3. Event Extraction Task
We focused on the event extraction task of the Automatic Context Extraction (ACE) evaluation. ACE defines an event as something that happens or leads to some change of state. We employed the following terminology:
Event mention: A phrase or sentence in which an event occurs, including one trigger and an arbitrary number of arguments.
Event trigger: The main word that most clearly expresses an event occurrence.
Event argument: An entity mention, temporal expression or value that servers as a participant or attribute with a specific role in an event mention.
ACE annotates 8 types and 33 subtypes (e.g., attack, die, start position) for event mentioned that also correspond to the types and subtypes of the event triggers. Each event subtype has its own set of roles to be filled by the event arguments.
Although an event extraction system needs to recognize event triggers with specific subtypes and their corresponding arguments with the roles for each sentence, in this paper, we only wanted to recognize the event trigger and three event arguments (event participants, event location and event time).
4. Methodology
We formalized the EE task as follows:
Let … be a sentence where n is the sentence length and is the i-th token. Additionally, let … be the labels in this sentence. We use the BIO annotation mode (“B-X” means the beginning of the X element, “I-X” means the middle (including the end) position of the X element, and “O” means not belonging to any type of elements).
For every token
in the sentence, we need to predict its label (trigger, time, location, participator or O) and we must make the prediction as accurate as possible. Our method considers character embedding and word features in an effort to improve word embedding.
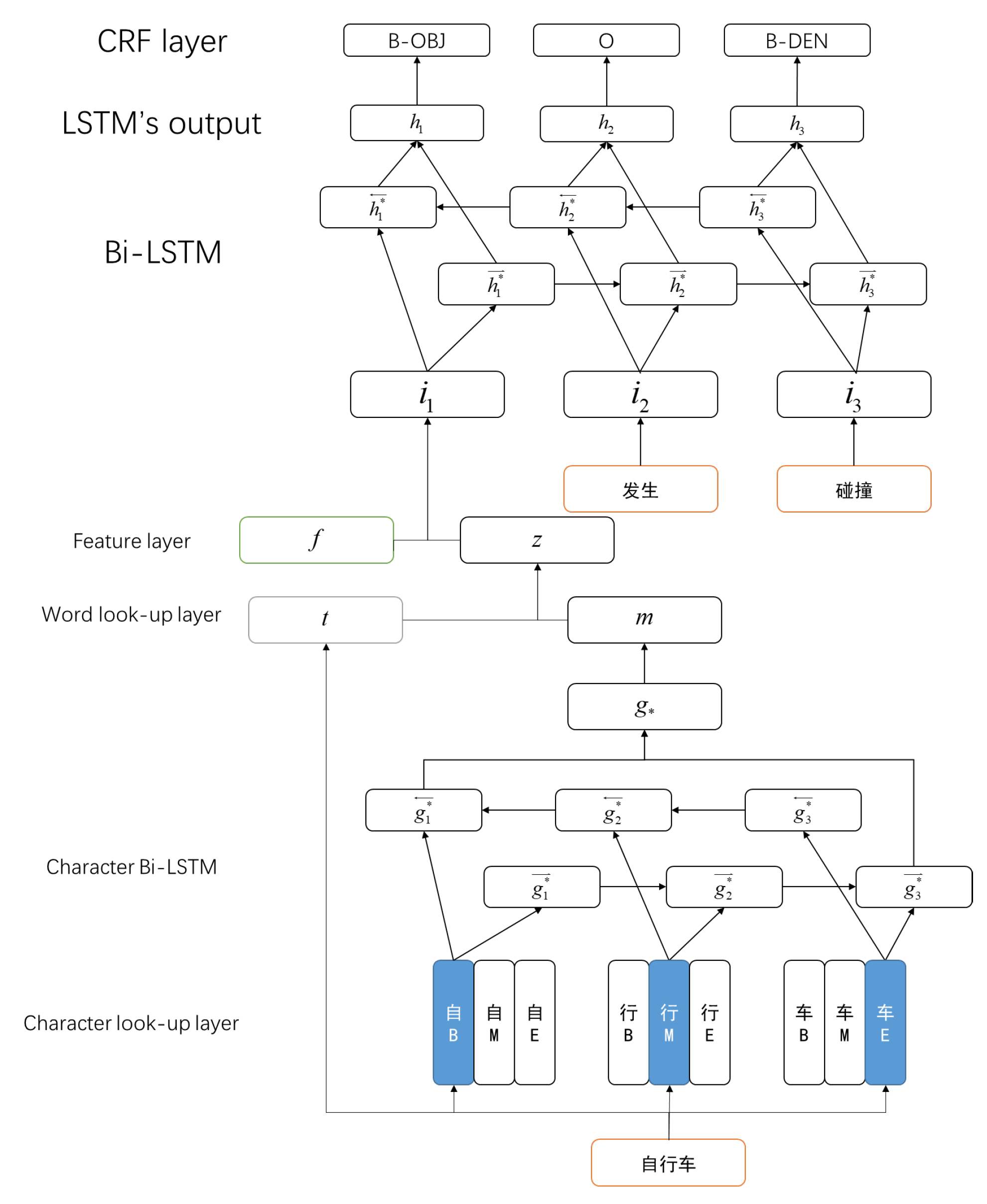
Figure 1 presents the architecture of event trigger and arguments recognition, which primarily involves the following four components: (a) character–word embedding based on attention; (b) feature representation; (c) Bi-LSTM (Bidirectional Long Short-Term Memory network); and (d) CRF (Conditional Random Field).
4.1. Word Representation
Character Level Embedding
Most methods use the external context of the words in the large corpus to learn the embedding of words. However, in Chinese, a word is usually composed of multiple characters, each containing rich internal information, for example, the word “自行车” (bicycle). The CBOW model can be used to learn the meaning of a word, but it can also be learned by characters: “自” (auto), “行” (walk) and “车” (car). Because of the nature of semantics, the semantic meaning of internal characters may play an important role in semantic meaning. Therefore, an intuitive idea is to consider the internal characters for the embedding of learning words.
