
Identification and Full Characterisation of Two Novel Crustacean Infecting Members of the Family Nudiviridae Provides Support for Two Subfamilies

 , ,
, ,  , , , ,
, , , ,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Collection
2.2. Histology
2.3. Transmission Electron Microscopy (TEM)
2.4. DNA Extraction
2.5. DNA Library Construction and Sequencing
2.6. Sequence Assembly
2.7. Gene Prediction and Annotation
2.8. Gene Orthology and Nudivirus Core Gene Analysis
2.9. Phylogenetic Analysis
3. Results
3.1. Histological and Ultrastructural Observations
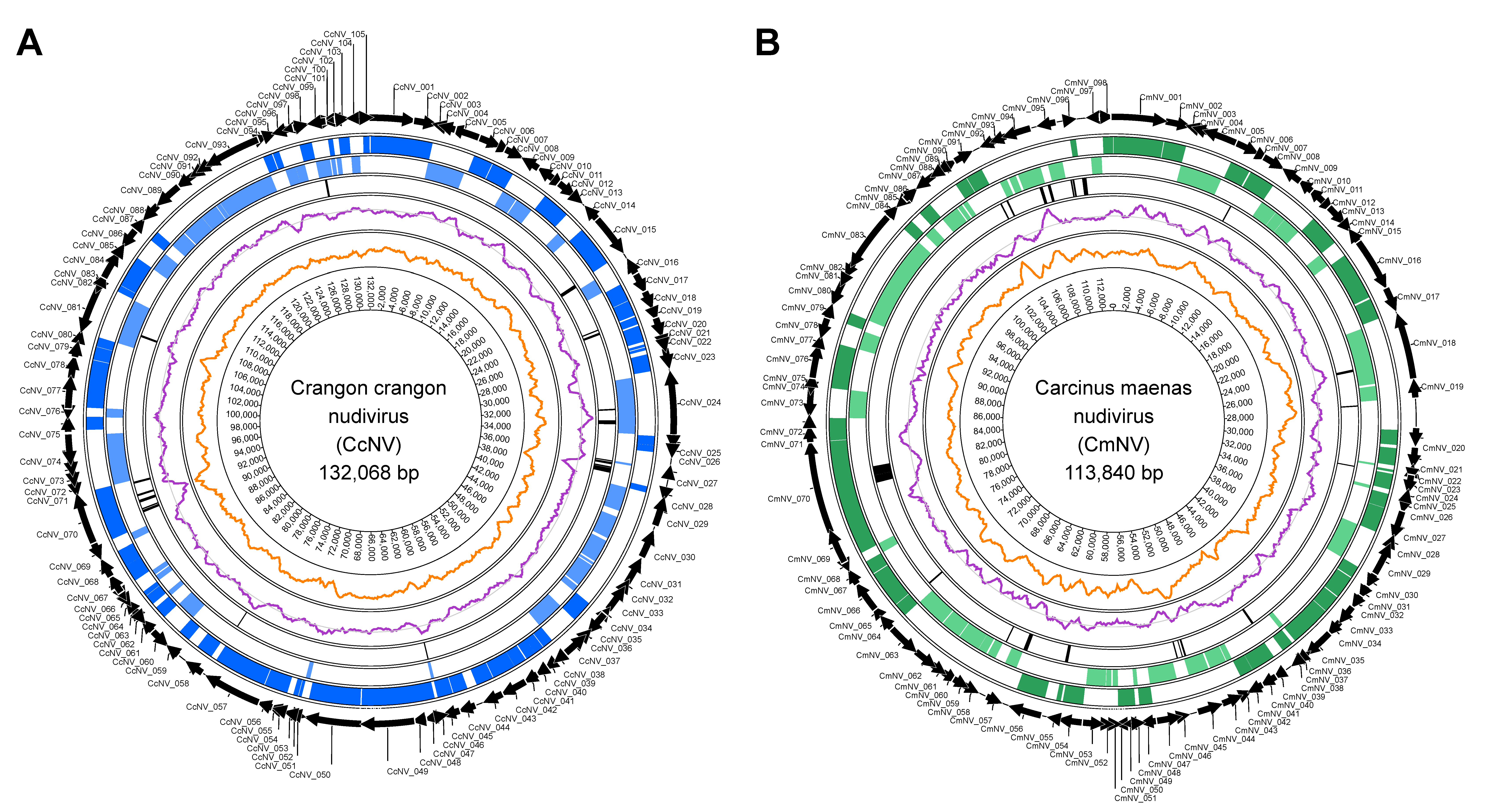
3.2. De Novo Genome Assembly of Two Novel Nudiviruses
3.3. Characterisation of the Nudivirus Genomes
3.3.1. Open Reading Frame (ORF) Prediction
3.3.2. Tandem Repeats
3.3.3. Protein Orthology and Gene Content
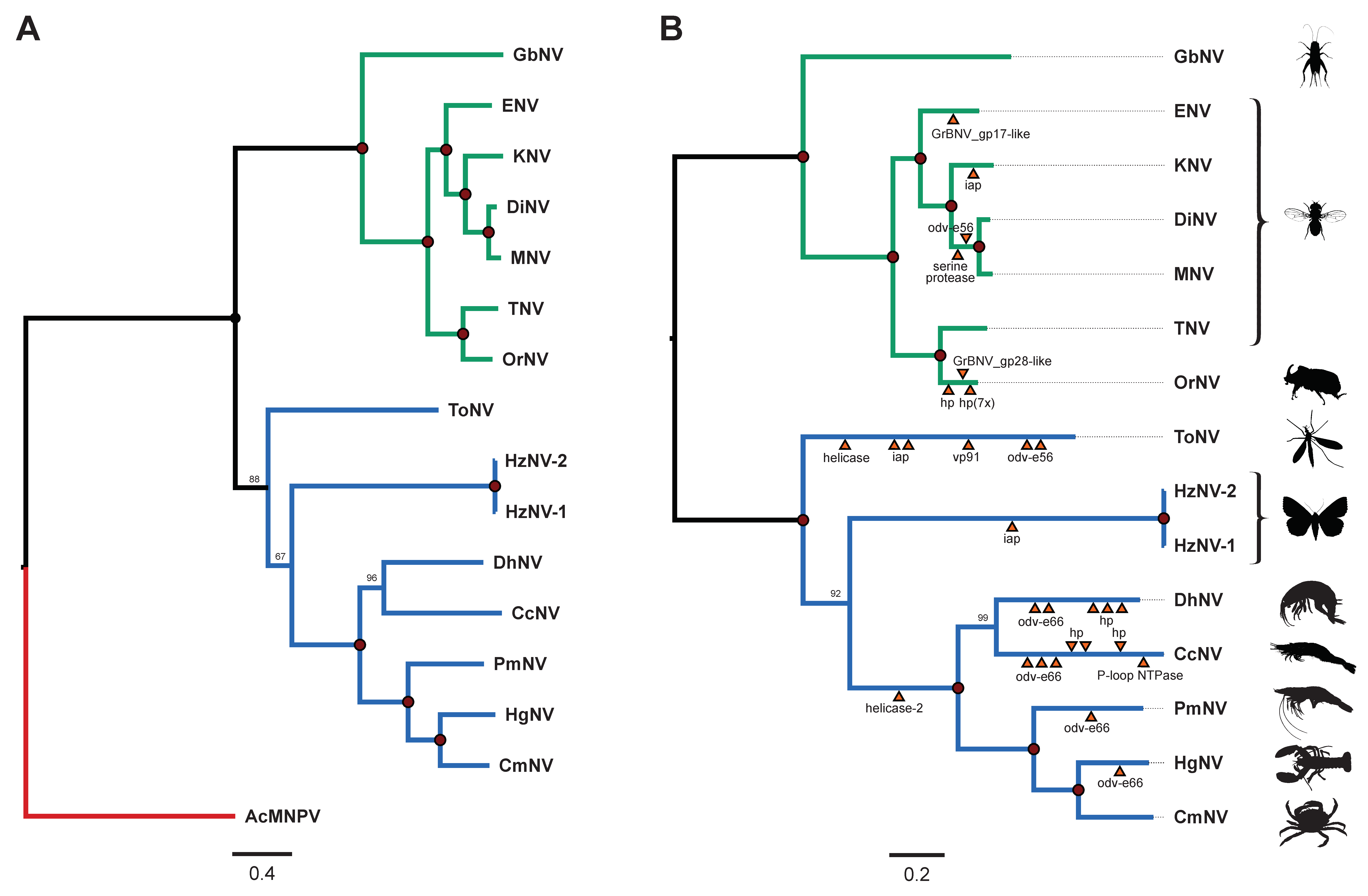
3.3.4. Phylogenetic Analysis Revealed Two Mayor Lineages within the Nudiviruses
3.3.5. Nudivirus Core Gene Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bateman, K.S.; Stentiford, G.D. A taxonomic review of viruses infecting crustaceans with an emphasis on wild hosts. J. Invertebr. Pathol. 2017, 147, 86–110. [Google Scholar] [CrossRef]
- Bayliss, S.C.; Verner-Jeffreys, D.W.; Bartie, K.L.; Aanensen, D.M.; Sheppard, S.K.; Adams, A.; Feil, E.J. The Promise of Whole Genome Pathogen Sequencing for the Molecular Epidemiology of Emerging Aquaculture Pathogens. Front. Microbiol. 2017, 8, 121. [Google Scholar] [CrossRef] [Green Version]
- Munang’andu, H.M.; Mugimba, K.K.; Byarugaba, D.K.; Mutoloki, S.; Evensen, Ø. Current Advances on Virus Discovery and Diagnostic Role of Viral Metagenomics in Aquatic Organisms. Front. Microbiol. 2017, 8, 406. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harrison, R.L.; Herniou, E.A.; Bézier, A.; Jehle, J.A.; Burand, J.P.; Theilmann, D.A.; Krell, P.J.; van Oers, M.M.; Nakai, M.; Consortium, I.R. ICTV Virus Taxonomy Profile: Nudiviridae. J. Gen. Virol. 2020, 101, 3–4. [Google Scholar] [CrossRef]
- Wang, Y.-J.; Burand, J.P.; Jehle, J.A. Nudivirus genomics: Diversity and classification. Virol. Sin. 2007, 22, 128–136. [Google Scholar] [CrossRef]
- Wang, Y.; Jehle, J.A. Nudiviruses and other large, double-stranded circular DNA viruses of invertebrates: New insights on an old topic. J. Invertebr. Pathol. 2009, 101, 187–193. [Google Scholar] [CrossRef] [PubMed]
- Jehle, J.A. Nudiviruses: Their Biology and Genetics; Caister Academic Press: Poole, UK, 2010. [Google Scholar]
- Bézier, A.; Thézé, J.; Gavory, F.; Gaillard, J.; Poulain, J.; Drezen, J.-M.; Herniou, E.A. The Genome of the Nucleopolyhedrosis-Causing Virus from Tipula oleracea Sheds New Light on the Nudiviridae Family. J. Virol. 2015, 89, 3008–3025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Sappington, T.W.; Coates, B.S.; Bonning, B.C. Nudivirus Sequences Identified from the Southern and Western Corn Rootworms (Coleoptera: Chrysomelidae). Viruses 2021, 13, 269. [Google Scholar] [CrossRef] [PubMed]
- Huger, A.M.; Krieg, A. Baculoviridae. Nonoccluded Baculoviruses; CRC Press: Boca Raton, FL, USA, 1991. [Google Scholar]
- Evans, L.H.; Edgerton, B.F. Pathogens, Parasites and Commensals; Blackwell Science: Hoboken, NJ, USA, 2002. [Google Scholar]
- Yang, Y.-T.; Lee, D.-Y.; Wang, Y.; Hu, J.-M.; Li, W.-H.; Leu, J.-H.; Chang, G.-D.; Ke, H.-M.; Kang, S.-T.; Lin, S.-S.; et al. The genome and occlusion bodies of marine Penaeus monodon nudivirus (PmNV, also known as MBV and PemoNPV) suggest that it should be assigned to a new nudivirus genus that is distinct from the terrestrial nudiviruses. BMC Genom. 2014, 15, 628. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, C.-H.; Liu, S.-M.; Chow, T.-Y.; Hsiao, Y.-Y.; Wang, D.-P.; Huang, J.-J.; Chen, H.-H. Analysis of the Complete Genome Sequence of the Hz-1 Virus Suggests that It Is Related to Members of the Baculoviridae. J. Virol. 2002, 76, 9024–9034. [Google Scholar] [CrossRef] [Green Version]
