Elastic Scheduling of Scientific Workflows under Deadline Constraints in Cloud Computing Environments

Abstract
:1. Introduction
- (1)
- Grouping homogeneous tasks with the same depth into BoTs according to their priorities and dependency constraints in order to minimize queuing overheads and then distributing the overall workflow deadline over different BoTs.
- (2)
- Implementation of a technique for scheduling of tasks on dynamic and scalable set of VMs in order to optimize cost while satisfying their deadlines.
- (3)
- The proposed algorithm involves dynamic provisioning of resources as MIP problem by the use of IBM ILOG CPLEX.
- (4)
- Extensive simulations with results for real world scientific applications.
2. Related Work
3. System Model
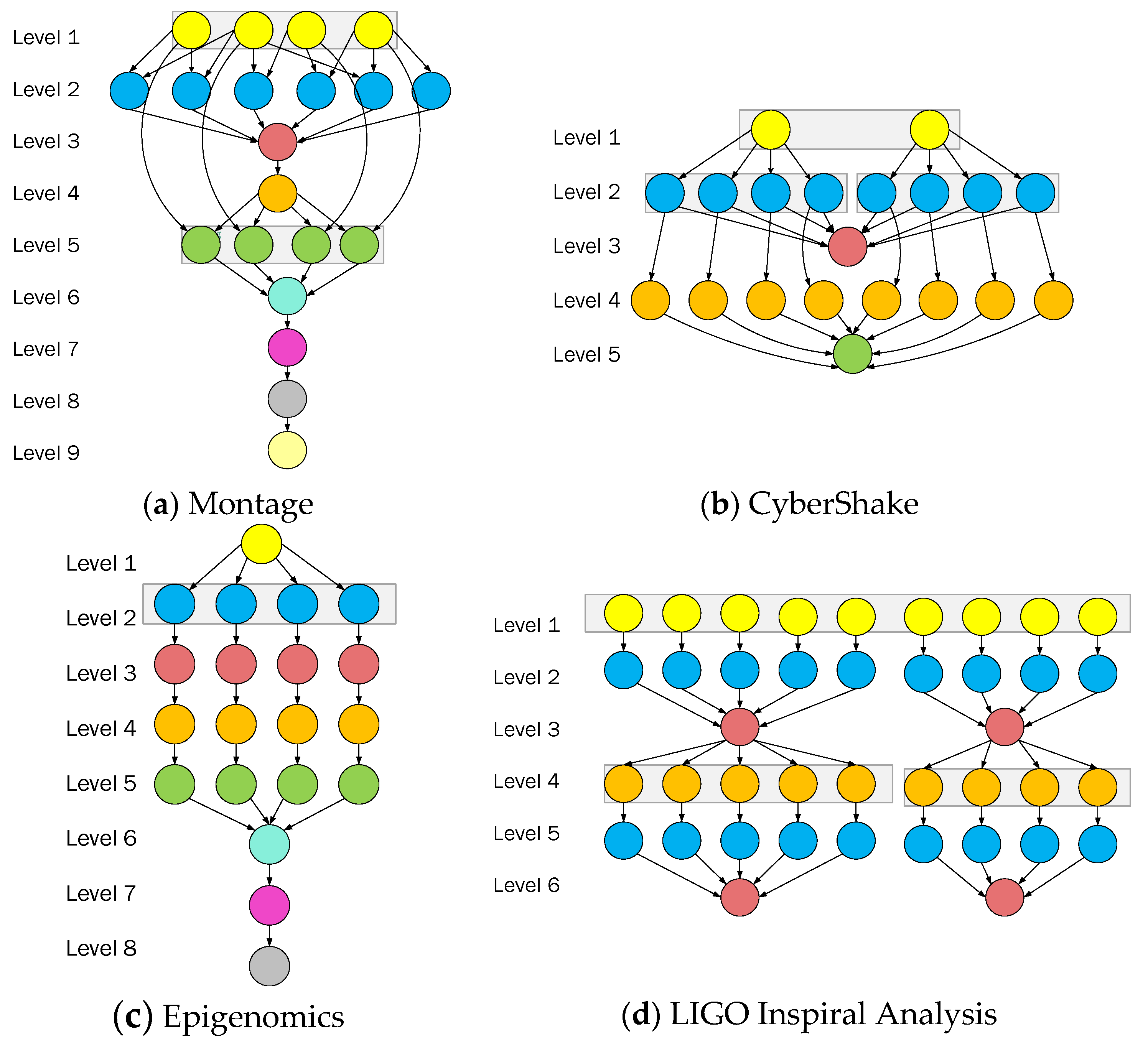
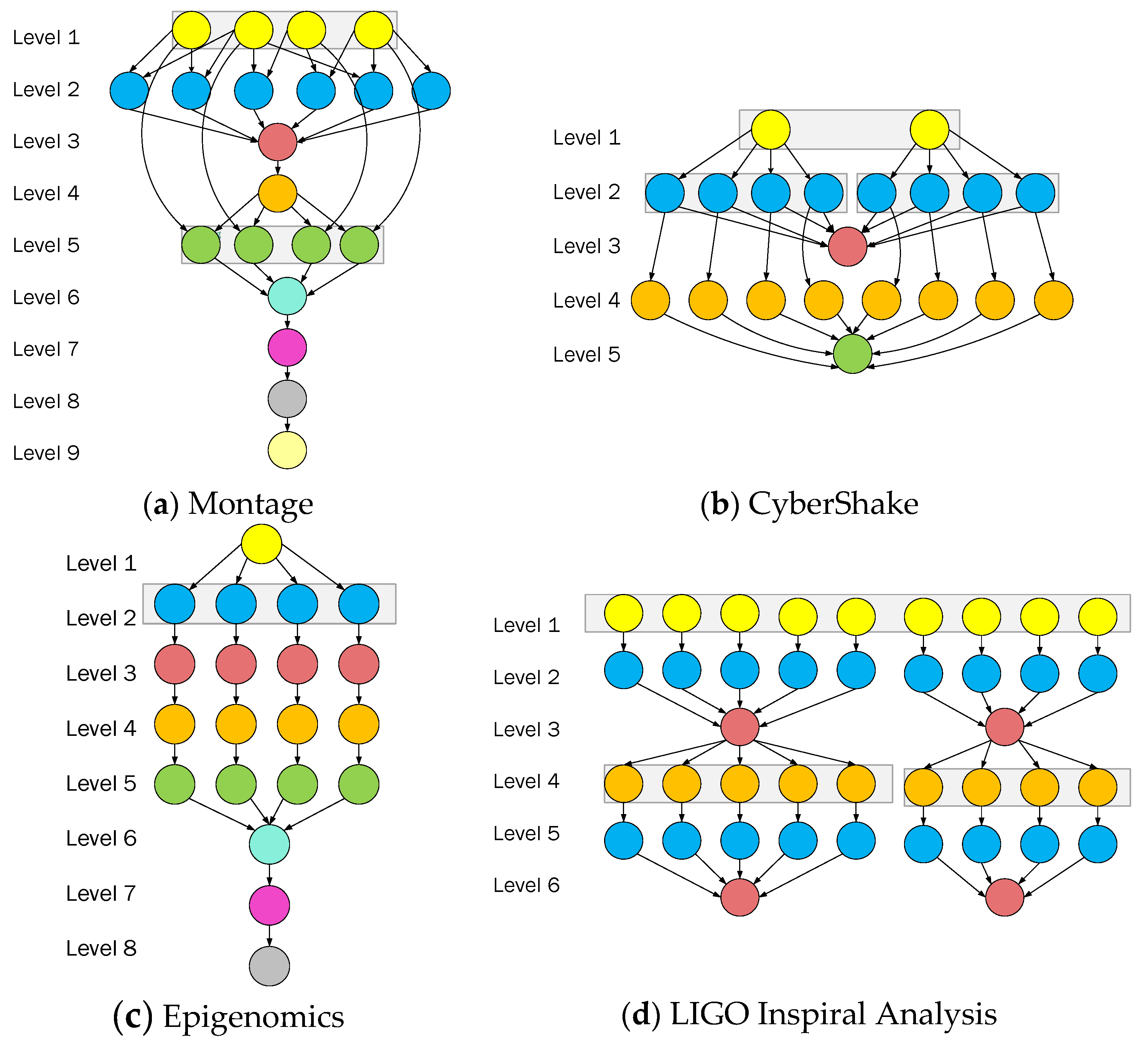
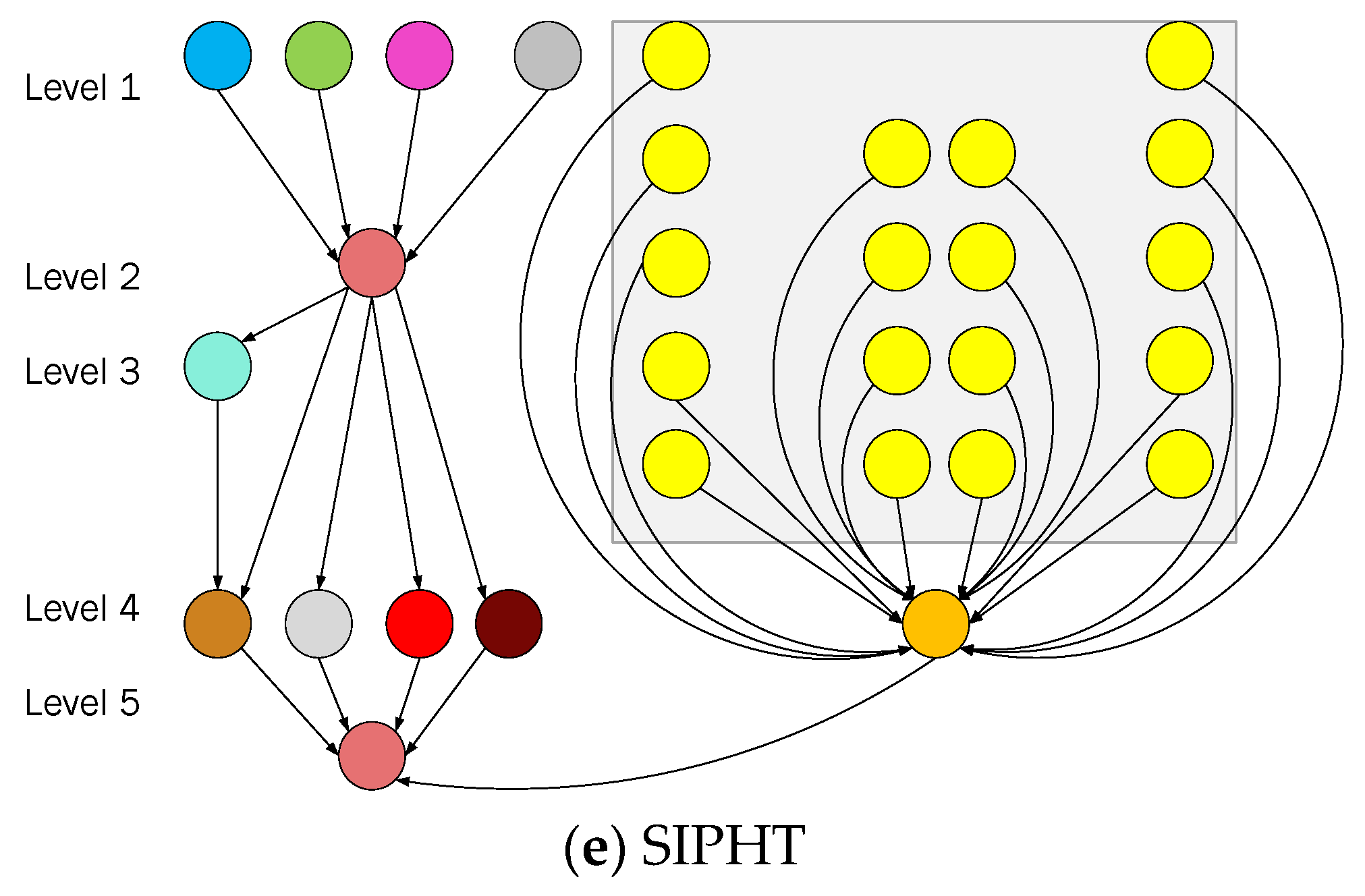
3.1. Scientific Workflow Application Model
3.2. Cloud Resource Model
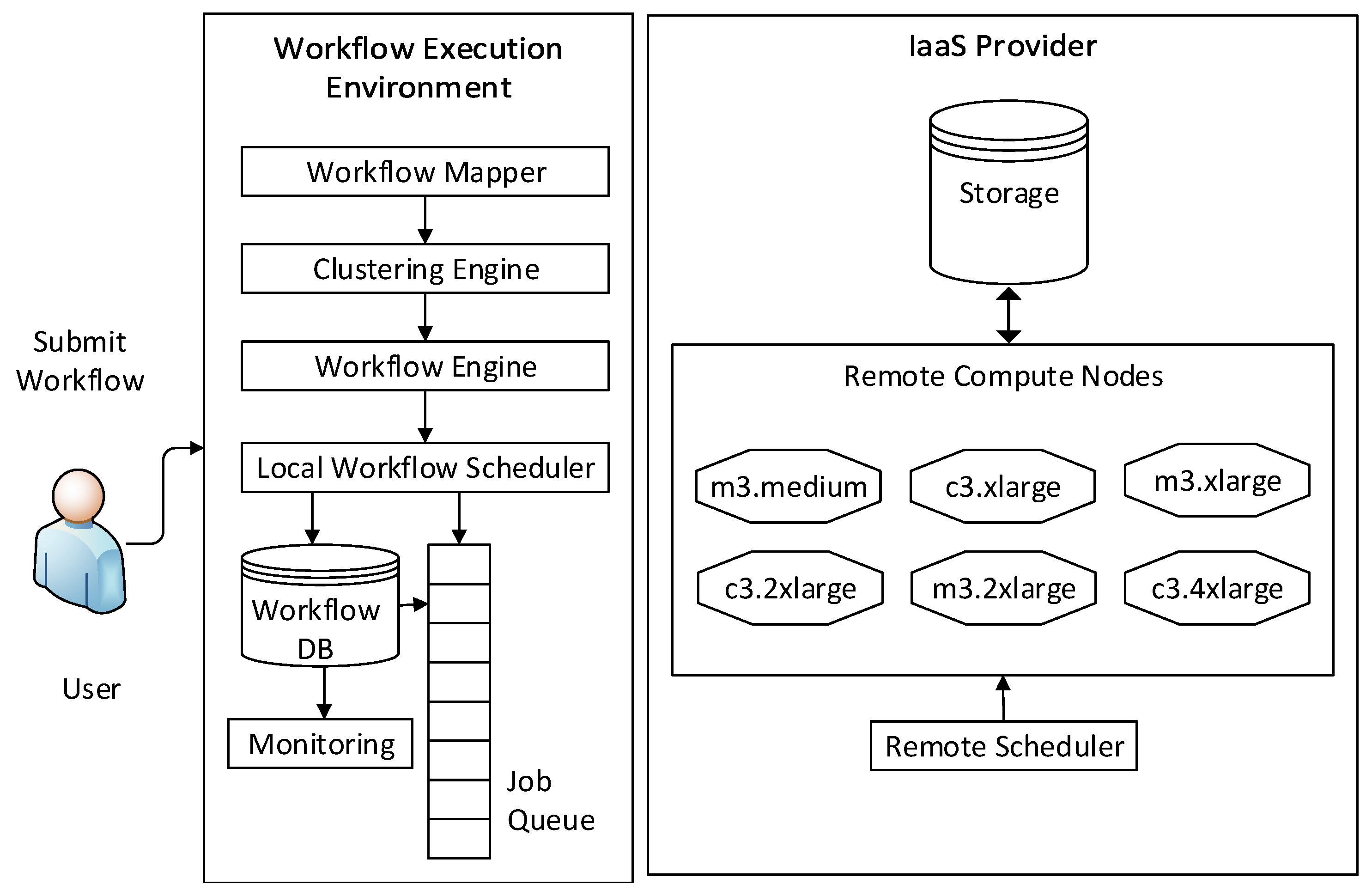
3.3. Workflow Execution Model
- Workflow submission: The user submits the workflow application to the WMS for scheduling of the workflow tasks. The WMS resides on the host machine which may be a user’s laptop or a community resource.
- Target execution environment: It can be a local machine, like the user’s laptop, or a virtual environment such as the cloud or a remote physical cluster or a grid [26]. On the basis of the available resources, the WMS maps given abstract workflow into an executable workflow and execute them. Moreover, it monitors the execution and manages the input data, intermediate files and output files of the workflow tasks. An overview of the main components of the target execution environment are discussed below:
- Workflow mapper: The workflow mapper produces an executable workflow on the basis of the abstract workflow submitted by the user. It identifies the appropriate data and the software and hardware resources required for the execution. Moreover, the mapper can restructure the workflow for performance optimization.
- Clustering engine: To reduce system overheads, one or more small tasks are clustered into single execution unit called job in WMS.
- Workflow engine: The workflow engine submits the jobs defined by the workflow in order of their dependency constraints. Thereafter, the jobs are submitted to the local workflow scheduling queue.
- Local workflow scheduler and local queue: The local workflow scheduler manages and supervises individual workflow jobs on local and remote resources. The elapsed time between the submission of a job to the job scheduler and its execution in a remote compute node (potentially on cloud) is denoted as the queue delay.
- Remote execution engine: It manages the execution of clustered jobs on one or more remote compute nodes.
