1. Introduction
Trees can reduce urban air pollution and noise, prevent soil erosion, and beautify the environment, which is important for ecosystems. The identification and mapping of the composition of tree species and the analysis of spatial distribution of tree species is crucial for forest conservation and urban planning and management. The remote sensing technology, which has the advantages of covering large areas and revisiting after several hours or days, has been employed in tree species identification for decades [
1,
2]. As early as the 1960s, aerial photographs were explored for the recognition of tree species [
1]. In 1980, Walsh explored satellite data (such as Landsat) to identify and map 12 land-cover types, including seven coniferous forest types [
2]. Early studies on tree species classification were mainly conducted at the pixel level [
3,
4]. For example, Dymond et al. used multitemporal Landsat TM imagery to improve the classification accuracy of deciduous forests at the landscape scale [
3]. Tree species classification at individual tree level using high-resolution imagery can also date back to the 2000s [
5,
6,
7]. The related works were mainly conducted using high-resolution aerial photographs. The rapid development of platforms and sensors makes the availability of high-resolution multisource data, such as airborne hyperspectral imagery and airborne LiDAR data. Recently, a large number of works at individual tree level explored the use of airborne hyperspectral and LiDAR (light detection and ranging) data, or the combination of the two [
8]. Studies showed that the individual tree species (ITS) classification using the combined airborne hyperspectral images and airborne LiDAR data obtained higher accuracy than a single data source [
9,
10,
11,
12,
13]. For example, hyperspectral and LiDAR data were fused at pixel-level by Jones et al. [
9] and then employed to classify 11 tree species in temperate forests of coastal southwestern Canada. The classification using a support vector machine (SVM) achieved an overall accuracy (OA) of 73.5%. Furthermore, individual tree crown-based classification has been demonstrated to perform better than pixel-based classification. Alonzo et al. [
10] used the fusion of airborne visible/infrared imaging spectrometer (AVIRIS) imagery and airborne LiDAR data to map 29 common tree species at tree crown level in an urban area of the USA, which yielded an OA of 83.4% using canonical discriminant analysis. Shen and Cao [
11] employed random forest (RF) to classify individual tree crowns using airborne hyperspectral and LiDAR data covering a subtropical forest in southeast China. An OA of 90.6% was achieved by the classification using both hyperspectral and LiDAR metrics, considering only sunlit portions of tree crowns. The outstanding performances of such works mainly attribute to the useful spectral and textural characteristics provided by airborne hyperspectral imagery, along with heights and structural metrics derived from airborne LiDAR data [
9].
The recent increase in the availability of high spatial resolution satellite imagery, such as WorldView-2/3/4, has attracted a lot of attention to exploiting its use in ITS classification [
14,
15,
16,
17,
18,
19]. For example, Pu et al. [
14] evaluated the capabilities of IKONOS and WorldView-2 (WV-2) to identify and map tree species of urban forest. Their results demonstrated the potential of WV-2 imagery for the identification of seven tree species in urban area. The classification using a decision tree classifier (CART) achieved an OA of 62.93%. Madonsela et al. [
17] used multi-phenology WV-2 imagery and RF to classify savannah tree species. An OA of 76.40% for four tree species was achieved. The combination of high-resolution aerial or satellite images and airborne LiDAR data has also been explored for ITS classification [
20,
21,
22,
23]. Specifically, Deng et al. [
20] compared several classification algorithms for the classification of four tree species using simultaneously acquired airborne LiDAR data and true colour (RGB) images with a spatial resolution of 25 cm. Several classification algorithms were employed, and the highest OA (90.8%) was provided by the quadratic SVM.
Based on the literature, exemplified by the above-mentioned studies, the most commonly used classifiers for ITS classification are SVM and RF. One of the challenges for this kind of classification algorithms is the extraction and selection of useful features that are crucial for accuracy. As a result, deep learning (DL) is gaining attention in ITS classification due to its capability of automatic learning from examples and allowing features to be extracted directly from data. DL, inspired by the human visual perception system, has initially gained success in computer vision and medical applications. Typical DL networks include convolutional neural networks (CNNs), stacked autoencoders, deep belief networks, and recurrent neural networks. Among these networks, CNNs are the most potential and popular for perceptual tasks. The application of CNNs has grown very fast in remote sensing since 2014. CNNs have been successfully used in various remote sensing tasks, such as image scene classification, object detection, image pan-sharpening and super-resolution, image registration, and image segmentation [
24,
25,
26,
27]. In the context of remote sensing image classification, the commonly used CNN models include AlexNet [
28], VGG [
29], ResNet [
30], Dense Convolutional Network (DenseNet) [
31,
32]. Despite the popularity of CNN in remote sensing image classification, its exploration in ITS classification is still limited. In 2019, Hartling et al. [
33] examined the potential of DenseNet in the identification of dominant tree species in a complex urban environment using the combination of WV-2 VNIR, WV-3 SWIR, and LiDAR datasets. DenseNet-40 yielded an OA of 82.6% for the classification of eight dominant tree species, which was significantly higher than those obtained by RF and SVM.
