

Machine Learning for Exposure-Response Analysis: Methodological Considerations and Confirmation of Their Importance via Computational Experimentations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
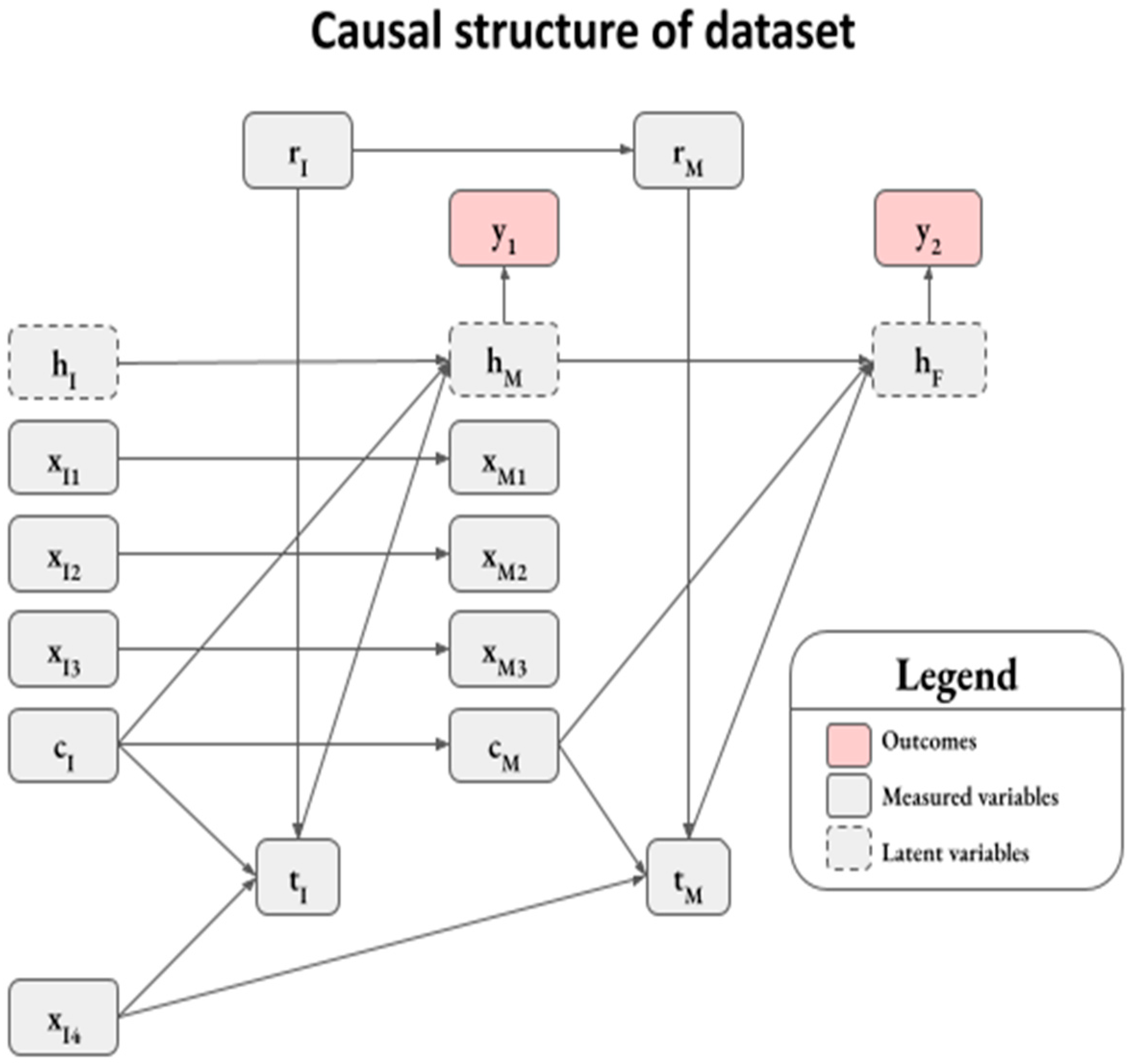
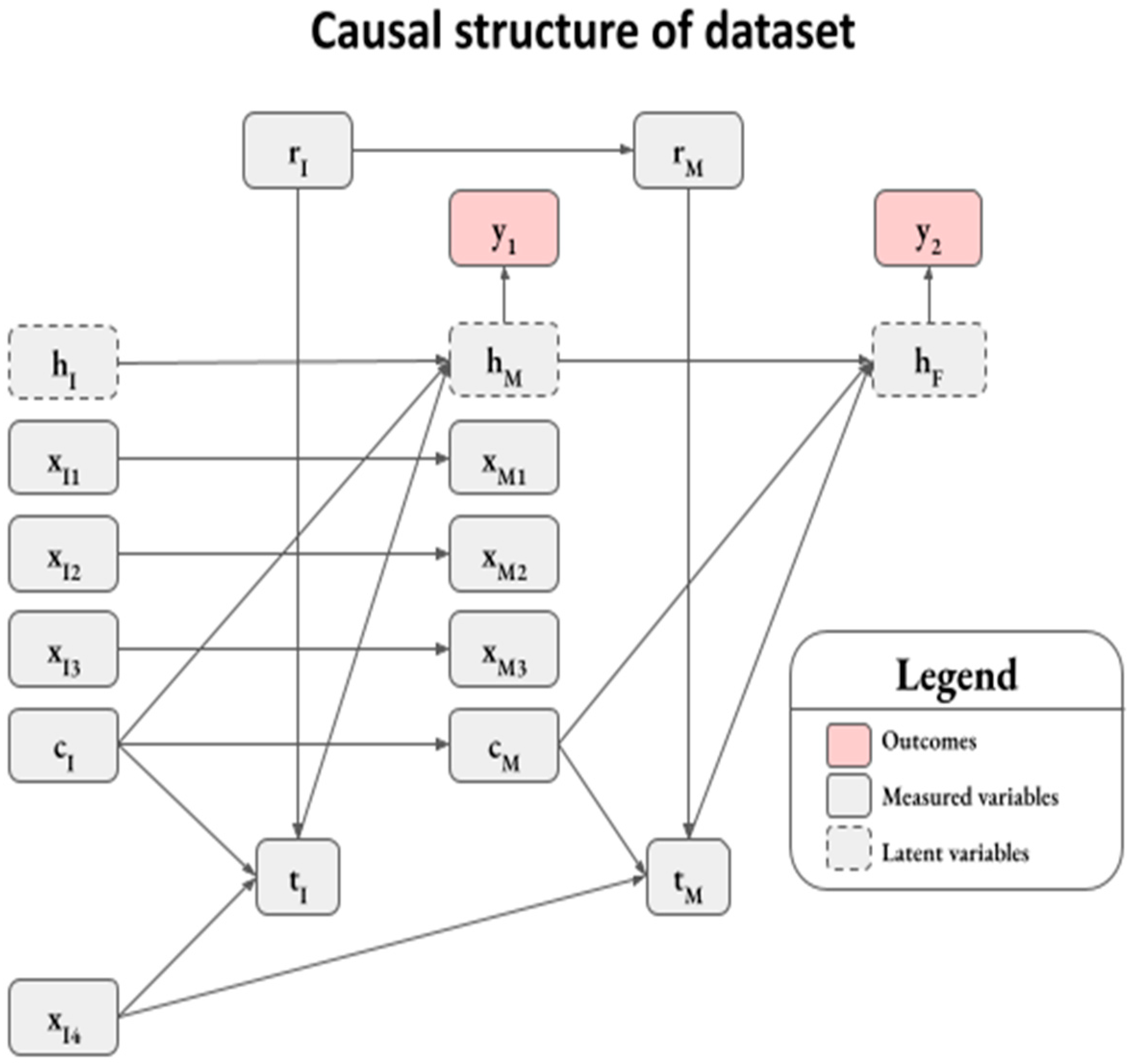
2.1. Synthetic Dataset
2.2. Machine Learning
2.3. SHAP Analysis
2.4. Ground Truth Marginal Effects
3. Results
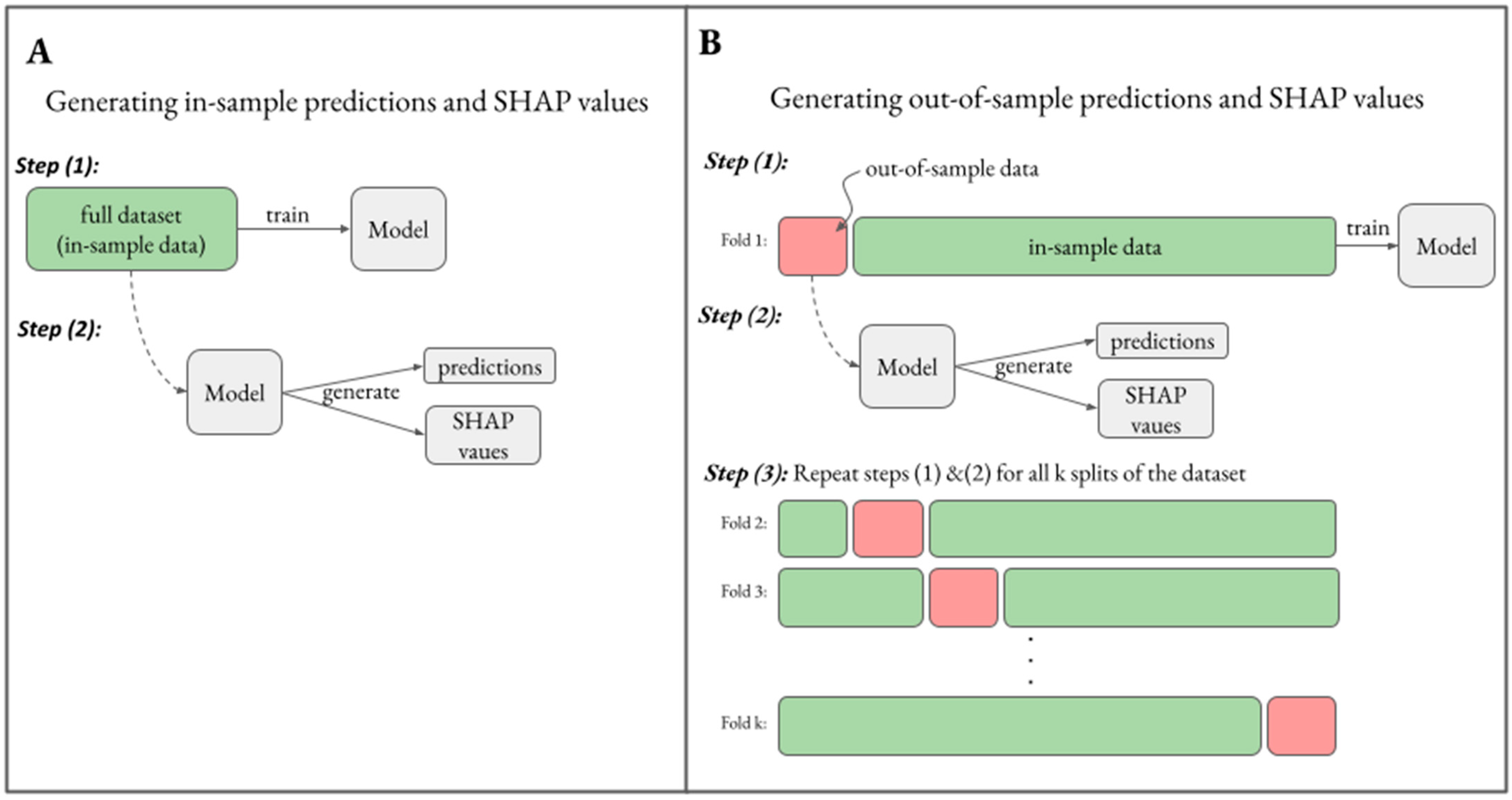
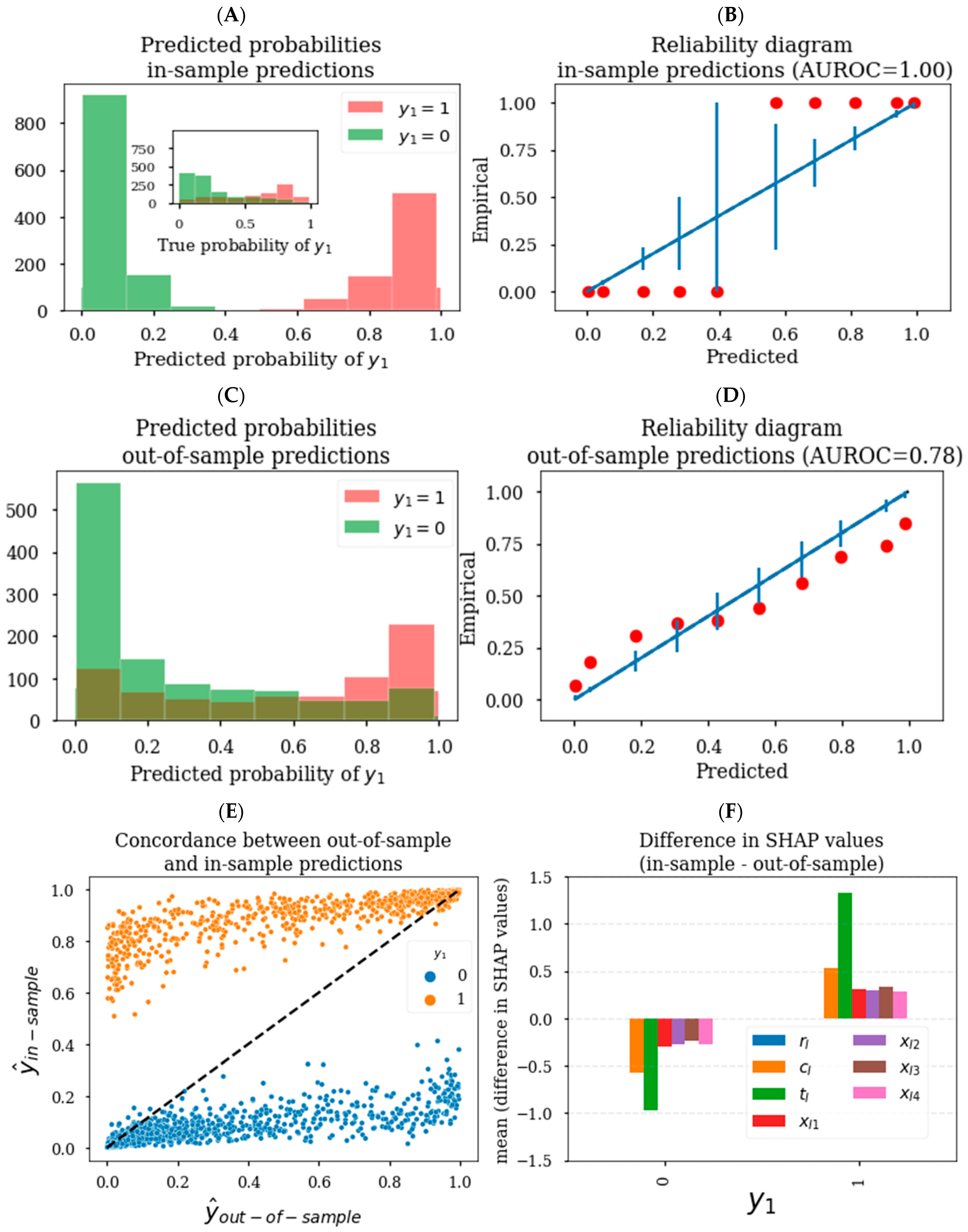
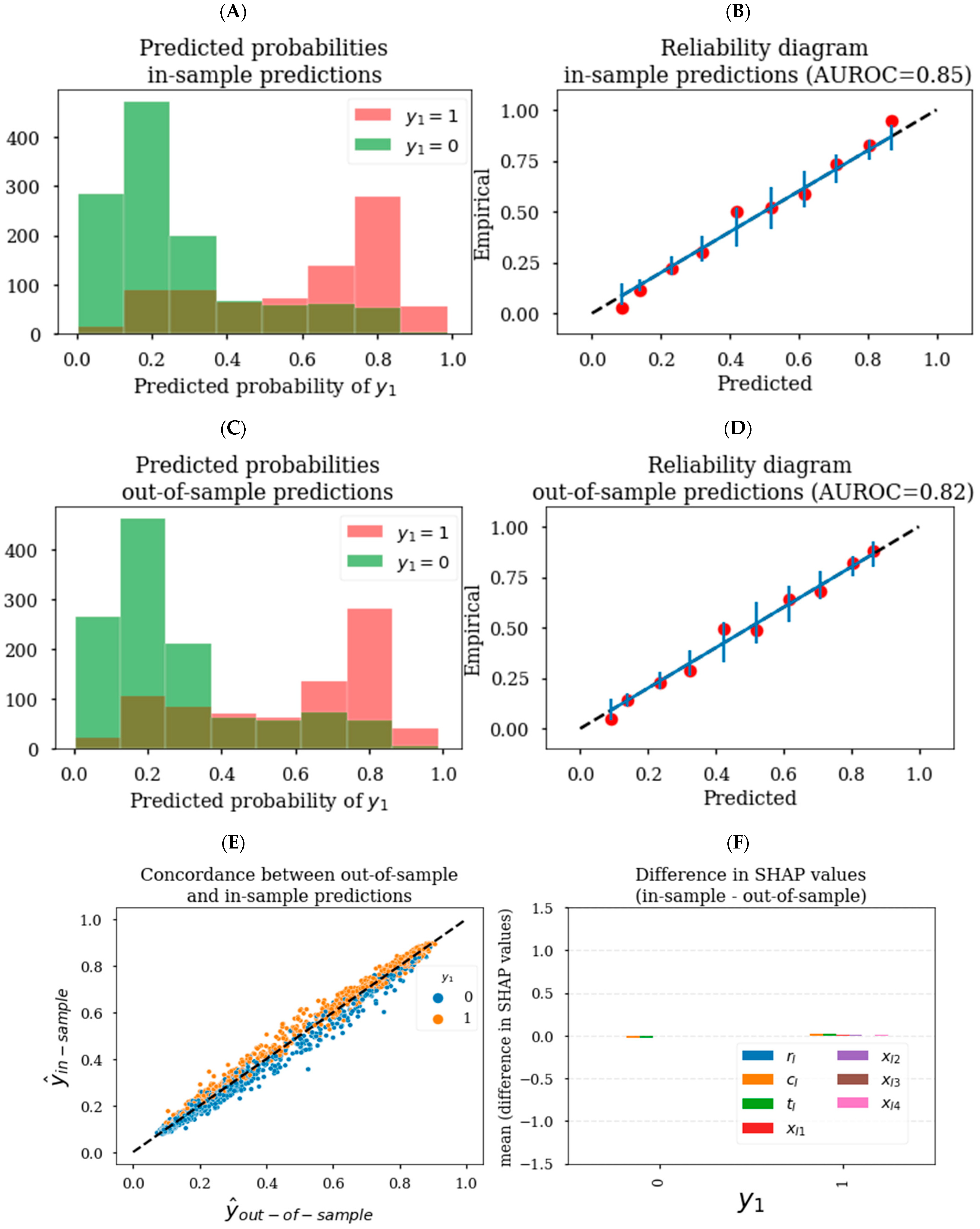
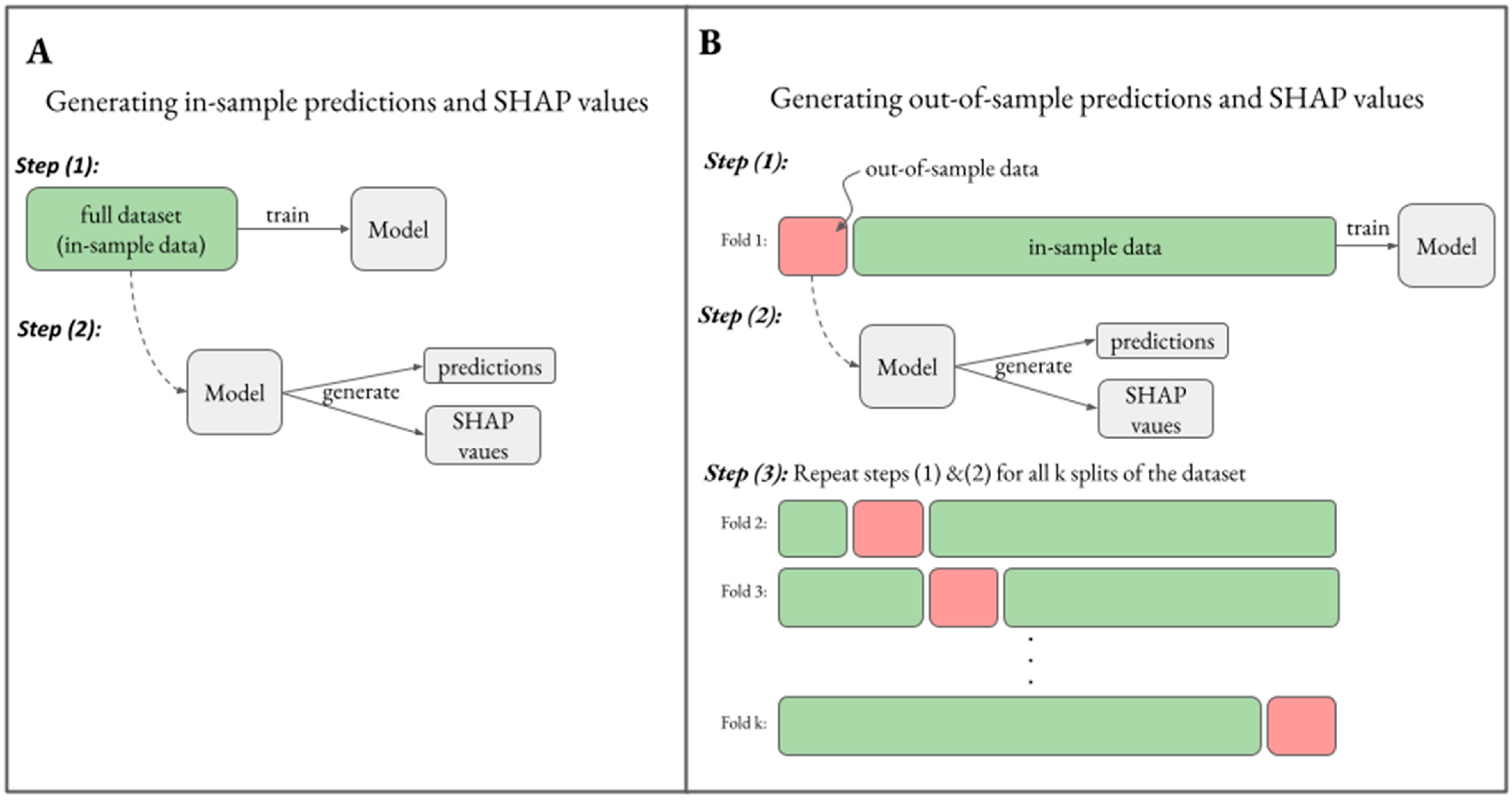
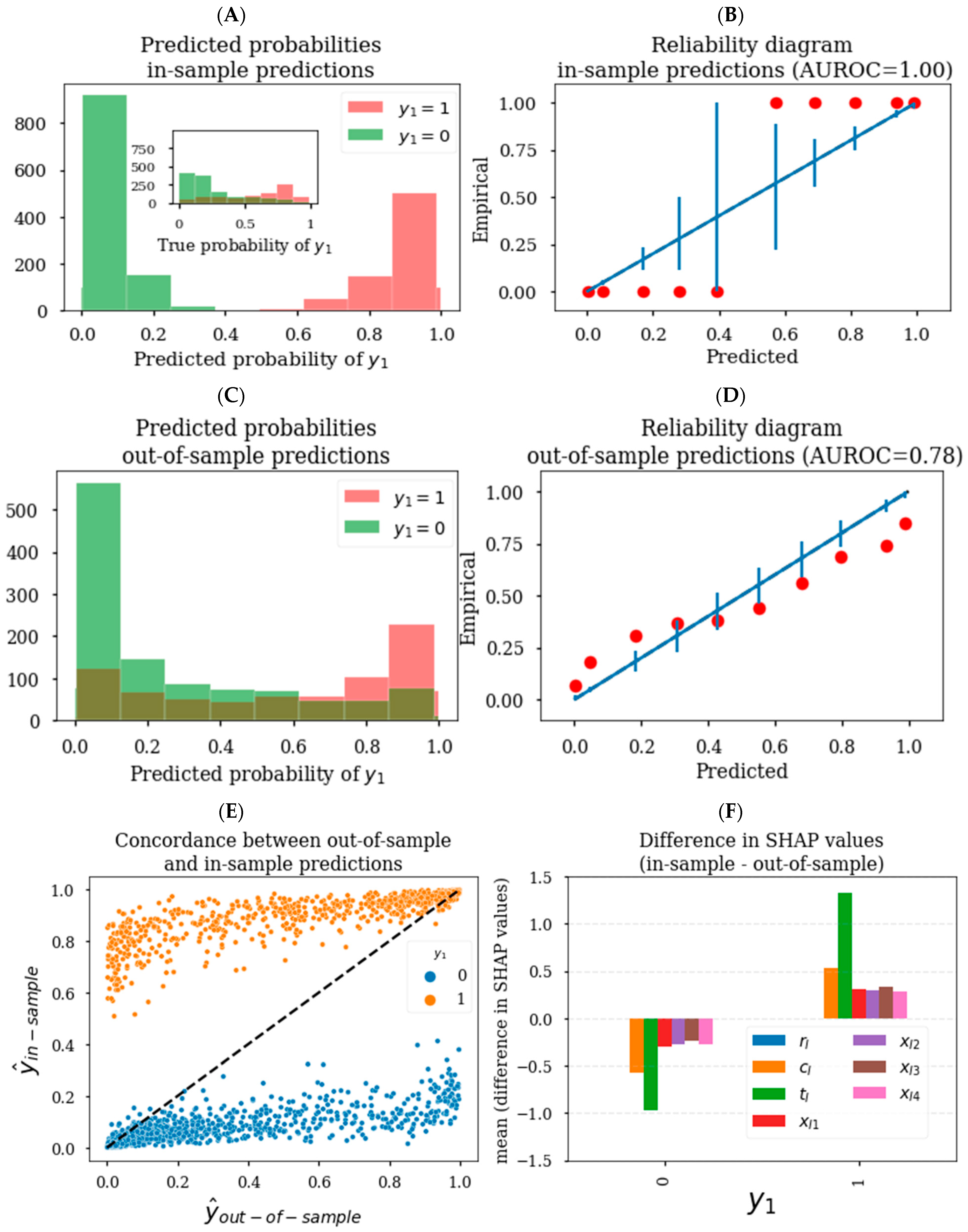
3.1. Generating Unbiased Predictions and SHAP Values
3.2. Generating Reliable Predictions and SHAP Values
3.3. Selection of Explanatory Variables for ML-Based E-R Analysis
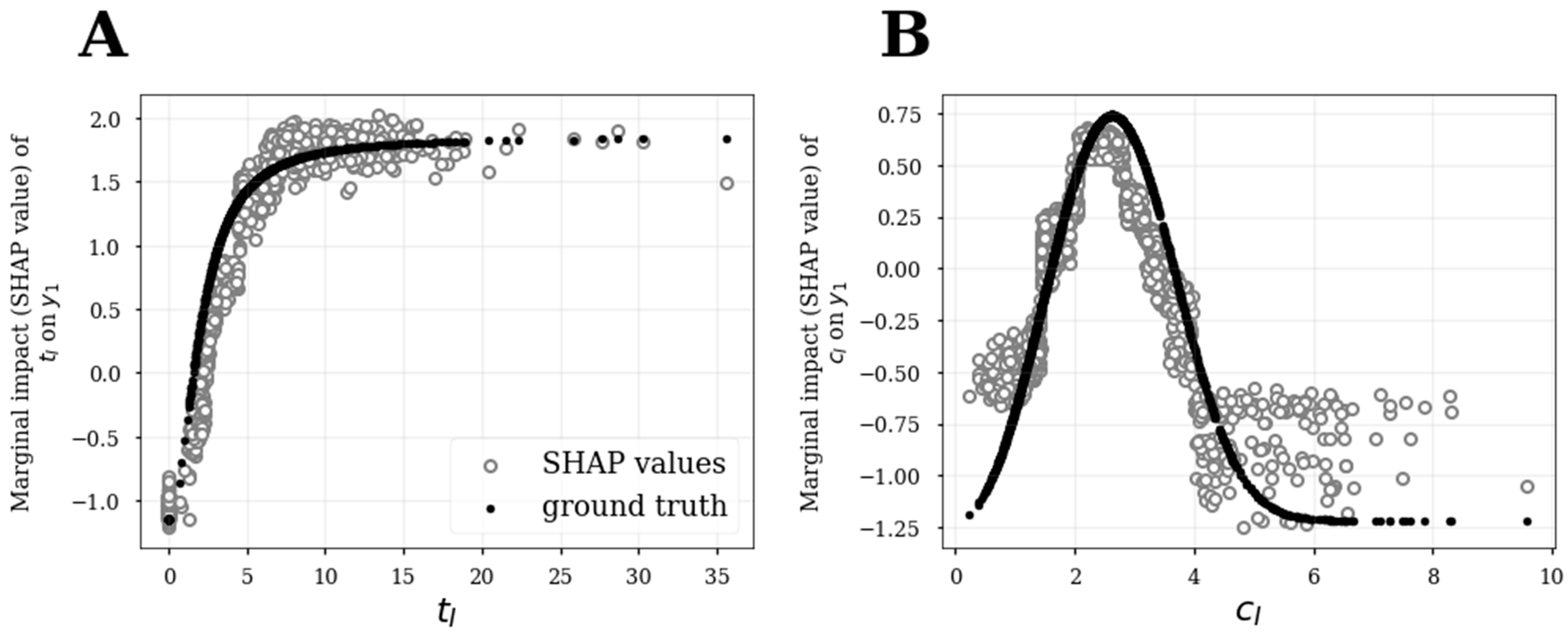
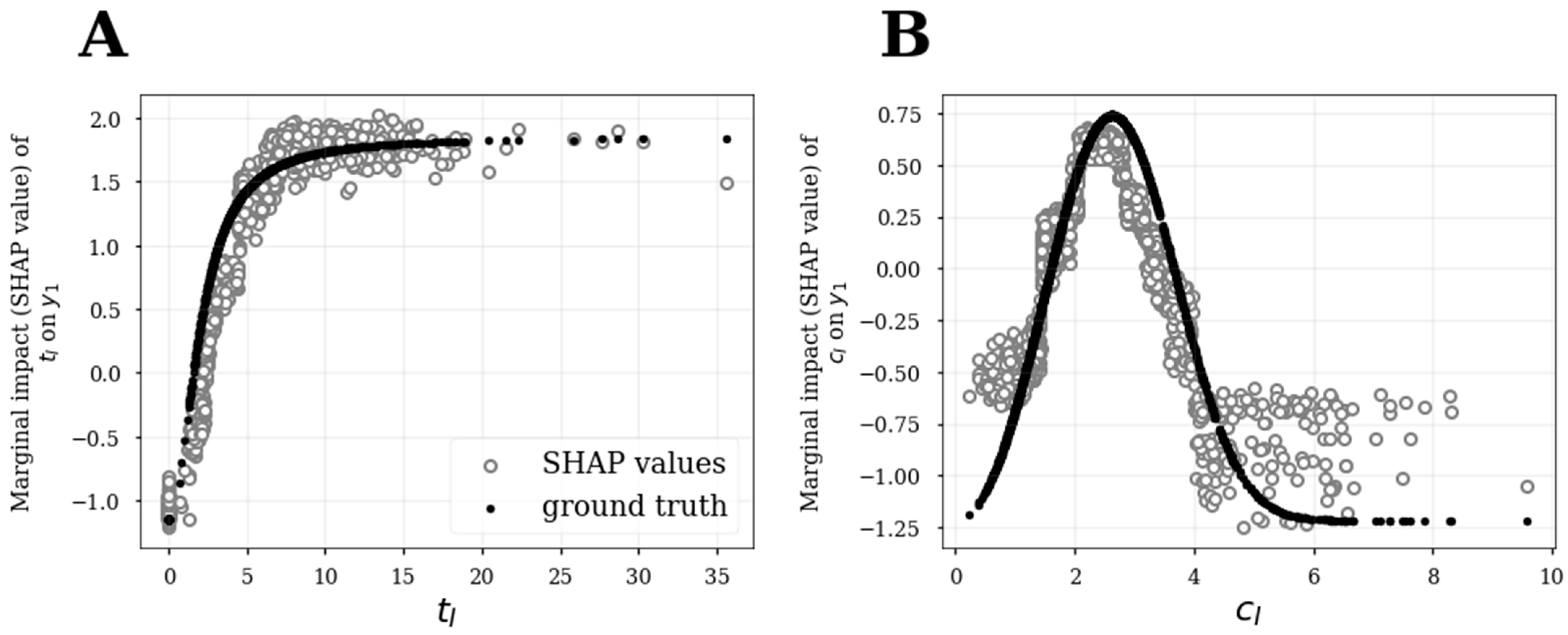
