Query Recommendation Using Hybrid Query Relevance

Abstract
:1. Introduction
- (1)
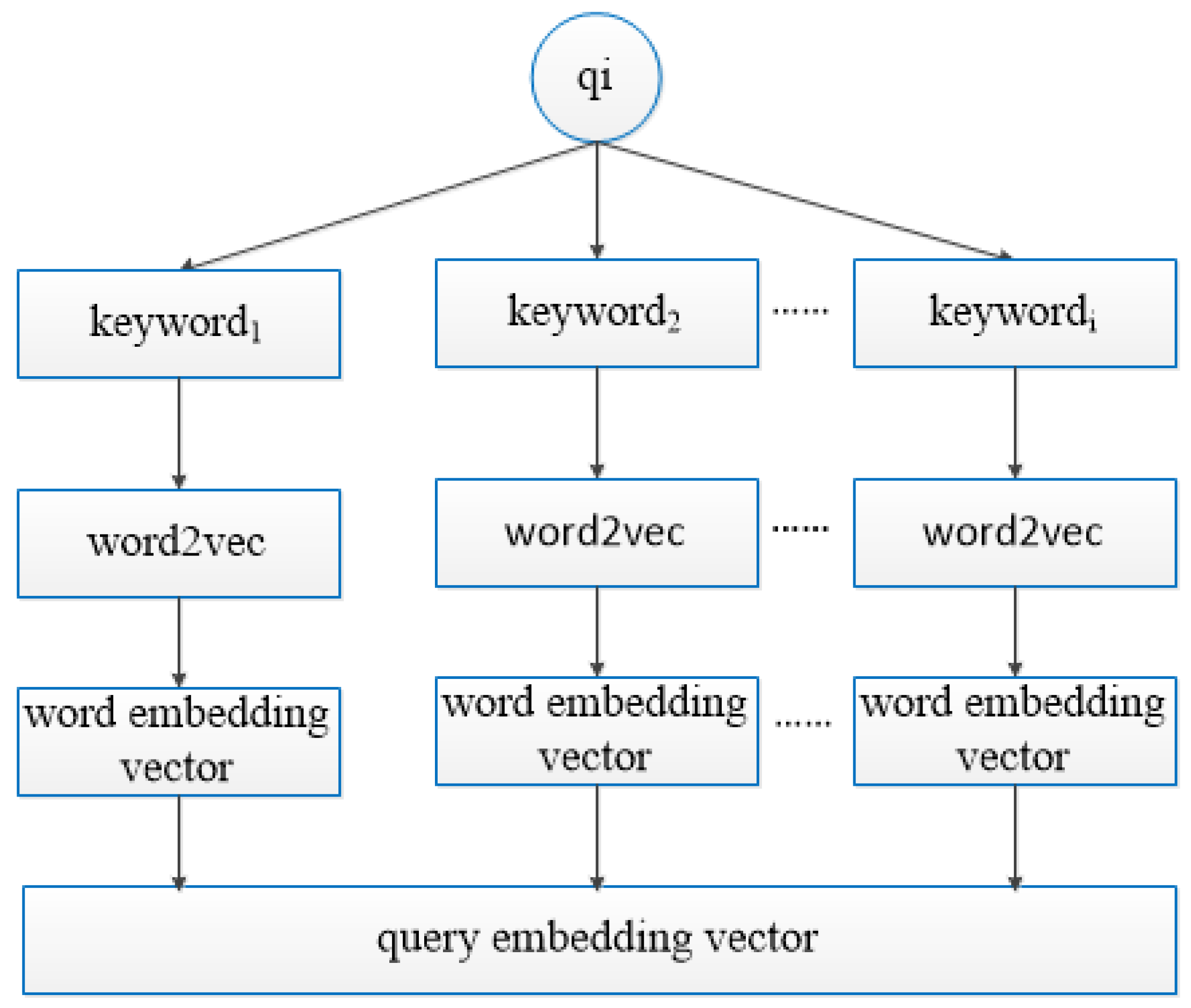
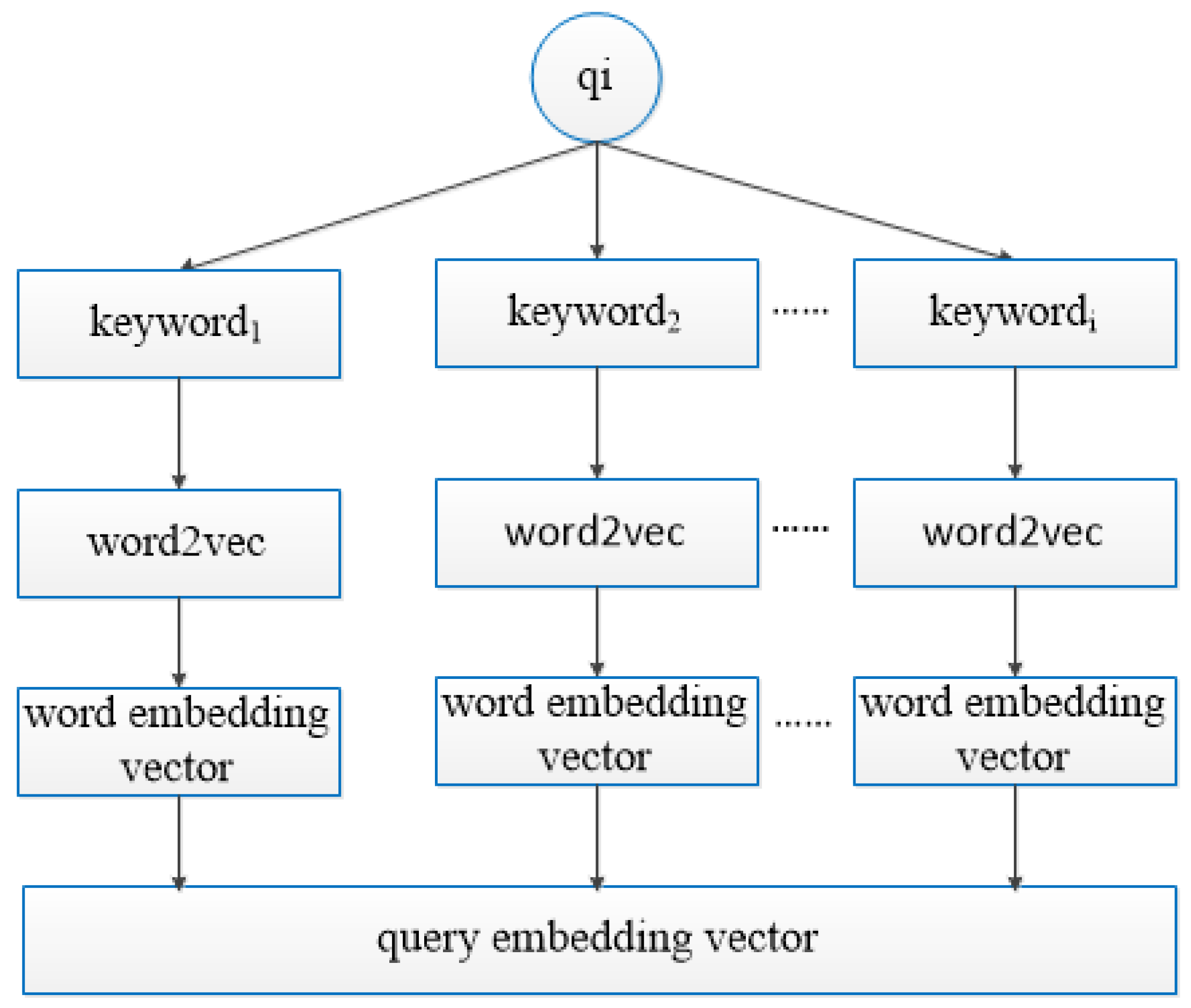
- Solely mining query information from a query log can obtain little useful information and cause data sparsity. Therefore, we use the corpus to train a query embedding vector, getting query semantics to expand the query information and improving the accuracy of the relevance between queries.
