Network Measurement and Performance Analysis at Server Side


Abstract
:1. Introduction
- Generic: Our solution neither relies on detailed knowledge of application nor congestion control. In fact, server side bidirectional packet traces are the only input of EVA.
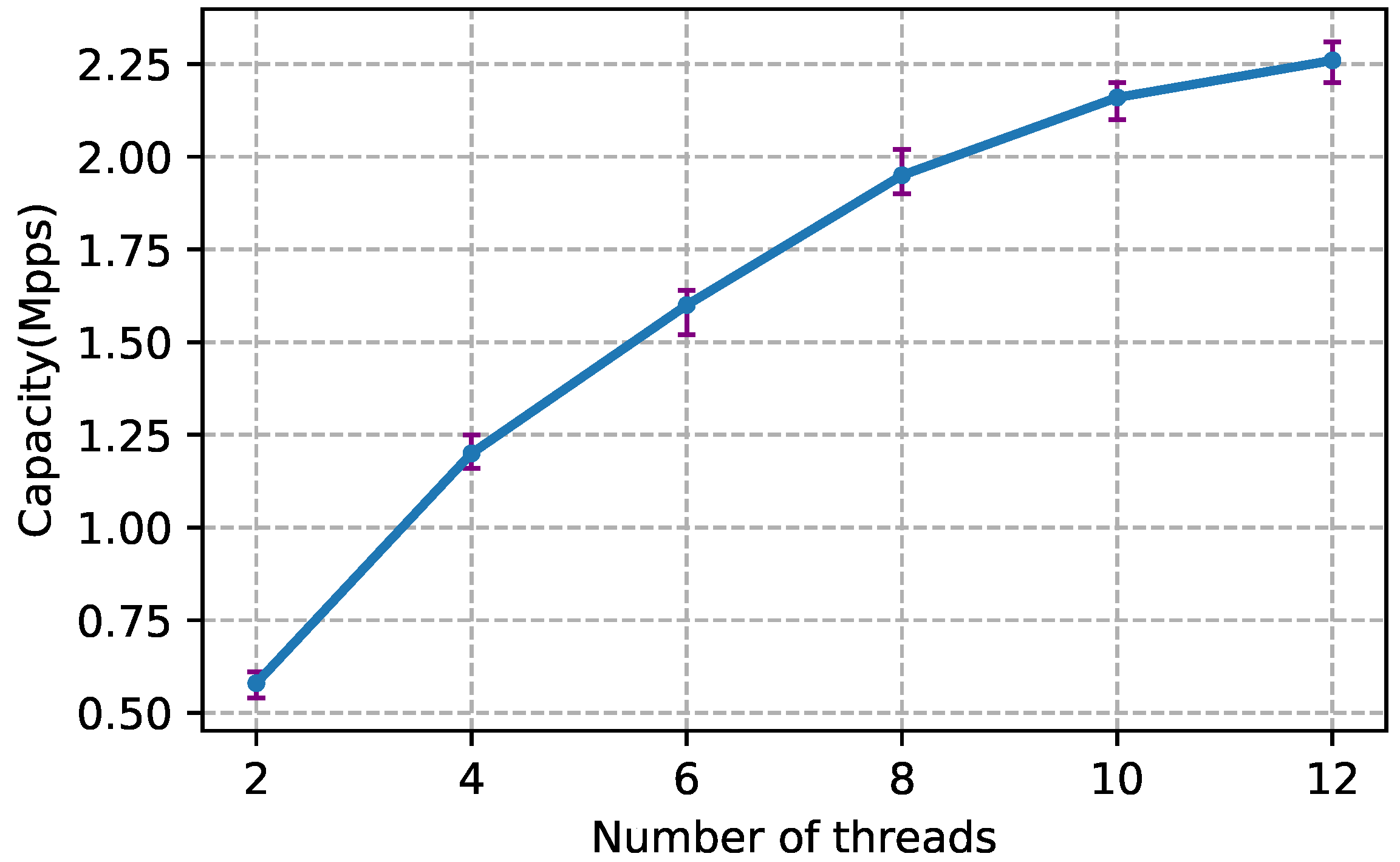
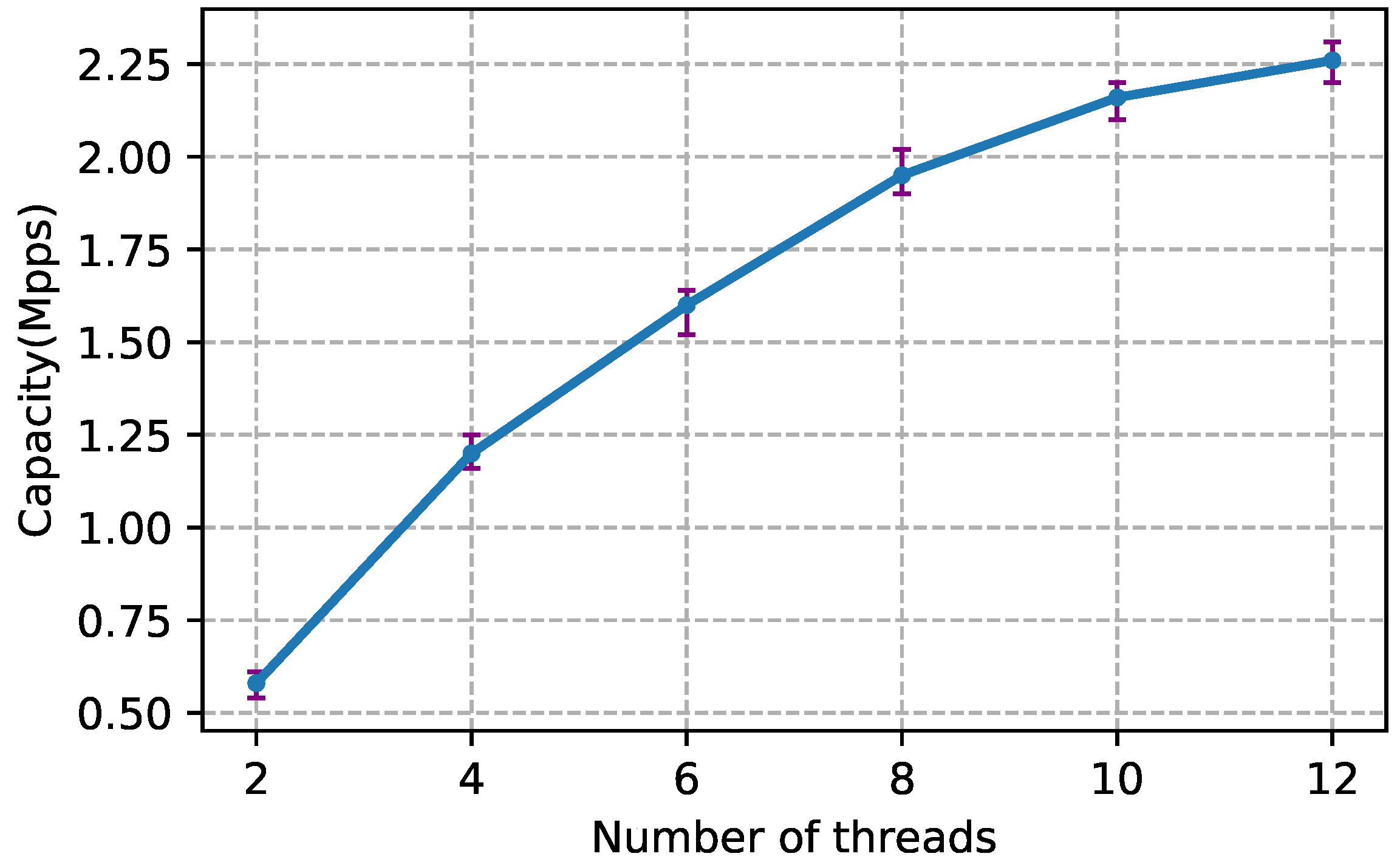
- Real-time: Our tool measures the network and pinpoints performance problems in a real-time manner (offline analysis also supported). Owing to multithreaded implementation and PF_RING [6] accelerated packet capture, EVA achieves 2.26 Mpps (packet per second) speed on commodity server equipped with 10 Gbps NIC.
- Accurate: In our experiments, EVA successfully identifies almost all the performance problems, which means it has a high diagnostic accuracy.
2. Related Work
3. Measurement Methodology
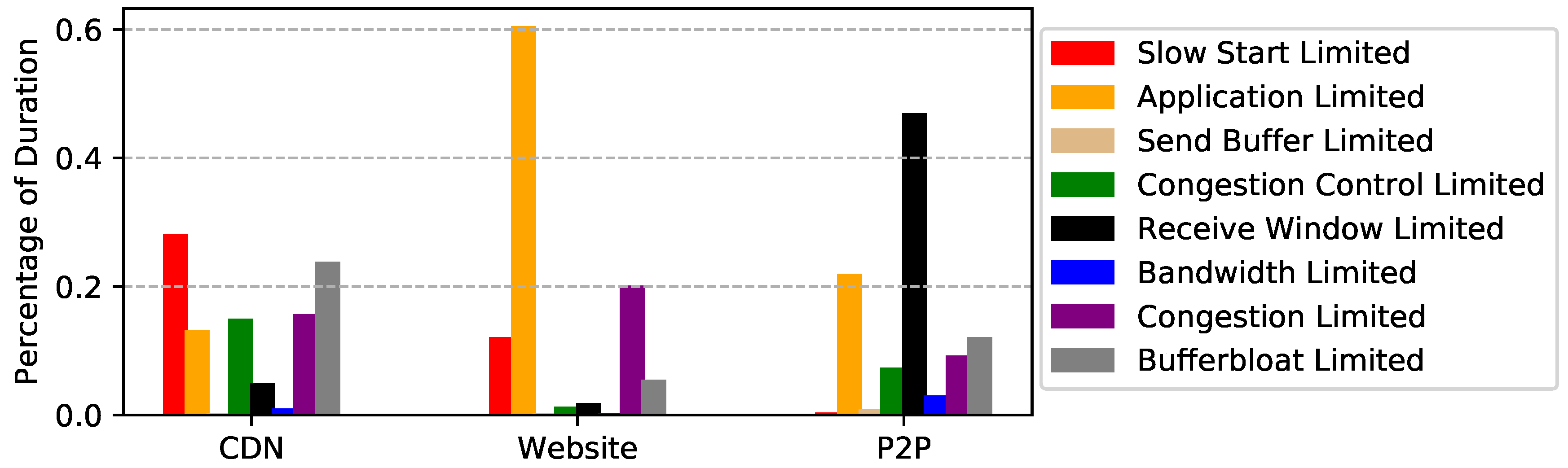
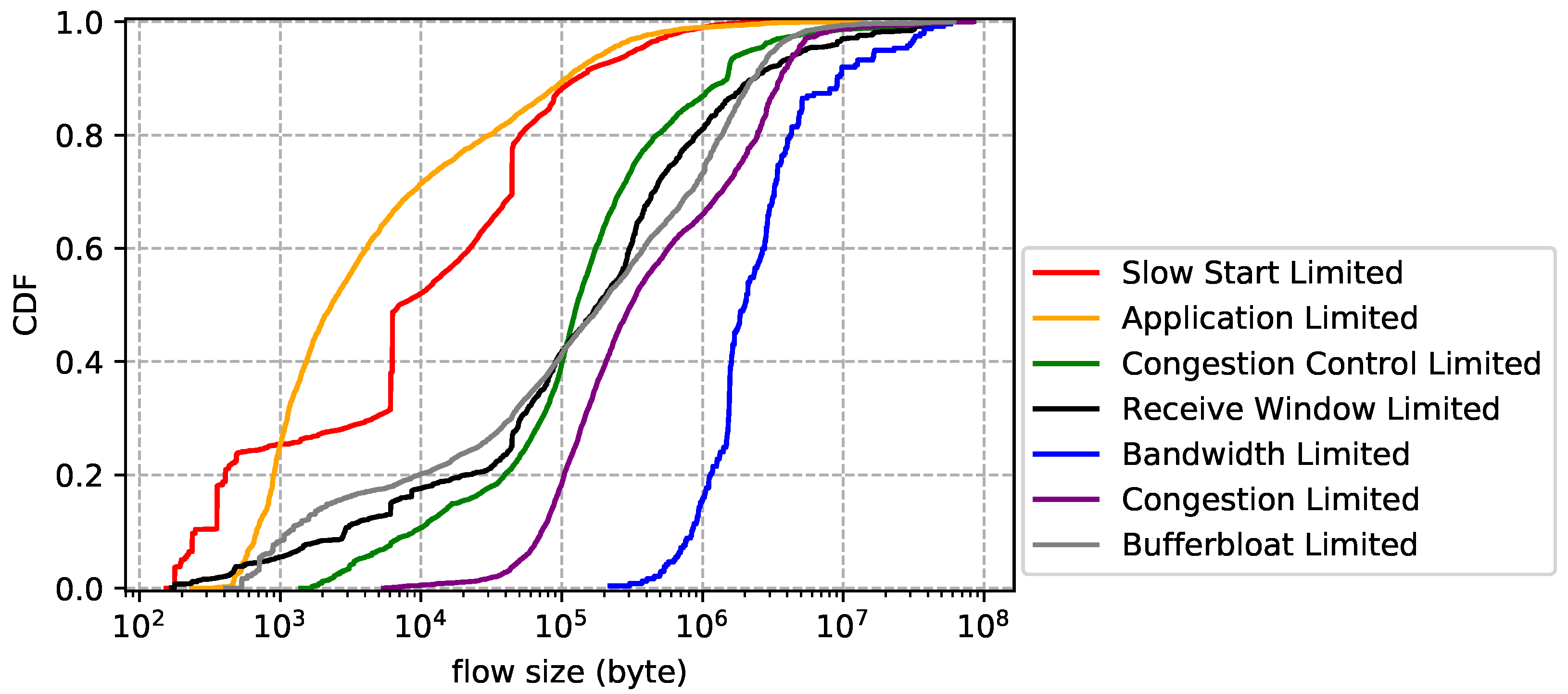
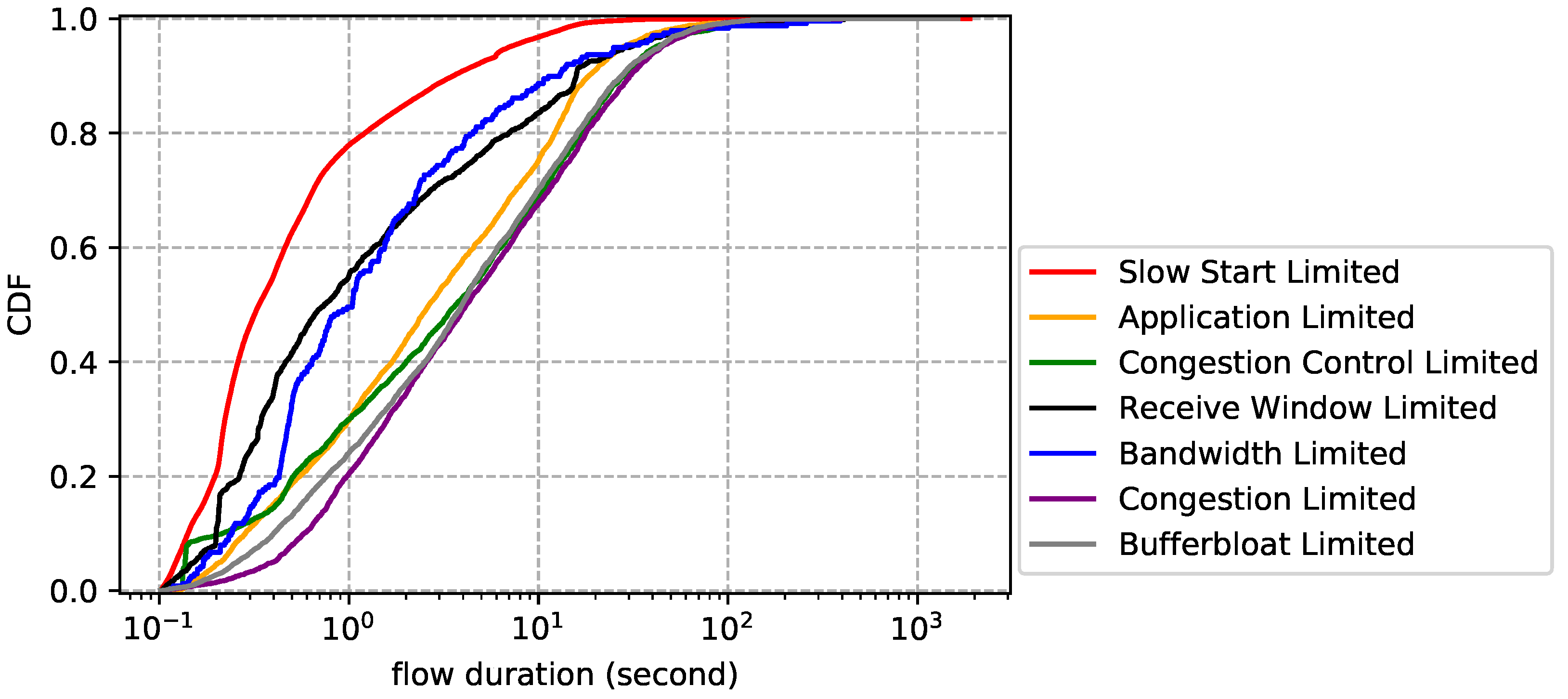
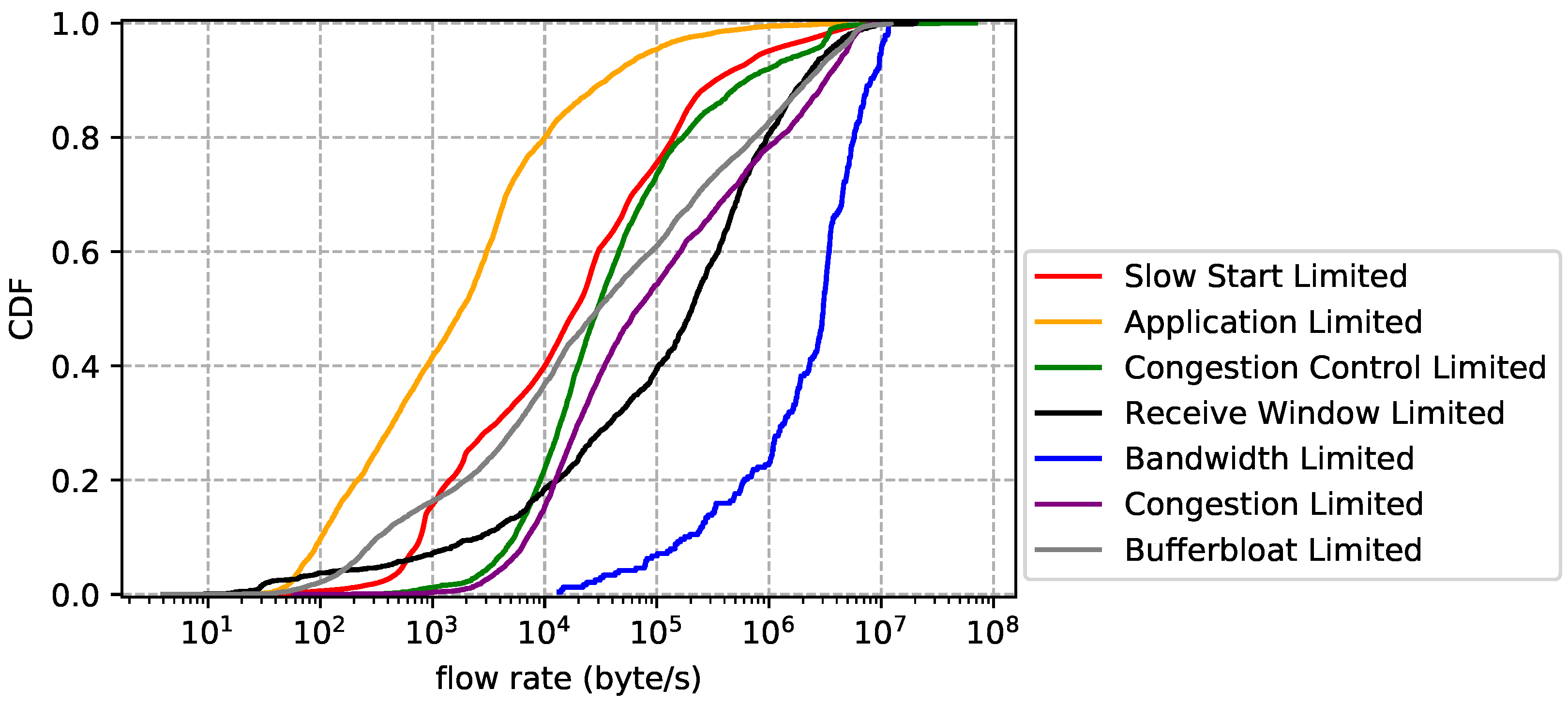
- Slow start limited. TCP flow is slow starting, thus unable to make full use of network resources. Some flows may never leave slow start (i.e., short-lived connection), while others may enter slow start stage multiple times (e.g., after timeout retransmission).
- Application limited. The sender application does not generate enough data to fill the network. This situation will appear in a variety of scenarios, e.g., a ssh server can send a single short packet in one flight. It is worth noting that an idle connection should also be treated as application limited.
