Forecasting Forest Areas in Myanmar Based on Socioeconomic Factors


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
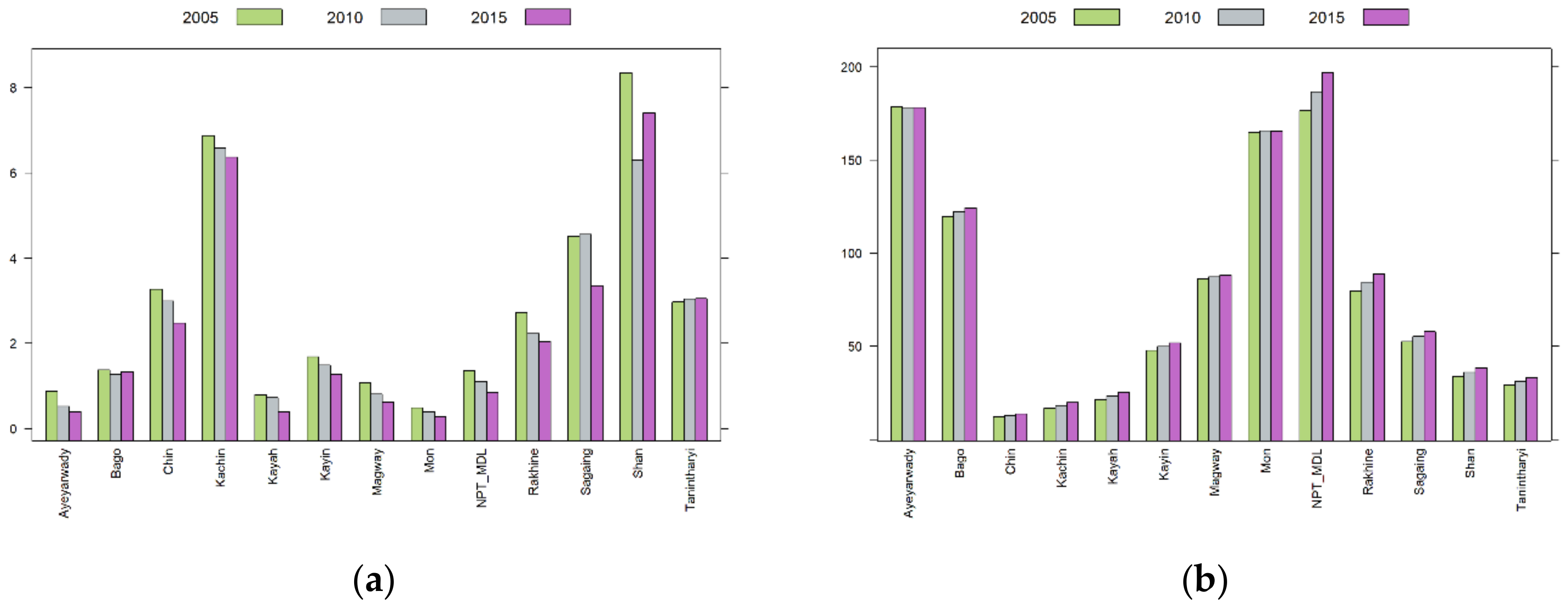
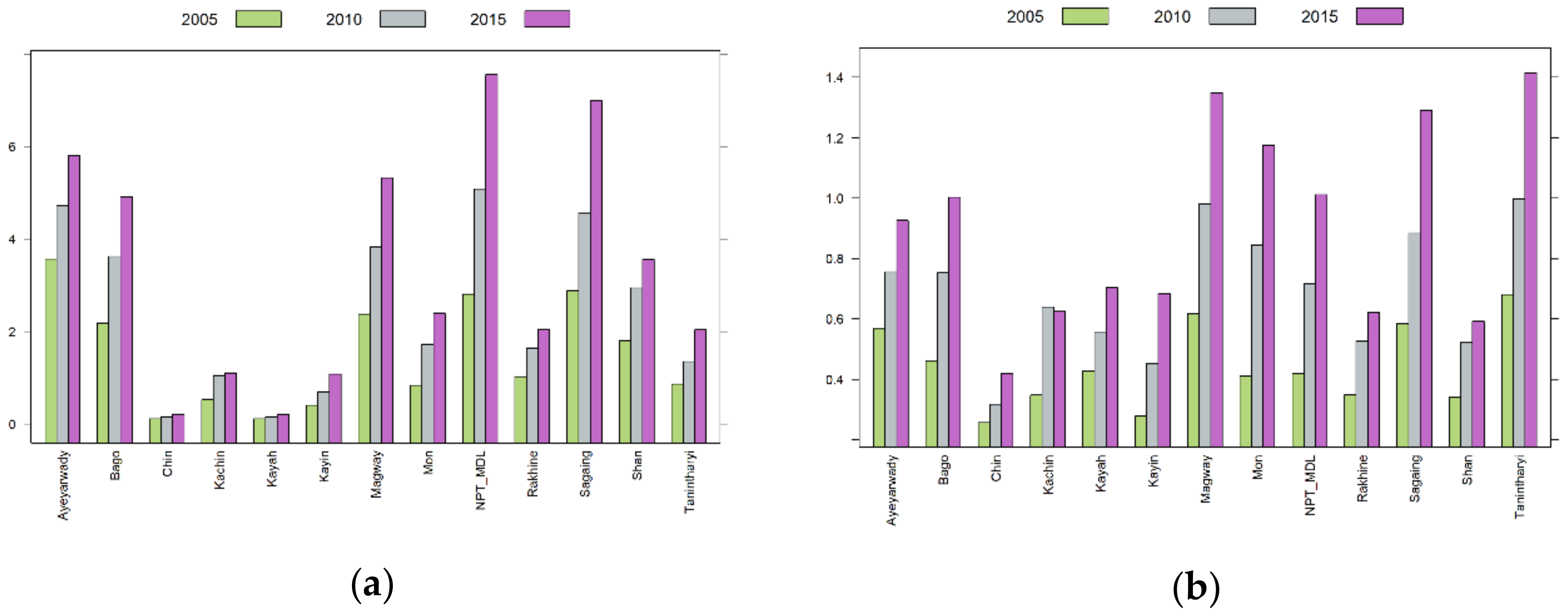
2.2. Variables and Data
2.3. Method
3. Results
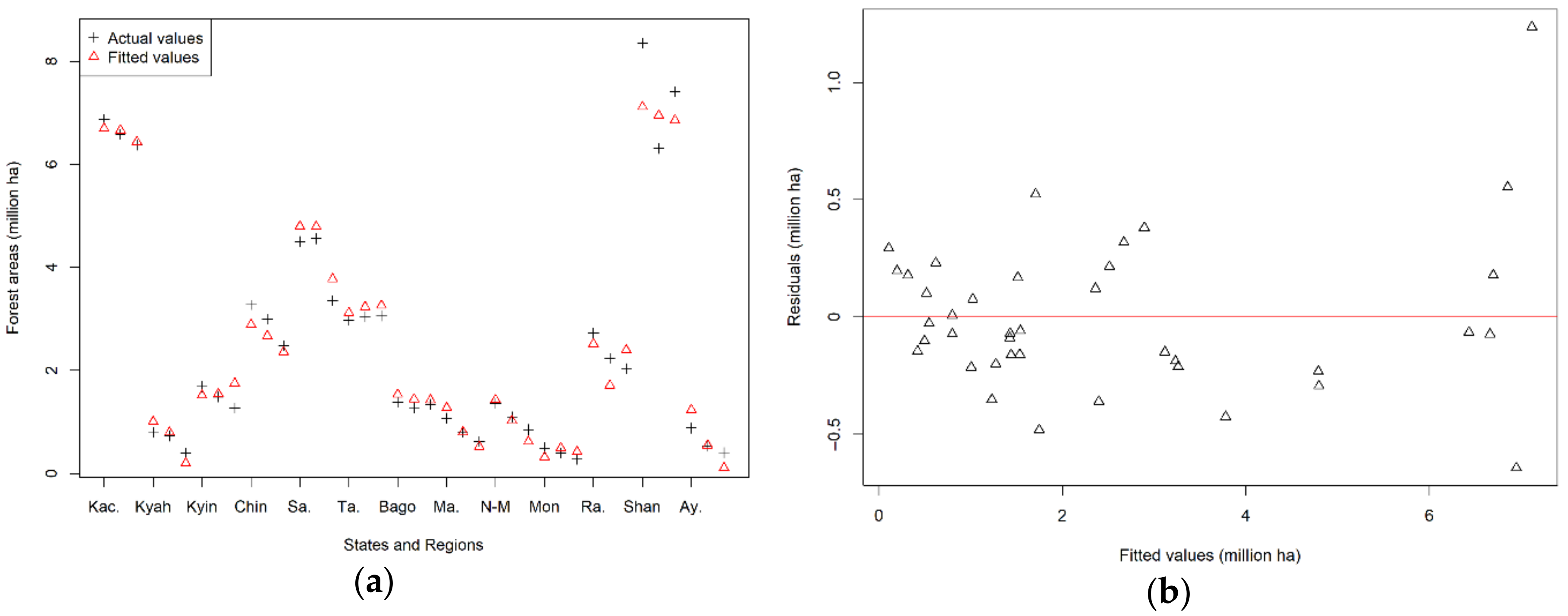
3.1. Fitting Models
3.1.1. Modeling and Model Selection
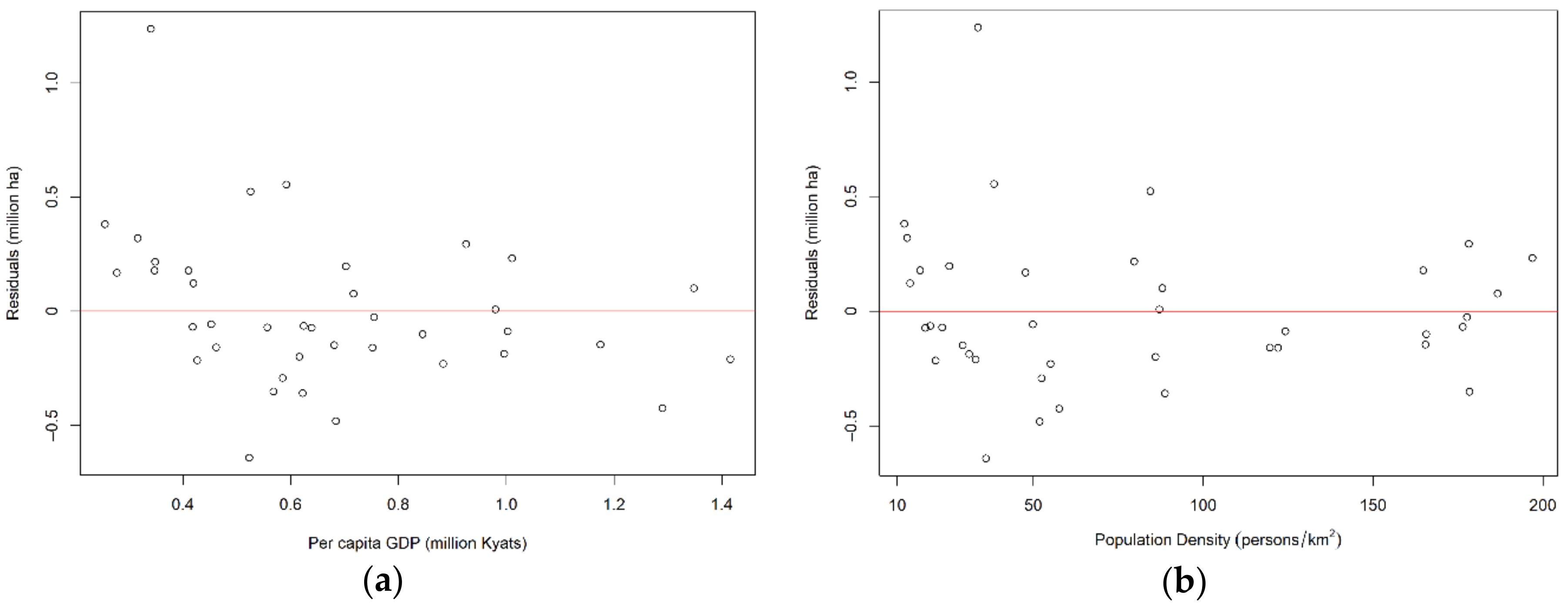
3.1.2. Validation of Model Estimations
3.2. Forecasting Forest Areas
3.2.1. Forecasting Using the RE Model
3.2.2. Forecast Intervals
3.2.3. Sensitivity Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ministry of Natural Resources and Environmental Conservation (MONREC), Myanmar. Forest Reference Level (FRL) of Myanmar. Nay Pyi Taw, Myanmar, 2018. Available online: https://redd.unfccc.int/files/revised-myanmar_frl_submission_to_unfccc_webposted.pdf (accessed on 18 October 2019).
- United Nations Framework Convention on Climate Change (UNFCCC). Report of the Technical Assessment of the Proposed Forest Reference Level of Myanmar Submitted in 2018; UNFCCC: Bonn, Germany, 2019; Available online: https://unfccc.int/sites/default/files/resource/tar2018_MMR.pdf (accessed on 18 October 2019).
- Ministry of Natural Resources and Environmental Conservation (MONREC), Myanmar, REDD+ Myanamr, UN-REDD. Drivers of deforestation and forest degradation in Myanmar. Nay Pyi Taw, Myanmar, 2017. Available online: http://www.myanmar-redd.org/wp-content/uploads/2017/10/Myanmar-Drivers-Report-final_Eng-Version.pdf (accessed on 18 October 2019).
