
Evolution of SARS-CoV-2 Envelope, Membrane, Nucleocapsid, and Spike Structural Proteins from the Beginning of the Pandemic to September 2020: A Global and Regional Approach by Epidemiological Week




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
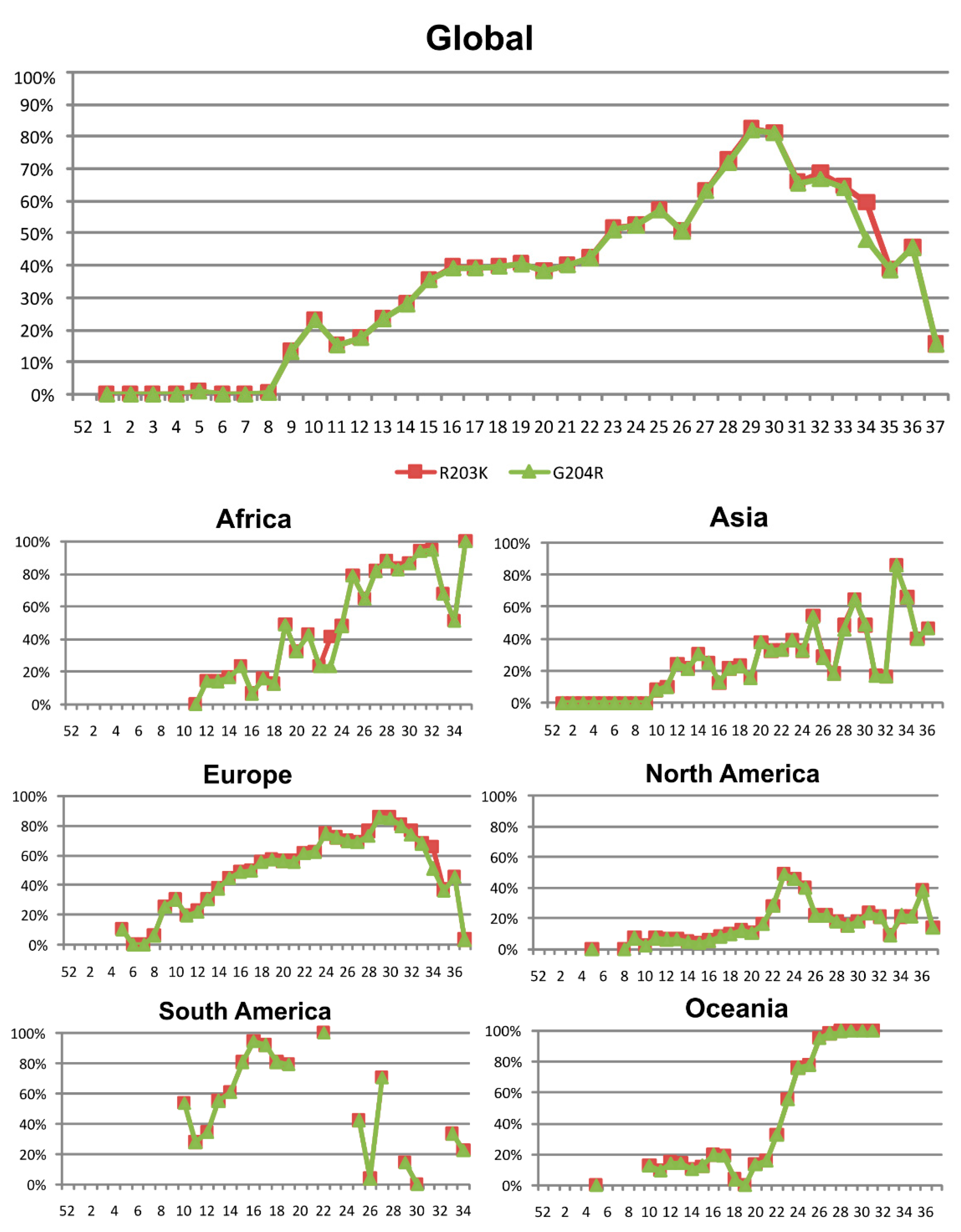
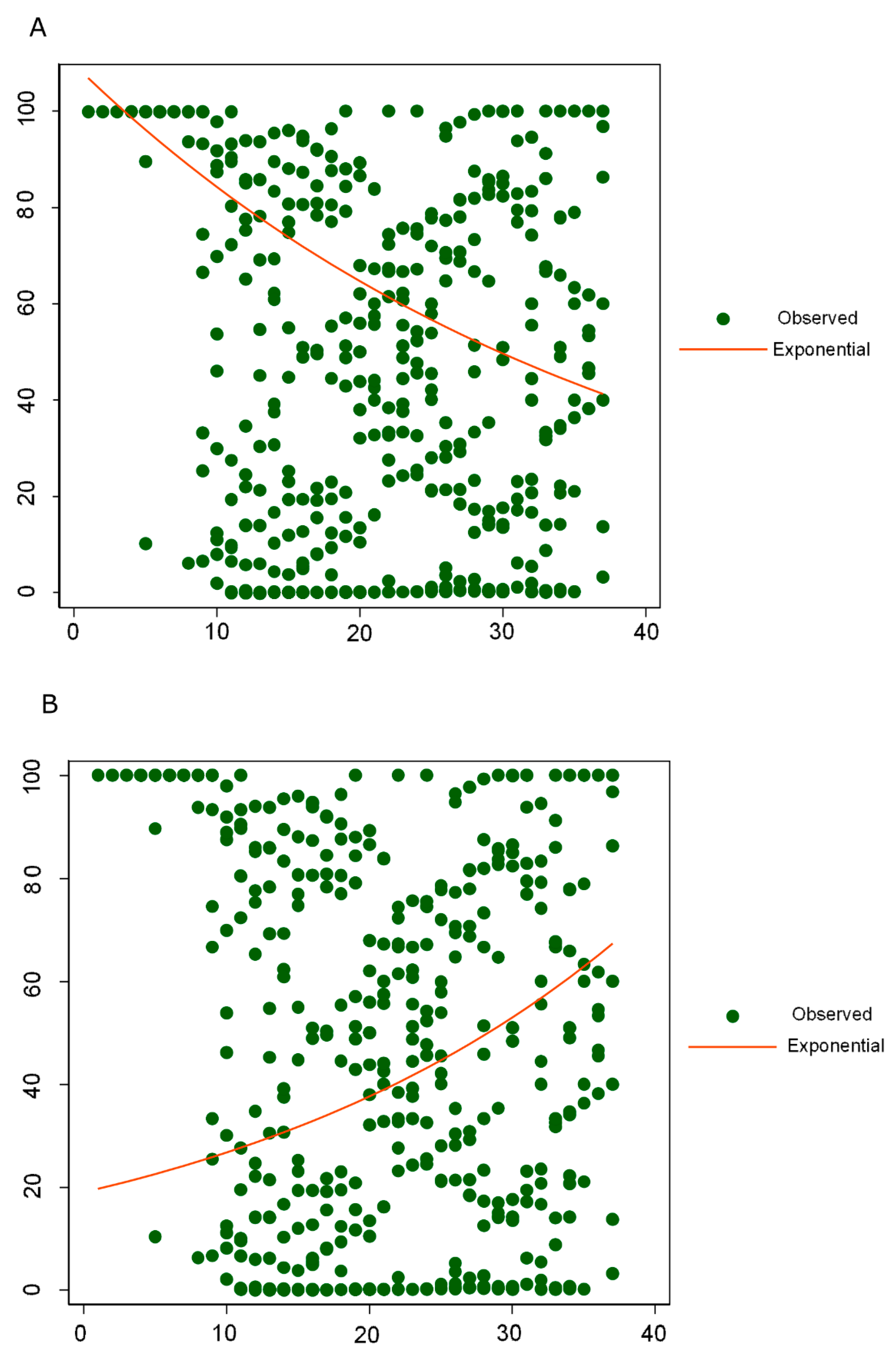
3. Results
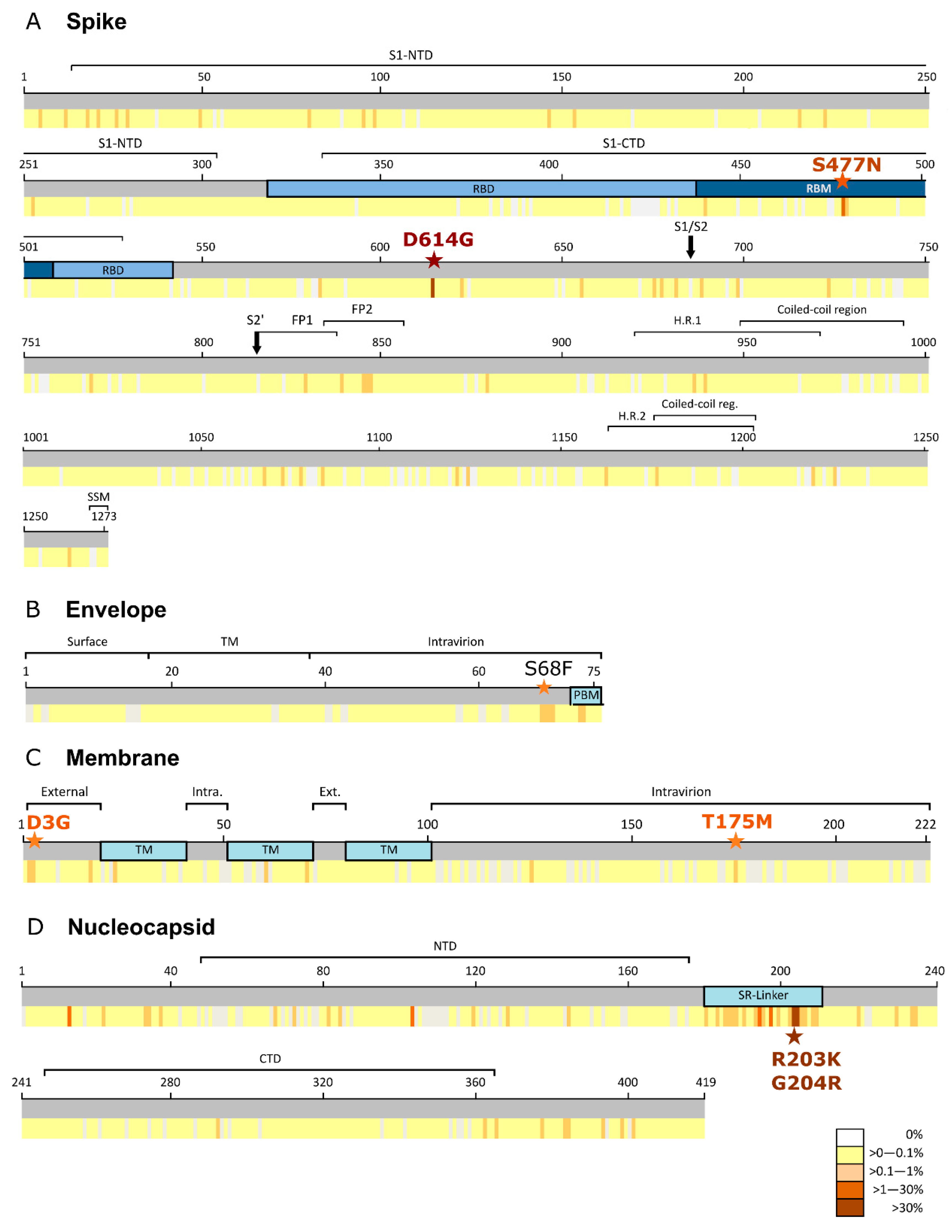
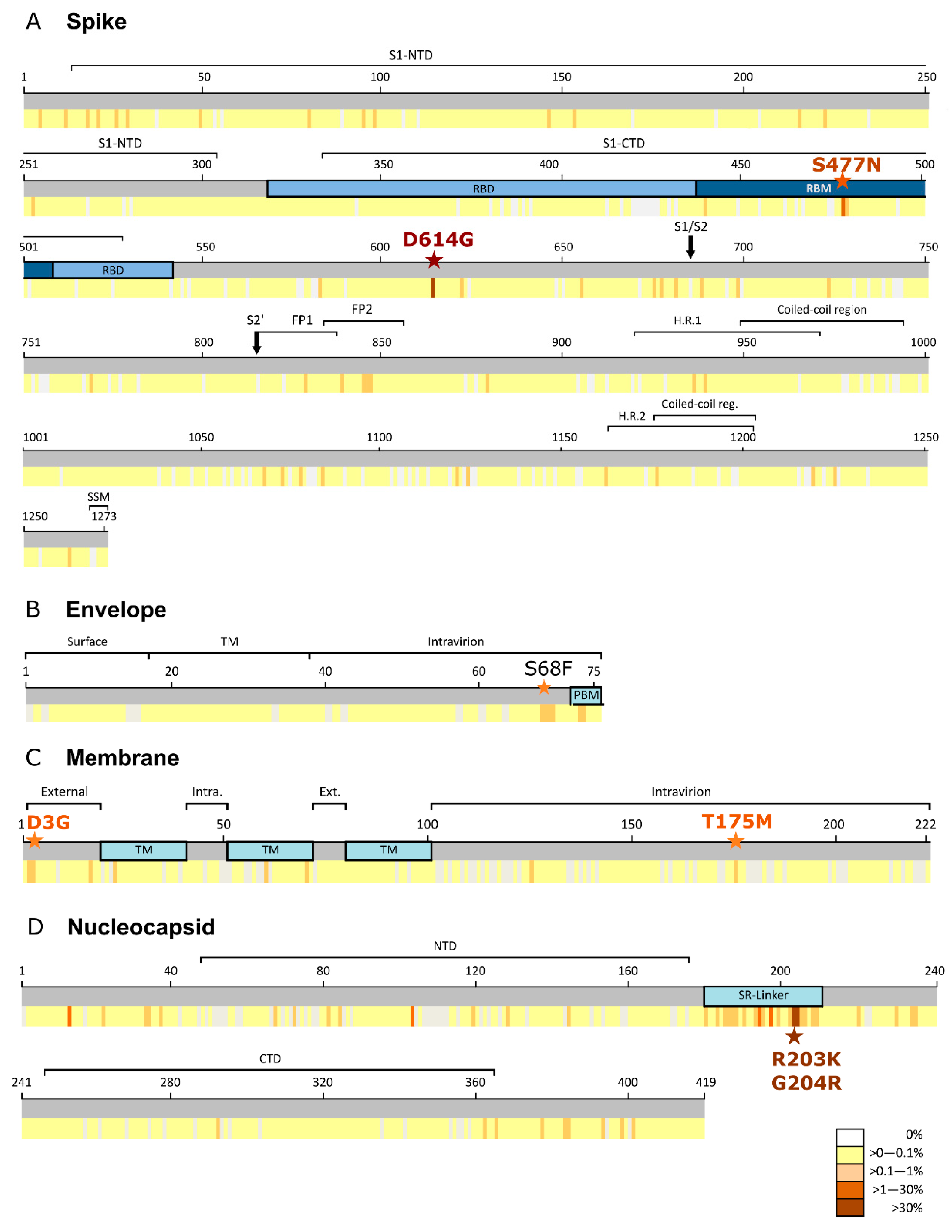
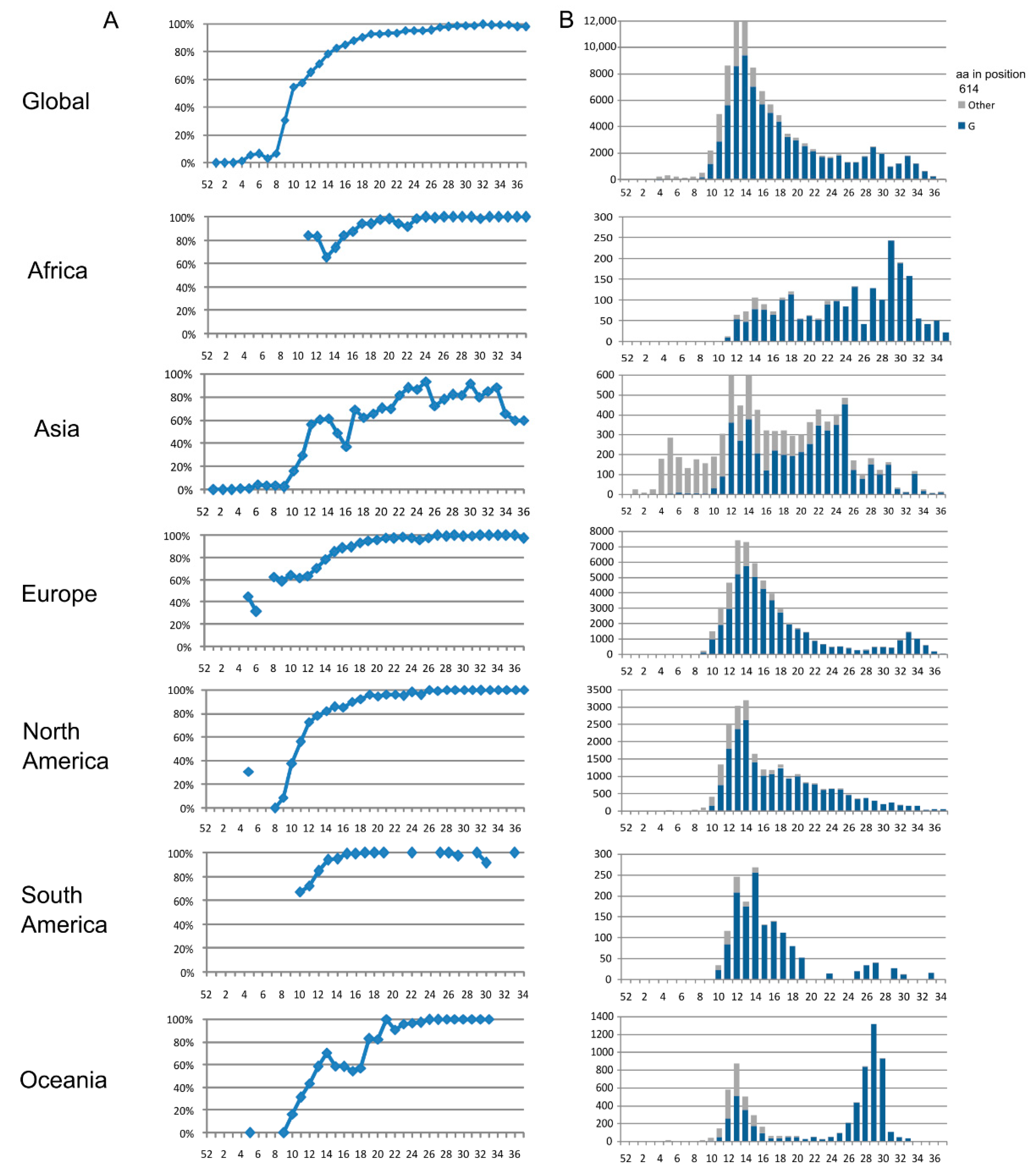
3.1. Spike Protein (S)
3.2. Envelope Protein (E)
3.3. Membrane (M) Protein
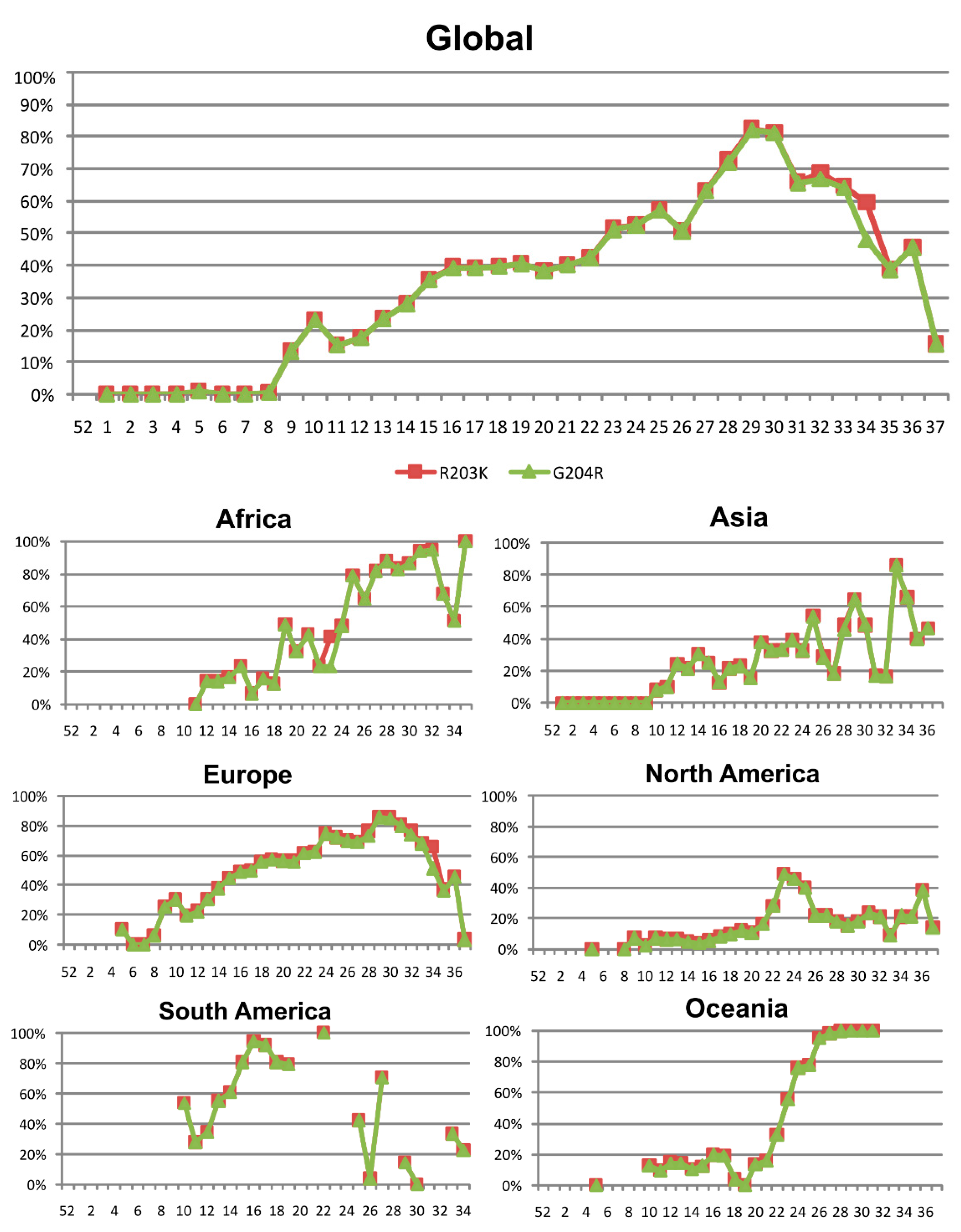
3.4. Nucleocapsid (N) Protein
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, C.; Horby, P.W.; Hayden, F.G.; Gao, G.F. A novel coronavirus outbreak of global health concern. Lancet 2020, 395, 470–473. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Liu, Z.; Chen, Z.; Huang, X.; Xu, M.; He, T.; Zhang, Z. The establishment of reference sequence for SARS-CoV-2 and variation analysis. J. Med. Virol. 2020, 92, 667–674. [Google Scholar] [CrossRef] [PubMed]
- Michel, C.J.; Mayer, C.; Poch, O.; Thompson, J.D. Characterization of accessory genes in coronavirus genomes. Virol. J. 2020, 17, 131. [Google Scholar] [CrossRef]
- Ahmadpour, D.; Ahmadpoor, P. How the COVID-19 Overcomes the Battle? An Approach to Virus Structure. Iran. J. Kidney Dis. 2020, 14, 167–172. [Google Scholar] [PubMed]
- Fehr, A.R.; Perlman, S. Coronaviruses: An overview of their replication and pathogenesis. Methods Mol. Biol. 2015, 1282, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Gordon, D.E.; Jang, G.M.; Bouhaddou, M.; Xu, J.; Obernier, K.; O’Meara, M.J.; Guo, J.Z.; Swaney, D.L.; Tummino, T.A.; Hüttenhain, R.; et al. A SARS-CoV-2-Human Protein-Protein Interaction Map Reveals Drug Targets and Potential Drug-Repurposing. bioRxiv Prepr. Serv. Biol. 2020. [Google Scholar] [CrossRef] [Green Version]
