1. Introduction
Phage therapy, the use of phages to cure bacterial infections, has received much attention in recent years due to the emergence and rapid spread of antibiotics resistance. In fact, resistance genes towards last resort treatments for multidrug-resistant bacteria are reported to be circulating all around the world. This highlights an urgent need to coordinate a global effort in the search for antibiotics adjuvants or alternative improved treatments [
1,
2,
3].
The practice of phage therapy was reported shortly after phage discovery in 1915 [
4], when a sudden enthusiasm emerged towards what was believed to be the cure for almost any disease, even before the biology of phages was fully understood [
5,
6]. The initial excitement rapidly faded, when phage therapy failed to meet the high expectations, and its practice in western countries soon became obsolete following the discovery of penicillin in 1928 and the advent of the antibiotic era [
7].
Despite the displacement of phage therapy by antibiotics in western countries, former Soviet Republics pursued investigations on phages over decades, which today provide a rich trove of knowledge in the field. The related literature has been thoroughly reviewed by Sthephen Abedon et al. [
6]. The world leading institution for phage therapy, The Eliava Institute of Bacteriophage, Microbiology and Virology, is located in the former Soviet Republic of Georgia and was founded by the Georgian microbiologist George Eliava in 1923.
In their clinical application, phages are used either as single therapeutic phages, prepared against specific bacterial strains resistant to antibiotics, or phage cocktails which have a broad spectrum of activity towards a set of the most prevalent bacterial strains considered a threat to human health [
8]. While the first approach is promoted by the Hirszfeld Institute in Poland, the second is mostly used by the Eliava Institute laboratories, where cocktails’ compositions are updated twice per year by adding new phages to target emerging virulent bacteria [
5].
Drug regulatory agencies in western countries, European Medicine Agency and Food and Drug Administration (FDA), are expected to require a comprehensive characterization of the components of a cocktail for it to be considered applicable in healthcare. Whole genome sequencing can be deployed for this purpose, along with methods to predict the host of the draft genomes.
In previous studies, the composition of the intestiphage (INTESTI) cocktail from the Georgian Eliava Institute and the ColiProteus cocktail, which is produced by the Russian company Microgen, have been investigated [
9,
10]. Among other exciting discoveries, these studies identified a new
Proteus phage genome sequence. However, both studies only examined the composition of a single batch of cocktail and did not look into changes in the composition of the cocktails over years.
In this metagenomic study, we have sequenced and compared the genomic composition of two pyophage (PYO) cocktails, one from 1997, here referred to as PYO97, and the other from 2014, PYO2014. Upon sequencing the DNA of the cocktails and trimming the reads, we assembled the reads into contigs and further binned the contigs from each sample into phage draft genomes. We then compared these draft genomes to phage sequences previously deposited in public databases and examined which draft genomes were common to both samples and in which abundances. Finally, we predicted the host for each phage draft genome. For a third batch of PYO cocktail from 2000 (PYO2000), we were not able to recover phage draft genomes, but we compared the sequence reads to the draft genomes from PYO97 and PYO2014 and found PYO2000 to resemble PYO97 the most.
2. Materials and Methods
Glass vials containing about 10 mL of each of the four PYO phage cocktails—1997, 2000, 2010, and 2014—were kindly provided by Elizabeth Kutter of The Evergreen State College, Olympia, and prepared for sequencing. The bottles are depicted in
Figure 1.
2.1. DNA Extraction and Library Preparation
The DNA was extracted and isolated using the NORGEN Phage DNA Isolation Kit (Cat. # 46800, Thorold, ON, Canada) following the manual. The extracted DNA was kept at −20 °C until library preparation. PYO97 and PYO2014 had a DNA concentration of 6.06 ng/µL and 1.12 ng/µL, respectively, and a 260/280 ratio within the desired range of 1.8–2.0. PYO2000 and PYO2010 had a DNA concentration of 1.62 ng/µL and 1.61 ng/µL, respectively, but a 260/280 ratio outside the desired 1.8–2.0 range. Due to the 260/280 range, we decided to only process PYO2000 further, and when the resulting sequence reads were of poor quality, refrained from sequencing PYO2010 at all. DNA libraries from PYO97, PYO2000, and PYO2014 were prepared from 1 ng of sample DNA using the NexteraXT Sequencing kit (San Diego, CA, USA) according to the manufacturer’s instructions. The resulting libraries were sequenced using the Illumina MiSeq platform (San Diego, CA, USA) yielding 250 bp long paired-end reads.
2.2. Read Trimming
Reads from PYO97, PYO2000, and PYO2014 were checked for quality with Fast Quality Control (FastQC) [
11], which produces several different statistics to enable assessment of the quality of short sequence reads. When we, in the following, classified reads as of low or high quality, we based this on the “Per base sequence quality”. Reads were trimmed using Prinseq-lite 0.20.4 [
12] with the following settings: -trim_qual_right 20 -min_qual_mean 20 -min_len 35 -trim_left 20 -trim_right 10 -derep 14. Non-parallel reads, resulting from trimming, were compensated using cmpfastq [
13].
Reads mapping to PhiX174 phage (NC_001422.1), which is used as an internal control in Illumina sequencing, were removed by running MGmapper [
14]. MGmapper is a pipeline that takes a fastq file as input and aligns reads to built-in databases using Burrows-Wheeler Alignment algorithm (BWA) [
15]. If none of the databases is specified (option -C 0), the program maps the reads to the PhiX174 genome and returns a fastq file of unmapped reads. MGmapper was launched with the following command: MGmapper_PE.pl -i F.fastq -j R.fastq -R -k -C 0 -S.
The reads quality of PYO2000 was low, even after trimming and removal of PhiX174 reads, therefore this sample was excluded from further analyses until we eventually calculated the distances in composition between the three cocktails; see section Distances in compositions of the cocktails in Material and Methods.
