1. Introduction
Opportunistic network (OppNet) [
1,
2] is a delay-tolerant Ad-hoc network, where the source node communicates with the destination without a complete communication route between them. Therefore, the message application uses the “opportunities” created by the movement of nodes to implement the end-to-end data transmission. In the background of big data and 5G networks, traditional face-to-face transmission methods are difficult to meet the communication requirements of large data volume, which implies it is vital for message carriers to select the proper relay nodes to forward messages. In recent years, with the rapid development of novel wireless devices, such as mobile phones, smart watches, Bluetooth earphones or other wearable sensor devices, the message applications in opportunistic social networks [
3,
4] may obtain more opportunities to communicate with each other. Moreover, the hot issues of opportunistic networks include routing algorithms [
5,
6,
7], mobile models [
8,
9], security and cooperation [
1,
10], and applications [
11,
12].
In [
8], an experiment, which anonymously tracked the movements of 700 mobile phone users in a special gathering of Boston metropolitan, shows that the delay-tolerance model is able to perform the effective emergency communication in an important subset of nodes, although the connectivity of the network is strictly dependent on the cooperation of mobile devices and the maximum permissible delay. Moreover, the experimentation on the mobile model also proves that the end-to-end connectivity in opportunistic networks can be implemented by node mobility and the store-carry-forward strategy: nodes carrying data packets use the encounter opportunities created by mobile to forward messages to the relay or destination nodes. However, destination addresses are not always available by the message applications, and this may be a big problem in the data transmission process. In particular, most traditional routing algorithms are more likely to adopt the specific addresses of nodes to implement the messages’ delivery decisions; it is difficult for them to overcome this strong limitation. Consequently, Profile-based network models [
13,
14] for OppNet proposed that the destination of a message can be multiple nodes or a group of nodes defined by their profiles. These profiles characterize nodes by the method of analyzing and comparing their attributes, such as physical characteristics, places of residence, workplaces or hobbies. In the profile-based network model, messages will be sent to the nodes which belong to a destination profile defined by certain attributes instead of network addresses.
Apparently, it is a complex task for the message model to obtain the attribute characteristics of nodes or the state of the network, because the complete connectivity never exists in OppNet. On the one hand, obtaining the state of the network through the broadcasting method is efficient, but it is a huge waste of storage space and computing resources. On the other hand, using the single message to study the attribute characteristics of nodes, which may raise another problem of how to choose an optimal moment between network routing and message forwarding. Fortunately, the optimal stopping theory [
15] provides a strategy to select an optimal phase to stop studying the state of the network. Consequently, in the process of exploring the state of the network, messages are able to establish enough and accurate statistics about the attribute characteristics of nodes in the network, and the nodes can make precise message delivery decisions in the next phase.
However, in the proposed algorithms for opportunistic networks, the node profile defined by their attributes is rarely taken into consideration. Moreover, there is no effective strategy to identify the node profile. In other words, there are two urgent problems in opportunistic networks: how to compare the attribute characteristics of nodes and how to find the destination profile through the gathered statistics. For instance, the after-school counseling agencies need to send an advertisement to the college student with poor grades, but there is no effective method for message applications to find these students. Therefore, the message applications need a special delivery function to compare the attribute values of nodes and to optimize the data transmission process. In addition, when getting adequate information about the attribute characteristics of nodes, the message carrier begins to make the appropriate transmission decisions for messages. However, how to efficiently use the collected statistics to forward messages to the destination profile is another new issue.
To solve the above problems, we propose the Predict and Forward algorithm, which is an efficient routing-delivery scheme based on node profile in opportunistic networks. According to the optimal stopping theory, this strategy consists of two phases: studying the state of the network and making the message delivery decisions. Moreover, we propose a new message model, Prelearn, which allows messages to be sent to a destination profile identified by their attribute characteristics. We also present a specific message delivery function, which is used to compare the attribute characteristics of nodes and to find the destination profile. Meanwhile, we propose a probability prediction matrix based on the historical encounter information of nodes, which contains the probabilities of the future meeting between nodes. The message carrier in the network employs the information carried by the probability prediction matrix to select the appropriate relay node as the next hop. In conclusion, the Predict and Forward scheme is a novel routing-delivery scheme, which implements the optimal transmission for Prelearn messages through the node profile and a probability prediction matrix. The contributions of this paper are listed as follows:
By defining a special message delivery function, the message applications implement end-to-end data communication based on node profile instead of specific network addresses. The state of the network and the attribute characteristics of nodes can be easily obtained by Prelearn message, and the destination profile can be found by the message delivery function.
According to the strategy of updating and predicting the probability of the future meeting between nodes, we establish the relationship between historical information and future encounters. The source node can select the suitable relay nodes through the information of the future meeting, and the efficient and sustainable data transmission occurs.
To avoid missing the optimal transition moment, the optimal stopping theory provides a way to select the best transition moment between studying the state of the network and making the message delivery decisions. Therefore, the method of exploring the network with a single message, can not only provide enough information about the state of the network but also optimize the data transmission process.
According to the simulation results on Opportunistic Networking Environment (ONE), the Predict and Forward routing algorithm shows enhanced performances in increasing the delivery ratio and reducing the delay of end-to-end data transmission.
3. Predict and Forward Scheme Based on Node Profile
At present, traditional routing algorithms of opportunistic networks select suitable relay nodes from the surrounding neighbors through their network addresses instead of a specific profile that is defined by node attributes. When the destination address is not available by message carriers, the Profile-based network model provides an effective method to identify the destination node by evaluating the attribute characteristics of nodes. Consequently, we propose Prelearn, a new profile-based message model for opportunistic networks, and Predict and Forward, an efficient routing-delivery algorithm for Prelearn messages. The proposed scheme consists of two phases: studying the state of the network to find the destination profile by collecting and comparing the attribute characteristics of nodes, and making delivery decisions for Prelearn messages through the collected statistics.
As shown in
Figure 1, different users in a social scenario contain different node attributes and belong to different node profiles, which are identified by different attribute characteristics of nodes. If a source user needs to send an advertisement to the lightest user in the network, the Prelearn message collects the attribute characteristics of users, and finally, it will be sent to the users that belong to the destination profile with the minimum value of the weight attribute. In the transmission process, the message delivery function is applied to find the destination profile, the Prelearn message model is used to carry and transport information, and the node in the network can handle computing tasks. Certainly, the detailed process for data transmission will be described in the following sections. Moreover, in order to improve the understanding of the Predict and Forward scheme, we give the following important definitions strictly.
