A Tiered Control Plane Model for Service Function Chaining Isolation


Abstract
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Research Challenges
2. Related Work
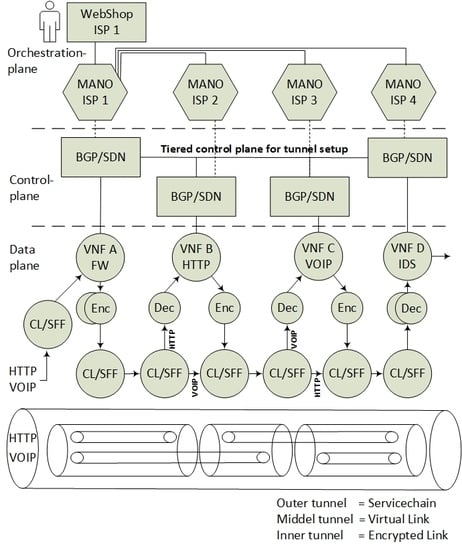
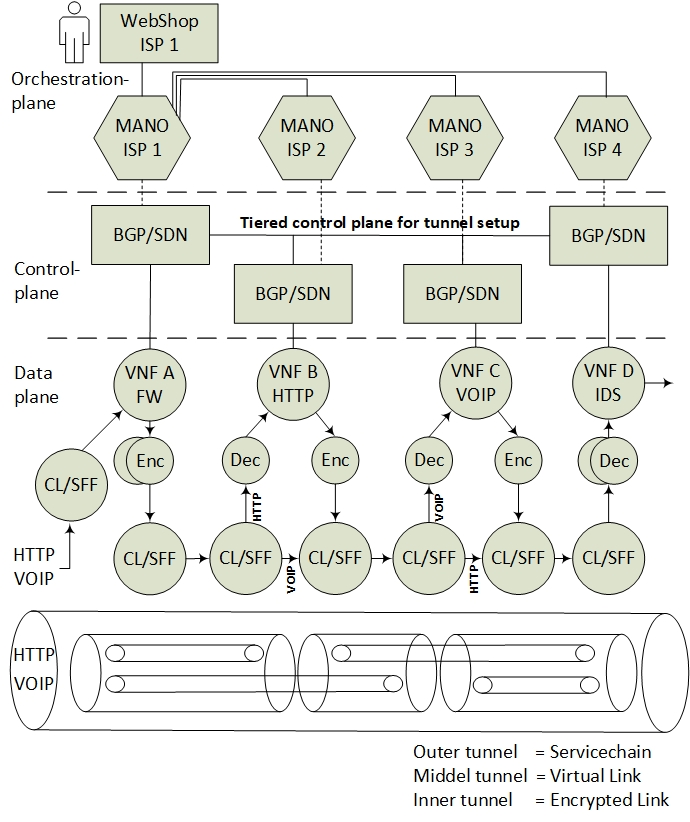
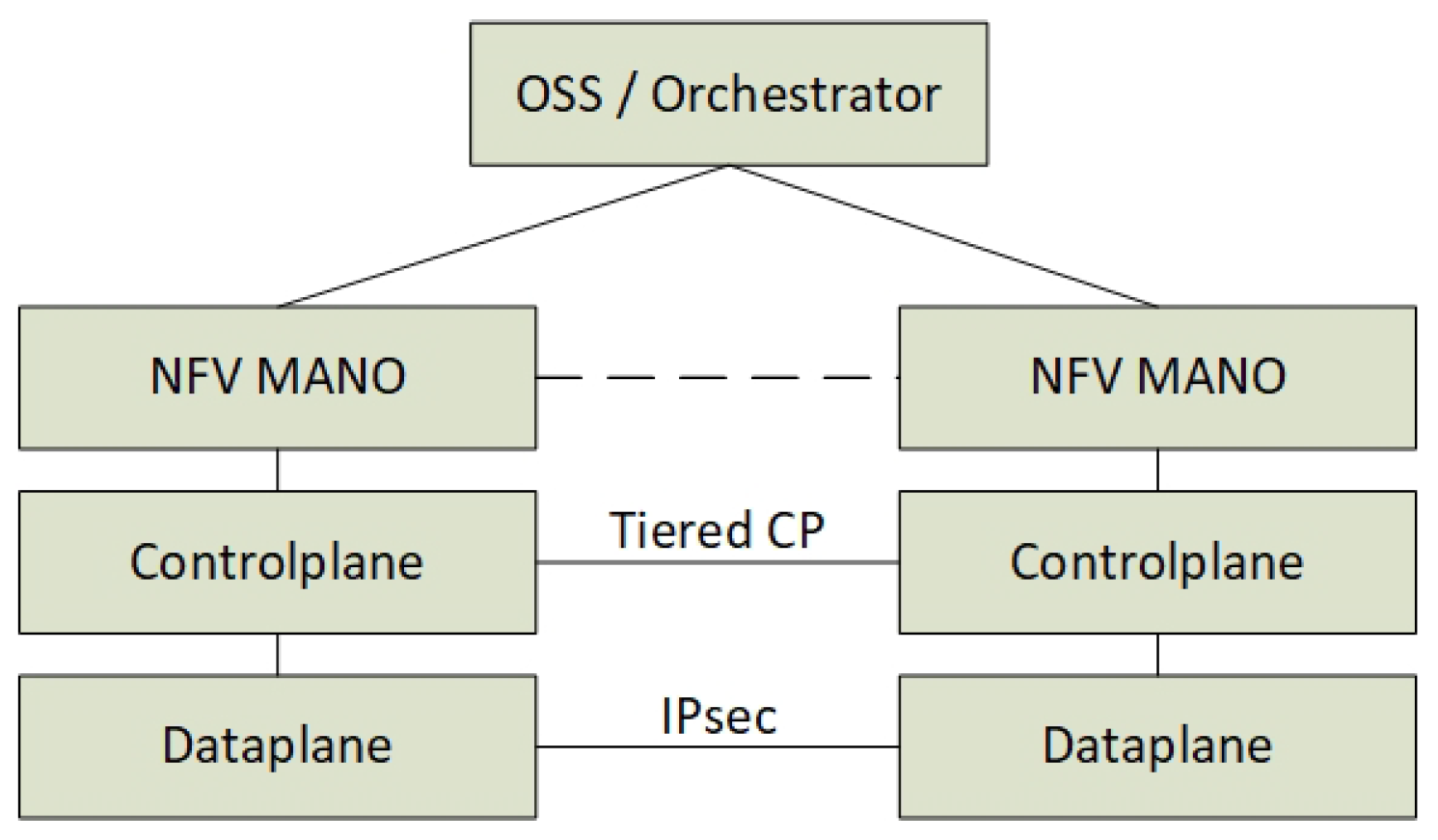
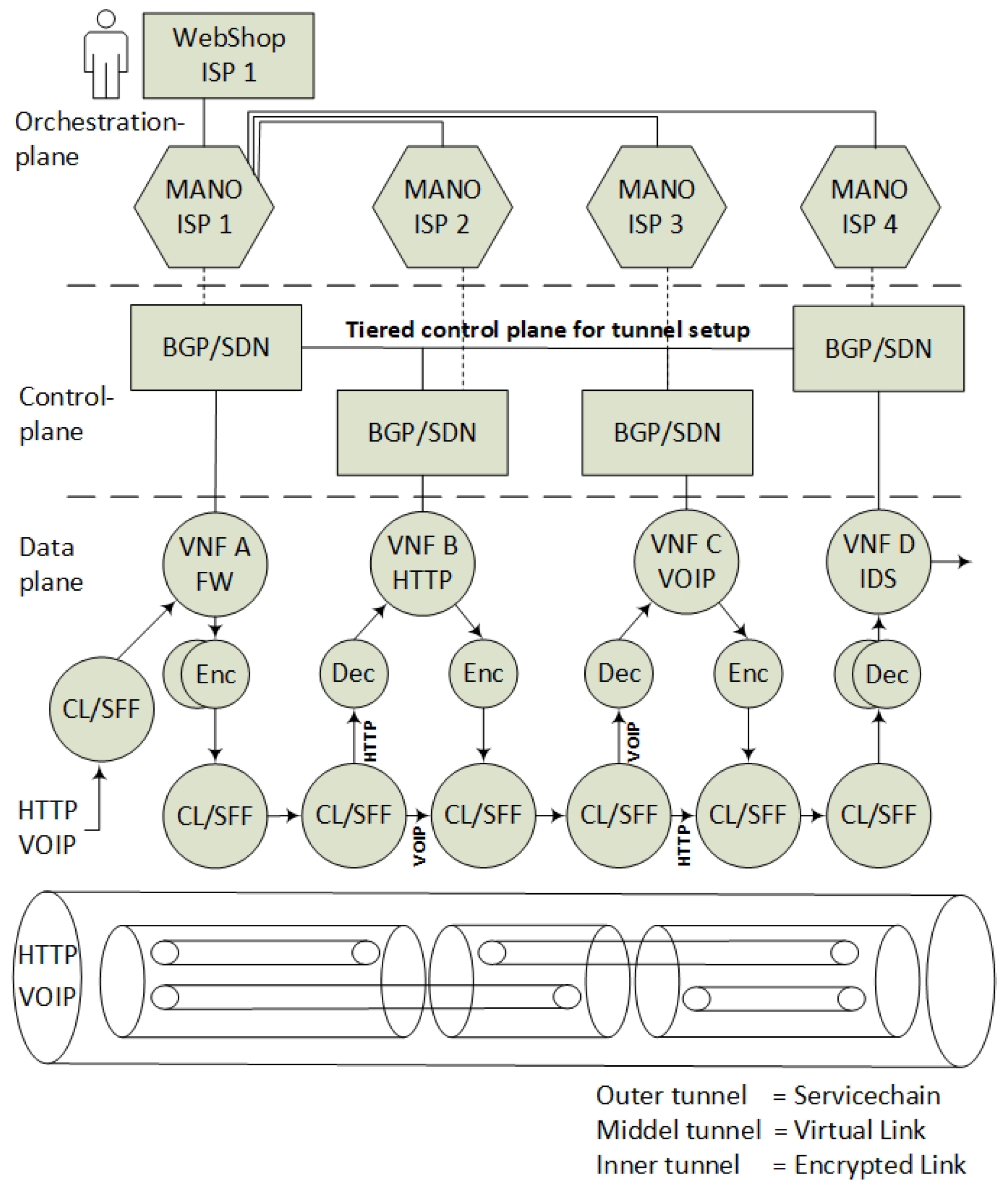
3. The Architectural Model
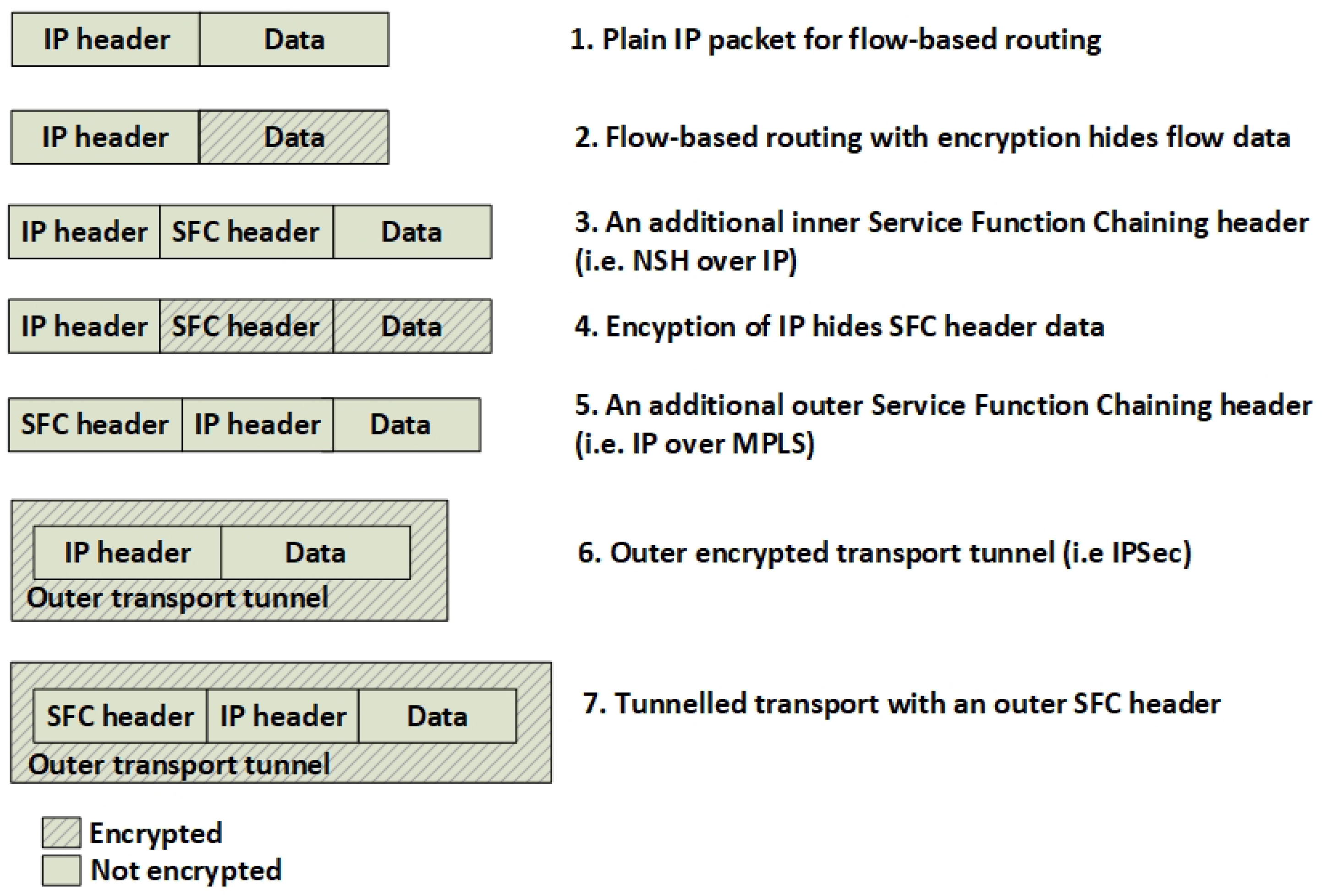
- Data-plane components for transitive SFC classification and forwarding. The SFC specification refers to these components as Classification Functions (CF) and Service Function Forwarders (SFF), that needs modification to support nested SFCs.