In this study, a comprehensive analysis of several CNN models (ResNet-18, ResNet34, ResNet-50, and DenseNet-40) for ITS classification was performed using the combination of the panchromatic band of WV-2, a pansharpened version of the WV-2 multispectral imagery, and a digital surface model (DSM) and an intensity map derived from airborne LiDAR data. The performances of the CNN models were also compared with those of traditional machine learning classification methods (such as RF and SVM). The helpfulness of the LiDAR intensity map and the atmospheric correction of the WV-2 imagery were analyzed to provide detailed directions for related studies. The input size of sample images of ResNet and DenseNet was firstly discussed in this work, which is meaningful for improving the performances of CNN models in ITS classification.
3. Methodology
Four object-based CNN networks were designed and implemented in this study to classify four tree species using the combined WV-2 imagery and LiDAR data. The flowchart of the method is presented in
Figure 2 [
34].
The LiDAR point cloud was first processed using ENVI LiDAR Version 5.3.0 (L3Harris Geospatial, Broomfield, CO, USA) to generate a digital surface model (DSM), a digital elevation model (DEM), and an intensity image. The intensity of LiDAR data was defined as the amount of reflected energy at the peak amplitude of the returned signal and has been demonstrated to be useful for distinguishing different tree species [
35,
36]. ENVI LiDAR filtered the point cloud data with filters based on triangulated irregular network (TIN) for the generation of DEM. We used the default parameters provided by the software, which include the maximum error of terrain TIN of 10 cm and the maximum TIN polygon density of 10,000. The intensity image and the DSM were produced with a spatial resolution of 0.25 m. The DEM was generated with a spatial resolution of 0.5 m, the highest resolution for DEM provided by the software. The DSM, DEM, and intensity image were then resampled to the spatial resolution of 0.4 m by 0.4 m using MATLAB to match the spatial resolution of the WV-2 imagery. A normalized DSM (nDSM), which is also referred to as a canopy height model (CHM), was derived as the difference between the DSM and DEM using MATLAB. Atmospheric correction was performed on the MS bands of the WV-2 imagery using the FLAASH Atmospheric Correction Model of the ENVI software to obtain an 8-band reflectance image of the study area. The resulting reflectance image was then orthorectified base on the DSM and the LiDAR intensity, along with the PAN band. Then, a pansharpened MS image with a spatial resolution of 0.4 m was produced through the fusion of the PAN band with the 8-band reflectance image. The fused MS, PAN, and the nDSM were then used to delineate individual tree crowns. Regarding the tree crowns and the inventory map, tree species samples were manually selected and labeled to obtain the sample dataset. Finally, three ResNet models and a DenseNet model were used to classify the tree species, and the classification results were evaluated and compared with traditional machine learning classification methods, namely SVM and RF. The four CNN models were selected because they gave excellent performances in similar works. The details of the four CNN models can be found in
Section 3.4.1.
The details of image orthorectification, individual tree crown delineation, tree crown sample generation and sample dataset preparation, tree species classification using CNN models and traditional machine learning methods, and accuracy assessment metrics are introduced in the following subsections.
3.1. Image Orthorectification
The orthorectification of the MS and PAN bands of WV-2 imagery was carried out by using the ENVI software (L3Harris Geospatial, Broomfield, CO, USA). Eight GCPs that were manually identified across the whole image were employed in the orthorectification to align the MS and PAN images with the LiDAR data. A sub-pixel accuracy (with the root mean square error of 0.43 pixel) was achieved. The orthorectified PAN image is shown in
Figure 3 as an example.
The orthorectified PAN and MS images were then fused using the Gramm-Schmidt pansharpening method provided in the ENVI software. The resulting pansharpened MS image with a spatial resolution of 0.4 m and the LiDAR nDSM were then employed for the delineation of individual tree crowns.
