Application of the YOLOv6 Combining CBAM and CIoU in Forest Fire and Smoke Detection



Abstract
:1. Introduction
- Most of the existing pyrotechnic detection techniques in the YOLO series use YOLOv5 as the benchmark model. To verify the performance of other techniques, we innovatively choose YOLOv6 to be the baseline model.
- Based on the original model, we introduce the CBAM attention mechanism so that the model achieves efficient inference in hardware while maintaining a better multi-scale feature fusion capability. We use CIoU as the loss function of the model as a way to obtain higher detection accuracy. In addition, we added an automatic mixed-precision AMP when training the model. It can be calculated with different data precision for different layers in the neural network inference process, thus realizing the purpose of saving video memory and speeding up the process. The detection accuracy of the model is further improved.
- We collected part of the public firework dataset independently and supplemented it with other datasets that were labeled. After data cleaning, we produced high-quality datasets. We conducted experiments on our data for comparison and validation. The final experimental results prove the merits of the model in this paper.
2. Datasets
3. Methods
3.1. Excellent Network Design
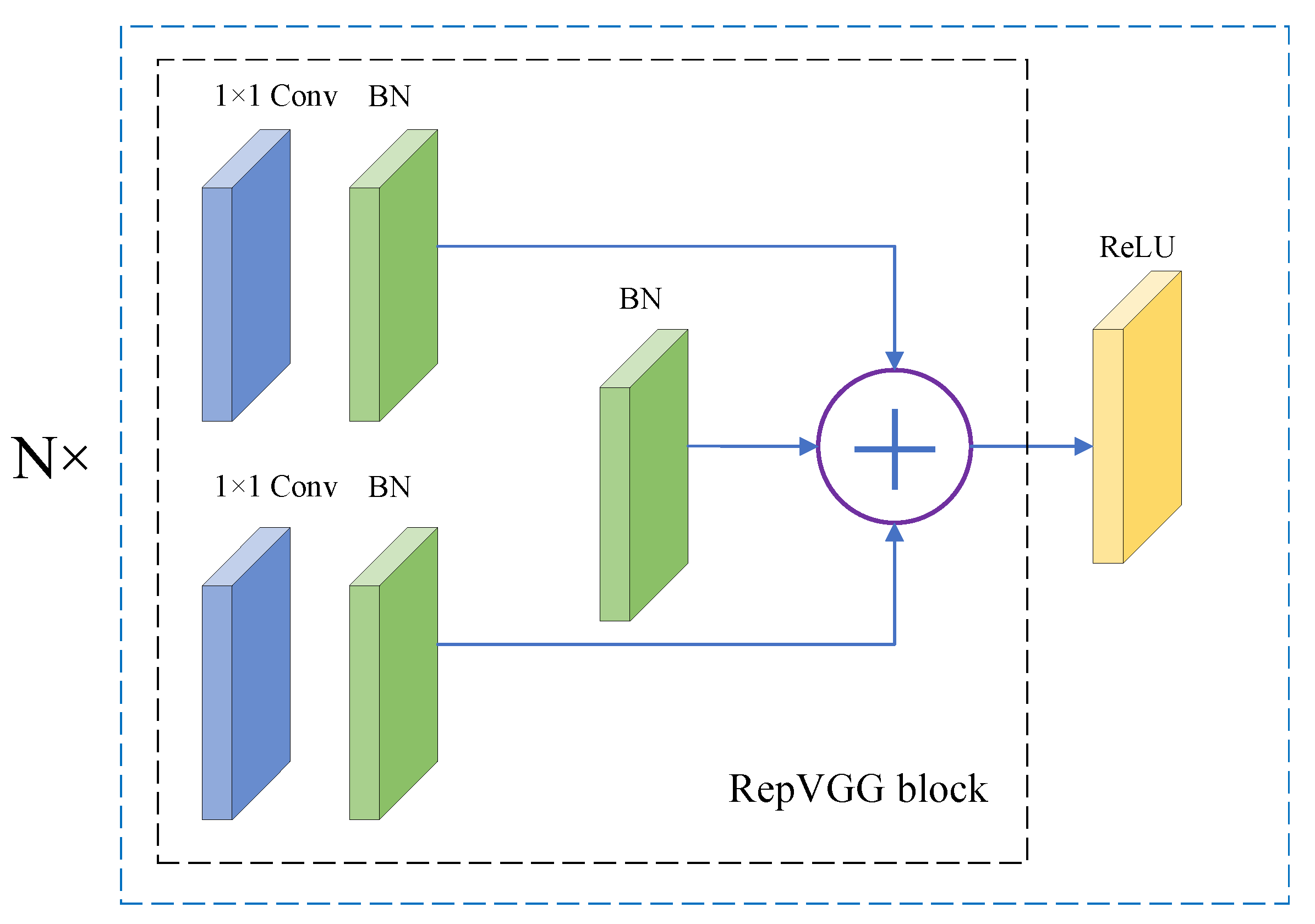
3.1.1. Backbone Network
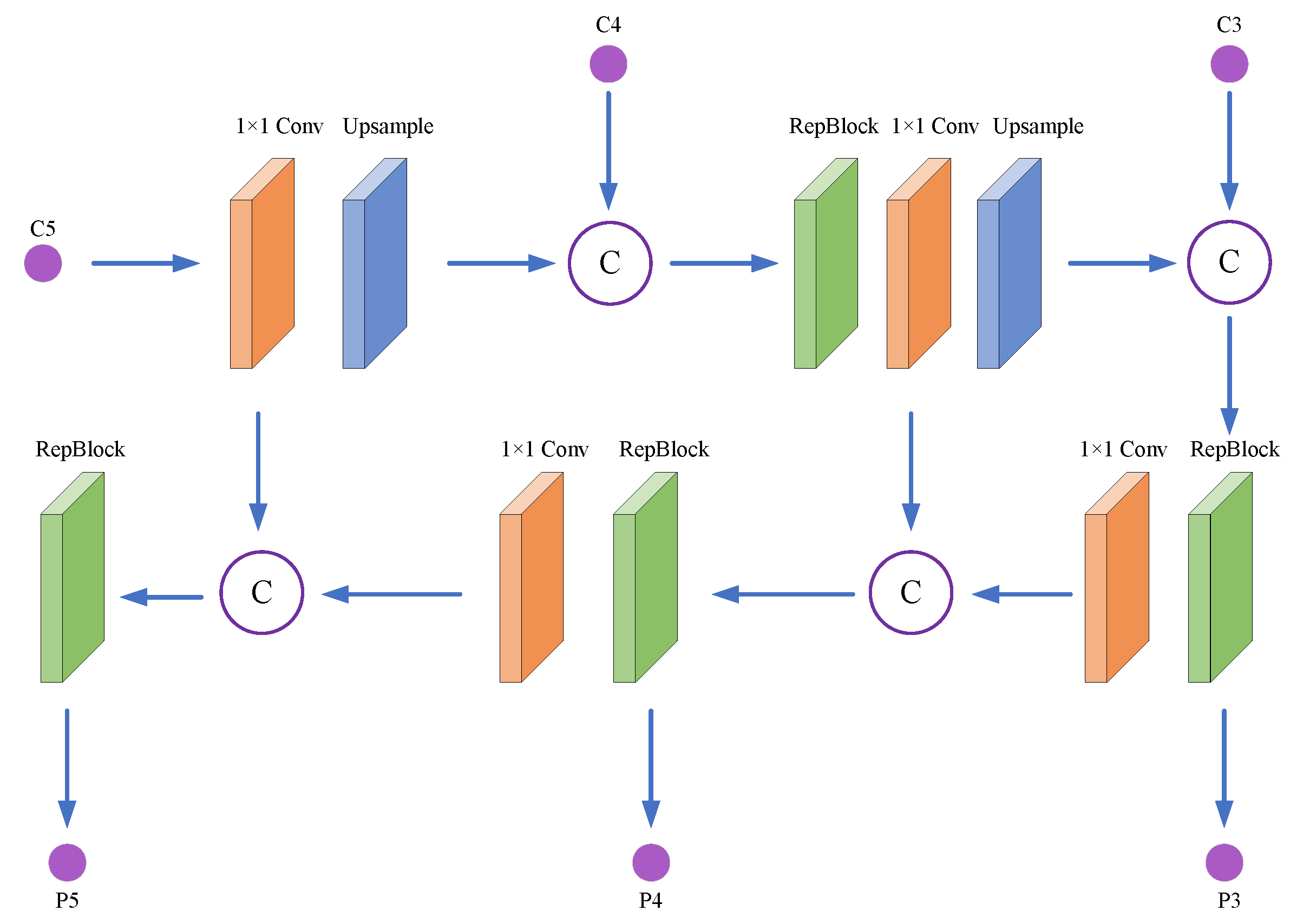
3.1.2. Neck Network
3.1.3. Head Network
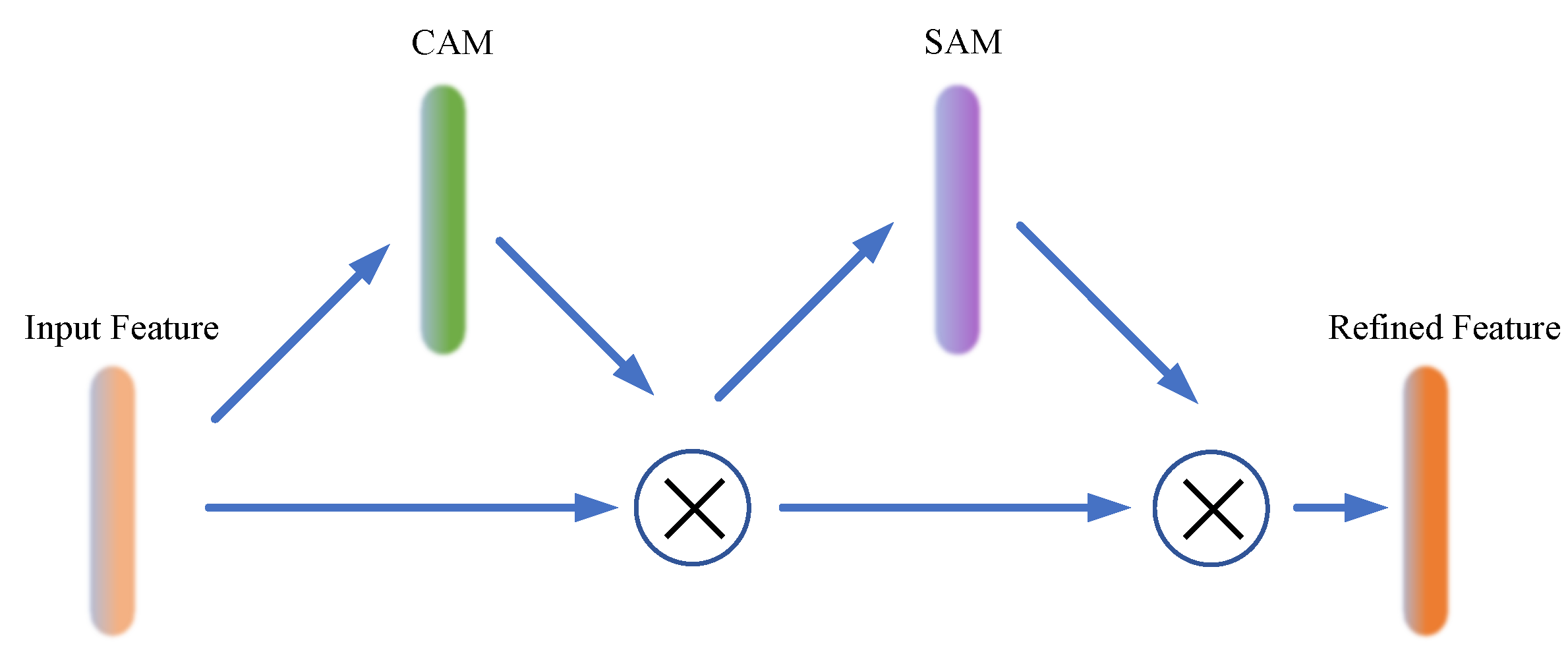
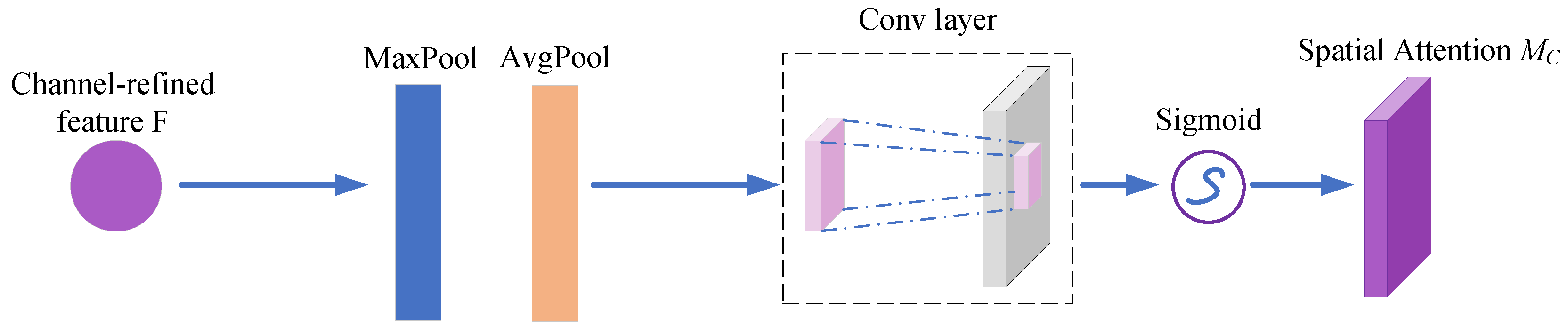
3.2. Effective Attention Mechanisms
3.3. Suitable Loss Function
4. Experiment
4.1. Experimental Setup
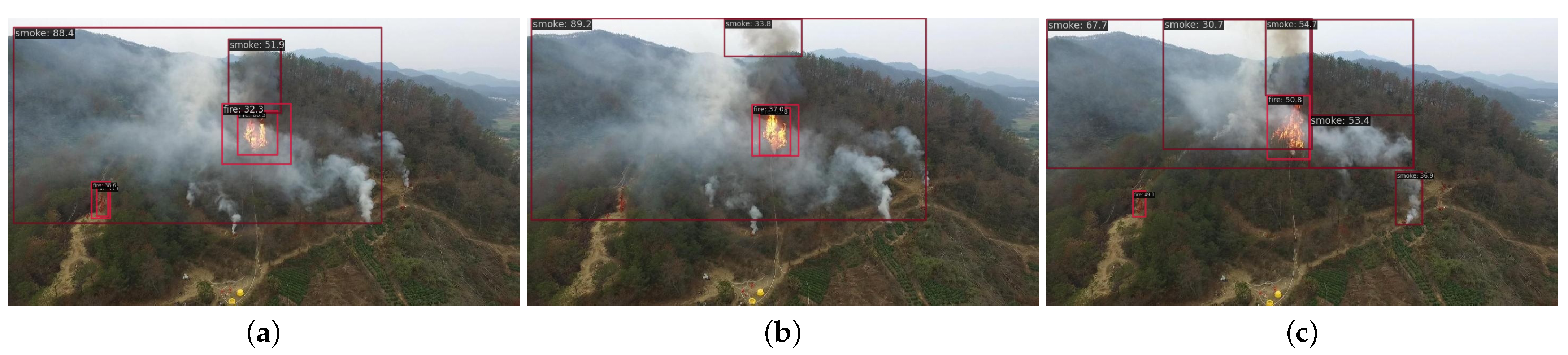
4.2. Method Comparison and Visualization
5. Current Challenges and Future Directions
5.1. Feature Extraction
5.2. Lightweight Network Framework
5.3. Datasets
5.4. Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Li, W.; Han, N.; Kan, J. Forest fire detection system based on a ZigBee wireless sensor network. Front. For. China 2008, 3, 369–374. [Google Scholar] [CrossRef]
- Aslan, Y.E.; Korpeoglu, I.; Ulusoy, Ö. A framework for use of wireless sensor networks in forest fire detection and monitoring. Comput. Environ. Urban Syst. 2012, 36, 614–625. [Google Scholar] [CrossRef]
- Dener, M.; Özkök, Y.; Bostancıoğlu, C. Fire detection systems in wireless sensor networks. Procedia-Soc. Behav. Sci. 2015, 195, 1846–1850. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, L.; Li, T.; Shi, P. A smoke detection model based on improved YOLOv5. Mathematics 2022, 10, 1190. [Google Scholar] [CrossRef]
