
PointDMS: An Improved Deep Learning Neural Network via Multi-Feature Aggregation for Large-Scale Point Cloud Segmentation in Smart Applications of Urban Forestry Management


Abstract
:1. Introduction
2. Materials and Methods
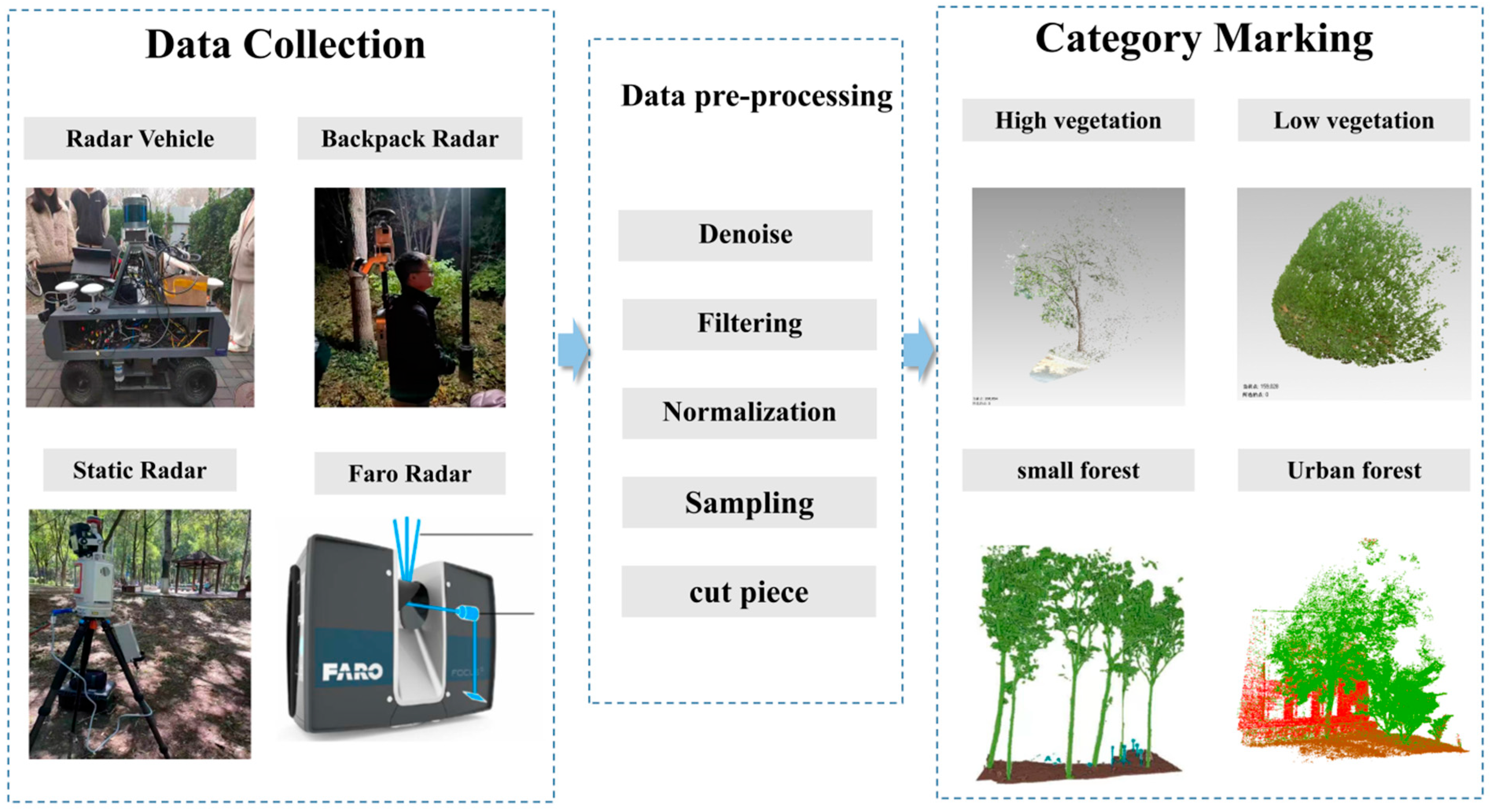
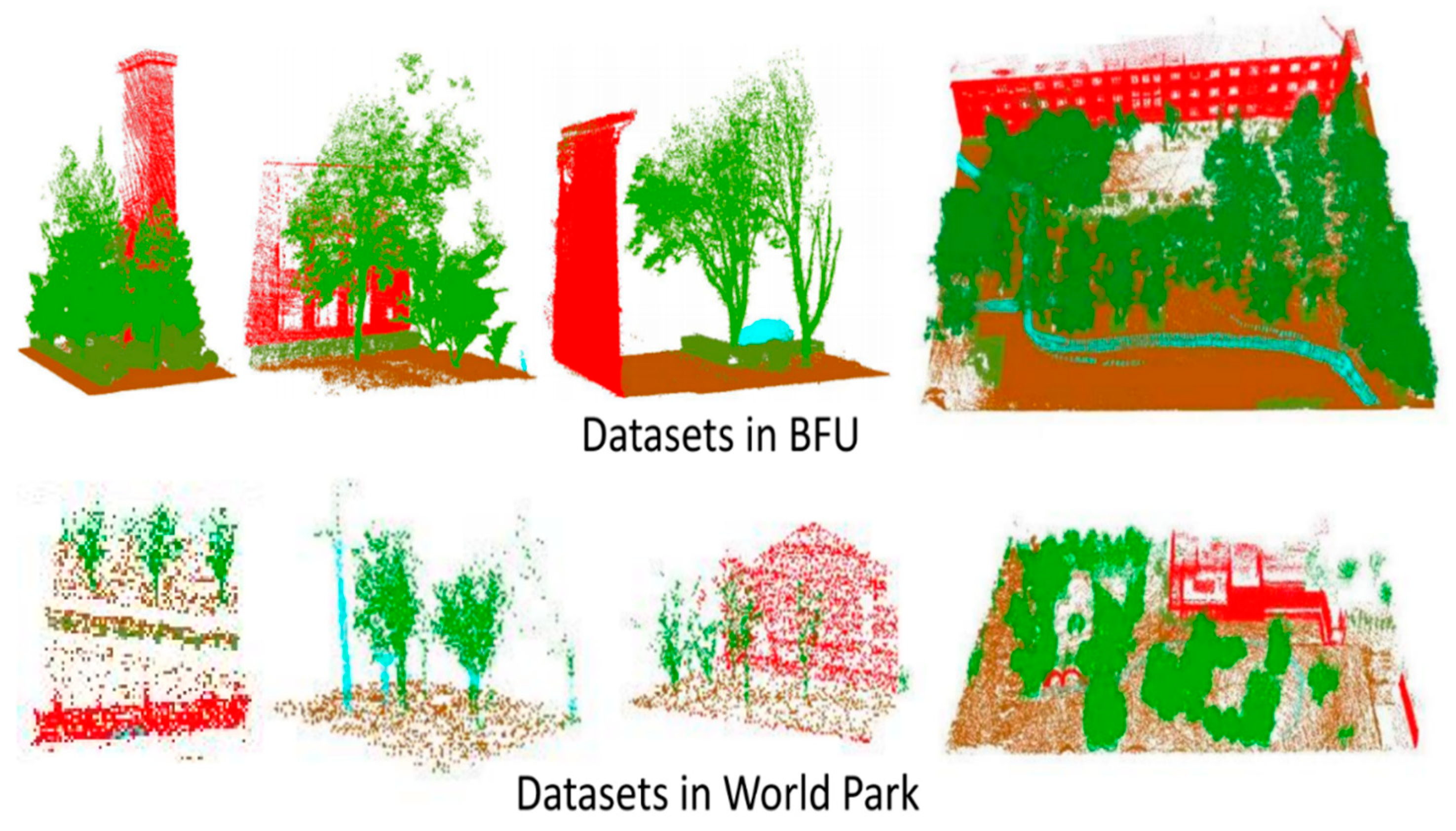
2.1. DMS Dataset in Urban Forestry Scenes
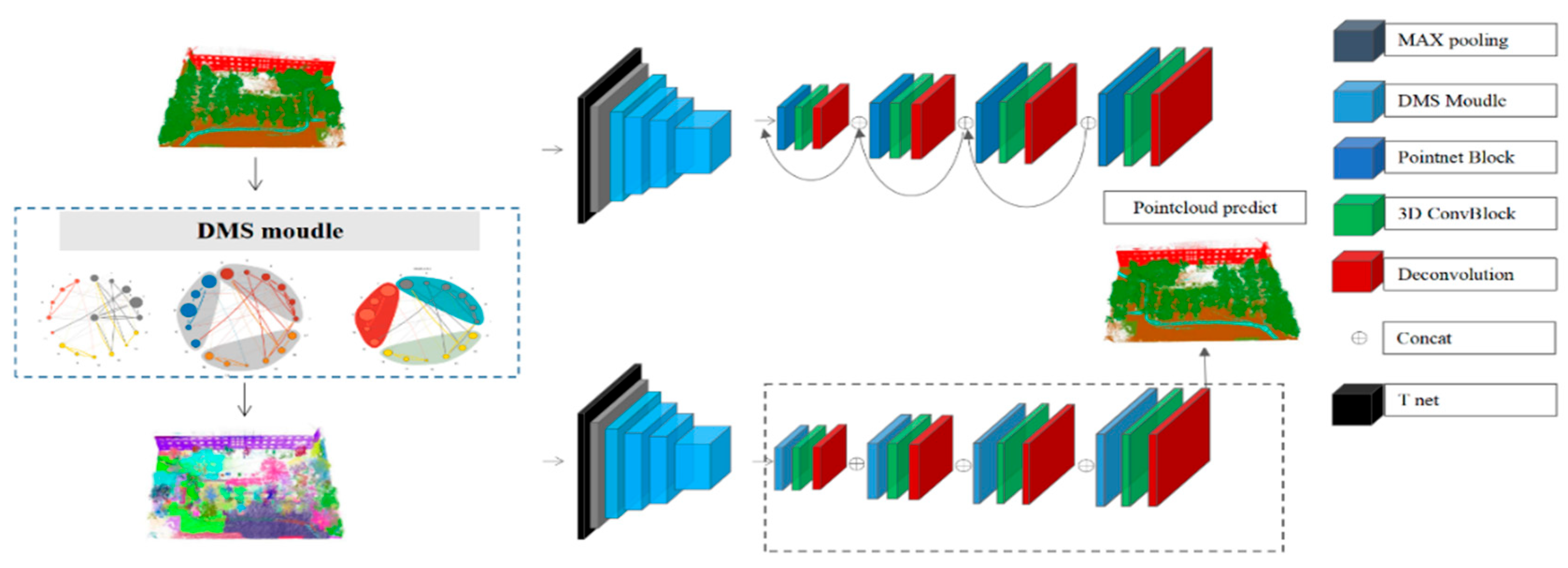
2.2. Pre-Segmentation Module DMS
2.3. PointDMS Framework
| Algorithm 1: Greedy graph-cut pursuit algorithm to optimize 3D point cloud over-segmentation. |
| Extraction of point cloud features linearity, planarity, and scattering Aggregation of effective point cloud features Construct the energy function Optimizing Q(x), create node diagram L repeat connected components of elements of find , stationary point of find minimizing maximal constant with until Input the optimized segmentation results into PointDMS training Obtain optimal segmentation results |
3. Results and Discussion
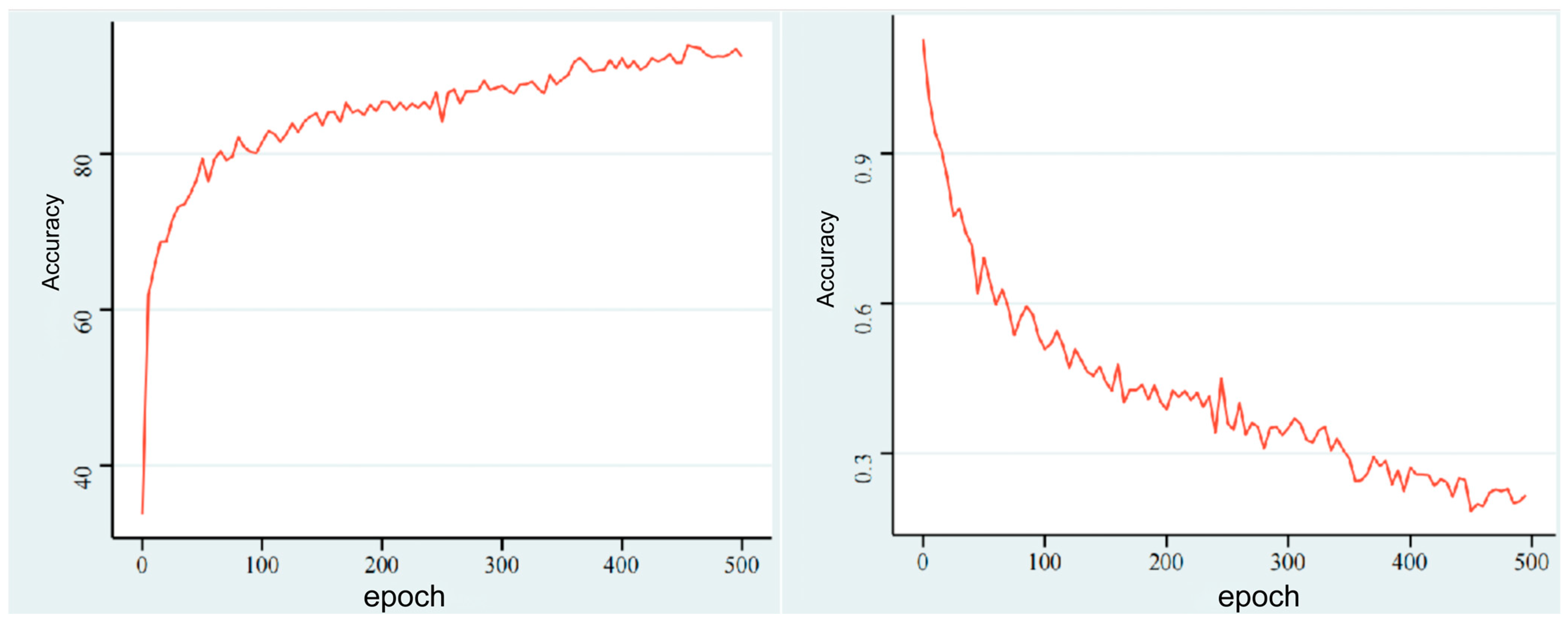
3.1. Model Sets and Evaluation
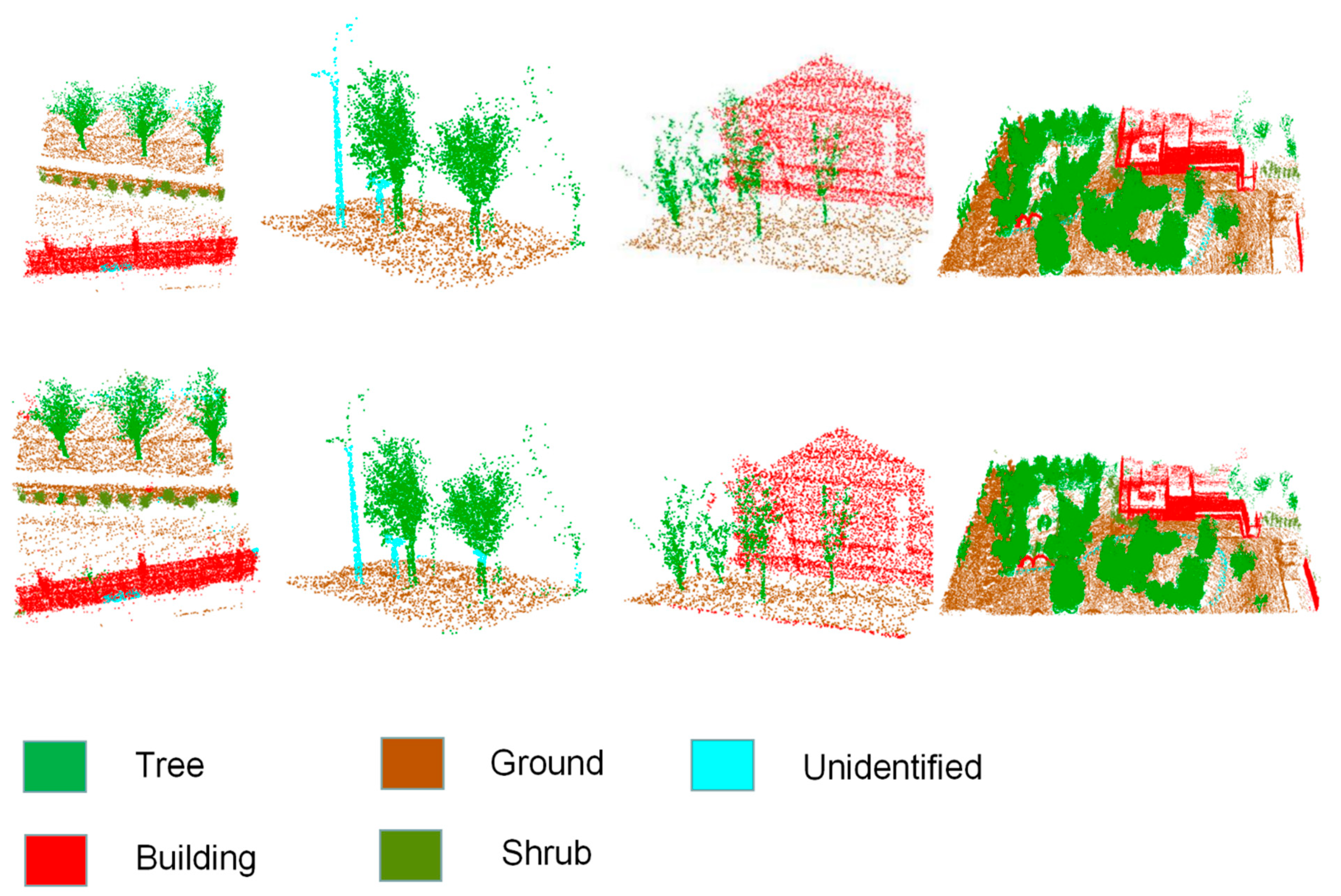
3.2. PointDMS Data Processing Results
3.3. Large-Scale Point Cloud Segmentation Results
3.4. Validity Analysis of Living Tree Identification
4. Discussion
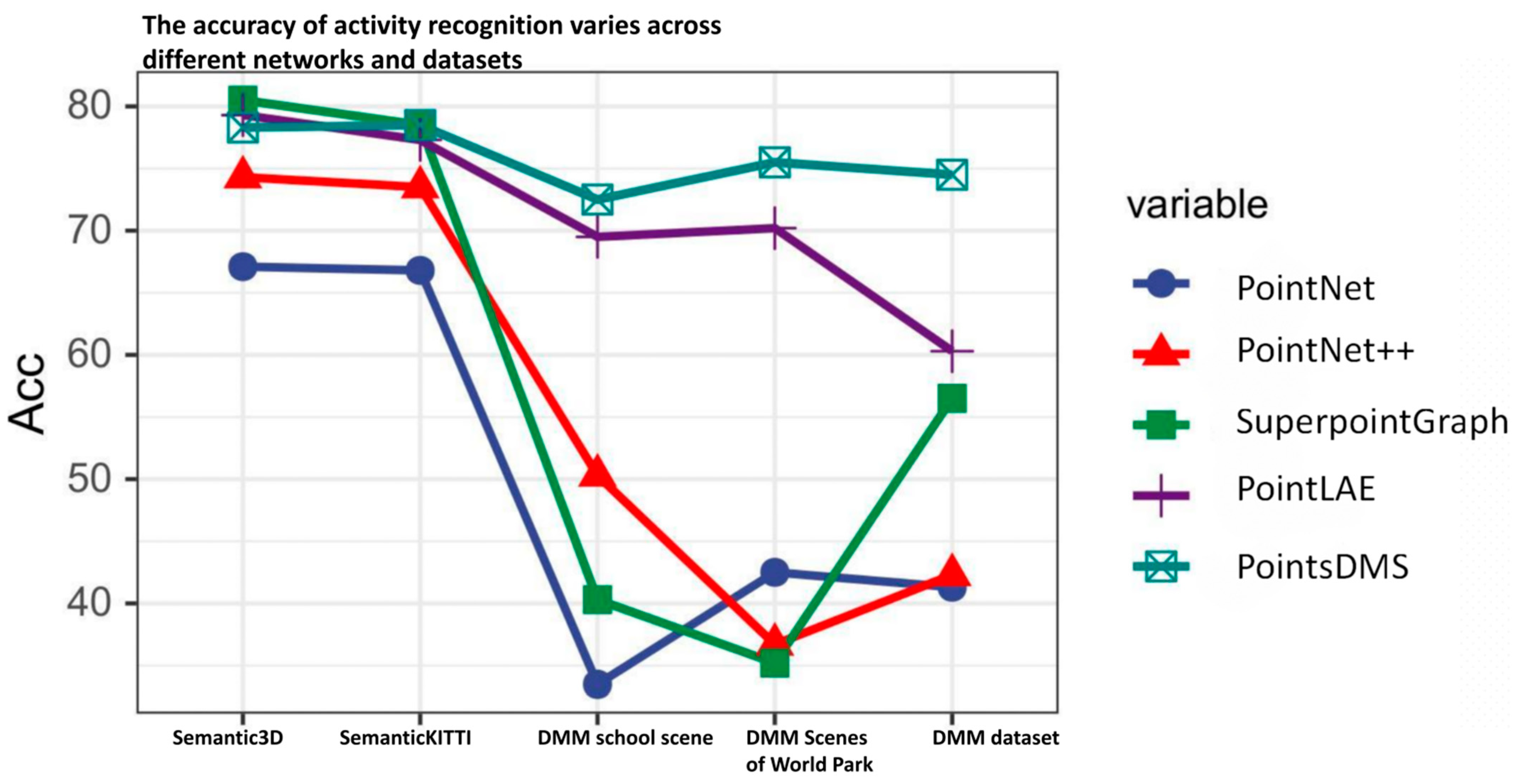
4.1. Evaluating PointDMS
4.2. Comparison with Similar Methodologies
4.3. Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nelson, R.; Krabill, W.; MacLean, G. Determining forest canopy characteristics using airborne laser data. Remote Sens. Environ. 1984, 15, 201–212. [Google Scholar] [CrossRef]