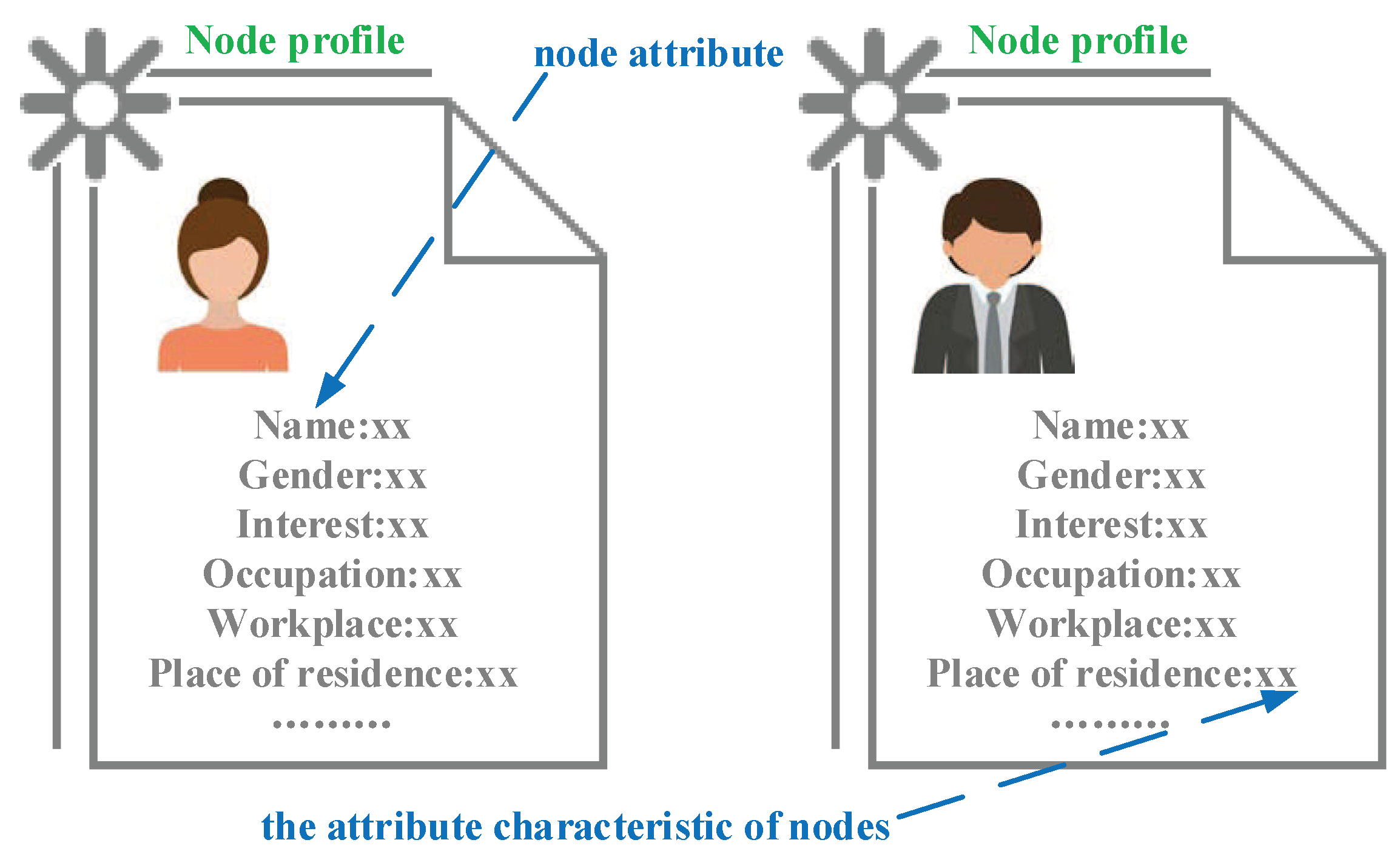
Definition 1 (node attributes).
The node attributes represent the social attributes of the users in an OppNet, such as their physical characteristics, places of residence, workplaces or hobbies.
Definition 2 (the attribute characteristics of nodes).
The attribute characteristics of nodes represent the attribute values of nodes in the networks, for example, the interest attribute includes the attribute characteristics of nodes (or the attribute values of nodes): movie, sport, music or reading.
Definition 3 (message delivery function).
Defined by the source node, this is a special function that is used to evaluate and compare the attribute characteristics of nodes, and to find the destination profile that meets the requirements of the source node.
Definition 4 (destination profile).
The destination profile is multiple nodes or a group of nodes. The attribute characteristics of nodes belonging to the destination profile, satisfy the message delivery function. Actually, the destination profile is a set of destinations, such as the blue eye profile; this means a set of users with blue eyes.
Definition 5 (the optimal candidate).
The optimal candidate is a node that plays an important role in the data transmission process, such as the destination node or a node that frequently encounters the destination.
3.1. Prelearn Message: Definition and Application
Opportunistic network belongs to multi-hop wireless network, where the source node communicates with the destination in the poor network state of high latency, low delivery ratio and intermittent connection. Destination addresses are not always available by the message applications in OppNet. In order to overcome this strong limitation, the profile-based network model proposed that data transmission is based on node attributes instead of destination addresses, which may emerge as another problem in the data transmission process: there is no efficient delivery strategy to characterize nodes based on their attribute characteristics. Therefore, we proposed Prelearn, a novel model that allows messages to be sent to the destination profile identified by node attributes, such as their physical characteristics, places of residence, workplaces or hobbies.
In order to find the nodes belonging to the destination profile, we firstly define S as the set of all nodes in an OppNet. Therefore, the set of all nodes
S can be shown as
where the label
n represents the number of nodes in the networks. Similarly, we define the destination profile
R as a set of the destination users, and the destination profile
R can be shown as
where the nodes
,
,
belonging to the destination profile
R, are a group of the destination users. Obviously, the destination profile
R is a subset of
S, so
. For a given attribute certification
defined by the source node,
,
,
are different attribute requirements for the destination profile. Consequently, the message delivery function
is a mathematical mapping from the set
S to the destination profile
R, and it can be shown as
For different application scenarios in opportunistic networks, various message applications may have different attribute requirements for the destination profile. Therefore, the optimal transmission process is achieved by defining different message delivery functions, such as maximum, minimum or the local optimum. Moreover, for a source node , a message delivery function , a probability prediction matrix that contains the probability of the future meeting between nodes in the network, and the data packets , we rigorously define the Prelearn message as L(,, , ), where the probability prediction matrix will be detailed in the following sections.
3.2. Predict Phase: Studying the State of the Network
During the Predict phase, Prelearn messages route from a node to another to study their attribute characteristics in the network, but the data packets are not forwarded to the nodes. Meanwhile, Prelearn message constantly builds enough and accurate statistics about the attribute characteristics of nodes. Whenever a new node is routed by Prelearn message, the statistics carried by Prelearn message are updated once in the Predict phase. Certainly, there are several different ways for a Prelearn message to build and update the statistics about the network.
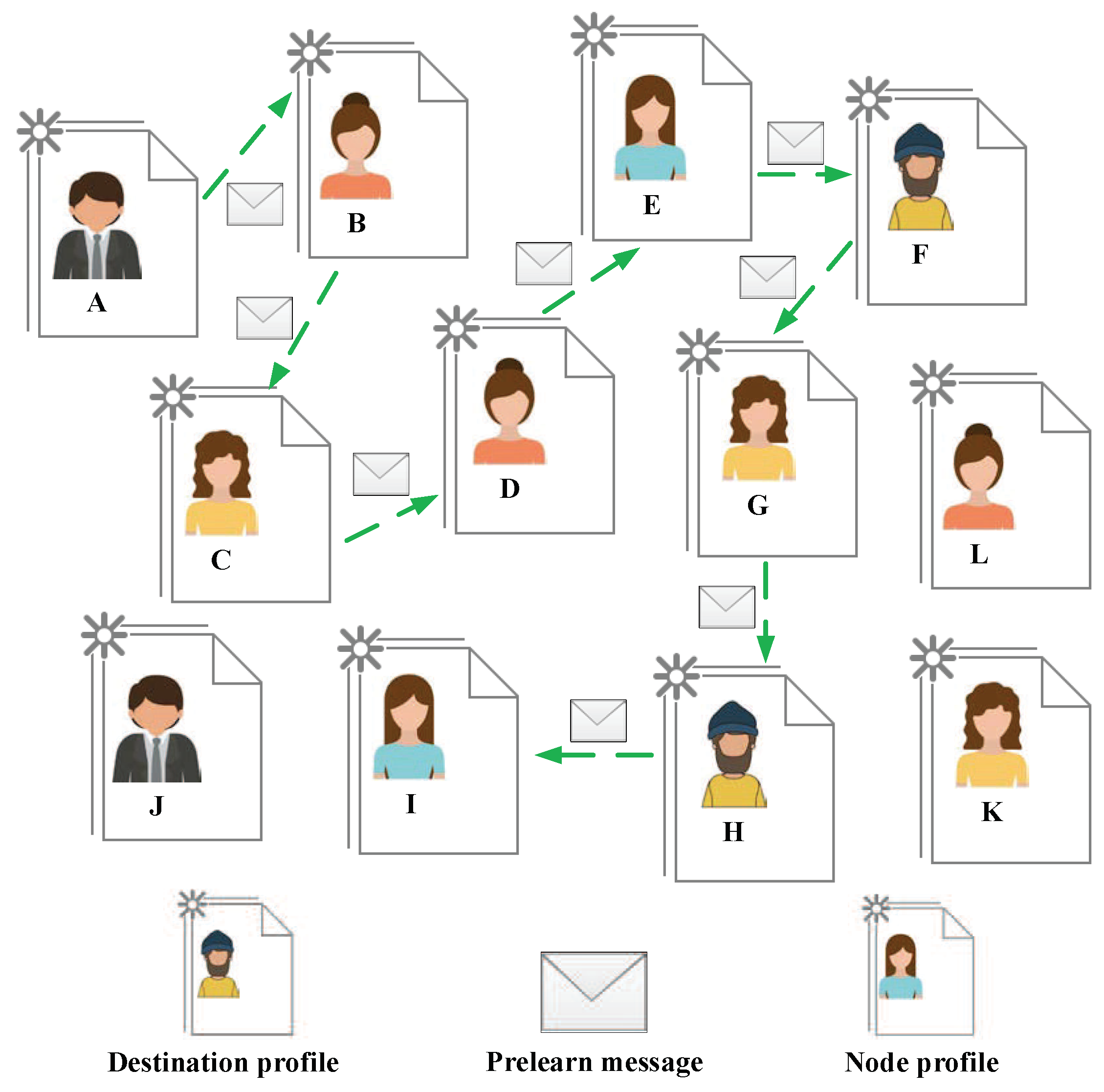
Figure 2 gives an example for the routing process in Predict phase. During this phase, the source
sends a Prelearn message to study the state of the network. The Prelearn message routes from
to
in the network, finds the nodes belonging to the destination profile, and collects and updates the historical encounter information between nodes. Moreover, each node in the network adopts the information carried by Prelearn message to predict the probability of future encounters with other nodes.