4. The Proposed DSB Workflow Scheduling Algorithm
4.1. Assumptions
4.2. Problem Statement
4.3. Basic Definitions
4.4. Proposed Algorithm
4.4.1. Task Prioritization
4.4.2. Task Grouping
4.4.3. Deadline Distribution
| Algorithm 1 Deadline Distribution |
| procedure DD(Workflow , Deadline , Runtime of tasks on VMs ) 1: Find cheapest VM type such that 2: if then 3: while do 4: Next cheapest VM type such that 5: end while 6:end if 7: Calculate available spare time of workflow //according to Equation (11) 8: Distribute proportionally over all levels //according to Equation (12) 9: Distribute proportionally over all tasks in each level //according to Equation (13) 10: Calculate estimated sub-deadline for each task //according to Equation (14) 11: Update sub-deadline of each BoT as the maximum finish time of its tasks |
4.4.4. Task Selection
4.4.5. Elastic Resource Provisioning
| Algorithm 2 Elastic Resource Provisioning | |
| procedure ERP(Execution queue containing set of ready BoTs , Set of VM types VM) | |
| 1 | |
| 2 | for all |
| 3 | if then |
| 4 | Solve the MIP problem by CPLEX and get |
| 5 | for all do |
| 6 | for all do |
| 7 | |
| 8 | |
| 9 | Call LFI() |
| 10 | if then |
| 11 | Call RSU() |
| 12 | end if |
| 13 | end for |
| 14 | end for |
| 15 | else if then |
| 16 | |
| 17 | select cheapest VM that can run task within deadline |
| 18 | Schedule to |
| 19 | |
| 20 | |
| 21 | Update next available time of |
| 22 | end if |
| 23 | end for |
| Algorithm 3 Lease Free Interval | |
| procedure LFI(Set of ready tasks of BoT , ) | |
| 1 | Get the next ready task with highest priority from |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | for all do |
| 7 | Calculate //according to Equation (5) |
| 8 | Calculate //according to Equation (9) |
| 9 | if and then |
| 10 | |
| 11 | |
| 12 | end if |
| 13 | end for |
| 14 | such that is minimum |
| 15 | if then |
| 16 | |
| 17 | end if |
| 18 | if then |
| 19 | Schedule to |
| 20 | |
| 21 | |
| 22 | Update next available time of |
| 23 | else |
| 24 | |
| 25 | end if |
| Algorithm 4 Resource Scaling Up | |
| procedure RSU(Set of ready BoTs , Set of VMs ) | |
| 1 | next ready task with highest priority |
| 2 | |
| 3 | |
| 4 | |
| 5 | for all do |
| 6 | Calculate //according to Equation (5) |
| 7 | Calculate //according to Equation (9) |
| 8 | if then |
| 9 | |
| 10 | |
| 11 | end if |
| 12 | end for |
| 13 | such that is minimum |
| 14 | if then |
| 15 | such that is maximum |
| 16 | end if |
| 17 | if then |
| 18 | Lease new interval and schedule task on it |
| 19 | |
| 20 | |
| 21 | end if |
| Algorithm 5 The Proposed DSB | |
| Input: Workflow , Deadline , Runtime of tasks on VMs | |
| 1 | Add and and their corresponding edges to the workflow W |
