
Spatial Autoregressive Models for Stand Top and Stand Mean Height Relationship in Mixed Quercus mongolica Broadleaved Natural Stands of Northeast China



Abstract
:1. Introduction
2. Data and Methods
2.1. Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Mean | SD | Min | Max |
|---|---|---|---|---|
| Ht (m) | 18.38 | 6.94 | 12.60 | 28.38 |
| Hm (m) | 10.85 | 3.00 | 7.47 | 17.42 |
| N (stem/ha) | 991.3 | 324.8 | 375 | 2275 |
| BA (m2/ha) | 20.67 | 5.77 | 6.65 | 35.83 |
| Dg (cm) | 16.58 | 5.65 | 10.99 | 24.42 |
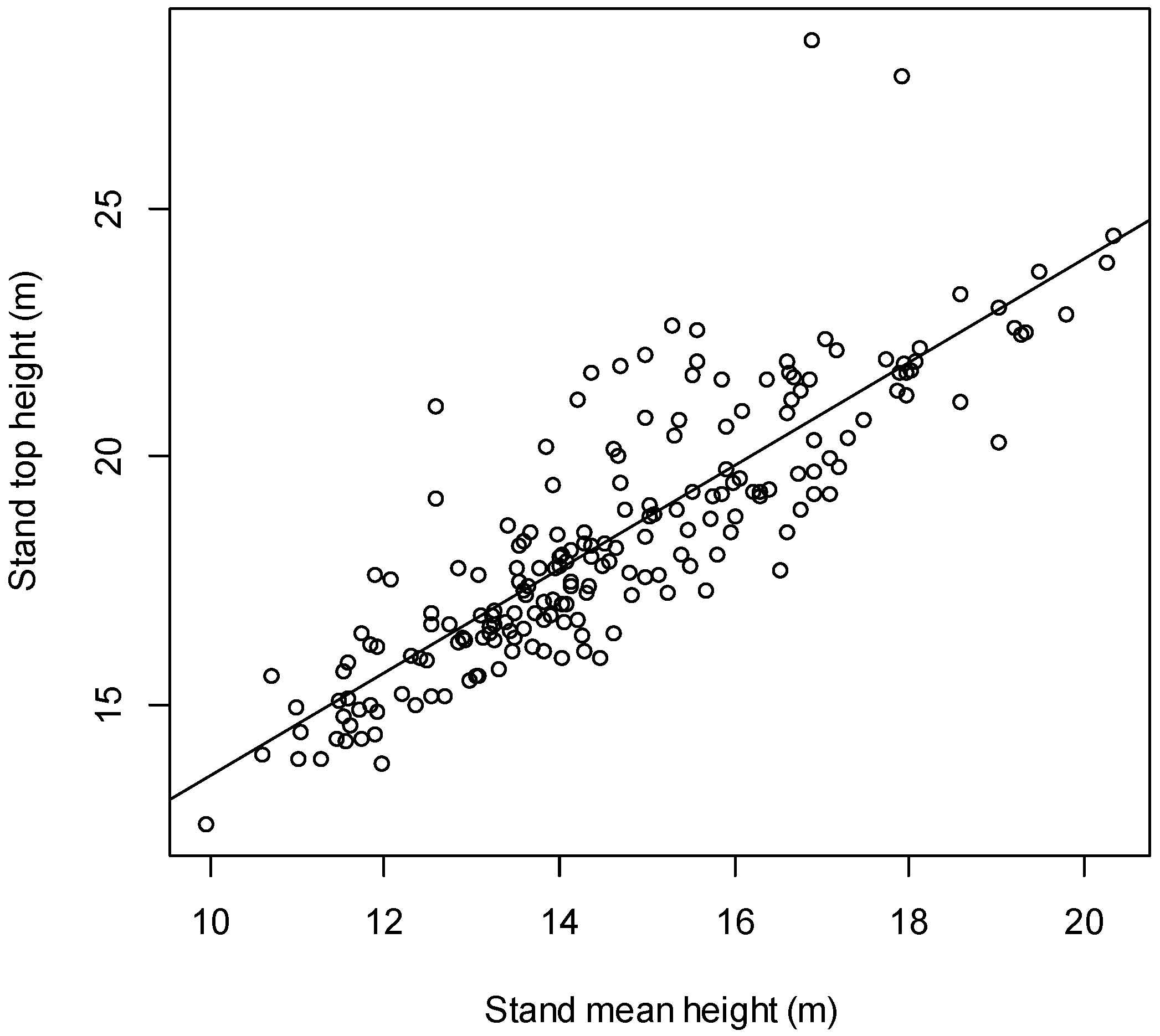
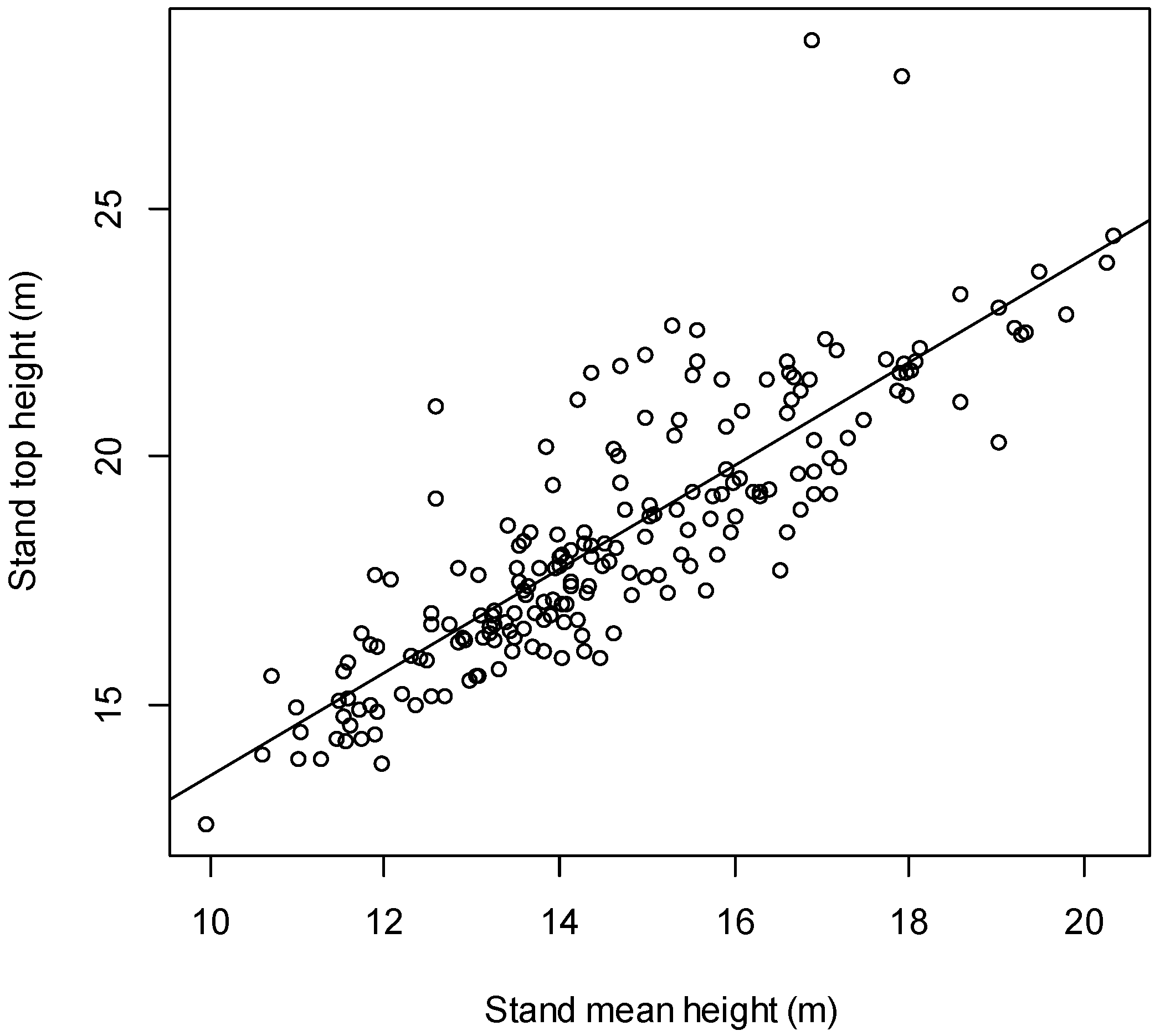
2.2. Stand Top and Stand Mean Height Relationship
2.3. Spatial Weight Matrix
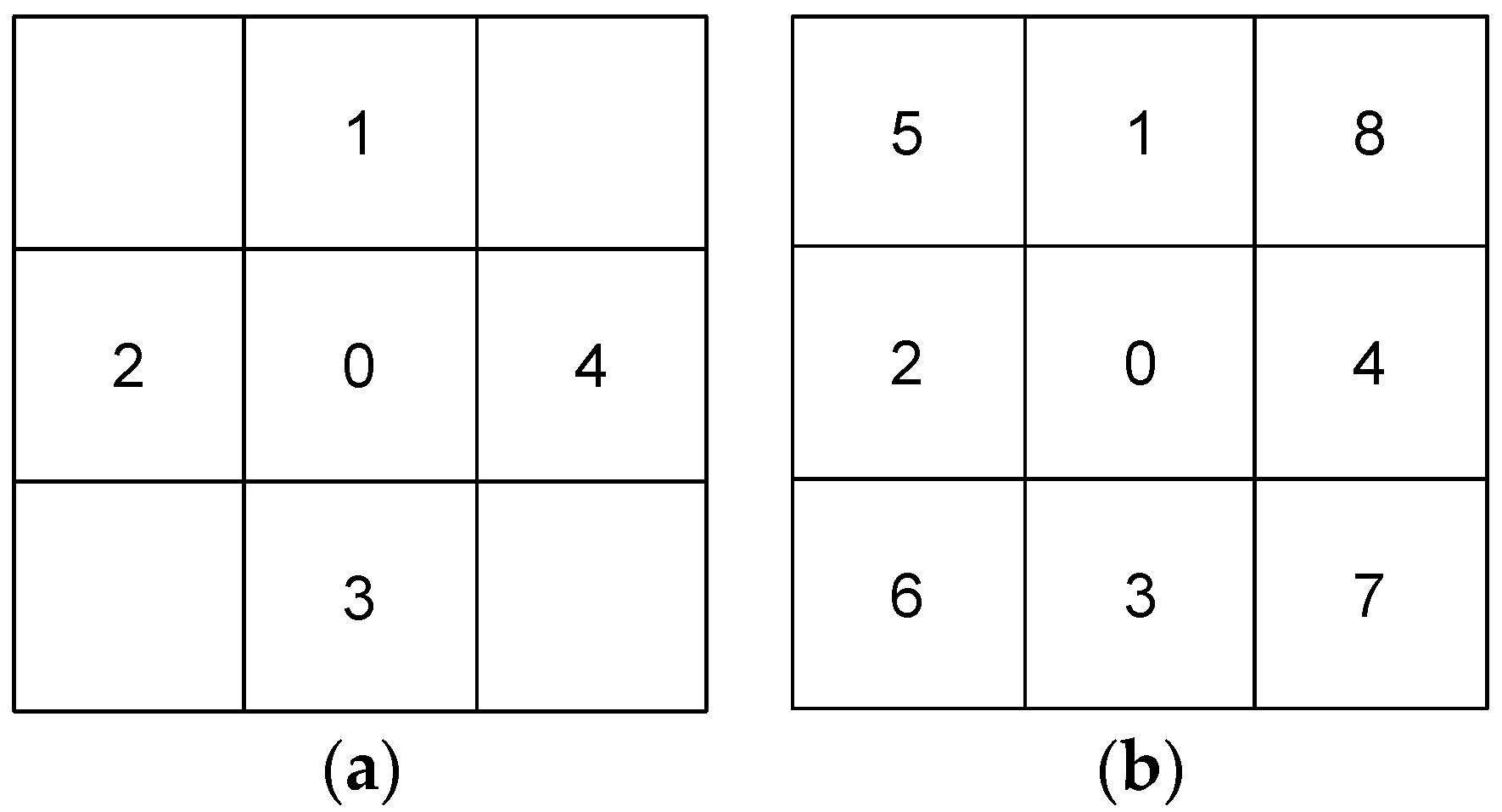
2.3.1. Contiguous Neighbors

2.3.2. Inverse Distances
2.3.3. Geostatistical Matrix
2.3.4. Local Statistics Model Matrix
2.4. Test Spatial Autocorrelation of Model Residuals
2.5. Model Fitting
3. Results
3.1. Relationship between Stand Top and Stand Mean Height
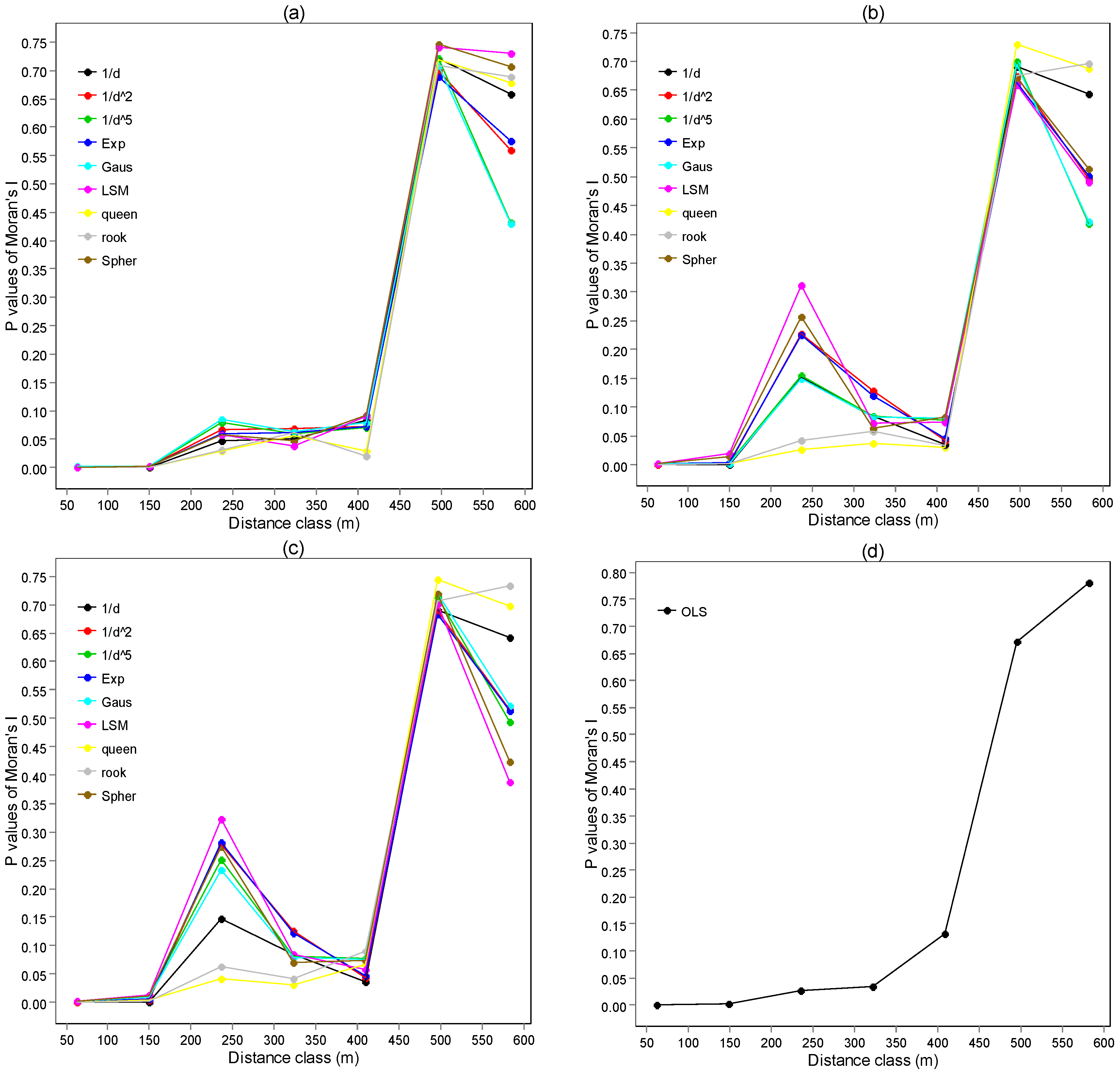
3.2. Test the Spatial Autocorrelation of Model Residuals
| W | OLS | SLM | SDM | SEM | ||||
|---|---|---|---|---|---|---|---|---|
| I | p-Value | I | p-Value | I | p-Value | I | p-Value | |
| queen | 0.221 | 0.0018 | 0.202 | 0.0040 | 0.021 | 0.7143 | 0.002 | 0.9171 |
| rook | 0.284 | 0.0004 | 0.272 | 0.0007 | 0.045 | 0.5420 | 0.017 | 0.7874 |
| 1/d | 0.047 | 0.0000 | 0.041 | 0.0001 | 0.010 | 0.2202 | 0.010 | 0.2164 |
| 1/d2 | 0.117 | 0.0000 | 0.082 | 0.0034 | 0.010 | 0.6204 | 0.008 | 0.6586 |
| 1/d5 | 0.162 | 0.0027 | 0.079 | 0.1304 | 0.012 | 0.7594 | 0.006 | 0.8450 |
| Exp | 0.130 | 0.0001 | 0.084 | 0.0079 | 0.008 | 0.7050 | 0.006 | 0.7365 |
| Gaus | 0.151 | 0.0048 | 0.070 | 0.1757 | 0.012 | 0.7544 | 0.005 | 0.8483 |
| Spher | 0.20 | 0.0026 | 0.196 | 0.0038 | 0.027 | 0.6410 | 0.002 | 0.9198 |
| LSM | 0.224 | 0.0008 | 0.217 | 0.0012 | 0.030 | 0.6057 | −0.005 | 0.9983 |
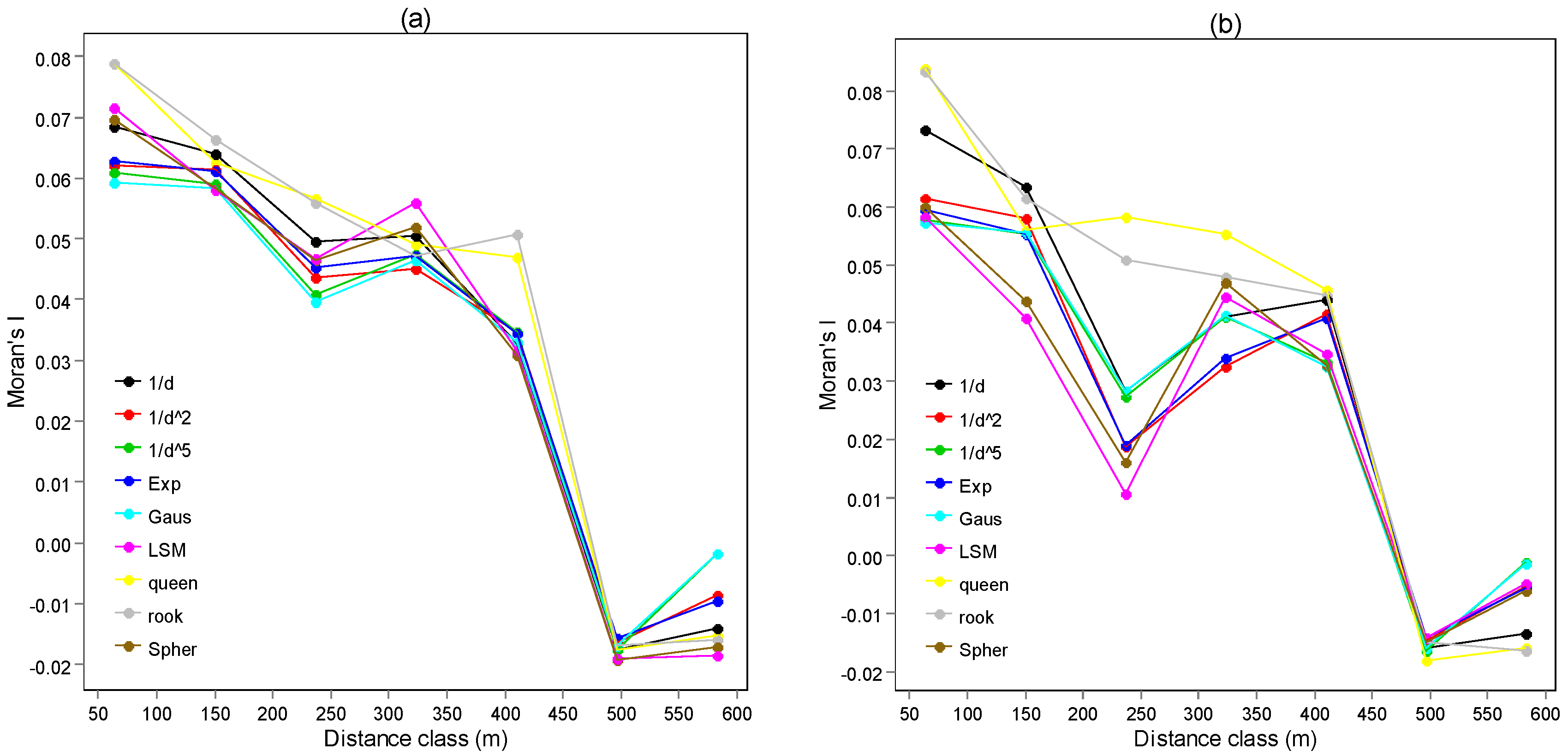
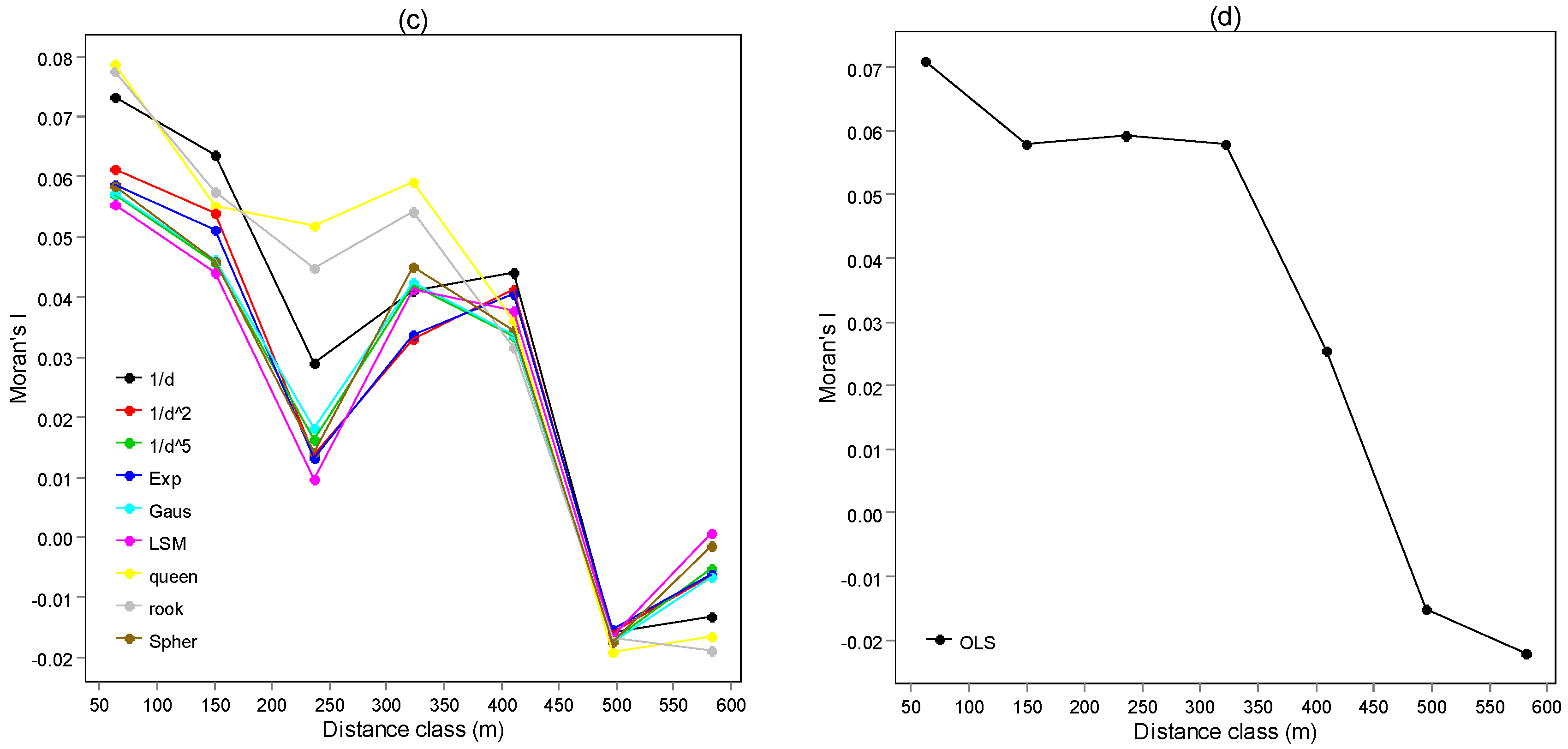
3.3. Spatial Correlogram of Model Residuals

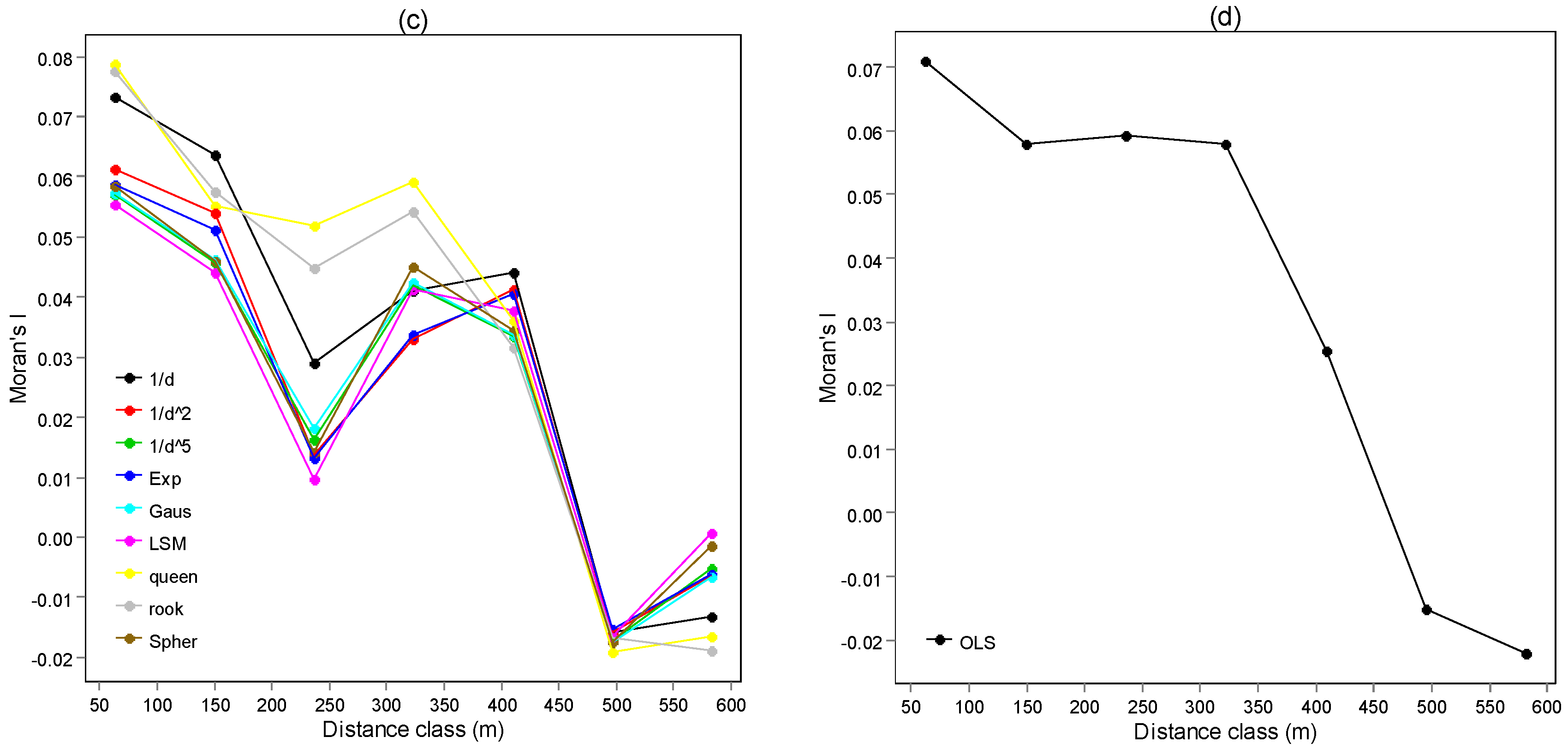

3.4. Model Fitting
| W | SLM | SDM | SEM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | AIC | R2 | RMSE | AIC | R2 | RMSE | AIC | |
| queen | 0.719 | 1.397 | 704.880 | 0.733 | 1.361 | 699.851 | 0.736 | 1.354 | 696.609 |
| rook | 0.718 | 1.399 | 705.258 | 0.739 | 1.346 | 697.043 | 0.745 | 1.332 | 692.527 |
