
Algorithm for Detecting Trees Affected by Pine Wilt Disease in Complex Scenes Based on CNN-Transformer

 , and
, and 
Abstract
1. Introduction
- (1)
- To construct two high-quality semantic segmentation datasets from distinct terrain areas using different sampling equipment.
- (2)
- To develop an efficient and accurate discolored tree segmentation model (EVitNet) through the innovative integration of a lightweight ViT feature extraction network and a CNN upsampling method.
- (3)
- To identify the optimal fine-tuning strategy that improves the model’s practicality, allowing it to achieve high accuracy with only a small amount of new sample learning.
2. Materials and Methods
2.1. Data Collection
2.2. Data Process
| Pseudocode 1: Generate samples from xml annotation information |
|
2.3. Methods
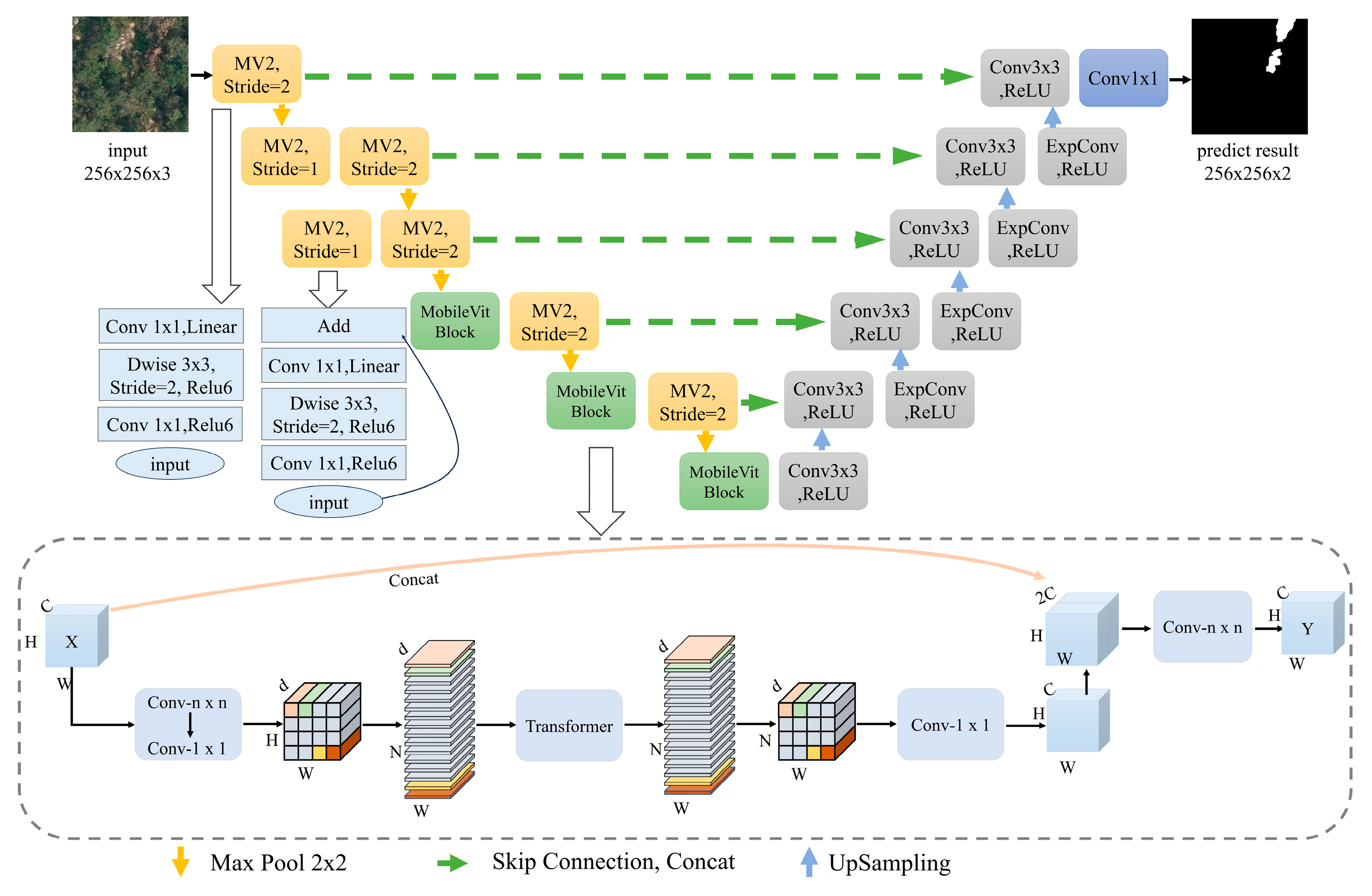
2.3.1. The Semantic Segmentation Model for Discolored Trees, EVitNet
2.3.2. EasyVit Backbone Network
2.3.3. Decoder with Expanded Convolution
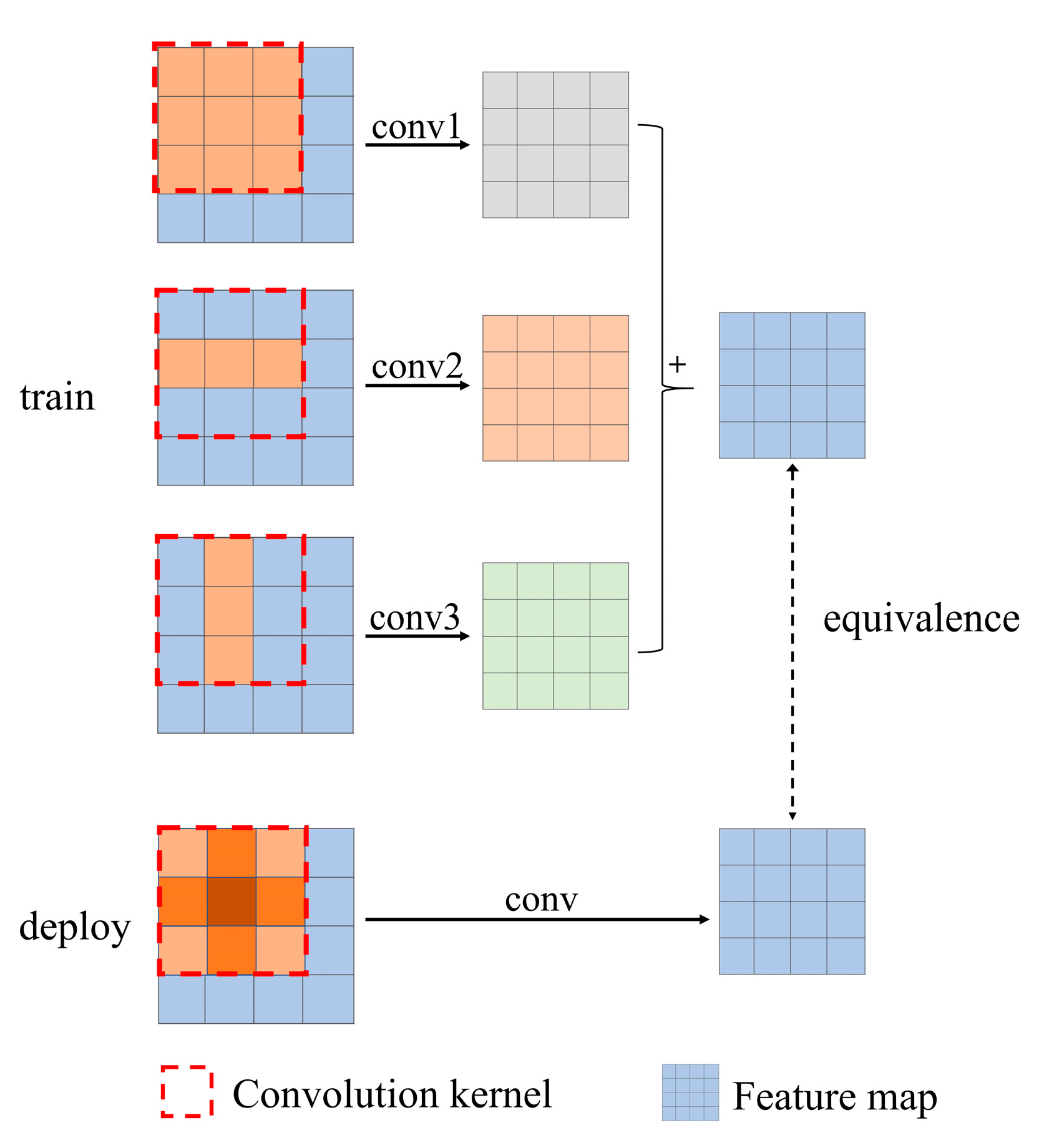
2.3.4. Model Fine-Tuning Method