| 2 | for all do |
| 3 | Calculate upward rank //according to Equation (6) |
| 4 | Calculate degree of dependency //according to Equation (7) |
| 5 | end for |
| 6 | Sort the tasks in descending order of priorities |
| 7 | Calculate level of each task //according to Equation (8) |
| 8 | Identify all the BoTs in the workflow |
| 9 | Call DD() |
| 10 | for all do |
| 11 | Put BoTs in priority queue and sort them based on the rules mentioned in Section 4.4.4 |
| 12 | end for |
| 13 | Put ready BoTs in execution queue |
| 14 | Call ERP() |
| Algorithm 6 Resource Scaling Down | |
| procedure RSD(Set of leased VMs ) | |
| 1 | Set of all leased VMs |
| 2 | for each do |
| 3 | if is currently idle then |
| 4 | if has no waiting tasks then |
| 5 | if is currently approaching the next pricing interval then |
| 6 | |
| 7 | Shut down |
| 8 | end if |
| 9 | end if |
| 10 | end if |
| 11 | end for |
4.5. Computational Complexity
5. Performance Analysis and Discussion
5.1. Experiment Environment
5.2. Performance Metric
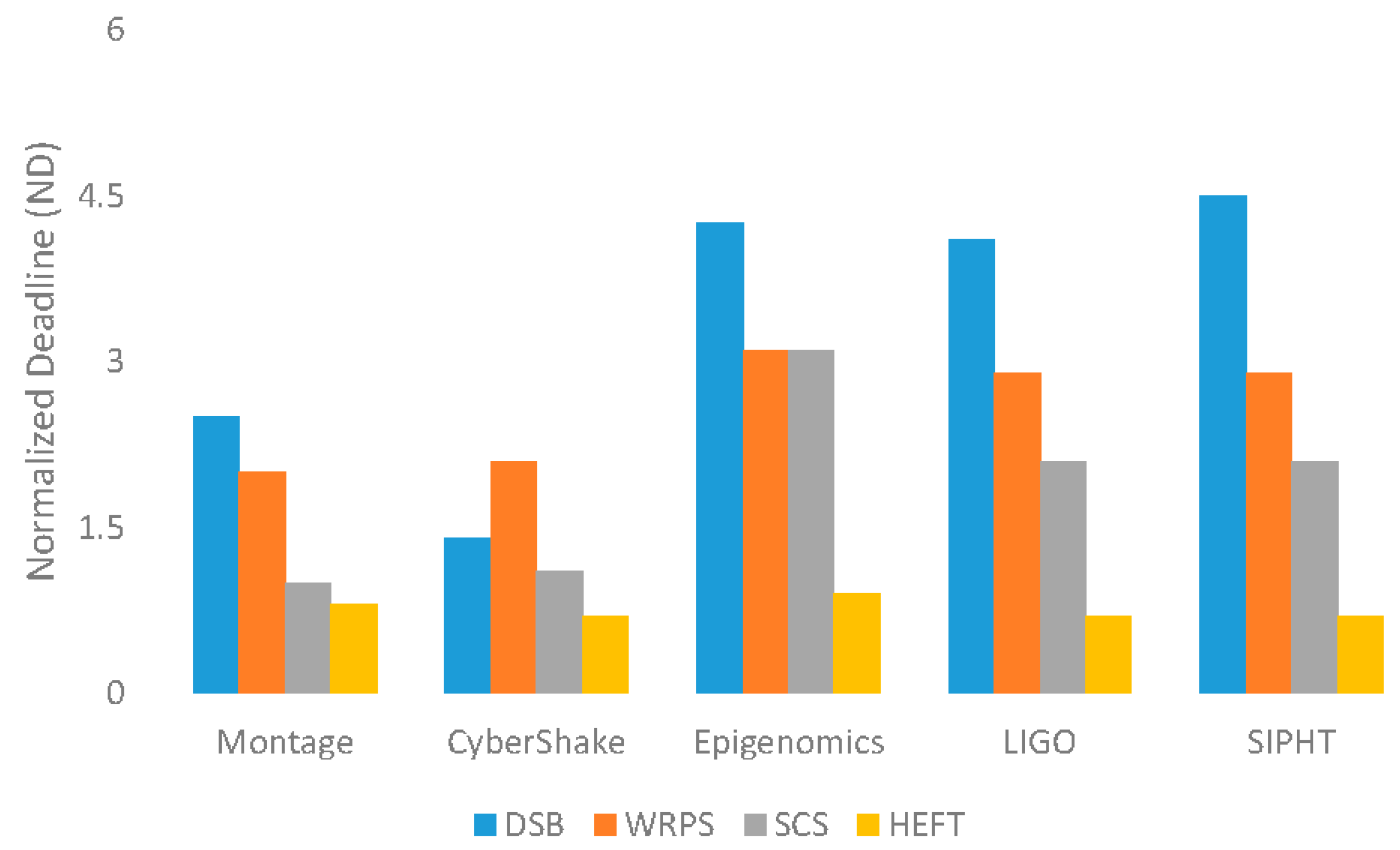
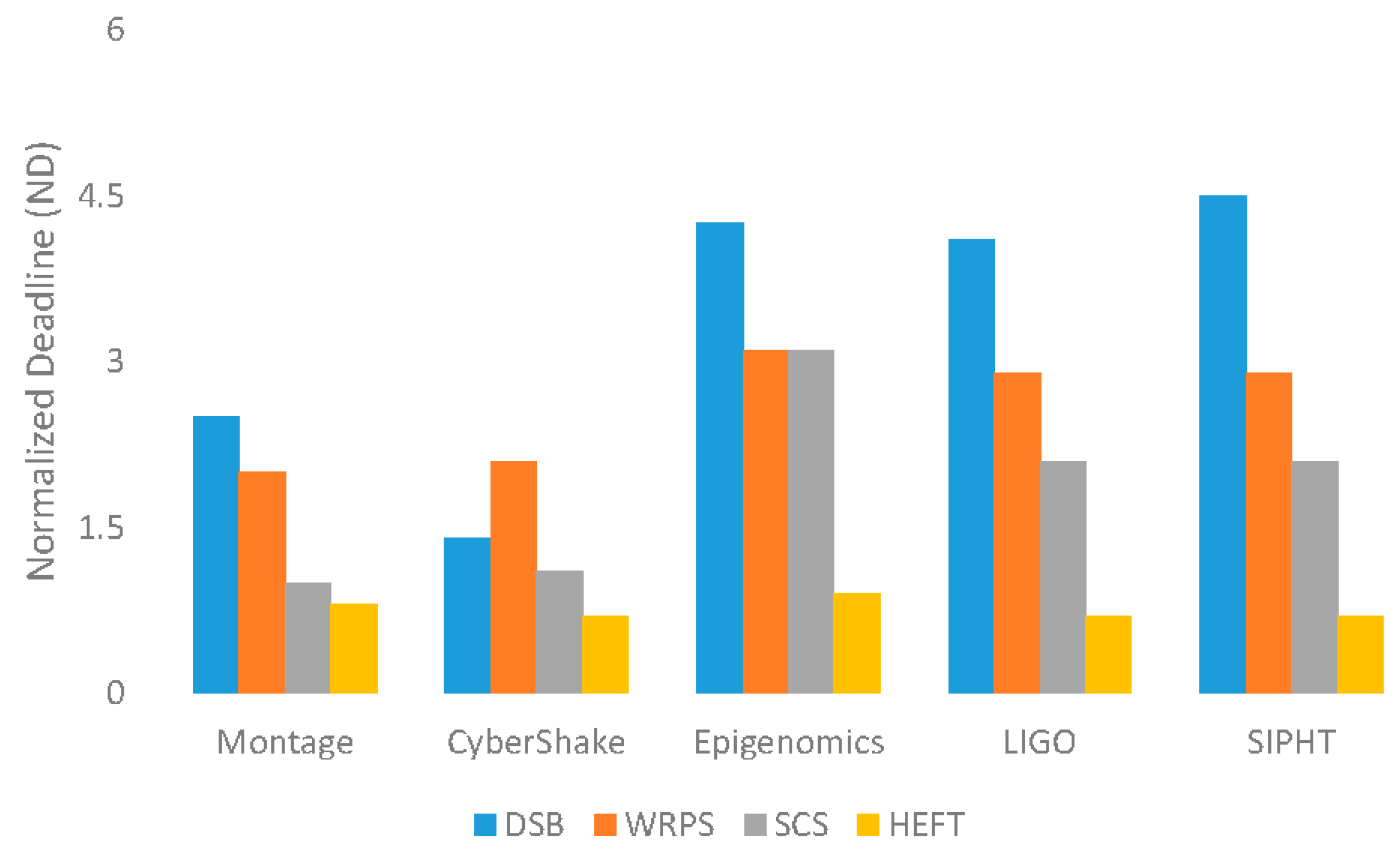
5.2.1. Normalized Deadline (ND)
5.2.2. Improvement Rate (IR)
5.2.3. Success Rate (SR)
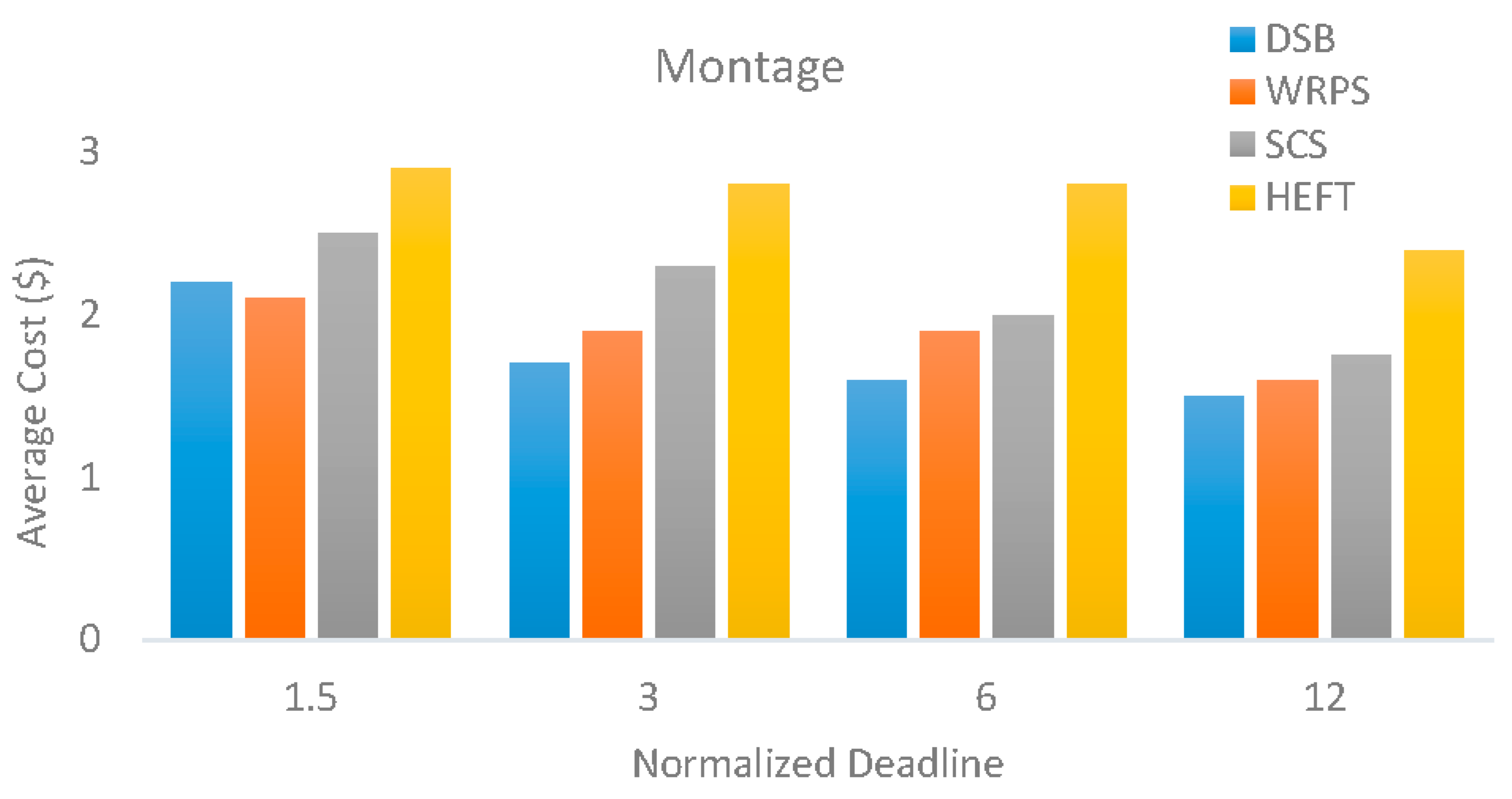
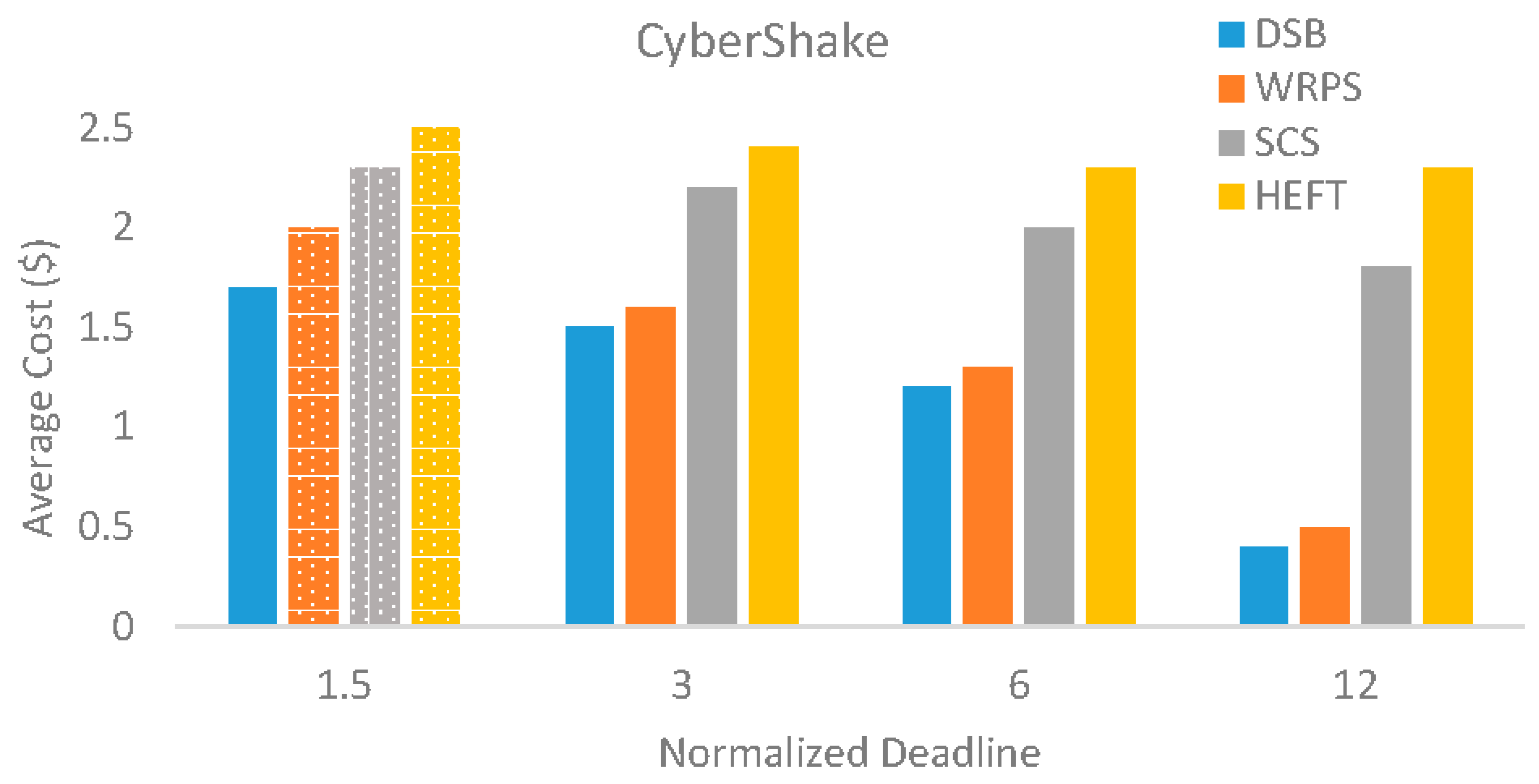
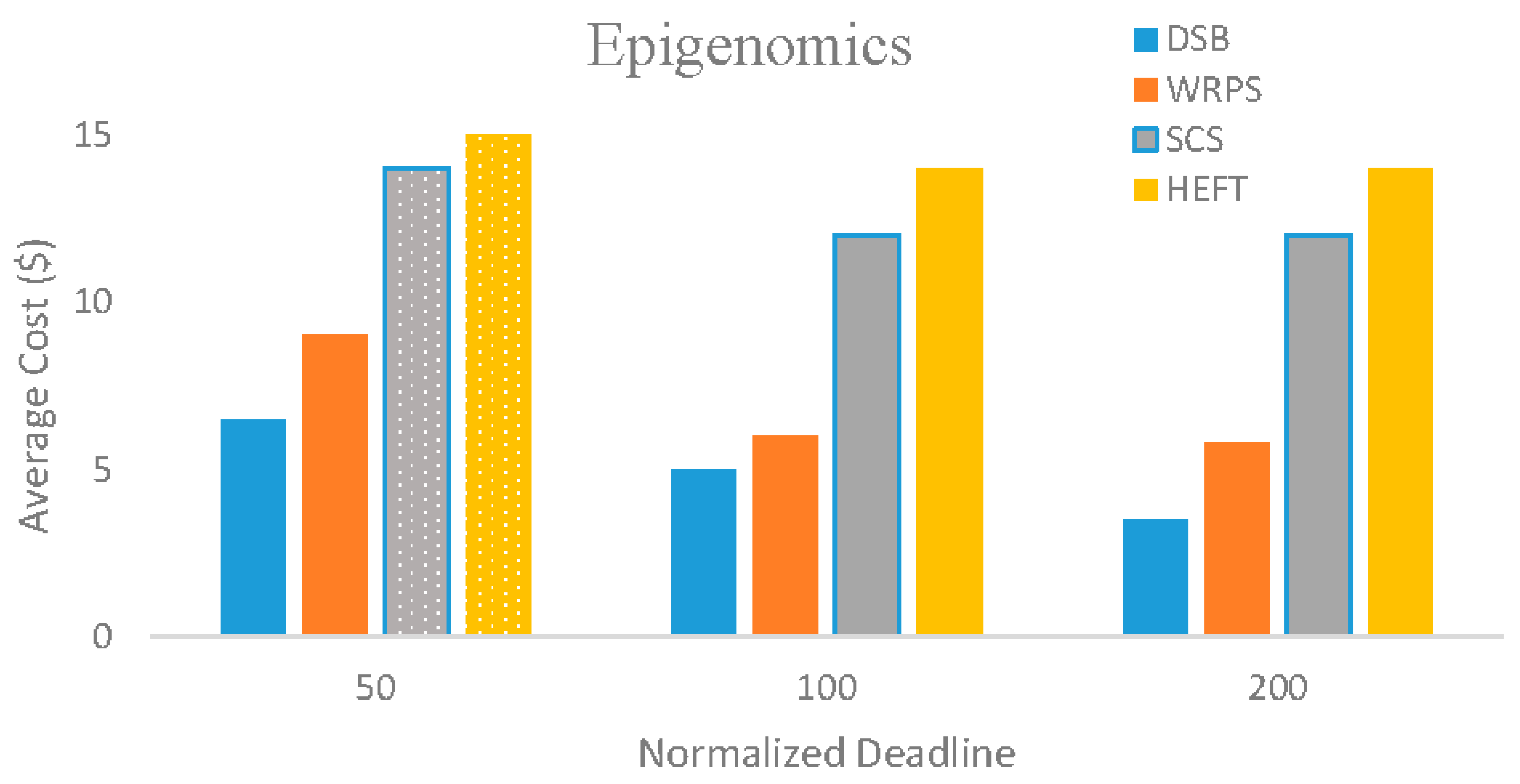
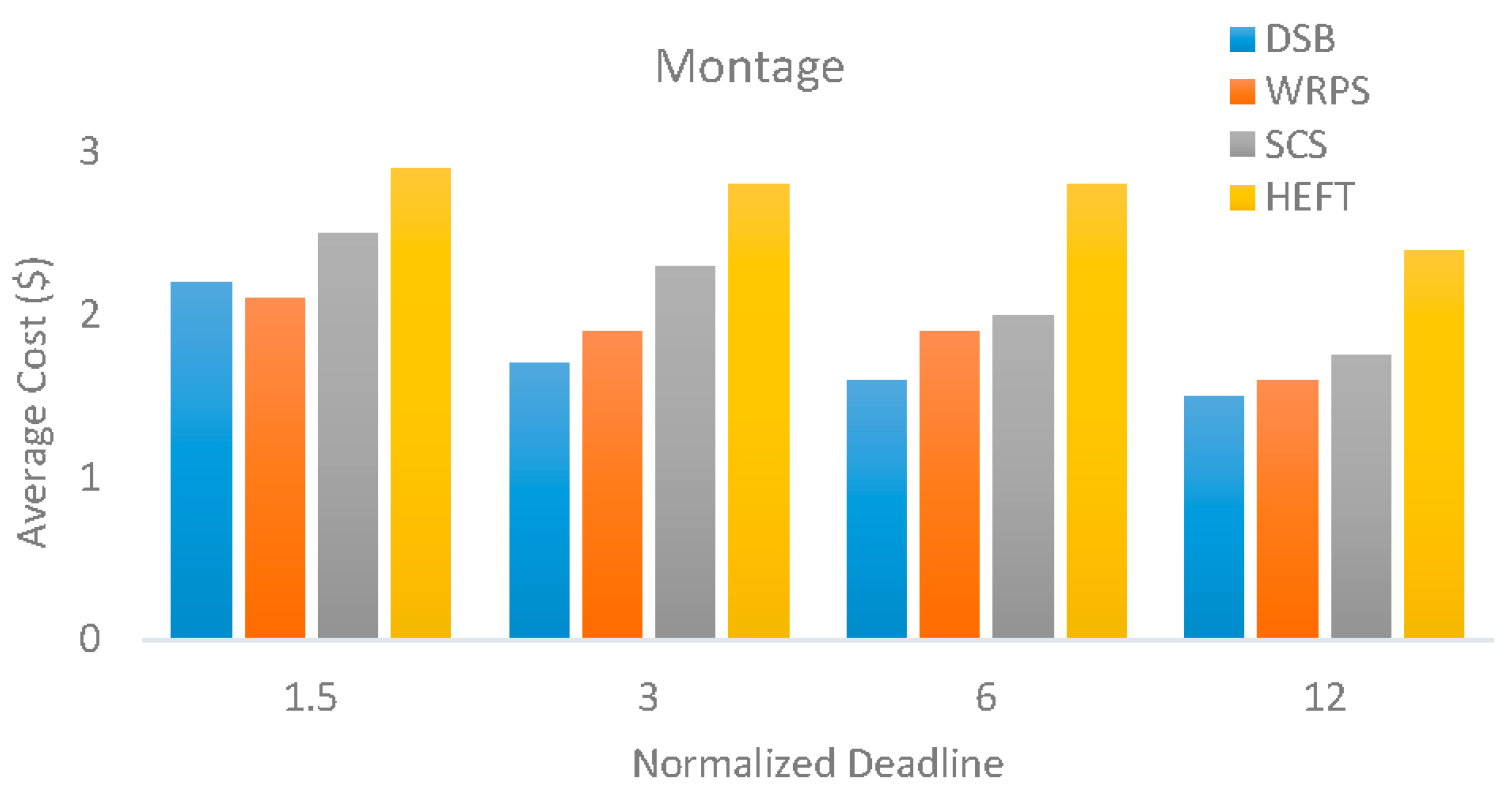
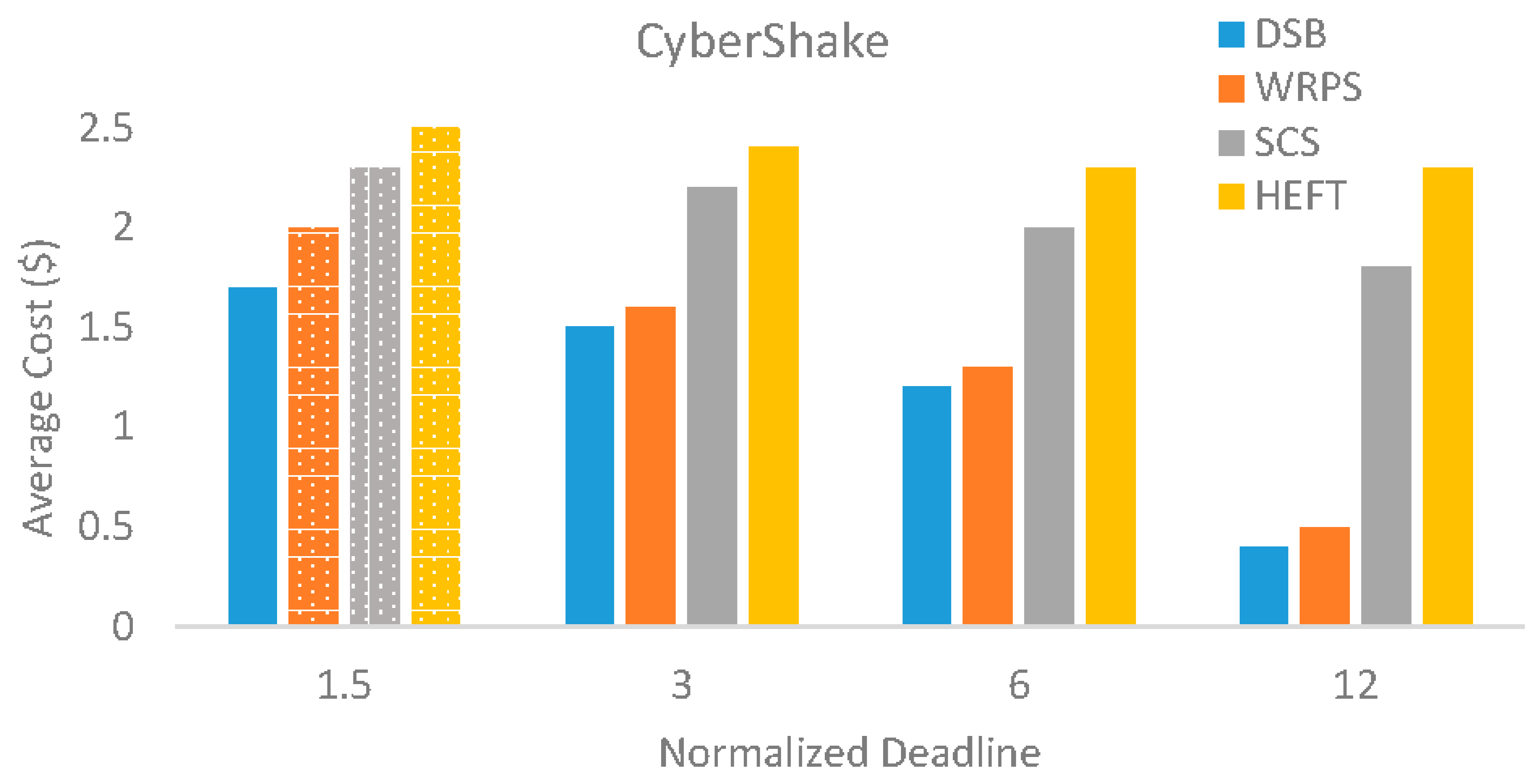
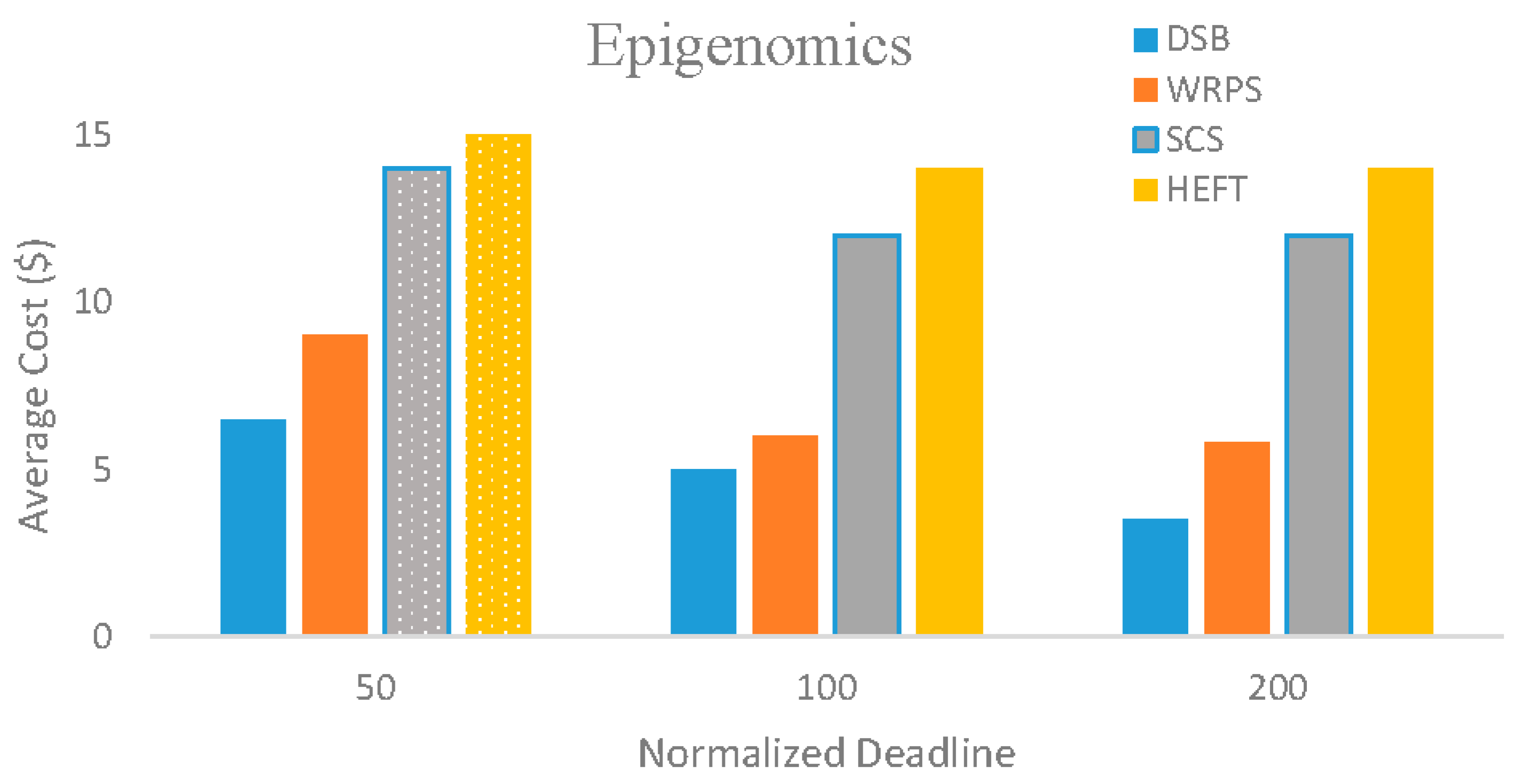
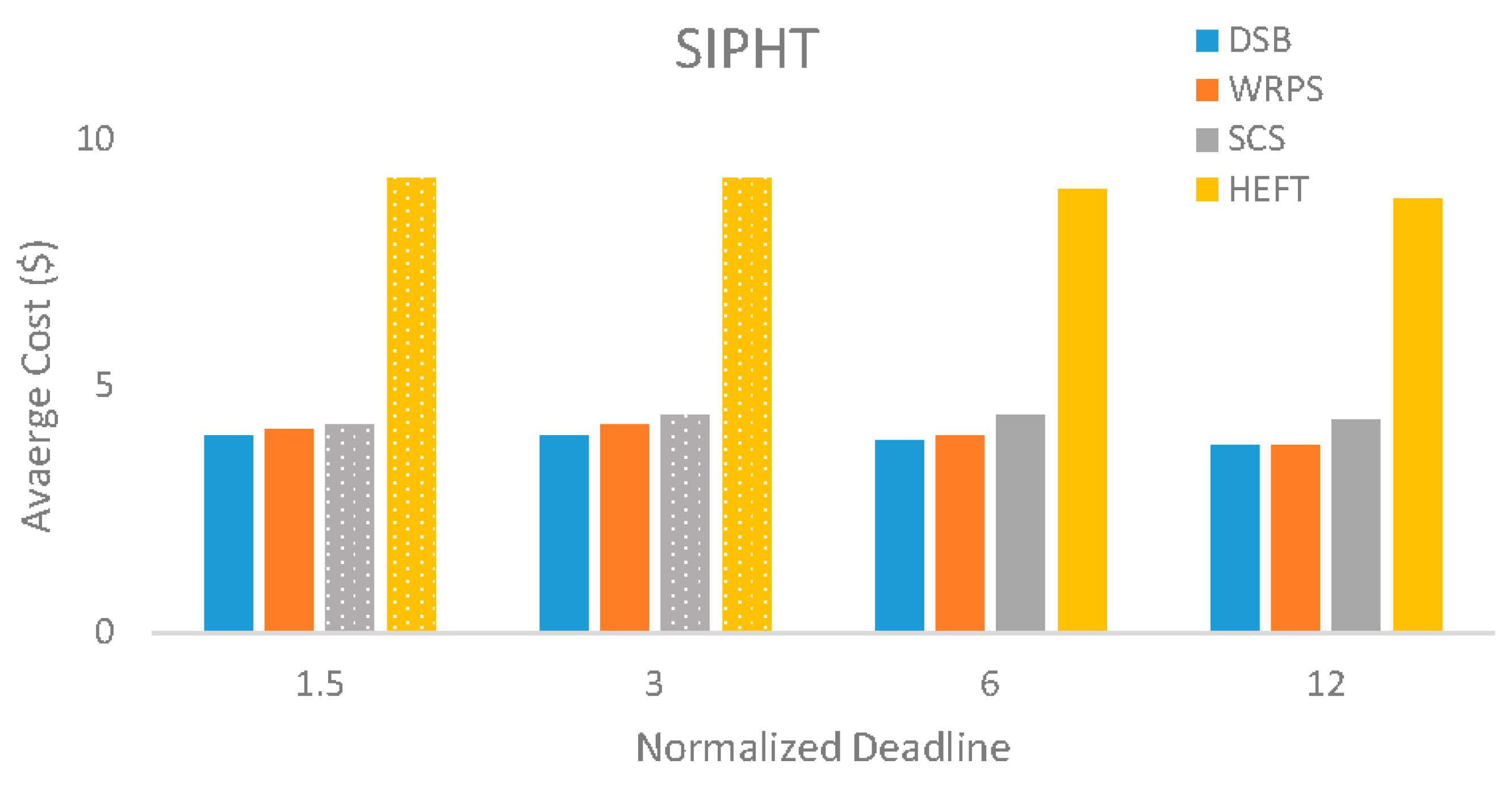
5.3. Evaluation Results
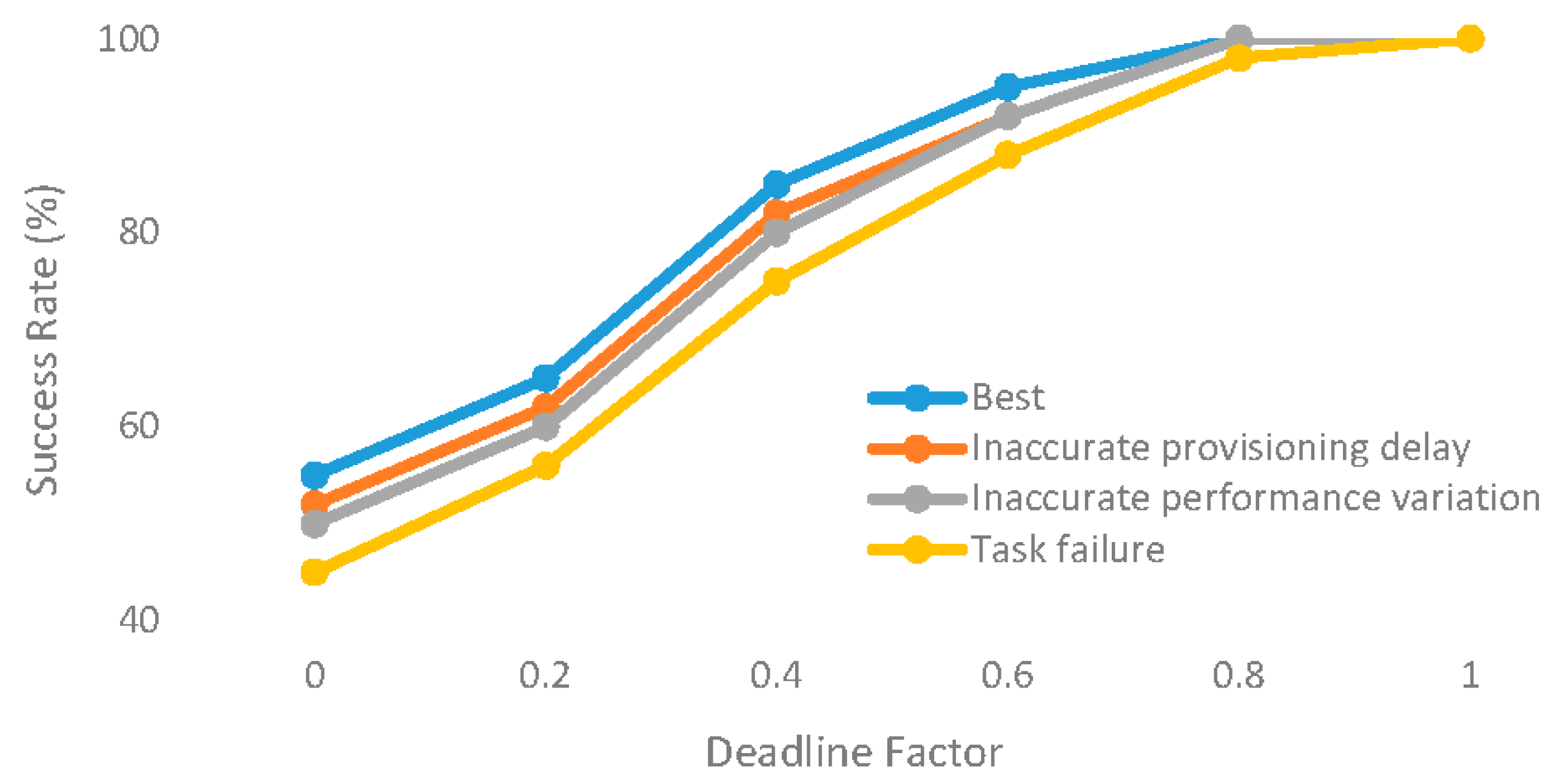
5.4. Sensitivity of Overheads, VM Performance Variations and Task Failures
5.5. Analysis of Variance (ANOVA) Test
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Rodriguez, M.A.; Buyya, R. A taxonomy and survey on scheduling algorithms for scientific workflows in IaaS cloud computing environments. Concurr. Comput. Pract. Exp. 2017, 29, 1–32. [Google Scholar] [CrossRef]
- Ullman, J.D. Np-complete scheduling problems. J. Comput. Syst. Sci. 1975, 10, 384–393. [Google Scholar] [CrossRef]
- Ostrowski, K.; Birman, K.; Dolev, D. Extensible architecture for high-performance, scalable, reliable publish-subscribe eventing and notification. Int. J. Web Serv. Res. 2007, 4, 18–58. [Google Scholar] [CrossRef]
- Chen, W.; Deelman, E. Workflow overhead analysis and optimizations. In Proceedings of the 6th Workshop on Workflows in Support of Large-Scale Science, Seattle, Washington, DC, USA, 14 November 2011; ACM: New York, NY, USA, 2011; pp. 11–20. [Google Scholar] [CrossRef]
- Chen, W.; Silva, R.F.; Deelman, E.; Sakellariou, R. Using imbalance metrics to optimize task clustering in scientific workflow executions. Future Gener. Comput. Syst. 2015, 46, 69–84. [Google Scholar] [CrossRef]
