
Human and Machine Reliability in Postural Assessment of Forest Operations by OWAS Method: Level of Agreement and Time Resources

 , ,
, ,  , and
, and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Deep Learning Model Used as a Reference
2.2. Dataset and Posture Rating by Human Experts
2.3. Reliability Assessment
2.4. Reliability Metrics Used for Assessment
2.5. Time Assessment
2.6. Statistical Analysis and Software Used
3. Results and Discussion
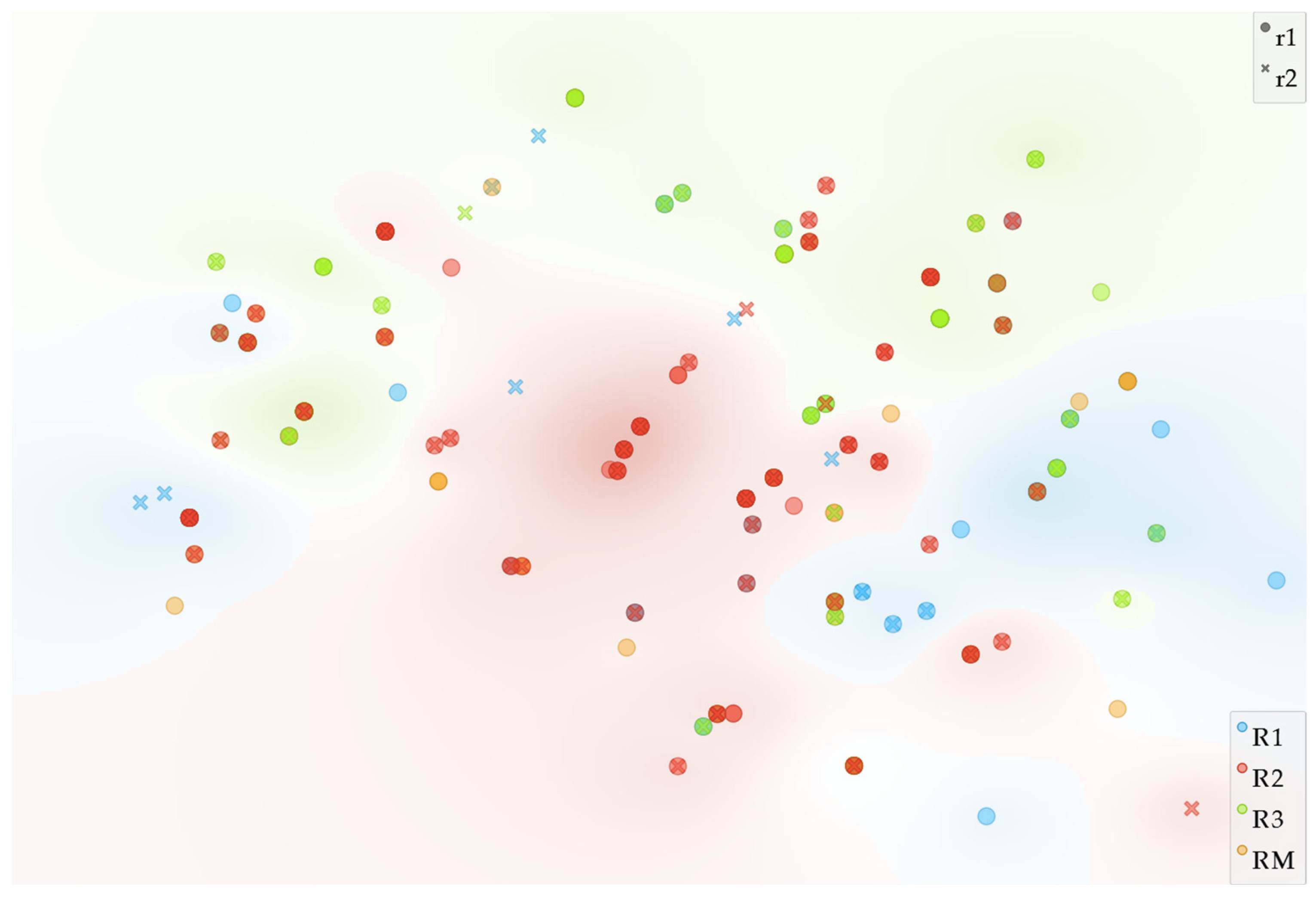
3.1. Overall Feature-Based Agreement
3.2. Intra-Rater Agreement
3.3. Pair-Based Inter-Rater Agreement
3.4. Pair-Based Agreement to the Ground Truth Data
3.5. Overall Agreement to the Ground Truth Data
3.6. Time Consumption
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Beims, R.F.; Arredondo, R.; Sosa Carrero, D.J.; Yuan, Z.; Li, H.; Shui, H.; Zhang, Y.; Leitch, M.; Xu, C.C. Functionalized Wood as Bio-Based Advanced Materials: Properties, Applications, and Challenges. Renew. Sustain. Energy Rev. 2022, 157, 112074. [Google Scholar] [CrossRef]
- Jiang, F.; Li, T.; Li, Y.; Zhang, Y.; Gong, A.; Dai, J.; Hitz, E.; Luo, W.; Hu, L. Wood-Based Nanotechnologies toward Sustainability. Adv. Mater. 2018, 30, 1703453. [Google Scholar] [CrossRef] [PubMed]
- Braga, C.I.; Petrea, S.; Zaharia, A.; Cucu, A.B.; Serban, T.; Ienasoiu, G.; Radu, G.R. Assessing the Greenhouse Gas Mitigation Potential of Harvested Wood Products in Romania and Their Contribution to Achieving Climate Neutrality. Sustainability 2025, 17, 640. [Google Scholar] [CrossRef]
- Do, T.T.H.; Ly, T.B.T.; Hoang, N.T. A new integrated circular economy index and a combined method for optimization of wood production chain considering carbon neutrality. Chemosphere 2023, 311, 137029. [Google Scholar] [CrossRef]
- Sudheshwar, A.; Vogel, K.; Nyström, G.; Malinverno, N.; Arnaudo, M.; Camacho, C.E.G.; Beloin-Saint-Pierre, D.; Hischier, R.; Som, C. Unraveling the climate neutrality of wood derivatives and biopolymers. RSC Sustain. 2024, 2, 1487–1497. [Google Scholar] [CrossRef]
- Jarre, M.; Petit-Boix, A.; Priefer, C.; Meyer, R.; Leipold, S. Transforming the bio-based sector towards a circular economy—What can we learn from wood cascading? For. Policy Econ. 2020, 110, 101872. [Google Scholar] [CrossRef]
- Hassegawa, M.; Brusselen, J.; Cramm, M.; Verkerk, P.J. Wood-based products in the circular bioeconomy: Status and opportunities towards environmental sustainability. Land 2022, 11, 2131. [Google Scholar] [CrossRef]
- Nishiguchi, S.; Tabata, T. Assessment of social, economic, and environmental aspects of woody biomass energy utilization: Direct burning and wood pellets. Renew. Sustain. Energy Rev. 2016, 57, 1279–1286. [Google Scholar] [CrossRef]
- Kropivšek, J.; Zupančič, A. Development of competencies in the Slovenian wood-industry. Dyn. Relat. Manag. J. 2016, 5, 3–20. [Google Scholar] [CrossRef]
- Klein, D.; Kies, U.; Schulte, A. Regional employment trends of wood-based industries in Germany’s forest cluster: A comparative shift-share analysis of post-reunification development. Eur. J. For. Res. 2009, 128, 205–219. [Google Scholar] [CrossRef]
- Pang, S.; H’ng, P.; Chai, L.; Lee, S.; Paridah, M.T. Value added productivity performance of the Peninsular Malaysian wood sawmilling industry. BioResources 2015, 10, 7324–7338. [Google Scholar] [CrossRef]
