1. Introduction
Land is a fundamental element for human survival and serves as a crucial foundation for social and economic development. Land is closely related to the human living environment and crop production, and yet it is also closely related to most of the pressing challenges facing mankind [
1,
2,
3]. The gradual development of remote sensing technology makes it play an increasingly important role in the fields of environmental monitoring, geological exploration, precision agriculture, and land cover mapping [
4,
5,
6,
7,
8,
9]. Among these applications, land cover classification, which is a vital component of remote sensing technology, has always been a prominent area of research and a challenging task in extracting valuable information from remote sensing images. How to recognize different features and classify them with high accuracy using remote sensing images, as well as the statistics of various types of feature information, is a key concern in the field.
In the past decades of research, scholars have studied and discussed various types of supervised classification models. These models include the maximum likelihood (ML) [
10,
11], support vector machine (SVM) [
12], and random forest(RF) [
13,
14]. In this case, the maximum likelihood method is based on the assumption that the statistical distribution of each category conforms to a normal distribution, and classification is achieved by calculating the likelihood that an input pixel belongs to a particular category. Support vector machine (SVM) is a supervised classification model that has been widely used in various applications with great success. In the classification of multispectral images, support vector machine has been proved an effective method. The model separates the data by investigating the optimal classification decision hyperplane, making it possible to better divide the training samples in a high-dimensional feature space. Random forest is a supervised classification model based on multiple decision trees. The model obtains the final prediction by randomly sampling the input spectral pixel sequences generating multiple decision trees and then combining the outputs of these decision trees through a voting mechanism. However, with the wide application of various multispectral or high-resolution remote sensing satellite image products, the classification accuracy of the traditional methods needs to be improved. To get around this problem, a deep learning approach was used for land cover classification.
Deep learning methods have significantly enhanced the capabilities of land cover classification by excelling in feature learning and prediction. Compared to traditional methods, deep learning techniques are capable of extracting more complex structural features from the data and possess superior feature selection and data noise processing capabilities. Particularly in recent years, deep learning has developed more and more rapidly, and it has become the mainstream method for land cover classification [
15,
16,
17]. Among these methods, the backpropagation (BP) neural network, a widely adopted artificial neural network, has demonstrated excellent performance in remote sensing classification. B. Ahmed et al. [
18] used the spectral and texture features of high-resolution images of Beijing as inputs to a BP neural network and used a backpropagation neural network (BPNN) to find a set of weights that minimized the error, thus completing the training of the network and obtaining classification results. Semantic segmentation is the segmentation of an entire remote sensing image by pixel-level classification, where each pixel is assigned to a different category. This method can extract the classification result for each pixel in the image [
19]. U-Net [
20] is a classical network architecture for dealing with semantic segmentation problems, which was initially widely used in the field of biomedical images. In recent years, U-Net and its variants have also been gradually used for land cover classification tasks due to their ability to achieve better segmentation results with relatively less data and in a shorter time. Stoian A et al. [
21] proposed FG-Unet, a network architecture specialized in processing sparsely annotated data and maintaining high-resolution image output, which was successfully used for land cover classification tasks in the Mediterranean region. Zhang P et al. [
22] proposed a model called Asp-Unet that consists of contraction paths with high-level features and generates high-resolution outputs by creating expansion paths. The model used the pyramid pooling (Aspp) technique for multi-scale feature fusion at the bottom layer to generate discriminative features. Chen S et al. [
23] enhanced the conventional U-Net semantic segmentation network by replacing the original U-Net convolution unit with a residual convolution module. This modification increased the network’s depth and improved its segmentation performance, especially for small target categories.
Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are widely used deep learning models in remote sensing data classification, and they have achieved good results in this field. Convolutional neural networks (CNNs) can learn and extract advanced spatial features efficiently due to their multi-layer feature extraction capability [
24]. Ce Zhang et al. [
25] came out with a new convolutional neural network (OCNN) specifically applied to land use, whose functional unit is object-based segmentation. In addition, Hu et al. [
26] proposed a 1D-CNN network for hyperspectral data classification, whose structure contains an input layer, a convolutional layer, a max-pooling layer, and a fully connected layer. To improve classification accuracy, researchers have also developed variant CNN structures, including 2D-CNN and 3D-CNN. Although CNN can extract spectral information and semantic features from satellite images, 1D-CNN can only handle one-dimensional sequence data and cannot deal with time series features. Thus, these new CNN variants can better handle multidimensional data and improve classification accuracy. Lu Y et al. [
27] presented a hybrid 2D and 3D CNN model, which firstly utilizes multiple 3D-CNN modules to extract spatiotemporal features and downscale the output feature sequence. Then, the downscaled features are used as inputs to the 2D-CNN module, and, finally, the fully connected layer is used to predict the class of the feature. Thus far, 2D-CNN cannot extract time-scale information, while 3D-CNN is computationally complex with a much larger number of parameters [
28].
Recurrent neural networks (RNNs) have great applications in processing time series data in multispectral remote sensing images. R. Hang et al. [
29] designed a backbone network consisting of two RNN layers. The first RNN layer efficiently reduces redundant information in adjacent spectral bands, simplifying the spectral feature information to be fed into the second RNN layer for feature complementation. With the advancement of RNNs, novel variants such as long short-term memory (LSTM) and gated recurrent unit (GRU) have been introduced to tackle the gradient vanishing problem and capture long-term dependencies. Feng Q et al. [
30] designed a bi-directional LSTM model to obtain spatio-temporal sequence features in UAV images. This model stacks two LSTMs, inputs the hidden states of the first LSTM to the second LSTM, and, in this way, fully understands the long-term dependencies between sequence signals. Erting Pan et al. [
31] proposed a hyperspectral image classification model based on a single-gate recursive unit (GRU), which realizes the simultaneous computation and unfolding of spatial–spectral features through a single GRU to improve computational efficiency and avoid the use of complex models. The GRU is a simplified structure of the LSTM network, which is more concise.
A single model may not be able to fulfill multiple tasks simultaneously when used independently [
32]. For example, most convolutional neural networks (CNNs) are based on convolutional operators only for spatial feature extraction and cannot utilize pixel information about spatial correlations between pixels. To further improve the accuracy of land cover classification, many scholars have proposed a combined modeling approach in the last few years. Zhao W et al. [
32] proposed a combined model architecture based on a CNN and RNN, in which a CNN is utilized to extract robust features from SAR noisy data, while an RNN is used to establish the relationship between optical information and SAR to achieve the goal of agricultural monitoring. Cao et al. [
33] utilized a CNN to extract the height–depth features of ships, which were then passed to SVM for automatic identification of ships. Yan C et al. [
34] presented a classification framework fusing 2D-CNN and Transformer, with 2D-CNN as the input to Transformer, to further improve the classification accuracy of pixel sequences and complete the distribution of features in the eastern part of Changxing County, Zhejiang Province.