3.2. Individual Tree Crown Delineation
Both the pansharpened MS image and the LiDAR nDSM were used for the individual tree crown delineation. To separate trees from buildings and grasses, a hierarchical rule-based classification method proposed in [
37] was first employed to produce a classification map with six categories, including building, road, tree, grass, water body, and shadow. During the classification, ground pixels were first separated from the non-ground pixels based on the height information provided by the nDSM map. The non-ground pixels were then divided into the tree class and the building class based on the corresponding values in a normalized difference vegetation index (NDVI) map generated using the pansharpened MS image. A preliminary tree map was then obtained based on the tree class. In this work, the NDVI was generated using the red and NIR1 bands of the WV-2 imagery. A subset of the pansharpened MS image and nDSM is shown in
Figure 4a,b, respectively. A subset of the tree map is shown in
Figure 4c. Due to the difference in acquisition time and the residual of co-registration, the preliminary tree map may include some pixels that are not corresponding to trees in the nDSM map. To obtain tree crowns that match well with both the WV-2 images and nDSM, only the overlapped portion of the preliminary tree map and nDSM were used for individual tree crown delineation. Therefore, the pixels that have high values in nDSM but do not belong to tree pixels in the preliminary tree map were set to zero. This resulted in a modified version of the nDSM map, which was used in the following steps for individual tree crown delineation.
The multiscale analysis and segmentation (MSAS) method proposed in [
38] was used for the delineation of individual tree crowns from the nDSM map. The MSAS method consists of three steps. The first step involved scale analysis to determine the sizes of multiscale morphological filters, which were used to detect tops of tree crowns of different sizes. Next, the nDSM map was filtered at multiple scale levels, and the marker-controlled watershed segmentation method was then adopted to detect candidate tree crowns of different sizes. Finally, the candidate tree crowns were merged to produce a tree crown map. In this work, scale sizes ranging from 9 to 23 pixels with a step of 2 pixels were used in the first step. The resulting tree crown map was manually refined according to the LiDAR data to eliminate some false positives, which were mainly caused by the different acquisition times of the WV-2 imagery and LiDAR. For example, some ashes shown in the LiDAR data disappeared in the WV-2 imagery. A subset of the individual tree crown map is shown in
Figure 4d. The refined version was finally converted to tree crown polygons to facilitate the selection of tree crown samples.
3.3. Tree Crown Sample Generation and Sample Dataset Preparation
Tree samples were manually selected from the delineated tree crown polygons, as shown in
Figure 4e,f. Some of the tree crown polygons were further validated using a field investigation. Finally, as shown in
Table 1, we obtained 1503 samples in total, which include 580, 408, 351, and 164 samples for maple, pine, locust, and spruce, respectively.
The tree crown sample images with 11 bands were generated through using two steps. First, the PAN band, eight fused MS bands, intensity image, and nDSM were merged band by band to produce a single image with 11 bands. This image was then clipped according to the minimum exterior rectangle of each tree crown polygon to produce tree crown sample images with a band number of 11.
The tree crown sample images were divided into two parts, which were used for training and testing, respectively. For each species, 70% (1052 in total) of the sample images were used for training, while the other 30% (451 in total) were used for testing.
