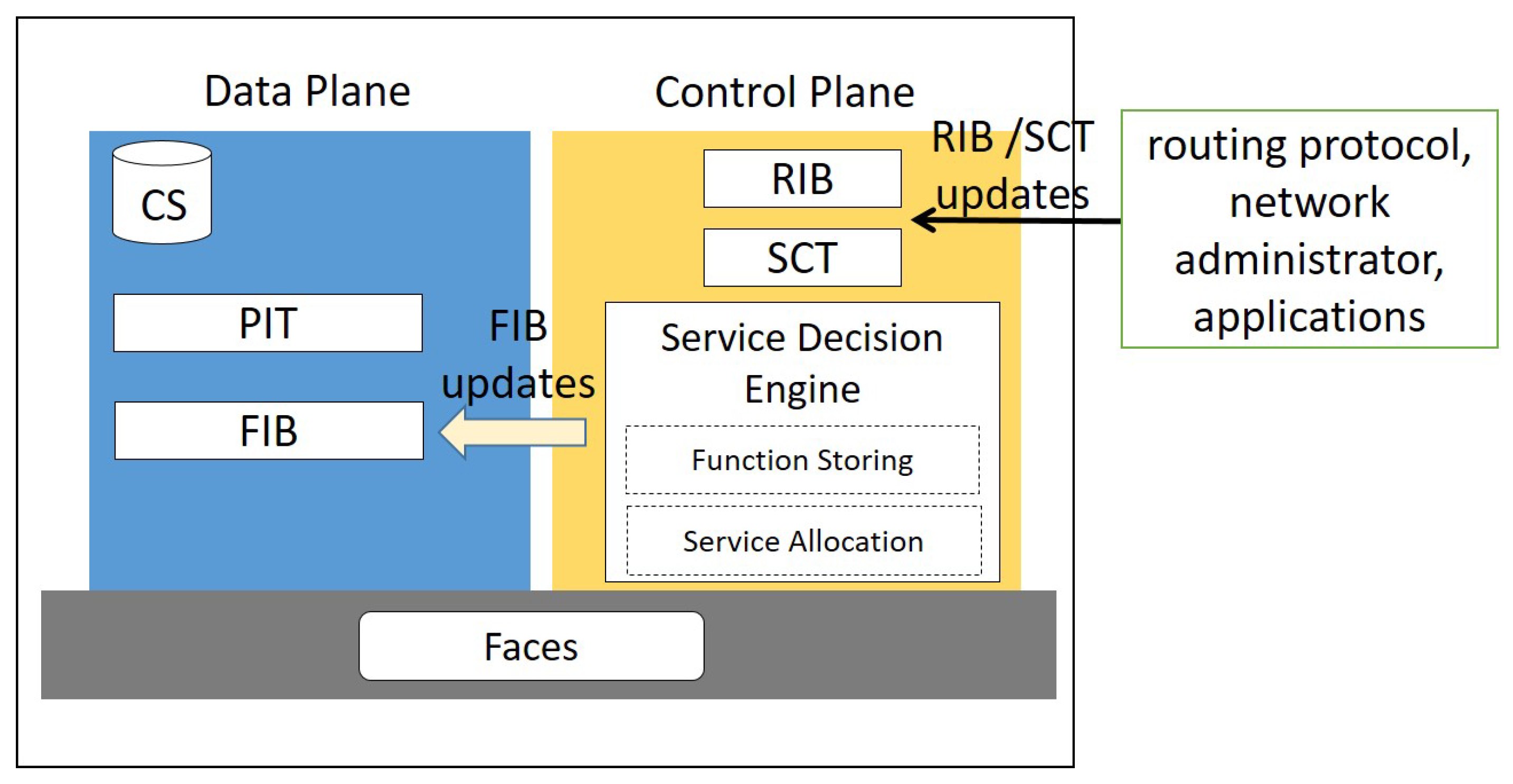
2.1.3. Control Plane
2.2. NDN in Smart Environments
3. NDN: The Networking Paradigm for Fog Computing
3.1. Fog Computing: Key Pillars and Issues
3.2. NDN as Enabler of Fog Computing
- Privacy-preserving schemes ensuring that results of computation inherit the same confidentiality of the input contents [39].