3.2.1. Prelearn Message Collects and Updates the Statistics about the State of the Network
For many years, the researchers have argued that the mobility of wireless devices is unpredictable in the network. However, in the literature [
9], an experiment, which focuses on exploring the human mobility in a real-word scene, shows that the distributions of both contact and inter-contact times in the network presents a power law distribution. According to the theory of the experiment, the movement of delay tolerant network (DTN) nodes may be based on the predictable mobility models. If a node encounters another node frequently, they are more likely to meet each other in the future. Therefore, we adopt the
function to convert the average number of historical encounters between nodes into the probability of the future meeting between them. Firstly, we define a routing metric
, which represents the number of encounters between
and
in the past period of time
t. Moreover, the forwarding metric (the possibility of the future meeting) between
and
can be defined as
where
represents the average number of encounters between between
and
during the previous period of time
t. After the Prelearn message obtains the attribute characteristics of a certain node, it may never route the node again, so it is important for nodes to update the forwarding metrics. Moreover, PRoPHET has provided an efficient scheme to update the forwarding metrics in opportunistic networks, so the updated forwarding metric
between
and
can be shown as
where
is defined as an initialization constant and
is the meeting probability before the update. If they do not contact with each other for a long time, the forwarding metric between them is gradually getting aged, so we define
as a constant, which is used to control the aging change of forwarding metrics. Additionally, the updated forwarding metric between
and
can be calculated as
where
t is the previous period of time before the update. In opportunistic networks, the geographic location of nodes changes over time and the forwarding metrics are the important basis for a successful data transmission, so it is necessary for Prelearn messages to execute the updating operation for the meeting probability between nodes.
3.2.2. The Node in the Network Predicts the Future Meeting Probabilities with Others
In the social application scene of opportunistic networks, the movement of nodes changes the topological structure of the network, and the meeting probability between nodes will also change over time. Consequently, the prediction of the probability of a future encounter between nodes may effectively evaluate the variational transmission relationships of users. Ordinarily, the traditional
SVD (snayperskaya vinyovka dragunov) method decomposes a matrix into three matrices, which will result in low computational efficiency and high cache consumption. Nevertheless, the
algorithm creatively decomposes a matrix into only two matrices, so it can be applied to the mobile devices with limited memory spaces and low computing power in opportunistic networks. Firstly, we define a symmetric matrix
, which includes the statistics about the forwarding metrics between nodes.
Based on the
algorithm, the probability matrix
can be decomposed into two different matrices
and
by the following Equation (
8).
where each element
in the probability matrix
will be decomposed into two vectors
and
, and it corresponds to a forwarding metric value in Equation (
7). The subscripts
i and
j represent the number of rows and columns of the element
in the matrix
, respectively. Additionally, this scheme considers all combinations of forwarding metrics and predictive values to minimize
, and it is necessary to add a regularization term
to prevent over-fitting, so the formal optimization function
will be defined as follows:
where
is a regularization coefficient. The stochastic gradient descent is commonly used to optimize the result of
, so the derivatives of
and
can be computed as
Therefore, the global minimum value of
is obtained by the method of the iterative calculation of the gradient descent, and the iteration formula for
and
can be defined as
where
is an adjustable constant, and the predictive value of
is the product of the derivatives of
and
. Consequently, the probability prediction matrix
, which is a predictive value of
, can be calculated by the iterative derivation and calculation of
and
. Consistent with PRoPHET, the Prelearn message keeps a single copy in the Predict phase, which effectively avoids the flooding mode of message routing in the network. During the Predict phase, whenever a new node is routed by Prelearn messages, the Prelearn message collects and updates the carrying information through the attribute characteristics of the node. Meanwhile, the node uses the latest statistics shared from Prelearn messages to predict the probabilities of the future meeting with others and then returns the updated information to the Prelearn message. During the Forward phase, message carriers select the suitable relay nodes through the predictive meeting probability between nodes which is stored in the probability prediction matrix
.
3.3. Phase Transition: The Optimal Stopping Theory
As we defined, there are two phases in the Predict and Forward scheme: studying the state of the network and making delivery decisions for Prelearn messages. During the Predict phase, if the Prelearn message studies the state of the network for a long time, excessive statistics may cause a lack of computing resources and storage spaces of the node, and the network latency will increase dramatically, so the Prelearn message may miss the optimal candidate in the data transmission process. On the contrary, a short-lived Predict phase may imply that the Prelearn message does not obtain enough information about the attribute characteristics of nodes. Consequently, it is vital for Prelearn messages to make a precise phase transition in the data transmission process.
To solve the problem, the optimal stopping theory provides a good paradigm to find the optimal moment between studying the state of the network and making delivery decisions for Prelearn messages, it allows the Prelearn message not only to get enough information about the networks but also not to miss the optimal candidate of data transmission.
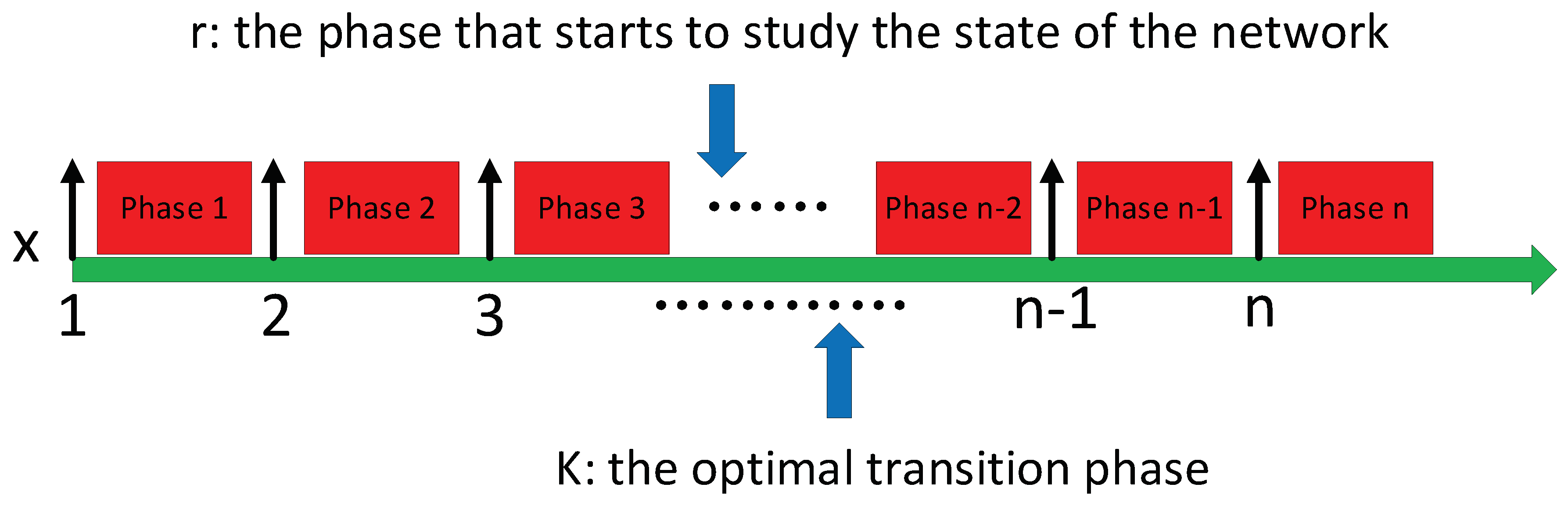
As depicted in
Figure 3, we denote
X, which represents the number of nodes that have routed by the Prelearn message in the Predict phase. We define
K as the optimal transition moment from Predict phase to Forward phase. This means the
K-th node is the last node that has been routed by the Prelearn message and the optimal candidate has appeared before the phase
K. Therefore, we assume that the Prelearn message starts to study the network from the
r-th node to the
K-th node and each phase has an equal probability of switching to the Forward phase. If the
K-th node is the optimal candidate, we define
, which is the probability of switching to the forward phase at the phase
K. To calculate the probability value of
, we define
, which represents the
K-th node is the optimal candidate, and define
, which represents the
K-th node begins to make message delivery decisions for Prelearn messages at the phase
K. Therefore, the probability value of
can be computed as
According to the hypothesis, the
K-th node is the optimal candidate in the data transmission process, so
is bigger than the probabilities of switching to Forward phase at any later phase, and this can be shown as
According to the general expression of
r in the above equation, the phase value
r can be used to calculate the probability value
, and the inference procedure is shown as follows.