| 1/d | 0.721 | 1.393 | 703.965 | 0.732 | 1.365 | 700.298 | 0.732 | 1.365 | 698.300 |
| 1/d2 | 0.726 | 1.380 | 700.548 | 0.740 | 1.344 | 696.125 | 0.739 | 1.345 | 694.419 |
| 1/d5 | 0.730 | 1.370 | 698.458 | 0.736 | 1.354 | 698.192 | 0.734 | 1.359 | 697.713 |
| Exp | 0.726 | 1.380 | 700.490 | 0.739 | 1.347 | 696.649 | 0.738 | 1.348 | 694.947 |
| Gaus | 0.730 | 1.369 | 698.405 | 0.735 | 1.357 | 698.723 | 0.732 | 1.364 | 698.633 |
| Spher | 0.718 | 1.399 | 705.502 | 0.731 | 1.367 | 701.003 | 0.736 | 1.355 | 696.863 |
| LSM | 0.718 | 1.400 | 705.707 | 0.732 | 1.364 | 700.207 | 0.739 | 1.345 | 694.634 |
3.5. Model Parameter Estimates
| W | β0 | Std. Error | z-Value | p-Value | β1 | Std. Error | z-Value | p-Value |
|---|---|---|---|---|---|---|---|---|
| queen | 2.968 | 0.703 | 4.224 | 0.0000 | 1.031 | 0.048 | 21.603 | <2.2 × 10−16 |
| rook | 2.970 | 0.715 | 4.152 | 0.0000 | 1.039 | 0.047 | 22.299 | <2.2 × 10−16 |
| 1/d | −1.125 | 2.657 | −0.424 | 0.6719 | 0.993 | 0.057 | 17.333 | <2.2 × 10−16 |
| 1/d2 | 0.947 | 1.080 | 0.877 | 0.3805 | 0.949 | 0.061 | 15.570 | <2.2 × 10−16 |
| 1/d5 | 1.770 | 0.809 | 2.187 | 0.0288 | 0.938 | 0.059 | 15.904 | <2.2 × 10−16 |
| Exp | 1.524 | 0.927 | 1.643 | 0.1003 | 0.948 | 0.062 | 15.370 | <2.2 × 10−16 |
| Gaus | 1.772 | 0.807 | 2.196 | 0.0281 | 0.936 | 0.059 | 15.853 | <2.2 × 10−16 |
| Spher | 2.980 | 0.733 | 4.068 | 0.0000 | 1.039 | 0.047 | 22.233 | <2.2 × 10−16 |
| LSM | 3.064 | 0.709 | 4.322 | 0.0000 | 1.041 | 0.047 | 22.359 | <2.2 × 10−16 |
| W | β0 | Std. Error | z-Value | p-Value | β1 | Std. Error | z-Value | p-Value |
|---|---|---|---|---|---|---|---|---|
| queen | 2.743 | 0.694 | 3.954 | 0.0001 | 1.058 | 0.048 | 22.096 | <2.2 × 10−16 |
| rook | 2.786 | 0.697 | 3.996 | 0.0001 | 1.060 | 0.046 | 23.129 | <2.2 × 10−16 |
| 1/d | 1.046 | 2.792 | 0.375 | 0.7080 | 1.049 | 0.061 | 17.274 | <2.2 × 10−16 |
| 1/d2 | 1.303 | 1.082 | 1.205 | 0.2284 | 1.011 | 0.064 | 15.869 | <2.2 × 10−16 |
| 1/d5 | 1.917 | 0.815 | 2.351 | 0.0187 | 0.977 | 0.064 | 15.311 | <2.2 × 10−16 |
| Exp | 1.665 | 0.921 | 1.807 | 0.0708 | 1.007 | 0.064 | 15.669 | <2.2 × 10−16 |
| Gaus | 1.893 | 0.814 | 2.327 | 0.0200 | 0.970 | 0.064 | 15.121 | <2.2 × 10−16 |
| Spher | 2.830 | 0.726 | 3.895 | 0.0001 | 1.058 | 0.047 | 22.517 | <2.2 × 10−16 |
| LSM | 2.849 | 0.706 | 4.037 | 0.0001 | 1.059 | 0.047 | 22.687 | <2.2 × 10−16 |
