1. Introduction
Forests, the Earth’s green treasures, are vital for ecological balance and human survival. They are complex ecosystems with diverse plant species, varying densities, and rich topographical features. The multi-layered structure of forests creates intricate spectral and spatial information patterns. Sunlight interacting with forest canopies produces unique spectral signatures that vary with tree species, health, and growth stages. Understorey vegetation, influenced by canopy density and light penetration, adds another layer to spectral information. The topography of forested areas further complicates spectral characteristics, with slope, aspect, and elevation causing spectral reflectance variations. These inherent forest features make accurate classification and analysis challenging but essential.
In the realm of forestry research, the integration of advanced remote sensing technologies has ushered in a new era of forest classification and monitoring. Accurate assessment of forest resources is crucial for sustainable management, biodiversity conservation, and ecosystem service evaluation. Traditional classification methods like Support Vector Machines (SVMs) and Random Forests (RFs) have contributed significantly to forest classification but often struggle with the high dimensionality and complex spectral–spatial information in forest hyperspectral images. Deep learning approaches, including convolutional neural networks (CNN) and U-Net, have shown greater capability in handling such complexity. However, they still face limitations in capturing long-range dependencies and fine-grained details critical for distinguishing subtle features among forest components. Semantic segmentation has emerged as a pivotal technique in computational vision, addressing pixel-level classification tasks through deep neural architectures. It has found significant implementation in forestry remote sensing systems, with operational deployments spanning applications like precision forestry resource auditing, multi-temporal canopy vitality assessment, and ecosystem biodiversity preservation.
As spatial resolution thresholds in earth observation systems progressively break through technical barriers, modern forestry research confronts massive streams of radiometrically calibrated canopy images. This paradigm shift demands innovative approaches for hierarchical feature abstraction, particularly in developing trainable architectures that transform raw spectral signatures into quantifiable ecological indicators for computational forestry applications. Semantic segmentation [
1] has emerged as a pivotal technique in computational vision, fundamentally addressing pixel-level classification tasks through deep neural architectures. This methodology has found significant implementation in forestry remote sensing systems, with operational deployments now spanning critical applications including precision forestry resource auditing, multi-temporal canopy vitality assessment, and ecosystem biodiversity preservation [
2,
3,
4,
5].
Multispectral remote sensing [
6] refers to the synchronized photographic remote sensing of different bands of the electromagnetic spectrum using a multispectral photography system or a multispectral scanning system, so as to obtain the image data of vegetation and other features in different bands. Multispectral remote sensing can not only discriminate features based on morphological and structural differences in the images, but also categorize features based on differences in spectral characteristics, thus expanding the information content of remote sensing data.
The advent of deep convolutional architectures has witnessed transformative breakthroughs in feature extraction capabilities since 2017, with CNN variants achieving unprecedented performance milestones in hierarchical representation learning. This architectural evolution, fueled by parallel computing breakthroughs and novel regularization paradigms, continues to redefine state-of-the-art benchmarks across multimodal data processing domains [
7], providing powerful technical support for semantic segmentation. Following this, researchers have proposed many innovative approaches. Among them, the encoder–decoder paradigm, demonstrating architectural superiority in semantic segmentation frameworks [
8], has evolved into the dominant framework through its hierarchical feature abstraction mechanism. This dual-path architecture employs convolutional hierarchies for multiscale feature extraction, while synchronously implementing resolution restoration through cross-stage feature fusion that strategically combines contextual abstractions with granular textural details during upsampling operations. For example, U-Net [
9] utilizes the decoder to learn the spatial correlation of the encoder process through skip connections.
However, the special characteristics of features [
10,
11,
12,
13] (e.g., small scale, high similarity, and mutual occlusion) pose new challenges to semantic segmentation of remote sensing images. CNNs commonly employ feature downsampling strategies during the feature extraction phase to optimize computational efficiency; however, this approach often compromises the preservation of fine-grained details. Furthermore, the challenge arises when distinct semantic categories exhibit comparable spectral, dimensional, and material characteristics, which poses significant challenges for accurate discrimination. The occlusion problem [
14] also often leads to semantic ambiguity (SEM). Therefore, to address these challenges, more global contextual information and fine-grained spatial features are needed to be used as cues for semantic reasoning.
CNN has certain advantages in processing spatial location information, but due to its localization, it is more difficult to directly model global semantic interactions and contextual information. In order to solve this problem, existing methods adopt the attention mechanism [
15]. For example, DANet [
16] employs parallel channel attention and location attention to construct long-range dependencies. Contemporary methodologies employing multiscale feature fusion frameworks [
17] typically aggregate localized CNN-derived patterns through hierarchical feature aggregation mechanisms, rather than explicitly modeling global contextual interdependencies. This architectural limitation becomes particularly pronounced when processing ecologically complex remote sensing scenes, where inadequate contextual modeling compromises holistic scene comprehension amidst intricate background textures and overlapping spectral signatures.
Recently, the Transformer [
18] model has achieved success in global relationship modeling and opened up new research ideas in this field. Transformer is widely used as a popular sequence prediction model in the field of natural language processing. Similar to CNN-based models, studies have shown that multiscale feature representation is equally effective for Vision Transformer (ViT).
Pioneering works including TransUNet [
19] and TransFuse [
20] have critically identified performance limitations in pure Transformer-based segmentation frameworks, primarily stemming from their inherent bias towards global context modeling at the expense of spatial acuity. To reconcile this dichotomy, hybrid computational paradigms integrating CNN–Transformer synergies have emerged [
21,
22]. TransUNet innovates through cascaded encoder architecture where convolutional feature hierarchies precede Transformer-based context aggregation, whereas TransFuse implements parallel modality fusion with coordinated multi-branch processing. Notably, the latter employs iterative feature upsampling within its Transformer decoder pathway, leveraging learned interpolation kernels for spatial resolution recovery while preserving attention-driven feature correlations. Based on this structure, researchers constructed SpectralFormer [
23] and demonstrated great potential in remote sensing image segmentation tasks.
Inspired by previous notable research [
24], this paper addresses the aforementioned challenges by introducing a novel network framework suitable for pixel-level classification of forest hyperspectral images, dubbed SF-UNet. Leveraging SpectralFormer to augment U-Net, the framework synergizes the strengths of both architectures. Initially, the HGSE module is employed to generate semiset spectral nesting, enhancing local information connectivity. Subsequently, integrating the CAM module’s SpectralFormer as an auxiliary encoder within the U-Net structure enables cross-level jump connections, facilitating the cascading of soft residuals between layers through cross-region adaptive learning, thereby enhancing feature representation. Ultimately, the U-Net decoder is employed to yield classification outcomes, ensuring high-performance hyperspectral image classification tasks at the pixel level for forest applications.
The main contributions of this paper can be summarized as follows:
To overcome the inherent constraints of conventional deep learning architectures in geospatial imagery analysis—where sub-optimal exploitation of spectral–textural correlations and insufficient discriminative capacity for endmember variability frequently induce cross-category confusion—we devise an innovative hybrid architecture. This architectural innovation synergistically integrates U-Net’s hierarchical feature abstraction with SpectralFormer’s spectral attention mechanisms, establishing a spectrally-aware classification framework optimized for hyperspectral datacubes.
