1. Introduction
Since the early 1990s, the tropical forest in several countries has been undergoing a transition period from degradation to reforestation [
1,
2,
3]. Forest transition is considered from the perspective of forest area changes and the conversion from other land use/land cover types to forest. With the rapid development of remote sensing technology and the wide application of landscape ecology, they supply effective tools to analyze spatial-temporal changes and related ecological processes. Improved understanding of forest transition provides many benefits, such as global carbon balance or land use and forest policy implementation [
4,
5]. Therefore, there is a need to further develop new methods for forest type classification and forest transition assessment.
Recently, remote sensing combined with the conventional method to supply validation data has been extensively used in forest inventory. The advantages of the remote sensing technique are cost- and labor-saving as well as swift observation of large scale forest changes over the long term. However, the classification accuracy associated with using remote sensing is affected by many factors, such as the classification techniques, training samples, and the signal reflected from objects.
A natural forest [
6] is a naturally regenerated forest comprising native species, where there are no clear or clearly visible indications of human activities and the ecological processes are not significantly disturbed. In this study, we classified natural forests based on the timber reserve of standing trees into four main types: rich, medium, poor, and restoration forest. Although these four types differ in species composition and timber reserves, we found that with only a single source of data (optical or radar data) it is often difficult to discriminate between different kinds of natural forest types because of the very similar information on canopy and forest structure captured by remotely sensed data [
7]. This highlights the need for multi-source remote sensing data to extract more information of interest regarding the objects for classification. By using multi-source data, the classification accuracy is improved compared to single data source. This has been shown, for example, with a combination of optical data and synthetic aperture radar (SAR, Congo Basin and Malawi city, Mzimba) [
8,
9]. The fusion of different frequencies (L– and P–band) of SAR products has also received much attention in recent years [
10,
11,
12].
Another challenge is that sampling is restricted because of the complexity of ecosystems and inaccessible regions [
13]. In this study, we used semi-supervised classification to overcome the paucity of ground truth samples. Semi-supervised classification focuses on enhancing supervised classification by minimizing errors in the labeled examples, but it must also be compatible with the input distribution of unlabeled instances [
14]. While supervision often provides higher classification accuracy, it requires a good dataset to ensure both the quantity and quality of training samples collected from the field survey. The constraint of field data collection is that it is not always achievable, owing to limitations in finance, terrain, or availability of the data source. To avoid this issue, semi-supervised classification aims at solving the limited number of labeled samples and taking advantage of the abundant unlabeled samples. Many semi-supervised classification algorithms such as expectation-maximization, co-training, and self-training have been developed. The graph-based method has also attracted an increasing amount of interest [
15,
16,
17,
18]. This method works by summarizing base model outputs in a group-object bipartite graph and maximizing the consensus by promoting smoothness of label assignment over the graph and consistency with the initial labeling. Recently, machine learning has received much attention and has been applied to the semi-supervised learning problem. This technology has been successfully developed for binary classification, such as in [
19], where a Laplacian Twin Support Vector Machine was used for semi-supervised classification that can exploit the geometry information of the marginal distribution embedded in unlabeled data to construct a more reasonable classifier-semi-supervised classification with graph convolutional networks [
20] which scales linearly in the number of graph edges and learns hidden layer representations that encode both the local graph structure and the features of nodes.
For land use/land cover, semi-supervised classification has been successfully adopted in the literature. For instance, in [
21], semi-supervised logistic regression was applied. This is a specific instance of the generalized maximum entropy that finds a probability distribution that minimizes a divergence based on the entropy of the weights of classifiers. In [
22], a semi-supervised clustering was presented that is simultaneously optimized using a modern multi-objective optimization technique based on the concepts of simulated annealing. In [
23], the weight support vector machine was used to keep the training effort low with a manually-collected set of pixels of the class of interest and a random sample of pixels. In [
24], extended label propagation and rolling guidance filtering that uses superpixel propagation were applied to assign the same labels to all pixels within the superpixels that are generated by the image segmentation method.
In this paper, we present a self-learning approach for forest classification that can propagate labels from labeled samples to unlabeled data to build a large volume of training data. This model does not make any specific assumptions for the input data, but it does accept that its own predictions tend to be correct [
14]. Self-learning, also known as Yarowsky’s algorithm, is a rule-based semi-supervised classification. The term “self-learning” is used because the algorithm uses its own prediction to teach itself. Self-learning is very popular, with an initial classifier trained by a small number of training data with given labels, before using this classifier to assign labels to the unlabeled sample. For each unlabeled sample, confidence values are extracted from the probabilistic of learning models [
14,
25]. The samples that have been labeled with the most confident prediction are then selected to combine with the training data and create a new training set. The classifier is then retrained on that new training set and the procedure repeated. Self-learning has been applied in several text processing tasks in the last few years. Recently, it has been applied with some developed supervisor classifiers to image classification [
23,
26]. This study developed self-learning with a kernel least square classifier for forest types classification. Least squares is a standard approach of statistical analysis and has been well-known for a long time. It was developed by applying kernel functions in high dimensional feature space to solve the problem of a large number of parameters [
27]. Kernel functions are an algorithm with the advantage of being able to flexibly transform an originally non-linear vector into a linear version in feature space. Therefore, they are widely applied in solving classification problems involving multiple features [
28,
29,
30].