- Bosch, B.J.; van der Zee, R.; de Haan, C.A.M.; Rottier, P.J.M. The coronavirus spike protein is a class I virus fusion protein: Structural and functional characterization of the fusion core complex. J. Virol. 2003, 77, 8801–8811. [Google Scholar] [CrossRef] [Green Version]
- Ou, X.; Liu, Y.; Lei, X.; Li, P.; Mi, D.; Ren, L.; Guo, L.; Guo, R.; Chen, T.; Hu, J.; et al. Characterization of spike glycoprotein of SARS-CoV-2 on virus entry and its immune cross-reactivity with SARS-CoV. Nat. Commun. 2020, 11, 1620. [Google Scholar] [CrossRef] [Green Version]
- Hoffmann, M.; Kleine-Weber, H.; Schroeder, S.; Krüger, N.; Herrler, T.; Erichsen, S.; Schiergens, T.S.; Herrler, G.; Wu, N.-H.; Nitsche, A.; et al. SARS-CoV-2 Cell Entry Depends on ACE2 and TMPRSS2 and Is Blocked by a Clinically Proven Protease Inhibitor. Cell 2020, 181, 271–280.e8. [Google Scholar] [CrossRef]
- Lau, S.-Y.; Wang, P.; Mok, B.W.-Y.; Zhang, A.J.; Chu, H.; Lee, A.C.-Y.; Deng, S.; Chen, P.; Chan, K.-H.; Song, W.; et al. Attenuated SARS-CoV-2 variants with deletions at the S1/S2 junction. Emerg. Microbes Infect. 2020, 9, 837–842. [Google Scholar] [CrossRef]
- Fischer, F.; Stegen, C.F.; Masters, P.S.; Samsonoff, W.A. Analysis of constructed E gene mutants of mouse hepatitis virus confirms a pivotal role for E protein in coronavirus assembly. J. Virol. 1998, 72, 7885–7894. [Google Scholar] [CrossRef] [Green Version]