3.4. SHAP Analysis to Infer Functional Relationships
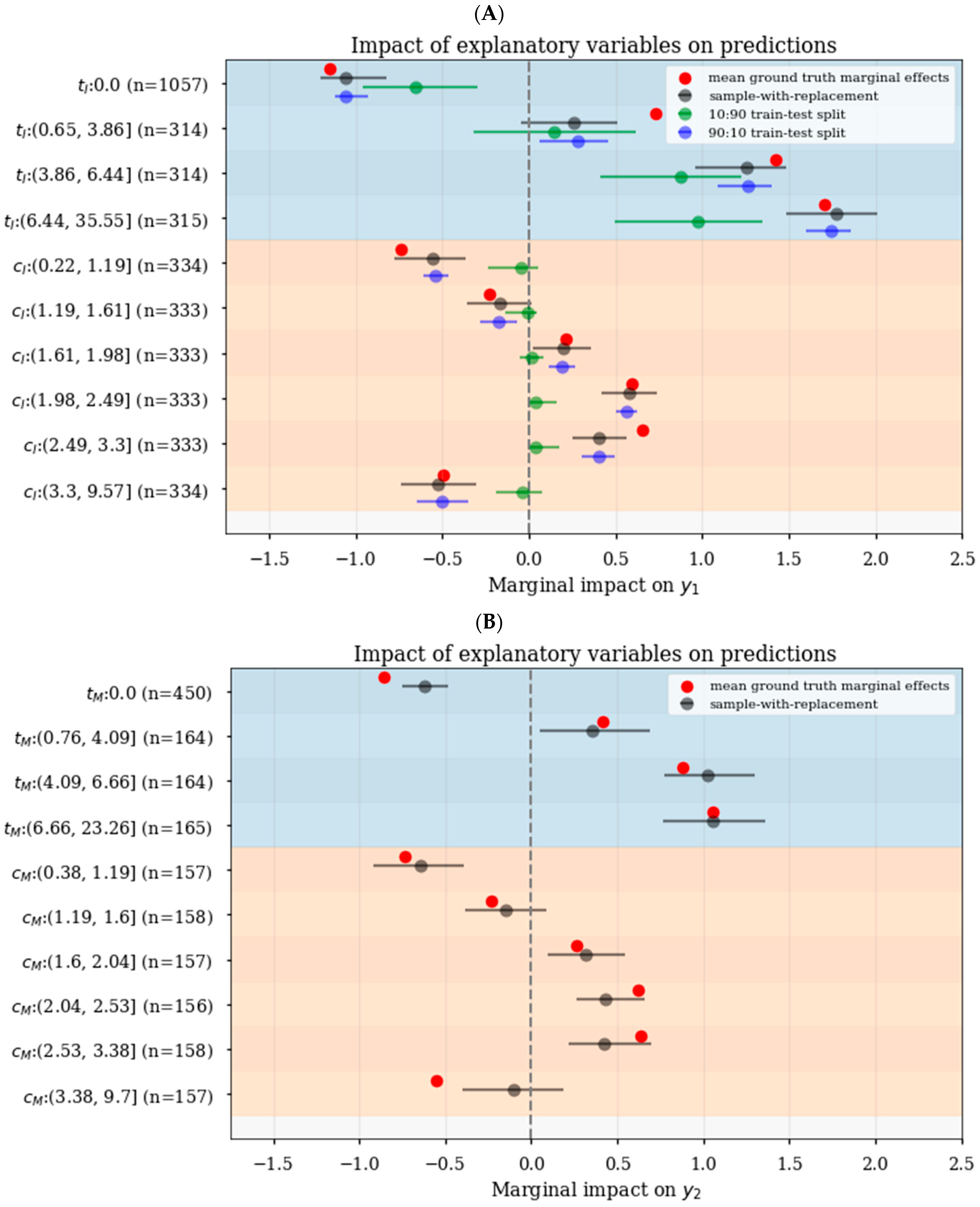
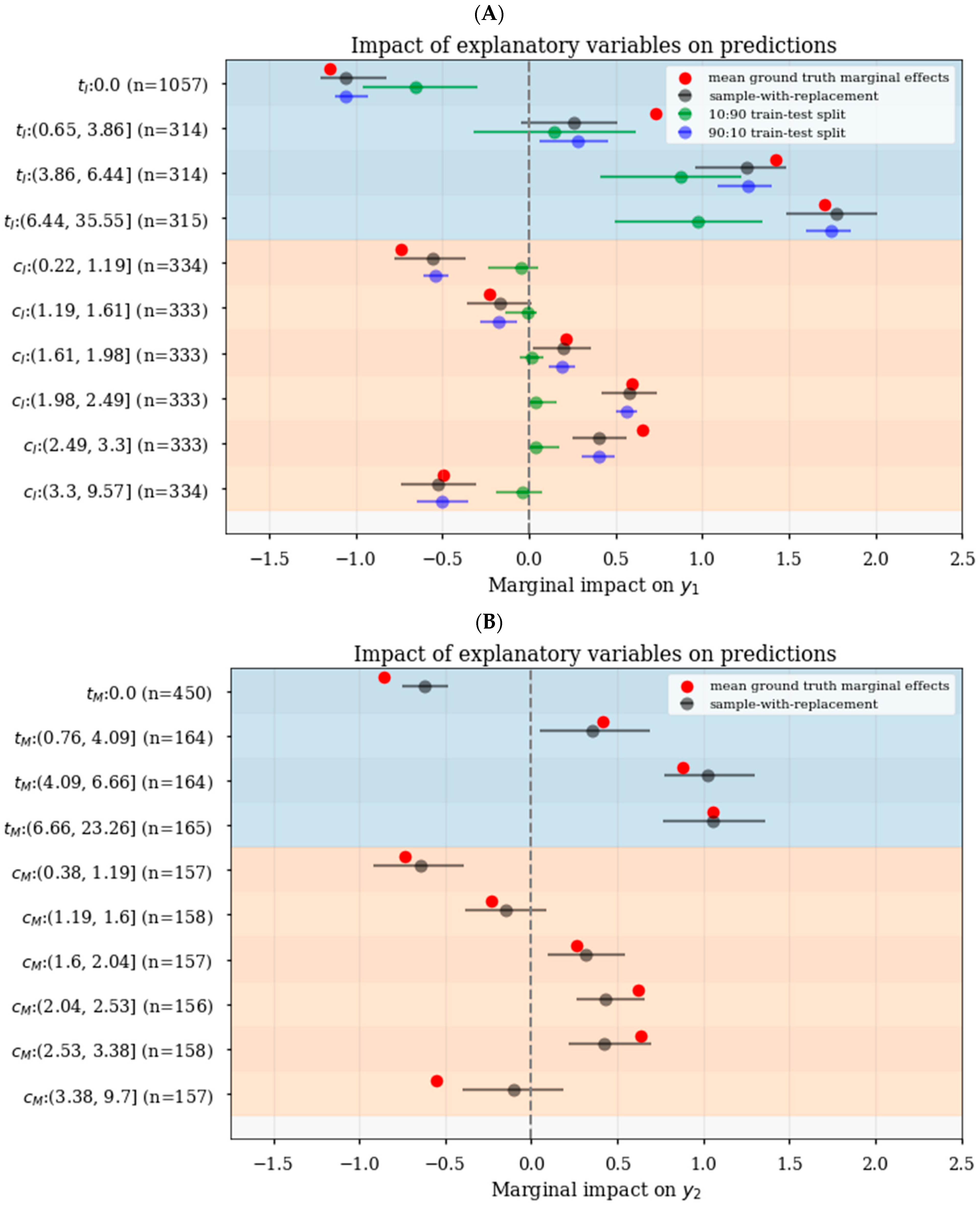
3.5. Realistic Estimation of Confidence Intervals
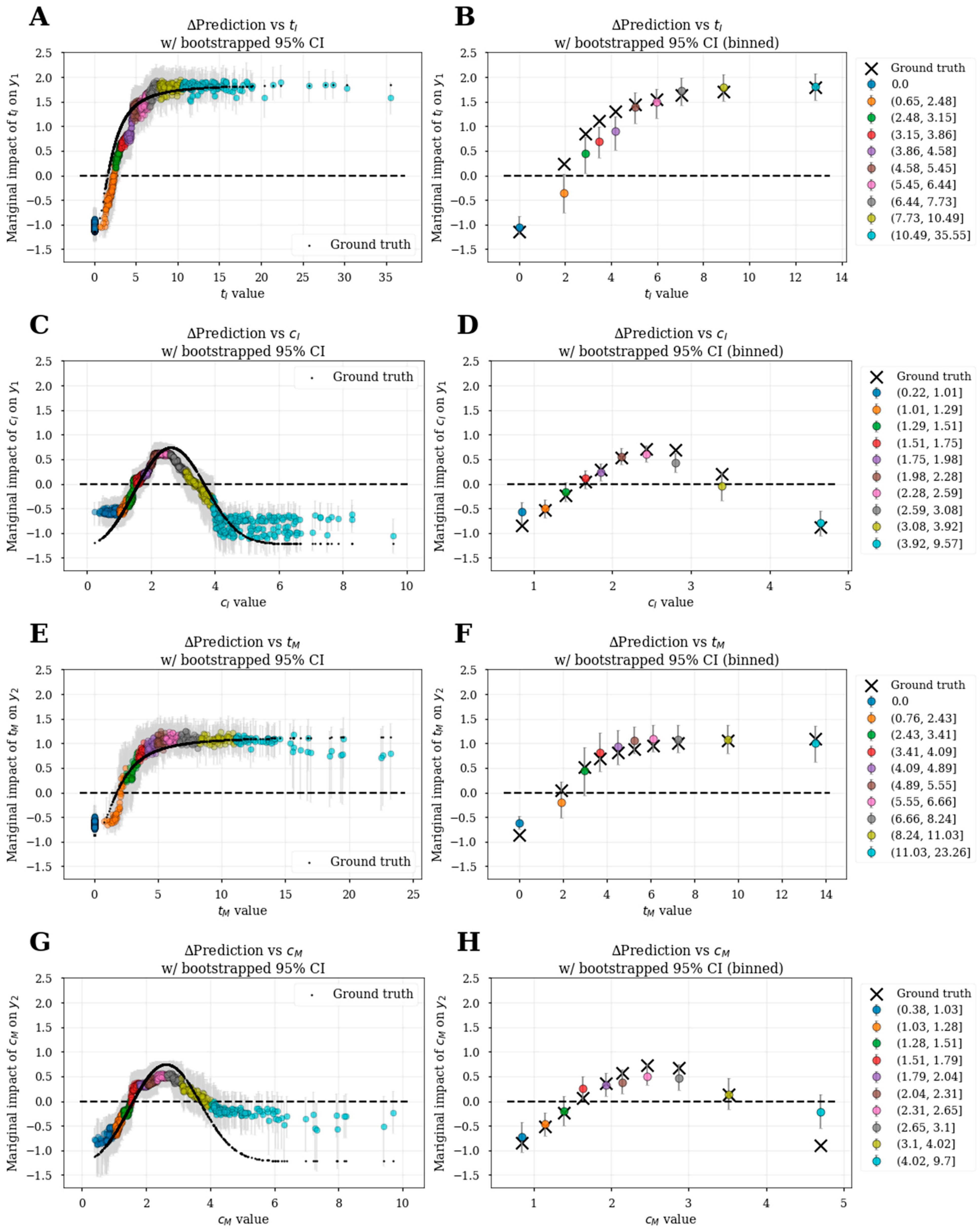
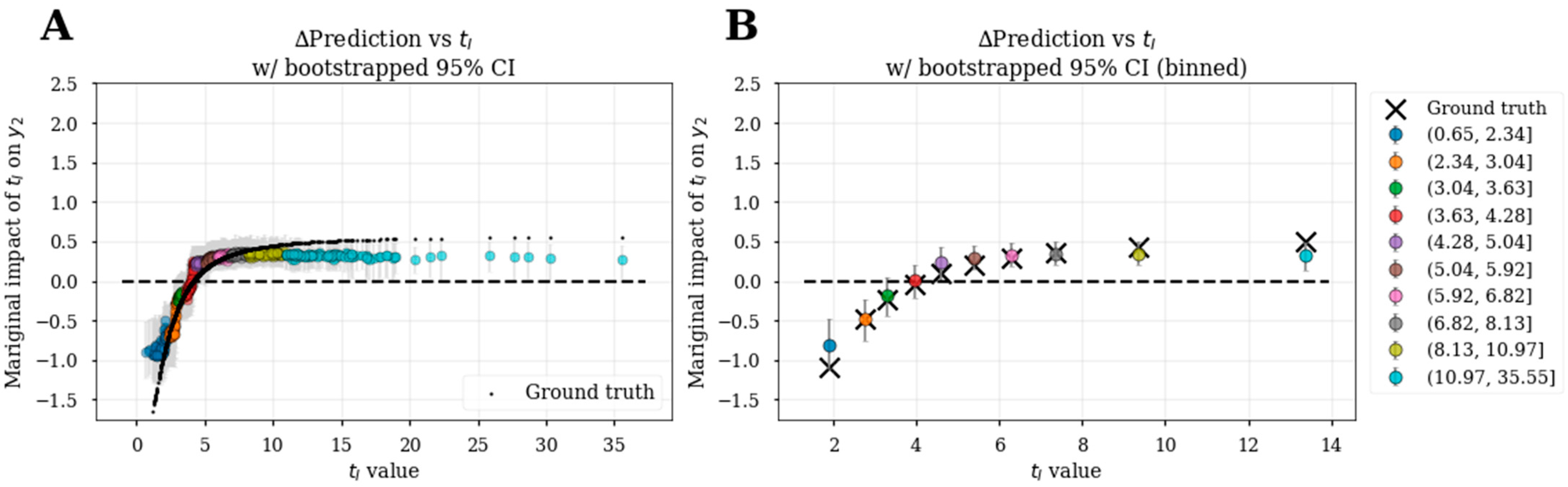
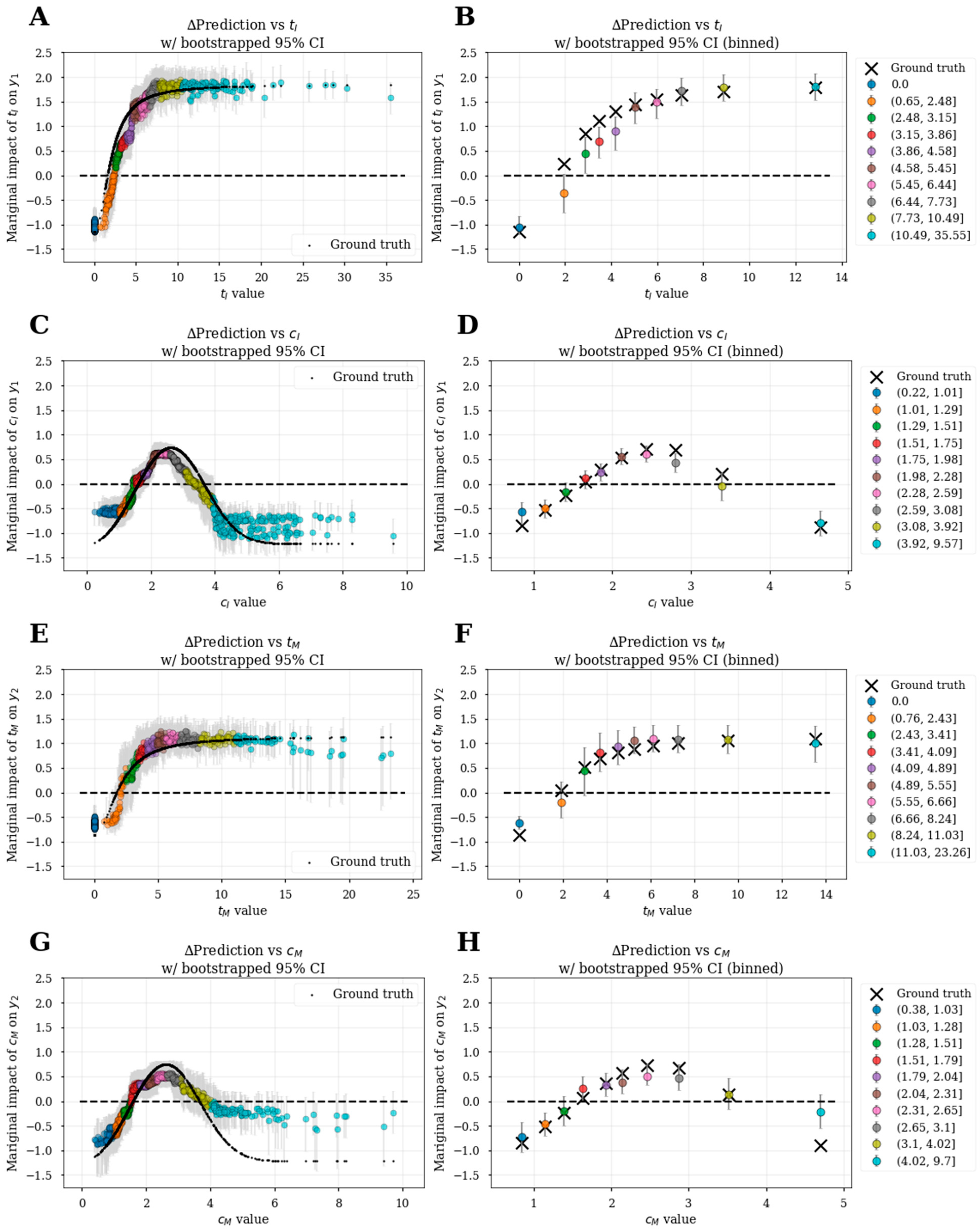
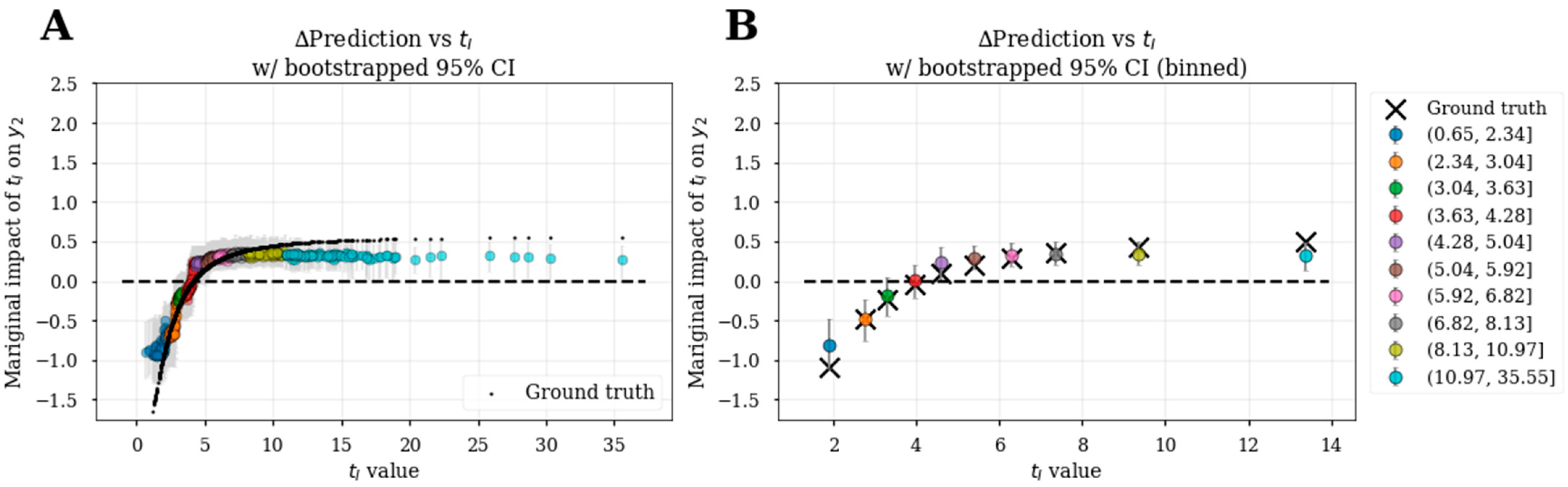
3.6. Bootstrapped Feature Dependence Plots
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Data Generation Process
Appendix A.2. Induction Stage
Appendix A.3. Maintenance Stage
Appendix A.4. Ground Truth Marginal Effects of Explanatory Variables
References
- Kawakatsu, S.; Bruno, R.; Kågedal, M.; Li, C.; Girish, S.; Joshi, A.; Wu, B. Confounding factors in exposure–response analyses and mitigation strategies for monoclonal antibodies in oncology. Br. J. Clin. Pharmacol. 2020, 87, 2493–2501. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.I.; Vugmeyster, Y.; Mangal, N. Characterizing Exposure-Response Relationship for Therapeutic Mono-clonal Antibodies in Immuno-Oncology and Beyond: Challenges, Perspectives, and Prospects. Clin. Pharmacol. Ther. 2020, 108, 1156–1170. [Google Scholar] [CrossRef] [PubMed]
- Overgaard, R.; Ingwersen, S.; Tornøe, C. Establishing Good Practices for Exposure–Response Analysis of Clinical Endpoints in Drug Development. CPT Pharmacomet. Syst. Pharmacol. 2015, 4, 565–575. [Google Scholar] [CrossRef] [PubMed]
- McComb, M.; Bies, R.; Ramanathan, M. Machine learning in pharmacometrics: Opportunities and challenges. Br. J. Clin. Pharmacol. 2021, 88, 1482–1499. [Google Scholar] [CrossRef] [PubMed]
- Terranova, N.; Venkatakrishnan, K.; Benincosa, L.J. Application of Machine Learning in Translational Medicine: Current Status and Future Opportunities. AAPS J. 2021, 23, 74. [Google Scholar] [CrossRef] [PubMed]
- Janssen, A.; Bennis, F.C.; Mathôt, R.A.A. Adoption of Machine Learning in Pharmacometrics: An Overview of Recent Implementations and Their Considerations. Pharmaceutics 2022, 14, 1814. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Xu, Y.; Liu, Q.; Zhu, H.; Wang, Y. Application of machine learning based methods in exposure-response analysis. J. Pharmacokinet. Pharmacodyn. 2022, 49, 401–410. [Google Scholar] [CrossRef] [PubMed]
- Gong, X.; Hu, M.; Basu, M.; Zhao, L. Heterogeneous treatment effect analysis based on machine-learning methodology. CPT Pharmacomet. Syst. Pharmacol. 2021, 10, 1433–1443. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Lu, J.; Lim, H.S.; Jin, J.Y.; Lu, D. Applying interpretable machine learning workflow to evaluate exposure–response relationships for large-molecule oncology drugs. CPT Pharmacomet. Syst. Pharmacol. 