- (2)
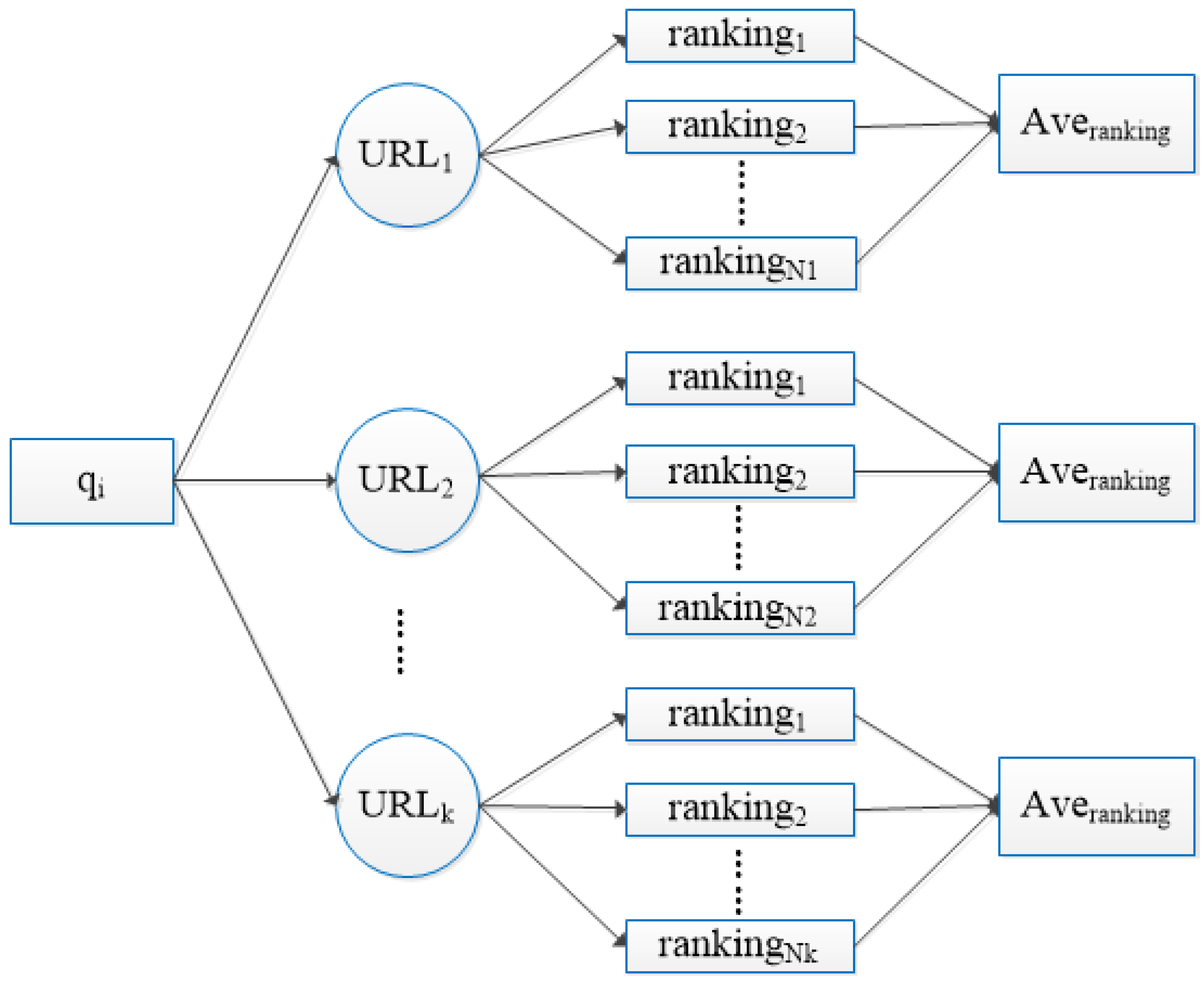
- We combine the number of clicked URLs and the ranking of URLs in the web pages to calculate query relevance. The two different queries are more similar when they have the numbers of the same clicked URLs. At the same time, the ranking of the URL in the web page is higher; the URL is more related to the query.
- (3)
- We calculate the hybrid query relevance by query information and URL information. Queries in a session have same query intention. The clicked URLs can more accurately understand query intention. Comprehensive consideration of the query information and query-URL pairs is an effective way to understand the user’s intention.