- Cheng, R.-L.; Li, X.-F.; Zhang, C.-X. Nudivirus Remnants in the Genomes of Arthropods. Genome Biol. Evol. 2020, 12, 578–588. [Google Scholar] [CrossRef] [PubMed]
- Cheng, R.-L.; Xi, Y.; Lou, Y.-H.; Wang, Z.; Xu, J.-Y.; Xu, H.-J.; Zhang, C.-X. Brown Planthopper Nudivirus DNA Integrated in Its Host Genome. J. Virol. 2014, 88, 5310–5318. [Google Scholar] [CrossRef] [Green Version]
- Bézier, A.; Annaheim, M.; Herbinière, J.; Wetterwald, C.; Gyapay, G.; Bernard-Samain, S.; Wincker, P.; Roditi, I.; Heller, M.; Belghazi, M.; et al. Polydnaviruses of Braconid Wasps Derive from an Ancestral Nudivirus. Science 2009, 323, 926–930. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Coates, B.S.; Bonning, B.C. Endogenous viral elements integrated into the genome of the soybean aphid, Aphis glycines. Insect Biochem. Mol. Biol. 2020, 123, 103405. [Google Scholar] [CrossRef] [PubMed]
- Holt, C.C.; Stone, M.; Bass, D.; Bateman, K.S.; Van Aerle, R.; Daniels, C.L.; Van der Giezen, M.; Ross, S.; Hooper, C.; Stentiford, G.D. The first clawed lobster virus Homarus gammarus nudivirus (HgNV n. sp.) expands the diversity of the Nudiviridae. Sci. Rep. 2019, 9, 10086. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Allain, T.W.; Stentiford, G.D.; Bass, D.; Behringer, D.C.; Bojko, J. A novel nudivirus infecting the invasive demon shrimp Dikerogammarus haemobaphes (Amphipoda). Sci. Rep. 2020, 10, 14816. [Google Scholar] [CrossRef] [PubMed]
- Van Eynde, B.; Christiaens, O.; Delbare, D.; Shi, C.; Vanhulle, E.; Yinda, C.K.; Matthijnssens, J.; Smagghe, G. Exploration of the virome of the European brown shrimp (Crangon crangon). J. Gen. Virol. 2020, 101, 651–666. [Google Scholar] [CrossRef] [PubMed]
- Stentiford, G.D.; Bateman, K.; Feist, S.W. Pathology and ultrastructure of an intranuclear bacilliform virus (IBV) infecting brown shrimp Crangon crangon (Decapoda: Crangonidae). Dis. Aquat. Org. 2004, 58, 89–97. [Google Scholar] [CrossRef] [Green Version]
- Van Eynde, B.; Christiaens, O.; Delbare, D.; Cooreman, K.; Bateman, K.S.; Stentiford, G.D.; Dullemans, A.M.; van Oers, M.M.; Smagghe, G. Development and application of a duplex PCR assay for detection of Crangon crangon bacilliform virus in populations of European brown shrimp (Crangon crangon). J. Invertebr. Pathol. 2018, 153, 195–202. [Google Scholar] [CrossRef]
- Stentiford, G.D.; Feist, S.W. A histopathological survey of shore crab (Carcinus maenas) and brown shrimp (Crangon crangon) from six estuaries in the United Kingdom. J. Invertebr. Pathol. 2005, 88, 136–146. [Google Scholar] [CrossRef]
- Bojko, J.; Stebbing, P.D.; Dunn, A.M.; Bateman, K.S.; Clark, F.; Kerr, R.C.; Stewart-Clark, S.; Johannesen, Á.; Stentiford, G.D. Green crab Carcinus maenas symbiont profiles along a North Atlantic invasion route. Dis. Aquat. Org. 2018, 128, 147–168. [Google Scholar] [CrossRef] [Green Version]
- Reynolds, E.S. The use of lead citrate at high pH as an electron-opaque stain in electron microscopy. J. Cell Biol. 1963, 17, 208–212. [Google Scholar] [CrossRef] [Green Version]
- Nishiguchi, M.K.; Doukakis, P.; Egan, M.; Kizirian, D.; Phillips, A.; Prendini, L.; Rosenbaum, H.C.; Torres, E.; Wyner, Y.; DeSalle, R.; et al. DNA Isolation Procedures. In Techniques in Molecular Systematics and Evolution; DeSalle, R., Giribet, G., Wheeler, W., Eds.; Birkhäuser Basel: Basel, Switzerland, 2002; pp. 249–287. [Google Scholar] [CrossRef]
- Chen, S.; Zhou, Y.; Chen, Y.; Gu, J. Fastp: An ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 2018, 34, i884–i890. [Google Scholar] [CrossRef]
