Regional Changes in the Sequence of Cotton Leaf Curl Multan Betasatellite

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Collection
2.2. PCR-Mediated Amplification and Cloning of Betasatellites
2.3. Sequence Analysis
3. Results
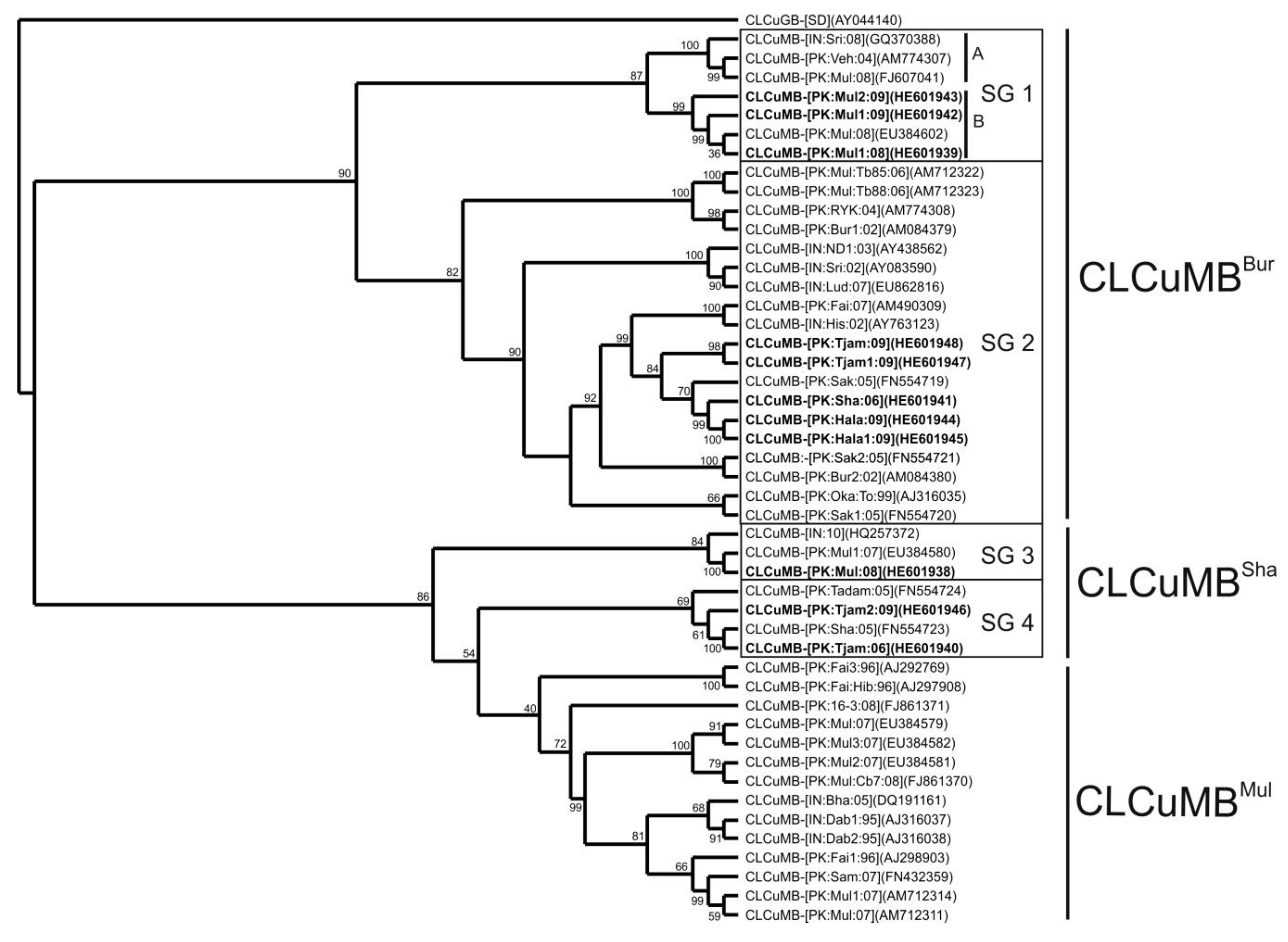
3.1. Analysis of Betasatellite Sequences

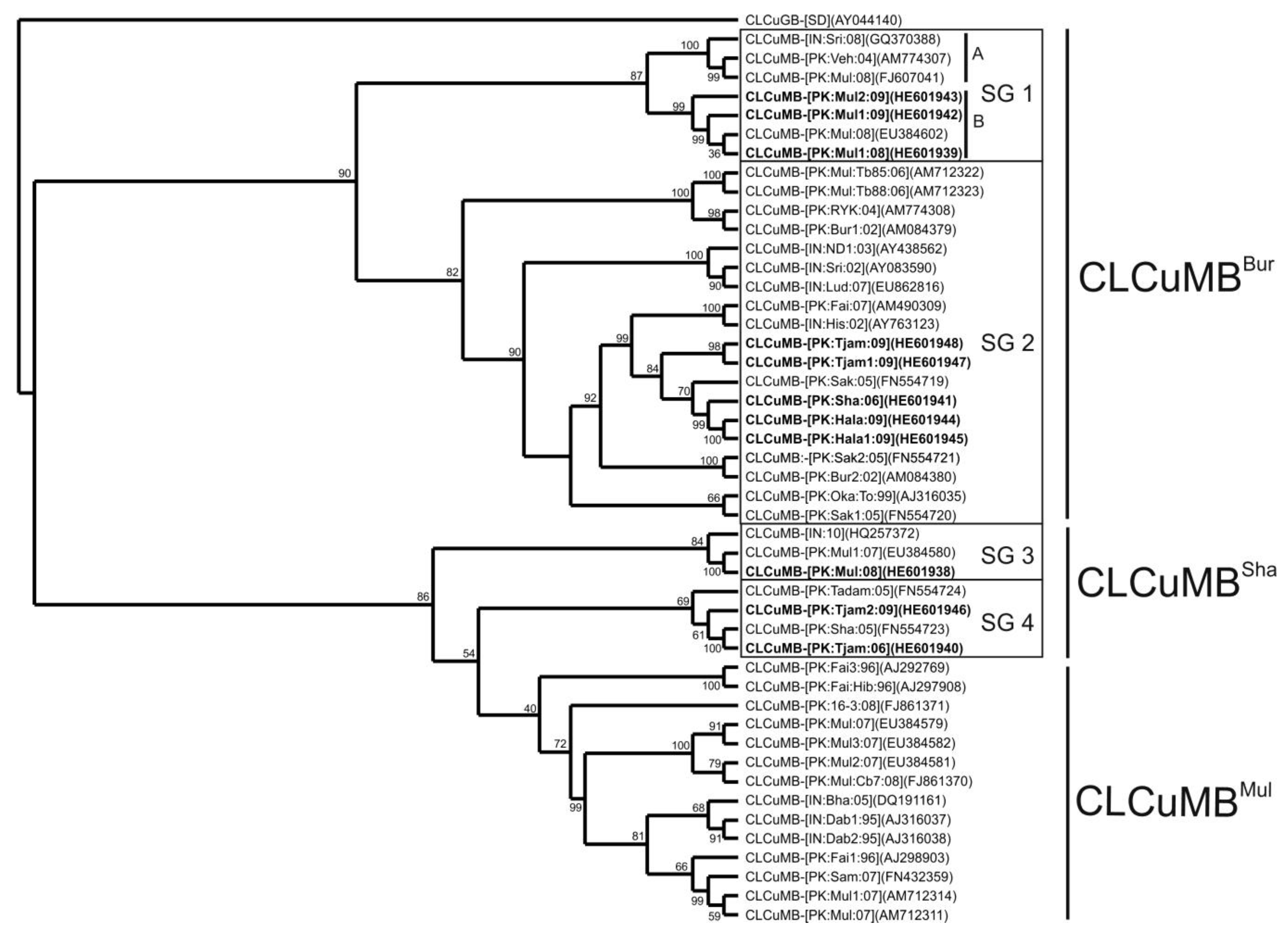{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Isolate descriptor | Origin | Accession number | Size (nt) | Position of βC1 gene (coordinates of start/stop codons) |
|---|---|---|---|---|
| [PK:Hala:09] | Hala/Sindh | HE601944 | 1350 | 195–551 |
| [PK:Hala1:09] | Hala/Sindh | HE601945 | 1350 | 195–551 |
| [PK:Sha:06] | Shahdadpur/Sindh | HE601941 | 1375 | 195–551 |
| [PK:Tjam2:09] | Tandojam/Sindh | HE601946 | 1364 | 195–551 |
| [PK:Tjam1:09] | Tandojam/Sindh | HE601947 | 1348 | 195–551 |
| [PK:Tjam:09] | Tandojam/Sindh | HE601948 | 1349 | 194–550 |
| [PK:Tjam:06] | Tandojam/Sindh | HE601940 | 1350 | 195–551 |
| [PK:Mul:08] | Multan/Punjab | HE601938 | 1345 | 195–551 |
| [PK:Mul1:08] | Multan/Punjab | HE601939 | 1349 | 195–551 |
| [PK:Mul1:09] | Multan/Punjab | HE601942 | 1350 | 195–551 |
| [PK:Mul2:09] | Multan/Punjab | HE601943 | 1355 | 195–551 |
3.2. Variation in SCR Sequences
| Isolate descriptor | Origin | Accession number | Size (nt) | Coordinates of deleted region * |
|---|---|---|---|---|
| [PK:Sak:06] | Sakrand/Sindh | HE602942 | 645 | 048–758 |
| [PK:Sak1:06] | Sakrand/Sindh | HE602943 | 690 | 065–731 |
| [PK:Sak2:06] | Sakrand/Sindh | HE602944 | 668 | 065–735 |
| [PK:Sha1:06] | Shahdadpur/Sindh | HE602945 | 727 | 096–721 |
| [PK:Hala:09] | Hala/Sindh | HE602950 | 788 | 202–763 |
| [PK:Hala1:09] | Hala/Sindh | HE602951 | 788 | 202–763 |
| [PK:Hala3:09] | Hala/Sindh | HE602953 | 818 | 208–740 |
| [PK:Hala4:09] | Hala/Sindh | HE602956 | 699 | 110–763 |
| [PK:Mat1:09] | Matiari/Sindh | HE602957 | 681 | 099–786 |
| [PK:Hala5:09] | Hala/Sindh | HE602958 | 694 | 097–753 |
| [PK:Tjam:09] | Tandojam/Sindh | HE602959 | 688 | 116–780 |
| [PK:Sha:06] | Shahdadpur/Sindh | HE602934 | 680 | 157–832 |
| [PK:Sha2:06] | Shahdadpur/Sindh | HE602948 | 678 | 130–801 |
| [PK:Hala2:09] | Hala/Sindh | HE602952 | 712 | 053–696 |
