
Research on Estimating and Evaluating Subtropical Forest Carbon Stocks by Combining Multi-Payload High-Resolution Satellite Data

 and
and
Abstract
:1. Introduction
2. Materials and Methods
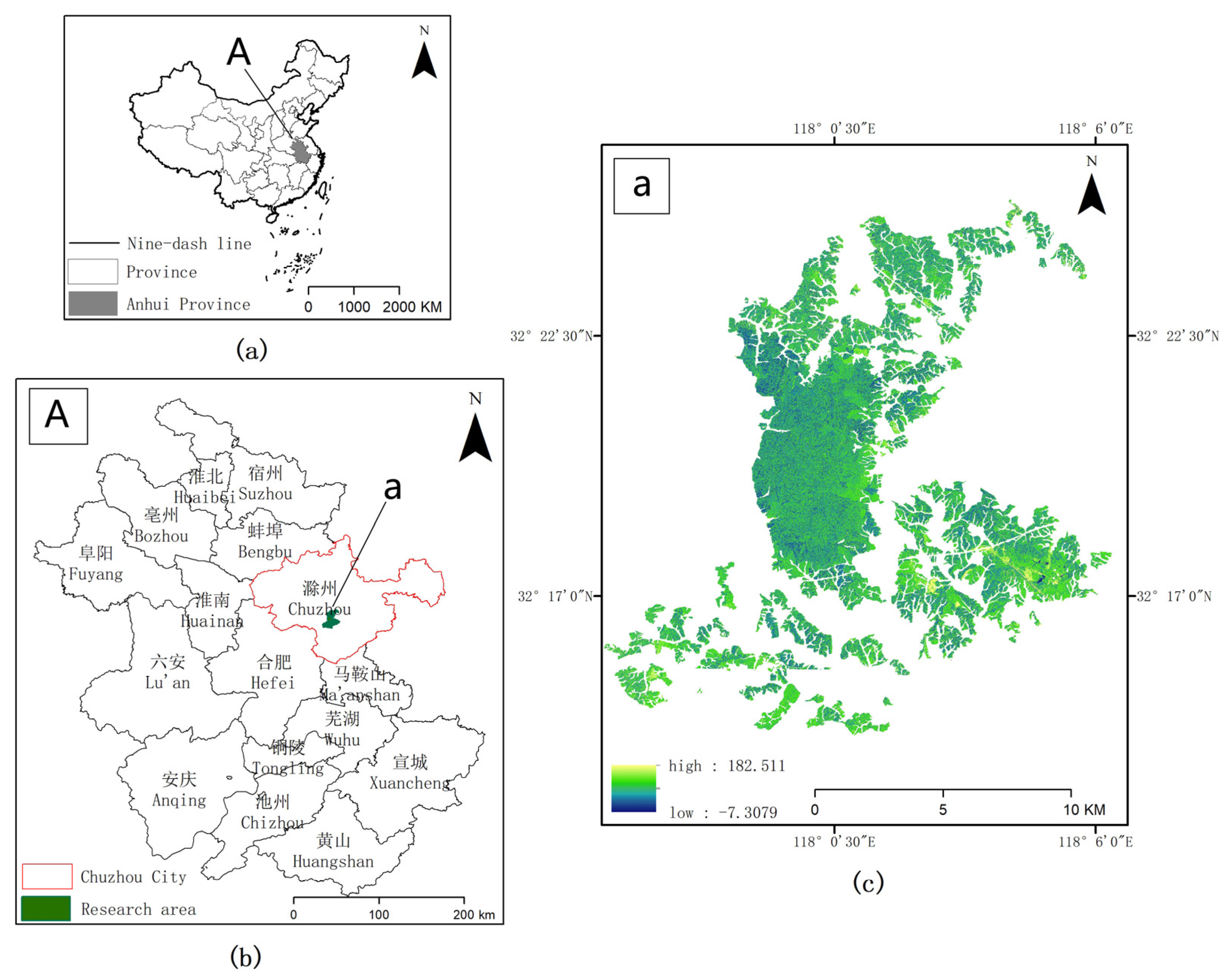
2.1. Study Area
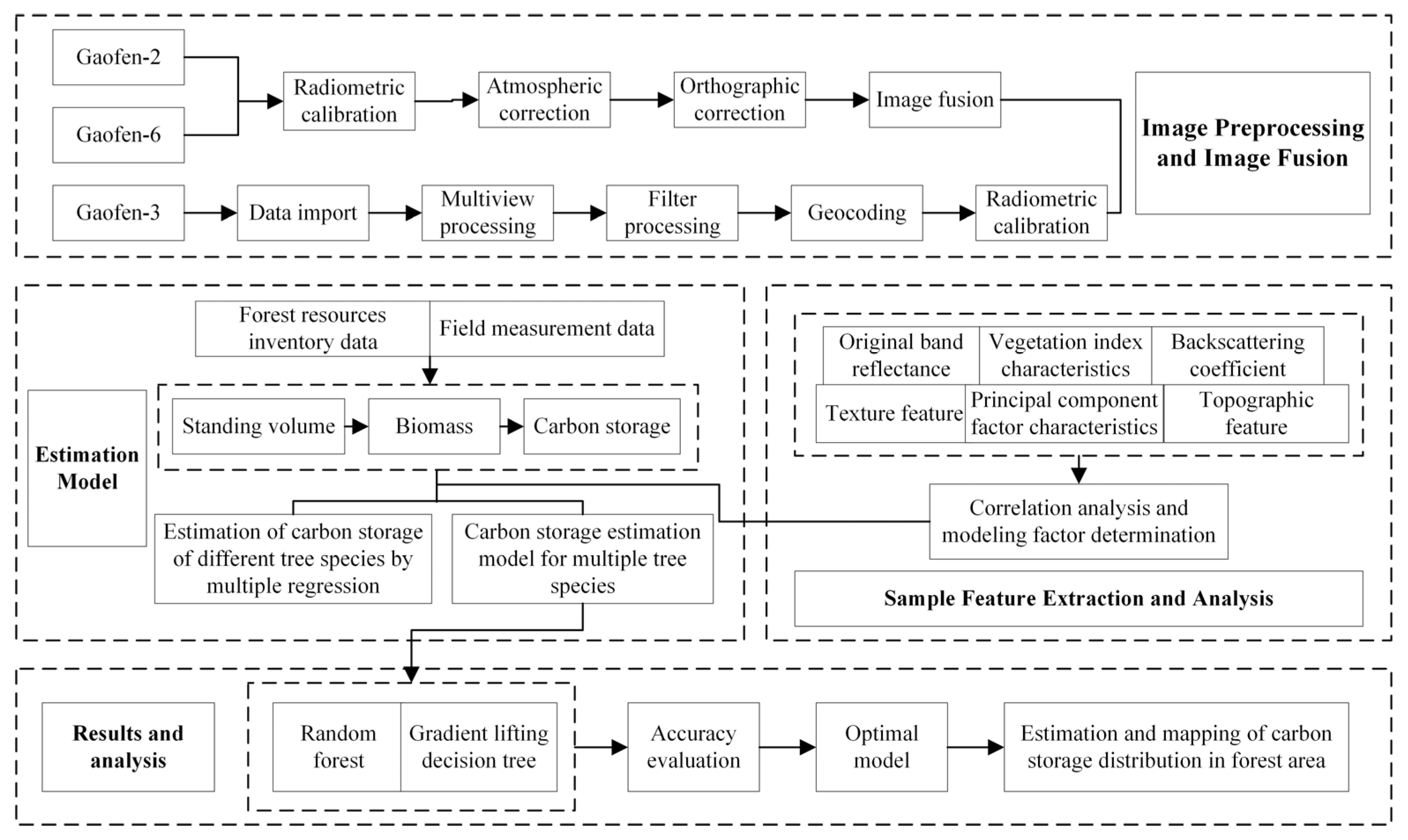
2.2. Technology Roadmap
2.3. Data
2.3.1. Remote Sensing Image
2.3.2. Ground Survey Data
- (a)
- In the ecosystem carbon pool survey, the results are used to determine the carbon content and tree species present.
- (b)
- According to the table of biomass conversion parameters for major dominant tree species (groups), the main advantages of tree species biomass conversion parameters are as follows.
- (c)
- Using the default 0.5 tC/T.D.M.
2.4. Feature Extraction
2.4.1. Optical Image Features
- (1)
- The Surface Reflectance
- (2)
- The Characteristics of Vegetation Index
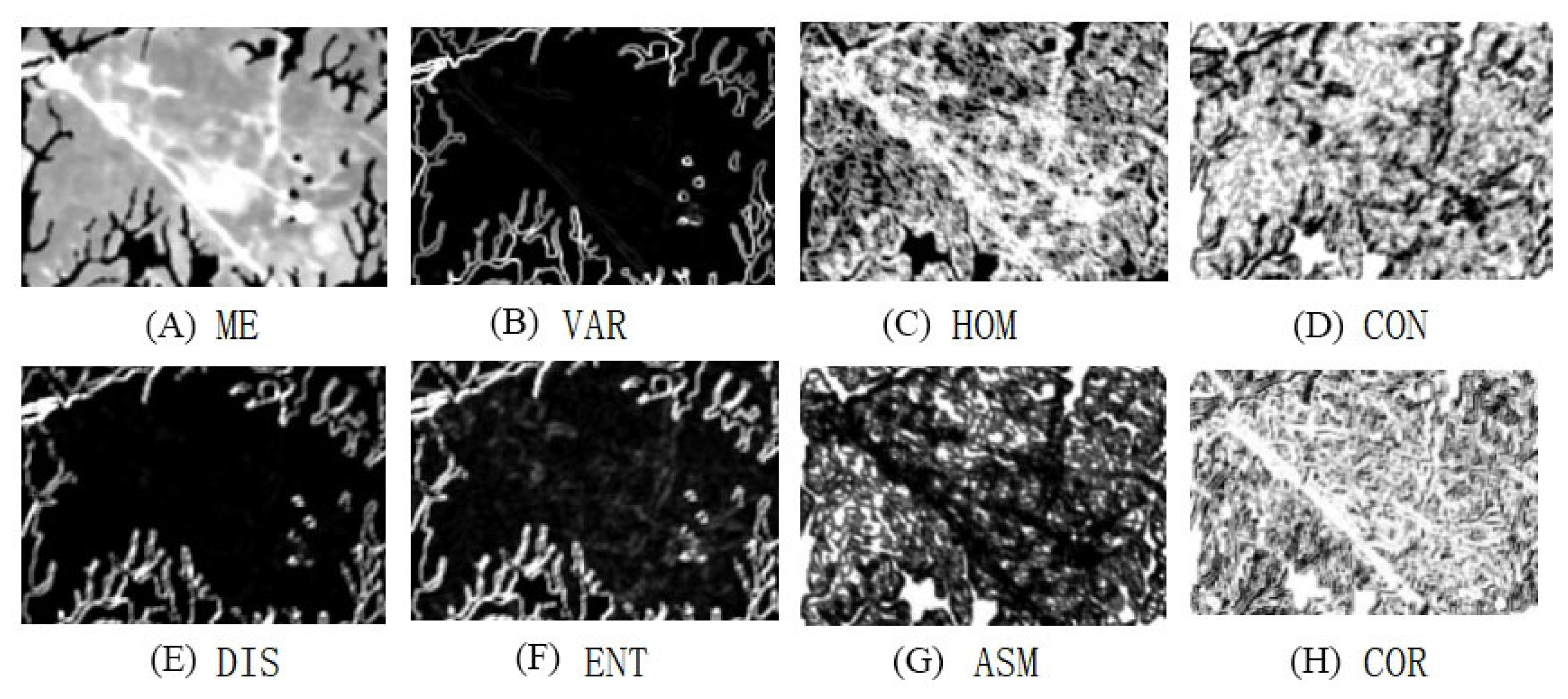
2.4.2. Extraction of Texture Feature
2.4.3. Extraction of Principal Component Characteristics
2.4.4. Radar Images to Scattering Coefficient
2.4.5. The Terrain Factor
2.5. Model Introduction
2.5.1. Multiple Linear Regression (MLR)
2.5.2. Random Forest (RF)
2.5.3. Gradient-Boosting Decision Tree (GBDT)
2.6. Accuracy Verification
3. Results