4. IoT Service Orchestration via NDN
4.1. Distributed Mechanisms
4.2. Centralized Mechanisms
4.3. Contribution
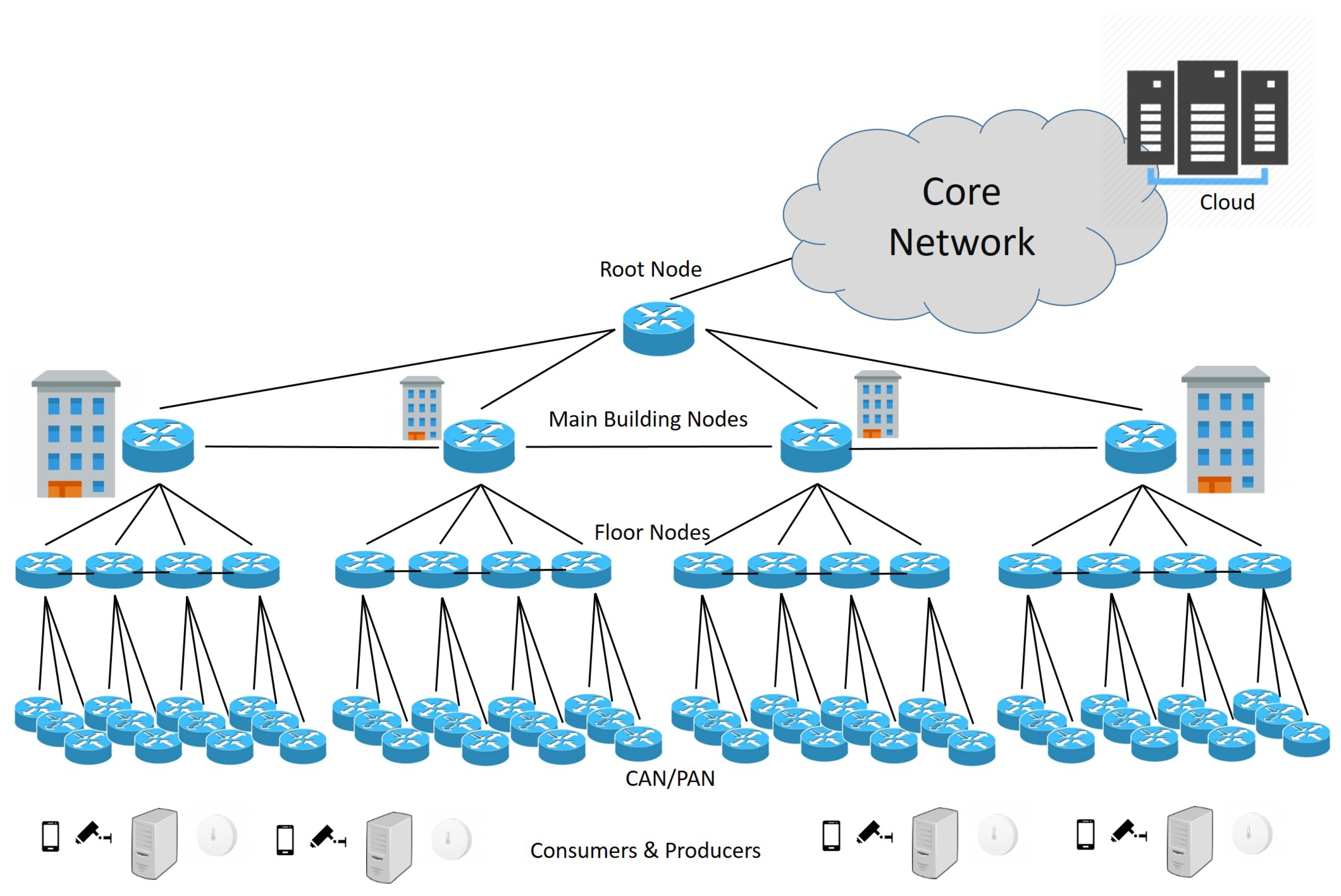
5. IoT Service Provisioning via NDN in the Smart Campus
5.1. Reference Scenario and Service Naming
5.2. NDN-Fog Node Design
- Function storing module decides which functions should be installed in the node and which functions should be evicted. The selection is performed in a proactive way by following a popularity-based approach, similar to Reference [8]. During the network bootstrap, a first manual configuration is performed by the network administrator, who may also decide that specific functions must be installed only in specific locations, e.g., for privacy purposes. When a function is available in the node, a FIB entry is configured that binds the function name with the AppFace of the node.
- Service allocation module decides, after the service interest reception, if the node can execute the service and manages the signalling related to this operation.
5.3. Service Provisioning
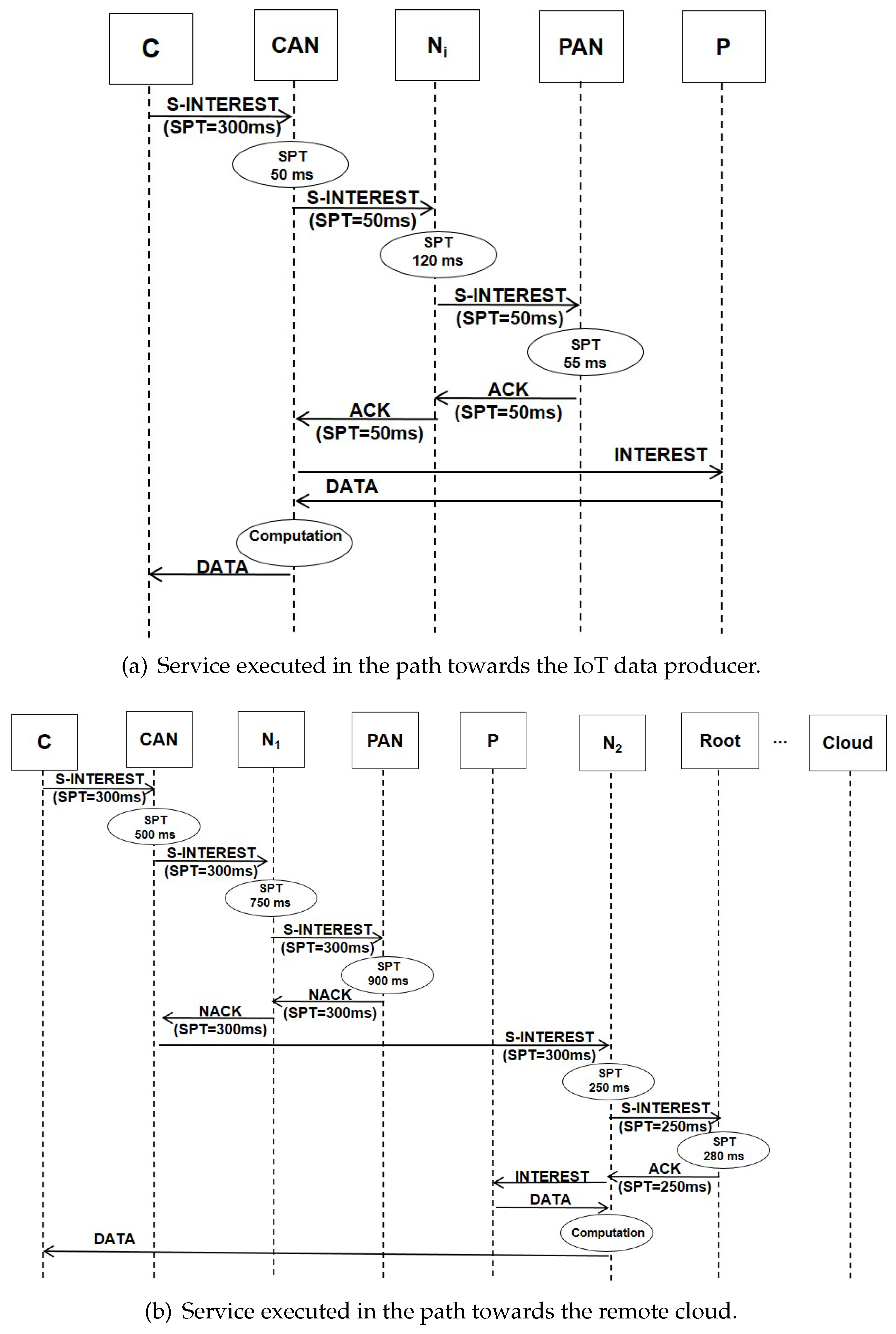
5.3.1. On-Path Forwarding
- First, looks in the CS for a matching name. If it is found, it means that the same service has been previously computed and the result can be immediately sent back to the consumer.