2. Related Work
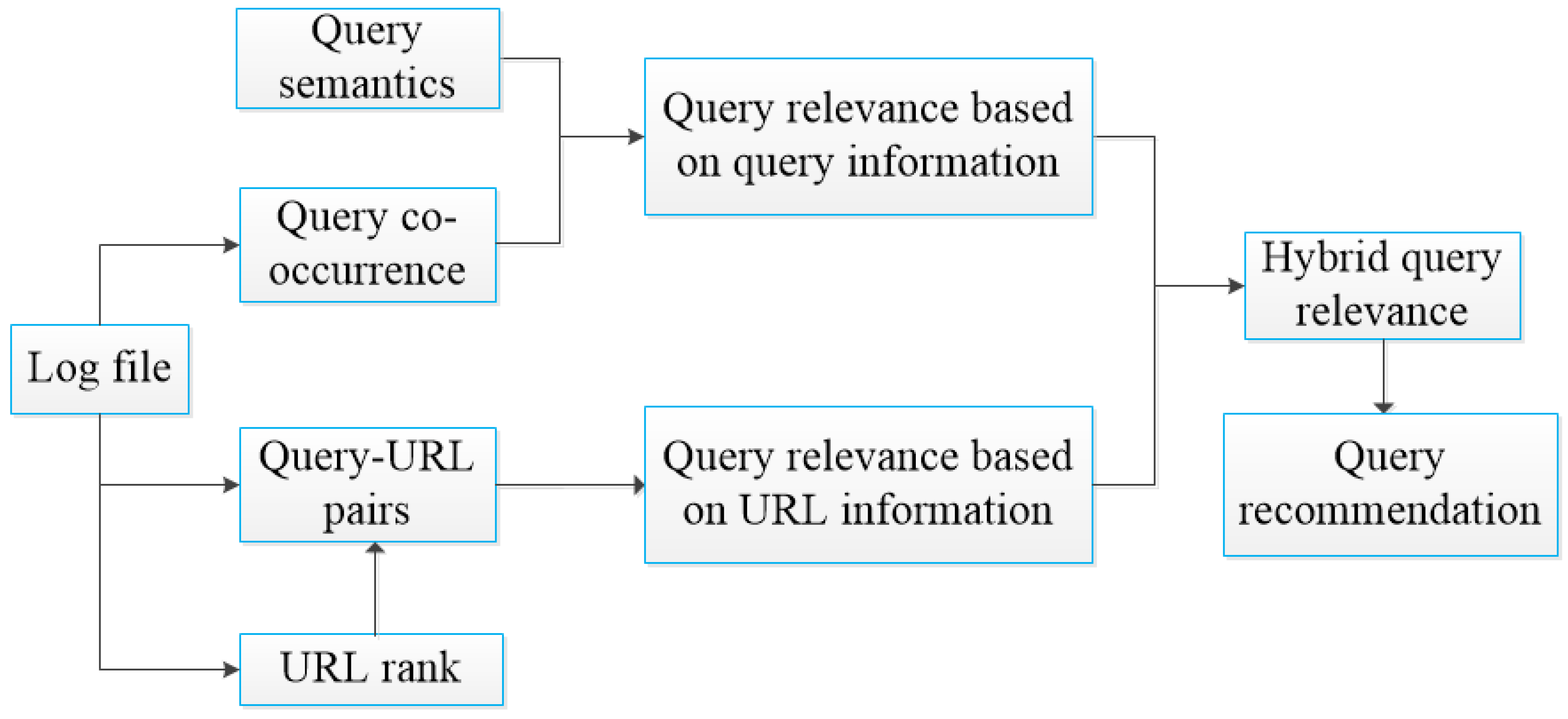
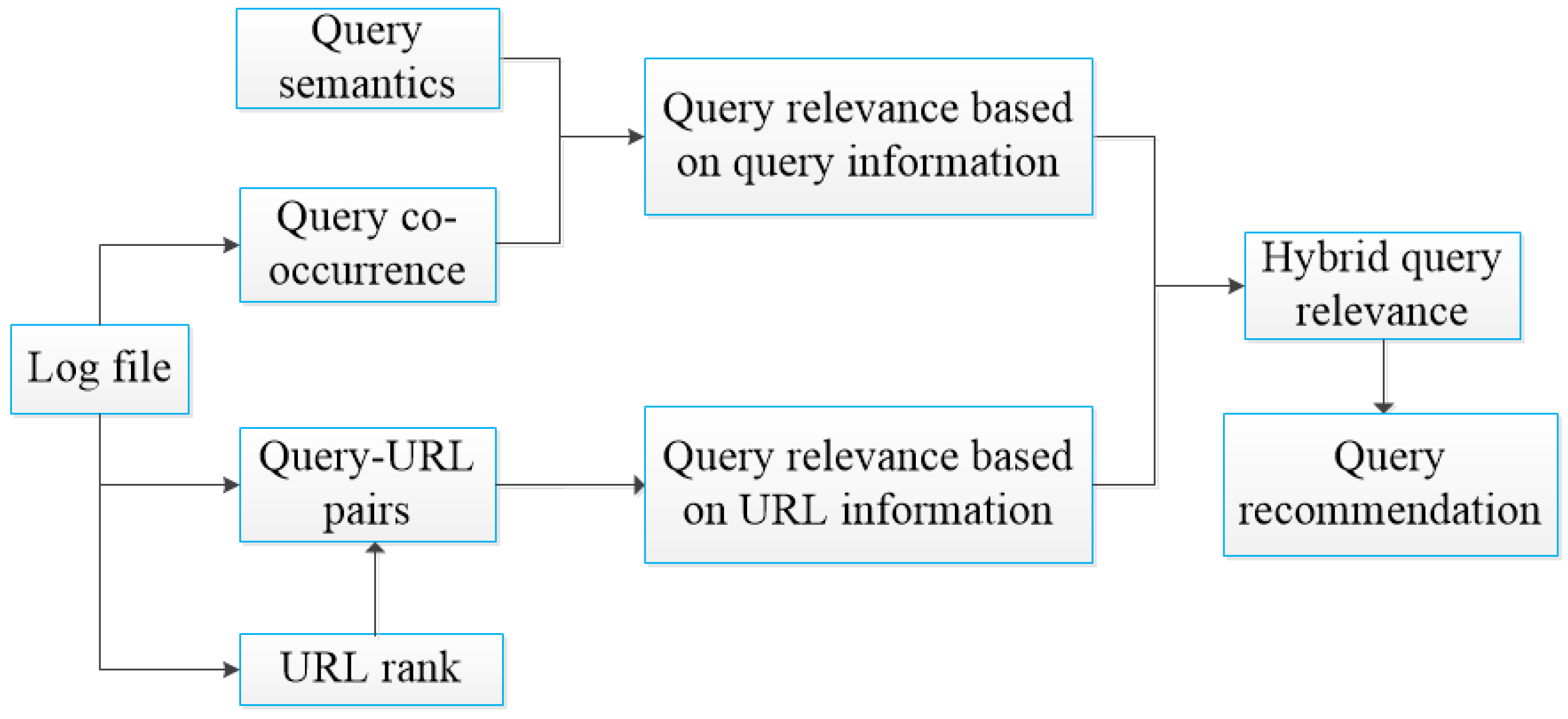
3. Our Approach
3.1. Preliminaries
3.2. Query Relevance Based on Query Information
3.3. Query Relevance Based on URL Information
3.4. Hybrid Query Relevance
4. Results
