1. Introduction
Aspect-level sentiment classification, or aspect-based sentiment analysis (ABSA), is a fine-grained sentence analysis, which recognizes the aspects mentioned in the sentence and their corresponding sentiment polarity [
1]. ABSA task consists of two subtasks, aspect category detection and sentiment polarity classification. For instance, given the sentence “The food is not cheap but quite delicious”, first the two aspects of sentiment target food are extracted: FOOD#PRICE and FOOD#TASTE. Then, the sentiment for each aspect is classified: negative for “not cheap” in FOOD#PRICE and positive for “quite delicious” in FOOD#TASTE.
ABSA task has become one of the research focuses in the sentiment analysis domain of natural language processing (NLP) [
2,
3]. Conventional machine learning methods such as Support Vector Machine (SVM) have been applied to the text classification issues [
4], and can also be used in sentiment analysis. These methods extract features in the sentence to build the model, and use these features to predict the categories of non-annotated data. There have been many achievements in the machine learning approaches [
4,
5]. However, conventional machine learning approaches have an obvious drawback that they treat the sentence as a bag of words and do not consider the sequence and the relationships between aspect terms and its corresponding opinion-indicating words, when the sentiment polarity is often determined by such sequence or relationships. Another problem is that these models depend too much on the feature engineering and require a quantity of manual preprocessing, which stops them from being more efficient or accurate.
Jiang et al. [
6] pointed out that considering target information tends to reduce errors about 40% in the sentiment classification tasks. Deep learning methods, especially recurrent neural network (RNN) [
7], consider the context when modeling the sentence, which enable them to analyze target information and its context word dependencies. Dong et al. [
8] introduced a self-adaptive recursive neural network AdaRNN. The model analyzes the sentiment structure and context information to learn the sentiment relationships between target and other words in the sentence. Nguyen et al. [
9] combined recursive neural network with dependency tree and presented PhraseRNN. The model builds a binary phrase dependency tree for features in different aspects and judges sentiment polarity of different aspects with the dependency tree. Tang et al. [
10] proposed Target-Dependent Long Short-Term Memory (TD-LSTM). The model uses two LSTM network, which, respectively, propagate the pre-context and back propagate the post-context, to evaluate the target in the context.
In addition to target information analysis, attention mechanism is put forward to promote the accuracy of the aspect-level sentiment analysis in recent years [
11]. The attention mechanism is an imitation of human’s behavior that, when a man is reading some text, he tends to focus on some specific words or phrases that are important for understanding the text. Attention is a vector whose length is equal to the sentence, and the value of each dimension represents the importance rank of the corresponding word. The attention vector usually element-wise multiplies the sentence representation, which allows the model to focus on the important parts of the sentence. Wang et al. [
11] proposed an attention-based LSTM network, who applies attention on the LSTM hidden layer through multiplication with aspect embedding vector. The model focuses on the aspect information and has made great progress in the ABSA tasks. Tang et al. [
12] raised an attention-based memory network which has two attentions, content-level attention and aspect position attention. The two attentions enhance the model’s ability to extract the features of targets from sentence with multi-aspect, which makes up the shortage of single attention models. Du at el. [
13] introduced a CNN-based attention model. The model uses CNN’s invariance feature to extract the attention vector, and has received better experiment results than LSTM-based attention implementations.
The above studies show that conventional NLP methods that focus on the sentence level features cannot meet the demand of aspect level sentiment classification. More specialized features, such as target of the sentence and people’s attention on the sentence, should be analyzed. The approaches mentioned above tend to use one of these features to solve the problems and have made some great progress in the aspect level sentiment analysis domain. In our opinion, the combination of target information analysis and attention mechanism can further simulate human’s activity and get better achievements in the domain. People tend to use idioms in the comments and attention mechanism can prevent the model from recognizing the target in the idioms by mistake. For instance, in the sentence “it is the service that leaves a bad taste in my mouth”, the highlighted target by the attention mechanism should be “service”. However, a non-attention model may also mark “taste” as a second target, when the idiom “leaves a bad taste in my mouth” actually means “leaves a bad impression” and does not mean the taste of the food is bad.
In this paper, we propose an attention-based aspect level model, AARCNN, to analyze the sentiment polarity at the aspect level. The model integrates Bi-LSTM network and convolutional neural network (CNN), which are, respectively, for target analysis and attention extraction.
The main contributions of our work are as follows:
We propose AARCNN, an integrated model for aspect-based sentiment analysis tasks. The model incorporates attention mechanism and aspect information, and uses the important part of the comment sentence to analyze the sentiment polarity in the aspects.
Both attention and aspect are essential in the ABSA tasks, so we introduce both modules in our model: CNN-based attention mechanism for attention extraction and weighted aspect embedding for aspect detection and analysis.
Experimental results indicate that the approach achieves state-of-the-art performance compared to several baseline methods, and further examples prove that the substitution of Bi-LSTM promotes that classification accuracy.
The rest of this paper is structured as follow:
Section 2 is the detailed description of AARCNN model.
Section 3 shows the experimental results and corresponding case study of AARCNN model.
Section 4 concludes our work.