2.3. Read Mapping
Using Kraken [
16], reads from PYO97 and PYO2014 were mapped to the Virus database, which contains complete viral genomes from RefSeq (as of May 2017). Kraken assigns taxonomic labels to metagenomic sequences by searching for exact-matching k-mers (oligonucleotides of length k) between a read and a database of k-mers present in a set of organisms. The Kraken database also stores information about the phylogeny of the organisms. Hence, whenever a query k-mer is present in two or multiple organisms in the database, Kraken assigns the hit to the lowest common ancestor that has these organisms as descendants. Further, reads from PYO97 and PYO2014 were mapped using the Best Mode of MGmapper (option -C) to the built-in databases Bacteria, Archaea, MetaHitAssembly, HumanMicrobiome, Bacteria_draft, Human, Virus, and Fungi downloaded from National Center for Biotechnology Information (NCBI) in June 2017. MGmapper classifies sequences based upon BWA read mapping to a database of reference sequences, allowing for nucleotide variations, inserts and deletions.
2.4. Assembly and Contigs Binning
Reads from PYO97 and PYO2014 were assembled into contigs using the metaSPAdes [
17] tool from the SPAdes assembly tool kit (version 3.10.1, Saint Petersburg, Russia) [
18] with increasing k-mer lengths (21, 33, 55, 77, 99, 127) as suggested in the software manual.
Metagenome Binning with Abundance and Tetra-nucleotide frequencies (MetaBAT) [
19], the software used in this study for binning of contigs into draft genomes, requires the assembly in a fasta file and a sorted Binary Alignment Map (BAM) file as input. Reads from PYO97 and PYO2014 were therefore mapped (BWA 0.7.15) [
15] to the respective contigs and the resulting BAM files were sorted using SAMtools sort (SAMtools 1.4) [
20]. The assembly fasta file and the sorted BAM file were fed to MetaBAT, v0.32.4 for each sample separately. The samples were binned based on tetranucleotide frequency distance probability. We set the minimum contig length to 2000 bp as previously done [
9], the minimum bin size to the minimum that MetaBAT allows, which is 10,000 bp, and the bootstrapping to be run 100 times. MetaBAT was ran in
specific mode: --p1 90 --p2 90 --pB 30 --minProb 80 --minBinned 40 --minCorr 96, to minimize contigs belonging to different phages being binned together.
2.5. Finding the Most Similar Reference Genome
Phage whole genome sequences (WGS) were downloaded from the NCBI viral RefSeq database [
21] and PhAnToMe [
22] resulting in 3889 unique WGS as of May 2017. To find the closest reference to each bin from PYO97 and PYO2014, we ran MetaPhinder [
23]. MetaPhinder is a Blast-based method, which for a given query entry provides a measure, the percentage Average Nucleotide Identity (ANI), that integrates multiple hits of the query genome to all sequences in a database. The ANI value is calculated as
where
is the number of Blastn hits between the query sequence and all sequences in the database with an e-value of 0.05 or smaller,
is the Blastn % identity value between the query and a given database hit,
is the corresponding Blastn alignment length, and
is the coverage of the query sequence over all hits. Using this approach, a Blast database was constructed from each bin and next queried with each of the 3889 phage Whole Genome Sequences (WGS). For each bin-database, MetaPhinder reported the ANI for each query WGS, and the query with the highest ANI was selected as the one matching the bin the most.
2.6. Checking Consistency within and between Bins
The trimmed reads devoid of PhiX174 of PYO97 and PYO2014 were aligned to the respective contigs using BWA [
15]. The coverage, here the number of reads mapping to the contigs times the read length divided by the length of the contigs in bp, was calculated using samtool depth [
20]. If high variance of coverage values were observed for the member contigs of a particular bin, the bin was manually split into smaller bins, each only containing contigs with a confined range of coverage values.
Bins that shared the best matching genome among the 3889 WGS had a similar coverage and no overlapping contigs between them were manually merged.
2.7. Bin Annotation
To classify if a given bin is a phage or not, we estimated the ANI of each bin from PYO97 and PYO2014 towards the Blastn database of the 3889 phage WGS described earlier. An ANI threshold of 10% was chosen to discriminate between phage and non-phage query bins. For bins containing more than one contig, a weighted ANI average was calculated as
where
n is the number of contigs in the bin and
l is the length of the member contigs. HostPhinder [
24] was used to predict the bacterial host of the draft genomes. HostPhinder predicts the host of a phage genome sequence by searching for overlapping 16-mers between the query and a database of phage genomes with an annotated host. Upon finding the best matching hits in the database, HostPhinder predicts the host to be the most represented host among the top hits. The prediction is associated with a reliability score from 0 to 1. Only scores higher than 0.1 are considered reliable [
24]; we therefore only reported results above this threshold.
2.8. Similarities between PYO97 and PYO2014.
To estimate the similarity between bins of PYO97 and PYO2014, MetaPhinder was used as follows: A Blast database of contigs from a given bin from one sample was searched with each contig of a bin of the other sample (the query bin). Next, the query bin was assigned a weighted mean ANI calculated from the ANIs and lengths (
l) of query contigs, Equation (2). For each database bin, the query bin with the highest
was considered the matching candidate. The reciprocal ANI was calculated using OrthoANI [
25], which takes into account only orthologous fragment pairs between the two sequences.
2.9. Phage Draft Genome Visualization
Phage draft genomes were visualized using BLAST Ring Image Generator v0.95 (BRIG) [
26]. Alternatively, we ran a customized python script to produce xml files from Blast results and used CGView Java Package to visualize them as circular genomes [
27].
2.10. Bin Classification
Bins were classified into six categories according to high (ANI ≥ 70%) or medium/low (ANI < 70%) resemblance to a reference genome or to a bin in the other sample. Bins that were more than 10% longer than the best matching reference genome and that included overlapping contigs were classified as collapsed bins. Bins with ANI < 10% towards phages in public databases were labeled as special cases. Bins composed by more than 20 contigs which were shorter than 7000 bp were too fragmented to be considered drafts of genomes and were therefore also designated as special cases. For simplicity, here we will refer to draft genomes to indicate bins that are not special cases. When the term bin is used, then all bins including special cases are intended.
2.11. Phage Abundances
To further check whether the phages of one cocktail sample were present in the other and with which relative abundance, we mapped the PYO97 reads to the PYO2014 bins and vice versa using BWA. The bin coverage values, calculated here as the number of reads mapping to the bins times the read length and divided by the length of the bins in bp, were obtained using samtools depth [
20].
