
Modeling Pharmacokinetics in Individual Patients Using Therapeutic Drug Monitoring and Artificial Population Quasi-Models: A Study with Piperacillin

 ,
,  , , ,
, , ,
Abstract
1. Introduction
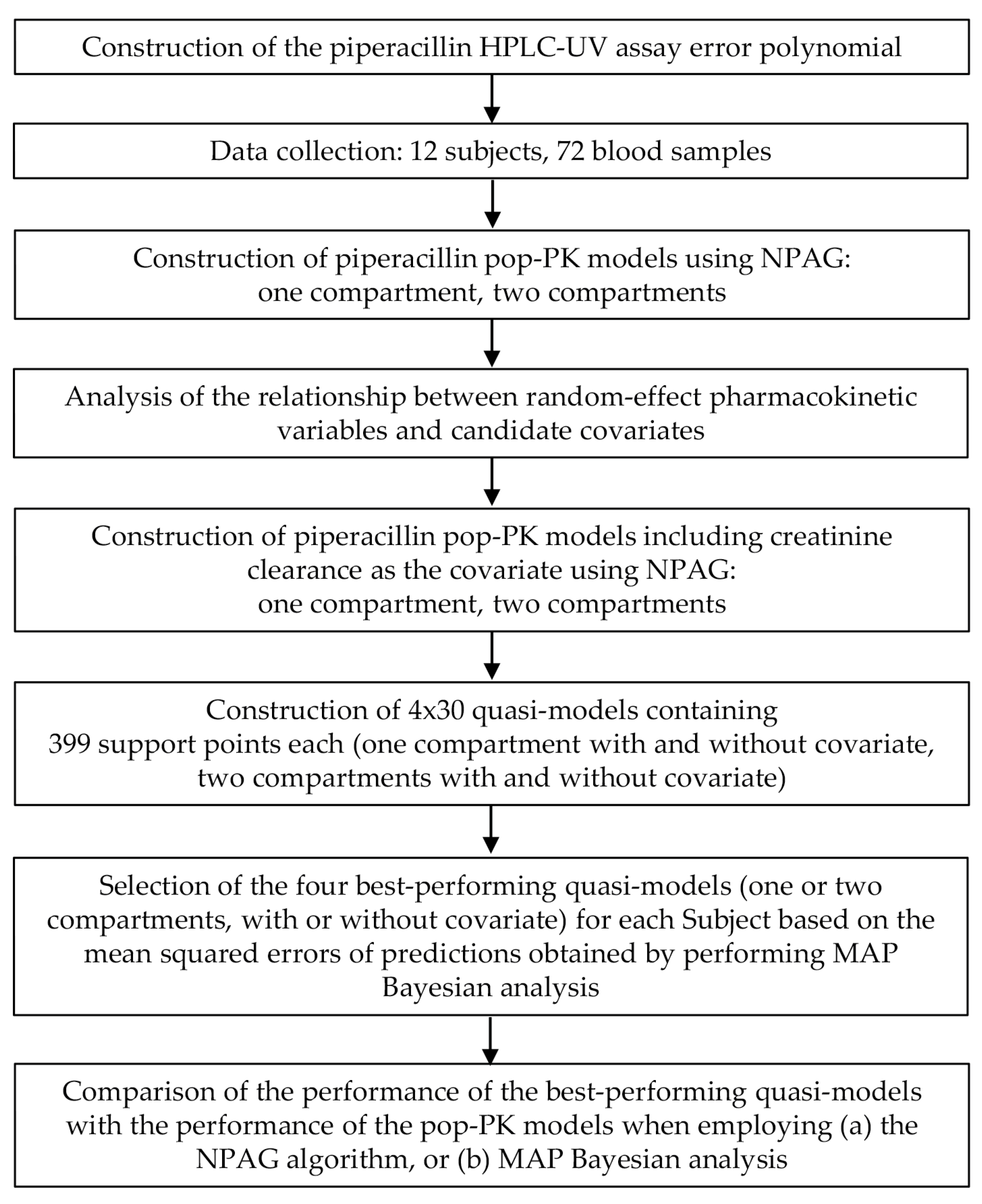
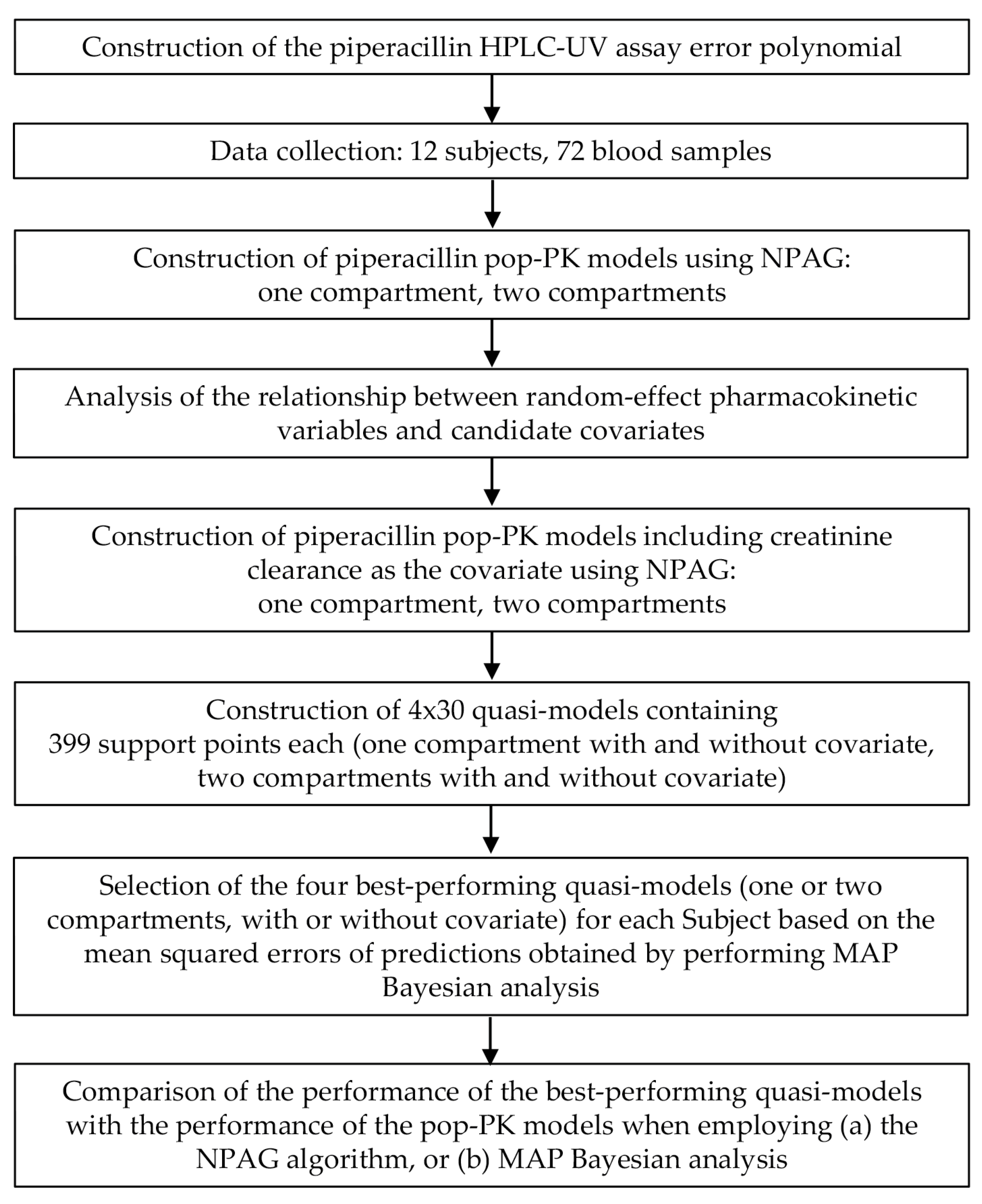
2. Materials and Methods
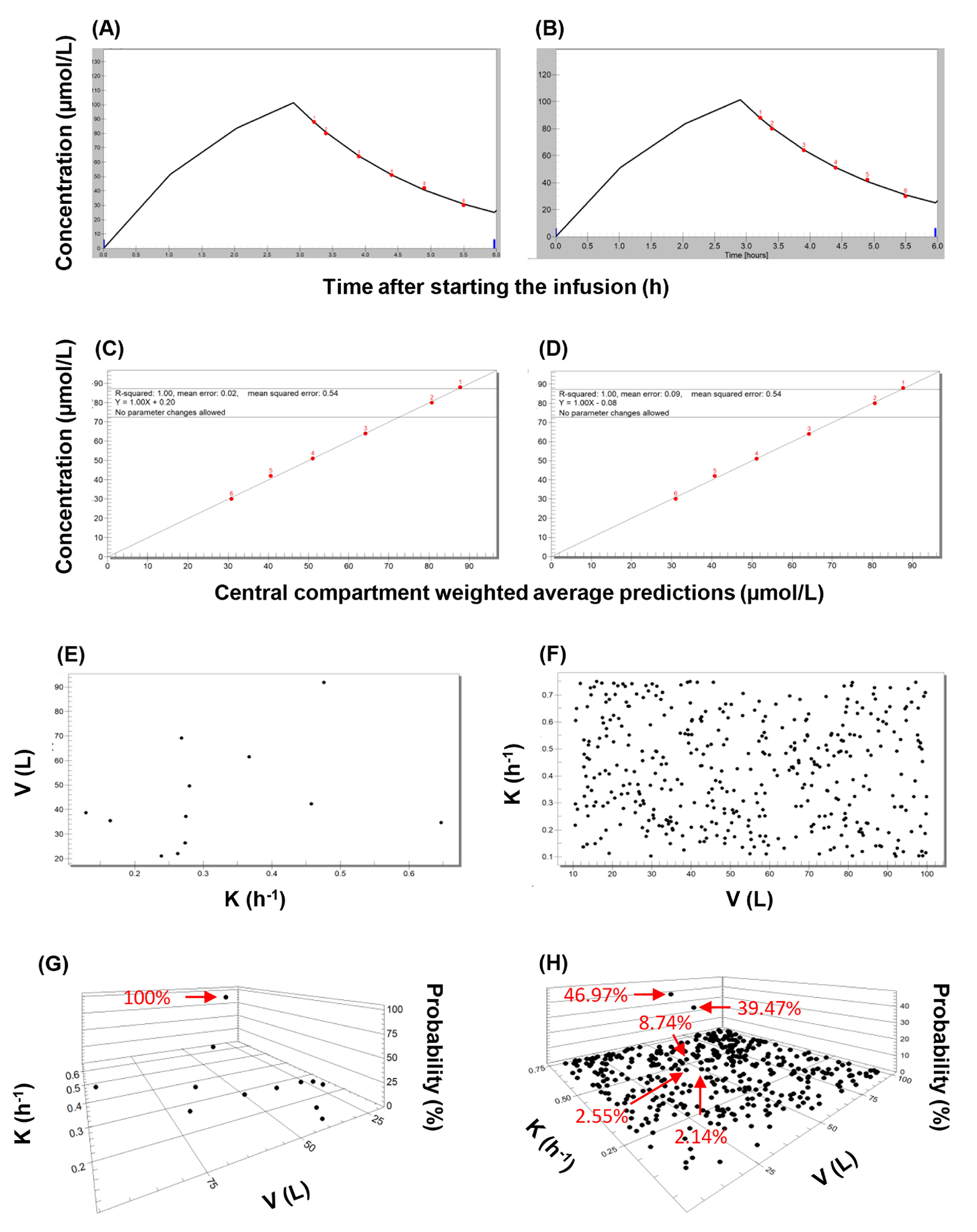
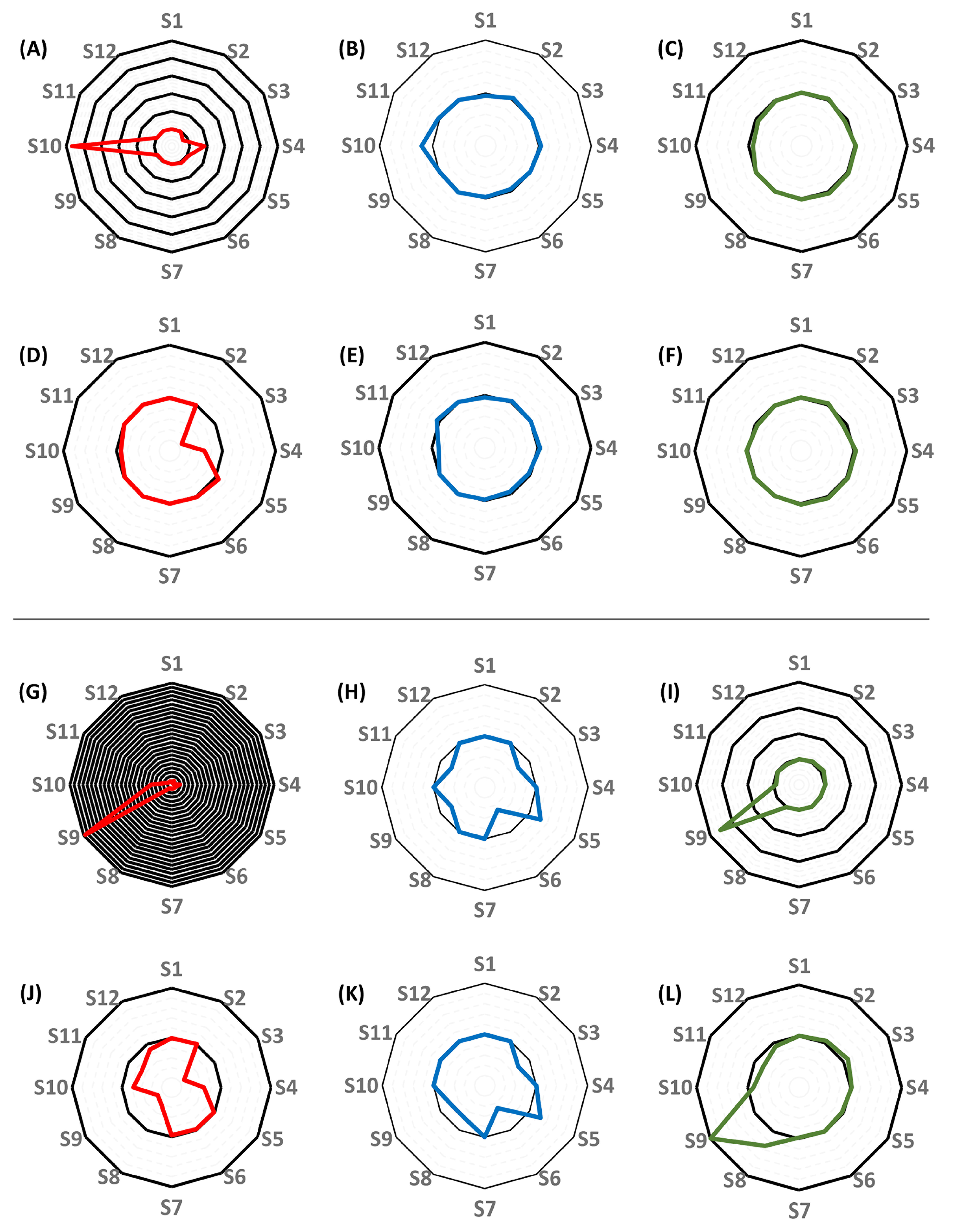
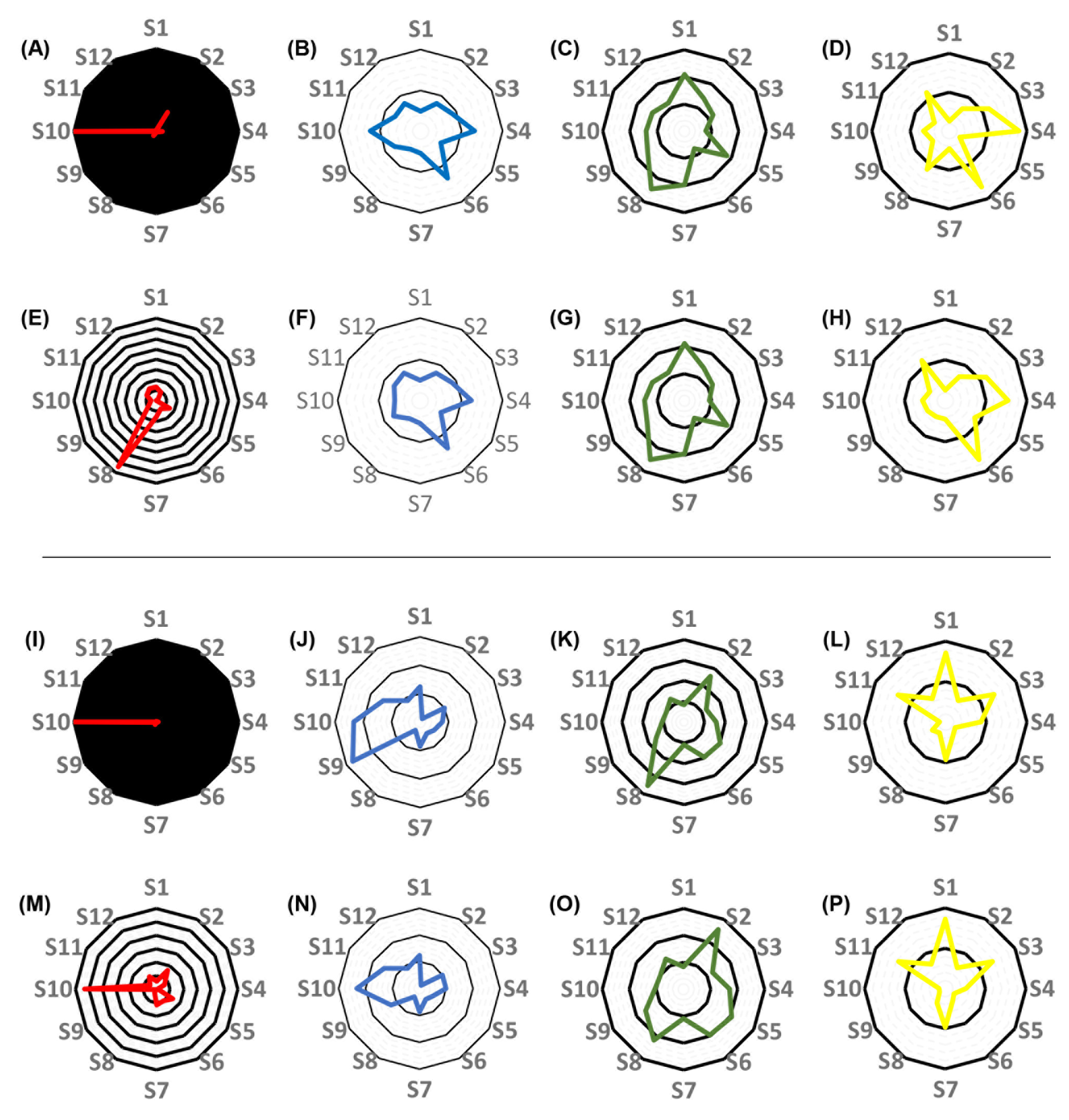
3. Results
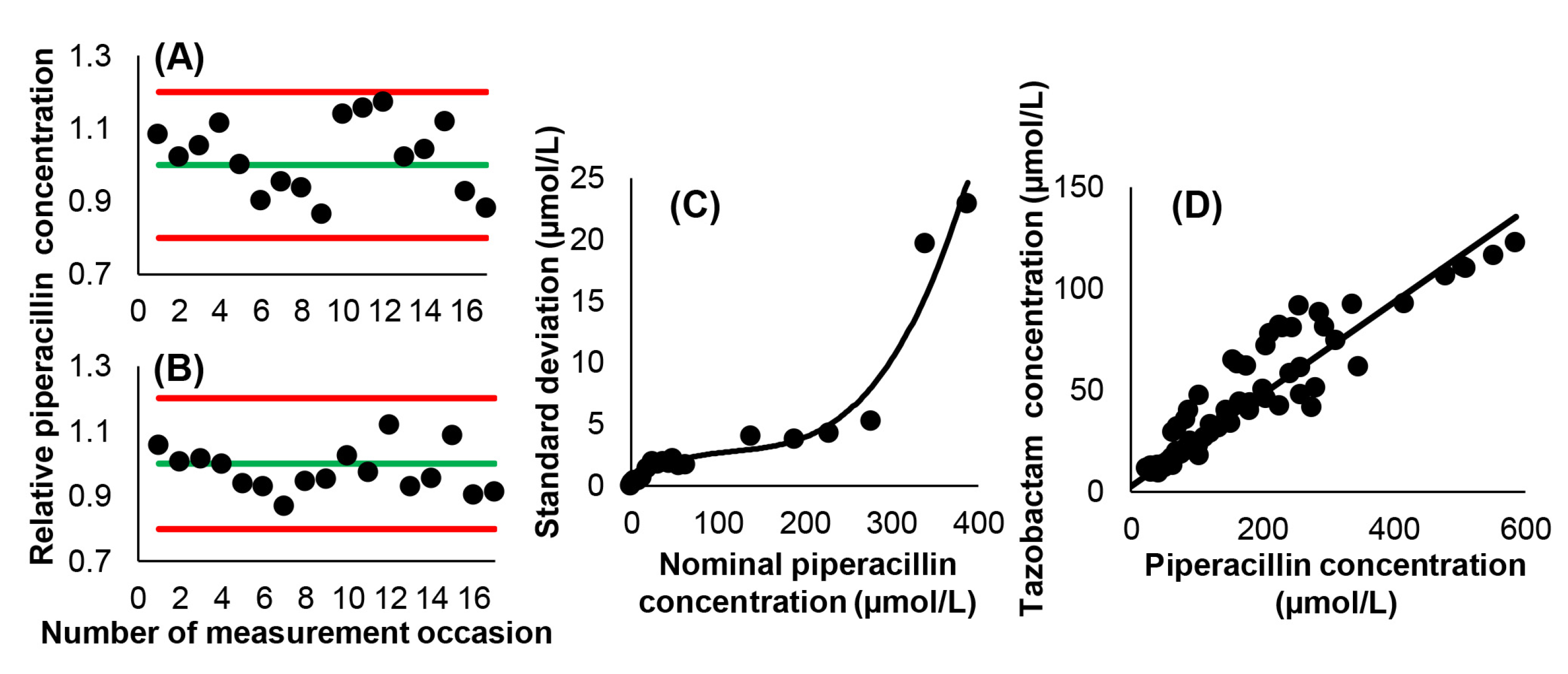
3.1. Analytical Considerations
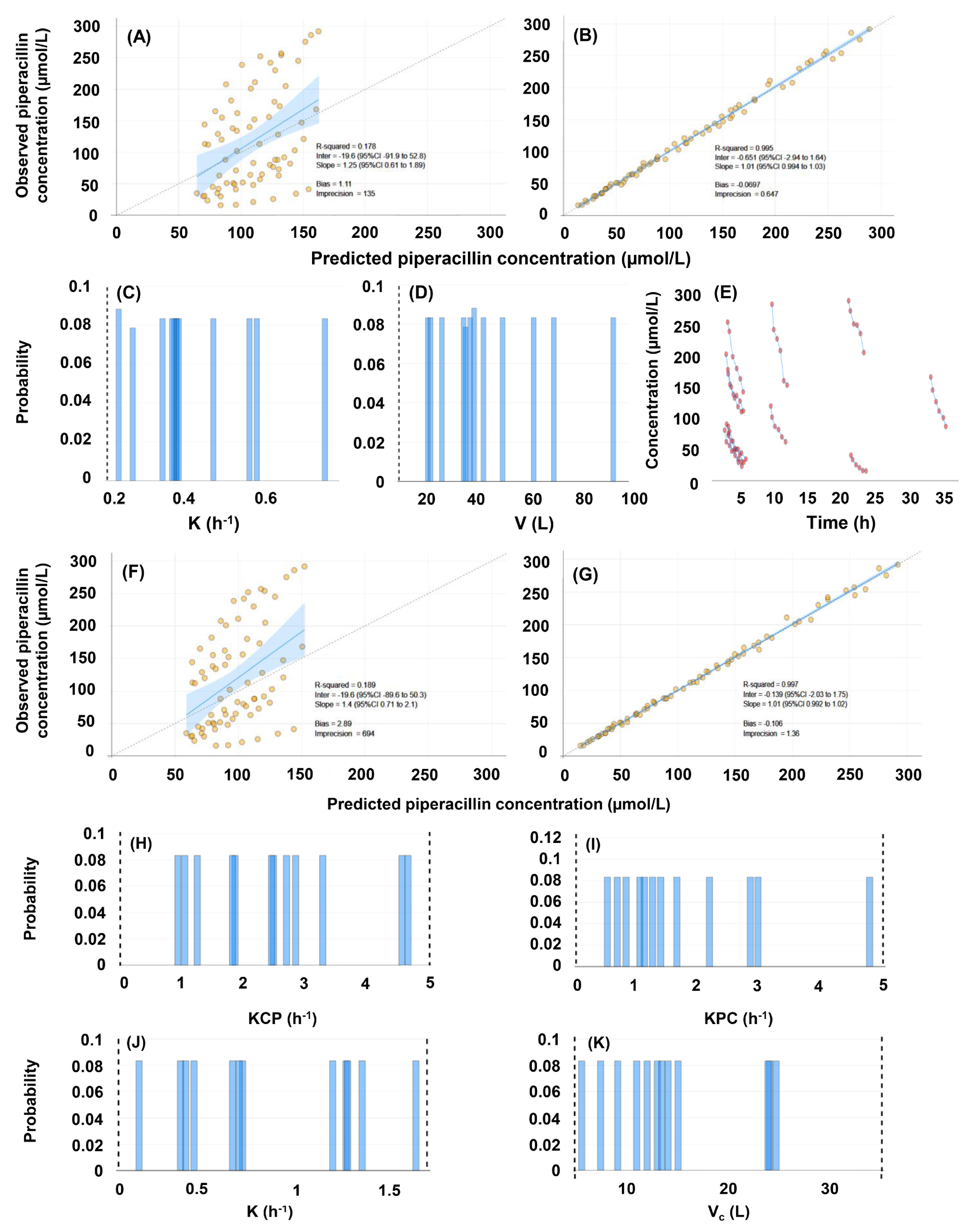
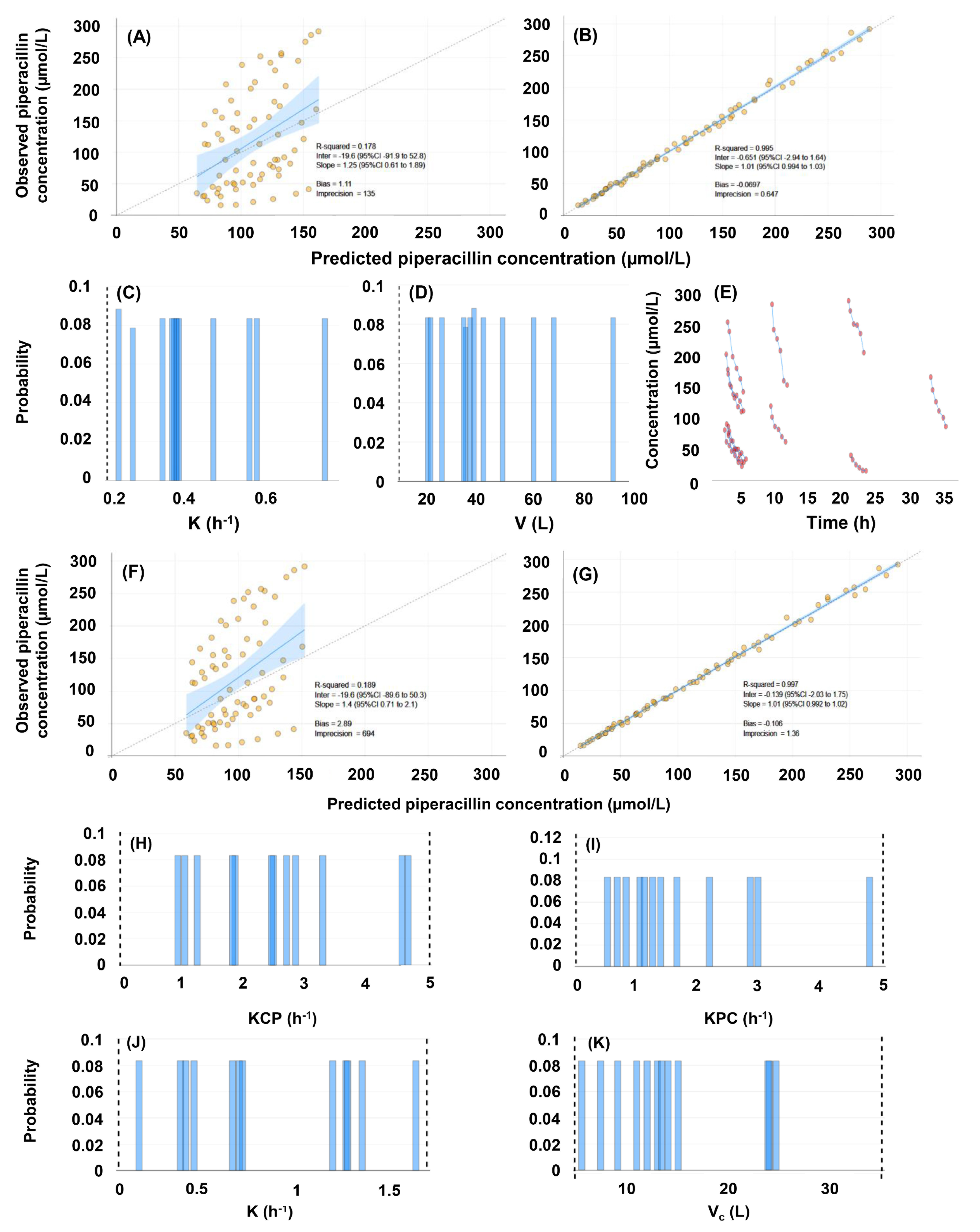
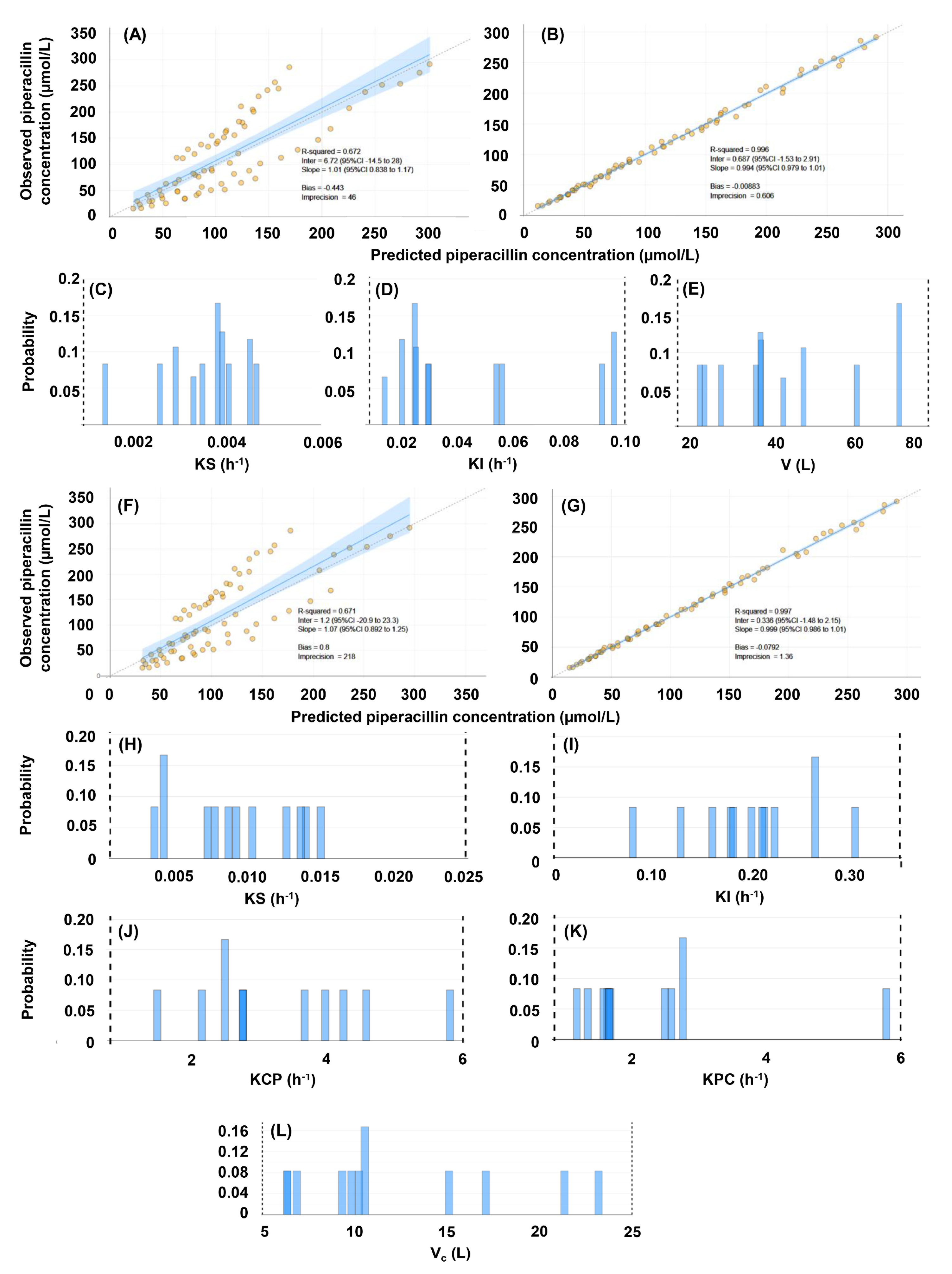
3.2. Population Pharmacokinetic Models
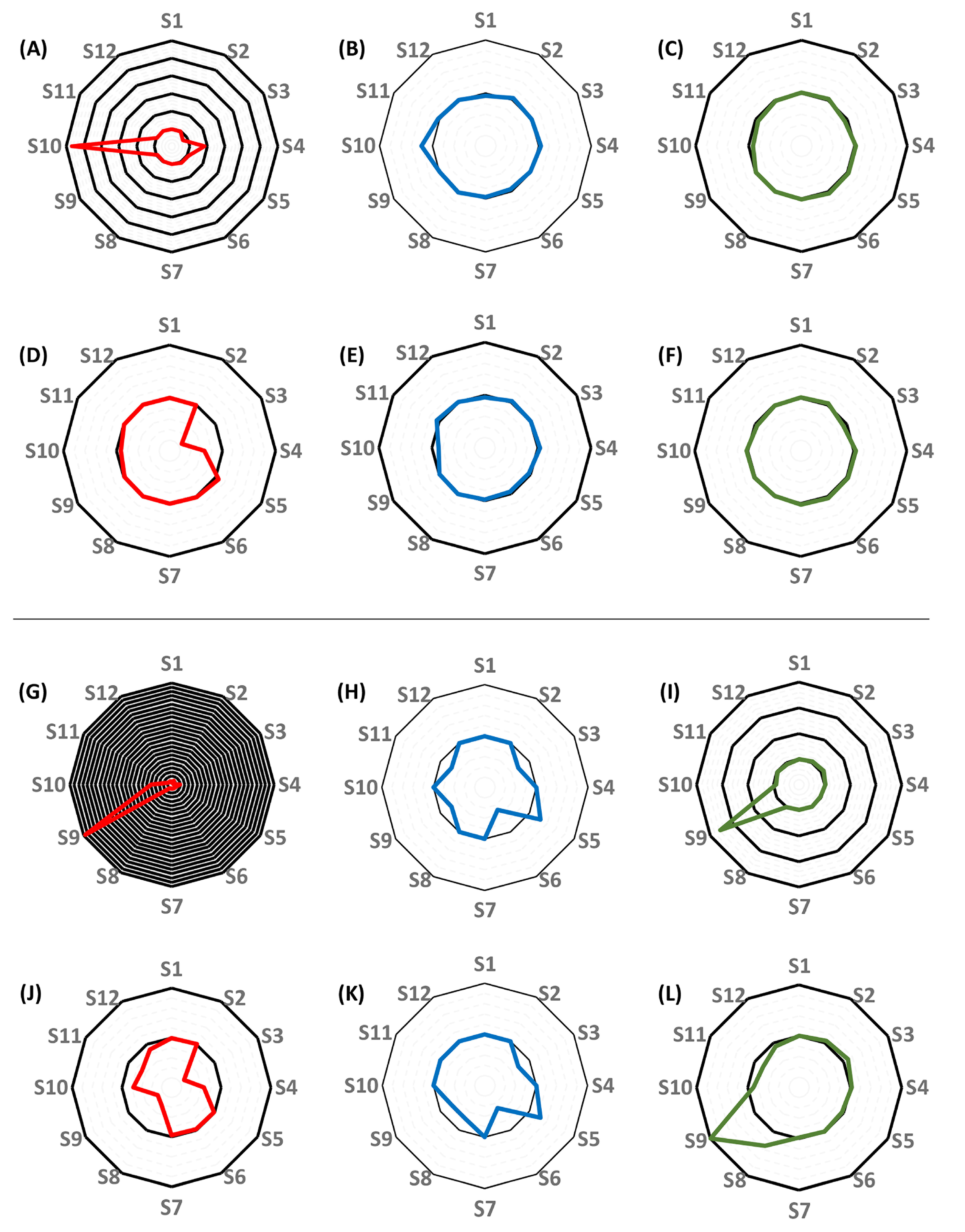
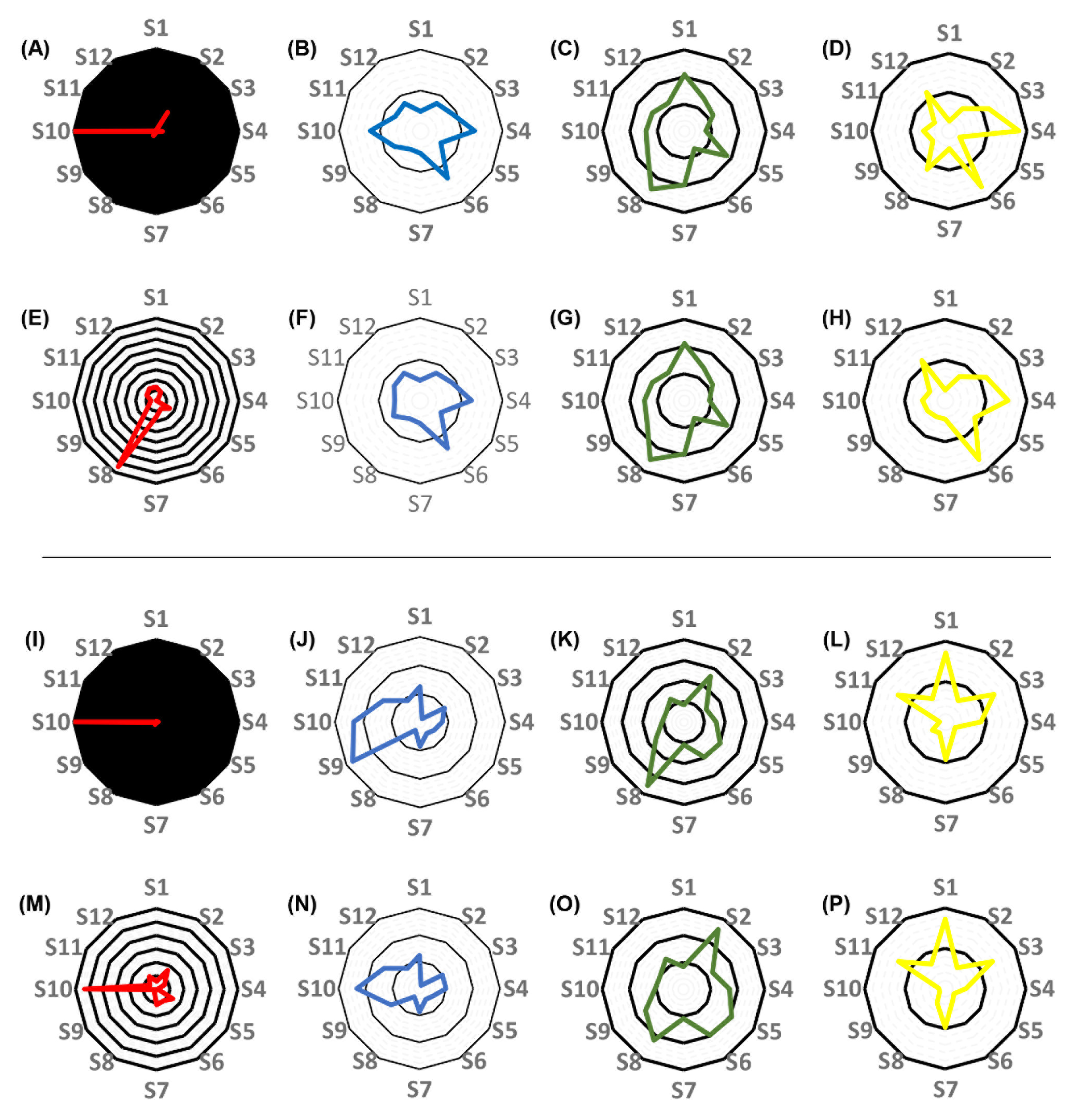
3.3. Individual Pharmacokinetic Models
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Darwich, A.S.; Polasek, T.M.; Aronson, J.K.; Ogungbenro, K.; Wright, D.F.; Achour, B.; Reny, J.-L.; Daali, Y.; Eiermann, B.; Cook, J.; et al. Model-informed precision dosing: Background, requirements, validation, implementation, and forward trajectory of individualizing drug therapy. Ann. Rec. Pharmacol. Toxicol. 