1. Introduction
Internet of things (IoT) [
1] connects mobile devices to the internet and makes it possible for objects to connect. However, due to their limited memory, storage, CPU, and battery life, mobile devices need to offload computing-intensive or energy-consuming tasks to cloud computing infrastructure via the internet. Mobile cloud computing (MCC) [
2] is a new paradigm for augmenting devices via remote cloud resource, which can overcome resource constraints for mobile devices. It is a hotspot for research on how to run applications on mobile devices by utilizing cloud resource effectively in an MCC environment.
Offloading the tasks that require considerable computational power and energy to the remote cloud server is the best way to augment ability and reduce the energy consumption for mobile devices. Many different offloading methods have been proposed in recent research. The offloading strategy is based on many factors such as the energy consumption of mobile devices, the network bandwidth, latency, the capacity of cloud servers, and the application structures that save bandwidth or speed up the execution, etc. Considering these factors, the offloading strategy compares the cost of local and remote execution in order to decide which tasks should be offloaded. The cloud computing [
3] makes task offloading possible which is adopted in MCC environment. One of its core techniques is virtualization, which is used to run multiple operating systems and applications based on maintaining isolation. The virtual machines (VMs) run on physical machines (PMs) in the remote cloud. By offloading tasks to the remote cloud, the energy consumption of mobile devices can be reduced [
4,
5]. The offloaded tasks run on corresponding VMs that are commonly deployed in distributed cloud centers. Offloading tasks to different PMs may lead to a different delay for mobile devices. Moreover, the utilization rate of PM in a cloud center should be considered as this could cause the waste of physical machine resources if it is at a lower level.
The main contributions of this paper are as follows:
First, we take into account utilization rate of PM and delay for task offloading simultaneously. Then, based on theoretical analysis, we find that a higher utilization rate of PM and a lower delay are conflicting commonly with each other. In order to trade off between utilization rate of PM and delay, we use deep reinforcement learning (DRL) to find optimal PM to execute the offloaded tasks by introducing a weighted reward. Moreover, a novel two-layered reinforcement learning algorithm is presented to address the problem, in which the high dimensionality of the state space and action space might affect the speed of learning optimal policy.
This paper is organized as follows:
Section 2 introduces the related works. We propose the problem that our paper focuses on and give the definition of the utilization rate of PM and delay in
Section 3.
Section 4 introduces the deep reinforcement learning. In
Section 5, we formulate our problem using DRL and propose an algorithm for task offloading based on DRL. Moreover, a two-layered reinforcement learning (TLRL) structure for task offloading is proposed to improve the speed of learning optimal policy. We show the advantage of our proposed algorithm for task offloading through simulation experiments in
Section 6. In
Section 7, we conclude our paper.
2. Related Works
Much research has studied the task offloading in MCC environment. They propose many different methods for different optimization objects. Zhang et al. [
6] provides a theoretical framework for energy-optimal MCC under stochastic wireless channel. They focus on conserving energy for the mobile device, by executing tasks in the local device or offloading to the remote cloud. The scheduling problem is formulated as a constrained optimization problem in their study. The paper [
7] proposed a scheduling algorithm based on Lyapunov optimizing problem, which schedules the tasks for the remote server or local execution dynamically. It aims at balancing the energy consumption and delay between the device and remote server according to the current network condition and task queue backlogs. Liu et al. [
8] formulate the delay minimization problem under power-constrained using Markov chain. An efficient one–dimensional search algorithm is proposed to find the optimal task offloading policy. Their experimental results show that proposed task scheduling policy could achieve a shorter average delay than the baseline policies. Considering the total execution time of tasks. Kim et al. [
9] considered the situation that the cloud server is not smooth and large-scale jobs are needed to process in MCC. They proposed an adaptive mobile resource offloading to balance the processing large-scale jobs by using mobile resources, where jobs could be offloaded to other mobile resources instead of the cloud. Shahzad and Szymanski [
10] proposed an offloading algorithm called dynamic programming with hamming distance termination. They try to offload as many tasks as possible to the cloud server when the bandwidth is high. Their algorithm can minimize the energy cost of the mobile device while meeting a task’s execution time constraints.
There are also some studies focused on resource management for task offloading. Wang et al. [
11] proposed a framework named ENORM for resource management in fog computing environment. A novel auto-scaling mechanism for managing the edge resources is studied, which can reduce the latency of target applications and improve the QoS. Lyu et al. [
12] considered the limited resource in the proximate cloud and studied the optimization for resource utilization and offloading decision. They try to optimize the resource utilization for an offloading decision, according to the user preferences on task completion time and energy consumption. They regard the resource of proximate clouds as a whole with limited resource. They proposed a heuristic offloading decision algorithm in order to optimize the offloading decision, and computation resources to maximize system utility. Ciobanu et al. [
13] introduced a Drop Computing paradigm that employs the mobile crowd formed of devices in close proximity for quicker and more efficient access. It was different from traditional method, where every data or computation request going directly to the cloud. This paper mainly proposed the decentralized computing over multilayered networks for mobile devices. This new paradigm could reduce the costs of employing a cloud platform without affecting the user experience. Chae et al. [
14] proposed a cost-effective mobile-to-cloud offloading platform, which aimed at minimizing the server costs and the user service fee. Based on ensuring the performance of target applications, the platform offloaded as many applications to the same server as possible.
Machine learning technologies have been applied for offloading decision. Liu et al. [
15] developed a mobile cloud platform to boost the general performance and application quality for mobile devices. The platform optimized computation partitioning scheme and tunable parameter setting for getting a higher comprehensive performance, based on history-based platform-learned knowledge, developer-provided information and the platform-monitored environment conditions. Eom et al. [
16] proposed a framework for mobile offloading scheduling based on online machine learning. The framework provided an online training mechanism for the machine learning-based runtime scheduler, which supported a flexible policy. Through the observation of previous offloading decisions and their correctness, it can adapt scheduling decisions dynamically. Crutcher et al. [
17] focused on reducing overall resource consumption for computing offloading in mobile edge networks. They obtained features composed of a “hyperprofile” and position nodes by predicting costs of offloading a particular task. Then a hyperprofile-based solution was formalized and a machine learning techniques based to predict metrics for computation offloading was explored in this paper.
However, existing researches have some limitations. Papers [
6,
7,
8,
10] only consider the energy and delay as optimization objects that ignore the management of cloud resources. Moreover, some works [
11,
12,
14] focus on resource management for task offloading, which do not consider utilization rate of cloud resources. These works rarely consider utilization rate of PM in cloud server and delay caused by arranging the offloaded task to different PMs in the cloud simultaneously. They do not consider the detail of the remote cloud, which has an impact on offloaded tasks. The bandwidth between the different PMs of the cloud and mobile devices are different because PMs of the cloud are distributed geographically in a real environment. This can affect the transmission time that a task is offloaded from mobile device to the PM. Moreover, a waiting time in the cloud for the offloaded task will be taken into consideration. Besides, the resources of the cloud are also limited. If the number of offloaded tasks is too large due to the popularity of mobile devices, the utilization rate of cloud resources should be considered to avoid waste of cloud resources. Our paper intends to study scheduling the offloaded tasks to optimal PM by trading off between utilization rate of physical machine and delay, in which the delay comprises of the waiting time, the execution time of offloaded task and data transmission time. We model the problem using DRL to obtain an optimal policy for task offloading, which is more effective than traditional reinforcement learning when facing to high-dimension state space and action space. Different from existing studies [
15,
16,
17] that applied machine learning technologies for offloading based on related historical data, we intend to study an online learning method based on DRL where a weighted reward is introduced for tradeoff between utilization rate of PM and delay. Furthermore, we propose a two-layered reinforcement learning (TLRL) algorithm for task offloading to improve learning speed, where the dimensions of state space and action space are reduced by utilizing the k-NN [
18] to classify the PMs in the remote cloud.
3. Problem Statement
Previous works for task offloading focus on whether to offload corresponding tasks to a cloud server in order to optimize a certain parameter. They regard the cloud resource as a whole and make decisions for task offloading according to resource availability, energy consumption etc. They do not consider improving the utilization rate of cloud resource, which may lead to a waste of cloud resources. A dedicated cloud resource manager is in charge of optimal resource allocation following its optimization objects, such as saving energy, decreasing the waste of computing resource etc. It does not consider the impact on mobile devices in mobile cloud computing environment. In our paper, we intend to improve the utilization rate of cloud resource and reduce the latency when the cloud resource is applied to augment mobile devices, which is seldom considered by other studies on the issue of task offloading. Moreover, the selection of physical machines that an offloaded task runs in can affect the delay of offloaded tasks. Therefore, it is necessary to make sure a high utilization rate of PM and a low delay for offloaded tasks when offloading tasks to the cloud. We will mainly study the tradeoff between the optimal utilization of cloud resource and the delay for offloaded tasks in our paper.