- Schreier, H.; Lougheed, J.; Tucker, C.; Leckie, D. Automated measurements of terrain reflection and height variations using an airborne infrared laser system. Int. J. Remote Sens. 1985, 6, 101–113. [Google Scholar] [CrossRef]
- Simonse, M.; Aschoff, T.; Spiecker, H.; Thies, M. Automatic determination of forest inventory parameters using terrestrial laser scanning. In Proceedings of the Scandlaser Scientific Workshop on Airborne Laser Scanning of Forests, Umeå, Sweden, 26 May 2003; pp. 252–258. [Google Scholar]
- Golovinskiy, A.; Kim, V.G.; Funkhouser, T. Shape-based recognition of 3D point clouds in urban environments. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2154–2161. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, L.; Zhang, X.; Tang, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition: 2015 28th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; Institute of Electrical and Electronics Engineers: New York, NY, USA, 2015; pp. 1912–1920. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2015), Hamburg, Germany, 28 September–2 October 2015; Institute of Electrical and Electronic Engineerings, Inc.: New York, NY, USA, 2015; Volume 2, pp. 922–928. [Google Scholar]
- Charles Ruizhongtai, Q.; Hao, S.; Matthias, N.; Angela, D.; Mengyuan, Y.; Leonidas, J.G. Volumetric and Multi-view CNNs for Object Classification on 3D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, San Juan, PR, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Li, Y.; Pirk, S.; Su, H.; Charles, R.Q.; Leonidas, J. FPNN: Field Probing Neural Networks for 3D Data. arXiv 2016, arXiv:1605.06240. [Google Scholar]