- Bos, E.C.; Luytjes, W.; van der Meulen, H.V.; Koerten, H.K.; Spaan, W.J. The production of recombinant infectious DI-particles of a murine coronavirus in the absence of helper virus. Virology 1996, 218, 52–60. [Google Scholar] [CrossRef]
- Schoeman, D.; Fielding, B.C. Coronavirus envelope protein: Current knowledge. Virol. J. 2019, 16, 69. [Google Scholar] [CrossRef] [Green Version]
- Neuman, B.W.; Kiss, G.; Kunding, A.H.; Bhella, D.; Baksh, M.F.; Connelly, S.; Droese, B.; Klaus, J.P.; Makino, S.; Sawicki, S.G.; et al. A structural analysis of M protein in coronavirus assembly and morphology. J. Struct. Biol. 2011, 174, 11–22. [Google Scholar] [CrossRef] [PubMed]
- De Haan, C.A.; Vennema, H.; Rottier, P.J. Assembly of the coronavirus envelope: Homotypic interactions between the M proteins. J. Virol. 2000, 74, 4967–4978. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.; Sue, S.-C.; Yu, T.; Hsieh, C.-M.; Tsai, C.-K.; Chiang, Y.-C.; Lee, S.; Hsiao, H.; Wu, W.-J.; Chang, W.-L.; et al. Modular organization of SARS coronavirus nucleocapsid protein. J. Biomed. Sci. 2006, 13, 59–72. [Google Scholar] [CrossRef] [Green Version]
- McBride, R.; van Zyl, M.; Fielding, B.C. The coronavirus nucleocapsid is a multifunctional protein. Viruses 2014, 6, 2991–3018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Dorp, L.; Acman, M.; Richard, D.; Shaw, L.P.; Ford, C.E.; Ormond, L.; Owen, C.J.; Pang, J.; Tan, C.C.S.; Boshier, F.A.T.; et al. Emergence of genomic diversity and recurrent mutations in SARS-CoV-2. Infect. Genet. Evol. J. Mol. Epidemiol. Evol. Genet. Infect. Dis. 2020, 83, 104351. [Google Scholar] [CrossRef]