2.12. Distances in Compositions of the Cocktails
We ran Mash v1.1.1 [
28] to determine the distances in terms of composition between the samples. Trimmed reads devoid of PhiX174 of samples PYO97, PYO2000 and PYO2014 were used.
Mash enables the comparison of metagenomic samples by splitting them into constituent k-mers and reducing the samples into sketches of representative k-mers. From these size-reduced sketches, Mash can rapidly calculate the Jaccard index based on co-occurring k-mers. Based on the Jaccard index, Mash estimates global mutation distances (0 ≤ D ≤ 1) between samples. The results have a strong correlation with the ANI. We chose a k-mer size of 16, a sketch size of 400 and a minimum of 2 copies of k-mers in order for the k-mer to be considered as a candidate for the sample sketch. Mash was launched as follows:
where tmp/*.fq represents the folder containing the fastq files of interleaved reads for the 3 samples.
To get the bootstrap mean and confidence interval of the distances, pair reads of the 3 samples were separately shuffled with resampling 100 times. In each resampling, Mash made sketches of the 3 samples and calculated pairwise distances between the samples. This resulted in one hundred 3 × 3 distance tables from which the mean and mean squared error of each pairwise distance were calculated.
3. Results
3.1. Reads Statistics
The DNA from each of the four batches of PYO cocktail was extracted. The yield from PYO2010 was very low and we, accordingly, chose not to sequence it.
Table 1 reports the number of reads before and after trimming and removal of PhiX174 reads obtained from PYO97, PYO2000, and PYO2014.
PYO2000 was shown to have poor read quality, with a per base sequence quality significantly lower than PYO97 and PYO2014. On account of this, we only attempted to generate phage draft genomes for PYO97, the first time point and PYO2014, the last time point. The trimmed reads devoid of PhiX174 of PYO2000 were mapped to the draft genomes of PYO97 and PYO2014 to examine genomic overlap; see Material and Methods and the section Phage abundance and bin comparison in the Results.
3.2. Reads Mapping
To get an overview of what was present in the PYO97 and PYO2014 cocktails, reads were initially mapped to the Kraken Virus database.
As seen in
Figure 2, 89% and 61% of the reads mapped to viruses of the order
Caudovirales in PYO97 and PYO2014, respectively. Of these, most mapped to the family
Myoviridae (85%), while 9% and 6% mapped to
Podoviridae and