2.4. Evaluation Metrics
2.5. Experimental Setting
3. Results
3.1. The Problem of Unbalanced Positive and Negative Samples
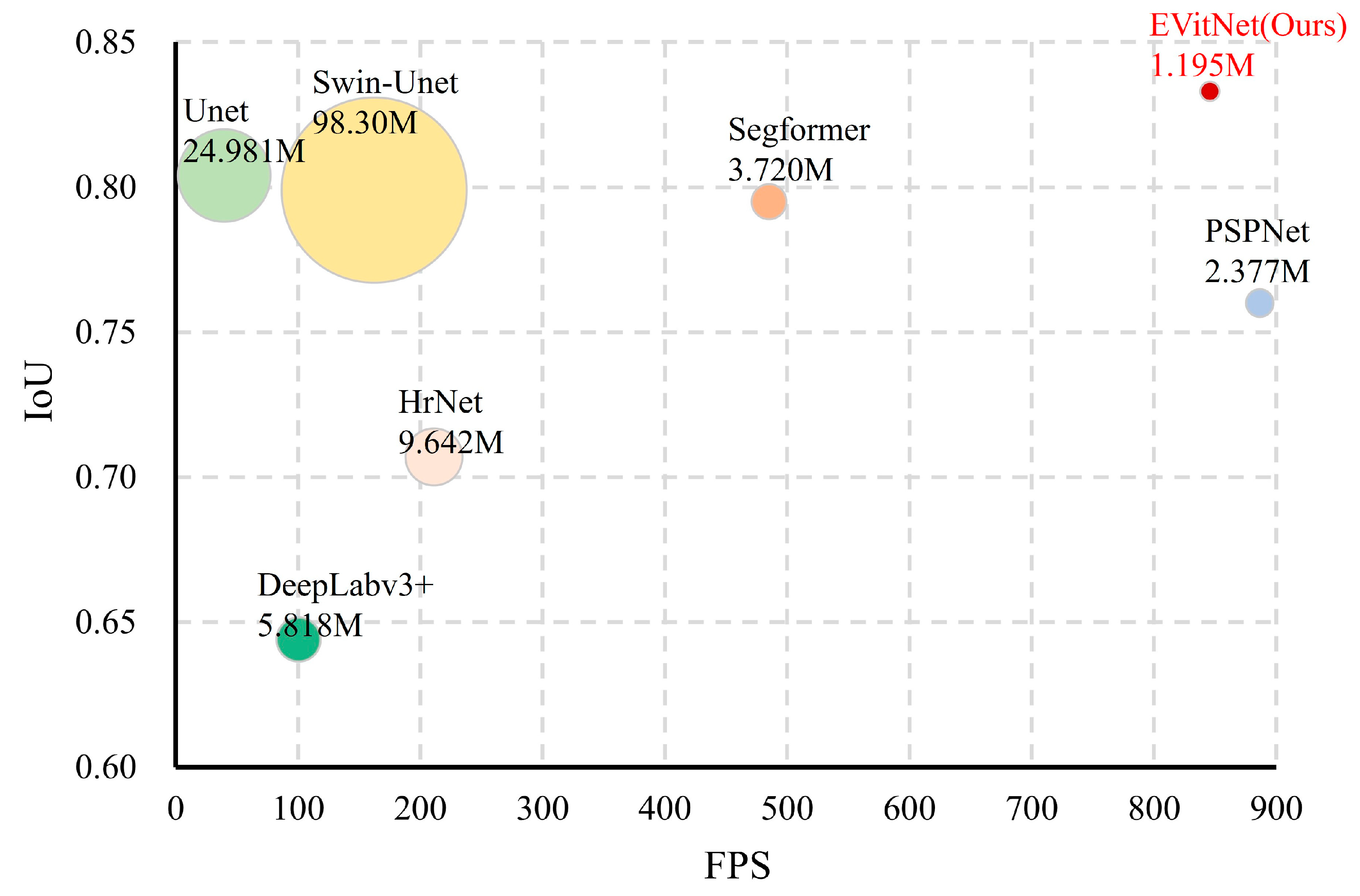
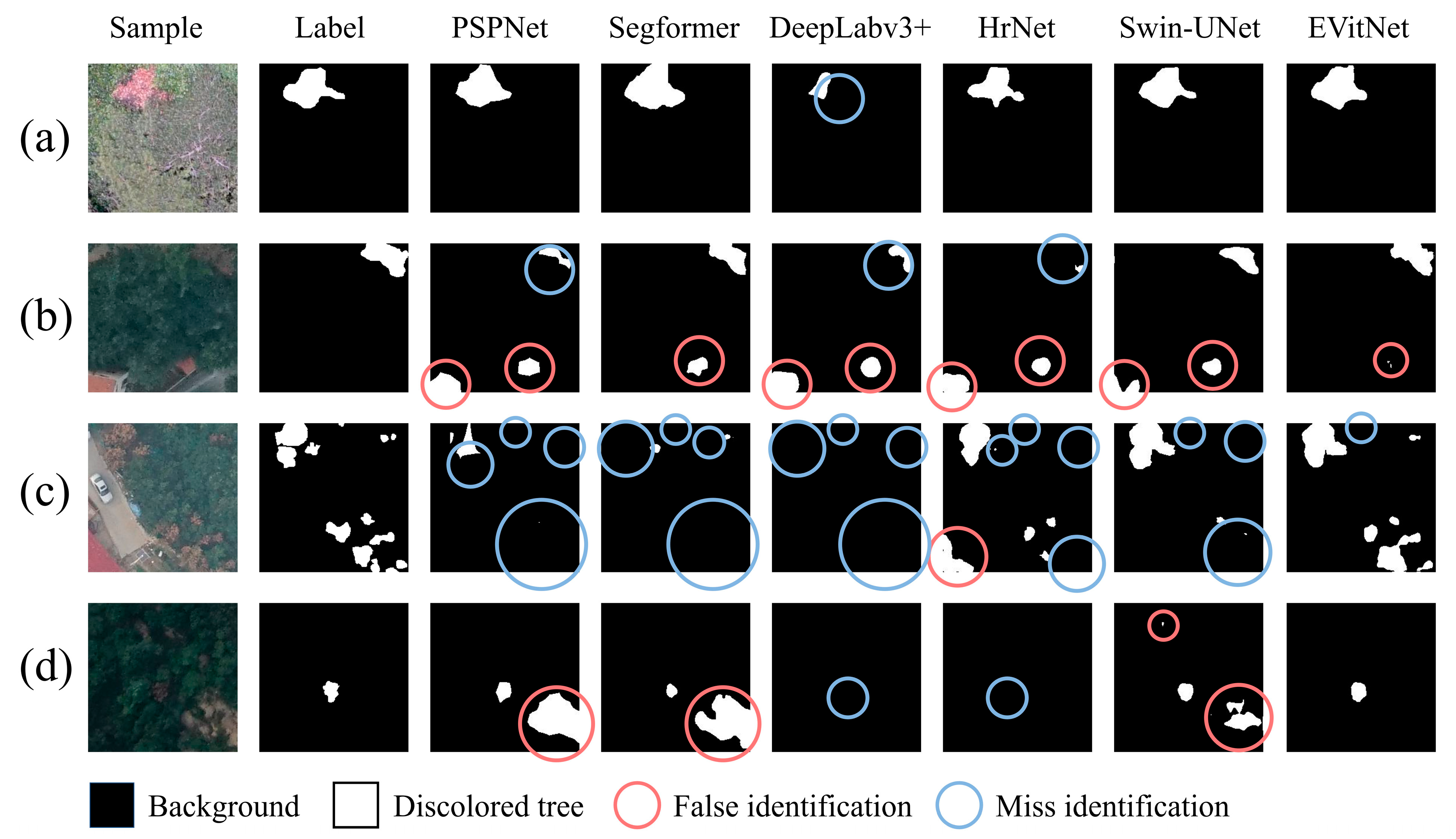
3.2. Comparison of Mainstream Models
3.3. Model Fine-Tuning Study
3.4. Ablation Study
4. Discussions
4.1. Network Performance Analysis
4.2. Advantages and Disadvantages
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DOAJ | Directory of open access journals |
| TLA | Three-letter acronym |
| LD | Linear dichroism |