- If the CS matching fails, it looks in the PIT. If a matching is found, it means that the same service has been requested and it is pending. Therefore, updates the correspondent PIT entry with the incoming service interest face and discards the packet.
- If the PIT matching fails, then the interest is processed by the SDE, which computes the service provisioning time and decides if can candidate itself for the execution. This choice depends on the available computing resources and the implemented service allocation strategy, as it will be clarified in the following section. If the locally computed service provisioning time is lower or equal than the value already included in the SPT field, then becomes the potential service executor: the SDE updates the SPT field and creates a new PIT entry that includes as additional record the service provisioning time. Then, the packet is forwarded to the next node towards the IoT provider (and, therefore, towards the PAN).
- If no on-path node is available for the execution, it sends back a NACK packet advertising that the service has not been allocated.
- Otherwise, the node with the lowest service provisioning time is selected as the executor. In particular, if the executor is the PAN itself, then it will take in charge the computation. Otherwise, it sends back a data acknowledgement (ACK) packet carrying the service name and the correspondent SPT. The first node with the correspondent SPT in the PIT will act as the executor.
5.3.2. Forwarding towards the Cloud
5.4. A Toy Example
6. Performance Evaluation
6.1. Simulation Settings
- Closest executor strategy (labeled as CE in the figures): Inspired by the work in Reference [10], it aims at executing the service as close as possible to the IoT providers.
- Least loaded executor strategy (labeled as LLE in the figures): It targets at selecting as the service executor the node with the lowest CPU usage, similarly to the work in Reference [34].
- Remote cloud (labeled as Cloud in the figures): It resembles the case when all services are executed in remote cloud facilities.
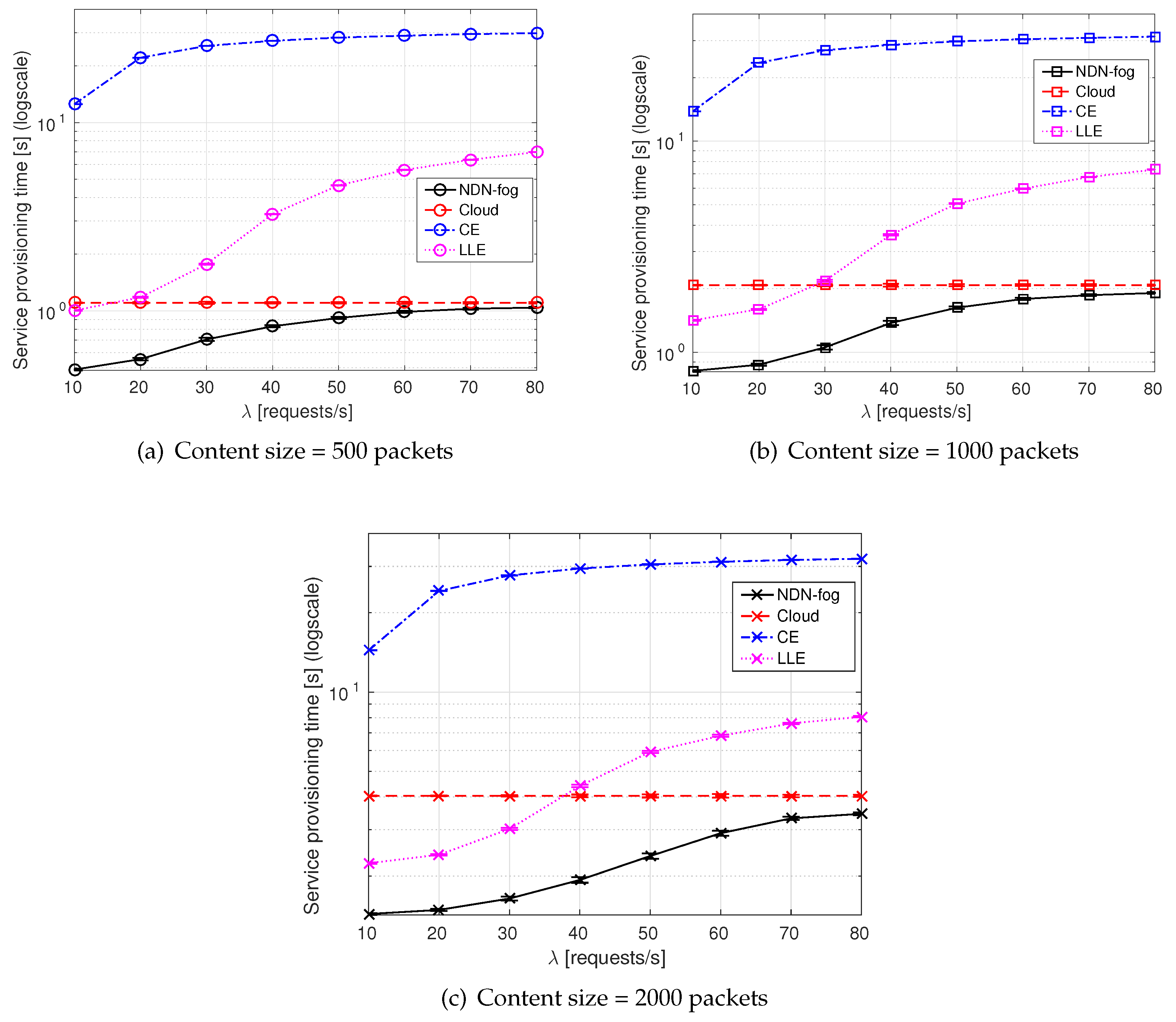
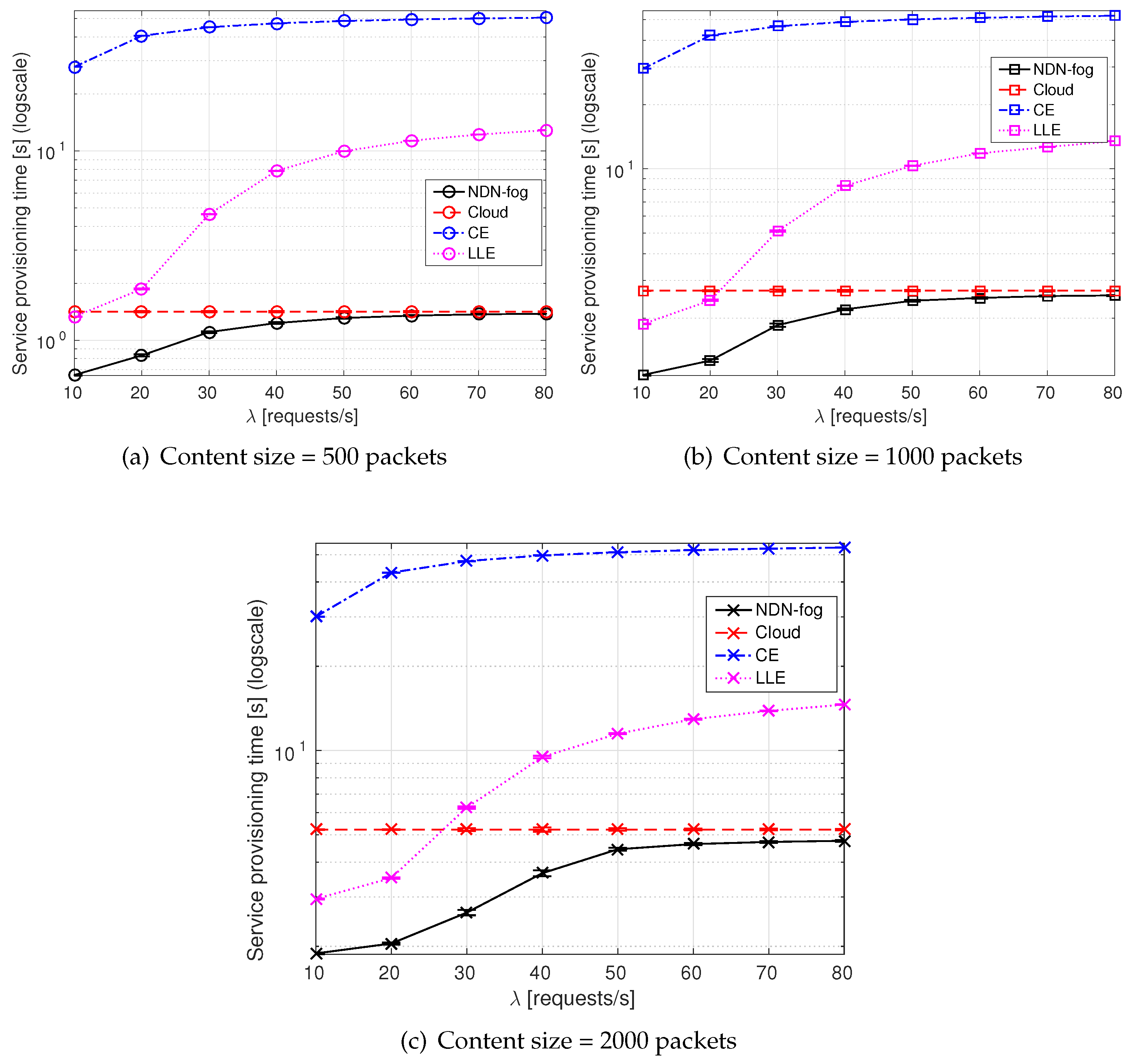
- Service provisioning time is computed as the time since the first interest is transmitted from a consumer to request the service until the output of the service execution is sent back (thus including the computation time at the executor).