- Temu, B.J.; Monela, G.C.; Darr, D.; Abdallah, J.M.; Pretzsch, J. Forest sector contribution to the National Economy: Example wood products value chains originating from Iringa region, Tanzania. For. Policy Econ. 2024, 164, 103246. [Google Scholar] [CrossRef]
- Michaud, G.; Jolley, G.J. Economic contribution of Ohio’s wood industry cluster: Identifying opportunities in the Appalachian region. Rev. Reg. Stud. 2019, 49, 149–171. [Google Scholar] [CrossRef]
- Heinimann, H.R. Forest operations engineering and management—The ways behind and ahead of a scientific discipline. Croat. J. For. Eng. 2007, 28, 107–121. [Google Scholar]
- Marchi, E.; Picchio, R.; Spinelli, R.; Verani, S.; Venanzi, R.; Certini, G. Environmental impact assessment of different logging methods in pine forests thinning. Ecol. Eng. 2014, 70, 429–436. [Google Scholar] [CrossRef]
- Szewczyk, G.; Spinelli, R.; Magagnotti, N.; Tylek, P.; Sowa, J.M.; Rudy, P.; Gaj-Gielarowiec, D. The mental workload of harvester operators working in steep terrain conditions. Silva Fenn. 2020, 54, 10355. [Google Scholar] [CrossRef]
- Passicot, P.; Murphy, G.E. Effect of work schedule design on productivity of mechanized harvesting operations in Chile. N. Z. J. For. Sci. 2013, 43, 2. [Google Scholar] [CrossRef]
- Moskalik, T.; Borz, S.A.; Dvořák, J.; Ferencik, M.; Glushkov, S.; Muiste, P.; Lazdiņš, A.; Styranivsky, O. Timber harvesting methods in Eastern European countries: A review. Croat. J. For. Eng. 2017, 38, 231–241. [Google Scholar]
- Gerasimov, Y.; Sokolov, A. Ergonomic evaluation and comparison of wood harvesting systems in Northwest Russia. Appl. Ergon. 2014, 45, 318–338. [Google Scholar] [CrossRef]
- Barbosa, R.P.; Fiedler, N.C.; Carmo, F.C.A.; Minette, L.J.; Silva, E.N. Analysis of posture in semi-mechanized forest harvesting in steep areas. Rev. Árvore 2014, 38, 733–738. [Google Scholar] [CrossRef]
- Häggström, C.; Lindroos, O. Human, technology, organization and environment—A human factors perspective on performance in forest harvesting. Int. J. For. Eng. 2016, 43, 2. [Google Scholar] [CrossRef]
- Grzywiński, W.; Wandycz, A.; Tomczak, A.; Jelonek, T. The prevalence of self-reported musculoskeletal symptoms among loggers in Poland. Int. J. Ind. Ergon. 2016, 52, 12–17. [Google Scholar] [CrossRef]
- Calvo, A. Musculoskeletal disorders (MSD) risks in forestry: A case study to propose an analysis method. Agric. Eng. Int. 2009, 11, 1–9. [Google Scholar]
- Cheţa, M.; Marcu, M.V.; Borz, S.A. Workload, exposure to noise, and risk of musculoskeletal disorders: A case study of motor-manual tree feeling and processing in poplar clear cuts. Forests 2018, 9, 300. [Google Scholar] [CrossRef]
- Gómez-Galán, M.; Pérez-Alonso, J.; Callejón-Ferre, Á.J.; López-Martínez, J. Musculoskeletal disorders: OWAS review. Ind. Health 2017, 55, 314–337. [Google Scholar] [CrossRef]
- Bevan, S. Economic Impact of Musculoskeletal Disorders (MSDs) on Work in Europe. Best Pract. Res. Clin. Rheumatol. 2015, 29, 356–373. [Google Scholar] [CrossRef]
- Oh, I.H.; Yoon, S.J.; Seo, H.Y.; Kim, E.J.; Kim, Y.A. The economic burden of musculoskeletal disease in Korea: A cross-sectional study. BMC Musculoskelet. Disord. 2011, 12, 157. [Google Scholar] [CrossRef]
- Borz, S.A.; Talagai, N.; Cheţa, M.; Chiriloiu, D.; Gavilanes Montoya, A.V.; Castillo Vizuete, D.D.; Marcu, M.V. Physical strain, exposure to noise and postural assessment in motor-manual felling of willow short rotation coppice: Results of a preliminary study. Croat. J. For. Eng. 2019, 40, 377–388. [Google Scholar] [CrossRef]