2021, 61, 225–245. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Blanco, J.S.; Lanao, J.M. Model-informed precision dosing. Pharmaceutics 2022, 14, 2731. [Google Scholar] [CrossRef] [PubMed]
- Tyson, R.J.; Park, C.C.; Powell, J.R.; Patterson, J.H.; Weiner, D.; Watkins, P.B.; Gonzalez, D. Precision dosing priority criteria: Drug, disease, and patient population variables. Front. Pharmacol. 2020, 11, 420. [Google Scholar] [CrossRef] [PubMed]
- Wicha, S.G.; Märtson, A.-G.; Nielsen, E.I.; Koch, B.C.P.; Friberg, L.E.; Alffenaar, J.-W.; Minichmayr, I.K. From therapeutic drug monitoring to model-informed precision dsing for antibiotics. Clin. Pharm. Ther. 2021, 109, 928–941. [Google Scholar] [CrossRef] [PubMed]
- Evans, L.; Rhodes, A.; Alhazzani, W.; Antonelli, M.; Coopersmith, C.M.; French, C.; Machado, F.R.; McIntyre, L.; Ostermann, M.; Prescott, H.C.; et al. Surviving sepsis campaign: International guidelines for management of sepsis and septic shock 2021. Intensiv. Care Med 2021, 47, 1181–1247. [Google Scholar] [CrossRef] [PubMed]