- Send buffer limited. The network stack allocates a send buffer for each TCP connection to manage in flight data (i.e., data that have sent but not acknowledged). Sender cannot fill the network if this buffer is too small.
- Congestion control limited. Some congestion controls may underestimate network capacity in certain situations. For example, when bottleneck buffers are small, loss-based congestion control misinterprets loss as a signal of congestion, leading to low throughput.
- Receive window limited. The network stack allocates a receive buffer for each TCP connection to manage data received but not retrieved by the application. Small receive buffer can limit the send rate. This happens when the application sets a small fixed receive buffer or retrieves data from the network stack slower than transport layer receives the data. It is worth noting that a zero window may be advertised, forcing the sender to stop immediately.
- Bandwidth limited. The sender fully utilizes, and is limited by, the bandwidth on the bottleneck link.
- Congestion limited. The network is congested, i.e., data packets are suffering loss and high latency. This definition is independent of congestion control, whether it is loss-based or delay-based.
- Bufferbloat limited. Bufferbloat is the undesirable latency that comes from a router or other network equipment buffering too much data. For example, when bottleneck buffers are large, loss-based congestion control keeps them full, causing bufferbloat.
- The RTprop estimator continuously estimates RTprop for a TCP flow.
- The BtlBw estimator continuously estimates BtlBw for a TCP flow.