- Verma, A.; Kaushal, S. Cost-time efficient scheduling plan for executing workflows flows in the cloud. J. Grid Comput. 2015, 13, 495–506. [Google Scholar] [CrossRef]
- Arabnejad, H.; Barbosa, J.G.; Prodan, R. Low-time complexity budget deadline constrained workflow scheduling on heterogeneous resources. Future Gener. Comput. Syst. 2016, 55, 29–40. [Google Scholar] [CrossRef]
- Malawski, M.; Juve, J.; Deelman, E.; Nabrzyski, J. Algorithms for cost- and deadline-constrained provisioning for scientific workflow ensembles in iaas clouds. Future Gener. Comput. Syst. 2015, 48, 1–18. [Google Scholar] [CrossRef]
- Mao, M.; Humphrey, M. Auto-scaling to minimize cost and meet application deadlines in cloud workflows. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Seatle, WA, USA, 12–18 November 2011. [Google Scholar] [CrossRef]
- Byun, E.-K.; Kee, Y.-S.; Kim, J.-S.; Maeng, S. Cost optimized provisioning of elastic resources for application workflows. Future Gener. Comput. Syst. 2011, 27, 1011–1026. [Google Scholar] [CrossRef]
- Tang, Z.; Liu, M.; Ammar, A.; Li, K.; Li, K. An optimized MapReduce workflow scheduling algorithm for heterogeneous computing. J. Supercomput. 2014, 72, 1–21. [Google Scholar] [CrossRef]
- Silva, R.F.; Glatard, T.; Desprez, F. On-Line, non-clairvoyant optimization of workflow activity granularity on grids. In Proceedings of the 19th International Conference on Parallel Processing, Aachen, Germany, 26–30 August 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8097, pp. 255–266. [Google Scholar] [CrossRef]
- Zuo, X.; Zhang, G.; Tan, W. Self-adaptive learning PSO-based deadline constrained task scheduling for hybrid IaaS cloud. IEEE Trans. Autom. Sci. Eng. 2014, 11, 564–573. [Google Scholar] [CrossRef]
- Moschakis, I.A.; Karatza, H.D. Multi-criteria scheduling of bag-of-tasks applications on heterogeneous interlinked clouds with simulated annealing. J. Syst. Softw. 2015, 101, 1–14. [Google Scholar] [CrossRef]
- Abrishami, S.; Naghibzadeh, M.; Epema, D.H. Deadline-constrained workflow scheduling algorithms for infrastructure as a service clouds. Future Gener. Comput. Syst. 2013, 29, 158–169. [Google Scholar] [CrossRef]
- Cai, Z.; Li, X.; Ruiz, R. Resource provisioning for task-batch based workflows with deadlines in public clouds. IEEE Trans. Cloud Comput. 2017, PP, 1-1. [Google Scholar] [CrossRef]
- Singh, V.; Gupta, I.; Jana, P.K. A novel cost-efficient approach for deadline-constrained workflow scheduling by dynamic provisioning of resources. Future Gener. Comput. Syst. 2018, 79, 95–110. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Buyya, R. Scheduling dynamic workloads in multi-tenant scientific workflow as a service platforms. Future Gener. Comput. Syst. 2018, 79, 739–750. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Buyya, R. Budget-Driven Scheduling of Scientific Workflows in IaaS Clouds with Fine-Grained Billing Periods. ACM Trans. Auton. Adapt. Syst. 2017, 12, 5. [Google Scholar] [CrossRef]