Prior studies have indicated that many deep learning algorithms adopt a patchwise approach for land cover classification in remote sensing images [
35]. Nevertheless, the patchwise method is not completely accurate in low-resolution remote sensing image data [
36]. This method takes each center pixel as the basis for deciding whether the surrounding pixels belong to the same category or not, and its precision will affect the classification results directly. Recently, researchers and scholars have more often selected multispectral satellite data with higher resolutions, such as the Landsat-8 satellite data with a 30 m resolution and the Sentinel-2 satellite data with a 10 m resolution, as open satellite data sources for the realization of land cover classification. Resolution refers to the actual ground area represented by each pixel, and a higher resolution provides more details about the land cover, resulting in more accurate and finer feature classification results. Nonetheless, a higher resolution also results in more complex computational requirements, necessitating the selection of appropriate resolution satellite imagery. While some unpublished hyperspectral data might have higher resolutions, they are unlikely to be practical for most scientific research due to the high cost of data collection. To get around this problem, we can choose a suitable mathematical method to turn 1D pixel spectral sequences into 3D spectral feature matrices to fit most 2D-CNN models, increasing the applicability of the model and enabling pixel-level classification. Meanwhile, this method avoids the overfitting problem of 3D-CNN caused by too many parameters.
Previously, several researchers and scholars have been concerned about classification models with the combination of a CNN and RNN. Liu Q et al. [
37] proposed a classification model combining a CNN and LSTM to classify three publicly available hyperspectral datasets. The CNN was used to replace the fully connected part of the LSTM for spatial feature pixel block extraction, and the unfolded 3D matrix spectral information was sequentially fed into the bidirectional cyclically connected Bi-CLSTM network. Wu H and Prasad S [
38] used a convolutional recurrent neural network (CRNN) for the classification of hyperspectral datasets. The architecture used 1D-CNN to extract features from the input sequence, and subsampling using max-pooling reduced the length of the features to half their original length, which forms the convolutional layer. The RNN part extracted the contextual information from the feature information of the previous convolutional layers, and the classification of hyperspectral images is achieved by the fusion of several convolutional layers and several recurrent layers. For 10 m resolution Sentinel-2 images, a pixel block may contain pixels of multiple classes, so the use of pixel blocks to extract feature information is not conducive to accurate classification for Sentinel-2 multispectral remote sensing data. The capability of 1D-CNN to extract spatial feature information is slightly less than that of 2D-CNN, which is more effective in capturing the spatial feature information required in classification tasks [
39]. In the conventional combined CNN and RNN model, feature extraction is mainly focused on the convolutional layer of the CNN and the output layer of the RNN, which might lose some feature details.
In summary, this paper proposes a network framework called HCRNN consisting of a 2D-CNN module and four parallel RNN structures for pixel-level classification of multispectral images. Firstly, the original 13-band information of Sentinel-2 is adjusted to a 1D multispectral sequence by using the fully connected layer and reshaped to the 3D multispectral feature matrix. Secondly, extracting the 2D-CNN features of each convolutional layer as inputs to the corresponding recurrent layer of the RNN captures spatial and temporal features in more detail and adapts the feature information of each convolutional layer to the same convolutional size. Finally, the feature information of the four levels is added and fused to obtain the classification results of the image data.
The contribution of this paper to the literature is reflected in the following three areas:
(1) A multispectral remote sensing image classification model fusing a CNN and RNN is proposed. The model extracts features from the four levels of the CNN as inputs to the RNN, enabling the architecture to deliver more effective feature information to deeper levels and improve classification accuracy.
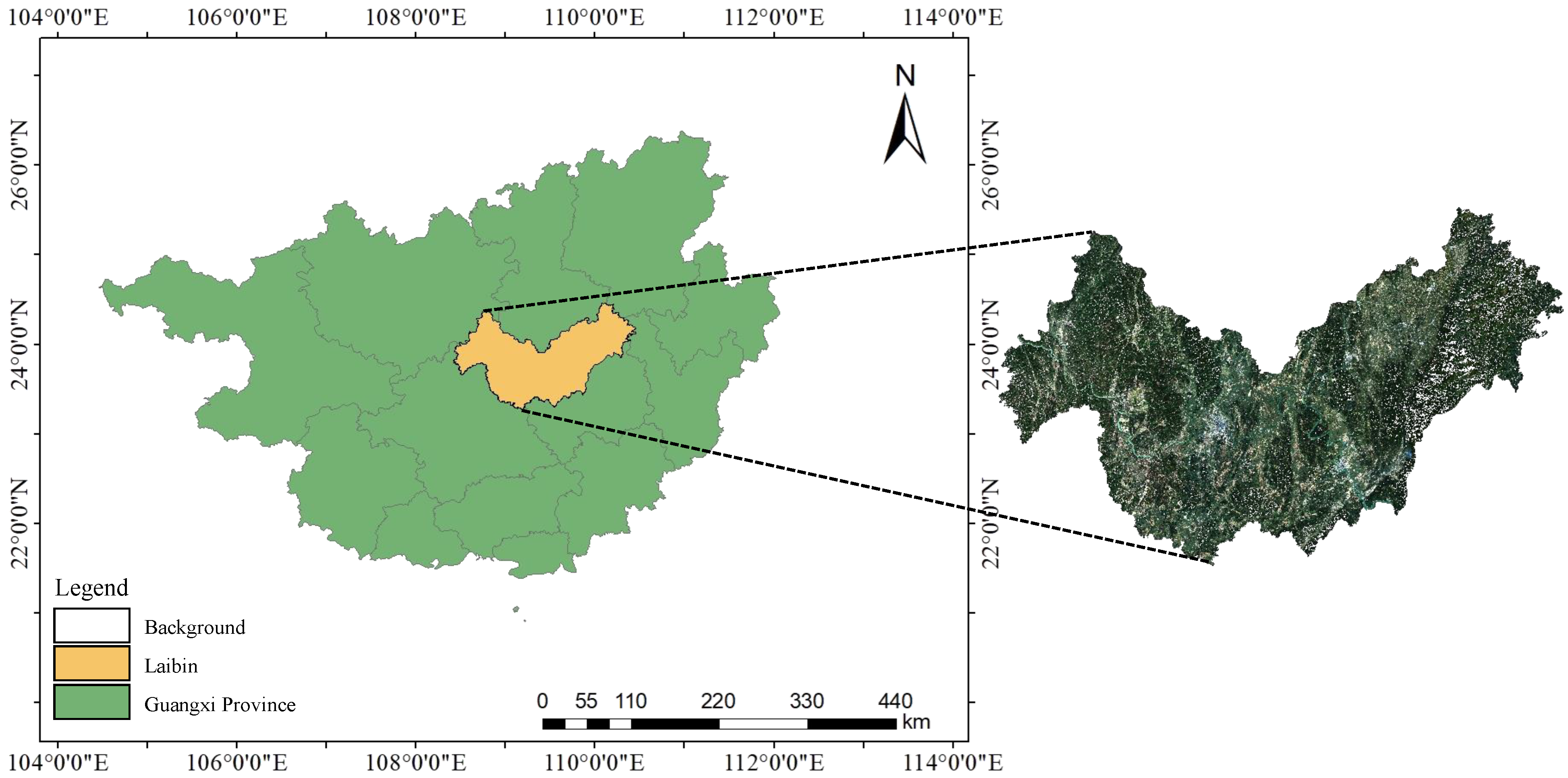
(2) Land cover in Laibin City, Guangxi Zhuang Autonomous Region, is classified using 10 m resolution public optical satellite images, and three public hyperspectral datasets are selected to test the generalizability of the classification model.