- Wang, D.Z.; Ingmar, P. Voting for Voting in Online Point Cloud Object Detection. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 17 July 2015. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view Convolutional Neural Networks for 3D Shape Recognition. arXiv 2015, arXiv:1505.00880. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 264–272. [Google Scholar]
- Charles, R.Q.; Su, H.; Mo, K.; Guibas, J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. arXiv 2016, arXiv:1612.00593. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing local neighborhood features for point cloud processing. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jiang, M. PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Duan, Y.; Zheng, Y.; Lu, J.; Zhou, J.; Tian, Q. Structural relational reasoning of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 949–958. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Liu, X.; Qi, C.R.; Guibas, L.J. FlowNet3D: Learning Scene Flow in 3D Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral Networks and Locally Connected Networks on Graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Masci, J.; Boscaini, D.; Bronstein, M.M.; Vandergheynst, P. Geodesic Convolutional Neural Networks on Riemannian Manifolds. arXiv 2015, arXiv:1501.06297. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. arXiv 2019, arXiv:1904.0888. [Google Scholar]
- Lan, S.; Yu, R.; Yu, G.; Larry, S.D. Modeling local geometric structure of 3D point clouds using GeoCNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 998–1008. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep convolutional networks on 3D point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Hermosilla, P.; Ritschel, T.; Pere-Pau, V.; Alvar, V.; Timo, R. Monte Carlo convolution for learning on non-uniformly sampled point clouds. ACM Trans. Graph. 2018, 37, 1–12. [Google Scholar] [CrossRef]
- Simonovsky, M.; Komodakis, N. Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2017; Volume 1, pp. 29–38. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Najibi, M.; Rastegari, M.; Davis, L.S. G-CNN: An Iterative Grid Based Object Detector. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, C.; Li, G.; Xu, R.; Chen, T.; Wang, M.; Lin, L. ClusterNet: Deep hierarchical cluster network with rigorously rotation-invariant representation for point cloud analysis. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4994–5002. [Google Scholar]
- Huang, Q.; Jiang, L.; Yang, Y.; Qin, H.; Zhang, J. Point Cloud Segmentation and Recognition Deep Learning Dataset for Ornamental trees and Shrubs Environment. Rev. Fac. Agron. Univ. Zulia 2019, 6, 2. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d.Net: A New Large-Scale Point Cloud Classification Benchmark. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2017, IV-1/W1, 91–98. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A Dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9296–9306. [Google Scholar]
- Daniel Munoz, J.; Andrew, B.; Nicolas, V.; Martial, H. Contextual Classification with Functional Max-Margin Markov Networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2009. [Google Scholar]