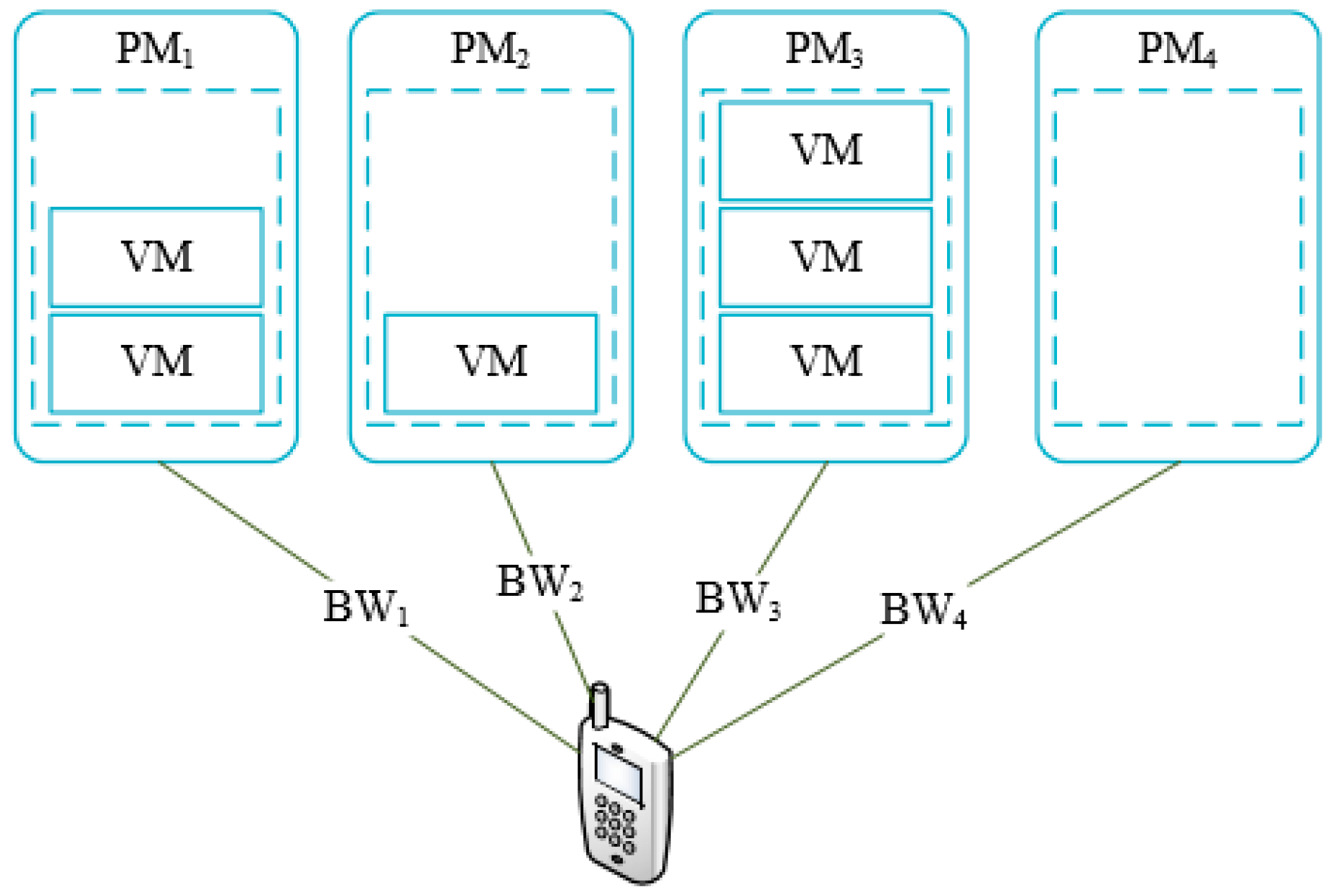
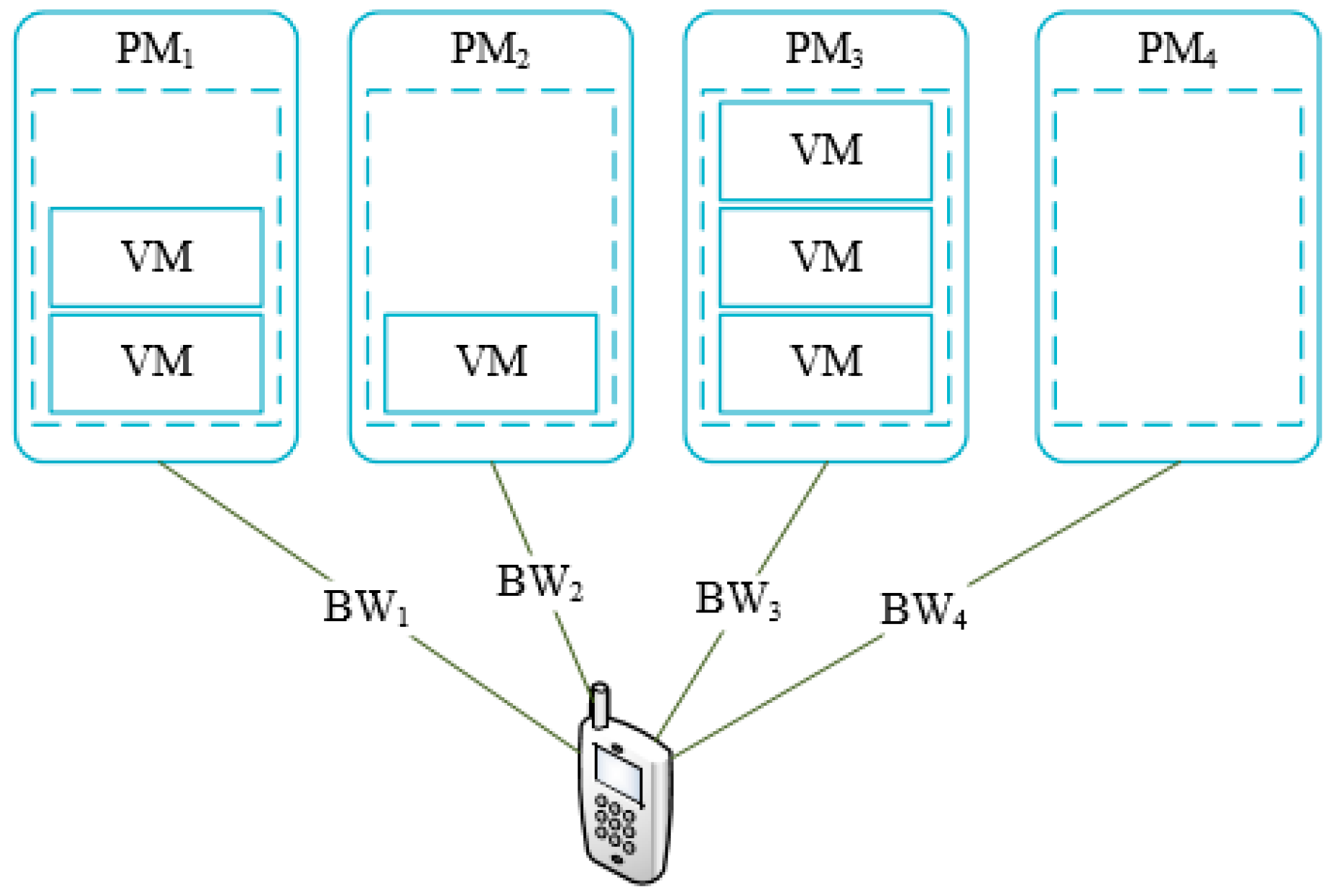
We consider the real cloud environment where all tasks run on the virtual machines and a physical machine could deploy several virtual machines. The proximity cloud may reduce data transmission time between the mobile device and cloud. In our paper, we consider the bandwidth between mobile devices and the PMs. As shown in
Figure 1,
represents the
physical machine (PM) in cloud center that is used to run VMs. We can see that the number of VMs running in each PM are different. The
is not in a running state that there are no VMs running in. The bandwidth between mobile devices and the
PM is denoted as
correspondingly. Suppose that the number of current running PMs is
and the max number of VMs that
PMs could run is
. The number of current running VMs on these
PMs is
and the max number of VMs each PM can run is
. We defined utilization rate of PM as follow
We can see that proposed algorithm should decrease the and increase the in order to get larger when offloading tasks to cloud server. Therefore, offloaded tasks should be assigned to those PMs that have run VMs preferentially than being assigned to a new PM. However, it may lead to a higher delay than offloading tasks to a new PM.
We define the delay caused by an offloading task as follow:
where
is the execution time of offloaded tasks in cloud server, and
is the amount of data to be transferred between the mobile device and the cloud server.
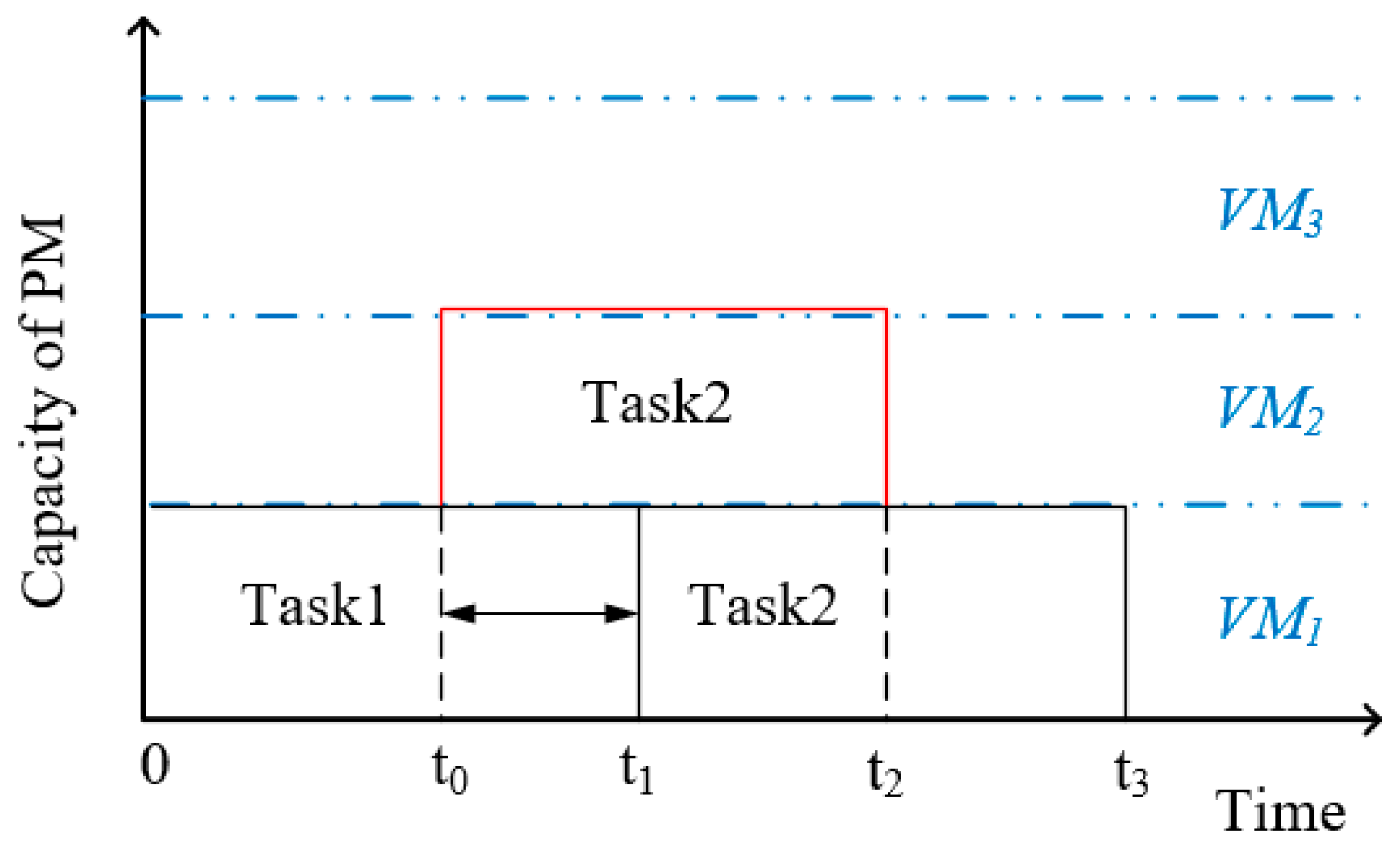
is the waiting time when an offloaded task is assigned to the VM that existing another task is running in. As shown in
Figure 2, the Task1 is running on
in the time among 0 and
, and only one VM is running in current PM during that period time. The
of Task1 is
. If an offloaded task Task2 arrives at
, then there are two ways to choose for running the offloaded task Task2. One way is that the Task2 is assigned to
, it will be executed at
when the Task1 is completed. Therefore the waiting time caused by this way is
. Another way is that the Task2 is offloaded to a new running VM
that no task is running on. The Task2 can be executed in
at
and there is no need to wait,
. Moreover, the VMs from different PMs are in different running states, which could lead to different waiting time for offloaded tasks. Meanwhile, the bandwidths between mobile devices and the PMs are also different. We need choosing the optimal PM for offloaded tasks to make the delay lower according to Formula (3).
Through this analysis above, we find that choosing different physical machines to run offloaded tasks may affect the latency and the utilization rate of physical machines. In this paper, we mainly focus on assigning the offloaded tasks to an optimal PM for making sure a higher utilization rate of PM and a lower delay .