To design a novel HGSE method to generate semiset spectral nesting, thereby enhancing connectivity among local information, and develop the HCAF method for effectively fusing semi-sequential features, enabling adaptive cross-layer feature fusion from intricate details.
Incorporate a CAM module into SpectralFormer to enable the capture of cross-channel information while attenuating irrelevant channel data. This enhancement not only aids in pinpointing and identifying targets of interest more accurately but also contributes to overall model performance improvement.
2. Data and Algorithms
2.1. Forest Multispectral Data
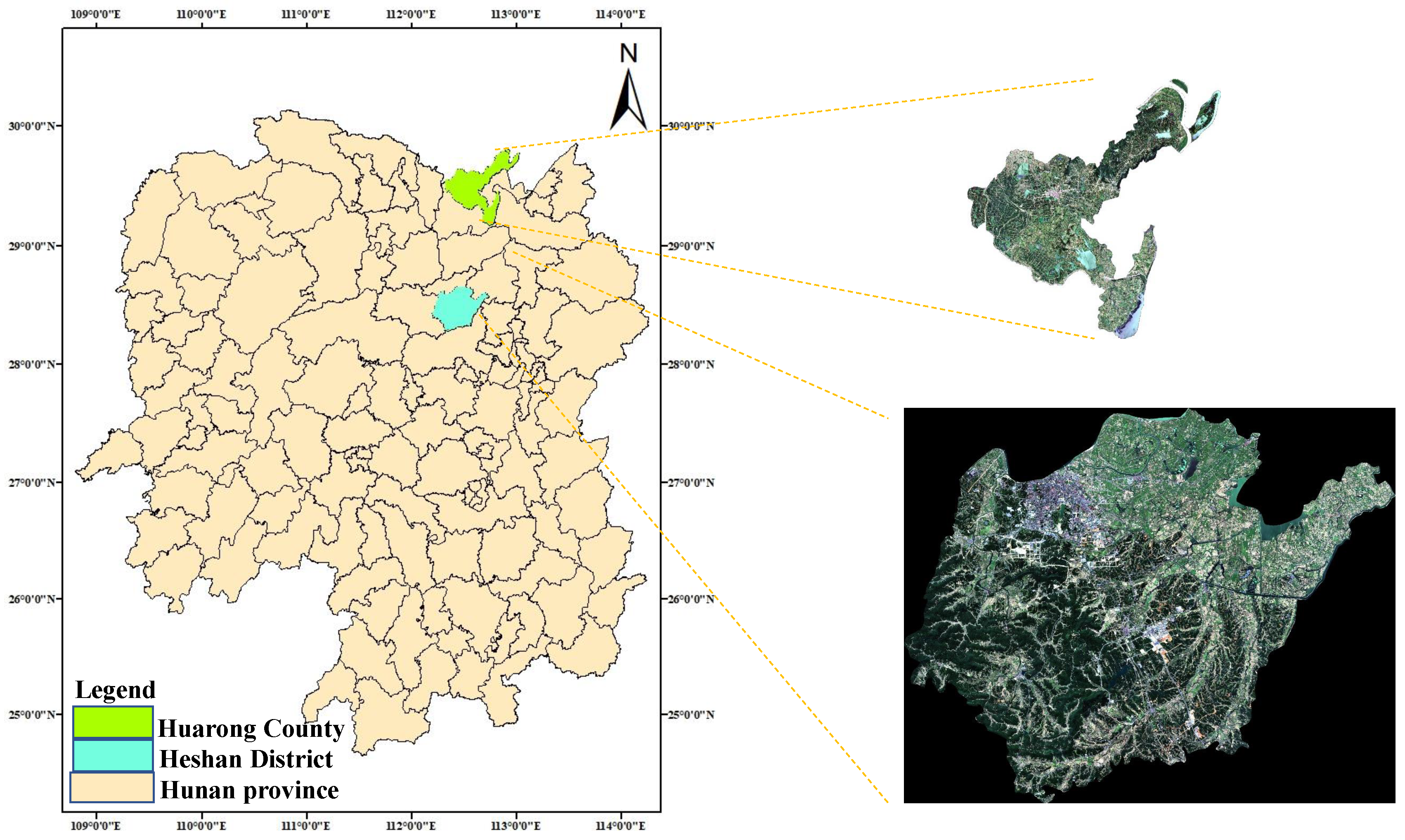
Heshan District, situated in Hunan Province, China, represents a typical mountainous region characterized by diverse terrain. The landscape predominantly comprises hills and mountains, resulting in intricate and varied topography. Factors such as topography, geomorphology, vegetation cover, and land use significantly influence the classification of forest features in this area. For instance, densely vegetated slopes contrast with rocky, barren areas in mountainous terrain, while river valleys exhibit distinct features such as water bodies, vegetation along riverbanks, human settlements, and other elements. Therefore, accurately and efficiently categorizing local features through remote sensing holds paramount importance in this context. The study area shown in
Figure 1.
The experimental framework employs Level 1C Sentinel-2 multispectral data (Mission ID: S2MSI1C) acquired on 6 June 2021 (UTC 10:30:21), characterized by 10 m spatial resolution across 13 spectral channels spanning VNIR-SWIR regions. Our systematic preprocessing pipeline implemented radiometrically calibrated multispectral data conversion through Sen2Cor processor (v2.11), generating Level 2A Bottom-of-Atmosphere (BOA) reflectance products via sequential atmospheric correction (including cirrus scattering compensation), terrain illumination normalization, and adjacency effect mitigation. Subsequently, employing SNAP 10.0 software, we uniformly resampled the resolution of various bands to 10 m, facilitating subsequent operations and generating band files in img format for ease of processing.
Following preprocessing, we conducted band synthesis using ENVI 5.6 software. During synthesis, we selected the 13 bands with an original resolution of 10 m. After band synthesis using ENVI software, we obtained a TIFF-format image containing comprehensive information.