- Mather, A.S. Global Forest Resources; Belhaven Press, a Division of Printer Publishers: London, UK, 1990. [Google Scholar]
- Mather, A.S. The forest transition. Area 1992, 24, 367–379. [Google Scholar]
- Kothke, M.; Leischaner, B.; Elsasser, P. Uniform global deforestation patterns—An empirical analysis. For. Policy Econ. 2013, 28, 23–37. [Google Scholar] [CrossRef]
- Ashraf, J.; Pandey, R.; Jong, W. Assessment of bio-physical, social and economic drivers for forest transition in Asia-Pacific region. For. Policy Econ. 2017, 76, 35–44. [Google Scholar] [CrossRef]
- Barbier, E.B.; Delacote, P.; Wolfersberger, J. The economic analysis of the forest transition: A review. J. For. Econ. 2017, 27, 10–17. [Google Scholar] [CrossRef]
- Angelsen, A. Forest Cover Change in Space and Time: Combining the Von Thunen and Forest Transition Theories. In World Bank Policy Research Working Paper # 4117; World Bank: Washington, DC, USA, 2007; p. 43. Available online: https://ssrn.com/abstract=959055 (accessed on 6 April 2018).
- Angelsen, A. How do we set the reference levels for REDD payments? In Moving Ahead with REDD: Issues, Options and Implications; Angelsen, A., Ed.; CIFOR: Bogor, Indonesia, 2008; Available online: https://www.cifor.org/library/4572/ (accessed on 5 November 2019).
- Rowcroft, P. Frontiers of change: The reasons behind land-use change in the Mekong Basin. AMBIO 2008, 37, 213–218. [Google Scholar] [CrossRef]
- Basu, A.; Nayak, N.C. Underlying causes of forest cover change in Odisha, India. For. Policy Econ. 2011, 13, 563–569. [Google Scholar] [CrossRef]
- Buongiorno, J.; Zhu, S. Using the Global Forest Products Model (GFPM version 2016 with BPMPD). In Staff Paper Series #85; Department of Forest and Wildlife Ecology, University of Wisconsin-Madison: Madison, WI, USA, 2016. Available online: https://www.srs.fs.usda.gov/pubs/ja/2016/ja_2016_buongiorno_003.pdf (accessed on 24 October 2019).
- Panayotou, T. Empirical tests and policy analysis of environmental degradation at different stages of economic development. In Working Paper WP238; Technology Publishing and Employment Programme, International Labour Organization: Geneva, Switzerland, 1993; Available online: http://www.ilo.org/public/libdoc/ilo/1993/93B09_31_engl.pdf (accessed on 27 November 2017).
- Culas, R.J. REDD and forest transition: Tunnelling through the environmental Kuxnet curve. Ecol. Econ. 2012, 79, 44–51. [Google Scholar] [CrossRef]
- Bhattarai, M.; Hammig, M. Institutions and the environmental Kuznets curve for deforestation: A crosscountry analysis for Latin America, Africa and Asia. World Dev. 2001, 29, 995–1010. [Google Scholar] [CrossRef]
- Choumert, J.; Motel, P.C.; Dakpo, H.K. Is the Environmental Kuznets Curve for deforestation a threatened theory? A meta-analysis of the literature. Ecol. Econ. 2013, 90, 19–28. [Google Scholar] [CrossRef]
- Michinaka, T. Approximating forest resource dynamics in Peninsular Malaysia using parametric and nonparametric models, and its implications for establishing forest reference (emission) levels under REDD+. Land 2018, 7, 70. [Google Scholar] [CrossRef]
- Nagata, S.; Inoue, M.; Oka, H. The Utility and Regeneration of Forest Resources; Rural Culture Association: Tokyo, Japan, 1994. (In Japanese) [Google Scholar]
- Michinaka, T.; Miyamoto, M. Forests and human development: An analysis of the socioeconomic factors affecting global forest area change. J. For. Plan. 2013, 18, 141–150. [Google Scholar] [CrossRef]
- Mather, A.S.; Needle, C.L. The forest transition: A theoretical basis. Area 1998, 30, 117–124. Available online: https://www.jstor.org/stable/20003865 (accessed on 5 November 2019). [CrossRef]
- Kimmins, H.; Blanco, J.A.; Brad, B.; Welham, C.; Scoullar, K. Forecasting Forest Futures: A Hybrid. Modelling Approach to the Assessment of Sustainability of Forest Ecosystems and Their Values; Earthscan Publications: London, UK, 2010. [Google Scholar]