(3) The Forest, Sugarcane, and Rice areas of Laibin City, Guangxi Zhuang Autonomous Region, the study area, are taken as the focused areas for land use analyses.
The structure of this paper is shown as follows:
Section 2 describes the study area and the data;
Section 3 introduces the land cover classification algorithm proposed in this paper, the HCRNN;
Section 4 consists of analyzing the experimental results and comparing them with various methods; and
Section 5 presents the conclusions of this paper and the outlook for future work.
3. Research Methods
The workflow of the method included the following steps: (1) preprocessing of the Sentinel-2 data, which focused on processing the raw data with corrections, radiometric corrections, atmospheric corrections, and geometric corrections to make the data more accurate and usable (please refer to
Section 2.1 for details); (2) production of sample library data, which selected a certain number of areas with known land cover types, collected and labeled within these areas, and constructed the sample library data used to train the model (please refer to
Section 2.1 for details); (3) training the model, using the CNN as a front-end to receive spectral information, and the RNN was responsible for processing and predicting the feature information output from CNN; and (4) prediction to realize the land cover-type images of Laibin City, Guangxi Zhuang Autonomous Region.
The structure of the HCRNN neural network proposed in this paper is shown in
Figure 2, which achieves the pixel-level classification of multispectral remote sensing images by fusing the CNN and RNN modules. Firstly, the original 13-band information of Sentinel-2 is adjusted to the 1D multispectral sequence using the fully connected layer and reshaped into a 3D multispectral feature matrix. The 2D-CNN structure, consisting of four convolutional layers, is designed to extract multi-scale feature information and generate higher-level, robust feature representations. The size of the input features is adjusted using the stride size to capture deeper feature information. Then, the extracted 2D-CNN spatial feature information at each level was input into the corresponding RNN structure, which consisted of two GRU units. To facilitate the following information fusion operation and to avoid overfitting, the global average pooling is used to adjust the 2D-CNN feature information at each level to the same convolution size before inputting the spectral–spatial feature information of the 2D-CNN into the RNN. The RNN is more sensitive to time series information, so the structure that contains four parallel RNNs can utilize the feature information generated by each convolutional layer to extract the contextual information among them, and capture the dependencies between different bands in multispectral images, thus making the classification task more stable and effective. Finally, the pixel superposition of the four levels of feature information through the add operation enriches the amount of information under the image features and realizes the fusion summation of the features, and then the fused features are processed by the activation function ReLU and sent to the MLP Head for classification, which achieved the high-precision pixel-level multispectral remote sensing image classification. The ReLU introduced the nonlinearities as the activation function. The network structure makes full use of the advantages of CNNs and RNNs to better mine time series information as well as spatial features in spectral data.
3.1. Recurrent Neural Network
The recurrent neural network (RNN) has become a popular method for processing sequence data and is distinct from the feedforward neural network in that the RNN is able to use recurrent edges to connect the neurons to themselves, which allows the probability distributions of the sequence data to be modeled at different time steps [
41].
Figure 3 shows the classical recurrent neural network (RNN) structure.
In multispectral image classification, give a sequence data
, and include among these
,
. In general, the information at moment
t is denoted as the input vector
, and the output of the hidden layer at the
time step is denoted as
. The output of the hidden layer can be calculated using the following formula:
The
in Equation (
1) denotes the hidden state of the current time step,
denotes the input of the current time step,
w is the weight matrix from the input to the hidden state,
is the weight matrix from the hidden state of the previous time step to the hidden state of the current time step, and
is the bias vector.
The output layer can be represented as:
The
v in Equation (
2) is the weight matrix, and
is the bias vector.
The RNN encountered the long-term dependency problem, i.e., it is difficult to train and process long-term sequential data because the gradient fades away as it propagates over time. To solve this problem, the LSTM [
42] and GRU [
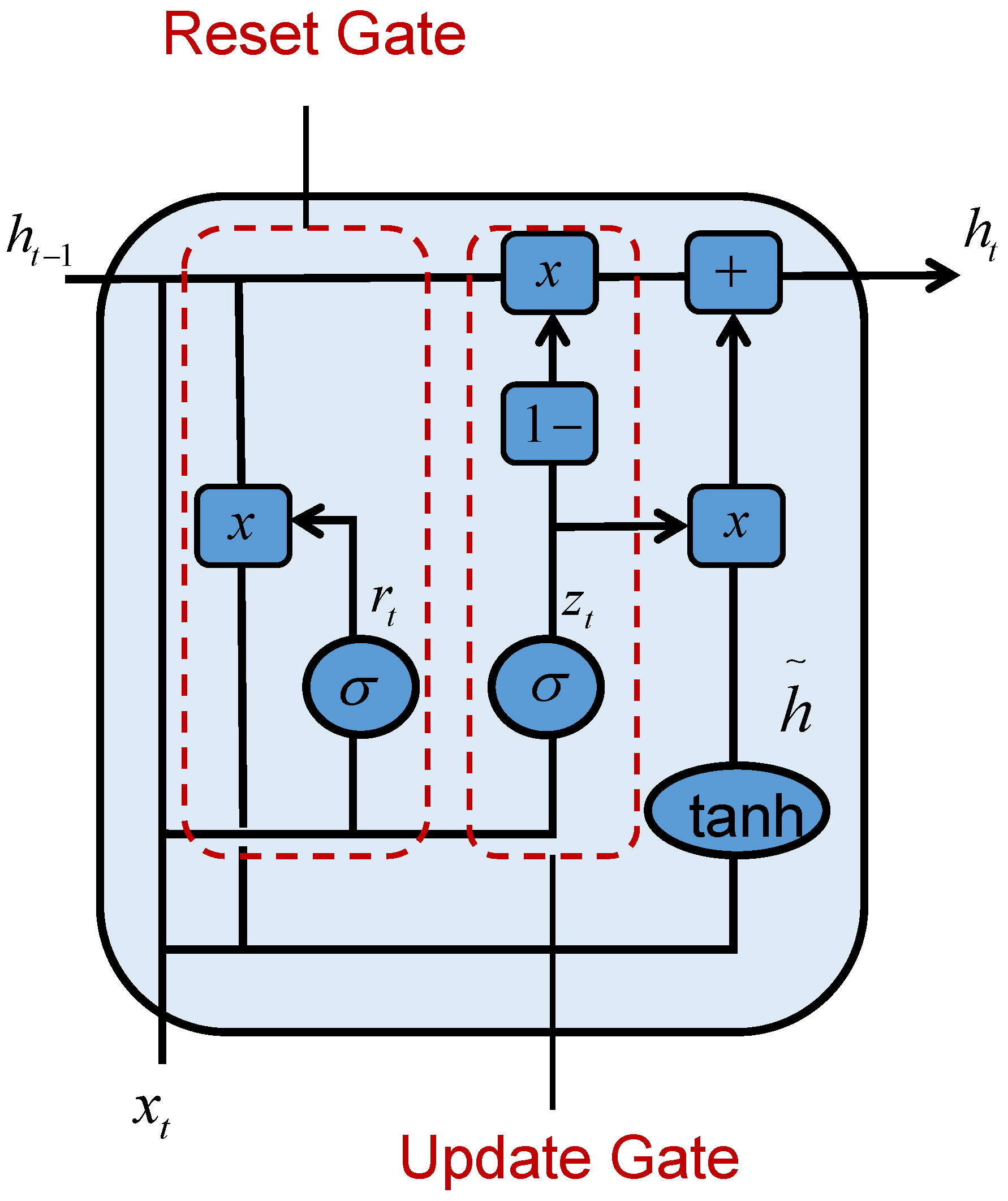
43] were proposed. In comparison to the LSTM, the GRU has fewer parameters and can be trained faster or requires fewer data to generalize. Therefore, we choose the GRU to constitute the RNN module in our proposed framework. We can overcome the problem of vanishing gradient by using the GRU while reducing model complexity and training time. The RNN used in the experiments of this paper is composed of two GRU recurrent layers. The structure of the GRU is shown in
Figure 4.
For the pixel-level input of the multispectral images, each pixel point in the image data is taken as an input in the form of