We adopted data augmentation to increase the number of training samples. Specifically, the original sample images were rotated by 90°, 180°, and 270°, separately and flipped horizontally and vertically. A total number of 6312 training samples were obtained, as presented in
Table 1.
3.4. Tree Species Classification
3.4.1. CNN Models
Typical CNN models include convolutional layers, pooling layers, and fully connected layers. The residual learning framework was proposed to resolve the degradation problem exposed during the training of deep networks [
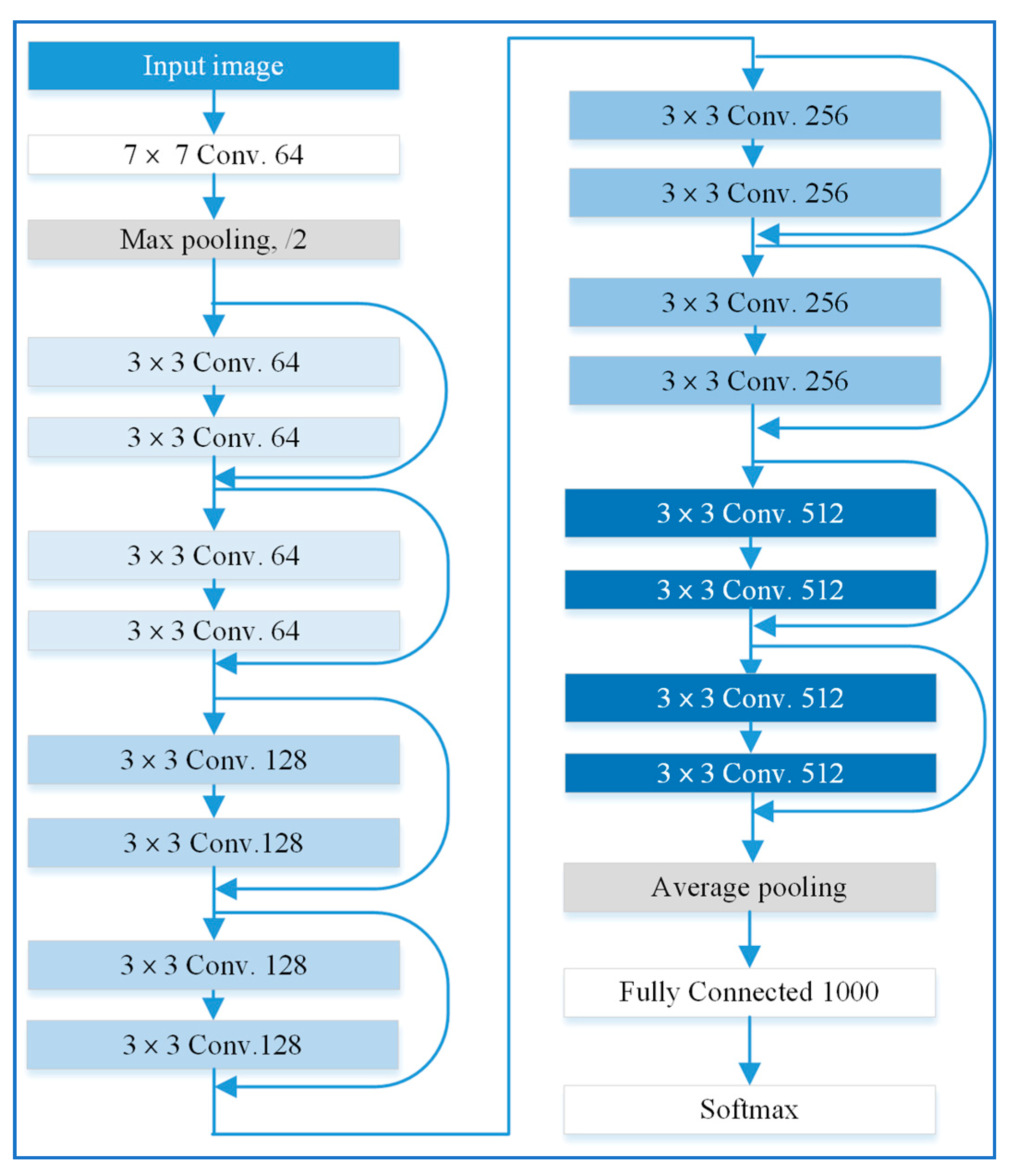
30]. Residual networks were implemented by inserting shortcut connections into plain networks, which add no extra parameters or computational complexity. Several ResNet models with different numbers of layers, which include ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-105, were proposed. Compared with the sizes of sample images used for scene classification, the size of tree crown samples was relatively small. Deeper networks have more convolution layers and more pooling layers which are used to reduce the size of output features. When the size of output features was reduced to 1 × 1 after a pooling layer, no additional features can be extracted by the following layers. In this case, some parameters may be untrainable. Deeper networks may even provide lower classification accuracy if the input image have relatively small sizes. Consequently, ResNet models with a relatively shallow network, such as ResNet-18, ResNet-34, and ResNet-50, were used in this work for ITS classification. As an example, the architecture of ResNet-18 is shown in
Figure 5. It comprises a convolutional layer with a filter size of 7 × 7, 16 convolutional layers with a filter size of 3 × 3, and a fully connected layer. A shortcut connection is added to each pair of 3 × 3 filters, which constructs a residual function.
Inspired by the idea of adding shortcut connections, DenseNet was proposed in 2017 [
31]. It is approved that DenseNets have some advantages, such as alleviating the problem of vanishing-gradient and strengthening the propagation of feature. They can also reduce the number of parameters. DenseNets include multiple densely connected dense blocks and transition layers. Transition layers are the layers between dense blocks. Each transition layer consists of a 1 × 1 convolutional layer followed by a 2 × 2 average pooling layer. A similar reason for the use of ResNet models, DenseNet-40, which has a shallower architecture than other DenseNets, was employed in this study. DenseNet-40 has three transition layers and three dense blocks, which have a growth rate of 4.
Figure 6 shows its architecture.
Compared with traditional machine learning methods, the advantage of CNN-based classification methods is that we do not need to design and select features used for classification. Instead, we just need to feed sample images (of which the bands we can design) into the models. Three experiments using different band combinations were performed for the classification using the CNN models. As shown in
Table 2, the first combination used only the PAN, denoted as P, and the second band combination used both the PAN and eight pansharpened MS bands, denoted as P+M. The third considered both the WV-2 imagery and LiDAR nDSM map was denoted as P+M+H, whereas the forth combination including the WV-2 imagery and the LiDAR nDSM and the intensity image was denoted as P+M+H+I.
For CNN-based ITS classification, all the training and testing samples were resized to a size of 32 × 32 pixels, according to the average size of all the tree crown samples. The classification using the four CNN models was performed on Python 3.6 and Keras 2.2. The Adam optimizer was employed. The initial learning rate and the maximum epoch number were set to 0.001 and 500, respectively. An early stopping strategy was also employed to avoid over-fitting problems.