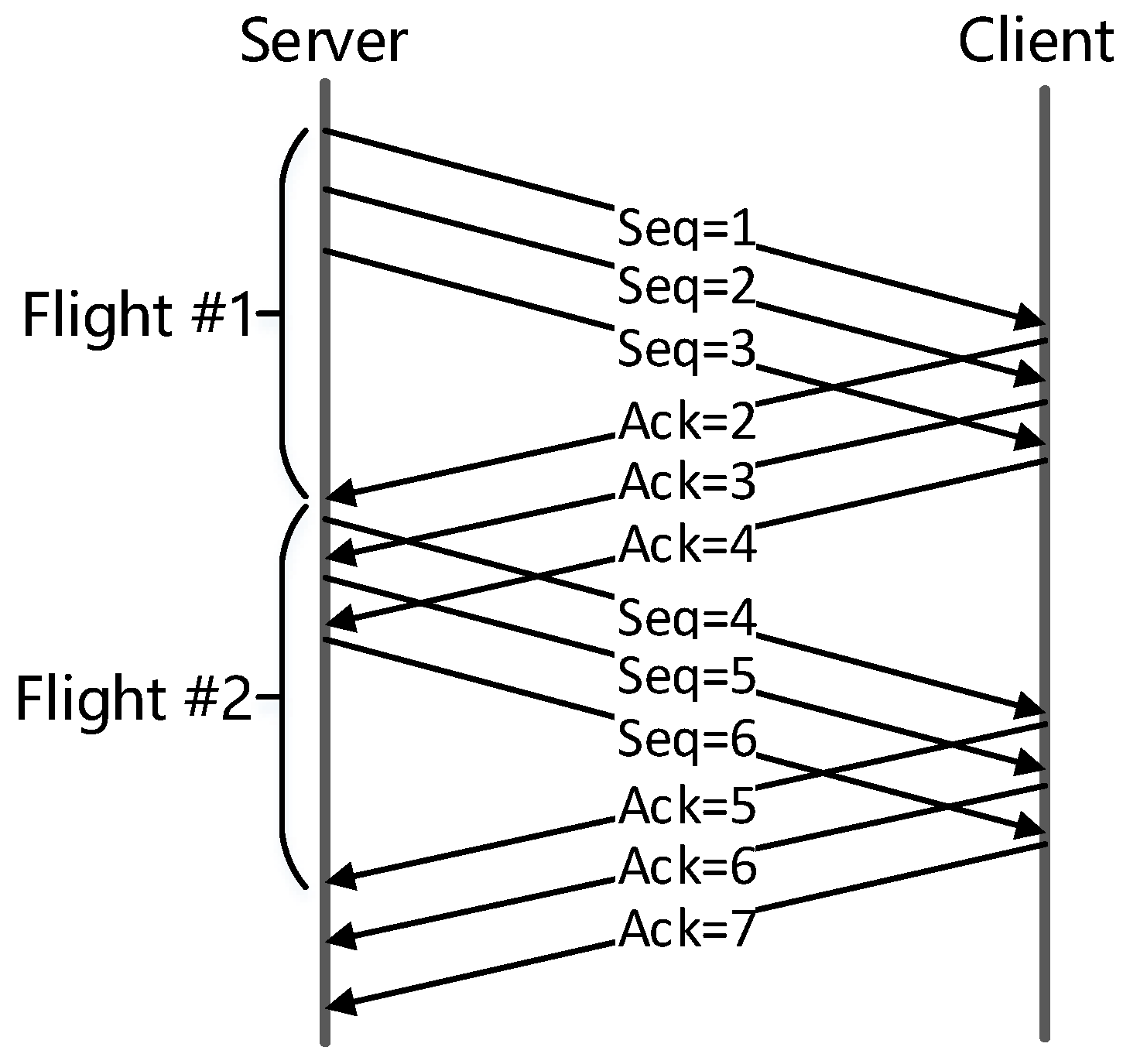
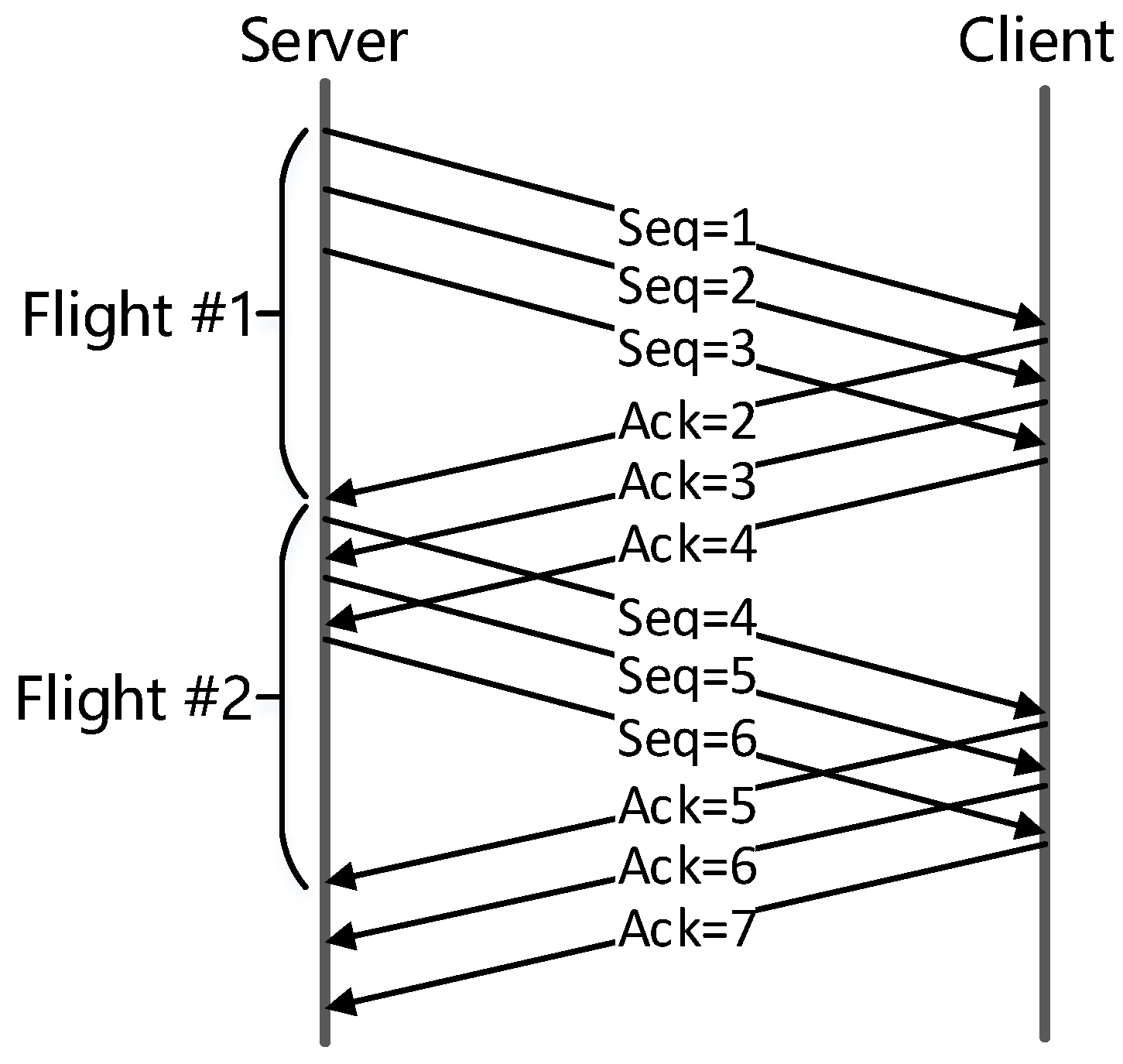
- Performance analysis first groups packets into flights, and then analyzes performance problems for each flight.
3.1. BtlBw Estimator
3.2. RTprop Estimator
| Algorithm 1: RTprop estimator. |
 |
3.3. Performance Analysis
- When slow start limited, flight size increases exponentially.
- When application limited, flight size is the amount of data the application is willing to send.
