
Optimizing Antibody Affinity and Developability Using a Framework–CDR Shuffling Approach—Application to an Anti-SARS-CoV-2 Antibody

 , ,
, ,
Abstract
1. Introduction
2. Results
2.1. A CDR–Framework Shuffling Approach Optimizing the Target-Binding Affinity and Developability

{kind=link}
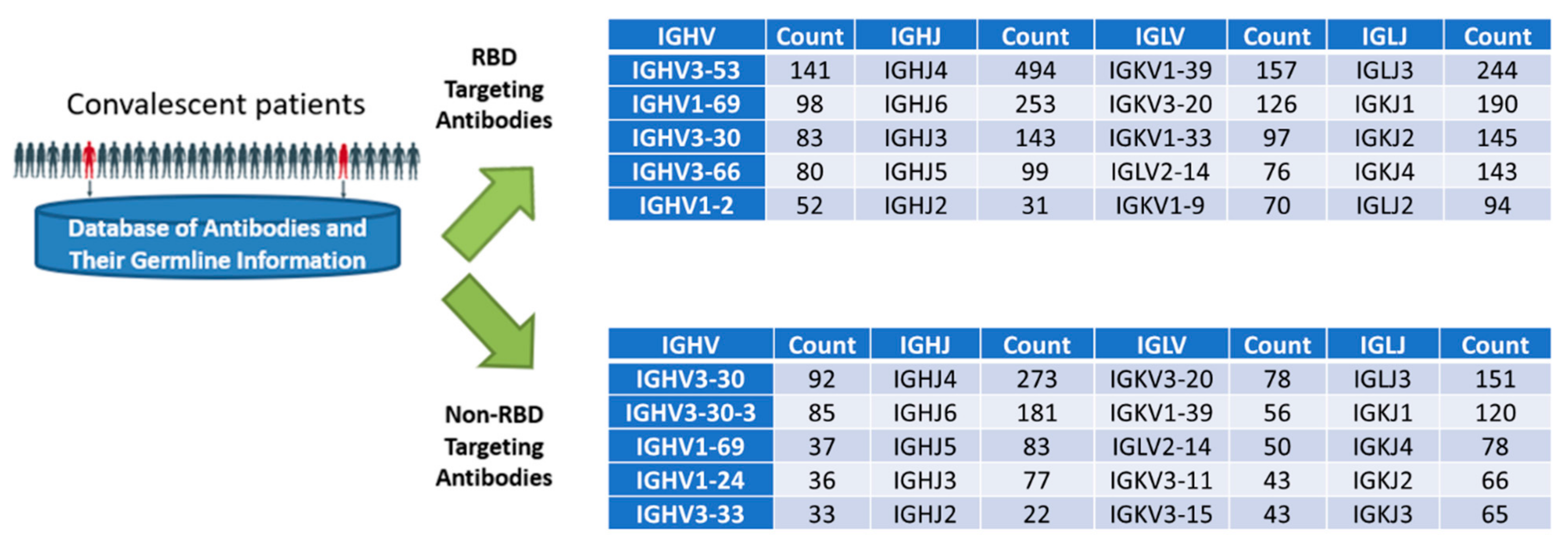{kind=link}
{kind=link}
{kind=link}
| Loop | Group | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | Full Loop DB Count | |||||
| H1 | 0 | K,53.67 | A,75.95 | S,97.66 | G,97.55 | Y,42.87 | T,70.22 | F,91.99 | T,37.38 | G,6.32 | Y,77.92 | Y,15.09 | M,46.29 | H,30.46 | 27772 | |||||
| 1 | F,39.16 | 20326 | ||||||||||||||||||
| 2 | S,43.75 | 1285 | ||||||||||||||||||
| 3 | W,21.37 | 220 | ||||||||||||||||||
| 4 | S,48.58 | 105 | ||||||||||||||||||
| 5 | D,11.18 | 3 | ||||||||||||||||||
| Parapred Score | 0 | 0 | 3.6 | 9.7 | 24 | 46 | 8.4 | 80 | 90 | 81 | 97 | 1.7 | 0 | |||||||
| Loop | Group | 50 | 51 | 52 | 52A | 53 | 54 | 55 | 56 | 57 | 58 | Full Loop DB Count | ||||||||
| H2 | 0 | R,10.87 | I,85.21 | N,28.33 | P,74.93 | N,16.16 | S,17.33 | G,66.48 | G,9.21 | T,70.29 | N,41.62 | 6726 | ||||||||
| 1 | T,4.95 | 324 | ||||||||||||||||||
| 2 | S,10.18 | 70 | ||||||||||||||||||
| 3 | S,15.98 | 59 | ||||||||||||||||||
| Parapred Score | 84 | 3.6 | 93 | 45 | 91 | 81 | 23 | 72 | 45 | 63 | ||||||||||
| Loop | Group | 93 | 94 | 95 | 96 | 97 | 98 | 99 | 100 | 100A | 100B | 100C | 100D | 100E | 100F | 100G | 100H | 100I | 101 | 102 |
| H3 | 0 | A,92 | R,76 | V,7 | P,7 | Y,50 | C,100 | S,62 | S,32 | T,31 | S,52 | C,100 | H,4 | R,7 | D,4 | W,5 | Y,18 | F,70 | D,80 | L,7 |
| 1 | W,0.29 | |||||||||||||||||||
| 2 | I,14 | |||||||||||||||||||
