VIRIDIC—A Novel Tool to Calculate the Intergenomic Similarities of Prokaryote-Infecting Viruses



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
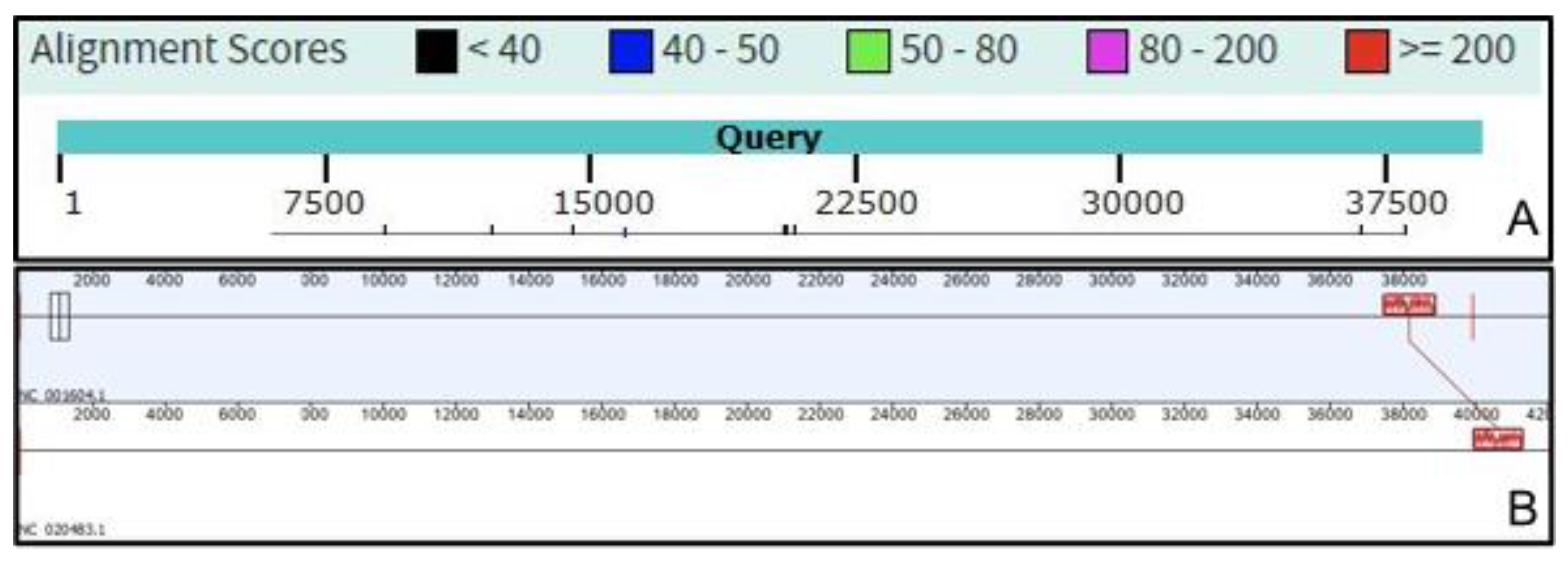
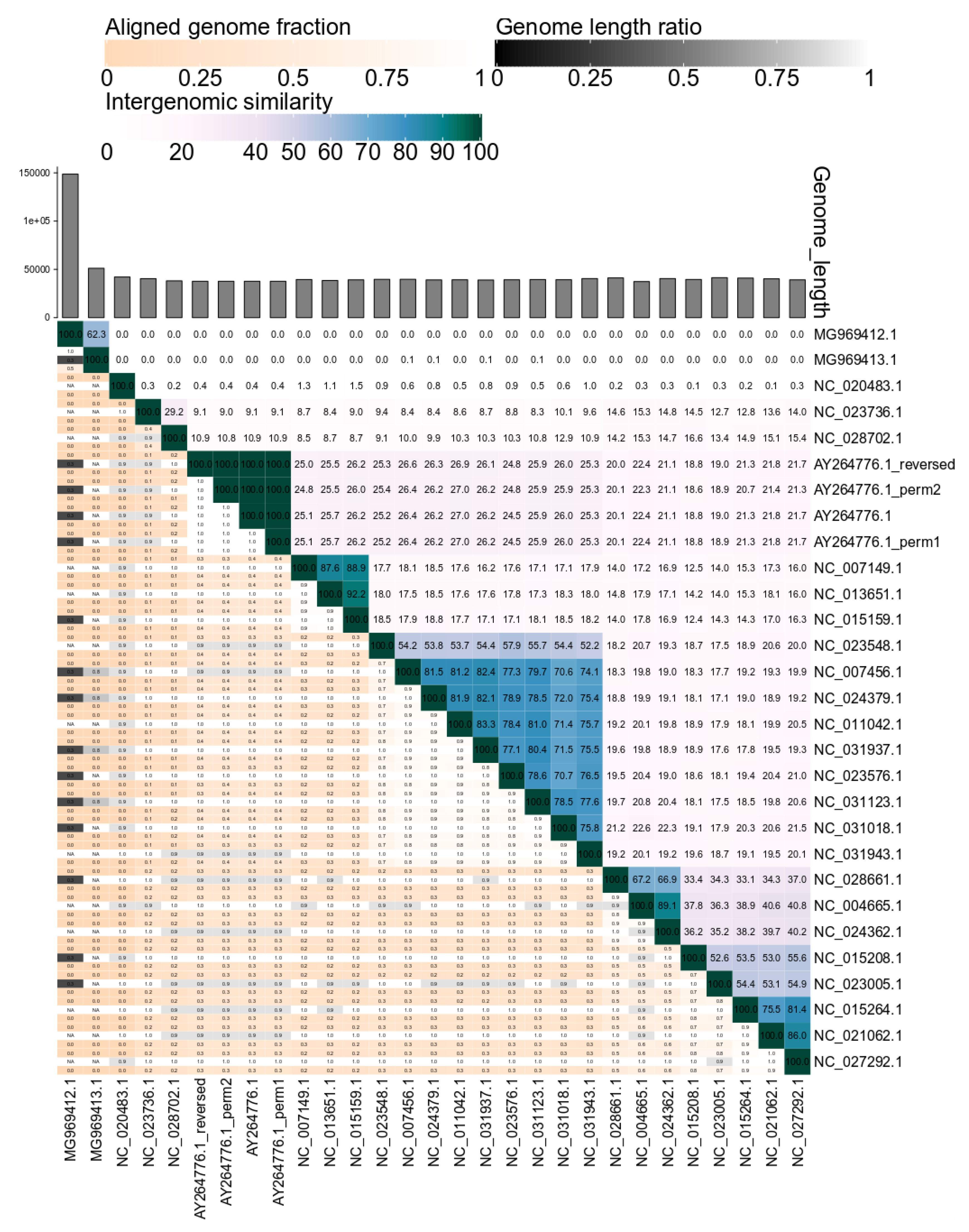
2.1. VIRIDIC—Development and Workflow
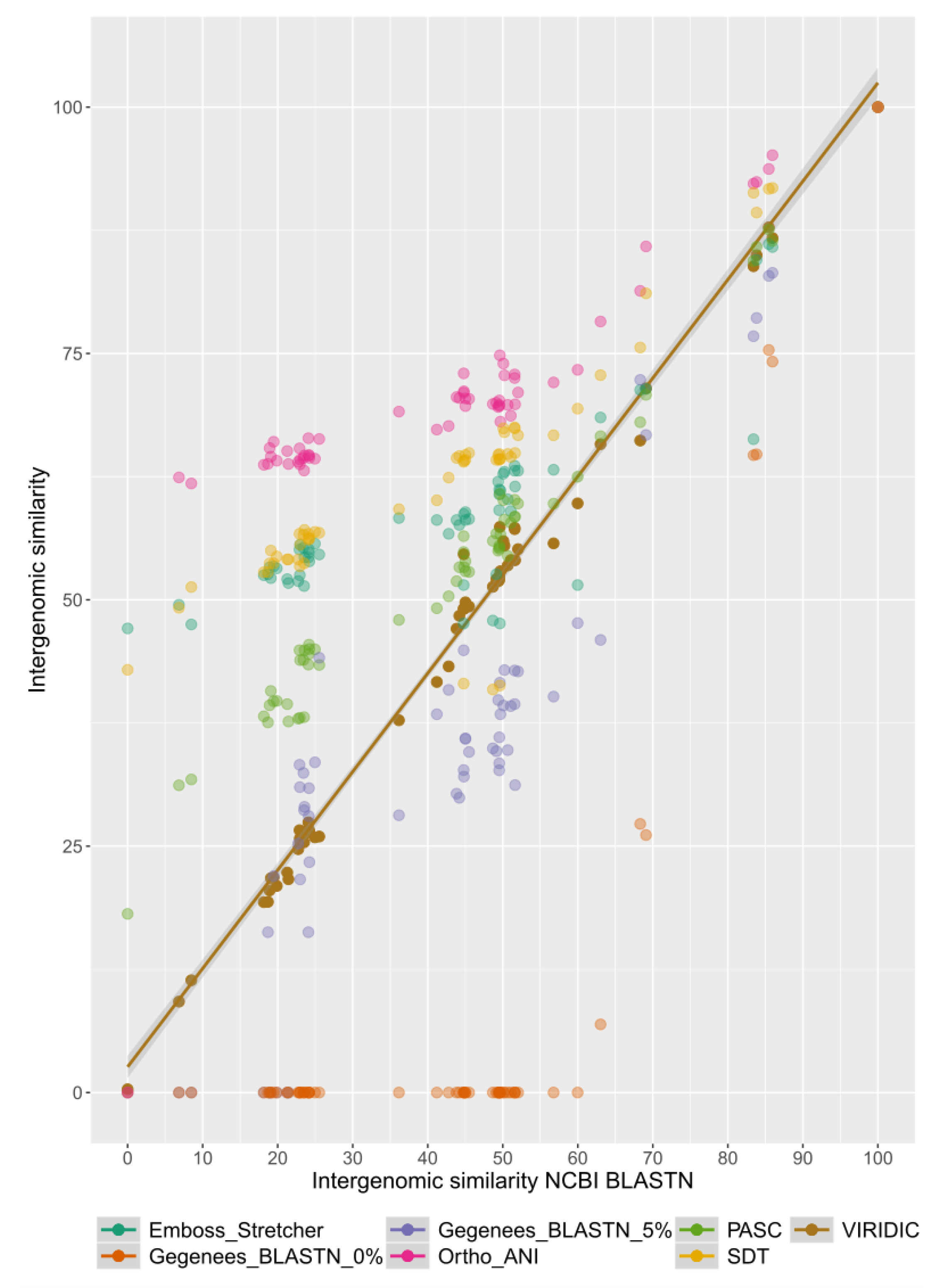
2.2. Benchmarking VIRIDIC
3. Results and Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Goris, J.; Konstantinidis, K.T.; Klappenbach, J.A.; Coenye, T.; Vandamme, P.; Tiedje, J.M. DNA-DNA hybridization values and their relationship to whole-genome sequence similarities. Int. J. Syst. Evol. Microbiol. 2007, 57, 81–91. [Google Scholar] [CrossRef] [PubMed]
- Yoon, S.-H.; Ha, S.-M.; Lim, J.; Kwon, S.; Chun, J. A large-scale evaluation of algorithms to calculate average nucleotide identity. Antonie Leeuwenhoek 2017, 110, 1281–1286. [Google Scholar] [CrossRef] [PubMed]
- Han, N.; Qiang, Y.; Zhang, W. ANItools web: A web tool for fast genome comparison within multiple bacterial strains. Database 2016, 2016. [Google Scholar] [CrossRef] [PubMed]
- Lee, I.; Ouk Kim, Y.; Park, S.-C.; Chun, J. OrthoANI: An improved algorithm and software for calculating average nucleotide identity. Int. J. Syst. Evol. Microbiol. 2016, 66, 1100–1103. [Google Scholar] [CrossRef]
- Ceyssens, P.-J.; Miroshnikov, K.; Mattheus, W.; Krylov, V.; Robben, J.; Noben, J.-P.; Vanderschraeghe, S.; Sykilinda, N.; Kropinski, A.M.; Volckaert, G.; et al. Comparative analysis of the widespread and conserved PB1-like viruses infecting Pseudomonas aeruginosa. Environ. Microbiol. 2009, 11, 2874–2883. [Google Scholar] [CrossRef]
