
Single-Species Leaf Detection against Complex Backgrounds with YOLOv5s

Abstract
1. Introduction
- To address the issue of feature map loss across different channels during the convolutional pooling process due to varying degrees of importance, we propose a backbone network integrated with an adaptive feature extraction module to enhance the representation capability of key leaf characteristic information;
- An improved feature fusion structure is proposed, which enhances the information transfer capabilities between the model’s deep semantic features and shallow contour texture features. This approach prevents the loss of feature information, accelerates detection speed, and improves the accuracy of object detection;
- A boundary box loss function based on angle cost is introduced, which integrates directional information between ground-truth boxes and predicted boxes, thereby enhancing the accuracy of leaf position detection.
2. Materials and Methods
2.1. Datasets
2.1.1. Dataset Acquisition
2.1.2. Data Preprocessing
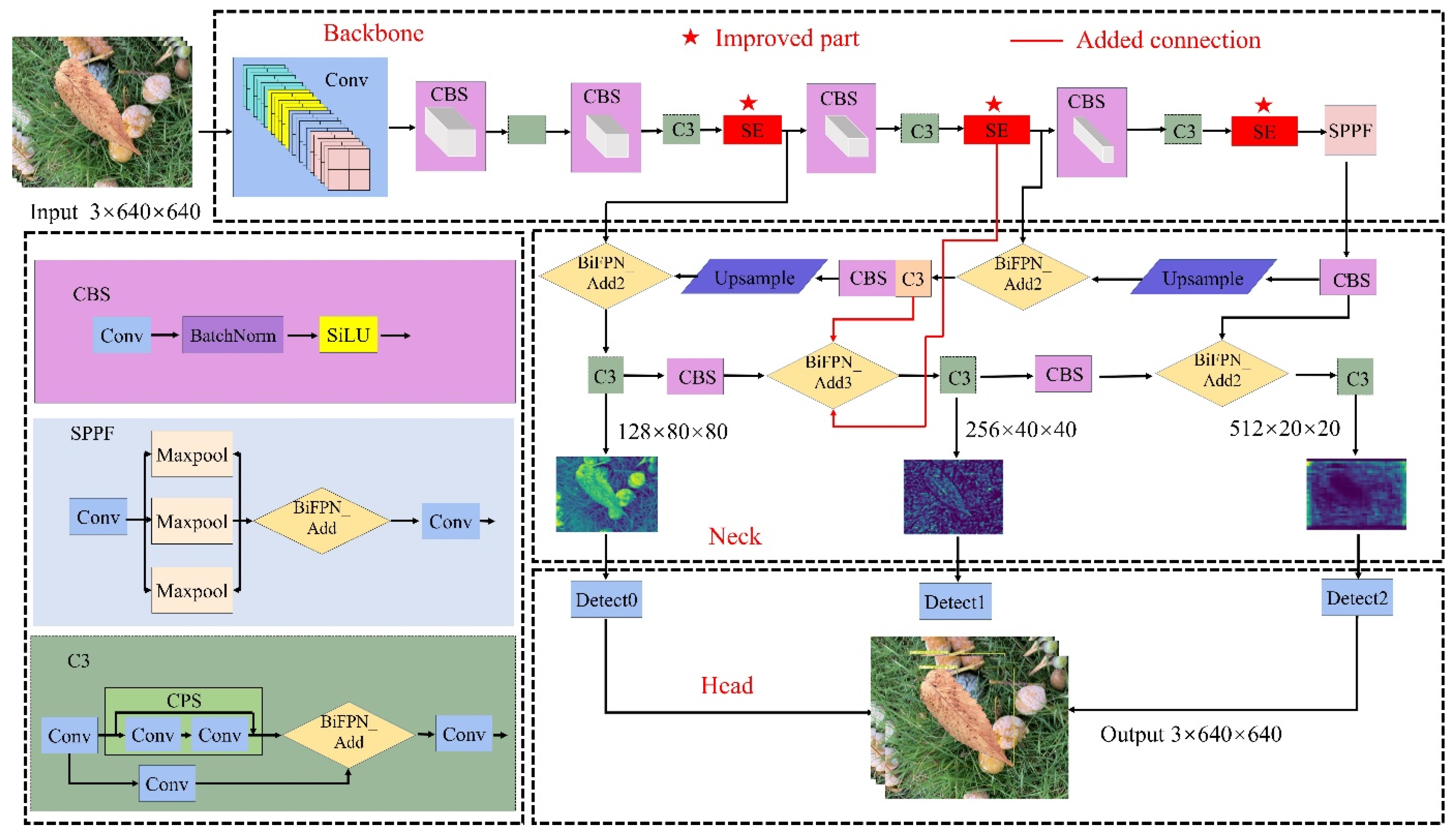
2.2. Model Architecture and Configuration
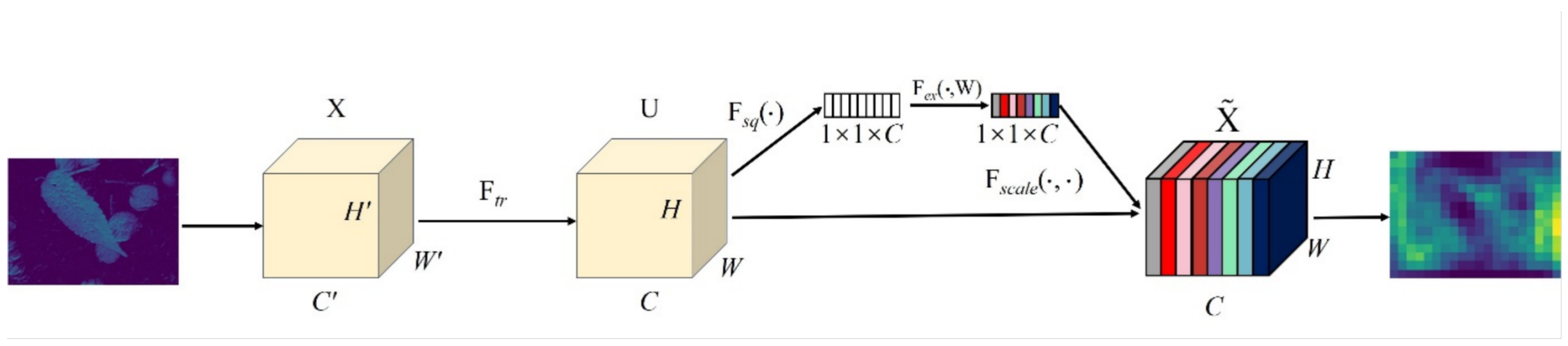
2.2.1. Backbone with SE Modules
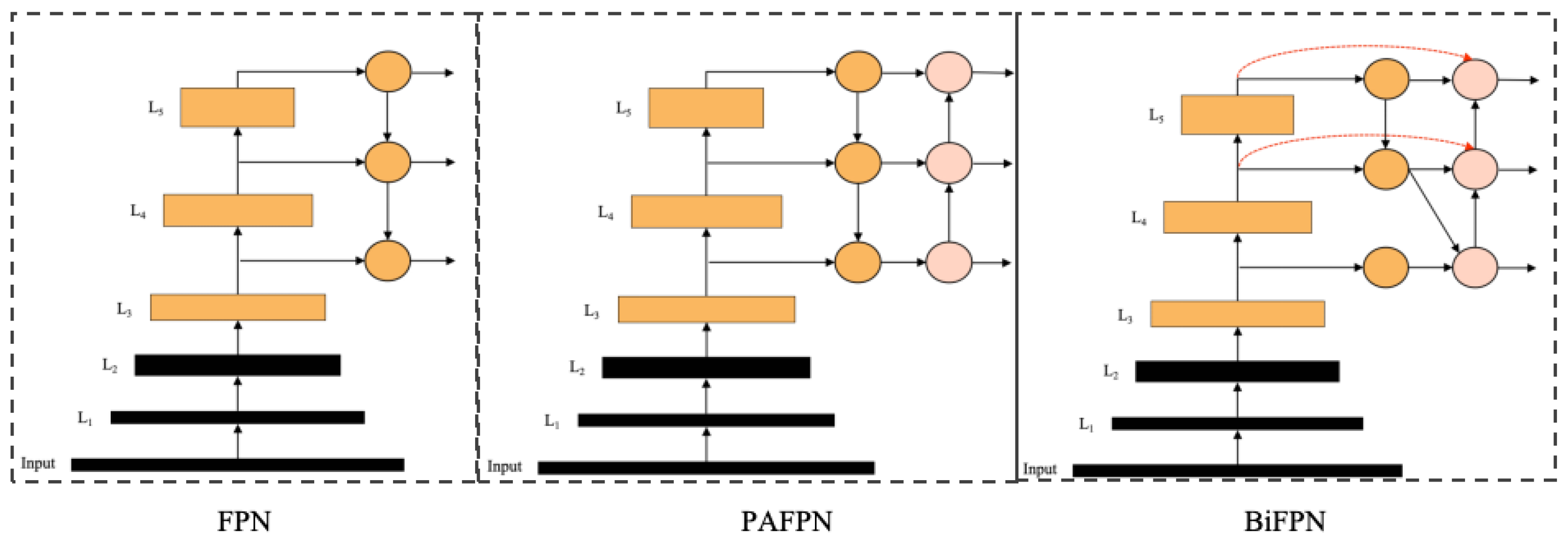
2.2.2. SE-BiFPN Architecture
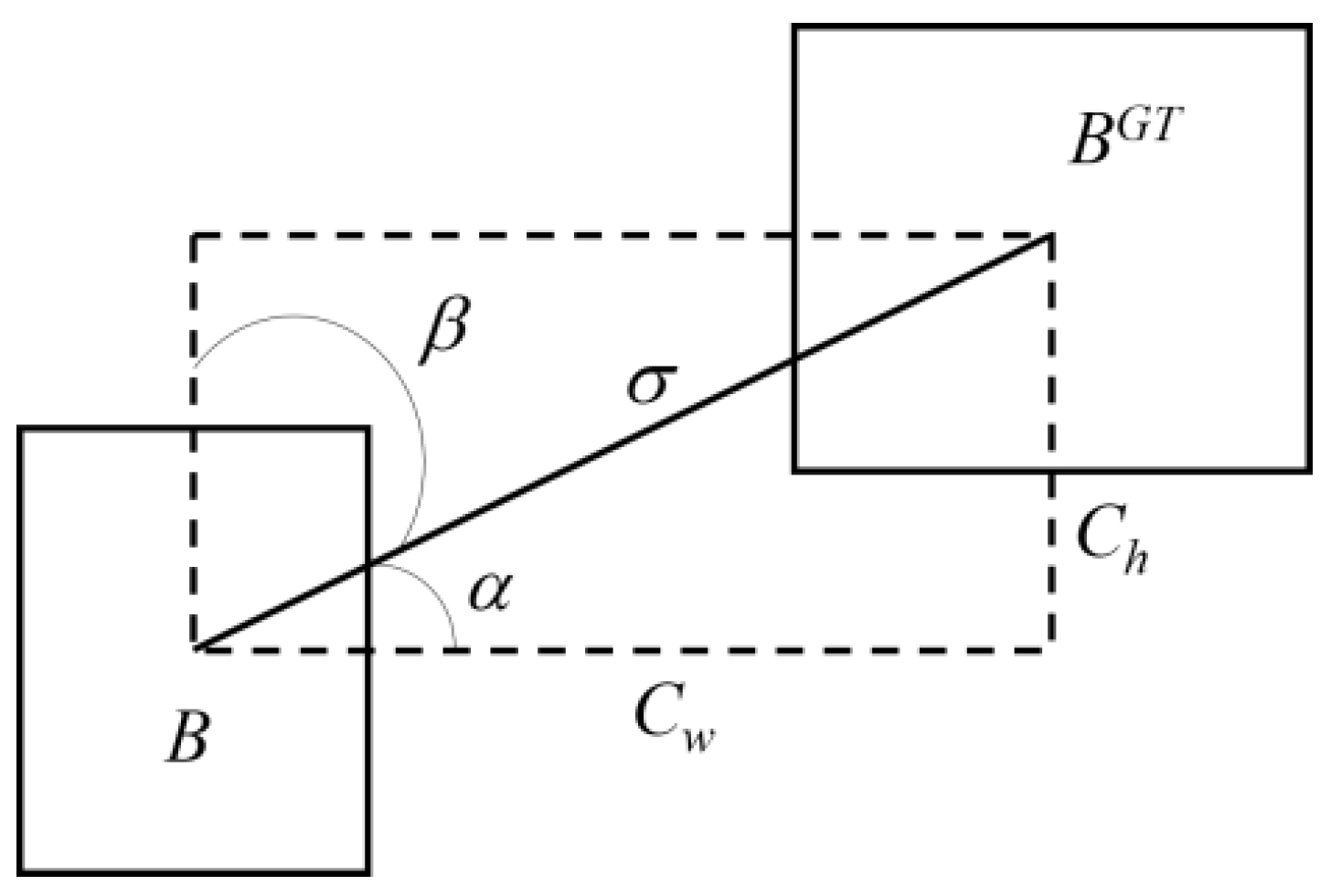
2.2.3. SIoU Loss Function
2.2.4. Experimental Environment
2.2.5. Accuracy Measurements
3. Results and Discussion
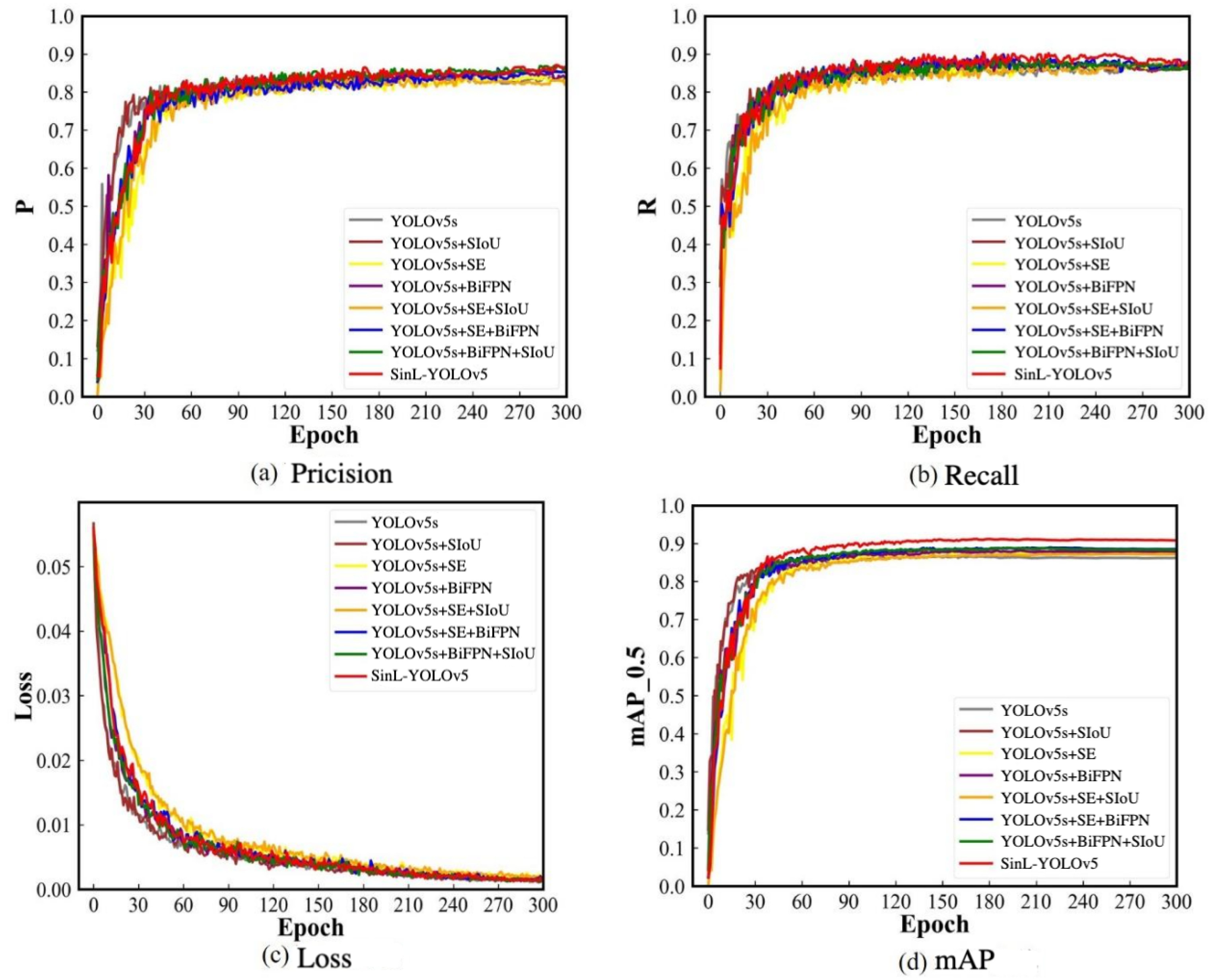
3.1. Model Performance and Ablation Experiment