| 3 | E,12 | |||||||||||||||||||
| 4 | T,11 | |||||||||||||||||||
| 5 | Y,64 | |||||||||||||||||||
| 6 | Y,64 | S,15 | ||||||||||||||||||
| Parapred Score | 1.5 | 37 | 65 | 69 | 93 | 90 | 81 | 75 | 80 | 75 | 69 | 80 | 82 | 57 | 85 | 20 | 3.8 | 19 | 4.5 | |
| Loop | Group | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 30A | 30B | 30C | 30D | 30E | 30F | 31 | 32 | 33 | 34 | Full Loop DB Count | |
| L1 | 0 | R,7.74 | S,97.64 | S,97.50 | Q,94.51 | S,85.60 | L,13.94 | L,88.90 | D,4.35 | S,74.50 | D,2.57 | D,7.77 | G,3.49 | N,5.35 | T,3.47 | Y,87.81 | L,96.02 | D,3.13 | 695 | |
| 1 | K,90.02 | 4 | ||||||||||||||||||
| 2 | I,10.89 | 1 | ||||||||||||||||||
| 3 | N,88.62 | 0 | ||||||||||||||||||
| 4 | S,3.57 | 0 | ||||||||||||||||||
| Parapred Score | 0.9 | 0.2 | 1.4 | 18 | 13 | 5.6 | 23 | 76 | 63 | 79 | 78 | 50 | 68 | 6.3 | 85 | 0.1 | 14 | |||
| Loop | Group | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | Full Loop DB Count | ||||||||||
| L2 | 0 | Y,87.77 | T,1.44 | L,0.25 | S,74.94 | Y,1.21 | R,71.09 | A,26.76 | S,69.71 | 774 | ||||||||||
| 1 | S,4.28 | 33 | ||||||||||||||||||
| 2 | V,15.37 | 32 | ||||||||||||||||||
| Parapred Score | 57 | 66 | 5.8 | 31 | 81 | 20 | 29 | 45 | ||||||||||||
| Loop | Group | 89 | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | Full Loop DB Count | |||||||||
| L3 | 0 | M,11.33 | Q,91.15 | R,7.35 | I,1.79 | E,1.20 | F,7.13 | P,85.24 | L,20.64 | T,88.31 | 56 | |||||||||
| 1 | W,16.28 | 34 | ||||||||||||||||||
| 2 | I,5.94 | 20 | ||||||||||||||||||
| 3 | L,8.20 | 0 | ||||||||||||||||||
| Parapred Score | 8.7 | 4.5 | 92 | 91 | 92 | 88 | 11 | 45 | 0.9 |
| VH Framework | VL Framework | ||||
|---|---|---|---|---|---|