- Control plane components for information sharing, with BGP and key distribution for encryption setup. The main components here consist of a Software Defined Network Controller with the BGP capabilities.
- Management and Orchestration (MANO) applications, in order to orchestrate and provide encryption services to automate the set up of VNF isolation.
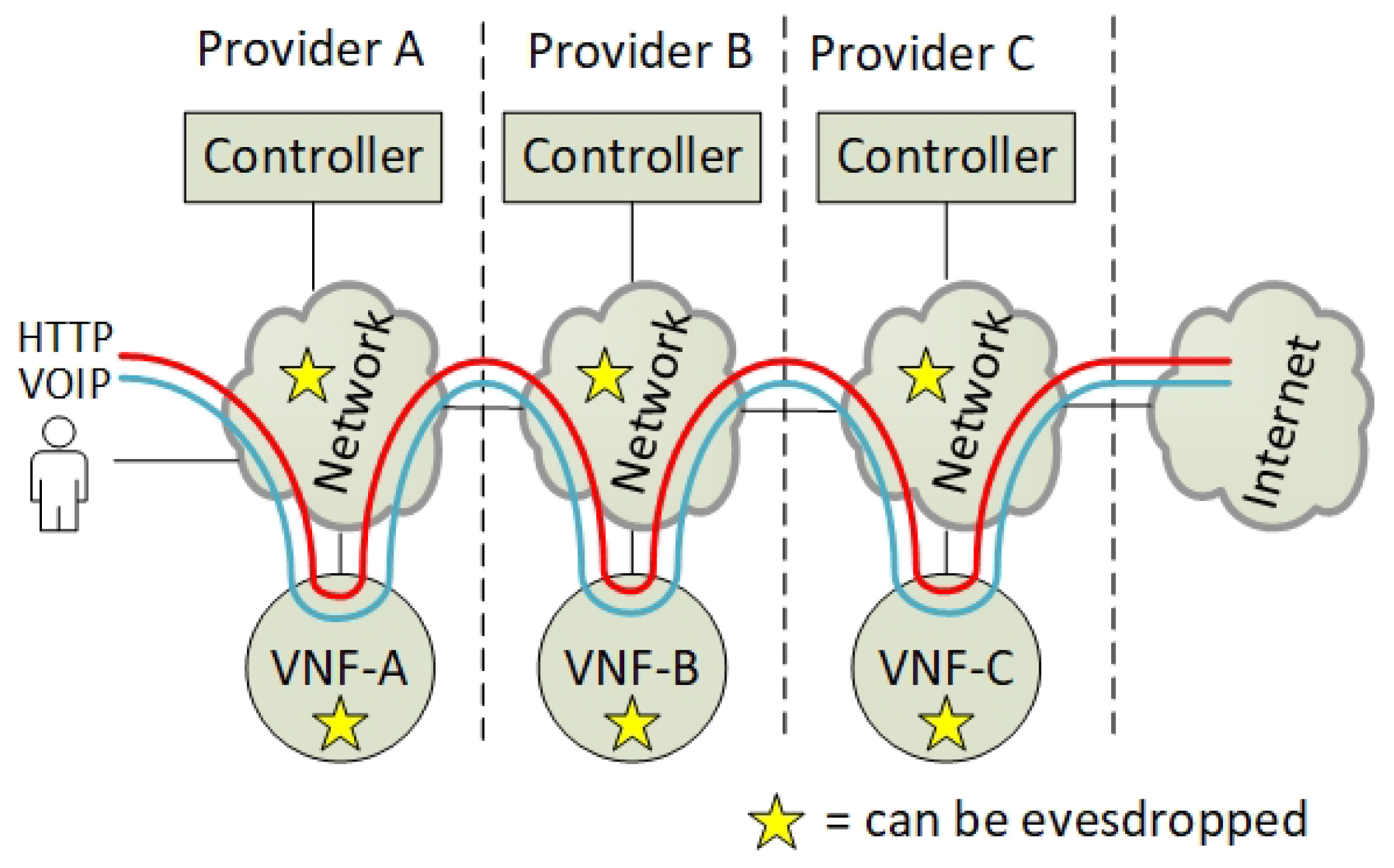
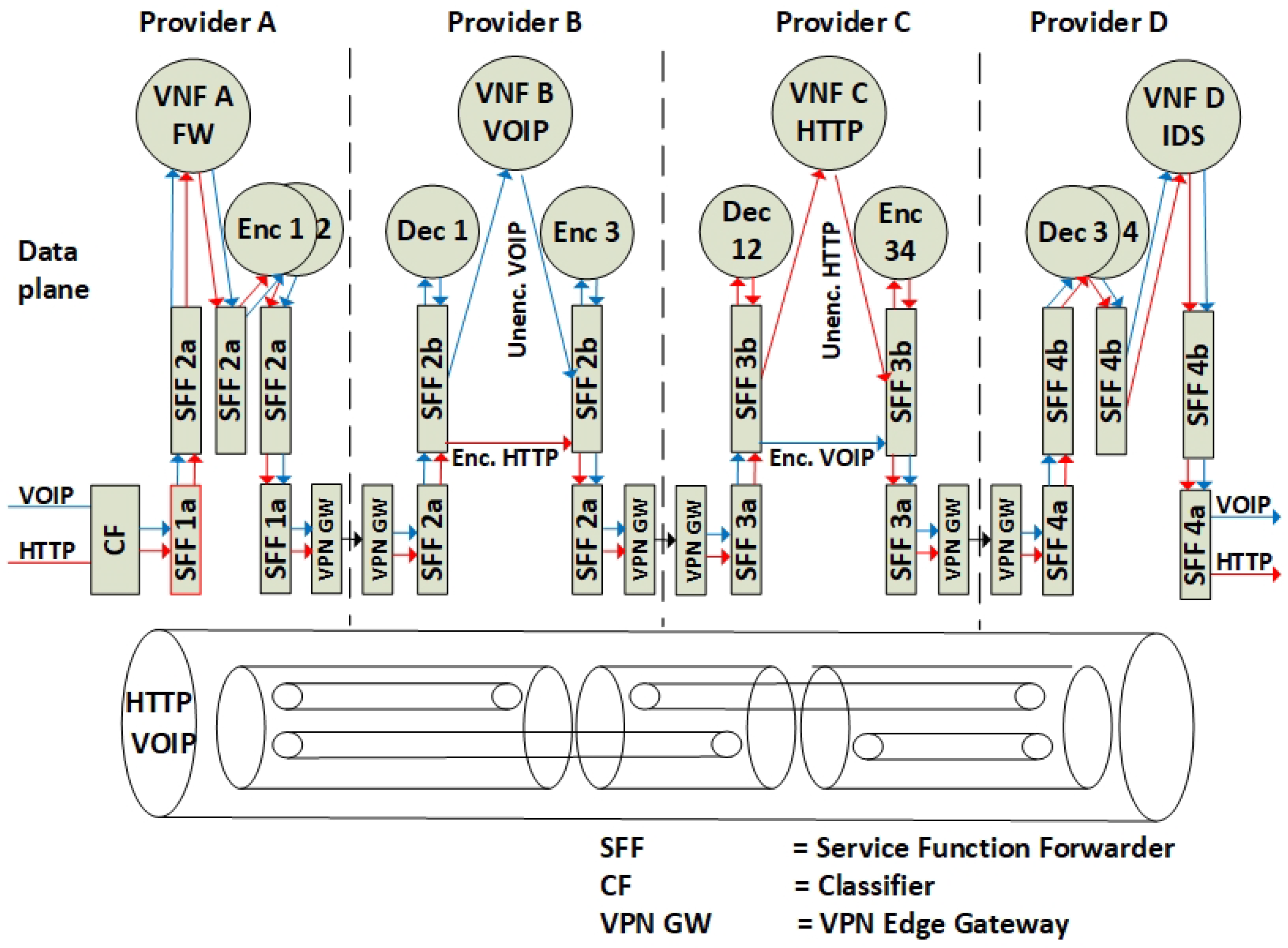
- The incoming data packets of the Voice Over Internet Protocol (VOIP) and the HyperText Transfer Protocol (HTTP) are classified according to the specific (VNF A>B>C>D) SFC path. Since the SFC path is predetermined by distributed route tables, the SFC headers are added to the packets.
- Due to VNF isolation requirements, the packets are classified and forwarded based on two layers of SFCs. Hence, the first classifier is also adding the second isolating SFC header. For this example, two inner SFCs are established: one for VNF A>B>D–HTTP components and one for VNF A>C>D–VOIP components. This ensures that, with respect to routing, VNF B and VNF C are isolated from each other.
- To ensure the encryption of the packets, each hop in the inner SFC paths must be encrypted. Hence, the network controller is distributing the SFC paths to traverse sets of pairwise encryption services. The network controller is also distributing the encrypting keys per link.