In this study, we also used time-series remotely sensed data for the evaluation of forest changes by landscape ecology. Landscape ecology can be generally defined as the science and art of studying and improving the relationship between spatial patterns and ecological processes on a multitude of scales and organizational levels [
31]. One fundamental aspect has been its explicit attention to the spatial dimension of ecological processes [
32]. Landscape metrics are one of the classical landscape ecological tools for measurement, analysis, and interpretation of spatial patterns [
33]. The contribution of remote sensing to landscape planning and conservation is mainly in the inventory and determination of objects of interest and in monitoring changes by time-series satellite data [
34]. A basic concern in forest management is spatial processes over time, such as deforestation, degradation, or restoration. The analysis of landscape structure is a classic approach for the understanding of spatial processes using various landscape metrics [
32,
35,
36,
37]. Several studies provide evidence of the value of remote sensing and landscape metrics for forest management [
38,
39,
40,
41,
42].
In summary, there are two main objectives in this study. The first objective is to assess the potential of a semi-supervised model to classify natural forest types by using multi-source remote sensing data. The second objective is to assess the process of forest transition from the perspective of landscape ecology by using multi-temporal data.
2. Study Area
In Vietnam, the forest plays an important role in the socio-economic system in the mountainous province, where local people have a low income and agroforestry-based livelihoods. Although centralization of forest resource management began in Vietnam very early in the 1950s [
4], the natural forest experienced a rapid decrease over the long term [
43], causing negative impacts to the environment, such as loss of carbon stock, biodiversity degradation, and habitat fragmentation [
44]. Since 2005, however, Vietnam has been experiencing a positive period in the application of forestry policies [
45], which is contributing to development of the forested area. This dramatic forest transition has resulted in changes to the biophysical, ecological process, as well as to the spatial landscape. However, there is a lack of up-to-date information on forest changes in Vietnam in the period from 2005 to the present, particularly in central Vietnam where the socio-economic dynamics have recently been increasing. To create a reliable forest management strategy, an improved understanding of forest changes is essential. This can be achieved by spatial analysis through multi-temporal remote sensing images processing, combined with landscape metrics assessment.
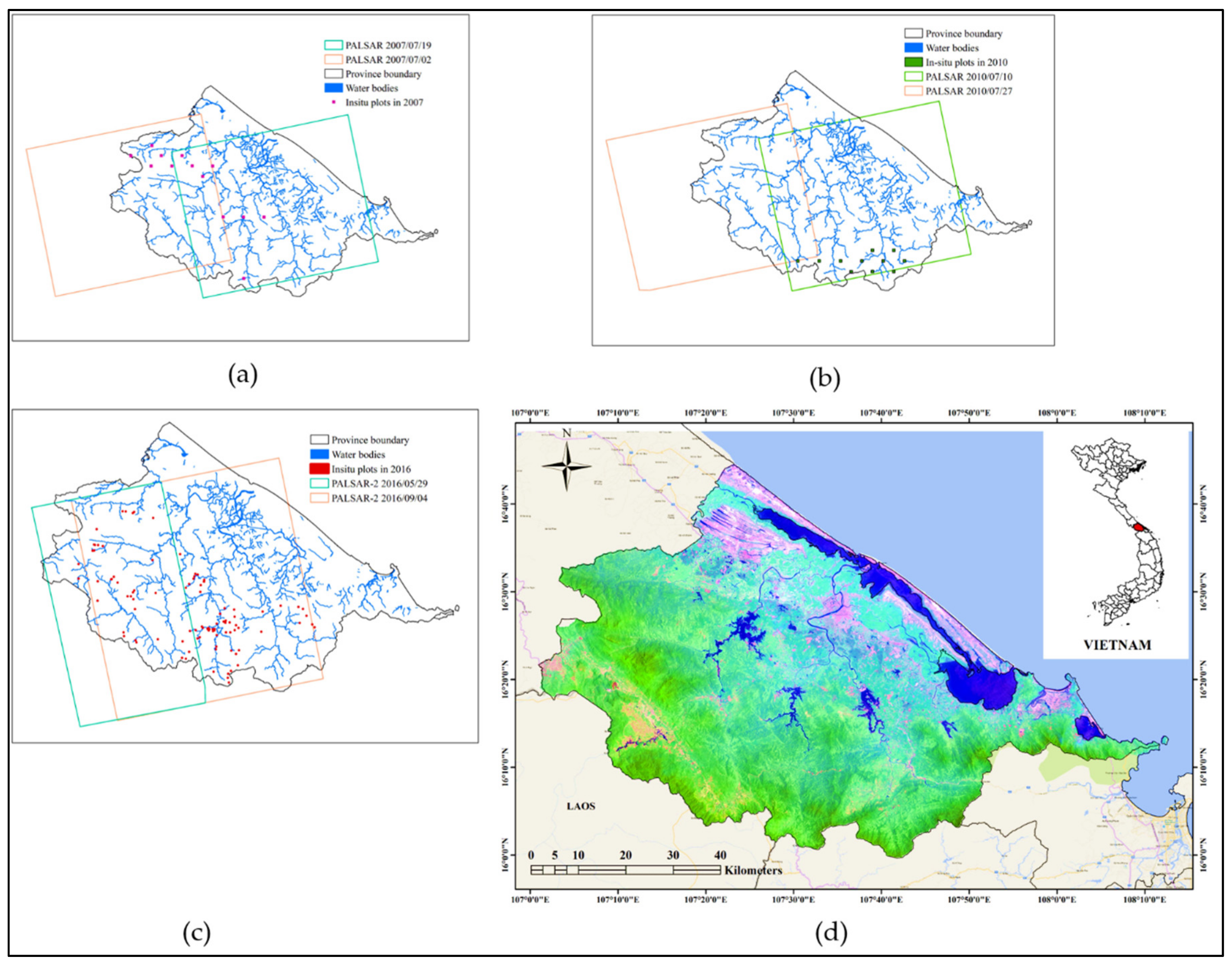
Thua Thien Hue province, located in central Vietnam (
Figure 1d), has a surface area of 5054 km² and the natural forest area accounts for approximately 40% of the total area. According to the General Statistics Office (GSO) in Vietnam, the natural forest in this study area slightly decreased from 203,800 ha in 2008 to 202,700 ha in 2010, with the principal causes of deforestation comprising the conversion from forest to other land uses (e.g., hydropower, roads, cultivation) and illegal exploitation of forest products. Conversely, from 2010, there was a significant extension of natural forest with the area reaching 212,200 ha in 2016. These fluctuations have not only caused changes in the area, but also in the forest landscape structure.