- Agren, J.; Sundström, A.; Håfström, T.; Segerman, B. Gegenees: Fragmented alignment of multiple genomes for determining phylogenomic distances and genetic signatures unique for specified target groups. PLoS ONE 2012, 7, e39107. [Google Scholar] [CrossRef]
- Richter, M.; Rosselló-Móra, R.; Oliver Glöckner, F.; Peplies, J. JSpeciesWS: A web server for prokaryotic species circumscription based on pairwise genome comparison. Bioinformatics 2016, 32, 929–931. [Google Scholar] [CrossRef]
- Bao, Y.; Chetvernin, V.; Tatusova, T. PAirwise Sequence Comparison (PASC) and its application in the classification of filoviruses. Viruses 2012, 4, 1318–1327. [Google Scholar] [CrossRef] [PubMed]
- Bao, Y.; Chetvernin, V.; Tatusova, T. Improvements to pairwise sequence comparison (PASC): A genome-based web tool for virus classification. Arch. Virol. 2014, 159, 3293–3304. [Google Scholar] [CrossRef]
- Muhire, B.M.; Varsani, A.; Martin, D.P. SDT: A virus classification tool based on pairwise sequence alignment and identity calculation. PLoS ONE 2014, 9, e108277. [Google Scholar] [CrossRef]
- Noé, L.; Kucherov, G. YASS: Enhancing the sensitivity of DNA similarity search. Nucleic Acids Res. 2005, 33, W540–W543. [Google Scholar] [CrossRef]
- Mahadevan, P. An Analysis of Adenovirus Genomes Using Whole Genome Software Tools. Bioinformation 2016, 12, 301–310. [Google Scholar] [CrossRef][Green Version]