3.1. Data Statistics and Processing
3.2. Determination of Feature Factors
3.2.1. The Different Forest Category Correlation Analysis
3.2.2. The Different Age Group Correlation Analysis
3.3. Analysis of Modeling Results of Different Images
3.4. Modeling Analysis on Different Models for Mixed Forest
3.4.1. Random Forest Algorithm
3.4.2. Gradient Promotion Decision Tree
- (1)
- Initialize
- (2)
- To
- (a)
- To , calculateThat is, the negative gradient of each sample loss function is used as an approximation of the sample residual .
- (b)
- is fitted into a CART and set of leaf nodes is obtained , j = 1, 2, …, J.
- (c)
- To , find the minimized loss function:
- (d)
- Update forecast results:
- (3)
- The GBDT model is obtained:
3.5. Distribution Map of Carbon Storage Estimation Results
4. Discussion
5. Conclusions
- The texture characteristics of the GF-2 image, the new band and the new red edge vegetation index of the GF-6 image, the radar intensity coefficient sigma, and the radar brightness coefficient beta of the HV polarization mode under the refined strip of the GF-3 image and forest carbon storage have good responsiveness;
- Regarding different forest species, Pinus massoniana carbon reserves have the best correlation with the new red edge band of GF-6 images; Slash pine carbon reserves have the best correlation with texture features of GF-2 images; Quercus acutissima carbon reserves have the best correlation with textural features of GF-2 images and new red edge index MTCI and greenness vegetation index GNDVI of GF-6 images; and the slope has a greater impact on the carbon storage of multiple tree species and single tree species, Pinus massoniana and Quercus acutissima. For different age groups, the carbon storage of sapling forests, half-mature forest, over-mature forests, and mature forests all have a high correlation with the texture characteristics of GF-2 images. Half-mature forests’, near-mature forests’ and over-mature forests’ carbon storage is also significantly correlated with the new bands of GF-6 images; there is a good correlation between carbon storage in sapling forests and half-mature forests and the sigma coefficient in the HV polarization mode of GF-3 images; near-mature forests’ and over-mature forests’ carbon storage is significantly correlated with the gamma coefficient under the HV polarization mode of GF-3 images; in addition, the slope aspect factor in the terrain factors has a strong correlation with the carbon storage of different age groups.