- Pheasant, S.; Haslegrave, C.M. Bodyspace: Anthropometry, Ergonomics and the Design of Work, 3rd ed.; Taylor & Francis: Abingdon, UK, 2006. [Google Scholar]
- Viviani, C.; Arezes, P.M.; Braganca, S.; Molenbroek, J.; Dianat, I.; Castellucci, H.I. Accuracy, precision and reliability in anthropometric surveys for ergonomics purposes in adult working populations: A literature review. Int. J. Ind. Ergon. 2018, 65, 1–16. [Google Scholar] [CrossRef]
- Corella Justavino, F.; Jimenez Ramirez, R.; Meza Perez, N.; Borz, S.A. The use of OWAS in forest operations postural assessment: Advantages and limitations. Bull. Transilv. Univ. Bras. Ser. II For. Wood Ind. Agric. Food Eng. 2015, 8, 7–16. [Google Scholar]
- Neitzel, R.; Yost, M. Task-based assessment of occupational vibration and noise exposure in forestry workers. Aiha J. 2002, 63, 617–627. [Google Scholar] [CrossRef]
- Yongan, W.; Baojun, J. Effects of low temperature on operation efficiency of tree-felling by chainsaw in North China. J. For. Res. 1998, 9, 57–58. [Google Scholar] [CrossRef]
- Li, G.; Buckle, P. Current techniques for assessing physical exposure to work-related musculoskeletal risks, with emphasis on posture-based methods. Ergonomics 1999, 42, 674–695. [Google Scholar] [CrossRef] [PubMed]
- David, G.C. Ergonomic methods for assessing exposure to risk factors for work-related musculoskeletal disorders. Occup. Med. 2005, 55, 190–199. [Google Scholar] [CrossRef]
- Kee, D. Systematic comparison of OWAS, RULA, and REBA based on a literature review. Int. J. Environ. Res. Public Health 2022, 19, 595. [Google Scholar] [CrossRef]
- Lopes, E.D.S.; Britto, P.C.; Rodrigues, C.K. Postural discomfort in manual operations of forest planting. Floresta Ambient. 2018, 26, 20170030. [Google Scholar] [CrossRef]
- Denbeigh, K.; Slot, T.R.; Dumas, G.A. Wrist postures and forces in tree planters during three tree unloading conditions. Ergonomics 2013, 56, 1599–1607. [Google Scholar] [CrossRef]
- Vosniak, J.; Lopes, E.D.S.; Fiedler, N.C.; Alves, R.T.; Venâncio, D.L. Demanded physical effort and posture in semi-mechanical hole-digging activity at forestry plantation. Sci. For./For. Sci. 2010, 33, 589–598. [Google Scholar]
- Zanuttini, R.; Cielo, P.; Poncino, D. The OWAS method. Preliminary results for the evaluation of the risk of work-related musculoskeletal disorders (WMSD) in the forestry sector in Italy. For. Riv. Selvic. Ecol. For. 2005, 2, 242–255. [Google Scholar] [CrossRef]
- Karhu, O.; Kansi, P.; Kuorinka, I. Correcting working postures in industry: A practical method for analysis. Appl. Ergon. 1977, 8, 199–201. [Google Scholar] [CrossRef]
- Takala, E.P.; Pehkonen, I.; Forsman, M.; Hansson, G.Å.; Mathiassen, S.E.; Neumann, W.P.; Sjøgaard, G.; Veiersted, K.B.; Westgaard, R.H.; Winkel, J. Systematic evaluation of observational methods assessing biomechanical exposures at work. Scand. J. Work Environ. Health 2010, 36, 3–24. [Google Scholar] [CrossRef] [PubMed]
- Helander, M. A Guide to Human Factors and Ergonomics, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Burdorf, A.; Derksen, J.; Naaktgeboren, B.; Riel, M. Measurement of trunk bending during work by direct observation and continuous measurement. Appl. Ergon. 1992, 23, 263–267. [Google Scholar] [CrossRef] [PubMed]
- Borz, S.A.; Castro Perez, S.N. Effect of the sampling strategy on the accuracy of postural classification: An example from motor-manual tree felling and processing. Rev. Pădurilor 2020, 135, 19–41. [Google Scholar]