- When receive window limited, flight size is bounded by receive window.
- When send buffer limited, flight size is bounded by send buffer size.
- Otherwise, flight size is determined by network and congestion control.
| Algorithm 2: Group packets into flights. |
 |
- Packet retransmissions are seen in current flight.
- At least one RTT sample is larger than .
- The flight is not slow start limited or receive window limited.
- The flight size .
- The flight size and remains unchanged for at least three flights.
- The flight is not limited by slow start, receive window or network congestion.
- The flight size .
- The flight contains at least one less-MSS-sized packet.
- The flight is not slow start limited, receive window limited, congestion limited or send buffer limited.
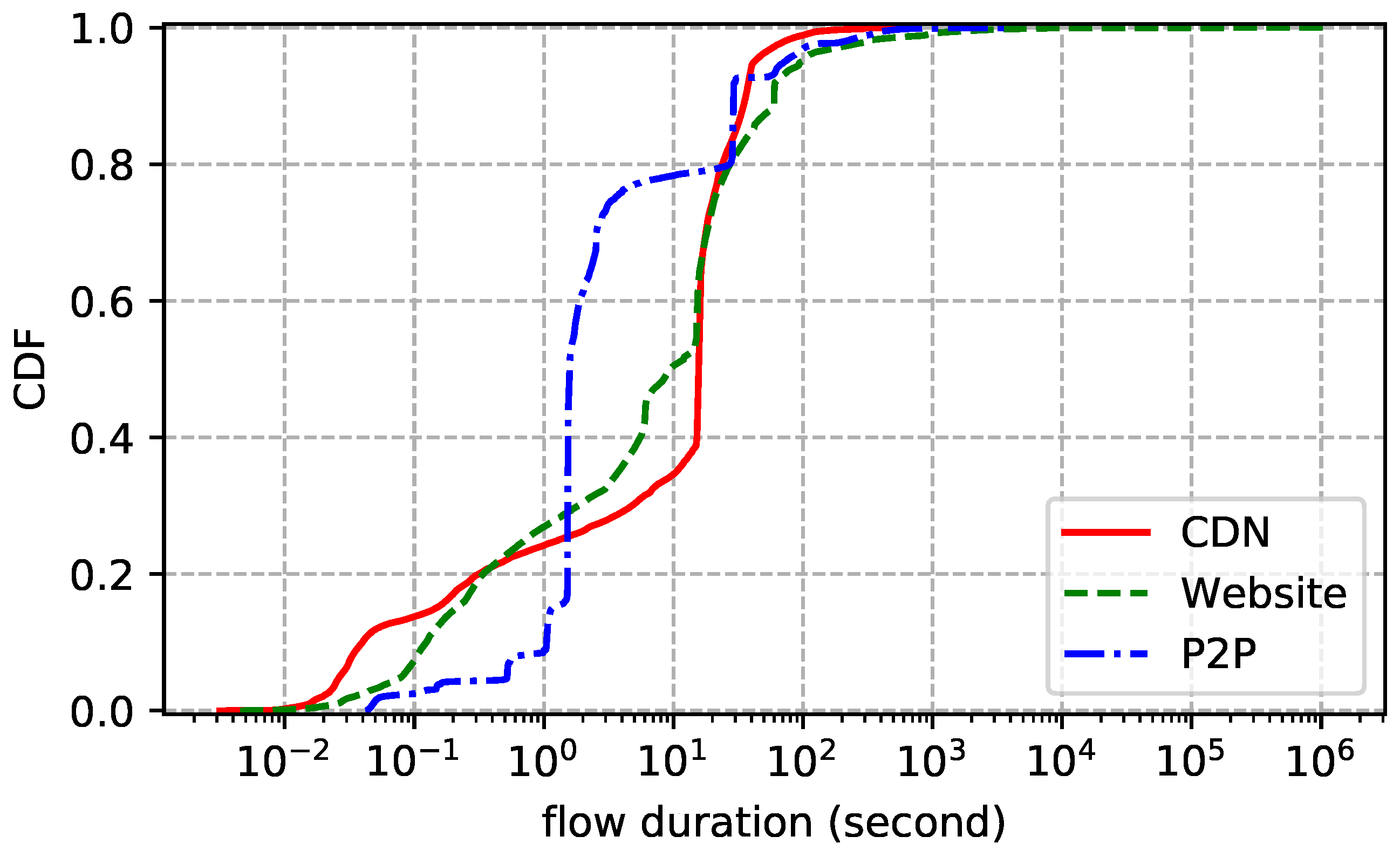
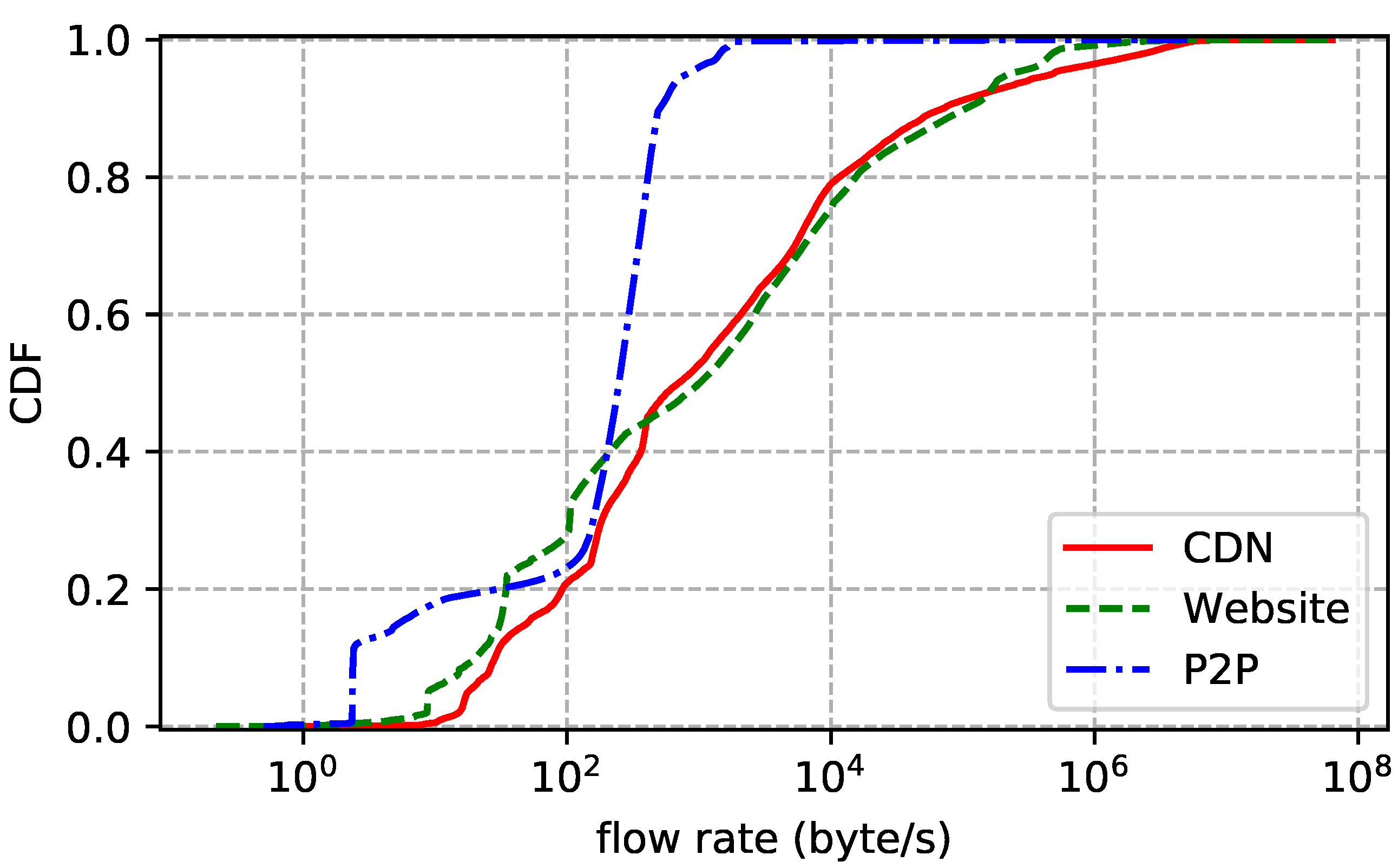
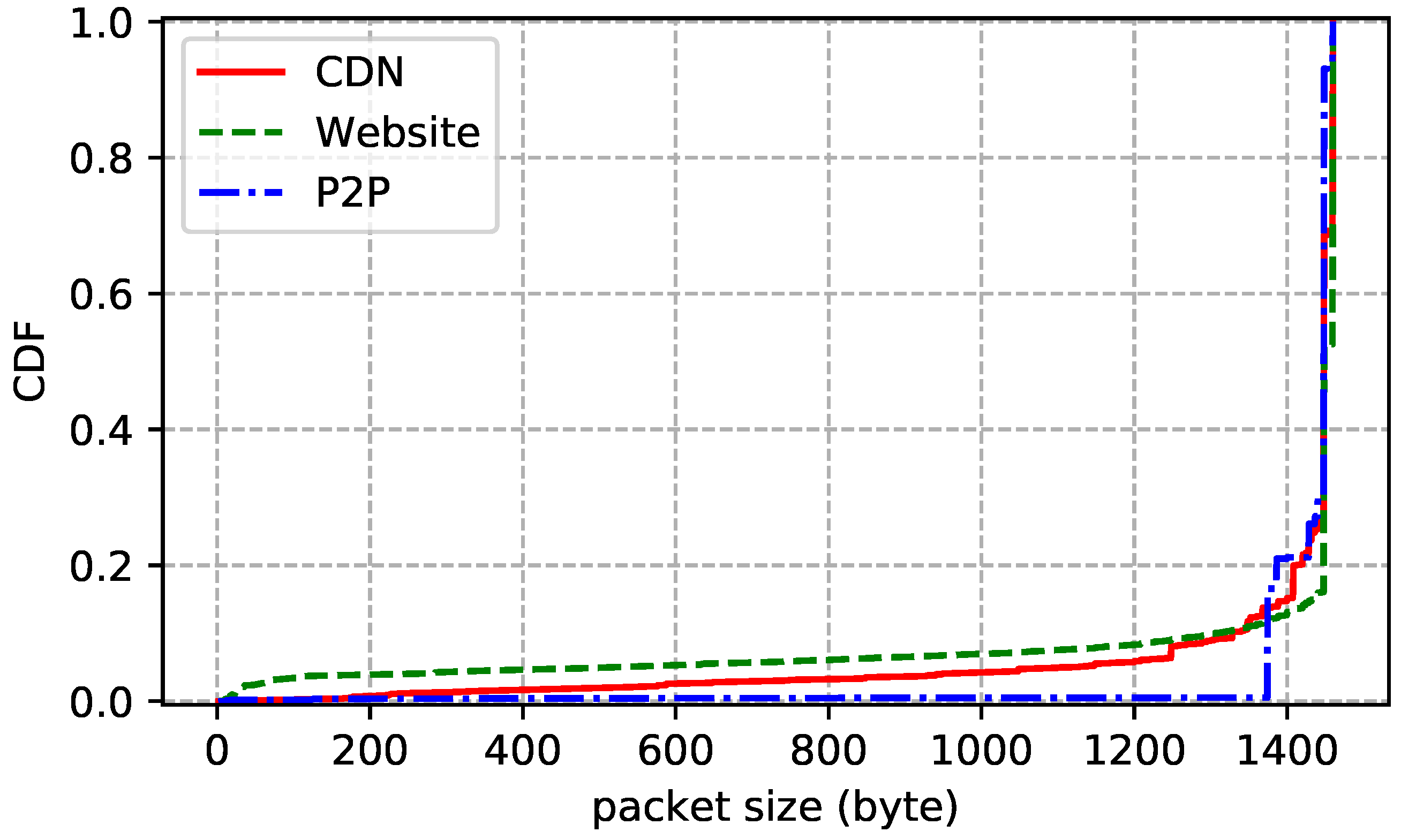