- Dziok, T.; Figiela, K.; Malawski, M. Adaptive multi-level workflow scheduling with uncertain task estimates. In Parallel Processing and Applied Mathematics; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9574, pp. 90–100. [Google Scholar] [CrossRef]
- Muthuvelu, N.; Vecchiola, C.; Chai, I.; Chikkannan, E.; Buyya, R. Task granularity policies for deploying bag-of-task applications on global grids. Future Gener. Comput. Syst. 2012, 29, 170–181. [Google Scholar] [CrossRef]
- Malawski, M.; Juve, G.; Deelman, E.; Nabrzyski, J. Cost- and deadline-constrained provisioning for scientific workflow ensembles in IaaS clouds. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 1–11. [Google Scholar]
- Deelman, E.; Singh, G.; Su, M.H.; Blythe, J.; Gil, Y.; Kesselman, C.; Laity, A. Pegasus: A framework for mapping complex scientific workflows onto distributed systems. Sci. Programm. 2005, 13, 219–237. [Google Scholar] [CrossRef]
- Abouelhoda, M.; Issa, S.A.; Ghanem, M. Tavaxy: Integrating Taverna and Galaxy workflows with cloud computing support. BMC Bioinform. 2012, 13, 77. [Google Scholar] [CrossRef] [PubMed]
- Deelman, E.; Vahi, K.; Juve, G.; Rynge, M.; Callaghan, S.; Maechling, P.J.; Wenger, K. Pegasus, a workflow management system for science automation. Future Gener. Comput. Syst. 2015, 46, 17–35. [Google Scholar] [CrossRef]
- Armbrust, M.; Fox, A.; Griffith, R.; Joseph, A.D.; Katz, R.; Konwinski, A.; Zaharia, M. A view of cloud computing. Commun. ACM 2010, 53, 50–58. [Google Scholar] [CrossRef]
- Ostermann, S.; Iosup, A.; Yigibasi, N.; Prodan, R.; Fahringer, T.; Epema, D. A performance analysis of EC2 cloud computing services for scientific computing. In Cloud Computing; Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering; Springer: Berlin/Heidelberg, Germany, 2010; Volume 34. [Google Scholar] [CrossRef]
- Jackson, K.R.; Ramakrishnan, L.; Muriki, K.; Canon, S.; Cholia, S.; Shalf, J.; Wright, N.J. Performance analysis of high performance computing applications on the Amazon Web Services cloud. In Proceedings of the 2nd International Conference on Cloud Computing Technology and Science (CloudCom), Indianapolis, IN, USA, 30 November–3 December 2010. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Hariri, S.; Wu, M. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef]