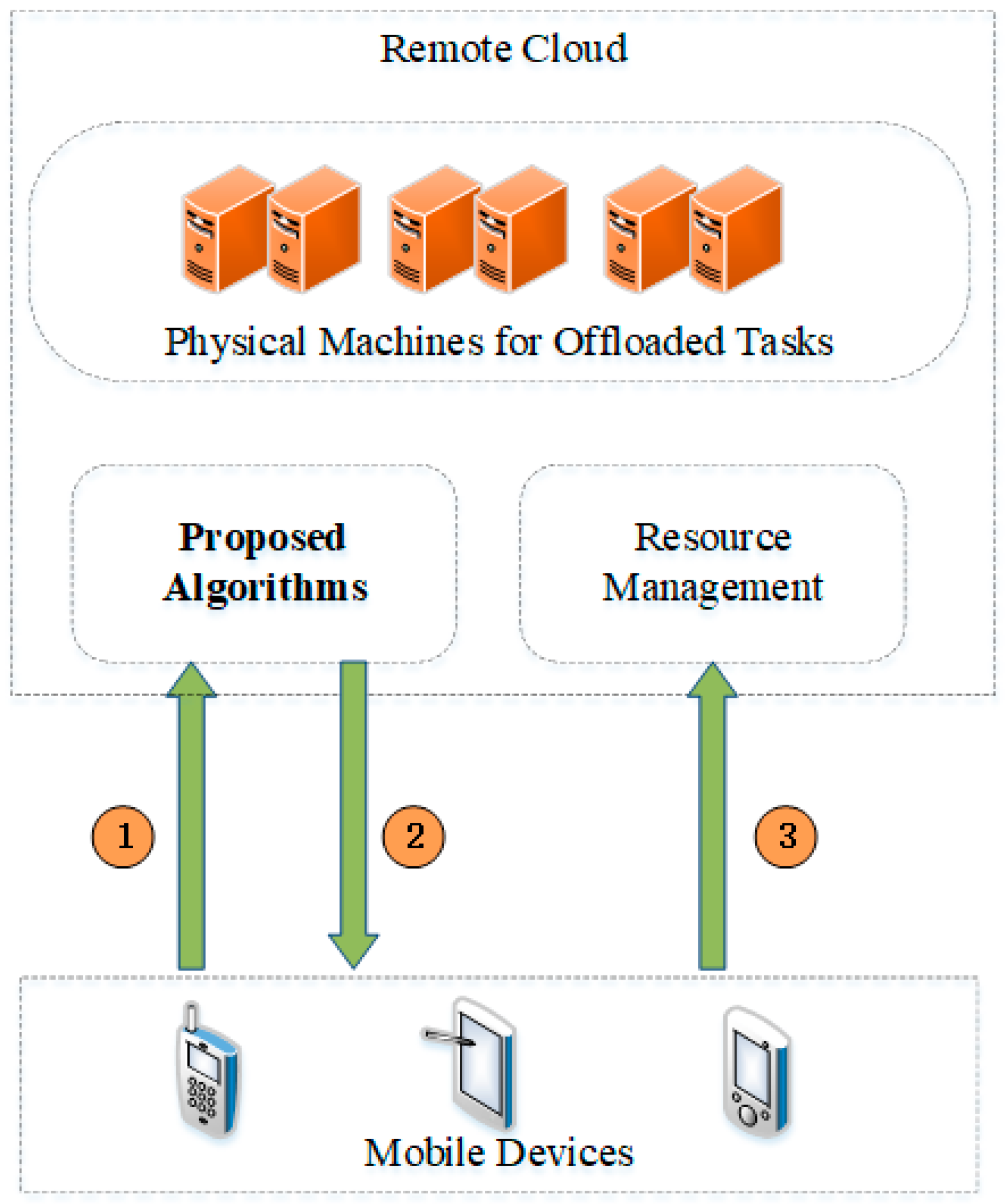
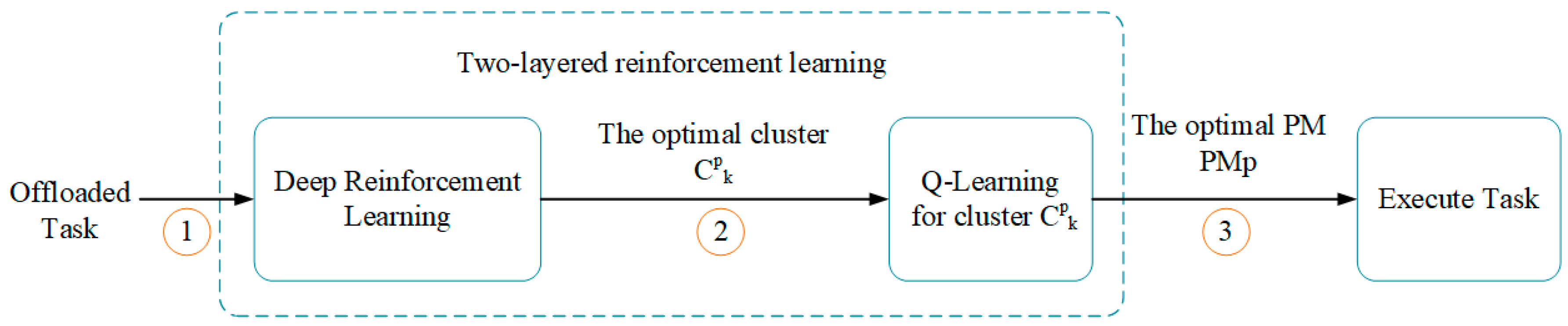
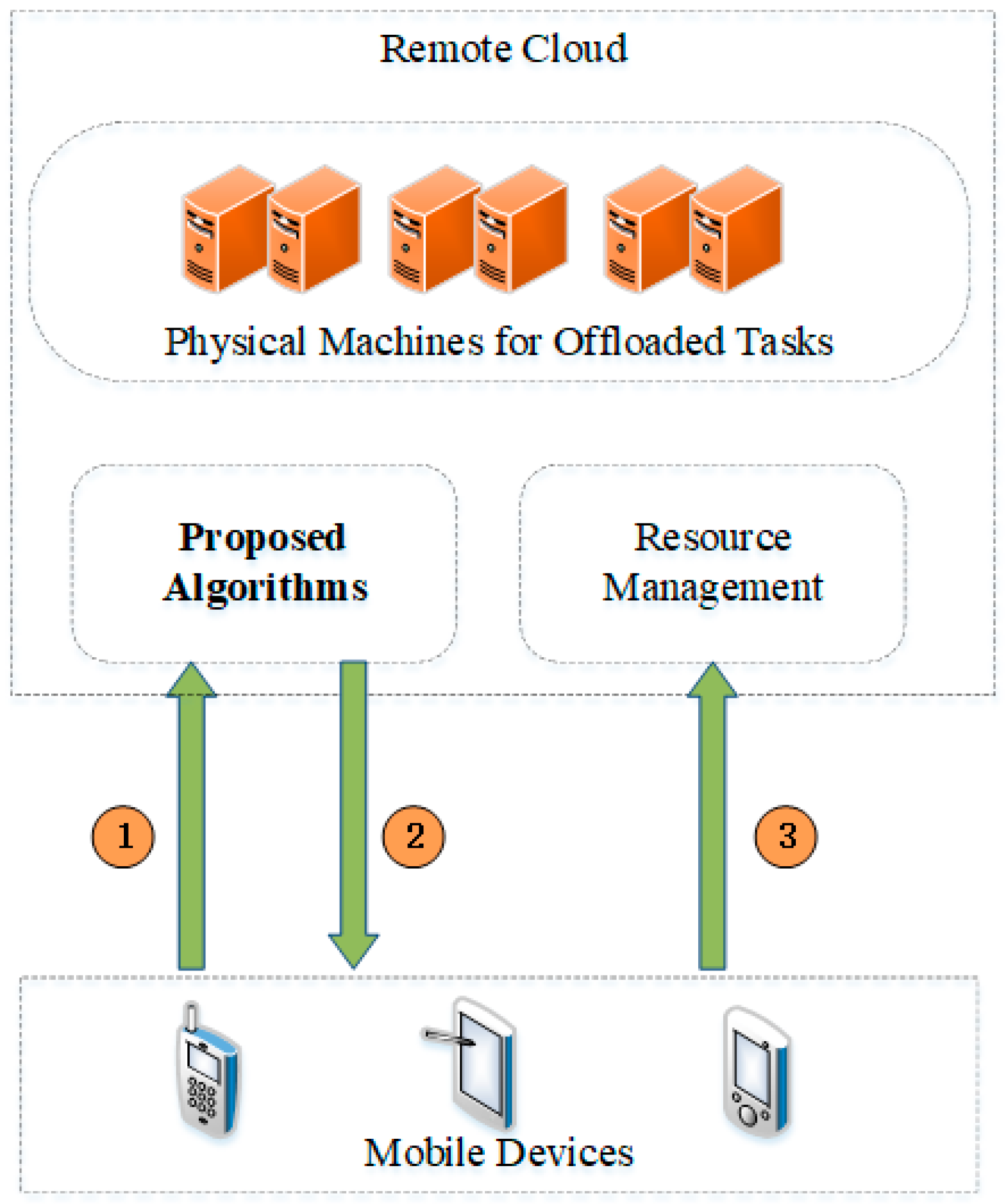
Our proposed algorithms will be deployed in the remote cloud, and the process of offloading tasks to the remote cloud is illustrated in
Figure 3. Fist, the information of offloaded tasks will be sent to Proposed Algorithms in step 1. According to the information, the module of Proposed Algorithms can select an optimal physical machine for executing the offloaded tasks. Therefore, the ID of the obtained optimal physical machine from the module of Proposed Algorithms will be sent back to the corresponding mobile devices in step 2. Moreover, the offloaded task and the ID of the optimal physical machine will be sent to the module of Resource Management. Finally, the module of Resource Management arrange the offloaded tasks to corresponding physical machines.
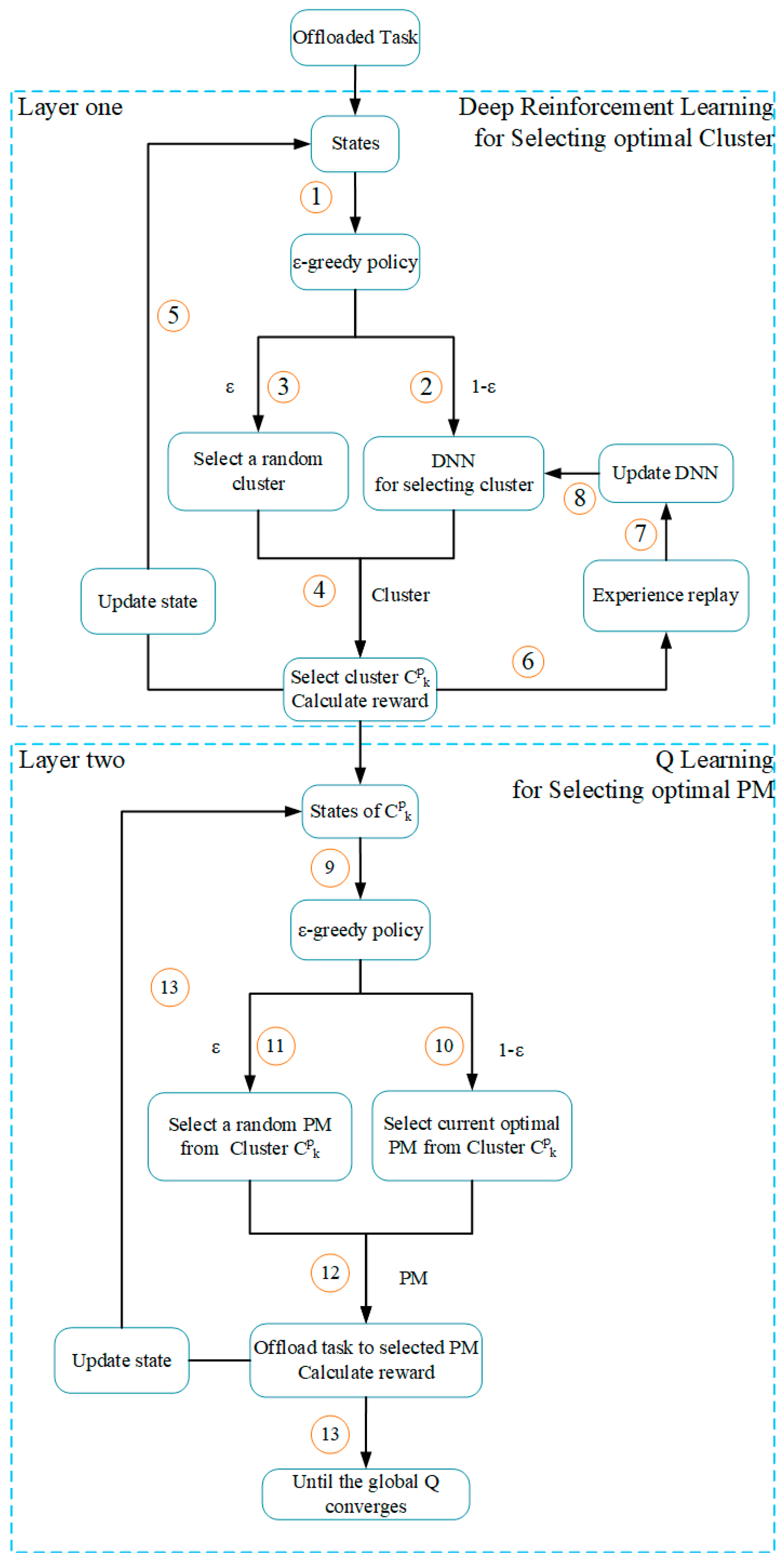
4. Deep Reinforcement Learning
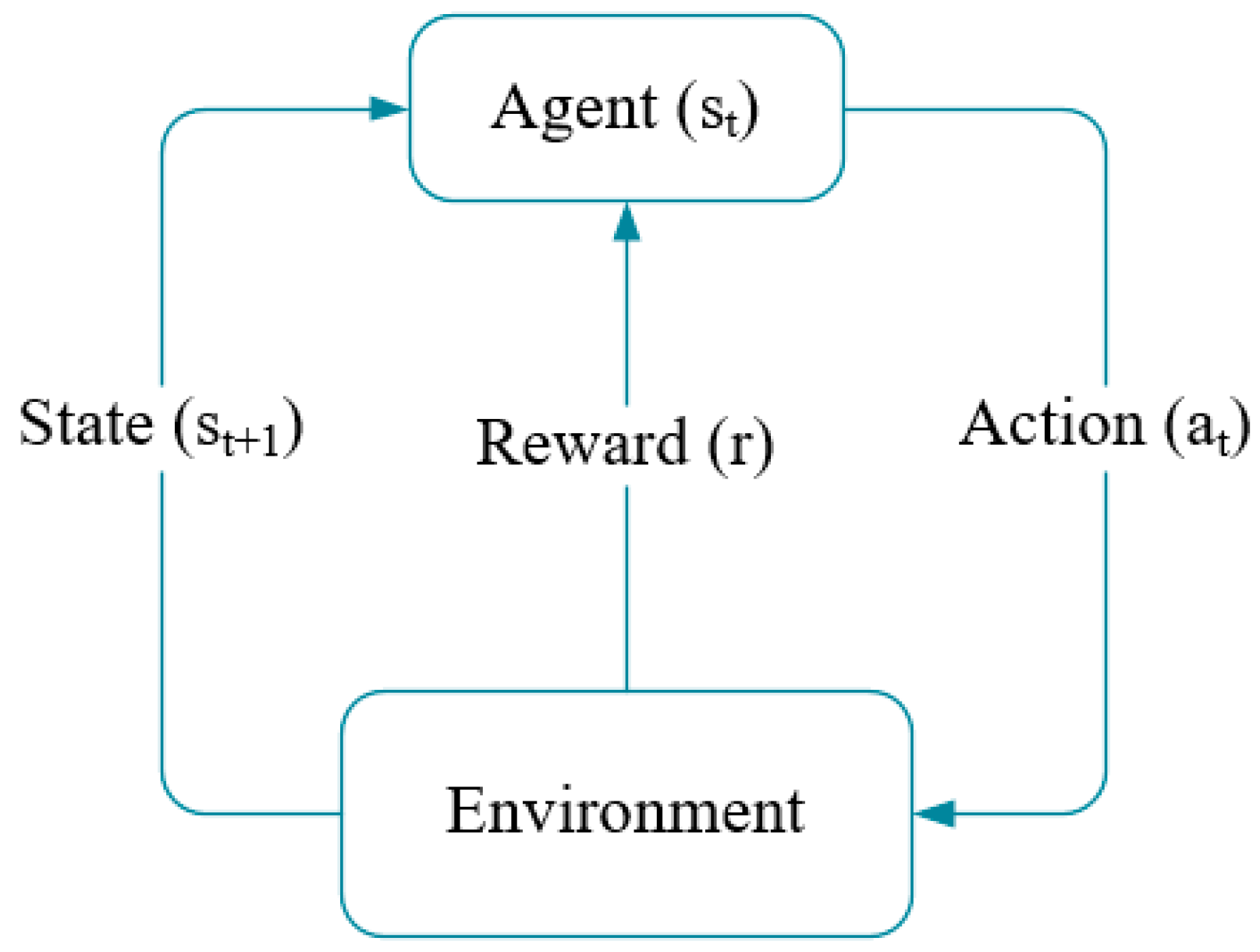
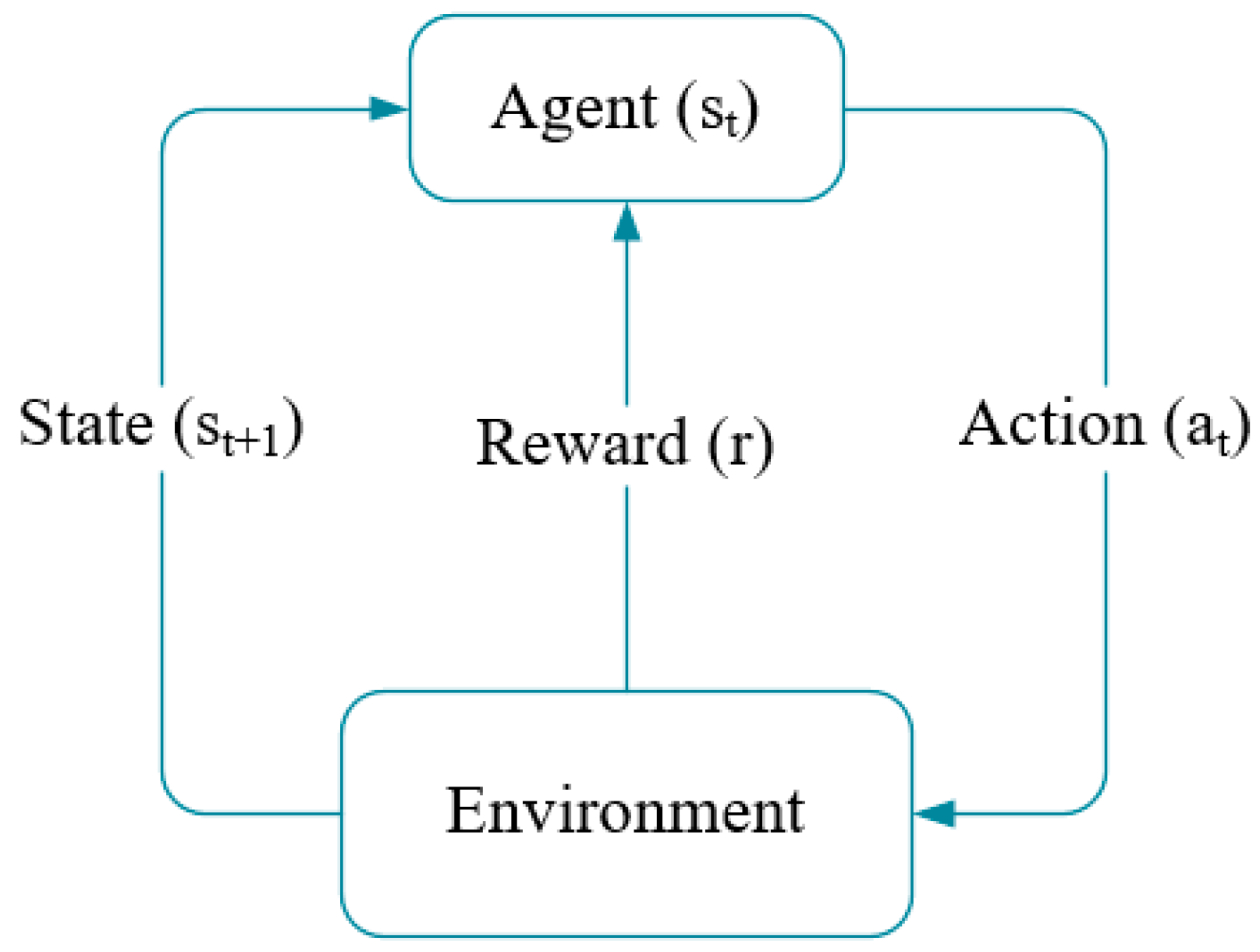
Reinforcement learning (RL) is a subfield in machine learning, in which the agent can learn from trial and error by interacting with the environment and observing reward [
19]. As shown in
Figure 4, the agent, also referred to as the decision-maker, obtains an immediate reward
from the environment according to the current action
when its current state is
. Moreover, the agent’s state transits to
after executing the action
. The goal of RL is to lean an optimal policy for an agent that can make it choose the best action according to current state.
We can use a tuple to present the RL, the action an agent can choose is and the state an agent can reach is . R represents the space of reward value.
Q learning is a model-free algorithm [
20] for RL, which can be used to get the optimal policy. The evaluation function
represents the maximum discount cumulative reward when the agent starts with state
and uses
as the first action. Therefore, the optimal policy
could be denoted as:
According to the Formula (4), in order to obtain the optimal policy
, an agent needs to select the action that maximizes
when agent is in state
. In general,
could be iteratively updated by the following Formula:
where
represents immediate reward when the agent is in state
and selects action
to execute.
is a constant that determines the discount value of a delayed reward.
is learning rate, a larger value of α will lead to a faster convergence for
Q function.
However, when the state space and the action space are too large, it is very hard to make
converge by traversing all states and actions. DRL can handle the complicated problems with large state space and action space [
21]. It has been successfully applied to Alpha Go [
22] and playing Atari [
23].
When facing high-dimension state space and action space, it is difficult to obtain according to the original method. Suppose that if could be represented by a function, it will be regarded as a value function approximation problem for obtaining . Therefore, we can approximate the function by using function , where represents related parameters.