- Brandl, C.; Mertens, A.; Schlick, C.M. Effect of sampling interval on the reliability of ergonomic analysis using the Ovako Working Posture Analysing System (OWAS). Int. J. Ind. Ergon. 2017, 57, 68–73. [Google Scholar] [CrossRef]
- Beek, A.J.; Mathiassen, S.E.; Windhorst, J.; Burdorf, A. An evaluation of methods assessing the physical demands of manual lifting in scaffolding. Appl. Ergon. 2005, 36, 213–222. [Google Scholar] [CrossRef]
- Kee, D.; Karwowski, W. A comparison of three observational techniques for assessing postural loads in industry. Int. J. Occup. Saf. Ergon. 2007, 13, 3–14. [Google Scholar] [CrossRef]
- Micheletti Cremasco, M.; Giustetto, A.; Caffaro, F.; Colantoni, A.; Cavallo, E.; Grigolato, S. Risk assessment for musculoskeletal disorders in forestry: A comparison between RULA and REBA in the manual feeding of a wood-chipper. Int. J. Environ. Res. Public Health 2019, 16, 793. [Google Scholar] [CrossRef]
- De Bruijn, I.; Engels, J.A.; Van Der Gulden, J.W. A simple method to evaluate the reliability of OWAS observations. Appl. Ergon. 1998, 29, 281–283. [Google Scholar] [CrossRef]
- Mattila, M.; Karwowski, W.; Vilkki, M. Analysis of working postures in hammering tasks on building construction sites using the computerized OWAS method. Appl. Ergon. 1993, 24, 405–412. [Google Scholar] [CrossRef]
- Kivi, P.; Mattila, M. Analysis and improvement of work postures in the building industry: Application of the computerised OWAS method. Appl. Ergon. 1991, 22, 43–48. [Google Scholar] [CrossRef]
- Lins, C.; Fudickar, S.; Hein, A. OWAS inter-rater reliability. Appl. Ergon. 2021, 95, 103357. [Google Scholar] [CrossRef] [PubMed]
- Fığlalı, N.; Cihan, A.; Esen, H.; Fığlalı, A.; Çeşmeci, D.; Güllü, M.K.; Yılmaz, M.K. Image processing-aided working posture analysis: I-OWAS. Comput. Ind. Eng. 2015, 85, 384–394. [Google Scholar] [CrossRef]
- Wahyudi, M.A.; Dania, W.A.; Silalahi, R.L. Work posture analysis of manual material handling using OWAS method. Agric. Agric. Sci. Procedia 2015, 3, 195–199. [Google Scholar] [CrossRef]
- Miedema, M.C.; Douwes, M.; Dul, J. Recommended maximum holding times for prevention of discomfort of static standing postures. Int. J. Ind. Ergon. 1997, 19, 9–18. [Google Scholar] [CrossRef]
- Gaskin, J.E. An ergonomic evaluation of two motor-manual delimbing techniques. Int. J. Ind. Ergon. 1990, 5, 211–218. [Google Scholar] [CrossRef]
- Landekić, M.; Bačić, M.; Bakarić, M.; Šporčić, M.; Pandur, Z. Working posture and the center of mass assessment while starting a chainsaw: A case study among forestry workers in Croatia. Forests 2023, 14, 395. [Google Scholar] [CrossRef]
- Forkuo, G.O.; Borz, S.A. Development and evaluation of automated postural classification models in forest operations using deep learning-based computer vision. SSRN Preprint 2024. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Klie, J.C.; Castilho, R.E.; Gurevych, I. Analyzing dataset annotation quality management in the wild. Comput. Ling. 2024, 50, 817–866. [Google Scholar] [CrossRef]
- Yogarajan, V.; Dobbie, G.; Pistotti, T.; Bensemann, J.; Knowles, K. Challenges in annotating datasets to quantify bias in under-represented society. arXiv 2023, arXiv:2309.08624. [Google Scholar]