- Steder, B.; Grisetti, G.; Burgard, W. Robust Place Recognition for 3D Range Data Based on Point Features. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–8 May 2010; pp. 1400–1405. [Google Scholar]
- Behley, J.; Steinhage, V.; Cremers, A.B. Performance of Histogram Descriptors for the Classification of 3D Laser Range Data in Urban Environments. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), St. Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Roynard, X.; Deschaud, J.-E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2018, 37, 545–557. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Guinard, S.; Landrieu, L. Weakly supervised segmentation-aided classification of urban scenes from 3D LiDAR point clouds. ISPRS Workshop 2018, 3, 1321. [Google Scholar] [CrossRef]
- Chen, T.; Carlos, G. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs. arXiv 2017, arXiv:1711.09869. [Google Scholar]
- Li, J.; Liu, J. PointLAE: A Point Cloud Semantic Segmentation Neural Network via Multifeature Aggregation for Large-Scale Application. Mob. Inf. Syst. 2022, 2022, 9433661. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instrument Modules | Indicators | Specific Parameters |
|---|---|---|
| Laser | Laser Class | Level 1 |
| Wavelength | 1550 nm | |
| Beam divergence | 0.3 mrad (0.024°) | |
| Beam diameter (exit) | 2.12 mm | |
| Beam diameter (exit) | Accuracy | 1 mm |
| Angular accuracy | Horizontal + Vertical:19 arcs | |
| Range | 0.6–350 m, Indoor or outdoor | |