The loss function was defined by using the mean-square error for DRL that was proposed in paper [
24]. Therefore, we follow their definition about the loss function in our paper:
Then, the gradient of
is:
In Formula (8),
could be calculated by a deep neural network (DNN) [
25]. Therefore, the DRL is composed of an offline DNN phase and an online
Q-learning progress. Different from RL, a DNN for estimating the
value is constructed according to each state-action pair and corresponding
value. Therefore, all the
Q value cloud be estimated by the DNN in each decision step, which makes algorithm not need to traverse all states and actions. The related training data is usually obtained from actual measurement [
22], where the experience memory
defined with capacity
is used to store state transition profiles and
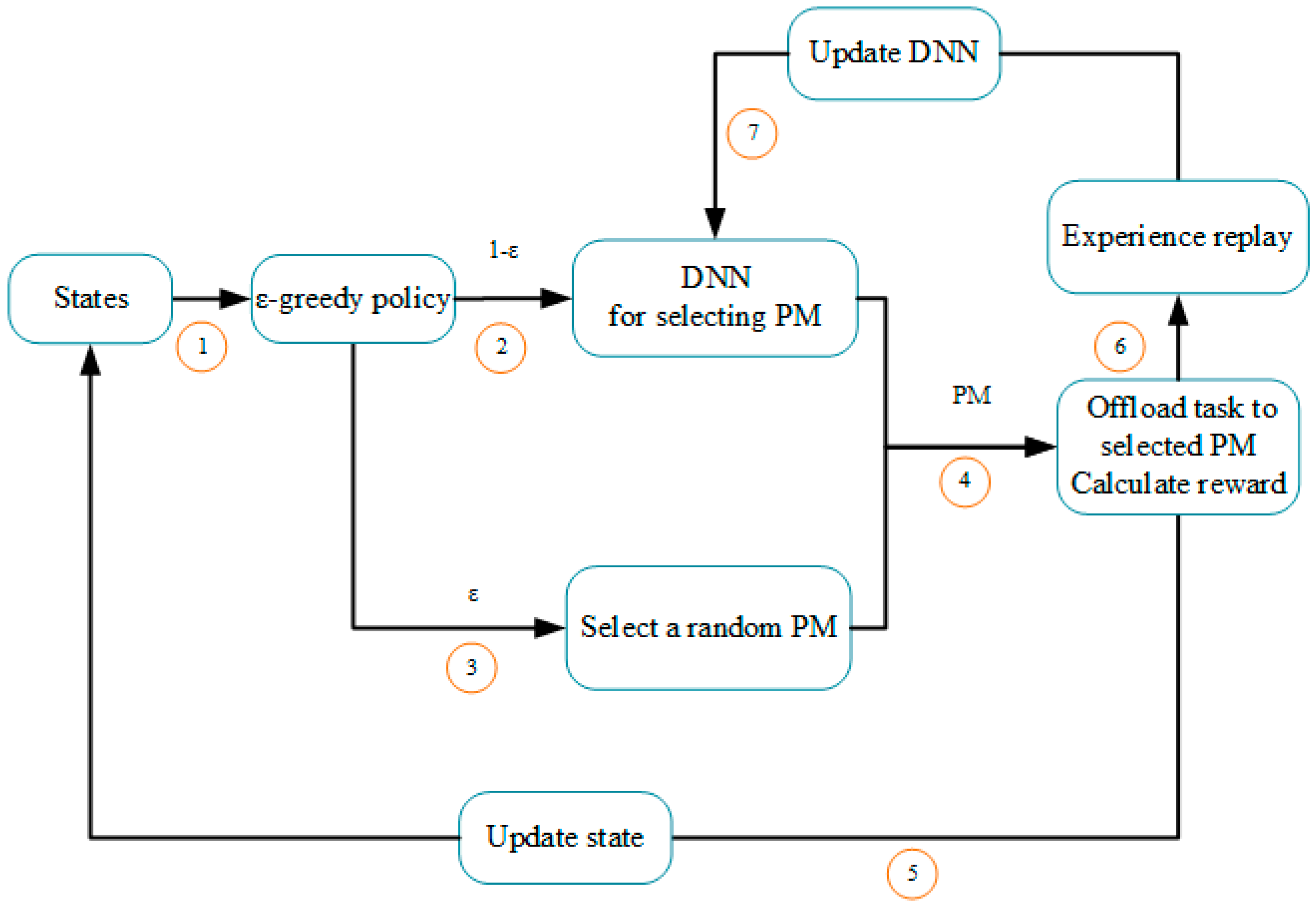
values. Then, the weight set
of the DNN could be trained by these training data. In the progress of online
Q-learning, the DRL also adopts the
-greedy policy for selecting action to update the
value. Take a decision step
as an example, the agent is in the state
. By using the constructed DNN, the agent can estimates the corresponding
for all possible actions. The agent can select the maximum
value estimate with probability
, and select a random action with probability
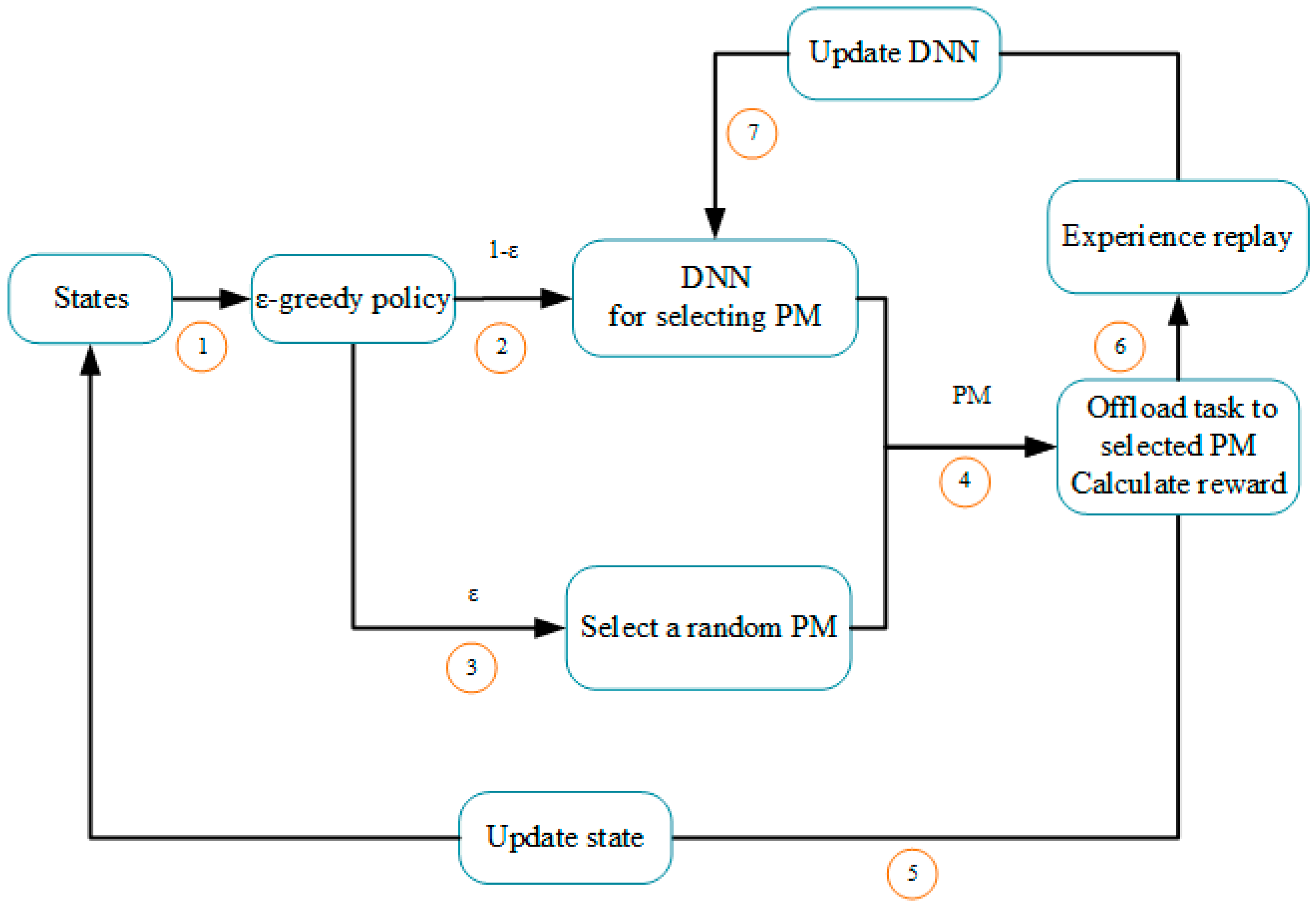
. When the selected action
is executed, the agent observes corresponding reward
that is used to update the
value according to Formula (5). After this decision, the DNN will be updated by the latest observed
value.
6. Simulation Study
In this section, we evaluate the performance of proposed algorithms for offloading tasks through simulations. First, we evaluate the utilization rate of physical machine and delay for 200 offloaded tasks by using three different methods, TLRL algorithm, DRL algorithm and random algorithm. Moreover, we compare our proposed TLRL algorithm with DRL algorithm and Q-learning for offloading tasks, observe convergence times and discounted cumulative reward. Finally, we show the validity of trading off between utilization rate of physical machine and delay for task offloading by using TLRL algorithm and adjust the weight factor .
In this simulation, we set the number of PMs in the remote cloud is 100. According to
Section 5, we know that the dimension of state in this simulation is 200 that is a high dimensional state space problem for RL. The bandwidths between these PMs and mobile devices are generated randomly among the interval (500 kbps, 10 Mbps). We suppose all PMs have almost the same hardware configuration. Each PMs could run three VMs at most for executing offloaded tasks. We consider multiple devices in our paper where different devices may contain the same tasks. Therefore, our proposed algorithm makes a decision according to the difference of tasks. In our experiments, we take 6 different tasks and the corresponding parameters are displayed in
Table 1. We set
,
-greedy strategy
and reward discount
for our proposed algorithms.
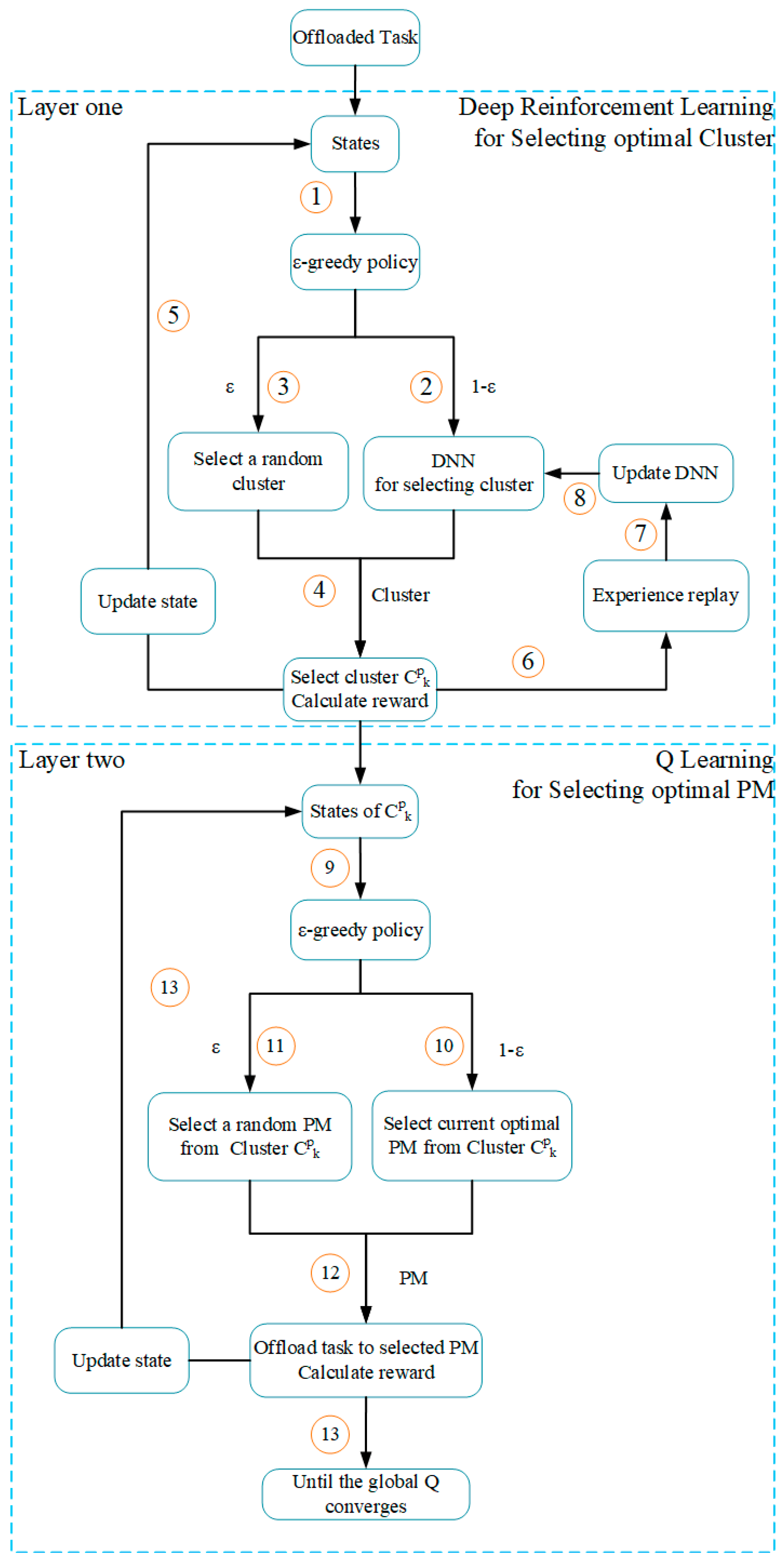
In order to evaluate the TLRL algorithm, we divide the 100 PMs into 20 clusters using k-NN algorithm where the k is equal to 20. Therefore, the dimension of state belonging to RL of TLRL is decreased to 20 × 2 and the number of corresponding actions is 20 according to
Section 5. Comparing with DRL algorithm, both the dimension of state and the number of actions have a significant reduction.
Before these experiments, we construct two full-connected CNNs with an input layer, an output layer, and two hidden layers. The details of the two full-connected CNNs are displayed in the
Table 2.
According to the
Table 2, we can see that our proposed TLRL contains less number of input and output compared with DRL by classifying the PMs into 20 clusters via k-NN algorithm. Correspondingly, the hidden layers also contain less number of neurons than DRL.