- Mascarenhas, S.; Agarwal, M. A comparison between VGG16, VGG19 and ResNet50 architecture frameworks for image classification. In Proceedings of the International Conference on Disruptive Technologies for Multi-Disciplinary Research and Applications (CENTCON), Bengaluru, India, 19–21 November 2021; pp. 96–99. [Google Scholar] [CrossRef]
- Siddharth, T. Fine-Tuning ResNet50 Pretrained on ImageNet for CIFAR-10. 2023. Available online: https://sidthoviti.com/fine-tuning-resnet50-pretrained-on-imagenet-for-cifar-10/ (accessed on 12 March 2025).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378–382. [Google Scholar] [CrossRef]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Viera, A.J.; Garrett, J.M. Understanding interobserver agreement: The kappa statistic. Fam. Med. 2005, 37, 360–363. [Google Scholar] [PubMed]
- DeVellis, R.F. Inter-Rater Reliability. In Encyclopedia of Social Measurement; Kimberly, K.-L., Ed.; Elsevier: Amsterdam, The Netherlands, 2005; pp. 317–322. ISBN 9780123693983. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 59–174. [Google Scholar] [CrossRef]
- Sim, J.; Wright, C.C. The kappa statistic in reliability studies: Use, interpretation, and sample size requirements. Phys. Ther. 2005, 85, 257–268. [Google Scholar] [CrossRef]
- Widyanti, A. Validity and inter-rater reliability of postural analysis among new raters. Malays. J. Public Health Med. 2020, 1, 161–166. [Google Scholar] [CrossRef]
- Fleiss, J.L.; Levin, B.; Paik, M.C. The measurement of interrater agreement. Stat. Methods Rates Proportions 1981, 2, 22–23. [Google Scholar]
- Gwet, K.L. Handbook of Inter-Rater Reliability, 4th ed.; Advanced Analytics LLC: Wayne, IN, USA, 2014; ISBN 978-0970806284. [Google Scholar]
- Demšar, J.; Curk, T.; Erjavec, A.; Gorup, Č.; Hočevar, T.; Milutinovič, M.; Možina, M.; Polajnar, M.; Toplak, M.; Starič, A.; et al. Orange: Data mining toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]
- Borg, I.; Groenen, P.J. Modern Multidimensional Scaling: Theory and Aplications; Springer Science Bussines Media: Berlin/Heidelberg, Germany, 2007; ISBN 100387251502. [Google Scholar]
- Saeed, N.; Nam, H.; Haq, M.I.U.; Muhammad Saqib, D.B. A survey on multidimensional scaling. ACM Comput. Surv. 2018, 51, 1–25. [Google Scholar] [CrossRef]
- JetBrains s.r.o. PyCharm Community Edition: The IDE for Pure Python Development. 2025. Available online: https://www.jetbrains.com/pycharm/download/?section=windows (accessed on 3 March 2025).
- Zaiontz, C. Real Statistics Using Excel. 2025. Available online: https://real-statistics.com/ (accessed on 5 March 2025).
- Heinsalmi, P. Method to Measure Working Posture Loads at Working Sites (OWAS). In Ergonomics of Working Postures; CRC Press: Boca Raton, FL, USA, 1986; pp. 100–104. [Google Scholar] [CrossRef]
- Liu, B.; Yu, L.; Che, C.; Lin, Q.; Hu, H.; Zhao, X. Integration and performance analysis of artificial intelligence and computer vision based on deep learning algorithms. arXiv 2023, arXiv:2312.12872. [Google Scholar] [CrossRef]
- Lee, J.; Kim, T.Y.; Beak, S.; Moon, Y.; Jeong, J. Real-time pose estimation based on ResNet-50 for rapid safety prevention and accident detection for field workers. Electronics 2023, 12, 3513. [Google Scholar] [CrossRef]
- Forkuo, G.O.; Borz, S.A.; Bilici, E. Approaching full accuracy by deep learning and computer vision in OWAS postural classification: An example on how computer generated body keypoints can improve deep learning based on conventional 2D data. SSRN Preprint SSRN-5037016 2024. [Google Scholar] [CrossRef]