. The spatial feature vector of the image extracted by the 2D-CNN is taken as the hidden state of the previous time step of
together with
as the input to the GRU, thus realizing the pixel-level classification of multispectral images. The expressions for the reset gate and update gate are as follows:
where
represents the logistic sigmoid function;
,
,
, and
are the weight matrices; and
,
represent the bias vectors in the neural network.
is denoted as
vectors in the pixel-level classification of multispectral images;
s is the number of wavebands; and, in this paper’s experiments, we have chosen the number of wavebands to be 13, i.e.,
.
The formula for calculating the candidate’s hidden state is:
In Equation (
5),
represents the hyperbolic tangent function,
,
are the weight matrices, and
represents the bias vector. This part integrates the spectral feature information stored in the GRU, which needs to be combined with the information of the update gate for the next calculation of the hidden state:
In the GRU, the hidden state is passed to the output layer, and then the output layer computation at a time step
t is expressed as:
where
is the weight matrix, and
represents the bias vector.
3.2. 2D-CNN
The convolutional neural network (CNN) was proposed by Yann Lecun of New York University in 1998 [
44]. The convolutional neural network (CNN) is a deep learning model that is commonly used in image recognition, speech recognition, and other fields.
The following equation is applied to define the multispectral image in this paper:
. In the above equation,
represents the
-th pixel in the image, and
H,
W, and
C represent the height, width, and number of bands of the multispectral image, respectively.
In this paper, w and b represent the weight matrix and bias vector of the fully connected layer, respectively. denotes the input 1D-pixel sequence, m is the output dimension of the fully connected layer, and represents the remodeling output with , , where and .
Throughout this section, we designed a 2D-CNN module as shown in
Figure 5. Firstly, we used a fully connected layer to linearly stretch the input 1D pixel sequence to resize it into a 1D pixel sequence. To enhance the dimensionality and as an input to the 2D-CNN, we reshaped the 1D pixel sequence to a 3D pixel feature matrix. This stretch 2D-CNN module contains four convolutional layers. The first convolutional layer contains 32 convolutional kernels, the second convolutional layer contains 64 convolutional kernels, the third convolutional layer contains 128 convolutional kernels, and the last convolutional layer contains 256 convolutional kernels. In the selection of convolution kernels, except for the first convolutional layer, which uses a convolution kernel of size 1 × 1, the remaining three convolutional layers use a convolution kernel of size 2 × 2. With the above design, we can achieve feature extraction and increase the dimensions of the input image for better application in subsequent tasks.
3.3. Loss Function
Cross-entropy is a commonly used loss function that is particularly suitable for multi-classification problems. In deep learning, the cross-entropy loss function can be used to evaluate the difference between the model output results and the true labels and update and optimize the model parameters accordingly. With a separate calculation for each node, cross-entropy can effectively measure the difference between the probability distribution of the model output and the probability distribution of the true labels. During the model training process, the back-propagation algorithm is used to calculate the gradient, and the model parameters are continuously adjusted to minimize the cross-entropy loss function. Eventually, a classification model with high accuracy can be obtained by continuously optimizing the cross-entropy loss function. The expression is as follows:
where
M represents the number of categories;
represents the sign function (0 or 1), taking 1 when the true category of sample
i is equal to
c, and 0 otherwise; and
is the predicted probability that the observation sample
i belongs to category
c.
3.4. Evaluation Metrics
A confusion matrix is a common method for evaluating the performance of classification models. For the multispectral pixel-level classification problem, the article used three confusion matrix-based evaluation metrics, namely, the accuracy rate, precision rate, and Kappa coefficient. The accuracy rate refers to the ratio of the number of samples correctly classified by the classifier to the total number of samples. The precision rate measures the percentage of samples that belong to a category out of all the samples classified by the classifier as belonging to that category. The Kappa coefficient, on the other hand, which considers the distribution of classification errors, is evaluated based on the classification consistency between samples. It is a more comprehensive and reliable indicator for model evaluation. The calculation of these three metrics is based on the confusion matrix, which can reflect the performance of the classifier more comprehensively. The three expressions are as follows:
In the above equations, (true positive) is the number of samples correctly predicted to be positive, (false positive) is the number of samples that are negative but incorrectly predicted to be positive, (true negative) is the number of samples that are correctly predicted to be negative, (false negative) is the number of samples that are positive but incorrectly predicted to be negative, is the overall classification accuracy, and is the expected consistency rate.