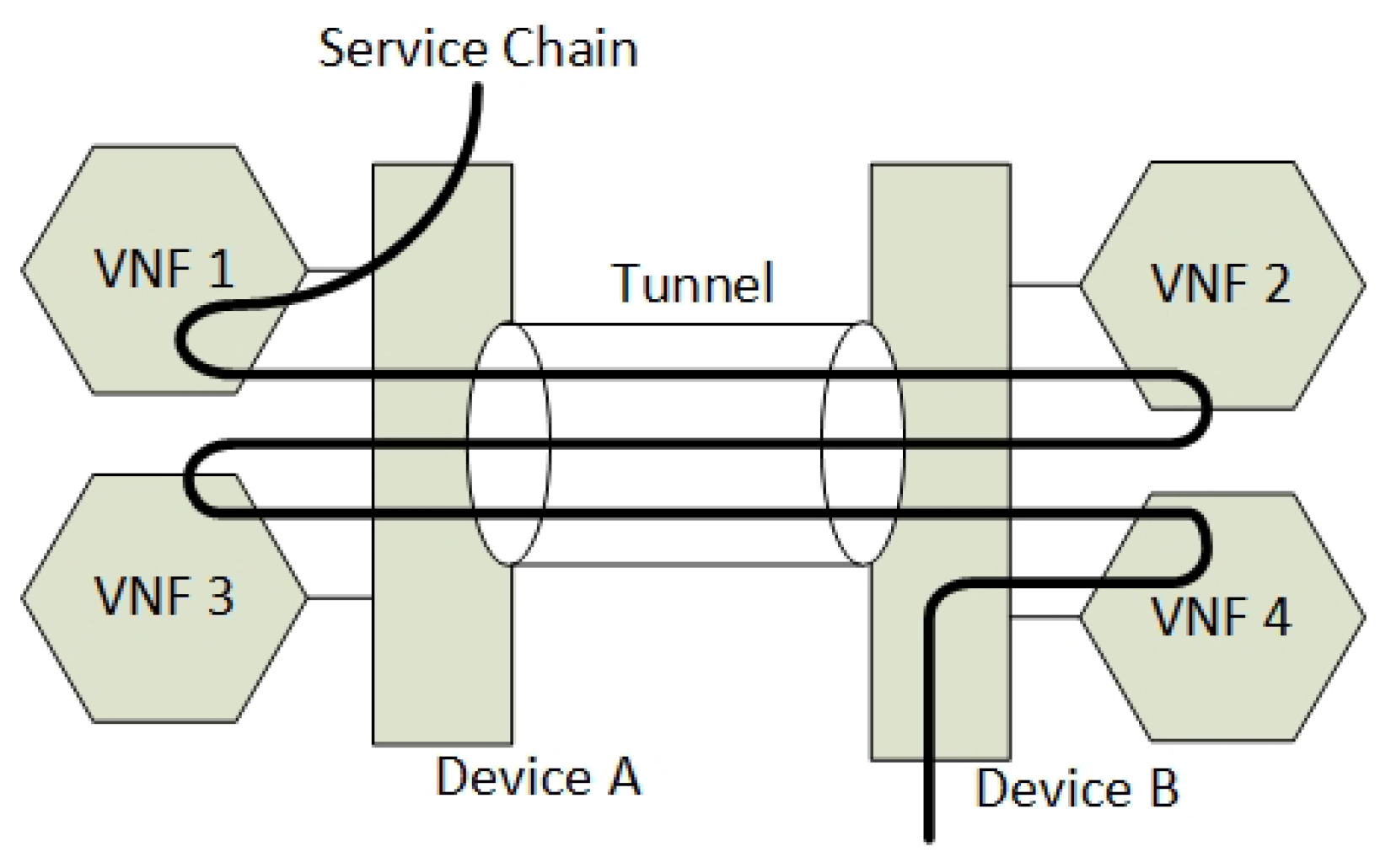
- The packet forwarding continues with consecutive encryption > processing > decryption sequences, in accordance with a distribution of pairwise keys among the providers, and with SFC header modification per hop. Pushing and popping of additional SFC headers ensure that the SFC path is maintained. The SFC path is therefore an end-to-end encrypted tunnel, implemented as interconnected chains of hierarchically encrypted links, where, in the presented example, providers A-B-D can access only the HTTP component, and providers A-C-D only the VOIP component of the SFC.
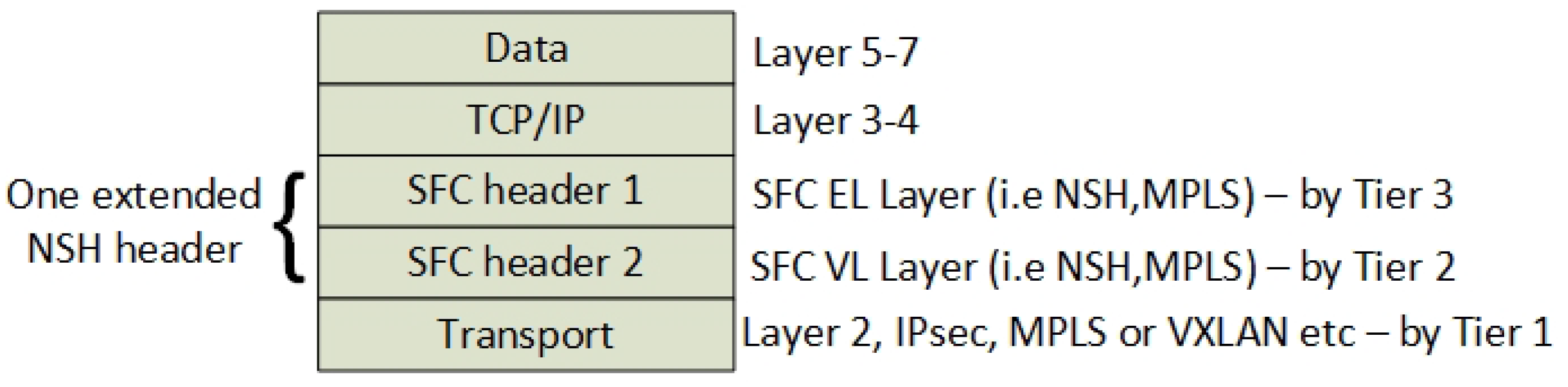
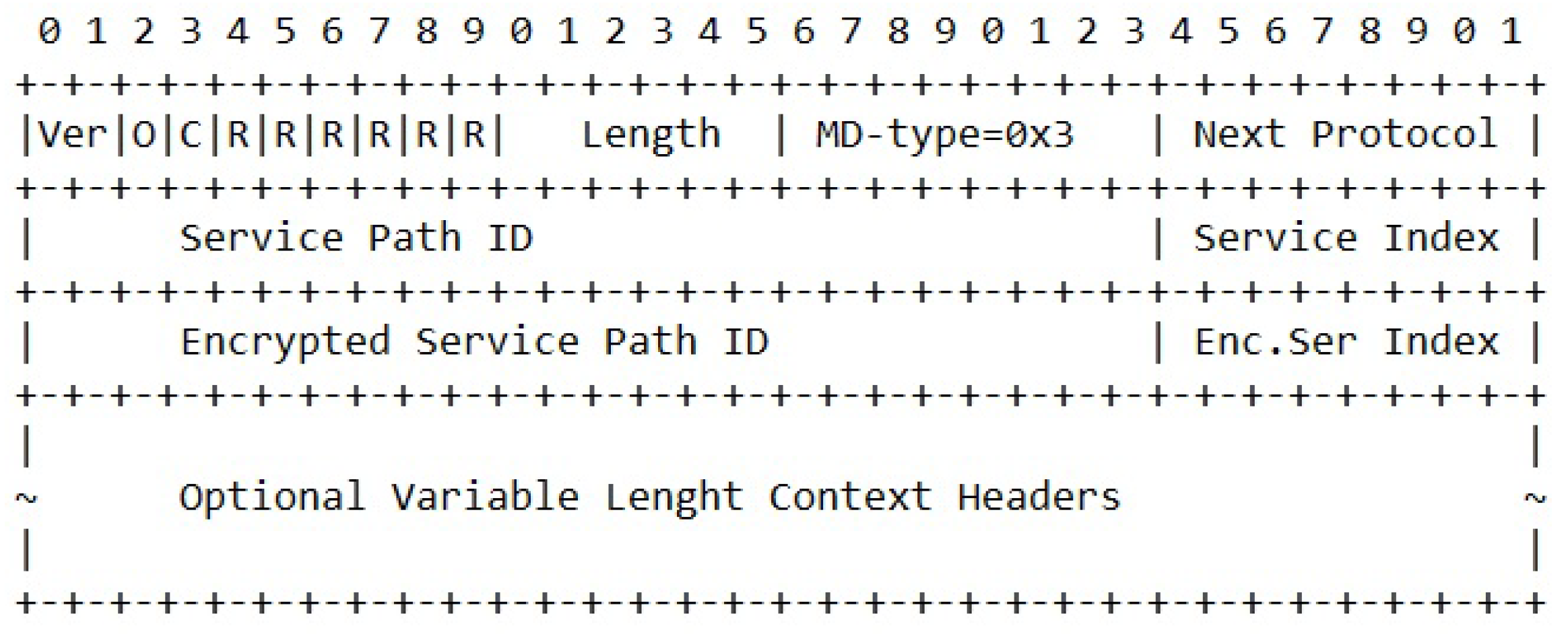
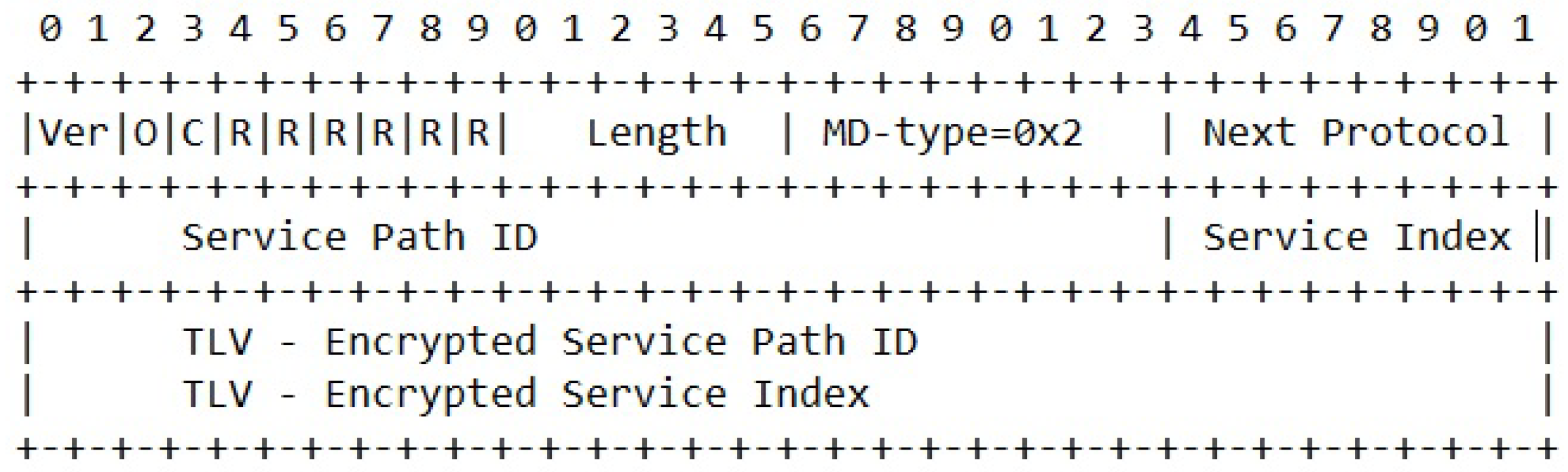
3.1. The Data-Plane—A Hierarchy of SFC Headers
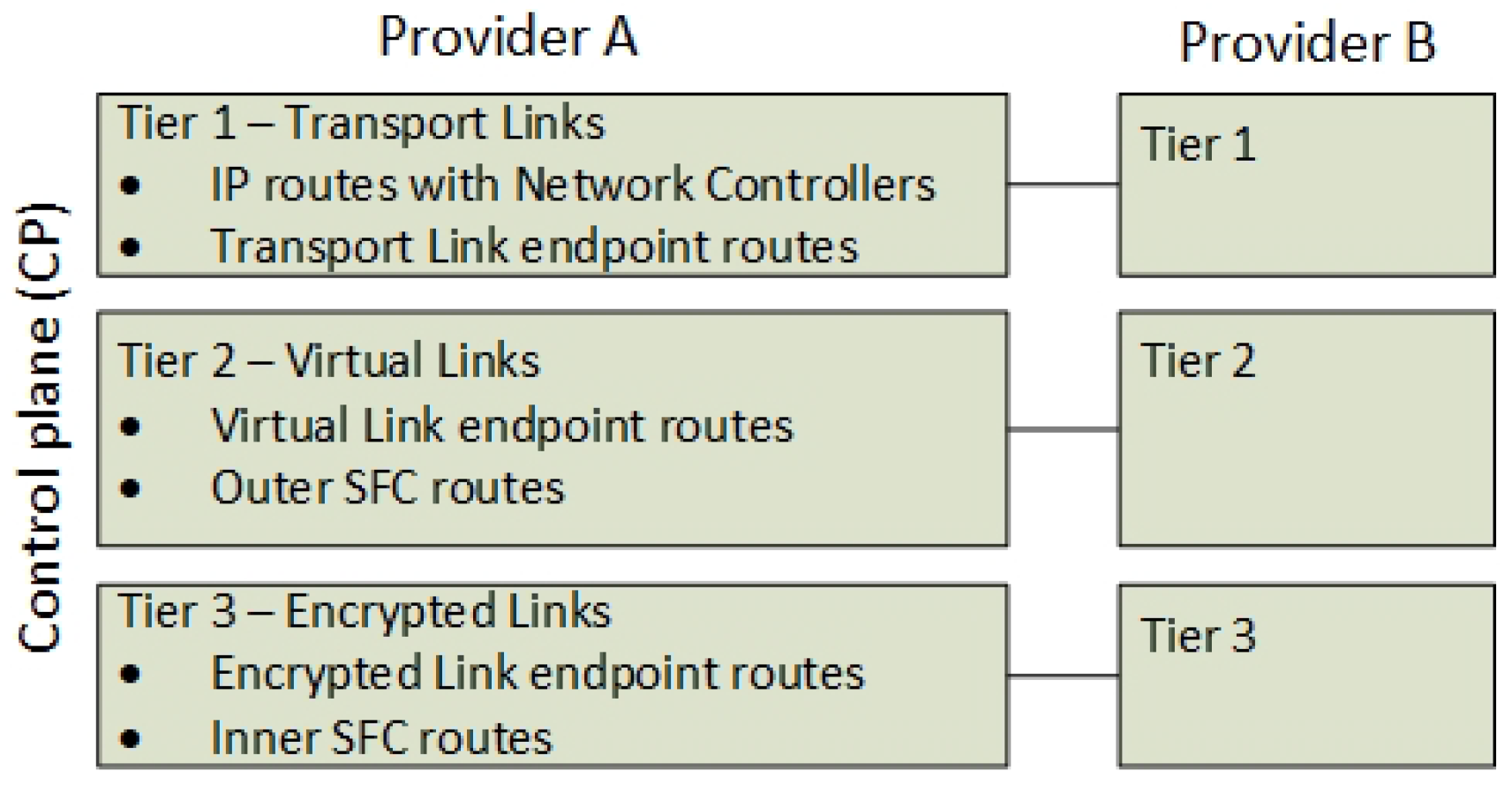
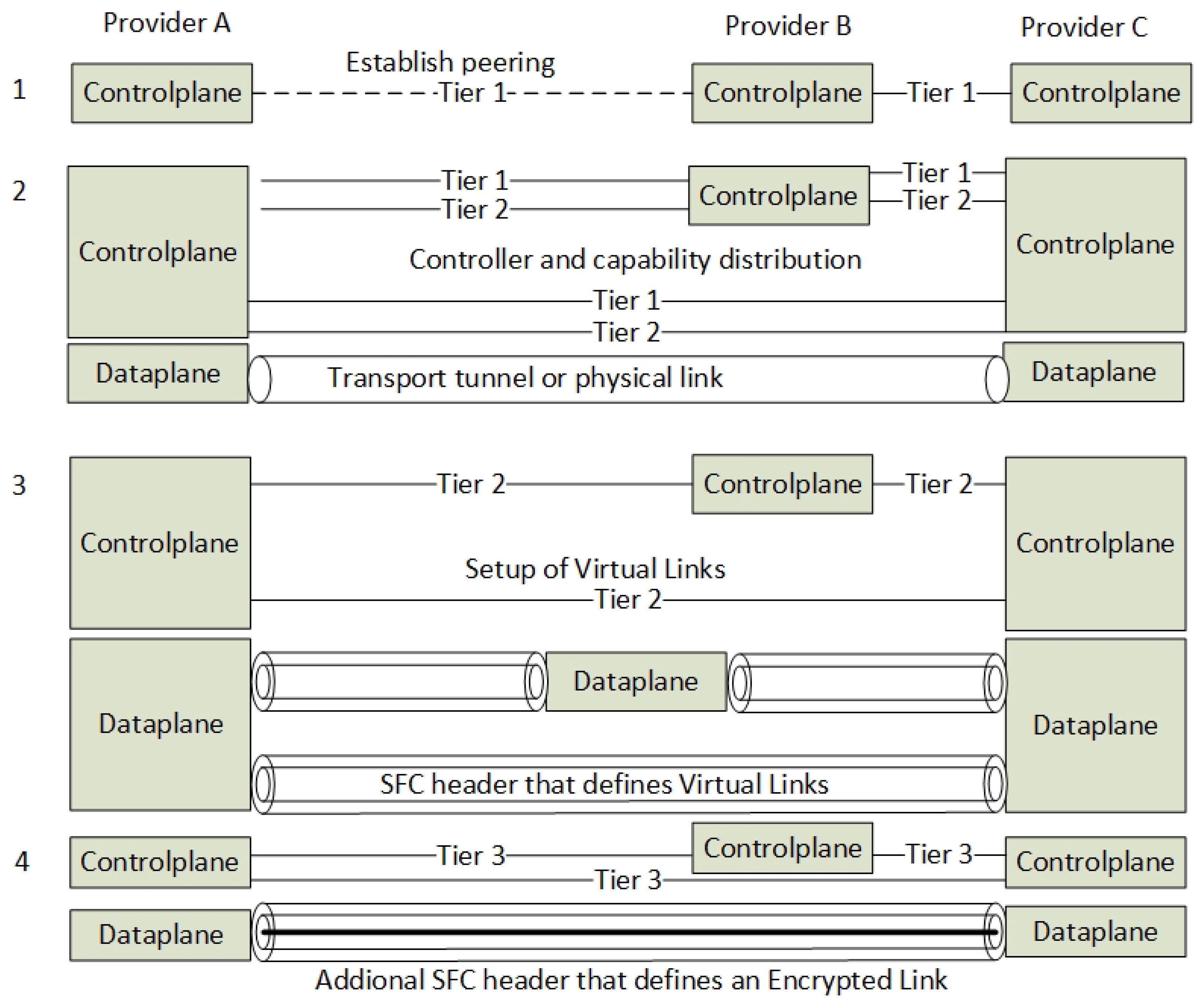
3.2. The Control Plane—Tiered Tunnel Automation
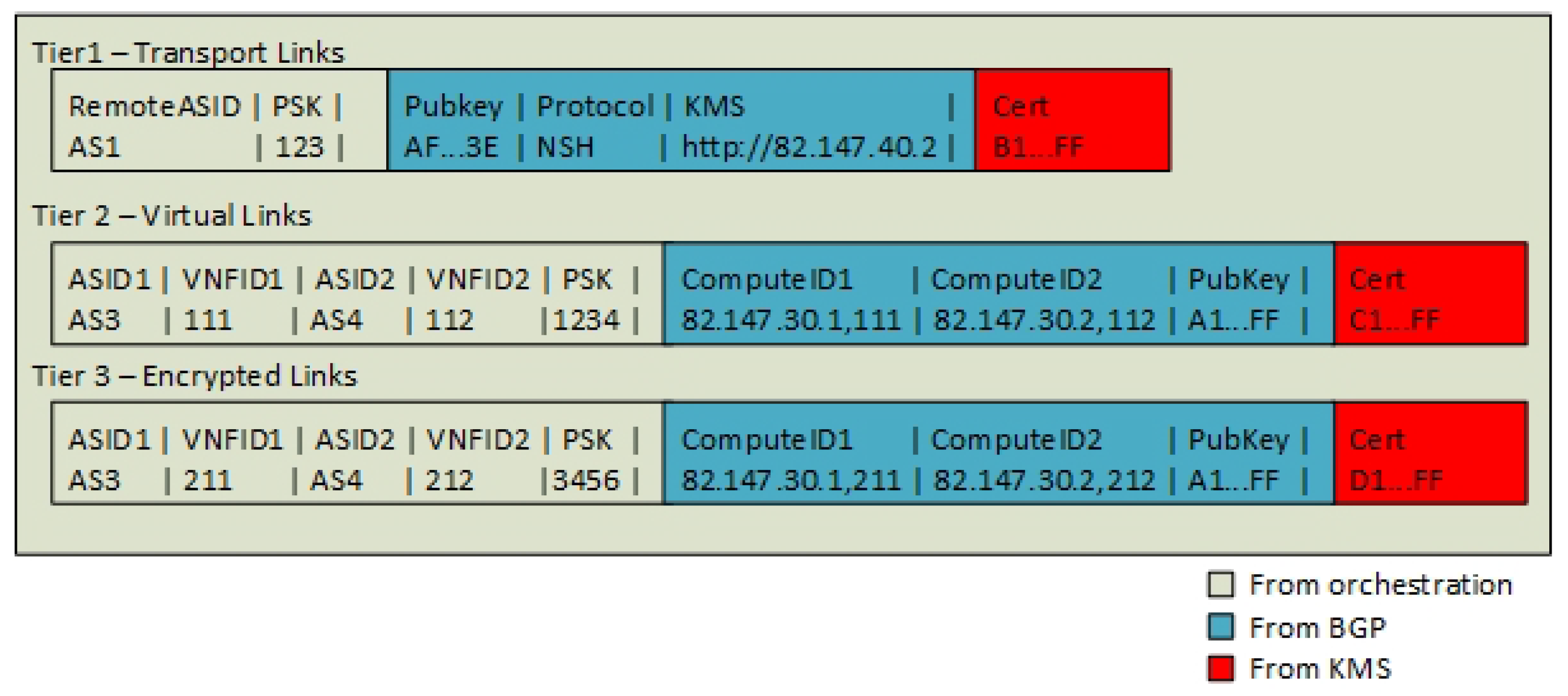