- Visibelli, A.; Roncaglia, B.; Spiga, O.; Santucci, A. The impact of artificial intelligence in the Odyssey of rare diseases. Biomedicines 2023, 11, 887. [Google Scholar] [CrossRef]
- Damnjanovic, I.; Tsyplakova, N.; Stefanovic, N.; Tosic, T.; Catic-Dordevic, A.; Karalis, V. Joint use of population pharmacokinetics and machine learning for optimizing antiepileptic treatment in paediatric population. Ther. Adv. Drug Saf. 2023, 14, 20420986231181336. [Google Scholar] [CrossRef]
- Mao, J.; Chen, Y.; Xu, L.; Chen, W.; Chen, B.; Fang, Z.; Qin, W.; Zhong, M. Applying machine learning to the pharmacokinetic modeling of cyclosporine in adult renal transplant recipients: A multi-method comparison. Front. Pharmacol. 2022, 13, 1016399. [Google Scholar] [CrossRef]
- Verhaeghe, J.; Dhaese, S.A.M.; De Corte, T.; Mijnsbrugge, D.V.; Aardema, H.; Zijlstra, J.G.; Verstraete, A.G.; Stove, V.; Colin, P.; Ongenae, F.; et al. Development and evaluation of uncertainty quantifying machine learning models to predict piperacillin plasma concentrations in critically ill patients. BMC Med. Inform. Decis. Mak. 2022, 22, 224. [Google Scholar] [CrossRef]
- Poweleit, E.A.; Vinks, A.A.; Mizuno, T. Artificial intelligence and machine learning approaches to facilitate therapeutic drug management and model-informed precision dosing. Ther. Drug Monit. 2023, 45, 143–150. [Google Scholar] [CrossRef] [PubMed]
- Leary, R.; Jelliffe, R.; Schumitzky, A.; Van Guilder, M. An adaptive grid non-parametric approach to pharmacokinetic and dynamic (PK/PD) population models. In Proceedings of the 14th IEEE Symposium on Computer-Based Medical Systems. CBMS 2001, Bethesda, MD, USA, 26–27 July 2001; pp. 389–394. [Google Scholar]
- Neely, M.; van Guilder, M.; Yamada, W.; Schumitzky, A.; Jelliffe, R. Accurate detection of outliers and subpopulations with Pmetrics, a non-parametric and parametric pharmacometrics modeling and simulation package for R. Ther. Drug Monit. 2012, 34, 467–476. [Google Scholar] [CrossRef]