We classified the natural forest into four types based on the specific condition of the study site as well as circular number 34/2009/TT-BNNPTNT of June 10, 2009 [
46] published by Vietnam Ministry of Agriculture and Rural Development, on the criteria for forest identification and classification in Vietnam:
Rich forests are forests with a timber reserve of standing trees of between 201 and 300 m3/hectare;
Average forests (or medium forests) are forests with a timber reserve of standing trees of between 101 and 200 m3/hectare;
Poor forests are forests with a reserve of standing trees of between 10 and 100 m3/hectare;
Forests with no reserve (“Restoration forest” in the case of our study site) are forests with a timber tree average diameter of less than 8 cm and a timber reserve of standing trees of less than 10 m3/hectare.
5. Discussion
To assess the trend of natural forest changes in the study area, we compared the results with those in global and tropical regions, as well as in Vietnam overall, in the same period. Keenan et al. [
3] reviewed the dynamics of global forest area between 1990 and 2015 based on statistics from the FAO global forest resources assessment 2015. Worldwide, the natural forest area declined by 2% between 2005 and 2015, with the vast majority of the losses occurring in the tropics where the rate of loss fell by 7.2 million ha.y
−1. Compared to the trend of forest transition worldwide and in Vietnam overall, the status of forest loss in the study area is similar in the period from 2007–2010. This status is confirmed by the findings of Quy Van Khuc et al. [
54] that degradation mainly occurred in natural forest at the rate of 3–4%. Cochard’s [