2022, 11, 1614–1627. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Sundrani, S.; Lu, J. Computing the Hazard Ratios Associated With Explanatory Variables Using Machine Learning Models of Survival Data. JCO Clin. Cancer Inform. 2021, 5, 364–378. [Google Scholar] [CrossRef] [PubMed]
- Ogami, C.; Tsuji, Y.; Seki, H.; Kawano, H.; To, H.; Matsumoto, Y.; Hosono, H. An artificial neural network−pharmacokinetic model and its interpretation using Shapley additive explanations. CPT Pharmacomet. Syst. Pharmacol. 2021, 10, 760–768. [Google Scholar] [CrossRef] [PubMed]
- Janssen, A.; Hoogendoorn, M.; Cnossen, M.H.; Mathôt, R.A.A.; Reitsma, S.H.; Leebeek, F.W.G.; Fijnvandraat, K.; Coppens, M.; Meijer, K.; Schols, S.E.M.; et al. Application of SHAP values for inferring the optimal functional form of covariates in pharmacokinetic modeling. CPT Pharmacomet. Syst. Pharmacol. 2022, 11, 1100–1110. [Google Scholar] [CrossRef]
- Jeong, D.Y.; Kim, S.; Son, M.J.; Son, C.Y.; Kim, J.Y.; Kronbichler, A.; Lee, K.H.; Shin, J.I. Induction and maintenance treatment of inflammatory bowel disease: A comprehensive review. Autoimmun. Rev. 2019, 18, 439–454. [Google Scholar] [CrossRef] [PubMed]
- Sandborn, W.J.; Vermeire, S.; Tyrrell, H.; Hassanali, A.; Lacey, S.; Tole, S.; Tatro, A.R. The Etrolizumab Global Steering Committee Etrolizumab for the Treatment of Ulcerative Colitis and Crohn’s Disease: An Overview of the Phase 3 Clinical Program. Adv. Ther. 2020, 37, 3417–3431. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Feurer, M.; Hutter, F. Hyperparameter optimization. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 3–33. [Google Scholar]
- Pearl, J. Causal diagrams for empirical research. Biometrika 1995, 82, 669–688. [Google Scholar] [CrossRef]