- Chan, J.F.-W.; Kok, K.-H.; Zhu, Z.; Chu, H.; To, K.K.-W.; Yuan, S.; Yuen, K.-Y. Genomic characterization of the 2019 novel human-pathogenic coronavirus isolated from a patient with atypical pneumonia after visiting Wuhan. Emerg. Microbes Infect. 2020, 9, 221–236. [Google Scholar] [CrossRef] [Green Version]
- Naqvi, A.A.T.; Fatima, K.; Mohammad, T.; Fatima, U.; Singh, I.K.; Singh, A.; Atif, S.M.; Hariprasad, G.; Hasan, G.M.; Hassan, M.I. Insights into SARS-CoV-2 genome, structure, evolution, pathogenesis and therapies: Structural genomics approach. Biochim. Biophys. Acta. Mol. Basis Dis. 2020, 1866, 165878. [Google Scholar] [CrossRef] [PubMed]
- Lu, R.; Zhao, X.; Li, J.; Niu, P.; Yang, B.; Wu, H.; Wang, W.; Song, H.; Huang, B.; Zhu, N.; et al. Genomic characterisation and epidemiology of 2019 novel coronavirus: Implications for virus origins and receptor binding. Lancet 2020, 395, 565–574. [Google Scholar] [CrossRef] [Green Version]
- Duffy, S. Why are RNA virus mutation rates so damn high? PLoS Biol. 2018, 16, e3000003. [Google Scholar] [CrossRef] [Green Version]
- Sevajol, M.; Subissi, L.; Decroly, E.; Canard, B.; Imbert, I. Insights into RNA synthesis, capping, and proofreading mechanisms of SARS-coronavirus. Virus Res. 2014, 194, 90–99. [Google Scholar] [CrossRef]
- Minskaia, E.; Hertzig, T.; Gorbalenya, A.E.; Campanacci, V.; Cambillau, C.; Canard, B.; Ziebuhr, J. Discovery of an RNA virus 3’->5’ exoribonuclease that is critically involved in coronavirus RNA synthesis. Proc. Natl. Acad. Sci. USA 2006, 103, 5108–5113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dearlove, B.; Lewitus, E.; Bai, H.; Li, Y.; Reeves, D.B.; Joyce, M.G.; Scott, P.T.; Amare, M.F.; Vasan, S.; Michael, N.L.; et al. A SARS-CoV-2 vaccine candidate would likely match all currently circulating variants. Proc. Natl. Acad. Sci. USA 2020, 117, 23652–23662. [Google Scholar] [CrossRef]