| HF_Group | Scaffold (Accession No.) | Sequence | LF_Group | Scaffold (Accession No.) | Sequence |
| 1 | CAB_NO: 1036253 | EVQLVQSGAEVKKPGASVKVACKASGYTFTDYYIHWVRQAPGQGLEWMGRINPNSGGTNYAQNFQGRVTMTRDTSINTASMELSRLTSDDTAVYYCARRGYCSGGSCYGGDYFDYWGQGTLVTVSS | 1 | CAB_NO:319636 | DIVLTQSPLSLPVTPGETASISCTSSQSLLDRDDGNTYLDWYLQKPGQSPQLLIYTLSSRASGVPDRFSASGSGTDFTLKISGVEAEDVGVYYCMQRIEFPLTFGGGTKLEIK |
| 2 | CAB_NO:33048 | QVQLVQSGAEVKKPGSSVKVSCKASGGTFSSYAISWVRQAPGQGLEWMGGIIPIFGTANYAQKFQGRVTITADKSTSTAYMELSSLRSEDTAVYYCAREVDCSSTSCYGSWYFDLWGRGTLVTVSS | 2 | CAB_NO: 355327 | DIVLTQTPLSLPVTPGEPASMSCRSSQSLLDSDDGNTYLDWYLQKPGQSPQLLIHTLSYRASGVSDRFSGSGSGTDFTLKISRVEADDVGVYYCMQRTQFPLTFGGGTKVEIK |
| 3 | CAB_NO:1142140 | QVQLVESGAEVKRPGASVKVSCKASGYTFTSSPIHWVRQAPGQGLQWMGLINPGGGTSTFAQRFQGRVTMTRDTSTNTVYMDLSGLRSEDTAMYYCARAPSYDSGGSFPADYLDYWGQGTLVTVSS | 3 | CAB_NO:11070 | DVLMTQTPLSLPVSLGDQASISCRSSQSLVHSDGNTYLEWYLQKPGQSPNLLIYKLSNRFSGVPDRFSGSGSGTDFTLKISRVEAEDLGVYYCFQGSHVPPTFGGGTKLEIK |
| 4 | CAB_NO:454656 | QVHLVQSGAEVKKPGASVKVSCKASGYTFTSHGISWVRQAPGQGLEWMGWISTYNGNTNYPETLQGRVTMTTDTSTSTAYLEVRSLTPDDTAVYYCARVGCRSTSCWAGTHWFDPWGQGTLVTVSS | |||


2.2. Biochemical and In Vitro Characterization of SARS-CoV-2 Antibodies
3. Discussion
4. Methods
4.1. Databases Employed
4.2. Selection of Candidate CDRs for the Sampling Process
- CDR filtering was used based on the north cluster and length to establish a set of candidate CDRs:
- H1: length = 7, cluster = 13-A − 1154116 CDRs;
- H2: length = 6, cluster = 10-A − 691070 CDRsH3: length = 17, cystine at position 98,100C – 2018 CDRs;
- L1: length = 17, cluster = 16,17-A − 52446 CDRs;
- L2: length = 7, cluster = 8-A – 793224 CDRs;
- L3:length = 9,cluster = 9,10-A − 329011 CDRs.