Because the word polysemy is more serious in Chinese, Chen [
14] proposed the Position-based Character Embedding model. There are different representations according to the position of each character in the word (begin:(c
); middle:(c
); end:(c
)).
For a word
x, (
x =
ccc, …,
c) is the character embedding. We use the last hidden vectors from each of the LSTM [
15] components and concatenate them together, as shown in
Figure 2:
Character–Word Embedding Based on Attention
We found that not all words are similar in meaning to their characters, and some foreign words are created from pronunciation, such as “巧克力” (chocolate), which is completely different from “巧” (artful), “克” (gram) and “力” (force). They only sound similar. At the same time, some characters may have different meanings but are in the same place.
Therefore, we need to jointly consider the weight relation between the word level embedding and the character level embedding. Based on Marek’s model, we let the last word embedding
z be:
where
t is the word embedding, and
W,
W are weight matrices for calculating
z. They decide how much information to use from the character level embedding or from the word embedding.
() is the logistic function with values in the range [0;1].
z has the same dimensions as
t or
m. This operation can also expand the word embedding dictionary. For words that have regular suffixes (or prefixes), we can share some character level features; words that did not previously have word vectors can also use character level embedding.
4.2. Feature Representation
Based on the results of semantic feature analysis, we defined three different feature abstraction layers. Feature representation mainly adopts the binary representation model. The characteristics of the three abstraction layers are the same as those of the value generation. The following describes the way in which each abstraction layer is represented and the way in which the eigenvalue is generated.
Part of Speech
POS (part of speech), as a generalization of the word, plays an important role in language recognition, syntactic analysis, and event extraction. In a sentence, the grammatical component has a strong restriction on the speech component. For example, a noun or pronoun can act as a subject in a sentence, but an interjection cannot. Therefore, POS, as an abstract feature, conforms to the expression characteristics of text semantic information and the basic cognition of human beings in the recognition of events. Based on the analysis of the part of speech in CEC (Chinese Emergency Corpus), we found that the event-trigger word is usually a verb or noun, while the location and the participant argument are both nouns. Therefore, it is possible to improve the accuracy of recognition based on the abstract feature layer.