- Phan, T. Genetic diversity and evolution of SARS-CoV-2. Infect. Genet. Evol. J. Mol. Epidemiol. Evol. Genet. Infect. Dis. 2020, 81, 104260. [Google Scholar] [CrossRef] [PubMed]
- Keck, J.G.; Makino, S.; Soe, L.H.; Fleming, J.O.; Stohlman, S.A.; Lai, M.M. RNA recombination of coronavirus. Adv. Exp. Med. Biol. 1987, 218, 99–107. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woo, P.C.Y.; Lau, S.K.P.; Huang, Y.; Yuen, K.-Y. Coronavirus diversity, phylogeny and interspecies jumping. Exp. Biol. Med. 2009, 234, 1117–1127. [Google Scholar] [CrossRef] [Green Version]
- Troyano-Hernáez, P.; Reinosa, R.; Holguín, A. Marcadores genéticos en la proteína de la Cápside p24 en los grupos, subtipos, sub-subtipos y recombinantes del VIH-1. In Proceedings of the XI Congreso Nacional GeSIDA, Toledo, Spain, 10–13 December 2019; pp. 124–125. [Google Scholar]
- Troyano-Hernáez, P.; Reinosa, R.; Holguín, A. Mutaciones en la proteína Spike de SARS-CoV-2 por Comunidades Autónomas en secuencias españolas recogidas hasta junio 2020. In Proceedings of the I Congreso Nacional COVID-19, Spain, 13–19 September 2020; p. 76. [Google Scholar]
- Troyano-Hernáez, P.; Reinosa, R.; Holguín, A. Update in natural antiretroviral-associated mutations among HIV-2 variants and discrepancies across HIV-2 resistance interpretation tools. AIDS Res. Hum. Retrovir. under review.