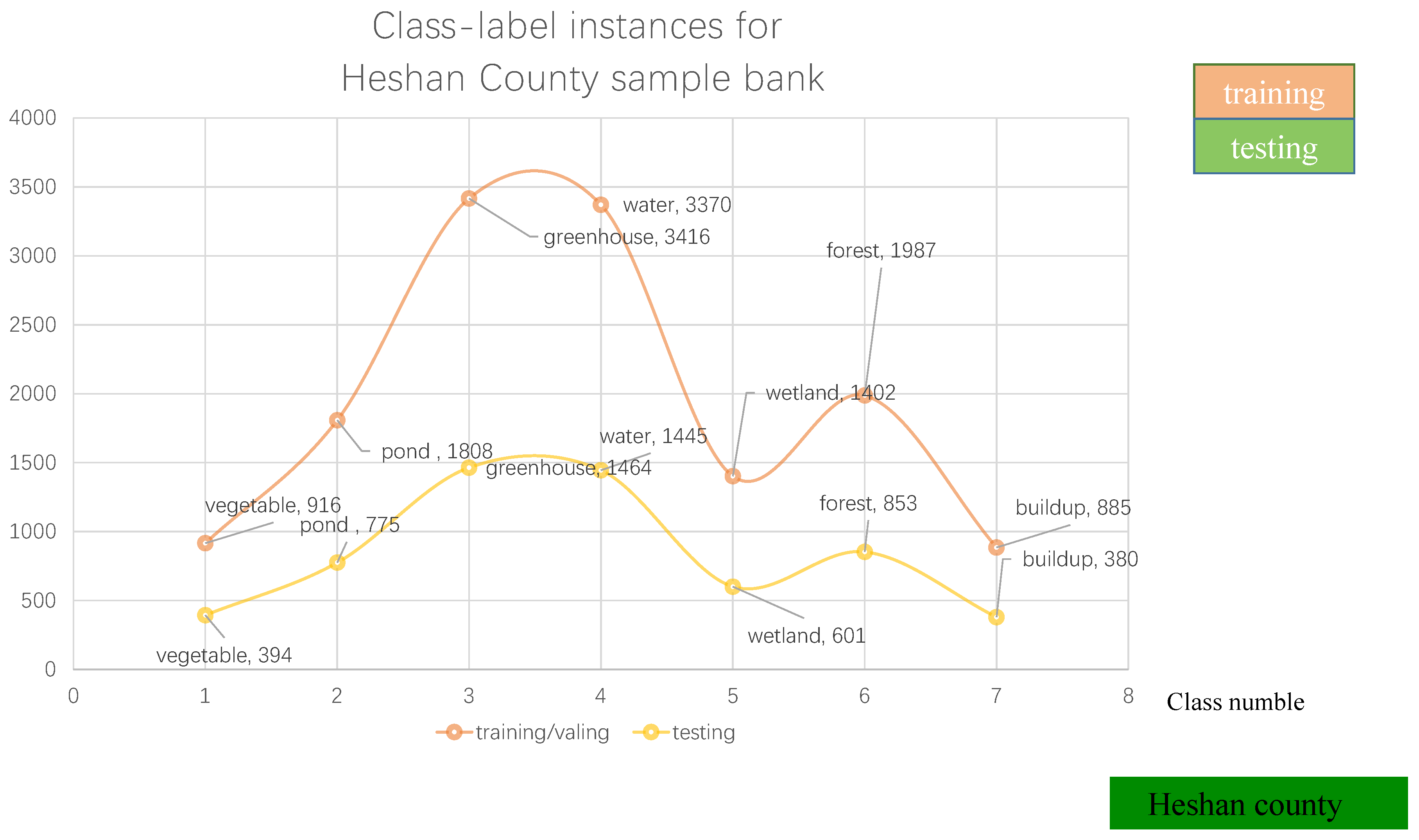
Lastly, leveraging both field-collected data and existing knowledge, we employed ENVI software to delineate regions of interest (ROIs) with the most diverse feature classes on the synthesized image, thus establishing a sample library dataset, as illustrated in
Figure 2. This sample library serves as crucial support for our subsequent classification and accuracy validation endeavors. The horizontal axis of
Figure 2 represents different types of land features, such as vegetables, forest, greenhouses, etc. The vertical axis represents the number of samples for each category. The numbers next to the category names represent the number of training and testing samples for each category.
As a typical area of the transition zone between Dongting Lake plain and hills, Huarong County’s forest resources have the dual characteristics of ecological barrier and economic function, providing unique advantages for the study of forest land use change. The subtropical evergreen broad-leaved forest and artificial forest in the county are interlaced and significantly affected by the hydrological fluctuations of the Yangtze River and the policy of returning farmland to forests. The forest coverage presents a gradient pattern of “wetland protective forest hilly economic forest plain farmland forest network”, which can clearly reflect the synergistic effect of natural conditions and human activities. Especially since the implementation of the Dongting Lake ecological restoration project in 2000, the forest wetland restoration area along the lake has formed a sharp contrast with the inland fast-growing economic forest expansion area, providing a natural experimental field for forest spatial reorganization driven by quantitative policies. In addition, as an important poplar industry base in the middle reaches of the Yangtze River, Huarong has fully recorded the transformation process of its commercial forest and ecological forest management mode. Through multi-temporal remote sensing monitoring, the evolution trajectory of forest quality and function can be accurately captured, which is of typical significance for studying the potential of forest carbon sinks and land use conflicts in subtropical regions.
Table 1 shows the sample data for the third phase of Huarong County.
2.2. Forest Hyperspectral Data Sources
To rigorously validate the ecological generalization potential of our proposed framework across heterogeneous forest landscapes, we establish a multi-scenario evaluation protocol using three benchmark hyperspectral datasets (comprising the Houston, Indian Pines, and Pavia University datasets) representing distinct forest ecosystem configurations. This experimental design specifically addresses two critical dimensions: (1) classification efficacy across multi-source satellite products, and (2) cross-domain generalization capability for arboreal species discrimination, with comprehensive spectral–spatial characterization metrics detailed in subsequent sections.
This dataset was acquired using the ITRES CASI-1500 imaging spectrometer (manufactured by ITRES Research Inc., Calgary, AB, Canada), deployed through the NSF-sponsored airborne observation facility at the University of Houston. The CASI-1500 system provides a spectral sampling interval of 4.8 nm, capturing the visible to near-infrared (VNIR) spectrum (364–1046 nm) across 144 spectral channels. The georeferenced scene (dimensions: 349 × 1905 pixels; GSD: 2.5 m) captures complex urban–forest interfaces surrounding the university campus, with radiometrically calibrated surface reflectance values stored in 16-bit signed integer format.
The dataset exhibits three core scientific attributes: (1) high-fidelity spectral preservation (SNR > 40 dB) with sub-pixel spatial detail retention, validated through in situ spectrometer measurements; (2) radiometric–geometric dual precision verification (RMSE < 0.5 reflectance unit) confirming its physical consistency with ground-truth signatures; (3) embedded multiscale geospatial metadata (projection: UTM Zone 15N) supporting cross-domain applications in urban ecology and biomass estimation. As quantitatively characterized in
Table 2, the stratified sampling protocol maintains spectral class distributions while implementing robust training–test partitions with spatial independence constraints.
Indian Pines Hyperspectral Dataset: This dataset was acquired in 1992 via the Airborne Visual Infrared Imaging Spectrometer (AVIRIS) to capture detailed hyperspectral measurements of the Indian Pines region in northwest Indiana, USA. The georeferenced scene encompasses a spatial extent of 145 × 145 pixels with a ground sampling distance (GSD) of 20 m. The spectral coverage spans the VNIR to SWIR domains (400–2500 nm), originally comprising 220 contiguous spectral channels. Notably, rigorous spectral noise filtering was implemented to exclude the 104th to 108th, 150th to 163rd, and 220th bands, which exhibited degraded signal quality. The curated dataset retains 200 high-fidelity spectral bands for subsequent analysis. As presented in
Table 3, the dataset’s stratified sampling strategy ensures balanced representation across 16 distinct land cover classes.