3.5. Experimental Setting
The experiments in this paper used ENVI software to obtain the coordinate point data of sample points and regions of interest collected outdoors and export them to text files as a dataset. During the model training, a batch size of 32, a maximum number of iterations of 300, and a learning rate decay multiplier of 0.9 were used. The experimental code is all implemented by Python 3.9 in PyTorch 1.10.2. The training environment for the model is Windows 11 + 12th Gen Intel(R) Core(TM) i5-12400F + NVIDA GeForce RTX 3060 GPU.
4. Results of the Experiment
The study area classification experiments in this paper are conducted using the data in
Table 1, and the hyperspectral dataset classification experiments are conducted using
Table 3,
Table 4 and
Table 5.
To evaluate the performance and effectiveness of our models, we selected SVM, KNN (k-nearest neighbor), RF (random forest), ViT (vision Transformer), SpectralFormer, 1D-CNN, an RNN, and the HCRNN for comparison on the study area Guangxi Laibin dataset, the Houston dataset, the Indian Pines dataset, and the Pavia University dataset.
(1) SVM: In the SVM model, the penalty factor is set to 10, which helps to limit model overfitting. Meanwhile, we use the radial basis function (RBF) as the kernel function to transform the SVM into a nonlinear model. When choosing the decision function, we use the “ovr” (one-vs.-rest) strategy to deal with multi-category classification problems.
(2) KNN: The number of nearest neighbors (the k value) is set to three, i.e., for each test data. The European distance is used as the distance metric.
(3) RF: Random forest with 100 trees.
(4) ViT: The structure of ViT is set up as five encoders. Each encoder’s module consists of four self-attentive layers, eight hidden layers of MLPs, and a dropout layer that suppresses 0% of the neurons, with an arbitrary grouping embedded in a spectral dimension of 64.
(5) SpectralFormer: The SpectralFormer module is designed with five encoder modules, each containing four self-attentive layers, eight hidden layers of MLPs, and a dropout layer that suppresses 10% of the neurons. The length of any group of spectral embedding vectors is 64.
(6) 1D-CNN: The 1D-CNN structure consists of a convolutional layer, a batch normalization layer, a maximum-pooling layer, a fully connected layer, an output layer, and a ReLU activation function.
(7) RNN: The structure of RNN is a two-layer gated recurrent unit (GRU).
(8) HCRNN: THe HCRNN model contains a CNN module and an RNN module. The fully connected layer of the CNN module has an input dimension of 13 and an output dimension of 256, which is transformed into an 8 × 8 × 4 3D feature matrix after the reshaping operation. The convolutional layers are set up as follows: the first convolutional layer has 32 convolutional kernels, the second convolutional layer has 64 convolutional kernels, the third convolutional layer has 128 convolutional kernels, and the last convolutional layer has 256 convolutional kernels. The RNN module consists of two layers of GRUs.
4.1. Comparative Analysis of Multiple Methods
In this section, we compared the proposed method with other representative and advanced models to obtain the corresponding qualitative results.
Table 6 gives the classification results of different models on the study area dataset with quantitative classification accuracies, OA, AA, and Kappa.
Table 6 shows the classification results of the 2017 Laibin dataset with different classification methods. In general, 1D-CNN performs the worst. The qualitative indexes’ OA, AA, and Kappa values are the lowest among all the classification methods, 92.79%, 82.54%, and 0.9031, respectively, and, for sugarcane and rice, the classification ability is weaker, only 72.03% and 37.50%. The reason for the poor classification effect of 1D-CNN on multispectral data is probably because multispectral data have multiple dimensions spatially, whereas 1D-CNN can only learn and extract features from the data in one dimension, which cannot make full use of the spatially rich information of multispectral data. SVM, KNN, and RF are traditional machine learning classification algorithms, and their classification performances are comparable as measured by the qualitative metrics OA, AA, and Kappa. The OA of SVM is 95.08%, the AA is 84.73%, and the Kappa is 0.9340, and the classification ability for rice is the worst among all of the compared methods with only 28.29%, but, in the classification performance for bareland, SVM achieves a classification accuracy of 100%, which is the best result among all of the classification methods. The classification methods for deep learning are ViT, SpectralFormer, the RNN, and our proposed HCRNN algorithm in addition to the 1D-CNN analyzed above. ViT also achieves a promising classification performance for bareland, with a classification accuracy of 100%, and SpectralFormer has the best classification ability of all classification methods for forest, with a classification accuracy of 99.31%. However, our proposed HCRNN algorithm outperforms the other models on the 2017 dataset, achieving an OA of 97.62%, an AA of 94.68%, and a Kappa value of 0.9681. The HCRNN has the best classification performance for the six feature classes of buildup, water, bareland, rice, sugarcane, and otherland with classification accuracies of 97.09%, 98.35%, 100%, 92.83%, 78.95%, and 96.34%, respectively. Our combined model algorithm, the HCRNN, compares favorably with the single RNN model with improvements in buildup (+1.76%), water (+1.39%), sugarcane (+4.65%), rice (+9.9%), and otherland (+4.7%). Undoubtedly, the HCRNN algorithm is better at mining time series information as well as spatial features in spectral data, and its classification accuracy is better than other methods.
The land cover-type maps of different classification methods to classify the city of Laibin in Guangxi are shown in
Figure 6. We marked and magnified the red boxes of the classification map based on the sample points information obtained from fieldwork and prior knowledge. In the red boxes are buildup, forest, water, bareland, sugarcane, rice, and otherland. 1D-CNN has a poor classification performance overall, but, for the better-differentiated categories (e.g., buildup, water, etc.), the differentiation is also higher. However, 1D-CNN is confused when facing indistinguishable categories, e.g., mistakenly detecting rice in categories such as bareland and otherland. SVM performs poorly in distinguishing rice and bareland and is prone to recognition errors in localized areas. Four deep learning classification models, ViT, SpectralFormer, the RNN, and the HCRNN are chosen for our experiments, and they perform well in terms of overall classification results, being able to clearly extract the outlines of feature classes and better identify classes with smaller differences. However, we find that the HCRNN performs much better when observed on a local scale, and it is significantly better at identifying otherland and sugarcane than the other classification methods.