| [PK:Tjam:06] | Tandojam/Sindh | HE602935 | 678 | 129–805 |
| [PK:Tjam1:06] | Tandojam/Sindh | HE602936 | 678 | 129–805 |
| [PK:Tadam:06] | Tandoadam/Sindh | HE602937 | 713 | 129–769 |
| [PK:Tadam1:06] | Tandoadam/Sindh | HE602938 | 697 | 115–771 |
| [PK:TAyar:06] | TandoAllahyar/Sindh | HE602939 | 680 | 116–780 |
| [PK:TAyar1:06] | TandoAllahyar/Sindh | HE602940 | 735 | 153–773 |
| [PK:TAyar2:06] | TandoAllahyar/Sindh | HE602941 | 690 | 084–748 |
| [PK:TAyar3:06] | TandoAllahyar/Sindh | HE602946 | 685 | 117–805 |
| [PK:TAyar4:06] | TandoAllahyar/Sindh | HE602947 | 809 | 151–714 |
| [PK:Mat:09] | Matiari/Sindh | HE602949 | 749 | 115–732 |
| [PK:Mul:09] | Multan/Punjab | HE602954 | 703 | 105–754 |
| [PK:Mul1:09] | Multan/Punjab | HE602955 | 953 | 224–631 |
3.3. Analysis of CLCuMB Sequences between the A-Rich Region and the SCR
3.4. Sequence Variation in the Predicted Amino Acid Sequences of βC1


4. Discussion
Supplementary Files
Acknowledgments
Author Contributions
Conflicts of Interest
References and Notes
- Sattar, M.N.; Kvarnheden, A.; Saeed, M.; Briddon, R.W. Cotton leaf curl disease—An emerging threat to cotton production worldwide. J. Gen. Virol. 2013, 94, 695–710. [Google Scholar] [CrossRef]
- Briddon, R.W.; Markham, P.G. Cotton leaf curl virus disease. Virus Res. 2000, 71, 151–159. [Google Scholar] [CrossRef]
- Mansoor, S.; Briddon, R.W.; Zafar, Y.; Stanley, J. Geminivirus disease complexes: An emerging threat. Trends Plant Sci. 2003, 8, 128–134. [Google Scholar] [CrossRef]
- Rajagopalan, P.A.; Naik, A.; Katturi, P.; Kurulekar, M.; Kankanallu, R.S.; Anandalakshmi, R. Dominance of resistance-breaking Cotton leaf curl Burewala virus (CLCuBuV) in northwestern India. Arch. Virol. 2012, 157, 855–868. [Google Scholar] [CrossRef]
- Briddon, R.W.; Mansoor, S.; Bedford, I.D.; Pinner, M.S.; Saunders, K.; Stanley, J.; Zafar, Y.; Malik, K.A.; Markham, P.G. Identification of DNA components required for induction of cotton leaf curl disease. Virology 2001, 285, 234–243. [Google Scholar] [CrossRef]
- Mansoor, S.; Briddon, R.W.; Bull, S.E.; Bedford, I.D.; Bashir, A.; Hussain, M.; Saeed, M.; Zafar, M.Y.; Malik, K.A.; Fauquet, C.; et al. Cotton leaf curl disease is associated with multiple monopartite begomoviruses supported by single DNA β. Arch. Virol. 2003, 148, 1969–1986. [Google Scholar] [CrossRef]