- Tatarinova, T.; Neely, M.; Bartroff, J.; van Guilder, M.; Yamada, W.; Bayard, D.; Jelliffe, R.; Leary, R.; Chubatiuk, A.; Schumitzky, A. Two general methods for population pharmacokinetic modeling: Non-parametric adaptive grid and non-parametric Bayesian. J. Pharmacokinet. Pharmacodyn. 2013, 40, 189–199. [Google Scholar] [CrossRef]
- Jelliffe, R. Using the BestDose clinical software—Examples with aminoglycosides. In Individualized Drug Therapy for Patients. Basic Foundations, Relevant Software, and Clinical Applications; Jelliffe, R.W., Neely, M., Eds.; Elsevier: Amsterdam, The Netherlands, 2016; pp. 59–75. [Google Scholar]
- de Velde, F.; de Winter, B.C.M.; Neely, M.N.; Strojil, J.; Yamada, W.M.; Harbarth, S.; Huttner, A.; van Gelder, T.; Koch, B.C.P.; Miller, A.E. Parametric and nonparametric population pharmacokinetic models to assess probability of target attainment of imipenem concentrations in critically ill patients. Pharmaceutics 2021, 13, 2170. [Google Scholar] [CrossRef] [PubMed]
- Vincze, I.; Czermann, R.; Nagy, Z.; Kovács, M.; Neely, M.N.; Farkas, R.; Kocsis, I.; Karvaly, G.B.; Kopitkó, C. Assessment of antibiotic pharmacokinetics, molecular biomarkers and clinical status in critically ill adults diagnosed with community-acquired pneumonia and receiving intravenous piperacillin/tazobactam and hydrocortisone over the first five days of intensive care: And observational study (STROBE compliant). J. Clin. Med. 2022, 11, 4140. [Google Scholar] [PubMed]
- Wallenburg, E.; ter Heine, R.; Schouten, J.A.; Raaijmakers, J.; ten Oever, J.; Kolwijck, E.; Burger, D.M.; Pickkers, P.; Frenzel, T.; Brüggemann, R.J.M. An integral pharmacokinetic analysis of piperacillin and tazobactam in plasma and urine in critically ill patients. Clin. Pharmacokinet. 2022, 61, 907–918. [Google Scholar] [CrossRef] [PubMed]
- Jelliffe, R.W.; Tahani, B. Pharmacoinformatics: Equations for serum drug assay error patterns; implications for therapeutic drug monitoring and dosage. Proc. Annu. Symp. Comput. Appl. Med. Care 1993, 517–521. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 5 December 2023).