- Bushnell, B. Available online: https://sourceforge.net/projects/bbmap/ (accessed on 16 February 2019).
- Wick, R.R.; Judd, L.M.; Gorrie, C.L.; Holt, K.E. Unicycler: Resolving bacterial genome assemblies from short and long sequencing reads. PLoS Comput. Biol. 2017, 13, e1005595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wick, R.R. Porechop. Github. Available online: https://Github.com/Rrwick/Porechop (accessed on 21 December 2019).
- Camacho, C.; Coulouris, G.; Avagyan, V.; Ma, N.; Papadopoulos, J.; Bealer, K.; Madden, T.L. BLAST+: Architecture and applications. BMC Bioinform. 2009, 10, 421. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, W.; Le, S.; Li, Y.; Hu, F. SeqKit: A Cross-Platform and Ultrafast Toolkit for FASTA/Q File Manipulation. PLoS ONE 2016, 11, e0163962. [Google Scholar] [CrossRef]
- Li, H. Minimap2: Pairwise alignment for nucleotide sequences. Bioinformatics 2018, 34, 3094–3100. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R. The Sequence Alignment/Map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [Green Version]
- Okonechnikov, K.; Conesa, A.; García-Alcalde, F. Qualimap 2: Advanced multi-sample quality control for high-throughput sequencing data. Bioinformatics 2016, 32, 292–294. [Google Scholar] [CrossRef]
- Benson, G. Tandem repeats finder: A program to analyze DNA sequences. Nucleic Acids Res. 1999, 27, 573–580. [Google Scholar] [CrossRef] [Green Version]
- Seemann, T. Prokka: Rapid prokaryotic genome annotation. Bioinformatics 2014, 30, 2068–2069. [Google Scholar] [CrossRef]
- Besemer, J.; Lomsadze, A.; Borodovsky, M. GeneMarkS: A self-training method for prediction of gene starts in microbial genomes. Implications for finding sequence motifs in regulatory regions. Nucleic Acids Res. 2001, 29, 2607–2618. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.-Y.; Gao, Y.-Z.; Du, M.-Z.; Liu, S.; Dong, C.; Guo, F.-B. Vgas: A Viral Genome Annotation System. Front. Microbiol. 2019, 10, 184. [Google Scholar] [CrossRef] [PubMed]
- Altschul, S.F.; Gish, W.; Miller, W.; Myers, E.W.; Lipman, D.J. Basic local alignment search tool. J. Mol. Biol. 1990, 215, 403–410. [Google Scholar] [CrossRef]
- Emms, D.M.; Kelly, S. OrthoFinder: Solving fundamental biases in whole genome comparisons dramatically improves orthogroup inference accuracy. Genome Biol. 2015, 16, 157. [Google Scholar] [CrossRef] [Green Version]
- Wickham, H. Ggplot2: Elegant Graphices for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Rstudio Team. RStudio: Integrated Development for R; RStudio Inc.: Boston, MA, USA, 2020; Available online: http://www.rstudio.com/ (accessed on 19 April 2020).
- Katoh, K.; Standley, D.M. MAFFT Multiple Sequence Alignment Software Version 7: Improvements in Performance and Usability. Mol. Biol. Evol. 2013, 30, 772–780. [Google Scholar] [CrossRef] [Green Version]
- Castresana, J. Selection of Conserved Blocks from Multiple Alignments for Their Use in Phylogenetic Analysis. Mol. Biol. Evol. 2000, 17, 540–552. [Google Scholar] [CrossRef] [Green Version]
- Stamatakis, A. RAxML version 8: A tool for phylogenetic analysis and post-analysis of large phylogenies. Bioinformatics 2014, 30, 1312–1313. [Google Scholar] [CrossRef]
- Kocot, K.M.; Citarella, M.R.; Moroz, L.L.; Halanych, K.M. PhyloTreePruner: A Phylogenetic Tree-Based Approach for Selection of Orthologous Sequences for Phylogenomics. Evol. Bioinform. 2013, 9, 429–435. [Google Scholar] [CrossRef] [Green Version]
- Capella-Gutierrez, S.; Silla-Martinez, J.M.; Gabaldon, T. trimAl: A tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics 2009, 25, 1972–1973. [Google Scholar] [CrossRef]
- Rambaut. Figtree v1.4.4. Available online: http://tree.bio.ed.ac.uk/software/figtree/ (accessed on 8 March 2019).