| Measuring speed (pts/sec) | 122,000/244,000/488,000/976,000 | |
| Ranging Error | ±1 mm | |
| Color unit | Resolution | Maximum 165 megapixel color |
| HDR | 2×, 3×, 5× | |
| Parallax | Coaxial design | |
| Deflection unit | Field of view (vertical/horizontal) | 300°/360° |
| Step size | 0.009° (40960 3D-Pixel on 360°) | |
| 5820 rpm 97 Hz | ||
| Multi-sensor | Dual-Axis Compensator | Leveling each scan: Accuracy 0.019°; size ± 2° |
| Altitude Sensor | Detection of the height relative | |
| Altitude | <2000 m | |
| Compass | Electronic compass provides | |
| GPS | Integrated GPS receiver |
| Training Hyperparameters | Parameter Values |
|---|---|
| Sensors | TOF method ranging 16 channels |
| Measurement: 40 cm to 150 m (20% target reflectivity) | |
| Accuracy: ±2 cm | |
| Angle of view (vertical): ±15° (30° total) | |
| Angular resolution (vertical): 2° Viewing angle (horizontal): 360° | |
| Angular resolution (horizontal/azimuth): 0.1° (5 Hz) to 0.4° (20 Hz) | |
| Speed: 300/600/1200 rpm (5/10/20 Hz) | |
| Laser | Class 1 |
| Wavelength: 905 nm | |
| Laser Emission Angle (full angle): 7.4 mrad horizontal, 1.4 mrad vertical | |
| Output | ~300 k dots/s |
| 100 Gigabit Ethernet | |
| UDP packets contain | |
| Distance information | |
| 16 line parameters | |
| Rotation angle information | |
| Calibrated reflectivity information | |
| Mechanical/electronic operation | Power consumption: 12 w (typical) |
| Operating voltage: 9–32 VDC (requires interface box and stable power supply) | |
| Weight: 0.87 kg (excluding data cable) | |