| W | β0 | Std. Error | z-Value | p-Value | β1 | Std. Error | z-Value | p-Value |
|---|---|---|---|---|---|---|---|---|
| queen | 3.257 | 0.751 | 4.335 | 0.0000 | 1.033 | 0.051 | 20.407 | <2.2 × 10−16 |
| rook | 3.435 | 0.751 | 4.574 | 0.0000 | 1.021 | 0.050 | 20.256 | <2.2 × 10−16 |
| 1/d | 3.059 | 0.816 | 3.748 | 0.0002 | 1.047 | 0.051 | 20.498 | <2.2 × 10−16 |
| 1/d2 | 3.331 | 0.817 | 4.078 | 0.0000 | 1.029 | 0.054 | 18.906 | <2.2 × 10−16 |
| 1/d5 | 3.424 | 0.774 | 4.423 | 0.0000 | 1.023 | 0.052 | 19.623 | <2.2 × 10−16 |
| Exp | 3.381 | 0.820 | 4.125 | 0.0000 | 1.026 | 0.055 | 18.688 | <2.2 × 10−16 |
| Gaus | 3.430 | 0.772 | 4.444 | 0.0000 | 1.023 | 0.052 | 19.668 | <2.2 × 10−16 |
| Spher | 3.450 | 0.762 | 4.529 | 0.0000 | 1.021 | 0.051 | 19.949 | <2.2 × 10−16 |
| LSM | 3.625 | 0.770 | 4.707 | 0.0000 | 1.009 | 0.052 | 19.519 | <2.2 × 10−16 |
| W | SLM | SDM | SEM | |||||
|---|---|---|---|---|---|---|---|---|
| ρ | p-Value | ρ | p-Value | γ | p-Value | λ | p-Value | |
| queen | 0.019 | 0.3327 | 0.197 | 0.0049 | −0.236 | 0.0060 | 0.219 | 0.0024 |
| rook | 0.013 | 0.4541 | 0.216 | 0.0010 | −0.267 | 0.0008 | 0.250 | 0.0003 |
| 1/d | 0.271 | 0.1734 | 0.695 | 0.0074 | −0.737 | 0.0099 | 0.696 | 0.0061 |
| 1/d2 | 0.193 | 0.0217 | 0.457 | 0.0007 | −0.418 | 0.0088 | 0.455 | 0.0007 |
| 1/d5 | 0.158 | 0.0067 | 0.251 | 0.0033 | −0.166 | 0.1383 | 0.245 | 0.0044 |
| Exp | 0.163 | 0.0210 | 0.392 | 0.0010 | −0.357 | 0.0113 | 0.393 | 0.0010 |
| Gaus | 0.159 | 0.0065 | 0.240 | 0.0053 | −0.143 | 0.2017 | 0.232 | 0.0074 |
| Spher | 0.011 | 0.5739 | 0.190 | 0.0092 | −0.233 | 0.0101 | 0.229 | 0.0028 |
| LSM | 0.005 | 0.7382 | 0.215 | 0.0059 | −0.267 | 0.0060 | 0.281 | 0.0008 |
4. Discussion
4.1. Spatial Autoregressive Model Selection
4.2. Model Parameter Estimates
4.3. Spatial Weight Matrices
4.4. Stand Top and Stand Mean Height Relationship
4.5. Modeling Approach Applications in LiDAR Data and Crown Fire Modeling
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bontemps, J.D.; Bouriaud, O. Predictive approaches to forest site productivity: Recent trends, challenges and future perspectives. Forestry 2014, 87, 109–128. [Google Scholar] [CrossRef]
- Sharma, M.; Amateis, R.L.; Burkhart, H.E. Top height definition and its effect on site index determination in thinned and unthinned loblolly pine plantations. For. Ecol. Manag. 2002, 168, 163–175. [Google Scholar] [CrossRef]