Now, we will discuss whether the model proposed in this paper has a high accuracy and better qualitative results for land cover classification of multiple-satellite remote sensing image products with universal and general applicability. In the Houston dataset, the Indian Pines dataset, and the Pavia University dataset, our proposed classification method is compared with other advanced and representative models to produce qualitative results. The classification results of different models on the Houston dataset, the Indian Pines dataset, and the Pavia University dataset with quantitative classification accuracies, the OA, AA, and, Kappa are given in
Table 7,
Table 8 and
Table 9. The data in bold in each row is the best result of classification for each category. From
Table 9, it can be concluded that as a whole ViT is the worst (the OA, AA, and Kappa are all lower than the other models), but interestingly, ViT has the best classification ability for shadows with 99.87%; meanwhile, SVM and 1D-CNN also have 99.87% classification accuracy for shadows.
Figure 7,
Figure 8 and
Figure 9 indicate the classification maps obtained from different classification models on the Houston dataset, the Indian Pines dataset, and the Pavia University dataset.
Overall, the traditional classifiers RF, KNN, and SVM appear to have similar classification performances on all three hyperspectral datasets, i.e., they are all ordinary in qualitative evaluation, with the OA, AA, and Kappa values in the lower-middle range of all the classifiers. However, their performance is more prominent in the individual classification categories. SVM has the highest classification accuracy in the Houston dataset for the categories of stressed grass, road, and railway with 98.68%, 78.94%, and 87.29%, respectively. RF even achieves 100% classification accuracy for the category of tennis court in the Houston dataset. Deep learning has powerful learning skills, the recurrent neural network (RNN) and SpectralFormer perform more prominently, and the three qualitative metrics of OA, AA, and Kappa are higher than the traditional classifiers on both the Houston dataset and the Pavia University dataset. However, in the Indian Pines dataset, the RNN has an overfitting problem for soybean notill, a category with more training and testing samples, which results in a classification accuracy of only 6.97% but still reflects the superiority of deep learning in land cover classification. 1D-CNN is more excellent at capturing spatial features in a large number of continuous spectral data, such as hyperspectral data, so 1D-CNN performs well in the three hyperspectral datasets, especially in the Houston dataset where OA, AA, and Kappa are the highest values among all classification methods. The HCRNN algorithm proposed in this paper can better mine the time series information as well as the spatial features in the spectral data, and its classification accuracy is better than the other methods, with the highest OA, AA, and Kappa values in the Indian Pines dataset and the Pavia University dataset. Additionally, for categories with a small number of training samples, such as alfalfa, oats, and grass pasture mowed, in the Indian Pines dataset, the HCRNN presents a better performance capability, with classification accuracies of 94.87%, 100%, and 90.91%.
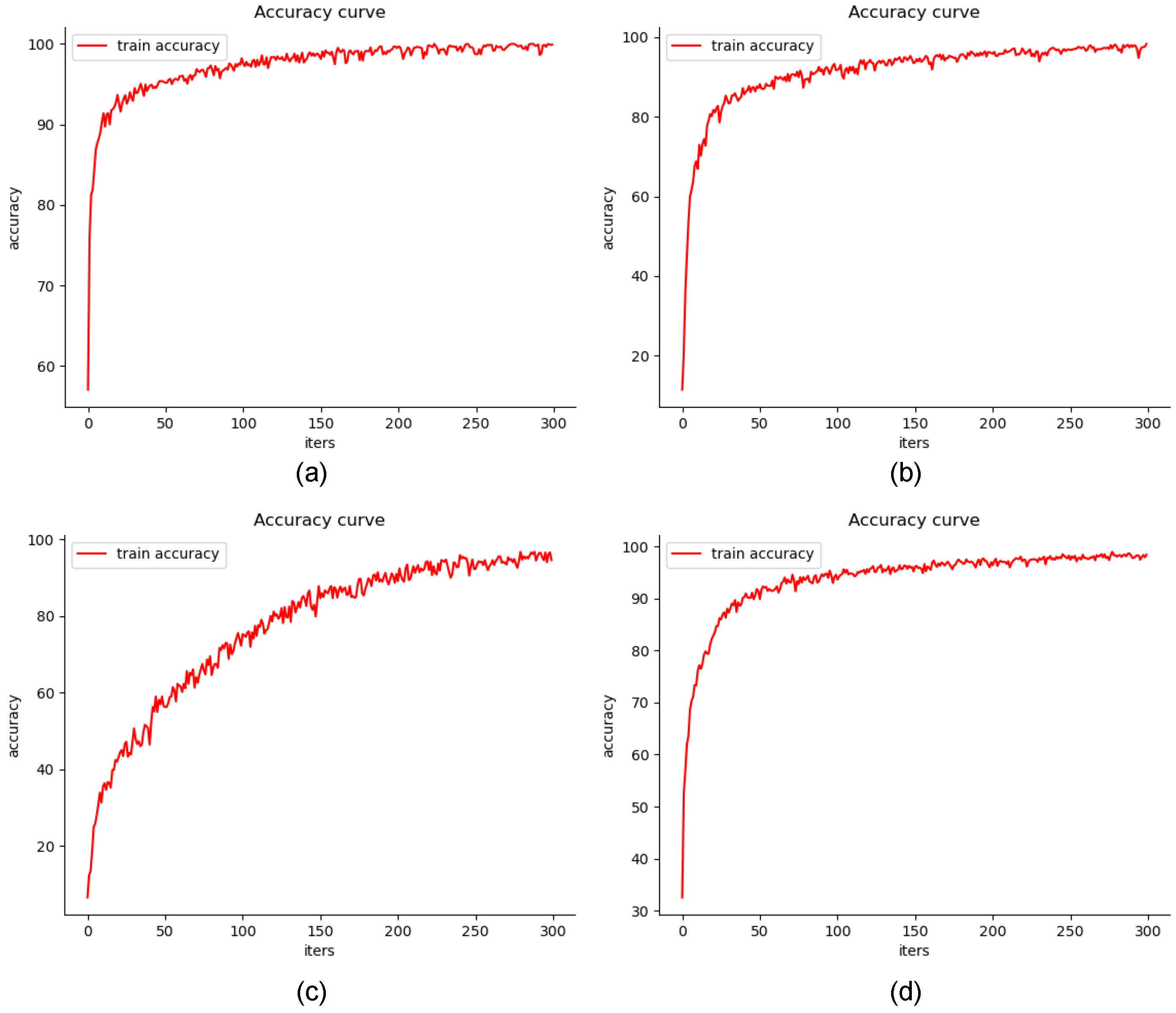
Figure 10 and
Figure 11 show the accuracy curves and loss curves of the HCRNN during training on the four datasets.
4.2. Analysis of Land-Use Change in the Study Area
In this paper, the land cover classification of Laibin was carried out using Sentinel-2 series imagery for 2017, 2019, and 2021, downloaded from the official ESA website (
https://scihub.copernicus.eu, accessed on 3 February 2023). After the preprocessing operation of the image data (please refer to
Section 2.1 for details), the ENVI software was used to mark the region of interest (ROI) of the sample data collected in the field, and the ROI coordinate point data were exported to text files. The training and testing sets were divided using a ratio of 1:9.