3.2.1. Tier 1—Datacenter Sharing
3.2.2. Tier 2—The Announcements of VNF Locations and SFCs
3.2.3. Tier 3—The Announcements of Transitive SFC Routes and Encryption Service Locations
3.2.4. Encryption Automation
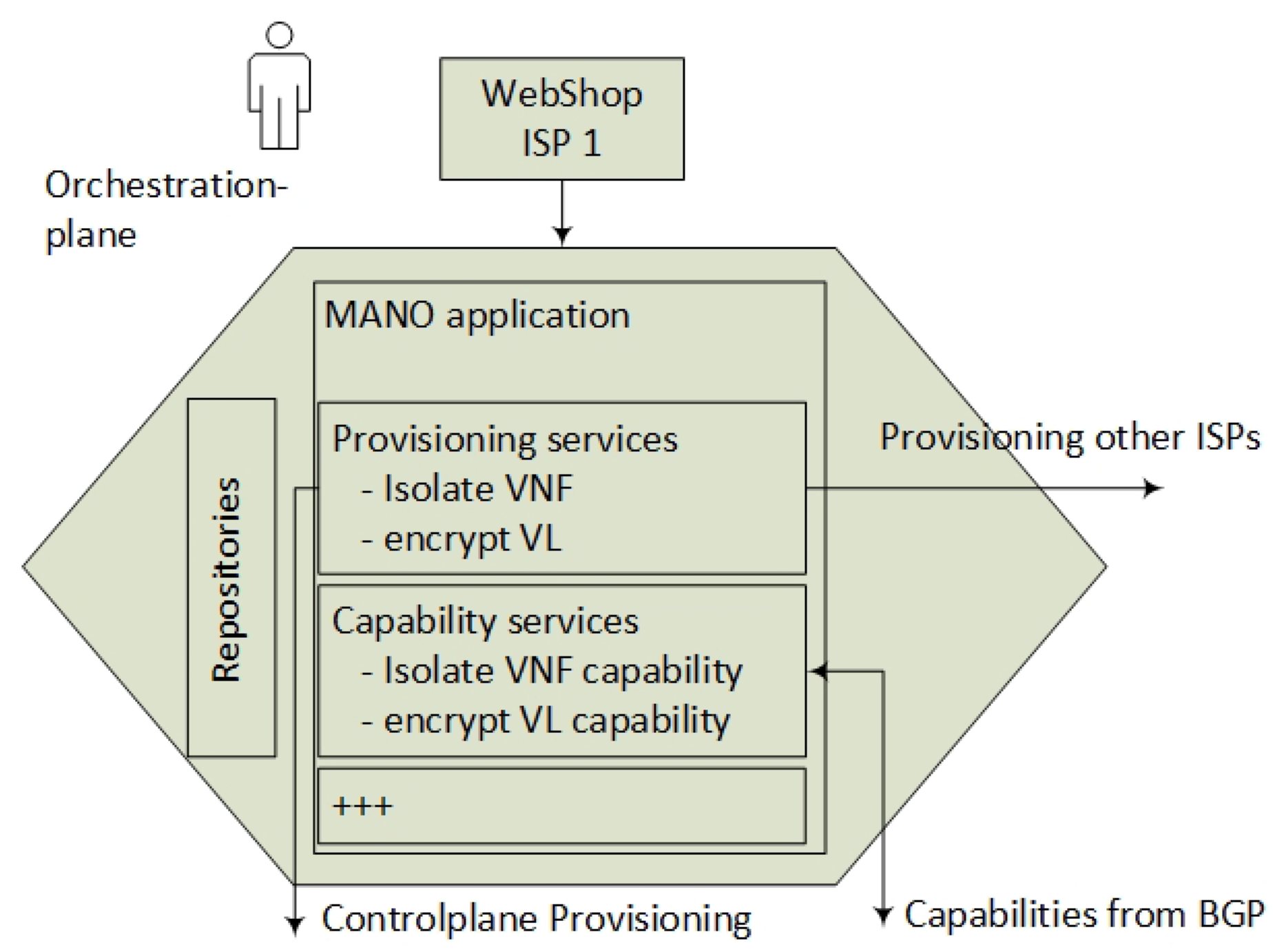
3.3. The Management and Orchestration (MANO) Plane
4. Services in the Architecture
4.1. Service Components on the Orchestration Plane
- Interpret end-user requests of VNFs and SFC in order to create the NSDs,
- Calculate where it is most efficient to run the VNFs,
- Consider any VNF constraints,
- Verify that it exists a Transport Link between every Service Provider that participates in the SFC,
- Ensures that the encrypting VNFs are co-located with normal VNF during provisioning,
- Provision VNFs at all Service Providers,
- Generate a pass-phrase (PSK) per VNF instance to enable authorization of the VNFs. When the VNF is provisioned, this key is submitted as a VNF application parameter.