4.1. Experimental Data and Evaluation Methods
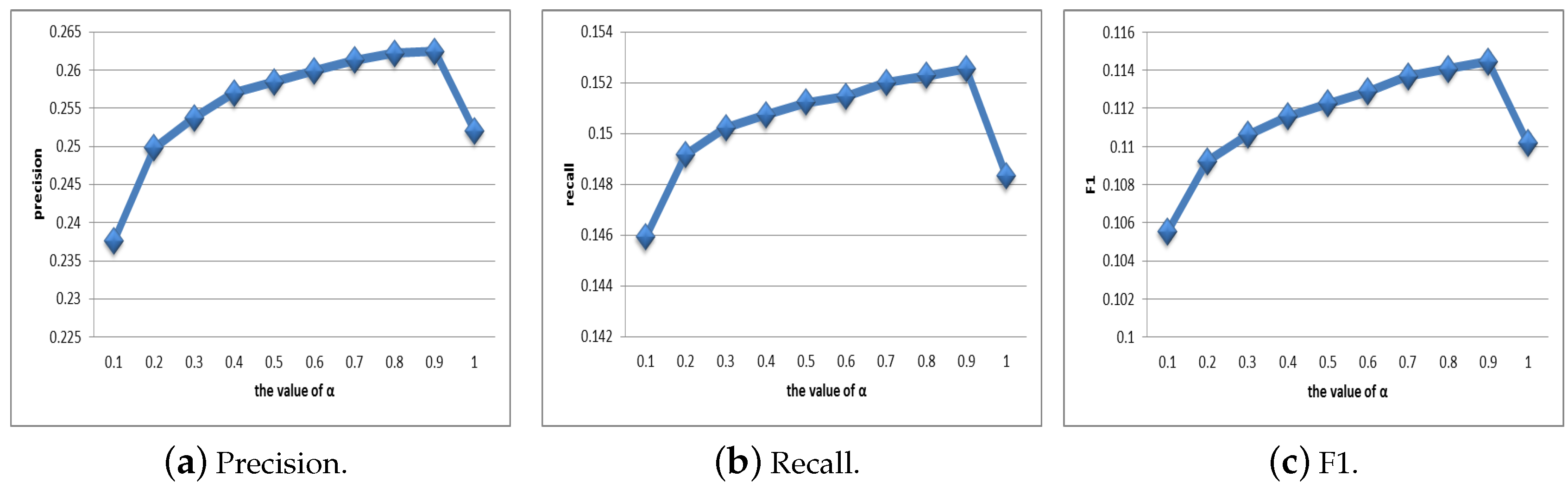
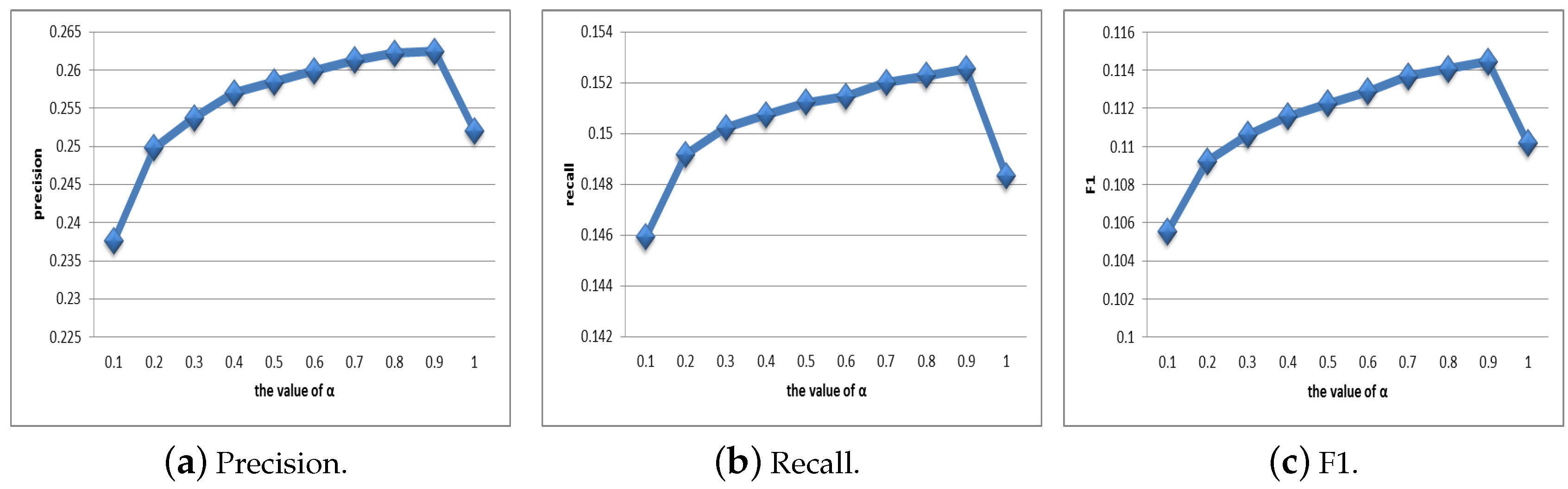
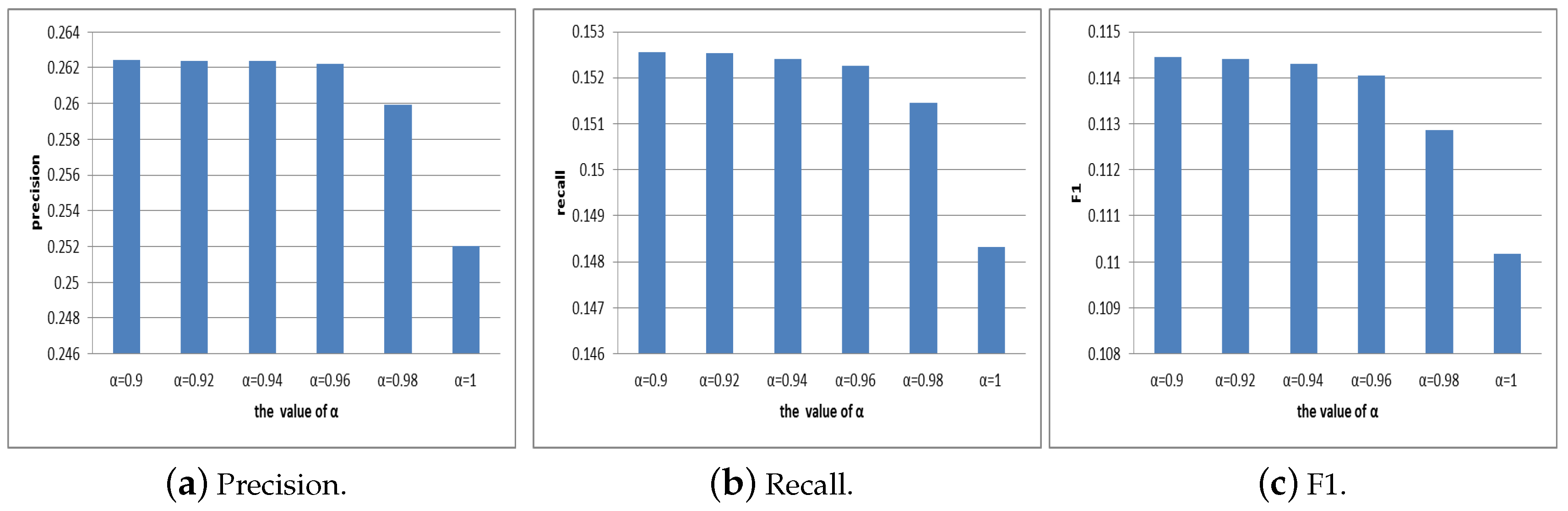
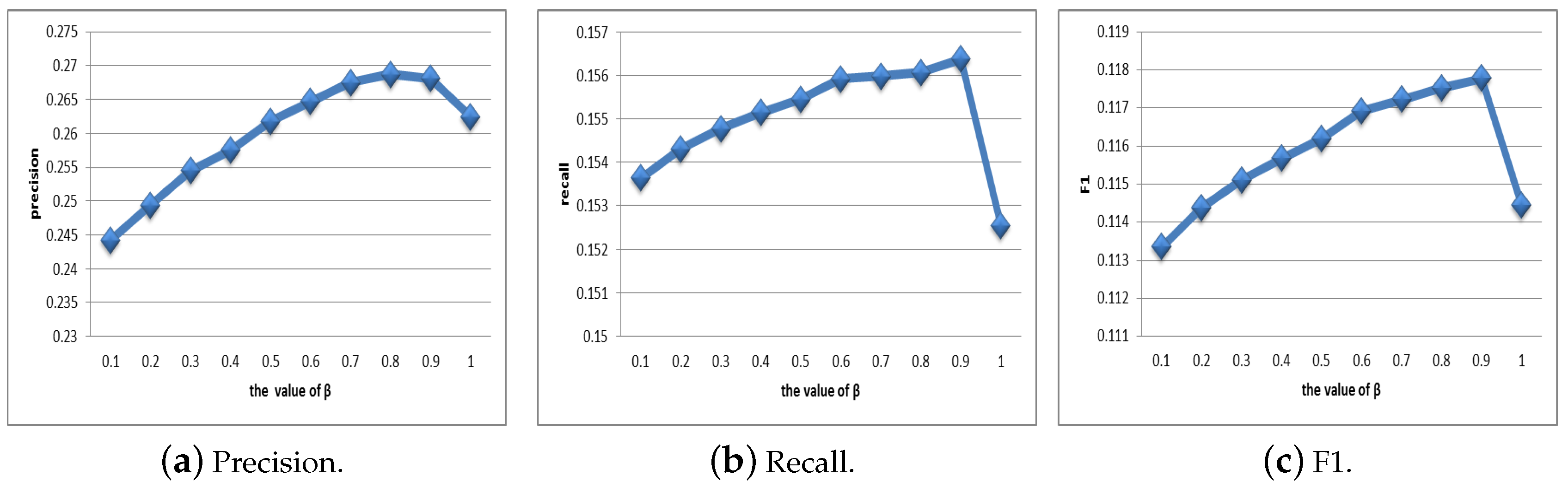
4.2. Selection of Parameters
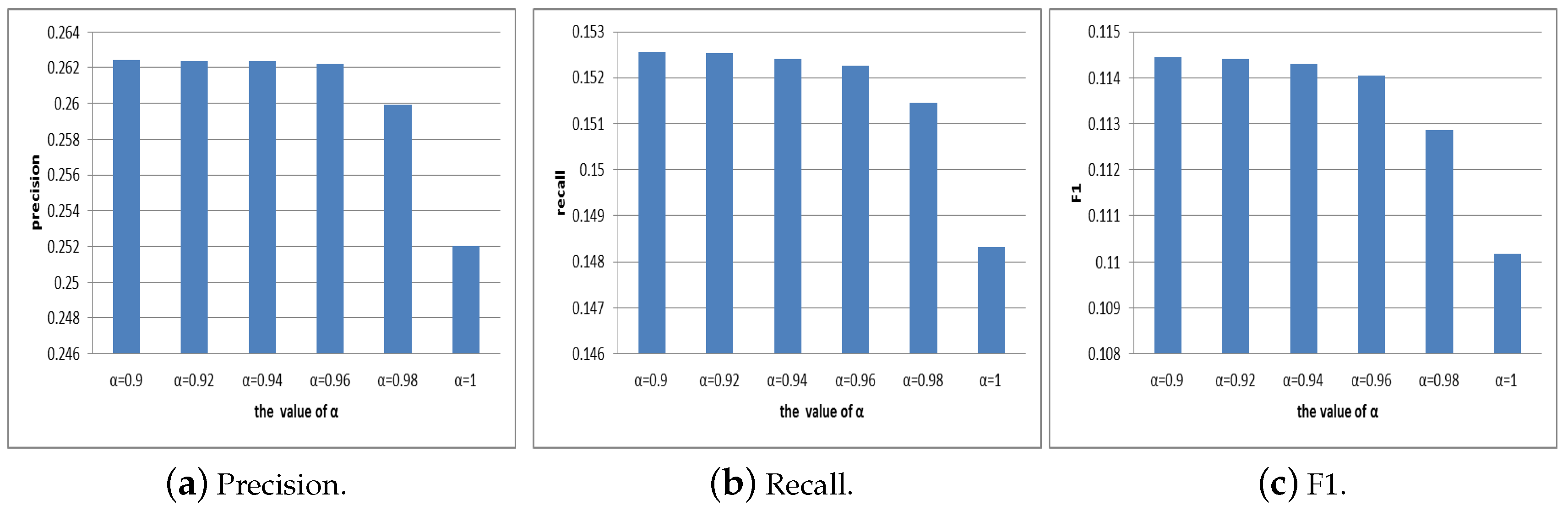