3.2. Comparative Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jianhui, D.; Jiajian, C.; Shengfa, L. Factors affecting thedisturbance: A review damage and recovery of coastal forest after typhoon. Acta Ecol. Sin. 2024, 44, 1–17. [Google Scholar] [CrossRef]
- McPherson, E.G.; Van Doorn, N.; De Goede, J. Structure, function and value of street trees in California, USA. Urban For. Urban Green. 2016, 17, 104–115. [Google Scholar] [CrossRef]
- Raj, J.N.; Rajeev, J.; Raj, M.J. Contribution of Urban Trees to Offset Carbon Dioxide Emissions from the Transportation Sector in the Ring Road Area of Kathmandu Valley, Central Himalaya. J. Resour. Ecol. 2023, 14, 1272. [Google Scholar] [CrossRef]
- Yanzi, M.; Zongwei, Z.; Hesheng, W.; Wei, D.; Zhongxiang, Z.; Xiaolin, W.; Chunyu, Y.; Yannuo, S. Detection method of fallen leaves on road based on AC-YOLO. Control Decis. 2023, 38, 1878–1886. [Google Scholar] [CrossRef]
- Sachar, S.; Kumar, A. Survey of feature extraction and classification techniques to identify plant through leaves. Expert Syst. Appl. 2021, 167, 114181. [Google Scholar] [CrossRef]
- Xiaolong, Z. Study of Tree Leaf Recognition in Habitat Based on Deep Convolutional Neural Networks. Ph.D. Thesis, Northeast Forestry University, Harbin, China, 2020. [Google Scholar]
- Yonekawa, S.; Sakai, N.; Kitani, O. Identification of idealized leaf types using simple dimensionless shape factors by image analysis. Trans. ASAE 1996, 39, 1525–1533. [Google Scholar] [CrossRef]