Dependency Grammar
As DP (dependency grammar) exactly describes the semantic role relationships between words, it has extremely high semantic performance. DP does not pay attention to the meaning of the word itself, but expresses the word through the grammatical relation of the word in the sentence, which can directly obtain the deep semantic information.
Containing the most information and having the clearest expression in a sentence, trigger words, in a certain sense, play the role of predicate verbs of dependency grammar. Based on the analysis of the trigger in the CEC corpus, we found that 62% of the trigger words in the sentence play the dependent grammatical role of the HEAD and 18% play the role of the verb object. The predicate verbs in the dependent grammar and the trigger words in the sentences are mostly consistent.
Distance from the HEAD
HEAD is the root node in dependency grammar, usually used to express the most important content in a sentence. The trigger is also used to express the core content in the event. Through the analysis of the CEC corpus, they are very close. Therefore, the distance from the HEAD can determine whether the word is a trigger or can recognize the event argument better.
Feature Representation
Feature representation mainly uses a binary representation model. We describe all feature representations in detail below.
Feature representation of POS (part of speech): The 28 dimensions of POS feature vectors represent 28 types of POS. If the POS of a candidate word corresponds with that of a certain dimension representation of a feature vector, then the feature vector value of the word at the dimension is 1, whereas the feature vector value at the remaining 27 dimensions is 0.
Feature representation of DP (dependency grammar): On this feature layer, 15 vector dimensions exist, thus representing 15 kinds of DP.
Feature representation of DIS (distance from the HEAD): The vector dimension is 7, representing distance from 0 to 6. If it is greater than 6, then each feature vector value of the candidate word is 6.
Based on the above three features, we constructed the feature representation of a 50-dimensional vector.
Table 2 shows some examples of feature representation.
The feature vector and the previous word vector are concatenated. The final vector is used to input the neural network:
4.3. Bidirectional LSTM
We now describe the Bidirectional Long Short-Term Memory network for this paper. The model receives a sequence of tokens … as input and predicts a label corresponding to each of the input tokens.
First, a sequence of tokens … is obtained. The tokens are mapped to a distributed vector space, which we have explained, resulting in a sequence of word embeddings ….
Next, the embeddings are given as input to two LSTM components moving in opposite directions through the text, creating context-specific representations. The respective forward- and backward-conditioned representations are concatenated for each word position, resulting in representations that are conditioned on the whole sequence:
Then, the results are mapped to the m dimension, resulting in a sequence of probability …. M is the number of entity types, and describes how confident the network is that the label on the word is j.
Finally, a CRF is used, which conditions each prediction on the previously predicted label. In this architecture, the last hidden layer is used to predict the confidence scores for the word with each of the possible labels. A separate weight matrix is used to learn the transition probabilities between different labels, and the Viterbi algorithm is used to find an optimal sequence of weights. Given that
y is a sequence of labels
…
, then the CRF score for this sequence can be calculated as
shows how confident the network is that the label on the
word is
.
shows the likelihood of transitioning from label
to label
, and these values are optimized during training. The output from the model is the sequence of labels with the largest
, which can be found efficiently using the Viterbi algorithm. In order to optimize the CRF model, the loss function maximizes the score for the correct label sequence, while minimizing the scores for all other sequences:
Y is the set of all possible label sequences.
5. Experiments
5.1. Corpus and Evaluation Metric
We used Chinese Corpus CEC [
16] as the corpus (
https://github.com/shijiebei2009/CEC-Corpus). CEC is an event ontology corpus developed by the Semantic Intelligence Laboratory of Shanghai University. It has 332 articles. Compared with the ACE and TimeBank corpus, CEC is smaller, but more comprehensive in the annotation of events and event arguments. Therefore, we used CEC as the experimental data for the event extraction. The text was divided into five categories: earthquake, fire, traffic accident, terrorist attack, food poisoning. In the experiment, the word segmentation and grammar analysis tools adopted the module provided by the LTP language technology platform of Harbin Institute of Technology. After pretreatment, there were 8804 sentences, 5853 trigger words, 1981 event participants, 1633 event locations, and 1388 event times. For the experiment, we divided the corpus into 20% test set, 64% training set, and 16% verification set.