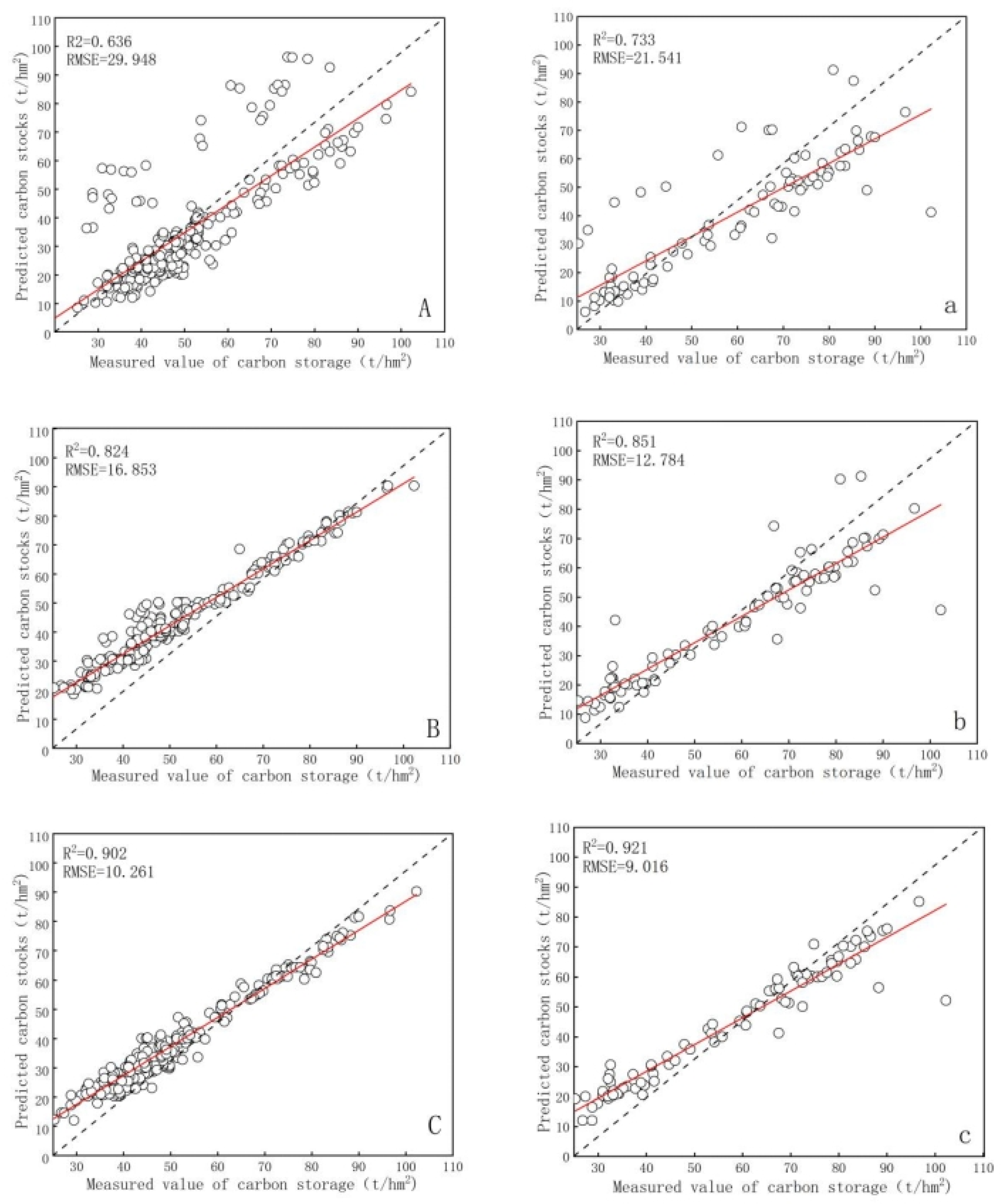
- On the basis of the traditional regression algorithm, multivariate stepwise regression, the random forest, and gradient-boosting decision tree models are introduced into multi-tree species modeling. The results show that among the two different integrated thinking algorithms, gradient-boosting decision tree has a higher estimation accuracy and the fitting effect is better than that of random forest; R2 reaches 0.902, RMSE is 10.261 t/ha; random forest is second; R2 reaches 0.824, RMSE is 16.853 t/ha; and multiple stepwise regression has the worst fitting effect; R2 reaches 0.636, RMSE is 29.948 t/ha.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kuuluvainen, T.; Gauthier, S. Young and old forest in the boreal: Critical stages of ecosystem dynamics and management under global change. For. Ecosyst. 2018, 5, 361–375. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, J.; Zhao, N.; Liu, Y.; Wang, Y.; Wilson, J.P.; Yue, T. Estimation of China’s forest stand biomass carbon sequestration based on the continuous biomass expansion factor model and seven forest inventories from 1977 to 2013. For. Ecol. Manag. 2019, 448, 528–534. [Google Scholar] [CrossRef]
- FAO. State of the World’s Forests 2011; FAO: Rome, Italy, 2011; p. 179. [Google Scholar]
- FAO. Global Forest Resources Assessment 2015—How Are the World’s Forests Changing, 2nd ed.; FAO: Rome, Italy, 2016; p. 54. [Google Scholar]
- Dixon, R.K.; Solomon, A.M.; Brown, S.; Houghton, R.A.; Trexier, M.C.; Wisniewski, J. Carbon pool and flux of global forest ecosystems. Science 1994, 263, 185–190. [Google Scholar] [CrossRef] [PubMed]
- Su, R.; Du, W.; Ying, H.; Shan, Y.; Liu, Y. Based on LiDAR and multi-spectral images of forest land carbon reserves estimation: Du, coniferous forest, for example. Forests 2023, 14, 992. [Google Scholar] [CrossRef]
- Kan, Y.; Han, Z.; Huang, G.; Wang, X.; Li, Y.; Zhou, J.; Dian, Y. Forest biomass inversion of north subtropical zone based on high-resolution remote sensing image. J. Ecol. 2021, 41, 2161–2169. [Google Scholar]
- Yu, G.; Chen, Z.; Piao, S.; Peng, C.; Ciais, P.; Wang, Q.; Li, X.; Zhu, X. High carbon dioxide uptake by subtropical forest ecosystems in the East Asiam monsoon region. Proc. Natl. Acad. Sci. USA 2014, 111, 4910–4915. [Google Scholar] [CrossRef] [PubMed]
- Wen, D.; He, N.P. Forest carbon storage along the north south transect of eastern China: Spatial patterns, allocation, and influencing factors. Ecol. Indic. 2016, 61, 960–967. [Google Scholar] [CrossRef]
- Ma, C.; Zhao, M.; Mou, H.; Liu, B. The yanshan mountains in north China larch plantation carbon density and distribution characteristics. J. Soil Water Conserv. Sci. 2017, 31, 208–214. [Google Scholar]
- Cheng, J.; Lee, X.; Theng, B.K.; Zhang, L.; Fang, B.; Li, F. Biomass accumulation and carbon sequestration in an age sequence of Zanthoxylum bungeanum plantations under the Grain for Green Program in karst regions, Guizhou Province. Agric. For. Meteorol. 2015, 203, 88–95. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, H.; Tao, S.; Chi, X.; Li, P.; Jiang, L.; Ji, C.; Zhu, J.; Tang, Z.; Pan, Y.; et al. Carbon stocks and changes of dead organic matter in China’s forests. Nat. Commun. 2017, 8, 151–160. [Google Scholar] [CrossRef]
- Cui, Y.; Sun, H.; Wang, G.; Li, C.; Xu, X. A Probability-based spectral unmixing analysis for percentage vegetation cover of arid and semi-arid areas. Remote Sens. 2019, 11, 3038. [Google Scholar] [CrossRef]