- Chen, W.; Liu, P.; Liu, Y.; Wang, Q.; Duan, W. A temperature-induced conductive coating via layer-by-layer assembly of functionalized graphene oxide and carbon nanotubes for a flexible, adjustable response time flame sensor. Chem. Eng. J. 2018, 353, 115–125. [Google Scholar] [CrossRef]
- Jia, Y.; Chen, W.; Yang, M.; Wang, L.; Liu, D.; Zhang, Q. Video smoke detection with domain knowledge and transfer learning from deep convolutional neural networks. Optik 2021, 240, 166947. [Google Scholar] [CrossRef]
- He, L.; Gong, X.; Zhang, S.; Wang, L.; Li, F. Efficient attention based deep fusion CNN for smoke detection in fog environment. Neurocomputing 2021, 434, 224–238. [Google Scholar] [CrossRef]
- Pan, J.; Ou, X.; Xu, L. A collaborative region detection and grading framework for forest fire smoke using weakly supervised fine segmentation and lightweight faster-RCNN. Forests 2021, 12, 768. [Google Scholar] [CrossRef]
- Li, F.; Yao, D.; Jiang, M.; Kang, X. Smoking behavior recognition based on a two-level attention fine-grained model and EfficientDet network. J. Intell. Fuzzy Syst. 2022, 43, 5733–5747. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, L. Using popular object detection methods for real time forest fire detection. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 1, pp. 280–284. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, X.; Xu, Z.; Shen, X.; Zhou, Y.; Xiao, B.; Li, T.Q. Detection of cervical cancer cells in whole slide images using deformable and global context aware faster RCNN-FPN. Curr. Oncol. 2021, 28, 3585–3601. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zell, A. Yolo+ FPN: 2D and 3D fused object detection with an RGB-D camera. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4657–4664. [Google Scholar]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1997–2017. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV); 2018; pp. 3–19. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. Damo-yolo: A report on real-time object detection design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans. Geosci. Rem. Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Guan, Y.; Aamir, M.; Hu, Z.; Abro, W.A.; Rahman, Z.; Dayo, Z.A.; Akram, S. A Region-Based Efficient Network for Accurate Object Detection. Traitement du Signal 2021, 38. [Google Scholar] [CrossRef]
- Tao, Y.; Zongyang, Z.; Jun, Z.; Xinghua, C.; Fuqiang, Z. Low-altitude small-sized object detection using lightweight feature-enhanced convolutional neural network. J. Syst. Eng. Electron. 2021, 32, 841–853. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number of Fire | Number of Smoke | Image Amount |
|---|---|---|---|
| train | 2015 | 1822 | 1576 |
| test | 688 | 597 | 525 |
| val | 632 | 625 | 525 |