- Brown, J.K.; Fauquet, C.M.; Briddon, R.W.; Zerbini, M.; Moriones, E.; Navas-Castillo, J. Geminiviridae. In Virus Taxonomy—Ninth Report of the International Committee on Taxonomy of Viruses; King, A.M.Q., Adams, M.J., Carstens, E.B., Lefkowitz, E.J., Eds.; Elsevier Inc.: London, UK; Waltham, MA/San Diego, CA, USA, 2012; pp. 351–373. [Google Scholar]
- Melgarejo, T.A.; Kon, T.; Rojas, M.R.; Paz-Carrasco, L.; Zerbini, F.M.; Gilbertson, R.L. Characterization of a New World monopartite begomovirus causing leaf curl disease of tomato in Ecuador and Peru reveals a new direction in geminivirus evolution. J. Virol. 2013, 87, 5397–5413. [Google Scholar] [CrossRef]
- Sánchez-Campos, S.; Martínez-Ayala, A.; Márquez-Martín, B.; Aragón-Caballero, L.; Navas-Castillo, J.; Moriones, E. Fulfilling Koch’s postulates confirms the monopartite nature of tomato leaf deformation virus, a begomovirus native to the New World. Virus Res. 2013, 173, 286–293. [Google Scholar] [CrossRef]
- Briddon, R.W.; Mansoor, S. Beta ssDNA satellites. In Encyclopedia of Virology; Mahy, B.W.J., van Regenmortel, M.H.V., Eds.; Academic Press: Oxford, UK, 2008; pp. 314–321. [Google Scholar]
- Briddon, R.W.; Ghabrial, S.; Lin, N.S.; Palukaitis, P.; Scholthof, K.B.G.; Vetten, H.J. Satellites and other virus-dependent nucleic acids. In Virus Taxonomy—Ninth Report of the International Committee on Taxonomy of Viruses; King, A.M.Q., Adams, M.J., Carstens, E.B., Lefkowitz, E.J., Eds.; Elsevier Inc.: London, UK; Waltham, MA/San Diego, CA, USA, 2012; pp. 1209–1219. [Google Scholar]
- Briddon, R.W.; Bull, S.E.; Amin, I.; Mansoor, S.; Bedford, I.D.; Dhawan, P.; Rishi, N.; Siwatch, S.S.; Abdel-Salam, A.M.; Markham, P.G. Diversity of DNA β; a satellite molecule associated with some monopartite begomoviruses. Virology 2003, 312, 106–121. [Google Scholar] [CrossRef]
- Leke, W.N.; Sattar, M.N.; Ngane, E.B.; Ngeve, J.M.; Kvarnheden, A.; Brown, J.K. Molecular characterization of begomoviruses and DNA satellites associated with okra leaf curl disease in Cameroon. Virus Res. 2013, 174, 116–125. [Google Scholar] [CrossRef]