- Rogers, J.A.; Maas, H.; Pitarch, A.P. An introduction to causal inference for pharmacometricians. CPT Pharmacomet. Syst. Pharmacol. 2022, 12, 27–40. [Google Scholar] [CrossRef] [PubMed]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Wang, J.; Wiens, J.; Lundberg, S. Shapley Flow: A Graph-based Approach to Interpreting Model Predictions. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 13–15 April 2021; Banerjee, A., Fukumizu, K., Eds.; PMLR: New York, NY, USA, 2021; pp. 721–729. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harun, R.; Yang, E.; Kassir, N.; Zhang, W.; Lu, J. Machine Learning for Exposure-Response Analysis: Methodological Considerations and Confirmation of Their Importance via Computational Experimentations. Pharmaceutics 2023, 15, 1381. https://doi.org/10.3390/pharmaceutics15051381
Harun R, Yang E, Kassir N, Zhang W, Lu J. Machine Learning for Exposure-Response Analysis: Methodological Considerations and Confirmation of Their Importance via Computational Experimentations. Pharmaceutics. 2023; 15(5):1381. https://doi.org/10.3390/pharmaceutics15051381
Chicago/Turabian StyleHarun, Rashed, Eric Yang, Nastya Kassir, Wenhui Zhang, and James Lu. 2023. "Machine Learning for Exposure-Response Analysis: Methodological Considerations and Confirmation of Their Importance via Computational Experimentations" Pharmaceutics 15, no. 5: 1381. https://doi.org/10.3390/pharmaceutics15051381
APA StyleHarun, R., Yang, E., Kassir, N., Zhang, W., & Lu, J. (2023). Machine Learning for Exposure-Response Analysis: Methodological Considerations and Confirmation of Their Importance via Computational Experimentations. Pharmaceutics, 15(5), 1381. https://doi.org/10.3390/pharmaceutics15051381