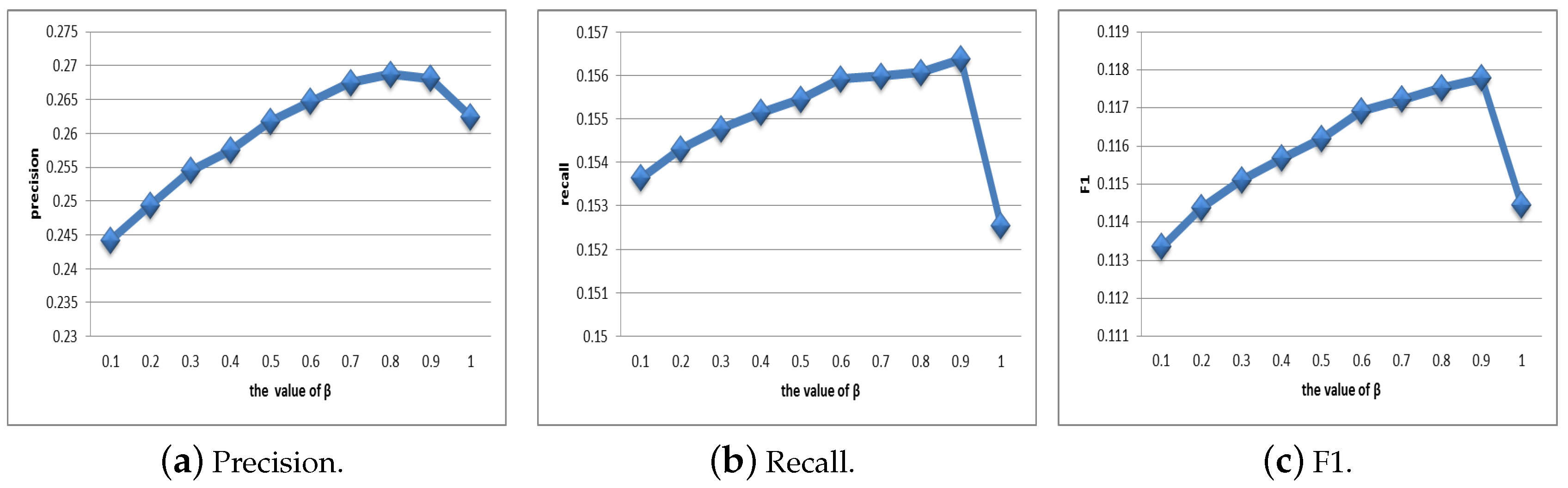
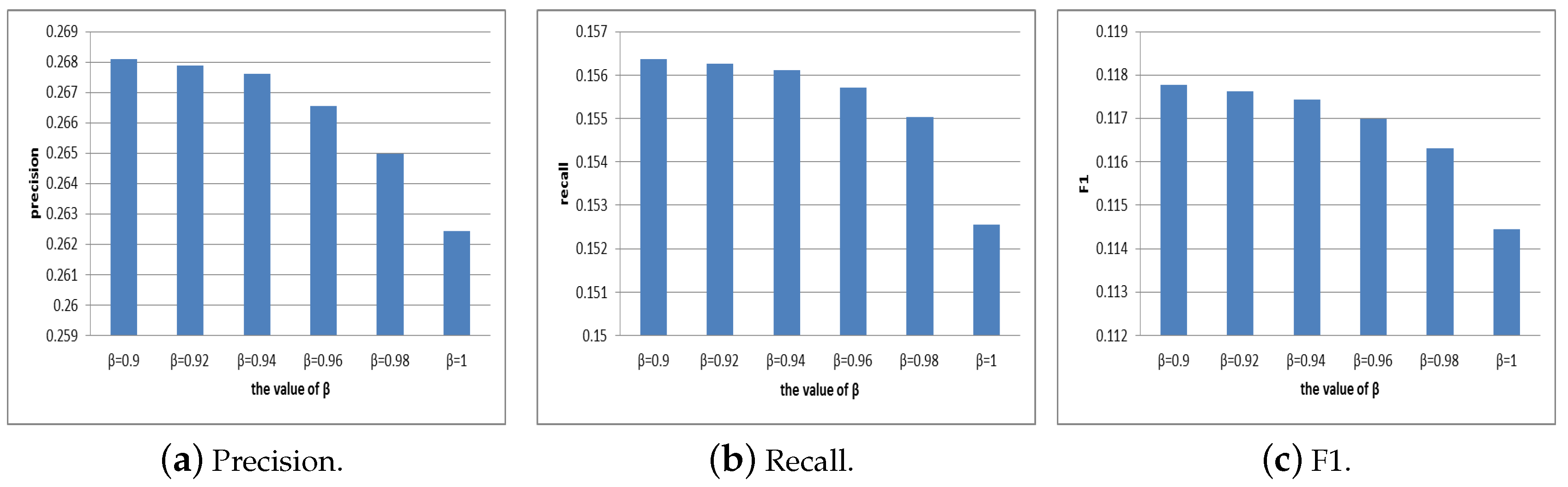
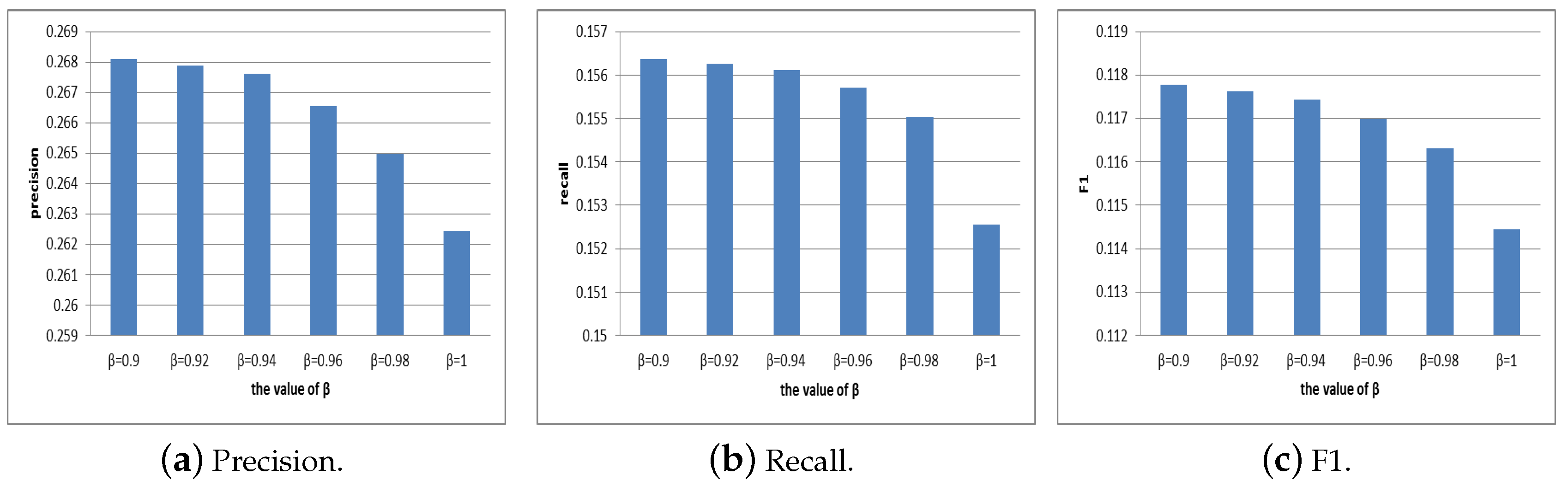
4.2.1. Selection of Parameter
4.2.2. Selection of Parameter
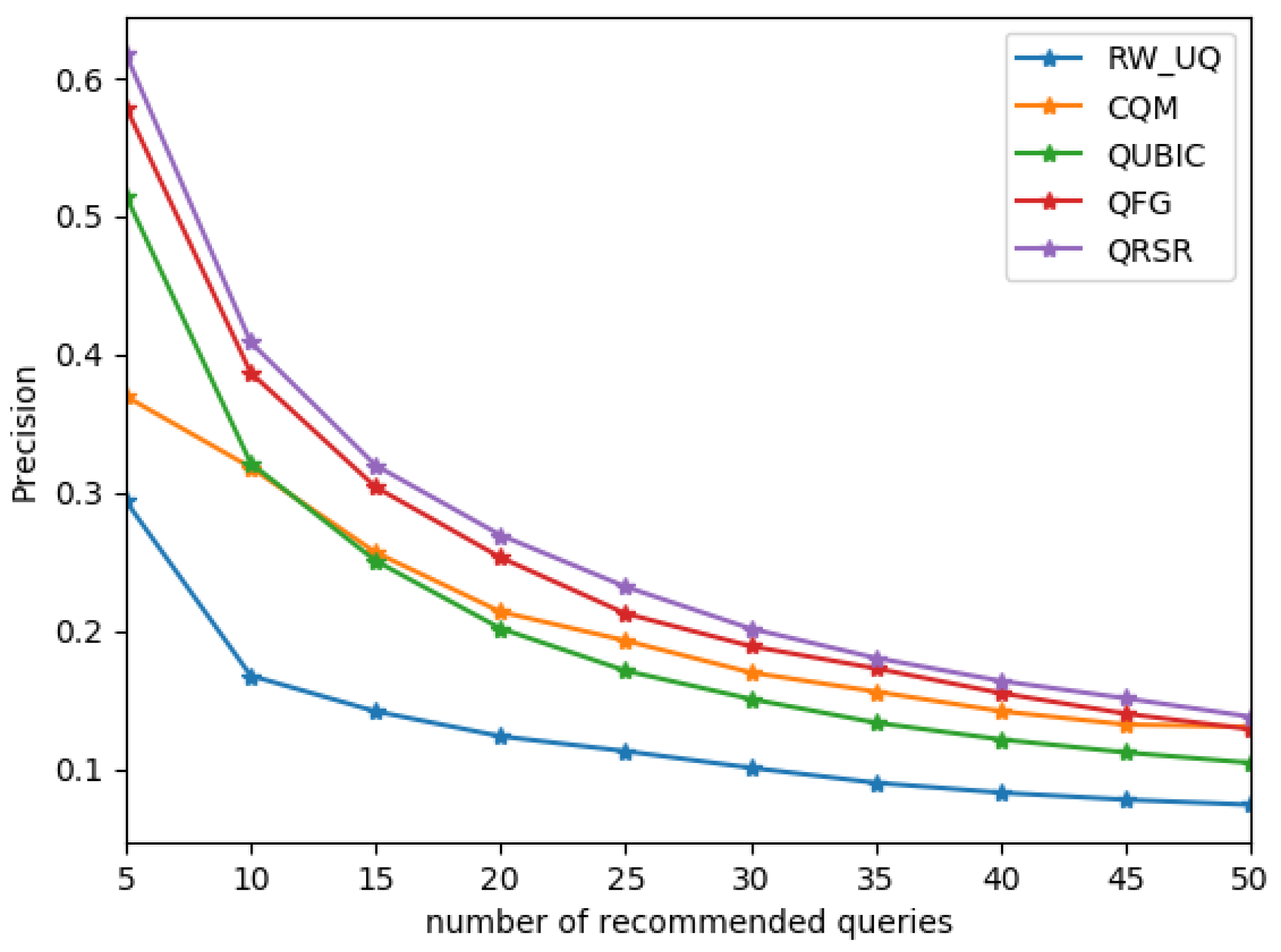
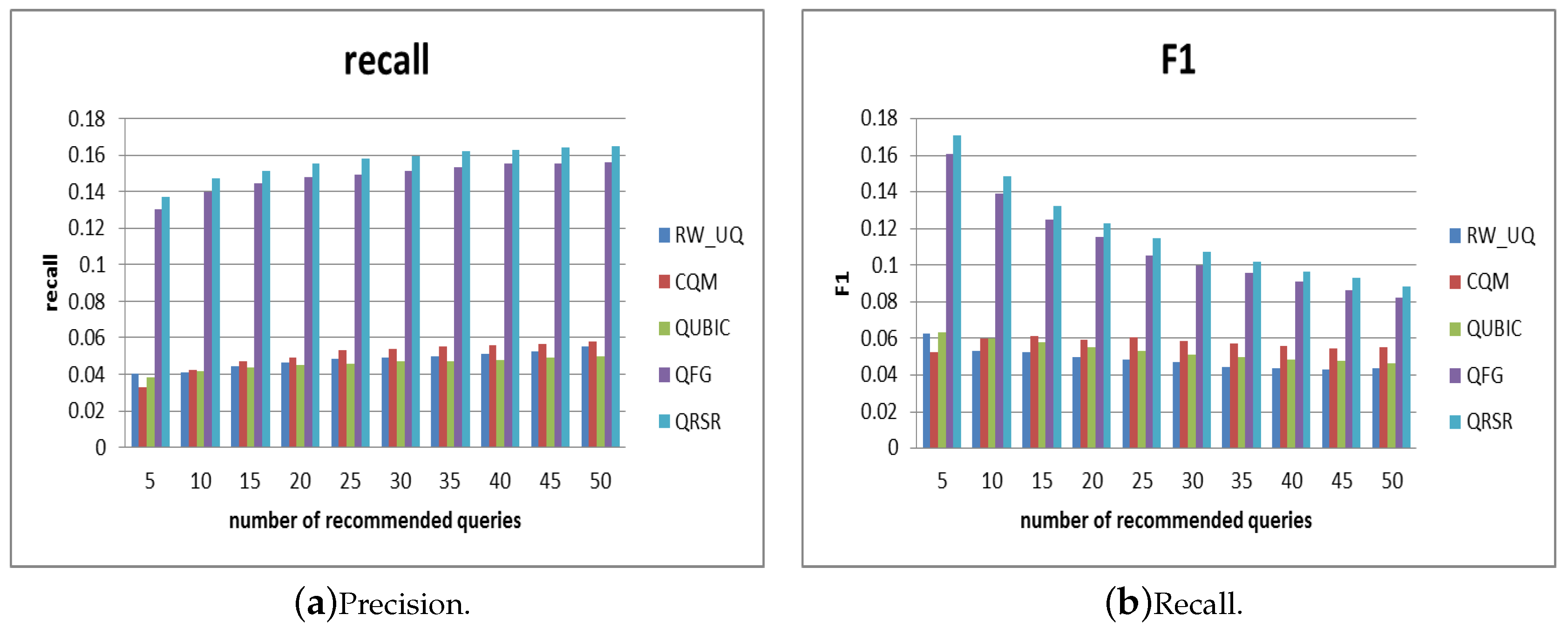
4.3. Evaluation of Efficiency
- (1)
- QFG [7]: This is a query flow graph model extracting queries to count the number of query co-occurrences.
- (2)
- QUBIC [12]: This is a bipartite graph model using query information and URL information in logs to build a query-URL bipartite graph.
- (3)
- [15]: This is a method calculating the bidirectional transition probability-based query-URL graph and making a strength metric of the query-URL edges.
- (4)
- CQM [6]:This is a method based on clustering processes in which groups of semantically similar queries are detected.