- Hou, D.; Kuang, W.; Luo, S.; Zhang, F.; Zhou, F.; Chen, T.; Zhang, Y.; Wang, H.; Hu, Z.; Deng, F.; et al. Baculovirus ODV-E66 degrades larval peritrophic membrane to facilitate baculovirus oral infection. Virology 2019, 537, 157–164. [Google Scholar] [CrossRef] [PubMed]
- Lee, L.E.J.; Bufalino, M.R.; Christie, A.E.; Frischer, M.E.; Soin, T.; Tsui, C.K.M.; Hanner, R.H.; Smagghe, G. Misidentification of OLGA-PH-J/92, believed to be the only crustacean cell line. Vitr. Cell. Dev. Biol.—Anim. 2011, 47, 665–674. [Google Scholar] [CrossRef] [PubMed]
- Tweeten, K.A.; Bulla, L.A.; Consigli, R.A. Characterization of an extremely basic protein derived from granulosis virus nucleocapsids. J. Virol. 1980, 33, 866–876. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, M.; Tuladhar, E.; Shen, S.; Wang, H.; van Oers, M.M.; Vlak, J.M.; Westenberg, M. Specificity of Baculovirus P6.9 Basic DNA-Binding Proteins and Critical Role of the C Terminus in Virion Formation. J. Virol. 2010, 84, 8821–8828. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene_ID (ORF) | Start | End | Strand | Protein Length (Amino Acids) | Best Hit (Description, Species, Accession Number) | Additional Annotations |
|---|---|---|---|---|---|---|
| CcNV_1 | 1 | 3111 | + | 1037 | DNA polymerase (Dikerogammarus haemobaphes nudivirus) (QLI62362.1) | |
| CcNV_2 | 3114 | 4613 | + | 500 | hypothetical protein (Apolygus lucorum) (KAF6208213.1) | Methyltransferase |
| CcNV_3 | 4617 | 4874 | - | 86 | KN57_gp007 (Dikerogammarus haemobaphes nudivirus) (QLI62363.1) | |
| CcNV_4 | 4877 | 5572 | - | 232 | Ac92 (Dikerogammarus haemobaphes nudivirus) (QLI62364.1) | P33 |
| CcNV_5 | 5544 | 7580 | - | 679 | Vp91 (Penaeus monodon nudivirus) (YP_009051847.1) | |
| CcNV_6 | 7843 | 9279 | + | 479 | ODV-E56 (Dikerogammarus haemobaphes nudivirus) (QLI62366.1) | PIF-5 |
| CcNV_7 | 9357 | 9833 | + | 159 | KN57_gp012 (Dikerogammarus haemobaphes nudivirus) (QLI62367.1) | |
| CcNV_8 | 9802 | 10995 | + | 398 | p47 (Dikerogammarus haemobaphes nudivirus) (QLI62368.1) | |
| CcNV_9 | 11,007 | 12,209 | - | 401 | Pif-2 (Homarus gammarus nudivirus) (YP_010087649.1) | |
| CcNV_10 | 12,317 | 13,708 | - | 464 | - | |
| CcNV_11 | 13,882 | 14,199 | + | 106 | - | |
| CcNV_12 | 14,208 | 15,503 | + | 432 | KN57_gp020 (Dikerogammarus haemobaphes nudivirus) (QLI62373.1) | FEN-1 |
| CcNV_13 | 15,500 | 15,985 | + | 162 | HgNV_014 (Dikerogammarus haemobaphes nudivirus) (QLI62374.1) | |
| CcNV_14 | 16,535 | 17,410 | - | 292 | hypothetical protein PmNV_022 (Penaeus monodon nudivirus) (YP_009051860.1) | VP39 |
| CcNV_15 | 17,589 | 20,660 | + | 1024 | LEF-8 (Dikerogammarus haemobaphes nudivirus) (QLI62376.1) | |
| CcNV_16 | 21,228 | 22,379 | - | 384 | - | |
| CcNV_17 | 22,523 | 23,827 | + | 435 | - | |
| CcNV_18 | 23,881 | 25,026 | + | 382 | - | |
| CcNV_19 | 25,154 | 25,723 | + | 190 | - | |
| CcNV_20 | 25,863 | 27,080 | + | 406 | p51 (Dikerogammarus haemobaphes nudivirus) (QLI62377.1) | |
| CcNV_21 | 27,305 | 27,478 | + | 58 | - | |
| CcNV_22 | 27,552 | 27,737 | + | 62 | - | |
| CcNV_23 | 28,064 | 29,332 | + | 423 | ODV-E66 (Penaeus monodon nudivirus) (YP_009051872.1) | |
| CcNV_24 | 29,595 | 34,061 | - | 1489 | DhNV_024 (Dikerogammarus haemobaphes nudivirus) (QLI62385.1) | |
| CcNV_25 | 34,158 | 34,835 | + | 226 | - | |
| CcNV_26 | 34,858 | 35,337 | + | 160 | - | dUTP pyrophosphatase/dUTPase |
| CcNV_27 | 36,459 | 36,614 | - | 52 | - | |
| CcNV_28 | 37,945 | 38,391 | + | 149 | - | |
| CcNV_29 | 38,420 | 40,342 | - | 641 | ODV_E66 (Dikerogammarus haemobaphes nudivirus) (QLI62384.1) | |
| CcNV_30 | 40,871 | 42,697 | - | 609 | ODV_E66 (Dikerogammarus haemobaphes nudivirus) (QLI62384.1) | |
| CcNV_31 | 42,958 | 44,778 | - | 607 | ODV_E66 (Dikerogammarus haemobaphes nudivirus) (QLI62384.1) | |
| CcNV_32 | 44,932 | 45,108 | - | 59 | - | |
| CcNV_33 | 45,218 | 47,050 | - | 611 | ODV_E66 (Dikerogammarus haemobaphes nudivirus) (QLI62384.1) | |
| CcNV_34 | 47,201 | 47,683 | - | 161 | - | |
| CcNV_35 | 47,675 | 49,270 | + | 532 | PIF-1 (Penaeus monodon nudivirus) (YP_009051877.1) | |
| CcNV_36 | 49,285 | 49,566 | - | 94 | - | |
| CcNV_37 | 49,556 | 51,547 | - | 664 | HgNV_030 (Dikerogammarus haemobaphes nudivirus) (QLI62398.1) | |
| CcNV_38 | 51,546 | 52,316 | + | 257 | DhNV_036 (Dikerogammarus haemobaphes nudivirus) (QLI62397.1) | |
| CcNV_39 | 52,382 | 53,083 | + | 234 | - | |
| CcNV_40 | 53,107 | 53,847 | + | 247 | HgNV_033 (Dikerogammarus haemobaphes nudivirus) (QLI62395.1) | PmV-like protein |
| CcNV_41 | 53,962 | 54,891 | + | 310 | hypothetical protein (Penaeus monodon nucleopolyhedrovirus) (ABX44696.1) | |
| CcNV_42 | 54,922 | 56,667 | + | 582 | KN57_gp048 (Dikerogammarus haemobaphes nudivirus) (QLI62392.1) | |
| CcNV_43 | 56,737 | 58,020 | + | 428 | - | |
| CcNV_44 | 58,774 | 59,850 | + | 359 | - | |
| CcNV_45 | 59,923 | 61,056 | + | 378 | - | |
| CcNV_46 | 60,983 | 61,204 | - | 74 | - | |
| CcNV_47 | 61,297 | 62,304 | + | 336 | - | |
| CcNV_48 | 62,323 | 63,135 | + | 271 | - | Polyhedrin |
| CcNV_49 | 63,152 | 66,742 | + | 1197 | - | |