- Hu, Y.; Xu, X.; Wu, F.; Sun, Z.; Xia, H.; Meng, Q.; Huang, W.; Zhou, H.; Gao, J.; Li, W.; et al. Estimating forest stock volume in Hunan province, China, by integrating in situ plot data, sentinel-2 images, and linear and machine learning regression models. Remote Sens. 2020, 12, 186. [Google Scholar] [CrossRef]
- Sinha, S.; Jeganathan, C.; Sharma, L.K.; Nathawat, M.S. A review of radar remote sensing for biomass estimation. Int. J. Environ. Sci. Technol. 2015, 12, 1779–1792. [Google Scholar] [CrossRef]
- Li, L.; Chen, E.; Li, Z.; Chong, R.; Zhao, L.; Gu, X. Forest aboveground biomass of InSAR baseline tomographic method estimates. Sci. Silvae Sin. 2017, 53, 85–93. [Google Scholar]
- Liu, X.; Sui, C.; Bai, Y.; Zhao, D.; Zhao, Y.; Liu, Y.; Zhai, Q. Ground-based lidar scrub grassland lobular caragana biomass estimation. J. Remote Sens. 2020, 24, 894. [Google Scholar] [CrossRef]
- Qiu, S.; Xing, Y.; Xu, W.; Ding, J.; Tian, J. Spaceborne large flare LiDAR with HJ-1 a hyperspectral data to estimate the regional forest biomass on the ground. Acta Ecol. Sin. 2016, 4, 7401–7411. [Google Scholar]
- Wang, X.; Guo, Y.; He, J. Based on HJ1B and ALOS/PALSAR data of forest aboveground biomass remote sensing estimation. Acta Ecol. Sin. 2016, 4, 4109–4121. [Google Scholar]
- Jiao, Y.; Wang, D.; Yao, X.; Wang, S.; Chi, T.; Meng, Y. Forest Emissions Reduction Assessment Using Optical Satellite Imagery and Space LiDAR Fusion for Carbon Stock Estimation. Remote Sens. 2023, 15, 1410. [Google Scholar] [CrossRef]
- Lu, D.; Chen, Q.; Wang, G.; Moran, E.; Saah, D. Aboveground forest biomass estimation with Landsat and LiDAD data and uncertainty analysis of the estimates. Int. J. For. Res. 2012, 2012, 1–17. [Google Scholar] [CrossRef]
- Chen, Q.; Qi, C. Lidar remote sensing of vegetation biomass. Remote Sens. Nat. Resour. 2013, 399, 399–420. [Google Scholar]
- Eckert, S. Improved forest biomass and carbon estimations using texture measures from World View-2 satellite data. Remote Sens. 2012, 4, 810–829. [Google Scholar] [CrossRef]
- Imhoff, M.L. Radar backscatter and biomass saturation: Ramifications for global biomass inventory. IEEE Trans. Geosci. Remote Sens. 1995, 33, 511–518. [Google Scholar] [CrossRef]
- Boyd, D.S.; Foody, G.M.; Curran, P.J. The relationship between the biomass of Cameroonian tropical forests and radiation reflected in middle infrared wavelengths. Int. J. Remote Sens. 1999, 20, 1017–1023. [Google Scholar] [CrossRef]
- Shen, X.; Cao, L.; She, G. Subtropical forest biomass estimation based on hyperspectral and high-resolution remotely sensed date. Remote Sens. 2016, 20, 1446–1460. [Google Scholar]
- Huang, K.; Pang, Y.; Shu, Q.; Fu, T. Aboveground forest biomass estimation using ICESat GLAS in Yunnan, China. Remote Sens. 2013, 17, 165–179. [Google Scholar]
- Ahmed, M.M.; Abdel-Aty, M. Application of stochastic gradient boosting technique to enhance reliability of real-time risk assessment: Use of automatic vehicle identification and remote traffic microwave sensor data. Transp. Res. Rec. 2018, 2386, 26–34. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, R.; Ma, Q.; Wang, Y.; Wang, Q.; Huang, Z.; Huang, L. A feature selection and multi-model fusion-based approach of predicting air quality. ISA Trans. 2020, 100, 210–220. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Cheng, B.; Liang, C.; Liu, X.; Liu, Y.; Ma, Y.; Wang, G. Research on a novel extraction method using Deep Learning based on GF-2 images for aquaculture areas. Int. J. Remote Sens. 2020, 41, 3575–3591. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, D.; Hou, X.; Ma, X.; Wang, J. Orthorectification of high-resolution remote sensing images using Google Earth and SRTMGL1. Surv. Mapp. Bull. 2018, 8, 62–67. [Google Scholar] [CrossRef]