- Jelliffe, R. Estimation of creatinine clearance in patients with unstable renal function, without a urine specimen. Am. J. Nephrol. 2002, 22, 320–324. [Google Scholar] [CrossRef] [PubMed]
- Jelliffe, R.W.; Iglesias, T.; Hurst, A.K.; Foo, K.A.; Rodriguez, J. Individualising gentamicin dosage regimens. A comparative review of selected models, data fitting methods and monitoring strategies. Clin. Pharmacokinet. 1991, 21, 461–478. [Google Scholar] [CrossRef]
- Alobaid, A.S.; Wallis, S.C.; Jarret, P.; Starr, T.; Stuart, J.; Lassig-Smith, M.; Mejia, J.L.O.; Roberts, M.S.; Roger, C.; Udy, A.A.; et al. Population pharmacokinetics of piperacillin in nonobese, obese, and morbidly obese critically ill patients. Antimicrob. Agents Chemother. 2017, 61, e01276-16. [Google Scholar] [CrossRef] [PubMed]
- Hemmersbach-Miller, M.; Balevic, S.J.; Winokur, P. Population pharmacokinetics of piperacillin/tazobactam across the adult lifespan. Clin. Pharmacokinet. 2023, 62, 127–139. [Google Scholar] [CrossRef]
- Greppmair, S.; Brinkmann, A.; Roehr, A.; Frey, O.; Hagel, S.; Dorn, C.; Marsot, A.; El-Haffaf, I.; Zoller, M.; Saller, T.; et al. Towards model-informed precision dosing of piperacillin: Multicenter systematic external evaluation of pharmacokinetic models in critically ill adults with a focus on Bayesian forecasting. Intensive Care Med. 2023, 49, 966–976. [Google Scholar] [CrossRef]
- Hoffert, Y.; Vanleberghe, B.T.K.; Kuypers, D.; Vos, R.; Vanuytsel, T.; Verbeek, J.; Dreesen, E. An Automated Multi-Model Selection Algorithm to Improve Precision Dosing of Tacrolimus in Liver, Lung, and Bowel Transplant Recipients; PAGE Meeting: A Coruna, Spain, 2023. [Google Scholar]
- Destere, A.; Marquet, P.; Gandonniere, C.S.; Asberg, A.; Loustaud-Ratti, V.; Carrier, P.; Ehrmann, S.; Barin-Le Guellec, C.; Premaud, A.; Woillard, J.-B. A hybrid model associating population pharmacokinetics with machine learning: A case study with iohexol clearance estimation. Clin. Pharmacokinet. 2022, 61, 1157–1165. [Google Scholar] [CrossRef]
- Destere, A.; Marquet, P.; Labriffe, M.; Drici, M.-D.; Woillard, J.-B. A hybrid algorithm combining population pharmacokinetic and machine learning for isavuconazole exposure prediction. Pharm. Res. 2023, 40, 951–959. [Google Scholar] [CrossRef]
- Keutzer, L.; You, H.; Farnoud, A.; Nyberg, J.; Wicha, S.G.; Maher-Edwards, G.; Vlasakakis, G.; Moghaddam, G.K.; Svensson, E.M.; Menden, M.P.; et al. Machine learning and pharmacometrics for prediction of pharmacokinetic data: Differences, similarities and challenges illustrated with rifampicin. Pharmaceutics 2022, 14, 1530. [Google Scholar] [CrossRef]
- Jelliffe, R.; Schumitzky, A.; Bayard, D.; Neely, M. Monitoring the patient: Four different Bayesian methods to make individual patient drug models. In Individualized Drug Therapy for Patients. Basic Foundations, Relevant Software, and Clinical Applications; Jelliffe, R.W., Neely, M., Eds.; Elsevier: Amsterdam, The Netherlands, 2016; pp. 77–90. [Google Scholar]
- Sherwin, C.M.T.; Kiang, T.K.L.; Spigarelli, M.G.; Ensom, M.H.H. Fundamentals of population pharmacokinetic modelling. Validation methods. Clin. Pharmacokinet. 2012, 51, 573–590. [Google Scholar] [CrossRef]
- De Rosa, S.; Greco, M.; Rauseo, M.; Annetta, M.G. The good, the bad, and the serum creatinine: Exploring the effect of muscle mass and nutrition. Blood Purif. 2023, 52, 775–785. [Google Scholar] [CrossRef]
- Ostermann, M.; Joannidis, M. Acute kidney injury 2016: Diagnosis and diagnostic workup. Crit Care 2016, 20, 299. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.-Y.; Bansal, N. Measured GFR as “Gold Standard”—All that glitters is not gold? Clin. J. Am. Soc. Nephrol. 2011, 6, 1813–1814. [Google Scholar] [CrossRef] [PubMed]
- Speeckaert, M.M.; Seegmiller, J.; Glorieux, G.; Lameire, N.; Van Biesen, W.; Vanholder, R.; Delanghe, J.R. Measured glomerular filtration rate: The query for a workable golden standard technique. J. Pers. Med. 2021, 11, 949. [Google Scholar] [CrossRef] [PubMed]
- Jelliffe, R.; Liu, J.; Drusano, G.L.; Martinez, M.N. Individualized patient care through model-informed precision dosing: Reflections on training futire practitioners. AAPS J. 2022, 24, 117. [Google Scholar] [CrossRef]
- Jelliffe, R.W.; Schumitzky, A.; Bayard, D.; Fu, X.; Neely, M.N. Describing assay precision—Reciprocal of variance is correct, not CV percent: Its use should significantly improve laboratory performance. Ther. Drug Monit. 2015, 37, 389–394. [Google Scholar] [CrossRef] [PubMed]
- Karvaly, G.B.; Neely, M.N.; Kovács, K.; Vincze, I.; Vásárhelyi, B.; Jelliffe, R.W. Development of a methodology to make individual estimates of the precision of liquid chromatography-tandem mass spectrometry drug assay results for use in population pharmacokinetic modeling and the optimization of dosage regimens. PLoS ONE 2020, 15, e0229873. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Value |
|---|---|
| Number of subjects | 12 |
| Age (years) | 69.7 (45.3–86.4) |
| Male gender (%) | 58 |
| APACHE II score on admission to ICU (no unit) | 25 (19–37) |
| CURB-65 mortality score on admission to ICU (no unit) | 6.8 (2.7–27.8) |
| SAPS-E mortality score on admission to ICU (no unit) | 42.3 (7.9–59.7) |
| SOFA mortality score on admission to ICU (no unit) | 33.3 (33.3–50.0) |