- Wang, X.F.; Huang, D.S.; Du, J.X.; Xu, H.; Heutte, L. Classification of plant leaf images with complicated background. Appl. Math. Comput. 2008, 205, 916–926. [Google Scholar] [CrossRef]
- Lei, W.; Dongjian, H.; Yongliang, Q. Plant Leaves Classification Based on Image Processing and SVM. J. Agric. Mech. Res. 2013, 35, 12–15. [Google Scholar]
- Munisami, T.; Ramsurn, M.; Kishnah, S.; Pudaruth, S. Plant leaf recognition using shape features and colour histogram with K-nearest neighbour classifiers. Procedia Comput. Sci. 2015, 58, 740–747. [Google Scholar] [CrossRef]
- Nian, L.; Jiangming, G. Plant leaf identifcation based on the multi-feature fusion and deep belief networks method. J. Beijing For. Univ. 2016, 38, 110–119. [Google Scholar] [CrossRef]
- Longlong, L. Semi-Supervised Clustering and Its Application on Plant Leaf Image Recognition. Ph.D. Thesis, Northwest A&F University, Yangling, China, 2017. [Google Scholar]
- Shanwen, Z.; Yu, S.; Ping, L. A plant recognition method based on global-local feature fusion by canonical correlation analysis. Jiangsu Agric. Sci. 2019, 47, 255–258. [Google Scholar] [CrossRef]
- Leihong, W.; Yongsheng, C.; Yuhong, Z. Automatic ldentification of Elaeagnus L. Based on Leaf Digital Texture Feature. Chin. Agric. Sci. Bull. 2020, 36, 20–25. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; TaoXie; Fang, J.; imyhxy; et al. Ultralytics/yolov5: V7.0—YOLOv5 SOTA Realtime Instance Segmentation; Zenedo: Geneva, Switzerland, 2022. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Shuai, Z.; Yongjian, H. Leaf image recognition based on layered convolutions neural network deep learning. J. Beijing For. Univ. 2016, 38, 108–115. [Google Scholar] [CrossRef]
- Iwata, K. Extending the peak bandwidth of parameters for softmax selection in reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1865–1877. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Jicheng, L.; Xiaobin, Y.; Daoxing, L.; Yixiang, S.; Senlin, Z. High similarity blade image recognition method based on HOG-CNN. Comput. Era 2019, 53–56. [Google Scholar] [CrossRef]
- Zhe, X. Design and Analysis of Crop Leaf Recognition System Based on Deep Learning. Master’s Thesis, Jilin University, Changchun, China, 2019. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- Wu, S.G.; Bao, F.S.; Xu, E.Y.; Wang, Y.X.; Chang, Y.F.; Xiang, Q.L. A leaf recognition algorithm for plant classification using probabilistic neural network. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology, Giza, Egypt, 15–18 December 2007; pp. 11–16. [Google Scholar]
- Kumar, N.; Belhumeur, P.N.; Biswas, A.; Jacobs, D.W.; Kress, W.J.; Lopez, I.C.; Soares, J.V. Leafsnap: A computer vision system for automatic plant species identification. In Proceedings of the Computer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 502–516. [Google Scholar]