| CcNV_50 | 66,844 | 70,668 | + | 1275 | - | |
| CcNV_51 | 70,945 | 71,277 | - | 111 | - | |
| CcNV_52 | 71,252 | 71,461 | + | 70 | Ac92 (Dikerogammarus haemobaphes nudivirus) (QLI62411.1) | |
| CcNV_53 | 71,517 | 71,873 | + | 119 | - | LEF-5 |
| CcNV_54 | 72,349 | 72,531 | + | 61 | hypothetical protein PmNV_053 (Penaeus monodon nudivirus) (YP_009051891.1) | |
| CcNV_55 | 72,528 | 73,169 | + | 214 | hypothetical protein, partial (Penaeus monodon nucleopolyhedrovirus) (ABX44701.1) | |
| CcNV_56 | 73,166 | 74,092 | + | 309 | Integrase (Dikerogammarus haemobaphes nudivirus) (QLI62415.1) | |
| CcNV_57 | 74,169 | 78,131 | + | 1321 | hypothetical protein KM727_gp62 (Homarus gammarus nudivirus) (YP_010087702.1) | |
| CcNV_58 | 78,592 | 79,830 | + | 413 | non-structural protein 1 (Penaeus monodon metallodensovirus) (QGX07563.1) | |
| CcNV_59 | 80,670 | 81,551 | + | 294 | VLF-1 (Dikerogammarus haemobaphes nudivirus) (QLI62416.1) | |
| CcNV_60 | 81,546 | 83,069 | - | 508 | LEF-9 (Dikerogammarus haemobaphes nudivirus) (QLI62417.1) | |
| CcNV_61 | 83,137 | 84,054 | + | 306 | 38K protein (Penaeus monodon nudivirus) (YP_009051897.1) | |
| CcNV_62 | 84,031 | 84,408 | - | 126 | - | |
| CcNV_63 | 84,420 | 85,166 | + | 249 | HgNV_049 (Dikerogammarus haemobaphes nudivirus) (QLI62423.1) | |
| CcNV_64 | 85,212 | 85,556 | + | 115 | - | GbNV_gp51-like |
| CcNV_65 | 85,560 | 85,988 | - | 143 | - | |
| CcNV_66 | 86,110 | 86,490 | - | 127 | - | |
| CcNV_67 | 86,589 | 87,866 | + | 426 | KN57gp_066 (Dikerogammarus haemobaphes nudivirus) (QLI62428.1) | |
| CcNV_68 | 87,891 | 89,111 | + | 407 | - | |
| CcNV_69 | 89,326 | 89,904 | - | 193 | - | |
| CcNV_70 | 90,070 | 93,882 | + | 1271 | - | Polyhedrin |
| CcNV_71 | 93,921 | 94,484 | - | 188 | KN57gp_068 (Dikerogammarus haemobaphes nudivirus) (QLI62436.1) | |
| CcNV_72 | 94,498 | 95,367 | - | 290 | KN57gp_069 (Dikerogammarus haemobaphes nudivirus) (QLI62435.1) | |
| CcNV_73 | 95,355 | 95,990 | - | 212 | KN57gp_070 (Dikerogammarus haemobaphes nudivirus) (QLI62434.1) | |
| CcNV_74 | 95,996 | 97,999 | - | 668 | P74 (Homarus gammarus nudivirus) (YP_010087703.1) | PIF-0 |
| CcNV_75 | 98,378 | 99,340 | + | 321 | - | |
| CcNV_76 | 99,315 | 100,034 | - | 240 | HgNV_068 (Dikerogammarus haemobaphes nudivirus) (QLI62449.1) | |
| CcNV_77 | 100,025 | 102,127 | + | 701 | Helicase 2 (Dikerogammarus haemobaphes nudivirus) (QLI62448.1) | |
| CcNV_78 | 102,130 | 103,560 | + | 477 | - | |
| CcNV_79 | 103,617 | 104,579 | + | 321 | DhNV_085 (Dikerogammarus haemobaphes nudivirus) (QLI62446.1) | |
| CcNV_80 | 104,623 | 105,300 | + | 226 | - | |
| CcNV_81 | 105,322 | 108,495 | - | 1058 | - | |
| CcNV_82 | 108,501 | 108,920 | - | 140 | HgNV_075 (Dikerogammarus haemobaphes nudivirus) (QLI62443.1) | |
| CcNV_83 | 108,991 | 109,458 | + | 156 | Ac81 (Dikerogammarus haemobaphes nudivirus) (QLI62442.1) | |
| CcNV_84 | 109,506 | 111,398 | + | 631 | hypothetical protein PmNV_087 (Penaeus monodon nudivirus) (YP_009051925.1) | |
| CcNV_85 | 111,385 | 111,831 | + | 149 | Ac68-like protein (Homarus gammarus nudivirus) (YP_010087718.1) | PIF-6 |
| CcNV_86 | 111,842 | 113,356 | - | 505 | DhNV_068 (Dikerogammarus haemobaphes nudivirus) (QLI62429.1) | |
| CcNV_87 | 113,499 | 114,260 | + | 254 | VLF-1 (Dikerogammarus haemobaphes nudivirus) (QLI62430.1) | |
| CcNV_88 | 114,264 | 115,541 | - | 426 | - | |
| CcNV_89 | 115,658 | 117,484 | - | 609 | Helicase 2 (Dikerogammarus haemobaphes nudivirus) (QLI62451.1) | |
| CcNV_90 | 117,522 | 118,901 | - | 460 | LEF-4 (Dikerogammarus haemobaphes nudivirus) (QLI62453.1) | |
| CcNV_91 | 118,976 | 119,311 | - | 112 | - | |
| CcNV_92 | 119,355 | 120,035 | - | 227 | PIF-3 (Homarus gammarus nudivirus) (YP_010087723.1) | |
| CcNV_93 | 120,035 | 123,916 | - | 1294 | Helicase (Dikerogammarus haemobaphes nudivirus) (QLI62456.1) | |
| CcNV_94 | 123,918 | 124,592 | + | 225 | ODV-E28 (Dikerogammarus haemobaphes nudivirus) (QLI62457.1) | PIF-4 |
| CcNV_95 | 124,681 | 125,151 | + | 157 | - | |
| CcNV_96 | 125,168 | 125,998 | - | 277 | - | |
| CcNV_97 | 126,024 | 126,755 | - | 244 | KN57gp_097 (Dikerogammarus haemobaphes nudivirus) (QLI62459.1) | |
| CcNV_98 | 126,754 | 127,662 | + | 303 | Esterase (Dikerogammarus haemobaphes nudivirus) (QLI62460.1) | GbNV_gp19-like |
| CcNV_99 | 127,679 | 128,800 | - | 374 | KN57gp_099 (Dikerogammarus haemobaphes nudivirus) (QLI62461.1) | GbNV_gp67-like |
| CcNV_100 | 128,897 | 129,250 | + | 118 | - | |
| CcNV_101 | 128,905 | 129,216 | - | 104 | 11K (Dikerogammarus haemobaphes nudivirus) (QLI62462.1) | |
| CcNV_102 | 129,348 | 129,707 | - | 120 | - | |
| CcNV_103 | 129,688 | 130,482 | + | 265 | KN57gp_102 (Dikerogammarus haemobaphes nudivirus) (QLI62464.1) | |
| CcNV_104 | 130,530 | 131,210 | - | 227 | KN57gp_107 (Dikerogammarus haemobaphes nudivirus) (QLI62465.1) | |
| CcNV_105 | 131,513 | 131,980 | + | 156 | - | |
| CcNV_106 | 72,007 | 72,231 | + | 75 | - | p6.9 |
| Gene_ID (ORF) | Start | End | Strand | Protein Length (Amino Acids) | Best Hit (Description, Species, Accession Number) | Additional Annotations |