3.4.2. Traditional Machine Learning Classification Methods
As commonly used traditional machine learning classification methods for land cover classification, RF and SVM algorithms were considered in this work for ITS classification. As introduced in
Section 3.4.1, we need to select useful features for the two classifiers. This is different from CNN-based classification, which has the capability of automatic learning from examples and allowing features to be extracted directly from images. As shown in
Table 3, spectral and texture features from the WV-2 imagery and height metrics derived from nDSM were calculated for each tree crown sample [
12]. A number of 18 spectral features were obtained using the mean and standard deviation of the PAN and pansharpened MS bands. Texture features were extracted from the PAN band using the grey-level co-occurrence matrix (GLCM). The considered texture metrics include contrast, correlation, energy, and homogeneity [
22,
39,
40]. In this case, 10 height variables, as shown in
Table 3, were extracted from the nDSM [
13,
20,
23,
41].
Additionally, five vegetation indexes were considered for both the RF and SVM. The indexes include the normalized difference vegetation index (NDVI) [
42,
43,
44] using NIR1, the NDVI using NIR2 [
45], the green normalized difference vegetation index (GNDVI) [
45,
46], the enhanced vegetation index (EVI) [
46,
47], and the visible atmospherically resistant indices (VARI) [
48,
49] using the red-edge band. The details of the five indexes are shown in
Table 4.
Different feature combinations were tested for the classification using RF and SVM. As shown in
Table 5, six feature combinations were considered in the experiment. The first four feature combinations considered only the WV-2 imagery, while the other two combinations involved both the WV-2 imagery and airborne LiDAR data. The feature combination P+M+V+T+H+I was compared with the feature combination P+M+V+T+H to evaluate the effectiveness of the LiDAR intensity image for tree species classification. We used the radial basis function as the kernel function for the SVM classifier and a decision tree parameter of 500 for the RF classifier.
3.5. Accuracy Assessment
A confusion matrix was employed to evaluate the accuracy of ITS classification using the testing samples. Producer accuracy (PA), user accuracy (UA), OA, and kappa coefficient were derived from the matrix. Average accuracy (AA) was the average of PA and UA.
4. Experimental Results
4.1. Results of the CNN Models
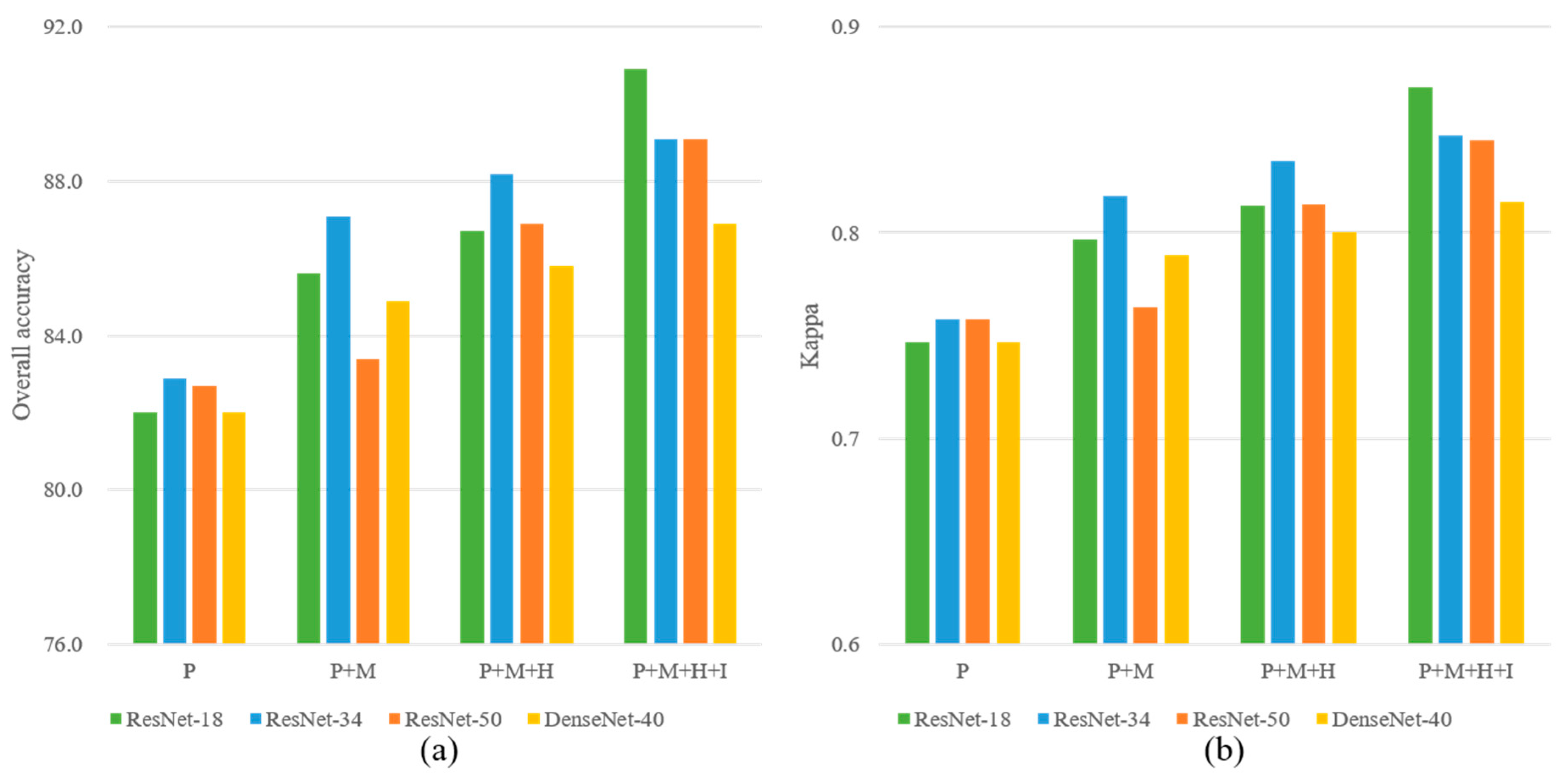
The OA and kappa values of CNN-based classification using the four band combinations P, P+M, P+M+H, and P+M+H+I are shown in
Figure 7, and the AA values of each tree species are presented in