References
- Fonseca, L.; Silva, H.; Cardoso, J.M.S.; Esteves, I.; Maleita, C.; Lopes, S.; Abrantes, I. Bursaphelenchus xylophilus in Pinus sylvestris—The First Report in Europe. Forests 2024, 15, 1556. [Google Scholar] [CrossRef]
- Hu, G.; Wang, T.; Wan, M.; Bao, W.; Zeng, W. UAV remote sensing monitoring of pine forest diseases based on improved Mask R-CNN. Int. J. Remote Sens. 2022, 43, 1274–1305. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, H.; Wang, J.; Li, D.; Wang, H.; Jiang, Y.; Fei, X.; Sun, L.; Li, F. Research progress on the resistance mechanism of host pine to pine wilt disease. Plant Pathol. 2024, 73, 469–477. [Google Scholar] [CrossRef]
- Zhang, K.; Liang, J.; Yan, D.; Zhang, X. Research Advances of Pine Wood Nematode Disease in China. World For. Res. 2010, 23, 59–63. [Google Scholar]
- Announcement of the National Forestry and Grassland Administration (No. 7 of 2023) (Pine Wood nematode Disease Epidemic Area in 2023). Available online: https://www.forestry.gov.cn/c/www/gkzfwj/380005.jhtml (accessed on 4 November 2024).