55] review of studies also demonstrated a slow increase in natural forest in the period 2000–2013 in Thua Thien Hue province. From 2010–2016, the natural forest in the study area demonstrated the opposite trend. While there was a significant decrease in the natural forest worldwide and in the tropics generally, growth occurred in Vietnam and in the study area. Due to the shortage of previous studies, it was only possible to compare the general trend of natural forests. It is difficult to compare fluctuations in forest types of rich, medium, poor, and restoration types because there are few documented records for the study area in particular, and Vietnam in general, particularly in the period 2010–2016. Therefore, the findings of this study contribute to the understanding of the transition of natural forest types in recent years, particularly in the ecological processes in terms of spatial patterns that have still not received adequate attention.
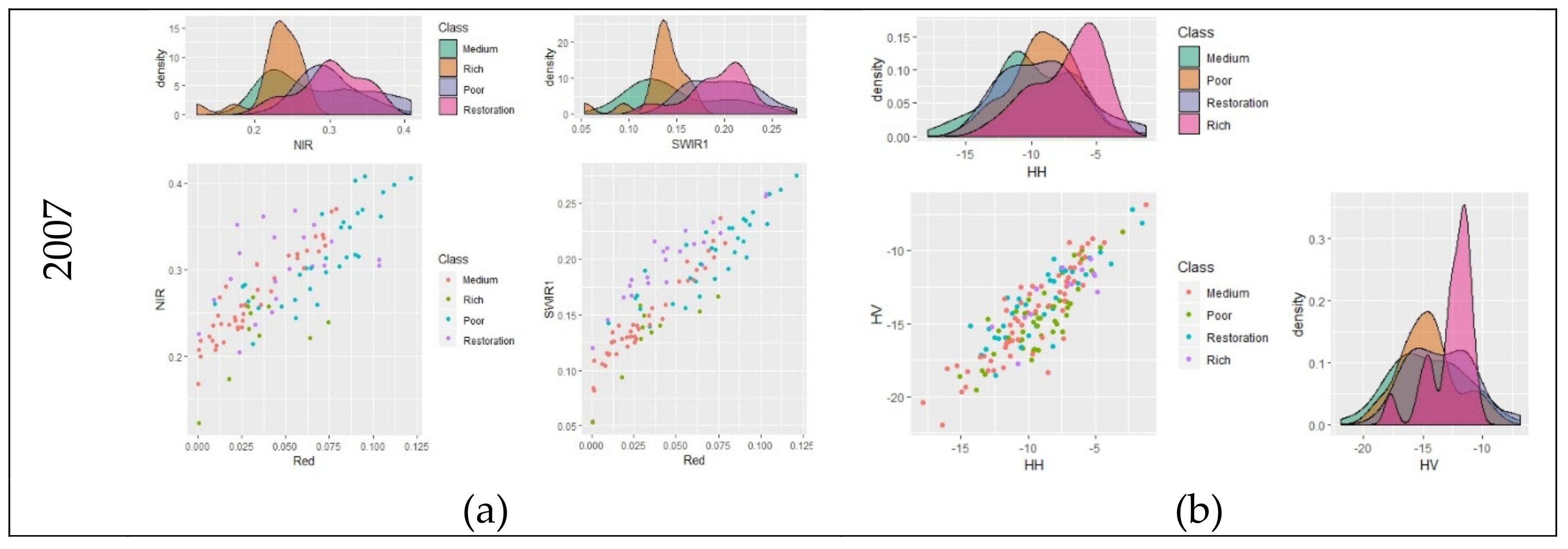
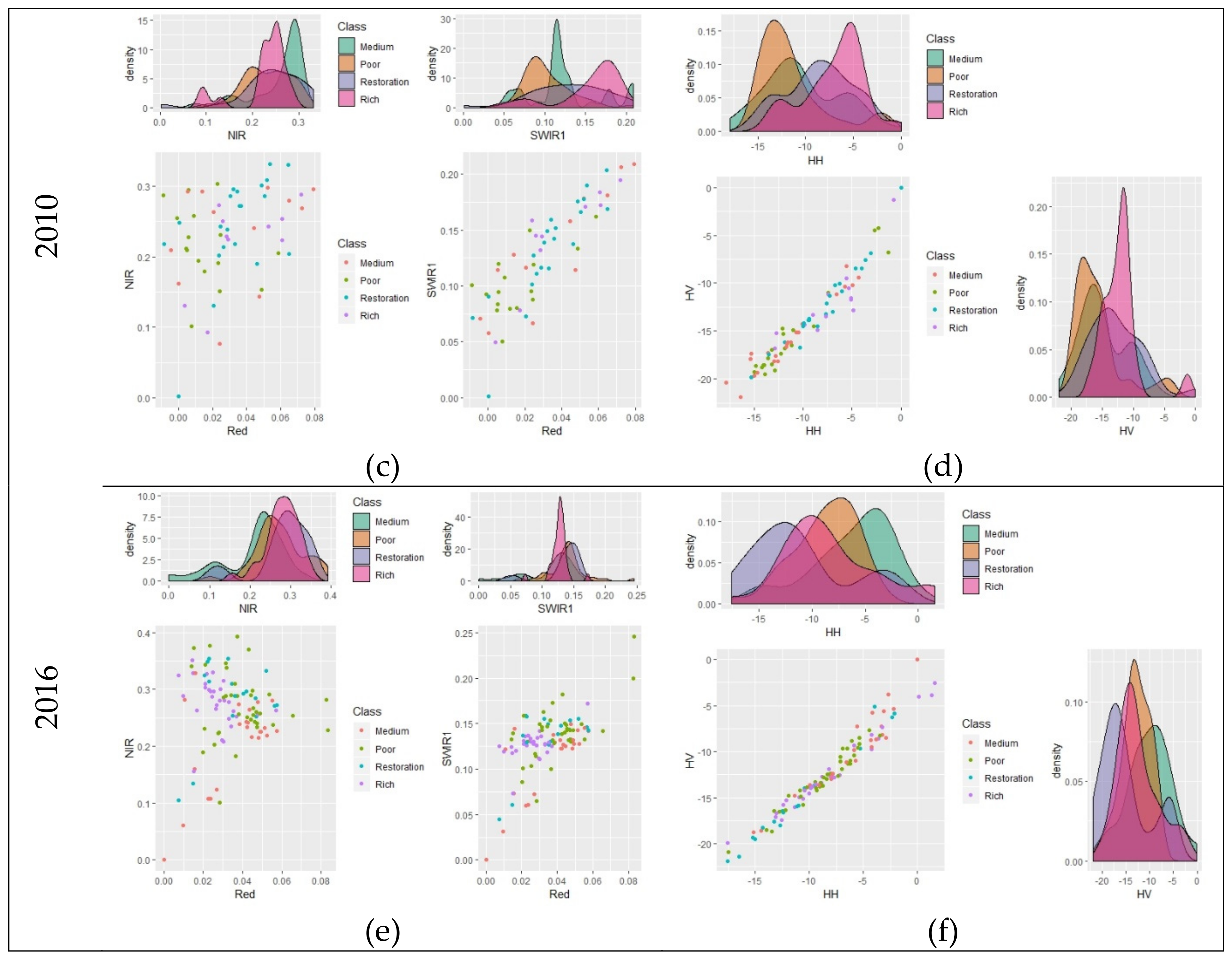
Analysis of the reflectance behavior on some bands on Landsat and backscatter on SAR images (
Figure A1) demonstrates on histograms the overlap of all four forest types. In image data from 2007 and 2010, rich forest exhibited better distinctions than other forest types. Histogram analysis of forest types in 2016 shows little separation, so its accuracy was lower than that of 2007 and 2010. This low separation is due to the characteristic of natural forest, with its combination of various canopy stories and species diversity. Sparser wood trees have more vines, which cover the whole canopy. Therefore, it is difficult to detect the difference between forest types based on optical images. Despite having a long wavelength that can supposedly penetrate the canopy and reach the trunk, L-band signals still demonstrate a low difference between polarization signals. In this study, to enhance the differences between classes, a multivariate model was essential to observe objects under multidimensional space and provide more information and attributes for objects.