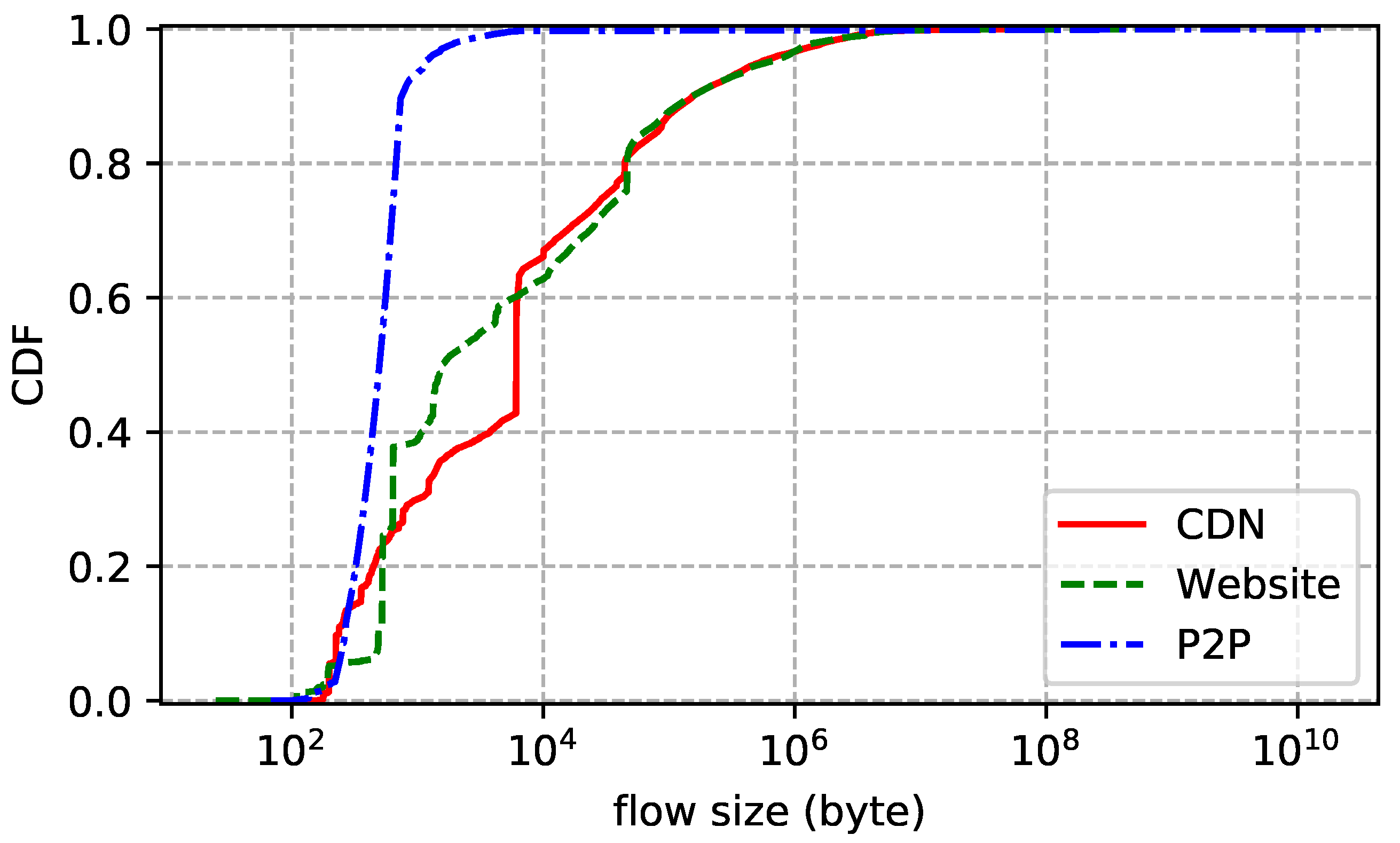
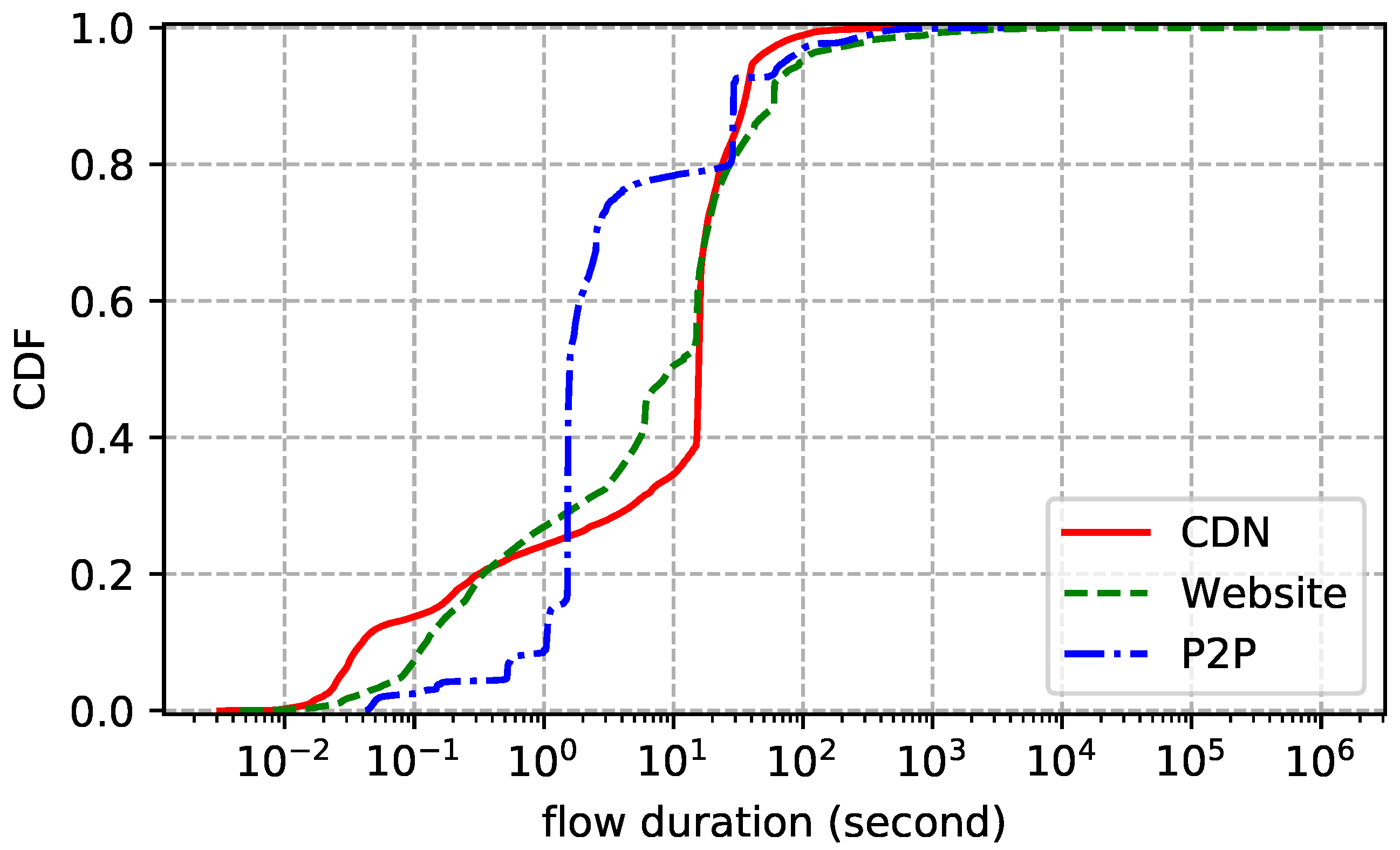
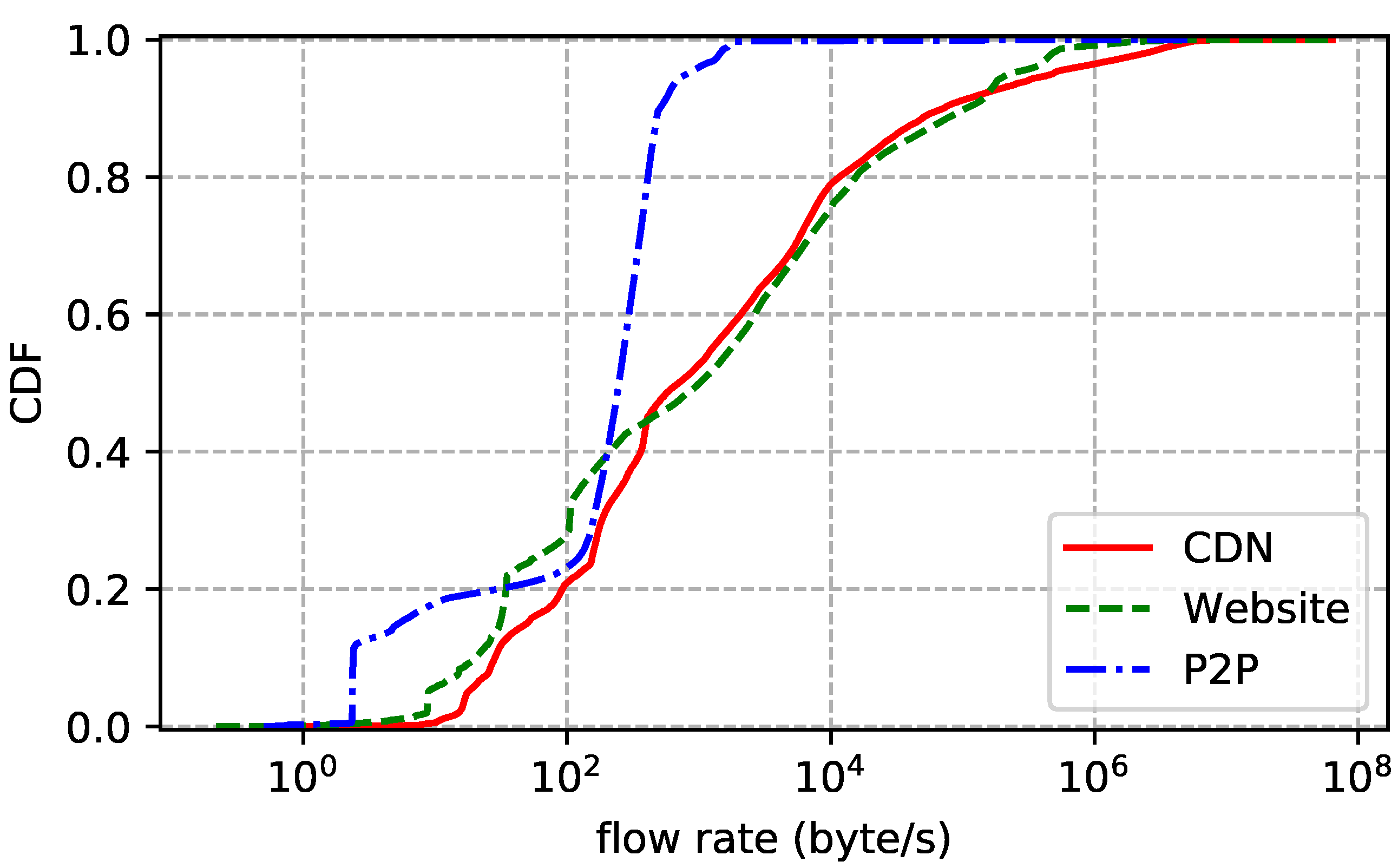
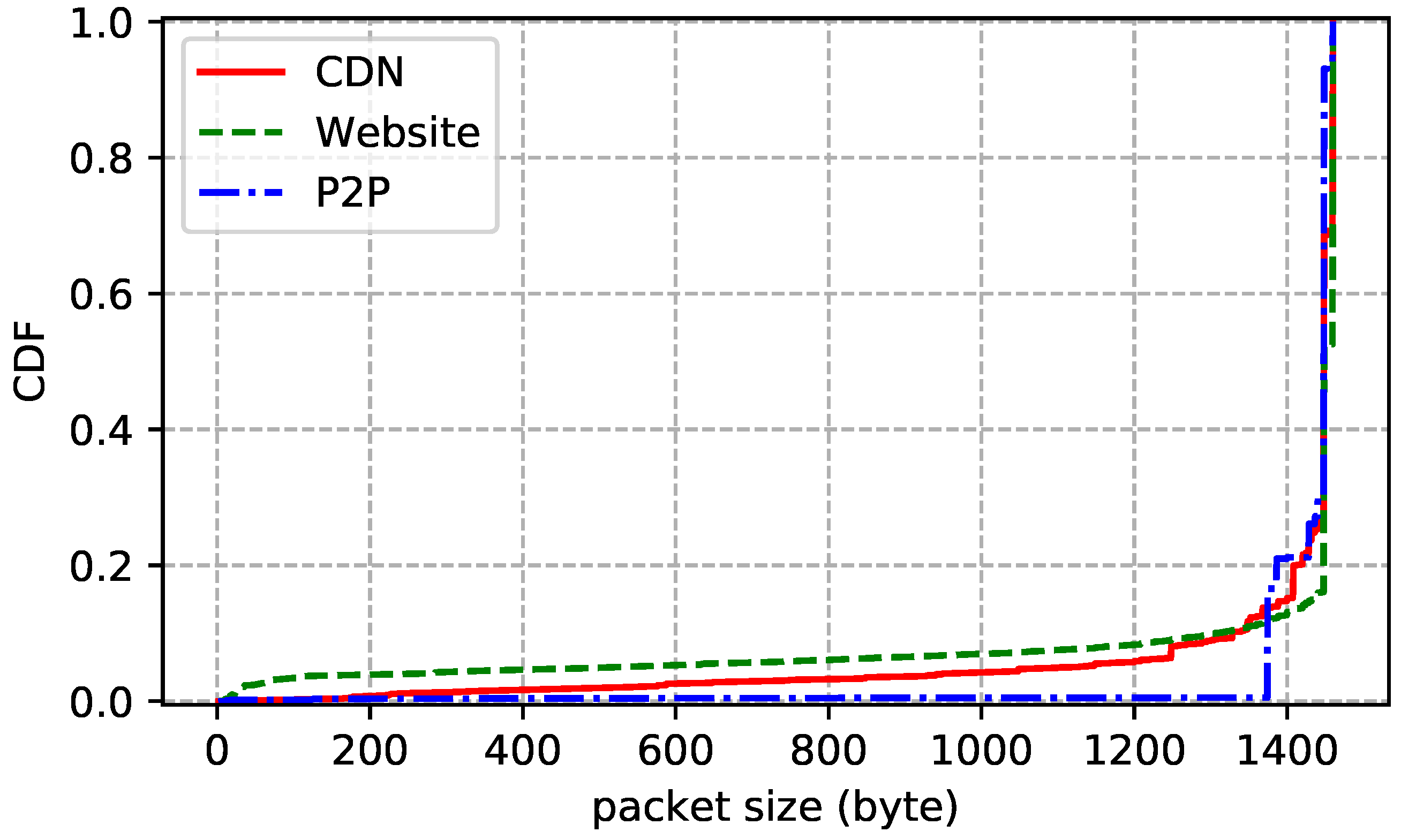
4. Datasets
5. Validation
5.1. Capacity
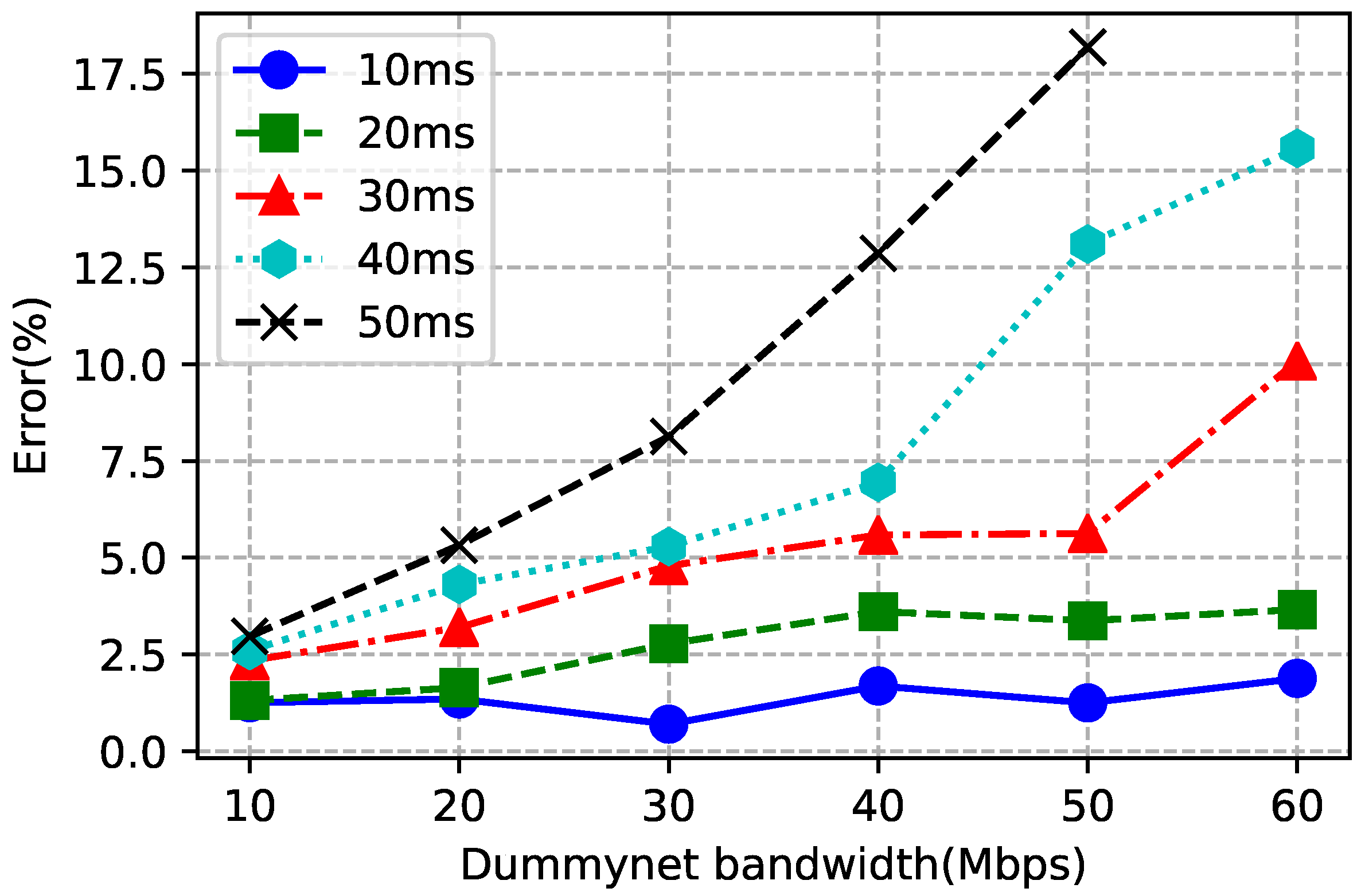
5.2. Dummynet Validation
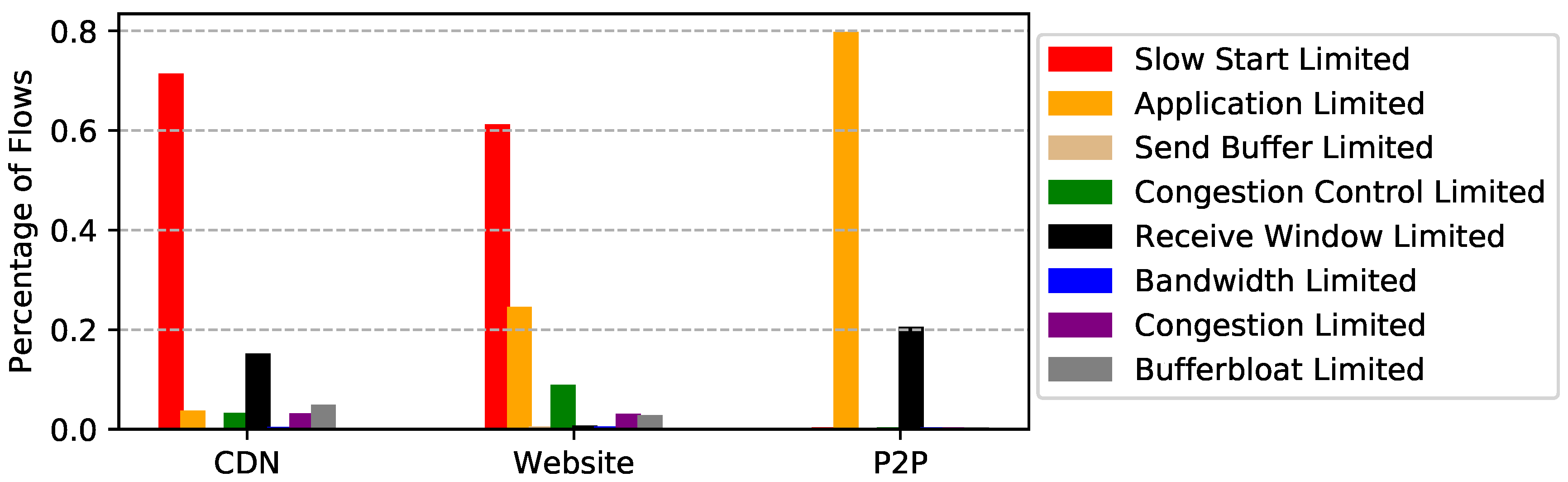
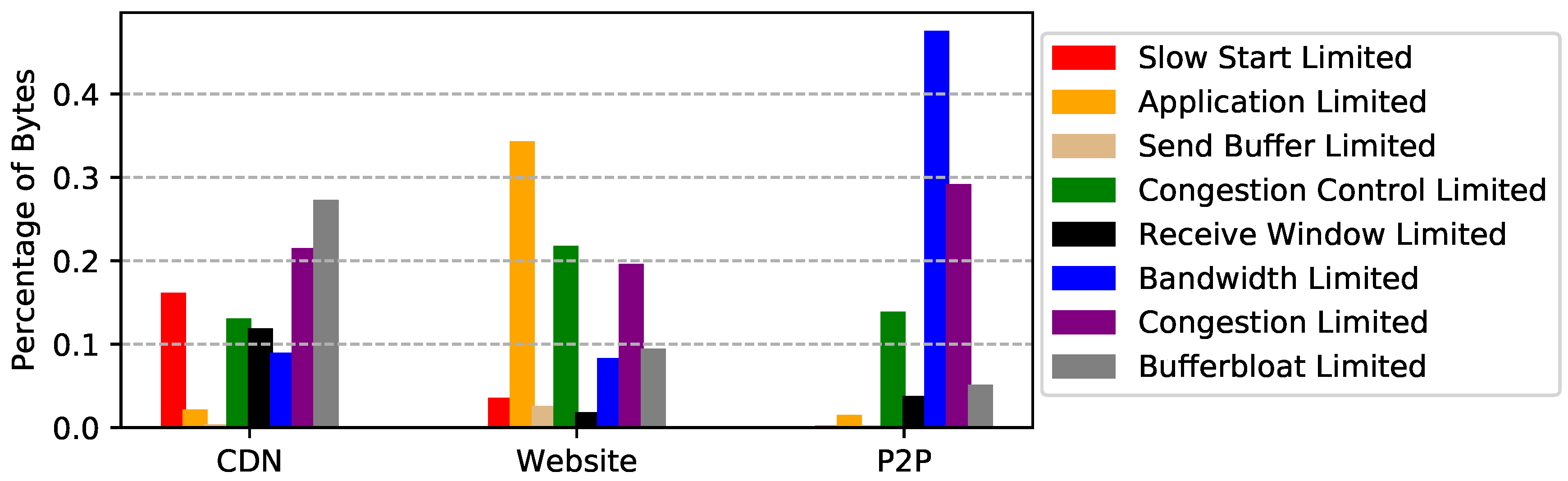
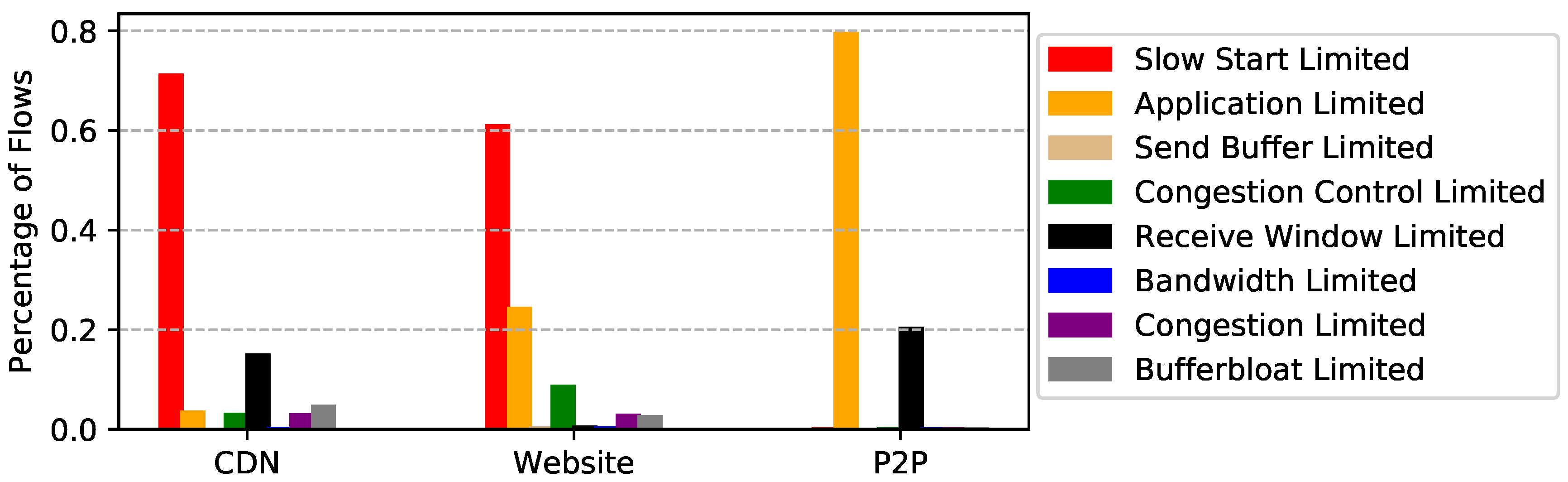
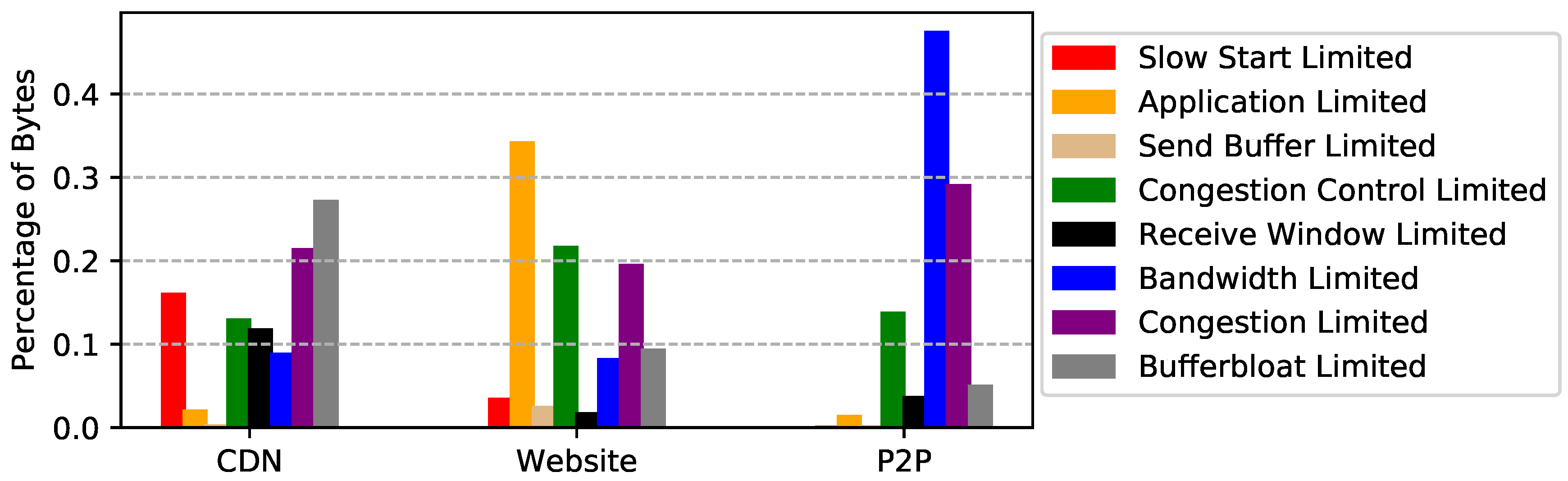
5.3. Performance Limit Validation