- Juve, G.; Chervenak, A.; Deelman, E.; Bharathi, S.; Mehta, G.; Vahi, K. Characterizing and profiling scientific workflows. Future Gener. Comput. Syst. 2013, 29, 682–692. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhang, G.; Li, M.; Liu, X. Evolutionary Multi-Objective Workflow Scheduling in Cloud. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1344–1357. [Google Scholar] [CrossRef]
- Chen, W.; Deelman, E. WorkflowSim: A toolkit for simulating scientific workflows in distributed environments. In Proceedings of the IEEE 8th International Conference on E-Science (e-Science), Chicago, IL, USA, 8–12 October 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Calheiros, R.N.; Ranjan, R.; Beloglazov, A.; De Rose, C.A.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pract. Exp. 2011, 41, 23–50. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Buyya, R. A Responsive Knapsack-based Algorithm for Resource Provisioning and Scheduling of Scientific Workflows in Clouds. In Proceedings of the IEEE 44th International Conference on Parallel Processing (ICPP), Beijing, China, 1–4 September 2015. [Google Scholar] [CrossRef]
- Muller, K.E.; Fetterman, B.A. Regression and ANOVA: An Integrated Approach Using SAS Software; SAS Institute: Cary, NC, USA, 2002. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Workflow represented by Directed Acyclic Graph (DAG) | |
| Set of tasks of the workflow, represented by vertices of the DAG | |
| Set of directed edges between the vertices | |
| Set of BoTs | |
| Set of Virtual Machines (VMs) | |
| Number of tasks | |
| Number of VM types | |
| Number of BoTs | |
| A task such that | |
| A task such that | |
| Virtual entry node | |
| Virtual exit node | |
| Running task | |
| An edge such that between the tasks and | |
| Inward edges of task | |
| Outward edges of task | |
| A BoT such that | |
| A virtual machine of type such that | |
| Immediate predecessor of task | |
| Immediate successor of task | |
| Estimated Runtime of task on VM | |
| Communication time of edge from tasks and on a VM | |
| Execution time of task on VM | |
| Start time of task on VM | |
| Finish time of task on VM | |
| Execution cost of task on VM | |
| Service length of task | |
| Processing power of VM | |
| Billing interval length of VM type | |
| Cost per interval unit of VM type | |
| Bandwidth capacity of VM | |
| Provisioning delay in VM allocation | |
| VM performance variability | |
| Start leasing time of VM | |
| Data transfer cost of communicating data from task to | |
| Size of data needed to be communicated from task and | |
| Upward rank of a task | |
| Degree of dependency of task | |
| Maximum number of edges from task to | |
| Number of tasks in the level | |
| Deadline associated with the workflow to complete its execution | |
| Overall schedule length of workflow | |
| Elapsed time between and the estimated | |
| Available spare time of a level | |