- Briddon, R.W. Cotton leaf curl disease, a multicomponent begomovirus complex. Mol. Plant Pathol. 2003, 4, 427–434. [Google Scholar] [CrossRef]
- Hanley-Bowdoin, L.; Settlage, S.B.; Orozco, B.M.; Nagar, S.; Robertson, D. Geminviruses: Models for plant DNA replication, transcription, and cell cycle regulation. Crit. Rev. Plant Sci. 1999, 18, 71–106. [Google Scholar] [CrossRef]
- Amin, I.; Hussain, K.; Akbergenov, R.; Yadav, J.S.; Qazi, J.; Mansoor, S.; Hohn, T.; Fauquet, C.M.; Briddon, R.W. Suppressors of RNA silencing encoded by the components of the cotton leaf curl begomovirus-betasatellite complex. Mol. Plant Microbe Interact. 2011, 24, 973–983. [Google Scholar] [CrossRef]
- Cui, X.; Li, G.; Wang, D.; Hu, D.; Zhou, X. A begomovirus DNA β-encoded protein binds DNA, functions as a suppressor of RNA silencing, and targets the cell nucleus. J. Virol. 2005, 79, 10764–10775. [Google Scholar] [CrossRef]
- Kon, T.; Sharma, P.; Ikegami, M. Suppressor of RNA silencing encoded by the monopartite tomato leaf curl Java begomovirus. Arch. Virol. 2007, 152, 1273–1282. [Google Scholar] [CrossRef]
- Qazi, J.; Amin, I.; Mansoor, S.; Iqbal, M.J.; Briddon, R.W. Contribution of the satellite encoded gene βC1 to cotton leaf curl disease symptoms. Virus Res. 2007, 128, 135–139. [Google Scholar] [CrossRef]
- Saeed, M.; Zafar, Y.; Randles, J.W.; Rezaian, M.A. A monopartite begomovirus-associated DNA β satellite substitutes for the DNA B of a bipartite begomovirus to permit systemic infection. J. Gen. Virol. 2007, 88, 2881–2889. [Google Scholar] [CrossRef]
- Iqbal, Z.; Sattar, M.N.; Kvarnheden, A.; Mansoor, S.; Briddon, R.W. Effects of the mutation of selected genes of Cotton leaf curl Kokhran virus on infectivity, symptoms and the maintenance of Cotton leaf curl Multan betasatellite. Virus Res. 2012, 169, 107–116. [Google Scholar] [CrossRef]
- Saunders, K.; Bedford, I.D.; Briddon, R.W.; Markham, P.G.; Wong, S.M.; Stanley, J. A unique virus complex causes Ageratum yellow vein disease. Proc. Natl. Acad. Sci. USA 2000, 97, 6890–6895. [Google Scholar] [CrossRef]
- Amrao, L.; Amin, I.; Shahid, M.S.; Briddon, R.W.; Mansoor, S. Cotton leaf curl disease in resistant cotton is associated with a single begomovirus that lacks an intact transcriptional activator protein. Virus Res. 2010, 152, 153–163. [Google Scholar]