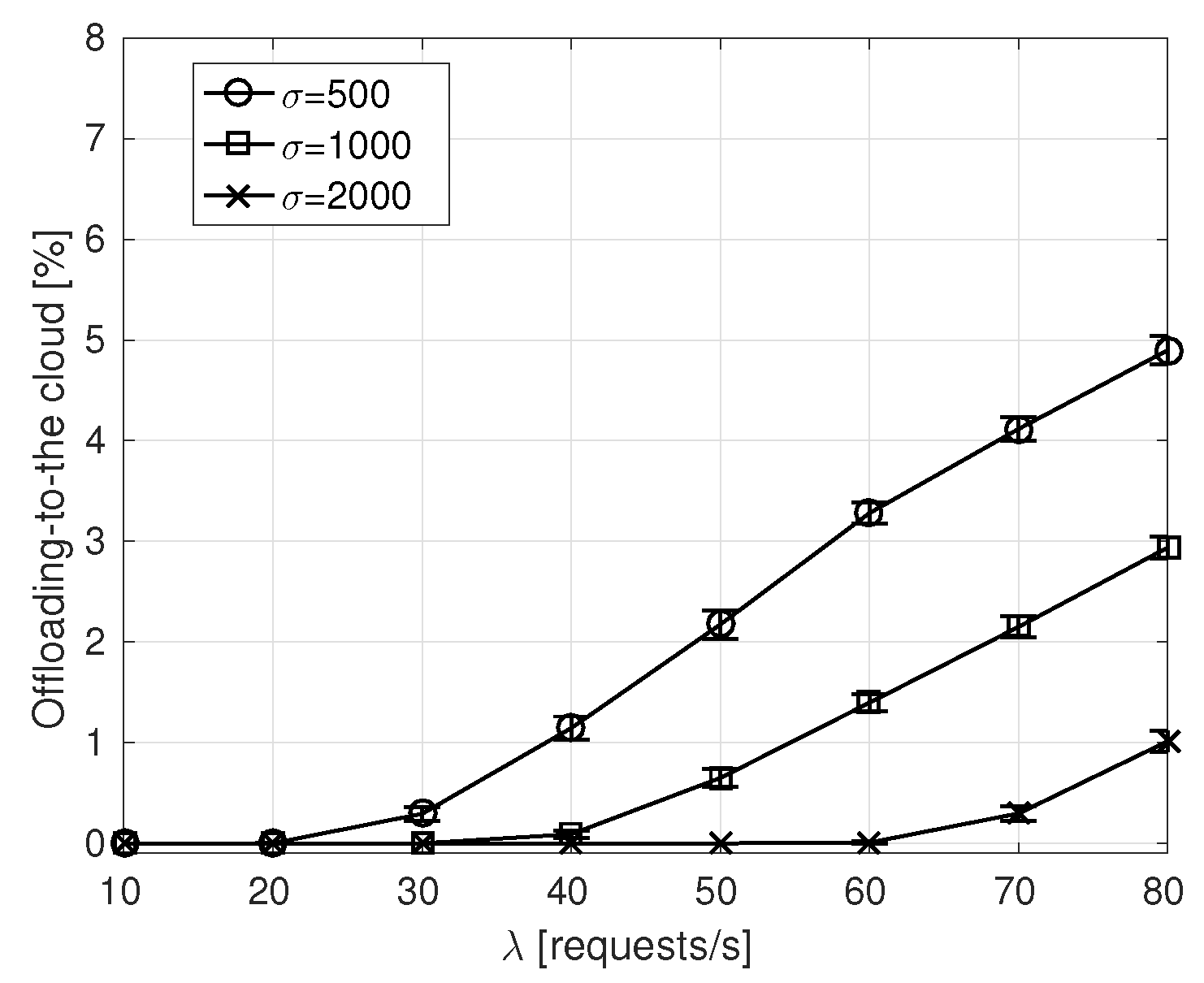
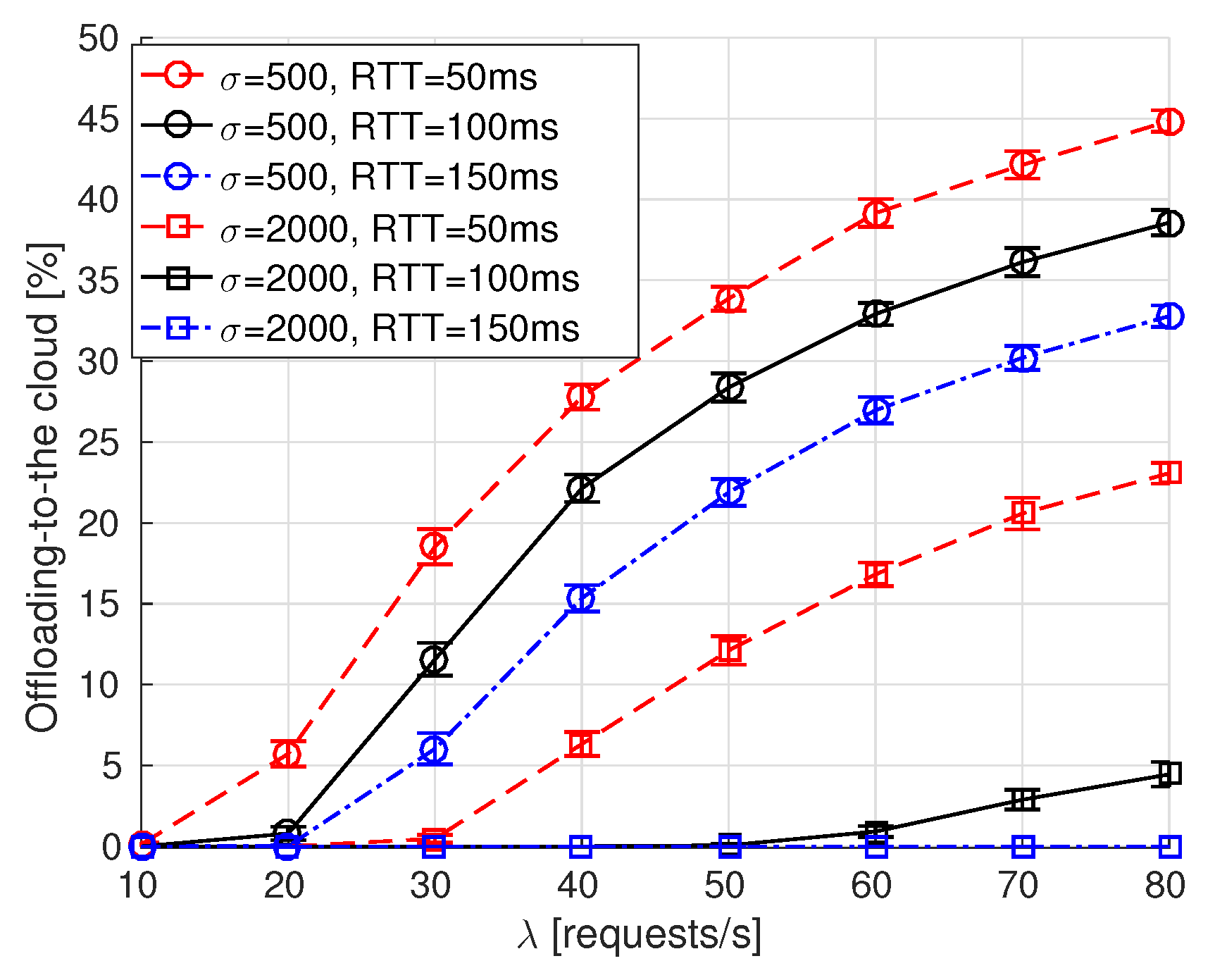
- Offloading-to-the-cloud percentage is derived as the percentage of times the service is executed in the remote cloud. It only applies to our proposal, labeled as NDN-fog.