- Skovsgaard, J.P.; Vanclay, J.K. Forest site productivity: A review of spatial and temporal variability in natural site conditions. Forestry 2013, 86, 305–315. [Google Scholar] [CrossRef]
- Carmean, W.H. Forest site quality evaluation in the United States. Adv. Agron. 1975, 27, 209–269. [Google Scholar]
- Vanclay, J.K. Assessing site productivity in tropical moist forests: A review. For. Ecol. Manag. 1992, 54, 257–287. [Google Scholar] [CrossRef]
- Skovsgaard, J.P.; Vanclay, J.K. Forest site productivity: A review of the evolution of dendrometric concepts for even-aged stands. Forestry 2008, 81, 13–31. [Google Scholar] [CrossRef]
- Ouzennou, H.; Pothier, D.; Raulier, F. Adjustment of the age-height relationship for uneven-aged black spruce stands. Can. J. For. Res. 2008, 38, 2003–2012. [Google Scholar] [CrossRef]
- Foggie, A. On the determination of quality class by top height instead of mean height for conifers in Great Britain. Forestry 1944, 18, 28–37. [Google Scholar] [CrossRef]
- Van Laar, A.; Akça, A. Forest Mensuration; Springer: Dordrecht, The Netherlands, 2007; pp. 118–119. [Google Scholar]
- Pienaar, L.V.; Shiver, B.D. An analysis and models of Basal area growth in 45-year-old unthinned and thinned slash pine plantation plots. For. Sci. 1984, 30, 933–942. [Google Scholar]
- Lanner, R.M. On the insensitivity of height growth to spacing. For. Ecol. Manag. 1985, 13, 143–148. [Google Scholar] [CrossRef]
- Hägglund, B.; Lundmark, J.E. Site index estimation by means of site properties. Scots pine and Norway spruce in Sweden. Stud. For. Suec. 1977, 138, 1–38. [Google Scholar]
- Seynave, I.; Gégout, J.C.; Hervé, J.C.; Dhôte, J.F.; Drapier, J.; Bruno, E.; Dumé, G. Picea abies site index prediction by environmental factors and understorey vegetation: A two-scale approach based on survey databases. Can. J. For. Sci. 2005, 35, 1669–1678. [Google Scholar]
- Watt, M.S.; Palmer, D.J.; Kimberley, M.O.; Hock, B.K.; Payn, T.W.; Lowe, D.J. Development of models to predict Pinus radiata productivity throughout New Zealand. Can. J. For. Sci. 2010, 40, 488–499. [Google Scholar]
- Beaulieu, J.; Raulier, F.; Prégent, G.; Bousquet, J. Predicting site index from climatic, edaphic, and stand structural properties for seven plantation-grown conifer species in Quebec. Can. J. For. Sci. 2011, 41, 682–693. [Google Scholar] [CrossRef]