Pavia University Hyperspectral Dataset: Captured via the ROSIS-03 The manufacturer of the imaging spectrometer is the German Aerospace Center, headquartered in Oberpfaffenhofen, Germany (Reflective Optics System Imaging Spectrometer) airborne platform during the 2003 Italian imaging campaign, this dataset provides high-resolution urban land cover characterization with a spatial resolution of 1.3 m (GSD). The datacube spans 610 × 340 pixels in spatial dimensions and 115 spectral channels across the VNIR spectral regime (430–860 nm, spectral sampling interval: 4.2 nm). Through a systematic band selection protocol, 12 spectral bands exhibiting atmospheric absorption features or sensor-induced artifacts were eliminated, retaining 103 radiometrically calibrated surface reflectance bands (12-bit radiometric resolution) for optimized spectral discriminability. The curated spectral subset demonstrates an enhanced signal-to-clutter ratio validated through in situ validation campaigns. As detailed in
Table 4, the dataset implements a stratified spatial partitioning strategy with per-class spectral purity criteria to maintain ecological representativeness across nine urban land use categories.
2.3. SF-UNet
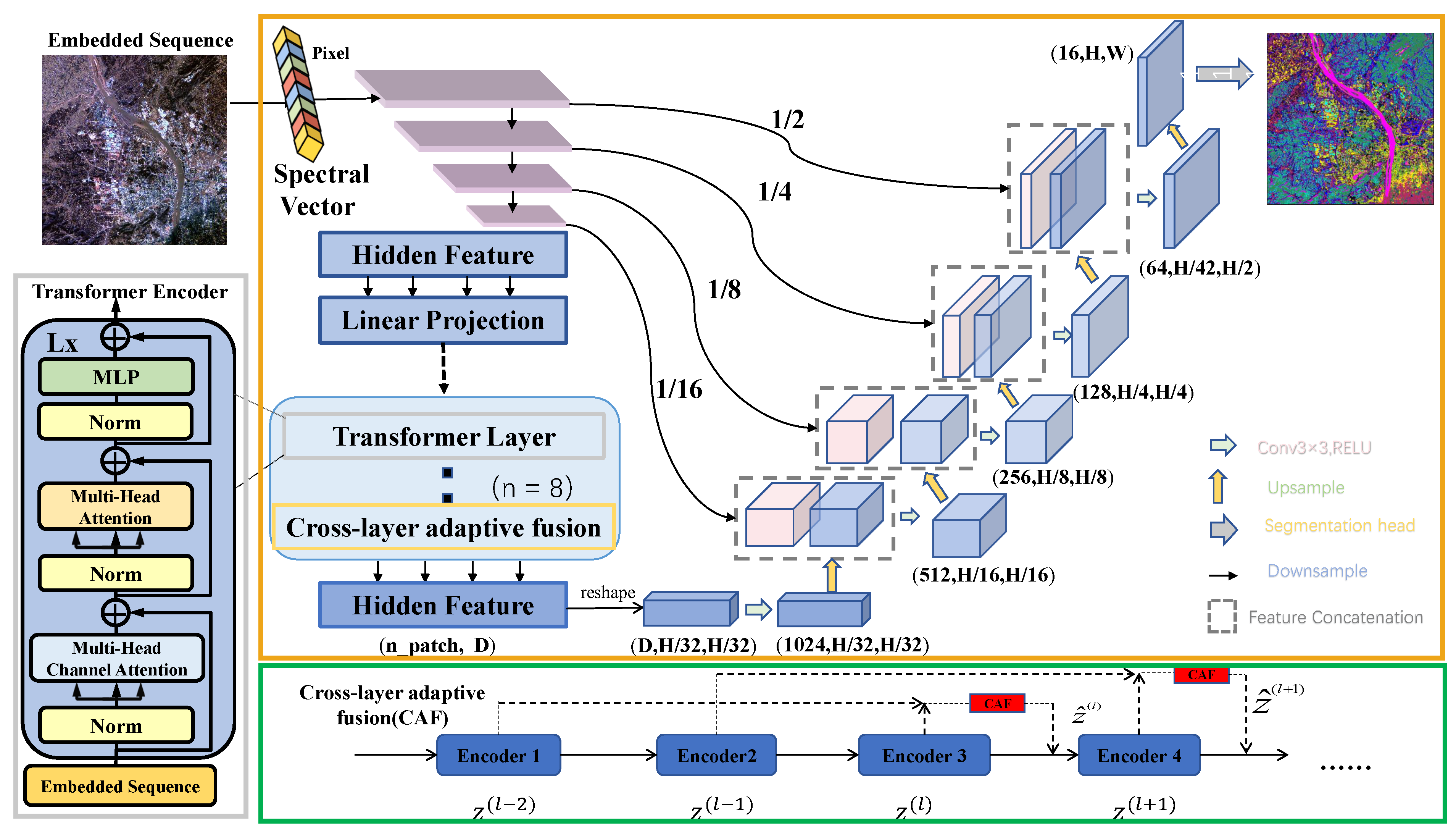
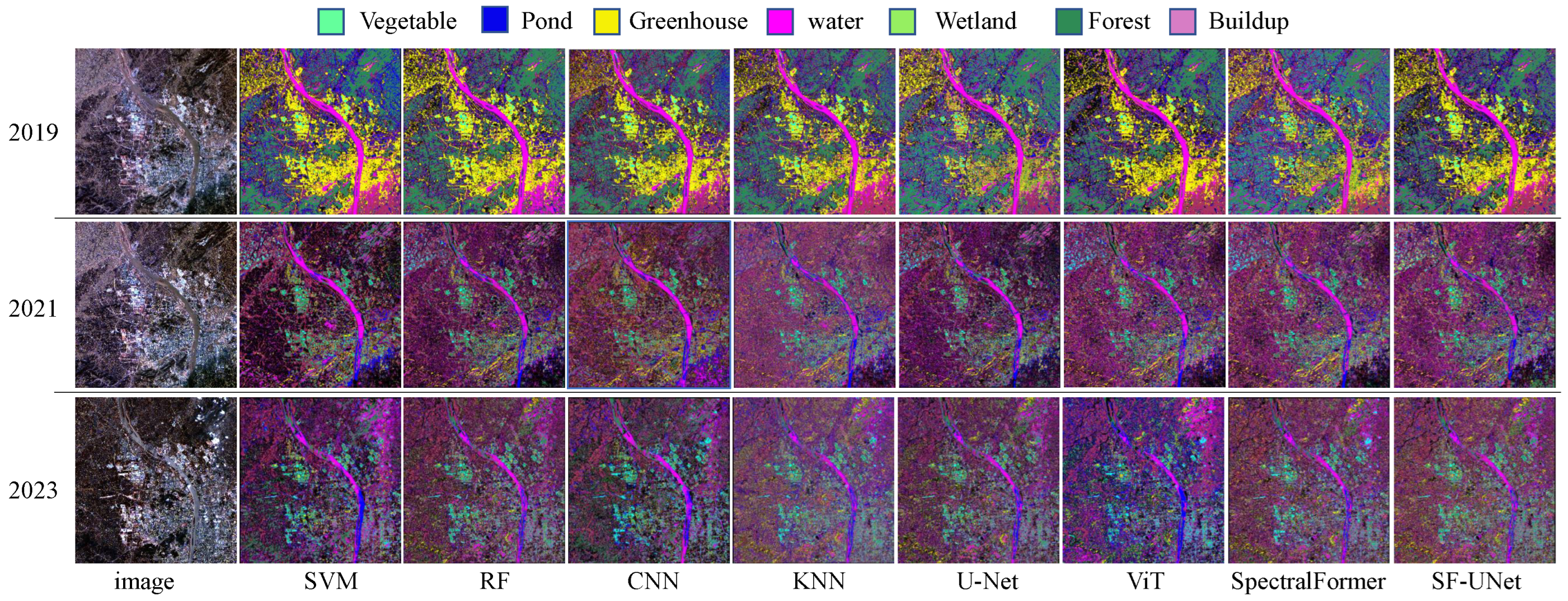
This paper addresses the limitations of traditional deep learning methods in effectively utilizing local spectral features and fail to effectively capture nuanced differences among features—leading to model confusion and misclassification in object class categories—we propose a novel pixel-by-pixel classification network for multispectral and hyperspectral images: SF-UNet, as depicted in