- Intra-edge exchanged traffic is computed as the overall number of NDN packets exchanged into the domain to request a given service, to select the executor, to retrieve the input data to be processed, and to return the result to the consumer.
6.2. Simulation Results
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AppFace | Application Face |
| CS | Content Store |
| FIB | Forwarding Information Base |
| ICN | Information Centric Networking |
| IEC | International Electrotechnical Commission |
| IoT | Internet of Things |
| ISO | International Organization for Standardization |
| NetDeviceFace | Network Device Face |
| NCN | Named Computation Networking |
| NDN | Named Data Networking |
| NFN | Named Function Networking |
| PIT | Pending Interest Table |
| RIB | Routing Information Base |
| RTT | Round Trip Time |
| SCT | Strategy Choice Table |
| SDE | Service Decision Engine |
References
- Lee, I.; Lee, K. The Internet of Things (IoT): Applications, investments, and challenges for enterprises. Bus. Horizons 2015, 58, 431–440. [Google Scholar] [CrossRef]
- Cicirelli, F.; Guerrieri, A.; Spezzano, G.; Vinci, A.; Briante, O.; Iera, A.; Ruggeri, G. Edge computing and social internet of things for large-scale smart environments development. IEEE Internet Things J. 2017, 5, 2557–2571. [Google Scholar] [CrossRef]
- Chiang, M.; Zhang, T. Fog and IoT: An overview of research opportunities. IEEE Internet Things J. 2016, 3, 854–864. [Google Scholar] [CrossRef]
- OFC. Openfog Consortium. Available online: http://www.openfogconsortium.org/ (accessed on 30 September 2019).
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B. Named Data Networking. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Tschudin, C.; Sifalakis, M. Named functions and cached computations. In Proceedings of the 2014 IEEE 11th Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 10–13 Janary 2014. [Google Scholar]
- Amadeo, M.; Ruggeri, G.; Campolo, C.; Molinaro, A. IoT Services Allocation at the Edge via Named Data Networking: From Optimal Bounds to Practical Design. IEEE Trans. Netw. Serv. Manag. 2019, 16, 661–674. [Google Scholar] [CrossRef]
- Król, M.; Psaras, I. NFaaS: Named function as a service. In Proceedings of the 4th ACM Conference on Information-Centric Networking, Berlin, Germany, 26–28 September 2017. [Google Scholar]
- Ascigil, O.; Reñé, S.; Xylomenos, G.; Psaras, I.; Pavlou, G. A keyword-based ICN-IoT platform. In Proceedings of the 4th ACM Conference on Information-Centric Networking, Berlin, Germany, 26–28 September 2017. [Google Scholar]
- Scherb, C.; Grewe, D.; Wagner, M.; Tschudin, C. Resolution strategies for networking the IoT at the edge via named functions. In Proceedings of the 2018 15th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 12–15 January 2018. [Google Scholar]
- Mastorakis, S.; Afanasyev, A.; Moiseenko, I.; Zhang, L. ndnSIM 2.0: A New Version of the NDN Simulator for NS-3. Available online: https://www.researchgate.net/profile/Spyridon_Mastorakis/publication/281652451_ndnSIM_20_A_new_version_of_the_NDN_simulator_for_NS-3/links/5b196020a6fdcca67b63660d/ndnSIM-20-A-new-version-of-the-NDN-simulator-for-NS-3.pdf (accessed on 22 October 2019).
- Ahlgren, B.; Dannewitz, C.; Imbrenda, C.; Kutscher, D.; Ohlman, B. A Survey of Information-centric Networking. IEEE Commun. Mag. 2012, 50, 26–36. [Google Scholar] [CrossRef]
- Afanasyev, A.; Shi, J.; Zhang, B.; Zhang, L.; Moiseenko, I.; Yu, Y.; Shang, W.; Li, Y.; Mastorakis, S.; Huang, Y.; et al. NFD Developer’s Guide. Available online: https://named-data.net/wp-content/uploads/2016/03/ndn-0021-diff-5..6-nfd-developer-guide.pdf (accessed on 22 October 2019).