- Vieilledent, G.; Grinand, C.; Vaudry, R. Forecasting deforestation and carbon emissions in tropical developing countries facing demographic expansion: A case study in Madagascar. Ecol. Evol. 2013, 3, 1702–1716. [Google Scholar] [CrossRef] [PubMed]
- Jha, S.; Bawa, K.S. Population growth, human development, and deforestation in biodiversity hotspots. Conserv. Biol. 2006, 20, 906–912. [Google Scholar] [CrossRef] [PubMed]
- Baptista, S.R.; Rudel, T.K. A re-emerging Atlantic forest? Urbanization, industrialization and the forest transition in Santa Catarina, southern Brazil. Environ. Conserv. 2006, 33, 195–202. [Google Scholar] [CrossRef]
- Miyamoto, M. Forest conversion to rubber around Sumatran villages in Indonesia: Comparing the impacts of road construction, transmigration projects and population. For. Policy Econ. 2006, 9, 1–12. [Google Scholar] [CrossRef]
- Rudel, T.K. Is there a forest transition? Deforestation, reforestation, and development. Rural Sociol. 1998, 63, 533–552. [Google Scholar] [CrossRef]
- Kok, K. The role of population in understanding Honduran land use patterns. J. Environ. Manag. 2004, 72, 73–89. [Google Scholar] [CrossRef]
- Top, N.; Mizoue, N.; Ito, S.; Kai, S.; Nakao, T.; Ty, S. Effects of population density on forest structure and species richness and diversity of trees in Kampong Thom Province, Cambodia. Biodivers. Conserv. 2009, 18, 717–738. [Google Scholar] [CrossRef]
- Foster, A.; Rosenzweig, M.; Behrman, J.R. Population Growth, Income Growth and Deforestation: Management of Village Common Land in India. In PIER Working Paper 97-037; Penn Pharmaceuticals (Limited Company) Institute for Economic Research, University of Pennsylvania: Philadelphia, PA, USA, 1997; Available online: https://economics.sas.upenn.edu/sites/default/files/filevault/working-papers/97-037.pdf (accessed on 29 October 2019).
- Michinaka, T.; Matsumoto, M.; Miyamoto, M.; Yokota, Y.; Sokh, H.; Lao, S.; Tsukada, N.; Matsuura, T.; Ma, V. Forecasting forest areas and carbon stocks in Cambodia based on socioeconomic factors. Int. Rev. 2015, 17, 66–75. [Google Scholar] [CrossRef]
- Miyamoto, M.; Parid, M.M.; Aini, Z.N.; Michinaka, T. Proximate and underlying causes of forest cover change in Peninsular Malaysia. For. Policy Econ. 2014, 44, 18–25. [Google Scholar] [CrossRef]
- Bae, J.S.; Joo, R.W.; Kim, Y.S. Forest transition in South Korea: Reality, path and drivers. Land Use Policy 2012, 29, 198–207. [Google Scholar] [CrossRef]
- Food and Agriculture Organization (FAO). Global Forest Resources Assessment 2015 (FRA 2015); FAO, UN: Rome, Italy, 2015; Available online: http://www.fao.org/forest-resources-assessment/past-assessments/fra-2015/en/ (accessed on 25 October 2019).
- Leimgruber, P.; Kelly, D.; Steininger, M.; Brunner, J.; Muller, T.; Songer, M. Forest cover change patterns in Myanmar (Burma) 1990–2000. Environ. Conserv. 2005, 32, 356–364. [Google Scholar] [CrossRef]
- Mon, M.S.; Kajisa, T.; Mizoue, N.; Yoshida, S. Factors affecting deforestation in Paunglaung watershed, Myanamr using remote sensing and GIS. J. For. Plan. 2009, 14, 7–16. [Google Scholar] [CrossRef]
- Mon, M.S.; Mizoue, N.; Htun, N.Z.; Kajisa, T.; Yoshida, S. Factors affecting deforestation and forest degradation in selectively logged production forest: A case study in Myanmar. For. Ecol. Manag. 2012, 267, 190–198. [Google Scholar] [CrossRef]
- Win, Z.C.; Mizoue, N.; Ota, T.; Wang, G.; Innes, J.L.; Kajisa, T.; Yoshida, S. Spatial and temporal patterns of illegal logging in selectively logged production forest: A case study in Yedashe, Myanmar. J. For. Plan. 2018, 23, 15–25. [Google Scholar] [CrossRef]
- Central Statistical Organization (CSO); Ministry of Planning and Finance, Myanmar. Myanmar Statistical Yearbook 2018; Central Statistical Organization, Ministry of Planning and Finance: Nay Pyi Taw, Myanmar, 2018.