- Darling, A.E.; Mau, B.; Perna, N.T. progressiveMauve: Multiple genome alignment with gene gain, loss and rearrangement. PLoS ONE 2010, 5, e11147. [Google Scholar] [CrossRef]
- Meier-Kolthoff, J.P.; Göker, M. VICTOR: Genome-based phylogeny and classification of prokaryotic viruses. Bioinformatics 2017, 33, 3396–3404. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 12 September 2020).
- Camacho, C.; Coulouris, G.; Avagyan, V.; Ma, N.; Papadopoulos, J.; Bealer, K.; Madden, T.L. BLAST+: Architecture and applications. BMC Bioinf. 2009, 10, 421. [Google Scholar] [CrossRef]
- Meier-Kolthoff, J.P.; Auch, A.F.; Klenk, H.-P.; Göker, M. Genome sequence-based species delimitation with confidence intervals and improved distance functions. BMC Bioinf. 2013, 14, 60. [Google Scholar] [CrossRef]
- Müllner, D. Fastcluster: Fast Hierarchical, Agglomerative Clustering Routines for R and Python. J. Stat. Soft. 2013, 53. [Google Scholar] [CrossRef]
- Gu, Z.; Eils, R.; Schlesner, M. Complex heatmaps reveal patterns and correlations in multidimensional genomic data. Bioinformatics 2016, 32, 2847–2849. [Google Scholar] [CrossRef]
- Haft, D.H.; DiCuccio, M.; Badretdin, A.; Brover, V.; Chetvernin, V.; O’Neill, K.; Li, W.; Chitsaz, F.; Derbyshire, M.K.; Gonzales, N.R.; et al. RefSeq: An update on prokaryotic genome annotation and curation. Nucleic Acids Res. 2018, 46, D851–D860. [Google Scholar] [CrossRef]
- Stothard, P. The sequence manipulation suite: JavaScript programs for analyzing and formatting protein and DNA sequences. Biotechniques 2000, 28, 1102–1104. [Google Scholar] [CrossRef]