- Xie, W.; Wang, H.; Liu, W.; Zang, H. Early-Stage Pine Wilt Disease Detection via Multi-Feature Fusion in UAV Imagery. Forests 2024, 15, 171. [Google Scholar] [CrossRef]
- Li, M.; Li, H.; Ding, X.; Wang, L.; Wang, X.; Chen, F. The Detection of Pine Wilt Disease: A Literature Review. Int. J. Mol. Sci. 2022, 23, 10797. [Google Scholar] [CrossRef]
- Ye, J. Epidemic Status of Pine Wilt Disease in China and Its Prevention and Control Techniques and Counter Measures. Sci. Silvae Sin. 2019, 55, 1–10. [Google Scholar]
- Zhao, J.; Huang, J.; Yan, J.; Fang, G. Economic Loss of Pine Wood Nematode Disease in Mainland China from 1998 to 2017. Forests 2020, 11, 1042. [Google Scholar] [CrossRef]
- Chen, Z.; Lin, H.; Bai, D.; Qian, J.; Zhou, H.; Gao, Y. PWDViTNet: A lightweight early pine wilt disease detection model based on the fusion of ViT and CNN. Comput. Electron. Agric. 2025, 230, 109910. [Google Scholar] [CrossRef]
- Koy, A.; Çolak, A.B. The Intraday High-Frequency Trading with Different Data Ranges: A Comparative Study with Artificial Neural Network and Vector Autoregressive Models. AAES 2023, 2, 123–133. [Google Scholar] [CrossRef]
- Purohit, J.; Dave, R. Leveraging Deep Learning Techniques to Obtain Efficacious Segmentation Results. AAES 2023, 1, 11–26. [Google Scholar] [CrossRef]
- Chiphiko, B.A.; Kim, H.; Ali, P.; Eneya, L. Forward Secrecy Attack on Privacy-Preserving Machine Authenticated Key Agreement for Internet of Things. AAES 2025, 3, 29–34. [Google Scholar] [CrossRef]
- Andreychev, A.V.; Lapshin, A.S.; Kuznetcov, V.A. Techniques for recording the Eagle Owl (Bubo bubo) based on vocal activity. Zool. Zhurnal 2017, 96, 601–605. [Google Scholar] [CrossRef]
- Zhang, M.; Yuan, C.; Liu, Q.; Liu, H.; Qiu, X.; Zhao, M. Detection of mulberry leaf diseases in natural environments based on improved YOLOv8. Forests 2024, 15, 1188. [Google Scholar] [CrossRef]
- Stone, C.; Mohammed, C. Application of Remote Sensing Technologies for Assessing Planted Forests Damaged by Insect Pests and Fungal Pathogens: A Review. Curr. For. Rep. 2017, 3, 75–92. [Google Scholar] [CrossRef]
- Dash, J.P.; Watt, M.S.; Pearse, G.D.; Heaphy, M.; Dungey, H.S. Assessing very high resolution UAV imagery for monitoring forest health during a simulated disease outbreak. ISPRS J. Photogramm. Remote Sens. 2017, 131, 1–14. [Google Scholar] [CrossRef]
- Tao, H.; Li, C.; Zhao, D.; Deng, S.; Hu, H.; Xu, X.; Jing, W. Deep learning-based dead pine tree detection from unmanned aerial vehicle images. Int. J. Remote Sens. 2020, 41, 8238–8255. [Google Scholar] [CrossRef]
- Wang, W.; You, Z.; Shao, L.; Li, X.; Wu, S.; Zhang, Z.; Huang, S.; Zhang, F. Recognition of dead pine trees using YOLOv5 by super-resolution reconstruction. Nongye Gongcheng XuebaoTransactions Chin. Soc. Agric. Eng. 2023, 39, 137–145. [Google Scholar] [CrossRef]
- Ye, X.; Pan, J.; Shao, F.; Liu, G.; Lin, J.; Xu, D.; Liu, J. Exploring the potential of visual tracking and counting for trees infected with pine wilt disease based on improved YOLOv5 and StrongSORT algorithm. Comput. Electron. Agric. 2024, 218, 108671. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, Z.; Rao, Y.; Zheng, J.; Zhang, N.; Wang, D.; Zhu, J.; Fang, Y.; Gao, X. Identification of Pine Wilt Disease Infected Wood Using UAV RGB Imagery and Improved YOLOv5 Models Integrated with Attention Mechanisms. Forests 2023, 14, 588. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2018, arXiv:1411.4038. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 3992–4003. [Google Scholar] [CrossRef]