- Burgos, M.C.; Llácer, T.; Reinosa, R.; Rubio-Garrido, M.; González, A.; Holguín, A. Impaired genotypic resistance interpretation due to HIV-1 variant specific Markers. In Proceedings of the 10th IAS Conference on HIV Science, Mexico City, Mexico, 21–24 July 2019. [Google Scholar]
- Korber, B.; Fischer, W.M.; Gnanakaran, S.; Yoon, H.; Theiler, J.; Abfalterer, W.; Hengartner, N.; Giorgi, E.E.; Bhattacharya, T.; Foley, B.; et al. Tracking Changes in SARS-CoV-2 Spike: Evidence that D614G Increases Infectivity of the COVID-19 Virus. Cell 2020, 182, 812–827.e19. [Google Scholar] [CrossRef]
- Zhang, L.; Jackson, C.B.; Mou, H.; Ojha, A.; Rangarajan, E.S.; Izard, T.; Farzan, M.; Choe, H. The D614G mutation in the SARS-CoV-2 spike protein reduces S1 shedding and increases infectivity. bioRxiv 2020. [Google Scholar] [CrossRef]
- Yurkovetskiy, L.; Wang, X.; Pascal, K.E.; Tomkins-Tinch, C.; Nyalile, T.P.; Wang, Y.; Baum, A.; Diehl, W.E.; Dauphin, A.; Carbone, C.; et al. Structural and Functional Analysis of the D614G SARS-CoV-2 Spike Protein Variant. Cell 2020, 183, 739–751.e8. [Google Scholar] [CrossRef] [PubMed]
- Bianchi, M.; Benvenuto, D.; Giovanetti, M.; Angeletti, S.; Ciccozzi, M.; Pascarella, S. Sars-CoV-2 Envelope and Membrane Proteins: Structural Differences Linked to Virus Characteristics? BioMed Res. Int. 2020, 2020, 4389089. [Google Scholar] [CrossRef] [PubMed]
- Jimenez-Guardeño, J.M.; Nieto-Torres, J.L.; DeDiego, M.L.; Regla-Nava, J.A.; Fernandez-Delgado, R.; Castaño-Rodriguez, C.; Enjuanes, L. The PDZ-binding motif of severe acute respiratory syndrome coronavirus envelope protein is a determinant of viral pathogenesis. PLoS Pathog. 2014, 10, e1004320. [Google Scholar] [CrossRef] [Green Version]