Based on the calculation results, is the maximum value for . Consequently, the optimal transition phase K is , which indicates that the n/e-th node is the last node to be routed by Prelearn messages and it begins to send Prelearn messages to the destination profile.
3.4. Forward Phase: Making Delivery Decisions for Prelearn Messages
After the Predict phase, the Prelearn message has received enough and accurate statistics about the state of the network and nodes in the network have determined the probabilities of the future meeting with other nodes. Moreover, the optimal candidate carrying Prelearn messages starts to make delivery decisions based on the information stored in the Prelearn message. During the Forward phase, if the destination profile has appeared in the Predict phase, the Prelearn message will directly or indirectly be forwarded to the nodes belonging to the destination profile based on the probability prediction matrix . Specifically, Prelearn message carriers transmit data packages to the relay nodes which have a bigger probability of future meeting with the destination profile than the Prelearn message carriers. Finally, the Prelearn messages will be forwarded to the destination profile. Otherwise, when the destination profile has not appeared in the Predict phase, the message carrier does not forward Prelearn message until it finds a node that satisfies the message delivery function , which is the same as the Wait phase in Spray and Wait algorithm.
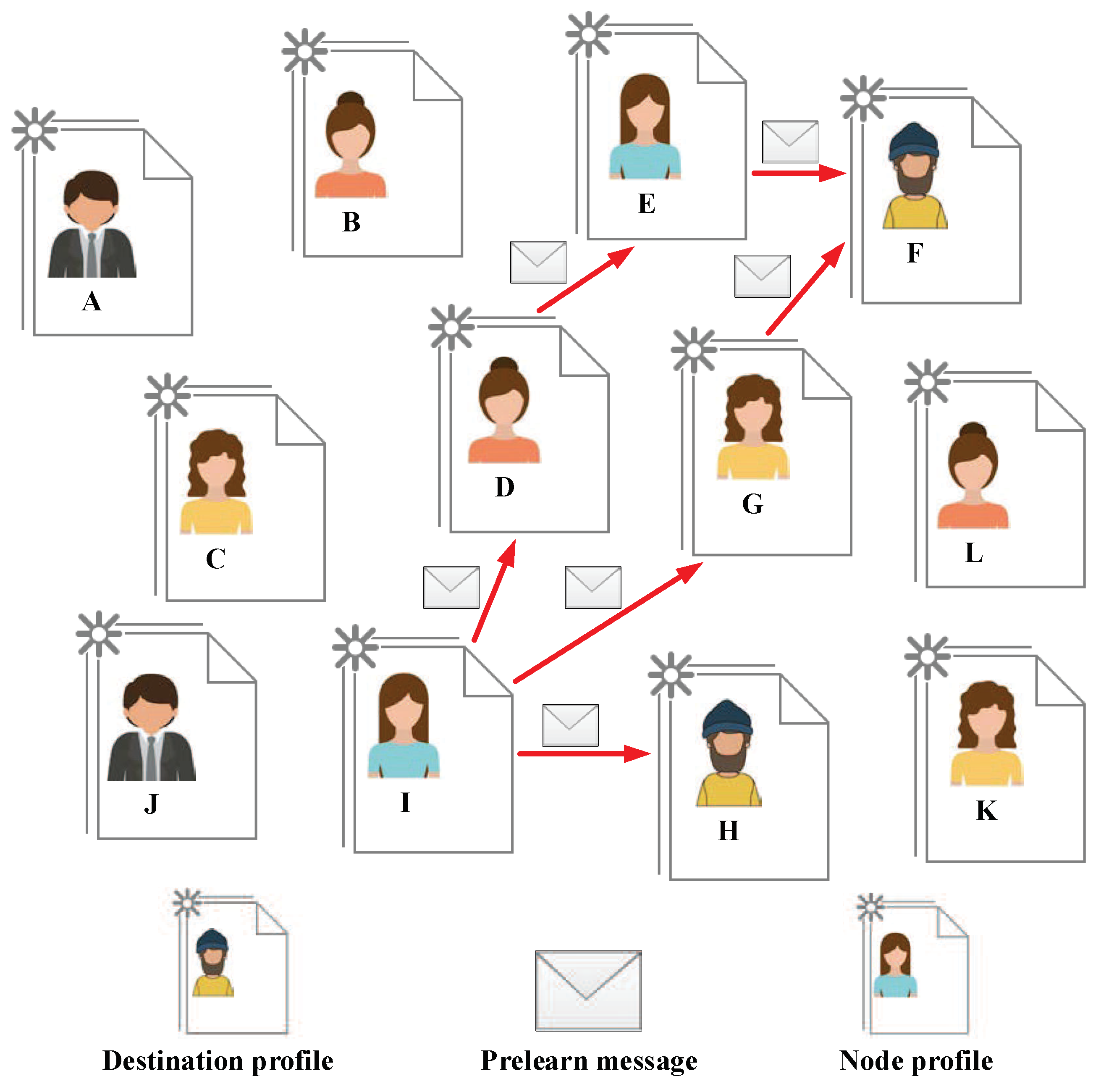
As shown in
Figure 4, during the Forward phase, the
, which is the last node to be routed in the Predict phase, starts to make delivery decisions for Prelean messages. The
and
belong to the destination profile that satisfies the message delivery function
defined by the minimum weight. Moreover, according to the probability prediction matrix
, the
,
and
are the users that possess a bigger probability of future meeting with the destination profile than the
. Therefore, the
directly or indirectly sends Prelearn messages to the suitable relay nodes
,
and
, and the Prelearn messages will be forwarded to the destination profile
and
eventually.
3.5. Complexity Analysis of the Proposed Algorithm
In conclusion, we propose an efficient routing-delivery scheme (Predict and Forward) based on node profile in opportunistic networks, and the detailed steps of the proposed algorithm are as follows.
Step 1: The source node defines the message delivery function through its previous experience.
Step 2: The Prelearn message starts to route from a node to another in the network, gathers and updates the statistics about the attribute characteristics of nodes, and finds the destination profile by the message delivery function defined by the source node.
Step 3: When routed by the Prelearn message, the new node adopts the historical meeting information shared from the Prelearn message to predict the future encounter probabilities with others.
Step 4: Based on the optimal stopping theory, Prelearn message carriers select an optimal transition moment to forward Prelearn messages to the relay nodes which have a bigger probability of a future meeting with the destination profile than the Prelearn message carriers.