2. Model
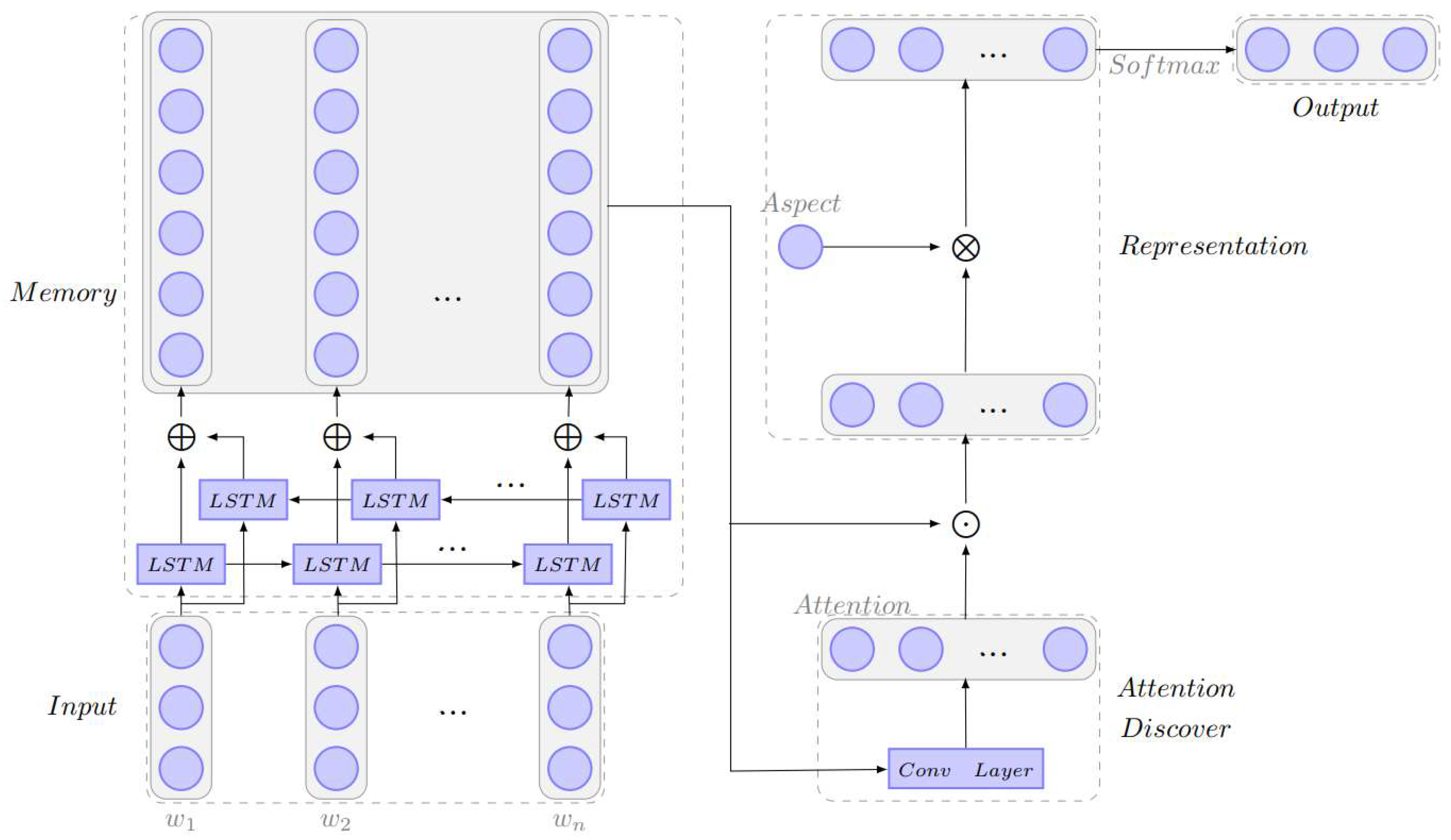
The architecture of AARCNN model is shown in
Figure 1, which consists of five parts: input module, memory module, attention discover module, representation module and output module. Suppose the input comment sentence is
where
is the
word of the sentence; the goal is to classify the sentiment polarity of each aspect of the comment. For example, given the comment “The food is not cheap but very delicious”, the output should indicate that it is negative in the “FOOD#PRICE” aspect and is positive in the “FOOD#TASTE” aspect.
2.1. Input Preprocess
The first step is formalizing the input comment sentence. Suppose the sentence is composed of a
-word sequence. Each word is transferred to a real-value vector with word embedding methods such as GloVe [
14] or CBOW [
15]. Word embedding is an unsupervised method that provides a dictionary mapping words to their unique corresponding vector. Then, we can get a sequence of word embedding
where
is the word vector of the
word and
is the dimension of vectors in the embedding dictionary. A pre-trained word embedding model is applied in our model.