4.2. Service Components on the Control Plane
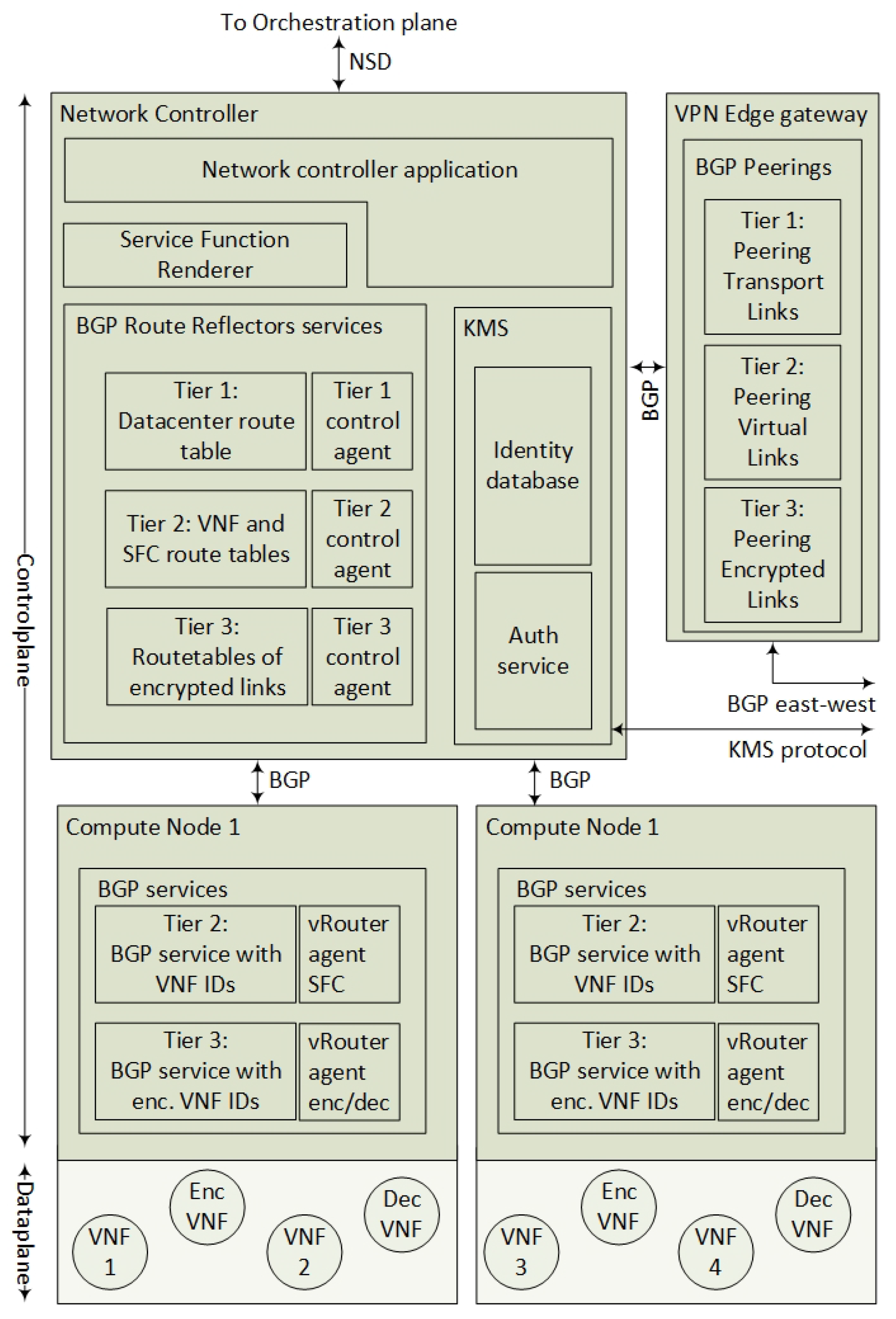
4.2.1. The Network Controller
- Mapping the instantiated VNF IDs to their Compute Node locations,
- Populating the KMS server with identities (see Section 4.2.4),
- Populating the Tiers 2 and 3 agents with the rendered SFC,
- Orchestrating Transport Links, Virtual Links and Encrypted Links,
- Recalculating SFCs for optimization or VNF bypassing during a network or Compute Node failure.
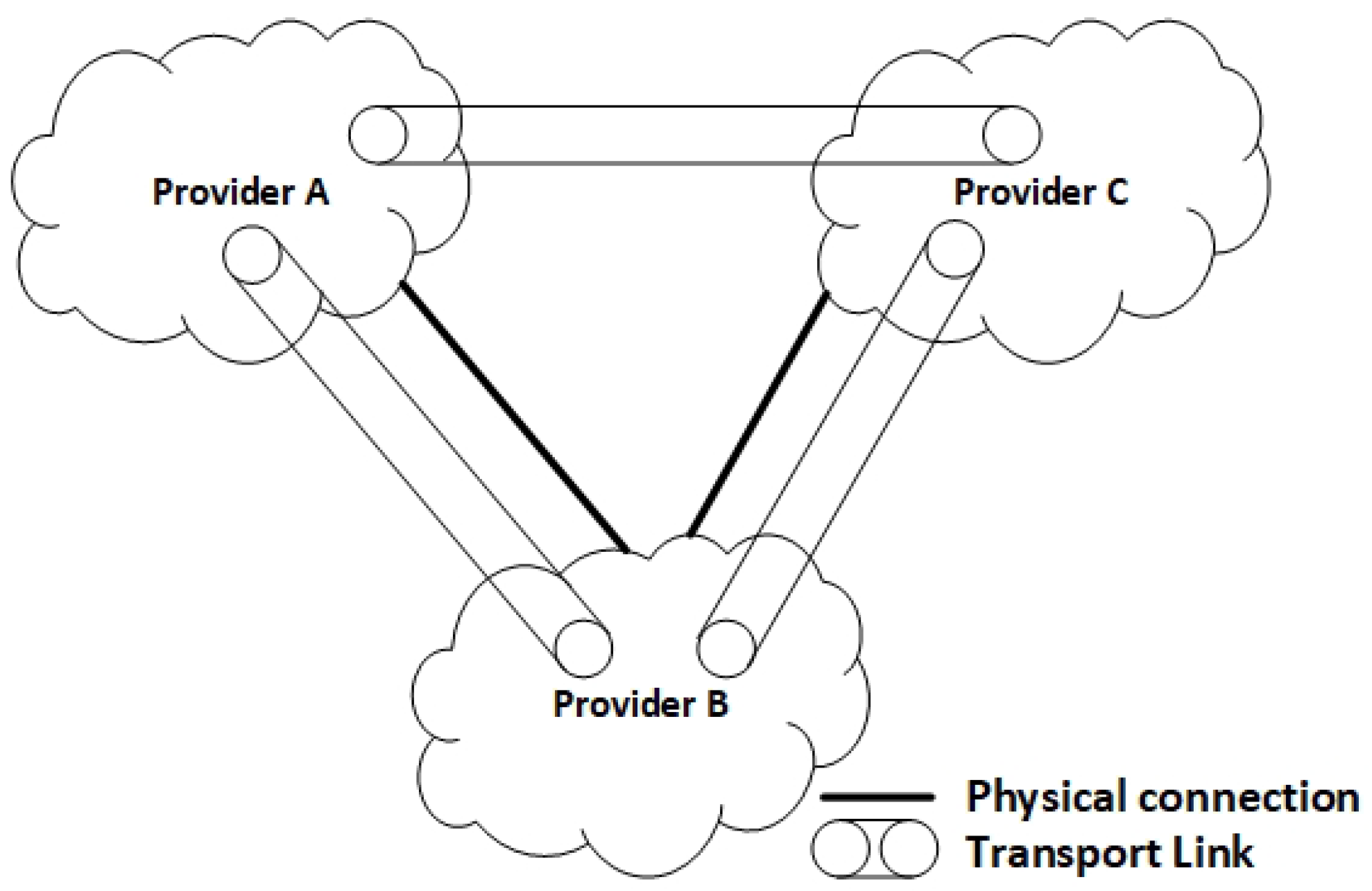
4.2.2. The Tier 1 BGP Service
- Sharing network information over BGP,
- Instantiating Transport Links,
- Populating the Tier 1 BGP with Transport Links,
- Serving an Application Programming Interface (API) towards the orchestration layer for end-user services regarding capabilities of encryption and isolation.
4.2.3. Tiers 2 and 3 BGP Peerings
- Distributing route information of how to route the SFCs to other Compute Nodes—this also includes redundant routes,
- Translating the SFC into BGP messages,
- Serving the KMS server with information from BGP, such as identities and encryption keys.