Figure 3. This network integrates SpectralFormer, U-Net, CAM, HGSE, and HCAF components. The first step involves utilizing the HGSE module to process a sequence of spectral pixels, creating a semigroup spectral nesting that enhances the connection between local information. The second step employs the CAM module’s SpectralFormer as an auxiliary encoder within the U-Net encoder structure, boosting the model’s feature representation capabilities through cross-level jump connections and cascading, which fuse soft residuals between layers via cross-regional adaptive learning. Finally, the U-Net decoder is used to achieve pixel-level classification results in detail.
2.3.1. Half-Groupwise Spectral Embedding for Forest Data
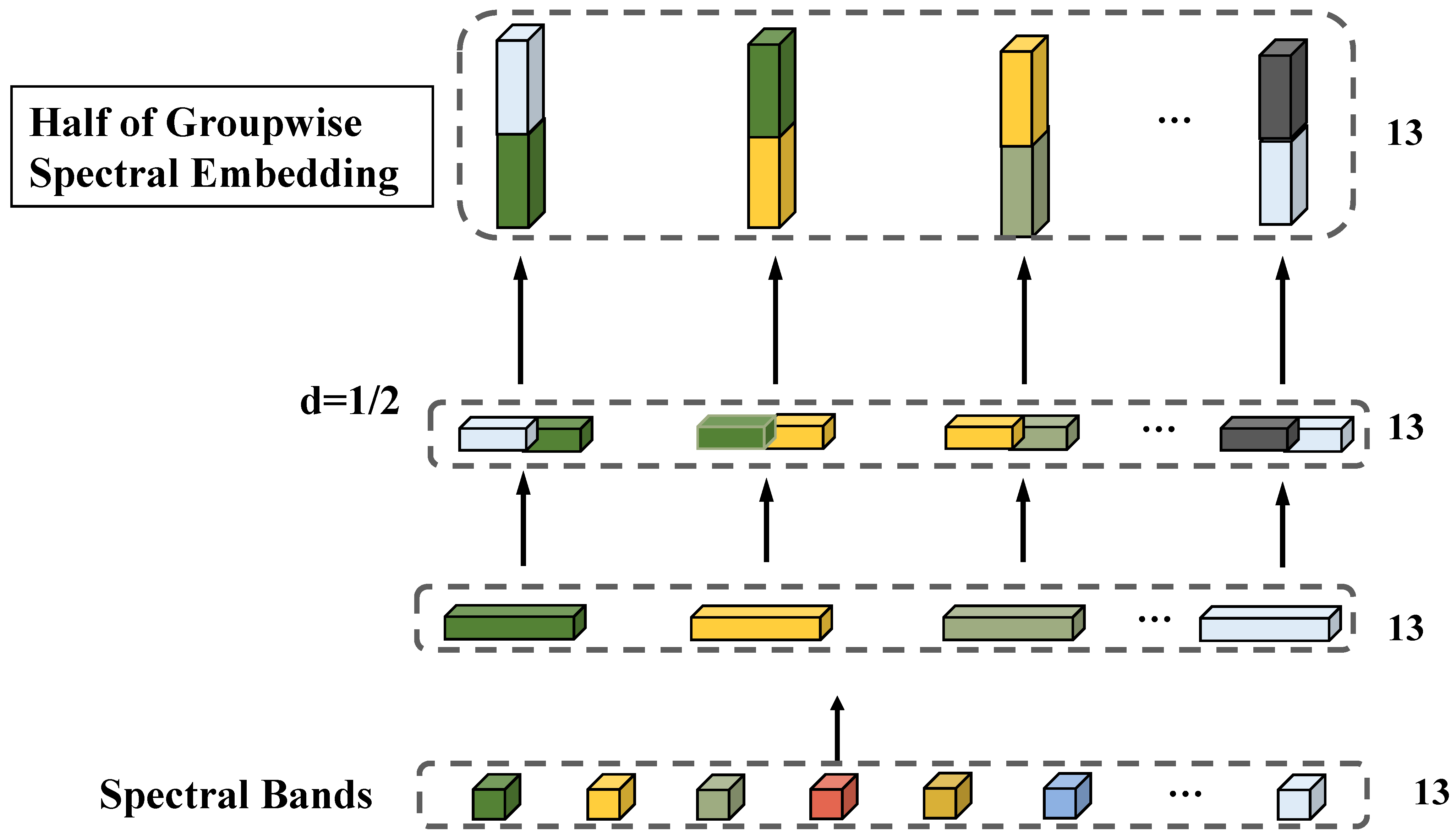
To enhance our ability to analyze the correlation between adjacent bands in forest hyperspectral images, we introduce the GSE module into our framework. Since different bands exhibit distinct spectral information due to varying absorption properties across wavelengths, capturing localized spectral feature changes becomes pivotal for accurate classification of forest features. Despite the limited number of bands in the multispectral Sentinel-2 image, which typically consists of only 13 bands, there remains a significant need to analyze band correlations.
When expressing an input feature as a 1D-pixel sequence, it is represented by Equation (
1):
where w denotes the linear transformation, equivalently used for all bands of the spectral band, and A collects the output features.
Here, X denotes the linear transformation variable, W corresponds to localized spectral signatures, and n indicates adjacent spectral channels. As illustrated in
Figure 4, the 1D-pixel sequence is partitioned into four 1 × 1 sub-sequences through Half-Group Spectral Embedding, where interleaved fusion of partial sub-sequences optimizes discriminative feature analysis while preserving spectral coherence.