For the readability of this algorithm, we provide the pseudo-code description to introduce our proposed scheme briefly. As the pseudocode shows, the first loop represents Prelearn messages route from the source node to the n/e-th node in the Predict phase, so its time complexity is . Additionally, the second loop of the pseudo-code indicates that the message carrier compares the probability of the future meeting between nodes and makes appropriate message delivery decisions in Forward phase, so its time complexity is . On the whole, the time complexity of the proposed algorithm is . Meanwhile, we may compare the proposed algorithm with other traditional algorithms of opportunistic networks. The time complexity in Spray and Wait algorithm is , while that in the Epidemic algorithm is .
| Algorithm 1 Predict and Forward scheme |
Input: Prelearn message L(,,,), ……., a destination node D;
Output: the node set R, the probability prediction matrix ;- 1:
Predict phase: the Prelearn message L routes the network form to - 2:
for (int ) do - 3:
if (. is destination profile()) then - 4:
- 5:
end if - 6:
Collect and update the encounter information between nodes - 7:
Predict the future meeting probability P between and the others - 8:
Add P to - 9:
- 10:
end for - 11:
Output the node set R and the probability matrix ; - 12:
Forward phase: making the delivery decisions for Prelearn message L - 13:
for (int ) do - 14:
if (.carry Prelearn message(L)) then - 15:
if () then - 16:
sends the Prelearn message L to - 17:
Finally Prelearn message L will be sent to the destination profile - 18:
end if - 19:
end if - 20:
end for
|
4. Performance Evaluation
The simulation adopts the Opportunistic Network Environment (ONE) to test in the Health Capability Maturity Model (HCMM) [
30]. In our work, the Predict and Forward algorithm will be compared with the other three algorithms: EIMST routing algorithm (effective information transmission based on socialization nodes) [
12], Epidemic routing algorithm [
27] and Spray and Wait routing algorithm [
20]. The EIMST routing algorithm is the latest strategy for OppNet and the other two algorithms are traditional methods in OppNet.
In this experimentation, the algorithm
is trained and tested in the mathematical tool MATLAB. According to the experimental results with different simulation settings, the
method shows the best performance when the regularization coefficient
is 0.02 and the constant
is 0.1, so the parameters
and
are initialized to 0.02 and 0.1 in the Predict and Forward scheme. Moreover, the other parameters are set as follows. The simulation area is 3000 m × 3000 m and there are 1000 nodes (the value of
n is 1000) in the communication area. Each node in the network includes six different node attributes and the destination profile consists of 50 nodes which satisfy the message delivery function. The simulation time is set as 1–12 h, the initial value for a period of time
t is 40 min and the maximum moving range of each node is 20 m
. The total number of Prelearn messages is 100 and the time to create a Prelearn message is 1–10 s. Each Prelearn message occupies 100 Kb storage space. During the Predict phase, the Prelearn message always keeps a single copy to route nodes in the network. With the movement speed of 1–4 m/s, each node in the network has the cache spaces of 50 Mb and carries 10 data packets. In order to improve the readability of the simulation settings, we build
Table 1 to introduce the simulation environment briefly. In the experimental results, we focus on the following parameters:
1. The probability of the destination profile receiving Prelearn messages (): This parameter represents the probability of the destination profile receiving Prelearn messages from the message carriers and its neighbors. The probability of the destination profile receiving Prelearn messages can be shown as , where is the total number of Prelearn messages forwarded by the node, and is the total number of Prelearn messages obtained by the destination profile.
2. Delivery ratio: This parameter represents the probability of the node receiving Prelearn messages from its neighbors. The delivery ratio can be calculated as , where is the number of Prelearn messages sent by message carriers and is the number of Prelearn messages received by the node.
3. Overhead on average: This parameter represents the network overhead of sending a Prelearn message from one node to another. Overhead on average can be calculated as , where is the total time taken for Prelearn message forwarding and is the time of a successful message forwarding.
4. Average end-to-end delay: This parameter represents the network delay of routing Prelearn messages, the delay of phase transition and the delay of forwarding Prelearn messages.
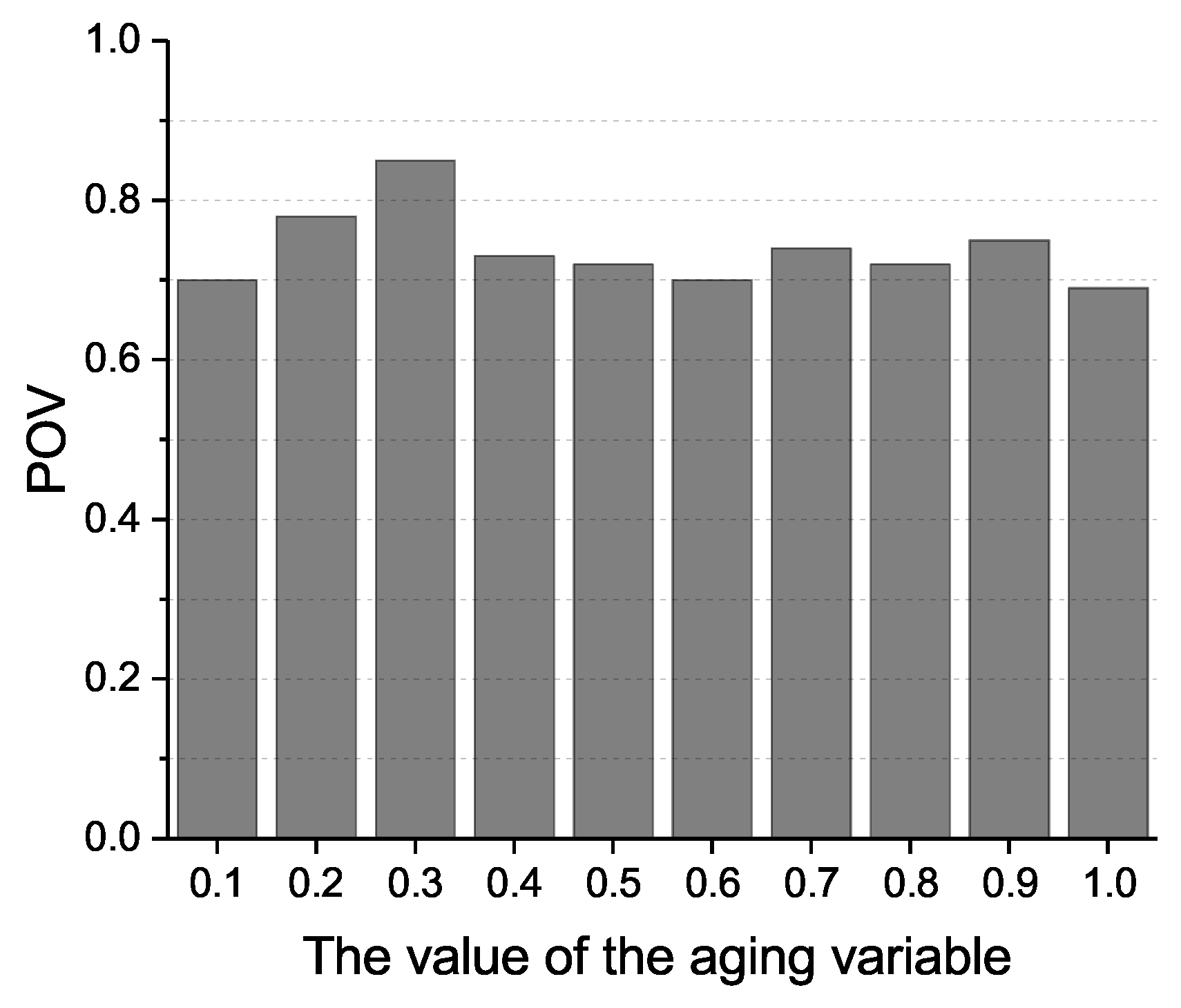
In this simulation, we first evaluate the impact of the aging variable on the probability of the destination profile receiving Prelearn messages
. As shown in
Figure 5, when the value of the aging variable changes, the corresponding value of
always exceeds 0.7. Moreover, the
reaches a maximum value of 0.85 when the aging variable is 0.3.