2.2. Memory Module
The sequence is input into a Bi-LSTM network to learn the hidden semantics of the words. Since the words may have strong connection with its context even if the distance between two words is long, we regard that LSTM [
16] is good at learning the long-term dependencies in this scenario. Especially, we mentioned that the comment sentences tend to have two kinds of expression order, e.g., “the spot is perfect” and “the perfect spot”. Considering the order affects the dependencies between words, we replace LSTM with Bi-LSTM, which calculates the hidden semantic in both normal order and opposite order.
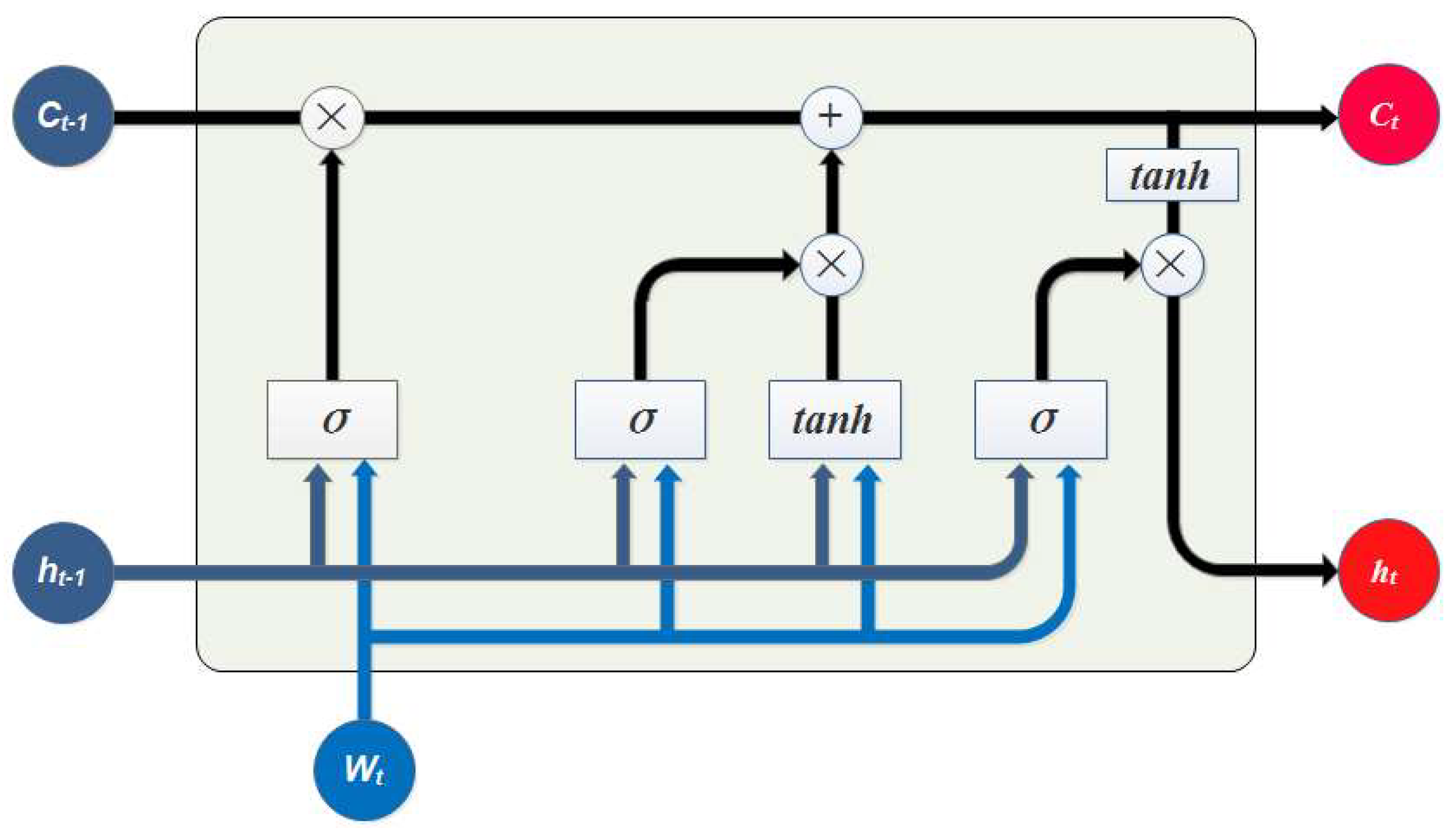
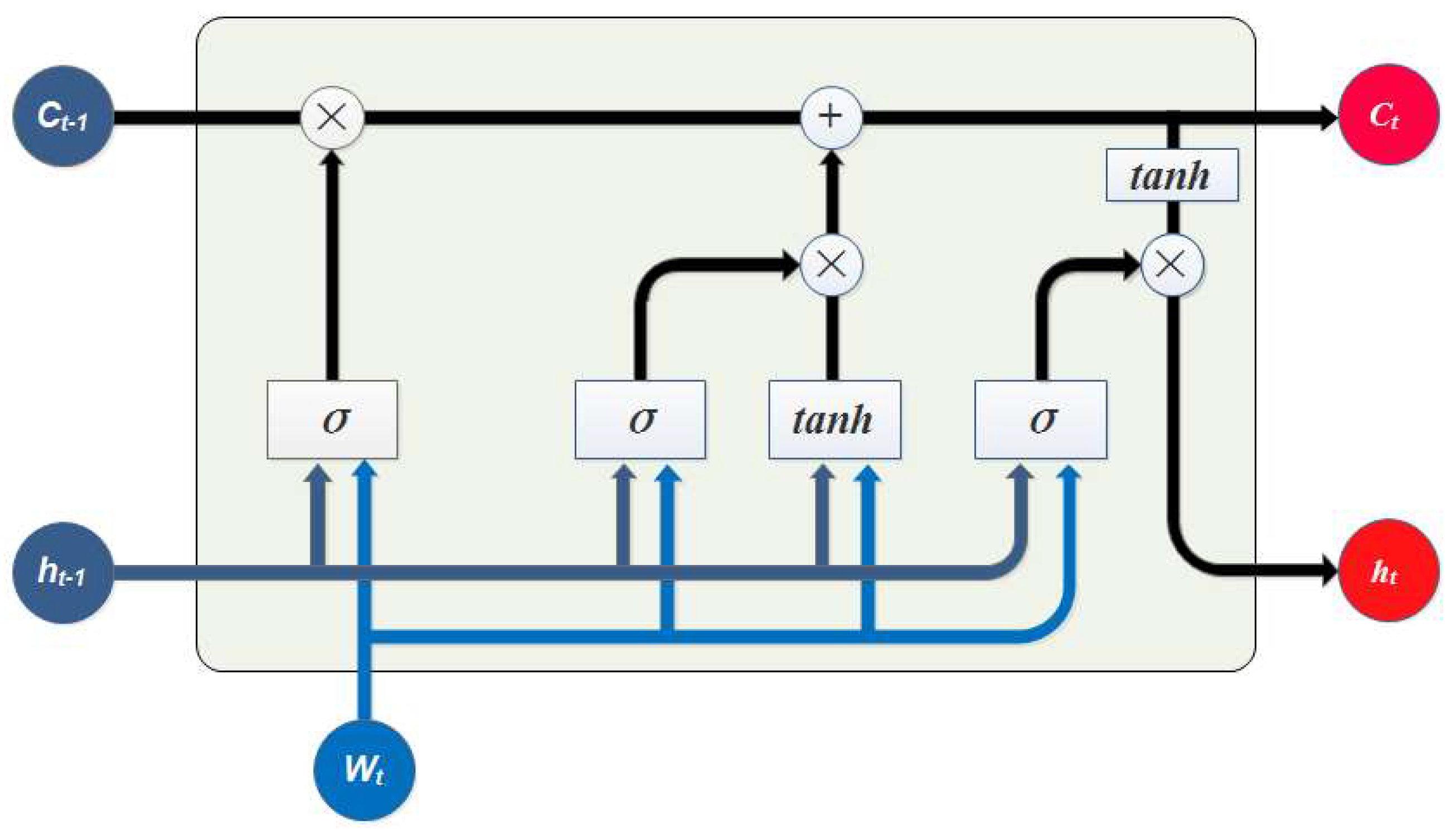
As shown in
Figure 2, at each time step
, given the word vector
, the previous hidden state
and the previous cell state
, the current state can be calculated as follows:
where
is the sigmoid function and
is the hyperbolic tangent function. The symbol
stands for matrix multiplication and
means element-wise multiplication.
s are the weight matrixes for the input vector
and
s are the weight matrixes for the previous hidden state vector
.
denote the input gate, forget gate and the output gate, which decide whether to update the cell state with the input, whether to forget the memory from the last time step and whether to output the memory, respectively.
The output of the forward LSTM is marked as . The backward LSTM uses the reversed sequence as the input and its output is remarked as , where is the index of the word in the sequence . The final representation of the sentence is , where .