- Mutations present in the candidate set of CDRs were scored using the following metrics:
- Frequency score: Here, , where is the probability of finding at position i in the candidate set, and is the probability of finding the template AA at position i in the candidate set. This score is meant to optimize the likelihood that the amino acid will be compatible with the structural properties of the paratope;
- Paratope probability: The probability that the position in question is in the paratope, given the template CDR sequence, as calculated by the Parapred tool [22]. This score was used to try and mutate amino acids mainly in the epitope–paratope interface;
- Blosum score: The Blosum62 matrix score for the AA substitution → . This score was intended to optimize the likelihood that will be compatible with the structural properties of the paratope;
- Substitution type: The type of AA substitution, where an identical AA = 0, substitution with an amino acid of the same class = 1, and substitution with an amino acid from a different class = 2. This score was intended to optimize the potential physiochemical changes in the epitope–paratope interface;
- CDR candidate selection using metrics and database occurrence. Given the metrics defined above and the database occurrence statistics, CDRs from the candidate were selected or new CDRs were engineered using mutations from the candidate set (Table 1).
4.3. Selection of Candidate VH/VL Frameworks for CDR/FWR Shuffling
- Heavy-Chain Filtering Process
- Stage 1:
- 1.
- North cluster: H1 = H1-13-A, H2 = H2-10-A, H3 length = 17:16,425 antibodies remaining;
- 2.
- Human germline identity > = 0.80: 16,231 antibodies remaining;
- 3.
- Orientation residues (36, 38, 42, 43, 44, 87, 98) match template residues (100% identity): 14,383;
- 4.
- Number of rare amino acids in the template (occurring in <1% of human residues in the antibody database) < = 10:9169.
- Stage 2:
- 5.
- Total rare amino acids after template CDR porting. Given the template CDRs may have unusual residues, the scaffolds are re-filtered to have less than 5 rare amino acids after porting the template CDRs (note that this looks redundant compared to step 4, but is necessary because the database only stores the total number of rare amino acids);
- 6.
- The PKA score is computed as a simple heuristic for antibody charge.
- Stage 3:
- 7.
- Scaffolds are sorted by their loop homology to the template, rare amino acids, and PKA scores and then sampled such that the final scaffold set will have a hamming distance of at least 12 between all final scaffolds; 40 scaffolds remained in the end.
- Stage 4:
- 8.
- Scaffolds satisfying the T-cell epitope criterion (no position should have more than the maximum number of alleles flagged at that position among CSTs, and no position should have more than the 90th percentile of alleles flagged at that position among CSTs) are considered for use in the candidate designs; 8 scaffolds remained in the end.
- Light-Chain Filtering Process
- Stage 1:
- 1.
- North cluster: L1 = L1-16,17-A, L2 = L2-8-A, L3 = L3-9,10-A: 101,166 antibodies remaining;
- 2.
- Human germline identity > = 85:74,839 antibodies remaining;
- 3.
- Orientation residues (36, 38, 42, 43, 44, 87, 98) match template residues (100% identity): 22,094;
- 4.
- Number of rare amino acids in the template (occurring in <1% of human residues in the antibody database) < = 5:21,184.
- Stage 2:
- 5.
- Total rare amino acids after template CDR porting. Given the template CDRs may have unusual residues, the scaffolds are re-filtered to have less than 5 rare amino acids after porting the template CDRs (note that this looks redundant compared to step 4, but is necessary because the DB only stores total number of rare amino acids);
- 6.
- The PKA score is computed as a simple heuristic for antibody charge.
- Stage 3:
- 7.
- Scaffolds are sorted by their loop homology to the template, rare amino acids, and PKA scores and then sampled such that the final scaffold set will have a hamming distance of at least 12 between all final scaffolds; 45 scaffolds remained in the end.
- Stage 4:
- 8.
- Scaffolds satisfying the T-cell epitope criterion (no position should have more than the maximum number of alleles flagged at that position among CSTs, and less than 5 positions should have more than the 90th percentile of alleles flagged at that position among CSTs) are considered for use in the candidate designs; 10 scaffolds remained in the end.
4.4. CDR–Framework Shuffling
- At least 1 HCDR and 1 LCDR came from the candidate pool in each construct;
- All candidate CDRs were used at least once;
- A given non-template CDR was used in at most 2 VH or VL chains, minimizing the risk of oversampling a deleterious CDR and losing valuable data on CDRs from the other paired chains;
- Each framework was paired with at least 2 non-template CDRs at least once, to ensure sufficient sampling diversity.