- Amin, I.; Mansoor, S.; Amrao, L.; Hussain, M.; Irum, S.; Zafar, Y.; Bull, S.E.; Briddon, R.W. Mobilisation into cotton and spread of a recombinant cotton leaf curl disease satellite. Arch. Virol. 2006, 151, 2055–2065. [Google Scholar] [CrossRef]
- Amrao, L.; Akhter, S.; Tahir, M.N.; Amin, I.; Briddon, R.W.; Mansoor, S. Cotton leaf curl disease in Sindh province of Pakistan is associated with recombinant begomovirus components. Virus Res. 2010, 153, 161–165. [Google Scholar] [CrossRef]
- Zaffalon, V.; Mukherjee, S.; Reddy, V.; Thompson, J.; Tepfer, M. A survey of geminiviruses and associated satellite DNAs in the cotton-growing areas of northwestern India. Arch. Virol. 2011, 157, 483–495. [Google Scholar]
- Tahir, M.N.; Amin, I.; Briddon, R.W.; Mansoor, S. The merging of two dynasties—Identification of an African cotton leaf curl disease-associated begomovirus with cotton in Pakistan. PLoS One 2011, 6, e20366. [Google Scholar]
- Doyle, J.J.; Doyle, J.L. Isolation of plant DNA from fresh tissue. Focus 1990, 12, 13–15. [Google Scholar]
- Briddon, R.W.; Bull, S.E.; Mansoor, S.; Amin, I.; Markham, P.G. Universal primers for the PCR-mediated amplification of DNA β; a molecule associated with some monopartite begomoviruses. Mol. Biotechnol. 2002, 20, 315–318. [Google Scholar] [CrossRef]
- Larkin, M.A.; Blackshields, G.; Brown, N.P.; Chenna, R.; McGettigan, P.A.; McWilliam, H.; Valentin, F.; Wallace, I.M.; Wilm, A.; Lopez, R. Clustal W and Clustal X version 2.0. Bioinformatics 2007, 23, 2947–2948. [Google Scholar] [CrossRef]
- Page, R.D.M. TREEVIEW: An application to display phylogenetic trees on personal computers. Comput. Appl. Biosci. 1996, 12, 357–358. [Google Scholar]
- Martin, D.P.; Lemey, P.; Lott, M.; Moulton, V.; Posada, D.; Lefeuvre, P. RDP3: A flexible and fast computer program for analyzing recombination. Bioinformatics 2010, 26, 2462–2463. [Google Scholar]
- Briddon, R.W.; Brown, J.K.; Moriones, E.; Stanley, J.; Zerbini, M.; Zhou, X.; Fauquet, C.M. Recommendations for the classification and nomenclature of the DNA-β satellites of begomoviruses. Arch. Virol. 2008, 153, 763–781. [Google Scholar] [CrossRef]