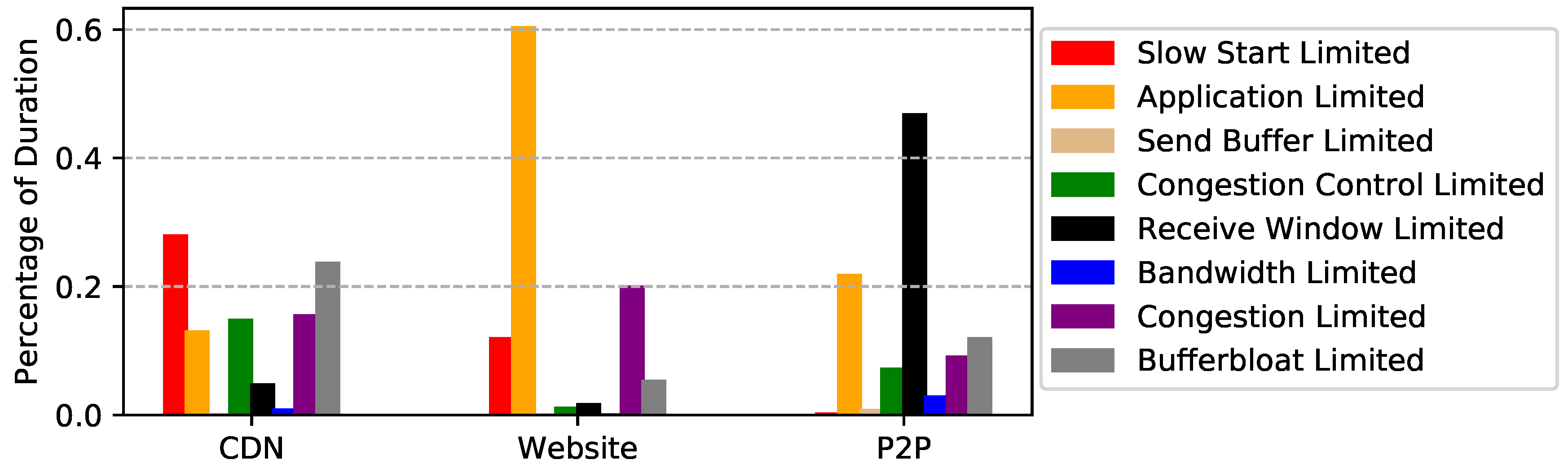
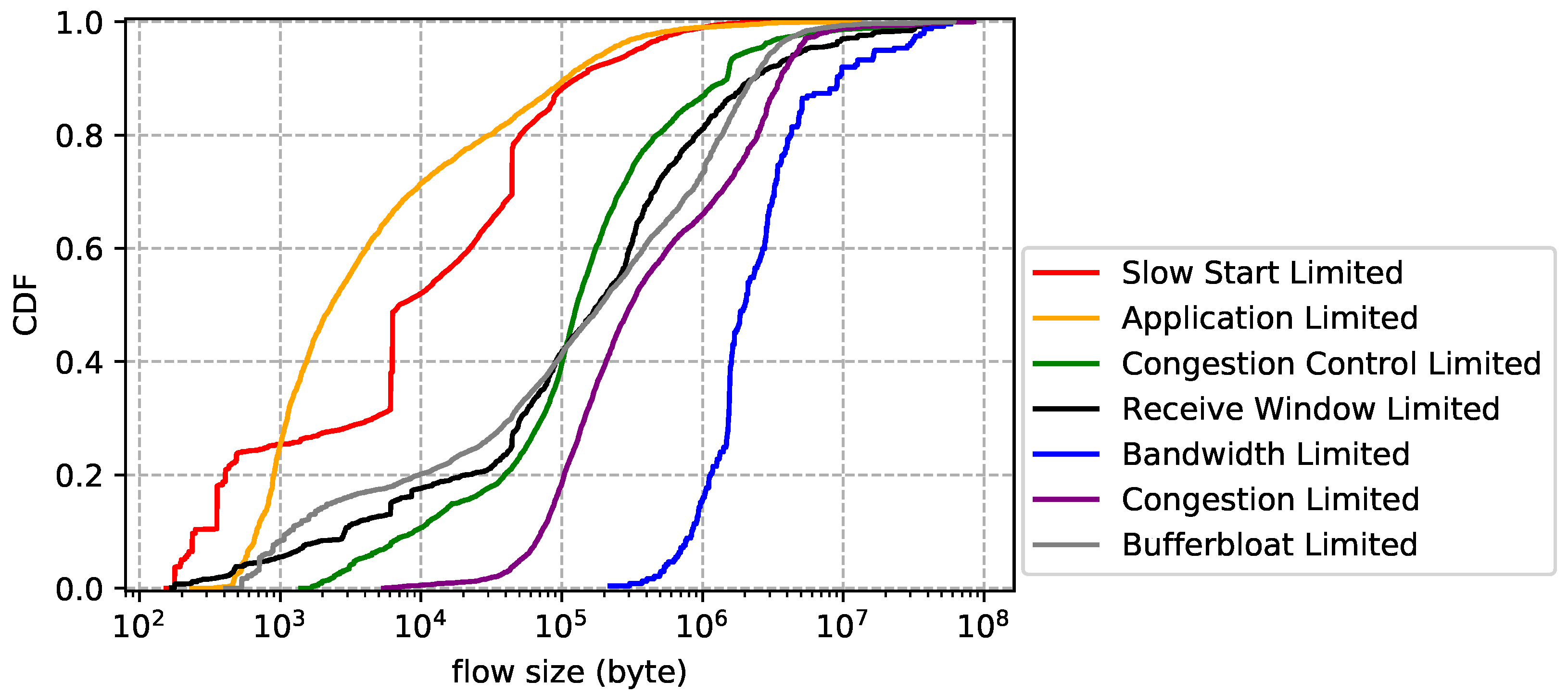
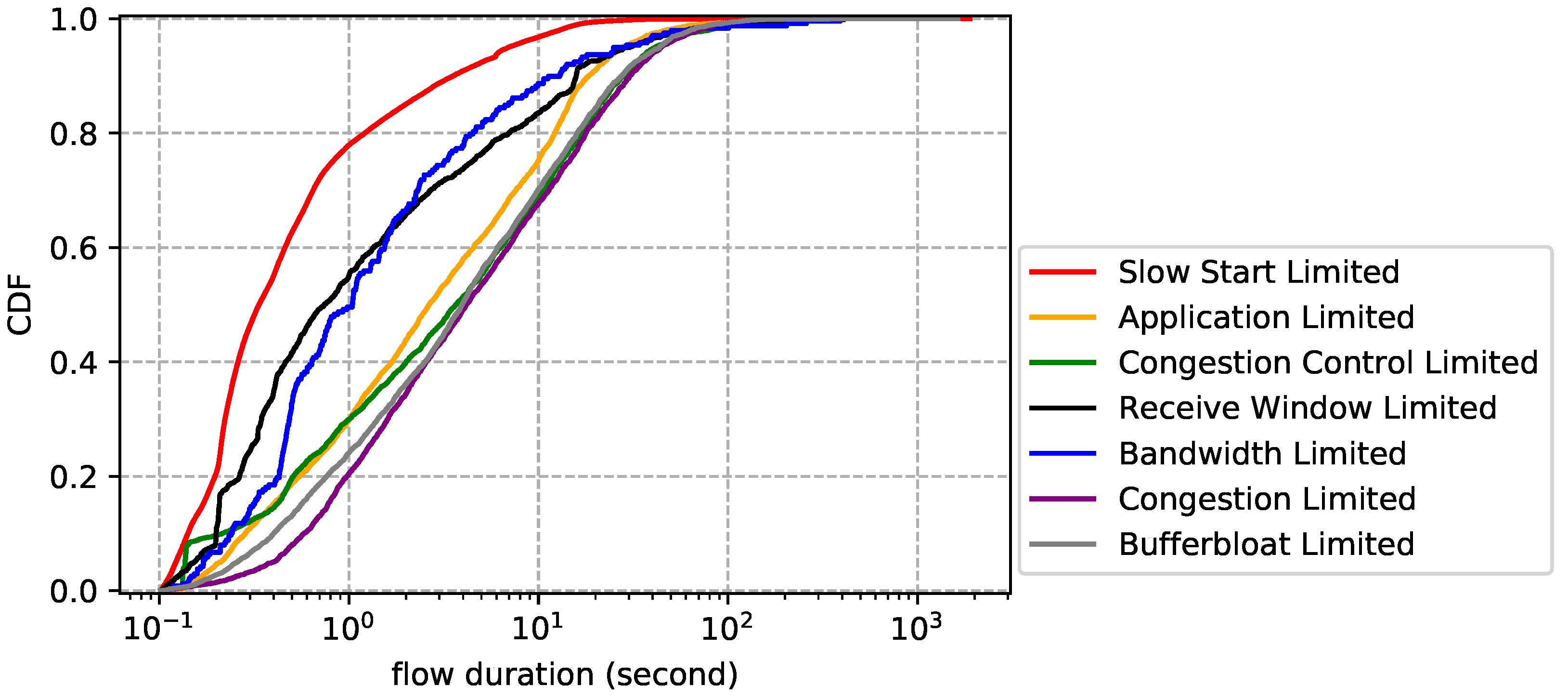
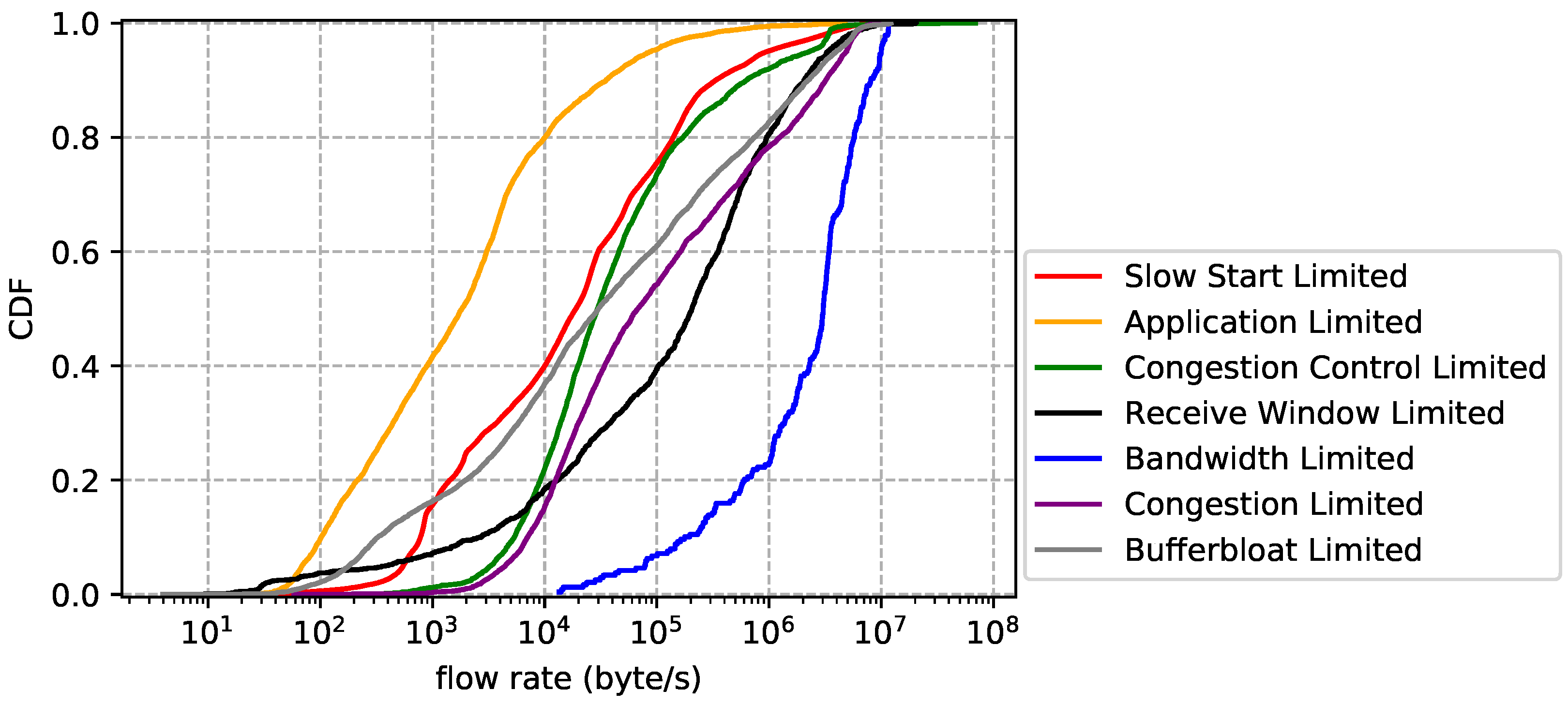
6. Observations
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gettys, J.; Nichols, K. Bufferbloat: Dark Buffers in the Internet. Commun. ACM 2012, 55, 57–65. [Google Scholar] [CrossRef]
- Nagle’s Algorithm. Available online: https://en.wikipedia.org/wiki/Nagle%27s_algorithm (accessed on 4 June 2018).