- Sharma, R.P.; Brunner, A.; Eid, T.; Øyen, B.-H. Modeling dominant height growth from national forest inventory individual tree data with short time series and large age errors. For. Ecol. Manag. 2011, 262, 2162–2175. [Google Scholar] [CrossRef]
- Sharma, R.P.; Brunner, A.; Eid, T. Site index prediction from site and climate variables for Norway spruce and Scots pine in Norway. Scand. J. For. Res. 2012, 27, 619–636. [Google Scholar] [CrossRef]
- Nishizono, T.; Kitahara, F.; Iehara, T.; Mitsuda, Y. Geographical variation in age-height relationships for dominant trees in Japanese cedar (Cryptomeria japonica D. Don) forests in Japan. J. For. Res. 2014, 19, 305–316. [Google Scholar] [CrossRef]
- Lei, X.D.; Tang, M.P.; Lu, Y.C.; Hong, L.X.; Tian, D.L. Forest inventory in China: Status and challenges. Int. For. Rev. 2009, 11, 52–62. [Google Scholar] [CrossRef]
- Zeng, W.S.; Tomppo, E.; Healey, S.P.; Gadow, K.V. The national forest inventory in China: History-results-international context. For. Ecosyst. 2015, 2, 1–16. [Google Scholar] [CrossRef]
- Li, T.Z.; Lin, C.G. Preparation of site class table of Chinese fir. For. Resour. Manag. 1979, 1, 9–13. (In Chinese) [Google Scholar]
- Balzter, H.; Luckman, A.; Skinner, L.; Rowland, C.; Dawson, T. Observations of forest stand top height and mean height from interferometric SAR and LIDAR over a conifer plantation at Thetford Forest, UK. Int. J. Remote Sens. 2007, 28, 1173–1197. [Google Scholar] [CrossRef]
- Legendre, P. Spatial autocorrelation: Trouble or new paradigm? Ecology 1993, 74, 1659–1673. [Google Scholar] [CrossRef]
- Lennon, J.J. Red-shifts and red herrings in geographical ecology. Ecography 2000, 23, 101–113. [Google Scholar] [CrossRef]
- Legendre, P.; Dale, M.R.T.; Fortin, M.-J.; Gurevitch, J.; Hohn, M.; Myers, D. The consequences of spatial structure for the design and analysis of ecological field surveys. Ecography 2002, 25, 601–615. [Google Scholar] [CrossRef]
- Dormann, C.F.; McPherson, J.M.; Araújo, M.B.; Bivand, R.; Bolliger, J.; Carl, G.; Davies, R.G.; Hirzel, A.; Jetz, W.; Kissling, W.D.; et al. Methods to account for spatial autocorrelation in analysis of species distributional data: A review. Ecography 2007, 30, 609–628. [Google Scholar] [CrossRef]
- Kissling, W.D.; Carl, G. Spatial autocorrelation and the selection of simultaneous autoregressive models. Glob. Ecol. Biogeogr. 2008, 17, 59–71. [Google Scholar] [CrossRef]