- Department of Population (DOP); Ministry of Immigration and Population, Myanmar. The 2014 Myanmar Population and Housing Census: The Union Report, Census Report Volume 2; Department of Population, Ministry of Labour, Immigration and Population: Nay Pyi Taw, Myanmar, 2015. Available online: https://myanmar.unfpa.org/en/publications/union-report-volume-2-main-census-report (accessed on 2 February 2016).
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef]
- Department of Population (DOP). The 2014 Myanmar Population and Housing Census, Thematic Report on Mortality, Census Report Volume 4-B; Department of Population, Ministry of Labour, Immigration and Population: Nay Pyi Taw, Myanmar, 2016. Available online: https://myanmar.unfpa.org/en/publications/thematic-report-mortality (accessed on 28 October 2019).
- Department of Population (DOP). The 2014 Myanmar Population and Housing Census, Thematic Report on Fertility and Nuptiality, Census Report Volume 4-A; Department of Population, Ministry of Labour, Immigration and Population: Nay Pyi Taw, Myanmar, 2016. Available online: https://myanmar.unfpa.org/en/publications/thematic-report-fertility-and-nuptiality (accessed on 28 October 2019).
- Department of Population (DOP). The 2014 Myanmar Population and Housing Census, Thematic Report on Population Projections for the Union of Myanmar, States/Regions, Rural and Urban. Areas, 2014–2050, Census Report Volume 4-F; Department of Population, Ministry of Labour, Immigration and Population: Nay Pyi Taw, Myanmar, 2017. Available online: https://myanmar.unfpa.org/en/publications/thematic-report-population-projections (accessed on 25 April 2017).
- Agriculture, Livestock and Fishery; Forestry Sector, Ministry of Planning and Finance, Myanmar: Nay Pyi Taw, Myanmar, 2019.
- World Bank. GDP Deflator. Available online: https://data.worldbank.org/indicator/NY.GDP.DEFL.ZS?end=2018&start=2018&view=map (accessed on 25 February 2019).
- Hargrave, J.; Kis-Katos, K. Economic Causes of Deforestation in the Brazilian Amazon: A Panel Data Analysis for the 2000s. Environ. Resour. Econ. 2013, 54, 471–494. [Google Scholar] [CrossRef]
- Hsiao, C. Analysis of Panel Data, 2nd ed.; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Breusch, T.S.; Pagan, A.R. The Lagrange multiplier test and its applications to model specification in econometrics. Rev. Econ. Stud. 1980, 47, 239–254. [Google Scholar] [CrossRef]
- Hausman, J. Specification tests in econometrics. Econometrica 1978, 46, 1251–1271. [Google Scholar] [CrossRef]
- Breusch, T.S.; Pagan, A.R.; Simple, A. A Simple Test for heteroscedasticity and random coefficient variation. Econometrica 1979, 47, 1287–1294. [Google Scholar] [CrossRef]
- R Core Team. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: www.R-project.org (accessed on 5 November 2019).
- Zeileis, A.; Hothorn, T. Diagnostic checking in regression relationships. R. News 2002, 2, 7–10. [Google Scholar]
- Croissant, Y.; Millo, G. Panel Data Econometrics in R. The plm Package. J. Stat. Softw. 2008, 27, 1–43. [Google Scholar] [CrossRef]
- Zeileis, A. Econometric computing with HC and HAC covariance matrix estimators. J. Stat. Softw. 2004, 11, 1–17. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis, 4th ed.; Prestice Hall International Editions: Upper Saddle River, NJ, USA, 2000; p. 1004. [Google Scholar]
- World Bank. Myanmar Economic Monitor June 2019. Available online: https://www.worldbank.org/en/country/myanmar/publication/myanmar-economic-monitor-reforms-building-momentum-for-growth (accessed on 5 November 2019).
- Griscom, B.; Shoch, D.; Stanley, B.; Cortez, R.; Virgilio, N. Sensitivity of amounts and distribution of tropical forest carbon credits depending on baseline rules. Environ. Sci. Policy 2009, 12, 897–911. [Google Scholar] [CrossRef]
- Myrskylä, M.; Kohler, H.; Billari, F. Advances in development reverse fertility declines. Nature 2009, 460, 741–743. [Google Scholar] [CrossRef] [PubMed]
- Galor, O. The demographic transition: Causes and consequences. Cliometrica 2012, 6, 1–28. [Google Scholar] [CrossRef]
- Gutman, P.; Aguilar-Amuchastegui, N. Reference Levels and Payments for REDD+: Lessons from the Recent Guyana-Norway Agreement. World Wildlife Fund USA, 2012. Available online: http://assets.panda.org/downloads/rls_and_payments_for_redd__lessons.pdf (accessed on 24 May 2012).