- Jimenez-Guardeño, J.M.; Regla-Nava, J.A.; Nieto-Torres, J.L.; DeDiego, M.L.; Castaño-Rodriguez, C.; Fernandez-Delgado, R.; Perlman, S.; Enjuanes, L. Identification of the Mechanisms Causing Reversion to Virulence in an Attenuated SARS-CoV for the Design of a Genetically Stable Vaccine. PLoS Pathog. 2015, 11, e1005215. [Google Scholar] [CrossRef] [Green Version]
- Ujike, M.; Taguchi, F. Incorporation of spike and membrane glycoproteins into coronavirus virions. Viruses 2015, 7, 1700–1725. [Google Scholar] [CrossRef] [Green Version]
- Kang, S.; Yang, M.; Hong, Z.; Zhang, L.; Huang, Z.; Chen, X.; He, S.; Zhou, Z.; Zhou, Z.; Chen, Q.; et al. Crystal structure of SARS-CoV-2 nucleocapsid protein RNA binding domain reveals potential unique drug targeting sites. Acta Pharm. Sin. B 2020, 10, 1228–1238. [Google Scholar] [CrossRef]
- Peng, T.-Y.; Lee, K.-R.; Tarn, W.-Y. Phosphorylation of the arginine/serine dipeptide-rich motif of the severe acute respiratory syndrome coronavirus nucleocapsid protein modulates its multimerization, translation inhibitory activity and cellular localization. FEBS J. 2008, 275, 4152–4163. [Google Scholar] [CrossRef] [Green Version]
- Tung, H.Y.L.; Limtung, P. Mutations in the phosphorylation sites of SARS-CoV-2 encoded nucleocapsid protein and structure model of sequestration by protein 14-3-3. Biochem. Biophys. Res. Commun. 2020, 532, 132–138. [Google Scholar] [CrossRef]
- Rahman, M.S.; Islam, M.R.; Alam, A.S.M.R.U.; Islam, I.; Hoque, M.N.; Akter, S.; Rahaman, M.M.; Sultana, M.; Hossain, M.A. Evolutionary dynamics of SARS-CoV-2 nucleocapsid protein and its consequences. J. Med. Virol. 2020. [Google Scholar] [CrossRef] [PubMed]