Siphoviridae, respectively, for PYO97. The ratios of represented phage families within the order
Caudovirales in PYO2014 were more even: 45%
Myoviridae, 38%
Podoviridae, and 17%
Siphoviridae.
For PYO97, 11% of the reads did not map to any of the sequences in the Kraken Virus database. The corresponding number for PYO2014 was 39%.
To examine if the unmapped reads from above mapped to sequences from other organisms than viruses, MGmapper was next ran using the databases of Bacteria, Archea, MetaHitAssembly [
29], HumanMicrobiome [
30], Bacteria draft, Human, Viruses and Fungi. No significant mapping to other databases besides Viruses was reported,
Table S1.
3.3. Assembly and Contigs Binning
In order to detect any draft genome that was common between PYO97 and PYO2014, we proceeded in the assembly and downstream analysis of the two samples with high quality reads.
The assembly yielded 179 and 270 contigs longer than 2000 bp for PYO97 and PYO2014, respectively (
Table 2). Note, that while the 270 contigs from PYO2014 in total encompass 2759 kbp to which 6,516,794 reads map, the 179 contigs from PYO97 encompass 3034 kbp to which only 1,924,746 reads map, indicating that the depth of coverage obtained for the PYO97 cocktail is not as high as for the PYO2014 cocktail.
The assembly of metagenome reads often fails to produce entire genomes even for small phage genomes. To arrive at a more complete assembly, MetaBAT was used to group contigs with similar tetranucleotide frequency, allowing to come close to what can be considered draft genomes. MetaBAT produced 33 bins from PYO97 and 31 from PYO2014 and were able to bin more than 90% bp of the contigs longer than 2000 bp for each sample (
Table 3).
3.4. Consistency within and between Bins
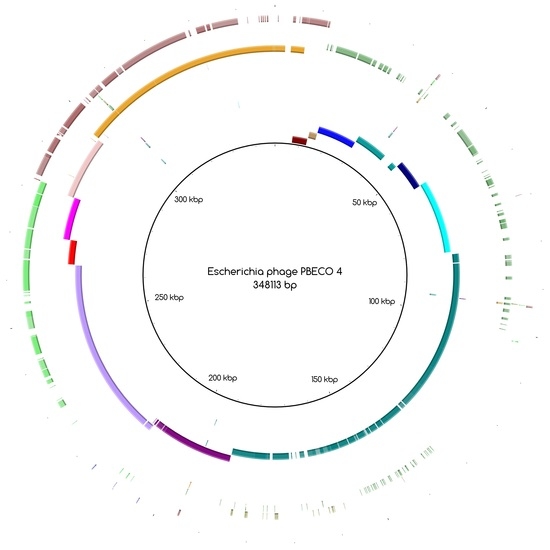
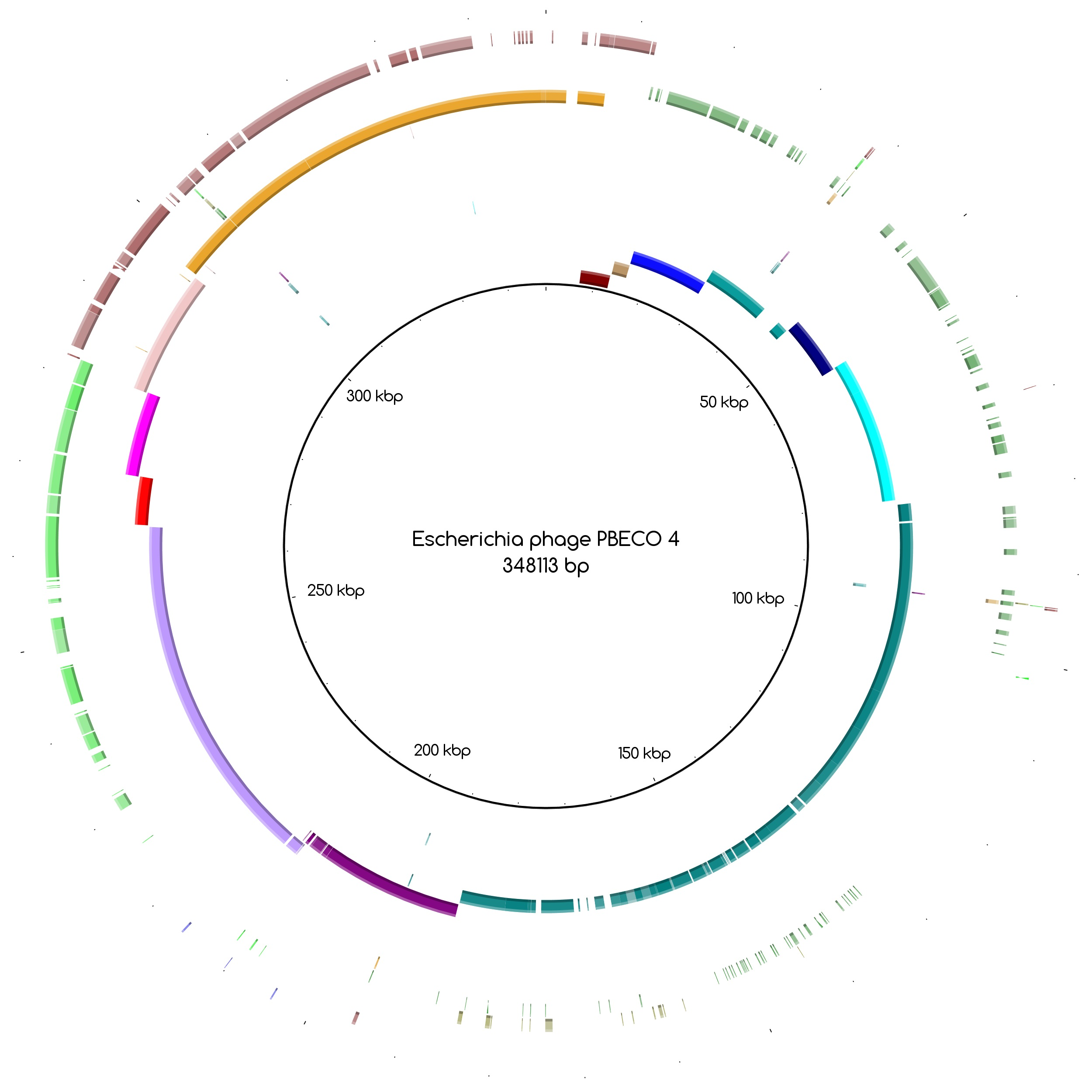
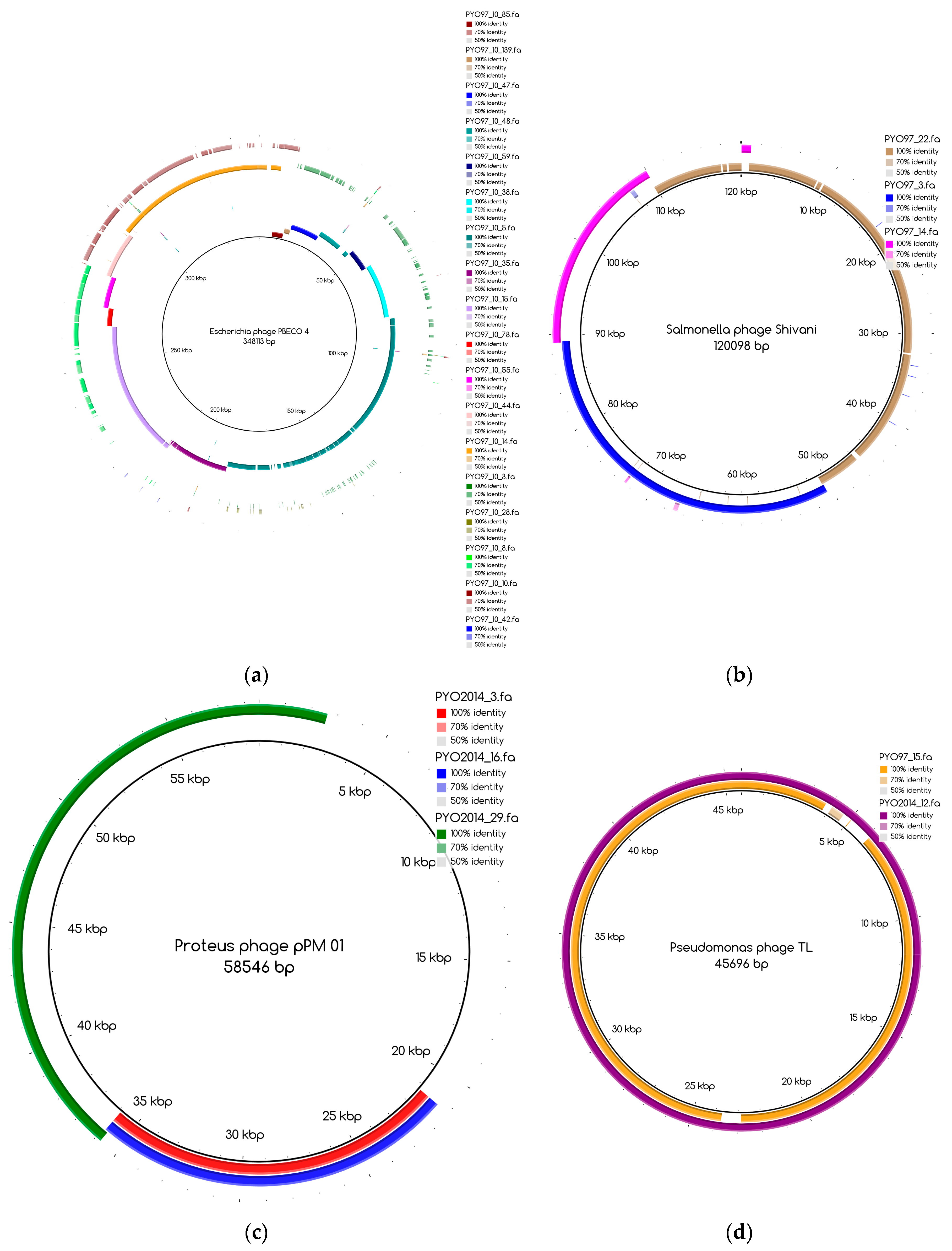
The bins produced by MetaBAT were composed of between 1 and 50 contigs. In cases where some of the binned contigs overlapped when mapped to the reference sequence, an effort was made to split the bin according to the differences in contig coverage values. After such splits, the newly formed bin generally had a different closest reference genome to the original bin. An illustration of this is shown in
Figure 3a. Here, the bin PYO97_10, with
Escherichia phage PBECO 4 as the closest reference, was split into PYO97_10_85.139.47.48.59.38.5.35.15.78.55.44.14 with the same reference as the original bin and PYO_10_3.8.10.28.42, which in turn had
Escherichia phage 121Q as the closest reference genome.