|---|---|---|---|---|---|---|
| CmNV_1 | 1 | 3200 | + | 1066 | DNA polymerase (Homarus gammarus nudivirus) (YP_010087641.1) | |
| CmNV_2 | 3264 | 4663 | + | 466 | methyltransferase (Homarus gammarus nudivirus) (YP_010087642.1) | |
| CmNV_3 | 4669 | 4880 | - | 70 | hypothetical protein PmNV_007 (Penaeus monodon nudivirus) (YP_009051845.1) | |
| CmNV_4 | 4868 | 5535 | - | 222 | Ac92-like protein (Homarus gammarus nudivirus) (YP_010087644.1) | P33 |
| CmNV_5 | 5523 | 7579 | - | 685 | Vp91 (Homarus gammarus nudivirus) (YP_010087645.1) | |
| CmNV_6 | 7716 | 9013 | + | 432 | ODV-E56 (Homarus gammarus nudivirus) (YP_010087646.1) | PIF-5 |
| CmNV_7 | 9132 | 9526 | + | 131 | hypothetical protein KM727_gp07 (Homarus gammarus nudivirus) (YP_010087647.1) | |
| CmNV_8 | 9537 | 10,774 | + | 412 | P47 (Homarus gammarus nudivirus) (YP_010087648.1) | |
| CmNV_9 | 10,793 | 11,949 | - | 385 | Pif-2 (Homarus gammarus nudivirus) (YP_010087649.1) | |
| CmNV_10 | 11,991 | 12,712 | - | 240 | HZV 115-like protein (Homarus gammarus nudivirus) (YP_010087650.1) | |
| CmNV_11 | 12,750 | 13,996 | - | 415 | hypothetical protein KM727_gp11 (Homarus gammarus nudivirus) (YP_010087651.1) | |
| CmNV_12 | 14,119 | 14,495 | + | 125 | hypothetical protein KM727_gp12 (Homarus gammarus nudivirus) (YP_010087652.1) | |
| CmNV_13 | 14,469 | 15,715 | + | 415 | hypothetical protein KM727_gp13 (Homarus gammarus nudivirus) (YP_010087653.1) | FEN-1 |
| CmNV_14 | 15,706 | 16,145 | + | 146 | hypothetical protein KM727_gp14 (Homarus gammarus nudivirus) (YP_010087654.1) | |
| CmNV_15 | 16,174 | 17,063 | - | 296 | Vp39/31 k (Homarus gammarus nudivirus) (YP_010087655.1) | VP39 |
| CmNV_16 | 17,183 | 20,256 | + | 1024 | LEF-8 (Homarus gammarus nudivirus) (YP_010087656.1) | |
| CmNV_17 | 20,397 | 21,742 | + | 448 | P51 (Homarus gammarus nudivirus) (YP_010087657.1) | |
| CmNV_18 | 21,993 | 25,855 | - | 1287 | hypothetical protein KM727_gp18 (Homarus gammarus nudivirus) (YP_010087658.1) | |
| CmNV_19 | 26,020 | 27,005 | - | 328 | E3 ubiquitin-protein ligase TRIM39-like protein | |
| CmNV_20 | 29,001 | 29,953 | + | 317 | ||
| CmNV_21 | 30,175 | 31,274 | + | 366 | serine/threonine protein kinase (Homarus gammarus nudivirus) (YP_010087663.1) | |
| CmNV_22 | 31,337 | 31,461 | - | 41 | ||
| CmNV_23 | 31,567 | 31,706 | + | 46 | ||
| CmNV_24 | 31,838 | 32,829 | + | 330 | dihydroxy-acid dehydratase (Homarus gammarus nudivirus) (YP_010087666.1) | |
| CmNV_25 | 32,866 | 33,068 | - | 67 | ||
| CmNV_26 | 33,141 | 34,036 | + | 298 | guanosine monophosphate kinase (Homarus gammarus nudivirus) (YP_010087667.1) | TK2 |
| CmNV_27 | 34,073 | 35,664 | + | 530 | PIF-1 (Homarus gammarus nudivirus) (YP_010087668.1) | |
| CmNV_28 | 35,695 | 36,065 | - | 123 | hypothetical protein PmNV_040 (Penaeus monodon nudivirus) (YP_009051878.1) | |
| CmNV_29 | 36,056 | 38,163 | - | 702 | hypothetical protein KM727_gp30 (Homarus gammarus nudivirus) (YP_010087670.1) | |
| CmNV_30 | 38,180 | 38,934 | + | 251 | hypothetical protein KM727_gp31 (Homarus gammarus nudivirus) (YP_010087671.1) | |
| CmNV_31 | 39,020 | 39,714 | + | 231 | hypothetical protein KM727_gp32 (Homarus gammarus nudivirus) (YP_010087672.1) | |
| CmNV_32 | 39,705 | 40,444 | + | 246 | PmV-like protein (Homarus gammarus nudivirus) (YP_010087673.1) | |
| CmNV_33 | 40,531 | 41,633 | + | 367 | p-loop NTPase (Homarus gammarus nudivirus) (YP_010087674.1) | |
| CmNV_34 | 41,687 | 42,612 | + | 308 | hypothetical protein KM727_gp35 (Homarus gammarus nudivirus) (YP_010087675.1) | |
| CmNV_35 | 42,619 | 44,375 | + | 585 | hypothetical protein KM727_gp36 (Homarus gammarus nudivirus) (YP_010087676.1) | |
| CmNV_36 | 44,330 | 44,643 | - | 104 | hypothetical protein KM727_gp37 (Homarus gammarus nudivirus) (YP_010087677.1) | |
| CmNV_37 | 44,618 | 44,826 | + | 69 | hypothetical protein PmNV_051 (Penaeus monodon nudivirus) (YP_009051889.1) | Ac92-like protein |
| CmNV_38 | 44,847 | 45,364 | + | 172 | hypothetical protein KM727_gp39 (Homarus gammarus nudivirus) (YP_010087679.1) | LEF-5 |
| CmNV_39 | 46,080 | 46,729 | + | 216 | hypothetical protein KM727_gp41 (Homarus gammarus nudivirus) (YP_010087681.1) | |
| CmNV_40 | 46,737 | 47,650 | + | 304 | integrase (Homarus gammarus nudivirus) (YP_010087682.1) | |
| CmNV_41 | 47,682 | 48,532 | + | 283 | VLF-1 (Homarus gammarus nudivirus) (YP_010087683.1) | |
| CmNV_42 | 48,543 | 48,910 | - | 122 | ||
| CmNV_43 | 48,980 | 50,133 | - | 384 | hypothetical protein KM727_gp94 (Homarus gammarus nudivirus) (YP_010087734.1) | |
| CmNV_44 | 50,276 | 51,675 | - | 466 | ||
| CmNV_45 | 52,559 | 52,812 | - | 84 | ||
| CmNV_46 | 52,816 | 54,416 | - | 533 | LEF-9 (Homarus gammarus nudivirus) (YP_010087686.1) | |
| CmNV_47 | 54,427 | 55,265 | + | 279 | 38K protein (Homarus gammarus nudivirus) (YP_010087687.1) | |
| CmNV_48 | 55,271 | 55,533 | - | 87 | hypothetical protein KM727_gp48 (Homarus gammarus nudivirus) (YP_010087688.1) | |
| CmNV_49 | 55,538 | 56,244 | + | 235 | hypothetical protein KM727_gp49 (Homarus gammarus nudivirus) (YP_010087689.1) | |