| Body mass index on admission to ICU (kg/m2) | 29.6 (24.2–51.9) |
| Mean arterial pressure (mm Hg) | 73.7 (56.7–120.7) |
| Serum creatinine (µmol/L) | 98 (34–224) |
| Sodium (mmol/L) | 137 (135–144) |
| Potassium (mmol/L) | 4.4 (3.6–5.8) |
| Glucose (mmol/L) | 9.1 (5.6–13.7) |
| Urea (mmol/L) | 11.1 (2.6–41.8) |
| Total bilirubin (µmol/L) | 15.9 (5.5–82.3) |
| Procalcitonin (µg/L) | 0.5 (0.0–126.6) |
| C-reactive protein (mg/L) | 129.4 (7.5–546.8) |
| White blood cell count (×109/L) | 17.0 (9.0–31.1) |
| Thrombocyte count (×103/L) | 274 (86–714) |
| Serum lactate (mmol/L) | 1.8 (1.1–3.0) |
| Base excess (mEq/L) | 5.0 (−8.4–13.7) |
| Hematocrit (L/L) | 0.4 (0.3–0.7) |
| Interleukin-6 (ng/L) | 32.0 (4.8–3629.0) |
| Pharmacokinetically relevant drugs administered on the day of blood sample collection (% of subjects): | |
| Dexmedetomidine | 8.3 |
| Alprazolam | 16.6 |
| Methylprednisolone | 25.0 |
| Ibuprofen | 8.3 |
| Fentanyl | 8.3 |
| Norepinephrine | 66.7 |
| Model No. | Compart-ments | Cova-riate | #SP | Bias (p-Value of Difference from 0) | Impre-cision | −2 × LL | AIC | BIC | Shrinkage (%) |
|---|---|---|---|---|---|---|---|---|---|
| #1 | 1 | None | 12 | −0.0697 (0.6591) | 0.6465 | 478.8 | 485.2 | 491.6 | 0.030–0.012 |
| #2 | 2 | None | 12 | −0.1061 (0.8310) | 1.3578 | 423.5 | 434.4 | 444.8 | 0.000–0.002 |
| #3 | 1 | CRCL | 10 | −0.0088 (0.8637) | 0.6061 | 474.4 | 483.0 | 491.5 | 0.348–14.91 |
| #4 | 2 | CRCL | 11 | −0.0792 (0.6000) | 1.3616 | 422.4 | 435.7 | 448.1 | 0.000–0.006 |
| Models with No Covariate Included | |||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model No. | Compartments | K (1/h) | V (L) or Vc (L) | KCP (1/h) | KPC (1/h) | ||||||||||||||||||||||||||||||||||||
| #1 | 1 | 0.10–0.75 | 10–100 | ||||||||||||||||||||||||||||||||||||||
| #2 | 2 | 0.10–1.70 | 5–35 | 0.05–5.00 | 0.05–5.00 | ||||||||||||||||||||||||||||||||||||
| Models with Creatinine Clearance Included as a Covariate | |||||||||||||||||||||||||||||||||||||||||
| Model No. | Compartments | KS (1/h) | KI (1/h) | V (L) or Vc (L) | KCP (1/h) | KPC (1/h) | |||||||||||||||||||||||||||||||||||
| #3 | 1 | 0.001–0.006 | 0.005–0.100 | 15–80 | |||||||||||||||||||||||||||||||||||||
| #4 | 2 | 0.0005–0.0250 | 0.00–0.35 | 5–25 | 0.2–6.0 | 0.2–6.0 | |||||||||||||||||||||||||||||||||||
| Model | Comparator | Value Obtained for QM/Value Obtained for pop-PK Model, NPAG | Value Obtained for QM/Value Obtained for pop-PK Model, MAP Bayesian Analysis |
|---|---|---|---|
| #1 | MSE | 0.70–1.08 (Subject 4: 1.83, Subject 10: 5.67) | 0.27–1.07 |
| K | 0.95–1.21 | 0.88–1.05 | |
| V | 0.91–1.04 | 0.93–1.04 | |
| #2 | MSE | 0.09–111 | 0.01–1.60 (Subject 8: 7.40) |
| K | 0.49–1.33 | 0.49–1.33 | |
| Vc | 0.75–2.45 | 0.75–2.49 | |
| KCP/KPC | 0.27–1.80 | 0.27–1.66 | |
| #3 | MSE | 0.37–1.83 (Subject 9: 32.54, Subject 10: 4.89) | 0.29–1.01 |
| KS | 0.50–1.25 | 0.50–1.25 | |
| V | 0.89–1.10 (Subject 9: 3.55) | 0.81–1.32 (Subject 9: 1.99) | |
| #4 | MSE | 1.02–5.47 (Subject 10: 181) | 0.05–1.61 (Subject 10: 5.33) |
| KS | 0.14–2.75 | 0.14–2.33 | |
| Vc | 0.84–3.55 | 0.83–2.56 | |
| KCP/KPC | 0.15–1.70 | 0.15–1.72 |
| Mean Squared Errors of the Quasi-Models Showing Best Performance | ||||
|---|---|---|---|---|
| Number of Subject | One Compartment, No Covariate | One Compartment, CRCL Covariate | Two Compartments, No Covariate | Two Compartments, CRCL Covariate |
| 1 | 0.538 | 0.534 | 0.679 | 0.629 |
| 2 | 22.552 | 22.853 | 15.219 | 16.599 |
| 3 | 1.623 | 1.727 | 0.755 | 1.196 |
| 4 | 66.147 | 65.318 | 9.096 | 13.452 |
| 5 | 14.362 | 13.305 | 5.292 | 5.968 |
| 6 | 49.163 | 47.331 | 46.657 | 46.923 |
| 7 | 16.046 | 15.458 | 13.018 | 8.677 |
| 8 | 22.919 | 22.909 | 28.703 | 24.227 |
| 9 | 26.125 | 612.196 | 18.442 | 23.742 |
| 10 | 25.978 | 25.999 | 455.938 | 743.067 |
| 11 | 99.281 | 99.798 | 96.929 | 94.461 |
| 12 | 10.755 | 10.732 | 6.882 | 5.302 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karvaly, G.B.; Vincze, I.; Neely, M.N.; Zátroch, I.; Nagy, Z.; Kocsis, I.; Kopitkó, C. Modeling Pharmacokinetics in Individual Patients Using Therapeutic Drug Monitoring and Artificial Population Quasi-Models: A Study with Piperacillin. Pharmaceutics 2024, 16, 358. https://doi.org/10.3390/pharmaceutics16030358
Karvaly GB, Vincze I, Neely MN, Zátroch I, Nagy Z, Kocsis I, Kopitkó C. Modeling Pharmacokinetics in Individual Patients Using Therapeutic Drug Monitoring and Artificial Population Quasi-Models: A Study with Piperacillin. Pharmaceutics. 2024; 16(3):358. https://doi.org/10.3390/pharmaceutics16030358
Chicago/Turabian StyleKarvaly, Gellért Balázs, István Vincze, Michael Noel Neely, István Zátroch, Zsuzsanna Nagy, Ibolya Kocsis, and Csaba Kopitkó. 2024. "Modeling Pharmacokinetics in Individual Patients Using Therapeutic Drug Monitoring and Artificial Population Quasi-Models: A Study with Piperacillin" Pharmaceutics 16, no. 3: 358. https://doi.org/10.3390/pharmaceutics16030358
APA StyleKarvaly, G. B., Vincze, I., Neely, M. N., Zátroch, I., Nagy, Z., Kocsis, I., & Kopitkó, C. (2024). Modeling Pharmacokinetics in Individual Patients Using Therapeutic Drug Monitoring and Artificial Population Quasi-Models: A Study with Piperacillin. Pharmaceutics, 16(3), 358. https://doi.org/10.3390/pharmaceutics16030358