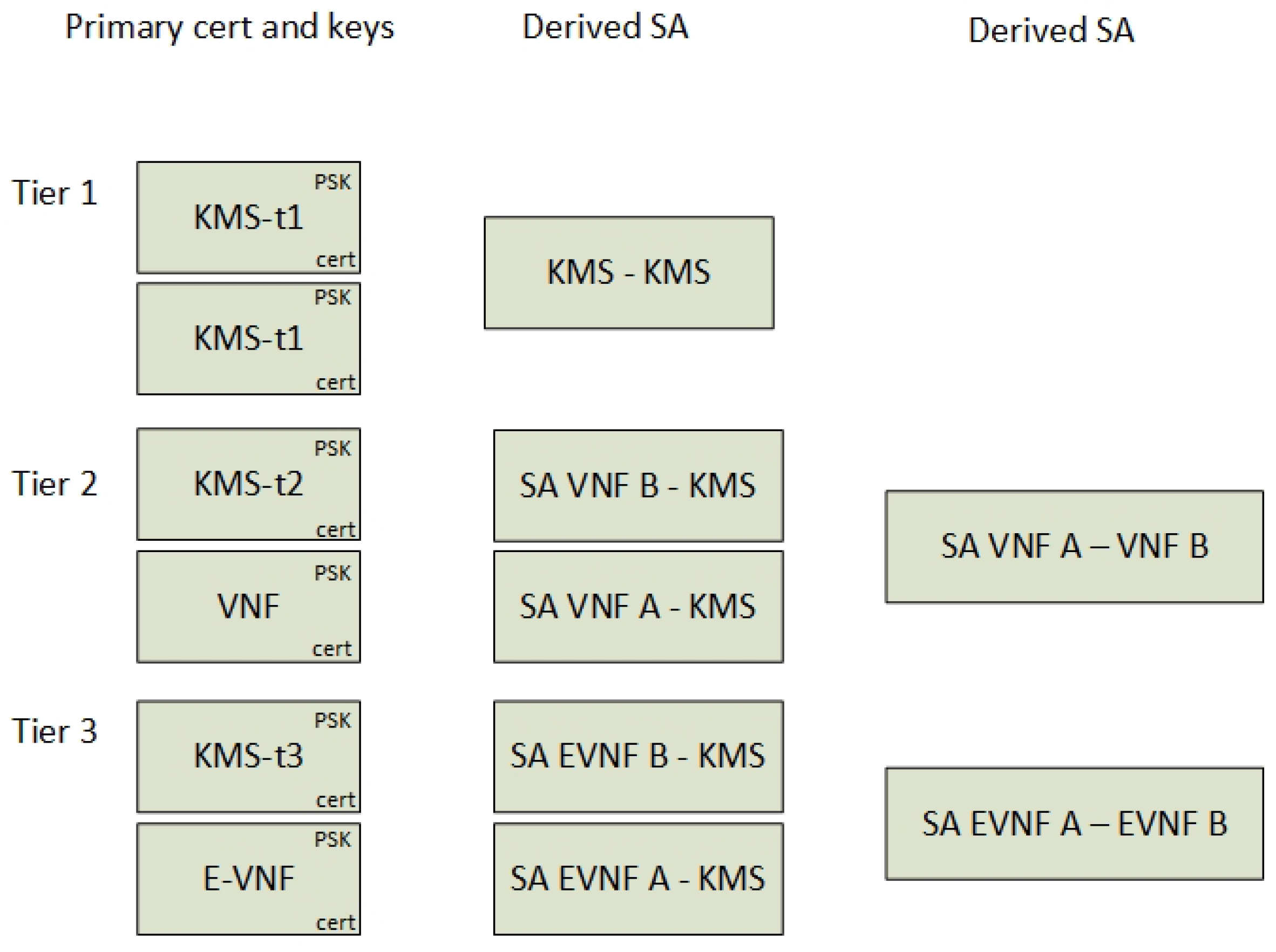
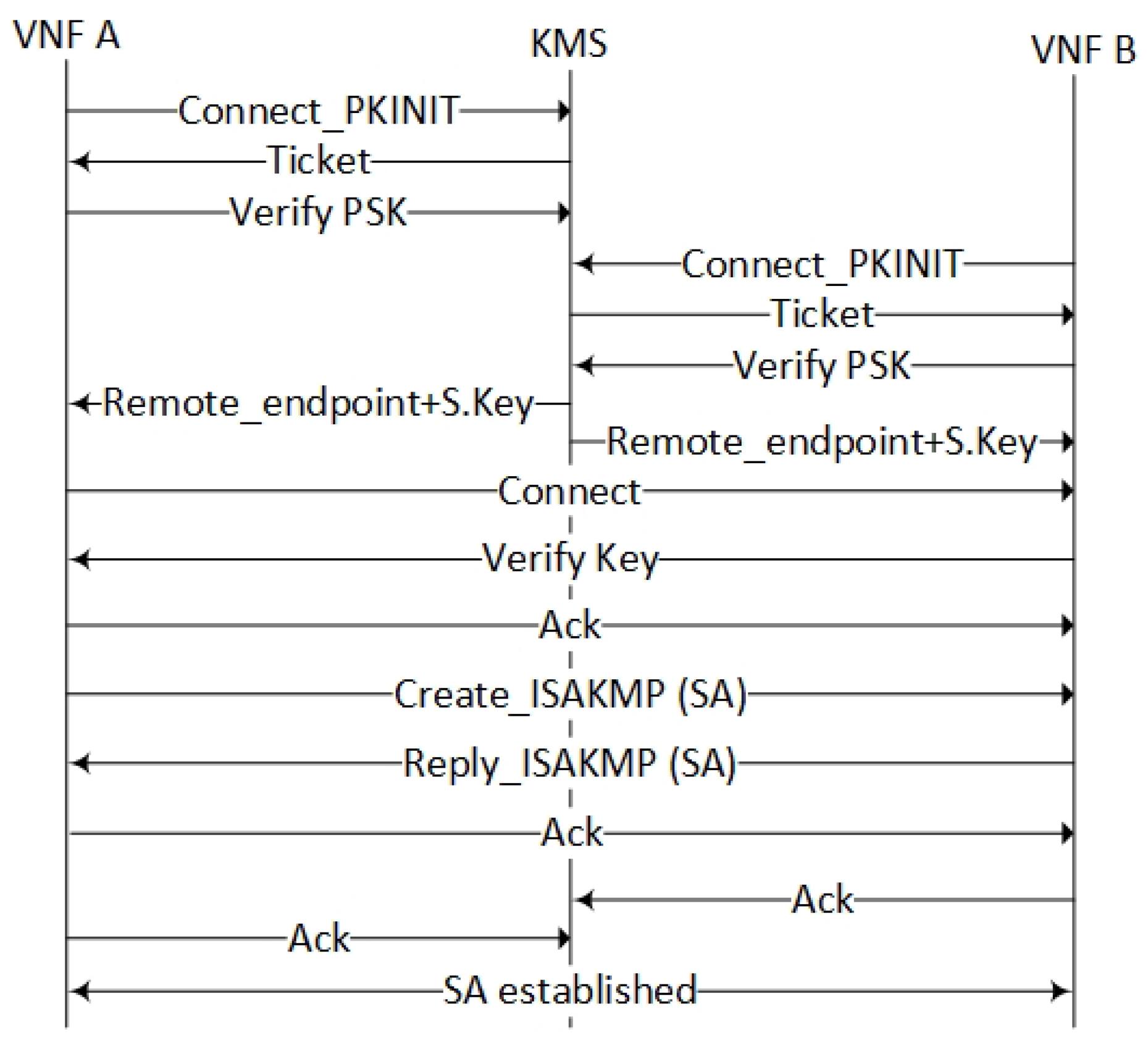
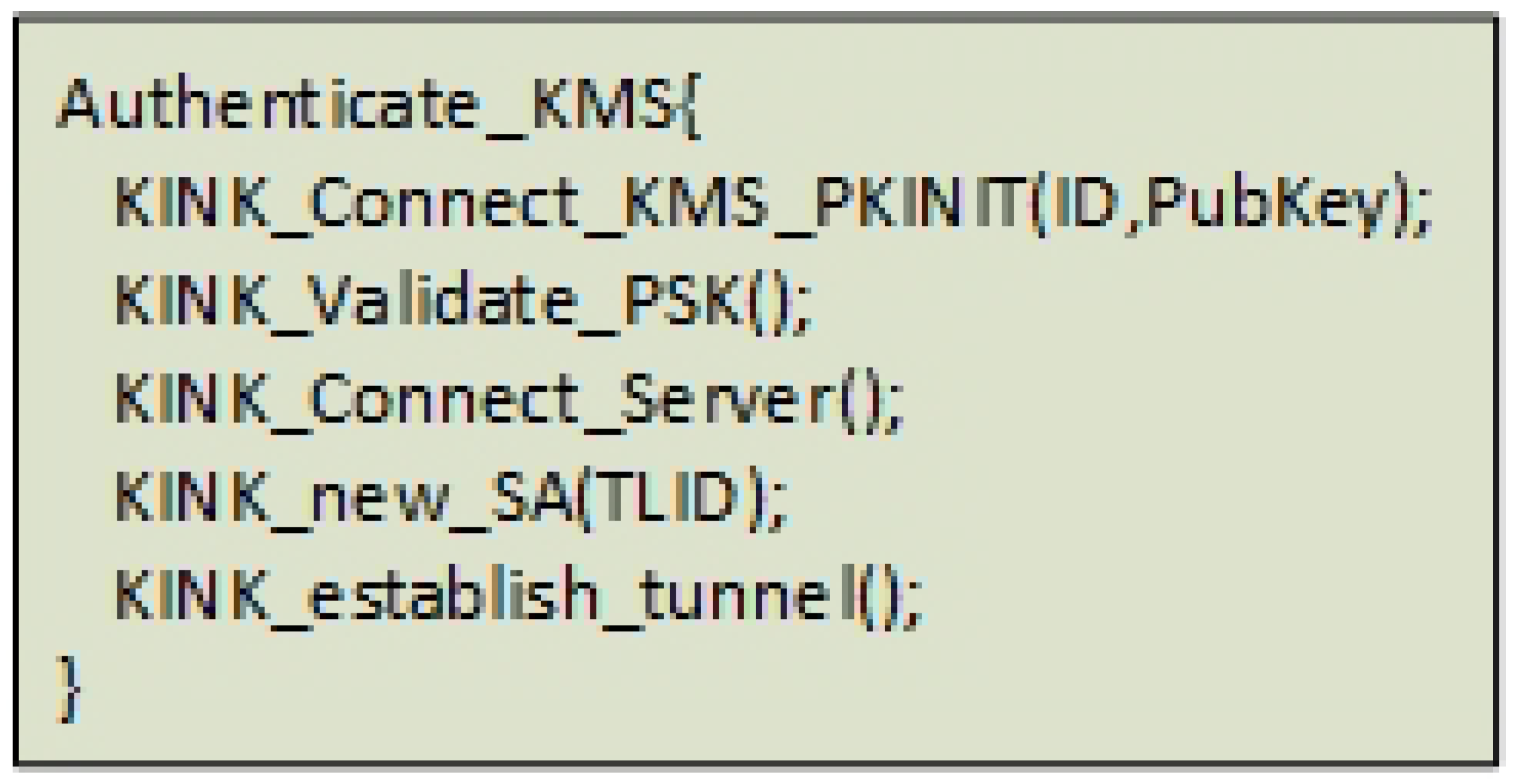
4.2.4. Distributed Key Management Services
- Give two random endpoints (VNFs) instructions about how to set up a secure IPsec transport mode channel between them,
- Authorize both endpoints based on their identifiers, a PSK and their certificates,
- Serve the setup of Encrypted Links, Virtual Links and Transport Links by a key exchange protocol.
4.2.5. The Edge VPN Gateway
- Dynamically establish the Transport Link to other data-centers by terminating VPN interfaces,
- Route SFCs to the corresponding Transport Links,
- Filter SFIR and SFIR-E routes for relevant peers.
4.3. Service Components on the Data Plane
4.3.1. Classification
4.3.2. Service Function Forwarder
4.3.3. Encryption Services as VNF
5. Protocol and Interfaces
5.1. Orchestration Interfaces
5.1.1. Provision SFC
- The Virtual Network Function Descriptor (VNFD), which in this prototype describes the instantiated Virtual Machines global identifier (VNF-ID). The VNFD also includes a description of whether the VNF is a normal VNF or an encrypting VNF (EVNF). Additionally, it includes a new Preshared Key variable (Key), which is a field that must be standardized. This is suggested to be standardized in the TOSCA VNF Configurable Property name-space [22].
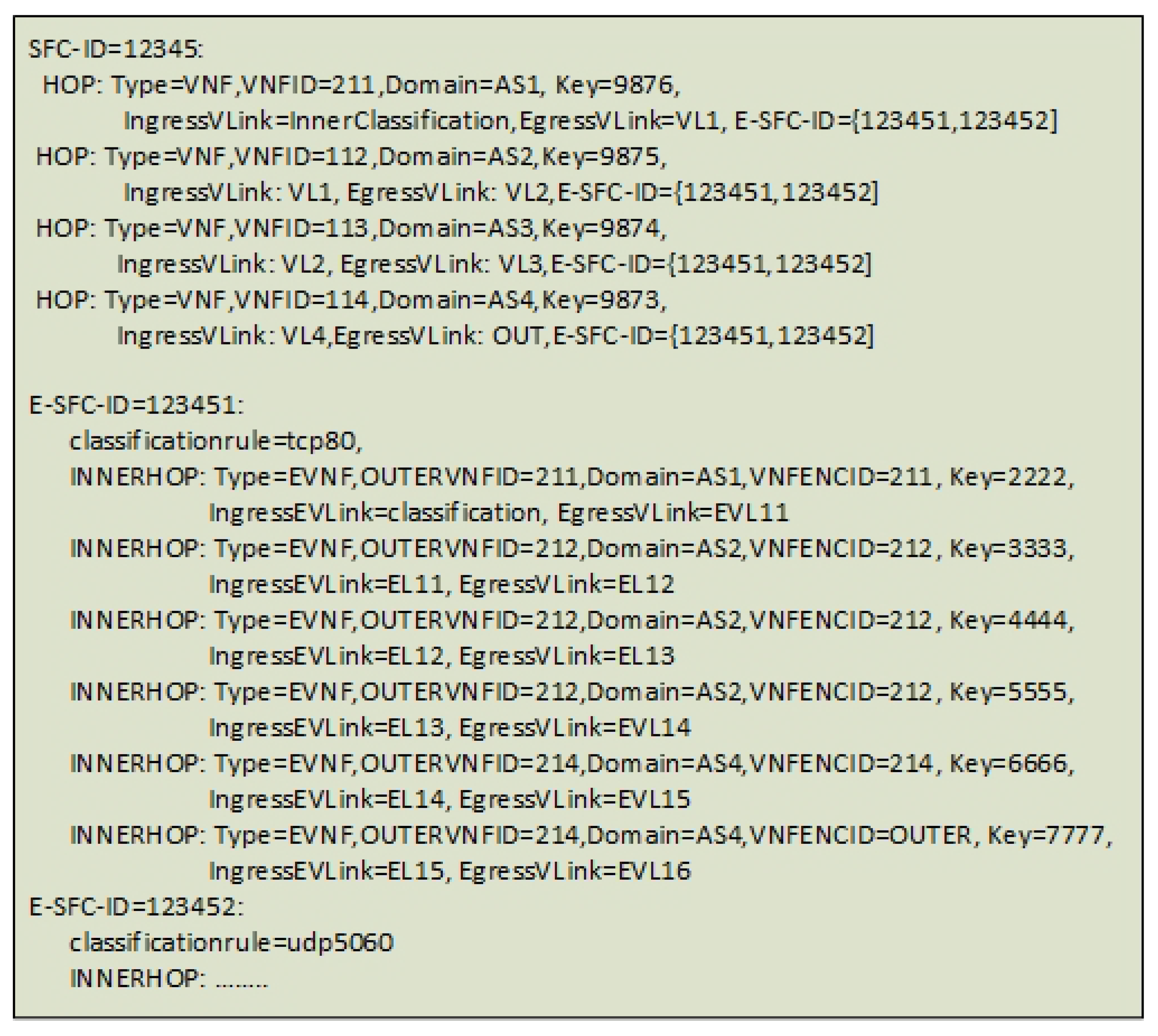
- The Virtual Network Function Forwarding Graph Descriptor (VNFFGD), which describes the SFC. The format of the VNFFGD needs to include both the inner and the outer SFCs. For Proof of concept purposes, we simplify the orchestration message to one new custom file descriptor as pseudo-YAML (Figure 15).