| Method | FLOPs | Params | FPS | mAP | |||
|---|---|---|---|---|---|---|---|
| YOLOv5 | 53.975G | 46.144M | 30.64 | 0.329 | 0.223 | 0.091 | 0.548 |
| YOLOv6 | 21.882G | 17.188M | 33.9 | 0.396 | 0.232 | 0.105 | 0.592 |
| YOLOv7 | 51.749G | 36.508M | 10 | 0.308 | 0.211 | 0.082 | 0.547 |
| YOLOv8 | 82.557G | 43.631M | 46.1 | 0.409 | 0.245 | 0.111 | 0.598 |
| YOLOX | 77.659G | 54.149M | 42.3 | 0.368 | 0.211 | 0.068 | 0.586 |
| Ours | 21.883G | 17.23M | 32.5 | 0.421 | 0.241 | 0.106 | 0.619 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, A.; Liang, G.; Wang, X.; Song, Y. Application of the YOLOv6 Combining CBAM and CIoU in Forest Fire and Smoke Detection. Forests 2023, 14, 2261. https://doi.org/10.3390/f14112261
Wang A, Liang G, Wang X, Song Y. Application of the YOLOv6 Combining CBAM and CIoU in Forest Fire and Smoke Detection. Forests. 2023; 14(11):2261. https://doi.org/10.3390/f14112261
Chicago/Turabian StyleWang, Aoran, Guanghao Liang, Xuan Wang, and Yongchao Song. 2023. "Application of the YOLOv6 Combining CBAM and CIoU in Forest Fire and Smoke Detection" Forests 14, no. 11: 2261. https://doi.org/10.3390/f14112261
APA StyleWang, A., Liang, G., Wang, X., & Song, Y. (2023). Application of the YOLOv6 Combining CBAM and CIoU in Forest Fire and Smoke Detection. Forests, 14(11), 2261. https://doi.org/10.3390/f14112261