6.1. The Comparison of Different Algorithms
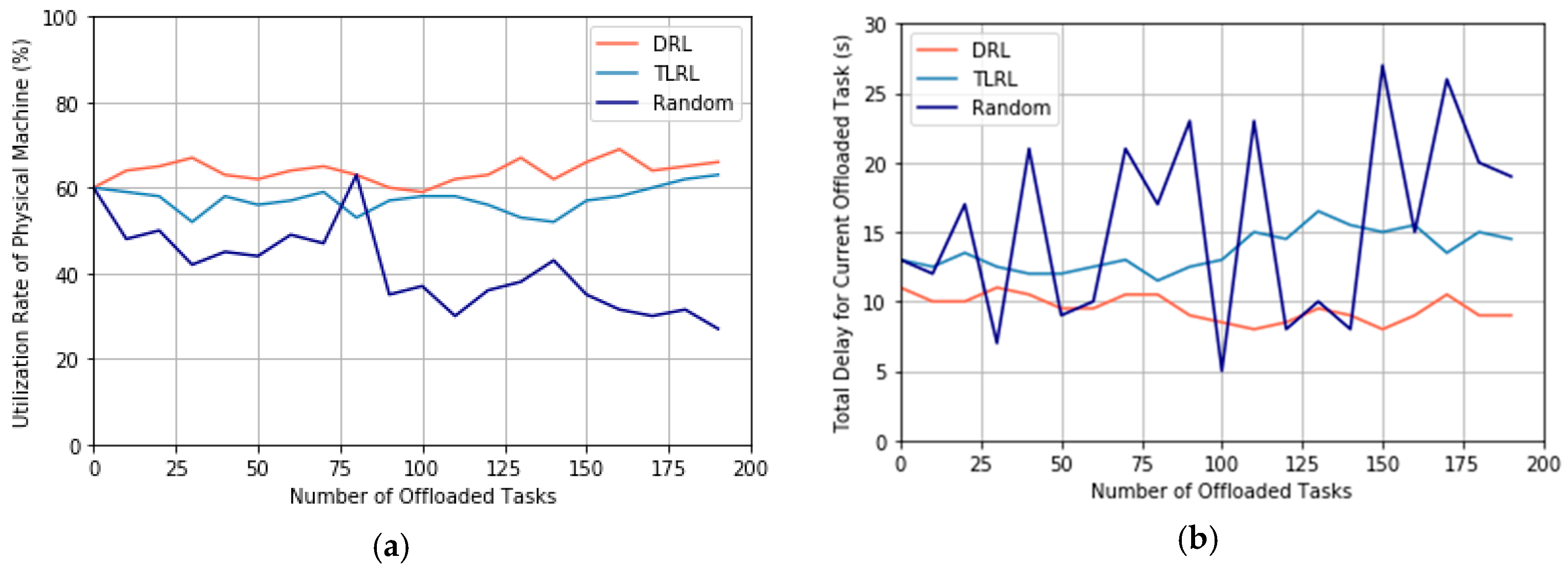
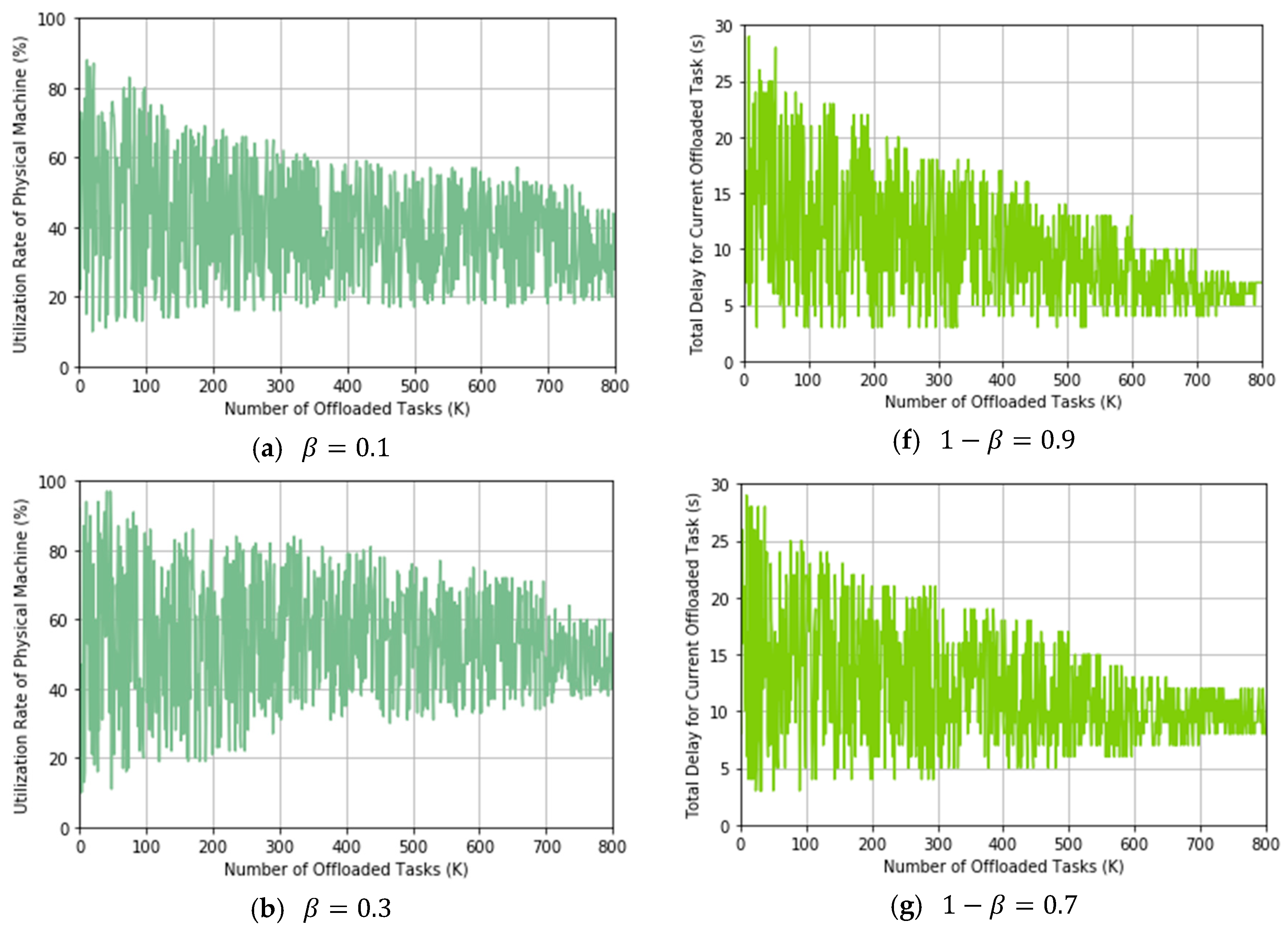
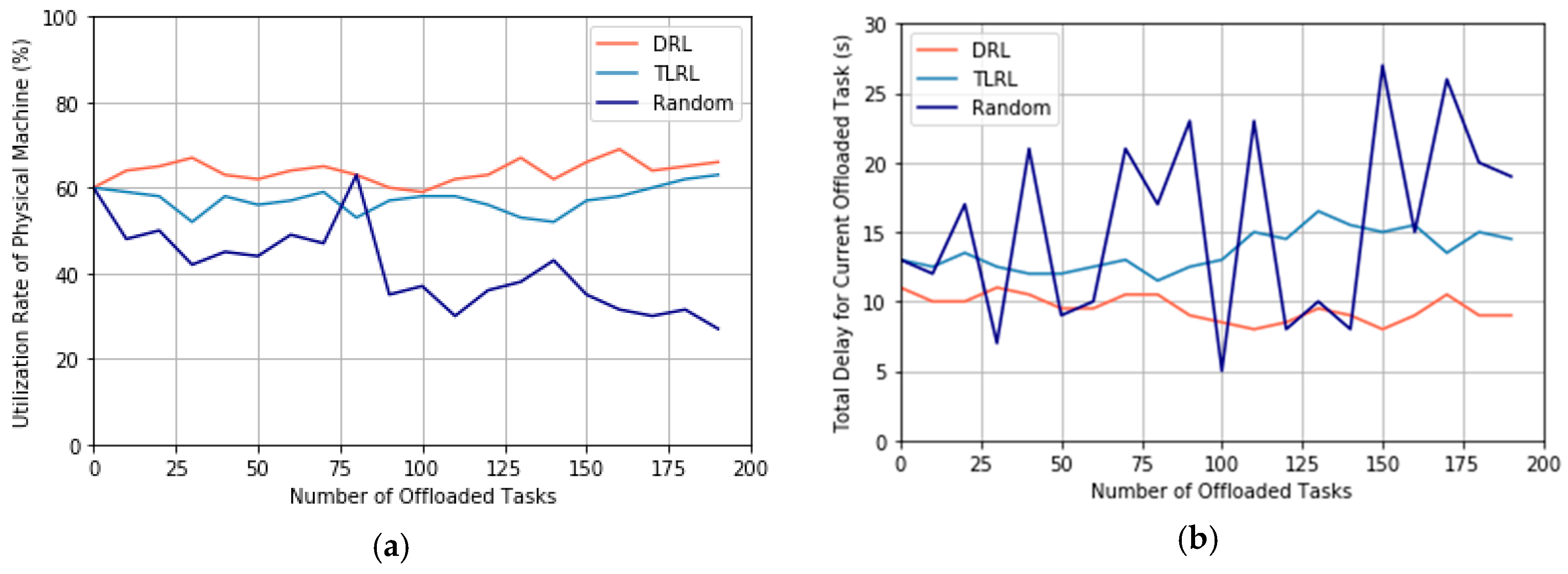
In this experiment, we compare our proposed TLRL algorithm and DRL algorithm with the random policy for task offloading. The random algorithm arranges the offloaded tasks to the PM randomly and ignores the utilization rate of PMs and delay. The beginning state is initialized randomly, and = 0.5 is selected for the weight factor of reward. We observe the change of utilization rate of PMs and delay through simulating offloading tasks, where the number of offloaded tasks increases from 1 to 200. We will compare the obtained optimal policy after learning process for DRL and TLRL with a random policy. We track the utilization rate of PMs and delay for 200 offloaded tasks by following the learned optimal policy for task offloading.
These results are shown in
Figure 8. It is shown that the random algorithm results in severe fluctuation, in terms of the utilization rate of PMs and delay, compared to the cases of DRL and TLRL. First, in
Figure 8a, both the DRL and TLRL, the utilization rate of PMs is maintained at the level around 60%, whereas the random algorithm leads to an inferior level around 23% for the utilization rate of PMs, which may lead to the waste of cloud resources. Second, in
Figure 8b, it can be seen that based on DRL and TLRL, a lower delay for each offloaded task can be obtained. It changes between 9 s and 15 s. However, frequent changes in the delay for the offloaded task by using the random algorithm, where the max delay is around 27 s. This is because the random approach selects a PM to execute the offloaded task randomly. According to the definition of delay in Formula (3), if
is larger and
is smaller, it will lead to a higher delay
correspondingly. On the contrary, if
is smaller and
is larger, a lower delay
is obtained. Therefore, this random selection approach for PMs can lead to a random delay in each decision step, which may cause the high jitter in the delay for offloaded tasks. We can conclude that our proposed algorithms based on DRL can get a better performance for increasing the utilization rate of PMs and decreasing the delay caused by task offloading than random policy.
From the above results, one can observe that the policy learned by DRL can achieve better results than the policy learned by TLRL. This is because we reduce both the dimension of state and action for decreasing the computational complex by proposing the TLRL algorithm, where we assume the PMs from the same cluster are similar. Then we assume the waiting time and bandwidth of PMs from the same cluster are equal to the cluster according to
Section 5, which may lead to a bias of learning optimal policy. However, our proposed TLRL algorithm could find the optimal policy than other methods when facing to high-dimension state space and action space.