- Eliasson, K.; Palm, P.; Nyman, T.; Forsman, M. Inter-and intra-observer reliability of risk assessment of repetitive work without an explicit method. Appl. Ergon. 2017, 62, 1–8. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Feature | Abbreviation in the Study | Number of Categories According to OWAS | Description |
|---|---|---|---|
| Back | B | 4 | Describes the posture of the back starting from a neutral straight posture and ending with the back being bent and twisted |
| Arms | A | 3 | Describes the posture of the arms starting from a neutral posture with both arms below shoulder level and ending with both arms being at or above the shoulder level |
| Legs | L | 7 | Describes the posture of the legs by seven categories starting from a neutral sitting posture and ending with legs being engaged in walking or moving |
| Force exertion | F | 3 | Describes the level of force exertion starting with handling loads or exerting forces less than 10 kg and ending with handling loads or exerting forces over 20 kg |
| Action category | AC | 4 | Indicates the level of postural risk by the urgency of the ergonomic interventions required, starting from no intervention required and ending with intervention required immediately |
| Rater No. | Replication No. | Abbreviation of the Dataset | Description of the Dataset |
|---|---|---|---|
| R1 | r1 | R1r1 | Ratings of the first rater in the first replication |
| R1 | r2 | R1r2 | Ratings of the first rater in the second replication |
| R2 | r1 | R2r1 | Ratings of the second rater in the first replication |
| R2 | r2 | R2r2 | Ratings of the second rater in the second replication |
| R3 | r1 | R3r1 | Ratings of the third rater in the first replication |
| R3 | r2 | R3r2 | Ratings of the third rater in the second replication |
| RM | - | RM | Rating of the deep learning model |
| Compared Datasets | # Ratings | Po | Pe | k | %Agreement | Interpretation of Kappa | |
|---|---|---|---|---|---|---|---|
| BR1r1 | BR1r2 | 100 | 0.69 | 0.29 | 0.56 | 69 | Moderate agreement |
| AR1r1 | AR1r2 | 100 | 0.93 | 0.71 | 0.76 | 93 | Substantial agreement |
| LR1r1 | LR1r2 | 100 | 0.68 | 0.26 | 0.57 | 68 | Moderate agreement |
| FR1r1 | FR1r2 | 100 | 0.90 | 0.62 | 0.74 | 90 | Substantial agreement |
| ACR1r1 | ACR1r2 | 100 | 0.61 | 0.25 | 0.48 | 61 | Moderate agreement |
| BR2r1 | BR2r2 | 100 | 0.97 | 0.33 | 0.96 | 97 | Almost perfect agreement |
| AR2r1 | AR2r2 | 100 | 1.00 | 0.73 | 1.00 | 100 | Almost perfect agreement |
| LR2r1 | LR2r2 | 97 | 0.99 | 0.25 | 0.99 | 99 | Almost perfect agreement |
| FR2r1 | FR2r2 | 100 | 0.95 | 0.51 | 0.90 | 95 | Almost perfect agreement |
| ACR2r1 | ACR2r2 | 97 | 0.95 | 0.26 | 0.93 | 95 | Almost perfect agreement |
| BR3r1 | BR3r2 | 100 | 0.96 | 0.39 | 0.93 | 96 | Almost perfect agreement |
| AR3r1 | AR3r2 | 100 | 0.98 | 0.84 | 0.88 | 98 | Almost perfect agreement |
| LR3r1 | LR3r2 | 100 | 0.99 | 0.32 | 0.99 | 99 | Almost perfect agreement |
| FR3r1 | FR3r2 | 100 | 0.98 | 0.48 | 0.96 | 98 | Almost perfect agreement |
| ACR3r1 | ACR3r2 | 100 | 0.96 | 0.32 | 0.94 | 96 | Almost perfect agreement |
| Compared Datasets | # Ratings | Po | Pe | k | %Agreement | Interpretation of Kappa | |
|---|---|---|---|---|---|---|---|
| BR1r1 | BR2r1 | 100 | 0.46 | 0.24 | 0.29 | 46 | Fair agreement |
| BR1r1 | BR3r1 | 100 | 0.62 | 0.36 | 0.41 | 62 | Moderate agreement |
| BR2r1 | BR3r1 | 100 | 0.34 | 0.29 | 0.07 | 34 | Slight agreement |
| AR1r1 | AR2r1 | 100 | 0.91 | 0.70 | 0.70 | 91 | Substantial agreement |