Figure 8. It can be observed that the band combination P+M+H+I provided the highest OAs for each CNN model, followed by the band combinations P+M+H and P+M. This finding supports the importance of the nDSM and intensity image in improving the classification accuracy. For example, the OA of ResNet-18 obtained using the band combination P+M+H+I was 90.9%, which was increased by 5.3% compared with that of the band combination P+M. The AA values of Locust, Pine, and Spruce were also increased by 5.4%, 8.6%, and 15.6%, respectively. The band combination P+M yielded higher OAs than those of the band combination P using only the WV-2 PAN imagery, indicating the effectiveness of the eight MS bands for ITS classification.
Among the four CNN models, ResNet-18 and ResNet-34 yielded higher OA values than the other two CNN models for the band combinations P+M, P+M+H, and P+M+H+I. ResNet-18 provided the highest OA values for the band combination P+M+H+I, whereas ResNet-34 offered the highest OA values for the band combination P+M and the band combination P+M+H.
In terms of the AA accuracies of each tree species, the highest AA values of the four tree species were reached by ResNet-18 using the band combination P+M+H+I. The AA values of the pine class were the highest, followed by those of the maple and spruce class. In contrast, the AA values of the locust class were the lowest. For the spruce class, the band combination P+M+H+I offered significantly higher AA values than those of the combinations P+M and P+M+H, indicating that LiDAR intensity data is crucial for improving the classification accuracy of spruce.
4.2. Results of the RF and SVM
The corresponding classification results are presented in
Figure 9 and
Figure 10. It shows that SVM achieved higher OA and kappa coefficients than RF for each of the six feature combinations. The feature combination P+M+V+T+H+I yielded the highest OA values, whereas the feature combination P obtained the lowest OA values for both RF and SVM. The OA values of the feature combination P+M+V using RF and SVM were not higher than those of P+M, indicating that the inclusion of the five vegetation indices provided limited improvements in the accuracy. In contrast, P+M+V+T yielded significantly higher OA values than P+M. This result indicated that it was very necessary to include texture features when only on the WV-2 imagery was considered for ITS classification. The feature combination P+M+V+T+H improved the accuracy more significantly than P+M+V+T, indicating the importance of LiDAR nDSM in the classification. The feature combination P+M+V+T+H+I yielded higher OA values than those of P+M+V+T+H for both RF and SVM. This indicates that the consideration of the LiDAR intensity image is also helpful for improving the classification accuracy.
Additionally, SVM offered higher AA values for all four tree species than RF for the feature combinations P+M+V+T and P+M+V+T+H+I. For SVM, the AA value of the pine class was higher than other classes, while that of the locust class was the lowest. Similar results can also be observed for RF.