- UN-REDD Programme. Submissions. Available online: https://redd.unfccc.int/submissions.html?topic=6 (accessed on 17 December 2019).
- Neeff, T.; Maniatis, D.; Lee, D.; Mertens, E.; Jonckheere, I.; Perez, J.G.; DeValue, K.; Birigazzi, L.; Sandker, M.; Condor, R. From Reference Levels to Results Reporting: REDD+ under the UNFCCC. In Forests and Climate Change Working Paper 15; Food and Agriculture Organization (FAO): Rome, Italy, 2017; Available online: http://www.fao.org/3/a-i7163e.pdf (accessed on 19 April 2018).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Combination 1 | Combination 2 | Combination 3 |
|---|---|---|---|
| PGDP + POP | PGDP + PD | GDP + PD |
| p-value < 0.001 | p-value < 0.001 | p-value < 0.001 |
| p-value < 0.001 | p-value < 0.001 | p-value < 0.001 |
| p-value = 0.256 | p-value = 0.996 | p-value = 0.114 |
| p-value = 0.041 | p-value = 0.042 | p-value = 0.045 |
| 1114.06 | 1118.05 | 1117.15 |
| 1.109.29 | 1109.66 | 1112.64 |
| 0.20 | 0.28 | 0.26 |
| 22.520 (p-value < 0.001) | 18.416 (p-value < 0.001) | 13.732 (p-value = 0.001) |
| Model | Variables | Estimates | Standard Errors 1 | z-Values 1 | p-Values 1 |
|---|---|---|---|---|---|
| 1 | Intercept | 3732,500 | 863,070 | 4.325 | 0.000 |
| PGDP (Kyat) | −0.758 | 0.268 | −2.820 | 0.005 | |
| POP (persons) | −0.210 | 0.157 | −1.340 | 0.180 | |
| 2 | Intercept | 4629,564 | 989,760 | 4.678 | 0.000 |
| PGDP (Kyat) | −0.660 | 0.230 | −2.870 | 0.004 | |
| PD (persons/km2) | −20,562 | 6775 | −3.035 | 0.002 | |
| 3 | Intercept | 4331,700 | 1013,200 | 4.275 | 0.000 |
| GDP (million Kyats) | −0.140 | 0.047 | −2.982 | 0.003 | |
| PD (persons/km2) | −18,259 | 6876 | −2.656 | 0.008 |
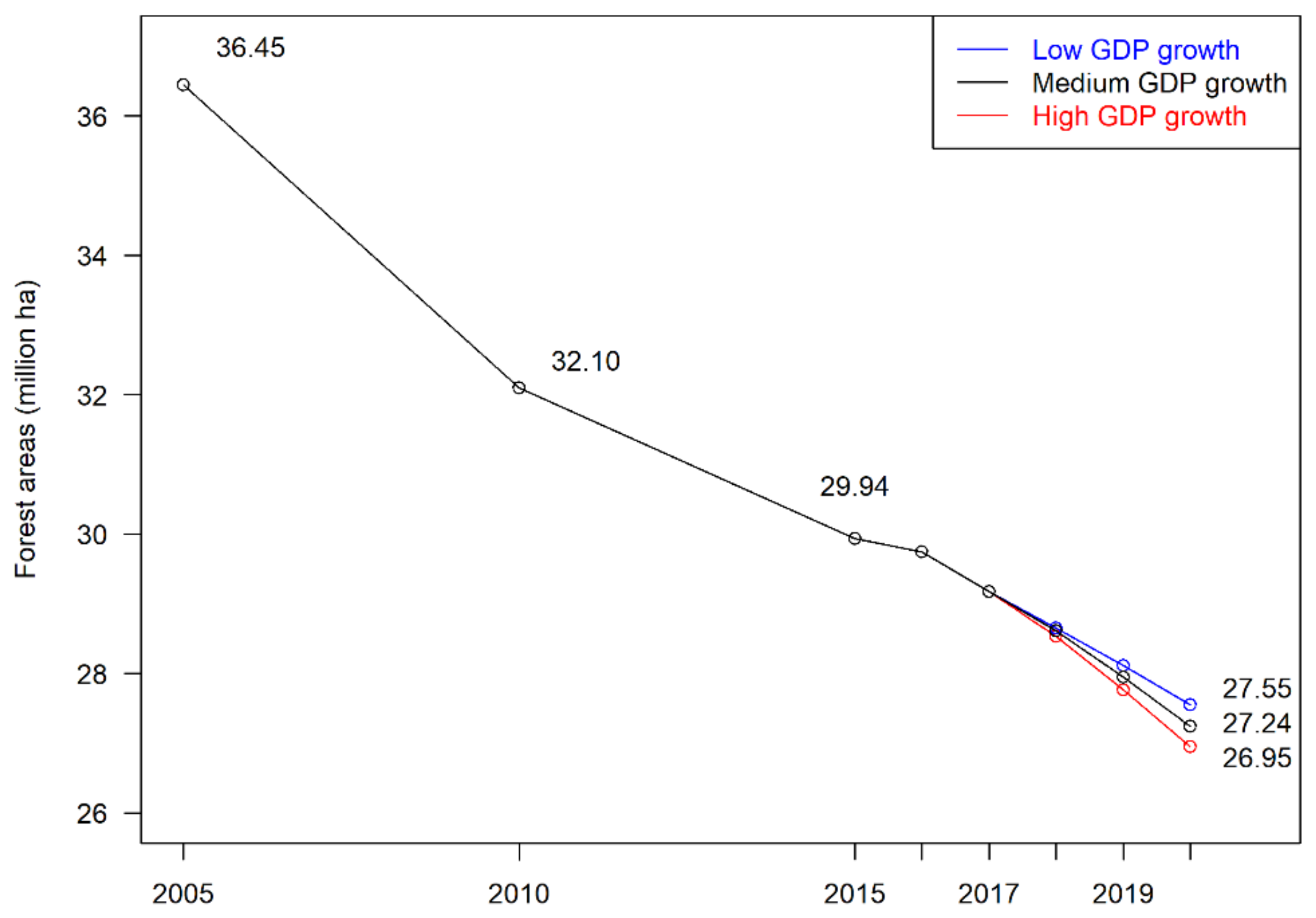
| Year | Scenarios by Per Capita GDP Growths | ||
|---|---|---|---|
| Low | Medium | High | |
| 2016 | 29.745 | 29.745 | 29.745 |