| Available spare time of a task level | |
| Estimated sub-deadline for task of the workflow | |
| Earliest finish time of task on VM | |
| Cumulative processing time of submitted tasks on VM | |
| Variable representing number of tasks assigned to VM of type | |
| Number of tasks in assigned to VM of type |
| Workflow | Number of Nodes | Number of Edges | Mean Data Size (MB) | Mean Runtime (CU = 1) |
|---|---|---|---|---|
| Montage_1000 | 1000 | 4485 | 3.21 | 11.36 s |
| CyberShake_1000 | 1000 | 3988 | 102.29 | 22.71 s |
| Epigenomics_997 | 997 | 3228 | 388.59 | 3858.67 s |
| LIGO_1000 | 1000 | 3246 | 8.90 | 2227.25 s |
| SIPHT_1000 | 1000 | 3528 | 5.91 | 179.05 s |
| VM Type | ECU | Memory | Price ($/h) |
|---|---|---|---|
| m3.medium | 1 | 3.75 | 0.067 |
| c3.xlarge | 4 | 3.75 | 0.21 |
| m3.xlarge | 4 | 15 | 0.266 |
| c3.2xlarge | 8 | 15 | 0.42 |
| m3.2xlarge | 16 | 30 | 0.532 |
| c3.4xlarge | 16 | 30 | 0.84 |
| Workflow | Source of Variation | SS | df | MS | F | p-Value |
|---|---|---|---|---|---|---|
| Montage_1000 | Between groups | 561,231.4 | 2 | 280615.7 | 35.683 | 3.04 × 10−8 |
| Within groups | 212,330 | 27 | 7864.074 | |||
| Total | 773,561.4 | 29 | ||||
| Between groups | 1,519,506.153 | 2 | 759,753.076 | 21.027 | 3.12× 10−6 | |
| CyberShake_1000 | Within groups | 975,550.9 | 27 | 36,131.515 | ||
| Total | 2,495,057.053 | 29 | ||||
| Between groups | 1,630,867.799 | 2 | 815,433.8995 | 60.632 | 0.0 | |
| Epigenomics_997 | Within groups | 363,117.4 | 27 | 13,448.792 | ||
| Total | 1,993,985.199 | 29 | ||||
| LIGO_1000 | Between groups | 1,000,549.365 | 2 | 500,274.682 | 63.815 | 0.0 |
| Within groups | 211,665.6 | 27 | 7839.467 | |||
| Total | 1,212,214.965 | 29 | ||||
| SIPHT_1000 | Between groups | 4,717,007.744 | 2 | 2,358,503.872 | 24.935 | 7.3 × 10−7 |
| Within groups | 2,553,788 | 27 | 94,584.741 | |||
| Total | 7,270,795.744 | 29 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anwar, N.; Deng, H. Elastic Scheduling of Scientific Workflows under Deadline Constraints in Cloud Computing Environments. Future Internet 2018, 10, 5. https://doi.org/10.3390/fi10010005
Anwar N, Deng H. Elastic Scheduling of Scientific Workflows under Deadline Constraints in Cloud Computing Environments. Future Internet. 2018; 10(1):5. https://doi.org/10.3390/fi10010005
Chicago/Turabian StyleAnwar, Nazia, and Huifang Deng. 2018. "Elastic Scheduling of Scientific Workflows under Deadline Constraints in Cloud Computing Environments" Future Internet 10, no. 1: 5. https://doi.org/10.3390/fi10010005
APA StyleAnwar, N., & Deng, H. (2018). Elastic Scheduling of Scientific Workflows under Deadline Constraints in Cloud Computing Environments. Future Internet, 10(1), 5. https://doi.org/10.3390/fi10010005