2.3. Attention Discover Module
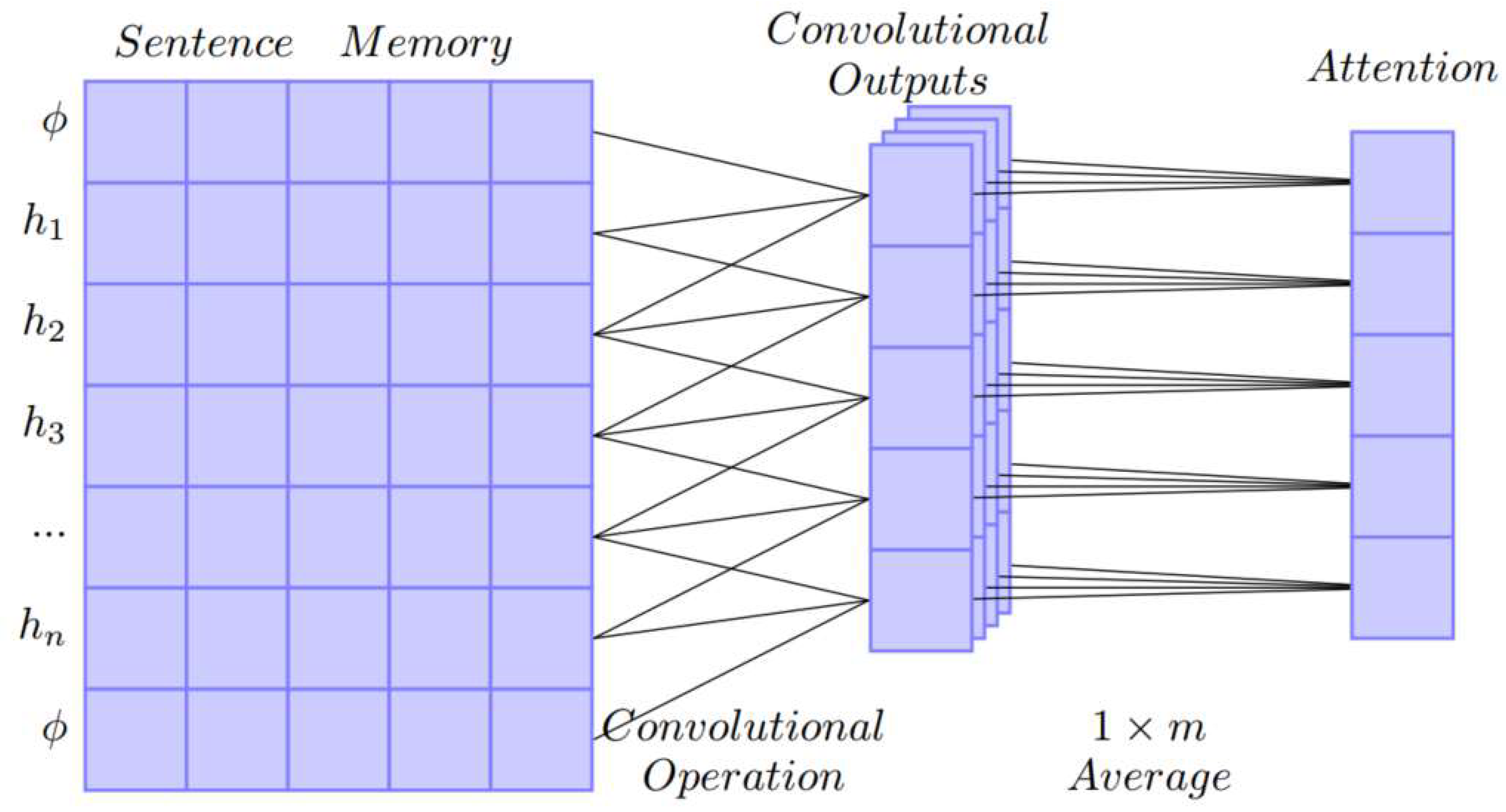
In a comment sentence, only a few words do good to aspect detection and sentiment polarity judgement. A word or a phrase, which may show the aspect or the sentiment, is focused on when people try to understand the opinion, wherever it appears in the sentence. This feature is similar to translation invariance, a key feature of CNN, which leads to the application of CNN to find out the attention signal of the sentence.
Attention signal is a real-value vector that expresses the importance of a word in the sentence. Attention is marked as , where is the length of the sentence and is the score of the word in the sentence; the higher score a word gets, the more important the word is in the sentence. The attention signal is calculated as the following steps:
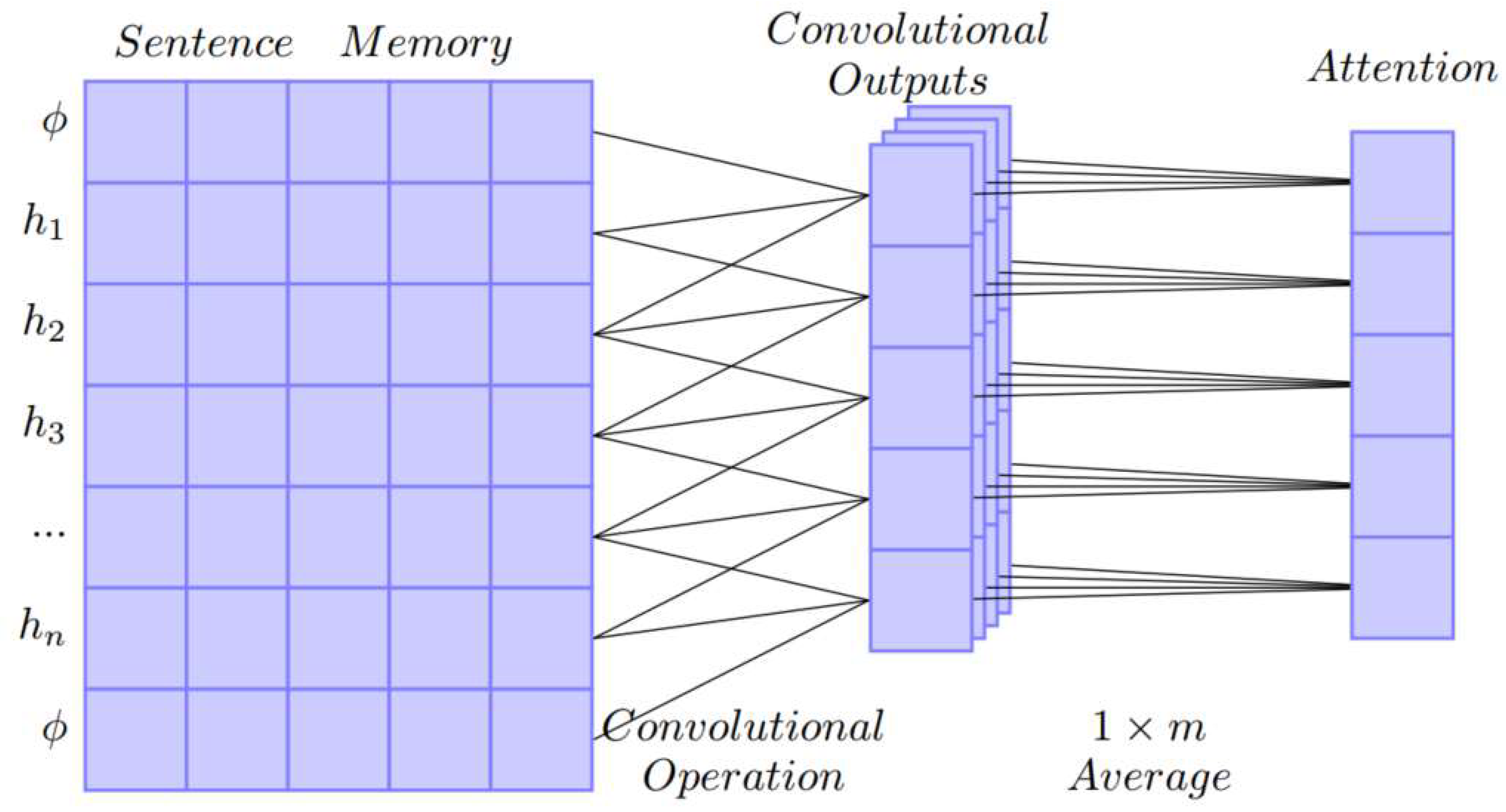
Sentence representation padding. The first word of the sentence has no pre-context and the last word has no post-context, which may weaken their importance score when calculated in the same way as words in the middle. Therefore, the representation is filled with start vector and end vector as , where and are pre-trained vector.
Scoring. We used the output of a CNN as the attention signal. To get a stable attention signal, the scoring module sets
filters in the convolution layer and uses their average as the final score. Let
be the output vector of filters
; the attention signal is shown in
Figure 3.
The attention signal highlights the important words in the sentence, which is applied through element-wise multiplication. Denote the sentence representation with attention by
where
which is computed as follow:
2.4. Aspect Embedding
Target information and aspects are important in the ABSA tasks. To use this information, we transfer the candidate targets and aspects to vectors through weighted aspect embedding. Weighted aspect embedding is finished as the following steps:
Given a target-aspect pair , both target and aspect word are put into the word embedding methods, and the output vectors are marked as and , where and are the embedding vectors for the target and aspect, respectively.
Each aspect embedding vector
is the weighted sum of
and
:
where
is the adjustment factor for the formula, which controls the model’s tendency to detect the target or the aspects.
All aspect embedding vectors are composed to a matrix , where is the word embedding vector for aspect word , and is the number of aspect embedding vectors.