- Krämer, W. Finite sample efficiency of ordinary least squares in linear regression model with autocorrelated errors. J. Am. Stat. Assoc. 1980, 75, 1005–1099. [Google Scholar]
- West, P.W.; Ratkowsky, D.A.; Davis, A.W. Problems of hypothesis testing of regression with multiple measurements from individual sampling units. For. Ecol. Manag. 1984, 7, 207–224. [Google Scholar] [CrossRef]
- Gregoire, T.G. Generalized error structure for forestry yield models. For. Sci. 1987, 33, 423–444. [Google Scholar]
- Fox, J.C.; Ades, P.K.; Bi, H. Stochastic structure and individual-tree growth models. For. Ecol. Manag. 2001, 154, 261–276. [Google Scholar] [CrossRef]
- Zhang, L.J.; Shi, H.J. Local modeling of tree growth by geographically weighted regression. For. Sci. 2004, 50, 225–244. [Google Scholar]
- Anselin, L. Spatial Econometrics: Methods and Models; Kluwer Academic: Dordrecht, The Netherlands, 1988; p. 284. [Google Scholar]
- Miller, H.J. Tobler’s first law and spatial analysis. Ann. Assoc. Am. Geogr. 2004, 94, 284–289. [Google Scholar] [CrossRef]
- LeSage, J.P. Spatial Econometrics. 1998. Available online: www.spatial-econometrics.com/html/wrook.pdf (accessed on 21 April 2015).
- Zhang, L.J.; Bi, H.Q.; Cheng, P.F.; Davis, C.J. Modeling spatial variation in tree diameter-height relationships. For. Ecol. Manag. 2004, 189, 317–329. [Google Scholar] [CrossRef]
- Zhang, L.J.; Ma, Z.H.; Guo, L. An evaluation of spatial autocorrelation and heterogeneity in the residuals of six regression models. For. Sci. 2009, 55, 533–548. [Google Scholar]
- Liu, J.P.; Burkhart, H.E. Spatial autocorrelation of diameter and height increment predictions from two stand simulators for loblolly pine. For. Sci. 1994, 40, 349–356. [Google Scholar]
- Fox, J.C.; Bi, H.Q.; Ades, P.K. Spatial dependence and individual tree growth models I. Characterising spatial dependence. For. Ecol. Manag. 2007, 245, 10–19. [Google Scholar] [CrossRef]
- Fox, J.C.; Bi, H.Q.; Ades, P.K. Spatial dependence and individual tree growth models II. Modelling spatial dependence. For. Ecol. Manag. 2007, 245, 20–30. [Google Scholar] [CrossRef]
- Fox, J.C.; Bi, H.Q.; Ades, P.K. Modelling Spatial Dependence in an Irregular Natural Forest. Silva Fennica 2008, 42, 35–48. [Google Scholar] [CrossRef]
- Meng, Q.M.; Cieszewski, C.J.; Strub, M.R.; Borders, B.E. Spatial regression modeling of tree height-diameter relationships. Can. J. For. Sci. 2009, 39, 2283–2293. [Google Scholar]