- Shahid, M.S.; Mansoor, S.; Briddon, R.W. Complete nucleotide sequences of cotton leaf curl Rajasthan virus and its associated DNA beta molecule infecting tomato. Arch. Virol. 2007, 152, 2131–2134. [Google Scholar] [CrossRef]
- Briddon, R.W.; Akbar, F.; Iqbal, Z.; Amrao, L.; Amin, I.; Saeed, M.; Mansoor, S. Effects of genetic changes to the begomovirus/betasatellite complex causing cotton leaf curl disease in South Asia post-resistance breaking. Virus Res. 2014, in press. [Google Scholar]
- Cai, J.H.; Xie, K.; Lin, L.; Qin, B.X.; Chen, B.S.; Meng, J.R.; Liu, Y.L. Cotton leaf curl Multan virus newly reported to be associated with cotton leaf curl disease in China. Plant Pathol. J. 2010, 59, 794–795. [Google Scholar]
- Mansoor, S.; Amin, I.; Iram, S.; Hussain, M.; Zafar, Y.; Malik, K.A.; Briddon, R.W. The breakdown of resistance in cotton to cotton leaf curl disease in Pakistan. Plant Pathol. 2003, 52, 784. [Google Scholar] [CrossRef]
- Saeed, M. Tomato leaf curl virus and Cotton leaf curl Multan betasatellite can cause mild transient symptoms in cotton. Australas. Plant Dis. Notes 2010, 5, 58–60. [Google Scholar]
- Saunders, K.; Briddon, R.W.; Stanley, J. Replication promiscuity of DNA-β satellites associated with monopartite begomoviruses; deletion mutagenesis of the Ageratum yellow vein virus DNA-β satellite localizes sequences involved in replication. J. Gen. Virol. 2008, 89, 3165–3172. [Google Scholar] [CrossRef]
- Lin, B.; Behjatnia, A.A.; Dry, I.B.; Randles, J.W.; Rezaian, M.A. High-affinity Rep-binding is not required for the replication of a geminivirus DNA and its satellite. Virology 2003, 305, 353–363. [Google Scholar] [CrossRef]
- Nawaz-ul-Rehman, M.S.; Mansoor, S.; Briddon, R.W.; Fauquet, C.M. Maintenance of an old world betasatellite by a new world helper begomovirus and possible rapid adaptation of the betasatellite. J. Virol. 2009, 83, 9347–9355. [Google Scholar] [CrossRef]
- Kumar, P.; Ushaa, R.; Zrachya, A.; Levyb, Y.; Spanov, H.; Gafni, Y. Protein–protein interactions and nuclear trafficking of coat protein and βC1 protein associated with bhendi yellow vein mosaic disease. Virus Res. 2006, 122, 127–136. [Google Scholar] [CrossRef]