The change of certain forest types between any two periods comprises the net effect [
3] of conversion from any one forest type to another or non-forested area and natural regeneration or restoration. A conversion matrix was used to clearly illustrate transition areas between forest types in this study area in the period 2007–2016 (
Table 6). In this table, the cross cells demonstrated no change values in terms of percentage of forest types’ area. The rows demonstrate an increase in the proportion converted from other types. The columns demonstrate a decrease in the proportion converted into other types. The net area change is the total effect of increase and decrease in the area of specific forest types.
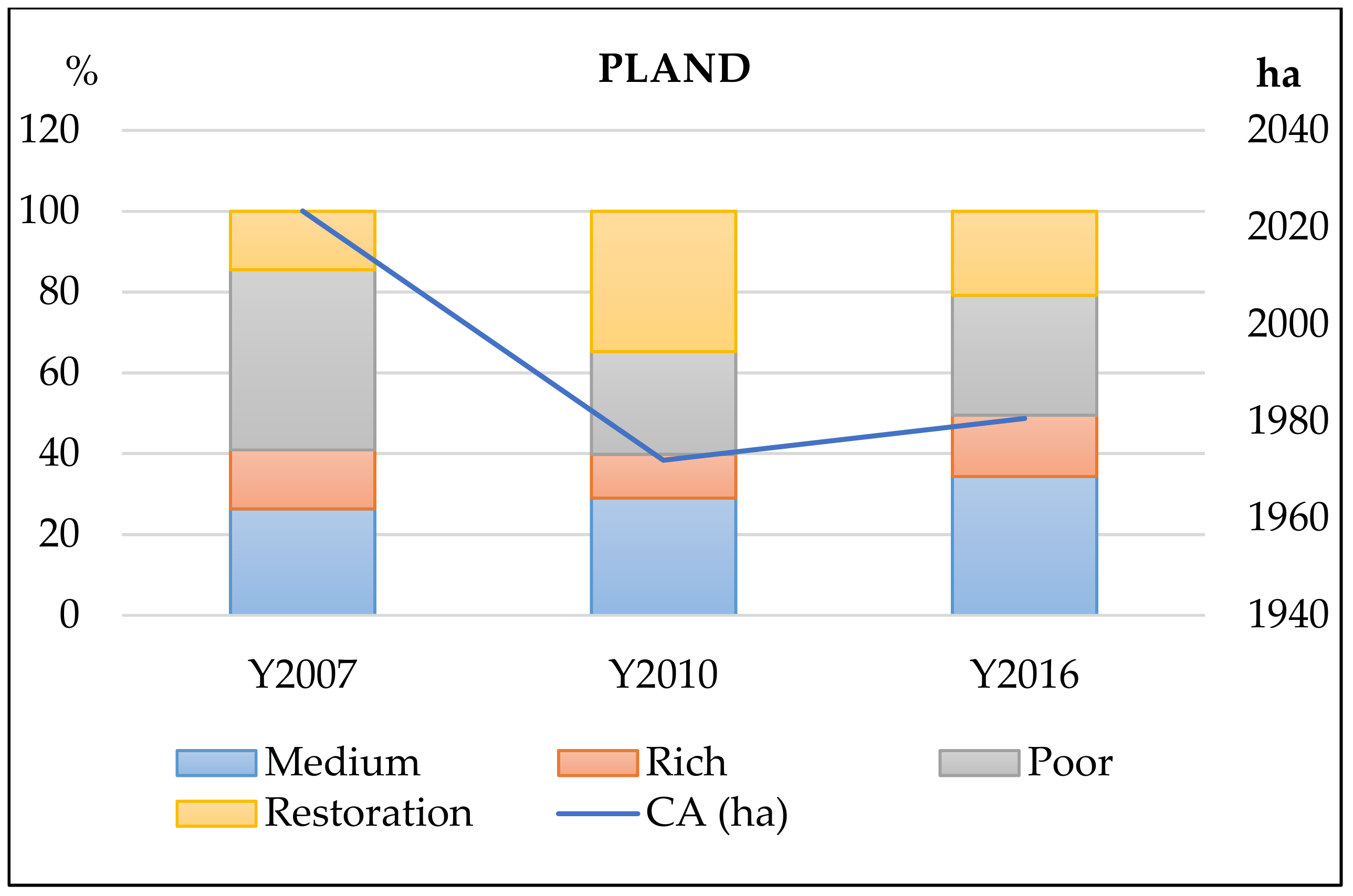
From the conversion matrix of forest types between 2007 and 2016 in this study area, we considered three main findings. First, the net trend of natural forest comprised a small loss of area, but this was due to two opposite trends of an area increase in one place and a decrease elsewhere. Second, the levels of forest restoration and deforestation were nearly equal (total of 145,873 ha and 150,143 ha, respectively) and occurred simultaneously in the study area during this period. Third, there was a strong internal transition between forest types and an external transition between them and other land use/land cover types. Medium forest had the highest gain area, followed by restoration forest, at 14,795 ha and 11,852 ha, respectively. Poor forest showed a sharp loss, while rich forest had an adequate increase. When considering the percentage of conversion area, the most dramatic transformation was in rich forest, which changed to medium forest at a rate of 36%, but was compensated by medium (16%) and poor forests (13%). However, when considering the changing area, medium and poor forest had areas of both high increase and decrease. Changes from natural forest to other types were the strongest in restoration forest at 31% of its area. Restoration forest is the most vulnerable forest type because it is often distributed in areas that are easily accessible and affected by human and agricultural activities.