- Piro, G.; Amadeo, M.; Boggia, G.; Campolo, C.; Grieco, L.A.; Molinaro, A.; Ruggeri, G. Gazing into the crystal ball: When the future internet meets the mobile clouds. IEEE Trans. Cloud Comput. 2016, 7, 210–223. [Google Scholar] [CrossRef]
- Zhang, G.; Li, Y.; Lin, T. Caching in Information Centric Networking: A Survey. Comput. Netw. 2013, 57, 3128–3141. [Google Scholar] [CrossRef]
- Yi, C.; Afanasyev, A.; Moiseenko, I.; Wang, L.; Zhang, B.; Zhang, L. A case for stateful forwarding plane. Comput. Commun. 2013, 36, 779–791. [Google Scholar] [CrossRef]
- Shang, W.; Bannis, A.; Liang, T.; Wang, Z.; Yu, Y.; Afanasyev, A.; Thompson, J.; Burke, J.; Zhang, B.; Zhang, L. Named Data Networking of Things. In Proceedings of the IEEE First International Conference on Internet-of-Things Design and Implementation (IoTDI), Berlin, Germany, 4–8 April 2016. [Google Scholar]
- Baccelli, E.; Mehlis, C.; Hahm, O.; Schmidt, T.C.; Wählisch, M. Information centric networking in the IoT: Experiments with NDN in the wild. In Proceedings of the 1st ACM Conference on Information-Centric Networking, Paris, France, 24–26 September 2014. [Google Scholar]
- Amadeo, M.; Campolo, C.; Iera, A.; Molinaro, A. Information Centric Networking in IoT scenarios: The case of a smart home. In Proceedings of the IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015. [Google Scholar]
- Burke, J.; Gasti, P.; Nathan, N.; Tsudik, G. Securing instrumented environments over content-centric networking: The case of lighting control and NDN. In Proceedings of the 2013 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Turin, Italy, 14–19 April 2013. [Google Scholar]
- Amadeo, M.; Briante, O.; Campolo, C.; Molinaro, A.; Ruggeri, G. Information-centric networking for M2M communications: Design and deployment. Comput. Commun. 2016, 89, 105–116. [Google Scholar] [CrossRef]
- Tourani, R.; Misra, S.; Mick, T.; Panwar, G. Security, privacy, and access control in information-centric networking: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 566–600. [Google Scholar] [CrossRef]
- Shang, W.; Yu, Y.; Liang, T.; Zhang, B.; Zhang, L. Ndn-ace: Access Control for Constrained Environments over Named Data Networking. Available online: http://new.named-data.net/wp-content/uploads/2015/12/ndn-0036-1-ndn-ace.pdf (accessed on 22 October 2019).
- Zhang, Z.; Yu, Y.; Zhang, H.; Newberry, E.; Mastorakis, S.; Li, Y.; Afanasyev, A.; Zhang, L. An overview of security support in Named Data Networking. IEEE Commun. Mag. 2018, 56, 62–68. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 17 August 2012. [Google Scholar]
- Fog Computing and the Internet of Things: Extend the Cloud to Where the Things Are. Cisco White Paper. Available online: https://www.cisco.com/c/dam/en_us/solutions/trends/iot/docs/computing-overview.pdf (accessed on 22 October 2019).
- Aazam, M.; Zeadally, S.; Harras, K.A. Deploying fog computing in industrial internet of things and industry 4.0. IEEE Trans. Ind. Inform. 2018, 14, 4674–4682. [Google Scholar] [CrossRef]
- Hou, X.; Li, Y.; Chen, M.; Wu, D.; Jin, D.; Chen, S. Vehicular fog computing: A viewpoint of vehicles as the infrastructures. IEEE Trans. Veh. Tech. 2016, 65, 3860–3873. [Google Scholar] [CrossRef]
- Menon, V.G.; Prathap, J. Vehicular fog computing: challenges applications and future directions. In Fog Computing: Breakthroughs in Research and Practice; IGI Global: Hershey, PA, USA, 2018; pp. 220–229. [Google Scholar]
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Baktir, A.C.; Ozgovde, A.; Ersoy, C. How can edge computing benefit from software-defined networking: A survey, use cases, and future directions. IEEE Commun. Surv. Tutor. 2017, 19, 2359–2391. [Google Scholar] [CrossRef]
- Duan, Q.; Yan, Y.; Vasilakos, A.V. A survey on service-oriented network virtualization toward convergence of networking and cloud computing. IEEE Trans. Netw. Serv. Manag. 2012, 9, 373–392. [Google Scholar] [CrossRef]
- Gedeon, J.; Meurisch, C.; Bhat, D.; Stein, M.; Wang, L.; Mühlhäuser, M. Router-based brokering for surrogate discovery in edge computing. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), Atlanta, GA, USA, 5–8 June 2017. [Google Scholar]
- Mtibaa, A.; Tourani, R.; Misra, S.; Burke, J.; Zhang, L. Towards Edge Computing over Named Data Networking. In Proceedings of the 2018 IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018. [Google Scholar]
- Amadeo, M.; Campolo, C.; Molinaro, A. NDNe: Enhancing Named Data Networking to Support Cloudification at the Edge. IEEE Commun. Lett. 2016, 20, 2264–2267. [Google Scholar] [CrossRef]
- Amadeo, M.; Campolo, C.; Molinaro, A.; Ruggeri, G. IoT data processing at the edge with Named Data Networking. In Proceedings of the 24th European Wireless Conference, Catania, Italy, 2–4 May 2018. [Google Scholar]
- Król, M.; Habak, K.; Oran, D.; Kutscher, D.; Psaras, I. Rice: Remote method invocation in icn. In Proceedings of the 5th ACM Conference on Information-Centric Networking, Boston, MA, USA, 21–23 September 2018. [Google Scholar]
- Krol, M.; Marxer, C.; Grewe, D.; Psaras, I.; Tschudin, C. Open security issues for edge named function environments. IEEE Commun. Mag. 2018, 56, 69–75. [Google Scholar] [CrossRef]
- Marxer, C.; Scherb, C.; Tschudin, C. Access-controlled in-network processing of named data. In Proceedings of the 3rd ACM Conference on Information-Centric Networking, Kyoto, Japan, 26–28 September 2016. [Google Scholar]
- Scherb, C.; Marxer, C.; Schnurrenberger, U.; Tschudin, C. In-network live stream processing with named functions. In Proceedings of the IFIP Networking Conference and Workshops, Stockholm, Sweden, 12–16 June 2017. [Google Scholar]