4.5. Expression and Purification of Recombinant Monoclonal Antibodies
4.6. Screening of Expressed Recombinant Antibodies Using an Enzyme-Linked Immunosorbant Assay (ELISA)
4.7. Affinity Determination using Octet (Biolayer Interferometry)
4.8. ELISA-Based ACE2 Inhibition Assay
4.9. Generation of SARS-CoV-2 Pseudoviral Particle
4.10. Pseudovirus Neutralization Assay
4.11. Plaque Reduction Neutralization Test (PRNT)
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saeed, A.F.; Wang, R.; Ling, S.; Wang, S. Antibody Engineering for Pursuing a Healthier Future. Front. Microbiol. 2017, 8, 495. [Google Scholar] [CrossRef]
- Jain, T.; Sun, T.; Durand, S.; Hall, A.; Houston, N.R.; Nett, J.H.; Sharkey, B.; Bobrowicz, B.; Caffry, I.; Yu, Y.; et al. Biophysical properties of the clinical-stage antibody landscape. Proc. Natl. Acad. Sci. USA 2017, 114, 944–949. [Google Scholar] [CrossRef]
- Thie, H.; Voedisch, B.; Dubel, S.; Hust, M.; Schirrmann, T. Affinity maturation by phage display. Methods Mol. Biol. 2009, 525, 309–322. [Google Scholar]
- Liu, X.; Taylor, R.D.; Griffin, L.; Coker, S.F.; Adams, R.; Ceska, T.; Shi, J.; Lawson, A.D.; Baker, T. Computational design of an epitope-specific Keap1 binding antibody using hotspot residues grafting and CDR loop swapping. Sci. Rep. 2017, 7, 41306. [Google Scholar] [CrossRef]
- Tharakaraman, K.; Robinson, L.N.; Hatas, A.; Chen, Y.L.; Siyue, L.; Raguram, S.; Sasisekharan, V.; Wogan, G.N.; Sasisekharan, R. Redesign of a cross-reactive antibody to dengue virus with broad-spectrum activity and increased in vivo potency. Proc. Natl. Acad. Sci. USA 2013, 110, E1555–E1564. [Google Scholar] [CrossRef]
- Tokuriki, N.; Stricher, F.; Serrano, L.; Tawfik, D.S. How protein stability and new functions trade off. PLoS Comput. Biol. 2008, 4, e1000002. [Google Scholar] [CrossRef]
- Soundararajan, V.; Zheng, S.; Patel, N.; Warnock, K.; Raman, R.; Wilson, I.A.; Raguram, S.; Sasisekharan, V.; Sasisekharan, R. Networks link antigenic and receptor-binding sites of influenza hemagglutinin: Mechanistic insight into fitter strain propagation. Sci. Rep. 2011, 1, 200. [Google Scholar] [CrossRef]
- Robinson, L.N.; Tharakaraman, K.; Rowley, K.J.; Costa, V.V.; Chan, K.R.; Wong, Y.H.; Ong, L.C.; Tan, H.C.; Koch, T.; Cain, D.; et al. Structure-Guided Design of an Anti-dengue Antibody Directed to a Non-immunodominant Epitope. Cell 2015, 162, 493–504. [Google Scholar] [CrossRef]
- Tit-Oon, P.; Tharakaraman, K.; Artpradit, C.; Godavarthi, A.; Sungkeeree, P.; Sasisekharan, V.; Kerdwong, J.; Miller, N.L.; Mahajan, B.; Khongmanee, A.; et al. Prediction of the binding interface between monoclonal antibody m102.4 and Nipah attachment glycoprotein using structure-guided alanine scanning and computational docking. Sci. Rep. 2020, 10, 18256. [Google Scholar] [CrossRef]
- Kanhasut, K.; Tharakaraman, K.; Ruchirawat, M.; Satayavivad, J.; Fuangthong, M.; Sasisekharan, R. Prediction of the structural interface between fibroblast growth factor23 and Burosumab using alanine scanning and molecular docking. Sci. Rep. 2022, 12, 14754. [Google Scholar] [CrossRef]