- Lu, J.F.; Zhang, L.J. Evaluation of parameter estimation methods for fitting spatial regression models. For. Sci. 2010, 56, 505–514. [Google Scholar]
- Lu, J.F.; Zhang, L.J. Modeling and predicition of tree height-diameter relationship using spatial autoregressive models. For. Sci. 2011, 573, 252–264. [Google Scholar]
- Zhang, L.J.; Gove, J.F.; Heath, L.S. Spatial residual analysis of six modeling techniques. Ecol. Model. 2005, 186, 154–177. [Google Scholar] [CrossRef]
- Cressie, N.A.C. Statistics for Spatial Data: Wiley Series in Probability and Mathematical Statistics; Wiley: Hoboken, NJ, USA, 1993. [Google Scholar]
- Haining, R. Spatial Data Analysis: Theory and Practice; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Cliff, A.D.; Ord, J.K. Spatial Processes-Models and Applications; Pion Ltd: London, UK, 1981. [Google Scholar]
- Getis, A.; Aldstadt, J. Constructing the spatial weight matrix using a local statistic. Geogr. Anal. 2004, 36, 90–104. [Google Scholar] [CrossRef]
- Yu, S.L.; Ma, K.P.; Chen, L.Z.; Zheng, C.J. Introduction to the research of Quercus mongolica and Quercus monglica forest. In Proceedings of the Third Biodiversity Conservation and Sustainable Use of Seminar, Kunming, China, 11 December 1998.
- Rennolls, K. “Top height”: Its definition and estimation. Commonw. For. Rev. 1978, 57, 215–219. [Google Scholar]
- García, O. Estimating top height with variable plot sizes. Can. J. For. Sci. 1998, 28, 1509–1517. [Google Scholar] [CrossRef]
- Burkhart, H.E.; Tomé, M. Modeling Forest Trees and Stands; Springer: Dordrecht, The Netherlands, 2012; p. 132. [Google Scholar]
- Meng, X.Y. Forest Mensuration, 3rd ed.; China Forestry Publishing House: Beijing, China, 2006. [Google Scholar]
- Curtis, R.O.; Post, B.W. Basal area, volume, and diameter related to site index and age in unmanaged even-aged northern hardwoods in the Green Mountains. J. For. 1964, 62, 864–870. [Google Scholar]
- Anyomi, K.A.; Raulier, F.; Bergeron, Y.; Mailly, D.; Girardin, M.P. Spatial and temporal heterogeneity of forest site productivity drivers: A case study within the eastern boreal forests of Canada. Landsc. Ecol. 2014, 29, 905–918. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language And Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2015; Available online: http://www.R-project.org (accessed on 3 May 2015).