- Liu, C.; Loo, B.T.; Mao, Y. Declarative automated cloud resource orchestration. In Proceedings of the 2nd ACM Symposium on Cloud Computing, Cascais, Portugal, 26–28 October 2011; p. 26. [Google Scholar]
- Wang, Q.; Lee, B.; Murray, N.; Qiao, Y. CS-Man: Computation service management for IoT in-network processing. In Proceedings of the 2016 27th Irish Signals and Systems Conference (ISSC), London, UK, 21–22 June 2016. [Google Scholar]
- Wang, Q.; Lee, B.; Murray, N.; Qiao, Y. IProIoT: An in-network processing framework for IoT using Information Centric Networking. In Proceedings of the 2017 Ninth International Conference on Ubiquitous and Future Networks (ICUFN), Milan, Italy, 4–7 July 2017. [Google Scholar]
- Amadeo, M.; Molinaro, A.; Paratore, S.Y.; Altomare, A.; Giordano, A.; Mastroianni, C. A Cloud of Things framework for smart home services based on Information Centric Networking. In Proceedings of the IEEE 14th International Conference on Networking, Sensing and Control (ICNSC), Calabria, Italy, 16–18 May 2017. [Google Scholar]
- Amadeo, M.; Giordano, A.; Mastroianni, C.; Molinaro, A. On the integration of information centric networking and fog computing for smart home services. In The Internet of Things for Smart Urban Ecosystems; Springer: Cham, Switzerland, 2019; pp. 75–93. [Google Scholar]
- Scherb, C.; Tschudin, C. Smart Execution Strategy Selection for Multi Tier Execution in Named Function Networking. In Proceedings of the 2018 IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Hoque, A.; Amin, S.O.; Alyyan, A.; Zhang, B.; Zhang, L.; Wang, L. NLSR: Named-data link state routing protocol. In Proceedings of the ACM SIGCOMM Workshop on Information-Centric Networking, Hong Kong, China, 12 August 2013; pp. 15–20. [Google Scholar]
- ISO/IEC. 11801-2:2017 Information Technology—Generic Cabling for Customer Premises. 2017. Available online: https://www.iso.org/standard/66183.html (accessed on 22 October 2019).
- Elbamby, M.S.; Bennis, M.; Saad, W. Proactive edge computing in latency-constrained fog networks. In Proceedings of the 2017 European conference on networks and communications (EuCNC), Oulu, Finland, 12–15 June 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mechanism | Type | Short description |
|---|---|---|
| NFN FoX [6] | Distributed | First, it tries to find a cached result on the path towards the data source. In case of failure, the computation is performed as close as possible to the data source or it is pushed into a node/server off-path. |
| NFN EdgeFox [10] | Distributed | Customizes FoX for edge domains, where nodes advertise the availability of the functions they provide, and they are queried for the result. |
| NFN FaX [10] | Distributed | The computation is started in the first available edge node, and it is stopped if a cached result is found in the meanwhile. |
| IoT-NCN [7] | Distributed | The cost of IoT service execution is computed by on-path nodes, according to a weighted function that takes as input the closeness cost and the processing cost. The node with the lowest cost is selected as the executor. |
| NDN edge computing [34] | Distributed | The less congested node is selected as the executor. |
| CS-Man [42,43] | Centralized | A service manager is in charge of identifying the executors of IoT services according to their capabilities. |
| ICN-isapiens [44,45] | Centralized | A software component called deployer is in charge of loading the IoT services in specific fog nodes depending on the physical IoT devices they control. |
| Parameter | Value |
|---|---|
| Number of services | 1000 |
| Zipf’s parameter | 0.4, 0.8 |
| Request arrival rate () | Varying (10–80 requests/s) |
| CPU requests of services | Uniformly distributed in [25, 750] Mcycles |
| Edge link latency | [5, 10] ms |
| RTT to the cloud | 50 ms, 100 ms, 150 ms |
| CPU node capabilities | [250–1500] MHz |
| Content size () | [500, 1000, 2000] 1024 large packets |
| Content size | NDN-fog | Cloud | CE | LLE | ||||
|---|---|---|---|---|---|---|---|---|
| = 0.4 | = 0.8 | = 0.4 | = 0.8 | = 0.4 | = 0.8 | = 0.4 | = 0.8 | |
| 500 packets | 2012 | 1567.4 | 1945 | 1497.5 | 496.4 | 384.54 | 2018 | 1517.4 |
| 1000 packets | 3572 | 2787.1 | 3884 | 2990.7 | 981.3 | 757.85 | 4024 | 3019.6 |
| 2000 packets | 6759 | 5132.6 | 7764 | 5977.2 | 1951 | 1504.5 | 8053 | 6043 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amadeo, M.; Ruggeri, G.; Campolo, C.; Molinaro, A.; Loscrí, V.; Calafate, C.T. Fog Computing in IoT Smart Environments via Named Data Networking: A Study on Service Orchestration Mechanisms. Future Internet 2019, 11, 222. https://doi.org/10.3390/fi11110222
Amadeo M, Ruggeri G, Campolo C, Molinaro A, Loscrí V, Calafate CT. Fog Computing in IoT Smart Environments via Named Data Networking: A Study on Service Orchestration Mechanisms. Future Internet. 2019; 11(11):222. https://doi.org/10.3390/fi11110222
Chicago/Turabian StyleAmadeo, Marica, Giuseppe Ruggeri, Claudia Campolo, Antonella Molinaro, Valeria Loscrí, and Carlos T. Calafate. 2019. "Fog Computing in IoT Smart Environments via Named Data Networking: A Study on Service Orchestration Mechanisms" Future Internet 11, no. 11: 222. https://doi.org/10.3390/fi11110222
APA StyleAmadeo, M., Ruggeri, G., Campolo, C., Molinaro, A., Loscrí, V., & Calafate, C. T. (2019). Fog Computing in IoT Smart Environments via Named Data Networking: A Study on Service Orchestration Mechanisms. Future Internet, 11(11), 222. https://doi.org/10.3390/fi11110222