- Yang, J.-Y.; Iwasaki, M.; Machida, C.; Machida, Y.; Zhou, X.; Chua, N.-H. βC1, the pathogenicity factor of TYLCCNV, interacts with AS1 to alter leaf development and suppress selective jasmonic acid responses. Genes Dev. 2008, 22, 2564–2577. [Google Scholar] [CrossRef]
- Argüello-Astorga, G.R.; Ruiz-Medrano, R. An iteron-related domain is associated to motif 1 in the replication proteins of geminiviruses: Identification of potential interacting amino acid-base pairs by a comparartive approach. Arch. Virol. 2001, 146, 1465–1485. [Google Scholar] [CrossRef]
- Eini, O.; Dogra, S.; Selth, L.A.; Dry, I.B.; Randles, J.W.; Rezaian, M.A. Interaction with a host ubiquitin-conjugating enzyme is required for the pathogenicity of a geminiviral DNA β satellite. Mol. Plant Microbe Interact. 2009, 22, 737–746. [Google Scholar] [CrossRef]
- Azhar, M.T.; Akhtar, S.; Mansoor, S. Cotton leaf curl Multan betasatellite strains cloned from Gossypium barbadense further supports selection due to host resistance. Virus Genes 2012, 45, 402–405. [Google Scholar] [CrossRef]
- Nawaz-ul-Rehman, M.S.; Briddon, R.W.; Fauquet, C.M. A melting pot of Old World begomovirusesand their satellites infecting a collection of Gossypium species in Pakistan. PLoS One 2012, 7, e40050. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Akhtar, S.; Tahir, M.N.; Baloch, G.R.; Javaid, S.; Khan, A.Q.; Amin, I.; Briddon, R.W.; Mansoor, S. Regional Changes in the Sequence of Cotton Leaf Curl Multan Betasatellite. Viruses 2014, 6, 2186-2203. https://doi.org/10.3390/v6052186
Akhtar S, Tahir MN, Baloch GR, Javaid S, Khan AQ, Amin I, Briddon RW, Mansoor S. Regional Changes in the Sequence of Cotton Leaf Curl Multan Betasatellite. Viruses. 2014; 6(5):2186-2203. https://doi.org/10.3390/v6052186
Chicago/Turabian StyleAkhtar, Sohail, Muhammad Nouman Tahir, Ghulam Rasool Baloch, Shaista Javaid, Ali Qaiser Khan, Imran Amin, Rob W. Briddon, and Shahid Mansoor. 2014. "Regional Changes in the Sequence of Cotton Leaf Curl Multan Betasatellite" Viruses 6, no. 5: 2186-2203. https://doi.org/10.3390/v6052186
APA StyleAkhtar, S., Tahir, M. N., Baloch, G. R., Javaid, S., Khan, A. Q., Amin, I., Briddon, R. W., & Mansoor, S. (2014). Regional Changes in the Sequence of Cotton Leaf Curl Multan Betasatellite. Viruses, 6(5), 2186-2203. https://doi.org/10.3390/v6052186