4.3. Comparisons between CNN Models and Machine Learning Methods
Comparisons between CNN models and machine learning methods were conducted in two aspects in this study. First, the ITS classification accuracies of CNN models and traditional machine learning obtained using only the WV-2 imagery were compared. As shown in
Table 6, the classification results of the four CNN models obtained using the test samples with the band combination P+M were compared with those of RF and SVM generated using the feature combination P+M+V+T. Then, the second comparison was conducted using both the WV-2 imagery and LiDAR data. As shown in
Table 7, the accuracies of the four CNN models obtained using test samples with the band combination P+M+H+I were compared with those of RF and SVM generated using the feature combination P+M+V+T+H+I. The band combination P+M+H+I includes the PAN band, the eight pansharpened MS bands, the nDSM, and the intensity image, whereas the feature combination P+M+V+T+H+I includes spectral and texture measures, NDVI indices, height metrics, and intensity-based measures.
It can be seen from
Table 6 that ResNet-34 provided an OA value of 87.1% and a kappa coefficient of 0.818, which were the highest, followed by ResNet-18 and DenseNet-40. The accuracies of ResNet-18, ResNet-34, and DenseNet-40 were also significantly higher than those of RF and SVM. Furthermore, ResNet-34 yielded higher AA values for the pine and spruce class than ResNet-18, which contributes to the increase of the OAs of ResNet-34. Compared with RF and SVM, the OA values of ResNet-34 was increased by 6.6% and 3.3%, respectively.
Table 6 also shows that the AA values of the pine and spruce classes provided by RF and SVM were comparable to those corresponding to the CNN models. However, the AA values of maple and locust offered by RF and SVM were remarkably lower than those of ResNet-18, ResNet-34, and DenseNet-40. This may be because that maple and locust trees usually have relatively larger crown sizes than pine and spruce trees. A large crown size can provide sufficient features that can be learned by the CNN models, which have the ability to learn deep abstract features. Consequently, the experimental results demonstrated that ResNet-18 and ResNet-34 outperformed RF and SVM for ITS classification using only WV-2 imagery.
It can be seen from
Table 7 that ResNet-18 offered the highest OA and kappa coefficients, followed by ResNet-34, ResNet-50, and SVM. Compared with SVM, the OA and kappa coefficient of ResNet-18 were increased by 1.8% and 0.023, respectively. The OA and kappa values of ResNet-34 and ResNet-50 were very close to those of SVM. This result indicates that SVM can provide comparable results with ResNet-34 and ResNet-50 when the combined WV-2 and LiDAR data were used, in case of the spectral and texture characteristics, height parameters, and intensity-based measures are considered. However, the extraction and selection of valuable features are important for both RF and SVM.
Table 7 also shows that the accuracies of DensNet-40 and RF were very close, although DenseNet-40 yielded significantly higher OA values than RF in the case of the classification using only WV-2 imagery.
ResNet-18 achieved the highest AA values for maple, locust, and pine, whereas SVM yielded the highest AA for spruce. Specifically, ResNet-18 reached an AA value of 84.1% for the locust class, which shows distinct improvement compared with the other four methods. SVM reached an AA of 90.9% for spruce, which is slightly higher than ResNet-18 (90.7%). DenseNet-40 achieved lower OA than that of SVM, mainly due to providing a significantly lower accuracy for the spruce class than other methods. Compared with other tree species, tree crowns of spruce are relatively small, which provides limited features that can be learned by CNN models. In the other hand, DenseNet-40 has a deeper network architecture and a larger number of pooling operations than ResNet-18 and ResNet-34. Consequently, DeseNet-40 cannot obtain higher accuracies than ReseNet-18 and ResNet-34 in this work.
6. Conclusions
This study explored the potential of four CNN models (ResNet-18, ResNet-34, ResNet-50, and DenseNet-40) for ITS classification using WV-2 imagery and airborne LiDAR data. The performances of the four CNN models were evaluated using different band combinations derived from the PAN band, eight pansharpened MS bands, the nDSM, and the intensity image. The accuracies of the four CNN models were also compared with those of two traditional machine learning methods (i.e., SVM and RF) using different feature combinations, which include spectral, vegetation indices, texture characteristics height metric. The determination of the input size of CNN models was firstly discussed in this work. As a result, we got the following conclusions.
First, the inclusion of the LiDAR DSM and intensity image was useful in improving ITS classification accuracy for both the CNN models and traditional machine learning methods. The classification accuracy of ResNet-18, ResNet-34, ResNet-50, DenseNet-40, RF, and SVM can be improved if the LiDAR intensity image is included. The inclusion of LiDAR intensity map was very important for improving the classification accuracy of spruce class.
Second, the accuracies of ResNet-18 and ResNet-34 were significantly higher than those of RF and SVM when only WV-2 images were used. ResNet-34 offered an OA of 87.1%, which was increased by 6.6% and 3.3%, respectively, compared with those of RF and SVM. ResNet-18 offered an OA of 90.9%, which is the highest, when both WV-2 and airborne LiDAR data were used. Compared with RF and SVM, the OA of ResNet-18 was increased by 4.0% and 1.8%, respectively. This result indicates that ResNet-18 outperformed traditional machine learning classification methods for ITS classification.
