A Fast and Lightweight Method with Feature Fusion and Multi-Context for Face Detection

Abstract
1. Introduction
2. Related Works
2.1. Face Detection
2.2. Multi-Scale Features and Context
2.3. Context Adding Approaches
3. Methods
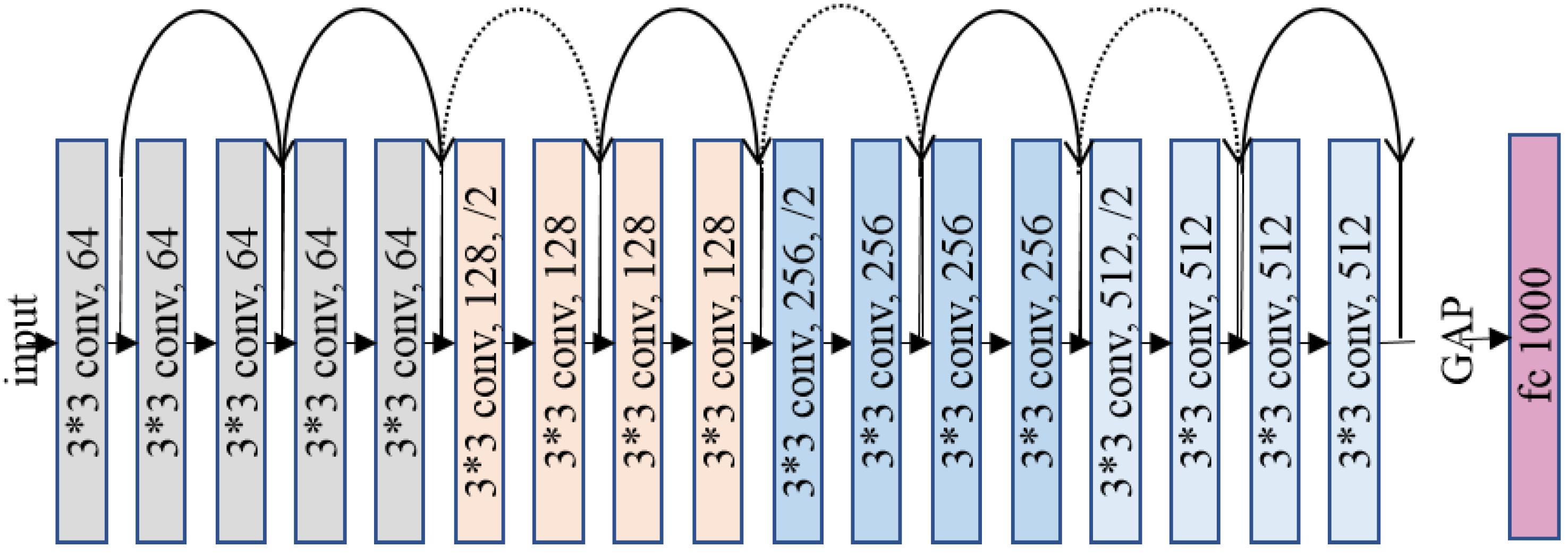
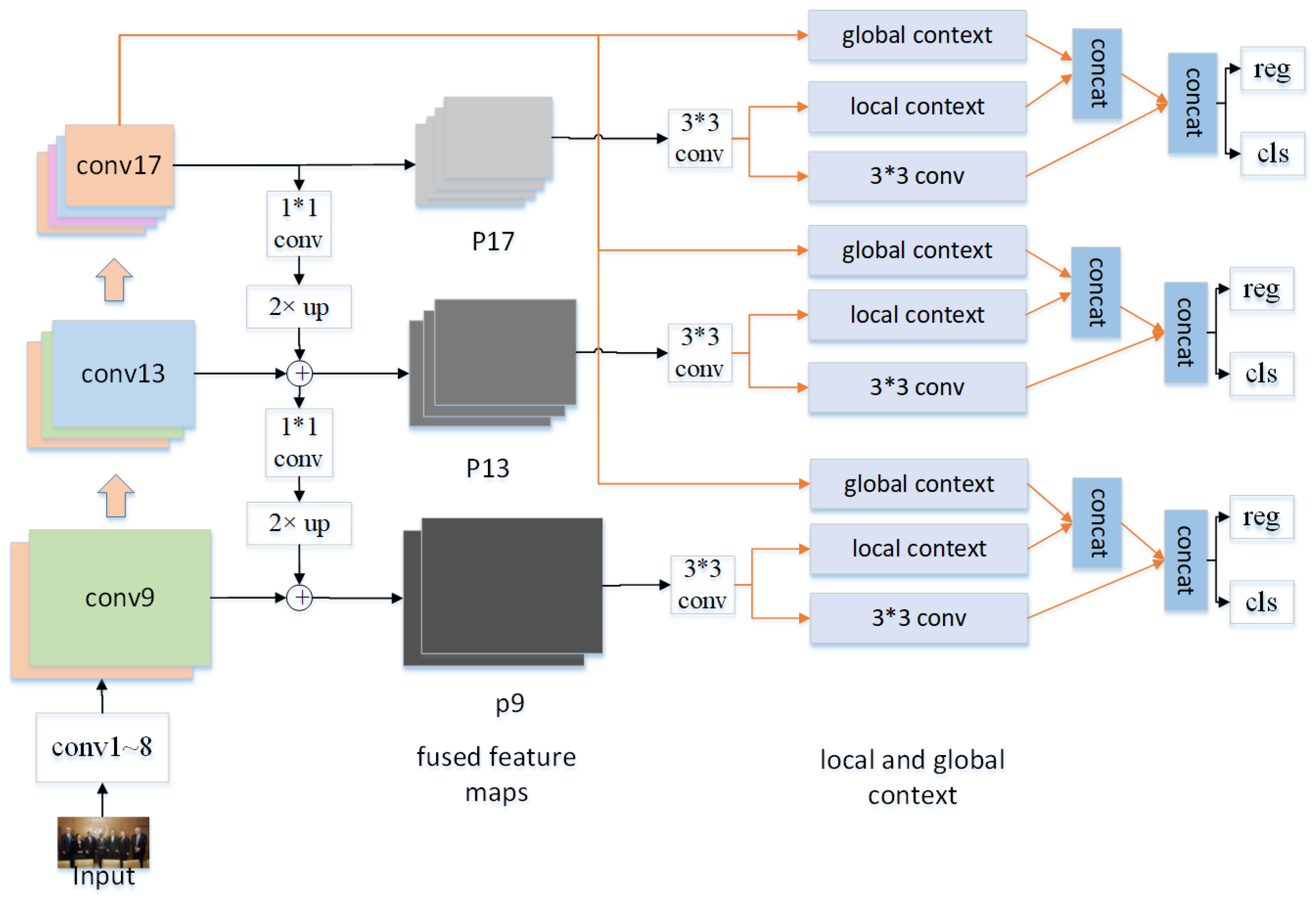
3.1. Architecture
3.1.1. Multi-Scale Features
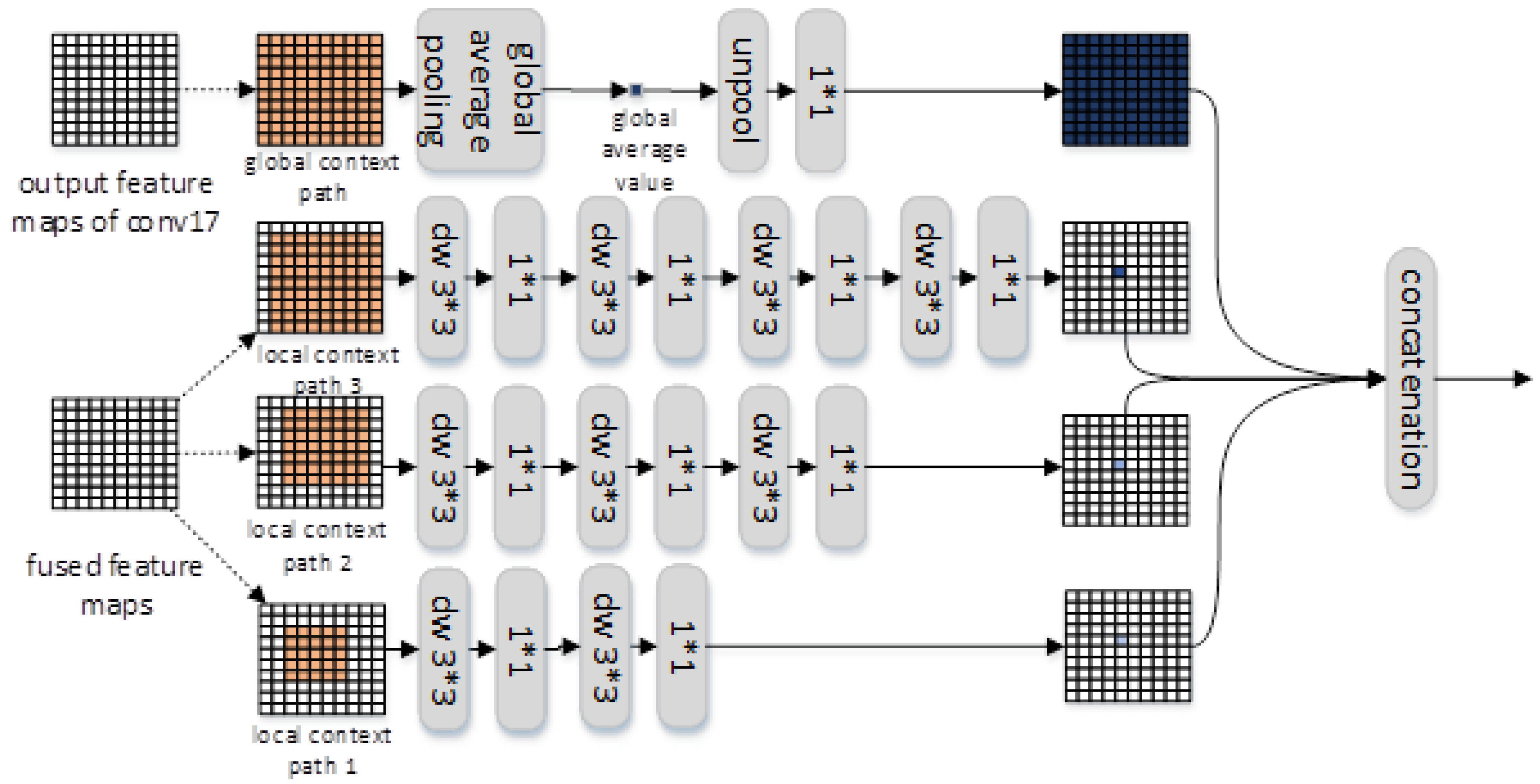
3.1.2. Local Context Gathering by Depthwise Separable Convolution
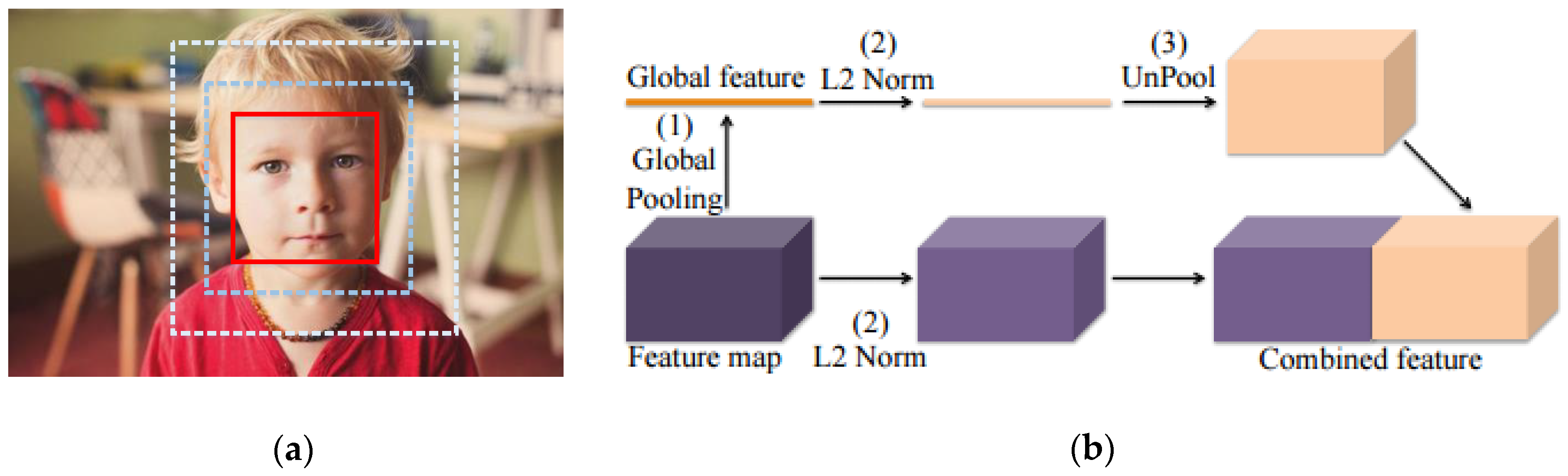
3.1.3. Global Context Gathering by Global Average Pooling
3.2. RPN-Like Approach to Predict Faces
3.3. Loss Function
4. Experiments
4.1. Experimental Setup
4.2. Results on WIDER FACE
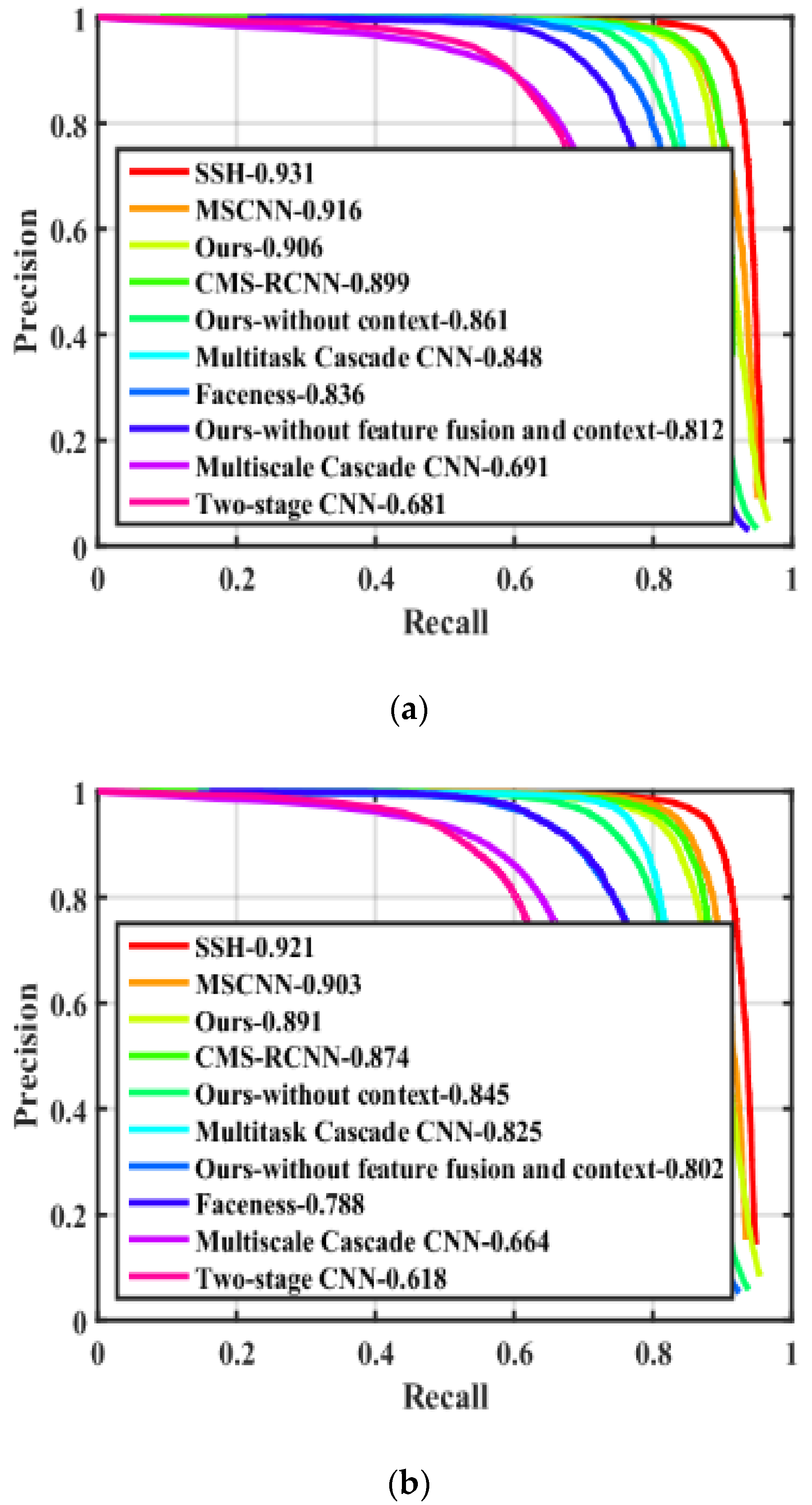
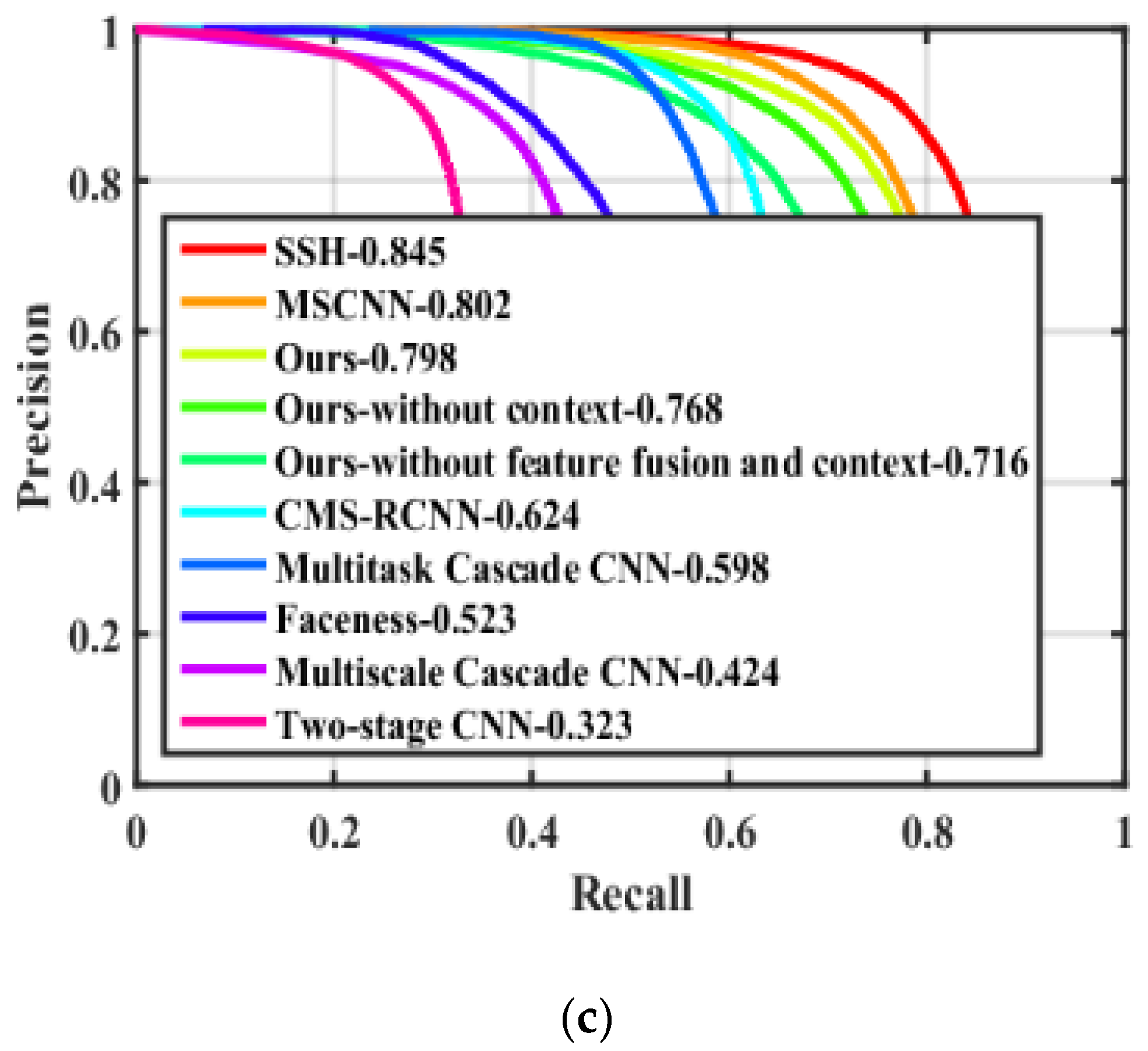