2.3.2. Cross-Layer Adaptive Fusion (HCAF) for Forest Feature Integration
In deep neural networks, the skip connection (SC) mechanism has been demonstrated as an effective strategy for enhancing information transfer between layers and mitigating information loss during the learning process. In recent years, SCs have achieved notable success in image recognition and segmentation tasks, with short SCs utilized in ResNet and long SCs in U-Net architectures. However, it is worth noting that short SCs have limited information “memorization” capabilities, while long SCs often struggle with insufficient fusion when bridging the substantial gap between high- and low-level features.
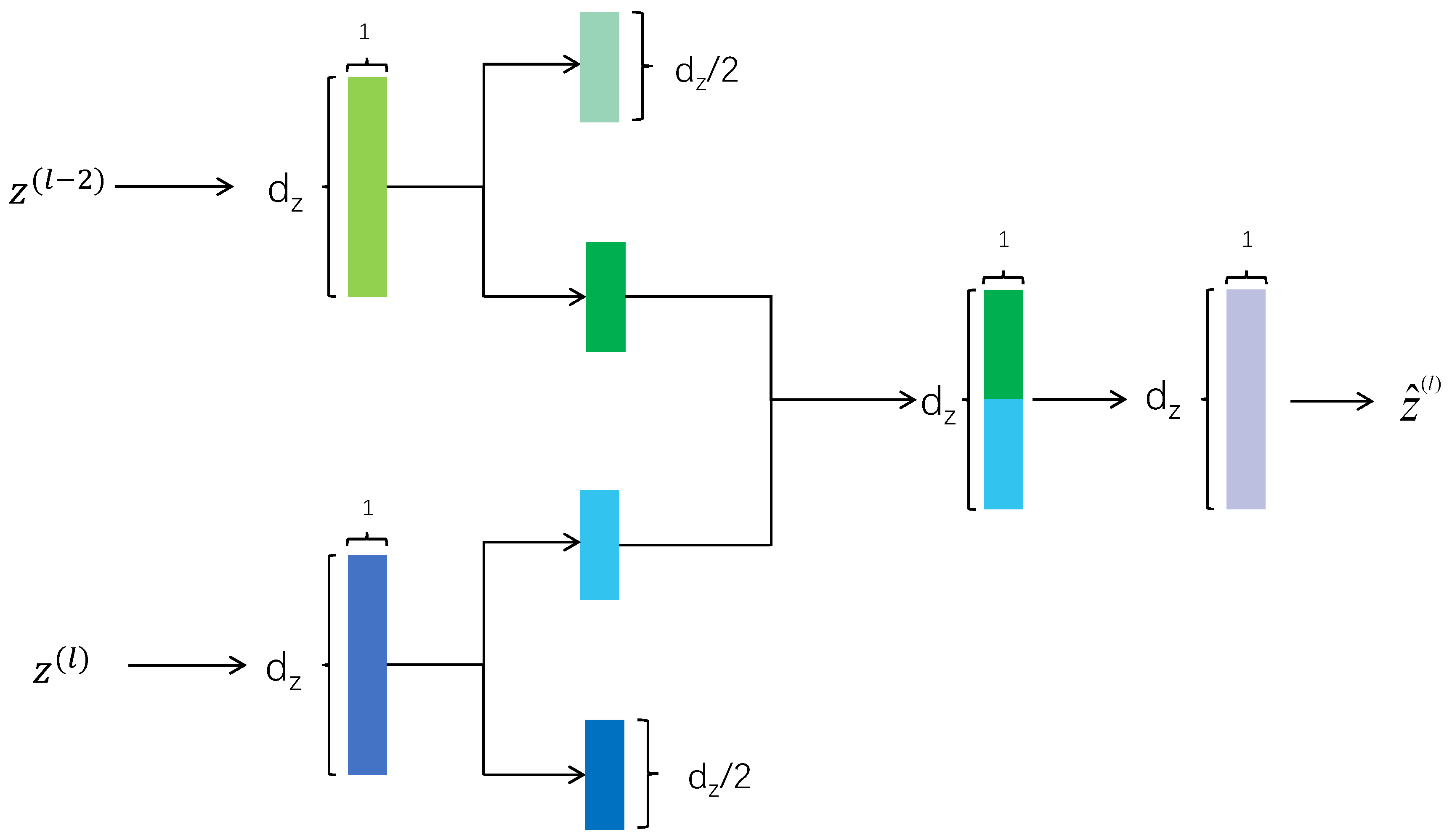
To address this challenge, SpectralFormer introduces a mid-range SC, termed adaptive learning cross-layer feature fusion (CAF). We extract half of the features for representation and fuse them, as depicted in
Figure 5. This approach facilitates improved fusion of high- and low-level features with significant gaps.
It is important to acknowledge the substantial semantic gap between low-level features and deep-level features extracted from shallow and deep layers using conventional methods. This disparity can result in insufficient fusion and potential information loss, particularly when employing relatively long skip connections (SCs), such as those spanning two, three, or more encoders. However, with the HCAF module, effective fusion of high- and low-level features with significant gaps can be achieved, irrespective of network depth.
2.3.3. Channel Attention Module (CAM) for Forest Feature Enhancement
The architecture integrates SpectralFormer with a U-Net backbone in a dual-branch encoder framework, where the Transformer branch incorporates fixed positional embeddings to encode token-level spatial coordinates. A parallel attention mechanism, embodied through multi-head channel attention, systematically models cross-region dependencies across all spatial positions rather than localized interactions. This attention module employs dual-path processing: maximum-pooled and average-pooled feature representations are independently derived from the input, enabling synergistic integration of complementary statistical perspectives for enhanced discriminative power. Subsequently, both outputs undergo the same MLP network within the activation function to yield the final output shown in
Figure 6.
Channel attention is an attention mechanism in neural networks that enhances the interaction and information transfer between different channels in a feature map, thereby improving model performance. Channel attention mechanisms enhance feature representation by adaptively recalibrating channel-wise feature responses. This process involves two key operations: compression and excitation. During compression, global spatial information from feature maps is aggregated, typically through operations such as global average or max pooling, to generate channel-wise statistics. These statistics capture the importance of each channel within the feature space. The subsequent excitation phase employs a learnable gating mechanism—often implemented via fully connected layers and non-linear activations—to dynamically recalibrate channel weights. By emphasizing informative channels while suppressing redundant ones, this mechanism enables the network to focus on discriminative features critical for downstream tasks. The architecture’s simplicity stems from its lightweight computational footprint, as the compression–excitation workflow introduces minimal parameters. Despite its straightforward implementation, the mechanism exhibits strong robustness across diverse datasets and tasks, owing to its ability to generalize spatial–channel relationships. Furthermore, its modular design allows seamless integration into existing convolutional neural networks (CNNs), enhancing feature refinement without altering core structural components. The effectiveness of this approach is mathematically formalized in Equations (3)–(5), which detail the transformation of input features into recalibrated outputs through learnable scaling factors. By prioritizing channel interdependencies, the mechanism inherently complements spatial attention paradigms, offering a holistic framework for feature optimization in complex vision tasks.