| 2017 | 29.175 | 29.175 | 29.175 |
| 2018 | 28.655 | 28.609 | 28.534 |
| 2019 | 28.115 | 27.948 | 27.767 |
| 2020 | 27.555 | 27.244 | 26.953 |
| Year | Scenarios by Per Capita GDP Growths | ||
|---|---|---|---|
| Low | Medium | High | |
| 2016 | 280 | 280 | 280 |
| 2017 | 570 | 570 | 570 |
| 2018 | 520 | 566 | 641 |
| 2019 | 540 | 661 | 767 |
| 2020 | 560 | 705 | 815 |
| Year | Lower Bound (95%) | Lower Bound (80%) | Medium GDP and POP Scenario | Upper Bound (80%) | Upper Bound (95%) |
|---|---|---|---|---|---|
| 2016 | 11.871 | 18.129 | 29.745 | 41.362 | 47.446 |
| 2017 | 11.317 | 17.569 | 29.175 | 40.781 | 46.860 |
| 2018 | 10.760 | 17.009 | 28.609 | 40.210 | 46.286 |
| 2019 | 10.096 | 16.346 | 27.948 | 39.551 | 45.628 |
| 2020 | 9.376 | 15.631 | 27.244 | 38.857 | 44.940 |
| Year | Low | Medium | High |
|---|---|---|---|
| 2016 | 29.750 | 29.745 | 29.741 |
| 2017 | 29.179 | 29.175 | 29.168 |
| 2018 | 28.614 | 28.609 | 28.600 |
| 2019 | 27.957 | 27.948 | 27.937 |
| 2020 | 27.253 | 27.244 | 27.230 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michinaka, T.; Hlaing, E.E.S.; Oo, T.N.; Mon, M.S.; Sato, T. Forecasting Forest Areas in Myanmar Based on Socioeconomic Factors. Forests 2020, 11, 100. https://doi.org/10.3390/f11010100
Michinaka T, Hlaing EES, Oo TN, Mon MS, Sato T. Forecasting Forest Areas in Myanmar Based on Socioeconomic Factors. Forests. 2020; 11(1):100. https://doi.org/10.3390/f11010100
Chicago/Turabian StyleMichinaka, Tetsuya, Ei Ei Swe Hlaing, Thaung Naing Oo, Myat Su Mon, and Tamotsu Sato. 2020. "Forecasting Forest Areas in Myanmar Based on Socioeconomic Factors" Forests 11, no. 1: 100. https://doi.org/10.3390/f11010100
APA StyleMichinaka, T., Hlaing, E. E. S., Oo, T. N., Mon, M. S., & Sato, T. (2020). Forecasting Forest Areas in Myanmar Based on Socioeconomic Factors. Forests, 11(1), 100. https://doi.org/10.3390/f11010100