| CmNV_50 | 56,229 | 56,626 | + | 132 | hypothetical protein KM727_gp50 (Homarus gammarus nudivirus) (YP_010087690.1) | GbNV_gp51-like |
| CmNV_51 | 56,625 | 56,974 | - | 116 | hypothetical protein PmNV_063 (Penaeus monodon nudivirus) (YP_009051901.1) | |
| CmNV_52 | 57,089 | 57,429 | - | 113 | ||
| CmNV_53 | 57,473 | 58,803 | - | 443 | p-loop NTPase (Homarus gammarus nudivirus) (YP_010087693.1) | TK1 |
| CmNV_54 | 58,872 | 60,178 | + | 435 | hypothetical protein KM727_gp54 (Homarus gammarus nudivirus) (YP_010087694.1) | |
| CmNV_55 | 60,317 | 60,600 | + | 94 | ||
| CmNV_56 | 61,344 | 63,214 | + | 623 | ODV-E66 (Penaeus monodon nudivirus) (YP_009051874.1) | |
| CmNV_57 | 63,746 | 64,575 | - | 276 | IAP | |
| CmNV_58 | 65,340 | 65,920 | - | 193 | hypothetical protein PmNV_067 (Penaeus monodon nudivirus) (YP_009051905.1) | |
| CmNV_59 | 66,051 | 66,622 | - | 190 | hypothetical protein KM727_gp58 (Homarus gammarus nudivirus) (YP_010087698.1) | |
| CmNV_60 | 66,657 | 67,597 | - | 313 | hypothetical protein KM727_gp59 (Homarus gammarus nudivirus) (YP_010087699.1) | |
| CmNV_61 | 67,580 | 68,187 | - | 202 | hypothetical protein KM727_gp60 (Homarus gammarus nudivirus) (YP_010087700.1) | |
| CmNV_62 | 68,259 | 69,631 | - | 457 | hypothetical protein KM727_gp61 (Homarus gammarus nudivirus) (YP_010087701.1) | |
| CmNV_63 | 69,724 | 71,798 | - | 691 | P74 (Homarus gammarus nudivirus) (YP_010087703.1) | PIF-0 |
| CmNV_64 | 71,846 | 72,693 | + | 282 | ||
| CmNV_65 | 72,750 | 73,375 | + | 208 | hypothetical protein KM727_gp65 (Homarus gammarus nudivirus) (YP_010087705.1) | |
| CmNV_66 | 73,336 | 75,113 | + | 592 | helicase 2 (Homarus gammarus nudivirus) (YP_010087706.1) | |
| CmNV_67 | 75,187 | 76,055 | + | 289 | hypothetical protein KM727_gp67 (Homarus gammarus nudivirus) (YP_010087707.1) | |
| CmNV_68 | 76,061 | 76,707 | - | 215 | hypothetical protein KM727_gp68 (Homarus gammarus nudivirus) (YP_010087708.1) | |
| CmNV_69 | 76,697 | 78,657 | + | 653 | helicase 2 (Homarus gammarus nudivirus) (YP_010087709.1) | |
| CmNV_70 | 78,639 | 84,124 | + | 1828 | hypothetical protein KM727_gp70 (Homarus gammarus nudivirus) (YP_010087710.1) | |
| CmNV_71 | 84,170 | 85,047 | + | 292 | hypothetical protein KM727_gp72 (Homarus gammarus nudivirus) (YP_010087712.1) | |
| CmNV_72 | 85,039 | 85,598 | + | 186 | hypothetical protein KM727_gp73 (Homarus gammarus nudivirus) (YP_010087713.1) | |
| CmNV_73 | 85,616 | 87,168 | - | 517 | hypothetical protein KM727_gp74 (Homarus gammarus nudivirus) (YP_010087714.1) | |
| CmNV_74 | 87,163 | 87,521 | - | 119 | hypothetical protein KM727_gp75 (Homarus gammarus nudivirus) (YP_010087715.1) | |
| CmNV_75 | 87,520 | 88,037 | + | 172 | Ac81-like protein (Homarus gammarus nudivirus) (YP_010087716.1) | |
| CmNV_76 | 88,025 | 89,913 | + | 629 | hypothetical protein KM727_gp77 (Homarus gammarus nudivirus) (YP_010087717.1) | |
| CmNV_77 | 89,921 | 90,351 | + | 143 | Ac68-like protein (Homarus gammarus nudivirus) (YP_010087718.1) | PIF-6 |
| CmNV_78 | 90,389 | 91,647 | - | 419 | hypothetical protein KM727_gp79 (Homarus gammarus nudivirus) (YP_010087719.1) | |
| CmNV_79 | 91,740 | 92,467 | + | 242 | VLF-1 (Homarus gammarus nudivirus) (YP_010087720.1) | |
| CmNV_80 | 92,474 | 93,867 | - | 464 | LEF-4 (Homarus gammarus nudivirus) (YP_010087721.1) | |
| CmNV_81 | 93,888 | 94,300 | - | 137 | hypothetical protein KM727_gp82 (Homarus gammarus nudivirus) (YP_010087722.1) | |
| CmNV_82 | 94,298 | 95,016 | - | 239 | PIF-3 (Homarus gammarus nudivirus) (YP_010087723.1) | |
| CmNV_83 | 95,017 | 98,831 | - | 1271 | helicase (Homarus gammarus nudivirus) (YP_010087724.1) | |
| CmNV_84 | 98,830 | 99,518 | + | 229 | ODV-E28 (Penaeus monodon nudivirus) (YP_009051934.1) | PIF-4 |
| CmNV_85 | 99,512 | 100,257 | - | 248 | hypothetical protein KM727_gp86 (Homarus gammarus nudivirus) (YP_010087726.1) | |
| CmNV_86 | 100,256 | 101,100 | + | 281 | esterase (Homarus gammarus nudivirus) (YP_010087727.1) | GbNV_gp19-like |
| CmNV_87 | 101,113 | 102,344 | - | 410 | hypothetical protein KM727_gp88 (Homarus gammarus nudivirus) (YP_010087728.1) | GbNV_gp67-like |
| CmNV_88 | 102,446 | 102,744 | - | 99 | 11K virion structural protein (Homarus gammarus nudivirus) (YP_010087729.1) | |
| CmNV_89 | 102,869 | 103,191 | - | 107 | hypothetical protein KM727_gp90 (Homarus gammarus nudivirus) (YP_010087730.1) | |
| CmNV_90 | 103,184 | 103,956 | + | 257 | hypothetical protein KM727_gp91 (Homarus gammarus nudivirus) (YP_010087731.1) | |
| CmNV_91 | 104,012 | 105,081 | + | 356 | death-associated inhibitor of apoptosis 1 (Homarus gammarus nudivirus) (YP_010087732.1) | IAP |
| CmNV_92 | 105,794 | 106,290 | - | 165 | ||
| CmNV_93 | 106,479 | 106,957 | - | 159 | ||
| CmNV_94 | 107,140 | 108,752 | - | 537 | polyhedrin, partial (Penaeus monodon nucleopolyhedrovirus) (AET06106.1) | |
| CmNV_95 | 109,297 | 110,303 | - | 335 | ||
| CmNV_96 | 111,058 | 111,419 | + | 120 | ||
| CmNV_97 | 112,295 | 113,013 | - | 239 | hypothetical protein KM727_gp96 (Homarus gammarus nudivirus) (YP_010087736.1) | |