Bins mapping to the same reference were merged, if their coverage was in the same range. An example of this is shown in
Figure 3b. Here, three bins from PYO97, PYO97_22, PYO97_3 and PYO97_14, which shared a high sequence similarity to
Salmonella phage Shivani and had coverage values between 58 and 72, were merged into a single bin PYO97_22.3.14 which preserved the reference genome and showed a coverage of 65 with a lower mean standard deviation compared to the original bins. This and other examples of bin merging are listed in
Table 4. PYO2014_3.16.29, in our view, represents two or more closely related phages (see
Figure 3c), that are identical in the region represented by PYO2014_29, but slightly differ in the regions represented by PYO2014_3 and PYO2014_16.
Eventually, after this manual splitting and merging of bins, 30 and 29 final bins were obtained from PYO97 and PYO2014, respectively.
Two bins of PYO2014 were both composed of 26 contigs, all shorter than 7000 bp. Due to this fragmentation, they were labeled as special cases.
3.5. Bin Annotation
We calculated the ANI of the final bins towards the set of publicly available phage genomes to discriminate between phage bins (bins similar to previously sequenced phages) and non-phage bins (bins that share little similarity to known phage sequences). We chose a very stringent threshold of 10% ANI to classify a bin as of phage origin. Using this threshold, five (17%) and three (10%) bins from PYO97 and PYO2014, respectively, were classified as non-phages and added to the special cases. One of the non-phage bins from PYO2014 was already a special case due to its fragmentation, see above. Bins not belonging to the special cases will hereafter be referred to as draft genomes.
To further characterize the draft genomes, we predicted their bacterial hosts using HostPhinder.
Table 5 reports the predicted represented bacterial hosts in the two samples.
3.6. Similarities between PYO97 and PYO2014
Approximately every 6 months, the Eliava Institute laboratories update the content of the PYO cocktail to cope with the emergence of new clinically problematic bacterial strains. New effective phages are added, while phages added in previous batches slowly dilute, leading to an overall change of the cocktail composition.
We investigated how much overlap in the compositions of PYO97 and PYO2014 was appreciable by looking for common phage draft genomes between the two cocktails. The corresponding pairs of draft genomes between the two samples were determined using MetaPhinder in a pairwise manner as described in Materials and Methods.
Table 6 reports the pairs identified by MetaPhinder, where at least one of the ANI, calculated either by using PYO97’s or PYO2014’s phage drafts as databases was higher than 70%.
The combined results of HostPhinder and pairwise MetaPhinder displayed in
Table 6 strongly suggest that the same phages against
E. faecalis (2),
E. faecium (1),
E.coli (2),
P. mirabilis (1),
P. aeruginosa (2), and
S. aureus (1) are present in both samples; where the numbers in parenthesis are the counts of likely identical phages found in both samples which are capable of infecting the specified host.
3.7. Draft Genomes Classification
According to their similarity to reference genomes and to the presence of a likely counterpart at the other time point (see Materials and Methods), draft genomes were classified within the categories listed in
Table 7. The special cases include highly fragmented bins and non-phage bins. For these reasons, special cases are referred to as bins and not as draft genomes.
Table 7 also displays the number of draft genomes/bins from each sample belonging to each category. As an illustrative example, the six draft genomes from PYO97 in category 1, have high similarity to a reference genome and to draft genomes in PYO2014. One example of pairs of corresponding draft genomes is given by PYO97_15 and PYO2014_12,
Figure 3d. The two draft genomes share high similarity to Pseudomonas phage TL.
The number of draft genomes belonging to each category does not necessarily match between the two samples, even for the categories of draft genomes with a counterpart in the other sample, categories 1 and 3. This is, for instance, the case for draft genome PYO97_29, category 1, mapping to the collapsed draft genome PYO2014_21, which belongs to the fifth category,
Figure A1.