4.2.1. Comparison with the State-of-the-Art Face Detection Methods
4.2.2. The Effectiveness of Our Multi-Scale Features and Multi-Context Design
4.2.3. Computational Complexity
4.2.4. Comparison of Inference Speed
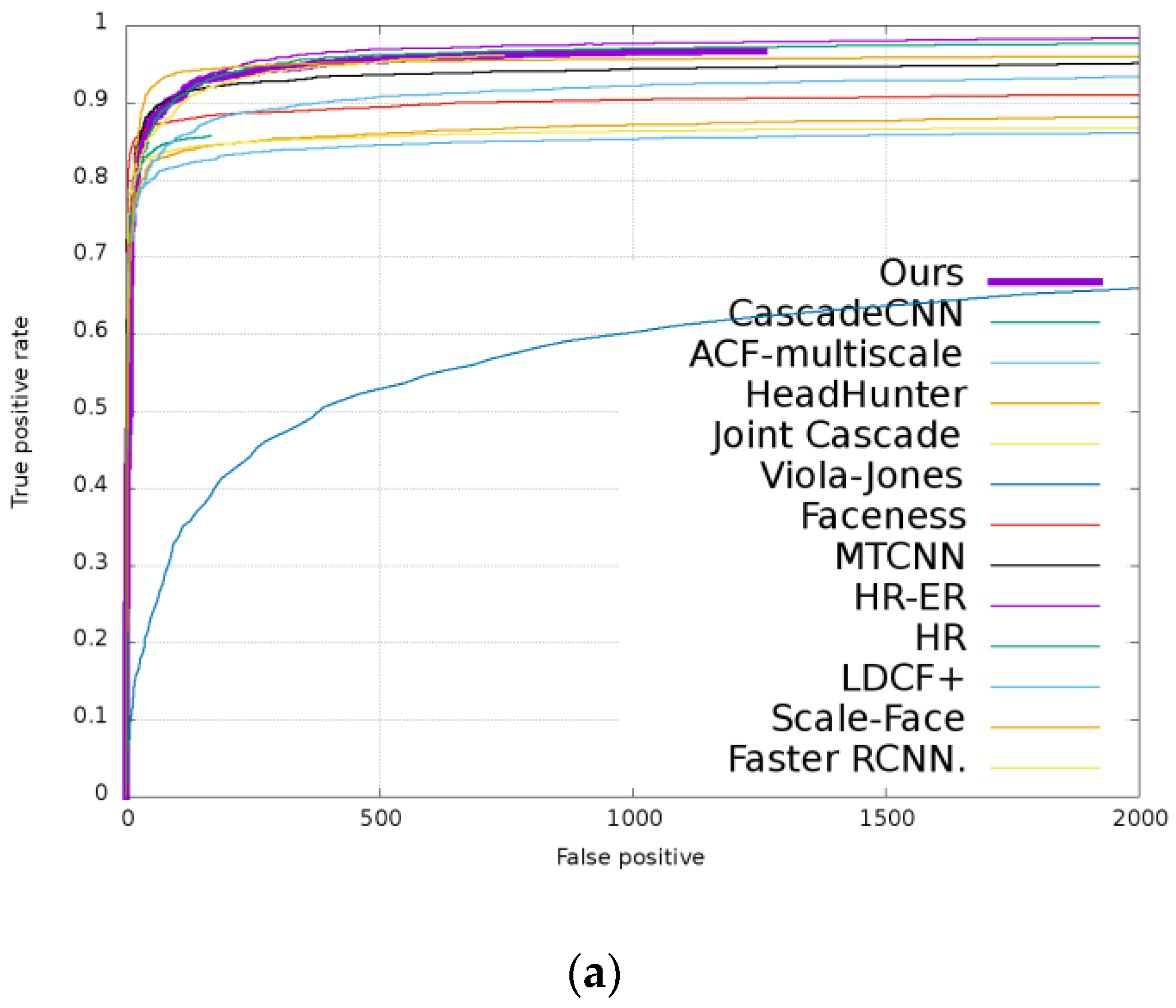
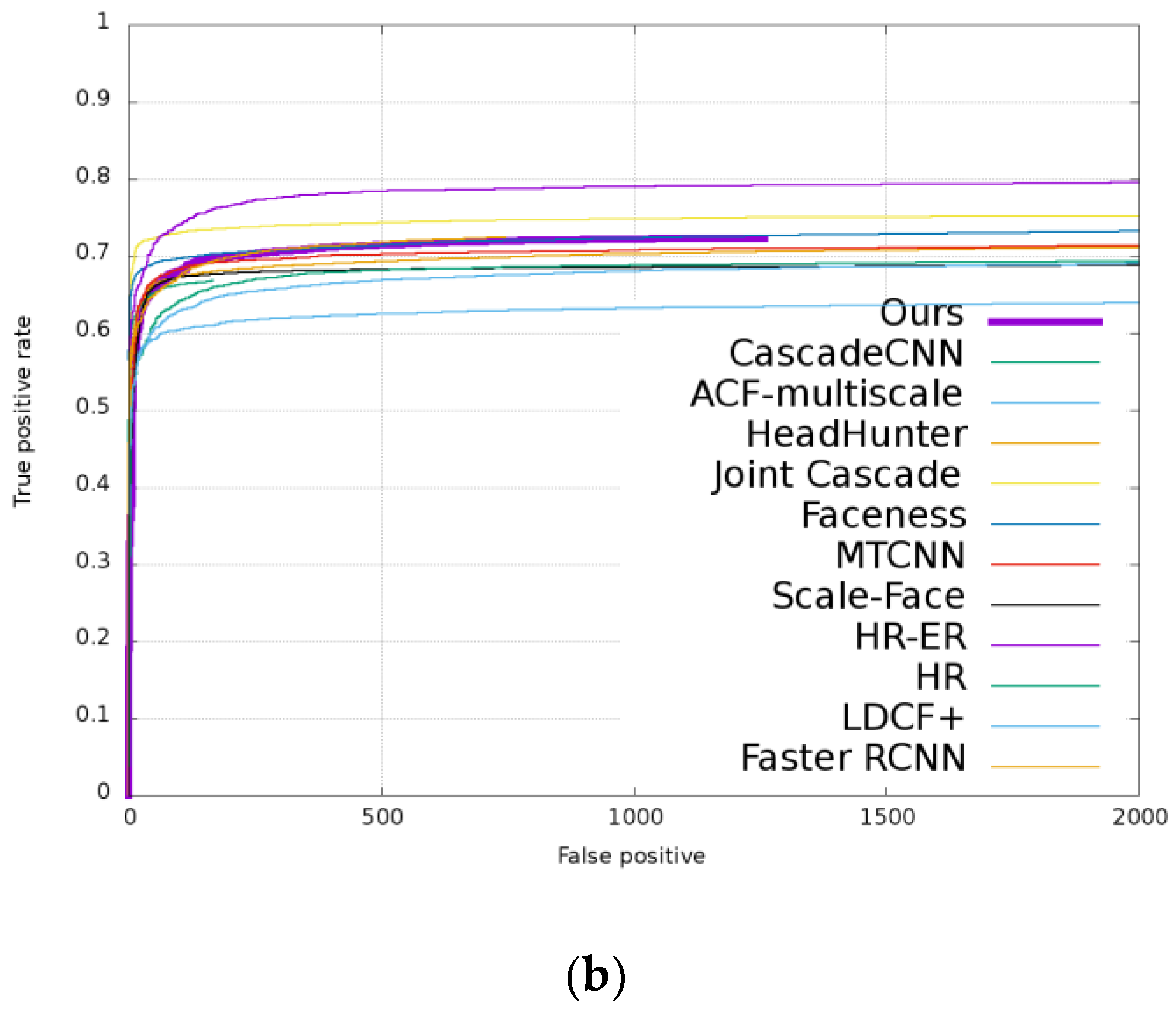
4.3. Evaluation Results on FDDB
4.4. Inference Time on Different Resolutions
4.5. Qualitative Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, D.; Ren, S.; Wei, Y.; Cao, X.; Sun, J. Joint cascade face detection and alignment. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 109–122. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S3fd: Single shot scale invariant face detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 192–201. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1522–1530. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv, 2016; arXiv:1512.03385. [Google Scholar]
- Pang, Y.; Ye, L.; Li, X.; Pan, J. Incremental Learning with Saliency Map for Moving Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 640–651. [Google Scholar] [CrossRef]
- Chen, B.-H.; Shi, L.-F.; Ke, X. A Robust Moving Object Detection in Multi-Scenario Big Data for Video Surveillance. IEEE Trans. Circuits Syst. Video Technol. 2018. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. arXiv, 2017; arXiv:1612.08242. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Zagoruyko, S.; Lerer, A.; Lin, T.-Y.; Pinheiro, P.O.; Gross, S.; Chintala, S.; Dollar, P. A multipath network for object detection. arXiv, 2016; arXiv:1604.02135. [Google Scholar]
- Zhu, C.; Zheng, Y.; Luu, K.; Savvides, M. CMS-RCNN: Contextual multi-scale region-based CNN for unconstrained face detection. arXiv, 2017; 57–79arXiv:1606.05413. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv, 2017; arXiv:1704.04861. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; IEEE Computer Society: Washington, DC, USA, 2015; pp. 91–99. [Google Scholar]
- Zhu, Q.; Yeh, M.C.; Cheng, K.T.; Avidan, S. Fast human detection using a cascade of histograms of oriented gradients. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1491–1498. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; p. 1. [Google Scholar]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J.; Hua, G. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5325–5334. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.-C.; Tang, X. From facial parts responses to face detection: A deep learning approach. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3676–3684. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. SSH: Single stage headless face detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4875–4884. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; p. 4. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking wider to see better. arXiv, 2015; arXiv:1506.04579. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Pinheiro, P.O.; Lin, T.-Y.; Collobert, R.; Dollar, P. Learning to refine object segments. arXiv, 2016; arXiv:1603.08695. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.-C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Jain, V.; Learned-Miller, E.G. FDDB: A Benchmark for Face Detection in Unconstrained Settings; UMass Amherst Technical Report; University of Massachusetts: Amherst, MA, USA, 2010. [Google Scholar]
- Triantafyllidou, D.; Nousi, P.; Tefas, A. Fast deep convolutional face detection in the wild exploiting hard sample mining. Big Data Res. 2018, 11, 65–76. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multi-task cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Sun, X.; Wu, P.; Hoi, S.C. Face detection using deep learning: An improved faster RCNN approach. Neurocomputing 2018, 299, 42–50. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Inference Time (ms) | AP (Easy) | AP (Medium) | AP (Hard) |
|---|---|---|---|---|
| Two-stage CNN [20] | 10 | 68.1 | 61.8 | 32.3 |
| Multiscale Cascade CNN [25] | - | 69.1 | 66.4 | 42.4 |
| Faceness [21] | 50 | 71.3 | 78.8 | 34.5 |
| FD-CNN [30] | 30 | 77.4 | 74.0 | 51.0 |
| Multitask cascade CNN [32] | 10 | 84.8 | 82.5 | 59.8 |
| CMS-RCNN [15]-VGG-16 | - | 89.9 | 87.4 | 62.4 |
| MSCNN [31]-VGG-16 | 25 | 91.6 | 90.3 | 80.2 |
| SSH [22]-VGG-16 | 30 | 93.1 | 92.1 | 84.5 |
| Ours-without feature fusion and context | 6 | 81.2 | 80.2 | 71.6 |
| Ours-without context | 7 | 86.1 | 84.5 | 76.8 |
| Ours | 9 | 90.6 | 89.1 | 79.8 |
| Image Size | Time | Fps |
|---|---|---|
| 288 × 288 | 3.3 ms | 303 |
| 416 × 416 | 5.7 ms | 150 |
| 800 × 1200 | 25.4 ms | 40 |
| 1200 × 1600 | 41.93 ms | 24 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Zhi, X. A Fast and Lightweight Method with Feature Fusion and Multi-Context for Face Detection. Future Internet 2018, 10, 80. https://doi.org/10.3390/fi10080080
Zhang L, Zhi X. A Fast and Lightweight Method with Feature Fusion and Multi-Context for Face Detection. Future Internet. 2018; 10(8):80. https://doi.org/10.3390/fi10080080
Chicago/Turabian StyleZhang, Lei, and Xiaoli Zhi. 2018. "A Fast and Lightweight Method with Feature Fusion and Multi-Context for Face Detection" Future Internet 10, no. 8: 80. https://doi.org/10.3390/fi10080080
APA StyleZhang, L., & Zhi, X. (2018). A Fast and Lightweight Method with Feature Fusion and Multi-Context for Face Detection. Future Internet, 10(8), 80. https://doi.org/10.3390/fi10080080