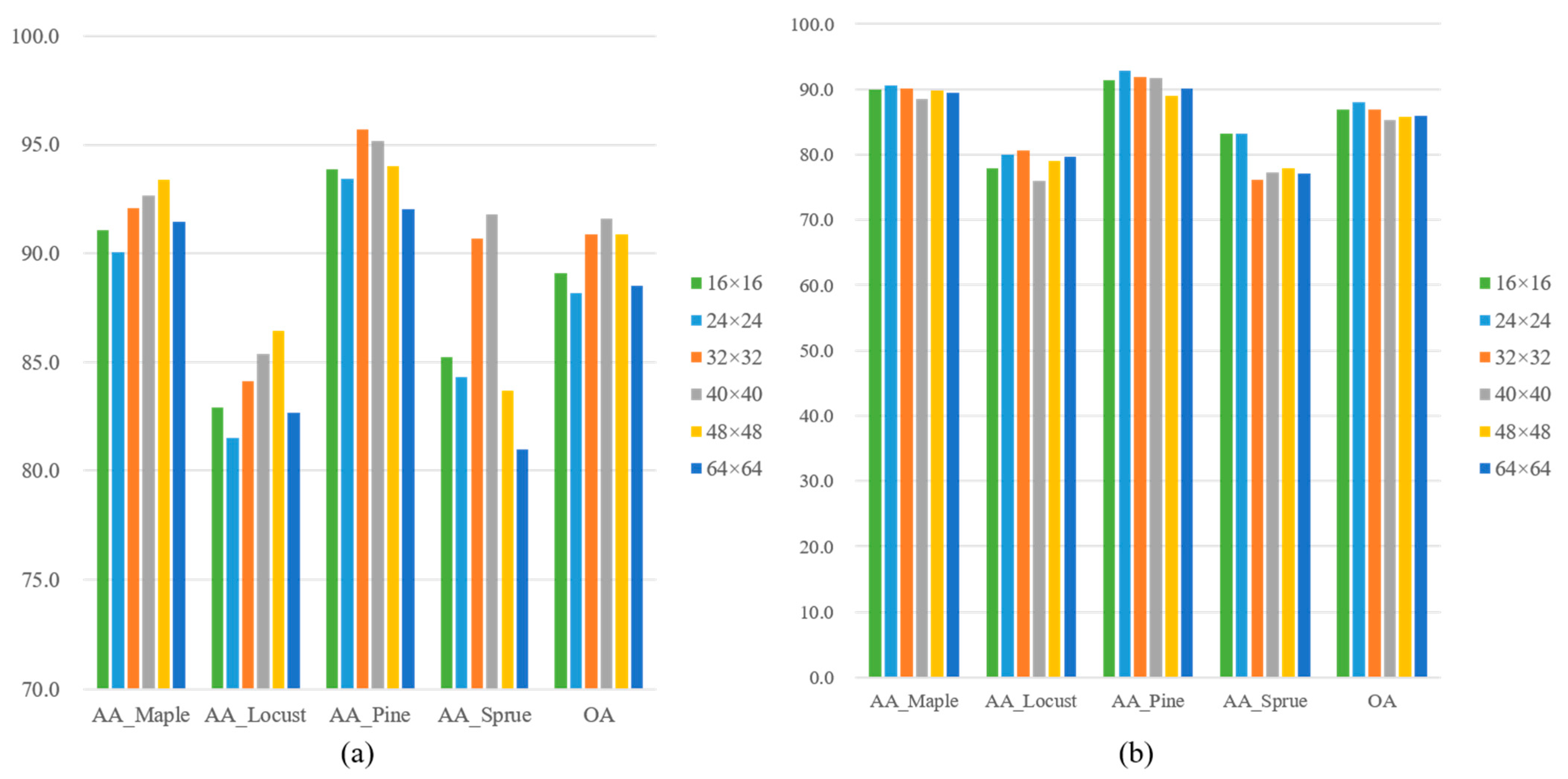
Furthermore, experimental results showed that the size of input samples has impact on the classification accuracy of ResNet-18. In contrast, the OA and kappa values of DenseNet-40 didn’t vary so much with the input sizes as those of ResNet-18. Therefore, it is suggested that the input size of ResNet models can be determined according to the maximum size of all tree crown sample images. Atmospheric correction is unnecessary when ITS classification was conducted using both pansharpened satellite images and airborne LiDAR data.
The use of satellite images with a higher spatial resolution, which can provide sample images with larger input size, would be beneficial for ITS classification, especially for the species with relatively small crown sizes, such as pine and spruce. For example, WorldView-3/4 can be used in further work. Additionally, more training samples could be collected to improve further and validate the networks.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}