Table 8 and
Table 9 provide a general overview of the phage draft genomes found in PYO97 and PYO2014, respectively, together with an indication of the most likely taxonomic group they belong to. For a more thorough description of the draft genomes in each category, see
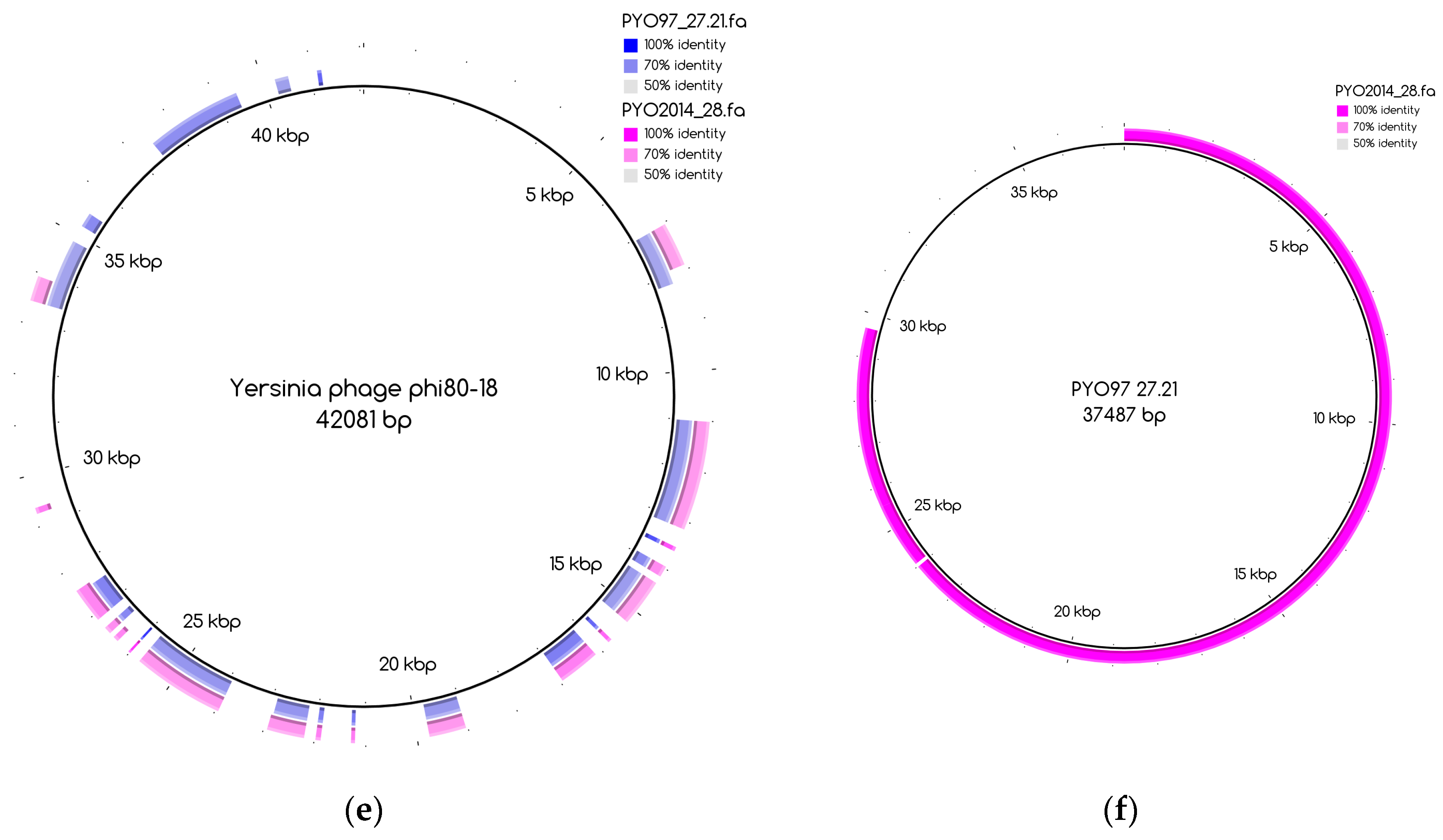
Tables S2 and S3 for PYO97 and PYO2014, respectively. A case worth noticing is that of the draft genomes PYO97_27.21 and PYO2014_28 in category 3. These draft genomes share similarity with ANI > 70%, but have low ANI to the common reference genome,
Yersinia phage phi80-18 (refer to,
Figure 3e,f for an illustration of the overlap between the two bins). This could suggest that the PYO97_27.21 and PYO2014_28 draft genomes represent a previously uncharacterized phage.
It is worth noticing that the percentage of reads that align to the bins with ANI < 40 towards known sequences was 6.87% and 22.79% for PYO97 and PYO2014, respectively. These percentages align with the differences in percentages of unclassified reads between the two samples, as found when using Kraken in paragraph 3.2: 11% for PYO97 and 39% for PYO2014. However, the results from BWA and Kraken analyses are not directly comparable since BWA alignment allows for indels and point mutation [
15], while Kraken only reports exact matching k-mers [
16].
3.8. Phage Abundances and Bin Comparison
To estimate the relative abundances of bins in PYO97 and PYO2014, we calculated the bin coverage of the PYO97’s and PYO2014’s bins by the reads of the samples PYO97 and PYO2014. To account for the difference in the number of reads between sample PYO97 and PYO2014, we normalized the coverage values by the total number of reads of the respective sample.
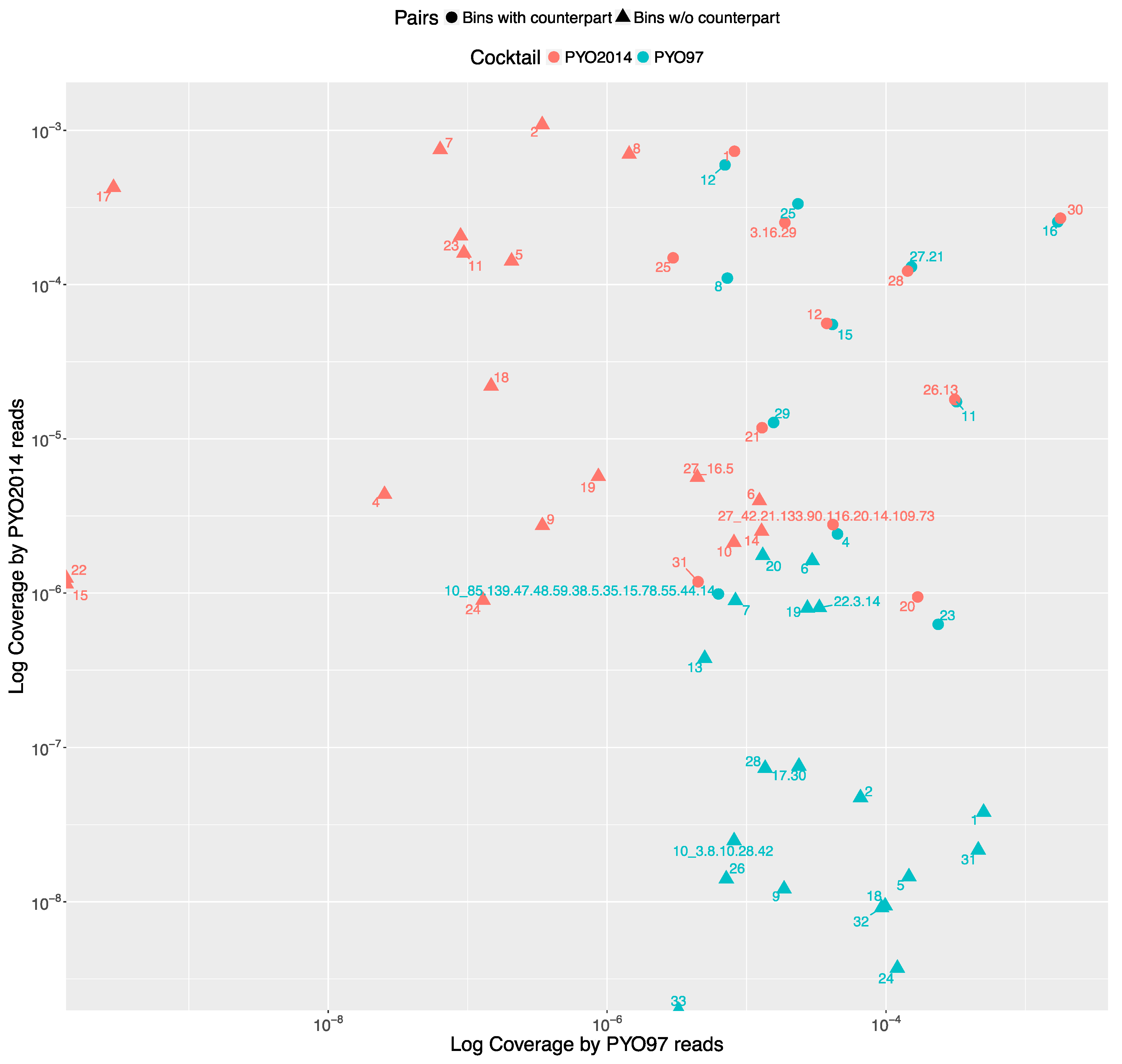
The distribution of the bins according to the bin coverage by the reads of PYO97 and PYO2014 is shown in
Figure 4. Circles represent draft genomes listed in
Table 6 having a counterpart in the other sample. These draft genomes had generally high abundances in both samples, which is deducible from the position of circle data points in the top right corner of the graph. PYO97_27.21 and PYO2014_28 offer an interesting example, as these two draft genomes are almost completely overlapping in terms of relative abundance in the two samples. As stated earlier, these two draft genomes have high ANI and both had low similarity to the common best reference,
Yersinia phage phi80-18. HostPhinder predicted
Yersinia enterocolitica to be the host of both, yet with a low confidence, see last column in
Tables S1 and S2.
Figure 3f displays the sequence similarity between the two bins. These results thus further support the conclusion that this phage draft is an example of a previously unsequenced phage genome.
The bottom right corner of
Figure 4 is populated by PYO97’s bins with low bin coverage by PYO2014’s reads, whilst the top left clusters PYO2014’s bins with low bin coverage by PYO97’s reads. The bins in these two parts of the figure are thus most likely phages added (top left corner) or removed (lower right corner) when constructing the cocktails at the two time points: 1997 and 2014.
We next determined the distances in composition between samples PYO97, PYO2000 and PYO2014 using Mash. The algorithm searches shared k-mers between samples and gave a measure of global mutation distance that takes continuous values between 0 and 1. For each representative k-mer, Mash does not take into account how many of those k-mers are present in each sample, only whether it is present or not. Therefore, the distances are to be considered qualitatively as distances in the variety of phages between samples and not as differences in phage abundances.