- Hadley, W. Ggplot2. Elegrant Graphics for Data Analysis, 2nd ed.; Springer: Cham, Switzerland, 2016; ISBN 978-3-319-24277-4. [Google Scholar]
- Accetto, T.; Janež, N. The lytic Myoviridae of Enterobacteriaceae form tight recombining assemblages separated by discontinuities in genome average nucleotide identity and lateral gene flow. Microb. Genom. 2018, 4. [Google Scholar] [CrossRef]
- Oliveira, H.; Sampaio, M.; Melo, L.D.R.; Dias, O.; Pope, W.H.; Hatfull, G.F.; Azeredo, J. Staphylococci phages display vast genomic diversity and evolutionary relationships. BMC Genom. 2019, 20, 357. [Google Scholar] [CrossRef]
- Rodriguez, R.L.M.; Konstantidinis, K.T. Bypassing Cultivation to Identify Bacterial Species. Microbe 2014, 9, 211–218. [Google Scholar] [CrossRef]
- Kearse, M.; Moir, R.; Wilson, A.; Stones-Havas, S.; Cheung, M.; Sturrock, S.; Buxton, S.; Cooper, A.; Markowitz, S.; Duran, C.; et al. Geneious Basic: An integrated and extendable desktop software platform for the organization and analysis of sequence data. Bioinformatics 2012, 28, 1647–1649. [Google Scholar] [CrossRef] [PubMed]
- Barylski, J.; Enault, F.; Dutilh, B.E.; Schuller, M.B.; Edwards, R.A.; Gillis, A.; Klumpp, J.; Knezevic, P.; Krupovic, M.; Kuhn, J.H.; et al. Analysis of Spounaviruses as a Case Study for the Overdue Reclassification of Tailed Phages. Syst. Biol. 2020, 69, 110–123. [Google Scholar] [CrossRef]