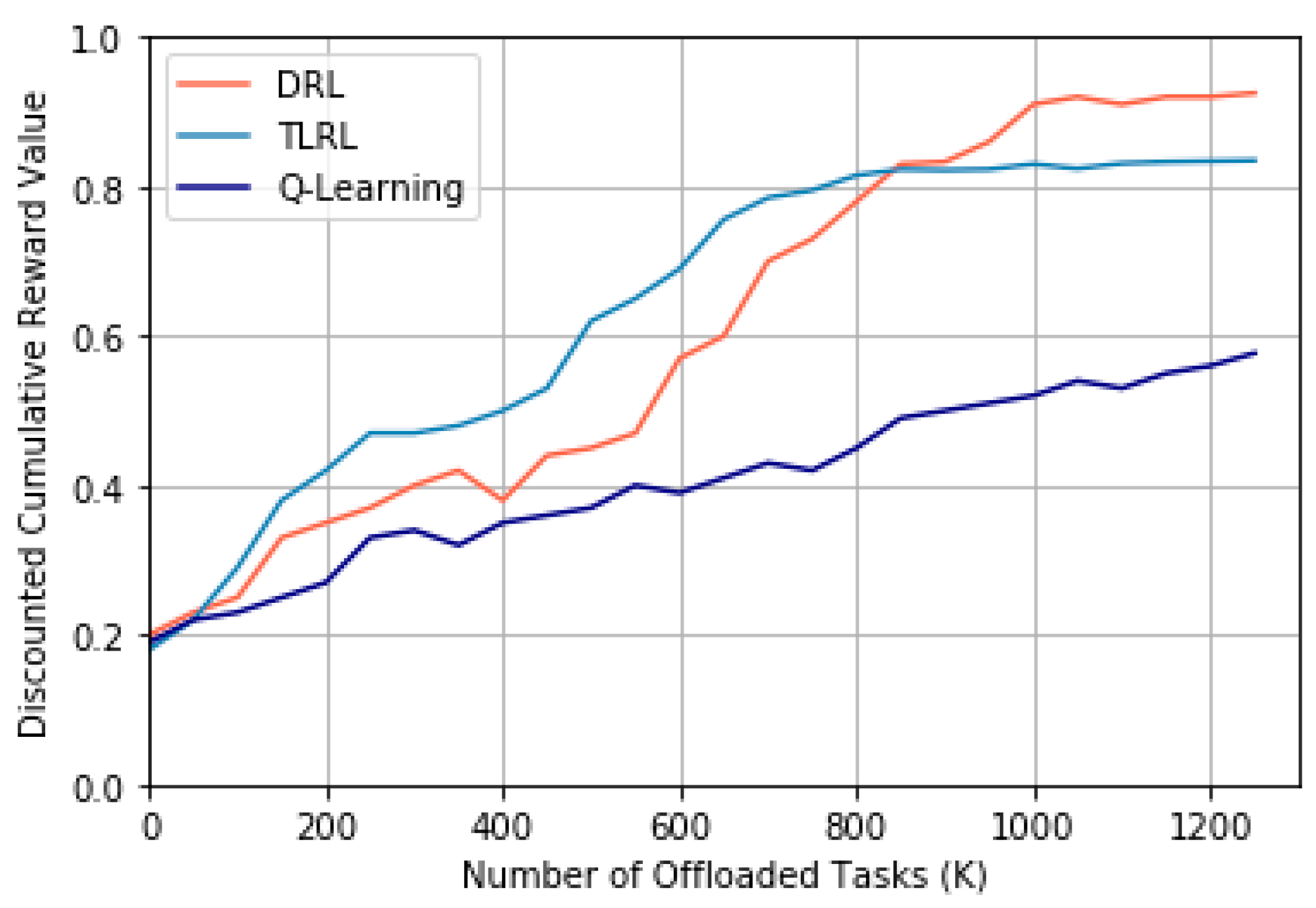
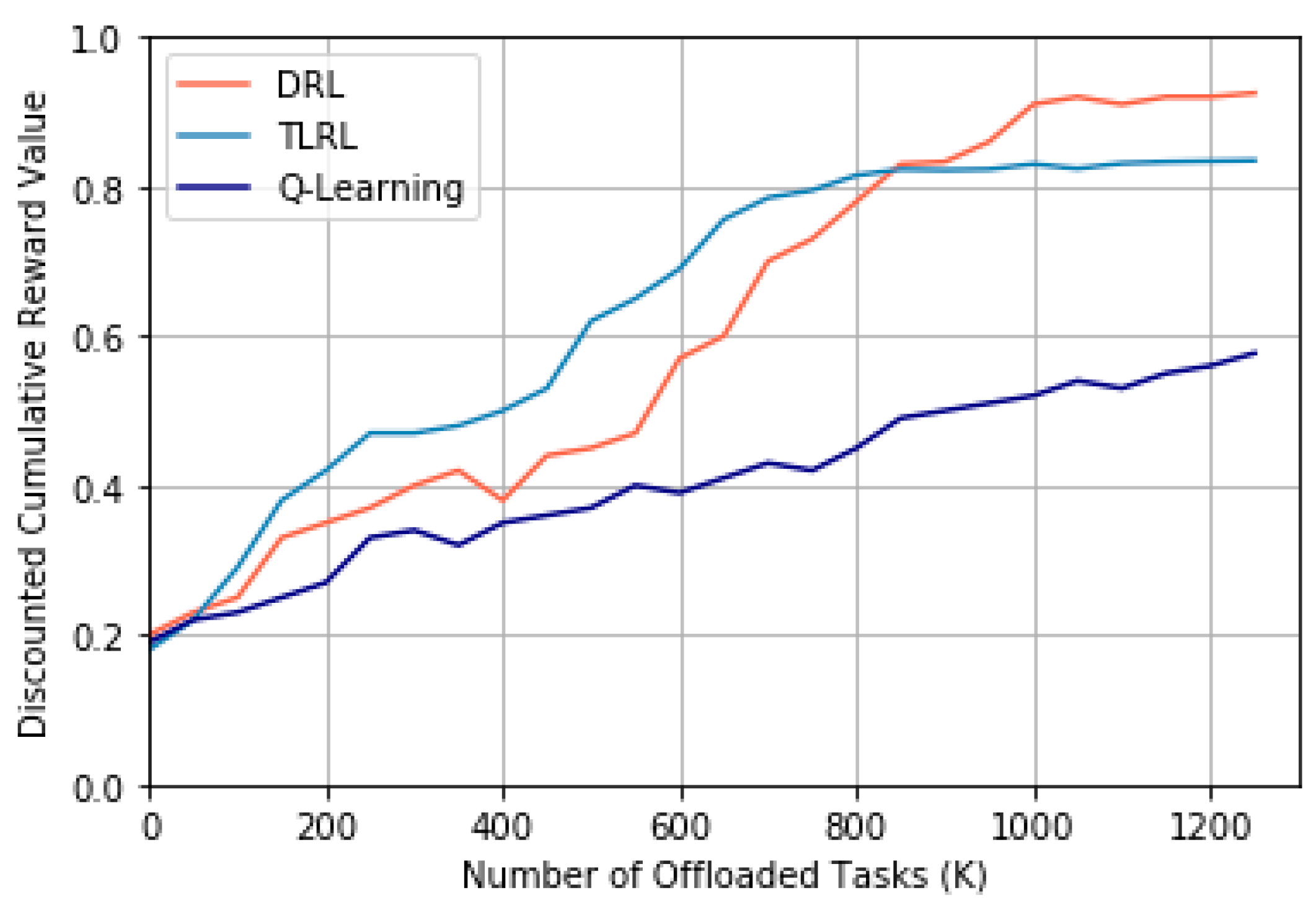
To discuss above problem, we start from a randomly initialized state for DRL, TLRL, and
Q-learning. We compare convergence speed of the three algorithms for task offloading. The results are given in
Figure 9.
Through observing the experimental results, it can be shown that both the DRL and TLRL can converge through a period learning process that is represented by the number of offloaded tasks. However, the traditional
Q-learning algorithm does not converge. This indicates that the algorithms based on DRL for task offloading are more suitable to the problem with high-dimension state space and action space than traditional
Q-learning. In addition, our proposed TLRL algorithm can converge faster than DRL owing to dimension reduction for the input and output of DNN and less number of needed neurons in hidden layers of DNN than DRL according to
Table 2. Therefore, our proposed TLRL could obtain a faster convergence speed than DRL.
6.2. The Verification of Tradeoff
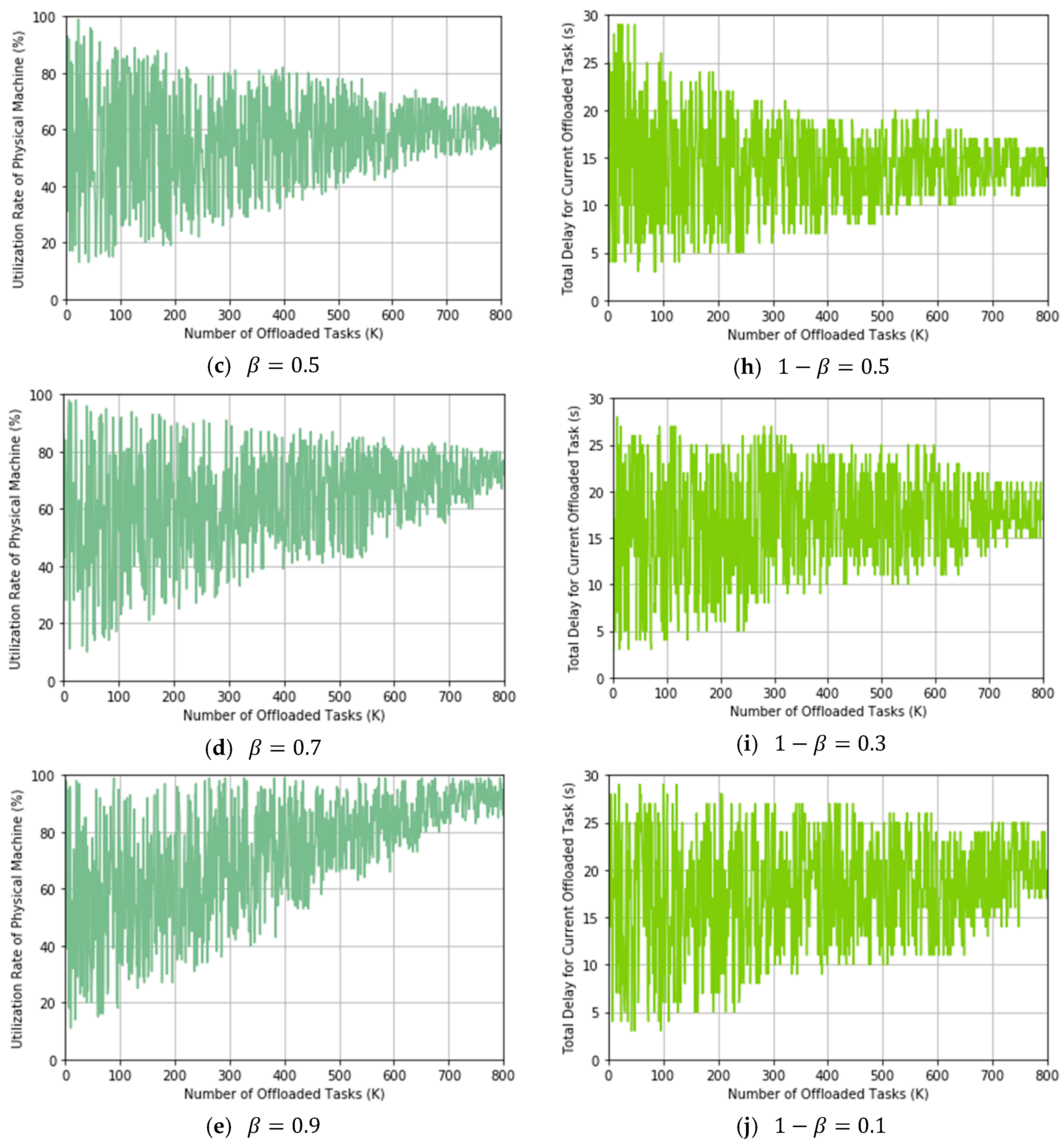
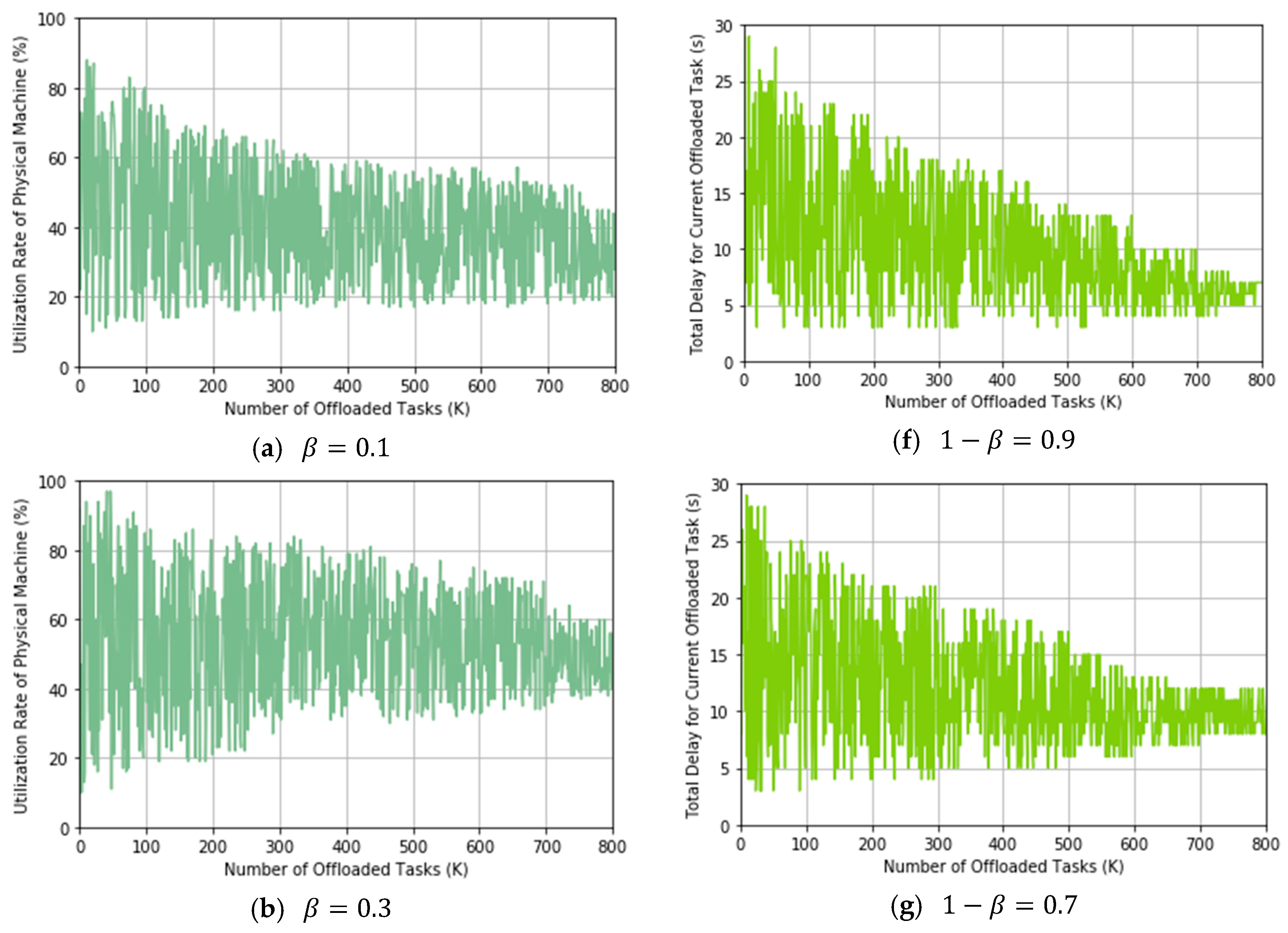
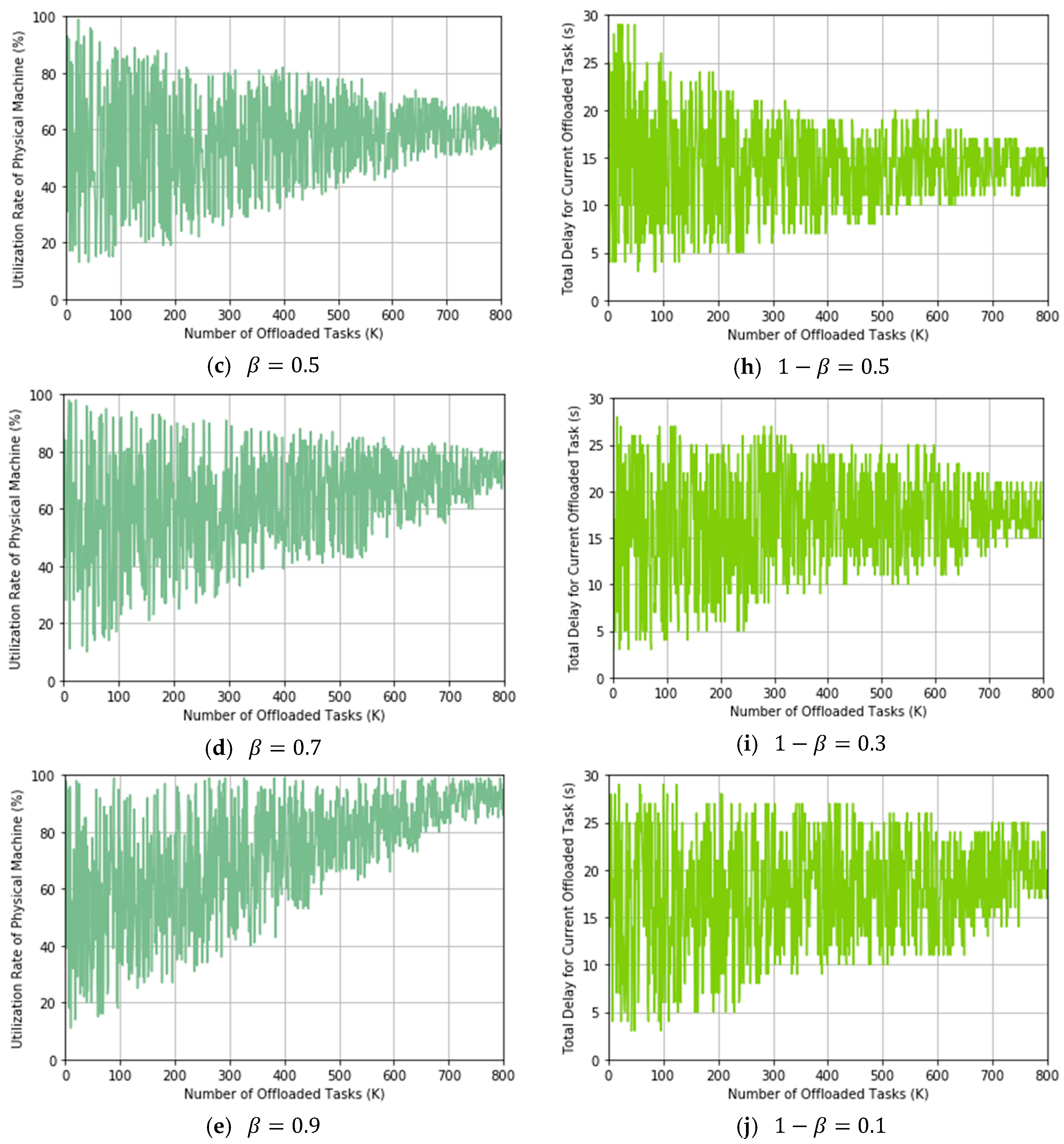
In this experiment, we will show the trading off between utilization rate of PMs and delay for task offloading by using our proposed TLRL algorithm. We evaluate these two indicators by simulating offloading tasks that are selected from
Table 1 randomly. We record these two indicators after each decision of TLRL for offloading tasks. We adjust the weight factor
from 0.1 to 0.9 to do experiments separately and observe the change of the two indicators.
From these results, we can conclude that our proposed TLRL algorithm can trade off the utilization rate of PMs and delay by adjusting the weight
in the reward effectively. According to Formula (10), the weights for the utilization rate of PMs and delay are
and
respectively. The experimental results in
Figure 10 show the process of online learning optimal policy when
β takes different values and track the changes of the utilization rate of PMs and delay during the learning process. We assume that the number of needed offloaded tasks is more than 800 in a real MCC environment and our proposed algorithm could converge. Therefore, our proposed algorithm will lean an optimal policy, which make the utilization rate of PM and delay keep stable in an interval. In
Figure 10a–e, we can see that the utilization rate of PMs converges to a larger value when the weight factor
is set to a larger value. Correspondingly, the weight of delay for current offloaded task
becomes smaller, which lead to a larger delay. Therefore, if the utilization rate of PM is preferred, then a larger
β is chosen and vice versa. Moreover, the TLRL algorithm can learn the optimal policy for task offloading with the increase of offloading tasks. This is because the TLRL comprises with DRL in layer one and
Q learning in layer two, both of the two methods can converge according to Bellman Equation. We define the global