- Sun, M. Research on Satellite Remote Sensing Inversion Method for Forest Carbon Stock in Beijing. Master’s Thesis, Beijing Forestry University, Beijing, China, 2017. [Google Scholar]
- Wang, Z. Research on Spatial and Temporal Changes of Forest Carbon Stock and Influencing Factors in Hangzhou Based on CASA Model. Master’s Thesis, Zhejiang Agriculture and Forestry University, Hangzhou, China, 2021. [Google Scholar]
- Zhang, G. Spatial distribution characteristics of urban forest carbon stock in Shanghai based on remote sensing estimation. J. Ecol. Environ. 2021, 30, 1777–1786. [Google Scholar]
- Zheng, Y.; Wu, B.; Zhang, M. Sentinel-2 data of winter wheat on dry biomass estimation and evaluation. J. Remote Sens. Sci. 2017, 21, 318–328. [Google Scholar]
- Dash, J.; Curran, P.J. Evaluation of the MERIS terrestrial chlorophyll index (MTCI). Adv. Space Res. 2007, 39, 100–104. [Google Scholar] [CrossRef]
- Liu, Q.; Yang, L.; Liu, Q.; Li, J. Review of forest above ground biomass inversion methods based on remote sensing technology. J. Remote Sens. 2015, 19, 62–74. [Google Scholar]
- Bu, X.; Dong, S.; Mi, W.; Li, F. Spatial-temporal change of carbon storage and sink of wetland ecosystem in arid regions, Ningxia Plain. Atmos. Environ. 2019, 204, 89–101. [Google Scholar]
- Dalla Corte, A.P.; Souza, D.V.; Rex, F.E.; Sanquetta, C.R.; Mohan, M.; Silva, C.A.; Zambrano, A.M.A.; Prata, G.; de Almeida, D.R.A.; Trautenmüller, J.W.; et al. Forest inventory with highdensity UAV-Lidar: Machine learning approaches for predicting individual tree attributes. Comput. Electron. Agric. 2020, 179, 105815. [Google Scholar] [CrossRef]
- Coops, N.C.; Tompalski, P.; Goodbody, T.R.; Queinnec, M.; Luther, J.E.; Bolton, D.K.; White, J.C.; Wulder, M.A.; van Lier, O.R.; Hermosilla, T. Modelling lidarderived estimates of forest attributes over space and time: A review of approaches and future trends. Remote Sens. Environ. 2021, 260, 112477. [Google Scholar] [CrossRef]
- Xu, G.; Manley, B.; Morgenroth, J. Evaluation of modelling approaches in predicting forest volume and stand age for smallscale plantation forests in New Zealand with Rapid Eye and LiDAR. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 386–396. [Google Scholar]
- Zhang, L.; Shao, Z.; Liu, J.; Cheng, Q. Deep learning based retrieval of forest aboveground biomass from combined LiDAR and landsat 8 data. Remote Sens. 2019, 11, 1459. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Maltamo, M.; McRoberts, R.E.; Næsset, E. Introduction to forestry applications of airborne laser scanning. In Forestry Applications of Airborne Laser Scanning-Concepts and Case Studies; Springer: Amsterdam, The Netherlands, 2014; pp. 1–16. [Google Scholar]
- Han, Q.; Zhang, X.; Shen, W. Lithology identification technology based on gradient boosting decision tree (GBDT) algorithm. Bull. Mineral. Petrol. Geochem. 2018, 37, 1173–1180. [Google Scholar]
- Xiao, Y.; Xu, X.; Long, J.; Lin, H. Based on the domestic high marks data of forest volume inversion study. For. Resour. Manag. 2021, 3, 101–107. [Google Scholar]
- Gou, R.; Chen, J.; Duan, G.; Yang, R.; Pu, Y.; Zhao, J.; Zhao, P. Biomass of pinus tabulaeformis plantation the ground inversion based on GF-2. J. Appl. Ecol. 2019, 30, 4031–4040. [Google Scholar]
- Jiang, F.; Sun, H.; Li, C.; Ma, K.; Chen, S.; Long, J.; Ren, L. Retrieving the forest aboveground biomass by combing the red edge bands of Sentinel-2 and GF-6. Acta Ecol. Sin. 2021, 41, 8222–8236. [Google Scholar]