- Tharakaraman, K.; Watanabe, S.; Chan, K.R.; Huan, J.; Subramanian, V.; Chionh, Y.H.; Raguram, A.; Quinlan, D.; McBee, M.; Ong, E.Z.; et al. Rational Engineering and Characterization of an mAb that Neutralizes Zika Virus by Targeting a Mutationally Constrained Quaternary Epitope. Cell Host Microbe 2018, 23, 618–627.e6. [Google Scholar] [CrossRef]
- Ong, E.Z.; Budigi, Y.; Tan, H.C.; Robinson, L.N.; Rowley, K.J.; Winnett, A.; Hobbie, S.; Shriver, Z.; Babcock, G.J.; Ooi, E.E. Preclinical evaluation of VIS513, a therapeutic antibody against dengue virus, in non-human primates. Antiviral Res. 2017, 144, 44–47. [Google Scholar] [CrossRef]
- Budigi, Y.; Ong, E.Z.; Robinson, L.N.; Ong, L.C.; Rowley, K.J.; Winnett, A.; Tan, H.C.; Hobbie, S.; Shriver, Z.; Babcock, G.J.; et al. Neutralization of antibody-enhanced dengue infection by VIS513, a pan serotype reactive monoclonal antibody targeting domain III of the dengue E protein. PLoS Negl. Trop. Dis. 2018, 12, e0006209. [Google Scholar] [CrossRef]
- Lee, D.C.P.; Raman, R.; Ghafar, N.A.; Budigi, Y. An antibody engineering platform using amino acid networks: A case study in development of antiviral therapeutics. Antiviral Res. 2021, 192, 105105. [Google Scholar] [CrossRef]
- Barreto, K.; Maruthachalam, B.V.; Hill, W.; Hogan, D.; Sutherland, A.R.; Kusalik, A.; Fonge, H.; DeCoteau, J.F.; Geyer, C.R. Next-generation sequencing-guided identification and reconstruction of antibody CDR combinations from phage selection outputs. Nucleic Acids Res. 2019, 47, e50. [Google Scholar] [CrossRef]
- Kovaltsuk, A.; Leem, J.; Kelm, S.; Snowden, J.; Deane, C.M.; Krawczyk, K. Observed Antibody Space: A Resource for Data Mining Next-Generation Sequencing of Antibody Repertoires. J. Immunol. 2018, 201, 2502–2509. [Google Scholar] [CrossRef]
- Negron, C.; Fang, J.; McPherson, M.J.; Stine, W.B., Jr.; McCluskey, A.J. Separating clinical antibodies from repertoire antibodies, a path to in silico developability assessment. MAbs 2022, 14, 2080628. [Google Scholar] [CrossRef]
- Saka, K.; Kakuzaki, T.; Metsugi, S.; Kashiwagi, D.; Yoshida, K.; Wada, M.; Tsunoda, H.; Teramoto, R. Antibody design using LSTM based deep generative model from phage display library for affinity maturation. Sci. Rep. 2021, 11, 5852. [Google Scholar] [CrossRef]
- Lim, Y.W.; Adler, A.S.; Johnson, D.S. Predicting antibody binders and generating synthetic antibodies using deep learning. MAbs 2022, 14, 2069075. [Google Scholar] [CrossRef]
- Wilman, W.; Wrobel, S.; Bielska, W.; Deszynski, P.; Dudzic, P.; Jaszczyszyn, I.; Kaniewski, J.; Mlokosiewicz, J.; Rouyan, A.; Satlawa, T.; et al. Machine-designed biotherapeutics: Opportunities, feasibility and advantages of deep learning in computational antibody discovery. Brief Bioinform. 2022, 23, bbac267. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, F.; Shen, C.; Peng, W.; Li, D.; Zhao, C.; Li, Z.; Li, S.; Bi, Y.; Yang, Y.; et al. A noncompeting pair of human neutralizing antibodies block COVID-19 virus binding to its receptor ACE2. Science 2020, 368, 1274–1278. [Google Scholar] [CrossRef]