- Söderkvist, O. Computer Vision Classification of Leaves from Swedish Trees. Professional Degree, Linköping University, Linköping, Sweden, 2001. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Li, S.; Zhang, S.; Xue, J.; Sun, H. Lightweight target detection for the field flat jujube based on improved YOLOv5. Comput. Electron. Agric. 2022, 202, 107391. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Quantity | Class | Quantity |
|---|---|---|---|
| Acer palmatum | 1900 | Styphnolobium japonicum | 1835 |
| Liriodendron chinense | 897 | Celtis sinensis | 1180 |
| Salix babylonica | 1286 | Aesculus chinensis | 2245 |
| Koelreuteria paniculata | 1326 | Zelkova serrata | 1820 |
| Model | Width | Depth | Params (M) | Size (MB) |
|---|---|---|---|---|
| YOLOv5n | 0.25 | 0.33 | 1.90 | 3.90 |
| YOLOv5s | 0.50 | 0.33 | 56.80 | 14.10 |
| YOLOv5m | 0.75 | 0.67 | 64.10 | 40.80 |
| YOLOv5l | 1.00 | 1.00 | 67.30 | 89.40 |
| YOLOv5x | 1.25 | 1.33 | 68.90 | 167.00 |
| Project | Value |
|---|---|
| Momentum | 0.95 |
| Weight decay | 0.0005 |
| Batch size | 16 |
| Workers thread | 12 |
| Initial learning rate | 0.01 |
| Final learning rate | 0.1 |
| Epochs | 300 |
| Thresh | 0.5 |
| Image size | pixels |
| Model | FLOPs (G) | Params (M) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Size (MB) |
|---|---|---|---|---|---|
| YOLOv5s | 15.80 | 7.03 | 86.10 | 74.30 | 14.40 |
| YOLOv5s + SIoU | 15.80 | 7.03 | 87.70 | 75.90 | 14.40 |
| YOLOv5s + SE | 16.90 | 7.88 | 87.60 | 73.70 | 14.40 |
| YOLOv5s + BiFPN | 16.40 | 7.18 | 87.90 | 74.70 | 14.70 |