- Xiong, H.; Yu, F.; Gu, X.; Wu, X. Biomass, net production, carbon storage and spatial distrubution features of different forest vegetation in Fanjing Mountains. Ecol. Environ. Sci. 2021, 30, 264–273. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plot | Number of Places | DBH/cm | Height of Tree/m | Trees/ha | Crown Density | |||
|---|---|---|---|---|---|---|---|---|
| Range | Average | Range | Average | Range | Average | Range | ||
| Single species | 283 | 5.21–18.36 | 12.02 | 2.41–15.12 | 7.36 | 752~2951 | 1674 | 0.6~0.9 |
| Pinus massoniana | 123 | 6.21~18.28 | 13.28 | 5.86~13.12 | 7.42 | 752~2745 | 1821 | 0.8~0.9 |
| Slash pine | 69 | 6.61–18.32 | 14.41 | 3.05~8.56 | 7.44 | 825~2350 | 1706 | 0.8~0.9 |
| Quercus acutissima | 52 | 6.12~15.22 | 9.01 | 2.62~9.56 | 5.52 | 725~2851 | 1224 | 0.9 |
| Broadleaf forest | 22 | 5.15~15.20 | 8.41 | 4.56~9.75 | 4.14 | 752~2125 | 1114 | 0.8~0.9 |
| Coniferous forest | 17 | 6.15~18.36 | 14.68 | 4.52~8.56 | 7.81 | 752~2359 | 1350 | 0.8~0.9 |
| Needle and broad-leaved Mixed forest | 32 | 6.15–16.16 | 10.28 | 3.21~8.56 | 4.92 | 1440~2550 | 1241 | 0.7~0.9 |
| Forest Tree Species | Coefficient of Carbon |
|---|---|
| Pinus massoniana | 0.5254 |
| Slash pine | 0.4756 |
| Quercus acutissima | 0.4827 |
| Broad-leaved mixed forest | 0.4900 |
| Vegetation Index | A Formula to Calculate |
|---|---|
| RVI | |
| NDVI | |
| EVI | |
| DVI | |
| SAVI | |
| GNDVI | |
| IPVI | |
| MTCI | |
| NDREI |
| GLCM | A Formula to Calculate |
|---|---|
| ME | |
| VAR | |
| HOM | |
| CON | |
| DIS | |
| ENT | |
| ASM | |
| COR |
| Multi-Tree Species | Correlation | Pinus massoniana | Correlation | Slash pine | Correlation | Quercus acutissima | Correlation | |
|---|---|---|---|---|---|---|---|---|
| GF-2 | pca1GF-2 | 0.348 | pca1GF-2 | 0.327 ** | b3_mean_5 | 0.489 ** | band2 | −0.565 ** |
| band1 | 0.364 | band1 | 0.419 ** | band 3 | 0.412 ** | b3_mean_13 | −0.625 ** | |
| b1-mean-3 | 0.430 | b1_mean_5 | 0.268 ** | |||||
| b1_hom_3 | −0.579 | b3_hom_13 | 0.538 ** | |||||
| b3_var_5 | 0.255 ** | b3_var_3 | −0.624 ** | |||||
| Terrain | SLOPE | 0.325 | SLOPE | 0.500 ** | SLOPE | 0.28 | ||
| DEM | 0.547 ** | |||||||
| GF-6 | MTCI | 0.487 ** | PCA1GF-6 | −0.369 ** | NDVI | 0.427 ** | MTCI | 0.449 * |
| B5_mean_13 | 0.540 | Band6 | −0.416 ** | PCA1 GF-6 | 0.352 ** | Band6 | −0.502 ** | |
| GNDVI | −0.217 * | Band4 | 0.405 ** | GNDVI | 0.376 * | |||
| PCA1GF-6 | −0.523 * | |||||||
| GF-3 | HVgamma HVsigma | 0.226 ** 0.227 ** | HVsigma | 0.219 | HVsigma | 0.225 | HVgamma | 0.258 * |
| Sapling Forest | Correlation | Half-Mature Forest | Correlation | Near-Mature Forest | Correlation | Over-Mature Forest | Correlation | Mature Forest | Correlation | |
|---|---|---|---|---|---|---|---|---|---|---|
| GF-2 | band3 | 0.256 ** | band2 | 0.376 ** | b4_mean_13 | 0.355 ** | band1 | −0.389 ** | band1 | −0.491 ** |
| b3_mean_5 | 0.275 ** | b2_mean_5 | 0.275 ** | band 3 | 0.368 ** | b3_hom_13 | −0.548 ** | b3_var_5 | −0.625 ** | |
| b3_var_5 | 0.455 ** | b3_cor_3 | −0.593 | b4_var_5 | 0.286 | b3_mean_13 | 0.633 | |||
| b2_ent_3 | −0.238 | b3_var_3 | −0.624 ** | |||||||
| Terrain | SLOPE | 0.439 ** | SLOPE | 0.517 ** | SLOPE | 0.28 | SLOPE | 0.28 | ||
| DEM | 0.524 | |||||||||
| GF-6 | SAVI | −0.53 | MTCI | −0.278 ** | NDREI | −0.473 ** | RVI | 0.468 * | B3_mean_3 | 0.373 * |
| B2_mean_5 | 0.572 | Band6 | −0.528 ** | B1_mean_3 | 0.527 | B6_mean_3 | −0.524 ** | Band6 | −0.488 ** | |
| GNDVI | −0.207 * | B1_mean_13 | 0.326 | NDREI | 0.382 * | NDREI | 0.397 * | |||