2.5. Representation and Output Module
We multiply
and
, and get the aspect-level sentence representation
:
As the Bi-LSTM network has discovered implied aspect word, the row of with aspect appearing will have a larger value. Each row of the final representation matrix represents the possibility of aspect that may be valid, which is vector of dimension. If an aspect appears in some part of the sentence, the value in the corresponding dimension will be high. The model detects aspects through max-pooling, which calculates the highest value of each row and uses a threshold filter to get the filtered aspect-level sentence representation where is the number of detected aspects.
The filtered aspect-level representation
is fed into a softmax layer to predict the sentiment polarity of each aspect:
where
is
row of
, and
and
are the parameters for softmax layer.
The cost function in our model is cross entropy, which is trained through back-propagation algorithm:
where
is the training dataset,
is the sentiment category set,
is a one-hot vector which denotes the true sentiment polarity in the aspect, and
is the prediction. L2 norm [
17] is introduced in the cost function to avoid the weights in softmax being too large, where
is the weight of
regularization term, and
is the sum of squares of the weight parameter in
. The model is trained by minimizing the cost and we adopt dropout [
18,
19] to avoid overfitting.
3. Experiment
3.1. Dataset
The dataset is from SemEval 2016 task5 [
1], where we picked comments about
Restaurants and
Cameras to verify our model. There are two parts in each piece of datum in the training set: the comment text and its opinions. The opinions are composed of the sentiment polarity and the category in the form of “ENTITY#ASPECT”. The restaurants dataset is an English dataset and camera is in Chinese. The detailed dataset statistics are shown in
Table 1.
3.2. Task Definition
Given a comment sentence and a set of aspects, the model first should recognize the target entities in the comment and their corresponding aspect. Then, the approach should predict the sentiment polarity of all “ENTITY#ASPECT” pair. Take a piece of sample datum in the restaurants dataset as an example; for the input sentence “For the price, you cannot eat this well in Manhattan”, the model should output positive for “RESTAURANT#PRICES” and positive for “FOOD#QUALITY”.