| Operating voltage: 9–32 VDC (requires interface box and stable power supply) | |
| Weight: 0.87 kg (excluding data cable) | |
| Dimensions: Diameter 109 mm × Height 80.7 mm | |
| Protection and safety level: IP67 | |
| Operating ambient temperature range: −30 °C~60 °C | |
| Storage ambient temperature range: −40 °C~85 °C |
| Dataset | Scenes | Points (Millions) | Classes | Sensor | Annotation |
|---|---|---|---|---|---|
| SemanticKITTI [31] | 23,201 | 4549 | 25 | Velodyne HDL-64E | point-wise |
| Oakland3d [32] | 17 | 1.6 | 5 | SICK LMS | point-wise |
| Freiburg [33] | 77 | 1.1 | 4 | SICK LMS | point-wise |
| Wachtberg [34] | 5 | 0.4 | 5 | Velodyne HDL-64E | point-wise |
| Semantic3d [30] | 15/15 | 4009 | 8 | Terrestrial Laser Scanner | point-wise |
| Paris-Lille-3D [35] | 3 | 143 | 9 | Velodyne HDL-32E | point-wise |
| KITTI [36] | 7481 | 1799 | 3 | Velodyne HDL-64E | bounding box |
| DMS dataset | 13,680 | 1299 | 5 | RS16E; Faro64E | point-wise |
| Training Hyperparameters | Parameter Values |
|---|---|
| Initial KNN parameter selection | 10 |
| Maximum number of iterative steps | 5000 |
| Learning rate | 0.001 |
| beta1 | 0.9 |
| beta2 | 0.999 |
| Block Size | 80 |
| Accuracy | Method | |||||||
|---|---|---|---|---|---|---|---|---|
| PointNet++ [13] | PointNet [12] | PointLae [40] | Spg [39] | Kpconv [21] | PointCNN [17] | PointDMS | ||
| 500 epochs in scene c | Ground | 78.1% | 74.5% | 73.2% | 81.5% | 92.7% | 90.3% | 94.5% |
| Tree | 64.3% | 59.8% | 79.4% | 77.5% | 81.4% | 80.7% | 93.5% | |
| Shrub | 51.7% | 60.8% | 73.9% | 55.3% | 70.5% | 76.8% | 91.5% | |