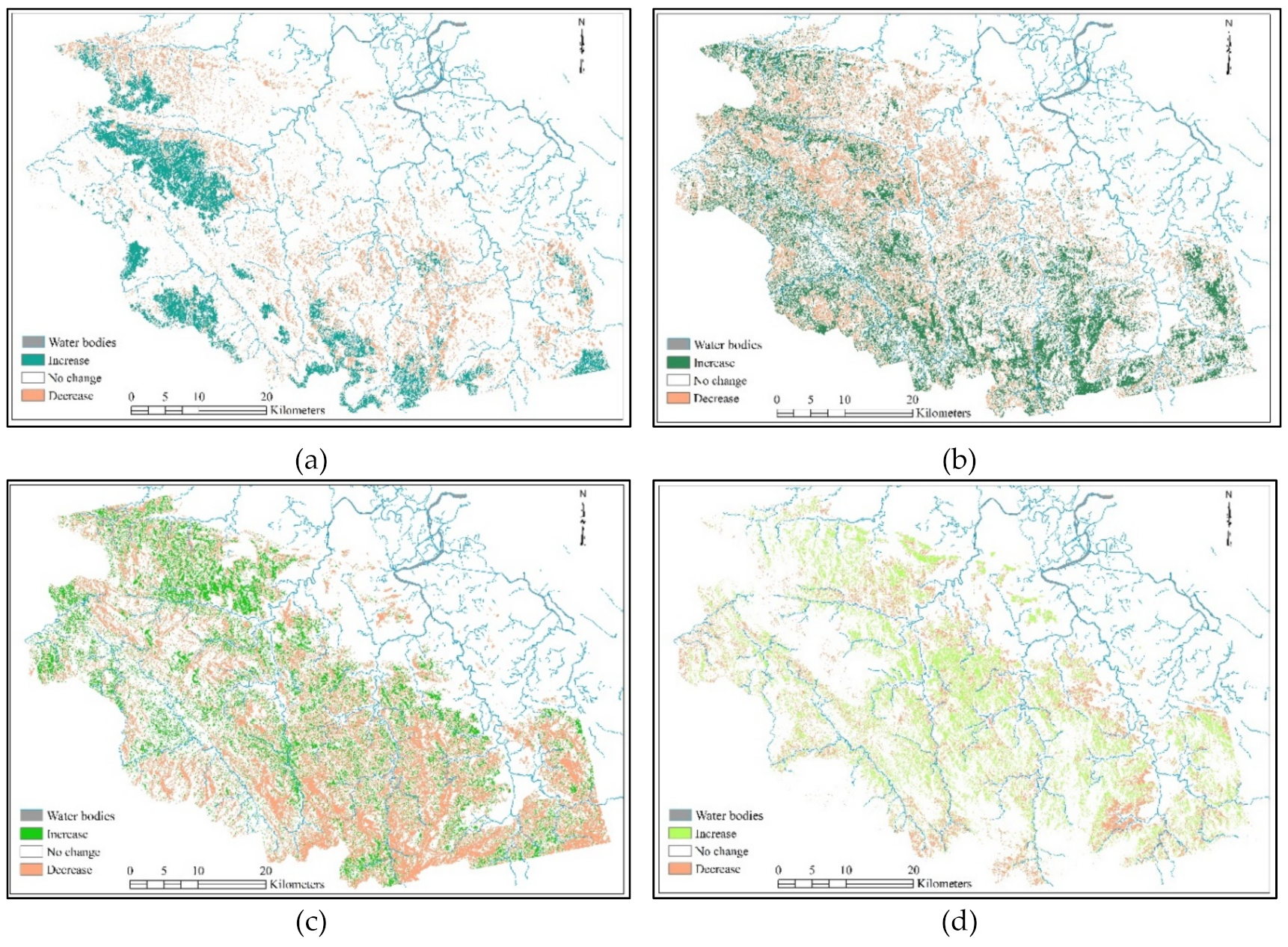
The spatial changes in natural forest types presented in
Figure 6 showed two change directions: increase and decrease. The area loss of forest types occurred throughout the study area, but it was mainly distributed near water bodies such as rivers and streams. The local population distribution is often concentrated in the downstream of rivers where conditions for agriculture are developing. Therefore, natural forests near rivers are easily deforested and degraded due to human activity. In the other direction, the expansion of rich forest created larger fragments and scattered distribution in the study area, resulting in increasing compactness, less connectivity, and higher isolation. The expansion in other types occurred more evenly and therefore with greater connectivity.