3.3. Model Training and Parameters
For the word embedding method in the input module and aspect embedding module, we pre-trained a GloVe [
14] model. The training corpora was
Leipzig Corpora Collection [
20] and the dimension of embedding vector was set to 300. To avoid out-of-vocabulary (OOV) problems, we sampled from a uniform distribution
for the words that were not recorded in the dictionary. The Chinese dataset was preprocessed by word segment with
Stanford Word Segmenter [
21].
For the CNN in the attention module, 100 filters were used to reduce the possibility of missing important signals. The CNN network contained one convolution layer, in which the filter was of with no padding and the stride was 1.
We trained the model through mini-batch gradient descend, and the mini-batch was 32. regularization factor was added to the loss function and the weight for factor was 3. The dropout rate was set to 0.5 and the learning rate was set to 0.01.
3.4. Comparison with Baseline Methods
We set several baseline methods, including LSTM, TD-LSTM, AT-LSTM, AT-CNN and RCNN-LSTM.
LSTM: Standard LSTM [
22] network is the improvement of conventional Recurrent Neural Network, which is also good at analyzing the dependencies between words in the sentence and has resolved the “long-dependency” problem.
TD-LSTM: TD-LSTM [
10] adds target information analysis to the standard LSTM network. It regards aspect as a target, which enables it to classify the sentiment in each aspect.
AT-LSTM: AT-LSTM [
11] applies attention mechanism to the LSTM network, so the model can focus on the important parts in the sentence. The model is more effective classifying the sentiment in each valid aspect.
AT-CNN: AT-CNN [
23] is a CNN-based attention mechanism implementation model, which takes advantages of the invariance feature of CNN to rank the importance.
RCNN-LSTM: RCNN-LSTM [
24] is a combined model with Regional Convolution Neural Network (RCNN) and LSTM network. The region works as the attention mechanism to capture the important parts and the RCNN outputs the attentive sentence representation. Through LSTM network, the representation is analyzed to get the final sentiment.
3.5. Result and Analysis
We performed experiment for AARCNN model and the five models in
Section 4 with same training dataset and test dataset. Each model was trained and tested five times with the same training data in different input order. The results are shown in
Table 2 as the average stats.
In
Table 2, we can see that LSTM gets the worst performance. Standard LSTM model only builds memory of the sentence and considers neither aspect information nor attention information. It fails to detect the sentiment for different aspects and only outputs an overall sentiment for the sentence. Therefore, standard LSTM network is not suitable for the ABSA task.
TD-LSTM beats LSTM by over 1% on both Restaurants and Cameras datasets, which shows that the aspect information does good to the ABSA task. However, TD-LSTM only introduces aspect information and does not contain attention mechanism, so it cannot recognize whether a word is truly important to express the sentiment. Unimportant words may disturb the analysis, and may lead to mistakes.
The two attention-based approaches, AT-LSTM and AT-CNN, outperform LSTM by about 2%. The two models only introduce attention mechanism. Although the models cannot analyze the aspect information, they still show better performance than TD-LSTM, which means attention mechanism alone is better to promote the accuracy of ABSA task than aspect information analysis alone. Additionally, AT-CNN gets a higher score than AT-LSTM, which means that CNN-based attention model is better than LSTM-based attention model.
RCNN-LSTM gets the highest score in the baseline methods. Compared to AT-CNN, RCNN-LSTM adds LSTM network to model sentence representation, which assures the dependency information does not get lost. Compared to AT-LSTM, its independent attention module has better performance to extract the important parts in the sentence.
Our model, AARCNN, gets the best score. Our model takes advantages of both attention mechanism and aspect information to analyze the sentiment of the comment sentence. The model has promotion on the accuracy and F1 value, but it costs about twice the time compared to single LSTM network.
3.6. The Use of Bi-LSTM
Bi-LSTM network is used instead of standard LSTM network in our model to optimize the sentence with reversed expression. We do an experiment to find out the improvement Bi-LSTM has made to the model. Our model is marked as Bi-LSTM-* and the model with LSTM network as LSTM-*. The LSTM-* model was trained and tested with the same set with the one used in the baseline experiment. The result is shown in
Table 3.
In
Table 3, we can find that Bi-LSTM-* has an average 0.3% better performance than LSTM-* with both accuracy and F1 score on restaurants and camera datasets. We go deep into the data, and find that Bi-LSTM-* has almost the same accuracy as LSTM-* on most review sentences. However, the model with Bi-LSTM has about 3% higher performance than LSTM-* on long sentences where the target is in front of its description and the distance between them is more than two words. For example, in the review sentence in restaurants “We took advantage of the half price sushi deal on Saturday so it was well worth it”, the target “half price sushi deal” and its description “well worth” are four words away, which causes the LSTM-* to fail to recognize the aspect “QUALITY” and mark the sentence as “RESTAURANT#GENERAL”. As shown in
Table 4, the sentences of this kind occupy about 10–15% in the test set, which leads to only 0.3% in the overall experiment result.