| Building | 75.9% | 81.7% | 81.5% | 90.3% | 91.5% | 92.7% | 93.7% | |
| OA | 67.5% | 69.2% | 77.0% | 74.5% | 84.0% | 85.1% | 93.3% | |
| 1000 epochs in scene b | Ground | 78.1% | 74.5% | 73.2% | 75.0% | 92.0% | 90.0% | 80.1% |
| Tree | 64.3% | 59.8% | 79.4% | 78.0% | 65.0% | 79.0% | 87.5% | |
| Shrub | 51.7% | 60.8% | 73.5% | 71.0% | 68.0% | 70.0% | 77.5% | |
| Building | 75.9% | 81.7% | 81.6% | 94.0% | 96.0% | 95.0% | 92.1% | |
| OA | 67.5% | 69.2% | 76.9% | 79.5% | 80.3% | 83.8% | 84.3% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Liu, J. PointDMS: An Improved Deep Learning Neural Network via Multi-Feature Aggregation for Large-Scale Point Cloud Segmentation in Smart Applications of Urban Forestry Management. Forests 2023, 14, 2169. https://doi.org/10.3390/f14112169
Li J, Liu J. PointDMS: An Improved Deep Learning Neural Network via Multi-Feature Aggregation for Large-Scale Point Cloud Segmentation in Smart Applications of Urban Forestry Management. Forests. 2023; 14(11):2169. https://doi.org/10.3390/f14112169
Chicago/Turabian StyleLi, Jiang, and Jinhao Liu. 2023. "PointDMS: An Improved Deep Learning Neural Network via Multi-Feature Aggregation for Large-Scale Point Cloud Segmentation in Smart Applications of Urban Forestry Management" Forests 14, no. 11: 2169. https://doi.org/10.3390/f14112169
APA StyleLi, J., & Liu, J. (2023). PointDMS: An Improved Deep Learning Neural Network via Multi-Feature Aggregation for Large-Scale Point Cloud Segmentation in Smart Applications of Urban Forestry Management. Forests, 14(11), 2169. https://doi.org/10.3390/f14112169