- Candido, D.S.; Claro, I.M.; de Jesus, J.G.; Souza, W.M.; Moreira, F.R.R.; Dellicour, S.; Mellan, T.A.; du Plessis, L.; Pereira, R.H.M.; Sales, F.C.S.; et al. Evolution and epidemic spread of SARS-CoV-2 in Brazil. Science 2020, 369, 1255–1260. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Troyano-Hernáez, P.; Reinosa, R.; Holguín, Á. Evolution of SARS-CoV-2 Envelope, Membrane, Nucleocapsid, and Spike Structural Proteins from the Beginning of the Pandemic to September 2020: A Global and Regional Approach by Epidemiological Week. Viruses 2021, 13, 243. https://doi.org/10.3390/v13020243
Troyano-Hernáez P, Reinosa R, Holguín Á. Evolution of SARS-CoV-2 Envelope, Membrane, Nucleocapsid, and Spike Structural Proteins from the Beginning of the Pandemic to September 2020: A Global and Regional Approach by Epidemiological Week. Viruses. 2021; 13(2):243. https://doi.org/10.3390/v13020243
Chicago/Turabian StyleTroyano-Hernáez, Paloma, Roberto Reinosa, and África Holguín. 2021. "Evolution of SARS-CoV-2 Envelope, Membrane, Nucleocapsid, and Spike Structural Proteins from the Beginning of the Pandemic to September 2020: A Global and Regional Approach by Epidemiological Week" Viruses 13, no. 2: 243. https://doi.org/10.3390/v13020243
APA StyleTroyano-Hernáez, P., Reinosa, R., & Holguín, Á. (2021). Evolution of SARS-CoV-2 Envelope, Membrane, Nucleocapsid, and Spike Structural Proteins from the Beginning of the Pandemic to September 2020: A Global and Regional Approach by Epidemiological Week. Viruses, 13(2), 243. https://doi.org/10.3390/v13020243