- Zhu, C.; Xu, Y.; Zhang, M.; Chen, J.; Li, S. Structure Characteristics of Pinus thunbergii Stand in Laoshan Mountain of Qingdao City. For. Inventory Plan. 2019, 44, 33–39. [Google Scholar] [CrossRef]
- Zhou, J.; Xing, S.; Han, C.; Zhang, F.; Zhao, M.; Liu, X. Analysis on Storm Surge Resistant Ability of Different Pine Tree Species. J. Southwest. For. Univ. 2009, 4, 26–28. [Google Scholar] [CrossRef]
- Hao, Z.; Huang, J.; Li, X.; Sun, H.; Fang, G. A multi-point aggregation trend of the outbreak of pine wilt disease in China over the past 20 years. For. Ecol. Manag. 2022, 505, 119890. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Liu, H.; Li, W.; Jia, W.; Sun, H.; Zhang, M.; Song, L.; Gui, Y. Clusterformer for Pine Tree Disease Identification Based on UAV Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2022, arXiv:2110.02178. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2019, arXiv:1801.04381. [Google Scholar]
- Liu, S.; Li, C.; Nan, N.; Zong, Z.; Song, R. MMDM: Multi-Frame and Multi-Scale for Image Demoireing. arXiv 2020, arXiv:1909.11947. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network, in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Zhang, R.; Xia, L.; Chen, L.; Xie, C.; Chen, M.; Wang, W. Recognition of wilt wood caused by pine wilt nematode based on U-Net network and unmanned aerial vehicle images. Trans. CSAE 2020, 36, 61–68. [Google Scholar] [CrossRef]
- Li, H.; Chen, L.; Yao, Z.; Li, N.; Long, L.; Zhang, X. Intelligent Identification of Pine Wilt Disease Infected Individual Trees Using UAV-Based Hyperspectral Imagery. Remote Sens. 2023, 15, 3295. [Google Scholar] [CrossRef]
- Zhi, J.; Li, L.; Zhu, H.; Li, Z.; Wu, M.; Dong, R.; Cao, X.; Liu, W.; Qu, L.; Song, X.; et al. Comparison of Deep Learning Models and Feature Schemes for Detecting Pine Wilt Diseased Trees. Forests 2024, 15, 1706. [Google Scholar] [CrossRef]
- Yu, R.; Luo, Y.; Zhou, Q.; Zhang, X.; Wu, D.; Ren, L. Early detection of pine wilt disease using deep learning algorithms and UAV-based multispectral imagery. For. Ecol. Manag. 2021, 497, 119493. [Google Scholar] [CrossRef]
- Xia, L.; Zhang, R.; Chen, L.; Li, L.; Yi, T.; Wen, Y.; Ding, C.; Xie, C. Evaluation of Deep Learning Segmentation Models for Detection of Pine Wilt Disease in Unmanned Aerial Vehicle Images. Remote Sens. 2021, 13, 3594. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, Y.; Pu, R.; Gonzalez-Moreno, P.; Yuan, L.; Wu, K.; Huang, W. Monitoring plant diseases and pests through remote sensing technology: A review. Comput. Electron. Agric. 2019, 165, 104943. [Google Scholar] [CrossRef]
- Yang, C. Remote Sensing and Precision Agriculture Technologies for Crop Disease Detection and Management with a Practical Application Example. Engineering 2020, 6, 528–532. [Google Scholar] [CrossRef]
- Jiang, M.; Huang, B.; Yu, X.; Zheng, W.; Jin, Y.; Liao, M.; Ni, J. Distribution, Damage and Control of Pine Wilt Disease. J. Zhejiang Sci. Technol. 2018, 6, 83–91. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset A | Dataset B | |