This experiment mainly recognized the event trigger, event participants, event time, and event location. We used recall (R), precision (P) and the F-measure (F) to evaluate the results.
5.2. Experiment Preparation
In the process of experimental preprocessing, we used Jieba (
https://pypi.org/project/jieba/) as the tool for word segmentation and semantic analysis, and used the Sogou news data (
http://www.sogou.com/labs/resource/ca.php) as the corpus to train the word embedding and the character embedding. There are many methods of training word embedding, which are introduced in the next chapter.
The unit number of LSTM was chosen to be 128, the size of word embedding was 300, that of character embedding was 300, that of feature representation embedding was 15, the maximum epoch was 20, the dropout was 0.5, and the batch size was 60. We used Adam (Kingma and Ba, 2014), with the learning rate of 0.001 for optimization.
5.3. Experiment Result
We used the following methods as comparative experiments:
SKIPGRAM: Mikolov [
17] first proposed this model of training word embedding. The SKIPGRAM model is intended to predict the surrounding words in the sentence given the current word.
CWE: Chen [
15] proposed Character-Enhanced Word Embedding. CWE considers character embedding in an effort to improve word embedding.
CWEP: Chen [
15] proposed the Position-based Character Embedding model. In the position-based CWE, various embeddings of each character are differentiated by the character position in the word, and the embedding assignment for a specific character in a word can be automatically determined by the character position.
Char-BLSTM-CRF: Misawa [
18] proposed a neural model for predicting a tag for each character using word and character information. This model is like Chen’s CWE but with a different method to concatenate the word embedding and the character embedding.
Segment-Level Neural CRF: Sato [
19] presented Segment-level Neural CRF, which combines neural networks with a linear chain CRF for segment-level sequence modeling tasks such as named entity recognition (NER) and syntactic chunking. According to this article, the effect is slightly better than xuezhe’s LSTM-CNN-CRF model. The experimental parameters of the model refer to this article. In addition, this experiment also provides three methods, including the use of two additional dictionary features. However, due to the lack of a dictionary in Chinese, dictionary features cannot be added.
Table 3 compares several advanced methods with our methods. It is divided into two parts: Word-based and Word–Character-based.
Word-Based Models: Segment-level Neural CRF improved the CRF layer on the basis of LSTM-CNN-CRF, and then achieved a better effect. However, due to the relative complexity of the CRF model and the CNN layer, the time required was much longer than other models.
Word–Character-Based Models: The combination of word and character embedding is one of the main research directions at present. The four different methods are mainly due to the different combinations of word and character embedding. According to the last chapter, not all words are similar in meaning to their characters, so our method can achieve better performance. In addition, we considered the semantic feature of words in sentences, so the effect could be better than other methods. Of course, we used attention mechanisms when combining word embedding and character embedding and added a BLSTM layer when combining character embedding, so our method took about 10% more time than the Segment-level Neural CRF method.
Table 4 mainly analyzes the F1 value of each event argument in several methods. As we can see, the Segment-level Neural CRF method is the best method for identifying the location, while our method has the best effect on several dimensions: event time, trigger, and event participants.
Table 5 shows the averaged word length after splitting an event into event arguments. As we can see, trigger is the shortest and location is the longest. Therefore, CNN can extract more information from location. This is the reason why Segment-level Neural CRF (BLSTM-CNNs-CRF) performs better than BLSTM-CRF in location.
We also conducted a statistical analysis to mark error information. It was found that these problems are mainly due to the following reasons:
The effect of incorrect participles, for example, “住” (in hospital). This is an intransitive verb. However, according to traditional semantics, “住” (live) is a verb and “院” (hospital) is a noun. The presence of different semantic analysis results leads to mistakes. In this regard, the performance of the word segmentation tool needs to be improved.
The effect of semantic ambiguity. As we all know, a word can have different meanings in different contexts. This can be resolved by generating multiple word representations for the word. In additional, a word may become a different part of an event argument. For example, “酒店” (hotel) may be part of a location or a participant. Such problems require further integration of the dependencies between words and content. Our method provides an idea, but it may not be enough.




{kind=link}
{kind=link}