| AR1r1 | AR3r1 | 100 | 0.89 | 0.75 | 0.56 | 89 | Moderate agreement |
| AR2r1 | AR3r1 | 100 | 0.88 | 0.78 | 0.46 | 88 | Moderate agreement |
| LR1r1 | LR2r1 | 97 | 0.57 | 0.21 | 0.45 | 57 | Moderate agreement |
| LR1r1 | LR3r1 | 100 | 0.64 | 0.26 | 0.52 | 64 | Moderate agreement |
| LR2r1 | LR3r1 | 100 | 0.60 | 0.25 | 0.46 | 60 | Moderate agreement |
| FR1r1 | FR2r1 | 100 | 0.74 | 0.52 | 0.46 | 74 | Moderate agreement |
| FR1r1 | FR3r1 | 100 | 0.70 | 0.53 | 0.37 | 70 | Fair agreement |
| FR2r1 | FR3r1 | 100 | 0.72 | 0.48 | 0.46 | 72 | Moderate agreement |
| ACR1r1 | ACR2r1 | 100 | 0.54 | 0.24 | 0.40 | 54 | Fair agreement |
| ACR1r1 | ACR3r1 | 100 | 0.52 | 0.27 | 0.34 | 52 | Fair agreement |
| ACR2r1 | ACR3r1 | 97 | 0.40 | 0.23 | 0.22 | 40 | Fair agreement |
| BR1r2 | BR2r2 | 100 | 0.58 | 0.28 | 0.41 | 58 | Moderate agreement |
| BR1r2 | BR3r2 | 100 | 0.41 | 0.30 | 0.15 | 41 | Slight agreement |
| BR2r2 | BR3r2 | 100 | 0.32 | 0.30 | 0.02 | 32 | Slight agreement |
| AR1r2 | AR2r2 | 100 | 0.90 | 0.73 | 0.62 | 90 | Substantial agreement |
| AR1r2 | AR3r2 | 100 | 0.92 | 0.79 | 0.63 | 92 | Substantial agreement |
| AR2r2 | AR3r2 | 100 | 0.86 | 0.78 | 0.37 | 86 | Fair agreement |
| LR1r2 | LR2r2 | 100 | 0.56 | 0.24 | 0.42 | 56 | Moderate agreement |
| LR1r2 | LR3r2 | 100 | 0.75 | 0.31 | 0.64 | 75 | Substantial agreement |
| LR2r2 | LR3r2 | 100 | 0.58 | 0.25 | 0.44 | 58 | Moderate agreement |
| FR1r2 | FR2r2 | 100 | 0.79 | 0.55 | 0.53 | 79 | Moderate agreement |
| FR1r2 | FR3r2 | 100 | 0.73 | 0.55 | 0.40 | 73 | Fair agreement |
| FR2r2 | FR3r2 | 100 | 0.75 | 0.48 | 0.52 | 75 | Moderate agreement |
| ACR1r2 | ACR2r2 | 100 | 0.56 | 0.25 | 0.42 | 56 | Moderate agreement |
| ACR1r2 | ACR3r2 | 100 | 0.41 | 0.25 | 0.22 | 41 | Fair agreement |
| ACR2r2 | ACR3r2 | 100 | 0.40 | 0.23 | 0.22 | 40 | Fair agreement |
| Ratings Under Comparison | # Ratings | Po | Pe | k | %Agreement | Interpretation of Kappa | |
|---|---|---|---|---|---|---|---|
| BR1r1 | BRM | 100 | 0.43 | 0.34 | 0.13 | 43 | Slight agreement |
| BR1r2 | BRM | 100 | 0.34 | 0.30 | 0.06 | 34 | Slight agreement |
| BR2r1 | BRM | 100 | 0.32 | 0.30 | 0.03 | 32 | Slight agreement |
| BR2r2 | BRM | 100 | 0.30 | 0.30 | 0.00 | 30 | Poor agreement |
| BR3r1 | BRM | 100 | 0.57 | 0.37 | 0.32 | 57 | Fair agreement |
| BR3r2 | BRM | 100 | 0.57 | 0.38 | 0.31 | 57 | Fair agreement |
| AR1r1 | ARM | 100 | 0.75 | 0.76 | −0.03 | 75 | Poor agreement |
| AR1r2 | ARM | 100 | 0.79 | 0.79 | −0.02 | 79 | Poor agreement |
| AR2r1 | ARM | 100 | 0.78 | 0.78 | −0.02 | 78 | Poor agreement |
| AR2r2 | ARM | 100 | 0.78 | 0.78 | −0.02 | 78 | Poor agreement |
| AR3r1 | ARM | 100 | 0.85 | 0.84 | 0.04 | 85 | Slight agreement |
| AR3r2 | ARM | 100 | 0.85 | 0.84 | 0.04 | 85 | Slight agreement |
| LR1r1 | LRM | 100 | 0.38 | 0.24 | 0.18 | 38 | Slight agreement |
| LR1r2 | LRM | 100 | 0.46 | 0.28 | 0.25 | 46 | Fair agreement |
| LR2r1 | LRM | 97 | 0.44 | 0.25 | 0.26 | 44 | Fair agreement |
| LR2r2 | LRM | 100 | 0.43 | 0.24 | 0.25 | 43 | Fair agreement |
| LR3r1 | LRM | 100 | 0.50 | 0.29 | 0.29 | 50 | Fair agreement |
| LR3r2 | LRM | 100 | 0.49 | 0.30 | 0.28 | 49 | Fair agreement |
| FR1r1 | FRM | 100 | 0.60 | 0.47 | 0.24 | 60 | Fair agreement |
| FR1r2 | FRM | 100 | 0.59 | 0.49 | 0.20 | 59 | Slight agreement |
| FR2R1 | FRM | 100 | 0.53 | 0.44 | 0.16 | 53 | Slight agreement |
| FR2r2 | FRM | 100 | 0.56 | 0.44 | 0.21 | 56 | Fair agreement |