The input tensor x has dimensions (N, C, H, W), where N represents the batch size. c denotes the number of channels, and H and W correspond to the spatial height and width, respectively. A channel-wise descriptor z is derived by applying global average pooling to x, the average value over the channel dimensions. and are vectors denoting the learnable weight matrices; activation is applied between these transformations to introduce non-linearity. The resulting channel-wise attention weights are normalized via a Sigmoid function. is the output tensor. ⊙ selectively amplifies or suppresses channels based on their learned importance.
The channel attention framework employs a dual-layer dense architecture coupled with a non-linear gating mechanism (Sigmoid) to establish data-driven channel-wise significance. This configuration allows the network to dynamically prioritize discriminative feature channels through learned inter-channel dependencies, where the Sigmoid-activated output normalizes attention weights between 0 and 1 for adaptive feature refinement.In this way, the model is able to weightedly average the signals from the useful channels to strengthen them and attenuate the information from the useless channels, thus improving the overall model performance.
2.4. Evaluation Metrics
The model’s effectiveness is quantitatively assessed through three key metrics: overall accuracy (OA) measuring total classification correctness, average accuracy (AA) reflecting mean class-wise performance, and the kappa coefficient evaluating classification consistency beyond random chance. This comprehensive evaluation framework ensures rigorous assessment of both global and class-specific predictive capabilities. These three evaluation metrics are based on the confusion matrix, which contains four terms: tp, fp, tn, and fn. The quantitative evaluation formula is calculated as follows.
(1) OA: The metric calculates classification precision by dividing correctly predicted instances by total prediction attempts.
where
denotes the positive categories that were classified accurately,
denotes the negative categories that were misclassified as positive,
denotes the negative categories that were classified accurately, and
denotes the positive categories that were misclassified as negative.
(2) AA: The ratio of true positive predictions to all positive predictions.
where w represents the total category count.
(3) Kappa coefficient: A statistical metric quantifying inter-rater agreement beyond chance.
where
represents the observed agreement rate between predicted and actual classifications, computed as the proportion of correctly classified samples in the confusion matrix;
denotes the expected probability of random agreement, derived from the product of marginal distributions.
2.5. Parameter Settings
The proposed model was implemented using Python 3.7 with PyTorch 1.12.1 as the deep learning framework. During training, we employed the Adam optimization algorithm with a mini-batch size of 32 samples per iteration. The training process was set to terminate after completing 300 epochs or reaching convergence, whichever occurred first. The initial learning rate was set to 5 × 10−4, with a decay factor of 0.9 applied every 30 iterations. All implementation code was executed on a system comprising Windows 11, an AMD Ryzen 9 5900HX processor (AMD, Santa Clara, CA, USA), and an NVIDIA GeForce RTX 3060 Laptop GPU (Nvidia, Santa Clara, CA, USA).
4. Discussion
The SF-UNet model has shown remarkable potential in the classification of forest hyperspectral images. Forest ecosystems are intricate, with diverse vegetation types, varying forest densities, and complex terrain conditions. These factors pose significant challenges for accurate classification. Traditional methods like SVM and RF, while effective in certain scenarios, often struggle with the high dimensionality and complex spectral–spatial information present in forest hyperspectral images. Deep learning approaches, including CNN and U-Net, have demonstrated greater capability in handling such complexity. However, they still face limitations in capturing long-range dependencies and fine-grained details critical for distinguishing subtle features among forest components.
SF-UNet addresses these challenges through its innovative architecture that combines the strengths of SpectralFormer and U-Net. The HGSE module within SF-UNet enhances the connectivity of local spectral information. This is particularly beneficial for identifying different forest species and distinguishing between healthy and stressed vegetation, as these often exhibit subtle differences in spectral signatures. The integration of the CAM module allows SF-UNet to effectively capture cross-channel information while suppressing irrelevant data. This is crucial for enhancing the model’s ability to accurately pinpoint and identify specific forest features such as understorey vegetation and forest edges. The cross-layer adaptive fusion mechanism further strengthens the model’s capacity to integrate multiscale features. In the context of forest monitoring, this capability is essential for tracking deforestation, reforestation efforts, and forest health changes over time. By combining these techniques, SF-UNet provides more detailed and accurate classification results. This advancement is highly significant for forest resource management and conservation efforts. However, despite its advantages, the SF-UNet method also has several limitations and disadvantages that need to be considered. The integration of multiple advanced modules increases the computational complexity of the model, leading to longer training times and higher hardware requirements. This may limit its accessibility for users with limited computational resources. Additionally, the performance of SF-UNet heavily depends on the quality and quantity of the training data. In cases where training data is limited or imbalanced, the model may not generalize well to new datasets. There is also a risk of overfitting, especially when trained on small datasets.
Future work should focus on optimizing the model to reduce computational complexity and improve its generalization ability. This could involve exploring more efficient architectural designs, implementing advanced regularization techniques, and developing strategies for better utilization of limited training data. Furthermore, the study could be extended by evaluating the model’s performance on a wider range of hyperspectral datasets and comparing it with other state-of-the-art methods in more detail. This would provide a more comprehensive understanding of the model’s strengths and weaknesses and its potential for practical applications in forest monitoring and management.