- Liberis, E.; Velickovic, P.; Sormanni, P.; Vendruscolo, M.; Lio, P. Parapred: Antibody paratope prediction using convolutional and recurrent neural networks. Bioinformatics 2018, 34, 2944–2950. [Google Scholar] [CrossRef]
- Raybould, M.I.J.; Marks, C.; Krawczyk, K.; Taddese, B.; Nowak, J.; Lewis, A.P.; Bujotzek, A.; Shi, J.; Deane, C.M. Five computational developability guidelines for therapeutic antibody profiling. Proc. Natl. Acad. Sci. USA 2019, 116, 4025–4030. [Google Scholar] [CrossRef]
- Tiller, K.E.; Chowdhury, R.; Li, T.; Ludwig, S.D.; Sen, S.; Maranas, C.D.; Tessier, P.M. Facile Affinity Maturation of Antibody Variable Domains Using Natural Diversity Mutagenesis. Front. Immunol. 2017, 8, 986. [Google Scholar] [CrossRef]
- Brouwer, P.J.M.; Caniels, T.G.; van der Straten, K.; Snitselaar, J.L.; Aldon, Y.; Bangaru, S.; Torres, J.L.; Okba, N.M.A.; Claireaux, M.; Kerster, G.; et al. Potent neutralizing antibodies from COVID-19 patients define multiple targets of vulnerability. Science 2020, 369, 643–650. [Google Scholar] [CrossRef]
- Raybould, M.I.J.; Kovaltsuk, A.; Marks, C.; Deane, C.M. CoV-AbDab: The coronavirus antibody database. Bioinformatics 2021, 37, 734–735. [Google Scholar] [CrossRef]
- Shehata, L.; Maurer, D.P.; Wec, A.Z.; Lilov, A.; Champney, E.; Sun, T.; Archambault, K.; Burnina, I.; Lynaugh, H.; Zhi, X.; et al. Affinity Maturation Enhances Antibody Specificity but Compromises Conformational Stability. Cell. Rep. 2019, 28, 3300–3308.e4. [Google Scholar] [CrossRef]
- Jensen, K.K.; Andreatta, M.; Marcatili, P.; Buus, S.; Greenbaum, J.A.; Yan, Z.; Sette, A.; Peters, B.; Nielsen, M. Improved methods for predicting peptide binding affinity to MHC class II molecules. Immunology 2018, 154, 394–406. [Google Scholar] [CrossRef]
- Warszawski, S.; Borenstein Katz, A.; Lipsh, R.; Khmelnitsky, L.; Ben Nissan, G.; Javitt, G.; Dym, O.; Unger, T.; Knop, O.; Albeck, S.; et al. Optimizing antibody affinity and stability by the automated design of the variable light-heavy chain interfaces. PLoS Comput. Biol. 2019, 15, e1007207. [Google Scholar] [CrossRef]
- Rapp, M.; Guo, Y.; Reddem, E.R.; Yu, J.; Liu, L.; Wang, P.; Cerutti, G.; Katsamba, P.; Bimela, J.S.; Bahna, F.A.; et al. Modular basis for potent SARS-CoV-2 neutralization by a prevalent VH1-2-derived antibody class. Cell. Rep. 2021, 35, 108950. [Google Scholar] [CrossRef]
- Hie, B.L.; Xu, D.; Shanker, V.R.; Bruun, T.U.J.; Weidenbacher, P.A.; Tang, S.; Kim, P.S. Efficient Evolution of Human Antibodies from General Protein Language Models and Sequence Information Alone. 2022. (Article Number. Name of Repository). Available online: https://www.biorxiv.org/content/10.1101/2022.04.10.487811v1 (accessed on 1 October 2022).