Q-function for TLRL algorithm given by Formula (18), which indicates the convergence of TLRL algorithm. We can see that
is composed of the
Q values from above two algorithms. Therefore, TLRL algorithm can also converge which indicates that it can learn the optimal policy. Therefore, the two indicators will become stable in a certain interval that is related to the value of
.
7. Conclusions
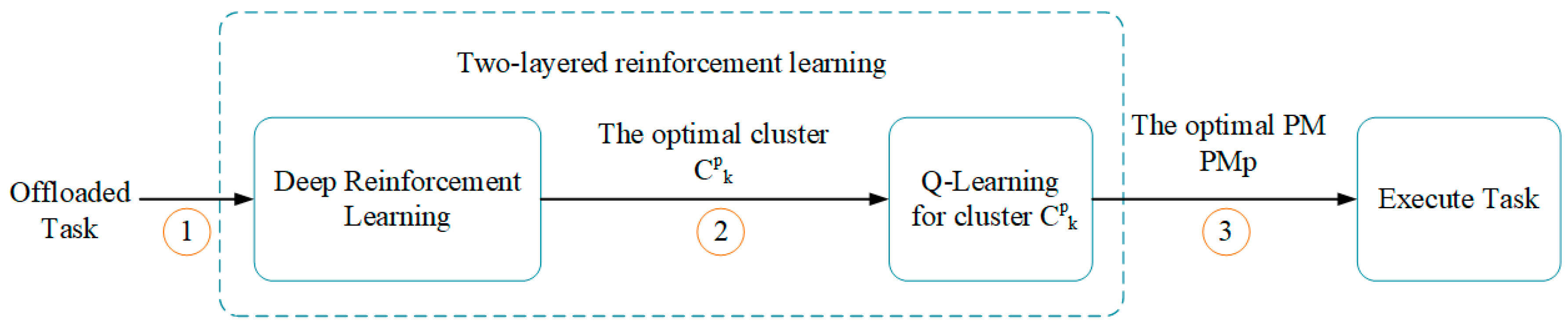
In this paper, we solve the problem of task offloading in order to decrease the delay for offloaded tasks and increase the utilization rate of physical machine in the cloud. Different from the traditional Q-learning algorithm, the DRL can be suited to the problem with high-dimension state space. Moreover, in order to improve the speed of learning optimal policy, we propose a novel TLRL algorithm for task offloading, where the k-NN algorithm is applied to divide the PMs into several clusters. With the reduced dimension of state space and action space, the DRL layer aims at learning the optimal policy to choose a cluster. Then, the Q-learning layer learns an optimal policy to select the optimal PM to execute the current offloaded task. The experiments show that the TLRL algorithm is faster than the DRL algorithm when learning the optimal policy for task offloading. By adjusting the weight factor , our proposed algorithms for task offloading can trade off between utilization rate of physical machine and delay effectively.
Our proposed algorithms intend to find the optimal PM for executing offloaded tasks by considering utilization rate of PM and delay for task offloading simultaneously. We simulate 100 PMs with different bandwidths and six different target applications to verify our proposed algorithms. Moreover, this paper is mainly focused on developing novel RL-based algorithms to solve the offloading problem. We verify the effectiveness of the proposed algorithms in theory, which can trade off between utilization rate of PM and delay effectively by designing a weighted reward. In the future study, we will verify our proposed algorithms in a real environment where the running environments of offloaded tasks are deployed on PMs. Besides, simulated tasks will be replaced by the real applications running on smartphones. Moreover, Different tasks have different attributes, which also cloud have different delay requirement. However, we mainly focus on the effective tradeoff between the utilization rate of PM and delay and try to decrease the delay as possible ignoring the delay requirement for different tasks. Take task 1 for example, if it requires that the delay cannot exceed a given time t, then the algorithm could choose a β that makes the utilization rate of PM larger before meeting its delay requirement. Therefore, we can find the relation between the value of β and the delay requirement for different tasks through analyzing the obtained real data. Therefore, we will research on choosing the adaptive value β according to offloading tasks conditions by using the prediction model in our future work.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}