5.1.2. Get Capabilities
5.1.3. Provision Transport Links
5.1.4. Provision VNFs
5.2. Control Plane Interfaces
5.2.1. Control Plane Application Interfaces
- An NSD interface for incoming requests from the orchestration plane. This includes the NSDs for SFC, the VNFs and the Transport Links.
- A service capability interface to get information about the Transport Links to inform the orchestration layer whether the Transport Links exist and how they are established. This service is reflected from the orchestration plane and proxies the BGP route table to the orchestration plane as an NSD.
5.2.2. Tier 1 Interfaces
- A BGP speaker service running on the network controller. The BGP messages consist of two new address families. The new address families are reflected by the announcement of the network controllers and the announcement of the Transport Links (Figure 17). The address families are defined as Network Controller routes (NCR) and Transport Link routes (TR). These BGP messages are distributed globally.
- A configuration interface to inject new Tier 1 routes. The Tier 1 control agent receives a “create Transport Link” message from the controller application, and it injects a Transport Link route into BGP.
- A Get-Capability interface, which transports the BGP table to a YAML format that consists of all Transport Links.
5.2.3. Tiers 2 and 3 Interfaces
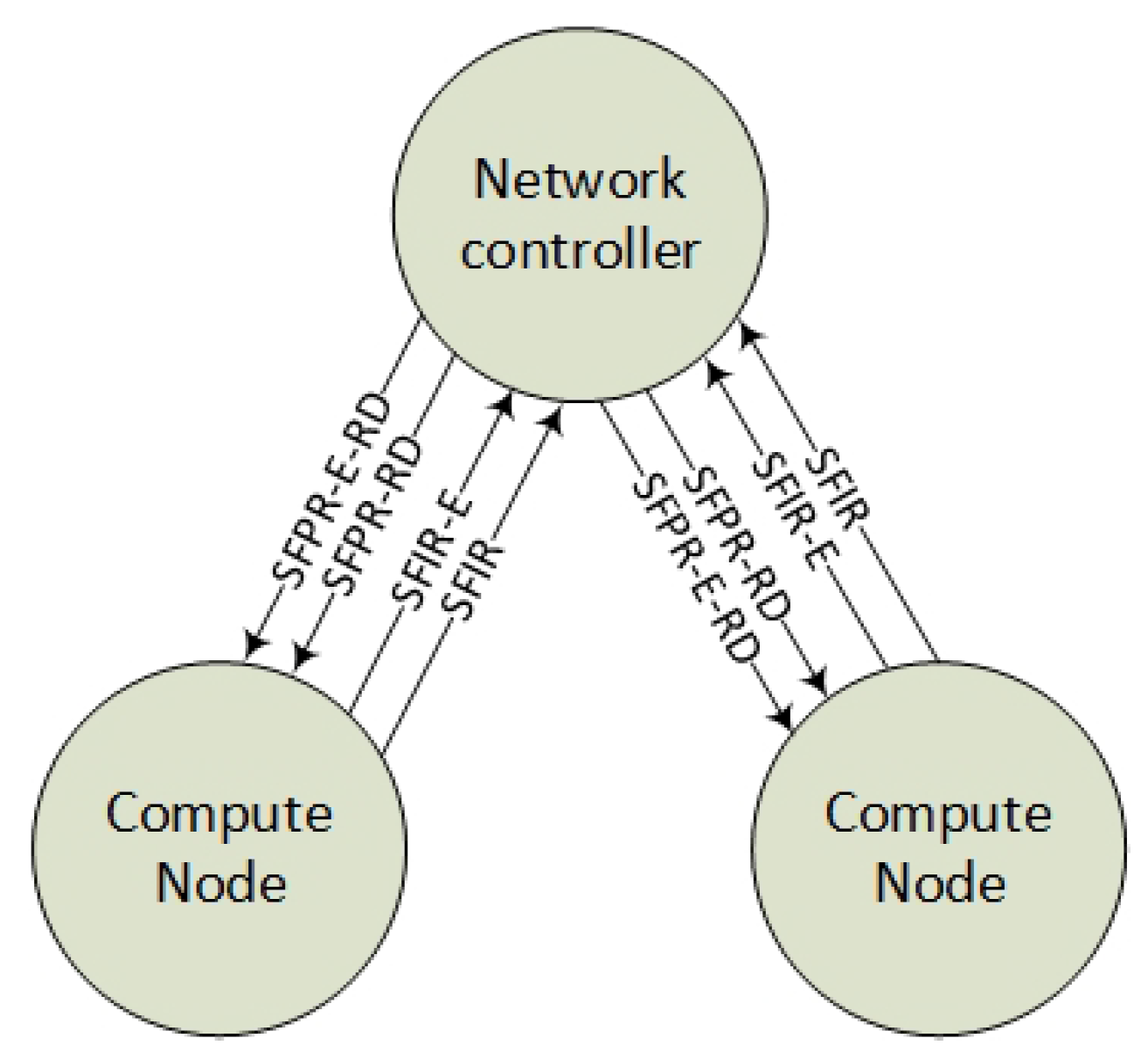
- BGP speakers on Compute Nodes that announce connected VNFs (SFIR and SFIR-E).
- A BGP speaker on the network controller that announces the SFCs (SFPR-RD and SFPR-E-RD).
- Compute Node agent configuration interfaces for maintaining SFIRs and SFIR-Es.
- A Network controller agent configuration interface to maintain SFPR-RDs and SFPR-E-RDs.
- A Network controller agent interface that can transform YAML into BGP Tiers 2 and 3 routes and vice versa.
5.2.4. The VPN Gateway
- An IPVPN BGP peering interface peering towards one or more Service Provider neighbours.
- A VPN tunnel or a direct interface to all other Service Providers.
- A BGP peering interface towards the Tier 1 route reflector that announces the VPN links.
- A Tiers 2 and 3 BGP peering over the Transport Link.
- A configuration interface such as RESTconf or CLI to set up VPN links.
- A KMS server interface to accept VPN connections authorized by the KMS server.
5.2.5. Key Management Service Interfaces
- An authentication protocol interface used by the encryption services and the VPN gateway,
- A management interface to maintain the “user” identities (Section 4.2.4) and their corresponding PSKs.
5.3. Data Plane Interfaces
6. Implementation Guidelines
6.1. Data Plane Implementation
6.2. BGP Services
6.3. KMS Server
6.4. Control Plane Application
7. Evaluation and Discussion
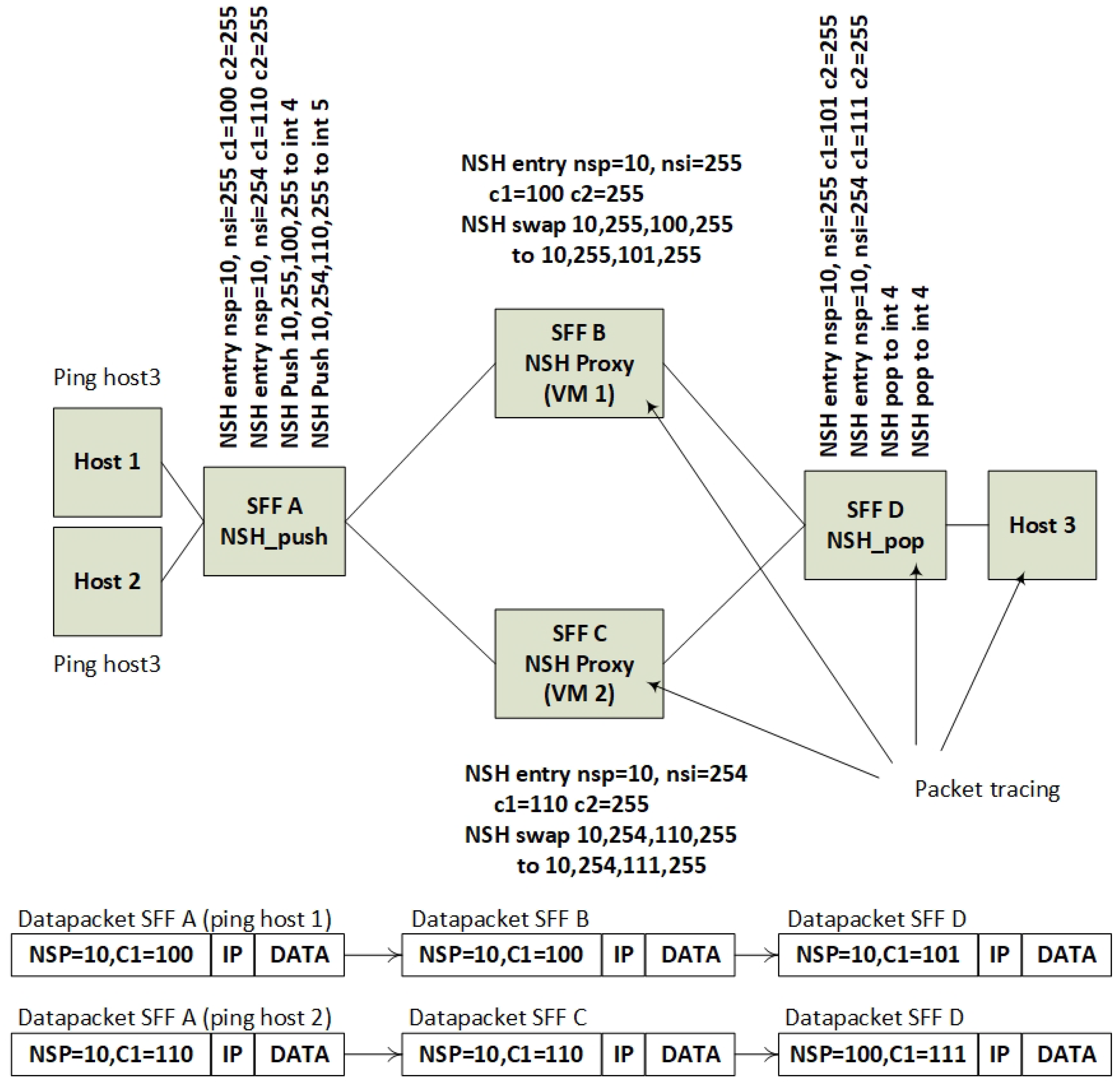
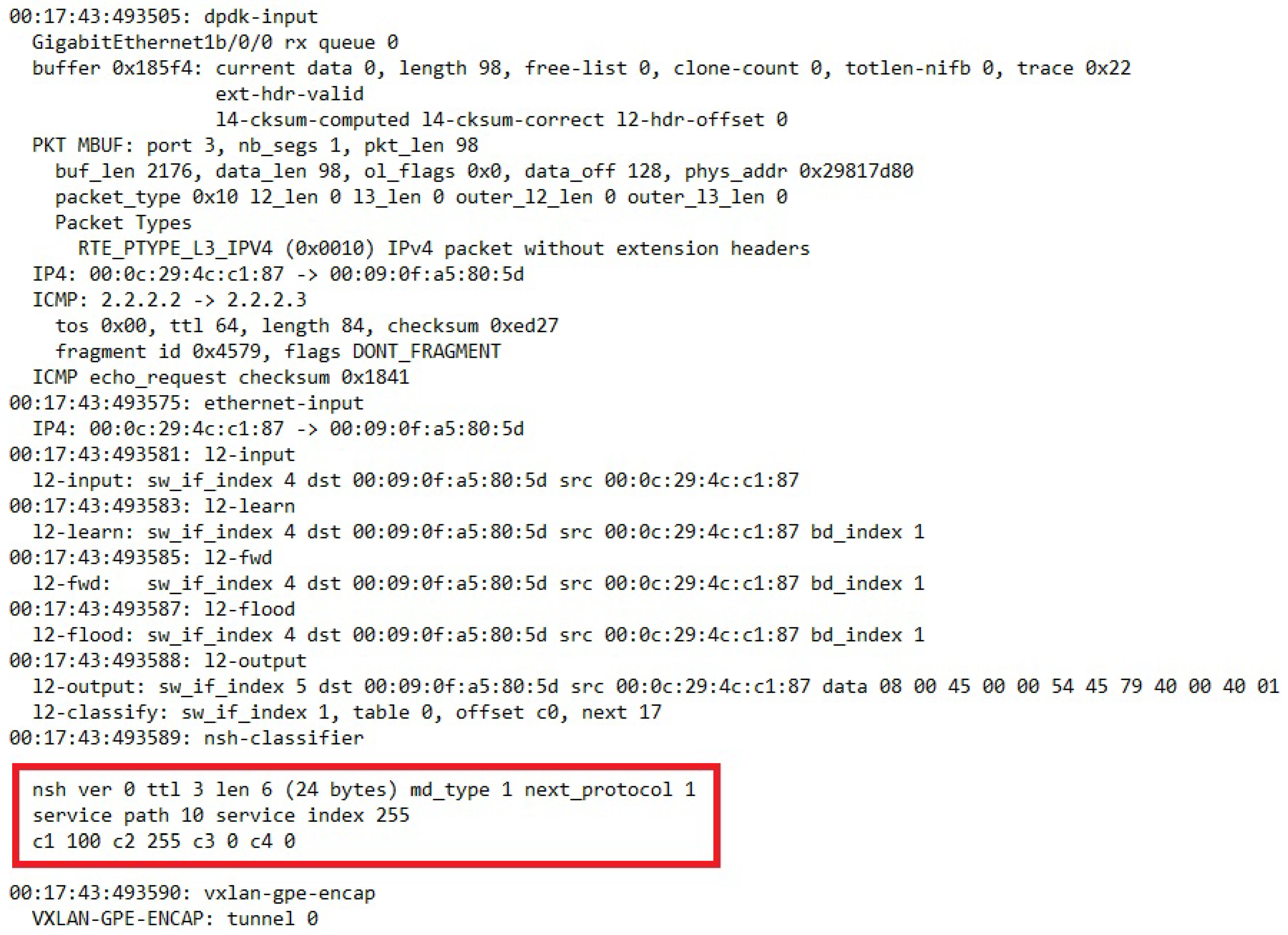
7.1. Proof of Concept Demonstration of Data Plane Forwarding
7.1.1. Discussion of Architectural Challenges
7.1.2. Computational Overhead
7.1.3. An MTU Increase
7.1.4. Backup Tunnels and Resilience
7.1.5. Encryption Key and Backup Keys Overhead
7.1.6. The Dynamic Behaviour of VNFs
7.1.7. Legacy Infrastructure
8. Future Work
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Quinn, P.; Elzur, U. Network Service Header; Internet-Draft Draft-IETF-SFC-NSH-13; Work in Progress; Internet Engineering Task Force: Fremont, CA, USA, 2017. [Google Scholar]
- Farrel, A.; Bryant, S.; Drake, J. An MPLS-Based Forwarding Plane for Service Function Chaining; Internet-Draft Draft-Farrel-MPLS-SFC-05; Work in Progress; Internet Engineering Task Force: Fremont, CA, USA, 2018. [Google Scholar]
- Gunleifsen, H.; Kemmerich, T.; Petrovic, S. An End-to-End Security Model of Inter-Domain Communication in Network Function Virtualization; Norsk Informasjonssikkerhetskonferanse (NISK): Bergen, Norway, 2016; pp. 7–18. [Google Scholar]
- Muñoz, R.; Vilalta, R.; Casellas, R.; Martinez, R.; Szyrkowiec, T.; Autenrieth, A.; López, V.; López, D. Integrated SDN/NFV management and orchestration architecture for dynamic deployment of virtual SDN control instances for virtual tenant networks. J. Opt. Commun. Netw. 2015, 7, B62–B70. [Google Scholar] [CrossRef]
- Chowdhury, N.M.K.; Rahman, M.R.; Boutaba, R. Virtual network embedding with coordinated node and link mapping. In Proceedings of the 2009 Conference on Computer Communications, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 783–791. [Google Scholar]
- Yin, H.; Xie, H.; Tsou, T.; Lopez, D.R.; Aranda, P.A.; Sidi, R. SDNi: A Message Exchange Protocol for Software Defined Networks (SDNS) across Multiple Domains; Internet-Draft Draft-Yin-SDN-SDNI-00; Work in Progress; Internet Engineering Task Force: Fremont, CA, USA, 2012. [Google Scholar]
- Haleplidis, E.; Joachimpillai, D.; Salim, J.H.; Lopez, D.; Martin, J.; Pentikousis, K.; Denazis, S.; Koufopavlou, O. ForCES applicability to SDN-enhanced NFV. In Proceedings of the 2014 Third European Workshop on Software Defined Networks (EWSDN), Budapest, Hungary, 1–3 September 2014; pp. 43–48. [Google Scholar]
- European Telecommunications Standards Institute (ETSI). Network Function Virtualization (NFV). Report on SDN Usage in NFV Architectural Framework. 2015. Available online: http://www.etsi.org/deliver/etsi_gs/NFV-EVE/001_099/005/01.01.01_60/gs_NFV-EVE005v010101p.pdf (accessed on 3 June 2018).