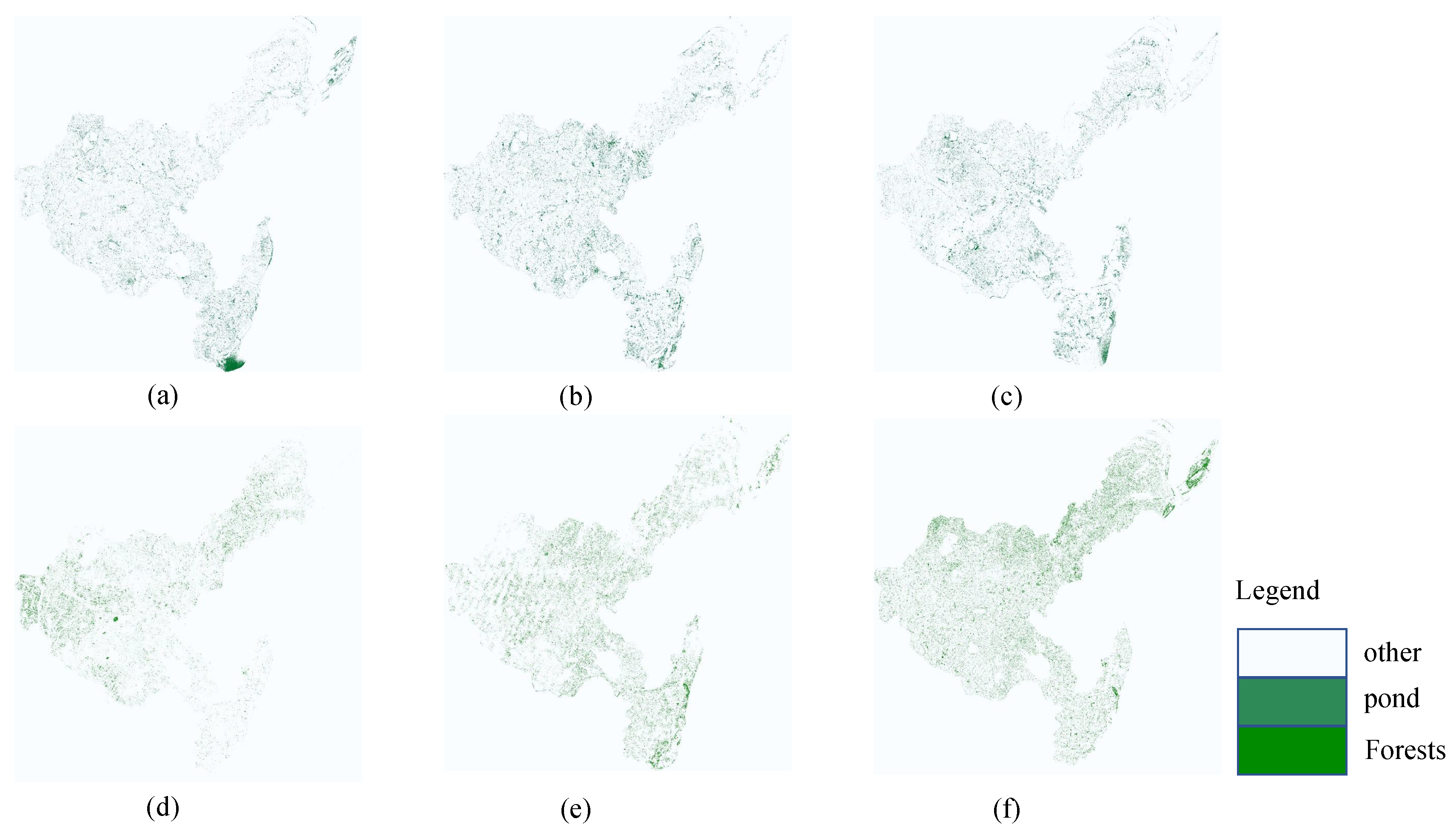
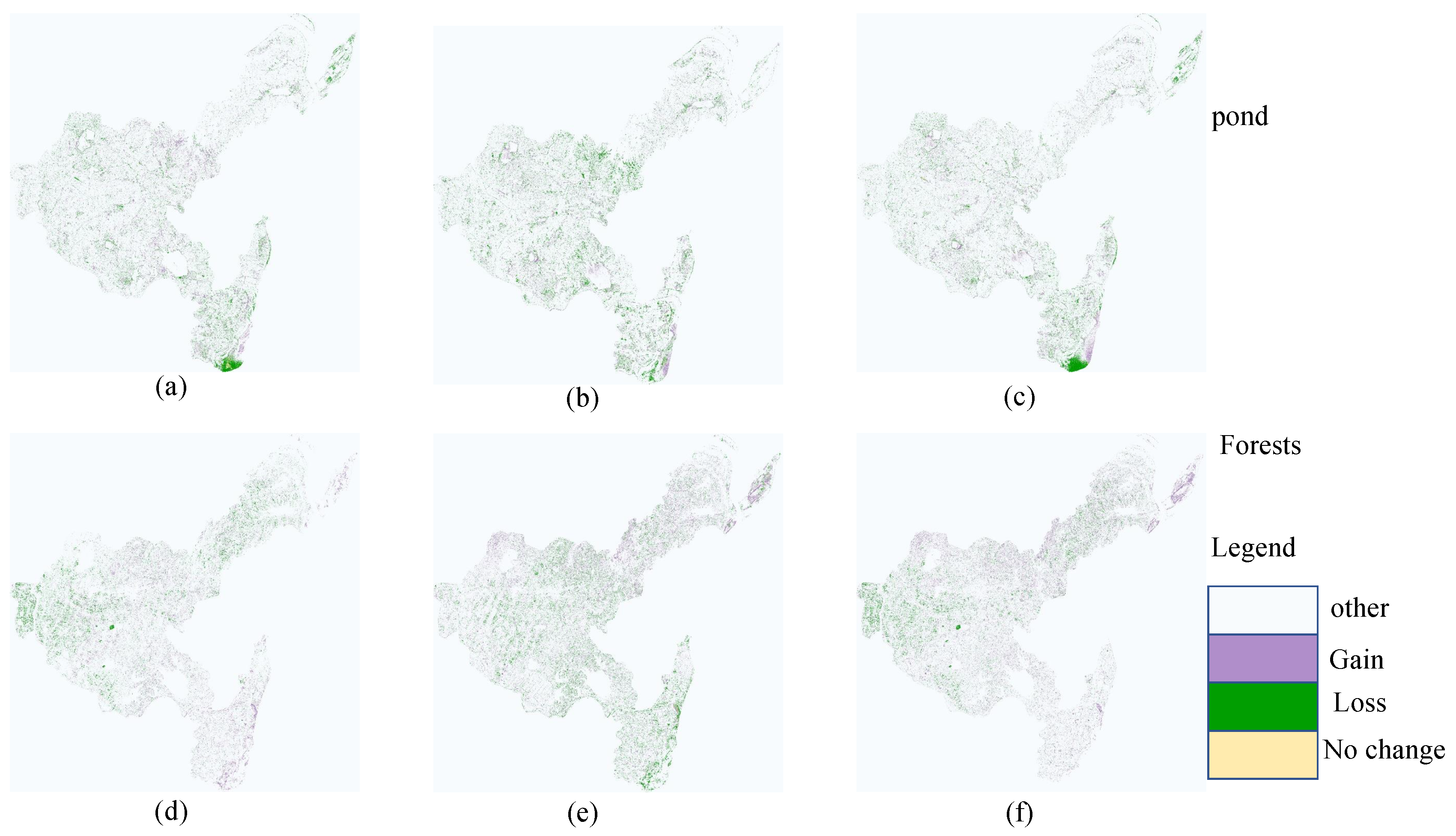
In the analysis of land cover changes in the Heshan area, the trend of forest changes has a significant impact on the ecosystem. As an important ecological resource, an increase or decrease in forest area directly affects multiple aspects such as biodiversity, soil and water conservation, and carbon sequestration capacity. This study shows that forest area experienced significant dynamic changes during the research period, which may be closely related to economic activities, policy changes, and natural factors within the region. The decrease in forest area in 2021 may be related to economic demand and land use policies at the time, while the rebound in 2023 may reflect the initial effectiveness of ecological restoration measures. In addition, the health status and species composition of forests can also affect their spectral characteristics, thereby affecting classification results. The high-precision performance of the SF UNet model in forest classification enables it to effectively monitor changes in forest cover and provide scientific basis for sustainable management of forest resources.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}