- Konstantinidis, K.T.; Tiedje, J.M. Genomic insights that advance the species definition for prokaryotes. Proc. Natl. Acad. Sci. USA 2005, 102, 2567–2572. [Google Scholar] [CrossRef]
- Gregory, A.C.; Zayed, A.A.; Conceição-Neto, N.; Temperton, B.; Bolduc, B.; Alberti, A.; Ardyna, M.; Arkhipova, K.; Carmichael, M.; Cruaud, C.; et al. Marine DNA viral macro- and microdiversity from Pole to Pole. Cell 2019. [Google Scholar] [CrossRef]
- Brum, J.R.; Ignacio-Espinoza, J.C.; Roux, S.; Doulcier, G.; Acinas, S.G.; Alberti, A.; Chaffron, S.; Cruaud, C.; Vargas, C.d.; Gasol, J.M.; et al. Patterns and ecological drivers of ocean viral communities. Science 2015, 348, 1261498. [Google Scholar] [CrossRef] [PubMed]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moraru, C.; Varsani, A.; Kropinski, A.M. VIRIDIC—A Novel Tool to Calculate the Intergenomic Similarities of Prokaryote-Infecting Viruses. Viruses 2020, 12, 1268. https://doi.org/10.3390/v12111268
Moraru C, Varsani A, Kropinski AM. VIRIDIC—A Novel Tool to Calculate the Intergenomic Similarities of Prokaryote-Infecting Viruses. Viruses. 2020; 12(11):1268. https://doi.org/10.3390/v12111268
Chicago/Turabian StyleMoraru, Cristina, Arvind Varsani, and Andrew M. Kropinski. 2020. "VIRIDIC—A Novel Tool to Calculate the Intergenomic Similarities of Prokaryote-Infecting Viruses" Viruses 12, no. 11: 1268. https://doi.org/10.3390/v12111268
APA StyleMoraru, C., Varsani, A., & Kropinski, A. M. (2020). VIRIDIC—A Novel Tool to Calculate the Intergenomic Similarities of Prokaryote-Infecting Viruses. Viruses, 12(11), 1268. https://doi.org/10.3390/v12111268