- Rives, A.; Meier, J.; Sercu, T.; Fergus, R. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences. Proc. Natl. Acad. Sci. USA 2022, 118, e2016239118. [Google Scholar] [CrossRef] [PubMed]
- Graves, J.; Byerly, J.; Priego, E.; Makkapati, N.; Parish, S.V.; Medellin, B.; Berrondo, M. A Review of Deep Learning Methods for Antibodies. Antibodies 2020, 9, 12. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Chen, K.; Kwong, P.D.; Shapiro, L.; Sheng, Z. cAb-Rep: A Database of Curated Antibody Repertoires for Exploring Antibody Diversity and Predicting Antibody Prevalence. Front. Immunol. 2019, 10, 2365. [Google Scholar] [CrossRef] [PubMed]
- Dunbar, J.; Krawczyk, K.; Leem, J.; Baker, T.; Fuchs, A.; Georges, G.; Shi, J.; Deane, C.M. SAbDab: The structural antibody database. Nucleic Acids Res. 2014, 42, D1140-6. [Google Scholar] [CrossRef]
- Dunbar, J.; Deane, C.M. ANARCI: Antigen receptor numbering and receptor classification. Bioinformatics 2016, 32, 298–300. [Google Scholar] [CrossRef]
- Wong, W.K.; Georges, G.; Ros, F.; Kelm, S.; Lewis, A.P.; Taddese, B.; Leem, J.; Deane, C.M. SCALOP: Sequence-based antibody canonical loop structure annotation. Bioinformatics 2019, 35, 1774–1776. [Google Scholar] [CrossRef]
- Chothia, C.; Lesk, A.M. Canonical structures for the hypervariable regions of immunoglobulins. J. Mol. Biol. 1987, 196, 901–917. [Google Scholar] [CrossRef]
- Bewley, K.R.; Coombes, N.S.; Gagnon, L.; McInroy, L.; Baker, N.; Shaik, I.; St-Jean, J.R.; St-Amant, N.; Buttigieg, K.R.; Humphries, H.E.; et al. Quantification of SARS-CoV-2 neutralizing antibody by wild-type plaque reduction neutralization, microneutralization and pseudotyped virus neutralization assays. Nat. Protocols 2021, 16, 3114–3140. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gopal, R.; Fitzpatrick, E.; Pentakota, N.; Jayaraman, A.; Tharakaraman, K.; Capila, I. Optimizing Antibody Affinity and Developability Using a Framework–CDR Shuffling Approach—Application to an Anti-SARS-CoV-2 Antibody. Viruses 2022, 14, 2694. https://doi.org/10.3390/v14122694
Gopal R, Fitzpatrick E, Pentakota N, Jayaraman A, Tharakaraman K, Capila I. Optimizing Antibody Affinity and Developability Using a Framework–CDR Shuffling Approach—Application to an Anti-SARS-CoV-2 Antibody. Viruses. 2022; 14(12):2694. https://doi.org/10.3390/v14122694
Chicago/Turabian StyleGopal, Ranjani, Emmett Fitzpatrick, Niharika Pentakota, Akila Jayaraman, Kannan Tharakaraman, and Ishan Capila. 2022. "Optimizing Antibody Affinity and Developability Using a Framework–CDR Shuffling Approach—Application to an Anti-SARS-CoV-2 Antibody" Viruses 14, no. 12: 2694. https://doi.org/10.3390/v14122694
APA StyleGopal, R., Fitzpatrick, E., Pentakota, N., Jayaraman, A., Tharakaraman, K., & Capila, I. (2022). Optimizing Antibody Affinity and Developability Using a Framework–CDR Shuffling Approach—Application to an Anti-SARS-CoV-2 Antibody. Viruses, 14(12), 2694. https://doi.org/10.3390/v14122694