Table 1 shows the sample data for the years 2017, 2019, and 2021. The algorithm proposed in this paper was used to classify the land cover, analyze the land use changes, and compare and analyze with the previously accumulated classification knowledge and models. Focused analyses of forest, rice, and sugarcane in Laibin were conducted, and we delineated these portions of the area as the key areas of focus for the region. The analysis of changes in these areas enables a better understanding of the distribution of forests and agricultural production in the region. According to the data in
Table 6,
Table 10, and
Table 11, it can be concluded that the HCRNN algorithm is the best at classifying the Sentinel-2 images of Laibin City for the years 2017, 2019, and 2021. Therefore, land use change in Laibin City was analyzed in this section using the classification proposed in this article.
The classification results obtained by the different classification methods on the datasets of Guangxi Laibin City for the years 2017, 2019, and 2021 are shown in
Table 6,
Table 10, and
Table 11. It is possible to clearly and unambiguously conclude that the qualitative results of the classification of the HCRNN model for all three phases of the city of Laibin, in Guangxi, are optimal. The HCRNN has OA values of 97.62%, 97.03%, and 93.93% in the 2017, 2019, and 2021 datasets, respectively. In comparison to the classification performance of a single RNN model, the HCRNN improves the OA values by 1.78%, 1.89%, and 3.23% over the RNN. For the focused forest region, the HCRNN performs well in the 2017 Laibin dataset, and even better in the 2019 and 2021 Laibin datasets, i.e., it is the most prominent in classifying this category of forest, with the highest classification accuracy of all the classification methods. In the agricultural cultivation area, focusing on rice and sugarcane regions, rice and sugarcane had the highest classification accuracy of all classification methods on the 2017 Laibin dataset, with the sugarcane category having a more favorable classification performance in 2019, and the rice category having the optimal classification in 2021, in comparison with the remaining methods. As a result, it is more appropriate to use the land cover classification results of Laibin City obtained from the HCRNN for land-use change analysis.
It is concluded from
Table 12 that the area occupied by the forest area is the largest in the city of Laibin, followed by otherland. The extent of the area covered by buildup varied considerably over the three years. The area of buildup is mainly concentrated around the areas of active agricultural cultivation in the central part of the city of Laibin, with a growing trend in general. The area covered by bareland is a small proportion of the size of the city of Laibin. It is mainly concentrated in the vicinity of the buildup area. The bareland region has seen a relatively small change in area, showing a downward trend from year to year over the three years. The water area is extensive in the city of Laibin, with the river spanning the entire city of Laibin, covering an area range that appears to be decreasing and then increasing over the three years and still showing an overall decreasing trend. The reason for this phenomenon may be attributed to the fact that there has been less rain and a significant increase in extreme weather in recent years. The type of crop cultivation in Laibin City mainly includes sugarcane and rice. The area range covered by sugarcane is increasing year by year, and the area range covered by rice shows an expansion and then a decline, but the overall observation is that it is still increasing. The detailed land cover distribution map of Laibin City is shown in
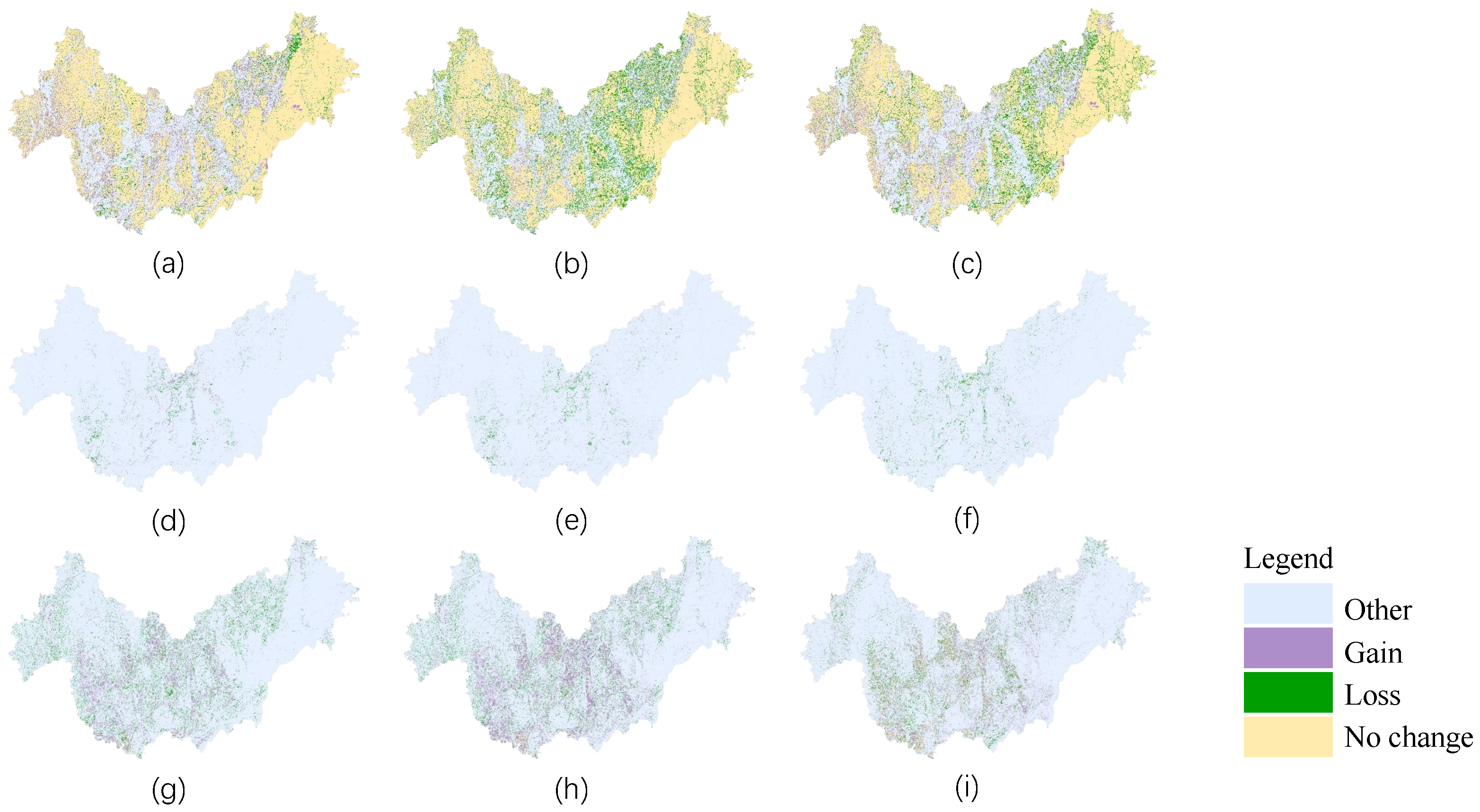
Figure 12.