During this period, there were many factors affecting forest dynamics. The policies of prohibiting logging in natural forests and enhancing forest protection and restoration are considered to be the correct policies in terms of reducing natural forest degradation, which was implemented by the Vietnamese government since the early 1990s [
56]. However, illegal logging still occurred [
57] due to the increasing demand for wood from population pressure, which is the main reason for the continued decline of natural forests in the period 2005–2010. There were also many other causes, such as poverty, forest resources, population density, agricultural production, and province-level governance [
54]. In parallel with the logging ban policy in natural forest, Vietnam has successfully socialized forestry organization, calling for public participation in afforestation and forest protection, and resulting in reduced deforestation and degradation and improved long-term income for people in rural mountainous areas. The speed of loss of natural forests has also decreased slightly and there have been signs of increase from 2010 to the present day. In 2016, Vietnam began to introduce bans on natural forest wood exploitation into the law on forest protection and development, which is the most powerful law in forestry. Simultaneously, it maximized the closure of natural forests, did not convert natural forests to other purposes, and did not convert poor natural forests to industrial crops. This is the driving force behind reductions in degradation and prevention of illegal logging, and allows us to predict recovery and increase in the quality of natural forests in the future.
Generally, this study provides information on the dynamics and spatial processes of natural forest change in a given study site between 2007 and 2016. The result obtained demonstrates the general trend of forest types conversion and provides useful information for sustainable forest planning.
6. Conclusions
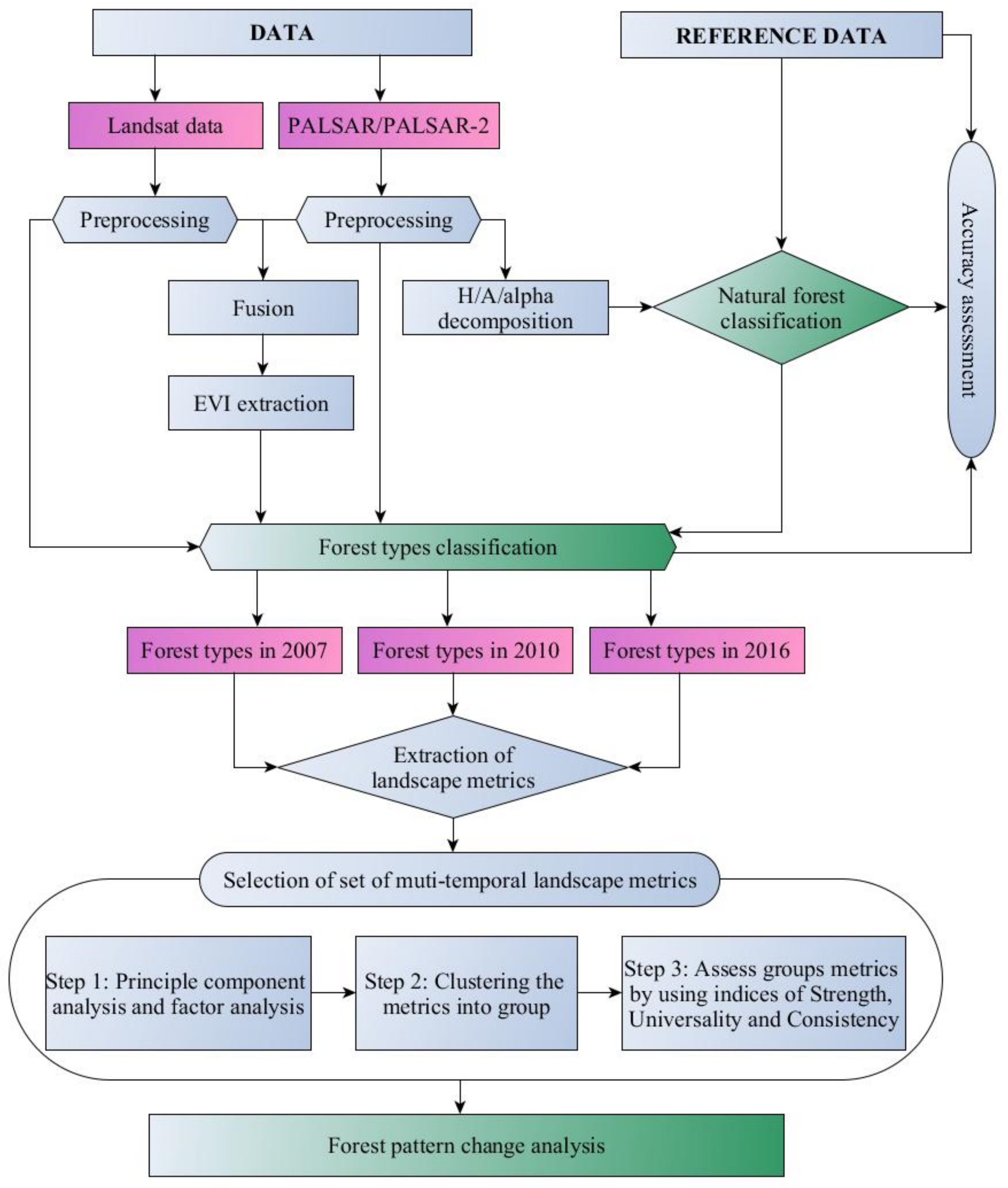
There is an essential requirement for forest management and protection to classify natural forests and assess their fluctuations over time. However, classifying the natural forest types in tropical areas using remote sensing images is challenging because of the very similar information captured by remotely sensed data as well as the constraint of samples data. Furthermore, there is a lack of research assessing forest transition in the natural forest from the perspective of landscape ecology, which can be used for forest structure management, and to quantitatively characterize the spatial patterns of forest landscapes. In this study, we addressed these issues by applying semi-supervised classification for data integration of optical and SAR data.