- Cardwell, N.; Cheng, Y.; Gunn, C.S.; Yeganeh, S.H.; Jacobson, V. BBR: Congestion-based Congestion Control. Commun. ACM 2017, 60, 58–66. [Google Scholar] [CrossRef]
- Arzani, B.; Ciraci, S.; Loo, B.T.; Schuster, A.; Outhred, G. Taking the Blame Game out of Data Centers Operations with NetPoirot. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 440–453. [Google Scholar]
- Ha, S.; Rhee, I.; Xu, L. CUBIC: A New TCP-friendly High-speed TCP Variant. SIGOPS Oper. Syst. Rev. 2008, 42, 64–74. [Google Scholar] [CrossRef]
- PF_RING: High-Speed Packet Capture, Filtering and Analysis. Available online: https://www.ntop.org/products/packet-capture/pfring (accessed on 4 June 2018).
- Zhang, Y.; Breslau, L.; Paxson, V.; Shenker, S. On the Characteristics and Origins of Internet Flow Rates. In Proceedings of the 2002 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Pittsburgh, PA, USA, 19–23 August 2002; pp. 309–322. [Google Scholar]
- Zhu, Y.; Kang, N.; Cao, J.; Greenberg, A.; Lu, G.; Mahajan, R.; Maltz, D.; Yuan, L.; Zhang, M.; Zhao, B.Y.; et al. Packet-Level Telemetry in Large Datacenter Networks. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, London, UK, 17–21 August 2015; pp. 479–491. [Google Scholar]
- Benko, P.; Malicsko, G.; Veres, A. A large-scale, passive analysis of end-to-end TCP performance over GPRS. In Proceedings of the IEEE INFOCOM 2004, Hong Kong, China, 7–11 March 2004; Volume 3, pp. 1882–1892. [Google Scholar]
- Sundaresan, S.; Feamster, N.T.R. Measuring the Performance of User Traffic in Home Wireless Networks. Commun. ACM 2015, 8995, 57–65. [Google Scholar] [CrossRef]
- Botta, A.; Pescapé, A.; Ventre, G.; Biersack, E.; Rugel, S. Performance footprints of heavy-users in 3G networks via empirical measurement. In Proceedings of the 8th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks, Avignon, France, 31 May–4 June 2010; pp. 330–335. [Google Scholar]
- Ricciato, F. Traffic monitoring and analysis for the optimization of a 3G network. IEEE Wirel. Commun. 2006, 13, 42–49. [Google Scholar] [CrossRef]
- Yu, M.; Greenberg, A.; Maltz, D.; Rexford, J.; Yuan, L.; Kandula, S.; Kim, C. Profiling Network Performance for Multi-tier Data Center Applications. In Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation, Boston, MA, USA, 30 May–1 April 2011; pp. 57–70. [Google Scholar]
- Cisco IOS NetFlow. Available online: https://www.cisco.com/c/en/us/products/ios-nx-os-software/ios-netflow/index.html (accessed on 4 June 2018).
- sFlow. Available online: https://en.wikipedia.org/wiki/SFlow (accessed on 4 June 2018).
- Cormode, G.; Korn, F.; Muthukrishnan, S.; Srivastava, D. Finding Hierarchical Heavy Hitters in Streaming Data. ACM Trans. Knowl. Discov. Data 2008, 1, 2:1–2:48. [Google Scholar] [CrossRef]
- Zhang, Y.; Singh, S.; Sen, S.; Duffield, N.; Lund, C. Online Identification of Hierarchical Heavy Hitters: Algorithms, Evaluation, and Applications. In Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement, Taormina, Sicily, Italy, 25–27 October 2004; pp. 101–114. [Google Scholar]
- Estan, C.; Varghese, G. New Directions in Traffic Measurement and Accounting. In Proceedings of the 1st ACM SIGCOMM Workshop on Internet Measurement, Pittsburgh, PA, USA, 19–23 August 2001; pp. 75–80. [Google Scholar]
- Zhao, Q.; Xu, J.; Liu, Z. Design of a Novel Statistics Counter Architecture with Optimal Space and Time Efficiency. SIGMETRICS Perform. Eval. Rev. 2006, 34, 323–334. [Google Scholar] [CrossRef]
- Narayana, S.; Tahmasbi, M.; Rexford, J.; Walker, D. Compiling Path Queries. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), Santa Clara, CA, USA, 16–18 March 2016; pp. 207–222. [Google Scholar]
- Foster, N.; Harrison, R.; Freedman, M.J.; Monsanto, C.; Rexford, J.; Story, A.; Walker, D. Frenetic: A Network Programming Language. SIGPLAN Not. 2011, 46, 279–291. [Google Scholar] [CrossRef]
- Narayana, S.; Sivaraman, A.; Nathan, V.; Goyal, P.; Arun, V.; Alizadeh, M.; Jeyakumar, V.; Kim, C. Language-Directed Hardware Design for Network Performance Monitoring. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 85–98. [Google Scholar]
- Tammana, P.; Agarwal, R.; Lee, M. Distributed Network Monitoring and Debugging with SwitchPointer. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), Renton, WA, USA, 9–11 April 2018; pp. 453–456. [Google Scholar]
- Li, W.; Wu, D.; Chang, R.K.; Mok, R.K. Demystifying and Puncturing the Inflated Delay in Smartphone-based WiFi Network Measurement. In Proceedings of the 12th International on Conference on Emerging Networking EXperiments and Technologies, Irvine, CA, USA, 12–15 December 2016; pp. 497–504. [Google Scholar]
- Huang, J.; Qian, F.; Gerber, A.; Mao, Z.M.; Sen, S.; Spatscheck, O. A Close Examination of Performance and Power Characteristics of 4G LTE Networks. In Proceedings of the 10th International Conference on Mobile Systems, Applications, and Services, Ambleside, UK, 25–29 June 2012; pp. 225–238. [Google Scholar]
- Huang, J.; Xu, Q.; Tiwana, B.; Mao, Z.M.; Zhang, M.; Bahl, P. Anatomizing Application Performance Differences on Smartphones. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, San Francisco, CA, USA, 15–18 June 2010; pp. 165–178. [Google Scholar]
- Deng, S.; Netravali, R.; Sivaraman, A.; Balakrishnan, H. WiFi, LTE, or Both?: Measuring Multi-Homed Wireless Internet Performance. In Proceedings of the 2014 Conference on Internet Measurement Conference, Vancouver, BC, Canada, 5–7 November 2014; pp. 181–194. [Google Scholar]
- Nguyen, B.; Banerjee, A.; Gopalakrishnan, V.; Kasera, S.; Lee, S.; Shaikh, A.; Van der Merwe, J. Towards Understanding TCP Performance on LTE/EPC Mobile Networks. In Proceedings of the 4th Workshop on All Things Cellular: Operations, Applications, & Challenges, Chicago, IL, USA, 22 August 2014; pp. 41–46. [Google Scholar]
- Karrer, R.P.; Matyasovszki, I.; Botta, A.; Pescape, A. MagNets-experiences from deploying a joint research-operational next-generation wireless access network testbed. In Proceedings of the 2007 3rd International Conference on Testbeds and Research Infrastructure for the Development of Networks and Communities, Lake Buena Vista, FL, USA, 21–23 May 2007; pp. 1–10. [Google Scholar]
- Karrer, R.P.; Matyasovszki, I.; Botta, A.; Pescapé, A. Experimental Evaluation and Characterization of the Magnets Wireless Backbone. In Proceedings of the 1st International Workshop on Wireless Network Testbeds, Experimental Evaluation & Characterization, Los Angeles, CA, USA, 29 September 2006; pp. 26–33. [Google Scholar]
- Paxson, V.; Allman, M. Computing TCP’s Retransmission Timer. RFC 2988, RFC Editor. 2000. Available online: https://tools.ietf.org/html/rfc2988 (accessed on 4 June 2018).
- UCloud: Leading Neutral Cloud Computing Service Provider of China. Available online: https://www.ucloud.cn/ (accessed on 4 June 2018).
- High Performance Load Balancer, Web Server, & Reverse Proxy. Available online: https://www.nginx.com/ (accessed on 4 July 2018).
- A Fast, Easy, and Free BitTorrent Client. Available online: https://transmissionbt.com/ (accessed on 4 July 2018).
- TCP Segmentation Offload. Available online: https://en.wikipedia.org/wiki/Large_send_offload (accessed on 4 June 2018).
- TCPDUMP/LIBPCAP Public Repository. Available online: https://http://www.tcpdump.org/ (accessed on 4 June 2018).
- Receive Side Scaling on Intel Network Adapters. Available online: https://www.intel.com/content/www/us/en/support/articles/000006703/network-and-i-o/ethernet-products.html (accessed on 4 June 2018).
- Tcpreplay: Pcap Editing and Replaying Utilities. Available online: https://tcpreplay.appneta.com/ (accessed on 4 June 2018).
- Carbone, M.; Rizzo, L. Dummynet Revisited. SIGCOMM Comput. Commun. Rev. 2010, 40, 12–20. [Google Scholar] [CrossRef]
- iPerf: The TCP, UDP and SCTP Network Bandwidth Measurement Tool. Available online: https://iperf.fr/ (accessed on 4 June 2018).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Bottleneck | Method |
|---|---|
| Slow start limited | Consecutive flight size fits the exponential relationship |
| Receive window limited | Minimum receive window size |
| Congestion limited | Packet retransmissions are seen and at least one RTT sample |
| Send buffer limited | Flight size and remains unchanged for at least three flights |
| Application limited | Flight size and at least one less-MSS-sized packet is seen |
| Congestion control limited | Flight size |
| Bandwidth limited | More than half of the delivery rate samples in the flight are large than |
| Bufferbloat limited | All the RTT samples are larger than |
| Trace | Date | Size | Length | #Packets | #Flows | #Max Concurrent Flows |
|---|---|---|---|---|---|---|
| CDN | 1 March 2018 | 30 GB | 20 min | 32 M | 160 K | 1382 |
| Website | 2 January 2018 | 100 GB | 3 days | 98 M | 550 K | 459 |
| P2P | 10 January 2018 | 400 GB | 5 days | 431 M | 1 M | 59 |
| Limiting Factor | Precision | Recall | F1 Score |
|---|---|---|---|
| Slow start limited | 0.95 | 0.80 | 0.86 |
| Application limited | 0.98 | 0.99 | 0.98 |
| Send buffer limited | 0.91 | 0.98 | 0.94 |
| Receive window limited | 1.00 | 0.99 | 0.99 |
| Congestion control limited | 0.94 | 0.90 | 0.91 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, G.-Q.; Xue, G.; Chen, Y.-C. Network Measurement and Performance Analysis at Server Side. Future Internet 2018, 10, 67. https://doi.org/10.3390/fi10070067
Peng G-Q, Xue G, Chen Y-C. Network Measurement and Performance Analysis at Server Side. Future Internet. 2018; 10(7):67. https://doi.org/10.3390/fi10070067
Chicago/Turabian StylePeng, Guang-Qian, Guangtao Xue, and Yi-Chao Chen. 2018. "Network Measurement and Performance Analysis at Server Side" Future Internet 10, no. 7: 67. https://doi.org/10.3390/fi10070067
APA StylePeng, G.-Q., Xue, G., & Chen, Y.-C. (2018). Network Measurement and Performance Analysis at Server Side. Future Internet, 10(7), 67. https://doi.org/10.3390/fi10070067