|---|---|---|
| Collection system |  DB-II + Snoy alpha 7 R II |  DJI Phantom 4 Pro |
| Resolution of raw data | 7952 × 5304 | 5472 × 3648 |
| Amount of raw data | 17,000 | 1096 |
| Area | 200 km2 | 0.7 km2 |
| Location | Qingdao, Shandong | Yantai, Shandong |
| Principal species | Pinus densiflora | Pinus densiflora and Pinus thunbergii |
| Training Scheme | IoUdiscoloredtree | IoUbackground | F1 Score | Precision | Recall | Time |
|---|---|---|---|---|---|---|
| original training set | 0.510 | 0.997 | 0.676 | 0.846 | 0.563 | 8.4 h |
| original training set + focal loss | 0.617 | 0.997 | 0.763 | 0.808 | 0.722 | 7.4 h |
| filtered training set | 0.647 | 0.996 | 0.804 | 0.715 | 0.871 | 2.1 h |
| filtered training set + focal loss | 0.668 | 0.997 | 0.802 | 0.797 | 0.807 | 2.0 h |
| Model | Backbone | IoU | F1 Score | Precision | Recall | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| UNet (Baseline) | vgg | 0.669 | 0.800 | 0.793 | 0.808 | 24.981 | 112.918 | 39.81 |
| DeepLabv3+ | mobilenet | 0.472 | 0.645 | 0.588 | 0.715 | 5.818 | 53.026 | 100.45 |
| HrNet | hrnetv2_w18 | 0.561 | 0.711 | 0.783 | 0.651 | 9.642 | 32.948 | 211.19 |
| PSPNet | mobilenet | 0.617 | 0.760 | 0.819 | 0.708 | 2.377 | 6.034 | 886.50 |
| Segformer | Segformer_b0 | 0.655 | 0.786 | 0.812 | 0.768 | 3.720 | 13.696 | 485.17 |
| Swin-Unet | Swin-Unet | 0.665 | 0.799 | 0.817 | 0.781 | 98.30 | 26.33 | 162.43 |
| EVitNet (Ours) | EasyVit | 0.713 | 0.833 | 0.853 | 0.814 | 1.195 | 1.636 | 850.43 |
| Ablation | MobileVit | Mv2 | ExpCov | Fine-Turning | IoU | IoU_B | F1 Score | Precision | Recall | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unet(baseline) | 0.669 | 0.109 | 0.800 | 0.793 | 0.808 | 24.981 | 112.918 | 39.81 | ||||
| Unet+MobileVit | ✓ | 0.687 | 0.211 | 0.816 | 0.819 | 0.812 | 1.331 | 1.937 | 771.76 | |||
| Unet+MobileVit+Mv2 | ✓ | ✓ | 0.709 | 0.297 | 0.830 | 0.835 | 0.825 | 1.195 | 1.636 | 839.28 | ||
| Unet+MobileVit+Mv2+ExpConv(EVitNet) | ✓ | ✓ | ✓ | 0.713 | 0.321 | 0.833 | 0.853 | 0.814 | 1.195 | 1.636 | 850.43 | |
| Unet+MobileVit+Mv2+ExpConv+fine-turning | ✓ | ✓ | ✓ | ✓ | 0.295 | 0.735 | 0. 470 | 0.314 | 0.831 | 1.195 | 1.636 | 845.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Q.; Chen, M.; Shi, H.; Yi, T.; Xu, G.; Wang, W.; Zhao, C.; Zhang, R. Algorithm for Detecting Trees Affected by Pine Wilt Disease in Complex Scenes Based on CNN-Transformer. Forests 2025, 16, 596. https://doi.org/10.3390/f16040596
Wu Q, Chen M, Shi H, Yi T, Xu G, Wang W, Zhao C, Zhang R. Algorithm for Detecting Trees Affected by Pine Wilt Disease in Complex Scenes Based on CNN-Transformer. Forests. 2025; 16(4):596. https://doi.org/10.3390/f16040596
Chicago/Turabian StyleWu, Qiangjia, Meixiang Chen, Hao Shi, Tongchuan Yi, Gang Xu, Weijia Wang, Chunjiang Zhao, and Ruirui Zhang. 2025. "Algorithm for Detecting Trees Affected by Pine Wilt Disease in Complex Scenes Based on CNN-Transformer" Forests 16, no. 4: 596. https://doi.org/10.3390/f16040596
APA StyleWu, Q., Chen, M., Shi, H., Yi, T., Xu, G., Wang, W., Zhao, C., & Zhang, R. (2025). Algorithm for Detecting Trees Affected by Pine Wilt Disease in Complex Scenes Based on CNN-Transformer. Forests, 16(4), 596. https://doi.org/10.3390/f16040596