Figure 6 shows the impact of the phase transition value on the probability of the destination profile receiving Prelearn messages
. As it can be seen, when the phase transition value increases from
to
N, the fluctuation range of the
is from 0.3 to 0.8. Particularly, when the phase transition is at
, the Prelearn message has not only obtained enough statistics about the state of the network but also found the destination profile by the message delivery function. Therefore, the message carrier can make the suitable delivery decisions for Prelearn messages, the efficient data transmission performs, and the
gets the maximum value of 0.8.
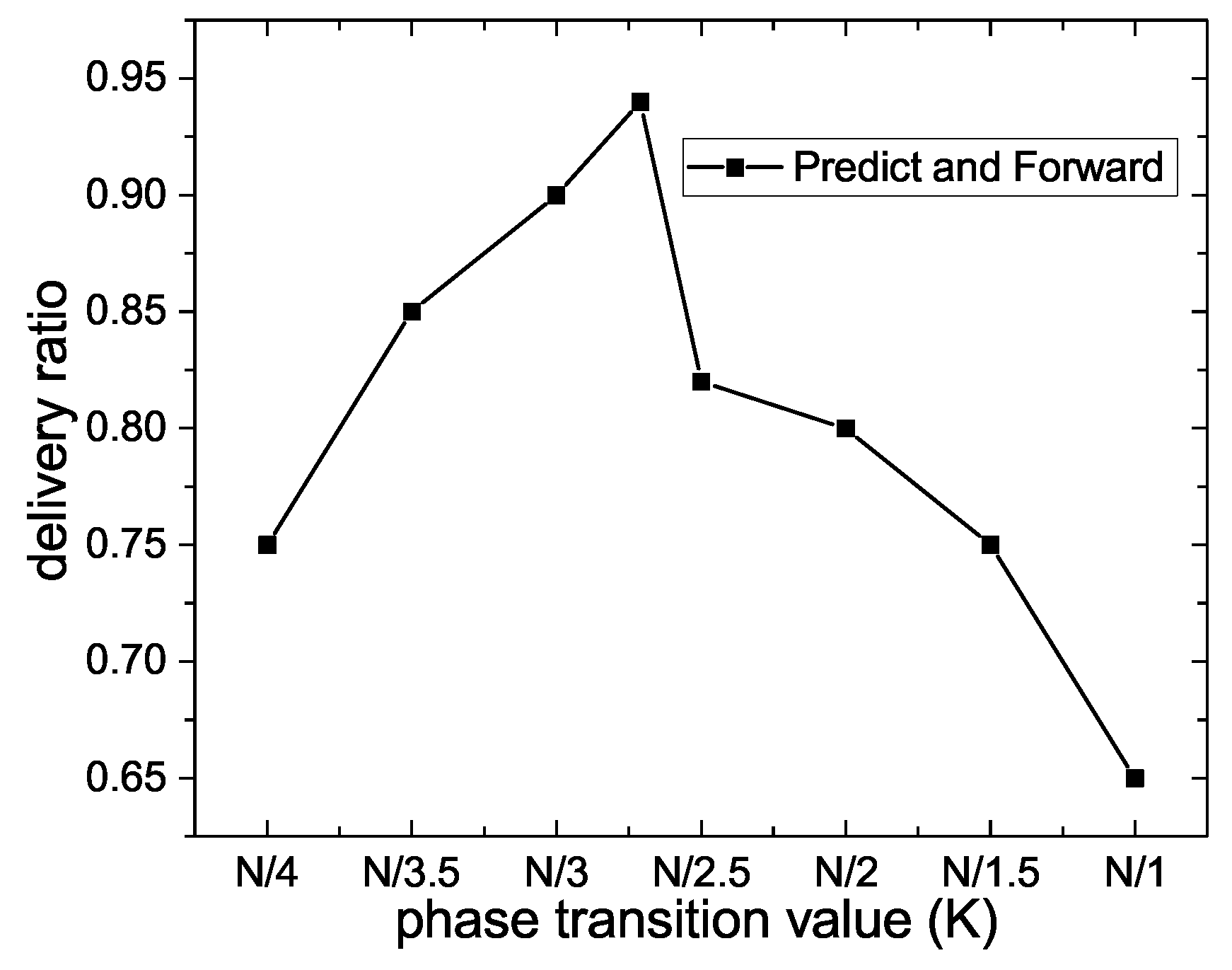
Figure 7 exhibits the impact of the phase transition value on delivery ratio. As it can be seen, the broken line first rises sharply and then falls rapidly. This means the phase transition value plays a significant role in the delivery ratio. A short Predict phase may miss the optimal candidate in the data transmission process, while a long Predict phase may imply that a large number of irrelevant nodes participate in the forwarding process of Prelearn messages. When the phase transition occurs at the optimal moment
, message carriers select the suitable relay nodes based on reliable information about the state of the network, and the destination profile is more likely to have appeared in the Predict phase, so the delivery ratio reaches the maximum value of 0.95.
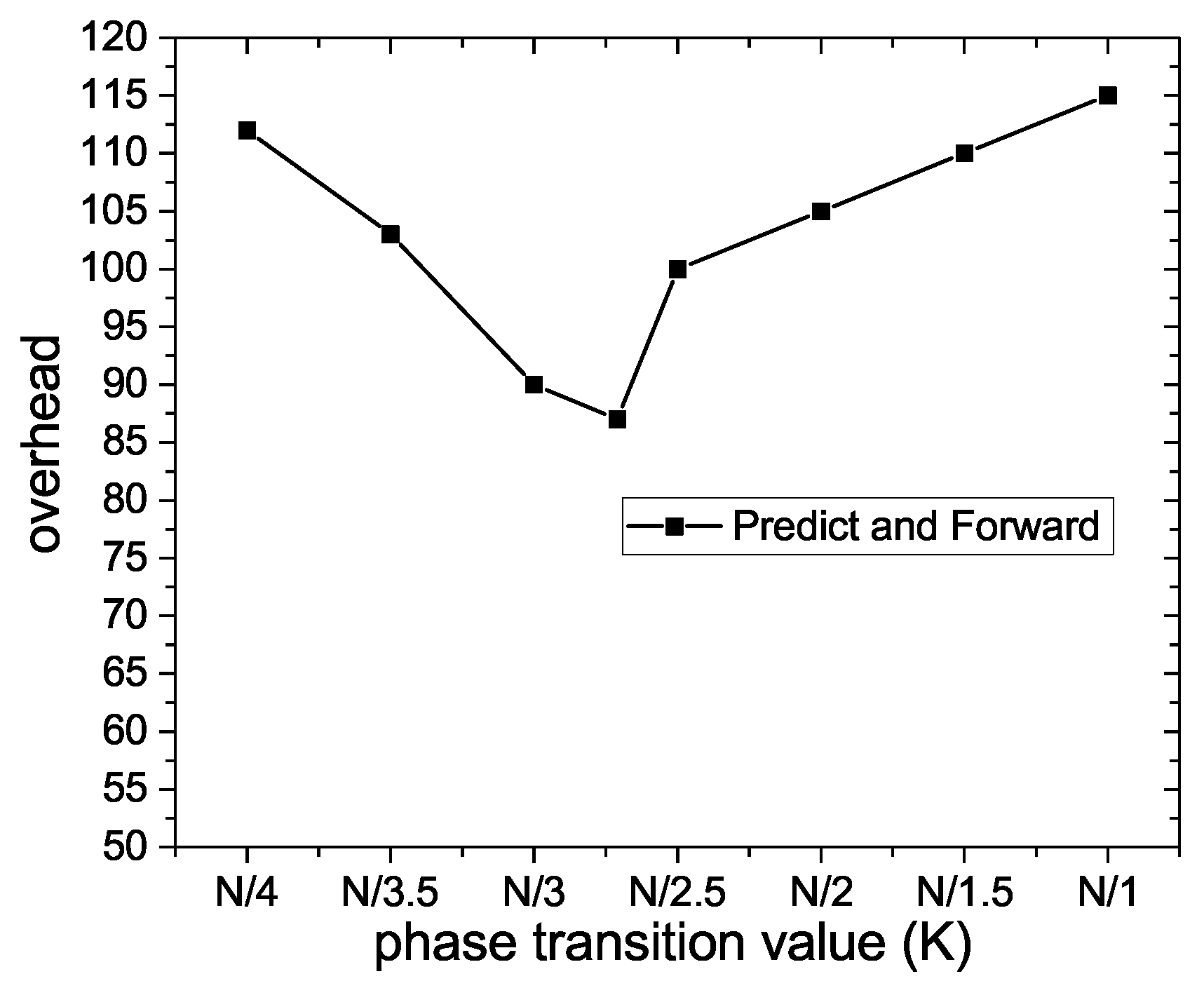
Figure 8 shows the influence of the phase transition value on network overhead. As it can be seen, the broken line first drops rapidly and then rises slowly. The later the phase transition occurs, the more the nodes take part in the forwarding process of Prelearn messages. Meanwhile, the number of nodes unrelated to the process of data transmission also increases, and more time and resources are wasted in transmitting Prelearn messages to the unrelated nodes, so the network overhead presents a rising trend. However, When the phase transition occurs at the optimal moment
, the Prelearn message acquires sufficient information about the state of the network, the node obtains the exact probability of future meeting with other nodes, and the routing and delivering of the Prelearn message are at their optimal state, so the network overhead gets the minimum value of 85.