The result proves the effect of Bi-LSTM cell in the model. However, Bi-LSTM-* model costs much more time than LSTM-* model, which is the main reason for the slow pace of model training.
Additionally, the test score of LSTM-* exceeds the best baseline method RCNN-LSTM, which demonstrates that the architecture of our model fully exploits each module in the ABSA tasks.
3.7. Case Study
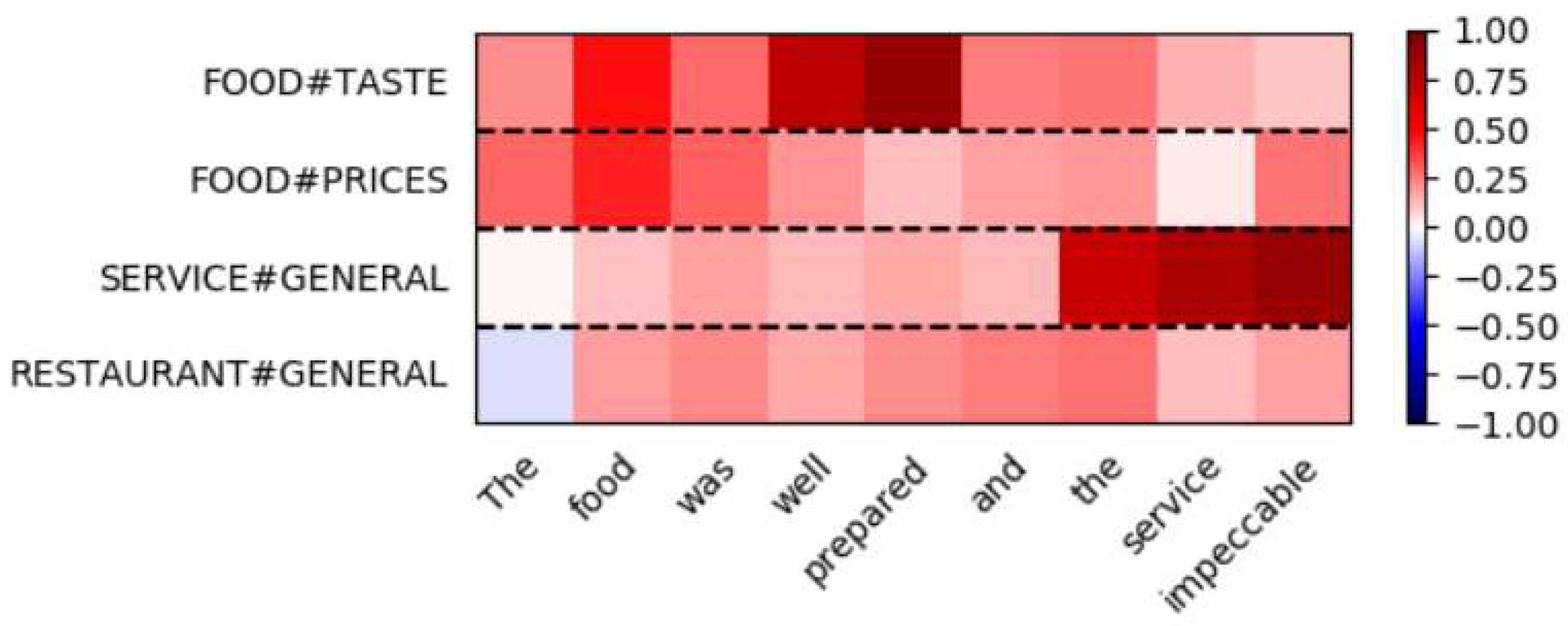
We analyzed a comment sentence “The food was well prepared and the service impeccable” as a case study. The true annotation of the sentence is positive in FOOD#TASTE and positive in SERVICE#GENERAL. Besides the two true aspects, two wrong aspects are also chosen in the test, which are RESTAURANT#GENERAL and FOOD#PRICE. RESTAURANT#GENERAL is weakly relevant to the sentence and FOOD#PRICE is totally irrelevant to the sentence.
Figure 4 shows the final representation of the sentence under the four circumstances. The red color in the figure is the signal of positive sentiment and the blue represents negative sentiment.
In
Figure 4, we can find that, to the first half of the sentence, the model gives high positive ranks to the FOOD#TASTE. Although the sentence is also relevant to the aspect FOOD#PRICES, its connection is not as strong. The second half is SERVICE#GENERAL, and the same reason as above has prevented the RESTAURANT#GENERAL from getting a high score. The irrelevant aspect FOOD#PRICES has the lowest score in each part of the sentence, which means the model does not choose it as a valid aspect. Because the model uses max-pooling as the filter to select aspects, both FOOD#TASTE and SERVICE#GENERAL that have top scores can pass through the filter, but the RESTAURANT#GENERAL with low scores in each half fails to pass it. The final representations of 1 and 3 is sent to the softmax classifier and the output of our model is positive in FOOD#TASTE and positive in SERVICE#GENERAL.



{kind=link}
{kind=link}
{kind=link}
{kind=link}