| YOLOv5s + SE + SIoU | 16.90 | 7.88 | 87.10 | 73.00 | 16.10 |
| YOLOv5s + SE + BiFPN | 16.90 | 7.70 | 88.50 | 74.60 | 15.70 |
| YOLOv5s + SIoU + BiFPN | 16.40 | 7.18 | 88.40 | 75.20 | 14.70 |
| SinL-YOLOv5 | 16.90 | 7.70 | 90.80 | 76.90 | 15.70 |
| Model | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | FPS | Size (MB) |
|---|---|---|---|---|---|---|
| SSD | 66.13 | 65.72 | 65.88 | 54.10 | 74 | 91.60 |
| YOLOv3 | 66.82 | 67.06 | 67.51 | 60.60 | 55 | 236.00 |
| YOLOv4 | 80.77 | 65.16 | 71.52 | 63.70 | 43 | 244.00 |
| EfficientDet | 86.30 | 69.64 | 77.65 | 57.00 | 36 | 15.00 |
| Faster R-CNN | 84.85 | 80.48 | 84.59 | 71.10 | 10 | 108.00 |
| YOLOv5s | 83.60 | 86.30 | 86.10 | 74.30 | 62 | 14.40 |
| SinL-YOLOv5 | 86.50 | 87.50 | 90.80 | 76.90 | 82 | 15.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Su, X.; Mao, S. Single-Species Leaf Detection against Complex Backgrounds with YOLOv5s. Forests 2024, 15, 894. https://doi.org/10.3390/f15060894
Wang Z, Su X, Mao S. Single-Species Leaf Detection against Complex Backgrounds with YOLOv5s. Forests. 2024; 15(6):894. https://doi.org/10.3390/f15060894
Chicago/Turabian StyleWang, Ziyi, Xiyou Su, and Shiwei Mao. 2024. "Single-Species Leaf Detection against Complex Backgrounds with YOLOv5s" Forests 15, no. 6: 894. https://doi.org/10.3390/f15060894
APA StyleWang, Z., Su, X., & Mao, S. (2024). Single-Species Leaf Detection against Complex Backgrounds with YOLOv5s. Forests, 15(6), 894. https://doi.org/10.3390/f15060894