- Kulkarni, S.; Arumaithurai, M.; Ramakrishnan, K.; Fu, X. Neo-NSH: Towards scalable and efficient dynamic service function chaining of elastic network functions. In Proceedings of the 2017 20th Conference on Innovations in Clouds, Internet and Networks (ICIN), Paris, France, 7–9 March 2017; pp. 308–312. [Google Scholar]
- Farrel, A.; Drake, J.; Rosen, E.C.; Uttaro, J.; Jalil, L. BGP Control Plane for NSH SFC; Internet-Draft Draft-Mackie-Bess-NSH-BGP-Control-Plane-04; Work in Progress; Internet Engineering Task Force: Fremont, CA, USA, 2017. [Google Scholar]
- Quinn, P.; Elzur, U.; Pignataro, C. Network Service Header (NSH)-[Review]. 2018. Available online: https://www.rfc-editor.org/rfc/rfc8300.txt (accessed on 3 June 2018).
- Internet Engineering Task Force. Authenticated and Encrypted NSH Service Chains; Internet-Draft Draft-Reddy-SFC-NSH-Encrypt-00; Internet Engineering Task Force: Fremont, CA, USA, 2015. [Google Scholar]
- Lopez, R.; Lopez-Millan, G. Software-Defined Networking (SDN)-Based IPsec Flow Protection; Internet-DraFt Draft-Abad-I2NSF-SDN-IPsec-Flow-Protection-03; Internet Engineering Task Force: Fremont, CA, USA, 2017. [Google Scholar]
- Marques, P.R.; Mauch, J.; Sheth, N.; Greene, B.; Raszuk, R.; McPherson, D.R. Dissemination of Flow Specification Rules. 2009. Available online: https://www.rfc-editor.org/rfc/rfc5575.txt (accessed on 3 June 2018).
- Halpern, J.M.; Pignataro, C. Service Function Chaining (SFC) Architecture. 2015. Available online: https://www.rfc-editor.org/rfc/rfc7665.txt (accessed on 3 June 2018).
- Gunleifsen, H.; Kemmerich, T.; Petrovic, S. Security Requirements for Service Function Chaining Isolation and Encryption. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology, Chengdu, China, 27–30 October 2017; pp. 231–240. [Google Scholar]
- Chandra, R.; Rekhter, Y.; Bates, T.J.; Katz, D. Multiprotocol Extensions for BGP-4. 2007. Available online: https://www.rfc-editor.org/rfc/rfc4760.txt (accessed on 3 June 2018).
- Bush, R.; Austein, R. The Resource Public Key Infrastructure (RPKI) to Router Protocol, Version 1. 2017. Available online: https://www.rfc-editor.org/rfc/rfc8210.txt (accessed on 3 June 2018).
- European Telecommunications Standards Institute (ETSI). Network Function Virtualization (NFV). Management and Orchestration. 2014. Available online: http://www.etsi.org/deliver/etsi_gs/NFV-MAN/001_099/001/01.01.01_60/gs_nfv-man001v010101p.pdf (accessed on 3 June 2018).
- European Telecommunications Standards Institute (ETSI). Network Function Virtualization (NFV). Architectual Framework v1.1.1; 2013. Available online: http://www.etsi.org/deliver/etsi_gs/NFV/001_ 099/002/01.01.01_60/gs_NFV002v010101p.pdf (accessed on 3 June 2018).
- Bierman, A.; Bjorklund, M.; Watsen, K. RESTCONF Protocol. 2017. Available online: https://rfc-editor.org/rfc/rfc8040.txt (accessed on 3 June 2018).
- Organization for the Advancement of Structured Information Standards (OASIS). TOSCA Simple Profile for Network Functions Virtualization (NFV) Version 1.0, Committee Specification Draft 04 2016. Available online: http://docs.oasis-open.org/tosca/tosca-nfv/v1.0/tosca-nfv-v1.0.pdf (accessed on 3 June 2018).
- Vilhuber, J.; Kamada, K.; Sakane, S.; Thomas, M. Kerberized Internet Negotiation of Keys (KINK). 2017. Available online: https://www.rfc-editor.org/rfc/rfc4430.txt (accessed on 3 June 2018).
- Bellovin, S.; Bush, R.; Ward, D. Security Requirements for BGP Path Validation. 2014. Available online: https://www.rfc-editor.org/rfc/rfc7353.txt (accessed on 3 June 2018).
- The Fast Data Project. Vector Packet Processing Test Framework. 2016. Available online: https://docs.fd.io/vpp/17.04/ (accessed on 3 June 2018).
- Quagga. Quagga Routing Suite. 1999. Available online: http://www.quagga.net (accessed on 3 June 2018).
- Raeburn, K. Encryption and Checksum Specifications for Kerberos 5. 2005. Available online: https://www.rfc-editor.org/rfc/rfc3961.txt (accessed on 3 June 2018).
- Racoon. Racoon IPSec Key Exchange System. 2006. Available online: http://www.racoon2.wide.ad.jp (accessed on 3 June 2018).
- Perino, D.; Gallo, M.; Laufer, R.; Houidi, Z.B.; Pianese, F. A programmable data plane for heterogeneous NFV platforms. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 77–82. [Google Scholar]
- Eiras, R.S.V.; Couto, R.S.; Rubinstein, M.G. Performance evaluation of a virtualized HTTP proxy in KVM and Docker. In Proceedings of the 2016 7th International Conference on the Network of the Future (NOF), Buzios, Brazil, 16–18 November 2016; pp. 1–5. [Google Scholar]


























© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gunleifsen, H.; Gkioulos, V.; Kemmerich, T. A Tiered Control Plane Model for Service Function Chaining Isolation. Future Internet 2018, 10, 46. https://doi.org/10.3390/fi10060046
Gunleifsen H, Gkioulos V, Kemmerich T. A Tiered Control Plane Model for Service Function Chaining Isolation. Future Internet. 2018; 10(6):46. https://doi.org/10.3390/fi10060046
Chicago/Turabian StyleGunleifsen, Håkon, Vasileios Gkioulos, and Thomas Kemmerich. 2018. "A Tiered Control Plane Model for Service Function Chaining Isolation" Future Internet 10, no. 6: 46. https://doi.org/10.3390/fi10060046
APA StyleGunleifsen, H., Gkioulos, V., & Kemmerich, T. (2018). A Tiered Control Plane Model for Service Function Chaining Isolation. Future Internet, 10(6), 46. https://doi.org/10.3390/fi10060046