| FR3r1 | FRM | 100 | 0.61 | 0.44 | 0.31 | 61 | Fair agreement |
| FR3r2 | FRM | 100 | 0.63 | 0.44 | 0.34 | 63 | Fair agreement |
| ACR1r1 | ACRM | 100 | 0.32 | 0.26 | 0.08 | 32 | Slight agreement |
| ACR1r2 | ACRM | 100 | 0.38 | 0.25 | 0.18 | 38 | Slight agreement |
| ACR2r1 | ACRM | 97 | 0.35 | 0.24 | 0.15 | 35 | Slight agreement |
| ACR2r2 | ACRM | 100 | 0.36 | 0.24 | 0.16 | 36 | Slight agreement |
| ACR3r1 | ACRM | 100 | 0.50 | 0.29 | 0.29 | 50 | Fair agreement |
| ACR3r2 | ACRM | 100 | 0.51 | 0.30 | 0.30 | 51 | Fair agreement |
| Ratings Under Comparison | # Ratings | Po | Pe | k | %Agreement | Interpretation of Kappa | |||
|---|---|---|---|---|---|---|---|---|---|
| BR1R1 | BR2R1 | BR3R1 | BRM | 100 | 0.53 | 0.34 | 0.28 | 53 | Fair agreement |
| AR1R1 | AR2R1 | AR3R1 | ARM | 100 | 0.88 | 0.77 | 0.49 | 88 | Moderate agreement |
| LR1R1 | LR2R1 | LR3R1 | LRM | 97 | 0.52 | 0.23 | 0.37 | 52 | Fair agreement |
| FR1R1 | FR2R1 | FR3R1 | FRM | 100 | 0.66 | 0.47 | 0.37 | 66 | Fair agreement |
| ACR1R1 | ACR2R1 | ACR2R1 | ACRM | 97 | 0.52 | 0.26 | 0.35 | 52 | Fair agreement |
| BR1R2 | BR2R2 | BR3R2 | BRM | 100 | 0.49 | 0.31 | 0.26 | 49 | Fair agreement |
| AR1R2 | AR2R2 | AR3R2 | ARM | 100 | 0.89 | 0.79 | 0.47 | 89 | Moderate agreement |
| LR1R2 | LR2R2 | LR3R2 | LRM | 100 | 0.53 | 0.25 | 0.38 | 53 | Fair agreement |
| FR1R2 | FR2R2 | FR3R2 | FRM | 100 | 0.68 | 0.47 | 0.37 | 68 | Fair agreement |
| ACR1R2 | ACR2R2 | ACR2R2 | ACRM | 100 | 0.51 | 0.27 | 0.33 | 51 | Fair agreement |
| Variables Under Comparison | Median Values (s) | Results of Normality Test 1 | Results of Comparison Test 2 |
|---|---|---|---|
| TR1r1-TR1r2 | 30.0–24.0 | No, p < 0.001-No, p < 0.001 | Yes, p < 0.001 |
| TR2r1-TR2r2 | 52.5–44.0 | No, p < 0.001-No, p < 0.001 | Yes, p < 0.001 |
| TR3r1-TR3r2 | 19.0–20.0 | No, p < 0.001-No, p < 0.001 | No, p = 0.608 |
| TR1r1-TR2r1 | 30.0–52.5 | No, p < 0.001-No, p < 0.001 | Yes, p < 0.001 |
| TR1r1-TR3r1 | 30.0–19.0 | No, p < 0.001-No, p < 0.001 | Yes, p < 0.001 |
| TR2r1-TR3r1 | 52.5–19.0 | No, p < 0.001-No, p < 0.001 | Yes, p < 0.001 |
| TR1r2-TR2r2 | 24.0–44.0 | No, p < 0.001-No, p < 0.001 | Yes, p < 0.001 |
| TR1r2-TR3r2 | 30.0–20.0 | No, p < 0.001-No, p < 0.001 | Yes, p = 0.003 |
| TR2r2-TR3r2 | 44.0–20.0 | No, p < 0.001-No, p < 0.001 | Yes, p < 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Forkuo, G.O.; Marcu, M.V.; Kaakkurivaara, N.; Kaakkurivaara, T.; Borz, S.A. Human and Machine Reliability in Postural Assessment of Forest Operations by OWAS Method: Level of Agreement and Time Resources. Forests 2025, 16, 759. https://doi.org/10.3390/f16050759
Forkuo GO, Marcu MV, Kaakkurivaara N, Kaakkurivaara T, Borz SA. Human and Machine Reliability in Postural Assessment of Forest Operations by OWAS Method: Level of Agreement and Time Resources. Forests. 2025; 16(5):759. https://doi.org/10.3390/f16050759
Chicago/Turabian StyleForkuo, Gabriel Osei, Marina Viorela Marcu, Nopparat Kaakkurivaara, Tomi Kaakkurivaara, and Stelian Alexandru Borz. 2025. "Human and Machine Reliability in Postural Assessment of Forest Operations by OWAS Method: Level of Agreement and Time Resources" Forests 16, no. 5: 759. https://doi.org/10.3390/f16050759
APA StyleForkuo, G. O., Marcu, M. V., Kaakkurivaara, N., Kaakkurivaara, T., & Borz, S. A. (2025). Human and Machine Reliability in Postural Assessment of Forest Operations by OWAS Method: Level of Agreement and Time Resources. Forests, 16(5), 759. https://doi.org/10.3390/f16050759