| PCA1GF-6 | −0.345 | MTCI | −0.285 * | |||||||
| GF-3 | HVsigma | 0.215 | HVsigma | 0.223 ** | HVgamma | 0.218 ** | HVgamma | 0.256 * | HVgamma HVsigma | 0.373 * 0.262 |
| Multi-Tree Species | R2 | RMSE (t/ha) /(t·hm−2) | F | Sig | |
|---|---|---|---|---|---|
| GF-2 | AGC = 0.128 × DEM + 0.267 × pca1 − 2.107 × b1_hom_3 −+ 12.457 × band1 + 4362.039 | 0.465 | 30.78 | 67.536 | 0 |
| GF-6 | AGC = 468.056 × MTCI + 1.576 × SLOPE + 14.826 × B5_mean_13 − 1.543 × GNDVI + 537.297 | 0.429 | 30.12 | 58.673 | 0 |
| GF-2&GF-6 | AGC = 1013.454 × MTCI + 1.683 × SLOPE + 561.873 × GNDVI + 0.263 × DEM + 7693.412 × b1_mean_3 − 0.42 × b3_var_5 + 542.861 | 0.538 | 28.01 | 51.498 | 0 |
| GF-2&GF-6&GF-3 | AGC = 824.31 × DEM + 3.586 × SLOPE + 482.16 × MTCI + 692.43 × b1_hom_3 ++ 0.23 × HV_sigma + 0.56 × HV_gamma + 592.432 | 0.649 | 25.14 | 46.489 | 0 |
| Pinus massoniana | |||||
| GF-2 | AGC = 4.13 × SLOPE + 0.547 × b3_var_3 − 2.357 × b3_hom_13 − 84.93 × band1 + 2315.364 | 0.514 | 17.25 | 38.279 | 0 |
| GF-6 | AGC = −5.384 × SLOPE − 2.548 × Band6 − 1.026 × PCA1 + 42.513 | 0.327 | 29.53 | 25.974 | 0 |
| GF-2&GF-6 | AGC = 5.317 × SLOPE + 6.482 × Band6 − 0.027 × PCA1 + 0.725 × b3_var_3 + 634.825 × b3_hom_13 + 516.089 | 0.589 | 16.29 | 34.171 | 0 |
| GF-2&GF-6&GF-3 | AGC = 3.574 × SLOPE + 1.035 × PCA1 − 13.541 × b3_var_3 − 1.164 × Band6 + 128.49 × band1 + 0.063 × HVsigma + 504.196 | 0.614 | 12.28 | 30.562 | 0 |
| Slash pine | |||||
| GF-2 | AGC = 0.057 × b3_mean_5 + 135.27 × band3 + 128.574 | 0.372 | 13.35 | 19.273 | 0 |
| GF-6 | AGC = 154.29 × NDVI − 1.569 × PCA1 + 3.67 × Band4 + 328.154 | 0.294 | 14.12 | 11.157 | 0 |
| GF-2&GF-6 | AGC = 0.058 × Band4 + 153.47 × b3_mean_5 + 0.027 × band3 + 159.262 | 0.405 | 14.01 | 15.147 | 0 |
| GF-2&GF-6&GF-3 | AGC = 1.472 × band3 + 0.013 × b3_mean_5 − 128.251 × PCA1 + 275.13 × NDVI + 0.254 × HVsigma + 783.45 | 0.496 | 13.23 | 9.174 | 0 |
| Quercus acutissima | |||||
| GF-2 | AGC = 0.218 × SLOPE + 1.517 × band2−11.974 × b3_mean_13 + 1047.17 | 0.521 | 42.07 | 18.138 | 0 |
| GF-6 | AGC = 894.271 × MTCI − 20.15 × PCA1 + 1182.3 × Band6 + 138.2 | 0.584 | 32.56 | 23.384 | 0 |
| GF-2&GF-6 | AGC = 681.29 × MTCI−0.35 × band2 − 0.272 × Band6 + 774.15 × b3_mean_13 + 579.24 | 0.612 | 29.71 | 21.147 | 0 |
| GF-2&GF-6&GF-3 | AGC = 0.013 × GNDVI + 134.56 × MTCI − 0.21 × band2 − 32.54 × PCA1 + 115.32 × b3_mean_13 + 0.258 × HVgamma + 514.067 | 0.659 | 27.09 | 20.573 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, Y.; Chen, D.; Li, H.; Liu, C.; Liu, S.; Zhang, N.; Fan, J.; Jiang, D. Research on Estimating and Evaluating Subtropical Forest Carbon Stocks by Combining Multi-Payload High-Resolution Satellite Data. Forests 2023, 14, 2388. https://doi.org/10.3390/f14122388
Du Y, Chen D, Li H, Liu C, Liu S, Zhang N, Fan J, Jiang D. Research on Estimating and Evaluating Subtropical Forest Carbon Stocks by Combining Multi-Payload High-Resolution Satellite Data. Forests. 2023; 14(12):2388. https://doi.org/10.3390/f14122388
Chicago/Turabian StyleDu, Yisha, Donghua Chen, Hu Li, Congfang Liu, Saisai Liu, Naiming Zhang, Jingwei Fan, and Deting Jiang. 2023. "Research on Estimating and Evaluating Subtropical Forest Carbon Stocks by Combining Multi-Payload High-Resolution Satellite Data" Forests 14, no. 12: 2388. https://doi.org/10.3390/f14122388
APA StyleDu, Y., Chen, D., Li, H., Liu, C., Liu, S., Zhang, N., Fan, J., & Jiang, D. (2023). Research on Estimating and Evaluating Subtropical Forest Carbon Stocks by Combining Multi-Payload High-Resolution Satellite Data. Forests, 14(12), 2388. https://doi.org/10.3390/f14122388