- Fortin, M.J.; Dale, M.R.T. Spatial Analysis-Guide for Ecologists; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Anselin, L. Under the hood issues in the specification and interpretation of spatial regression models. Agric. Econ. 2002, 27, 247–267. [Google Scholar] [CrossRef]
- Bivand, R. Spdep: Spatial Dependence: Weighting Schemes, Statistics and Models. R Package Version 0.5–88. 2015. Available online: www.cran.r-project.org/web/packages/spdep/spdep.pdf (accessed on 17 March 2015).
- Bivand, R. Creating Neighbours. 2015. Available online: cran.r-project.org/web/packages/spdep/vignettes/nb.pdf (accessed on 17 March 2015).
- Anselin, L. Spatial effects in econometric practice in environment and resource economics. Am. J. Agric. Econ. 2001, 83, 705–710. [Google Scholar] [CrossRef]
- Littell, R.C.; Milliken, G.A.; Stroup, W.W.; Wolfinger, R.D.; Schabenberger, A. SAS for Mixed Models; SAS Press: Cary, NC, USA, 2006; p. 441. [Google Scholar]
- Pinheiro, J.C.; Bates, D.M.; Debroy, S.; Sarkar, D. EISPACK; R-core. nlme: Linear and Nonlinear Mixed Effects Models. R Package Version 3.1–120. 2015. Available online: www.cran.r-project.org/web/packages/nlme/nlme.pdf (accessed on 20 February 2015).
- Getis, A.; Ord, J.K. The analysis of spatial association by use of distance statistics. Geogr. Anal. 1992, 243, 189–206. [Google Scholar] [CrossRef]
- Ord, J.K.; Getis, A. Local Spatial autocorrelation statistics: Distributional issues and an application. Geogr. Anal. 1995, 27, 286–306. [Google Scholar] [CrossRef]
- Paradis, E. Moran’s Autocorrelation Coefficient in Comparative Methods. 2014. Available online: www.cran.r-project.org/web/packages/ape/vignettes/MoranI.pdf (accessed on 4 December 2015).
- Giraudoux, P. Pgirmess: Data Analysis in Ecology. R Package Version 1.6.3. 2015. Available online: cran.r-project.org/web/packages/pgirmess/pgirmess.pdf (accessed on 20 December 2015).
- Diniz-Filho, J.A.F.; Bini, L.M.; Hawkins, B.A. Spatial autocorrelation and red herrings in geographical ecology. Glob. Ecol. Biogeogr. 2003, 12, 53–64. [Google Scholar] [CrossRef]
- Kühn, I. Incorporating spatial autocorrelation may invert observed patterns. Divers. Distrib. 2007, 13, 66–69. [Google Scholar] [CrossRef]
- Dark, S.J. The biogeography of invasive alien plants in California: An application of GIS and spatial regression analysis. Divers. Distrib. 2004, 10, 1–9. [Google Scholar] [CrossRef]
- Raulier, F.; Lambert, M.C.; Pothier, P.; Ung, C.H. Impact of dominant tree dynamics on site index curves. For. Ecol. Manag. 2003, 184, 65–78. [Google Scholar] [CrossRef]
- Aulinger, T.; Mette, T.; Papathanassion, K.P.; Hajnsek, I.; Heurich, M.; Krzystek, P. Validation of heights from interferometric SAR and LIDAR over the temperate forest site “National park Bayerischer Wald”. ESA Spec. Publ. 2005, 586, 11. [Google Scholar]
- Mcinerney, D.O.; Suarez-Minguez, J.; Valbuena, R.; Nieuwenhuis, M. Forest canopy height retrieval using LiDAR data, medium-resolution satellite imagery and kNN estimation in Aberfoyle, Scotland. Forestry 2010, 83, 198–206. [Google Scholar] [CrossRef]
- Watt, M.S.; Meredith, A.; Watt, P.; Gunn, A. Use of LiDAR to estimate stand characteristics for thinning operations in young Douglas-fir plantations. N. Z. J. For. Sci. 2013, 43, 18. [Google Scholar] [CrossRef]
- Mcroberts, R.E. Estimating forest attribute parameters for small areas using nearest neighbors techniques. For. Ecol. Manag. 2012, 272, 3–12. [Google Scholar] [CrossRef]
- Mcroberts, R.E.; Nelson, M.D.; Wendt, D.G. Stratified estimation of forest area using satellite imagery, inventory data, and the k-Nearest Neighbors technique. Remote Sens. Environ. 2002, 82, 457–468. [Google Scholar] [CrossRef]
- Mcroberts, R.; Tomppo, E.; Finley, A.; Heikkinen, J. Estimating areal means and variances of forest attributes using the k-Nearest Neighbors technique and satellite imagery. Remote Sens. Environ. 2007, 111, 466–480. [Google Scholar] [CrossRef]
- Van Wagner, C.E. Conditions for the start and spread of crown fire. Can. J. For. Sci. 1977, 7, 23–34. [Google Scholar] [CrossRef]
- Scott, J.H.; Reinhardt, E.D. Assessing Crown Fire Potential by Linking Models of Surface and Crown Fire Behavior; Res. Pap. RMRS-RP-29; USA Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2001.
- Scott, J.H.; Reinhardt, E.D. Comparison of Crown Fire Modeling Systems Used in Three Fire Management Applications; Res. Pap. RMRS-RP-58; USA Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2006.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lou, M.; Zhang, H.; Lei, X.; Li, C.; Zang, H. Spatial Autoregressive Models for Stand Top and Stand Mean Height Relationship in Mixed Quercus mongolica Broadleaved Natural Stands of Northeast China. Forests 2016, 7, 43. https://doi.org/10.3390/f7020043
Lou M, Zhang H, Lei X, Li C, Zang H. Spatial Autoregressive Models for Stand Top and Stand Mean Height Relationship in Mixed Quercus mongolica Broadleaved Natural Stands of Northeast China. Forests. 2016; 7(2):43. https://doi.org/10.3390/f7020043
Chicago/Turabian StyleLou, Minghua, Huiru Zhang, Xiangdong Lei, Chunming Li, and Hao Zang. 2016. "Spatial Autoregressive Models for Stand Top and Stand Mean Height Relationship in Mixed Quercus mongolica Broadleaved Natural Stands of Northeast China" Forests 7, no. 2: 43. https://doi.org/10.3390/f7020043
APA StyleLou, M., Zhang, H., Lei, X., Li, C., & Zang, H. (2016). Spatial Autoregressive Models for Stand Top and Stand Mean Height Relationship in Mixed Quercus mongolica Broadleaved Natural Stands of Northeast China. Forests, 7(2), 43. https://doi.org/10.3390/f7020043