Distances are, in general, low between the samples (D < 0.2),
Table 10, as expected since the different samples are of the same cocktail and contain mostly shared sequences. PYO2014 has the highest distance to the other two samples. From this, it can be derived that a higher number of phages are unique to PYO2014 and absent in the other samples. Conceivably from the date of production, PYO97 and PYO2000 are less distant to each other (0.113 ± 0.0006) than they are to PYO2014, (0.132 ± 0.0008 and 0.138 ± 0.0009, respectively).
4. Discussion
In this paper, we aimed to investigate the composition of four batches of PYO cocktail, produced at the Eliava Institute in 1997, 2000, 2010, and 2014, by means of sequencing and metagenomic analysis. The PYO cocktails from 1997 and 2014 had been stored in a fridge at approximately 4 °C. We were able to extract DNA of high quality from these samples and likewise obtained high-quality sequence reads. We did not test the infectivity of the phages in the cocktails, but have previously found that phages from another cocktail from the Eliava Institute, the INTESTI cocktail, retain their infectivity after storage under similar conditions for at least two years [
9]. The phages in the INTESTI cocktail lost their infectivity when they were frozen by mistake without the addition of glycerol. Similarly, the PYO cocktails from 2000 and 2010 had been frozen without the recommended addition of glycerol [
31]. Following thawing, we were not able to extract enough DNA of good quality from these cocktails and only obtained sequence reads from PYO2000, which were furthermore of a poorer quality than from PYO97 and PYO2014. We did not test whether the phages in PYO2000 and PYO2010 had also lost their infectivity, but expect that they had. It is worth mentioning that the recommended long-term storage of phages is freezing −80 °C after addition of glycerol [
31]. Alternatively, phages can be freeze dried and stored at room temperature [
32].
The reads from PYO97 and PYO2014 were assembled into contigs, which were binned into phage draft genomes in a reference independent manner. This is contrary to what was previously done for the INTESTI cocktail [
9], where contigs were binned based on Blast searches to public databases. For the purpose of binning the contigs, we used MetaBAT, a method that bins according to the tetranucleotide frequency distances of the contigs. Further, MetaBAT is able to use the co-abundances of contigs in multiple samples, i.e., the consistency in coverage fluctuations of groups of contigs between samples. The method is optimized to handle huge assemblies for a number of samples greater than ten. Since our study involved only two samples of good quality, MetaBAT could not base contigs binning on the co-abundance information, but only on the tetranucleotide frequency distances. This might explain why, consequent to binning, we had to manually curate the generated bins. Two phage draft genomes, one from each sample, were in fact each manually split into two phage draft genomes and other bins were merged according to the coverage consistency and closest reference genome, resulting in five merged draft genomes.