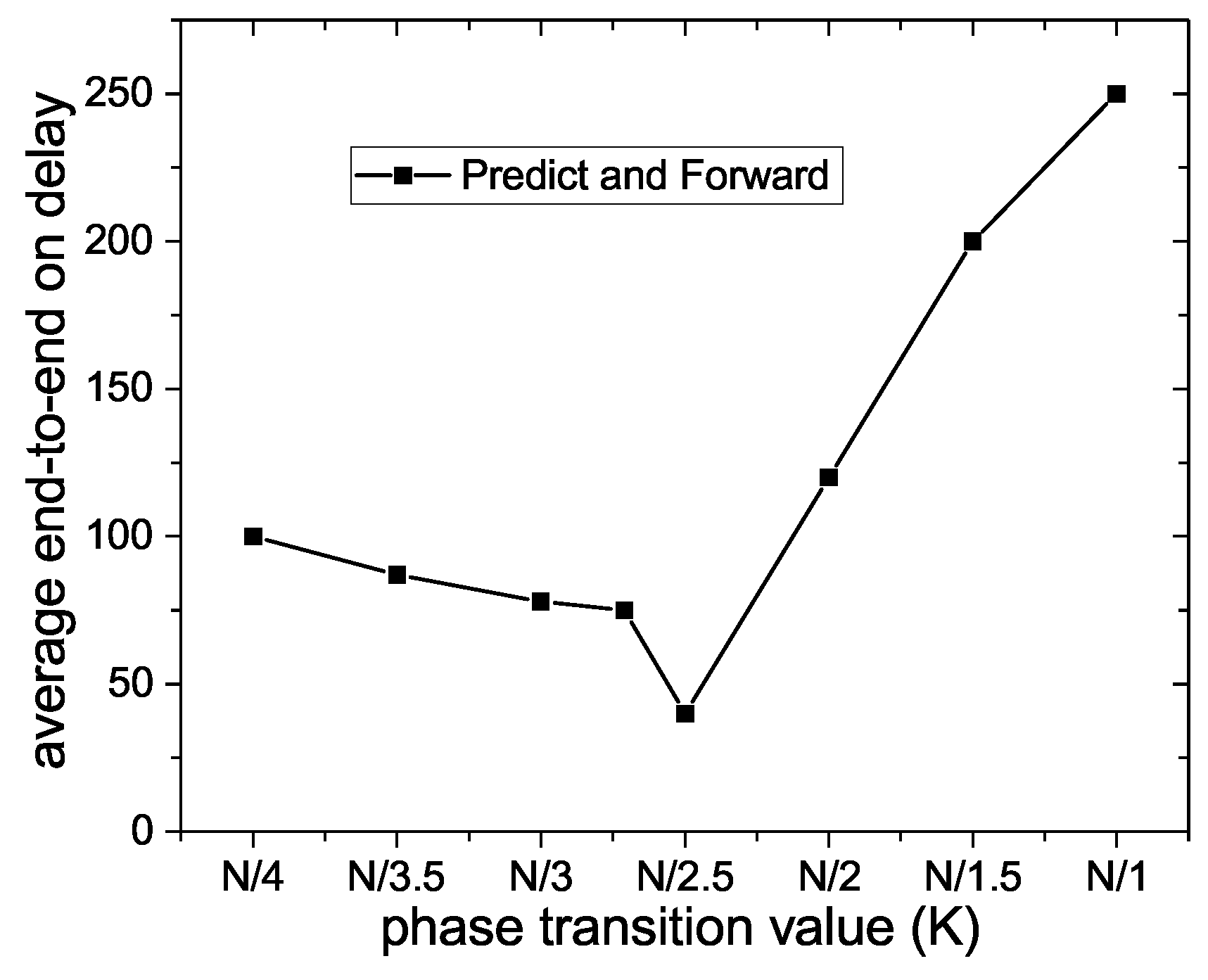
Figure 9 exhibits the influence of the phase transition value on average end-to-end delay. As it can be seen, the broken line first declines slowly and then rises rapidly. In other words, when the number of the nodes routed by Prelearn messages increases, the number of the nodes participating in the data transmission process also goes up, so the average end-to-end delay in Predict and Forward algorithm decreases constantly. However, when the transition phase exceeds the optimal moment, more unrelated nodes participate in the routing and forwarding of Prelearn messages, the number of hops in a successful data transmission increases and a large amount of energy is consumed in mission calculations and information transportation. Consequently, the average end-to-end delay in the Predict and Forward algorithm begins to rise.
Figure 10 shows the comparison results between the four algorithms in terms of delivery ratio. As it can be seen, the average delivery ratio in the Predict and Forward algorithm is the highest among them. This is because the data transmission in Predict and Forward algorithm is implemented through node attributes, and Prelearn messages are transmitted to the relay nodes, which have a relatively high probability of meeting the destination profile. As the cache space continues to increase, nodes in the network can handle complex computing tasks and carry more information, so the delivery ratio is growing rapidly. In Predict and Forward scheme, the delivery ratio is over 0.9 when data cache exceeds 37.5 Mb, and it reaches the maximum value when data cache is 40 Mb. As for EIMST algorithm, it does not have an effective way to implement cache management of nodes, so the delivery ratio in this algorithm is lower than Predict and Forward. In addition, Epidemic routing algorithm and Spray and Wait algorithm produce a large number of message copies in the data transmission process, so the delivery ratio in the two algorithms is always relatively low. Overall, the delivery ratio in the Predict and Forward algorithm is 0.85 on average, which is higher than the other three algorithms.