The combination of Landsat and PolSAR data resulted in improved discrimination of forest types. The using of multi-source remotely sensed data can provide more information about the object, as well mitigate the disadvantages of Landsat images (cloud, lower spatial resolution), and limited information regarding objects in PALSAR/PALSAR-2 image (only two polarization HH and HV).
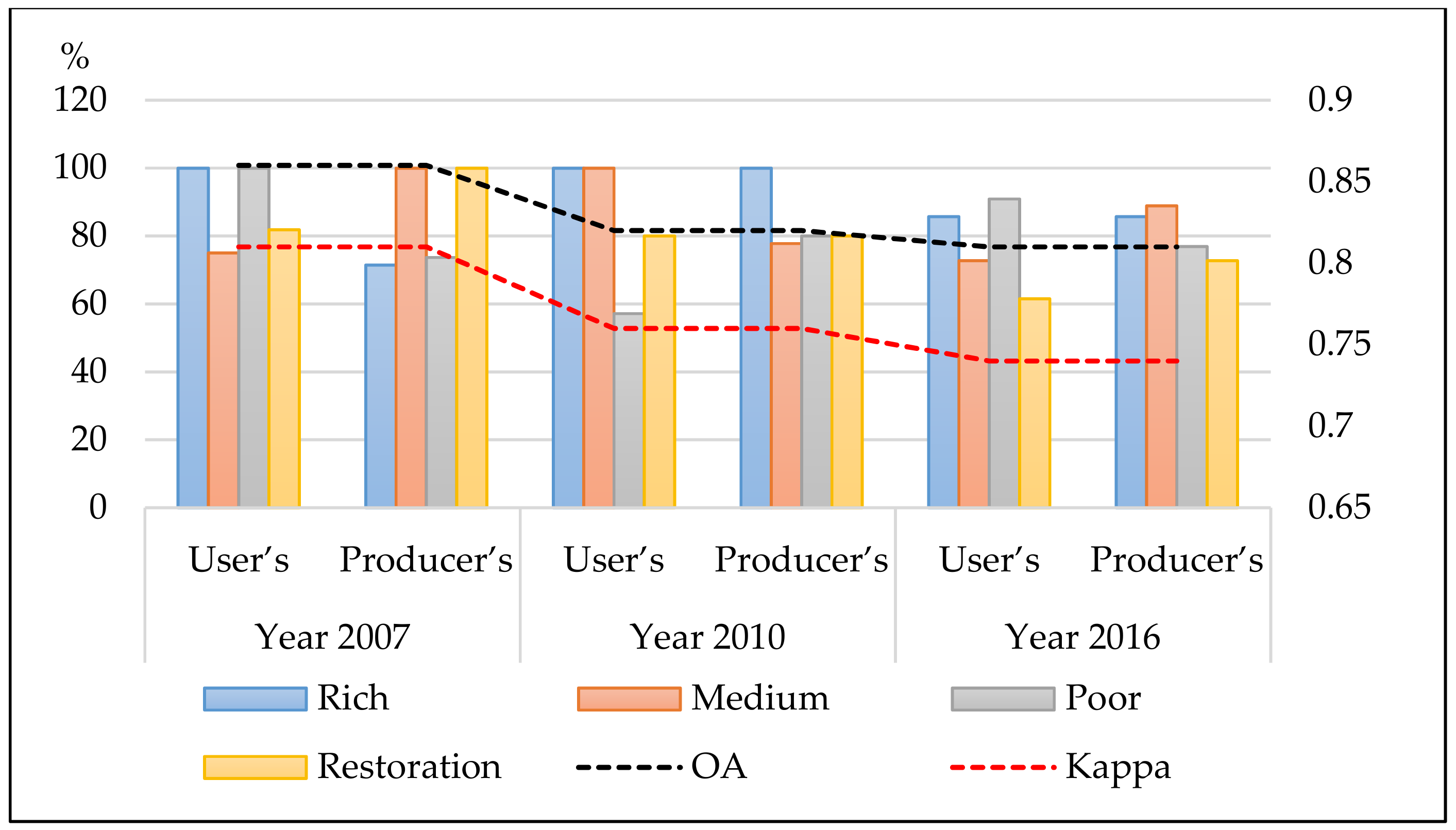
In this study, we assessed the potential of a proposed semi-supervised model developed and validated for mapping forest types and assessed the process of forest transition in a tropical natural forest in Vietnam. The model produced high accuracies in the classified images in 2007, 2010, and 2016 with over 0.74 for kappa, and over 0.8 for OA. Additionally, landscape metrics were used to evaluate the forest changes based on the spatial processes, such as aggregation, fragmentation, and compaction. At the class level, the poor forest demonstrated the largest variation with more dispersed growth patterns, while other types had a low level of aggregation. At the landscape level, the natural forest experiences increased fragmentation, which involved an increase in landscape area with shrinkage of patch size and disproportionate distribution of patches.
We recommend that future research include comparison of different models to estimate the improvement resulting from the proposed model. Another important study that should be conducted is testing of the proposed methods on larger areas.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