Phage draft genomes were further classified into categories based on their similarity to a reference genome and/or to a phage draft genome in the other sample. This allowed us to identify a group of phage draft genomes that were highly similar to a reference genome and present in both samples. These included draft genomes predicted to target
E. faecalis,
E. faecium,
E. coli,
P. mirabilis,
P. aeruginosa, and
S. aureus. Other near-complete and partial draft genomes, even if without a counterpart in the other sample or reference genome, were predicted to target also
C. sakazakii,
K. pneumoniae,
Shigella, and species of
Salmonella. Only the prediction of phages targeting
C. sakazakii and
K. pneumoniae were counter to our expectations as the declared activity of the PYO cocktail includes
Shigella,
Salmonella,
E. coli,
Proteus,
S. aureus,
P. aeruginosa and
Enterococcus. Previous studies have shown the close taxonomic relatedness between bacteria of the Enterobacteriaceae family [
33,
34], which includes
Escherichia,
Klebsiella,
Salmonella and
Shigella, suggesting that the prediction of
K. pneumoniae might be a misprediction. Besides, even though phages are usually strain-specific, phages capable of infecting distinct but related hosts, polyvalent phages, are commonly observed among phages of Enterobacteria [
35,
36,
37,
38], which does not rule out the presence of this type of phages in the cocktail.
To the best of our knowledge, the ANI thresholds for when a phage belongs to a certain species, genus, or family have not been defined. However, we suggest that the phage draft genomes in category 1 and 2 represent phages that likely belong to previously sequenced phage species or at least previously defined genera. Examples include PYO97_11 and PYO2014_26.13 that both closely resemble Pseudomonas phage PEV2, a N4likevirus. The phage draft genomes in categories 3 and 4 are, on the other hand, likely to be the first representatives of previously undefined genera, in some cases perhaps even previously undefined sub-families or families, with ANI to the closest reference genomes from 10% to 70%. Examples include PYO97_27.21 which closely resembles PYO2014_28. Both phage draft genomes have an ANI to the closest reference of only approximately 20%. Another example is PYO2014_7, which does not have a counterpart in PYO97 and only has a ANI of 14.3% to the closest reference.
A total of twenty-two new near-complete or partial draft genomes were discovered, which did not resemble any publicly available genomes, or had only poor similarity to one. One of these phage draft genomes was even found to be present in both samples and with high relative abundance (PYO97_27.21/PYO2014_28).
In correspondence to this high number of previously unsequenced phage draft genomes, we also observed a relatively high percentage of reads that could not be mapped to any known phage genome. For PYO97, 11% of the reads could not be mapped to known phage sequences, while the corresponding percentage for PYO2014 was 39%. This relates to the continued scarceness of phage genome representation in public databases compared to bacterial sequences [
39]. A previous study from 2013 was able to map 61% of the reads from the Microgen ColiProteus cocktail to public genomes [
10].
For PYO97, 17% of the bins were not predicted to be of phage origin, while for PYO2014 the corresponding percentage was 10. When predicting if bins were of phage origin, we used MetaPhinder with a very stringent threshold of 10% ANI. This is a far more conservative threshold than suggested in the original paper describing the MetaPhinder method [
23], where the ANI threshold to classify a contig as of phage origin was set to 1.7% ANI. Further, the performance of MetaPhinder is dependent on the size and diversity of a reference database of previously sequenced phages. We thus consider it likely that the bins predicted to be of non-phage origin are due to a limited diversity in the previously sequenced phage genomes rather than, e.g., contamination. This hypothesis is supported by the analysis using MGmapper, which showed that only a negligible amount of the raw sequence reads mapped to reference databases containing sequences from Bacteria, Archaea, MetaHitAssembly, HumanMicrobiome, Bacteria_draft, Human, Virus, or Fungi. Most of the bins predicted to be of non-phage origin had the highest similarity to sequences annotated as uncultured Mediterranean phages. It is worth noticing that phages annotated as uncultured Mediterranean phages counted 28.8% of the 3889 WGS used to search for references to the bins, which raises the chance that they were randomly selected.
A coverage analysis that included PYO2000 showed a closer similarity of this cocktail batch to the batch from 1997 than that from 2014, in terms of composition. This is also to be expected as there are only 3 years between the production of the first two cocktails compared to the second and the last batches, which were produced with 14 years in between. The phage draft genomes of the PYO97 and PYO2014 cocktails showed huge differences in depth coverages within the samples, indicating as much as a thousand-fold difference between the most and least abundant phages. We speculate that the draft genomes represented by few sequence reads may derive from phages of older batches that have been diluted over time. Alternatively, they may derive from activated prophages integrated in the bacterial hosts used for phage enrichment, as previously suggested [
10]. In the previous study by our group of the INTESTI cocktail [
9], we did not observe such high differences in abundances. This might, however, be due to the general much lower sequencing depth of the INTESTI cocktail, which would not have allowed for the detection of the phages found at very low concentrations. It is worth pointing out the composition comparison presented here could not account for potential compositional variations within the batches nor for any biases that might have been introduced during sample processing. This is an insight that could be gained by analyzing multiple samples per batch and/or introducing replicates; however, this was beyond the scope of this study.
One of the limitations of the analysis applied here is that neither the lab sample preparation nor the sequencing library construction enriched for RNA sequences. Therefore, likely present
Pseudomonas phages of potential clinical importance as antimicrobials [
40], could not be detected. Besides small RNA coliphages, ssDNA phages were likely missed. In fact, the amplification step of the Illumina sequencing used here is based on the ligation of dsDNA adapters to sheared DNA. Since the ligation occurs between dsDNA fragments, ssDNA phages of the families
Microviridae and
Inoviridae could not be efficiently recovered by this approach [
41,
42]. Furthermore, the binning method that we chose yielded only bins of 10,000 bp or larger. Although we were able to bin more than 90% of the basepairs represented in the contigs, the threshold of 10,000 bp might have sorted out small DNA phages, for instance small
E.coli phages [
43].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}