The vegetation cover type of Laibin City is mainly forest, sugarcane, and rice. To better monitor the vegetation change and understand the ecological development, we considered the forest, sugarcane, and rice areas as the focus areas of the study in this region. In the spatial feature distribution maps of forest, rice, and sugarcane in Laibin City, the other feature categories were unified in the same color, as shown in
Figure 13. It is clear from the graph that the forest and rice areas had the largest acreage in 2019 of the last three years, while the sugarcane area had the largest planting acreage in 2021 of the last three years. An in-depth study of the changes in these key areas can help us better understand the trends in land resource use and changes in the region, further promoting optimization of resource allocation, balance in ecological development, and enhancement of agricultural and plantation production capacity. The land use analyses of forest, rice, and sugarcane have significant implications for achieving sustainable development and ecological protection in Laibin City.
In
Table 12, we analyze the change in land-use types in the Laibin City area of Guangxi during the three years of 2017, 2019, and 2021. For the forest area, which has the largest coverage, the change in area is relatively small, with 7997.1016 km
2 in 2017, and a three-year peak of 8990.4149 km
2 in 2019, which is an increase of 12.42% compared to 2017. The area covered by forest area was 8103.0020 km
2 in 2021, which is a decrease of 9.87% in comparison with 2019, but still shows a small increase in comparison with the area covered in 2017, with an improvement of 1.32%. This may be due to the call to return farmland to forests in recent years, so the forest area still shows an increasing trend. The gradual expansion of sugarcane cultivation areas to fulfill the needs of the development of the agricultural economy in Laibin City is probably the reason for the reduction of forest cover during a short period in the year 2021. The cultivated rice area was 110.5949 km
2 in 2017, 184.1268 km
2 in 2019, and 164.9869 km
2 in 2021. The rate of change in the area under cultivation for rice improved by 66.49% from 2017 to 2019 and then decreased by 10.40% from 2019 to 2021, compared to 2017–2021, when the rice area under cultivation was still growing, improving by 49.18%. It is possible that due to the advancement of modernization of food crops in Laibin in recent years, the cultivation range is wider than before, so the rice cultivation area shows a substantial increase in 2017–2019, and the agricultural cultivation area is more stable. Therefore, this may be the reason for a slight decline in rice acreage in 2019–2021. The sugarcane region is more variable in terms of acreage. The cultivation area for sugarcane is 832.3258 km
2 in 2017, which increases to 965.4852 km
2 in 2019, and further expands to 1546.5997 km
2 in 2021. The growth rate of the cultivation area for sugarcane has shown improvement over these years, with a 14.92% increase from 2017 to 2019, a 60.76% increase from 2019 to 2021, and a substantial 85.52% increase from 2017 to 2021. This is due to the vigorous development of modern characteristic agriculture in Laibin City in recent years, and the climate and soil conditions in Laibin City are suitable for cultivating sugarcane. The annual sugarcane production in Laibin City can account for one-eighth of China’s total sugarcane production. Sugar production in Laibin City in 2021 has reached another historical high, which proves that the area of sugarcane cultivation has changed so much and grown so rapidly.
Figure 14 shows the dynamics of forest, rice and sugarcane in Laibin City over three years.
4.3. Analysis of Samples with Different Proportions
In order to assess the impact of the small number of training samples on the experimental results, in this paper, we randomly selected different proportions of training samples from a given dataset in our sample data of Laibin City in 2017, 2019, and 2021, and run it nine times with 10%, 20%, …, 90% intervals of 10%, and the remaining samples in each run were used as the testing set without setting up the validation set. The classification accuracies obtained by the HCRNN algorithm proposed in this paper with different proportions of training samples in the 2017, 2019, and 2021 Laibin data are shown in
Figure 15. As the training samples increase, the classification accuracy becomes higher and higher, while the noise gradually decreases. For example, when the proportion of training samples reaches 70%, 80%, and 90%, the classification accuracy is further improved, and the OA value stabilizes more and more, which shows that the HCRNN algorithm is reliable.
4.4. Discussion
In this article, the Sentinel-2 image data of Laibin City was selected for the experiments, and all 13 bands were included to achieve the land cover classification of the study area. The aim is to obtain more complete information about the land, which will help to achieve a more detailed and comprehensive classification of features for the identification of the different land cover types. Meanwhile, 13 bands are selected so that we can also flexibly combine them according to different classification requirements. In the study area dataset and the three hyperspectral public datasets, the traditional classification methods SVM, KNN, and RF, and the deep learning classification methods 1D-CNN, ViT, SpectralFormer, the RNN, and the HCRNN present different experimental results. SVM and RF have the advantage of lower computational cost and the ability to handle relatively complex classification tasks with fewer training samples [
45]. However, their classification performance is not superior enough when compared to deep learning methods such as RNN and SpectralFormer, which are good at capturing deep feature information, such as sequences [
46]. In multispectral datasets, the performance of SVM and RF is not outstanding compared to the RNN and SpectralFormer in deep learning methods. KNN can learn from a limited number of samples to complete the classification task, but KNN is similarly not sensitive enough to sequence information [
47] and performs moderately well in experiments. 1D-CNN is widely used in problems related to time series and is better at capturing spatial features in large amounts of continuous spectral data, such as hyperspectral data [
48]. Thus, 1D-CNN performs well in the three hyperspectral datasets, with the best classification performance in the Houston dataset. The reason for the weak performance in multispectral data may be that multispectral data has multiple dimensions in space, whereas 1D-CNN can only learn and extract features from one dimension of the data. ViT still outperforms traditional methods in multispectral datasets due to its ability to long-term dependence on modeling [
49]. In contrast, although the RNN can process time-series data in multispectral remote sensing images, it does not work as well as the HCRNN which combines a CNN and an RNN, when the RNN is used alone.
Based on the experimental results presented in this paper, it can be concluded that the proposed HCRNN model outperforms the other classification methods in achieving pixel-level classification of Sentinel-2 remote sensing images. The HCRNN model exhibits the best classification performance in the multispectral dataset and produces good results in the three hyperspectral datasets, demonstrating its reliability and universality in different scenarios. However, it is worth noting that the HCRNN model has a larger number of parameters due to the extraction of multi-scale features. As a result, the computation time is longer, and the computation cost is higher than single deep learning classification models, such as a CNN or an RNN. Therefore, it is essential to explore more efficient methods of combining a CNN and RNN, which will be a focus of future work.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}