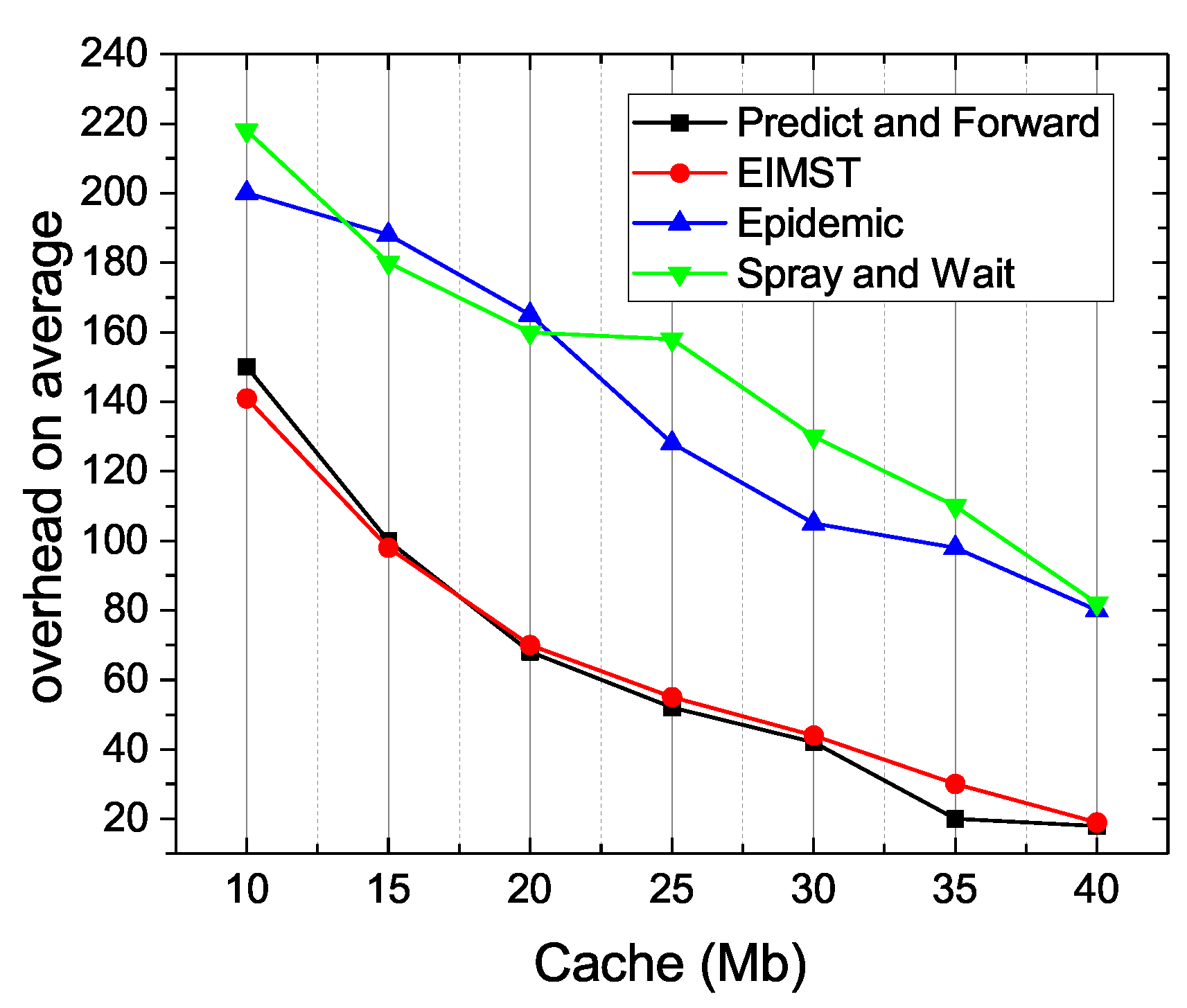
Figure 11 shows the comparison results between the four algorithms in terms of overhead on average. As it can be seen, with the increase of the cache space, the overhead on average drops dramatically. Moreover, the overhead on average in Predict and Forward scheme is the lowest among the four algorithms. When the cache space is over 20 Mb, the overhead on average in Predict and Forward algorithm always keeps the lowest, because it adopts two different phases to implement the optimal process for data transmission. When an optimal phase transition is found between Predict and Forward phases, the number of hops of a successful data transmission in Predict and Forward is less than the other algorithms, and the time spending on the routing and forwarding of Prelearn messages is also less than the other algorithms. Moreover, the increase of the cache space means there are more resources for nodes to carry information and execute computational tasks. As for the other three algorithms, the overhead on average in EIMST fluctuates between 20–150 and the overhead on average is between 80–220 in Spray and Wait or Epidemic.
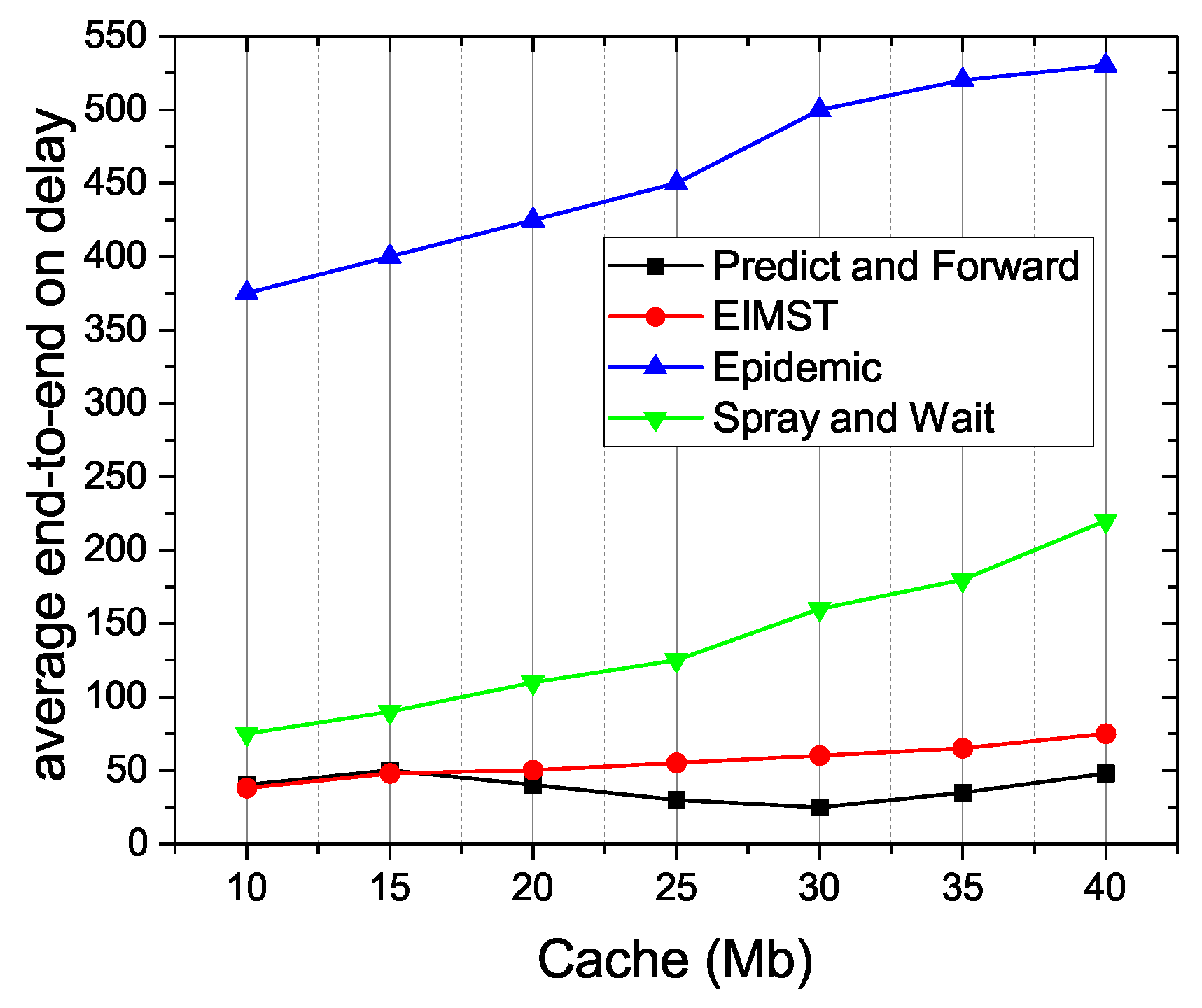
Figure 12 shows the comparison results between the four algorithms in terms of average end-to-end delay. As it can be seen, the average end-to-end delay in Epidemic is always the highest among them, because the node in the network may have more computation tasks in this algorithm. However, in Spray and Wait or EIMST, the multicopy model is used to implement data transmission so that the average end-to-end delay in them is superior to the Epidemic. It is clear that the average end-to-end delay in Predict and Forward algorithm is the lowest among the four algorithms, because this scheme always selects the relay nodes which have a high probability of meeting the destination profile as the next hop. When the transition phase is at the optimal moment, this scheme keeps a balanced state between exploring the network and forwarding Prelearn messages, so the average end-to-end delay in the Predict and Forward gets a minimum value of 25. Meanwhile, when the cache space of nodes increases from 10 Mb to 40 Mb, the average end-to-end delay in Predict and Forward never exceeds 50.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}