| CmNV_98 | 113,157 | 113,803 | + | 215 | hypothetical protein KM727_gp97 (Homarus gammarus nudivirus) (YP_010087737.1) | |
| CmNV_99 | 45,460 | 45,651 | + | 64 | p6.9 |
| Gene | Description | CcNV | CmNV | DhNV | DiNV | ENV | GbNV | HgNV | HzNV-1 | HzNV-2 | KNV | MNV | OrNV | PmNV | TNV | ToNV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11K-like | Occlusion body component | 101 | 88 | 101 | 17 | 37 | 95 | 89 | 124 | 25 | 44 | 40 | 41 | 100 | 32 | 28 |
| 38K | Nucleocapsid protein | 61 | 47 | 60 | 46 | 14 | 1 | 47 | 10 | 108 | 20 | 14 | 87 | 59 | 59 | 63 |
| ac81 | Nucleocapsid envelopment | 83 | 75 | 81 | 62 | 4 | 14 | 76 | 33 | 96 | 7 | 4 | 4 | 86 | 4 | 123 |
| dnapol | DNA polymerase | 1 | 1 | 1 | 65 | 1 | 12 | 1 | 131 | 18 | 10 | 1 | 1 | 5 | 1 | 12 |
| fen-1 | FEN-1/FLAP endonuclease | 12 | 13 | 12 | 100 | 56 | 65 | 13 | 68 | 70 | 68 | 62 | 16 | 20 | 17 | 1 |
| GbNV_gp19-like | Unknown | 98 | 86 | 99 | 22 | 32 | 19 | 87 | 30 | 99 | 39 | 35 | 47 | 98 | 38 | 27 |
| GbNV_gp51-like | Unknown | 64 | 50 | 63 | 34 | 22 | 51 | 50 | a | 79 | 30 | 26 | 61 | 62 | 48 | 19 |
| GbNV_gp67-like | Unknown | 99 | 87 | 100 | 102 | 54 | 67 | 88 | 122 | 27 | 66 | 60 | 18 | 99 | 15 | 6 |
| helicase | DNA helicase | 93 | 83 | 95 | 12 | 42 | 88 | 84 | 104 | 38 | 49 | 45 | 34 | 94 | 26 | 118, 55 |
| helicase-2 | DNA helicase | 77, 89 | 66, 69 | 87, 90 | 90 | 65 | 46 | 66, 69 | 60 | 76 | 78 | 71 | 108 | 76, 79 | 74 | 105 |
| integrase | DNA processing | 56 | 40 | 54 | 39 | 18 | 57 | 42 | 144 | 8 | 25 | 21 | 75 | 55 | 54 | 43 |
| lef-4 | RNA polymerase subunit | 90 | 80 | 92 | 18 | 36 | 96 | 81 | 98 | 43 | 43 | 39 | 42 | 91 | 33 | 25 |
| lef-5 | Transcription initiation factor | 53 | 38 | 51 | 25 | c | 85 | 39 | 101 | 40 | c | c | 52 | 52 | 40 | 50, 66 |
| lef-8 | RNA polymerase subunit | 15 | 16 | 15 | 32 | 24 | 49 | 16 | 90 | 51 | 33 | 29 | 64 | 23 | 46 | 88 |
| lef-9 | RNA polymerase subunit | 60 | 46 | 56 | 57 | 9 | 24 | 46 | 75 a,* | 63 a,* | 4 | 8 | 96 | 58 | 65 | 131 |
| p33_ac92 | Sulfhydryl oxidase | 4 | 4 | 3 | 87 | 67 | 7 | 4 | 13 | 104 | 82 | 74 | 113 | 8 | 75 | 99 |
| p47 | RNA polymerase subunit | 8 | 8 | 7 | 104 | 53 | 69 | 8 | 75 a,* | 63 a,* | 64 | 58 | 20 | 14 | 13 | 115 |
| p6.9 | Nucleocapsid packaging/assembly | 106 b | 99 b | - | 1 | 51 | 72 | 40 | 142 a | a | 61 | 56 | 22 | a | 11 | 51 |
| pif-0/p74 | Per os infectivity factor | 74 | 63 | 71 | 74 | 80 | 45 | 63 | 11 | 106 | 95 | 88 | 126 | 72 | 88 | 45 |
| pif-1 | Per os infectivity factor | 35 | 27 | 39 | 35 | 21 | 52 | 28 | 55 | 82 | 29 | 25 | 60 | 39 | 49 | 69 |
| pif-2 | Per os infectivity factor | 9 | 9 | 8 | 101 | 55 | 66 | 9 | 123 | 26 | 67 | 61 | 17 | 15 | 16 | 7 |
| pif-3 | Per os infectivity factor | 92 | 82 | 94 | 91 | 64 | 3 | 83 | 88 | 53 | 77 | 70 | 107 | 93 | 73 | 13 |
| pif-4 | Per os infectivity factor | 94 | 84 | 96 | 11 | 43 | 87 | 85 | 103 | 39 | 51 | 46 | 33 | 96 | 25 | 119 |
| pif-5/odv-e56 | Per os infectivity factor | 6 | 6 | 5 | 6, 85 | 69 | 5 | 6 | 76 | 62 | 56, 84 | 51, 76 | 115 | 10 | 77 | 102, 74, 96 |
| pif-6 | Per os infectivity factor | 85 | 77 | 79 | 36 | 20 | 55 | 78 | 74 | 64 | 28 | 24 | 72 | 88 | 51 | 56 |
| vlf-1 | Very late gene expression factor | 59 | 41 | 55 | 9 | 45 | 80 | 43 | 121 | 28 | 53 | 48 | 30 | 56 | 24 | 65 |
| vp39 | Major capsid protein | 14 | 15 | 14 | 99 | 57 | 64 | 15 | 89 | 52 | 69 | 63 | 15 | 22 | 18 | 87 |
| vp91/p95 | Nucleocapsid protein | 5 | 5 | 4 | 92 | 63 | 2 | 5 | 46 | 89 | 76 | 69 | 106 | 9 | 72 | 16, 83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bateman, K.S.; Kerr, R.; Stentiford, G.D.; Bean, T.P.; Hooper, C.; Van Eynde, B.; Delbare, D.; Bojko, J.; Christiaens, O.; Taning, C.N.T.; et al. Identification and Full Characterisation of Two Novel Crustacean Infecting Members of the Family Nudiviridae Provides Support for Two Subfamilies. Viruses 2021, 13, 1694. https://doi.org/10.3390/v13091694
Bateman KS, Kerr R, Stentiford GD, Bean TP, Hooper C, Van Eynde B, Delbare D, Bojko J, Christiaens O, Taning CNT, et al. Identification and Full Characterisation of Two Novel Crustacean Infecting Members of the Family Nudiviridae Provides Support for Two Subfamilies. Viruses. 2021; 13(9):1694. https://doi.org/10.3390/v13091694
Chicago/Turabian StyleBateman, Kelly S., Rose Kerr, Grant D. Stentiford, Tim P. Bean, Chantelle Hooper, Benigna Van Eynde, Daan Delbare, Jamie Bojko, Olivier Christiaens, Clauvis N. T. Taning, and et al. 2021. "Identification and Full Characterisation of Two Novel Crustacean Infecting Members of the Family Nudiviridae Provides Support for Two Subfamilies" Viruses 13, no. 9: 1694. https://doi.org/10.3390/v13091694
APA StyleBateman, K. S., Kerr, R., Stentiford, G. D., Bean, T. P., Hooper, C., Van Eynde, B., Delbare, D., Bojko, J., Christiaens, O., Taning, C. N. T., Smagghe, G., van Oers, M. M., & van Aerle, R. (2021). Identification and Full Characterisation of Two Novel Crustacean Infecting Members of the Family Nudiviridae Provides Support for Two Subfamilies. Viruses, 13(9), 1694. https://doi.org/10.3390/v13091694