- (5)
- QRSR: Our method considers query information and URL information. The relevance based on URL combines the query-URL pairs with URL ranking which can more accurately calculate the relation between query and URL.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kop, R. The Unexpected Connection: Serendipity and Human Mediation in Networked Learning. J. Educ. Technol. Soc. 2010, 2, 2–11. [Google Scholar]
- Choudhary, D.; Subhash, C. Adaptive Query Recommendation Techniques for Log Files Mining to Analysis User’s Session Pattern. Int. J. Comput. Appl. 2016, 133, 22–27. [Google Scholar] [CrossRef]
- Thirumalai, C.S.; Sree, K.S.; Gannu, H. Analysis of Cost Estimation Function for Facebook Web Click Data. In Proceedings of the IEEE International Conference on Electronics, Communication and Aerospace Technology Iceca, Coimbatore, India, 20–22 April 2017. [Google Scholar]
- Chen, Z.; Yamamoto, T.; Tanaka, K. Query Suggestion for Struggling Search by Struggling Flow Graph. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Omaha, NE, USA, 13–16 October 2017; pp. 224–231. [Google Scholar]
- Hu, Y.; Qian, Y.; Li, H.; Jiang, D.; Pei, J.; Zheng, Q. Mining query subtopics from search log data. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 305–314. [Google Scholar]
- Zahera, H.M.; El-Hady, G.F.; El-Wahed, W.F.A. Query Recommendation for Improving Search Engine Results. Lect. Notes Eng. Comput. Sci. 2010, 2186, 45–52. [Google Scholar]
- Boldi, P.; Bonchi, F.; Castillo, C.; Donato, D.; Gionis, A.; Vigna, S. The query-flow graph: Model and applications. In Proceedings of the CIKM’08, Napa Valley, CA, USA, 26–30 October 2008; pp. 609–618. [Google Scholar]
- Sordoni, A.; Bengio, Y.; Vahabi, H.; Lioma, C.; Simonsen, J.G.; Nie, J.Y. A Hierarchical Recurrent Encoder-Decoder for Generative Context-Aware Query Suggestion. In Proceedings of the CIKM’15, Melbourne, Australia, 19–23 October 2015; pp. 553–562. [Google Scholar]
- Bonchi, F.; Perego, R.; Silvestri, F.; Vahabi, H.; Venturini, R. Efficient query recommendations in the long tail via center-piece subgraphs. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 224–231. [Google Scholar]
- Qiao, D.; Zhang, J.; Wei, Q.; Chen, G. Finding Competitive Keywords from Query Logs to Enhance Search Engine Advertising. Inf. Manag. 2016, 54, 531–543. [Google Scholar] [CrossRef]
- Li, X.; Guo, C.; Chu, W. Deep learning powered in-session contextual ranking using clickthrough data. In Workshop on Personalization: Methods and Applications, at Neural Information Processing Systems; Computer Sciences and Statistics: Madison, WI, USA, 2014. [Google Scholar]
- Li, L.; Yang, Z.; Liu, L.; Kitsuregawa, M. Query-url bipartite based approach to personalized query recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; pp. 1189–1194. [Google Scholar]
- Ma, H.; Yang, H.; King, I.; Lyu, M.R. Learning latent semantic relations from clickthrough data for query suggestion. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 709–718. [Google Scholar]
- Noce, L.; Gallo, I.; Zamberletti, A. Query and Product Suggestion for Price Comparison Search Engines based on Query-product Click-through Bipartite Graphs. In Proceedings of the International Conference on Web Information Systems and Technologies, Rome, Italy, 23–25 April 2016; pp. 17–24. [Google Scholar]
- Ye, F.; Sun, J. Combining Query Ambiguity and Query-URL Strength for Log-Based Query Suggestion. In Proceedings of the International Conference on Swarm Intelligence, Brussels, Belgium, 7–9 September 2016. [Google Scholar]
- White, R.W.; Dumais, S.T. Characterizing and predicting search engine switching behavior. In Proceedings of the 18th ACM conference on Information and knowledge management, Hong Kong, China, 2–6 November 2009; pp. 87–96. [Google Scholar]
- White, L.; Togneri, R.; Liu, W.; Bennamoun, M. How Well Sentence Embeddings Capture Meaning. In Proceedings of the 20th Australasian Document Computing Symposium, Parramatta, Australia, 8–9 December 2015; pp. 1–8. [Google Scholar]
- Rong, X. Word2vec Parameter Learning Explained. Comput. Sci. 2015, arXiv:1411.2738. [Google Scholar]
- Li, Y.; Lyons, K. Word representation using a deep neural network. In Proceedings of the International Conference on Computer Science and Software Engineerin, Toronto, ON, Canada, 31 October–2 November 2016; pp. 268–279. [Google Scholar]
- Ling, W.; Dyer, C.; Black, A.W.; Trancoso, I. Two/Too Simple Adaptations of Word2Vec for Syntax Problems. In Proceedings of the Conference on North American Chapter of the Association for Computational Linguistics—Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015. [Google Scholar]
- Barbosa, J.J.G.; Solís, J.F.; Terán-Villanueva, J.D.; Valdés, G.C.; Florencia-Juárez, R.; Mata, M.B. Mojica: Implementation of an Information Retrieval System Using the Soft Cosine Measure; Springer International Publishing: Berlin, Germany, 2017. [Google Scholar]
- Tong, H.; Faloutsos, C.; Pan, J.Y. Fast Random Walk with Restart and Its Applications. In Proceedings of the International Conference on Data Mining, Hong Kong, China, 18–22 December 2016; pp. 613–622. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Query | Recommended Queries |
|---|---|
| apple | apple website, apple hk, iphone xr, apple watch4 |
| book | table, pencil box, study, desk |
| basketball | basketball player, basketball court, soccer |
| UseID | Query Content | Timestamp | URL Ranking | Clicked URL |
|---|---|---|---|---|
| 217 | lottery | 1 March 2006 11:58:51 | 1 | http://www.calottery.com |
| 1268 | ozark horse blankets | 1 March 2006 17:39:28 | 8 | http://www.blanketsnmore.com |
| 2334 | jesse mccartney | 1 March 2006 18:53:50 | 4 | http://www.hyfntrak.com |
| 2421 | cstoons | 9 May 2006 17:32:44 | 2 | http://www.xtracrispy.com |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Ye, F. Query Recommendation Using Hybrid Query Relevance. Future Internet 2018, 10, 112. https://doi.org/10.3390/fi10110112
Xu J, Ye F. Query Recommendation Using Hybrid Query Relevance. Future Internet. 2018; 10(11):112. https://doi.org/10.3390/fi10110112
Chicago/Turabian StyleXu, Jialu, and Feiyue Ye. 2018. "Query Recommendation Using Hybrid Query Relevance" Future Internet 10, no. 11: 112. https://doi.org/10.3390/fi10110112
APA StyleXu, J., & Ye, F. (2018). Query Recommendation Using Hybrid Query Relevance. Future Internet, 10(11), 112. https://doi.org/10.3390/fi10110112